ArangoDB - คู่มือฉบับย่อ
ArangoDB ได้รับการยกย่องว่าเป็นฐานข้อมูลหลายรุ่นโดยนักพัฒนา ซึ่งแตกต่างจากฐานข้อมูล NoSQL อื่น ๆ ในฐานข้อมูลนี้สามารถจัดเก็บข้อมูลเป็นเอกสารคู่คีย์ / ค่าหรือกราฟ และด้วยภาษาแบบสอบถามที่เปิดเผยเพียงภาษาเดียวข้อมูลใด ๆ หรือทั้งหมดของคุณก็สามารถเข้าถึงได้ นอกจากนี้ยังสามารถรวมโมเดลต่างๆในแบบสอบถามเดียวได้ และเนื่องจากรูปแบบหลายรูปแบบเราสามารถสร้างแอปพลิเคชันแบบลีนได้ซึ่งจะปรับขนาดได้ในแนวนอนด้วยโมเดลข้อมูลทั้งสามแบบหรือทั้งหมด
ฐานข้อมูลหลายรุ่นแบบหลายชั้นเทียบกับเนทีฟ
ในส่วนนี้เราจะเน้นความแตกต่างที่สำคัญระหว่างฐานข้อมูลแบบจำลองแบบเนทีฟและแบบหลายชั้น
ผู้จำหน่ายฐานข้อมูลจำนวนมากเรียกผลิตภัณฑ์ของตนว่า "หลายรุ่น" แต่การเพิ่มเลเยอร์กราฟให้กับคีย์ / ค่าหรือที่เก็บเอกสารไม่ถือเป็นแบบหลายรูปแบบดั้งเดิม
ด้วย ArangoDB ซึ่งเป็นแกนหลักเดียวกันที่มีภาษาแบบสอบถามเดียวกันเราสามารถรวมโมเดลข้อมูลและคุณลักษณะต่างๆไว้ด้วยกันในแบบสอบถามเดียวดังที่เราได้กล่าวไปแล้วในส่วนก่อนหน้า ใน ArangoDB ไม่มีการ“ สลับ” ระหว่างโมเดลข้อมูลและไม่มีการเปลี่ยนข้อมูลจาก A ไป B เพื่อดำเนินการสืบค้น ซึ่งนำไปสู่ข้อได้เปรียบด้านประสิทธิภาพของ ArangoDB เมื่อเปรียบเทียบกับวิธีการแบบ "เลเยอร์"
ความต้องการฐานข้อมูลหลายรูปแบบ
การตีความแนวคิดพื้นฐานของ [Fowler's] ทำให้เราตระหนักถึงประโยชน์ของการใช้แบบจำลองข้อมูลที่หลากหลายสำหรับส่วนต่างๆของเลเยอร์การคงอยู่ซึ่งเลเยอร์ที่เป็นส่วนหนึ่งของสถาปัตยกรรมซอฟต์แวร์ขนาดใหญ่
ตามนี้ตัวอย่างเช่นอาจใช้ฐานข้อมูลเชิงสัมพันธ์เพื่อคงอยู่ข้อมูลแบบตารางที่มีโครงสร้าง ที่เก็บเอกสารสำหรับข้อมูลที่ไม่มีโครงสร้างเหมือนวัตถุ ที่เก็บคีย์ / ค่าสำหรับตารางแฮช และฐานข้อมูลกราฟสำหรับข้อมูลอ้างอิงที่มีการเชื่อมโยงสูง
อย่างไรก็ตามการนำแนวทางนี้ไปใช้แบบดั้งเดิมจะนำไปสู่การใช้ฐานข้อมูลหลายฐานข้อมูลในโครงการเดียวกัน อาจทำให้เกิดความไม่ลงรอยกันในการดำเนินงาน (การปรับใช้ที่ซับซ้อนมากขึ้นการอัปเกรดบ่อยขึ้น) รวมถึงความสอดคล้องของข้อมูลและปัญหาการทำซ้ำ
ความท้าทายต่อไปหลังจากการรวมข้อมูลสำหรับโมเดลข้อมูลทั้งสามแบบคือการคิดค้นและใช้ภาษาแบบสอบถามทั่วไปที่สามารถช่วยให้ผู้ดูแลระบบข้อมูลสามารถแสดงข้อความค้นหาที่หลากหลายเช่นการสืบค้นเอกสารการค้นหาคีย์ / ค่าการสืบค้นแบบกราฟีและการรวมกันโดยพลการ ของเหล่านี้.
โดย graphy queriesเราหมายถึงข้อความค้นหาที่เกี่ยวข้องกับการพิจารณากราฟ - ทฤษฎี โดยเฉพาะอย่างยิ่งสิ่งเหล่านี้อาจเกี่ยวข้องกับคุณสมบัติการเชื่อมต่อเฉพาะที่มาจากขอบ ตัวอย่างเช่น,ShortestPath, GraphTraversalและ Neighbors.
กราฟเป็นแบบจำลองข้อมูลสำหรับความสัมพันธ์อย่างสมบูรณ์แบบ ในหลายกรณีในโลกแห่งความเป็นจริงเช่นเครือข่ายสังคมระบบผู้แนะนำ ฯลฯ แบบจำลองข้อมูลที่เป็นธรรมชาติมากคือกราฟ จับความสัมพันธ์และสามารถเก็บข้อมูลฉลากด้วยขอบแต่ละด้านและจุดยอดแต่ละจุด นอกจากนี้เอกสาร JSON ยังเหมาะอย่างยิ่งในการจัดเก็บข้อมูลจุดยอดและขอบประเภทนี้
ArangoDB ─คุณสมบัติ
ArangoDB มีคุณสมบัติเด่นหลายประการ เราจะเน้นคุณสมบัติที่โดดเด่นด้านล่าง -
- กระบวนทัศน์หลายรูปแบบ
- คุณสมบัติของกรด
- HTTP API
ArangoDB รองรับโมเดลฐานข้อมูลยอดนิยมทั้งหมด ต่อไปนี้เป็นโมเดลบางส่วนที่รองรับโดย ArangoDB -
- แบบจำลองเอกสาร
- แบบจำลองคีย์ / ค่า
- โมเดลกราฟ
ภาษาแบบสอบถามเดียวก็เพียงพอที่จะดึงข้อมูลออกจากฐานข้อมูล
คุณสมบัติทั้งสี่ Atomicity, Consistency, Isolationและ Durability(ACID) อธิบายการรับประกันธุรกรรมฐานข้อมูล ArangoDB รองรับธุรกรรมที่เป็นไปตาม ACID
ArangoDB อนุญาตให้ไคลเอนต์เช่นเบราว์เซอร์โต้ตอบกับฐานข้อมูลด้วย HTTP API API ที่เน้นทรัพยากรและขยายได้ด้วย JavaScript
ต่อไปนี้เป็นข้อดีของการใช้ ArangoDB -
การรวมบัญชี
ในฐานะฐานข้อมูลแบบหลายรูปแบบดั้งเดิม ArangoDB ไม่จำเป็นต้องปรับใช้ฐานข้อมูลหลายฐานข้อมูลและลดจำนวนส่วนประกอบและการบำรุงรักษา ดังนั้นจึงช่วยลดความซับซ้อนของเทคโนโลยีกองซ้อนสำหรับแอปพลิเคชัน นอกเหนือจากการรวมความต้องการทางเทคนิคโดยรวมของคุณแล้วการทำให้เข้าใจง่ายนี้ยังช่วยลดต้นทุนรวมในการเป็นเจ้าของและเพิ่มความยืดหยุ่น
การปรับขนาดประสิทธิภาพที่ง่ายขึ้น
ด้วยแอพพลิเคชั่นที่เพิ่มขึ้นเรื่อย ๆ ArangoDB สามารถจัดการกับประสิทธิภาพและความต้องการพื้นที่จัดเก็บที่เพิ่มขึ้นโดยการปรับขนาดด้วยโมเดลข้อมูลที่แตกต่างกัน เนื่องจาก ArangoDB สามารถปรับขนาดได้ทั้งแนวตั้งและแนวนอนดังนั้นในกรณีที่ประสิทธิภาพของคุณต้องการลดลง (โดยเจตนาและต้องการการชะลอตัว) ระบบแบ็คเอนด์ของคุณจึงสามารถปรับขนาดลงได้อย่างง่ายดายเพื่อประหยัดฮาร์ดแวร์และค่าใช้จ่ายในการดำเนินงาน
ลดความซับซ้อนในการดำเนินงาน
คำสั่งของ Polyglot Persistence คือการใช้เครื่องมือที่ดีที่สุดสำหรับทุกงานที่คุณทำ งานบางอย่างจำเป็นต้องมีฐานข้อมูลเอกสารในขณะที่งานอื่น ๆ อาจต้องการฐานข้อมูลกราฟ ผลจากการทำงานกับฐานข้อมูลแบบจำลองเดียวสามารถนำไปสู่ความท้าทายในการดำเนินงานหลายประการ การรวมฐานข้อมูลแบบจำลองเดียวเป็นงานที่ยากในตัวเอง แต่ความท้าทายที่ยิ่งใหญ่ที่สุดคือการสร้างโครงสร้างที่เหนียวแน่นขนาดใหญ่โดยมีความสอดคล้องของข้อมูลและความทนทานต่อข้อผิดพลาดระหว่างระบบฐานข้อมูลที่แยกจากกันและไม่เกี่ยวข้องกัน อาจพิสูจน์ได้ว่าแทบจะเป็นไปไม่ได้
Polyglot Persistence สามารถจัดการได้ด้วยฐานข้อมูลหลายรูปแบบดั้งเดิมเนื่องจากช่วยให้มีข้อมูลหลายภาษาได้อย่างง่ายดาย แต่ในขณะเดียวกันก็มีความสอดคล้องของข้อมูลในระบบที่ทนต่อความผิดพลาด ด้วย ArangoDB เราสามารถใช้แบบจำลองข้อมูลที่ถูกต้องสำหรับงานที่ซับซ้อนได้
ความสม่ำเสมอของข้อมูลที่แข็งแกร่ง
หากใช้ฐานข้อมูลแบบจำลองเดียวหลายแบบความสอดคล้องของข้อมูลอาจกลายเป็นปัญหาได้ ฐานข้อมูลเหล่านี้ไม่ได้ออกแบบมาเพื่อสื่อสารกันดังนั้นจึงต้องใช้ฟังก์ชันการทำธุรกรรมบางรูปแบบเพื่อให้ข้อมูลของคุณสอดคล้องกันระหว่างโมเดลต่างๆ
สนับสนุนการทำธุรกรรม ACID ArangoDB จัดการโมเดลข้อมูลที่แตกต่างกันของคุณด้วยแบ็คเอนด์เดียวให้ความสอดคล้องที่แข็งแกร่งในอินสแตนซ์เดียวและการดำเนินการของอะตอมเมื่อทำงานในโหมดคลัสเตอร์
ความทนทานต่อความผิดพลาด
เป็นความท้าทายในการสร้างระบบที่ทนต่อความผิดพลาดโดยมีส่วนประกอบที่ไม่เกี่ยวข้องจำนวนมาก ความท้าทายนี้จะซับซ้อนมากขึ้นเมื่อทำงานกับคลัสเตอร์ จำเป็นต้องมีความเชี่ยวชาญในการปรับใช้และบำรุงรักษาระบบดังกล่าวโดยใช้เทคโนโลยีและ / หรือเทคโนโลยีที่แตกต่างกัน ยิ่งไปกว่านั้นการรวมระบบย่อยหลายระบบซึ่งออกแบบมาให้ทำงานอย่างอิสระทำให้เกิดต้นทุนทางวิศวกรรมและการดำเนินงานจำนวนมาก
ในฐานะที่เป็นกลุ่มเทคโนโลยีที่รวมฐานข้อมูลหลายรุ่นจึงนำเสนอโซลูชันที่สวยงาม ออกแบบมาเพื่อเปิดใช้งานสถาปัตยกรรมโมดูลาร์ที่ทันสมัยพร้อมโมเดลข้อมูลที่แตกต่างกัน ArangoDB ทำงานสำหรับการใช้งานคลัสเตอร์เช่นกัน
ลดต้นทุนรวมในการเป็นเจ้าของ
เทคโนโลยีฐานข้อมูลแต่ละอย่างต้องการการบำรุงรักษาอย่างต่อเนื่องแพตช์แก้ไขข้อบกพร่องและการเปลี่ยนแปลงโค้ดอื่น ๆ ซึ่งผู้จำหน่ายให้บริการ การใช้ฐานข้อมูลหลายรุ่นช่วยลดต้นทุนการบำรุงรักษาที่เกี่ยวข้องได้อย่างมากเพียงแค่กำจัดเทคโนโลยีฐานข้อมูลจำนวนมากในการออกแบบแอปพลิเคชัน
ธุรกรรม
การให้การรับประกันการทำธุรกรรมในหลาย ๆ เครื่องถือเป็นความท้าทายอย่างแท้จริงและฐานข้อมูล NoSQL เพียงไม่กี่แห่งให้การรับประกันเหล่านี้ ArangoDB กำหนดธุรกรรมเพื่อรับประกันความสอดคล้องของข้อมูล
