AVRO - คู่มือฉบับย่อ
ในการถ่ายโอนข้อมูลผ่านเครือข่ายหรือสำหรับพื้นที่จัดเก็บถาวรคุณต้องทำให้ข้อมูลเป็นลำดับ ก่อนหน้าserialization APIs จัดทำโดย Java และ Hadoop เรามียูทิลิตี้พิเศษที่เรียกว่า Avroซึ่งเป็นเทคนิคการจัดลำดับตามสคีมา
บทช่วยสอนนี้จะสอนวิธีการทำให้ข้อมูลเป็นอนุกรมและแยกส่วนของข้อมูลโดยใช้ Avro Avro มีไลบรารีสำหรับภาษาโปรแกรมต่างๆ ในบทช่วยสอนนี้เราจะสาธิตตัวอย่างโดยใช้ไลบรารี Java
Avro คืออะไร?
Apache Avro เป็นระบบอนุกรมข้อมูลที่เป็นกลางภาษา ได้รับการพัฒนาโดย Doug Cutting บิดาของ Hadoop เนื่องจากคลาสที่เขียนได้ของ Hadoop ไม่มีความสามารถในการพกพาภาษา Avro จึงมีประโยชน์มากเนื่องจากเกี่ยวข้องกับรูปแบบข้อมูลที่สามารถประมวลผลได้หลายภาษา Avro เป็นเครื่องมือที่ต้องการในการจัดลำดับข้อมูลใน Hadoop
Avro มีระบบตามสคีมา สคีมาที่ไม่ขึ้นกับภาษาเชื่อมโยงกับการดำเนินการอ่านและเขียน Avro ทำให้ข้อมูลเป็นอนุกรมซึ่งมีสคีมาในตัว Avro ทำให้ข้อมูลเป็นอนุกรมเป็นรูปแบบไบนารีขนาดกะทัดรัดซึ่งแอปพลิเคชันใดก็ได้
Avro ใช้รูปแบบ JSON เพื่อประกาศโครงสร้างข้อมูล ปัจจุบันรองรับภาษาต่างๆเช่น Java, C, C ++, C #, Python และ Ruby
Avro Schemas
Avro ขึ้นอยู่กับมันเป็นอย่างมาก schema. อนุญาตให้เขียนข้อมูลทั้งหมดโดยไม่มีความรู้เกี่ยวกับสคีมามาก่อน มันทำให้เป็นอนุกรมอย่างรวดเร็วและข้อมูลที่ต่อเนื่องเป็นผลลัพธ์มีขนาดน้อยกว่า สคีมาจะถูกจัดเก็บพร้อมกับข้อมูล Avro ในไฟล์สำหรับการประมวลผลเพิ่มเติม
ใน RPC ไคลเอนต์และสกีมาแลกเปลี่ยนเซิร์ฟเวอร์ระหว่างการเชื่อมต่อ การแลกเปลี่ยนนี้ช่วยในการสื่อสารระหว่างเขตข้อมูลที่มีชื่อเดียวกันเขตข้อมูลที่ขาดหายไปเขตข้อมูลเพิ่มเติม ฯลฯ
สคีมา Avro ถูกกำหนดด้วย JSON ที่ช่วยลดความยุ่งยากในการใช้งานในภาษาด้วยไลบรารี JSON
เช่นเดียวกับ Avro มีกลไกการทำให้เป็นอนุกรมอื่น ๆ ใน Hadoop เช่น Sequence Files, Protocol Buffers, และ Thrift.
เปรียบเทียบกับ Thrift และ Protocol Buffers
Thrift และ Protocol Buffersเป็นไลบรารีที่มีความสามารถมากที่สุดด้วย Avro Avro แตกต่างจากกรอบเหล่านี้ด้วยวิธีต่อไปนี้ -
Avro รองรับทั้งประเภทไดนามิกและแบบคงที่ตามความต้องการ Protocol Buffers และ Thrift ใช้ Interface Definition Languages (IDLs) เพื่อระบุสกีมาและประเภท IDL เหล่านี้ใช้ในการสร้างโค้ดสำหรับการทำให้เป็นอนุกรมและการดีซีเรียลไลเซชัน
Avro สร้างขึ้นในระบบนิเวศ Hadoop Thrift และ Protocol Buffers ไม่ได้สร้างขึ้นในระบบนิเวศ Hadoop
ซึ่งแตกต่างจาก Thrift และ Protocol Buffer คำจำกัดความของสคีมาของ Avro อยู่ใน JSON และไม่อยู่ใน IDL ที่เป็นกรรมสิทธิ์ใด ๆ
| ทรัพย์สิน | Avro | Thrift & Protocol Buffer |
|---|---|---|
| สคีมาแบบไดนามิก | ใช่ | ไม่ |
| สร้างขึ้นใน Hadoop | ใช่ | ไม่ |
| สคีมาใน JSON | ใช่ | ไม่ |
| ไม่ต้องคอมไพล์ | ใช่ | ไม่ |
| ไม่ต้องประกาศไอดี | ใช่ | ไม่ |
| ขอบเลือดออก | ใช่ | ไม่ |
คุณสมบัติของ Avro
ด้านล่างนี้เป็นคุณสมบัติเด่นบางประการของ Avro -
Avro คือไฟล์ language-neutral ระบบอนุกรมข้อมูล
สามารถประมวลผลได้หลายภาษา (ปัจจุบันคือ C, C ++, C #, Java, Python และ Ruby)
Avro สร้างรูปแบบโครงสร้างไบนารีที่เป็นทั้งสองอย่าง compressible และ splittable. ดังนั้นจึงสามารถใช้เป็นอินพุตสำหรับงาน Hadoop MapReduce ได้อย่างมีประสิทธิภาพ
Avro ให้ rich data structures. ตัวอย่างเช่นคุณสามารถสร้างเรกคอร์ดที่มีอาร์เรย์ประเภทที่แจกแจงและระเบียนย่อย ประเภทข้อมูลเหล่านี้สามารถสร้างในภาษาใดก็ได้สามารถประมวลผลใน Hadoop และผลลัพธ์สามารถป้อนเป็นภาษาที่สามได้
Avro schemas กำหนดไว้ใน JSONอำนวยความสะดวกในการใช้งานในภาษาที่มีไลบรารี JSON อยู่แล้ว
Avro สร้างไฟล์อธิบายตัวเองชื่อAvro Data Fileซึ่งจะจัดเก็บข้อมูลพร้อมกับสคีมาในส่วนข้อมูลเมตา
Avro ยังใช้ใน Remote Procedure Calls (RPCs) ระหว่าง RPC สกีมาไคลเอนต์และเซิร์ฟเวอร์แลกเปลี่ยนในการจับมือการเชื่อมต่อ
การทำงานทั่วไปของ Avro
ในการใช้ Avro คุณต้องทำตามขั้นตอนการทำงานที่กำหนด -
Step 1- สร้างสคีมา ที่นี่คุณต้องออกแบบสคีมา Avro ตามข้อมูลของคุณ
Step 2- อ่าน schemas ในโปรแกรมของคุณ ทำได้สองวิธี -
By Generating a Class Corresponding to Schema- รวบรวมสคีมาโดยใช้ Avro สิ่งนี้สร้างไฟล์คลาสที่สอดคล้องกับสคีมา
By Using Parsers Library - คุณสามารถอ่านสคีมาได้โดยตรงโดยใช้ไลบรารีตัวแยกวิเคราะห์
Step 3 - ทำให้ข้อมูลเป็นอนุกรมโดยใช้ Serialization API ที่จัดเตรียมไว้สำหรับ Avro ซึ่งพบได้ในไฟล์ package org.apache.avro.specific.
Step 4 - Deserialize ข้อมูลโดยใช้ deserialization API ที่จัดเตรียมไว้สำหรับ Avro ซึ่งพบได้ในไฟล์ package org.apache.avro.specific.
