Apache Tajo - คำสั่ง SQL
ในบทที่แล้วคุณได้เข้าใจวิธีสร้างตารางใน Tajo แล้ว บทนี้อธิบายเกี่ยวกับคำสั่ง SQL ใน Tajo
สร้างคำสั่งตาราง
ก่อนที่จะย้ายไปสร้างตารางให้สร้างไฟล์ข้อความ“ students.csv” ในพา ธ ไดเร็กทอรีการติดตั้ง Tajo ดังนี้ -
students.csv
| Id | ชื่อ | ที่อยู่ | อายุ | เครื่องหมาย |
|---|---|---|---|---|
| 1 | อดัม | 23 ถนนใหม่ | 21 | 90 |
| 2 | Amit | 12 Old Street | 13 | 95 |
| 3 | บ๊อบ | 10 ครอสสตรีท | 12 | 80 |
| 4 | เดวิด | 15 Express Avenue | 12 | 85 |
| 5 | Esha | 20 Garden Street | 13 | 50 |
| 6 | คงคา | 25 North Street | 12 | 55 |
| 7 | แจ็ค | 2 Park Street | 12 | 60 |
| 8 | ลีน่า | 24 South Street | 12 | 70 |
| 9 | แมรี่ | 5 West Street | 12 | 75 |
| 10 | ปีเตอร์ | 16 พาร์คอเวนิว | 12 | 95 |
หลังจากสร้างไฟล์แล้วให้ย้ายไปที่เทอร์มินัลและเริ่มเซิร์ฟเวอร์ Tajo และเชลล์ทีละรายการ
สร้างฐานข้อมูล
สร้างฐานข้อมูลใหม่โดยใช้คำสั่งต่อไปนี้ -
แบบสอบถาม
default> create database sampledb;
OKเชื่อมต่อกับฐานข้อมูล“ ตัวอย่าง” ซึ่งสร้างขึ้นในขณะนี้
default> \c sampledb
You are now connected to database "sampledb" as user “user1”.จากนั้นสร้างตารางใน "ตัวอย่าง" ดังนี้ -
แบบสอบถาม
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
OKที่นี่ตารางภายนอกถูกสร้างขึ้น ตอนนี้คุณต้องป้อนตำแหน่งไฟล์ หากคุณต้องกำหนดตารางจาก hdfs ให้ใช้ hdfs แทนไฟล์
ถัดไป “students.csv”ไฟล์มีค่าที่คั่นด้วยลูกน้ำ text.delimiter ฟิลด์ถูกกำหนดด้วย ","
ตอนนี้คุณได้สร้าง "mytable" ใน "sampledb" เรียบร้อยแล้ว
แสดงตาราง
หากต้องการแสดงตารางใน Tajo ให้ใช้แบบสอบถามต่อไปนี้
แบบสอบถาม
sampledb> \d
mytable
sampledb> \d mytableผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
table name: sampledb.mytable
table uri: file:/Users/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 261 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4ตารางรายการ
ในการดึงข้อมูลทั้งหมดในตารางให้พิมพ์แบบสอบถามต่อไปนี้ -
แบบสอบถาม
sampledb> select * from mytable;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้

แทรกคำชี้แจงตาราง
Tajo ใช้ไวยากรณ์ต่อไปนี้เพื่อแทรกระเบียนในตาราง
ไวยากรณ์
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;คำสั่งแทรกของ Tajo คล้ายกับ INSERT INTO SELECT คำสั่งของ SQL
แบบสอบถาม
มาสร้างตารางเพื่อเขียนทับข้อมูลตารางของตารางที่มีอยู่
sampledb> create table test(sno int,name text,addr text,age int,mark int);
OK
sampledb> \dผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
mytable
testแทรกบันทึก
หากต้องการแทรกระเบียนในตาราง "ทดสอบ" ให้พิมพ์แบบสอบถามต่อไปนี้
แบบสอบถาม
sampledb> insert overwrite into test select * from mytable;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
Progress: 100%, response time: 0.518 secที่นี่ระเบียน "mytable" จะเขียนทับตาราง "test" หากคุณไม่ต้องการสร้างตาราง "test" ให้กำหนดตำแหน่งเส้นทางทางกายภาพตามที่กล่าวไว้ในตัวเลือกอื่นสำหรับการแทรกคิวรีทันที
ดึงข้อมูลบันทึก
ใช้แบบสอบถามต่อไปนี้เพื่อแสดงรายการระเบียนทั้งหมดในตาราง "ทดสอบ" -
แบบสอบถาม
