Cassandra - คู่มือฉบับย่อ
Apache Cassandra เป็นฐานข้อมูลแบบกระจายที่ปรับขนาดได้และมีประสิทธิภาพสูงซึ่งออกแบบมาเพื่อจัดการข้อมูลจำนวนมากในเซิร์ฟเวอร์สินค้าจำนวนมากโดยให้ความพร้อมใช้งานสูงโดยไม่มีจุดล้มเหลวแม้แต่จุดเดียว เป็นฐานข้อมูล NoSQL ประเภทหนึ่ง ก่อนอื่นให้เราเข้าใจว่าฐานข้อมูล NoSQL ทำหน้าที่อะไร
NoSQLDatabase
ฐานข้อมูล NoSQL (บางครั้งเรียกว่า Not Only SQL) เป็นฐานข้อมูลที่มีกลไกในการจัดเก็บและดึงข้อมูลนอกเหนือจากความสัมพันธ์แบบตารางที่ใช้ในฐานข้อมูลเชิงสัมพันธ์ ฐานข้อมูลเหล่านี้ไม่มีสคีมารองรับการจำลองแบบง่ายมี API ที่เรียบง่ายสอดคล้องกันในที่สุดและสามารถจัดการข้อมูลจำนวนมหาศาลได้
วัตถุประสงค์หลักของฐานข้อมูล NoSQL คือการมี
- ความเรียบง่ายของการออกแบบ
- มาตราส่วนแนวนอนและ
- ควบคุมความพร้อมใช้งานได้ละเอียดขึ้น
ฐานข้อมูล NoSql ใช้โครงสร้างข้อมูลที่แตกต่างกันเมื่อเทียบกับฐานข้อมูลเชิงสัมพันธ์ ทำให้การทำงานบางอย่างเร็วขึ้นใน NoSQL ความเหมาะสมของฐานข้อมูล NoSQL ที่กำหนดขึ้นอยู่กับปัญหาที่ต้องแก้ไข
NoSQL กับฐานข้อมูลเชิงสัมพันธ์
ตารางต่อไปนี้แสดงจุดที่ทำให้ฐานข้อมูลเชิงสัมพันธ์แตกต่างจากฐานข้อมูล NoSQL
| ฐานข้อมูลเชิงสัมพันธ์ | ฐานข้อมูล NoSql |
|---|---|
| รองรับภาษาแบบสอบถามที่มีประสิทธิภาพ | รองรับภาษาแบบสอบถามที่เรียบง่ายมาก |
| มีสคีมาที่ตายตัว | ไม่มีสคีมาที่ตายตัว |
| ติดตามกรด (อะตอมมิก, ความสม่ำเสมอ, การแยกและความทนทาน) | มันเป็นเพียง "สอดคล้องกันในที่สุด" |
| รองรับการทำธุรกรรม | ไม่รองรับการทำธุรกรรม |
นอกจาก Cassandra แล้วเรายังมีฐานข้อมูล NoSQL ต่อไปนี้ที่ค่อนข้างเป็นที่นิยม -
Apache HBase- HBase เป็นฐานข้อมูลแบบโอเพ่นซอร์สที่ไม่เกี่ยวข้องและกระจายซึ่งจำลองแบบมาจาก BigTable ของ Google และเขียนด้วย Java ได้รับการพัฒนาโดยเป็นส่วนหนึ่งของโปรเจ็กต์ Apache Hadoop และทำงานบน HDFS ซึ่งให้ความสามารถเหมือน BigTable สำหรับ Hadoop
MongoDB - MongoDB เป็นระบบฐานข้อมูลที่เน้นเอกสารข้ามแพลตฟอร์มที่หลีกเลี่ยงการใช้โครงสร้างฐานข้อมูลเชิงสัมพันธ์แบบตารางแบบเดิมเพื่อสนับสนุนเอกสารที่มีลักษณะคล้าย JSON ที่มีแผนภาพแบบไดนามิกทำให้การรวมข้อมูลในแอปพลิเคชันบางประเภททำได้ง่ายขึ้นและเร็วขึ้น
Apache Cassandra คืออะไร?
Apache Cassandra เป็นระบบจัดเก็บข้อมูลแบบโอเพ่นซอร์สกระจายและกระจายอำนาจ / กระจายอำนาจสำหรับการจัดการข้อมูลที่มีโครงสร้างจำนวนมากที่กระจายออกไปทั่วโลก ให้บริการที่พร้อมใช้งานสูงโดยไม่มีจุดล้มเหลวแม้แต่จุดเดียว
รายการด้านล่างนี้เป็นจุดที่น่าสังเกตบางประการของ Apache Cassandra -
สามารถปรับขนาดได้ทนต่อความผิดพลาดและสม่ำเสมอ
เป็นฐานข้อมูลเชิงคอลัมน์
การออกแบบการจัดจำหน่ายขึ้นอยู่กับ Dynamo ของ Amazon และแบบจำลองข้อมูลบน Bigtable ของ Google
สร้างขึ้นที่ Facebook ซึ่งแตกต่างอย่างมากกับระบบจัดการฐานข้อมูลเชิงสัมพันธ์
คาสซานดราใช้โมเดลจำลองแบบไดนาโมโดยไม่มีจุดล้มเหลวแม้แต่จุดเดียว แต่เพิ่มโมเดลข้อมูล "คอลัมน์ตระกูล" ที่มีประสิทธิภาพมากขึ้น
Cassandra ถูกใช้โดย บริษัท ที่ใหญ่ที่สุดบางแห่งเช่น Facebook, Twitter, Cisco, Rackspace, ebay, Twitter, Netflix และอื่น ๆ
คุณสมบัติของ Cassandra
Cassandra ได้รับความนิยมอย่างมากเนื่องจากคุณสมบัติทางเทคนิคที่โดดเด่น ด้านล่างนี้เป็นคุณสมบัติบางอย่างของ Cassandra:
Elastic scalability- Cassandra สามารถปรับขนาดได้สูง ช่วยให้สามารถเพิ่มฮาร์ดแวร์เพิ่มเติมเพื่อรองรับลูกค้าและข้อมูลเพิ่มเติมตามความต้องการ
Always on architecture - Cassandra ไม่มีจุดล้มเหลวแม้แต่จุดเดียวและพร้อมใช้งานอย่างต่อเนื่องสำหรับแอปพลิเคชันที่สำคัญทางธุรกิจที่ไม่สามารถล้มเหลวได้
Fast linear-scale performance- Cassandra สามารถปรับขนาดได้เชิงเส้นกล่าวคือจะเพิ่มปริมาณงานของคุณเมื่อคุณเพิ่มจำนวนโหนดในคลัสเตอร์ ดังนั้นจึงรักษาเวลาตอบสนองที่รวดเร็ว
Flexible data storage- Cassandra รองรับรูปแบบข้อมูลที่เป็นไปได้ทั้งหมด ได้แก่ : มีโครงสร้างกึ่งโครงสร้างและไม่มีโครงสร้าง สามารถรองรับการเปลี่ยนแปลงโครงสร้างข้อมูลของคุณแบบไดนามิกตามความต้องการของคุณ
Easy data distribution - Cassandra มอบความยืดหยุ่นในการกระจายข้อมูลในที่ที่คุณต้องการโดยการจำลองข้อมูลในศูนย์ข้อมูลหลายแห่ง
Transaction support - Cassandra รองรับคุณสมบัติต่างๆเช่น Atomicity, Consistency, Isolation และ Durability (ACID)
Fast writes- Cassandra ได้รับการออกแบบให้ทำงานบนฮาร์ดแวร์สินค้าราคาถูก มันเขียนได้อย่างรวดเร็วอย่างเห็นได้ชัดและสามารถจัดเก็บข้อมูลได้หลายร้อยเทราไบต์โดยไม่ทำให้ประสิทธิภาพในการอ่านลดลง
ประวัติของคาสซานดรา
- Cassandra ได้รับการพัฒนาที่ Facebook สำหรับการค้นหาในกล่องจดหมาย
- Facebook เปิดแหล่งที่มาในเดือนกรกฎาคม 2551
- Cassandra ได้รับการยอมรับให้เข้าสู่ Apache Incubator ในเดือนมีนาคม 2552
- จัดทำโครงการระดับบนสุดของ Apache ตั้งแต่เดือนกุมภาพันธ์ 2010
เป้าหมายการออกแบบของ Cassandra คือการจัดการปริมาณงานข้อมูลขนาดใหญ่ในหลาย ๆ โหนดโดยไม่เกิดความล้มเหลวแม้แต่จุดเดียว Cassandra มีระบบกระจายแบบเพียร์ทูเพียร์ข้ามโหนดและข้อมูลจะกระจายไปตามโหนดทั้งหมดในคลัสเตอร์
โหนดทั้งหมดในคลัสเตอร์มีบทบาทเดียวกัน แต่ละโหนดเป็นอิสระและเชื่อมต่อกับโหนดอื่นในเวลาเดียวกัน
แต่ละโหนดในคลัสเตอร์สามารถยอมรับคำขออ่านและเขียนได้ไม่ว่าข้อมูลจะอยู่ที่ใดในคลัสเตอร์ก็ตาม
เมื่อโหนดหยุดทำงานคำขออ่าน / เขียนสามารถให้บริการจากโหนดอื่นในเครือข่าย
การจำลองข้อมูลในคาสซานดรา
ใน Cassandra โหนดอย่างน้อยหนึ่งโหนดในคลัสเตอร์จะทำหน้าที่เป็นแบบจำลองสำหรับข้อมูลที่กำหนด หากตรวจพบว่าโหนดบางโหนดตอบสนองด้วยค่าที่ล้าสมัย Cassandra จะส่งคืนค่าล่าสุดให้กับไคลเอ็นต์ หลังจากส่งคืนค่าล่าสุด Cassandra จะดำเนินการ aread repair ในพื้นหลังเพื่ออัปเดตค่าเก่า
รูปต่อไปนี้แสดงมุมมองแผนผังของวิธีที่ Cassandra ใช้การจำลองข้อมูลระหว่างโหนดในคลัสเตอร์เพื่อให้แน่ใจว่าไม่มีจุดล้มเหลวแม้แต่จุดเดียว
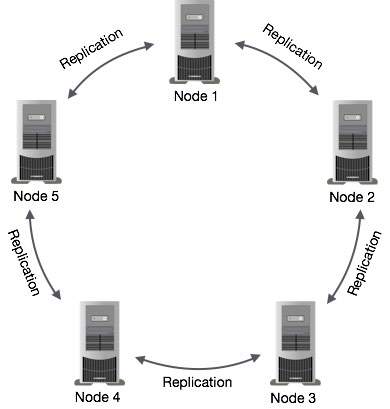
Note - Cassandra ใช้ไฟล์ Gossip Protocol อยู่เบื้องหลังเพื่อให้โหนดสื่อสารกันและตรวจพบโหนดที่ผิดพลาดในคลัสเตอร์
ส่วนประกอบของ Cassandra
ส่วนประกอบสำคัญของ Cassandra มีดังนี้ -
Node - เป็นสถานที่จัดเก็บข้อมูล
Data center - เป็นชุดของโหนดที่เกี่ยวข้อง
Cluster - คลัสเตอร์คือส่วนประกอบที่มีศูนย์ข้อมูลตั้งแต่หนึ่งศูนย์ขึ้นไป
Commit log- บันทึกการคอมมิตเป็นกลไกการกู้คืนความผิดพลาดใน Cassandra ทุกการดำเนินการเขียนถูกเขียนลงในบันทึกการคอมมิต
Mem-table- ตาราง mem เป็นโครงสร้างข้อมูลที่อาศัยหน่วยความจำ หลังจากคอมมิตบันทึกข้อมูลจะถูกเขียนลงใน mem-table บางครั้งสำหรับตระกูลคอลัมน์เดียวจะมีตาราง mem หลายตาราง
SSTable - เป็นไฟล์ดิสก์ที่ข้อมูลจะถูกล้างออกจากตาราง mem เมื่อเนื้อหาถึงค่าเกณฑ์
Bloom filter- อัลกอริทึมเหล่านี้เป็นเพียงอัลกอริทึมที่รวดเร็วไม่เป็นไปตามข้อกำหนดสำหรับการทดสอบว่าองค์ประกอบนั้นเป็นสมาชิกของเซตหรือไม่ เป็นแคชชนิดพิเศษ มีการเข้าถึงตัวกรอง Bloom หลังจากทุกการค้นหา
ภาษาแบบสอบถาม Cassandra
ผู้ใช้สามารถเข้าถึง Cassandra ผ่านโหนดโดยใช้ Cassandra Query Language (CQL) CQL ปฏิบัติต่อฐานข้อมูล(Keyspace)เป็นภาชนะของโต๊ะ โปรแกรมเมอร์ใช้cqlsh: ข้อความแจ้งให้ทำงานกับ CQL หรือไดรเวอร์ภาษาของแอปพลิเคชันแยกต่างหาก
ไคลเอ็นต์เข้าใกล้โหนดใด ๆ สำหรับการดำเนินการอ่านเขียน โหนดนั้น (ผู้ประสานงาน) เล่นพร็อกซีระหว่างไคลเอนต์และโหนดที่เก็บข้อมูล
เขียนการดำเนินงาน
ทุกกิจกรรมการเขียนของโหนดถูกจับโดยไฟล์ commit logsเขียนในโหนด หลังจากนั้นข้อมูลจะถูกจับและจัดเก็บในไฟล์mem-table. เมื่อใดก็ตามที่ตาราง mem เต็มข้อมูลจะถูกเขียนลงในไฟล์ SStableแฟ้มข้อมูล. การเขียนทั้งหมดจะถูกแบ่งพาร์ติชันและจำลองโดยอัตโนมัติทั่วทั้งคลัสเตอร์ Cassandra รวบรวม SSTables เป็นระยะโดยทิ้งข้อมูลที่ไม่จำเป็น
อ่านการดำเนินการ
ในระหว่างการดำเนินการอ่าน Cassandra จะได้รับค่าจากตาราง mem และตรวจสอบตัวกรอง bloom เพื่อค้นหา SSTable ที่เหมาะสมซึ่งเก็บข้อมูลที่ต้องการ
แบบจำลองข้อมูลของ Cassandra นั้นแตกต่างจากที่เราเห็นใน RDBMS อย่างเห็นได้ชัด บทนี้ให้ภาพรวมเกี่ยวกับวิธีที่ Cassandra จัดเก็บข้อมูล
คลัสเตอร์
ฐานข้อมูล Cassandra ถูกกระจายไปยังเครื่องต่างๆที่ทำงานร่วมกัน คอนเทนเนอร์ด้านนอกสุดเรียกว่าคลัสเตอร์ สำหรับการจัดการความล้มเหลวทุกโหนดจะมีแบบจำลองและในกรณีที่เกิดความล้มเหลวแบบจำลองจะรับผิดชอบ Cassandra จัดเรียงโหนดในคลัสเตอร์ในรูปแบบวงแหวนและกำหนดข้อมูลให้
คีย์สเปซ
Keyspace เป็นคอนเทนเนอร์ชั้นนอกสุดสำหรับข้อมูลใน Cassandra คุณสมบัติพื้นฐานของ Keyspace ใน Cassandra คือ -
Replication factor - เป็นจำนวนเครื่องในคลัสเตอร์ที่จะรับสำเนาข้อมูลเดียวกัน
Replica placement strategy- ไม่มีอะไรนอกจากกลยุทธ์ในการวางแบบจำลองไว้ในวงแหวน เรามีกลยุทธ์เช่นsimple strategy (กลยุทธ์การรับรู้ชั้นวาง) old network topology strategy (กลยุทธ์การรับรู้ชั้นวาง) และ network topology strategy (กลยุทธ์ที่ใช้ร่วมกับศูนย์ข้อมูล)
Column families- Keyspace เป็นที่เก็บรายชื่อของคอลัมน์อย่างน้อยหนึ่งตระกูล ในทางกลับกันตระกูลคอลัมน์คือที่เก็บของชุดของแถว แต่ละแถวประกอบด้วยคอลัมน์ตามลำดับ กลุ่มคอลัมน์แสดงถึงโครงสร้างของข้อมูลของคุณ แต่ละคีย์สเปซมีตระกูลคอลัมน์อย่างน้อยหนึ่งตระกูลและบ่อยครั้ง
ไวยากรณ์ของการสร้าง Keyspace มีดังนี้ -
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};ภาพประกอบต่อไปนี้แสดงมุมมองแผนผังของ Keyspace
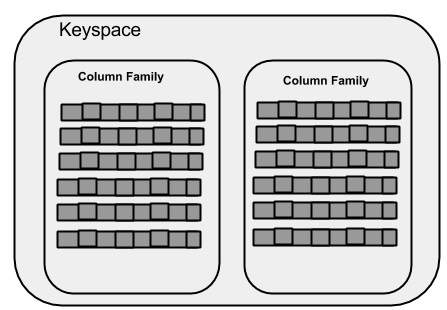
คอลัมน์ครอบครัว
กลุ่มคอลัมน์คือคอนเทนเนอร์สำหรับคอลเลกชันของแถวที่เรียงลำดับ แต่ละแถวจะเป็นคอลเลกชันคอลัมน์ตามลำดับ ตารางต่อไปนี้แสดงจุดที่ทำให้ตระกูลคอลัมน์แตกต่างจากตารางฐานข้อมูลเชิงสัมพันธ์
| ตารางเชิงสัมพันธ์ | ครอบครัวคอลัมน์คาสซานดรา |
|---|---|
| สคีมาในโมเดลเชิงสัมพันธ์ได้รับการแก้ไข เมื่อเรากำหนดคอลัมน์บางคอลัมน์สำหรับตารางในขณะที่แทรกข้อมูลในทุกแถวคอลัมน์ทั้งหมดจะต้องเต็มอย่างน้อยด้วยค่า null | ในคาสซานดราแม้ว่าจะมีการกำหนดตระกูลคอลัมน์ แต่คอลัมน์จะไม่ถูกกำหนด คุณสามารถเพิ่มคอลัมน์ใด ๆ ลงในตระกูลคอลัมน์ใดก็ได้อย่างอิสระตลอดเวลา |
| ตารางเชิงสัมพันธ์กำหนดเฉพาะคอลัมน์และผู้ใช้กรอกค่าในตาราง | ใน Cassandra ตารางประกอบด้วยคอลัมน์หรือสามารถกำหนดเป็นตระกูลซุปเปอร์คอลัมน์ |
