Cassandra - แบบจำลองข้อมูล
แบบจำลองข้อมูลของ Cassandra นั้นแตกต่างจากที่เราเห็นใน RDBMS อย่างเห็นได้ชัด บทนี้ให้ภาพรวมเกี่ยวกับวิธีที่ Cassandra จัดเก็บข้อมูล
คลัสเตอร์
ฐานข้อมูล Cassandra ถูกกระจายไปยังเครื่องต่างๆที่ทำงานร่วมกัน คอนเทนเนอร์ด้านนอกสุดเรียกว่าคลัสเตอร์ สำหรับการจัดการความล้มเหลวทุกโหนดจะมีแบบจำลองและในกรณีที่เกิดความล้มเหลวแบบจำลองจะรับผิดชอบ Cassandra จัดเรียงโหนดในคลัสเตอร์ในรูปแบบวงแหวนและกำหนดข้อมูลให้
คีย์สเปซ
Keyspace เป็นคอนเทนเนอร์ด้านนอกสุดสำหรับข้อมูลใน Cassandra คุณสมบัติพื้นฐานของ Keyspace ใน Cassandra คือ -
Replication factor - เป็นจำนวนเครื่องในคลัสเตอร์ที่จะรับสำเนาข้อมูลเดียวกัน
Replica placement strategy- ไม่มีอะไรนอกจากกลยุทธ์ในการวางแบบจำลองไว้ในวงแหวน เรามีกลยุทธ์เช่นsimple strategy (กลยุทธ์การรับรู้ชั้นวาง) old network topology strategy (กลยุทธ์การรับรู้ชั้นวาง) และ network topology strategy (กลยุทธ์ที่ใช้ร่วมกับศูนย์ข้อมูล)
Column families- Keyspace เป็นที่เก็บรายชื่อของคอลัมน์อย่างน้อยหนึ่งตระกูล ในทางกลับกันตระกูลคอลัมน์คือที่เก็บของคอลเลกชันของแถว แต่ละแถวประกอบด้วยคอลัมน์ตามลำดับ กลุ่มคอลัมน์แสดงถึงโครงสร้างของข้อมูลของคุณ แต่ละคีย์สเปซมีตระกูลคอลัมน์อย่างน้อยหนึ่งตระกูลและบ่อยครั้ง
ไวยากรณ์ของการสร้าง Keyspace มีดังนี้ -
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};ภาพประกอบต่อไปนี้แสดงมุมมองแผนผังของ Keyspace
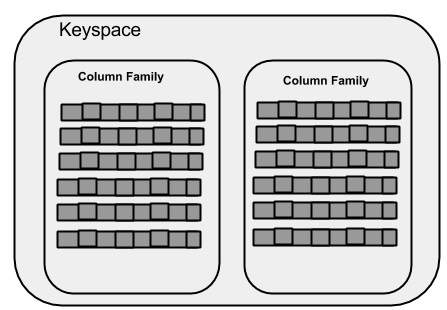
คอลัมน์ครอบครัว
กลุ่มคอลัมน์คือคอนเทนเนอร์สำหรับคอลเลกชันของแถวที่เรียงลำดับ แต่ละแถวจะเป็นคอลเลกชันคอลัมน์ตามลำดับ ตารางต่อไปนี้แสดงรายการจุดที่ทำให้ตระกูลคอลัมน์แตกต่างจากตารางฐานข้อมูลเชิงสัมพันธ์
| ตารางเชิงสัมพันธ์ | ครอบครัวคอลัมน์คาสซานดรา |
|---|---|
| สคีมาในโมเดลเชิงสัมพันธ์ได้รับการแก้ไข เมื่อเรากำหนดคอลัมน์บางคอลัมน์สำหรับตารางในขณะที่แทรกข้อมูลในทุกแถวคอลัมน์ทั้งหมดจะต้องเต็มอย่างน้อยด้วยค่า null | ในคาสซานดราแม้ว่าจะมีการกำหนดตระกูลคอลัมน์ แต่คอลัมน์จะไม่ถูกกำหนด คุณสามารถเพิ่มคอลัมน์ใด ๆ ลงในตระกูลคอลัมน์ใดก็ได้อย่างอิสระตลอดเวลา |
| ตารางเชิงสัมพันธ์กำหนดเฉพาะคอลัมน์และผู้ใช้กรอกค่าในตาราง | ใน Cassandra ตารางประกอบด้วยคอลัมน์หรือสามารถกำหนดเป็นตระกูลซุปเปอร์คอลัมน์ |