ข้อมูลถูกทำให้เป็นอนุกรมสำหรับวัตถุประสงค์สองประการ -
สำหรับการจัดเก็บถาวร
ในการขนส่งข้อมูลผ่านเครือข่าย
Serialization คืออะไร?
Serialization คือกระบวนการในการแปลโครงสร้างข้อมูลหรือสถานะของวัตถุให้อยู่ในรูปแบบไบนารีหรือแบบข้อความเพื่อขนส่งข้อมูลผ่านเครือข่ายหรือเพื่อจัดเก็บในหน่วยเก็บข้อมูลที่ยังคงมีอยู่ เมื่อข้อมูลถูกส่งผ่านเครือข่ายหรือดึงมาจากที่จัดเก็บข้อมูลถาวรข้อมูลนั้นจะต้องถูกแยกสายอีกครั้ง การทำให้เป็นอนุกรมเรียกว่าmarshalling และ deserialization เรียกว่า unmarshalling.
Serialization ใน Java
Java จัดเตรียมกลไกที่เรียกว่า object serialization โดยที่อ็อบเจ็กต์สามารถแสดงเป็นลำดับของไบต์ที่มีข้อมูลของอ็อบเจ็กต์เช่นเดียวกับข้อมูลเกี่ยวกับประเภทของอ็อบเจ็กต์และประเภทของข้อมูลที่จัดเก็บในอ็อบเจ็กต์
หลังจากที่มีการเขียนอ็อบเจ็กต์แบบอนุกรมลงในไฟล์แล้วสามารถอ่านได้จากไฟล์และ deserialized นั่นคือข้อมูลชนิดและไบต์ที่แสดงถึงอ็อบเจ็กต์และข้อมูลของอ็อบเจ็กต์สามารถใช้เพื่อสร้างอ็อบเจ็กต์ใหม่ในหน่วยความจำ
ObjectInputStream และ ObjectOutputStream คลาสถูกใช้เพื่อทำให้เป็นอนุกรมและดีซีเรียลไลซ์อ็อบเจ็กต์ตามลำดับใน Java
Serialization ใน Hadoop
โดยทั่วไปในระบบกระจายเช่น Hadoop จะใช้แนวคิดของการทำให้เป็นอนุกรมสำหรับ Interprocess Communication และ Persistent Storage.
การสื่อสารระหว่างกระบวนการ
ในการสร้างการสื่อสารระหว่างกระบวนการระหว่างโหนดที่เชื่อมต่อในเครือข่ายใช้เทคนิค RPC
RPC ใช้การทำให้เป็นอนุกรมภายในเพื่อแปลงข้อความเป็นรูปแบบไบนารีก่อนที่จะส่งไปยังโหนดระยะไกลผ่านเครือข่าย ในอีกด้านหนึ่งระบบรีโมตยกเลิกการกำหนดค่าสถานะไบนารีสตรีมลงในข้อความต้นฉบับ
รูปแบบการทำให้เป็นอนุกรม RPC จำเป็นต้องเป็นดังนี้ -
Compact - ใช้แบนด์วิธเครือข่ายให้เกิดประโยชน์สูงสุดซึ่งเป็นทรัพยากรที่หายากที่สุดในศูนย์ข้อมูล
Fast - เนื่องจากการสื่อสารระหว่างโหนดมีความสำคัญอย่างยิ่งในระบบแบบกระจายกระบวนการทำให้เป็นอนุกรมและดีซีเรียลไลเซชันจึงควรรวดเร็วทำให้มีค่าใช้จ่ายน้อยลง
Extensible - โปรโตคอลมีการเปลี่ยนแปลงอยู่ตลอดเวลาเพื่อให้เป็นไปตามข้อกำหนดใหม่ ๆ ดังนั้นจึงควรพัฒนาโปรโตคอลในลักษณะควบคุมสำหรับไคลเอนต์และเซิร์ฟเวอร์อย่างตรงไปตรงมา
Interoperable - รูปแบบข้อความควรรองรับโหนดที่เขียนในภาษาต่างๆ
ที่เก็บถาวร
Persistent Storage เป็นอุปกรณ์จัดเก็บข้อมูลดิจิทัลที่ไม่สูญเสียข้อมูลไปกับการสูญเสียแหล่งจ่ายไฟ ไฟล์โฟลเดอร์ฐานข้อมูลเป็นตัวอย่างของหน่วยเก็บข้อมูลถาวร
อินเตอร์เฟซที่เขียนได้
นี่คืออินเทอร์เฟซใน Hadoop ซึ่งมีวิธีการสำหรับการทำให้เป็นอนุกรมและการดีซีเรียลไลเซชัน ตารางต่อไปนี้อธิบายวิธีการ -
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | void readFields(DataInput in) วิธีนี้ใช้เพื่อยกเลิกการกำหนดค่าฟิลด์ของวัตถุที่กำหนด |
| 2 | void write(DataOutput out) วิธีนี้ใช้เพื่อจัดลำดับฟิลด์ของวัตถุที่กำหนด |
ส่วนต่อประสานที่สามารถเขียนได้
มันคือการรวมกันของ Writable และ Comparableอินเทอร์เฟซ อินเทอร์เฟซนี้สืบทอดWritable อินเทอร์เฟซของ Hadoop เช่นเดียวกับ Comparableอินเทอร์เฟซของ Java ดังนั้นจึงมีวิธีการสำหรับการทำให้เป็นอนุกรมข้อมูลการแยกสารและการเปรียบเทียบ
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | int compareTo(class obj) วิธีนี้เปรียบเทียบวัตถุปัจจุบันกับวัตถุที่กำหนด obj |
นอกเหนือจากคลาสเหล่านี้ Hadoop ยังรองรับคลาส Wrapper จำนวนมากที่ใช้อินเทอร์เฟซ WritableComparable แต่ละคลาสจะรวม Java primitive type ลำดับชั้นของการทำให้อนุกรม Hadoop ได้รับด้านล่าง -
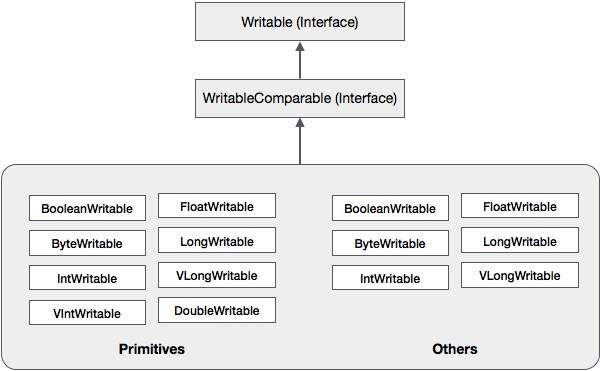
คลาสเหล่านี้มีประโยชน์ในการจัดลำดับข้อมูลประเภทต่างๆใน Hadoop ตัวอย่างเช่นให้เราพิจารณาไฟล์IntWritableชั้นเรียน ให้เรามาดูกันว่าคลาสนี้ใช้ในการทำให้เป็นอนุกรมและแยกสายข้อมูลใน Hadoop ได้อย่างไร
คลาส IntWritable
คลาสนี้ดำเนินการ Writable, Comparable, และ WritableComparableอินเทอร์เฟซ มันรวมชนิดข้อมูลจำนวนเต็มไว้ คลาสนี้จัดเตรียมเมธอดที่ใช้ในการทำให้เป็นอนุกรมและแยกประเภทของข้อมูลจำนวนเต็ม
ตัวสร้าง
| ส. | สรุป |
|---|---|
| 1 | IntWritable() |
| 2 | IntWritable( int value) |
วิธีการ
| ส. | สรุป |
|---|---|
| 1 | int get() การใช้วิธีนี้คุณจะได้รับค่าจำนวนเต็มที่มีอยู่ในวัตถุปัจจุบัน |
| 2 | void readFields(DataInput in) วิธีนี้ใช้เพื่อแยกข้อมูลในข้อมูลที่กำหนด DataInput วัตถุ. |
| 3 | void set(int value) วิธีนี้ใช้เพื่อกำหนดค่าของกระแสไฟฟ้า IntWritable วัตถุ. |
| 4 | void write(DataOutput out) วิธีนี้ใช้เพื่อจัดลำดับข้อมูลในวัตถุปัจจุบันไปยังวัตถุที่กำหนด DataOutput วัตถุ. |
การจัดลำดับข้อมูลใน Hadoop
ขั้นตอนในการจัดลำดับข้อมูลประเภทจำนวนเต็มจะกล่าวถึงด้านล่าง
ทันที IntWritable คลาสโดยการรวมค่าจำนวนเต็มไว้ในนั้น
ทันที ByteArrayOutputStream ชั้นเรียน
ทันที DataOutputStream คลาสและส่งผ่านวัตถุของ ByteArrayOutputStream ชั้นเรียนไปเลย
จัดลำดับค่าจำนวนเต็มในวัตถุ IntWritable โดยใช้ write()วิธี. เมธอดนี้ต้องการอ็อบเจ็กต์ของคลาส DataOutputStream
