การเรียนรู้เชิงลึกด้วย Keras - คู่มือฉบับย่อ
Deep Learning กลายเป็นคำที่แพร่หลายในช่วงไม่กี่วันที่ผ่านมาในสาขาปัญญาประดิษฐ์ (AI) เป็นเวลาหลายปีที่เราใช้ Machine Learning (ML) เพื่อถ่ายทอดข้อมูลอัจฉริยะให้กับเครื่องจักร ในช่วงไม่กี่วันที่ผ่านมาการเรียนรู้เชิงลึกได้รับความนิยมมากขึ้นเนื่องจากมีอำนาจสูงสุดในการคาดการณ์เมื่อเทียบกับเทคนิค ML แบบดั้งเดิม
โดยพื้นฐานแล้ว Deep Learning หมายถึงการฝึกอบรม Artificial Neural Network (ANN) ด้วยข้อมูลจำนวนมหาศาล ในการเรียนรู้เชิงลึกเครือข่ายจะเรียนรู้ด้วยตัวเองดังนั้นจึงต้องใช้ข้อมูลมหาศาลเพื่อการเรียนรู้ ในขณะที่แมชชีนเลิร์นนิงแบบเดิมเป็นชุดของอัลกอริทึมที่แยกวิเคราะห์ข้อมูลและเรียนรู้จากมัน จากนั้นพวกเขาใช้การเรียนรู้นี้ในการตัดสินใจอย่างชาญฉลาด
ตอนนี้มาถึง Keras ซึ่งเป็น API เครือข่ายประสาทระดับสูงที่ทำงานบน TensorFlow ซึ่งเป็นแพลตฟอร์มการเรียนรู้ของเครื่องโอเพนซอร์สแบบ end-to-end เมื่อใช้ Keras คุณสามารถกำหนดสถาปัตยกรรม ANN ที่ซับซ้อนเพื่อทดลองกับข้อมูลขนาดใหญ่ของคุณได้อย่างง่ายดาย Keras ยังรองรับ GPU ซึ่งจำเป็นสำหรับการประมวลผลข้อมูลจำนวนมากและการพัฒนาโมเดลการเรียนรู้ของเครื่อง
ในบทช่วยสอนนี้คุณจะได้เรียนรู้การใช้ Keras ในการสร้างเครือข่ายประสาทเทียมระดับลึก เราจะดูตัวอย่างที่ใช้ได้จริงสำหรับการสอน ปัญหาในมือคือการจดจำตัวเลขที่เขียนด้วยลายมือโดยใช้เครือข่ายประสาทเทียมที่ได้รับการฝึกฝนด้วยการเรียนรู้เชิงลึก
เพื่อให้คุณตื่นเต้นยิ่งขึ้นในการเรียนรู้เชิงลึกด้านล่างนี้คือภาพหน้าจอของแนวโน้มของ Google เกี่ยวกับการเรียนรู้เชิงลึกที่นี่ -

ดังที่คุณเห็นจากแผนภาพความสนใจในการเรียนรู้เชิงลึกนั้นเพิ่มขึ้นอย่างต่อเนื่องในช่วงหลายปีที่ผ่านมา มีหลายด้านเช่นการมองเห็นด้วยคอมพิวเตอร์การประมวลผลภาษาธรรมชาติการรู้จำเสียงชีวสารสนเทศศาสตร์การออกแบบยาและอื่น ๆ ซึ่งการเรียนรู้เชิงลึกได้ถูกนำไปใช้อย่างประสบความสำเร็จ บทแนะนำนี้จะช่วยให้คุณเริ่มเรียนรู้เชิงลึกได้อย่างรวดเร็ว
ดังนั้นอ่านต่อไป!
ดังที่ได้กล่าวไว้ในบทนำการเรียนรู้เชิงลึกเป็นกระบวนการฝึกเครือข่ายประสาทเทียมที่มีข้อมูลจำนวนมาก เมื่อผ่านการฝึกอบรมแล้วเครือข่ายจะสามารถคาดเดาข้อมูลที่มองไม่เห็นได้ ก่อนที่ฉันจะอธิบายเพิ่มเติมว่าการเรียนรู้เชิงลึกคืออะไรให้เราอ่านคำศัพท์บางคำที่ใช้ในการฝึกอบรมเครือข่ายประสาทเทียมอย่างรวดเร็ว
โครงข่ายประสาท
ความคิดของโครงข่ายประสาทเทียมได้มาจากโครงข่ายประสาทในสมองของเรา โครงข่ายประสาทเทียมโดยทั่วไปประกอบด้วยสามชั้น - อินพุตเอาต์พุตและเลเยอร์ที่ซ่อนอยู่ดังแสดงในภาพด้านล่าง