sampledb> select * from test;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้

คำสั่งนี้ใช้เพื่อเพิ่มลบหรือแก้ไขคอลัมน์ของตารางที่มีอยู่
ในการเปลี่ยนชื่อตารางให้ใช้ไวยากรณ์ต่อไปนี้ -
Alter table table1 RENAME TO table2;แบบสอบถาม
sampledb> alter table test rename to students;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
OKหากต้องการตรวจสอบชื่อตารางที่เปลี่ยนแปลงให้ใช้แบบสอบถามต่อไปนี้
sampledb> \d
mytable
studentsตอนนี้ตาราง“ ทดสอบ” เปลี่ยนเป็นตาราง“ นักเรียน”
เพิ่มคอลัมน์
หากต้องการแทรกคอลัมน์ใหม่ในตาราง "นักเรียน" ให้พิมพ์ไวยากรณ์ต่อไปนี้ -
Alter table <table_name> ADD COLUMN <column_name> <data_type>แบบสอบถาม
sampledb> alter table students add column grade text;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
OKตั้งค่าคุณสมบัติ
คุณสมบัตินี้ใช้เพื่อเปลี่ยนคุณสมบัติของตาราง
แบบสอบถาม
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD',
'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ;
OKที่นี่มีการกำหนดประเภทการบีบอัดและคุณสมบัติตัวแปลงสัญญาณ
ในการเปลี่ยนคุณสมบัติตัวคั่นข้อความให้ใช้สิ่งต่อไปนี้ -
แบบสอบถาม
ALTER TABLE students SET PROPERTY ‘text.delimiter'=',';
OKผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
sampledb> \d students
table name: sampledb.students
table uri: file:/tmp/tajo-user1/warehouse/sampledb/students
store type: TEXT
number of rows: 10
volume: 228 B
Options:
'compression.type' = 'RECORD'
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec'
'text.delimiter' = ','
schema:
id INT4
name TEXT
addr TEXT
age INT4
mark INT4
grade TEXTผลลัพธ์ข้างต้นแสดงให้เห็นว่าคุณสมบัติของตารางมีการเปลี่ยนแปลงโดยใช้คุณสมบัติ "SET"
เลือกคำชี้แจง
คำสั่ง SELECT ใช้เพื่อเลือกข้อมูลจากฐานข้อมูล
ไวยากรณ์สำหรับคำสั่ง Select มีดังนี้ -
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...]
[FROM <table reference> [[AS] <table alias name>] [, ...]]
[WHERE <condition>]
[GROUP BY <expression> [, ...]]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]ที่ข้อ
ส่วนคำสั่ง Where ใช้เพื่อกรองเรกคอร์ดจากตาราง
แบบสอบถาม
sampledb> select * from mytable where id > 5;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
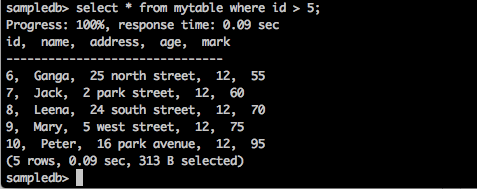
แบบสอบถามจะส่งคืนระเบียนของนักเรียนที่มี id มากกว่า 5
แบบสอบถาม
sampledb> select * from mytable where name = ‘Peter’;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
Progress: 100%, response time: 0.117 sec
id, name, address, age
-------------------------------
10, Peter, 16 park avenue , 12ผลลัพธ์จะกรองบันทึกของปีเตอร์เท่านั้น
ข้อแตกต่าง
คอลัมน์ของตารางอาจมีค่าที่ซ้ำกัน สามารถใช้คีย์เวิร์ด DISTINCT เพื่อส่งคืนเฉพาะค่าที่แตกต่างกัน (ต่างกัน)
ไวยากรณ์
SELECT DISTINCT column1,column2 FROM table_name;แบบสอบถาม
sampledb> select distinct age from mytable;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
Progress: 100%, response time: 0.216 sec
age
-------------------------------
13
12ข้อความค้นหาจะแสดงอายุที่แตกต่างกันของนักเรียนจาก mytable.