กลุ่มคอลัมน์ Cassandra มีคุณสมบัติดังต่อไปนี้ -
keys_cached - แสดงจำนวนสถานที่ที่จะเก็บแคชต่อ SSTable
rows_cached - แสดงจำนวนแถวที่เนื้อหาทั้งหมดจะถูกแคชในหน่วยความจำ
preload_row_cache - ระบุว่าคุณต้องการเติมข้อมูลแถวแคชล่วงหน้าหรือไม่
Note − ไม่เหมือนกับตารางเชิงสัมพันธ์ที่สคีมาของตระกูลคอลัมน์ไม่ได้รับการแก้ไข Cassandra ไม่ได้บังคับให้แต่ละแถวมีคอลัมน์ทั้งหมด
รูปต่อไปนี้แสดงตัวอย่างของคอลัมน์ตระกูล Cassandra
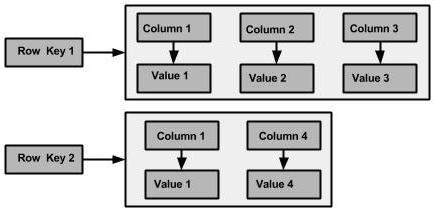
คอลัมน์
คอลัมน์เป็นโครงสร้างข้อมูลพื้นฐานของคาสซานดราที่มีค่าสามค่า ได้แก่ คีย์หรือชื่อคอลัมน์ค่าและการประทับเวลา ด้านล่างคือโครงสร้างของคอลัมน์

SuperColumn
คอลัมน์พิเศษเป็นคอลัมน์พิเศษดังนั้นจึงเป็นคู่คีย์ - ค่าด้วย แต่ซุปเปอร์คอลัมน์จะเก็บแผนที่ของคอลัมน์ย่อย
โดยทั่วไปคอลัมน์ตระกูลจะถูกเก็บไว้ในดิสก์ในแต่ละไฟล์ ดังนั้นเพื่อเพิ่มประสิทธิภาพการทำงานจึงเป็นสิ่งสำคัญที่จะต้องเก็บคอลัมน์ที่คุณมีแนวโน้มที่จะสืบค้นร่วมกันในกลุ่มคอลัมน์เดียวกันและคอลัมน์พิเศษจะมีประโยชน์ที่นี่ข้อมูลด้านล่างคือโครงสร้างของซูเปอร์คอลัมน์

แบบจำลองข้อมูลของ Cassandra และ RDBMS
ตารางต่อไปนี้แสดงจุดที่ทำให้โมเดลข้อมูลของ Cassandra แตกต่างจาก RDBMS
| RDBMS | คาสซานดรา |
|---|---|
| RDBMS เกี่ยวข้องกับข้อมูลที่มีโครงสร้าง | Cassandra เกี่ยวข้องกับข้อมูลที่ไม่มีโครงสร้าง |
| มีสคีมาที่ตายตัว | Cassandra มีสคีมาที่ยืดหยุ่น |
| ใน RDBMS ตารางคืออาร์เรย์ของอาร์เรย์ (แถว x คอลัมน์) | ใน Cassandra ตารางคือรายการของ "คู่คีย์ - ค่าที่ซ้อนกัน" (คีย์ ROW x COLUMN x ค่า COLUMN) |
| ฐานข้อมูลเป็นคอนเทนเนอร์ด้านนอกสุดที่มีข้อมูลที่สอดคล้องกับแอปพลิเคชัน | Keyspace เป็นคอนเทนเนอร์ชั้นนอกสุดที่มีข้อมูลที่สอดคล้องกับแอปพลิเคชัน |
| ตารางเป็นเอนทิตีของฐานข้อมูล | ตารางหรือตระกูลคอลัมน์เป็นเอนทิตีของคีย์สเปซ |
| Row เป็นระเบียนส่วนบุคคลใน RDBMS | Row คือหน่วยของการจำลองแบบใน Cassandra |
| คอลัมน์แสดงถึงคุณลักษณะของความสัมพันธ์ | คอลัมน์เป็นหน่วยเก็บข้อมูลในคาสซานดรา |
| RDBMS สนับสนุนแนวคิดของคีย์ต่างประเทศรวม | ความสัมพันธ์จะแสดงโดยใช้คอลเลกชัน |
Cassandra สามารถเข้าถึงได้โดยใช้ cqlsh รวมทั้งไดรเวอร์ของภาษาต่างๆ บทนี้อธิบายถึงวิธีการตั้งค่าสภาพแวดล้อม cqlsh และ java เพื่อทำงานกับ Cassandra
การตั้งค่าก่อนการติดตั้ง
ก่อนที่จะติดตั้ง Cassandra ในสภาพแวดล้อม Linux เราจำเป็นต้องตั้งค่า Linux โดยใช้ไฟล์ ssh(Secure Shell) ทำตามขั้นตอนด้านล่างเพื่อตั้งค่าสภาพแวดล้อม Linux
สร้างผู้ใช้
ในตอนต้นขอแนะนำให้สร้างผู้ใช้แยกต่างหากสำหรับ Hadoop เพื่อแยกระบบไฟล์ Hadoop ออกจากระบบไฟล์ Unix ทำตามขั้นตอนด้านล่างเพื่อสร้างผู้ใช้
เปิดรูทโดยใช้คำสั่ง “su”.
สร้างผู้ใช้จากบัญชีรูทโดยใช้คำสั่ง “useradd username”.
ตอนนี้คุณสามารถเปิดบัญชีผู้ใช้ที่มีอยู่โดยใช้คำสั่ง “su username”.
เปิดเทอร์มินัล Linux และพิมพ์คำสั่งต่อไปนี้เพื่อสร้างผู้ใช้
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdการตั้งค่า SSH และการสร้างคีย์
จำเป็นต้องมีการตั้งค่า SSH เพื่อดำเนินการต่างๆบนคลัสเตอร์เช่นการเริ่มต้นการหยุดและการดำเนินการเชลล์ daemon แบบกระจาย ในการรับรองความถูกต้องของผู้ใช้ Hadoop ที่แตกต่างกันจำเป็นต้องให้คู่คีย์สาธารณะ / ส่วนตัวสำหรับผู้ใช้ Hadoop และแชร์กับผู้ใช้รายอื่น
คำสั่งต่อไปนี้ใช้สำหรับสร้างคู่ค่าคีย์โดยใช้ SSH -
- คัดลอกคีย์สาธารณะในรูปแบบ id_rsa.pub ไปยัง Authorized_keys
- และจัดหาเจ้าของ
- อ่านและเขียนสิทธิ์ในไฟล์ Authorized_keys ตามลำดับ
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys- ตรวจสอบ ssh:
ssh localhostการติดตั้ง Java
Java เป็นข้อกำหนดเบื้องต้นหลักสำหรับ Cassandra ก่อนอื่นคุณควรตรวจสอบการมีอยู่ของ Java ในระบบของคุณโดยใช้คำสั่งต่อไปนี้ -
$ java -versionหากทุกอย่างทำงานได้ดีจะให้ผลลัพธ์ดังต่อไปนี้
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)หากคุณไม่มี Java ในระบบของคุณให้ทำตามขั้นตอนด้านล่างเพื่อติดตั้ง Java
ขั้นตอนที่ 1
ดาวน์โหลด java (JDK <เวอร์ชันล่าสุด> - X64.tar.gz) จากลิงค์ต่อไปนี้:
Then jdk-7u71-linux-x64.tar.gz will be downloaded onto your system.
ขั้นตอนที่ 2
โดยทั่วไปคุณจะพบไฟล์ java ที่ดาวน์โหลดมาในโฟลเดอร์ดาวน์โหลด ตรวจสอบและแตกไฟล์jdk-7u71-linux-x64.gz ไฟล์โดยใช้คำสั่งต่อไปนี้
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzขั้นตอนที่ 3
เพื่อให้ผู้ใช้ทุกคนสามารถใช้งาน Java ได้คุณต้องย้ายไปที่ตำแหน่ง“ / usr / local /” เปิดรูทและพิมพ์คำสั่งต่อไปนี้
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitขั้นตอนที่ 4
สำหรับการตั้งค่า PATH และ JAVA_HOME ตัวแปรเพิ่มคำสั่งต่อไปนี้ ~/.bashrc ไฟล์.
export JAVA_HOME = /usr/local/jdk1.7.0_71
export PATH = $PATH:$JAVA_HOME/binตอนนี้ใช้การเปลี่ยนแปลงทั้งหมดในระบบที่กำลังทำงานอยู่
$ source ~/.bashrcขั้นตอนที่ 5
ใช้คำสั่งต่อไปนี้เพื่อกำหนดค่าทางเลือก java
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarตอนนี้ใช้ไฟล์ java -version คำสั่งจากเทอร์มินัลตามที่อธิบายไว้ข้างต้น
การตั้งค่าเส้นทาง
กำหนดเส้นทางของเส้นทาง Cassandra ใน“ /.bashrc” ดังที่แสดงด้านล่าง
[hadoop@linux ~]$ gedit ~/.bashrc
export CASSANDRA_HOME = ~/cassandra
export PATH = $PATH:$CASSANDRA_HOME/binดาวน์โหลด Cassandra
Apache Cassandra มีอยู่ที่Download Link Cassandra โดยใช้คำสั่งต่อไปนี้
$ wget http://supergsego.com/apache/cassandra/2.1.2/apache-cassandra-2.1.2-bin.tar.gzคลายซิป Cassandra โดยใช้คำสั่ง zxvf ดังแสดงด้านล่าง
$ tar zxvf apache-cassandra-2.1.2-bin.tar.gz.สร้างไดเร็กทอรีใหม่ชื่อ Cassandra และย้ายเนื้อหาของไฟล์ที่ดาวน์โหลดมาดังที่แสดงด้านล่าง
$ mkdir Cassandra $ mv apache-cassandra-2.1.2/* cassandra.กำหนดค่า Cassandra
เปิด cassandra.yaml: ซึ่งจะมีอยู่ในไฟล์ bin ไดเรกทอรีของ Cassandra
$ gedit cassandra.yamlNote - หากคุณติดตั้ง Cassandra จากแพ็คเกจ deb หรือ rpm ไฟล์การกำหนดค่าจะอยู่ใน /etc/cassandra ไดเรกทอรีของ Cassandra
คำสั่งดังกล่าวเปิดไฟล์ cassandra.yamlไฟล์. ตรวจสอบการกำหนดค่าต่อไปนี้ ตามค่าเริ่มต้นค่าเหล่านี้จะถูกตั้งค่าเป็นไดเร็กทอรีที่ระบุ
data_file_directories “/var/lib/cassandra/data”
คอมมิทล็อก _ ไดเร็กทอรี “/var/lib/cassandra/commitlog”
save_caches_directory “/var/lib/cassandra/saved_caches”
ตรวจสอบให้แน่ใจว่ามีไดเร็กทอรีเหล่านี้และสามารถเขียนถึงได้ดังที่แสดงด้านล่าง
สร้างไดเรกทอรี
ในฐานะผู้ใช้ขั้นสูงให้สร้างทั้งสองไดเรกทอรี /var/lib/cassandra และ /var./log/cassandra ซึ่ง Cassandra เขียนข้อมูล
[root@linux cassandra]# mkdir /var/lib/cassandra
[root@linux cassandra]# mkdir /var/log/cassandraGive Permissions to Folders
Give read-write permissions to the newly created folders as shown below.
[root@linux /]# chmod 777 /var/lib/cassandra
[root@linux /]# chmod 777 /var/log/cassandraStart Cassandra
To start Cassandra, open the terminal window, navigate to Cassandra home directory/home, where you unpacked Cassandra, and run the following command to start your Cassandra server.
$ cd $CASSANDRA_HOME $./bin/cassandra -fUsing the –f option tells Cassandra to stay in the foreground instead of running as a background process. If everything goes fine, you can see the Cassandra server starting.
Programming Environment
To set up Cassandra programmatically, download the following jar files −
- slf4j-api-1.7.5.jar
- cassandra-driver-core-2.0.2.jar
- guava-16.0.1.jar
- metrics-core-3.0.2.jar
- netty-3.9.0.Final.jar
Place them in a separate folder. For example, we are downloading these jars to a folder named “Cassandra_jars”.
Set the classpath for this folder in “.bashrc”file as shown below.
[hadoop@linux ~]$ gedit ~/.bashrc //Set the following class path in the .bashrc file. export CLASSPATH = $CLASSPATH:/home/hadoop/Cassandra_jars/*Eclipse Environment
Open Eclipse and create a new project called Cassandra _Examples.
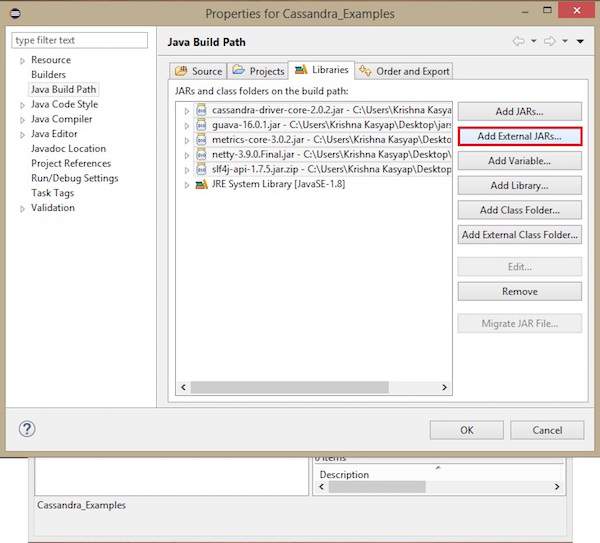
Right click on the project, select Build Path→Configure Build Path as shown below.
It will open the properties window. Under Libraries tab, select Add External JARs. Navigate to the directory where you saved your jar files. Select all the five jar files and click OK as shown below.
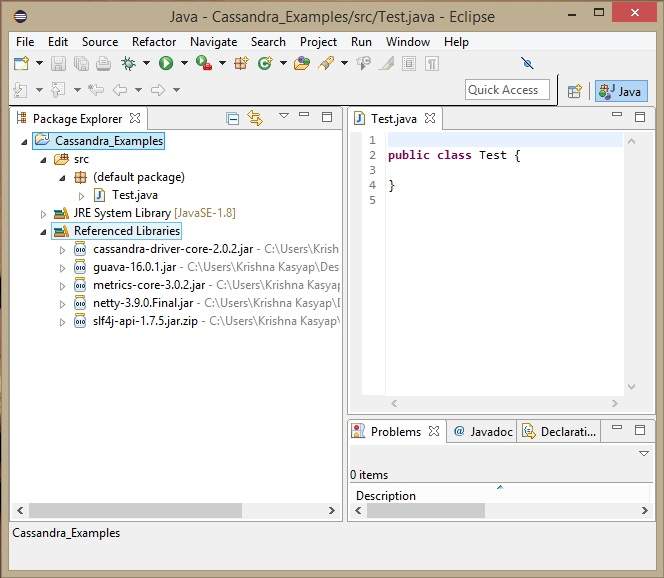
Under Referenced Libraries, you can see all the required jars added as shown below −
Maven Dependencies
Given below is the pom.xml for building a Cassandra project using maven.
<project xmlns = "http://maven.apache.org/POM/4.0.0"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>com.datastax.cassandra</groupId>
<artifactId>cassandra-driver-core</artifactId>
<version>2.0.2</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0.1</version>
</dependency>
<dependency>
<groupId>com.codahale.metrics</groupId>
<artifactId>metrics-core</artifactId>
<version>3.0.2</version>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty</artifactId>
<version>3.9.0.Final</version>
</dependency>
</dependencies>
</project>This chapter covers all the important classes in Cassandra.
Cluster
This class is the main entry point of the driver. It belongs to com.datastax.driver.core package.
Methods
| S. No. | Methods and Description |
|---|---|
| 1 | Session connect() It creates a new session on the current cluster and initializes it. |
| 2 | void close() It is used to close the cluster instance. |
| 3 | static Cluster.Builder builder() It is used to create a new Cluster.Builder instance. |
Cluster.Builder
This class is used to instantiate the Cluster.Builder class.