ในบทนี้เราจะกล่าวถึงแนวคิดและคำศัพท์พื้นฐานสำหรับ ArangoDB เป็นสิ่งสำคัญมากที่จะต้องมีความรู้เกี่ยวกับคำศัพท์พื้นฐานที่เกี่ยวข้องกับหัวข้อทางเทคนิคที่เรากำลังดำเนินการอยู่
คำศัพท์สำหรับ ArangoDB มีดังต่อไปนี้ -
- Document
- Collection
- ตัวระบุคอลเลกชัน
- ชื่อคอลเล็กชัน
- Database
- ชื่อฐานข้อมูล
- องค์กรฐานข้อมูล
จากมุมมองของแบบจำลองข้อมูล ArangoDB อาจถือได้ว่าเป็นฐานข้อมูลเชิงเอกสารเนื่องจากแนวคิดของเอกสารเป็นแนวคิดทางคณิตศาสตร์ในยุคหลัง ฐานข้อมูลเชิงเอกสารเป็นหนึ่งในประเภทหลักของฐานข้อมูล NoSQL
ลำดับชั้นจะเป็นดังนี้: เอกสารถูกจัดกลุ่มเป็นคอลเล็กชันและคอลเล็กชันจะอยู่ในฐานข้อมูล
ควรชัดเจนว่า Identifier และ Name เป็นสองแอตทริบิวต์สำหรับคอลเลกชันและฐานข้อมูล
โดยปกติเอกสารสองชุด (จุดยอด) ที่จัดเก็บในคอลเลกชันเอกสารจะเชื่อมโยงกันโดยเอกสาร (ขอบ) ที่เก็บไว้ในคอลเลกชันขอบ นี่คือโมเดลข้อมูลกราฟของ ArangoDB เป็นไปตามแนวคิดทางคณิตศาสตร์ของกราฟที่มีป้ายกำกับยกเว้นว่าขอบไม่ได้มีเพียงป้ายกำกับ แต่เป็นเอกสารเต็มรูปแบบ
เมื่อคุ้นเคยกับคำศัพท์หลักสำหรับฐานข้อมูลนี้เราจึงเริ่มเข้าใจโมเดลข้อมูลกราฟของ ArangoDB ในรุ่นนี้มีคอลเล็กชันสองประเภท: คอลเลคชันเอกสารและคอลเลกชันขอบ คอลเลกชัน Edge จัดเก็บเอกสารและยังมีคุณลักษณะพิเศษสองอย่าง: ประการแรกคือไฟล์_from แอตทริบิวต์และประการที่สองคือ _toแอตทริบิวต์ แอตทริบิวต์เหล่านี้ใช้เพื่อสร้างขอบ (ความสัมพันธ์) ระหว่างเอกสารที่จำเป็นสำหรับฐานข้อมูลกราฟ คอลเลกชันเอกสารเรียกอีกอย่างว่าคอลเลกชันจุดยอดในบริบทของกราฟ (ดูหนังสือทฤษฎีกราฟใด ๆ )
ตอนนี้ให้เราดูว่าฐานข้อมูลมีความสำคัญอย่างไร มีความสำคัญเนื่องจากมีคอลเล็กชันอยู่ภายในฐานข้อมูล ใน ArangoDB หนึ่งฐานข้อมูลอาจมีฐานข้อมูลเดียวหรือหลายฐานข้อมูลก็ได้ โดยทั่วไปฐานข้อมูลที่แตกต่างกันจะใช้สำหรับการตั้งค่าหลายผู้เช่าเนื่องจากชุดข้อมูลที่แตกต่างกันภายใน (คอลเล็กชันเอกสาร ฯลฯ ) จะแยกออกจากกัน ฐานข้อมูลเริ่มต้น_systemเป็นพิเศษเนื่องจากไม่สามารถลบออกได้ ผู้ใช้จะได้รับการจัดการในฐานข้อมูลนี้และข้อมูลประจำตัวนั้นถูกต้องสำหรับฐานข้อมูลทั้งหมดของอินสแตนซ์เซิร์ฟเวอร์
ในบทนี้เราจะพูดถึงข้อกำหนดของระบบสำหรับ ArangoDB
ข้อกำหนดของระบบสำหรับ ArangoDB มีดังต่อไปนี้ -
- เซิร์ฟเวอร์ VPS พร้อมการติดตั้ง Ubuntu
- แรม: 1 GB; ซีพียู: 2.2 GHz
สำหรับคำสั่งทั้งหมดในบทช่วยสอนนี้เราได้ใช้อินสแตนซ์ของ Ubuntu 16.04 (xenial) ของ RAM 1GB กับ CPU หนึ่งตัวที่มีกำลังประมวลผล 2.2 GHz และคำสั่ง arangosh ทั้งหมดในบทช่วยสอนนี้ได้รับการทดสอบสำหรับ ArangoDB เวอร์ชัน 3.1.27
วิธีการติดตั้ง ArangoDB
ในส่วนนี้เราจะดูวิธีการติดตั้ง ArangoDB ArangoDB มาพร้อมระบบปฏิบัติการและการแจกแจงจำนวนมาก สำหรับรายละเอียดเพิ่มเติมโปรดดูเอกสาร ArangoDB ดังที่ได้กล่าวไปแล้วสำหรับบทช่วยสอนนี้เราจะใช้ Ubuntu 16.04x64
ขั้นตอนแรกคือการดาวน์โหลดคีย์สาธารณะสำหรับที่เก็บ -
# wget https://www.arangodb.com/repositories/arangodb31/
xUbuntu_16.04/Release.keyเอาต์พุต
--2017-09-03 12:13:24-- https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04/Release.key
Resolving https://www.arangodb.com/
(www.arangodb.com)... 104.25.1 64.21, 104.25.165.21,
2400:cb00:2048:1::6819:a415, ...
Connecting to https://www.arangodb.com/
(www.arangodb.com)|104.25. 164.21|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 3924 (3.8K) [application/pgpkeys]
Saving to: ‘Release.key’
Release.key 100%[===================>] 3.83K - .-KB/s in 0.001s
2017-09-03 12:13:25 (2.61 MB/s) - ‘Release.key’ saved [39 24/3924]จุดสำคัญคือคุณควรเห็นไฟล์ Release.key บันทึกไว้ที่ส่วนท้ายของเอาต์พุต
ให้เราติดตั้งคีย์ที่บันทึกไว้โดยใช้โค้ดบรรทัดต่อไปนี้ -
# sudo apt-key add Release.keyเอาต์พุต
OKรันคำสั่งต่อไปนี้เพื่อเพิ่มที่เก็บ apt และอัพเดตดัชนี -
# sudo apt-add-repository 'deb
https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04/ /'
# sudo apt-get updateในขั้นตอนสุดท้ายเราสามารถติดตั้ง ArangoDB -
# sudo apt-get install arangodb3เอาต์พุต
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following package was automatically installed and is no longer required:
grub-pc-bin
Use 'sudo apt autoremove' to remove it.
The following NEW packages will be installed:
arangodb3
0 upgraded, 1 newly installed, 0 to remove and 17 not upgraded.
Need to get 55.6 MB of archives.
After this operation, 343 MB of additional disk space will be used.กด Enter. ตอนนี้กระบวนการติดตั้ง ArangoDB จะเริ่มขึ้น -
Get:1 https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04
arangodb3 3.1.27 [55.6 MB]
Fetched 55.6 MB in 59s (942 kB/s)
Preconfiguring packages ...
Selecting previously unselected package arangodb3.
(Reading database ... 54209 files and directories currently installed.)
Preparing to unpack .../arangodb3_3.1.27_amd64.deb ...
Unpacking arangodb3 (3.1.27) ...
Processing triggers for systemd (229-4ubuntu19) ...
Processing triggers for ureadahead (0.100.0-19) ...
Processing triggers for man-db (2.7.5-1) ...
Setting up arangodb3 (3.1.27) ...
Database files are up-to-date.เมื่อการติดตั้ง ArangoDB กำลังจะเสร็จสิ้นหน้าจอต่อไปนี้จะปรากฏขึ้น -
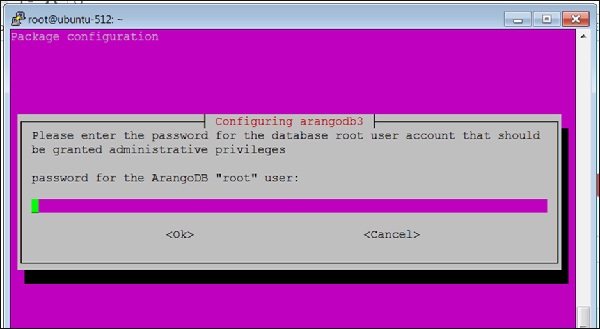
ที่นี่คุณจะถูกขอให้ระบุรหัสผ่านสำหรับ ArangoDB rootผู้ใช้ จดไว้อย่างระมัดระวัง
เลือกไฟล์ yes ตัวเลือกเมื่อกล่องโต้ตอบต่อไปนี้ปรากฏขึ้น -
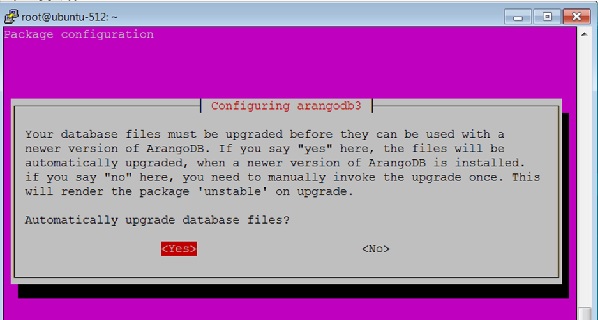
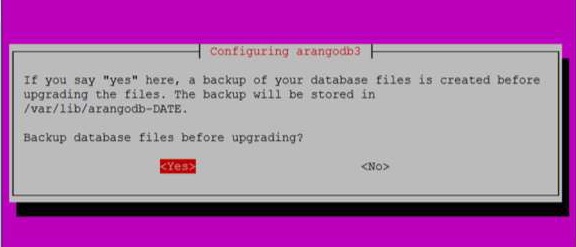
เมื่อคุณคลิก Yesดังในกล่องโต้ตอบด้านบนกล่องโต้ตอบต่อไปนี้จะปรากฏขึ้น คลิกYes ที่นี่.
คุณยังสามารถตรวจสอบสถานะของ ArangoDB ด้วยคำสั่งต่อไปนี้ -
# sudo systemctl status arangodb3เอาต์พุต
arangodb3.service - LSB: arangodb
Loaded: loaded (/etc/init.d/arangodb3; bad; vendor pre set: enabled)
Active: active (running) since Mon 2017-09-04 05:42:35 UTC;
4min 46s ago
Docs: man:systemd-sysv-generator(8)
Process: 2642 ExecStart=/etc/init.d/arangodb3 start (code = exited,
status = 0/SUC
Tasks: 22
Memory: 158.6M
CPU: 3.117s
CGroup: /system.slice/arangodb3.service
├─2689 /usr/sbin/arangod --uid arangodb
--gid arangodb --pid-file /va
└─2690 /usr/sbin/arangod --uid arangodb
--gid arangodb --pid-file /va
Sep 04 05:42:33 ubuntu-512 systemd[1]: Starting LSB: arangodb...
Sep 04 05:42:33 ubuntu-512 arangodb3[2642]: * Starting arango database server a
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: {startup} starting up in daemon mode
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: changed working directory for child
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: ...done.
Sep 04 05:42:35 ubuntu-512 systemd[1]: StartedLSB: arang odb.
