ArangoDB - แบบสอบถามตัวอย่าง AQL
ในบทนี้เราจะพิจารณาตัวอย่างแบบสอบถาม AQL บางส่วนในไฟล์ Actors and Moviesฐานข้อมูล. คำค้นหาเหล่านี้อ้างอิงจากกราฟ
ปัญหา
ให้คอลเลกชันของนักแสดงและคอลเลกชันของภาพยนตร์และคอลเลกชัน actIn edge (พร้อมคุณสมบัติปี) เพื่อเชื่อมต่อจุดยอดตามที่ระบุด้านล่าง -
[Actor] <- act in -> [Movie]
เราจะได้รับอย่างไร -
- นักแสดงทุกคนที่แสดงใน "movie1" OR "movie2"?
- นักแสดงทุกคนที่แสดงทั้ง "movie1" และ "movie2"?
- ภาพยนตร์ทั่วไปทั้งหมดระหว่าง "ดารา 1" และ "นักแสดง 2"?
- นักแสดงทุกคนที่แสดงในภาพยนตร์ 3 เรื่องขึ้นไป?
- ภาพยนตร์ทั้งหมดที่มีนักแสดง 6 คนแสดง?
- จำนวนนักแสดงตามภาพยนตร์?
- จำนวนภาพยนตร์โดยนักแสดง?
- จำนวนภาพยนตร์ที่แสดงในระหว่างปี 2548 ถึง 2553 โดยนักแสดง?
วิธีการแก้
ในระหว่างขั้นตอนการแก้ปัญหาและรับคำตอบของคำถามข้างต้นเราจะใช้ Arangosh เพื่อสร้างชุดข้อมูลและเรียกใช้การสืบค้นนั้น ข้อความค้นหา AQL ทั้งหมดเป็นสตริงและสามารถคัดลอกไปยังไดรเวอร์ที่คุณชื่นชอบแทน Arangosh ได้
เริ่มต้นด้วยการสร้างชุดข้อมูลทดสอบใน Arangosh ก่อนอื่นให้ดาวน์โหลดไฟล์นี้ -
# wget -O dataset.js
https://drive.google.com/file/d/0B4WLtBDZu_QWMWZYZ3pYMEdqajA/view?usp=sharingเอาต์พุต
...
HTTP request sent, awaiting response... 200 OK
Length: unspecified [text/html]
Saving to: ‘dataset.js’
dataset.js [ <=> ] 115.14K --.-KB/s in 0.01s
2017-09-17 14:19:12 (11.1 MB/s) - ‘dataset.js’ saved [117907]คุณจะเห็นในผลลัพธ์ด้านบนว่าเราได้ดาวน์โหลดไฟล์ JavaScript dataset.js.ไฟล์นี้มีคำสั่ง Arangosh เพื่อสร้างชุดข้อมูลในฐานข้อมูล แทนที่จะคัดลอกและวางคำสั่งทีละคำเราจะใช้ไฟล์--javascript.executeตัวเลือกบน Arangosh เพื่อดำเนินการคำสั่งหลายคำสั่งแบบไม่โต้ตอบ พิจารณาคำสั่งช่วยชีวิต!