กลุ่มคอลัมน์ Cassandra มีคุณสมบัติดังต่อไปนี้ -
keys_cached - แสดงจำนวนสถานที่ที่จะเก็บแคชต่อ SSTable
rows_cached - แสดงจำนวนแถวที่เนื้อหาทั้งหมดจะถูกแคชไว้ในหน่วยความจำ
preload_row_cache - ระบุว่าคุณต้องการเติมข้อมูลแถวแคชล่วงหน้าหรือไม่
Note − ไม่เหมือนกับตารางเชิงสัมพันธ์ที่สคีมาของตระกูลคอลัมน์ไม่ได้รับการแก้ไข Cassandra ไม่ได้บังคับให้แต่ละแถวมีคอลัมน์ทั้งหมด
รูปต่อไปนี้แสดงตัวอย่างของคอลัมน์ตระกูล Cassandra
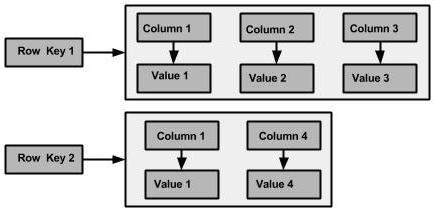
คอลัมน์
คอลัมน์เป็นโครงสร้างข้อมูลพื้นฐานของคาสซานดราที่มีค่าสามค่า ได้แก่ คีย์หรือชื่อคอลัมน์ค่าและการประทับเวลา ด้านล่างคือโครงสร้างของคอลัมน์

SuperColumn
คอลัมน์พิเศษเป็นคอลัมน์พิเศษดังนั้นจึงเป็นคู่คีย์ - ค่าด้วย แต่ซุปเปอร์คอลัมน์จะเก็บแผนที่ของคอลัมน์ย่อย
โดยทั่วไปคอลัมน์ตระกูลจะถูกเก็บไว้ในดิสก์ในแต่ละไฟล์ ดังนั้นเพื่อเพิ่มประสิทธิภาพการทำงานจึงเป็นสิ่งสำคัญที่จะต้องเก็บคอลัมน์ที่คุณมีแนวโน้มที่จะสืบค้นร่วมกันในกลุ่มคอลัมน์เดียวกันและคอลัมน์พิเศษจะมีประโยชน์ที่นี่ต่อไปนี้เป็นโครงสร้างของซุปเปอร์คอลัมน์

แบบจำลองข้อมูลของ Cassandra และ RDBMS
ตารางต่อไปนี้แสดงรายการจุดที่ทำให้โมเดลข้อมูลของคาสซานดราแตกต่างจาก RDBMS
| RDBMS | คาสซานดรา |
|---|---|
| RDBMS เกี่ยวข้องกับข้อมูลที่มีโครงสร้าง | Cassandra เกี่ยวข้องกับข้อมูลที่ไม่มีโครงสร้าง |
| มีสคีมาที่ตายตัว | Cassandra มีสคีมาที่ยืดหยุ่น |
| ใน RDBMS ตารางคืออาร์เรย์ของอาร์เรย์ (แถว x คอลัมน์) | ใน Cassandra ตารางคือรายการของ "คู่คีย์ - ค่าที่ซ้อนกัน" (คีย์ ROW x COLUMN x ค่า COLUMN) |
| ฐานข้อมูลเป็นคอนเทนเนอร์ชั้นนอกสุดที่มีข้อมูลที่สอดคล้องกับแอปพลิเคชัน | Keyspace เป็นคอนเทนเนอร์ชั้นนอกสุดที่มีข้อมูลที่สอดคล้องกับแอปพลิเคชัน |
| ตารางเป็นเอนทิตีของฐานข้อมูล | ตารางหรือตระกูลคอลัมน์เป็นเอนทิตีของคีย์สเปซ |
| Row คือระเบียนส่วนบุคคลใน RDBMS | Row คือหน่วยของการจำลองแบบใน Cassandra |
| คอลัมน์แสดงถึงคุณลักษณะของความสัมพันธ์ | คอลัมน์เป็นหน่วยเก็บข้อมูลในคาสซานดรา |
| RDBMS สนับสนุนแนวคิดของคีย์ต่างประเทศรวม | ความสัมพันธ์จะแสดงโดยใช้คอลเลกชัน |