Sep 04 05:46:59 ubuntu-512 systemd[1]: Started LSB: arangodb. lines 1-19/19 (END)ตอนนี้ ArangoDB พร้อมใช้งานแล้ว
ในการเรียกใช้เทอร์มินัล arangosh ให้พิมพ์คำสั่งต่อไปนี้ในเทอร์มินัล -
# arangoshเอาต์พุต
Please specify a password:จัดหา root รหัสผ่านที่สร้างขึ้นเมื่อติดตั้ง -
_
__ _ _ __ __ _ _ __ __ _ ___ | |
/ | '__/ _ | ’ \ / ` |/ _ / | ’
| (| | | | (| | | | | (| | () _ \ | | |
_,|| _,|| ||_, |_/|/| ||
|__/arangosh (ArangoDB 3.1.27 [linux] 64bit, using VPack 0.1.30, ICU 54.1, V8
5.0.71.39, OpenSSL 1.0.2g 1 Mar 2016)
Copyright (c) ArangoDB GmbH
Pretty printing values.
Connected to ArangoDB 'http+tcp://127.0.0.1:8529' version: 3.1.27 [server],
database: '_system', username: 'root'
Please note that a new minor version '3.2.2' is available
Type 'tutorial' for a tutorial or 'help' to see common examples
127.0.0.1:8529@_system> exit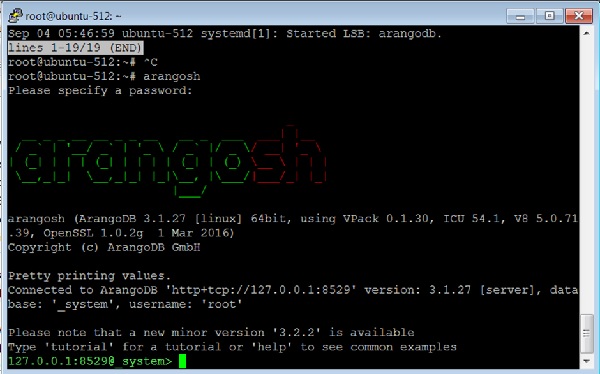
ในการออกจากระบบ ArangoDB ให้พิมพ์คำสั่งต่อไปนี้ -
127.0.0.1:8529@_system> exitเอาต์พุต
Uf wiederluege! Na shledanou! Auf Wiedersehen! Bye Bye! Adiau! ¡Hasta luego!
Εις το επανιδείν!
להתראות ! Arrivederci! Tot ziens! Adjö! Au revoir! さようなら До свидания! Até
Breve! !خداحافظในบทนี้เราจะพูดถึงวิธีการทำงานของ Arangosh เป็น Command Line สำหรับ ArangoDB เราจะเริ่มต้นด้วยการเรียนรู้วิธีการเพิ่มผู้ใช้ฐานข้อมูล
Note - จำแป้นพิมพ์ตัวเลขอาจใช้ไม่ได้กับ Arangosh
สมมติว่าผู้ใช้คือ "แฮร์รี่" และรหัสผ่านคือ "hpwdb"
127.0.0.1:8529@_system> require("org/arangodb/users").save("harry", "hpwdb");เอาต์พุต
{
"user" : "harry",
"active" : true,
"extra" : {},
"changePassword" : false,
"code" : 201
}ในบทนี้เราจะเรียนรู้วิธีการเปิด / ปิดการใช้งานการพิสูจน์ตัวตนและวิธีการผูก ArangoDB กับ Public Network Interface
# arangosh --server.endpoint tcp://127.0.0.1:8529 --server.database "_system"จะแจ้งให้คุณป้อนรหัสผ่านที่บันทึกไว้ก่อนหน้านี้ -
Please specify a password:ใช้รหัสผ่านที่คุณสร้างสำหรับรูทที่คอนฟิกูเรชัน
คุณยังสามารถใช้ curl เพื่อตรวจสอบว่าคุณได้รับการตอบสนองของเซิร์ฟเวอร์ HTTP 401 (ไม่ได้รับอนุญาต) จริงสำหรับคำขอที่ต้องการการตรวจสอบสิทธิ์ -
# curl --dump - http://127.0.0.1:8529/_api/versionเอาต์พุต
HTTP/1.1 401 Unauthorized
X-Content-Type-Options: nosniff
Www-Authenticate: Bearer token_type = "JWT", realm = "ArangoDB"
Server: ArangoDB
Connection: Keep-Alive
Content-Type: text/plain; charset = utf-8
Content-Length: 0เพื่อหลีกเลี่ยงการป้อนรหัสผ่านทุกครั้งในระหว่างกระบวนการเรียนรู้ของเราเราจะปิดใช้งานการตรวจสอบสิทธิ์ เพื่อที่จะเปิดไฟล์กำหนดค่า -
# vim /etc/arangodb3/arangod.confคุณควรเปลี่ยนรูปแบบสีหากมองไม่เห็นรหัสอย่างถูกต้อง
:colorscheme desertตั้งค่าการรับรองความถูกต้องเป็นเท็จตามที่แสดงในภาพหน้าจอด้านล่าง
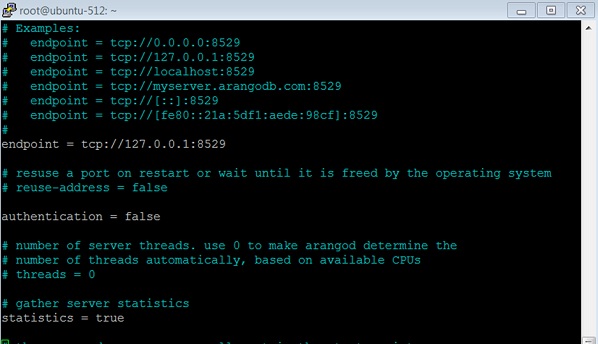
เริ่มบริการใหม่ -
# service arangodb3 restartในการตรวจสอบสิทธิ์เป็นเท็จคุณจะสามารถเข้าสู่ระบบได้ (ไม่ว่าจะด้วยรูทหรือผู้ใช้ที่สร้างขึ้นเช่น Harry ในกรณีนี้) โดยไม่ต้องป้อนรหัสผ่านใด ๆ ใน please specify a password.
ให้เราตรวจสอบไฟล์ api เวอร์ชันเมื่อปิดการตรวจสอบสิทธิ์ -
# curl --dump - http://127.0.0.1:8529/_api/versionเอาต์พุต
HTTP/1.1 200 OK
X-Content-Type-Options: nosniff
Server: ArangoDB
Connection: Keep-Alive
Content-Type: application/json; charset=utf-8
Content-Length: 60
{"server":"arango","version":"3.1.27","license":"community"}ในบทนี้เราจะพิจารณาสถานการณ์ตัวอย่างสองสถานการณ์ ตัวอย่างเหล่านี้เข้าใจง่ายขึ้นและจะช่วยให้เราเข้าใจวิธีการทำงานของ ArangoDB
เพื่อสาธิต APIs ArangoDB มาพร้อมกับชุดกราฟที่เข้าใจง่าย มีสองวิธีในการสร้างอินสแตนซ์ของกราฟเหล่านี้ใน ArangoDB ของคุณ -
- เพิ่มแท็บตัวอย่างในหน้าต่างสร้างกราฟในเว็บอินเตอร์เฟส
- หรือโหลดโมดูล @arangodb/graph-examples/example-graph ใน Arangosh
ในการเริ่มต้นให้เราโหลดกราฟด้วยความช่วยเหลือของเว็บอินเทอร์เฟซ จากนั้นให้เปิดเว็บอินเทอร์เฟซและคลิกที่ไฟล์graphs แท็บ
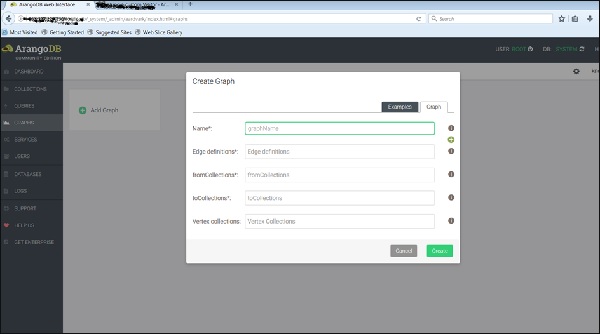
Create Graphกล่องโต้ตอบปรากฏขึ้น ตัวช่วยสร้างประกอบด้วยสองแท็บ -Examples และ Graph. Graphแท็บจะเปิดตามค่าเริ่มต้น สมมติว่าเราต้องการสร้างกราฟใหม่มันจะถามชื่อและคำจำกัดความอื่น ๆ สำหรับกราฟ
ตอนนี้เราจะอัปโหลดกราฟที่สร้างไว้แล้ว สำหรับสิ่งนี้เราจะเลือกไฟล์Examples แท็บ
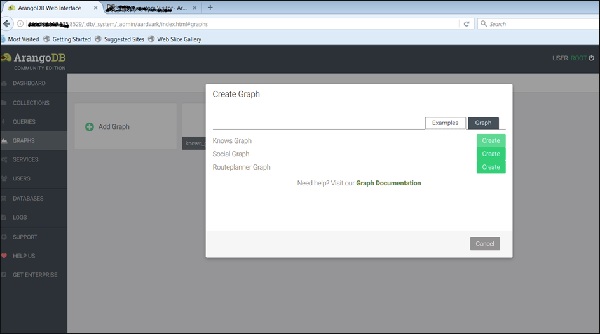
เราสามารถดูกราฟตัวอย่างทั้งสาม เลือกไฟล์Knows_Graph และคลิกที่ปุ่มสีเขียวสร้าง
เมื่อคุณสร้างแล้วคุณสามารถตรวจสอบได้ในอินเทอร์เฟซเว็บซึ่งใช้ในการสร้างรูปภาพด้านล่าง
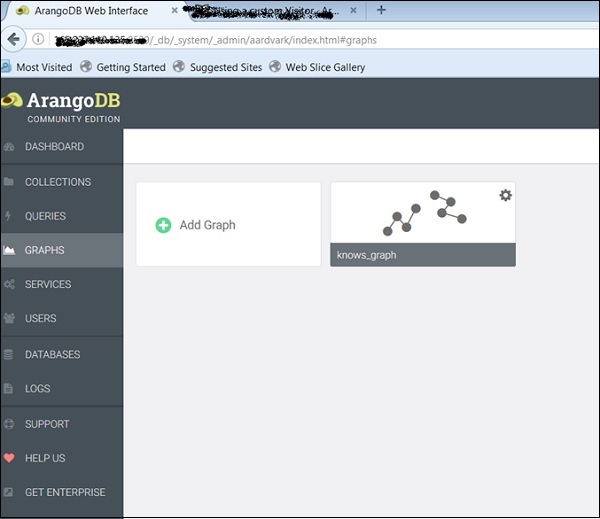
Knows_Graph
ตอนนี้ให้เราดูว่า Knows_Graphได้ผล เลือก Knows_Graph จากนั้นจะดึงข้อมูลกราฟ
Knows_Graph ประกอบด้วยคอลเล็กชันจุดยอดหนึ่งชุด persons เชื่อมต่อผ่านคอลเลกชันขอบเดียว knows. โดยจะมีบุคคลห้าคนคือ Alice, Bob, Charlie, Dave และ Eve เป็นจุดยอด เราจะมีความสัมพันธ์โดยตรงต่อไปนี้
Alice knows Bob
Bob knows Charlie
Bob knows Dave
Eve knows Alice
Eve knows Bob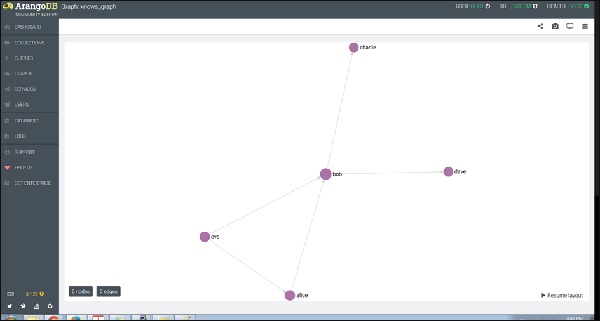
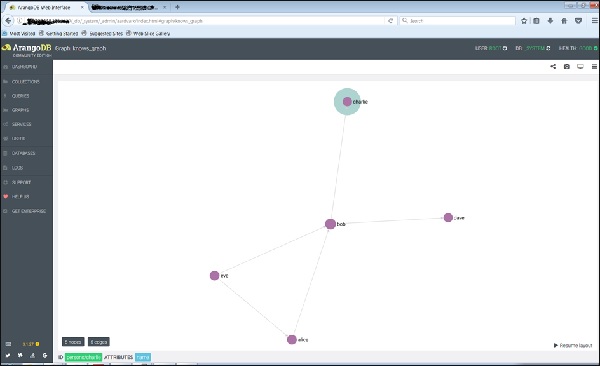
หากคุณคลิกโหนด (จุดยอด) พูดว่า 'bob' มันจะแสดงชื่อแอตทริบิวต์ ID (persons / bob)
และเมื่อคลิกที่ขอบใด ๆ ก็จะแสดงแอตทริบิวต์ ID (know / 4590)
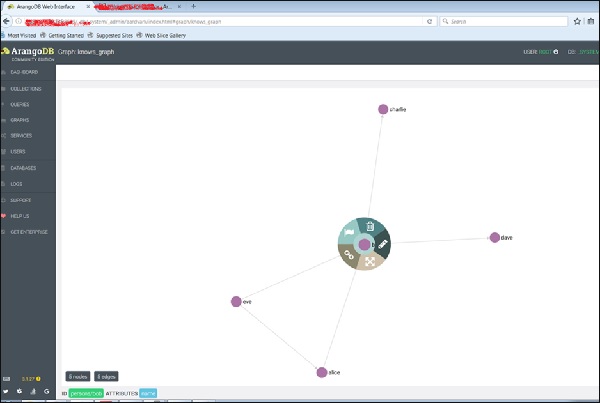
นี่คือวิธีที่เราสร้างขึ้นตรวจสอบจุดยอดและขอบ
ให้เราเพิ่มกราฟอีกครั้งคราวนี้ใช้ Arangosh ด้วยเหตุนี้เราจึงต้องรวมจุดสิ้นสุดอื่นในไฟล์คอนฟิกูเรชัน ArangoDB
วิธีเพิ่มจุดสิ้นสุดหลายจุด
เปิดไฟล์กำหนดค่า -
# vim /etc/arangodb3/arangod.confเพิ่มจุดสิ้นสุดอื่นตามที่แสดงในภาพหน้าจอเทอร์มินัลด้านล่าง
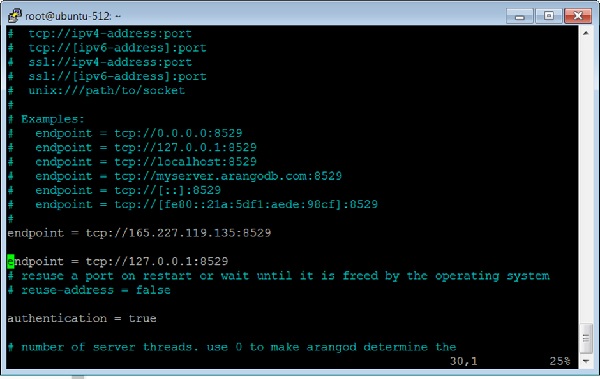
รีสตาร์ท ArangoDB -
# service arangodb3 restartเปิดตัว Arangosh -
# arangosh
Please specify a password:
_
__ _ _ __ __ _ _ __ __ _ ___ ___| |__
/ _` | '__/ _` | '_ \ / _` |/ _ \/ __| '_ \
| (_| | | | (_| | | | | (_| | (_) \__ \ | | |
\__,_|_| \__,_|_| |_|\__, |\___/|___/_| |_|
|___/
arangosh (ArangoDB 3.1.27 [linux] 64bit, using VPack 0.1.30, ICU 54.1, V8
5.0.71.39, OpenSSL 1.0.2g 1 Mar 2016)
Copyright (c) ArangoDB GmbH
Pretty printing values.
Connected to ArangoDB 'http+tcp://127.0.0.1:8529' version: 3.1.27