ตอนนี้ดำเนินการคำสั่งต่อไปนี้บนเชลล์ -
$ arangosh --javascript.execute dataset.js
ระบุรหัสผ่านเมื่อได้รับแจ้งดังที่คุณเห็นในภาพหน้าจอด้านบน ตอนนี้เราได้บันทึกข้อมูลแล้วดังนั้นเราจะสร้างแบบสอบถาม AQL เพื่อตอบคำถามเฉพาะที่เกิดขึ้นในตอนต้นของบทนี้
คำถามแรก
ให้เราถามคำถามแรก: All actors who acted in "movie1" OR "movie2". สมมติว่าเราต้องการค้นหาชื่อของนักแสดงทุกคนที่แสดงใน "TheMatrix" หรือ "TheDevilsAdvocate" -
เราจะเริ่มด้วยภาพยนตร์ทีละเรื่องเพื่อรับชื่อนักแสดง -
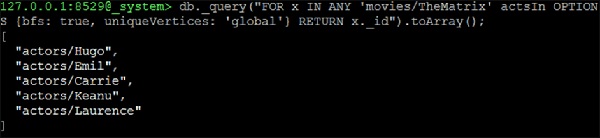
127.0.0.1:8529@_system> db._query("FOR x IN ANY 'movies/TheMatrix' actsIn
OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN x._id").toArray();เอาต์พุต
เราจะได้รับผลลัพธ์ต่อไปนี้ -
[
"actors/Hugo",
"actors/Emil",
"actors/Carrie",
"actors/Keanu",
"actors/Laurence"
]
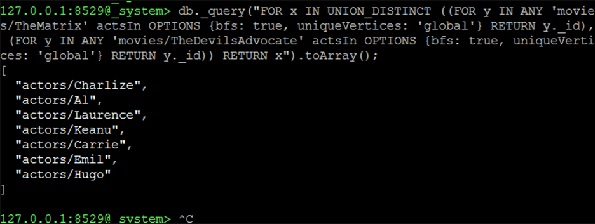
ตอนนี้เรายังคงสร้าง UNION_DISTINCT จากแบบสอบถาม NEIGHBORS สองรายการซึ่งจะเป็นทางออก -
127.0.0.1:8529@_system> db._query("FOR x IN UNION_DISTINCT ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();เอาต์พุต
[
"actors/Charlize",
"actors/Al",
"actors/Laurence",
"actors/Keanu",
"actors/Carrie",
"actors/Emil",
"actors/Hugo"
]
คำถามที่สอง
ตอนนี้ให้เราพิจารณาคำถามที่สอง: All actors who acted in both "movie1" AND "movie2". ซึ่งเกือบจะเหมือนกับคำถามข้างต้น แต่คราวนี้เราไม่สนใจ UNION แต่เป็น INTERSECTION -
127.0.0.1:8529@_system> db._query("FOR x IN INTERSECTION ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();เอาต์พุต
เราจะได้รับผลลัพธ์ต่อไปนี้ -
[
"actors/Keanu"
]
คำถามที่สาม
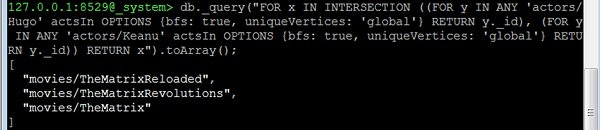
ตอนนี้ให้เราพิจารณาคำถามที่สาม: All common movies between "actor1" and "actor2". คำถามนี้เหมือนกับคำถามเกี่ยวกับนักแสดงทั่วไปใน movie1 และ movie2 เราต้องเปลี่ยนจุดเริ่มต้น ตัวอย่างเช่นให้เราค้นหาภาพยนตร์ทั้งหมดที่ Hugo Weaving ("Hugo") และ Keanu Reeves ร่วมแสดง -
127.0.0.1:8529@_system> db._query(
"FOR x IN INTERSECTION (
(
FOR y IN ANY 'actors/Hugo' actsIn OPTIONS
{bfs: true, uniqueVertices: 'global'}
RETURN y._id
),
(
FOR y IN ANY 'actors/Keanu' actsIn OPTIONS
{bfs: true, uniqueVertices:'global'} RETURN y._id
)
)
RETURN x").toArray();เอาต์พุต
เราจะได้รับผลลัพธ์ต่อไปนี้ -
[
"movies/TheMatrixReloaded",
