AVRO - การทำให้เป็นอนุกรม
ข้อมูลถูกทำให้เป็นอนุกรมสำหรับวัตถุประสงค์สองประการ -
สำหรับการจัดเก็บถาวร
ในการขนส่งข้อมูลผ่านเครือข่าย
Serialization คืออะไร?
Serialization คือกระบวนการในการแปลโครงสร้างข้อมูลหรือสถานะของวัตถุให้อยู่ในรูปแบบไบนารีหรือแบบข้อความเพื่อขนส่งข้อมูลผ่านเครือข่ายหรือเพื่อจัดเก็บในหน่วยเก็บข้อมูลที่ยังคงมีอยู่ เมื่อข้อมูลถูกส่งผ่านเครือข่ายหรือดึงมาจากที่จัดเก็บข้อมูลถาวรข้อมูลนั้นจะต้องถูกแยกสายอีกครั้ง การทำให้เป็นอนุกรมเรียกว่าmarshalling และ deserialization เรียกว่า unmarshalling.
Serialization ใน Java
Java จัดเตรียมกลไกที่เรียกว่า object serialization โดยที่อ็อบเจ็กต์สามารถแสดงเป็นลำดับของไบต์ที่มีข้อมูลของอ็อบเจ็กต์เช่นเดียวกับข้อมูลเกี่ยวกับประเภทของอ็อบเจ็กต์และประเภทของข้อมูลที่จัดเก็บในอ็อบเจ็กต์
หลังจากที่มีการเขียนอ็อบเจ็กต์แบบอนุกรมลงในไฟล์แล้วสามารถอ่านได้จากไฟล์และ deserialized นั่นคือข้อมูลชนิดและไบต์ที่แสดงถึงอ็อบเจ็กต์และข้อมูลของอ็อบเจ็กต์สามารถใช้เพื่อสร้างอ็อบเจ็กต์ใหม่ในหน่วยความจำ
ObjectInputStream และ ObjectOutputStream คลาสถูกใช้เพื่อทำให้เป็นอนุกรมและดีซีเรียลไลซ์อ็อบเจ็กต์ตามลำดับใน Java
Serialization ใน Hadoop
โดยทั่วไปในระบบกระจายเช่น Hadoop จะใช้แนวคิดของการทำให้เป็นอนุกรมสำหรับ Interprocess Communication และ Persistent Storage.
การสื่อสารระหว่างกระบวนการ
ในการสร้างการสื่อสารระหว่างกระบวนการระหว่างโหนดที่เชื่อมต่อในเครือข่ายใช้เทคนิค RPC
RPC ใช้การทำให้เป็นอนุกรมภายในเพื่อแปลงข้อความเป็นรูปแบบไบนารีก่อนที่จะส่งไปยังโหนดระยะไกลผ่านเครือข่าย ในอีกด้านหนึ่งระบบรีโมตยกเลิกการกำหนดค่าสถานะไบนารีสตรีมลงในข้อความต้นฉบับ
รูปแบบการทำให้เป็นอนุกรม RPC จำเป็นต้องเป็นดังนี้ -
Compact - ใช้แบนด์วิธเครือข่ายให้เกิดประโยชน์สูงสุดซึ่งเป็นทรัพยากรที่หายากที่สุดในศูนย์ข้อมูล
Fast - เนื่องจากการสื่อสารระหว่างโหนดมีความสำคัญอย่างยิ่งในระบบแบบกระจายกระบวนการทำให้เป็นอนุกรมและดีซีเรียลไลเซชันจึงควรรวดเร็วทำให้มีค่าใช้จ่ายน้อยลง
Extensible - โปรโตคอลมีการเปลี่ยนแปลงอยู่ตลอดเวลาเพื่อให้เป็นไปตามข้อกำหนดใหม่ ๆ ดังนั้นจึงควรพัฒนาโปรโตคอลในลักษณะควบคุมสำหรับไคลเอนต์และเซิร์ฟเวอร์อย่างตรงไปตรงมา
Interoperable - รูปแบบข้อความควรรองรับโหนดที่เขียนในภาษาต่างๆ
ที่เก็บถาวร
Persistent Storage เป็นอุปกรณ์จัดเก็บข้อมูลดิจิทัลที่ไม่สูญเสียข้อมูลไปกับการสูญเสียแหล่งจ่ายไฟ ไฟล์โฟลเดอร์ฐานข้อมูลเป็นตัวอย่างของหน่วยเก็บข้อมูลถาวร
อินเตอร์เฟซที่เขียนได้
นี่คืออินเทอร์เฟซใน Hadoop ซึ่งมีวิธีการสำหรับการทำให้เป็นอนุกรมและการดีซีเรียลไลเซชัน ตารางต่อไปนี้อธิบายวิธีการ -
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | void readFields(DataInput in) วิธีนี้ใช้เพื่อยกเลิกการกำหนดค่าฟิลด์ของวัตถุที่กำหนด |
| 2 | void write(DataOutput out) วิธีนี้ใช้เพื่อจัดลำดับฟิลด์ของวัตถุที่กำหนด |