Methods
| S. No | Methods and Description |
|---|---|
| 1 | Cluster.Builder addContactPoint(String address) This method adds a contact point to cluster. |
| 2 | Cluster build() This method builds the cluster with the given contact points. |
Session
This interface holds the connections to Cassandra cluster. Using this interface, you can execute CQL queries. It belongs to com.datastax.driver.core package.
Methods
| S. No. | Methods and Description |
|---|---|
| 1 | void close() This method is used to close the current session instance. |
| 2 | ResultSet execute(Statement statement) This method is used to execute a query. It requires a statement object. |
| 3 | ResultSet execute(String query) This method is used to execute a query. It requires a query in the form of a String object. |
| 4 | PreparedStatement prepare(RegularStatement statement) This method prepares the provided query. The query is to be provided in the form of a Statement. |
| 5 | PreparedStatement prepare(String query) This method prepares the provided query. The query is to be provided in the form of a String. |
This chapter introduces the Cassandra query language shell and explains how to use its commands.
By default, Cassandra provides a prompt Cassandra query language shell (cqlsh) that allows users to communicate with it. Using this shell, you can execute Cassandra Query Language (CQL).
Using cqlsh, you can
- define a schema,
- insert data, and
- execute a query.
Starting cqlsh
Start cqlsh using the command cqlsh as shown below. It gives the Cassandra cqlsh prompt as output.
[hadoop@linux bin]$ cqlsh
Connected to Test Cluster at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]
Use HELP for help.
cqlsh>Cqlsh − As discussed above, this command is used to start the cqlsh prompt. In addition, it supports a few more options as well. The following table explains all the options of cqlsh and their usage.
| Options | Usage |
|---|---|
| cqlsh --help | Shows help topics about the options of cqlsh commands. |
| cqlsh --version | Provides the version of the cqlsh you are using. |
| cqlsh --color | Directs the shell to use colored output. |
| cqlsh --debug | Shows additional debugging information. |
| cqlsh --execute cql_statement |
Directs the shell to accept and execute a CQL command. |
| cqlsh --file= “file name” | If you use this option, Cassandra executes the command in the given file and exits. |
| cqlsh --no-color | Directs Cassandra not to use colored output. |
| cqlsh -u “user name” | Using this option, you can authenticate a user. The default user name is: cassandra. |
| cqlsh-p “pass word” | Using this option, you can authenticate a user with a password. The default password is: cassandra. |
Cqlsh Commands
Cqlsh has a few commands that allow users to interact with it. The commands are listed below.
Documented Shell Commands
Given below are the Cqlsh documented shell commands. These are the commands used to perform tasks such as displaying help topics, exit from cqlsh, describe,etc.
HELP − Displays help topics for all cqlsh commands.
CAPTURE − Captures the output of a command and adds it to a file.
CONSISTENCY − Shows the current consistency level, or sets a new consistency level.
COPY − Copies data to and from Cassandra.
DESCRIBE − Describes the current cluster of Cassandra and its objects.
EXPAND − Expands the output of a query vertically.
EXIT − Using this command, you can terminate cqlsh.
PAGING − Enables or disables query paging.
SHOW − Displays the details of current cqlsh session such as Cassandra version, host, or data type assumptions.
SOURCE − Executes a file that contains CQL statements.
TRACING − Enables or disables request tracing.
CQL Data Definition Commands
CREATE KEYSPACE − Creates a KeySpace in Cassandra.
USE − Connects to a created KeySpace.
ALTER KEYSPACE − Changes the properties of a KeySpace.
DROP KEYSPACE − Removes a KeySpace
CREATE TABLE − Creates a table in a KeySpace.
ALTER TABLE − Modifies the column properties of a table.
DROP TABLE − Removes a table.
TRUNCATE − Removes all the data from a table.
CREATE INDEX − Defines a new index on a single column of a table.
DROP INDEX − Deletes a named index.
CQL Data Manipulation Commands
INSERT − Adds columns for a row in a table.
UPDATE − Updates a column of a row.
DELETE − Deletes data from a table.
BATCH − Executes multiple DML statements at once.
CQL Clauses
SELECT − This clause reads data from a table
WHERE − The where clause is used along with select to read a specific data.
ORDERBY − The orderby clause is used along with select to read a specific data in a specific order.
Cassandra provides documented shell commands in addition to CQL commands. Given below are the Cassandra documented shell commands.
Help
The HELP command displays a synopsis and a brief description of all cqlsh commands. Given below is the usage of help command.
cqlsh> help
Documented shell commands:
===========================
CAPTURE COPY DESCRIBE EXPAND PAGING SOURCE
CONSISTENCY DESC EXIT HELP SHOW TRACING.
CQL help topics:
================
ALTER CREATE_TABLE_OPTIONS SELECT
ALTER_ADD CREATE_TABLE_TYPES SELECT_COLUMNFAMILY
ALTER_ALTER CREATE_USER SELECT_EXPR
ALTER_DROP DELETE SELECT_LIMIT
ALTER_RENAME DELETE_COLUMNS SELECT_TABLECapture
This command captures the output of a command and adds it to a file. For example, take a look at the following code that captures the output to a file named Outputfile.
cqlsh> CAPTURE '/home/hadoop/CassandraProgs/Outputfile'When we type any command in the terminal, the output will be captured by the file given. Given below is the command used and the snapshot of the output file.
cqlsh:tutorialspoint> select * from emp;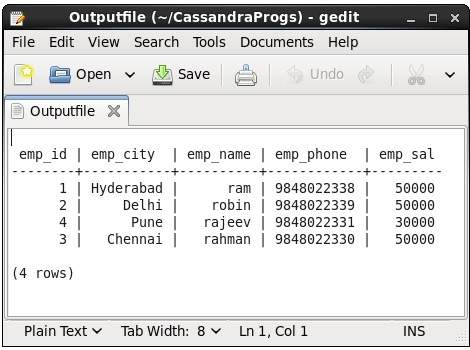
You can turn capturing off using the following command.
cqlsh:tutorialspoint> capture off;Consistency
This command shows the current consistency level, or sets a new consistency level.
cqlsh:tutorialspoint> CONSISTENCY
Current consistency level is 1.Copy
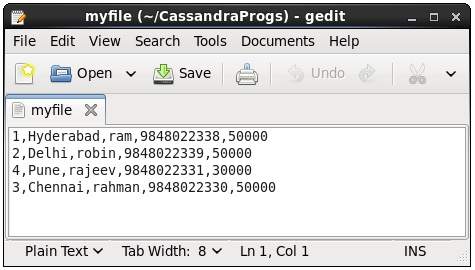
This command copies data to and from Cassandra to a file. Given below is an example to copy the table named emp to the file myfile.
cqlsh:tutorialspoint> COPY emp (emp_id, emp_city, emp_name, emp_phone,emp_sal) TO ‘myfile’;
4 rows exported in 0.034 seconds.If you open and verify the file given, you can find the copied data as shown below.
Describe
This command describes the current cluster of Cassandra and its objects. The variants of this command are explained below.
Describe cluster − This command provides information about the cluster.
cqlsh:tutorialspoint> describe cluster;
Cluster: Test Cluster
Partitioner: Murmur3Partitioner
Range ownership:
-658380912249644557 [127.0.0.1]
-2833890865268921414 [127.0.0.1]
-6792159006375935836 [127.0.0.1]Describe Keyspaces − This command lists all the keyspaces in a cluster. Given below is the usage of this command.
cqlsh:tutorialspoint> describe keyspaces;
system_traces system tp tutorialspointDescribe tables − This command lists all the tables in a keyspace. Given below is the usage of this command.
cqlsh:tutorialspoint> describe tables;
empDescribe table − This command provides the description of a table. Given below is the usage of this command.
cqlsh:tutorialspoint> describe table emp;
CREATE TABLE tutorialspoint.emp (
emp_id int PRIMARY KEY,
emp_city text,
emp_name text,
emp_phone varint,
emp_sal varint
) WITH bloom_filter_fp_chance = 0.01
AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'
AND comment = ''
AND compaction = {'min_threshold': '4', 'class':
'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy',
'max_threshold': '32'}
AND compression = {'sstable_compression':
'org.apache.cassandra.io.compress.LZ4Compressor'}
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99.0PERCENTILE';
CREATE INDEX emp_emp_sal_idx ON tutorialspoint.emp (emp_sal);Describe Type
This command is used to describe a user-defined data type. Given below is the usage of this command.
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
mail text
);Describe Types
This command lists all the user-defined data types. Given below is the usage of this command. Assume there are two user-defined data types: card and card_details.
cqlsh:tutorialspoint> DESCRIBE TYPES;
card_details cardExpand
This command is used to expand the output. Before using this command, you have to turn the expand command on. Given below is the usage of this command.
cqlsh:tutorialspoint> expand on;
cqlsh:tutorialspoint> select * from emp;
@ Row 1
-----------+------------
emp_id | 1
emp_city | Hyderabad
emp_name | ram
emp_phone | 9848022338
emp_sal | 50000
@ Row 2
-----------+------------
emp_id | 2
emp_city | Delhi
emp_name | robin
emp_phone | 9848022339
emp_sal | 50000
@ Row 3
-----------+------------
emp_id | 4
emp_city | Pune
emp_name | rajeev
emp_phone | 9848022331
emp_sal | 30000
@ Row 4
-----------+------------
emp_id | 3
emp_city | Chennai
emp_name | rahman
emp_phone | 9848022330
emp_sal | 50000
(4 rows)Note − You can turn the expand option off using the following command.
cqlsh:tutorialspoint> expand off;
Disabled Expanded output.Exit
This command is used to terminate the cql shell.
Show
This command displays the details of current cqlsh session such as Cassandra version, host, or data type assumptions. Given below is the usage of this command.
cqlsh:tutorialspoint> show host;
Connected to Test Cluster at 127.0.0.1:9042.
cqlsh:tutorialspoint> show version;
[cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]Source
Using this command, you can execute the commands in a file. Suppose our input file is as follows −
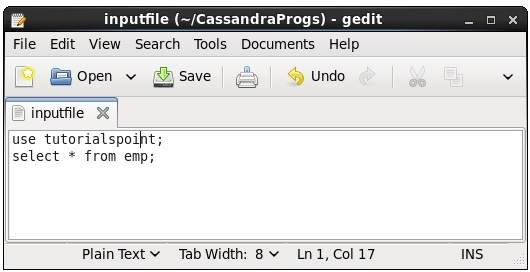
Then you can execute the file containing the commands as shown below.
cqlsh:tutorialspoint> source '/home/hadoop/CassandraProgs/inputfile';
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Pune | rajeev | 9848022331 | 30000
4 | Chennai | rahman | 9848022330 | 50000
(4 rows)Creating a Keyspace using Cqlsh
A keyspace in Cassandra is a namespace that defines data replication on nodes. A cluster contains one keyspace per node. Given below is the syntax for creating a keyspace using the statement CREATE KEYSPACE.
Syntax
CREATE KEYSPACE <identifier> WITH <properties>i.e.
CREATE KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’};
CREATE KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’}
AND durable_writes = ‘Boolean value’;The CREATE KEYSPACE statement has two properties: replication and durable_writes.
Replication
The replication option is to specify the Replica Placement strategy and the number of replicas wanted. The following table lists all the replica placement strategies.
| Strategy name | Description |
|---|---|
| Simple Strategy' | Specifies a simple replication factor for the cluster. |
| Network Topology Strategy | Using this option, you can set the replication factor for each data-center independently. |
| Old Network Topology Strategy | This is a legacy replication strategy. |
Using this option, you can instruct Cassandra whether to use commitlog for updates on the current KeySpace. This option is not mandatory and by default, it is set to true.
Example
Given below is an example of creating a KeySpace.
Here we are creating a KeySpace named TutorialsPoint.
We are using the first replica placement strategy, i.e.., Simple Strategy.
And we are choosing the replication factor to 1 replica.
cqlsh.> CREATE KEYSPACE tutorialspoint
WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};Verification
You can verify whether the table is created or not using the command Describe. If you use this command over keyspaces, it will display all the keyspaces created as shown below.
cqlsh> DESCRIBE keyspaces;
tutorialspoint system system_tracesHere you can observe the newly created KeySpace tutorialspoint.
Durable_writes
By default, the durable_writes properties of a table is set to true, however it can be set to false. You cannot set this property to simplex strategy.
Example
Given below is the example demonstrating the usage of durable writes property.
cqlsh> CREATE KEYSPACE test
... WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3 }
... AND DURABLE_WRITES = false;Verification
You can verify whether the durable_writes property of test KeySpace was set to false by querying the System Keyspace. This query gives you all the KeySpaces along with their properties.
cqlsh> SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | False | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1" : "3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor" : "4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor" : "2"}
(4 rows)Here you can observe the durable_writes property of test KeySpace was set to false.
Using a Keyspace
You can use a created KeySpace using the keyword USE. Its syntax is as follows −
Syntax:USE <identifier>Example
In the following example, we are using the KeySpace tutorialspoint.
cqlsh> USE tutorialspoint;
cqlsh:tutorialspoint>Creating a Keyspace using Java API
You can create a Keyspace using the execute() method of Session class. Follow the steps given below to create a keyspace using Java API.
Step1: Create a Cluster Object
First of all, create an instance of Cluster.builder class of com.datastax.driver.core package as shown below.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Add a contact point (IP address of the node) using addContactPoint() method of Cluster.Builder object. This method returns Cluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Using the new builder object, create a cluster object. To do so, you have a method called build() in the Cluster.Builder class. The following code shows how to create a cluster object.
//Building a cluster
Cluster cluster = builder.build();You can build a cluster object in a single line of code as shown below.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Step 2: Create a Session Object
Create an instance of Session object using the connect() method of Cluster class as shown below.
Session session = cluster.connect( );This method creates a new session and initializes it. If you already have a keyspace, you can set it to the existing one by passing the keyspace name in string format to this method as shown below.
Session session = cluster.connect(“ Your keyspace name ” );Step 3: Execute Query
You can execute CQL queries using the execute() method of Session class. Pass the query either in string format or as a Statement class object to the execute() method. Whatever you pass to this method in string format will be executed on the cqlsh.
In this example, we are creating a KeySpace named tp. We are using the first replica placement strategy, i.e., Simple Strategy, and we are choosing the replication factor to 1 replica.
You have to store the query in a string variable and pass it to the execute() method as shown below.
String query = "CREATE KEYSPACE tp WITH replication "
+ "= {'class':'SimpleStrategy', 'replication_factor':1}; ";
session.execute(query);Step4 : Use the KeySpace
You can use a created KeySpace using the execute() method as shown below.
execute(“ USE tp ” );Given below is the complete program to create and use a keyspace in Cassandra using Java API.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_KeySpace {
public static void main(String args[]){
//Query
String query = "CREATE KEYSPACE tp WITH replication "
+ "= {'class':'SimpleStrategy', 'replication_factor':1};";
//creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
//using the KeySpace
session.execute("USE tp");
System.out.println("Keyspace created");
}
}Save the above program with the class name followed by .java, browse to the location where it is saved. Compile and execute the program as shown below.
$javac Create_KeySpace.java
$java Create_KeySpaceUnder normal conditions, it will produce the following output −
Keyspace createdAltering a KeySpace
ALTER KEYSPACE can be used to alter properties such as the number of replicas and the durable_writes of a KeySpace. Given below is the syntax of this command.
Syntax
ALTER KEYSPACE <identifier> WITH <properties>i.e.
ALTER KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’};The properties of ALTER KEYSPACE are same as CREATE KEYSPACE. It has two properties: replication and durable_writes.
Replication
The replication option specifies the replica placement strategy and the number of replicas wanted.
Durable_writes
Using this option, you can instruct Cassandra whether to use commitlog for updates on the current KeySpace. This option is not mandatory and by default, it is set to true.
Example
Given below is an example of altering a KeySpace.
Here we are altering a KeySpace named TutorialsPoint.