ข้อมูลที่ทำให้เป็นอนุกรมจะถูกเก็บไว้ในออบเจ็กต์ไบต์อาร์เรย์ซึ่งถูกส่งเป็นพารามิเตอร์ไปยัง DataOutputStreamในช่วงเวลาของการสร้างอินสแตนซ์ แปลงข้อมูลในออบเจ็กต์เป็นไบต์อาร์เรย์
ตัวอย่าง
ตัวอย่างต่อไปนี้แสดงวิธีการจัดลำดับข้อมูลประเภทจำนวนเต็มใน Hadoop -
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
public class Serialization {
public byte[] serialize() throws IOException{
//Instantiating the IntWritable object
IntWritable intwritable = new IntWritable(12);
//Instantiating ByteArrayOutputStream object
ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream();
//Instantiating DataOutputStream object
DataOutputStream dataOutputStream = new
DataOutputStream(byteoutputStream);
//Serializing the data
intwritable.write(dataOutputStream);
//storing the serialized object in bytearray
byte[] byteArray = byteoutputStream.toByteArray();
//Closing the OutputStream
dataOutputStream.close();
return(byteArray);
}
public static void main(String args[]) throws IOException{
Serialization serialization= new Serialization();
serialization.serialize();
System.out.println();
}
}Deserializing ข้อมูลใน Hadoop
ขั้นตอนในการ deserialize ประเภทของข้อมูลจะกล่าวถึงด้านล่าง -
ทันที IntWritable คลาสโดยการรวมค่าจำนวนเต็มไว้ในนั้น
ทันที ByteArrayOutputStream ชั้นเรียน
ทันที DataOutputStream คลาสและส่งผ่านวัตถุของ ByteArrayOutputStream ชั้นเรียนไปเลย
Deserialize ข้อมูลในออบเจ็กต์ของ DataInputStream โดยใช้ readFields() วิธีการของคลาส IntWritable
ข้อมูล deserialized จะถูกเก็บไว้ในออบเจ็กต์ของคลาส IntWritable คุณสามารถดึงข้อมูลนี้โดยใช้ไฟล์get() วิธีการของคลาสนี้
ตัวอย่าง
ตัวอย่างต่อไปนี้แสดงให้เห็นถึงวิธีการแยกส่วนของข้อมูลประเภทจำนวนเต็มใน Hadoop -
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import org.apache.hadoop.io.IntWritable;
public class Deserialization {
public void deserialize(byte[]byteArray) throws Exception{
//Instantiating the IntWritable class
IntWritable intwritable =new IntWritable();
//Instantiating ByteArrayInputStream object
ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray);
//Instantiating DataInputStream object
DataInputStream datainputstream=new DataInputStream(InputStream);
//deserializing the data in DataInputStream
intwritable.readFields(datainputstream);
//printing the serialized data
System.out.println((intwritable).get());
}
public static void main(String args[]) throws Exception {
Deserialization dese = new Deserialization();
dese.deserialize(new Serialization().serialize());
}
}ข้อได้เปรียบของ Hadoop ผ่าน Java Serialization
Hadoop's Writable-based Serialization สามารถลดค่าใช้จ่ายในการสร้างอ็อบเจ็กต์โดยการนำอ็อบเจ็กต์ที่เขียนได้กลับมาใช้ใหม่ซึ่งเป็นไปไม่ได้กับเฟรมเวิร์กการทำให้เป็นอนุกรมเนทีฟของ Java
ข้อเสียของ Hadoop Serialization
ในการจัดลำดับข้อมูล Hadoop มีสองวิธี -
คุณสามารถใช้ไฟล์ Writable ชั้นเรียนที่จัดทำโดยห้องสมุดพื้นเมืองของ Hadoop
คุณยังสามารถใช้ Sequence Files ซึ่งจัดเก็บข้อมูลในรูปแบบไบนารี
ข้อเสียเปรียบหลักของกลไกทั้งสองนี้คือ Writables และ SequenceFiles มีเพียง Java API และไม่สามารถเขียนหรืออ่านในภาษาอื่นได้
ดังนั้นไฟล์ใด ๆ ที่สร้างใน Hadoop ด้วยกลไกสองอย่างข้างต้นจึงไม่สามารถอ่านได้ด้วยภาษาที่สามอื่น ๆ ซึ่งทำให้ Hadoop เป็นกล่องที่ จำกัด เพื่อแก้ไขข้อเสียนี้ Doug Cutting ได้สร้างขึ้นAvro, ซึ่งคือ language independent data structure.
มูลนิธิซอฟต์แวร์ Apache นำเสนอ Avro ด้วยรุ่นต่างๆ คุณสามารถดาวน์โหลดรีลีสที่ต้องการได้จาก Apache mirrors ให้เราดูวิธีตั้งค่าสภาพแวดล้อมเพื่อทำงานกับ Avro -
กำลังดาวน์โหลด Avro
ในการดาวน์โหลด Apache Avro ให้ดำเนินการดังต่อไปนี้ -
เปิดหน้าเว็บApache.org คุณจะเห็นหน้าแรกของ Apache Avro ดังที่แสดงด้านล่าง -
คลิกที่โครงการ→การเผยแพร่ คุณจะได้รับรายชื่อเผยแพร่
เลือกรุ่นล่าสุดที่นำคุณไปสู่ลิงค์ดาวน์โหลด
mirror.nexcessเป็นหนึ่งในลิงค์ที่คุณสามารถค้นหารายชื่อไลบรารีทั้งหมดของภาษาต่างๆที่ Avro รองรับดังที่แสดงด้านล่าง -

คุณสามารถเลือกและดาวน์โหลดไลบรารีสำหรับภาษาใด ๆ ที่มีให้ ในบทช่วยสอนนี้เราใช้ Java ดังนั้นดาวน์โหลดไฟล์ jaravro-1.7.7.jar และ avro-tools-1.7.7.jar.
Avro กับ Eclipse
ในการใช้ Avro ในสภาพแวดล้อม Eclipse คุณต้องทำตามขั้นตอนที่ระบุด้านล่าง -
Step 1. เปิดคราส
Step 2. สร้างโครงการ
Step 3.คลิกขวาที่ชื่อโครงการ คุณจะได้รับเมนูทางลัด
Step 4. คลิกที่ Build Path. จะนำคุณไปสู่เมนูทางลัดอื่น
Step 5. คลิกที่ Configure Build Path... คุณสามารถดูหน้าต่างคุณสมบัติของโครงการของคุณดังที่แสดงด้านล่าง -

Step 6. ภายใต้แท็บไลบรารีคลิกที่ ADD EXternal JARs... ปุ่ม.