เรียกอีกอย่างว่าไฟล์ shallowโครงข่ายประสาทเนื่องจากมีเพียงชั้นเดียวที่ซ่อนอยู่ คุณเพิ่มเลเยอร์ที่ซ่อนอยู่ในสถาปัตยกรรมด้านบนเพื่อสร้างสถาปัตยกรรมที่ซับซ้อนมากขึ้น
เครือข่ายระดับลึก
แผนภาพต่อไปนี้แสดงเครือข่ายระดับลึกซึ่งประกอบด้วยเลเยอร์ที่ซ่อนอยู่สี่ชั้นชั้นอินพุตและชั้นเอาต์พุต
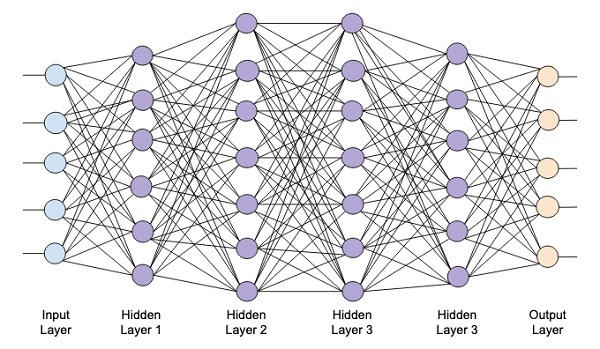
เมื่อเพิ่มจำนวนเลเยอร์ที่ซ่อนอยู่ในเครือข่ายการฝึกอบรมจึงมีความซับซ้อนมากขึ้นในแง่ของทรัพยากรที่จำเป็นและเวลาที่ใช้ในการฝึกอบรมเครือข่ายอย่างเต็มที่
การฝึกอบรมเครือข่าย
หลังจากที่คุณกำหนดสถาปัตยกรรมเครือข่ายแล้วคุณจะฝึกมันเพื่อทำการคาดคะเนบางประเภท การฝึกอบรมเครือข่ายเป็นกระบวนการในการหาน้ำหนักที่เหมาะสมสำหรับแต่ละลิงค์ในเครือข่าย ในระหว่างการฝึกอบรมข้อมูลจะไหลจากชั้นอินพุตไปยังเอาต์พุตผ่านชั้นต่างๆที่ซ่อนอยู่ เนื่องจากข้อมูลเคลื่อนที่ไปในทิศทางเดียวเสมอจากอินพุตไปยังเอาต์พุตเราจึงเรียกเครือข่ายนี้ว่า Feed-forward Network และเราเรียกการแพร่กระจายข้อมูลว่า Forward Propagation
ฟังก์ชั่นการเปิดใช้งาน
ในแต่ละเลเยอร์เราคำนวณผลรวมของอินพุตที่ถ่วงน้ำหนักและป้อนไปยังฟังก์ชันการเปิดใช้งาน ฟังก์ชันการเปิดใช้งานนำความไม่เป็นเชิงเส้นมาสู่เครือข่าย มันเป็นเพียงฟังก์ชันทางคณิตศาสตร์บางอย่างที่แยกผลลัพธ์ออก ฟังก์ชันการกระตุ้นที่ใช้บ่อยที่สุด ได้แก่ sigmoid, hyperbolic, tangent (tanh), ReLU และ Softmax
Backpropagation