[server], database: '_system', username: 'root'
Please note that a new minor version '3.2.2' is available
Type 'tutorial' for a tutorial or 'help' to see common examples
127.0.0.1:8529@_system>Social_Graph
ตอนนี้ให้เราเข้าใจว่า Social_Graph คืออะไรและทำงานอย่างไร กราฟแสดงกลุ่มบุคคลและความสัมพันธ์ -
ตัวอย่างนี้มีบุคคลเพศหญิงและเพศชายเป็นจุดยอดในคอลเลกชันจุดสุดยอดสองชุด - หญิงและชาย ขอบคือการเชื่อมต่อในคอลเลกชันขอบความสัมพันธ์ เราได้อธิบายวิธีสร้างกราฟนี้โดยใช้ Arangosh ผู้อ่านสามารถแก้ไขและสำรวจคุณลักษณะของมันได้เช่นเดียวกับที่เราทำกับ Knows_Graph
ในบทนี้เราจะเน้นหัวข้อต่อไปนี้ -
- ปฏิสัมพันธ์ฐานข้อมูล
- แบบจำลองข้อมูล
- การดึงข้อมูล
ArangoDB รองรับรูปแบบข้อมูลที่ใช้เอกสารและแบบจำลองข้อมูลตามกราฟ ก่อนอื่นให้เราอธิบายรูปแบบข้อมูลตามเอกสาร
เอกสารของ ArangoDB มีลักษณะใกล้เคียงกับรูปแบบ JSON มีแอตทริบิวต์ตั้งแต่ศูนย์ขึ้นไปมีอยู่ในเอกสารและมีค่าที่แนบมากับแต่ละแอตทริบิวต์ ค่าเป็นประเภทอะตอมเช่นตัวเลขบูลีนหรือค่าว่างสตริงตามตัวอักษรหรือชนิดข้อมูลแบบผสมเช่นเอกสาร / อ็อบเจ็กต์หรืออาร์เรย์แบบฝัง อาร์เรย์หรือออบเจ็กต์ย่อยอาจประกอบด้วยชนิดข้อมูลเหล่านี้ซึ่งหมายความว่าเอกสารเดียวสามารถแสดงโครงสร้างข้อมูลที่ไม่สำคัญได้
นอกจากนี้ตามลำดับชั้นเอกสารจะถูกจัดเรียงเป็นคอลเลคชันซึ่งอาจไม่มีเอกสาร (ตามทฤษฎี) หรือเอกสารมากกว่าหนึ่งชุด เราสามารถเปรียบเทียบเอกสารกับแถวและคอลเลกชันกับตารางได้ (ในที่นี้ตารางและแถวหมายถึงระบบการจัดการฐานข้อมูลเชิงสัมพันธ์ - RDBMS)
แต่ใน RDBMS การกำหนดคอลัมน์เป็นสิ่งที่จำเป็นต้องมีในการจัดเก็บเรกคอร์ดลงในตารางโดยเรียกใช้สกีมานิยามเหล่านี้ อย่างไรก็ตามในฐานะที่เป็นคุณลักษณะใหม่ ArangoDB จึงไม่มีสคีมา - ไม่มีเหตุผลเบื้องต้นในการระบุว่าเอกสารจะมีคุณลักษณะใด
และแตกต่างจาก RDBMS เอกสารแต่ละฉบับสามารถจัดโครงสร้างได้แตกต่างจากเอกสารอื่นอย่างสิ้นเชิง เอกสารเหล่านี้สามารถบันทึกร่วมกันในคอลเลกชั่นเดียว ในทางปฏิบัติลักษณะทั่วไปอาจมีอยู่ในเอกสารในคอลเลกชันอย่างไรก็ตามระบบฐานข้อมูลเช่น ArangoDB ไม่ได้ผูกมัดคุณกับโครงสร้างข้อมูลเฉพาะ
ตอนนี้เราจะพยายามทำความเข้าใจ [ของ ArangoDBgraph data model] ซึ่งต้องใช้คอลเลคชันสองประเภทประเภทแรกคือคอลเล็กชันเอกสาร (เรียกว่าคอลเลกชันจุดยอดในภาษากลุ่ม - ทฤษฎี) ส่วนที่สองคือคอลเลกชันขอบ มีความแตกต่างเล็กน้อยระหว่างสองประเภทนี้ คอลเลกชัน Edge ยังจัดเก็บเอกสาร แต่มีลักษณะเฉพาะด้วยคุณสมบัติเฉพาะสองประการ_from และ _toสำหรับการสร้างความสัมพันธ์ระหว่างเอกสาร ในทางปฏิบัติเอกสาร (ขอบอ่าน) เชื่อมโยงเอกสารสองฉบับ (อ่านจุดยอด) ทั้งสองเก็บไว้ในคอลเลกชันที่เกี่ยวข้อง สถาปัตยกรรมนี้ได้มาจากแนวคิดทางทฤษฎีของกราฟที่มีป้ายกำกับกราฟกำกับโดยไม่รวมขอบที่มีป้ายกำกับไม่เพียง แต่สามารถเป็น JSON ที่สมบูรณ์เหมือนเอกสารได้ในตัวเอง
ในการคำนวณข้อมูลใหม่ลบเอกสารหรือจัดการข้อมูลจะใช้คิวรีซึ่งเลือกหรือกรองเอกสารตามเกณฑ์ที่กำหนด ไม่ว่าจะเป็นแบบเรียบง่ายในฐานะ "เคียวรีตัวอย่าง" หรือซับซ้อนเท่ากับ "รวม" คิวรีจะถูกเข้ารหัสใน AQL - ArangoDB Query Language
ในบทนี้เราจะพูดถึงวิธีการฐานข้อมูลต่างๆใน ArangoDB
เริ่มต้นด้วยการให้เราได้รับคุณสมบัติของฐานข้อมูล -
- Name
- ID
- Path
ก่อนอื่นเราเรียก Arangosh เมื่อเรียกใช้ Arangosh เราจะแสดงรายการฐานข้อมูลที่เราสร้างขึ้นจนถึงตอนนี้ -
เราจะใช้โค้ดบรรทัดต่อไปนี้เพื่อเรียกใช้ Arangosh -
127.0.0.1:8529@_system> db._databases()เอาต์พุต
[
"_system",
"song_collection"
]เราเห็นสองฐานข้อมูลหนึ่ง _system สร้างขึ้นโดยค่าเริ่มต้นและครั้งที่สอง song_collection ที่เราได้สร้างขึ้น
ให้เราเปลี่ยนเป็นฐานข้อมูล song_collection ด้วยรหัสบรรทัดต่อไปนี้ -
127.0.0.1:8529@_system> db._useDatabase("song_collection")เอาต์พุต
true
127.0.0.1:8529@song_collection>เราจะสำรวจคุณสมบัติของฐานข้อมูล song_collection ของเรา
เพื่อค้นหาชื่อ
เราจะใช้โค้ดบรรทัดต่อไปนี้เพื่อค้นหาชื่อ
127.0.0.1:8529@song_collection> db._name()เอาต์พุต
song_collectionเพื่อค้นหารหัส -
เราจะใช้บรรทัดของโค้ดต่อไปนี้เพื่อค้นหา id
song_collectionเอาต์พุต
4838เพื่อค้นหาเส้นทาง -
เราจะใช้โค้ดบรรทัดต่อไปนี้เพื่อค้นหาเส้นทาง
127.0.0.1:8529@song_collection> db._path()เอาต์พุต
/var/lib/arangodb3/databases/database-4838ตอนนี้ให้เราตรวจสอบว่าเราอยู่ในฐานข้อมูลระบบหรือไม่โดยใช้โค้ดบรรทัดต่อไปนี้ -
127.0.0.1:8529@song_collection&t; db._isSystem()เอาต์พุต
falseหมายความว่าเราไม่ได้อยู่ในฐานข้อมูลระบบ (ตามที่เราสร้างและเปลี่ยนไปที่ song_collection) ภาพหน้าจอต่อไปนี้จะช่วยให้คุณเข้าใจสิ่งนี้
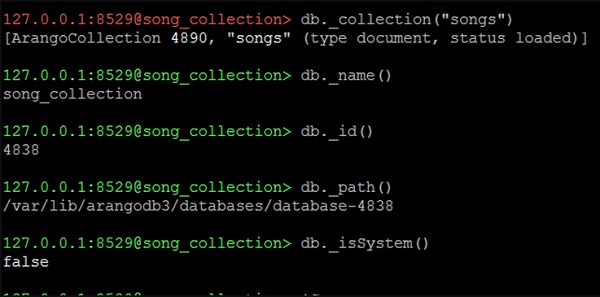
พูดเพลง -
เราจะใช้โค้ดบรรทัดต่อไปนี้เพื่อรับคอลเล็กชันเฉพาะ
127.0.0.1:8529@song_collection> db._collection("songs")เอาต์พุต
[ArangoCollection 4890, "songs" (type document, status loaded)]บรรทัดของรหัสส่งคืนคอลเล็กชันเดียว
ให้เราไปยังส่วนสำคัญของการดำเนินการฐานข้อมูลด้วยบทต่อ ๆ ไปของเรา
ในบทนี้เราจะเรียนรู้การดำเนินการต่างๆของ Arangosh
ต่อไปนี้คือการดำเนินการที่เป็นไปได้กับ Arangosh -
- การสร้างคอลเล็กชันเอกสาร
- การสร้างเอกสาร
- การอ่านเอกสาร
- การอัปเดตเอกสาร
ให้เราเริ่มต้นด้วยการสร้างฐานข้อมูลใหม่ เราจะใช้โค้ดบรรทัดต่อไปนี้เพื่อสร้างฐานข้อมูลใหม่ -
127.0.0.1:8529@_system> db._createDatabase("song_collection")
trueบรรทัดรหัสต่อไปนี้จะช่วยให้คุณเปลี่ยนไปใช้ฐานข้อมูลใหม่ -
127.0.0.1:8529@_system> db._useDatabase("song_collection")
trueข้อความแจ้งจะเปลี่ยนเป็น "@@ song_collection"
127.0.0.1:8529@song_collection>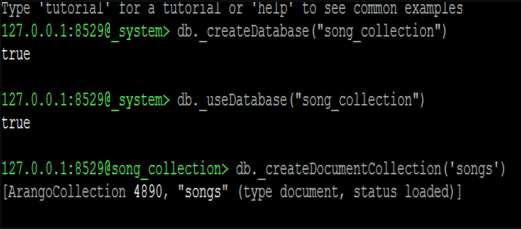
จากที่นี่เราจะศึกษาการดำเนินงานของ CRUD ให้เราสร้างคอลเลกชันลงในฐานข้อมูลใหม่ -
127.0.0.1:8529@song_collection> db._createDocumentCollection('songs')เอาต์พุต
[ArangoCollection 4890, "songs" (type document, status loaded)]
127.0.0.1:8529@song_collection>ให้เราเพิ่มเอกสารบางอย่าง (ออบเจ็กต์ JSON) ในคอลเลคชัน 'เพลง' ของเรา
เราเพิ่มเอกสารแรกด้วยวิธีต่อไปนี้ -
127.0.0.1:8529@song_collection> db.songs.save({title: "A Man's Best Friend",
lyricist: "Johnny Mercer", composer: "Johnny Mercer", Year: 1950, _key:
"A_Man"})เอาต์พุต
{
"_id" : "songs/A_Man",
"_key" : "A_Man",
"_rev" : "_VjVClbW---"
}ให้เราเพิ่มเอกสารอื่น ๆ ในฐานข้อมูล สิ่งนี้จะช่วยให้เราเรียนรู้กระบวนการสืบค้นข้อมูล คุณสามารถคัดลอกรหัสเหล่านี้และวางรหัสเดียวกันใน Arangosh เพื่อเลียนแบบกระบวนการ -
127.0.0.1:8529@song_collection> db.songs.save(
{