We are changing the replication factor from 1 to 3.
cqlsh.> ALTER KEYSPACE tutorialspoint
WITH replication = {'class':'NetworkTopologyStrategy', 'replication_factor' : 3};กำลังแก้ไข Durable_writes
คุณยังสามารถแก้ไขคุณสมบัติ Durable_writes ของ KeySpace ด้านล่างคือคุณสมบัติ Durable_writes ของไฟล์test คีย์สเปซ
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | False | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1":"3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
(4 rows)ALTER KEYSPACE test
WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}
AND DURABLE_WRITES = true;อีกครั้งหากคุณตรวจสอบคุณสมบัติของ KeySpaces ระบบจะสร้างผลลัพธ์ต่อไปนี้
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | True | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1":"3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
(4 rows)การแก้ไข Keyspace โดยใช้ Java API
คุณสามารถเปลี่ยนคีย์สเปซโดยใช้ไฟล์ execute() วิธีการของ Sessionชั้นเรียน. ทำตามขั้นตอนด้านล่างเพื่อแก้ไขคีย์สเปซโดยใช้ Java API
ขั้นตอนที่ 1: สร้างวัตถุคลัสเตอร์
ก่อนอื่นสร้างอินสแตนซ์ของ Cluster.builder ชั้นเรียนของ com.datastax.driver.core แพ็คเกจตามที่แสดงด้านล่าง
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();เพิ่มจุดติดต่อ (ที่อยู่ IP ของโหนด) โดยใช้ addContactPoint() วิธีการของ Cluster.Builderวัตถุ. วิธีนี้ส่งกลับCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );ใช้วัตถุตัวสร้างใหม่สร้างวัตถุคลัสเตอร์ ในการทำเช่นนั้นคุณมีวิธีการที่เรียกว่าbuild() ใน Cluster.Builderชั้นเรียน. รหัสต่อไปนี้แสดงวิธีสร้างวัตถุคลัสเตอร์
//Building a cluster
Cluster cluster = builder.build();คุณสามารถสร้างวัตถุคลัสเตอร์โดยใช้โค้ดบรรทัดเดียวดังที่แสดงด้านล่าง
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();ขั้นตอนที่ 2: สร้างวัตถุเซสชัน
สร้างอินสแตนซ์ของ Session วัตถุโดยใช้ connect() วิธีการของ Clusterคลาสดังที่แสดงด้านล่าง
Session session = cluster.connect( );วิธีนี้จะสร้างเซสชันใหม่และเริ่มต้น หากคุณมีคีย์สเปซอยู่แล้วคุณสามารถตั้งค่าเป็นคีย์สเปซที่มีอยู่ได้โดยส่งชื่อคีย์สเปซในรูปแบบสตริงไปยังวิธีนี้ดังที่แสดงด้านล่าง
Session session = cluster.connect(“ Your keyspace name ” );ขั้นตอนที่ 3: ดำเนินการสืบค้น
คุณสามารถดำเนินการสืบค้น CQL โดยใช้เมธอด execute () ของคลาส Session ส่งแบบสอบถามในรูปแบบสตริงหรือเป็นStatementคลาสอ็อบเจ็กต์ไปยังเมธอด execute () สิ่งที่คุณส่งไปยังวิธีนี้ในรูปแบบสตริงจะถูกดำเนินการบนไฟล์cqlsh.
ในตัวอย่างนี้
เรากำลังแก้ไขคีย์สเปซที่ชื่อ tp. เรากำลังเปลี่ยนแปลงตัวเลือกการจำลองแบบจาก Simple Strategy เป็น Network Topology Strategy
เรากำลังแก้ไขไฟล์ durable_writes เป็นเท็จ
คุณต้องเก็บแบบสอบถามไว้ในตัวแปรสตริงและส่งต่อไปยังเมธอด execute () ดังที่แสดงด้านล่าง
//Query
String query = "ALTER KEYSPACE tp WITH replication " + "= {'class':'NetworkTopologyStrategy', 'datacenter1':3}" +" AND DURABLE_WRITES = false;";
session.execute(query);ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการสร้างและใช้คีย์สเปซในคาสซานดราโดยใช้ Java API
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Alter_KeySpace {
public static void main(String args[]){
//Query
String query = "ALTER KEYSPACE tp WITH replication " + "= {'class':'NetworkTopologyStrategy', 'datacenter1':3}"
+ "AND DURABLE_WRITES = false;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
System.out.println("Keyspace altered");
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Alter_KeySpace.java
$java Alter_KeySpaceภายใต้สภาวะปกติจะสร้างผลลัพธ์ต่อไปนี้ -
Keyspace Alteredการวางคีย์สเปซ
คุณสามารถวาง KeySpace โดยใช้คำสั่ง DROP KEYSPACE. ด้านล่างเป็นไวยากรณ์สำหรับการวาง KeySpace
ไวยากรณ์
DROP KEYSPACE <identifier>กล่าวคือ
DROP KEYSPACE “KeySpace name”ตัวอย่าง
รหัสต่อไปนี้จะลบคีย์สเปซ tutorialspoint.
cqlsh> DROP KEYSPACE tutorialspoint;การยืนยัน
ตรวจสอบคีย์สเปซโดยใช้คำสั่ง Describe และตรวจสอบว่าตารางหลุดตามที่แสดงด้านล่างหรือไม่
cqlsh> DESCRIBE keyspaces;
system system_tracesเนื่องจากเราได้ลบจุดสอนคีย์สเปซแล้วคุณจะไม่พบมันในรายการคีย์สเปซ
การทิ้ง Keyspace โดยใช้ Java API
คุณสามารถสร้าง Keyspace โดยใช้เมธอด execute () ของคลาส Session ทำตามขั้นตอนด้านล่างเพื่อวางคีย์สเปซโดยใช้ Java API
ขั้นตอนที่ 1: สร้างวัตถุคลัสเตอร์
ก่อนอื่นสร้างอินสแตนซ์ของ Cluster.builder ชั้นเรียนของ com.datastax.driver.core แพ็คเกจตามที่แสดงด้านล่าง
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();เพิ่มจุดติดต่อ (ที่อยู่ IP ของโหนด) โดยใช้ addContactPoint() วิธีการของ Cluster.Builderวัตถุ. วิธีนี้ส่งกลับCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );ใช้วัตถุตัวสร้างใหม่สร้างวัตถุคลัสเตอร์ ในการทำเช่นนั้นคุณมีวิธีการที่เรียกว่าbuild() ใน Cluster.Builderชั้นเรียน. รหัสต่อไปนี้แสดงวิธีสร้างวัตถุคลัสเตอร์
//Building a cluster
Cluster cluster = builder.build();คุณสามารถสร้างออบเจ็กต์คลัสเตอร์โดยใช้โค้ดบรรทัดเดียวดังที่แสดงด้านล่าง
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();ขั้นตอนที่ 2: สร้างวัตถุเซสชัน
สร้างอินสแตนซ์ของวัตถุเซสชันโดยใช้เมธอด connect () ของคลาสคลัสเตอร์ดังที่แสดงด้านล่าง
Session session = cluster.connect( );วิธีนี้จะสร้างเซสชันใหม่และเริ่มต้น หากคุณมีคีย์สเปซอยู่แล้วคุณสามารถตั้งค่าเป็นคีย์สเปซที่มีอยู่ได้โดยส่งชื่อคีย์สเปซในรูปแบบสตริงไปยังวิธีนี้ดังที่แสดงด้านล่าง
Session session = cluster.connect(“ Your keyspace name”);ขั้นตอนที่ 3: ดำเนินการสืบค้น
คุณสามารถดำเนินการสืบค้น CQL โดยใช้เมธอด execute () ของคลาส Session ส่งแบบสอบถามในรูปแบบสตริงหรือเป็นวัตถุคลาส Statement ไปยังเมธอด execute () สิ่งที่คุณส่งไปยังวิธีนี้ในรูปแบบสตริงจะถูกดำเนินการบน cqlsh
ในตัวอย่างต่อไปนี้เรากำลังลบคีย์สเปซที่ชื่อ tp. คุณต้องเก็บแบบสอบถามไว้ในตัวแปรสตริงและส่งต่อไปยังเมธอด execute () ดังที่แสดงด้านล่าง
String query = "DROP KEYSPACE tp; ";
session.execute(query);ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการสร้างและใช้คีย์สเปซในคาสซานดราโดยใช้ Java API
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_KeySpace {
public static void main(String args[]){
//Query
String query = "Drop KEYSPACE tp";
//creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
System.out.println("Keyspace deleted");
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Delete_KeySpace.java
$java Delete_KeySpaceภายใต้สภาวะปกติควรให้ผลลัพธ์ดังต่อไปนี้ -
Keyspace deletedการสร้างตาราง
คุณสามารถสร้างตารางโดยใช้คำสั่ง CREATE TABLE. ด้านล่างคือไวยากรณ์สำหรับการสร้างตาราง
ไวยากรณ์
CREATE (TABLE | COLUMNFAMILY) <tablename>
('<column-definition>' , '<column-definition>')
(WITH <option> AND <option>)การกำหนดคอลัมน์
คุณสามารถกำหนดคอลัมน์ตามที่แสดงด้านล่าง
column name1 data type,
column name2 data type,
example:
age int,
name textคีย์หลัก
คีย์หลักคือคอลัมน์ที่ใช้เพื่อระบุแถวโดยไม่ซ้ำกัน ดังนั้นการกำหนดคีย์หลักจึงเป็นสิ่งจำเป็นในขณะที่สร้างตาราง คีย์หลักประกอบด้วยคอลัมน์ของตารางอย่างน้อยหนึ่งคอลัมน์ คุณสามารถกำหนดคีย์หลักของตารางดังที่แสดงด้านล่าง
CREATE TABLE tablename(
column1 name datatype PRIMARYKEY,
column2 name data type,
column3 name data type.
)or
CREATE TABLE tablename(
column1 name datatype PRIMARYKEY,
column2 name data type,
column3 name data type,
PRIMARY KEY (column1)
)ตัวอย่าง
ด้านล่างเป็นตัวอย่างในการสร้างตารางใน Cassandra โดยใช้ cqlsh เราอยู่ที่นี่ -
การใช้คีย์สเปซ tutorialspoint
การสร้างตารางชื่อ emp
จะมีรายละเอียดเช่นชื่อพนักงานรหัสเมืองเงินเดือนและหมายเลขโทรศัพท์ รหัสพนักงานเป็นคีย์หลัก
cqlsh> USE tutorialspoint;
cqlsh:tutorialspoint>; CREATE TABLE emp(
emp_id int PRIMARY KEY,
emp_name text,
emp_city text,
emp_sal varint,
emp_phone varint
);การยืนยัน
คำสั่ง select จะให้สคีมาแก่คุณ ตรวจสอบตารางโดยใช้คำสั่ง select ดังที่แสดงด้านล่าง
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+----------+----------+-----------+---------
(0 rows)ที่นี่คุณสามารถสังเกตตารางที่สร้างขึ้นด้วยคอลัมน์ที่กำหนด เนื่องจากเราได้ลบจุดสอนคีย์สเปซแล้วคุณจะไม่พบมันในรายการคีย์สเปซ
การสร้างตารางโดยใช้ Java API
คุณสามารถสร้างตารางโดยใช้เมธอด execute () ของคลาส Session ทำตามขั้นตอนด้านล่างเพื่อสร้างตารางโดยใช้ Java API
ขั้นตอนที่ 1: สร้างวัตถุคลัสเตอร์
ก่อนอื่นให้สร้างอินสแตนซ์ของไฟล์ Cluster.builder ชั้นเรียนของ com.datastax.driver.core แพ็คเกจตามที่แสดงด้านล่าง
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();เพิ่มจุดติดต่อ (ที่อยู่ IP ของโหนด) โดยใช้ addContactPoint() วิธีการของ Cluster.Builderวัตถุ. วิธีนี้ส่งกลับCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );ใช้วัตถุตัวสร้างใหม่สร้างวัตถุคลัสเตอร์ ในการทำเช่นนั้นคุณมีวิธีการที่เรียกว่าbuild() ใน Cluster.Builderชั้นเรียน. รหัสต่อไปนี้แสดงวิธีสร้างวัตถุคลัสเตอร์
//Building a cluster
Cluster cluster = builder.build();คุณสามารถสร้างออบเจ็กต์คลัสเตอร์โดยใช้โค้ดบรรทัดเดียวดังที่แสดงด้านล่าง
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();ขั้นตอนที่ 2: สร้างวัตถุเซสชัน
สร้างอินสแตนซ์ของวัตถุเซสชันโดยใช้ connect() วิธีการของ Cluster คลาสดังที่แสดงด้านล่าง
Session session = cluster.connect( );วิธีนี้จะสร้างเซสชันใหม่และเริ่มต้น หากคุณมีคีย์สเปซอยู่แล้วคุณสามารถตั้งค่าเป็นคีย์สเปซที่มีอยู่ได้โดยส่งชื่อคีย์สเปซในรูปแบบสตริงไปยังวิธีนี้ดังที่แสดงด้านล่าง
Session session = cluster.connect(“ Your keyspace name ” );ที่นี่เรากำลังใช้คีย์สเปซชื่อ tp. ดังนั้นให้สร้างวัตถุเซสชันดังที่แสดงด้านล่าง
Session session = cluster.connect(“ tp” );ขั้นตอนที่ 3: ดำเนินการสืบค้น
คุณสามารถดำเนินการสืบค้น CQL โดยใช้เมธอด execute () ของคลาส Session ส่งแบบสอบถามในรูปแบบสตริงหรือเป็นวัตถุคลาส Statement ไปยังเมธอด execute () สิ่งที่คุณส่งไปยังวิธีนี้ในรูปแบบสตริงจะถูกดำเนินการบน cqlsh
ในตัวอย่างต่อไปนี้เรากำลังสร้างตารางชื่อ emp. คุณต้องเก็บแบบสอบถามไว้ในตัวแปรสตริงและส่งต่อไปยังเมธอด execute () ดังที่แสดงด้านล่าง
//Query
String query = "CREATE TABLE emp(emp_id int PRIMARY KEY, "
+ "emp_name text, "
+ "emp_city text, "
+ "emp_sal varint, "
+ "emp_phone varint );";
session.execute(query);ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการสร้างและใช้คีย์สเปซในคาสซานดราโดยใช้ Java API
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Table {
public static void main(String args[]){
//Query
String query = "CREATE TABLE emp(emp_id int PRIMARY KEY, "
+ "emp_name text, "
+ "emp_city text, "
+ "emp_sal varint, "
+ "emp_phone varint );";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table created");
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Create_Table.java
$java Create_Tableภายใต้สภาวะปกติควรให้ผลลัพธ์ดังต่อไปนี้ -
Table createdการแก้ไขตาราง
คุณสามารถแก้ไขตารางโดยใช้คำสั่ง ALTER TABLE. ด้านล่างคือไวยากรณ์สำหรับการสร้างตาราง
ไวยากรณ์
ALTER (TABLE | COLUMNFAMILY) <tablename> <instruction>ใช้คำสั่ง ALTER คุณสามารถดำเนินการดังต่อไปนี้ -
เพิ่มคอลัมน์
วางคอลัมน์
การเพิ่มคอลัมน์
ใช้คำสั่ง ALTER คุณสามารถเพิ่มคอลัมน์ลงในตารางได้ ในขณะที่เพิ่มคอลัมน์คุณต้องดูแลให้ชื่อคอลัมน์ไม่ขัดแย้งกับชื่อคอลัมน์ที่มีอยู่และตารางไม่ได้กำหนดด้วยตัวเลือกหน่วยเก็บข้อมูลขนาดกะทัดรัด ด้านล่างนี้คือไวยากรณ์เพื่อเพิ่มคอลัมน์ลงในตาราง
ALTER TABLE table name
ADD new column datatype;Example
ด้านล่างเป็นตัวอย่างในการเพิ่มคอลัมน์ลงในตารางที่มีอยู่ ที่นี่เรากำลังเพิ่มคอลัมน์ชื่อemp_email ประเภทข้อมูลข้อความไปยังตารางที่ชื่อ emp.
cqlsh:tutorialspoint> ALTER TABLE emp
... ADD emp_email text;Verification
ใช้คำสั่ง SELECT เพื่อตรวจสอบว่ามีการเพิ่มคอลัมน์หรือไม่ คุณสามารถสังเกตคอลัมน์ emp_email ที่เพิ่มใหม่ได้ที่นี่
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_email | emp_name | emp_phone | emp_sal
--------+----------+-----------+----------+-----------+---------การทิ้งคอลัมน์
ใช้คำสั่ง ALTER คุณสามารถลบคอลัมน์จากตารางได้ ก่อนวางคอลัมน์จากตารางให้ตรวจสอบว่าไม่ได้กำหนดตารางด้วยตัวเลือกพื้นที่เก็บข้อมูลขนาดกะทัดรัด ให้ด้านล่างเป็นไวยากรณ์สำหรับการลบคอลัมน์จากตารางโดยใช้คำสั่ง ALTER
ALTER table name
DROP column name;Example
ด้านล่างนี้เป็นตัวอย่างในการวางคอลัมน์จากตาราง ที่นี่เรากำลังลบคอลัมน์ชื่อemp_email.
cqlsh:tutorialspoint> ALTER TABLE emp DROP emp_email;Verification
ตรวจสอบว่าคอลัมน์ถูกลบโดยใช้ select คำสั่งดังที่แสดงด้านล่าง
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+----------+----------+-----------+---------
(0 rows)ตั้งแต่ emp_email คอลัมน์ถูกลบแล้วคุณไม่สามารถค้นหาได้อีกต่อไป
การแก้ไขตารางโดยใช้ Java API
คุณสามารถสร้างตารางโดยใช้เมธอด execute () ของคลาส Session ทำตามขั้นตอนที่ระบุด้านล่างเพื่อแก้ไขตารางโดยใช้ Java API
ขั้นตอนที่ 1: สร้างวัตถุคลัสเตอร์
ก่อนอื่นสร้างอินสแตนซ์ของ Cluster.builder ชั้นเรียนของ com.datastax.driver.core แพ็คเกจตามที่แสดงด้านล่าง
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();เพิ่มจุดติดต่อ (ที่อยู่ IP ของโหนด) โดยใช้ addContactPoint() วิธีการของ Cluster.Builderวัตถุ. วิธีนี้ส่งกลับCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );ใช้วัตถุตัวสร้างใหม่สร้างวัตถุคลัสเตอร์ ในการทำเช่นนั้นคุณมีวิธีการที่เรียกว่าbuild() ใน Cluster.Builderชั้นเรียน. รหัสต่อไปนี้แสดงวิธีสร้างวัตถุคลัสเตอร์
//Building a cluster
Cluster cluster = builder.build();คุณสามารถสร้างออบเจ็กต์คลัสเตอร์โดยใช้โค้ดบรรทัดเดียวดังที่แสดงด้านล่าง
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();ขั้นตอนที่ 2: สร้างวัตถุเซสชัน
สร้างอินสแตนซ์ของวัตถุเซสชันโดยใช้เมธอด connect () ของคลาสคลัสเตอร์ดังที่แสดงด้านล่าง
Session session = cluster.connect( );วิธีนี้จะสร้างเซสชันใหม่และเริ่มต้น หากคุณมีคีย์สเปซอยู่แล้วคุณสามารถตั้งค่าเป็นคีย์สเปซที่มีอยู่ได้โดยส่งชื่อคีย์สเปซในรูปแบบสตริงไปยังเมธอดนี้
Session session = cluster.connect(“ Your keyspace name ” );
Session session = cluster.connect(“ tp” );เรากำลังใช้ KeySpace ชื่อ tp ดังนั้นให้สร้างวัตถุเซสชันดังที่แสดงด้านล่าง
ขั้นตอนที่ 3: ดำเนินการสืบค้น
คุณสามารถดำเนินการสืบค้น CQL โดยใช้เมธอด execute () ของคลาส Session ส่งแบบสอบถามในรูปแบบสตริงหรือเป็นวัตถุคลาส Statement ไปยังเมธอด execute () สิ่งที่คุณส่งไปยังวิธีนี้ในรูปแบบสตริงจะถูกดำเนินการบนไฟล์cqlsh.