Backpropagation เป็นอัลกอริทึมสำหรับการเรียนรู้ภายใต้การดูแล ใน Backpropagation ข้อผิดพลาดจะแพร่กระจายย้อนกลับจากเอาต์พุตไปยังเลเยอร์อินพุต ด้วยฟังก์ชันข้อผิดพลาดเราจะคำนวณการไล่ระดับสีของฟังก์ชันข้อผิดพลาดตามน้ำหนักที่กำหนดในการเชื่อมต่อแต่ละครั้ง การคำนวณการไล่ระดับสีจะดำเนินการย้อนกลับผ่านเครือข่าย การไล่ระดับสีของชั้นสุดท้ายของน้ำหนักจะถูกคำนวณก่อนและการไล่ระดับสีของน้ำหนักชั้นแรกจะถูกคำนวณเป็นอันดับสุดท้าย
ในแต่ละเลเยอร์การคำนวณบางส่วนของการไล่ระดับสีจะถูกใช้ซ้ำในการคำนวณการไล่ระดับสีสำหรับเลเยอร์ก่อนหน้า สิ่งนี้เรียกว่า Gradient Descent
ในแบบฝึกหัดตามโครงการนี้คุณจะกำหนดโครงข่ายประสาทเทียมแบบฟีดไปข้างหน้าและฝึกด้วยเทคนิคการย้อนกลับและการไล่ระดับสี โชคดีที่ Keras ให้ API ระดับสูงทั้งหมดแก่เราสำหรับการกำหนดสถาปัตยกรรมเครือข่ายและฝึกอบรมโดยใช้การไล่ระดับสี ต่อไปคุณจะได้เรียนรู้วิธีการทำใน Keras
ระบบจดจำตัวเลขที่เขียนด้วยลายมือ
ในโครงการขนาดเล็กนี้คุณจะใช้เทคนิคที่อธิบายไว้ก่อนหน้านี้ คุณจะสร้างเครือข่ายประสาทเทียมในการเรียนรู้เชิงลึกซึ่งจะได้รับการฝึกฝนให้รู้จักตัวเลขที่เขียนด้วยลายมือ ในโครงการแมชชีนเลิร์นนิงความท้าทายแรกคือการรวบรวมข้อมูล โดยเฉพาะอย่างยิ่งสำหรับเครือข่ายการเรียนรู้เชิงลึกคุณต้องมีข้อมูลมหาศาล โชคดีสำหรับปัญหาที่เรากำลังพยายามแก้ไขมีคนสร้างชุดข้อมูลสำหรับการฝึกอบรมไว้แล้ว สิ่งนี้เรียกว่า mnist ซึ่งเป็นส่วนหนึ่งของไลบรารี Keras ชุดข้อมูลประกอบด้วยภาพตัวเลข 28x28 พิกเซลจำนวนมากที่เขียนด้วยลายมือ คุณจะฝึกโมเดลของคุณในส่วนหลักของชุดข้อมูลนี้และข้อมูลที่เหลือจะถูกใช้เพื่อตรวจสอบโมเดลที่ได้รับการฝึกฝนของคุณ
คำอธิบายโครงการ
mnistชุดข้อมูลประกอบด้วยภาพตัวเลขที่เขียนด้วยลายมือ 70000 ภาพ มีการจำลองภาพตัวอย่างบางส่วนที่นี่เพื่อเป็นข้อมูลอ้างอิงของคุณ