title: "Accentchuate The Politics",
lyricist: "Johnny Mercer",
composer: "Harold Arlen", Year: 1944,
_key: "Accentchuate_The"
}
)
{
"_id" : "songs/Accentchuate_The",
"_key" : "Accentchuate_The",
"_rev" : "_VjVDnzO---"
}
127.0.0.1:8529@song_collection> db.songs.save(
{
title: "Affable Balding Me",
lyricist: "Johnny Mercer",
composer: "Robert Emmett Dolan",
Year: 1950,
_key: "Affable_Balding"
}
)
{
"_id" : "songs/Affable_Balding",
"_key" : "Affable_Balding",
"_rev" : "_VjVEFMm---"
}วิธีอ่านเอกสาร
_keyหรือที่จับเอกสารสามารถใช้เพื่อดึงเอกสาร ใช้ตัวจัดการเอกสารหากไม่จำเป็นต้องสำรวจคอลเลกชันเอง หากคุณมีคอลเล็กชันฟังก์ชันเอกสารจะใช้งานง่าย -
127.0.0.1:8529@song_collection> db.songs.document("A_Man");
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVClbW---",
"title" : "A Man's Best Friend",
"lyricist" : "Johnny Mercer",
"composer" : "Johnny Mercer",
"Year" : 1950
}วิธีอัปเดตเอกสาร
มีสองตัวเลือกในการอัปเดตข้อมูลที่บันทึกไว้ - replace และ update.
ฟังก์ชันการอัปเดตจะแก้ไขเอกสารโดยรวมเข้ากับแอตทริบิวต์ที่กำหนด ในทางกลับกันฟังก์ชันแทนที่จะแทนที่เอกสารก่อนหน้าด้วยเอกสารใหม่ การแทนที่จะยังคงเกิดขึ้นแม้ว่าจะมีแอตทริบิวต์ที่แตกต่างกันโดยสิ้นเชิงก็ตาม ก่อนอื่นเราจะสังเกตการอัปเดตแบบไม่ทำลายการอัปเดตแอตทริบิวต์การผลิต "ในเพลง -
127.0.0.1:8529@song_collection> db.songs.update("songs/A_Man",{production:
"Top Banana"});เอาต์พุต
{
"_id" : "songs/A_Man",
"_key" : "A_Man",
"_rev" : "_VjVOcqe---",
"_oldRev" : "_VjVClbW---"
}ตอนนี้ให้เราอ่านคุณสมบัติของเพลงที่อัปเดต -
127.0.0.1:8529@song_collection> db.songs.document('A_Man');เอาต์พุต
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVOcqe---",
"title" : "A Man's Best Friend",
"lyricist" : "Johnny Mercer",
"composer" : "Johnny Mercer",
"Year" : 1950,
"production" : "Top Banana"
}เอกสารขนาดใหญ่สามารถอัปเดตได้อย่างง่ายดายด้วยไฟล์ update โดยเฉพาะเมื่อแอตทริบิวต์มีน้อยมาก
ในทางตรงกันข้ามไฟล์ replace ฟังก์ชันจะยกเลิกข้อมูลของคุณเมื่อใช้กับเอกสารเดียวกัน
127.0.0.1:8529@song_collection> db.songs.replace("songs/A_Man",{production:
"Top Banana"});ตอนนี้ให้เราตรวจสอบเพลงที่เราเพิ่งอัปเดตด้วยรหัสบรรทัดต่อไปนี้ -
127.0.0.1:8529@song_collection> db.songs.document('A_Man');เอาต์พุต
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVRhOq---",
"production" : "Top Banana"
}ตอนนี้คุณสามารถสังเกตได้ว่าเอกสารไม่มีข้อมูลเดิมอีกต่อไป
วิธีการลบเอกสาร
ฟังก์ชันลบถูกใช้ร่วมกับที่จับเอกสารเพื่อลบเอกสารออกจากคอลเลกชัน -
127.0.0.1:8529@song_collection> db.songs.remove('A_Man');ตอนนี้ให้เราตรวจสอบคุณสมบัติของเพลงที่เราเพิ่งลบออกโดยใช้โค้ดบรรทัดต่อไปนี้ -
127.0.0.1:8529@song_collection> db.songs.document('A_Man');เราจะได้รับข้อผิดพลาดข้อยกเว้นดังต่อไปนี้เป็นผลลัพธ์ -
JavaScript exception in file
'/usr/share/arangodb3/js/client/modules/@arangodb/arangosh.js' at 97,7:
ArangoError 1202: document not found
! throw error;
! ^
stacktrace: ArangoError: document not found
at Object.exports.checkRequestResult
(/usr/share/arangodb3/js/client/modules/@arangodb/arangosh.js:95:21)
at ArangoCollection.document
(/usr/share/arangodb3/js/client/modules/@arangodb/arango-collection.js:667:12)
at <shell command>:1:10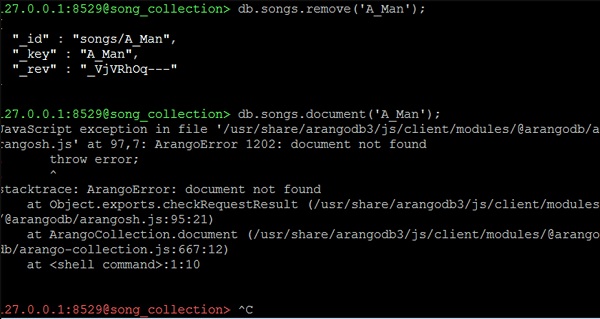
ในบทที่แล้วเราได้เรียนรู้วิธีดำเนินการต่างๆกับเอกสารด้วย Arangosh ซึ่งเป็นบรรทัดคำสั่ง ตอนนี้เราจะเรียนรู้วิธีดำเนินการเดียวกันโดยใช้เว็บอินเทอร์เฟซ เริ่มต้นด้วยการใส่ที่อยู่ต่อไปนี้ - http: // your_server_ip: 8529 / _db / song_collection / _admin / aardvark / index.html # login ในแถบที่อยู่ของเบราว์เซอร์ของคุณ คุณจะถูกนำไปยังหน้าเข้าสู่ระบบต่อไปนี้
ตอนนี้ป้อนชื่อผู้ใช้และรหัสผ่าน
หากทำได้สำเร็จหน้าจอต่อไปนี้จะปรากฏขึ้น เราจำเป็นต้องเลือกให้ฐานข้อมูลทำงานได้_systemฐานข้อมูลเป็นฐานข้อมูลเริ่มต้น ให้เราเลือกsong_collection ฐานข้อมูลและคลิกที่แท็บสีเขียว -
การสร้างคอลเล็กชัน
ในส่วนนี้เราจะเรียนรู้วิธีสร้างคอลเลกชัน กดแท็บคอลเล็กชันในแถบนำทางที่ด้านบน
คอลเลกชันเพลงที่เพิ่มบรรทัดคำสั่งของเราสามารถมองเห็นได้ คลิกที่รายการนั้นจะแสดงรายการ ตอนนี้เราจะเพิ่มไฟล์artists’คอลเลกชันโดยใช้เว็บอินเตอร์เฟส คอลเลกชันsongsที่เราสร้างด้วย Arangosh นั้นมีอยู่แล้ว ในฟิลด์ชื่อให้เขียนartists ใน New Collectionกล่องโต้ตอบที่ปรากฏขึ้น ตัวเลือกขั้นสูงสามารถละเว้นได้อย่างปลอดภัยและประเภทคอลเลกชันเริ่มต้นเช่นเอกสารก็ใช้ได้

ในที่สุดการคลิกที่ปุ่มบันทึกจะเป็นการสร้างคอลเลกชันและตอนนี้ทั้งสองคอลเล็กชันจะปรากฏในหน้านี้
เติมเอกสารที่สร้างขึ้นใหม่ในคอลเลคชัน
คุณจะเห็นคอลเล็กชันว่างเมื่อคลิกที่ไฟล์ artists คอลเลกชัน -
ในการเพิ่มเอกสารคุณต้องคลิกเครื่องหมาย + ที่มุมขวาบน เมื่อคุณได้รับพร้อมท์สำหรับไฟล์_keyป้อน Affable_Balding เป็นกุญแจสำคัญ
ตอนนี้แบบฟอร์มจะปรากฏขึ้นเพื่อเพิ่มและแก้ไขแอตทริบิวต์ของเอกสาร มีสองวิธีในการเพิ่มแอตทริบิวต์:Graphical และ Tree. วิธีกราฟิกนั้นใช้งานง่าย แต่ช้าดังนั้นเราจะเปลี่ยนไปใช้Code ดูโดยใช้เมนูแบบเลื่อนลง Tree เพื่อเลือก -
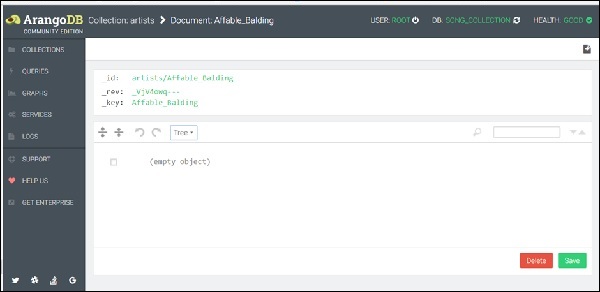
เพื่อให้กระบวนการง่ายขึ้นเราได้สร้างข้อมูลตัวอย่างในรูปแบบ JSON ซึ่งคุณสามารถคัดลอกแล้ววางลงในพื้นที่ตัวแก้ไขคิวรี -
{"artist": "Johnny Mercer", "title": "Affable Balding Me", "composer": "Robert Emmett Dolan", "Year": 1950}
(หมายเหตุ: ควรใช้วงเล็บปีกกาเพียงคู่เดียวดูภาพหน้าจอด้านล่าง)
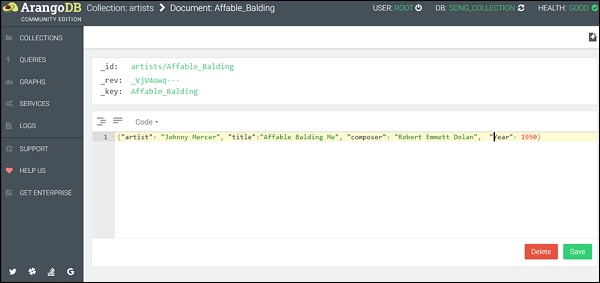
คุณสามารถสังเกตได้ว่าเราได้ยกคีย์และค่าในโหมดดูโค้ด ตอนนี้คลิกSave. เมื่อดำเนินการสำเร็จแฟลชสีเขียวจะปรากฏบนหน้านั้นชั่วขณะ
วิธีอ่านเอกสาร
หากต้องการอ่านเอกสารให้กลับไปที่หน้าคอลเล็กชัน
เมื่อคลิกที่ไฟล์ artist คอลเลกชันรายการใหม่จะปรากฏขึ้น
วิธีอัปเดตเอกสาร
การแก้ไขรายการในเอกสารทำได้ง่าย คุณเพียงแค่คลิกที่แถวที่คุณต้องการแก้ไขในภาพรวมเอกสาร ที่นี่อีกครั้งตัวแก้ไขแบบสอบถามเดียวกันจะถูกนำเสนอเมื่อสร้างเอกสารใหม่
การลบเอกสาร
คุณสามารถลบเอกสารได้โดยกดไอคอน "-" ทุกแถวเอกสารมีเครื่องหมายนี้ต่อท้าย จะแจ้งให้คุณยืนยันเพื่อหลีกเลี่ยงการลบที่ไม่ปลอดภัย
ยิ่งไปกว่านั้นสำหรับคอลเลกชันเฉพาะการดำเนินการอื่น ๆ เช่นการกรองเอกสารการจัดการดัชนีและการนำเข้าข้อมูลยังมีอยู่ในไฟล์ Collections Overview หน้า.