ในตัวอย่างต่อไปนี้เรากำลังเพิ่มคอลัมน์ในตารางที่มีชื่อว่า emp. ในการทำเช่นนั้นคุณต้องเก็บแบบสอบถามไว้ในตัวแปรสตริงและส่งต่อไปยังเมธอด execute () ดังที่แสดงด้านล่าง
//Query
String query1 = "ALTER TABLE emp ADD emp_email text";
session.execute(query);ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการเพิ่มคอลัมน์ลงในตารางที่มีอยู่
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Add_column {
public static void main(String args[]){
//Query
String query = "ALTER TABLE emp ADD emp_email text";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Column added");
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Add_Column.java
$java Add_Columnภายใต้สภาวะปกติควรให้ผลลัพธ์ดังต่อไปนี้ -
Column addedการลบคอลัมน์
ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการลบคอลัมน์จากตารางที่มีอยู่
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Delete_Column {
public static void main(String args[]){
//Query
String query = "ALTER TABLE emp DROP emp_email;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//executing the query
session.execute(query);
System.out.println("Column deleted");
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Delete_Column.java
$java Delete_Columnภายใต้สภาวะปกติควรให้ผลลัพธ์ดังต่อไปนี้ -
Column deletedวางตาราง
คุณสามารถวางตารางโดยใช้คำสั่ง Drop Table. ไวยากรณ์มีดังนี้ -
ไวยากรณ์
DROP TABLE <tablename>ตัวอย่าง
รหัสต่อไปนี้จะนำตารางที่มีอยู่ออกจาก KeySpace
cqlsh:tutorialspoint> DROP TABLE emp;การยืนยัน
ใช้คำสั่ง Describe เพื่อตรวจสอบว่าตารางถูกลบหรือไม่ เนื่องจากตาราง emp ถูกลบคุณจะไม่พบในรายการคอลัมน์ตระกูล
cqlsh:tutorialspoint> DESCRIBE COLUMNFAMILIES;
employeeการลบตารางโดยใช้ Java API
คุณสามารถลบตารางโดยใช้เมธอด execute () ของคลาส Session ทำตามขั้นตอนด้านล่างเพื่อลบตารางโดยใช้ Java API
ขั้นตอนที่ 1: สร้างวัตถุคลัสเตอร์
ก่อนอื่นสร้างอินสแตนซ์ของ Cluster.builder ชั้นเรียนของ com.datastax.driver.core แพคเกจดังแสดงด้านล่าง -
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();เพิ่มจุดติดต่อ (ที่อยู่ IP ของโหนด) โดยใช้ addContactPoint() วิธีการของ Cluster.Builderวัตถุ. วิธีนี้ส่งกลับCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );ใช้วัตถุตัวสร้างใหม่สร้างวัตถุคลัสเตอร์ ในการทำเช่นนั้นคุณมีวิธีการที่เรียกว่าbuild() ใน Cluster.Builderชั้นเรียน. รหัสต่อไปนี้แสดงวิธีสร้างวัตถุคลัสเตอร์
//Building a cluster
Cluster cluster = builder.build();คุณสามารถสร้างออบเจ็กต์คลัสเตอร์โดยใช้โค้ดบรรทัดเดียวดังที่แสดงด้านล่าง
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();ขั้นตอนที่ 2: สร้างวัตถุเซสชัน
สร้างอินสแตนซ์ของวัตถุเซสชันโดยใช้เมธอด connect () ของคลาสคลัสเตอร์ดังที่แสดงด้านล่าง
Session session = cluster.connect( );วิธีนี้จะสร้างเซสชันใหม่และเริ่มต้น หากคุณมีคีย์สเปซอยู่แล้วคุณสามารถตั้งค่าเป็นคีย์สเปซที่มีอยู่ได้โดยส่งชื่อคีย์สเปซในรูปแบบสตริงไปยังเมธอดนี้
Session session = cluster.connect(“Your keyspace name”);ที่นี่เรากำลังใช้คีย์สเปซชื่อ tp. ดังนั้นให้สร้างวัตถุเซสชันดังที่แสดงด้านล่าง
Session session = cluster.connect(“tp”);ขั้นตอนที่ 3: ดำเนินการสืบค้น
คุณสามารถดำเนินการสืบค้น CQL โดยใช้เมธอด execute () ของคลาส Session ส่งแบบสอบถามในรูปแบบสตริงหรือเป็นวัตถุคลาส Statement ไปยังเมธอด execute () สิ่งที่คุณส่งไปยังวิธีนี้ในรูปแบบสตริงจะถูกดำเนินการบนไฟล์cqlsh.
ในตัวอย่างต่อไปนี้เรากำลังลบตารางชื่อ emp. คุณต้องเก็บแบบสอบถามไว้ในตัวแปรสตริงและส่งต่อไปยังเมธอด execute () ดังที่แสดงด้านล่าง
// Query
String query = "DROP TABLE emp1;”;
session.execute(query);ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการวางตารางใน Cassandra โดยใช้ Java API
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_Table {
public static void main(String args[]){
//Query
String query = "DROP TABLE emp1;";
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table dropped");
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Drop_Table.java
$java Drop_Tableภายใต้สภาวะปกติควรให้ผลลัพธ์ดังต่อไปนี้ -
Table droppedการตัดตาราง
คุณสามารถตัดตารางโดยใช้คำสั่ง TRUNCATE เมื่อคุณตัดทอนตารางแถวทั้งหมดของตารางจะถูกลบอย่างถาวร ให้ด้านล่างเป็นไวยากรณ์ของคำสั่งนี้
ไวยากรณ์
TRUNCATE <tablename>ตัวอย่าง
ให้เราถือว่ามีตารางที่เรียกว่า student ด้วยข้อมูลต่อไปนี้
| s_id | s_name | s_branch | s_aggregate |
|---|---|---|---|
| 1 | แกะ | มัน | 70 |
| 2 | ราห์มาน | EEE | 75 |
| 3 | robbin | Mech | 72 |
เมื่อคุณรันคำสั่ง select เพื่อรับตาราง student, จะให้ผลลัพธ์ดังต่อไปนี้
cqlsh:tp> select * from student;
s_id | s_aggregate | s_branch | s_name
------+-------------+----------+--------
1 | 70 | IT | ram
2 | 75 | EEE | rahman
3 | 72 | MECH | robbin
(3 rows)ตอนนี้ตัดตารางโดยใช้คำสั่ง TRUNCATE
cqlsh:tp> TRUNCATE student;การยืนยัน
ตรวจสอบว่าตารางถูกตัดทอนหรือไม่โดยการเรียกใช้ selectคำให้การ. ให้ด้านล่างนี้คือผลลัพธ์ของคำสั่ง select บนโต๊ะนักเรียนหลังจากการตัดทอน
cqlsh:tp> select * from student;
s_id | s_aggregate | s_branch | s_name
------+-------------+----------+--------
(0 rows)การตัดตารางโดยใช้ Java API
คุณสามารถตัดทอนตารางโดยใช้เมธอด execute () ของคลาส Session ทำตามขั้นตอนด้านล่างเพื่อตัดทอนตาราง
ขั้นตอนที่ 1: สร้างวัตถุคลัสเตอร์
ก่อนอื่นสร้างอินสแตนซ์ของ Cluster.builder ชั้นเรียนของ com.datastax.driver.core แพ็คเกจตามที่แสดงด้านล่าง
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();เพิ่มจุดติดต่อ (ที่อยู่ IP ของโหนด) โดยใช้ addContactPoint() วิธีการของ Cluster.Builderวัตถุ. วิธีนี้ส่งกลับCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );ใช้วัตถุตัวสร้างใหม่สร้างวัตถุคลัสเตอร์ ในการทำเช่นนั้นคุณมีวิธีการที่เรียกว่าbuild() ใน Cluster.Builderชั้นเรียน. รหัสต่อไปนี้แสดงวิธีสร้างวัตถุคลัสเตอร์
//Building a cluster
Cluster cluster = builder.build();คุณสามารถสร้างออบเจ็กต์คลัสเตอร์โดยใช้โค้ดบรรทัดเดียวดังที่แสดงด้านล่าง
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();ขั้นตอนที่ 2: การสร้างวัตถุเซสชัน
สร้างอินสแตนซ์ของวัตถุเซสชันโดยใช้เมธอด connect () ของคลาสคลัสเตอร์ดังที่แสดงด้านล่าง
Session session = cluster.connect( );วิธีนี้จะสร้างเซสชันใหม่และเริ่มต้น หากคุณมีคีย์สเปซอยู่แล้วคุณสามารถตั้งค่าเป็นคีย์สเปซที่มีอยู่ได้โดยส่งชื่อคีย์สเปซในรูปแบบสตริงไปยังเมธอดนี้ดังที่แสดงด้านล่าง
Session session = cluster.connect(“ Your keyspace name ” );
Session session = cluster.connect(“ tp” );ที่นี่เรากำลังใช้คีย์สเปซชื่อ tp ดังนั้นให้สร้างวัตถุเซสชันดังที่แสดงด้านล่าง
ขั้นตอนที่ 3: ดำเนินการสืบค้น
คุณสามารถดำเนินการสืบค้น CQL โดยใช้เมธอด execute () ของคลาส Session ส่งแบบสอบถามในรูปแบบสตริงหรือเป็นวัตถุคลาส Statement ไปยังเมธอด execute () สิ่งที่คุณส่งไปยังวิธีนี้ในรูปแบบสตริงจะถูกดำเนินการบนไฟล์cqlsh.
ในตัวอย่างต่อไปนี้เรากำลังตัดทอนตารางที่ชื่อ emp. คุณต้องจัดเก็บแบบสอบถามในตัวแปรสตริงและส่งต่อไปยังไฟล์execute() วิธีการดังแสดงด้านล่าง
//Query
String query = "TRUNCATE emp;;”;
session.execute(query);ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการตัดทอนตารางใน Cassandra โดยใช้ Java API
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Truncate_Table {
public static void main(String args[]){
//Query
String query = "Truncate student;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table truncated");
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Truncate_Table.java
$java Truncate_Tableภายใต้สภาวะปกติควรให้ผลลัพธ์ดังต่อไปนี้ -
Table truncatedการสร้างดัชนีโดยใช้ Cqlsh
คุณสามารถสร้างดัชนีใน Cassandra โดยใช้คำสั่ง CREATE INDEX. ไวยากรณ์มีดังนี้ -
CREATE INDEX <identifier> ON <tablename>ด้านล่างเป็นตัวอย่างในการสร้างดัชนีไปยังคอลัมน์ ที่นี่เรากำลังสร้างดัชนีไปยังคอลัมน์ 'emp_name' ในตารางชื่อ emp
cqlsh:tutorialspoint> CREATE INDEX name ON emp1 (emp_name);การสร้างดัชนีโดยใช้ Java API
คุณสามารถสร้างดัชนีไปยังคอลัมน์ของตารางโดยใช้เมธอด execute () ของคลาส Session ทำตามขั้นตอนด้านล่างเพื่อสร้างดัชนีไปยังคอลัมน์ในตาราง
ขั้นตอนที่ 1: สร้างวัตถุคลัสเตอร์
ก่อนอื่นสร้างอินสแตนซ์ของ Cluster.builder ชั้นเรียนของ com.datastax.driver.core แพ็คเกจตามที่แสดงด้านล่าง
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();เพิ่มจุดติดต่อ (ที่อยู่ IP ของโหนด) โดยใช้ addContactPoint() วิธีการของ Cluster.Builderวัตถุ. วิธีนี้ส่งกลับCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );ใช้วัตถุตัวสร้างใหม่สร้างวัตถุคลัสเตอร์ ในการทำเช่นนั้นคุณมีวิธีการที่เรียกว่าbuild() ใน Cluster.Builderชั้นเรียน. รหัสต่อไปนี้แสดงวิธีสร้างวัตถุคลัสเตอร์
//Building a cluster
Cluster cluster = builder.build();คุณสามารถสร้างวัตถุคลัสเตอร์โดยใช้โค้ดบรรทัดเดียวดังที่แสดงด้านล่าง
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();ขั้นตอนที่ 2: สร้างวัตถุเซสชัน
สร้างอินสแตนซ์ของวัตถุเซสชันโดยใช้เมธอด connect () ของ Cluster คลาสดังที่แสดงด้านล่าง
Session session = cluster.connect( );วิธีนี้จะสร้างเซสชันใหม่และเริ่มต้น หากคุณมีคีย์สเปซอยู่แล้วคุณสามารถตั้งค่าเป็นคีย์สเปซที่มีอยู่ได้โดยส่งชื่อคีย์สเปซในรูปแบบสตริงไปยังเมธอดนี้ดังที่แสดงด้านล่าง
Session session = cluster.connect(“ Your keyspace name ” );ที่นี่เรากำลังใช้ KeySpace ที่เรียกว่า tp. ดังนั้นให้สร้างวัตถุเซสชันดังที่แสดงด้านล่าง
Session session = cluster.connect(“ tp” );ขั้นตอนที่ 3: ดำเนินการสืบค้น
คุณสามารถดำเนินการสืบค้น CQL โดยใช้เมธอด execute () ของคลาส Session ส่งแบบสอบถามในรูปแบบสตริงหรือเป็นวัตถุคลาส Statement ไปยังเมธอด execute () สิ่งที่คุณส่งไปยังวิธีนี้ในรูปแบบสตริงจะถูกดำเนินการบนไฟล์cqlsh.
ในตัวอย่างต่อไปนี้เรากำลังสร้างดัชนีไปยังคอลัมน์ชื่อ emp_name ในตารางที่มีชื่อว่า emp. คุณต้องเก็บแบบสอบถามไว้ในตัวแปรสตริงและส่งต่อไปยังเมธอด execute () ดังที่แสดงด้านล่าง
//Query
String query = "CREATE INDEX name ON emp1 (emp_name);";
session.execute(query);ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการสร้างดัชนีของคอลัมน์ในตารางใน Cassandra โดยใช้ Java API
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Index {
public static void main(String args[]){
//Query
String query = "CREATE INDEX name ON emp1 (emp_name);";
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Index created");
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Create_Index.java
$java Create_Indexภายใต้สภาวะปกติควรให้ผลลัพธ์ดังต่อไปนี้ -
Index createdการทิ้งดัชนี
คุณสามารถดร็อปดัชนีโดยใช้คำสั่ง DROP INDEX. ไวยากรณ์มีดังนี้ -
DROP INDEX <identifier>ให้ด้านล่างนี้เป็นตัวอย่างการวางดัชนีของคอลัมน์ในตาราง ที่นี่เรากำลังวางดัชนีของชื่อคอลัมน์ในตาราง emp
cqlsh:tp> drop index name;การทิ้งดัชนีโดยใช้ Java API
คุณสามารถดร็อปดัชนีของตารางโดยใช้เมธอด execute () ของคลาส Session ทำตามขั้นตอนด้านล่างเพื่อดร็อปดัชนีจากตาราง
ขั้นตอนที่ 1: สร้างวัตถุคลัสเตอร์
สร้างอินสแตนซ์ของ Cluster.builder ชั้นเรียนของ com.datastax.driver.core แพ็คเกจตามที่แสดงด้านล่าง
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();เพิ่มจุดติดต่อ (ที่อยู่ IP ของโหนด) โดยใช้ addContactPoint() วิธีการของ Cluster.Builder object. วิธีนี้ส่งกลับCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );ใช้วัตถุตัวสร้างใหม่สร้างวัตถุคลัสเตอร์ ในการทำเช่นนั้นคุณมีวิธีการที่เรียกว่าbuild() ใน Cluster.Builderชั้นเรียน. รหัสต่อไปนี้แสดงวิธีสร้างวัตถุคลัสเตอร์
//Building a cluster
Cluster cluster = builder.build();คุณสามารถสร้างออบเจ็กต์คลัสเตอร์โดยใช้โค้ดบรรทัดเดียวดังที่แสดงด้านล่าง
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();ขั้นตอนที่ 2: สร้างวัตถุเซสชัน
สร้างอินสแตนซ์ของวัตถุเซสชันโดยใช้เมธอด connect () ของคลาสคลัสเตอร์ดังที่แสดงด้านล่าง
Session session = cluster.connect( );วิธีนี้จะสร้างเซสชันใหม่และเริ่มต้น หากคุณมีคีย์สเปซอยู่แล้วคุณสามารถตั้งค่าเป็นคีย์สเปซที่มีอยู่ได้โดยส่งชื่อคีย์สเปซในรูปแบบสตริงไปยังเมธอดนี้ดังที่แสดงด้านล่าง
Session session = cluster.connect(“ Your keyspace name ” );ที่นี่เรากำลังใช้ KeySpace ชื่อ tp. ดังนั้นให้สร้างวัตถุเซสชันดังที่แสดงด้านล่าง
Session session = cluster.connect(“ tp” );ขั้นตอนที่ 3: ดำเนินการสืบค้น
คุณสามารถดำเนินการสืบค้น CQL โดยใช้เมธอด execute () ของคลาส Session ส่งแบบสอบถามในรูปแบบสตริงหรือเป็นStatementคลาสอ็อบเจ็กต์ไปยังเมธอด execute () สิ่งที่คุณส่งไปยังวิธีนี้ในรูปแบบสตริงจะถูกดำเนินการบนไฟล์cqlsh.