แต่ละภาพมีขนาด 28 x 28 พิกเซลทำให้มีระดับสีเทาทั้งหมด 768 พิกเซล พิกเซลส่วนใหญ่มีแนวโน้มเป็นสีดำในขณะที่มีเพียงไม่กี่พิกเซลเท่านั้นที่เป็นสีขาว เราจะใส่การกระจายของพิกเซลเหล่านี้ในอาร์เรย์หรือเวกเตอร์ ตัวอย่างเช่นการกระจายของพิกเซลสำหรับรูปภาพทั่วไปของตัวเลข 4 และ 5 จะแสดงในรูปด้านล่าง
แต่ละภาพมีขนาด 28 x 28 พิกเซลทำให้มีระดับสีเทาทั้งหมด 768 พิกเซล พิกเซลส่วนใหญ่มีแนวโน้มเป็นสีดำในขณะที่มีเพียงไม่กี่พิกเซลเท่านั้นที่เป็นสีขาว เราจะใส่การกระจายของพิกเซลเหล่านี้ในอาร์เรย์หรือเวกเตอร์ ตัวอย่างเช่นการกระจายของพิกเซลสำหรับรูปภาพทั่วไปของตัวเลข 4 และ 5 จะแสดงในรูปด้านล่าง

คุณจะเห็นได้อย่างชัดเจนว่าการกระจายของพิกเซล (โดยเฉพาะพิกเซลที่พุ่งเข้าหาโทนสีขาว) นั้นแตกต่างกันซึ่งทำให้ตัวเลขที่แสดงนั้นแตกต่างกัน เราจะป้อนการกระจาย 784 พิกเซลนี้ไปยังเครือข่ายของเราเป็นข้อมูลป้อนเข้า ผลลัพธ์ของเครือข่ายจะประกอบด้วย 10 หมวดหมู่ที่แสดงตัวเลขระหว่าง 0 ถึง 9
เครือข่ายของเราจะประกอบด้วย 4 ชั้น - ชั้นอินพุตหนึ่งชั้น, ชั้นเอาท์พุทหนึ่งชั้นและชั้นที่ซ่อนอยู่สองชั้น แต่ละเลเยอร์ที่ซ่อนอยู่จะมี 512 โหนด แต่ละชั้นเชื่อมต่อกับเลเยอร์ถัดไปอย่างเต็มที่ เมื่อเราฝึกอบรมเครือข่ายเราจะคำนวณน้ำหนักสำหรับการเชื่อมต่อแต่ละครั้ง เราฝึกอบรมเครือข่ายโดยใช้ backpropagation และการไล่ระดับสีที่เราพูดถึงก่อนหน้านี้
ด้วยพื้นหลังนี้ให้เราเริ่มสร้างโครงการ
การตั้งค่าโครงการ
เราจะใช้ Jupyter ผ่าน Anacondaตัวนำทางสำหรับโครงการของเรา เนื่องจากโครงการของเราใช้ TensorFlow และ Keras คุณจะต้องติดตั้งสิ่งเหล่านี้ในการตั้งค่า Anaconda ในการติดตั้ง Tensorflow ให้รันคำสั่งต่อไปนี้ในหน้าต่างคอนโซลของคุณ:
>conda install -c anaconda tensorflowในการติดตั้ง Keras ให้ใช้คำสั่งต่อไปนี้ -
>conda install -c anaconda kerasตอนนี้คุณพร้อมที่จะเริ่ม Jupyter แล้ว
เริ่มต้น Jupyter
เมื่อคุณเริ่มเครื่องนำทาง Anaconda คุณจะเห็นหน้าจอเปิดดังต่อไปนี้

คลิก ‘Jupyter’เพื่อเริ่มต้น หน้าจอจะแสดงโครงการที่มีอยู่ในไดรฟ์ของคุณ
การเริ่มโครงการใหม่
เริ่มโครงการ Python 3 ใหม่ใน Anaconda โดยเลือกตัวเลือกเมนูต่อไปนี้ -
File | New Notebook | Python 3ภาพหน้าจอของการเลือกเมนูจะแสดงสำหรับการอ้างอิงอย่างรวดเร็วของคุณ -