ในบทต่อไปเราจะพูดถึงคุณลักษณะที่สำคัญของ Web Interface นั่นคือ AQL query Editor
ในบทนี้เราจะพูดถึงวิธีการสืบค้นข้อมูลด้วย AQL เราได้กล่าวไปแล้วในบทก่อนหน้านี้ว่า ArangoDB ได้พัฒนาภาษาแบบสอบถามของตัวเองและใช้ชื่อ AQL
ให้เราเริ่มโต้ตอบกับ AQL ดังที่แสดงในภาพด้านล่างในอินเทอร์เฟซเว็บให้กดปุ่มAQL Editorแท็บวางไว้ที่ด้านบนสุดของแถบนำทาง ตัวแก้ไขแบบสอบถามว่างจะปรากฏขึ้น
เมื่อต้องการคุณสามารถเปลี่ยนไปใช้ตัวแก้ไขจากมุมมองผลลัพธ์และในทางกลับกันโดยคลิกที่แบบสอบถามหรือแท็บผลลัพธ์ที่มุมบนขวาตามที่แสดงในภาพด้านล่าง -
เหนือสิ่งอื่นใดโปรแกรมแก้ไขมีการเน้นไวยากรณ์ฟังก์ชันเลิกทำ / ทำซ้ำและการบันทึกคำค้นหา สำหรับการอ้างอิงโดยละเอียดคุณสามารถดูเอกสารอย่างเป็นทางการ เราจะเน้นคุณสมบัติพื้นฐานและใช้งานทั่วไปบางส่วนของตัวแก้ไขคิวรี AQL
พื้นฐาน AQL
ใน AQL แบบสอบถามแสดงถึงผลลัพธ์สุดท้ายที่จะบรรลุ แต่ไม่ใช่กระบวนการที่จะบรรลุผลลัพธ์สุดท้าย คุณลักษณะนี้เป็นที่รู้จักกันทั่วไปว่าเป็นคุณสมบัติที่เปิดเผยของภาษา ยิ่งไปกว่านั้น AQL สามารถสืบค้นและแก้ไขข้อมูลได้เช่นกันดังนั้นจึงสามารถสร้างแบบสอบถามที่ซับซ้อนได้โดยการรวมทั้งสองกระบวนการเข้าด้วยกัน
โปรดทราบว่า AQL เป็นไปตาม ACID ทั้งหมด การอ่านหรือแก้ไขแบบสอบถามจะสรุปทั้งหมดหรือไม่ก็ได้ แม้แต่การอ่านข้อมูลของเอกสารก็จะจบลงด้วยหน่วยข้อมูลที่สอดคล้องกัน
เราเพิ่มใหม่สองรายการ songsไปยังคอลเลคชันเพลงที่เราสร้างไว้แล้ว แทนที่จะพิมพ์คุณสามารถคัดลอกแบบสอบถามต่อไปนี้และวางลงในโปรแกรมแก้ไข AQL -
FOR song IN [
{
title: "Air-Minded Executive", lyricist: "Johnny Mercer",
composer: "Bernie Hanighen", Year: 1940, _key: "Air-Minded"
},
{
title: "All Mucked Up", lyricist: "Johnny Mercer", composer:
"Andre Previn", Year: 1974, _key: "All_Mucked"
}
]
INSERT song IN songsกดปุ่มดำเนินการที่ด้านล่างซ้าย
มันจะเขียนเอกสารใหม่สองชุดในไฟล์ songs คอลเลกชัน
แบบสอบถามนี้อธิบายถึงการทำงานของลูป FOR ใน AQL มันจะวนซ้ำในรายการเอกสารที่เข้ารหัส JSON โดยดำเนินการตามรหัสกับเอกสารแต่ละชุดในคอลเล็กชัน การดำเนินการที่แตกต่างกันสามารถสร้างโครงสร้างใหม่การกรองการเลือกเอกสารการแก้ไขหรือการแทรกเอกสารลงในฐานข้อมูล (ดูตัวอย่างทันที) โดยพื้นฐานแล้ว AQL สามารถดำเนินการ CRUD ได้อย่างมีประสิทธิภาพ
หากต้องการค้นหาเพลงทั้งหมดในฐานข้อมูลของเราให้เราเรียกใช้แบบสอบถามต่อไปนี้อีกครั้งซึ่งเทียบเท่ากับไฟล์ SELECT * FROM songs ของฐานข้อมูลประเภท SQL (เนื่องจากตัวแก้ไขจดจำแบบสอบถามสุดท้ายให้กดปุ่ม *New* ปุ่มเพื่อทำความสะอาดตัวแก้ไข) -
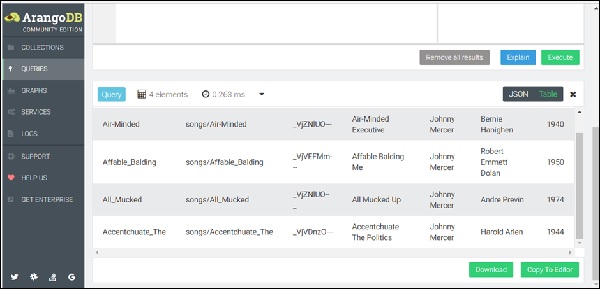
FOR song IN songs
RETURN songชุดผลลัพธ์จะแสดงรายการเพลงที่บันทึกไว้ในไฟล์ songs คอลเลกชันดังแสดงในภาพหน้าจอด้านล่าง
การดำเนินงานเช่น FILTER, SORT และ LIMIT สามารถเพิ่มลงในไฟล์ For loop ร่างกายให้แคบลงและเรียงลำดับผลลัพธ์
FOR song IN songs
FILTER song.Year > 1940
RETURN songข้อความค้นหาด้านบนจะให้เพลงที่สร้างขึ้นหลังปี 1940 ในแท็บผลลัพธ์ (ดูภาพด้านล่าง)
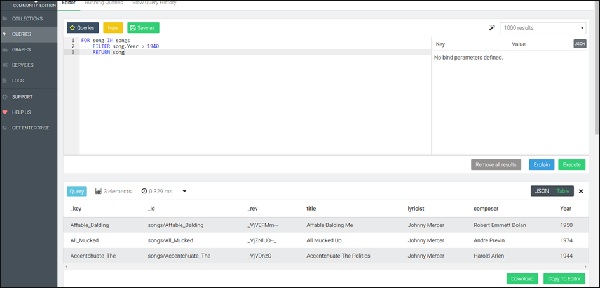
คีย์เอกสารถูกใช้ในตัวอย่างนี้ แต่แอตทริบิวต์อื่น ๆ ยังสามารถใช้เทียบเท่ากับการกรองได้ เนื่องจากคีย์เอกสารได้รับการรับรองว่าไม่ซ้ำกันจึงไม่มีเอกสารมากกว่าหนึ่งฉบับที่ตรงกับตัวกรองนี้ สำหรับแอตทริบิวต์อื่น ๆ อาจไม่เป็นเช่นนั้น ในการส่งคืนชุดย่อยของผู้ใช้ที่ใช้งานอยู่ (กำหนดโดยแอตทริบิวต์ที่เรียกว่าสถานะ) โดยเรียงตามชื่อจากน้อยไปหามากเราใช้ไวยากรณ์ต่อไปนี้ -
FOR song IN songs
FILTER song.Year > 1940
SORT song.composer
RETURN song
LIMIT 2เราได้รวมตัวอย่างนี้ไว้โดยเจตนา ที่นี่เราสังเกตเห็นข้อความแสดงข้อผิดพลาดเกี่ยวกับไวยากรณ์แบบสอบถามที่เน้นด้วยสีแดงโดย AQL ไวยากรณ์นี้เน้นข้อผิดพลาดและเป็นประโยชน์ในการแก้ไขข้อบกพร่องของการสืบค้นดังที่แสดงในภาพหน้าจอด้านล่าง
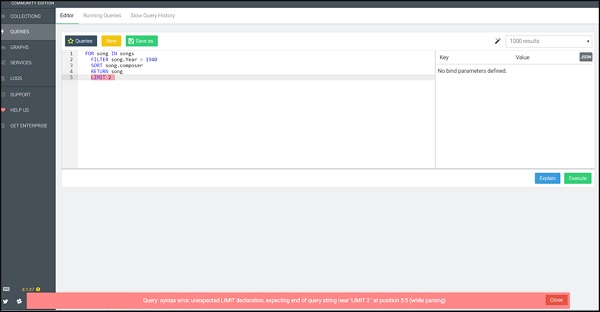
ตอนนี้ให้เราเรียกใช้แบบสอบถามที่ถูกต้อง (สังเกตการแก้ไข) -
FOR song IN songs
FILTER song.Year > 1940
SORT song.composer
LIMIT 2
RETURN song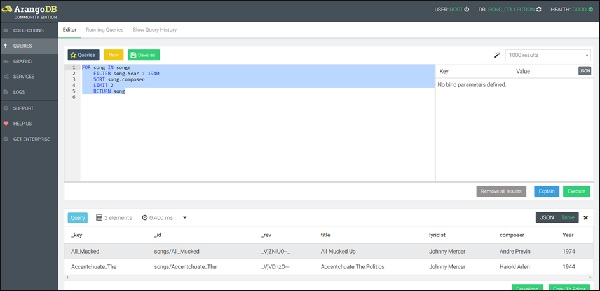
แบบสอบถามที่ซับซ้อนใน AQL
AQL มาพร้อมกับฟังก์ชั่นที่หลากหลายสำหรับประเภทข้อมูลที่รองรับทั้งหมด การกำหนดตัวแปรภายในแบบสอบถามช่วยให้สร้างโครงสร้างซ้อนที่ซับซ้อนมาก ด้วยวิธีนี้การดำเนินการที่ใช้ข้อมูลจำนวนมากจะเข้าใกล้ข้อมูลที่แบ็กเอนด์มากกว่าบนไคลเอนต์ (เช่นเบราว์เซอร์) เพื่อให้เข้าใจสิ่งนี้ก่อนอื่นให้เราเพิ่มระยะเวลา (ความยาว) ให้กับเพลง
ให้เราเริ่มต้นด้วยฟังก์ชันแรกนั่นคือฟังก์ชัน Update -
UPDATE { _key: "All_Mucked" }
WITH { length: 180 }
IN songs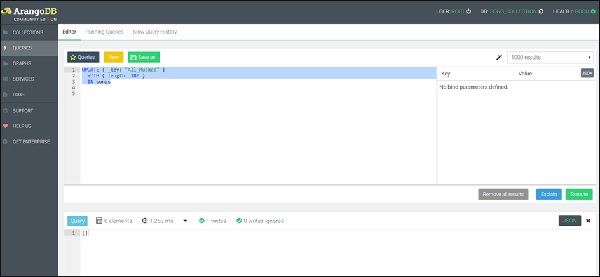
เราสามารถเห็นเอกสารหนึ่งฉบับถูกเขียนขึ้นตามที่แสดงในภาพหน้าจอด้านบน
ตอนนี้ให้เราอัปเดตเอกสารอื่น ๆ (เพลง) ด้วย
UPDATE { _key: "Affable_Balding" }
WITH { length: 200 }
IN songsตอนนี้เราสามารถตรวจสอบได้ว่าเพลงทั้งหมดของเรามีคุณลักษณะใหม่หรือไม่ length -
FOR song IN songs
RETURN songเอาต์พุต
[
{
"_key": "Air-Minded",
"_id": "songs/Air-Minded",
"_rev": "_VkC5lbS---",
"title": "Air-Minded Executive",
"lyricist": "Johnny Mercer",
"composer": "Bernie Hanighen",
"Year": 1940,
"length": 210
},
{
"_key": "Affable_Balding",
"_id": "songs/Affable_Balding",
"_rev": "_VkC4eM2---",
"title": "Affable Balding Me",
"lyricist": "Johnny Mercer",
"composer": "Robert Emmett Dolan",
"Year": 1950,
"length": 200
},
{
"_key": "All_Mucked",
"_id": "songs/All_Mucked",
"_rev": "_Vjah9Pu---",
"title": "All Mucked Up",
"lyricist": "Johnny Mercer",
"composer": "Andre Previn",
"Year": 1974,
"length": 180
},
{
"_key": "Accentchuate_The",
"_id": "songs/Accentchuate_The",
"_rev": "_VkC3WzW---",
"title": "Accentchuate The Politics",
"lyricist": "Johnny Mercer",
"composer": "Harold Arlen",
"Year": 1944,
"length": 190
}
]เพื่อแสดงให้เห็นถึงการใช้คำหลักอื่น ๆ ของ AQL เช่น LET, FILTER, SORT เป็นต้นตอนนี้เราจัดรูปแบบระยะเวลาของเพลงใน mm:ss รูปแบบ.