ส่วนต่อประสานที่สามารถเขียนได้
มันคือการรวมกันของ Writable และ Comparableอินเทอร์เฟซ อินเทอร์เฟซนี้สืบทอดWritable อินเทอร์เฟซของ Hadoop เช่นเดียวกับ Comparableอินเทอร์เฟซของ Java ดังนั้นจึงมีวิธีการสำหรับการทำให้เป็นอนุกรมข้อมูลการแยกสารและการเปรียบเทียบ
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | int compareTo(class obj) วิธีนี้เปรียบเทียบวัตถุปัจจุบันกับวัตถุที่กำหนด obj |
นอกเหนือจากคลาสเหล่านี้ Hadoop ยังรองรับคลาส Wrapper จำนวนมากที่ใช้อินเทอร์เฟซ WritableComparable แต่ละคลาสจะรวม Java primitive type ลำดับชั้นของการทำให้อนุกรม Hadoop ได้รับด้านล่าง -
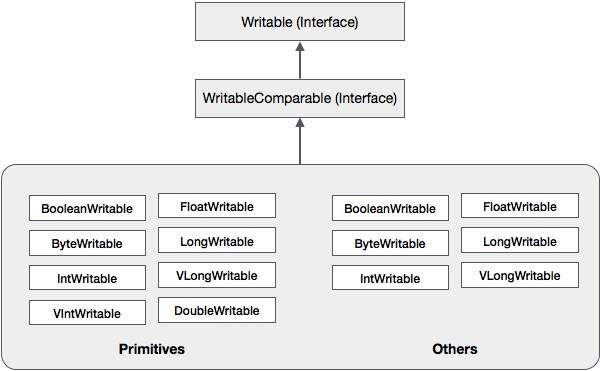
คลาสเหล่านี้มีประโยชน์ในการจัดลำดับข้อมูลประเภทต่างๆใน Hadoop ตัวอย่างเช่นให้เราพิจารณาไฟล์IntWritableชั้นเรียน ให้เรามาดูกันว่าคลาสนี้ใช้ในการทำให้เป็นอนุกรมและแยกสายข้อมูลใน Hadoop ได้อย่างไร
คลาส IntWritable
คลาสนี้ดำเนินการ Writable, Comparable, และ WritableComparableอินเทอร์เฟซ มันรวมชนิดข้อมูลจำนวนเต็มไว้ คลาสนี้จัดเตรียมเมธอดที่ใช้ในการทำให้เป็นอนุกรมและแยกประเภทของข้อมูลจำนวนเต็ม
ตัวสร้าง
| ส. | สรุป |
|---|---|
| 1 | IntWritable() |
| 2 | IntWritable( int value) |
วิธีการ
| ส. | สรุป |
|---|---|
| 1 | int get() การใช้วิธีนี้คุณจะได้รับค่าจำนวนเต็มที่มีอยู่ในวัตถุปัจจุบัน |
| 2 | void readFields(DataInput in) วิธีนี้ใช้เพื่อแยกข้อมูลในข้อมูลที่กำหนด DataInput วัตถุ. |
| 3 | void set(int value) วิธีนี้ใช้เพื่อกำหนดค่าของกระแสไฟฟ้า IntWritable วัตถุ. |
| 4 | void write(DataOutput out) วิธีนี้ใช้เพื่อจัดลำดับข้อมูลในวัตถุปัจจุบันไปยังวัตถุที่กำหนด DataOutput วัตถุ. |
การจัดลำดับข้อมูลใน Hadoop
ขั้นตอนในการจัดลำดับข้อมูลประเภทจำนวนเต็มจะกล่าวถึงด้านล่าง
ทันที IntWritable คลาสโดยการรวมค่าจำนวนเต็มไว้ในนั้น
ทันที ByteArrayOutputStream ชั้นเรียน
ทันที DataOutputStream คลาสและส่งผ่านวัตถุของ ByteArrayOutputStream ชั้นเรียนไปเลย
จัดลำดับค่าจำนวนเต็มในวัตถุ IntWritable โดยใช้ write()วิธี. เมธอดนี้ต้องการอ็อบเจ็กต์ของคลาส DataOutputStream
ข้อมูลที่ทำให้เป็นอนุกรมจะถูกเก็บไว้ในออบเจ็กต์ไบต์อาร์เรย์ซึ่งถูกส่งเป็นพารามิเตอร์ไปยัง DataOutputStreamในช่วงเวลาของการสร้างอินสแตนซ์ แปลงข้อมูลในออบเจ็กต์เป็นไบต์อาร์เรย์
ตัวอย่าง
ตัวอย่างต่อไปนี้แสดงวิธีการจัดลำดับข้อมูลประเภทจำนวนเต็มใน Hadoop -
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
public class Serialization {
public byte[] serialize() throws IOException{
//Instantiating the IntWritable object
IntWritable intwritable = new IntWritable(12);
//Instantiating ByteArrayOutputStream object
ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream();
//Instantiating DataOutputStream object
DataOutputStream dataOutputStream = new
DataOutputStream(byteoutputStream);