โปรเจ็กต์เปล่าใหม่จะปรากฏขึ้นบนหน้าจอของคุณดังที่แสดงด้านล่าง -
เปลี่ยนชื่อโครงการเป็น DeepLearningDigitRecognition โดยคลิกและแก้ไขชื่อเริ่มต้น “UntitledXX”.
อันดับแรกเรานำเข้าไลบรารีต่างๆที่รหัสในโครงการของเราต้องการ
การจัดการและการวางแผนอาร์เรย์
ตามปกติเราใช้ numpy สำหรับการจัดการอาร์เรย์และ matplotlibสำหรับการวางแผน ไลบรารีเหล่านี้นำเข้าในโครงการของเราโดยใช้สิ่งต่อไปนี้import งบ
import numpy as np
import matplotlib
import matplotlib.pyplot as plotการระงับคำเตือน
เนื่องจากทั้ง Tensorflow และ Keras ทำการแก้ไขอยู่เสมอหากคุณไม่ซิงค์เวอร์ชันที่เหมาะสมในโปรเจ็กต์ขณะรันไทม์คุณจะเห็นข้อผิดพลาดคำเตือนมากมาย เมื่อพวกเขาเบี่ยงเบนความสนใจของคุณจากการเรียนรู้เราจะระงับคำเตือนทั้งหมดในโครงการนี้ สิ่งนี้ทำได้โดยใช้โค้ดบรรทัดต่อไปนี้ -
# silent all warnings
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='3'
import warnings
warnings.filterwarnings('ignore')
from tensorflow.python.util import deprecation
deprecation._PRINT_DEPRECATION_WARNINGS = FalseKeras
เราใช้ไลบรารี Keras เพื่อนำเข้าชุดข้อมูล เราจะใช้ไฟล์mnistชุดข้อมูลสำหรับตัวเลขที่เขียนด้วยลายมือ เรานำเข้าแพ็คเกจที่ต้องการโดยใช้คำสั่งต่อไปนี้
from keras.datasets import mnistเราจะกำหนดโครงข่ายประสาทเทียมเชิงลึกของเราโดยใช้แพ็คเกจ Keras เรานำเข้าไฟล์Sequential, Dense, Dropout และ Activationแพ็คเกจสำหรับกำหนดสถาปัตยกรรมเครือข่าย เราใช้load_modelแพ็คเกจสำหรับบันทึกและเรียกค้นโมเดลของเรา เรายังใช้np_utilsสำหรับสาธารณูปโภคบางอย่างที่เราต้องการในโครงการของเรา การนำเข้าเหล่านี้ทำได้โดยใช้คำสั่งโปรแกรมต่อไปนี้ -
from keras.models import Sequential, load_model
from keras.layers.core import Dense, Dropout, Activation
from keras.utils import np_utilsเมื่อคุณเรียกใช้รหัสนี้คุณจะเห็นข้อความบนคอนโซลที่ระบุว่า Keras ใช้ TensorFlow ที่แบ็กเอนด์ ภาพหน้าจอในขั้นตอนนี้จะแสดงที่นี่ -

ขณะนี้เนื่องจากเรามีการนำเข้าทั้งหมดที่จำเป็นสำหรับโครงการของเราเราจะดำเนินการกำหนดสถาปัตยกรรมสำหรับเครือข่าย Deep Learning ของเรา
แบบจำลองเครือข่ายประสาทเทียมของเราจะประกอบด้วยเลเยอร์เชิงเส้น ในการกำหนดรูปแบบดังกล่าวเราเรียกว่าSequential ฟังก์ชัน -
model = Sequential()ชั้นอินพุต
เรากำหนดชั้นอินพุตซึ่งเป็นชั้นแรกในเครือข่ายของเราโดยใช้คำสั่งโปรแกรมต่อไปนี้ -
model.add(Dense(512, input_shape=(784,)))สิ่งนี้สร้างเลเยอร์ที่มี 512 โหนด (เซลล์ประสาท) ที่มีโหนดอินพุต 784 โหนด นี่คือภาพด้านล่าง -

โปรดทราบว่าโหนดอินพุตทั้งหมดเชื่อมต่อกับ Layer 1 อย่างสมบูรณ์นั่นคือแต่ละโหนดอินพุตเชื่อมต่อกับโหนดทั้งหมด 512 โหนดของ Layer 1
ต่อไปเราต้องเพิ่มฟังก์ชั่นการเปิดใช้งานสำหรับเอาต์พุตของเลเยอร์ 1 เราจะใช้ ReLU เป็นการเปิดใช้งานของเรา ฟังก์ชันการเปิดใช้งานถูกเพิ่มโดยใช้คำสั่งโปรแกรมต่อไปนี้ -
model.add(Activation('relu'))ต่อไปเราเพิ่ม Dropout 20% โดยใช้คำสั่งด้านล่าง การออกกลางคันเป็นเทคนิคที่ใช้เพื่อป้องกันไม่ให้โมเดลฟิตติ้งมากเกินไป
model.add(Dropout(0.2))ณ จุดนี้เลเยอร์อินพุตของเราถูกกำหนดไว้อย่างสมบูรณ์ ต่อไปเราจะเพิ่มเลเยอร์ที่ซ่อนอยู่
เลเยอร์ที่ซ่อนอยู่
เลเยอร์ที่ซ่อนอยู่ของเราจะประกอบด้วย 512 โหนด อินพุตไปยังเลเยอร์ที่ซ่อนอยู่มาจากเลเยอร์อินพุตที่เรากำหนดไว้ก่อนหน้านี้ โหนดทั้งหมดเชื่อมต่ออย่างสมบูรณ์เหมือนในกรณีก่อนหน้านี้ ผลลัพธ์ของเลเยอร์ที่ซ่อนอยู่จะไปที่เลเยอร์ถัดไปในเครือข่ายซึ่งจะเป็นเลเยอร์สุดท้ายและเลเยอร์เอาต์พุตของเรา เราจะใช้การเปิดใช้งาน ReLU เช่นเดียวกับเลเยอร์ก่อนหน้าและการออกกลางคัน 20% รหัสสำหรับการเพิ่มเลเยอร์นี้มีให้ที่นี่ -
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))เครือข่ายในขั้นตอนนี้สามารถมองเห็นได้ดังนี้ -