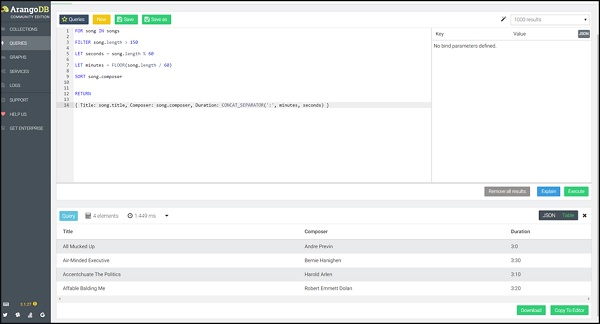
แบบสอบถาม
FOR song IN songs
FILTER song.length > 150
LET seconds = song.length % 60
LET minutes = FLOOR(song.length / 60)
SORT song.composer
RETURN
{
Title: song.title,
Composer: song.composer,
Duration: CONCAT_SEPARATOR(':',minutes, seconds)
}
คราวนี้เราจะกลับชื่อเพลงพร้อมกับระยะเวลา Return ฟังก์ชันช่วยให้คุณสร้างออบเจ็กต์ JSON ใหม่เพื่อส่งคืนสำหรับเอกสารอินพุตแต่ละรายการ
ตอนนี้เราจะพูดถึงคุณสมบัติ 'Joins' ของฐานข้อมูล AQL
เริ่มต้นด้วยการสร้างคอลเลกชัน composer_dob. นอกจากนี้เราจะสร้างเอกสารสี่ชุดพร้อมวันเดือนปีเกิดของผู้แต่งโดยการเรียกใช้แบบสอบถามต่อไปนี้ในช่องแบบสอบถาม -
FOR dob IN [
{composer: "Bernie Hanighen", Year: 1909}
,
{composer: "Robert Emmett Dolan", Year: 1922}
,
{composer: "Andre Previn", Year: 1943}
,
{composer: "Harold Arlen", Year: 1910}
]
INSERT dob in composer_dob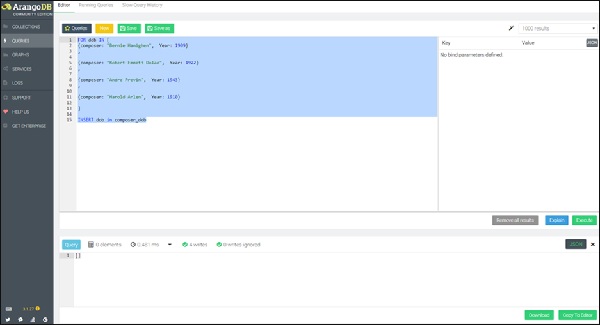
เพื่อเน้นความคล้ายคลึงกันกับ SQL เรานำเสนอแบบสอบถาม FOR-loop ที่ซ้อนกันใน AQL ซึ่งนำไปสู่การดำเนินการ REPLACE โดยจะวนซ้ำเป็นอันดับแรกในวงในจากนั้นบน dob ของผู้แต่งทั้งหมดจากนั้นในเพลงที่เกี่ยวข้องทั้งหมดสร้างเอกสารใหม่ที่มี แอตทริบิวต์ song_with_composer_key แทนที่จะเป็น song แอตทริบิวต์
นี่คือคำถาม -
FOR s IN songs
FOR c IN composer_dob
FILTER s.composer == c.composer
LET song_with_composer_key = MERGE(
UNSET(s, 'composer'),
{composer_key:c._key}
)
REPLACE s with song_with_composer_key IN songs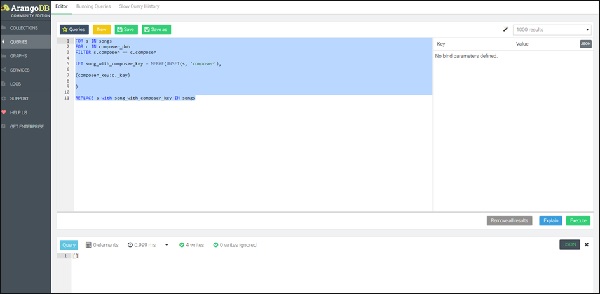
ให้เราเรียกใช้แบบสอบถาม FOR song IN songs RETURN song อีกครั้งเพื่อดูว่าคอลเลคชันเพลงเปลี่ยนไปอย่างไร
เอาต์พุต
[
{
"_key": "Air-Minded",
"_id": "songs/Air-Minded",
"_rev": "_Vk8kFoK---",
"Year": 1940,
"composer_key": "5501",
"length": 210,
"lyricist": "Johnny Mercer",
"title": "Air-Minded Executive"
},
{
"_key": "Affable_Balding",
"_id": "songs/Affable_Balding",
"_rev": "_Vk8kFoK--_",
"Year": 1950,
"composer_key": "5505",
"length": 200,
"lyricist": "Johnny Mercer",
"title": "Affable Balding Me"
},
{
"_key": "All_Mucked",
"_id": "songs/All_Mucked",
"_rev": "_Vk8kFoK--A",
"Year": 1974,
"composer_key": "5507",
"length": 180,
"lyricist": "Johnny Mercer",
"title": "All Mucked Up"
},
{
"_key": "Accentchuate_The",
"_id": "songs/Accentchuate_The",
"_rev": "_Vk8kFoK--B",
"Year": 1944,
"composer_key": "5509",
"length": 190,
"lyricist": "Johnny Mercer",
"title": "Accentchuate The Politics"
}
]ข้อความค้นหาข้างต้นเสร็จสิ้นกระบวนการย้ายข้อมูลโดยเพิ่มไฟล์ composer_key ในแต่ละเพลง
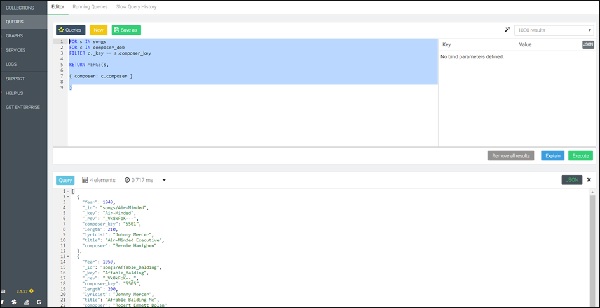
ตอนนี้คำค้นหาถัดไปเป็นการค้นหา FOR-loop ที่ซ้อนกันอีกครั้ง แต่คราวนี้นำไปสู่การดำเนินการเข้าร่วมโดยเพิ่มชื่อผู้แต่งที่เกี่ยวข้อง (เลือกด้วยความช่วยเหลือของ "composer_key`) ให้กับแต่ละเพลง -
FOR s IN songs
FOR c IN composer_dob
FILTER c._key == s.composer_key
RETURN MERGE(s,
{ composer: c.composer }
)เอาต์พุต
[
{
"Year": 1940,
"_id": "songs/Air-Minded",
"_key": "Air-Minded",
"_rev": "_Vk8kFoK---",
"composer_key": "5501",
"length": 210,
"lyricist": "Johnny Mercer",
"title": "Air-Minded Executive",
"composer": "Bernie Hanighen"
},
{
"Year": 1950,
"_id": "songs/Affable_Balding",
"_key": "Affable_Balding",
"_rev": "_Vk8kFoK--_",
"composer_key": "5505",
"length": 200,
"lyricist": "Johnny Mercer",
"title": "Affable Balding Me",
"composer": "Robert Emmett Dolan"
},
{
"Year": 1974,
"_id": "songs/All_Mucked",
"_key": "All_Mucked",
"_rev": "_Vk8kFoK--A",
"composer_key": "5507",
"length": 180,
"lyricist": "Johnny Mercer",
"title": "All Mucked Up",
"composer": "Andre Previn"
},
{
"Year": 1944,
"_id": "songs/Accentchuate_The",
"_key": "Accentchuate_The",
"_rev": "_Vk8kFoK--B",
"composer_key": "5509",
"length": 190,
"lyricist": "Johnny Mercer",
"title": "Accentchuate The Politics",
"composer": "Harold Arlen"
}
]
ในบทนี้เราจะพิจารณาตัวอย่างแบบสอบถาม AQL บางส่วนในไฟล์ Actors and Moviesฐานข้อมูล. คำค้นหาเหล่านี้อ้างอิงจากกราฟ
ปัญหา
ให้คอลเลกชันของนักแสดงและคอลเลกชันของภาพยนตร์และคอลเลกชัน actIn edge (พร้อมคุณสมบัติปี) เพื่อเชื่อมต่อจุดยอดตามที่ระบุด้านล่าง -
[Actor] <- act in -> [Movie]
เราจะได้รับอย่างไร -
- นักแสดงทุกคนที่แสดงใน "movie1" OR "movie2"?
- นักแสดงทุกคนที่แสดงทั้ง "movie1" และ "movie2"?
- ภาพยนตร์ทั่วไปทั้งหมดระหว่าง "ดารา 1" และ "นักแสดง 2"?
- นักแสดงทุกคนที่แสดงในภาพยนตร์ 3 เรื่องขึ้นไป?
- ภาพยนตร์ทั้งหมดที่มีนักแสดง 6 คนแสดง?
- จำนวนนักแสดงตามภาพยนตร์?
- จำนวนภาพยนตร์โดยนักแสดง?