Step 7. เลือกไฟล์ jar avro-1.77.jar คุณได้ดาวน์โหลด
Step 8. คลิกที่ OK.
Avro กับ Maven
คุณยังสามารถรับไลบรารี Avro ในโปรเจ็กต์ของคุณโดยใช้ Maven ด้านล่างนี้คือไฟล์ pom.xml สำหรับ Avro
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=" http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>Test</groupId>
<artifactId>Test</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-tools</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.0-beta9</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.0-beta9</version>
</dependency>
</dependencies>
</project>การตั้งค่า Classpath
ในการทำงานกับ Avro ในสภาพแวดล้อม Linux ให้ดาวน์โหลดไฟล์ jar ต่อไปนี้ -
- avro-1.77.jar
- avro-tools-1.77.jar
- log4j-api-2.0-beta9.jar
- og4j-core-2.0.beta9.jar.
คัดลอกไฟล์เหล่านี้ลงในโฟลเดอร์และตั้งค่า classpath ไปที่โฟลเดอร์ในไฟล์./bashrc ไฟล์ดังที่แสดงด้านล่าง
#class path for Avro
export CLASSPATH=$CLASSPATH://home/Hadoop/Avro_Work/jars/*
Avro ซึ่งเป็นยูทิลิตี้การทำให้อนุกรมตามสคีมายอมรับสคีมาเป็นอินพุต แม้ว่าจะมีสคีมาที่หลากหลาย Avro ก็ปฏิบัติตามมาตรฐานของตัวเองในการกำหนดสคีมา แผนผังเหล่านี้อธิบายรายละเอียดต่อไปนี้ -
- ประเภทของไฟล์ (บันทึกโดยค่าเริ่มต้น)
- สถานที่บันทึก
- ชื่อของบันทึก
- เขตข้อมูลในระเบียนที่มีชนิดข้อมูลที่สอดคล้องกัน
ด้วยการใช้สกีมาเหล่านี้คุณสามารถจัดเก็บค่าอนุกรมในรูปแบบไบนารีโดยใช้พื้นที่น้อยลง ค่าเหล่านี้จะถูกจัดเก็บโดยไม่มีข้อมูลเมตา
การสร้าง Avro Schemas
สคีมา Avro ถูกสร้างขึ้นในรูปแบบเอกสาร JavaScript Object Notation (JSON) ซึ่งเป็นรูปแบบการแลกเปลี่ยนข้อมูลแบบข้อความที่มีน้ำหนักเบา มันถูกสร้างขึ้นด้วยวิธีใดวิธีหนึ่งดังต่อไปนี้ -
- สตริง JSON
- ออบเจ็กต์ JSON
- อาร์เรย์ JSON
Example - ตัวอย่างต่อไปนี้แสดงสคีมาซึ่งกำหนดเอกสารภายใต้พื้นที่ชื่อ Tutorialspoint โดยมีชื่อพนักงานมีชื่อฟิลด์และอายุ
{
"type" : "record",
"namespace" : "Tutorialspoint",
"name" : "Employee",
"fields" : [
{ "name" : "Name" , "type" : "string" },
{ "name" : "Age" , "type" : "int" }
]
}ในตัวอย่างนี้คุณจะสังเกตได้ว่าแต่ละระเบียนมีสี่ฟิลด์ -
type - ฟิลด์นี้อยู่ภายใต้เอกสารเช่นเดียวกับฟิลด์ที่มีชื่อฟิลด์
ในกรณีของเอกสารจะแสดงประเภทของเอกสารโดยทั่วไปเป็นระเบียนเนื่องจากมีหลายเขตข้อมูล
เมื่อเป็นฟิลด์ประเภทจะอธิบายประเภทข้อมูล
namespace - ฟิลด์นี้อธิบายชื่อของเนมสเปซที่ออบเจ็กต์อาศัยอยู่
name - ฟิลด์นี้อยู่ภายใต้เอกสารเช่นเดียวกับฟิลด์ที่มีชื่อฟิลด์
ในกรณีของเอกสารจะอธิบายชื่อสคีมา ชื่อสคีมานี้พร้อมกับเนมสเปซระบุสคีมาภายในร้านค้าโดยไม่ซ้ำกัน (Namespace.schema name). ในตัวอย่างข้างต้นชื่อเต็มของสคีมาจะเป็น Tutorialspoint.Employee
ในกรณีของเขตข้อมูลจะอธิบายถึงชื่อของเขตข้อมูล
ประเภทข้อมูลดั้งเดิมของ Avro
สคีมาของ Avro มีประเภทข้อมูลดั้งเดิมและประเภทข้อมูลที่ซับซ้อน ตารางต่อไปนี้อธิบายถึงไฟล์primitive data types ของ Avro -
| ประเภทข้อมูล | คำอธิบาย |
|---|---|
| โมฆะ | Null เป็นประเภทที่ไม่มีค่า |
| int | จำนวนเต็มลงนาม 32 บิต |
| ยาว | จำนวนเต็ม 64 บิตที่ลงชื่อ |
| ลอย | single precision (32-bit) เลขทศนิยม IEEE 754 |
| สองเท่า | ความแม่นยำสองเท่า (64 บิต) เลขทศนิยม IEEE 754 |
| ไบต์ | ลำดับของไบต์ที่ไม่ได้ลงชื่อ 8 บิต |
| สตริง | ลำดับอักขระ Unicode |
ประเภทข้อมูลที่ซับซ้อนของ Avro
นอกเหนือจากประเภทข้อมูลดั้งเดิมแล้ว Avro ยังมีข้อมูลที่ซับซ้อนหกประเภท ได้แก่ Records, Enums, Arrays, Maps, Unions และ Fixed
บันทึก
ชนิดข้อมูลเรกคอร์ดใน Avro คือชุดของแอตทริบิวต์หลายรายการ รองรับคุณสมบัติดังต่อไปนี้ -
name - ค่าของฟิลด์นี้ถือเป็นชื่อของเรกคอร์ด
namespace - ค่าของฟิลด์นี้ถือชื่อของเนมสเปซที่เก็บออบเจ็กต์
type - ค่าของแอตทริบิวต์นี้มีทั้งประเภทของเอกสาร (บันทึก) หรือประเภทข้อมูลของฟิลด์ในสคีมา
fields - ฟิลด์นี้มีอาร์เรย์ JSON ซึ่งมีรายการของฟิลด์ทั้งหมดในสคีมาโดยแต่ละฟิลด์จะมีชื่อและแอตทริบิวต์ประเภท
Example
ด้านล่างนี้เป็นตัวอย่างของบันทึก
{
" type " : "record",
" namespace " : "Tutorialspoint",
" name " : "Employee",
" fields " : [
{ "name" : " Name" , "type" : "string" },
{ "name" : "age" , "type" : "int" }
]
}Enum
การแจงนับคือรายการของรายการในคอลเลกชันการแจงนับ Avro สนับสนุนคุณลักษณะต่อไปนี้ -
name - ค่าของฟิลด์นี้ถือเป็นชื่อของการแจงนับ
namespace - ค่าของฟิลด์นี้ประกอบด้วยสตริงที่มีคุณสมบัติตรงตามชื่อของการแจงนับ
symbols - ค่าของฟิลด์นี้ถือสัญลักษณ์ของ enum เป็นอาร์เรย์ของชื่อ
Example
ด้านล่างเป็นตัวอย่างของการแจงนับ
{
"type" : "enum",
"name" : "Numbers",
"namespace": "data",
"symbols" : [ "ONE", "TWO", "THREE", "FOUR" ]
}อาร์เรย์
ชนิดข้อมูลนี้กำหนดฟิลด์อาร์เรย์ที่มีรายการแอตทริบิวต์เดียว แอ็ตทริบิวต์ items นี้ระบุชนิดของไอเท็มในอาร์เรย์
Example
{ " type " : " array ", " items " : " int " }แผนที่