ต่อไปเราจะเพิ่มเลเยอร์สุดท้ายลงในเครือข่ายของเราซึ่งก็คือเลเยอร์เอาต์พุต โปรดทราบว่าคุณสามารถเพิ่มเลเยอร์ที่ซ่อนอยู่จำนวนเท่าใดก็ได้โดยใช้รหัสที่คล้ายกับรหัสที่คุณใช้ที่นี่ การเพิ่มเลเยอร์มากขึ้นจะทำให้เครือข่ายซับซ้อนสำหรับการฝึกอบรม อย่างไรก็ตามให้ข้อได้เปรียบที่ชัดเจนของผลลัพธ์ที่ดีกว่าในหลาย ๆ กรณีแม้ว่าจะไม่ใช่ทั้งหมด
เลเยอร์เอาต์พุต
เลเยอร์เอาต์พุตประกอบด้วยโหนดเพียง 10 โหนดเนื่องจากเราต้องการจัดประเภทรูปภาพที่กำหนดเป็นตัวเลข 10 หลัก เราเพิ่มเลเยอร์นี้โดยใช้คำสั่งต่อไปนี้ -
model.add(Dense(10))เนื่องจากเราต้องการจำแนกเอาต์พุตเป็น 10 หน่วยที่แตกต่างกันเราจึงใช้การเปิดใช้งาน softmax ในกรณีของ ReLU เอาต์พุตจะเป็นไบนารี เราเพิ่มการเปิดใช้งานโดยใช้คำสั่งต่อไปนี้ -
model.add(Activation('softmax'))ณ จุดนี้เครือข่ายของเราสามารถมองเห็นได้ดังแสดงในแผนภาพด้านล่าง -

ณ จุดนี้รูปแบบเครือข่ายของเราถูกกำหนดไว้อย่างสมบูรณ์ในซอฟต์แวร์ เรียกใช้เซลล์รหัสและหากไม่มีข้อผิดพลาดคุณจะได้รับข้อความยืนยันบนหน้าจอดังที่แสดงในภาพหน้าจอด้านล่าง -

ต่อไปเราต้องรวบรวมแบบจำลอง
การคอมไพล์จะดำเนินการโดยใช้การเรียกวิธีเดียวที่เรียกว่า compile.
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')compileวิธีการต้องใช้หลายพารามิเตอร์ พารามิเตอร์การสูญเสียถูกระบุให้มีประเภท'categorical_crossentropy'. พารามิเตอร์เมตริกถูกตั้งค่าเป็น'accuracy' และในที่สุดเราก็ใช้ไฟล์ adamเครื่องมือเพิ่มประสิทธิภาพสำหรับการฝึกอบรมเครือข่าย ผลลัพธ์ในขั้นตอนนี้แสดงไว้ด้านล่าง -

ตอนนี้เราพร้อมที่จะป้อนข้อมูลเข้าสู่เครือข่ายของเราแล้ว
กำลังโหลดข้อมูล
ดังที่ได้กล่าวไว้ก่อนหน้านี้เราจะใช้ไฟล์ mnistชุดข้อมูลจัดทำโดย Keras เมื่อเราโหลดข้อมูลลงในระบบของเราเราจะแบ่งข้อมูลในการฝึกอบรมและข้อมูลการทดสอบ ข้อมูลถูกโหลดโดยเรียกไฟล์load_data วิธีการดังนี้ -
(X_train, y_train), (X_test, y_test) = mnist.load_data()ผลลัพธ์ในขั้นตอนนี้มีลักษณะดังต่อไปนี้ -