- จำนวนภาพยนตร์ที่แสดงในระหว่างปี 2548 ถึง 2553 โดยนักแสดง?
วิธีการแก้
ในระหว่างกระบวนการแก้ปัญหาและรับคำตอบของคำถามข้างต้นเราจะใช้ Arangosh เพื่อสร้างชุดข้อมูลและเรียกใช้การสืบค้น ข้อความค้นหา AQL ทั้งหมดเป็นสตริงและสามารถคัดลอกไปยังไดรเวอร์ที่คุณชื่นชอบแทน Arangosh ได้
เริ่มต้นด้วยการสร้างชุดข้อมูลทดสอบใน Arangosh ก่อนอื่นให้ดาวน์โหลดไฟล์นี้ -
# wget -O dataset.js
https://drive.google.com/file/d/0B4WLtBDZu_QWMWZYZ3pYMEdqajA/view?usp=sharingเอาต์พุต
...
HTTP request sent, awaiting response... 200 OK
Length: unspecified [text/html]
Saving to: ‘dataset.js’
dataset.js [ <=> ] 115.14K --.-KB/s in 0.01s
2017-09-17 14:19:12 (11.1 MB/s) - ‘dataset.js’ saved [117907]คุณจะเห็นในผลลัพธ์ด้านบนว่าเราได้ดาวน์โหลดไฟล์ JavaScript dataset.js.ไฟล์นี้มีคำสั่ง Arangosh เพื่อสร้างชุดข้อมูลในฐานข้อมูล แทนที่จะคัดลอกและวางคำสั่งทีละคำเราจะใช้ไฟล์--javascript.executeตัวเลือกบน Arangosh เพื่อดำเนินการคำสั่งหลายคำสั่งแบบไม่โต้ตอบ พิจารณาคำสั่งช่วยชีวิต!
ตอนนี้ดำเนินการคำสั่งต่อไปนี้บนเชลล์ -
$ arangosh --javascript.execute dataset.js
ระบุรหัสผ่านเมื่อได้รับแจ้งดังที่คุณเห็นในภาพหน้าจอด้านบน ตอนนี้เราได้บันทึกข้อมูลแล้วดังนั้นเราจะสร้างแบบสอบถาม AQL เพื่อตอบคำถามเฉพาะที่เกิดขึ้นในตอนต้นของบทนี้
คำถามแรก
ให้เราถามคำถามแรก: All actors who acted in "movie1" OR "movie2". สมมติว่าเราต้องการค้นหาชื่อของนักแสดงทุกคนที่แสดงใน "TheMatrix" หรือ "TheDevilsAdvocate" -
เราจะเริ่มด้วยภาพยนตร์ทีละเรื่องเพื่อรับชื่อนักแสดง -
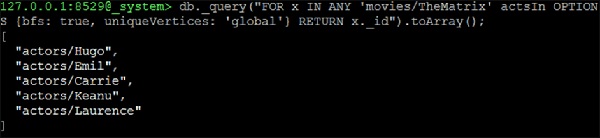
127.0.0.1:8529@_system> db._query("FOR x IN ANY 'movies/TheMatrix' actsIn
OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN x._id").toArray();เอาต์พุต
เราจะได้รับผลลัพธ์ต่อไปนี้ -
[
"actors/Hugo",
"actors/Emil",
"actors/Carrie",
"actors/Keanu",
"actors/Laurence"
]
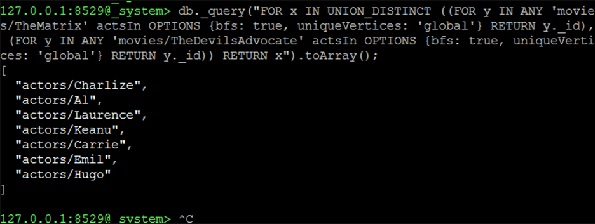
ตอนนี้เรายังคงสร้าง UNION_DISTINCT จากแบบสอบถาม NEIGHBORS สองรายการซึ่งจะเป็นทางออก -
127.0.0.1:8529@_system> db._query("FOR x IN UNION_DISTINCT ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();เอาต์พุต
[
"actors/Charlize",
"actors/Al",
"actors/Laurence",
"actors/Keanu",
"actors/Carrie",
"actors/Emil",
"actors/Hugo"
]
คำถามที่สอง
ตอนนี้ให้เราพิจารณาคำถามที่สอง: All actors who acted in both "movie1" AND "movie2". ซึ่งเกือบจะเหมือนกับคำถามข้างต้น แต่คราวนี้เราไม่สนใจ UNION แต่เป็น INTERSECTION -
127.0.0.1:8529@_system> db._query("FOR x IN INTERSECTION ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();เอาต์พุต
เราจะได้รับผลลัพธ์ต่อไปนี้ -
[
"actors/Keanu"
]
คำถามที่สาม
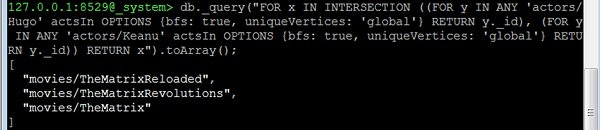
ตอนนี้ให้เราพิจารณาคำถามที่สาม: All common movies between "actor1" and "actor2". คำถามนี้เหมือนกับคำถามเกี่ยวกับนักแสดงทั่วไปใน movie1 และ movie2 เราต้องเปลี่ยนจุดเริ่มต้น ตัวอย่างเช่นให้เราค้นหาภาพยนตร์ทั้งหมดที่ Hugo Weaving ("Hugo") และ Keanu Reeves ร่วมแสดง -
127.0.0.1:8529@_system> db._query(
"FOR x IN INTERSECTION (
(
FOR y IN ANY 'actors/Hugo' actsIn OPTIONS
{bfs: true, uniqueVertices: 'global'}
RETURN y._id
),
(
FOR y IN ANY 'actors/Keanu' actsIn OPTIONS
{bfs: true, uniqueVertices:'global'} RETURN y._id
)
)
RETURN x").toArray();เอาต์พุต
เราจะได้รับผลลัพธ์ต่อไปนี้ -
[
"movies/TheMatrixReloaded",
"movies/TheMatrixRevolutions",
"movies/TheMatrix"
]
คำถามที่สี่
ตอนนี้ให้เราพิจารณาคำถามที่สี่ All actors who acted in 3 or more movies. คำถามนี้แตกต่างกัน เราไม่สามารถใช้ประโยชน์จากฟังก์ชันเพื่อนบ้านที่นี่ได้ เราจะใช้ edge-index และคำสั่ง COLLECT ของ AQL ในการจัดกลุ่มแทน แนวคิดพื้นฐานคือการจัดกลุ่มขอบทั้งหมดตามstartVertex(ซึ่งในชุดข้อมูลนี้เป็นตัวแสดงเสมอ) จากนั้นเราจะลบนักแสดงทั้งหมดที่มีภาพยนตร์น้อยกว่า 3 เรื่องออกจากผลลัพธ์เนื่องจากที่นี่เราได้รวมจำนวนภาพยนตร์ที่นักแสดงแสดงไว้ -
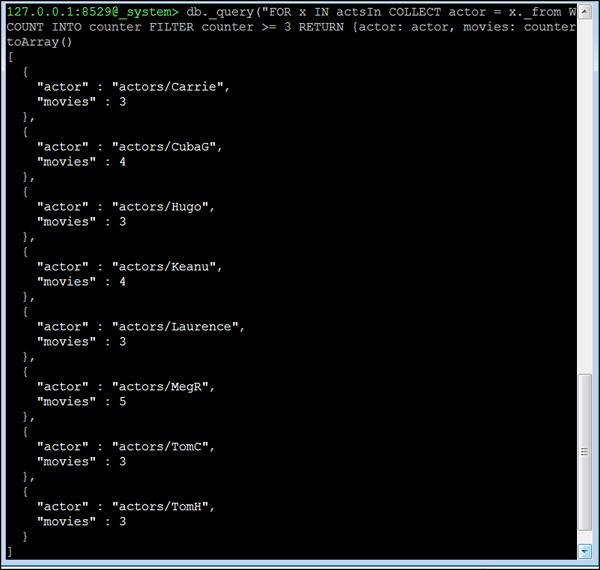
127.0.0.1:8529@_system> db._query("FOR x IN actsIn COLLECT actor = x._from WITH
COUNT INTO counter FILTER counter >= 3 RETURN {actor: actor, movies:
counter}"). toArray()เอาต์พุต
[
{
"actor" : "actors/Carrie",
"movies" : 3
},
{
"actor" : "actors/CubaG",
"movies" : 4
},
{
"actor" : "actors/Hugo",
"movies" : 3
},
{
"actor" : "actors/Keanu",
"movies" : 4
},
{
"actor" : "actors/Laurence",
"movies" : 3
},
{
"actor" : "actors/MegR",
"movies" : 5
},
{
"actor" : "actors/TomC",
"movies" : 3
},
{
"actor" : "actors/TomH",
"movies" : 3
}
]
สำหรับคำถามที่เหลือเราจะพูดคุยเกี่ยวกับรูปแบบการสืบค้นและให้เฉพาะคำถามเท่านั้น ผู้อ่านควรเรียกใช้แบบสอบถามด้วยตัวเองบนเทอร์มินัล Arangosh
คำถามที่ห้า
ตอนนี้ให้เราพิจารณาคำถามที่ห้า: All movies where exactly 6 actors acted in. แนวคิดเดียวกับในแบบสอบถามก่อนหน้านี้ แต่มีตัวกรองความเท่าเทียมกัน อย่างไรก็ตามตอนนี้เราต้องการภาพยนตร์แทนนักแสดงดังนั้นเราจึงส่งคืนไฟล์_to attribute -
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter FILTER
counter == 6 RETURN movie").toArray()จำนวนนักแสดงตามภาพยนตร์?
เราจำไว้ในชุดข้อมูลของเรา _to ตรงขอบตรงกับภาพยนตร์ดังนั้นเราจึงนับว่าบ่อยแค่ไหน _toปรากฏขึ้น นี่คือจำนวนนักแสดง แบบสอบถามเกือบจะเหมือนกันกับคำค้นหาก่อนหน้านี้without the FILTER after COLLECT -
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter RETURN
{movie: movie, actors: counter}").toArray()คำถามที่หก
ตอนนี้ให้เราพิจารณาคำถามที่หก: The number of movies by an actor.
วิธีที่เราพบวิธีแก้ไขสำหรับคำถามข้างต้นของเราจะช่วยให้คุณพบวิธีแก้ปัญหาสำหรับคำถามนี้เช่นกัน
db._query("FOR x IN actsIn COLLECT actor = x._from WITH COUNT INTO counter
RETURN {actor: actor, movies: counter}").toArray()ในบทนี้เราจะอธิบายถึงความเป็นไปได้ต่างๆในการปรับใช้ ArangoDB
การปรับใช้: อินสแตนซ์เดียว
เราได้เรียนรู้วิธีปรับใช้อินสแตนซ์เดียวของ Linux (Ubuntu) ในหนึ่งในบทก่อนหน้าของเราแล้ว ตอนนี้ให้เราดูวิธีการปรับใช้โดยใช้ Docker
การปรับใช้: Docker
สำหรับการปรับใช้โดยใช้นักเทียบท่าเราจะติดตั้ง Docker บนเครื่องของเรา สำหรับข้อมูลเพิ่มเติมเกี่ยวหางโปรดดูการกวดวิชาของเราในการเทียบท่า
เมื่อติดตั้ง Docker แล้วคุณสามารถใช้คำสั่งต่อไปนี้ -
docker run -e ARANGO_RANDOM_ROOT_PASSWORD = 1 -d --name agdb-foo -d
arangodb/arangodbมันจะสร้างและเปิดอินสแตนซ์ Docker ของ ArangoDB ด้วยชื่อที่ระบุ agdbfoo เป็นกระบวนการพื้นหลัง Docker
เทอร์มินัลจะพิมพ์ตัวระบุกระบวนการด้วย
โดยค่าเริ่มต้นพอร์ต 8529 จะสงวนไว้สำหรับ ArangoDB เพื่อรับฟังคำขอ นอกจากนี้พอร์ตนี้จะพร้อมใช้งานโดยอัตโนมัติสำหรับคอนเทนเนอร์แอปพลิเคชัน Docker ทั้งหมดที่คุณอาจเชื่อมโยงไว้