จัดกลุ่มตามข้อ
คำสั่ง GROUP BY ใช้ร่วมกับคำสั่ง SELECT เพื่อจัดเรียงข้อมูลที่เหมือนกันเป็นกลุ่ม
ไวยากรณ์
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;แบบสอบถาม
select age,sum(mark) as sumofmarks from mytable group by age;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
age, sumofmarks
-------------------------------
13, 145
12, 610ที่นี่คอลัมน์ "mytable" มีอายุ 2 ประเภทคือ 12 และ 13 ตอนนี้การสืบค้นจะจัดกลุ่มระเบียนตามอายุและสร้างผลรวมของเครื่องหมายสำหรับอายุของนักเรียน
มีข้อ
HAVING clause ช่วยให้คุณสามารถระบุเงื่อนไขที่กรองผลลัพธ์ของกลุ่มที่จะปรากฏในผลลัพธ์สุดท้าย WHERE clause วางเงื่อนไขบนคอลัมน์ที่เลือกในขณะที่ HAVING clause วางเงื่อนไขบนกลุ่มที่สร้างโดย GROUP BY clause
ไวยากรณ์
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]แบบสอบถาม
sampledb> select age from mytable group by age having sum(mark) > 200;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
age
-------------------------------
12แบบสอบถามจัดกลุ่มระเบียนตามอายุและส่งกลับอายุเมื่อผลรวมเงื่อนไข (เครื่องหมาย)> 200
เรียงตามข้อ
คำสั่ง ORDER BY ใช้เพื่อเรียงลำดับข้อมูลจากน้อยไปมากหรือมากไปหาน้อยโดยยึดตามคอลัมน์อย่างน้อยหนึ่งคอลัมน์ ฐานข้อมูล Tajo จะเรียงลำดับผลลัพธ์จากน้อยไปหามากตามค่าเริ่มต้น
ไวยากรณ์
SELECT column-list FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];แบบสอบถาม
sampledb> select * from mytable where mark > 60 order by name desc;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้

คำค้นหาจะส่งคืนชื่อของนักเรียนเหล่านั้นตามลำดับจากมากไปหาน้อยซึ่งมีเครื่องหมายมากกว่า 60
สร้างคำชี้แจงดัชนี
คำสั่ง CREATE INDEX ใช้เพื่อสร้างดัชนีในตาราง ดัชนีใช้สำหรับการดึงข้อมูลอย่างรวดเร็ว เวอร์ชันปัจจุบันรองรับดัชนีสำหรับรูปแบบ TEXT ธรรมดาที่จัดเก็บบน HDFS เท่านั้น
ไวยากรณ์
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }แบบสอบถาม
create index student_index on mytable(id);ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
id
———————————————หากต้องการดูดัชนีที่กำหนดสำหรับคอลัมน์ให้พิมพ์แบบสอบถามต่อไปนี้
default> \d mytable
table name: default.mytable
table uri: file:/Users/deiva/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 307 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
Indexes:
"student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )ที่นี่มีการใช้เมธอด TWO_LEVEL_BIN_TREE โดยค่าเริ่มต้นใน Tajo
วางคำสั่งตาราง
Drop Table Statement ใช้เพื่อวางตารางจากฐานข้อมูล
ไวยากรณ์
drop table table name;แบบสอบถาม
sampledb> drop table mytable;หากต้องการตรวจสอบว่าตารางหลุดออกจากตารางหรือไม่ให้พิมพ์แบบสอบถามต่อไปนี้
sampledb> \d mytable;ผลลัพธ์
แบบสอบถามข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
ERROR: relation 'mytable' does not existคุณยังสามารถตรวจสอบการสืบค้นโดยใช้คำสั่ง“ \ d” เพื่อแสดงรายการตาราง Tajo ที่มีอยู่