ประเภทข้อมูลแผนที่เป็นอาร์เรย์ของคู่คีย์ - ค่าซึ่งจัดระเบียบข้อมูลเป็นคู่คีย์ - ค่า คีย์สำหรับแผนที่ Avro ต้องเป็นสตริง ค่าของแผนที่ถือประเภทข้อมูลของเนื้อหาของแผนที่
Example
{"type" : "map", "values" : "int"}สหภาพแรงงาน
ประเภทข้อมูลยูเนี่ยนถูกใช้เมื่อใดก็ตามที่เขตข้อมูลมีประเภทข้อมูลอย่างน้อยหนึ่งประเภท โดยจะแสดงเป็นอาร์เรย์ JSON ตัวอย่างเช่นหากฟิลด์ที่สามารถเป็น int หรือ null ได้ยูเนี่ยนจะแสดงเป็น ["int", "null"]
Example
ด้านล่างเป็นเอกสารตัวอย่างโดยใช้สหภาพแรงงาน -
{
"type" : "record",
"namespace" : "tutorialspoint",
"name" : "empdetails ",
"fields" :
[
{ "name" : "experience", "type": ["int", "null"] }, { "name" : "age", "type": "int" }
]
}แก้ไขแล้ว
ชนิดข้อมูลนี้ใช้เพื่อประกาศเขตข้อมูลขนาดคงที่ซึ่งสามารถใช้สำหรับจัดเก็บข้อมูลไบนารี มีชื่อฟิลด์และข้อมูลเป็นแอตทริบิวต์ ชื่อถือชื่อของเขตข้อมูลและขนาดถือขนาดของเขตข้อมูล
Example
{ "type" : "fixed" , "name" : "bdata", "size" : 1048576}ในบทที่แล้วเราได้อธิบายประเภทอินพุตของ Avro ได้แก่ Avro schemas ในบทนี้เราจะอธิบายคลาสและวิธีการที่ใช้ในการทำให้เป็นอนุกรมและการดีซีเรียลไลเซชันของสคีมาของ Avro
คลาส SpecificDatumWriter
คลาสนี้เป็นของแพ็คเกจ org.apache.avro.specific. มันใช้DatumWriter อินเทอร์เฟซซึ่งแปลงอ็อบเจ็กต์ Java เป็นรูปแบบอนุกรมในหน่วยความจำ
ตัวสร้าง
| ส. | คำอธิบาย |
|---|---|
| 1 | SpecificDatumWriter(Schema schema) |
วิธี
| ส. | คำอธิบาย |
|---|---|
| 1 | SpecificData getSpecificData() ส่งกลับการใช้งาน SpecificData ที่ใช้โดยผู้เขียนนี้ |
คลาส SpecificDatumReader
คลาสนี้เป็นของแพ็คเกจ org.apache.avro.specific. มันใช้DatumReader อินเทอร์เฟซที่อ่านข้อมูลของสคีมาและกำหนดการแสดงข้อมูลในหน่วยความจำ SpecificDatumReader เป็นคลาสที่รองรับคลาส java ที่สร้างขึ้น
ตัวสร้าง
| ส. | คำอธิบาย |
|---|---|
| 1 | SpecificDatumReader(Schema schema) สร้างที่แผนผังของผู้เขียนและผู้อ่านเหมือนกัน |
วิธีการ
| ส. | คำอธิบาย |
|---|---|
| 1 | SpecificData getSpecificData() ส่งคืนข้อมูลเฉพาะที่มีอยู่ |
| 2 | void setSchema(Schema actual) วิธีนี้ใช้เพื่อตั้งค่าสคีมาของผู้เขียน |
DataFileWriter
อินสแตนซ์ DataFileWrite สำหรับ empชั้นเรียน คลาสนี้เขียนเร็กคอร์ดที่ทำให้เป็นอนุกรมตามลำดับของข้อมูลที่สอดคล้องกับสคีมาพร้อมกับสคีมาในไฟล์
ตัวสร้าง
| ส. | คำอธิบาย |
|---|---|
| 1 | DataFileWriter(DatumWriter<D> dout) |
วิธีการ
| ส. เลขที่ | คำอธิบาย |
|---|---|
| 1 | void append(D datum) ผนวกข้อมูลเข้ากับไฟล์ |
| 2 | DataFileWriter<D> appendTo(File file) วิธีนี้ใช้เพื่อเปิดตัวเขียนที่ต่อท้ายไฟล์ที่มีอยู่ |
Data FileReader
คลาสนี้ให้การเข้าถึงโดยสุ่มไปยังไฟล์ที่เขียนด้วย DataFileWriter. มันสืบทอดคลาสDataFileStream.
ตัวสร้าง
| ส. | คำอธิบาย |
|---|---|
| 1 | DataFileReader(File file, DatumReader<D> reader)) |
วิธีการ
| ส. | คำอธิบาย |
|---|---|
| 1 | next() อ่านข้อมูลถัดไปในไฟล์ |
| 2 | Boolean hasNext() ส่งคืนจริงหากยังมีรายการอยู่ในไฟล์นี้มากขึ้น |
คลาส Schema.parser
คลาสนี้เป็นตัวแยกวิเคราะห์สำหรับสกีมารูปแบบ JSON ประกอบด้วยเมธอดในการแยกวิเคราะห์สคีมา มันเป็นของorg.apache.avro แพ็คเกจ
ตัวสร้าง
| ส. | คำอธิบาย |
|---|---|
| 1 | Schema.Parser() |
วิธีการ
| ส. | คำอธิบาย |
|---|---|
| 1 | parse (File file) แยกวิเคราะห์สคีมาที่ระบุในที่ระบุ file. |
| 2 | parse (InputStream in) แยกวิเคราะห์สคีมาที่ระบุในที่ระบุ InputStream. |
| 3 | parse (String s) แยกวิเคราะห์สคีมาที่ระบุในที่ระบุ String. |
อินเทอร์เฟซ GenricRecord
อินเทอร์เฟซนี้จัดเตรียมวิธีการเข้าถึงฟิลด์ตามชื่อและดัชนี
วิธีการ
| ส. | คำอธิบาย |
|---|---|
| 1 | Object get(String key) ส่งคืนค่าของเขตข้อมูลที่กำหนด |
| 2 | void put(String key, Object v) ตั้งค่าของเขตข้อมูลตามชื่อ |
คลาส GenericData บันทึก
ตัวสร้าง
| ส. | คำอธิบาย |
|---|---|
| 1 | GenericData.Record(Schema schema) |
วิธีการ
| ส. | คำอธิบาย |
|---|---|
| 1 | Object get(String key) ส่งคืนค่าของเขตข้อมูลของชื่อที่กำหนด |
| 2 | Schema getSchema() ส่งคืนสคีมาของอินสแตนซ์นี้ |
| 3 | void put(int i, Object v) ตั้งค่าของฟิลด์ที่กำหนดตำแหน่งในสคีมา |
| 4 | void put(String key, Object value) ตั้งค่าของเขตข้อมูลตามชื่อ |
เราสามารถอ่านสคีมา Avro ในโปรแกรมได้โดยการสร้างคลาสที่สอดคล้องกับสคีมาหรือโดยใช้ไลบรารีตัวแยกวิเคราะห์ บทนี้อธิบายวิธีการอ่านสคีมาby generating a class และ Serializing ข้อมูลโดยใช้ Avr.

การทำให้เป็นอนุกรมโดยการสร้างคลาส
ในการจัดลำดับข้อมูลโดยใช้ Avro ให้ทำตามขั้นตอนด้านล่าง -
เขียนสคีมา Avro
คอมไพล์สคีมาโดยใช้ยูทิลิตี้ Avro คุณได้รับรหัส Java ที่ตรงกับสคีมานั้น
เติมข้อมูลสคีมาด้วยข้อมูล
ทำให้เป็นอนุกรมโดยใช้ไลบรารี Avro
การกำหนดสคีมา
สมมติว่าคุณต้องการสคีมาที่มีรายละเอียดดังต่อไปนี้ -
| Field | ชื่อ | id | อายุ | เงินเดือน | ที่อยู่ |
| type | สตริง | int | int | int | สตริง |
สร้างสคีมา Avro ดังที่แสดงด้านล่าง
บันทึกเป็นไฟล์ emp.avsc.