ตอนนี้เราจะเรียนรู้โครงสร้างของชุดข้อมูลที่โหลด
ข้อมูลที่ให้กับเราคือภาพกราฟิกขนาด 28 x 28 พิกเซลแต่ละภาพมีตัวเลขหลักเดียวระหว่าง 0 ถึง 9 เราจะแสดงภาพสิบภาพแรกบนคอนโซล รหัสสำหรับการดำเนินการดังกล่าวได้รับด้านล่าง -
# printing first 10 images
for i in range(10):
plot.subplot(3,5,i+1)
plot.tight_layout()
plot.imshow(X_train[i], cmap='gray', interpolation='none')
plot.title("Digit: {}".format(y_train[i]))
plot.xticks([])
plot.yticks([])ในการวนซ้ำ 10 ครั้งเราสร้างพล็อตย่อยสำหรับการวนซ้ำแต่ละครั้งและแสดงภาพจาก X_trainเวกเตอร์อยู่ในนั้น เราตั้งชื่อภาพแต่ละภาพจากสิ่งที่เกี่ยวข้องy_trainเวกเตอร์. โปรดทราบว่าไฟล์y_train เวกเตอร์มีค่าจริงสำหรับรูปภาพที่เกี่ยวข้องใน X_trainเวกเตอร์. เราลบเครื่องหมายแกน x และ y โดยเรียกสองวิธีxticks และ yticksด้วยอาร์กิวเมนต์ว่าง เมื่อคุณเรียกใช้รหัสคุณจะเห็นผลลัพธ์ต่อไปนี้ -

ต่อไปเราจะเตรียมข้อมูลสำหรับป้อนเข้าสู่เครือข่ายของเรา
ก่อนที่เราจะป้อนข้อมูลไปยังเครือข่ายของเราข้อมูลนั้นจะต้องถูกแปลงเป็นรูปแบบที่เครือข่ายต้องการ เรียกว่าการเตรียมข้อมูลสำหรับเครือข่าย โดยทั่วไปจะประกอบด้วยการแปลงอินพุตหลายมิติให้เป็นเวกเตอร์มิติเดียวและทำให้จุดข้อมูลเป็นปกติ
การปรับรูปแบบเวกเตอร์อินพุต
ภาพในชุดข้อมูลของเราประกอบด้วย 28 x 28 พิกเซล สิ่งนี้ต้องถูกแปลงเป็นเวกเตอร์มิติเดียวขนาด 28 * 28 = 784 เพื่อป้อนลงในเครือข่ายของเรา เราทำได้โดยโทรไปที่ไฟล์reshape วิธีการบนเวกเตอร์
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)ตอนนี้เวกเตอร์การฝึกของเราจะประกอบด้วยจุดข้อมูล 60000 จุดแต่ละจุดประกอบด้วยเวกเตอร์มิติเดียวขนาด 784 ในทำนองเดียวกันเวกเตอร์ทดสอบของเราจะประกอบด้วยจุดข้อมูล 10,000 จุดของเวกเตอร์มิติเดียวขนาด 784
Normalizing ข้อมูล
ข้อมูลที่เวกเตอร์อินพุตมีอยู่ในปัจจุบันมีค่าที่ไม่ต่อเนื่องระหว่าง 0 ถึง 255 - ระดับสีเทา การปรับค่าพิกเซลให้เป็นปกติระหว่าง 0 ถึง 1 จะช่วยในการเร่งการฝึกอบรม ในขณะที่เรากำลังจะใช้การสืบเชื้อสายแบบสุ่มการไล่ระดับสีข้อมูลการทำให้เป็นมาตรฐานจะช่วยลดโอกาสที่จะติดอยู่ในออพติมาในเครื่อง
ในการทำให้ข้อมูลเป็นปกติเราจะแสดงเป็นประเภทลอยและหารด้วย 255 ดังที่แสดงในข้อมูลโค้ดต่อไปนี้ -
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255ตอนนี้ให้เราดูว่าข้อมูลปกติมีลักษณะอย่างไร
การตรวจสอบข้อมูลปกติ
หากต้องการดูข้อมูลที่ทำให้เป็นมาตรฐานเราจะเรียกฟังก์ชันฮิสโตแกรมดังที่แสดงไว้ที่นี่ -
plot.hist(X_train[0])
plot.title("Digit: {}".format(y_train[0]))ที่นี่เราพล็อตฮิสโตแกรมขององค์ประกอบแรกของไฟล์ X_trainเวกเตอร์. นอกจากนี้เรายังพิมพ์ตัวเลขที่แสดงโดยจุดข้อมูลนี้ ผลลัพธ์ของการรันโค้ดด้านบนแสดงไว้ที่นี่ -