ในตัวอย่างต่อไปนี้เราจะทิ้งดัชนี "ชื่อ" ของ empตาราง. คุณต้องเก็บแบบสอบถามไว้ในตัวแปรสตริงและส่งต่อไปยังเมธอด execute () ดังที่แสดงด้านล่าง
//Query
String query = "DROP INDEX user_name;";
session.execute(query);ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการวางดัชนีใน Cassandra โดยใช้ Java API
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_Index {
public static void main(String args[]){
//Query
String query = "DROP INDEX user_name;";
//Creating cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();.
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Index dropped");
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Drop_index.java
$java Drop_indexภายใต้สภาวะปกติควรให้ผลลัพธ์ดังต่อไปนี้ -
Index droppedการใช้คำสั่งชุดงาน
การใช้ BATCH,คุณสามารถเรียกใช้คำสั่งการปรับเปลี่ยนได้หลายรายการ (แทรกอัปเดตลบ) พร้อมกัน ไวยากรณ์มีดังนี้ -
BEGIN BATCH
<insert-stmt>/ <update-stmt>/ <delete-stmt>
APPLY BATCHตัวอย่าง
สมมติว่ามีตารางใน Cassandra เรียกว่า emp ที่มีข้อมูลต่อไปนี้ -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | แกะ | ไฮเดอราบาด | 9848022338 | 50000 |
| 2 | โรบิน | เดลี | 9848022339 | 50000 |
| 3 | ราห์มาน | เจนไน | 9848022330 | 45000 |
ในตัวอย่างนี้เราจะดำเนินการดังต่อไปนี้ -
- แทรกแถวใหม่พร้อมรายละเอียดต่อไปนี้ (4, rajeev, pune, 9848022331, 30000)
- อัปเดตเงินเดือนของพนักงานด้วยรหัสแถว 3 เป็น 50000
- ลบเมืองของพนักงานด้วยรหัสแถว 2
ในการดำเนินการข้างต้นในครั้งเดียวให้ใช้คำสั่ง BATCH ต่อไปนี้ -
cqlsh:tutorialspoint> BEGIN BATCH
... INSERT INTO emp (emp_id, emp_city, emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);
... UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;
... DELETE emp_city FROM emp WHERE emp_id = 2;
... APPLY BATCH;การยืนยัน
หลังจากทำการเปลี่ยนแปลงตรวจสอบตารางโดยใช้คำสั่ง SELECT ควรให้ผลลัพธ์ดังต่อไปนี้ -
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)คุณสามารถสังเกตตารางที่มีข้อมูลที่แก้ไขได้ที่นี่
Batch Statements โดยใช้ Java API
คำสั่งแบตช์สามารถเขียนโดยใช้โปรแกรมในตารางโดยใช้เมธอด execute () ของคลาสเซสชัน ทำตามขั้นตอนด้านล่างเพื่อดำเนินการหลายคำสั่งโดยใช้คำสั่งแบตช์ด้วยความช่วยเหลือของ Java API
ขั้นตอนที่ 1: สร้างวัตถุคลัสเตอร์
สร้างอินสแตนซ์ของ Cluster.builder ชั้นเรียนของ com.datastax.driver.core แพ็คเกจตามที่แสดงด้านล่าง
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();เพิ่มจุดติดต่อ (ที่อยู่ IP ของโหนด) โดยใช้ addContactPoint() วิธีการของ Cluster.Builderวัตถุ. วิธีนี้ส่งกลับCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );ใช้วัตถุตัวสร้างใหม่สร้างวัตถุคลัสเตอร์ ในการทำเช่นนั้นคุณมีวิธีการที่เรียกว่าbuild() ใน Cluster.Builderชั้นเรียน. ใช้รหัสต่อไปนี้เพื่อสร้างวัตถุคลัสเตอร์ -
//Building a cluster
Cluster cluster = builder.build();คุณสามารถสร้างวัตถุคลัสเตอร์โดยใช้โค้ดบรรทัดเดียวดังที่แสดงด้านล่าง
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();ขั้นตอนที่ 2: สร้างวัตถุเซสชัน
สร้างอินสแตนซ์ของวัตถุเซสชันโดยใช้เมธอด connect () ของคลาสคลัสเตอร์ดังที่แสดงด้านล่าง
Session session = cluster.connect( );วิธีนี้จะสร้างเซสชันใหม่และเริ่มต้น หากคุณมีคีย์สเปซอยู่แล้วคุณสามารถตั้งค่าเป็นคีย์สเปซที่มีอยู่ได้โดยส่งชื่อคีย์สเปซในรูปแบบสตริงไปยังเมธอดนี้ดังที่แสดงด้านล่าง
Session session = cluster.connect(“ Your keyspace name ”);ที่นี่เรากำลังใช้ KeySpace ชื่อ tp. ดังนั้นให้สร้างวัตถุเซสชันดังที่แสดงด้านล่าง
Session session = cluster.connect(“tp”);ขั้นตอนที่ 3: ดำเนินการสืบค้น
คุณสามารถดำเนินการสืบค้น CQL โดยใช้เมธอด execute () ของคลาส Session ส่งแบบสอบถามในรูปแบบสตริงหรือเป็นวัตถุคลาส Statement ไปยังเมธอด execute () สิ่งที่คุณส่งไปยังวิธีนี้ในรูปแบบสตริงจะถูกดำเนินการบนไฟล์cqlsh.
ในตัวอย่างนี้เราจะดำเนินการดังต่อไปนี้ -
- แทรกแถวใหม่พร้อมรายละเอียดต่อไปนี้ (4, rajeev, pune, 9848022331, 30000)
- อัปเดตเงินเดือนของพนักงานด้วยรหัสแถว 3 เป็น 50000
- ลบเมืองของพนักงานด้วยรหัสแถว 2
คุณต้องเก็บแบบสอบถามไว้ในตัวแปรสตริงและส่งต่อไปยังเมธอด execute () ดังที่แสดงด้านล่าง
String query1 = ” BEGIN BATCH INSERT INTO emp (emp_id, emp_city, emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);
UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;
DELETE emp_city FROM emp WHERE emp_id = 2;
APPLY BATCH;”;ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการรันคำสั่งหลายคำสั่งพร้อมกันบนตารางใน Cassandra โดยใช้ Java API
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Batch {
public static void main(String args[]){
//query
String query =" BEGIN BATCH INSERT INTO emp (emp_id, emp_city,
emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);"
+ "UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;"
+ "DELETE emp_city FROM emp WHERE emp_id = 2;"
+ "APPLY BATCH;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Changes done");
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Batch.java
$java Batchภายใต้สภาวะปกติควรให้ผลลัพธ์ดังต่อไปนี้ -
Changes doneการสร้างข้อมูลในตาราง
คุณสามารถแทรกข้อมูลลงในคอลัมน์ของแถวในตารางโดยใช้คำสั่ง INSERT. ด้านล่างคือไวยากรณ์สำหรับการสร้างข้อมูลในตาราง
INSERT INTO <tablename>
(<column1 name>, <column2 name>....)
VALUES (<value1>, <value2>....)
USING <option>ตัวอย่าง
ให้เราถือว่ามีตารางที่เรียกว่า emp ด้วยคอลัมน์ (emp_id, emp_name, emp_city, emp_phone, emp_sal) และคุณต้องแทรกข้อมูลต่อไปนี้ลงใน emp ตาราง.
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | แกะ | ไฮเดอราบาด | 9848022338 | 50000 |
| 2 | โรบิน | ไฮเดอราบาด | 9848022339 | 40000 |
| 3 | ราห์มาน | เจนไน | 9848022330 | 45000 |
ใช้คำสั่งที่ระบุด้านล่างเพื่อเติมข้อมูลที่จำเป็นในตาราง
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(3,'rahman', 'Chennai', 9848022330, 45000);การยืนยัน
หลังจากใส่ข้อมูลแล้วให้ใช้คำสั่ง SELECT เพื่อตรวจสอบว่าข้อมูลถูกแทรกหรือไม่ หากคุณตรวจสอบตาราง emp โดยใช้คำสั่ง SELECT จะให้ผลลัพธ์ดังต่อไปนี้
cqlsh:tutorialspoint> SELECT * FROM emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Hyderabad | robin | 9848022339 | 40000
3 | Chennai | rahman | 9848022330 | 45000
(3 rows)คุณสามารถสังเกตได้ที่นี่ว่าตารางได้เติมข้อมูลที่เราใส่เข้าไป
การสร้างข้อมูลโดยใช้ Java API
คุณสามารถสร้างข้อมูลในตารางโดยใช้เมธอด execute () ของคลาส Session ทำตามขั้นตอนด้านล่างเพื่อสร้างข้อมูลในตารางโดยใช้ java API
ขั้นตอนที่ 1: สร้างวัตถุคลัสเตอร์
สร้างอินสแตนซ์ของ Cluster.builder ชั้นเรียนของ com.datastax.driver.core แพ็คเกจตามที่แสดงด้านล่าง
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();เพิ่มจุดติดต่อ (ที่อยู่ IP ของโหนด) โดยใช้ addContactPoint() วิธีการของ Cluster.Builderวัตถุ. วิธีนี้ส่งกลับCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint("127.0.0.1");ใช้วัตถุตัวสร้างใหม่สร้างวัตถุคลัสเตอร์ ในการทำเช่นนั้นคุณมีวิธีการที่เรียกว่าbuild() ใน Cluster.Builderชั้นเรียน. รหัสต่อไปนี้แสดงวิธีสร้างวัตถุคลัสเตอร์
//Building a cluster
Cluster cluster = builder.build();คุณสามารถสร้างออบเจ็กต์คลัสเตอร์โดยใช้โค้ดบรรทัดเดียวดังที่แสดงด้านล่าง
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();ขั้นตอนที่ 2: สร้างวัตถุเซสชัน
สร้างอินสแตนซ์ของวัตถุเซสชันโดยใช้เมธอด connect () ของคลาสคลัสเตอร์ดังที่แสดงด้านล่าง
Session session = cluster.connect( );วิธีนี้จะสร้างเซสชันใหม่และเริ่มต้น หากคุณมีคีย์สเปซอยู่แล้วคุณสามารถตั้งค่าเป็นคีย์สเปซที่มีอยู่ได้โดยส่งชื่อคีย์สเปซในรูปแบบสตริงไปยังเมธอดนี้ดังที่แสดงด้านล่าง
Session session = cluster.connect(“ Your keyspace name ” );ที่นี่เรากำลังใช้ KeySpace ที่เรียกว่า tp. ดังนั้นให้สร้างวัตถุเซสชันดังที่แสดงด้านล่าง
Session session = cluster.connect(“ tp” );ขั้นตอนที่ 3: ดำเนินการสืบค้น
คุณสามารถดำเนินการสืบค้น CQL โดยใช้เมธอด execute () ของคลาส Session ส่งแบบสอบถามในรูปแบบสตริงหรือเป็นStatementคลาสอ็อบเจ็กต์ไปยังเมธอด execute () สิ่งที่คุณส่งไปยังวิธีนี้ในรูปแบบสตริงจะถูกดำเนินการบนไฟล์cqlsh.
ในตัวอย่างต่อไปนี้เรากำลังแทรกข้อมูลในตารางที่เรียกว่า emp. คุณต้องเก็บแบบสอบถามไว้ในตัวแปรสตริงและส่งต่อไปยังเมธอด execute () ดังที่แสดงด้านล่าง
String query1 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);” ;
String query2 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);” ;
String query3 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(3,'rahman', 'Chennai', 9848022330, 45000);” ;
session.execute(query1);
session.execute(query2);
session.execute(query3);ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการแทรกข้อมูลลงในตารางใน Cassandra โดยใช้ Java API
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Data {
public static void main(String args[]){
//queries
String query1 = "INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)"
+ " VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);" ;
String query2 = "INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal)"
+ " VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);" ;
String query3 = "INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)"
+ " VALUES(3,'rahman', 'Chennai', 9848022330, 45000);" ;
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query1);
session.execute(query2);
session.execute(query3);
System.out.println("Data created");
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Create_Data.java
$java Create_Dataภายใต้สภาวะปกติควรให้ผลลัพธ์ดังต่อไปนี้ -
Data createdการอัปเดตข้อมูลในตาราง
UPDATEเป็นคำสั่งที่ใช้ในการอัปเดตข้อมูลในตาราง คำหลักต่อไปนี้ใช้ขณะอัปเดตข้อมูลในตาราง -
Where - ประโยคนี้ใช้เพื่อเลือกแถวที่จะอัปเดต
Set - กำหนดมูลค่าโดยใช้คำสำคัญนี้
Must - รวมคอลัมน์ทั้งหมดที่เขียนคีย์หลัก
ในขณะอัปเดตแถวหากไม่สามารถใช้งานแถวที่ระบุได้ UPDATE จะสร้างแถวใหม่ ด้านล่างเป็นไวยากรณ์ของคำสั่ง UPDATE -
UPDATE <tablename>
SET <column name> = <new value>
<column name> = <value>....
WHERE <condition>ตัวอย่าง
สมมติว่ามีตารางชื่อ emp. ตารางนี้จัดเก็บรายละเอียดของพนักงานของ บริษัท บางแห่งและมีรายละเอียดดังต่อไปนี้ -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | แกะ | ไฮเดอราบาด | 9848022338 | 50000 |
| 2 | โรบิน | ไฮเดอราบาด | 9848022339 | 40000 |
| 3 | ราห์มาน | เจนไน | 9848022330 | 45000 |
ตอนนี้ให้เราอัปเดต emp_city ของ robin เป็น Delhi และเงินเดือนของเขาเป็น 50000 ให้ด้านล่างเป็นแบบสอบถามเพื่อดำเนินการอัปเดตที่จำเป็น
cqlsh:tutorialspoint> UPDATE emp SET emp_city='Delhi',emp_sal=50000
WHERE emp_id=2;การยืนยัน
ใช้คำสั่ง SELECT เพื่อตรวจสอบว่าข้อมูลได้รับการอัพเดตหรือไม่ หากคุณตรวจสอบตาราง emp โดยใช้คำสั่ง SELECT จะให้ผลลัพธ์ดังต่อไปนี้
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 45000
(3 rows)ที่นี่คุณสามารถสังเกตได้ว่าข้อมูลตารางได้รับการอัปเดตแล้ว
การอัปเดตข้อมูลโดยใช้ Java API
คุณสามารถอัพเดตข้อมูลในตารางโดยใช้เมธอด execute () ของคลาส Session ทำตามขั้นตอนด้านล่างเพื่ออัปเดตข้อมูลในตารางโดยใช้ Java API
ขั้นตอนที่ 1: สร้างวัตถุคลัสเตอร์
สร้างอินสแตนซ์ของ Cluster.builder ชั้นเรียนของ com.datastax.driver.core แพ็คเกจตามที่แสดงด้านล่าง
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();เพิ่มจุดติดต่อ (ที่อยู่ IP ของโหนด) โดยใช้ addContactPoint() วิธีการของ Cluster.Builderวัตถุ. วิธีนี้ส่งกลับCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint("127.0.0.1");ใช้วัตถุตัวสร้างใหม่สร้างวัตถุคลัสเตอร์ ในการทำเช่นนั้นคุณมีวิธีการที่เรียกว่าbuild() ใน Cluster.Builderชั้นเรียน. ใช้รหัสต่อไปนี้เพื่อสร้างวัตถุคลัสเตอร์
//Building a cluster
Cluster cluster = builder.build();คุณสามารถสร้างวัตถุคลัสเตอร์โดยใช้โค้ดบรรทัดเดียวดังที่แสดงด้านล่าง
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();ขั้นตอนที่ 2: สร้างวัตถุเซสชัน
สร้างอินสแตนซ์ของวัตถุเซสชันโดยใช้เมธอด connect () ของคลาสคลัสเตอร์ดังที่แสดงด้านล่าง
Session session = cluster.connect( );วิธีนี้จะสร้างเซสชันใหม่และเริ่มต้น หากคุณมีคีย์สเปซอยู่แล้วคุณสามารถตั้งค่าเป็นคีย์สเปซที่มีอยู่ได้โดยส่งชื่อคีย์สเปซในรูปแบบสตริงไปยังเมธอดนี้ดังที่แสดงด้านล่าง
Session session = cluster.connect(“ Your keyspace name”);ที่นี่เรากำลังใช้ KeySpace ชื่อ tp. ดังนั้นให้สร้างวัตถุเซสชันดังที่แสดงด้านล่าง
Session session = cluster.connect(“tp”);ขั้นตอนที่ 3: ดำเนินการสืบค้น
คุณสามารถดำเนินการสืบค้น CQL โดยใช้เมธอด execute () ของคลาส Session ส่งแบบสอบถามในรูปแบบสตริงหรือเป็นวัตถุคลาส Statement ไปยังเมธอด execute () สิ่งที่คุณส่งไปยังวิธีนี้ในรูปแบบสตริงจะถูกดำเนินการบนไฟล์cqlsh.