"movies/TheMatrixRevolutions",
"movies/TheMatrix"
]
คำถามที่สี่
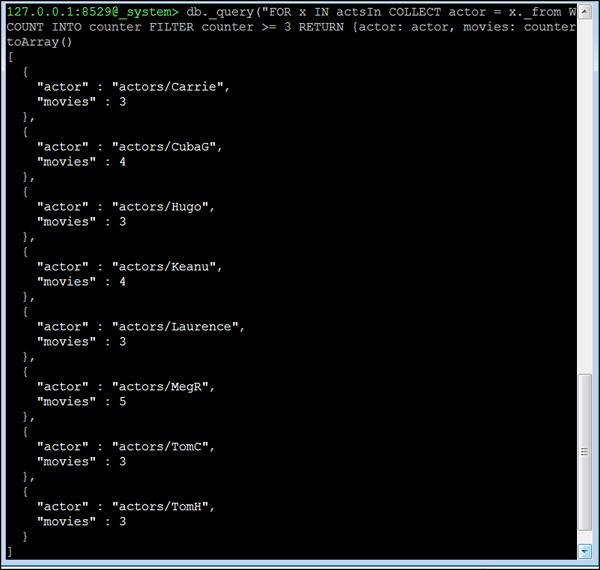
ตอนนี้ให้เราพิจารณาคำถามที่สี่ All actors who acted in 3 or more movies. คำถามนี้แตกต่างกัน เราไม่สามารถใช้ประโยชน์จากฟังก์ชันเพื่อนบ้านที่นี่ได้ เราจะใช้ edge-index และคำสั่ง COLLECT ของ AQL ในการจัดกลุ่มแทน แนวคิดพื้นฐานคือการจัดกลุ่มขอบทั้งหมดตามstartVertex(ซึ่งในชุดข้อมูลนี้เป็นตัวแสดงเสมอ) จากนั้นเราจะลบนักแสดงทั้งหมดที่มีภาพยนตร์น้อยกว่า 3 เรื่องออกจากผลลัพธ์เนื่องจากที่นี่เราได้รวมจำนวนภาพยนตร์ที่นักแสดงแสดงไว้ -
127.0.0.1:8529@_system> db._query("FOR x IN actsIn COLLECT actor = x._from WITH
COUNT INTO counter FILTER counter >= 3 RETURN {actor: actor, movies:
counter}"). toArray()เอาต์พุต
[
{
"actor" : "actors/Carrie",
"movies" : 3
},
{
"actor" : "actors/CubaG",
"movies" : 4
},
{
"actor" : "actors/Hugo",
"movies" : 3
},
{
"actor" : "actors/Keanu",
"movies" : 4
},
{
"actor" : "actors/Laurence",
"movies" : 3
},
{
"actor" : "actors/MegR",
"movies" : 5
},
{
"actor" : "actors/TomC",
"movies" : 3
},
{
"actor" : "actors/TomH",
"movies" : 3
}
]
สำหรับคำถามที่เหลือเราจะพูดคุยเกี่ยวกับรูปแบบการสืบค้นและให้เฉพาะคำถามเท่านั้น ผู้อ่านควรเรียกใช้แบบสอบถามด้วยตัวเองบนเทอร์มินัล Arangosh
คำถามที่ห้า
ตอนนี้ให้เราพิจารณาคำถามที่ห้า: All movies where exactly 6 actors acted in. แนวคิดเดียวกับในแบบสอบถามก่อนหน้านี้ แต่มีตัวกรองความเท่าเทียมกัน อย่างไรก็ตามตอนนี้เราต้องการภาพยนตร์แทนนักแสดงดังนั้นเราจึงส่งคืนไฟล์_to attribute -
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter FILTER
counter == 6 RETURN movie").toArray()จำนวนนักแสดงตามภาพยนตร์?
เราจำไว้ในชุดข้อมูลของเรา _to ตรงขอบตรงกับภาพยนตร์ดังนั้นเราจึงนับว่าบ่อยแค่ไหน _toปรากฏขึ้น นี่คือจำนวนนักแสดง แบบสอบถามเกือบจะเหมือนกันกับคำค้นหาก่อนหน้านี้without the FILTER after COLLECT -
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter RETURN
{movie: movie, actors: counter}").toArray()คำถามที่หก
ตอนนี้ให้เราพิจารณาคำถามที่หก: The number of movies by an actor.
วิธีที่เราพบวิธีแก้ไขสำหรับคำถามข้างต้นของเราจะช่วยให้คุณพบวิธีแก้ปัญหาสำหรับคำถามนี้เช่นกัน
db._query("FOR x IN actsIn COLLECT actor = x._from WITH COUNT INTO counter
RETURN {actor: actor, movies: counter}").toArray()