{
"namespace": "tutorialspoint.com",
"type": "record",
"name": "emp",
"fields": [
{"name": "name", "type": "string"},
{"name": "id", "type": "int"},
{"name": "salary", "type": "int"},
{"name": "age", "type": "int"},
{"name": "address", "type": "string"}
]
}การรวบรวมสคีมา
หลังจากสร้างสคีมา Avro คุณต้องรวบรวมสคีมาที่สร้างขึ้นโดยใช้เครื่องมือ Avro avro-tools-1.7.7.jar คือโถที่มีเครื่องมือ
ไวยากรณ์เพื่อรวบรวมสคีมา Avro
java -jar <path/to/avro-tools-1.7.7.jar> compile schema <path/to/schema-file> <destination-folder>เปิดเทอร์มินัลในโฮมโฟลเดอร์
สร้างไดเร็กทอรีใหม่เพื่อทำงานกับ Avro ดังที่แสดงด้านล่าง -
$ mkdir Avro_Workในไดเร็กทอรีที่สร้างขึ้นใหม่สร้างไดเร็กทอรีย่อยสามไดเร็กทอรี -
ชื่อแรก schema, เพื่อวางสคีมา
ชื่อที่สอง with_code_gen, เพื่อวางรหัสที่สร้างขึ้น
ชื่อที่สาม jars, เพื่อวางไฟล์ jar
$ mkdir schema
$ mkdir with_code_gen
$ mkdir jarsภาพหน้าจอต่อไปนี้แสดงให้เห็นว่าไฟล์ Avro_work โฟลเดอร์ควรมีลักษณะดังนี้หลังจากสร้างไดเร็กทอรีทั้งหมด
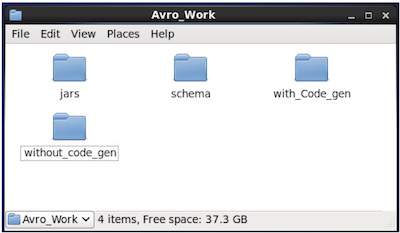
ตอนนี้ /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar คือพา ธ สำหรับไดเร็กทอรีที่คุณดาวน์โหลดไฟล์ avro-tools-1.7.7.jar
/home/Hadoop/Avro_work/schema/ คือพา ธ สำหรับไดเร็กทอรีที่เก็บไฟล์ schema ของคุณ emp.avsc
/home/Hadoop/Avro_work/with_code_gen เป็นไดเร็กทอรีที่คุณต้องการจัดเก็บไฟล์คลาสที่สร้างขึ้น
ตอนนี้รวบรวมสคีมาดังที่แสดงด้านล่าง -
$ java -jar /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar compile schema /home/Hadoop/Avro_work/schema/emp.avsc /home/Hadoop/Avro/with_code_genหลังจากคอมไพล์แพ็กเกจตามพื้นที่ชื่อของสคีมาจะถูกสร้างขึ้นในไดเร็กทอรีปลายทาง ภายในแพ็กเกจนี้ซอร์สโค้ด Java ที่มีชื่อสกีมาจะถูกสร้างขึ้น ซอร์สโค้ดที่สร้างขึ้นนี้เป็นโค้ด Java ของสคีมาที่กำหนดซึ่งสามารถใช้ในแอปพลิเคชันได้โดยตรง
ตัวอย่างเช่นในกรณีนี้แพคเกจ / โฟลเดอร์ชื่อ tutorialspoint ถูกสร้างขึ้นซึ่งมีโฟลเดอร์อื่นชื่อ com (เนื่องจากพื้นที่ชื่อคือ tutorialspoint.com) และภายในนั้นคุณสามารถสังเกตไฟล์ที่สร้างขึ้น emp.java. ภาพรวมต่อไปนี้แสดงให้เห็นemp.java -

คลาสนี้มีประโยชน์ในการสร้างข้อมูลตามสคีมา
คลาสที่สร้างขึ้นประกอบด้วย -
- ตัวสร้างเริ่มต้นและตัวสร้างพารามิเตอร์ซึ่งยอมรับตัวแปรทั้งหมดของสคีมา
- เมธอด setter และ getter สำหรับตัวแปรทั้งหมดในสคีมา
- Get () วิธีการที่ส่งคืนสคีมา
- วิธีการสร้าง
การสร้างและอนุกรมข้อมูล
ก่อนอื่นให้คัดลอกไฟล์ java ที่สร้างขึ้นซึ่งใช้ในโปรเจ็กต์นี้ไปยังไดเร็กทอรีปัจจุบันหรือนำเข้าจากตำแหน่งที่อยู่
ตอนนี้เราสามารถเขียนไฟล์ Java ใหม่และสร้างอินสแตนซ์คลาสในไฟล์ที่สร้างขึ้น (emp) เพื่อเพิ่มข้อมูลพนักงานในสคีมา
ให้เราดูขั้นตอนในการสร้างข้อมูลตามสคีมาโดยใช้ apache Avro
ขั้นตอนที่ 1
สร้างอินสแตนซ์ที่สร้างขึ้น emp ชั้นเรียน
emp e1=new emp( );ขั้นตอนที่ 2
ใช้วิธีการ setter ใส่ข้อมูลของพนักงานคนแรก ตัวอย่างเช่นเราได้สร้างรายละเอียดของพนักงานชื่อ Omar
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);ในทำนองเดียวกันให้กรอกรายละเอียดพนักงานทั้งหมดโดยใช้วิธี setter
ขั้นตอนที่ 3
สร้างวัตถุของ DatumWriter อินเทอร์เฟซโดยใช้ SpecificDatumWriterชั้นเรียน สิ่งนี้จะแปลงวัตถุ Java เป็นรูปแบบอนุกรมในหน่วยความจำ ตัวอย่างต่อไปนี้สร้างอินสแตนซ์SpecificDatumWriter คลาสออบเจ็กต์สำหรับ emp ชั้นเรียน
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);ขั้นตอนที่ 4
ทันที DataFileWriter สำหรับ empชั้นเรียน คลาสนี้เขียนเร็กคอร์ดลำดับที่เป็นลำดับของข้อมูลที่สอดคล้องกับสคีมาพร้อมกับสคีมาในไฟล์ คลาสนี้ต้องการไฟล์DatumWriter วัตถุเป็นพารามิเตอร์ของตัวสร้าง
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);ขั้นตอนที่ 5
เปิดไฟล์ใหม่เพื่อจัดเก็บข้อมูลที่ตรงกับสคีมาที่กำหนดโดยใช้ create()วิธี. วิธีนี้ต้องใช้สคีมาและเส้นทางของไฟล์ที่จะจัดเก็บข้อมูลเป็นพารามิเตอร์
ในตัวอย่างต่อไปนี้สคีมาจะถูกส่งผ่านโดยใช้ getSchema() วิธีการและไฟล์ข้อมูลจะถูกเก็บไว้ในเส้นทาง - /home/Hadoop/Avro/serialized_file/emp.avro.
empFileWriter.create(e1.getSchema(),new File("/home/Hadoop/Avro/serialized_file/emp.avro"));ขั้นตอนที่ 6
เพิ่มเรกคอร์ดที่สร้างขึ้นทั้งหมดลงในไฟล์โดยใช้ append() วิธีการดังแสดงด้านล่าง -
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);ตัวอย่าง - การทำให้เป็นอนุกรมโดยการสร้างคลาส
โปรแกรมที่สมบูรณ์ต่อไปนี้แสดงวิธีการจัดลำดับข้อมูลลงในไฟล์โดยใช้ Apache Avro -
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.specific.SpecificDatumWriter;
public class Serialize {
public static void main(String args[]) throws IOException{
//Instantiating generated emp class
emp e1=new emp();
//Creating values according the schema
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);
emp e2=new emp();
e2.setName("ram");
e2.setAge(30);
e2.setSalary(40000);
e2.setAddress("Hyderabad");
e2.setId(002);
emp e3=new emp();
e3.setName("robbin");
e3.setAge(25);
e3.setSalary(35000);
e3.setAddress("Hyderabad");
e3.setId(003);
//Instantiate DatumWriter class
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);
empFileWriter.create(e1.getSchema(), new File("/home/Hadoop/Avro_Work/with_code_gen/emp.avro"));
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);
empFileWriter.close();
System.out.println("data successfully serialized");
}
}เรียกดูไดเร็กทอรีที่วางโค้ดที่สร้างขึ้น ในกรณีนี้ที่home/Hadoop/Avro_work/with_code_gen.