ในตัวอย่างต่อไปนี้เรากำลังอัปเดตตาราง emp คุณต้องเก็บแบบสอบถามไว้ในตัวแปรสตริงและส่งต่อไปยังเมธอด execute () ดังที่แสดงด้านล่าง:
String query = “ UPDATE emp SET emp_city='Delhi',emp_sal=50000
WHERE emp_id = 2;” ;ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการอัปเดตข้อมูลในตารางโดยใช้ Java API
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Update_Data {
public static void main(String args[]){
//query
String query = " UPDATE emp SET emp_city='Delhi',emp_sal=50000"
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Data updated");
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Update_Data.java
$java Update_Dataภายใต้สภาวะปกติควรให้ผลลัพธ์ดังต่อไปนี้ -
Data updatedการอ่านข้อมูลโดยใช้ Select Clause
คำสั่ง SELECT ใช้เพื่ออ่านข้อมูลจากตารางใน Cassandra เมื่อใช้ประโยคนี้คุณสามารถอ่านทั้งตารางคอลัมน์เดียวหรือเซลล์ใดเซลล์หนึ่งได้ ให้ด้านล่างนี้คือไวยากรณ์ของคำสั่ง SELECT
SELECT FROM <tablename>ตัวอย่าง
สมมติว่ามีตารางในคีย์สเปซชื่อ emp โดยมีรายละเอียดดังต่อไปนี้ -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | แกะ | ไฮเดอราบาด | 9848022338 | 50000 |
| 2 | โรบิน | โมฆะ | 9848022339 | 50000 |
| 3 | ราห์มาน | เจนไน | 9848022330 | 50000 |
| 4 | rajeev | ปูน | 9848022331 | 30000 |
ตัวอย่างต่อไปนี้แสดงวิธีการอ่านทั้งตารางโดยใช้คำสั่ง SELECT เรากำลังอ่านตารางที่เรียกว่าemp.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)การอ่านคอลัมน์ที่จำเป็น
ตัวอย่างต่อไปนี้แสดงวิธีการอ่านคอลัมน์เฉพาะในตาราง
cqlsh:tutorialspoint> SELECT emp_name, emp_sal from emp;
emp_name | emp_sal
----------+---------
ram | 50000
robin | 50000
rajeev | 30000
rahman | 50000
(4 rows)ที่ข้อ
การใช้คำสั่ง WHERE คุณสามารถกำหนดข้อ จำกัด ในคอลัมน์ที่ต้องการได้ ไวยากรณ์มีดังนี้ -
SELECT FROM <table name> WHERE <condition>;Note - คำสั่ง WHERE สามารถใช้ได้เฉพาะกับคอลัมน์ที่เป็นส่วนหนึ่งของคีย์หลักหรือมีดัชนีรองอยู่
ในตัวอย่างต่อไปนี้เรากำลังอ่านรายละเอียดของพนักงานที่มีเงินเดือน 50000 ก่อนอื่นตั้งค่าดัชนีรองเป็นคอลัมน์ emp_sal
cqlsh:tutorialspoint> CREATE INDEX ON emp(emp_sal);
cqlsh:tutorialspoint> SELECT * FROM emp WHERE emp_sal=50000;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000การอ่านข้อมูลโดยใช้ Java API
คุณสามารถอ่านข้อมูลจากตารางโดยใช้เมธอด execute () ของคลาส Session ทำตามขั้นตอนด้านล่างเพื่อดำเนินการหลายคำสั่งโดยใช้คำสั่งแบตช์ด้วยความช่วยเหลือของ Java API
ขั้นตอนที่ 1: สร้างวัตถุคลัสเตอร์
สร้างอินสแตนซ์ของ Cluster.builder ชั้นเรียนของ com.datastax.driver.core แพ็คเกจตามที่แสดงด้านล่าง
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();เพิ่มจุดติดต่อ (ที่อยู่ IP ของโหนด) โดยใช้ addContactPoint() วิธีการของ Cluster.Builderวัตถุ. วิธีนี้ส่งกลับCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );ใช้วัตถุตัวสร้างใหม่สร้างวัตถุคลัสเตอร์ ในการทำเช่นนั้นคุณมีวิธีการที่เรียกว่าbuild() ใน Cluster.Builderชั้นเรียน. ใช้รหัสต่อไปนี้เพื่อสร้างวัตถุคลัสเตอร์
//Building a cluster
Cluster cluster = builder.build();คุณสามารถสร้างวัตถุคลัสเตอร์โดยใช้โค้ดบรรทัดเดียวดังที่แสดงด้านล่าง
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();ขั้นตอนที่ 2: สร้างวัตถุเซสชัน
สร้างอินสแตนซ์ของวัตถุเซสชันโดยใช้เมธอด connect () ของคลาสคลัสเตอร์ดังที่แสดงด้านล่าง
Session session = cluster.connect( );วิธีนี้จะสร้างเซสชันใหม่และเริ่มต้น หากคุณมีคีย์สเปซอยู่แล้วคุณสามารถตั้งค่าเป็นคีย์สเปซที่มีอยู่ได้โดยส่งชื่อคีย์สเปซในรูปแบบสตริงไปยังเมธอดนี้ดังที่แสดงด้านล่าง
Session session = cluster.connect(“Your keyspace name”);ที่นี่เรากำลังใช้ KeySpace ที่เรียกว่า tp. ดังนั้นให้สร้างวัตถุเซสชันดังที่แสดงด้านล่าง
Session session = cluster.connect(“tp”);ขั้นตอนที่ 3: ดำเนินการสืบค้น
คุณสามารถดำเนินการสืบค้น CQL โดยใช้เมธอด execute () ของคลาส Session ส่งแบบสอบถามในรูปแบบสตริงหรือเป็นวัตถุคลาส Statement ไปยังเมธอด execute () สิ่งที่คุณส่งไปยังวิธีนี้ในรูปแบบสตริงจะถูกดำเนินการบนไฟล์cqlsh.
ในตัวอย่างนี้เรากำลังดึงข้อมูลจาก empตาราง. จัดเก็บคิวรีเป็นสตริงและส่งต่อไปยังเมธอด execute () ของคลาสเซสชันดังที่แสดงด้านล่าง
String query = ”SELECT 8 FROM emp”;
session.execute(query);ดำเนินการสืบค้นโดยใช้เมธอด execute () ของคลาส Session
ขั้นตอนที่ 4: รับวัตถุ ResultSet
แบบสอบถามที่เลือกจะส่งคืนผลลัพธ์ในรูปแบบของ ResultSet วัตถุจึงเก็บผลลัพธ์ไว้ในวัตถุของ RESULTSET คลาสดังที่แสดงด้านล่าง
ResultSet result = session.execute( );ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการอ่านข้อมูลจากตาราง
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Session;
public class Read_Data {
public static void main(String args[])throws Exception{
//queries
String query = "SELECT * FROM emp";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tutorialspoint");
//Getting the ResultSet
ResultSet result = session.execute(query);
System.out.println(result.all());
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Read_Data.java
$java Read_Dataภายใต้สภาวะปกติควรให้ผลลัพธ์ดังต่อไปนี้ -
[Row[1, Hyderabad, ram, 9848022338, 50000], Row[2, Delhi, robin,
9848022339, 50000], Row[4, Pune, rajeev, 9848022331, 30000], Row[3,
Chennai, rahman, 9848022330, 50000]]การอ่านข้อมูลโดยใช้ Select Clause
คำสั่ง SELECT ใช้เพื่ออ่านข้อมูลจากตารางใน Cassandra เมื่อใช้ประโยคนี้คุณสามารถอ่านทั้งตารางคอลัมน์เดียวหรือเซลล์ใดเซลล์หนึ่งได้ ให้ด้านล่างนี้คือไวยากรณ์ของคำสั่ง SELECT
SELECT FROM <tablename>ตัวอย่าง
สมมติว่ามีตารางในคีย์สเปซชื่อ emp โดยมีรายละเอียดดังต่อไปนี้ -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | แกะ | ไฮเดอราบาด | 9848022338 | 50000 |
| 2 | โรบิน | โมฆะ | 9848022339 | 50000 |
| 3 | ราห์มาน | เจนไน | 9848022330 | 50000 |
| 4 | rajeev | ปูน | 9848022331 | 30000 |
ตัวอย่างต่อไปนี้แสดงวิธีการอ่านทั้งตารางโดยใช้คำสั่ง SELECT เรากำลังอ่านตารางที่เรียกว่าemp.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)การอ่านคอลัมน์ที่จำเป็น
ตัวอย่างต่อไปนี้แสดงวิธีการอ่านคอลัมน์เฉพาะในตาราง
cqlsh:tutorialspoint> SELECT emp_name, emp_sal from emp;
emp_name | emp_sal
----------+---------
ram | 50000
robin | 50000
rajeev | 30000
rahman | 50000
(4 rows)ที่ข้อ
การใช้คำสั่ง WHERE คุณสามารถกำหนดข้อ จำกัด ในคอลัมน์ที่ต้องการได้ ไวยากรณ์มีดังนี้ -
SELECT FROM <table name> WHERE <condition>;Note - คำสั่ง WHERE สามารถใช้ได้เฉพาะกับคอลัมน์ที่เป็นส่วนหนึ่งของคีย์หลักหรือมีดัชนีรองอยู่
ในตัวอย่างต่อไปนี้เรากำลังอ่านรายละเอียดของพนักงานที่มีเงินเดือน 50000 ก่อนอื่นตั้งค่าดัชนีรองเป็นคอลัมน์ emp_sal
cqlsh:tutorialspoint> CREATE INDEX ON emp(emp_sal);
cqlsh:tutorialspoint> SELECT * FROM emp WHERE emp_sal=50000;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000การอ่านข้อมูลโดยใช้ Java API
คุณสามารถอ่านข้อมูลจากตารางโดยใช้เมธอด execute () ของคลาส Session ทำตามขั้นตอนด้านล่างเพื่อดำเนินการหลายคำสั่งโดยใช้คำสั่งแบตช์ด้วยความช่วยเหลือของ Java API
ขั้นตอนที่ 1: สร้างวัตถุคลัสเตอร์
สร้างอินสแตนซ์ของ Cluster.builder ชั้นเรียนของ com.datastax.driver.core แพ็คเกจตามที่แสดงด้านล่าง
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();เพิ่มจุดติดต่อ (ที่อยู่ IP ของโหนด) โดยใช้ addContactPoint() วิธีการของ Cluster.Builderวัตถุ. วิธีนี้ส่งกลับCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );ใช้วัตถุตัวสร้างใหม่สร้างวัตถุคลัสเตอร์ ในการทำเช่นนั้นคุณมีวิธีการที่เรียกว่าbuild() ใน Cluster.Builderชั้นเรียน. ใช้รหัสต่อไปนี้เพื่อสร้างวัตถุคลัสเตอร์
//Building a cluster
Cluster cluster = builder.build();คุณสามารถสร้างวัตถุคลัสเตอร์โดยใช้โค้ดบรรทัดเดียวดังที่แสดงด้านล่าง
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();ขั้นตอนที่ 2: สร้างวัตถุเซสชัน
สร้างอินสแตนซ์ของวัตถุเซสชันโดยใช้เมธอด connect () ของคลาสคลัสเตอร์ดังที่แสดงด้านล่าง
Session session = cluster.connect( );วิธีนี้จะสร้างเซสชันใหม่และเริ่มต้น หากคุณมีคีย์สเปซอยู่แล้วคุณสามารถตั้งค่าเป็นคีย์สเปซที่มีอยู่ได้โดยส่งชื่อคีย์สเปซในรูปแบบสตริงไปยังเมธอดนี้ดังที่แสดงด้านล่าง
Session session = cluster.connect(“Your keyspace name”);ที่นี่เรากำลังใช้ KeySpace ที่เรียกว่า tp. ดังนั้นให้สร้างวัตถุเซสชันดังที่แสดงด้านล่าง
Session session = cluster.connect(“tp”);ขั้นตอนที่ 3: ดำเนินการสืบค้น
คุณสามารถดำเนินการสืบค้น CQL โดยใช้เมธอด execute () ของคลาส Session ส่งแบบสอบถามในรูปแบบสตริงหรือเป็นวัตถุคลาส Statement ไปยังเมธอด execute () สิ่งที่คุณส่งไปยังวิธีนี้ในรูปแบบสตริงจะถูกดำเนินการบนไฟล์cqlsh.
ในตัวอย่างนี้เรากำลังดึงข้อมูลจาก empตาราง. จัดเก็บคิวรีเป็นสตริงและส่งต่อไปยังเมธอด execute () ของคลาสเซสชันดังที่แสดงด้านล่าง
String query = ”SELECT 8 FROM emp”;
session.execute(query);ดำเนินการสืบค้นโดยใช้เมธอด execute () ของคลาส Session
ขั้นตอนที่ 4: รับวัตถุ ResultSet
แบบสอบถามที่เลือกจะส่งคืนผลลัพธ์ในรูปแบบของ ResultSet วัตถุจึงเก็บผลลัพธ์ไว้ในวัตถุของ RESULTSET คลาสดังที่แสดงด้านล่าง
ResultSet result = session.execute( );ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการอ่านข้อมูลจากตาราง
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Session;
public class Read_Data {
public static void main(String args[])throws Exception{
//queries
String query = "SELECT * FROM emp";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tutorialspoint");
//Getting the ResultSet
ResultSet result = session.execute(query);
System.out.println(result.all());
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Read_Data.java
$java Read_Dataภายใต้สภาวะปกติควรให้ผลลัพธ์ดังต่อไปนี้ -
[Row[1, Hyderabad, ram, 9848022338, 50000], Row[2, Delhi, robin,
9848022339, 50000], Row[4, Pune, rajeev, 9848022331, 30000], Row[3,
Chennai, rahman, 9848022330, 50000]]การลบ Dataf จากตาราง
คุณสามารถลบข้อมูลจากตารางโดยใช้คำสั่ง DELETE. ไวยากรณ์มีดังนี้ -
DELETE FROM <identifier> WHERE <condition>;ตัวอย่าง
สมมติว่ามีตารางใน Cassandra เรียกว่า emp มีข้อมูลต่อไปนี้ -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | แกะ | ไฮเดอราบาด | 9848022338 | 50000 |
| 2 | โรบิน | ไฮเดอราบาด | 9848022339 | 40000 |
| 3 | ราห์มาน | เจนไน | 9848022330 | 45000 |
คำสั่งต่อไปนี้ลบคอลัมน์ emp_sal ของแถวสุดท้าย -
cqlsh:tutorialspoint> DELETE emp_sal FROM emp WHERE emp_id=3;การยืนยัน
ใช้คำสั่ง SELECT เพื่อตรวจสอบว่าข้อมูลถูกลบหรือไม่ หากคุณตรวจสอบตาราง emp โดยใช้ SELECT จะให้ผลลัพธ์ดังต่อไปนี้ -
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | null
(3 rows)เนื่องจากเราได้ลบเงินเดือนของ Rahman คุณจะสังเกตเห็นค่าว่างแทนเงินเดือน
การลบทั้งแถว
คำสั่งต่อไปนี้จะลบทั้งแถวออกจากตาราง
cqlsh:tutorialspoint> DELETE FROM emp WHERE emp_id=3;การยืนยัน
ใช้คำสั่ง SELECT เพื่อตรวจสอบว่าข้อมูลถูกลบหรือไม่ หากคุณตรวจสอบตาราง emp โดยใช้ SELECT จะให้ผลลัพธ์ดังต่อไปนี้ -
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
(2 rows)เนื่องจากเราได้ลบแถวสุดท้ายแล้วจึงเหลือเพียงสองแถวในตาราง
การลบข้อมูลโดยใช้ Java API
คุณสามารถลบข้อมูลในตารางโดยใช้เมธอด execute () ของคลาส Session ทำตามขั้นตอนด้านล่างเพื่อลบข้อมูลจากตารางโดยใช้ java API
ขั้นตอนที่ 1: สร้างวัตถุคลัสเตอร์
สร้างอินสแตนซ์ของ Cluster.builder ชั้นเรียนของ com.datastax.driver.core แพ็คเกจตามที่แสดงด้านล่าง
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();เพิ่มจุดติดต่อ (ที่อยู่ IP ของโหนด) โดยใช้ addContactPoint() วิธีการของ Cluster.Builderวัตถุ. วิธีนี้ส่งกลับCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );ใช้วัตถุตัวสร้างใหม่สร้างวัตถุคลัสเตอร์ ในการทำเช่นนั้นคุณมีวิธีการที่เรียกว่าbuild() ใน Cluster.Builderชั้นเรียน. ใช้รหัสต่อไปนี้เพื่อสร้างวัตถุคลัสเตอร์
//Building a cluster
Cluster cluster = builder.build();คุณสามารถสร้างวัตถุคลัสเตอร์โดยใช้โค้ดบรรทัดเดียวดังที่แสดงด้านล่าง
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();ขั้นตอนที่ 2: สร้างวัตถุเซสชัน
สร้างอินสแตนซ์ของวัตถุเซสชันโดยใช้เมธอด connect () ของคลาสคลัสเตอร์ดังที่แสดงด้านล่าง
Session session = cluster.connect();วิธีนี้จะสร้างเซสชันใหม่และเริ่มต้น หากคุณมีคีย์สเปซอยู่แล้วคุณสามารถตั้งค่าเป็นคีย์สเปซที่มีอยู่ได้โดยส่งชื่อคีย์สเปซในรูปแบบสตริงไปยังเมธอดนี้ดังที่แสดงด้านล่าง
Session session = cluster.connect(“ Your keyspace name ”);ที่นี่เรากำลังใช้ KeySpace ที่เรียกว่า tp. ดังนั้นให้สร้างวัตถุเซสชันดังที่แสดงด้านล่าง
Session session = cluster.connect(“tp”);ขั้นตอนที่ 3: ดำเนินการสืบค้น
คุณสามารถดำเนินการสืบค้น CQL โดยใช้เมธอด execute () ของคลาส Session ส่งแบบสอบถามในรูปแบบสตริงหรือเป็นวัตถุคลาส Statement ไปยังเมธอด execute () สิ่งที่คุณส่งไปยังวิธีนี้ในรูปแบบสตริงจะถูกดำเนินการบนไฟล์cqlsh.