//Serializing the data
intwritable.write(dataOutputStream);
//storing the serialized object in bytearray
byte[] byteArray = byteoutputStream.toByteArray();
//Closing the OutputStream
dataOutputStream.close();
return(byteArray);
}
public static void main(String args[]) throws IOException{
Serialization serialization= new Serialization();
serialization.serialize();
System.out.println();
}
}Deserializing ข้อมูลใน Hadoop
ขั้นตอนในการ deserialize ประเภทของข้อมูลจะกล่าวถึงด้านล่าง -
ทันที IntWritable คลาสโดยการรวมค่าจำนวนเต็มไว้ในนั้น
ทันที ByteArrayOutputStream ชั้นเรียน
ทันที DataOutputStream คลาสและส่งผ่านวัตถุของ ByteArrayOutputStream ชั้นเรียนไปเลย
Deserialize ข้อมูลในออบเจ็กต์ของ DataInputStream โดยใช้ readFields() วิธีการของคลาส IntWritable
ข้อมูล deserialized จะถูกเก็บไว้ในออบเจ็กต์ของคลาส IntWritable คุณสามารถดึงข้อมูลนี้โดยใช้ไฟล์get() วิธีการของคลาสนี้
ตัวอย่าง
ตัวอย่างต่อไปนี้แสดงให้เห็นถึงวิธีการแยกส่วนของข้อมูลประเภทจำนวนเต็มใน Hadoop -
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import org.apache.hadoop.io.IntWritable;
public class Deserialization {
public void deserialize(byte[]byteArray) throws Exception{
//Instantiating the IntWritable class
IntWritable intwritable =new IntWritable();
//Instantiating ByteArrayInputStream object
ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray);
//Instantiating DataInputStream object
DataInputStream datainputstream=new DataInputStream(InputStream);
//deserializing the data in DataInputStream
intwritable.readFields(datainputstream);
//printing the serialized data
System.out.println((intwritable).get());
}
public static void main(String args[]) throws Exception {
Deserialization dese = new Deserialization();
dese.deserialize(new Serialization().serialize());
}
}ข้อได้เปรียบของ Hadoop ผ่าน Java Serialization
Hadoop's Writable-based Serialization สามารถลดค่าใช้จ่ายในการสร้างอ็อบเจ็กต์โดยการนำอ็อบเจ็กต์ที่เขียนได้กลับมาใช้ใหม่ซึ่งเป็นไปไม่ได้กับเฟรมเวิร์กการทำให้เป็นอนุกรมเนทีฟของ Java
ข้อเสียของ Hadoop Serialization
ในการจัดลำดับข้อมูล Hadoop มีสองวิธี -
คุณสามารถใช้ไฟล์ Writable ชั้นเรียนที่จัดทำโดยห้องสมุดพื้นเมืองของ Hadoop
คุณยังสามารถใช้ Sequence Files ซึ่งจัดเก็บข้อมูลในรูปแบบไบนารี
ข้อเสียเปรียบหลักของกลไกทั้งสองนี้คือ Writables และ SequenceFiles มีเพียง Java API และไม่สามารถเขียนหรืออ่านในภาษาอื่นได้
ดังนั้นไฟล์ใด ๆ ที่สร้างใน Hadoop ด้วยกลไกสองอย่างข้างต้นจึงไม่สามารถอ่านได้ด้วยภาษาที่สามอื่น ๆ ซึ่งทำให้ Hadoop เป็นกล่องที่ จำกัด เพื่อแก้ไขข้อเสียนี้ Doug Cutting ได้สร้างขึ้นAvro, ซึ่งคือ language independent data structure.