In Terminal −
$ cd home/Hadoop/Avro_work/with_code_gen/In GUI −
ตอนนี้คัดลอกและบันทึกโปรแกรมข้างต้นในไฟล์ชื่อ Serialize.java
รวบรวมและดำเนินการตามที่แสดงด้านล่าง -
$ javac Serialize.java
$ java Serializeเอาต์พุต
data successfully serializedหากคุณตรวจสอบเส้นทางที่ระบุในโปรแกรมคุณจะพบไฟล์ซีเรียลที่สร้างขึ้นดังที่แสดงด้านล่าง
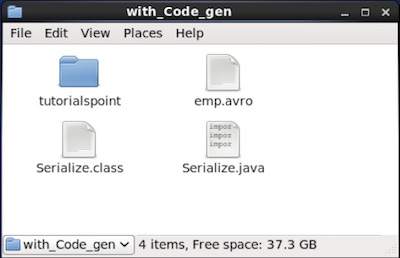
ตามที่อธิบายไว้ก่อนหน้านี้เราสามารถอ่านสคีมา Avro ในโปรแกรมได้โดยการสร้างคลาสที่สอดคล้องกับสคีมาหรือโดยใช้ไลบรารีตัวแยกวิเคราะห์ บทนี้อธิบายวิธีการอ่านสคีมาby generating a class และ Deserialize ข้อมูลโดยใช้ Avro
Deserialization โดยการสร้างคลาส
ข้อมูลอนุกรมจะถูกเก็บไว้ในไฟล์ emp.avro. คุณสามารถ deserialize และอ่านโดยใช้ Avro

ทำตามขั้นตอนที่ระบุด้านล่างเพื่อแยกข้อมูลซีเรียลออกจากไฟล์
ขั้นตอนที่ 1
สร้างวัตถุของ DatumReader อินเทอร์เฟซโดยใช้ SpecificDatumReader ชั้นเรียน
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);ขั้นตอนที่ 2
ทันที DataFileReader สำหรับ empชั้นเรียน คลาสนี้อ่านข้อมูลอนุกรมจากไฟล์ มันต้องใช้Dataumeader อ็อบเจ็กต์และพา ธ ของไฟล์ที่มีข้อมูลซีเรียลไลซ์เป็นพารามิเตอร์ไปยังคอนสตรัคเตอร์
DataFileReader<emp> dataFileReader = new DataFileReader(new File("/path/to/emp.avro"), empDatumReader);ขั้นตอนที่ 3
พิมพ์ข้อมูล deserialized โดยใช้วิธีการ DataFileReader.
hasNext() วิธีการจะส่งคืนบูลีนหากมีองค์ประกอบใด ๆ ใน Reader
next() วิธีการของ DataFileReader ส่งคืนข้อมูลใน Reader
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}ตัวอย่าง - Deserialization โดยการสร้างคลาส
โปรแกรมที่สมบูรณ์ต่อไปนี้แสดงวิธีการแยกข้อมูลในไฟล์โดยใช้ Avro
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileReader;
import org.apache.avro.io.DatumReader;
import org.apache.avro.specific.SpecificDatumReader;
public class Deserialize {
public static void main(String args[]) throws IOException{
//DeSerializing the objects
DatumReader<emp> empDatumReader = new SpecificDatumReader<emp>(emp.class);
//Instantiating DataFileReader
DataFileReader<emp> dataFileReader = new DataFileReader<emp>(new
File("/home/Hadoop/Avro_Work/with_code_genfile/emp.avro"), empDatumReader);
emp em=null;
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}
}
}เรียกดูไดเร็กทอรีที่วางโค้ดที่สร้างขึ้น ในกรณีนี้ที่home/Hadoop/Avro_work/with_code_gen.
$ cd home/Hadoop/Avro_work/with_code_gen/ตอนนี้คัดลอกและบันทึกโปรแกรมข้างต้นในไฟล์ชื่อ DeSerialize.java. รวบรวมและดำเนินการตามที่แสดงด้านล่าง -
$ javac Deserialize.java
$ java Deserializeเอาต์พุต
{"name": "omar", "id": 1, "salary": 30000, "age": 21, "address": "Hyderabad"}
{"name": "ram", "id": 2, "salary": 40000, "age": 30, "address": "Hyderabad"}
{"name": "robbin", "id": 3, "salary": 35000, "age": 25, "address": "Hyderabad"}เราสามารถอ่านสคีมาของ Avro ในโปรแกรมได้โดยการสร้างคลาสที่สอดคล้องกับสคีมาหรือโดยใช้ไลบรารีตัวแยกวิเคราะห์ ใน Avro ข้อมูลจะถูกจัดเก็บด้วยสคีมาที่เกี่ยวข้องเสมอ ดังนั้นเราสามารถอ่านสคีมาได้ตลอดเวลาโดยไม่ต้องสร้างโค้ด
บทนี้อธิบายวิธีการอ่านสคีมา by using parsers library และ serialize ข้อมูลโดยใช้ Avro

การทำให้เป็นอนุกรมโดยใช้ไลบรารีพาร์เซอร์
ในการทำให้ข้อมูลเป็นอนุกรมเราต้องอ่านสคีมาสร้างข้อมูลตามสคีมาและจัดลำดับสคีมาโดยใช้ Avro API ขั้นตอนต่อไปนี้ทำให้ข้อมูลเป็นอนุกรมโดยไม่ต้องสร้างรหัสใด ๆ -
ขั้นตอนที่ 1
ก่อนอื่นอ่านสคีมาจากไฟล์ โดยใช้Schema.Parserชั้นเรียน คลาสนี้จัดเตรียมเมธอดในการแยกวิเคราะห์สคีมาในรูปแบบต่างๆ
เริ่มต้นไฟล์ Schema.Parser คลาสโดยส่งเส้นทางไฟล์ที่เก็บสคีมา
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));ขั้นตอนที่ 2
สร้างวัตถุของ GenericRecord อินเทอร์เฟซโดยการสร้างอินสแตนซ์ GenericData.Recordคลาสดังที่แสดงด้านล่าง ส่งผ่านวัตถุสคีมาที่สร้างไว้ข้างต้นไปยังตัวสร้าง
GenericRecord e1 = new GenericData.Record(schema);ขั้นตอนที่ 3
แทรกค่าในสคีมาโดยใช้ put() วิธีการของ GenericData ชั้นเรียน
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chennai");ขั้นตอนที่ 4
สร้างวัตถุของ DatumWriter อินเทอร์เฟซโดยใช้ SpecificDatumWriterชั้นเรียน มันแปลงวัตถุ Java เป็นรูปแบบอนุกรมในหน่วยความจำ ตัวอย่างต่อไปนี้สร้างอินสแตนซ์SpecificDatumWriter คลาสออบเจ็กต์สำหรับ emp ชั้นเรียน -
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);ขั้นตอนที่ 5
ทันที DataFileWriter สำหรับ empชั้นเรียน คลาสนี้เขียนเร็กคอร์ดที่เป็นอนุกรมของข้อมูลที่สอดคล้องกับสคีมาพร้อมกับสคีมาในไฟล์ คลาสนี้ต้องการไฟล์DatumWriter วัตถุเป็นพารามิเตอร์ของตัวสร้าง
DataFileWriter<emp> dataFileWriter = new DataFileWriter<emp>(empDatumWriter);ขั้นตอนที่ 6
เปิดไฟล์ใหม่เพื่อจัดเก็บข้อมูลที่ตรงกับสคีมาที่กำหนดโดยใช้ create()วิธี. วิธีนี้ต้องใช้สคีมาและเส้นทางของไฟล์ที่จะจัดเก็บข้อมูลเป็นพารามิเตอร์
ในตัวอย่างที่ระบุด้านล่างสคีมาจะถูกส่งผ่านโดยใช้ getSchema() วิธีการและไฟล์ข้อมูลจะถูกเก็บไว้ในเส้นทาง
/home/Hadoop/Avro/serialized_file/emp.avro.