ในตัวอย่างต่อไปนี้เรากำลังลบข้อมูลจากตารางชื่อ emp. คุณต้องจัดเก็บแบบสอบถามในตัวแปรสตริงและส่งต่อไปยังไฟล์ execute() วิธีการดังแสดงด้านล่าง
String query1 = ”DELETE FROM emp WHERE emp_id=3; ”;
session.execute(query);ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการลบข้อมูลจากตารางใน Cassandra โดยใช้ Java API
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Delete_Data {
public static void main(String args[]){
//query
String query = "DELETE FROM emp WHERE emp_id=3;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Data deleted");
}
}บันทึกโปรแกรมด้านบนด้วยชื่อคลาสตามด้วย. java เรียกดูตำแหน่งที่บันทึกไว้ คอมไพล์และรันโปรแกรมดังที่แสดงด้านล่าง
$javac Delete_Data.java
$java Delete_Dataภายใต้สภาวะปกติควรให้ผลลัพธ์ดังต่อไปนี้ -
Data deletedCQL มีชุดข้อมูลในตัวที่หลากหลายรวมถึงประเภทการรวบรวม นอกจากประเภทข้อมูลเหล่านี้แล้วผู้ใช้ยังสามารถสร้างประเภทข้อมูลที่กำหนดเองได้อีกด้วย ตารางต่อไปนี้แสดงรายการชนิดข้อมูลในตัวที่มีอยู่ใน CQL
| ประเภทข้อมูล | ค่าคงที่ | คำอธิบาย |
|---|---|---|
| ascii | สตริง | แสดงสตริงอักขระ ASCII |
| bigint | bigint | แสดงถึง 64 บิตที่ลงชื่อยาว |
| blob | blobs | แสดงไบต์ตามอำเภอใจ |
| บูลีน | บูลีน | แสดงถึงจริงหรือเท็จ |
| counter | จำนวนเต็ม | แสดงคอลัมน์ตัวนับ |
| ทศนิยม | จำนวนเต็มลอย | แสดงทศนิยมที่มีความแม่นยำตัวแปร |
| สองเท่า | จำนวนเต็ม | แสดงจุดลอยตัว 64 บิต IEEE-754 |
| ลอย | จำนวนเต็มลอย | แสดงจุดลอยตัว 32 บิต IEEE-754 |
| inet | สตริง | แสดงที่อยู่ IP, IPv4 หรือ IPv6 |
| int | จำนวนเต็ม | แสดงถึง int ที่ลงชื่อแบบ 32 บิต |
| ข้อความ | สตริง | แสดงสตริงที่เข้ารหัส UTF8 |
| timestamp | จำนวนเต็มสตริง | แสดงถึงการประทับเวลา |
| timeuuid | uuids | แสดง UUID ประเภท 1 |
| uuid | uuids | แสดงประเภท 1 หรือประเภท 4 |
| UUID | ||
| varchar | สตริง | แสดงสตริงที่เข้ารหัส uTF8 |
| varint | จำนวนเต็ม | แสดงจำนวนเต็มที่มีความแม่นยำโดยพลการ |
ประเภทคอลเลกชัน
Cassandra Query Language ยังมีชนิดข้อมูลการรวบรวม ตารางต่อไปนี้แสดงรายการคอลเลกชันที่มีอยู่ใน CQL
| คอลเลกชัน | คำอธิบาย |
|---|---|
| รายการ | รายการคือชุดขององค์ประกอบที่เรียงลำดับอย่างน้อยหนึ่งรายการ |
| แผนที่ | แผนที่คือชุดของคู่คีย์ - ค่า |
| ชุด | ชุดคือชุดขององค์ประกอบตั้งแต่หนึ่งรายการขึ้นไป |
ประเภทข้อมูลที่ผู้ใช้กำหนดเอง
Cqlsh ให้ผู้ใช้มีความสะดวกในการสร้างชนิดข้อมูลของตนเอง ด้านล่างนี้เป็นคำสั่งที่ใช้ในขณะที่จัดการกับประเภทข้อมูลที่ผู้ใช้กำหนด
CREATE TYPE - สร้างประเภทข้อมูลที่ผู้ใช้กำหนดเอง
ALTER TYPE - แก้ไขประเภทข้อมูลที่ผู้ใช้กำหนดเอง
DROP TYPE - วางประเภทข้อมูลที่ผู้ใช้กำหนดเอง
DESCRIBE TYPE - อธิบายประเภทข้อมูลที่ผู้ใช้กำหนดเอง
DESCRIBE TYPES - อธิบายประเภทข้อมูลที่ผู้ใช้กำหนดเอง
CQL ให้ความสะดวกในการใช้ประเภทข้อมูล Collection เมื่อใช้ประเภทคอลเล็กชันเหล่านี้คุณสามารถจัดเก็บหลายค่าในตัวแปรเดียวได้ บทนี้จะอธิบายถึงวิธีการใช้ Collections ใน Cassandra
รายการ
รายการใช้ในกรณีที่
- ลำดับขององค์ประกอบจะต้องได้รับการบำรุงรักษาและ
- ค่าจะถูกจัดเก็บหลายครั้ง
คุณสามารถรับค่าของชนิดข้อมูลรายการโดยใช้ดัชนีขององค์ประกอบในรายการ
การสร้างตารางด้วยรายการ
ด้านล่างนี้เป็นตัวอย่างในการสร้างตารางตัวอย่างที่มีสองคอลัมน์ชื่อและอีเมล ในการจัดเก็บอีเมลหลายฉบับเรากำลังใช้รายการ
cqlsh:tutorialspoint> CREATE TABLE data(name text PRIMARY KEY, email list<text>);การแทรกข้อมูลลงในรายการ
ในขณะที่แทรกข้อมูลลงในองค์ประกอบในรายการให้ป้อนค่าทั้งหมดที่คั่นด้วยลูกน้ำภายในวงเล็บเหลี่ยม [] ดังที่แสดงด้านล่าง
cqlsh:tutorialspoint> INSERT INTO data(name, email) VALUES ('ramu',
['[email protected]','[email protected]'])การอัปเดตรายการ
ให้ด้านล่างนี้เป็นตัวอย่างในการอัปเดตประเภทข้อมูลรายการในตารางที่เรียกว่า data. ที่นี่เรากำลังเพิ่มอีเมลอื่นในรายการ
cqlsh:tutorialspoint> UPDATE data
... SET email = email +['[email protected]']
... where name = 'ramu';การยืนยัน
หากคุณตรวจสอบตารางโดยใช้คำสั่ง SELECT คุณจะได้ผลลัพธ์ดังต่อไปนี้ -
cqlsh:tutorialspoint> SELECT * FROM data;
name | email
------+--------------------------------------------------------------
ramu | ['[email protected]', '[email protected]', '[email protected]']
(1 rows)SET
Set คือชนิดข้อมูลที่ใช้ในการจัดเก็บกลุ่มขององค์ประกอบ องค์ประกอบของชุดจะถูกส่งคืนตามลำดับที่จัดเรียง
การสร้างตารางด้วยชุด
ตัวอย่างต่อไปนี้สร้างตารางตัวอย่างที่มีสองคอลัมน์ชื่อและหมายเลขโทรศัพท์ สำหรับการจัดเก็บหมายเลขโทรศัพท์หลายหมายเลขเราใช้ set
cqlsh:tutorialspoint> CREATE TABLE data2 (name text PRIMARY KEY, phone set<varint>);การแทรกข้อมูลลงในชุด
ขณะแทรกข้อมูลลงในองค์ประกอบในชุดให้ป้อนค่าทั้งหมดที่คั่นด้วยลูกน้ำภายในวงเล็บปีกกา {} ตามที่แสดงด้านล่าง
cqlsh:tutorialspoint> INSERT INTO data2(name, phone)VALUES ('rahman', {9848022338,9848022339});การอัปเดตชุด
รหัสต่อไปนี้แสดงวิธีอัปเดตชุดในตารางชื่อ data2 เรากำลังเพิ่มหมายเลขโทรศัพท์อื่นในชุดนี้
cqlsh:tutorialspoint> UPDATE data2
... SET phone = phone + {9848022330}
... where name = 'rahman';การยืนยัน
หากคุณตรวจสอบตารางโดยใช้คำสั่ง SELECT คุณจะได้ผลลัพธ์ดังต่อไปนี้ -
cqlsh:tutorialspoint> SELECT * FROM data2;
name | phone
--------+--------------------------------------
rahman | {9848022330, 9848022338, 9848022339}
(1 rows)แผนที่
แผนที่เป็นชนิดข้อมูลที่ใช้ในการจัดเก็บคู่คีย์ - ค่าขององค์ประกอบ
การสร้างตารางด้วยแผนที่
ตัวอย่างต่อไปนี้แสดงวิธีสร้างตารางตัวอย่างที่มีสองคอลัมน์ชื่อและที่อยู่ สำหรับการจัดเก็บค่าที่อยู่หลายรายการเรากำลังใช้แผนที่
cqlsh:tutorialspoint> CREATE TABLE data3 (name text PRIMARY KEY, address
map<timestamp, text>);การแทรกข้อมูลลงในแผนที่
ในขณะที่แทรกข้อมูลลงในองค์ประกอบในแผนที่ให้ป้อนไฟล์ key : value คั่นด้วยเครื่องหมายจุลภาคภายในวงเล็บปีกกา {} ดังที่แสดงด้านล่าง
cqlsh:tutorialspoint> INSERT INTO data3 (name, address)
VALUES ('robin', {'home' : 'hyderabad' , 'office' : 'Delhi' } );การอัปเดตชุด
รหัสต่อไปนี้แสดงวิธีการอัปเดตชนิดข้อมูลแผนที่ในตารางชื่อ data3 ที่นี่เรากำลังเปลี่ยนค่าของสำนักงานสำคัญนั่นคือเรากำลังเปลี่ยนที่อยู่สำนักงานของบุคคลที่ชื่อโรบิน
cqlsh:tutorialspoint> UPDATE data3
... SET address = address+{'office':'mumbai'}
... WHERE name = 'robin';การยืนยัน
หากคุณตรวจสอบตารางโดยใช้คำสั่ง SELECT คุณจะได้ผลลัพธ์ดังต่อไปนี้ -
cqlsh:tutorialspoint> select * from data3;
name | address
-------+-------------------------------------------
robin | {'home': 'hyderabad', 'office': 'mumbai'}
(1 rows)CQL ให้ความสะดวกในการสร้างและใช้ชนิดข้อมูลที่ผู้ใช้กำหนดเอง คุณสามารถสร้างชนิดข้อมูลเพื่อจัดการหลายเขตข้อมูล บทนี้อธิบายวิธีการสร้างแก้ไขและลบชนิดข้อมูลที่ผู้ใช้กำหนดเอง
การสร้างชนิดข้อมูลที่ผู้ใช้กำหนด
คำสั่ง CREATE TYPEใช้เพื่อสร้างชนิดข้อมูลที่ผู้ใช้กำหนดเอง ไวยากรณ์มีดังนี้ -
CREATE TYPE <keyspace name>. <data typename>
( variable1, variable2).ตัวอย่าง
ด้านล่างเป็นตัวอย่างสำหรับการสร้างประเภทข้อมูลที่ผู้ใช้กำหนดเอง ในตัวอย่างนี้เรากำลังสร้างไฟล์card_details ชนิดข้อมูลที่มีรายละเอียดดังต่อไปนี้
| ฟิลด์ | ชื่อฟิลด์ | ประเภทข้อมูล |
|---|---|---|
| หมายเลขบัตรเครดิต | num | int |
| พินบัตรเครดิต | พิน | int |
| ชื่อบนบัตรเครดิต | ชื่อ | ข้อความ |
| ประวัติย่อ | ประวัติย่อ | int |
| รายละเอียดการติดต่อของผู้ถือบัตร | โทรศัพท์ | ชุด |
cqlsh:tutorialspoint> CREATE TYPE card_details (
... num int,
... pin int,
... name text,
... cvv int,
... phone set<int>
... );Note - ชื่อที่ใช้สำหรับประเภทข้อมูลที่ผู้ใช้กำหนดไม่ควรตรงกับชื่อประเภทที่สงวนไว้
การยืนยัน
ใช้ DESCRIBE คำสั่งเพื่อตรวจสอบว่ามีการสร้างประเภทที่สร้างขึ้นหรือไม่
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>
);การแก้ไขประเภทข้อมูลที่ผู้ใช้กำหนดเอง
ALTER TYPE- คำสั่งใช้เพื่อแก้ไขประเภทข้อมูลที่มีอยู่ เมื่อใช้ ALTER คุณสามารถเพิ่มฟิลด์ใหม่หรือเปลี่ยนชื่อฟิลด์ที่มีอยู่
การเพิ่มเขตข้อมูลในประเภท
ใช้ไวยากรณ์ต่อไปนี้เพื่อเพิ่มฟิลด์ใหม่ให้กับชนิดข้อมูลที่ผู้ใช้กำหนดเองที่มีอยู่
ALTER TYPE typename
ADD field_name field_type;รหัสต่อไปนี้จะเพิ่มฟิลด์ใหม่ลงในไฟล์ Card_detailsประเภทข้อมูล. เรากำลังเพิ่มฟิลด์ใหม่ที่เรียกว่าอีเมล
cqlsh:tutorialspoint> ALTER TYPE card_details ADD email text;การยืนยัน
ใช้ DESCRIBE คำสั่งเพื่อตรวจสอบว่ามีการเพิ่มฟิลด์ใหม่หรือไม่
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
);การเปลี่ยนชื่อฟิลด์ในประเภท
ใช้ไวยากรณ์ต่อไปนี้เพื่อเปลี่ยนชื่อชนิดข้อมูลที่ผู้ใช้กำหนดเองที่มีอยู่
ALTER TYPE typename
RENAME existing_name TO new_name;รหัสต่อไปนี้เปลี่ยนชื่อของเขตข้อมูลในประเภท เรากำลังเปลี่ยนชื่อฟิลด์อีเมลเป็นเมล
cqlsh:tutorialspoint> ALTER TYPE card_details RENAME email TO mail;การยืนยัน
ใช้ DESCRIBE คำสั่งเพื่อตรวจสอบว่าชื่อประเภทเปลี่ยนไปหรือไม่
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
mail text
);การลบประเภทข้อมูลที่ผู้ใช้กำหนด
DROP TYPEคือคำสั่งที่ใช้ในการลบชนิดข้อมูลที่ผู้ใช้กำหนดเอง ด้านล่างนี้เป็นตัวอย่างในการลบประเภทข้อมูลที่ผู้ใช้กำหนดเอง
ตัวอย่าง
ก่อนที่จะลบให้ตรวจสอบรายการประเภทข้อมูลที่ผู้ใช้กำหนดทั้งหมดโดยใช้ DESCRIBE_TYPES คำสั่งดังที่แสดงด้านล่าง
cqlsh:tutorialspoint> DESCRIBE TYPES;
card_details cardจากสองประเภทให้ลบประเภทที่มีชื่อว่า card ดังแสดงด้านล่าง
cqlsh:tutorialspoint> drop type card;ใช้ DESCRIBE คำสั่งเพื่อตรวจสอบว่าประเภทข้อมูลหลุดหรือไม่
cqlsh:tutorialspoint> describe types;
card_details