empFileWriter.create(e1.getSchema(), new
File("/home/Hadoop/Avro/serialized_file/emp.avro"));ขั้นตอนที่ 7
เพิ่มเรกคอร์ดที่สร้างขึ้นทั้งหมดลงในไฟล์โดยใช้ append( ) วิธีการดังแสดงด้านล่าง
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);ตัวอย่าง - การทำให้เป็นอนุกรมโดยใช้พาร์เซอร์
โปรแกรมที่สมบูรณ์ต่อไปนี้แสดงวิธีการจัดลำดับข้อมูลโดยใช้ตัวแยกวิเคราะห์ -
import java.io.File;
import java.io.IOException;
import org.apache.avro.Schema;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.io.DatumWriter;
public class Seriali {
public static void main(String args[]) throws IOException{
//Instantiating the Schema.Parser class.
Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc"));
//Instantiating the GenericRecord class.
GenericRecord e1 = new GenericData.Record(schema);
//Insert data according to schema
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chenni");
GenericRecord e2 = new GenericData.Record(schema);
e2.put("name", "rahman");
e2.put("id", 002);
e2.put("salary", 35000);
e2.put("age", 30);
e2.put("address", "Delhi");
DatumWriter<GenericRecord> datumWriter = new GenericDatumWriter<GenericRecord>(schema);
DataFileWriter<GenericRecord> dataFileWriter = new DataFileWriter<GenericRecord>(datumWriter);
dataFileWriter.create(schema, new File("/home/Hadoop/Avro_work/without_code_gen/mydata.txt"));
dataFileWriter.append(e1);
dataFileWriter.append(e2);
dataFileWriter.close();
System.out.println(“data successfully serialized”);
}
}เรียกดูไดเร็กทอรีที่วางโค้ดที่สร้างขึ้น ในกรณีนี้ที่home/Hadoop/Avro_work/without_code_gen.
$ cd home/Hadoop/Avro_work/without_code_gen/
ตอนนี้คัดลอกและบันทึกโปรแกรมข้างต้นในไฟล์ชื่อ Serialize.java. รวบรวมและดำเนินการตามที่แสดงด้านล่าง -
$ javac Serialize.java
$ java Serializeเอาต์พุต
data successfully serializedหากคุณตรวจสอบเส้นทางที่ระบุในโปรแกรมคุณจะพบไฟล์ซีเรียลที่สร้างขึ้นดังที่แสดงด้านล่าง
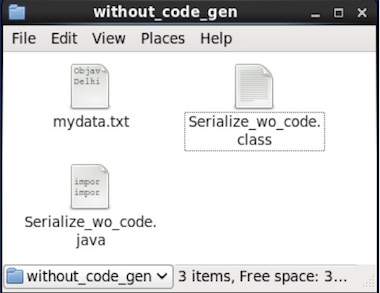
ดังที่ได้กล่าวไว้ก่อนหน้านี้เราสามารถอ่านสคีมา Avro ในโปรแกรมได้โดยการสร้างคลาสที่สอดคล้องกับสคีมาหรือโดยใช้ไลบรารีตัวแยกวิเคราะห์ ใน Avro ข้อมูลจะถูกจัดเก็บด้วยสคีมาที่เกี่ยวข้องเสมอ ดังนั้นเราสามารถอ่านรายการที่ทำให้เป็นอนุกรมได้ตลอดเวลาโดยไม่ต้องสร้างรหัส
บทนี้อธิบายวิธีการอ่านสคีมา using parsers library และ Deserializing ข้อมูลโดยใช้ Avro
Deserialization โดยใช้ Parsers Library
ข้อมูลอนุกรมจะถูกเก็บไว้ในไฟล์ mydata.txt. คุณสามารถ deserialize และอ่านโดยใช้ Avro
ทำตามขั้นตอนที่ระบุด้านล่างเพื่อแยกข้อมูลซีเรียลออกจากไฟล์
ขั้นตอนที่ 1
ก่อนอื่นอ่านสคีมาจากไฟล์ โดยใช้Schema.Parserชั้นเรียน คลาสนี้จัดเตรียมเมธอดในการแยกวิเคราะห์สคีมาในรูปแบบต่างๆ
เริ่มต้นไฟล์ Schema.Parser คลาสโดยส่งเส้นทางไฟล์ที่เก็บสคีมา
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));ขั้นตอนที่ 2
สร้างวัตถุของ DatumReader อินเทอร์เฟซโดยใช้ SpecificDatumReader ชั้นเรียน
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);ขั้นตอนที่ 3
ทันที DataFileReaderชั้นเรียน คลาสนี้อ่านข้อมูลอนุกรมจากไฟล์ มันต้องใช้DatumReader ออบเจ็กต์และเส้นทางของไฟล์ที่มีข้อมูลซีเรียลเป็นพารามิเตอร์ไปยังตัวสร้าง
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/path/to/mydata.txt"), datumReader);ขั้นตอนที่ 4
พิมพ์ข้อมูล deserialized โดยใช้วิธีการ DataFileReader.
hasNext() วิธีการคืนค่าบูลีนหากมีองค์ประกอบใด ๆ ใน Reader
next() วิธีการของ DataFileReader ส่งคืนข้อมูลใน Reader
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}ตัวอย่าง - Deserialization โดยใช้ Parsers Library
โปรแกรมที่สมบูรณ์ต่อไปนี้แสดงวิธีการแยกซีเรียลไลซ์ข้อมูลซีเรียลโดยใช้ไลบรารีพาร์เซอร์ -
public class Deserialize {
public static void main(String args[]) throws Exception{
//Instantiating the Schema.Parser class.
Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc"));
DatumReader<GenericRecord> datumReader = new GenericDatumReader<GenericRecord>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/home/Hadoop/Avro_Work/without_code_gen/mydata.txt"), datumReader);
GenericRecord emp = null;
while (dataFileReader.hasNext()) {
emp = dataFileReader.next(emp);
System.out.println(emp);
}
System.out.println("hello");
}
}เรียกดูไดเร็กทอรีที่วางโค้ดที่สร้างขึ้น ในกรณีนี้จะอยู่ที่home/Hadoop/Avro_work/without_code_gen.
$ cd home/Hadoop/Avro_work/without_code_gen/ตอนนี้คัดลอกและบันทึกโปรแกรมข้างต้นในไฟล์ชื่อ DeSerialize.java. รวบรวมและดำเนินการตามที่แสดงด้านล่าง -
$ javac Deserialize.java
$ java Deserializeเอาต์พุต
{"name": "ramu", "id": 1, "salary": 30000, "age": 25, "address": "chennai"}
{"name": "rahman", "id": 2, "salary": 35000, "age": 30, "address": "Delhi"}