คุณจะสังเกตเห็นความหนาแน่นของจุดที่มีค่าใกล้เคียงกับศูนย์ จุดเหล่านี้คือจุดสีดำในภาพซึ่งเห็นได้ชัดว่าเป็นส่วนหลักของภาพ ส่วนที่เหลือของจุดสเกลสีเทาซึ่งใกล้เคียงกับสีขาวจะแสดงตัวเลข คุณสามารถตรวจสอบการกระจายของพิกเซลสำหรับตัวเลขอื่น รหัสด้านล่างจะพิมพ์ฮิสโตแกรมของตัวเลขที่ดัชนี 2 ในชุดข้อมูลการฝึกอบรม
plot.hist(X_train[2])
plot.title("Digit: {}".format(y_train[2])ผลลัพธ์ของการรันโค้ดด้านบนแสดงไว้ด้านล่าง -

เมื่อเปรียบเทียบสองรูปด้านบนคุณจะสังเกตได้ว่าการกระจายของพิกเซลสีขาวในสองภาพแตกต่างกันโดยบ่งบอกถึงการแสดงตัวเลขที่แตกต่างกัน -“ 5” และ“ 4” ในสองภาพด้านบน
ต่อไปเราจะตรวจสอบการกระจายของข้อมูลในชุดข้อมูลการฝึกอบรมทั้งหมดของเรา
ตรวจสอบการกระจายข้อมูล
ก่อนที่เราจะฝึกโมเดลแมชชีนเลิร์นนิงบนชุดข้อมูลของเราเราควรทราบการกระจายของตัวเลขที่ไม่ซ้ำกันในชุดข้อมูลของเรา รูปภาพของเราแสดงตัวเลข 10 หลักที่แตกต่างกันตั้งแต่ 0 ถึง 9 เราต้องการทราบจำนวนหลัก 0, 1 ฯลฯ ในชุดข้อมูลของเรา เราสามารถรับข้อมูลนี้ได้โดยใช้ไฟล์unique วิธีการ Numpy
ใช้คำสั่งต่อไปนี้เพื่อพิมพ์จำนวนค่าที่ไม่ซ้ำกันและจำนวนครั้งที่เกิดขึ้นของแต่ละค่า
print(np.unique(y_train, return_counts=True))เมื่อคุณรันคำสั่งด้านบนคุณจะเห็นผลลัพธ์ต่อไปนี้ -
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949]))แสดงให้เห็นว่ามีค่าที่แตกต่างกัน 10 ค่า - 0 ถึง 9 มีการเกิดขึ้น 5923 ครั้งของตัวเลข 0, 6742 ครั้งที่เกิดขึ้นของหลัก 1 และอื่น ๆ ภาพหน้าจอของผลลัพธ์แสดงที่นี่ -

ในขั้นตอนสุดท้ายในการเตรียมข้อมูลเราจำเป็นต้องเข้ารหัสข้อมูลของเรา
การเข้ารหัสข้อมูล
เรามีสิบหมวดหมู่ในชุดข้อมูลของเรา ดังนั้นเราจะเข้ารหัสผลลัพธ์ของเราในสิบประเภทนี้โดยใช้การเข้ารหัสแบบร้อนเดียว เราใช้วิธี to_categorial ของยูทิลิตี้ Numpy เพื่อทำการเข้ารหัส หลังจากเข้ารหัสข้อมูลเอาต์พุตแล้วจุดข้อมูลแต่ละจุดจะถูกแปลงเป็นเวกเตอร์มิติเดียวที่มีขนาด 10 ตัวอย่างเช่นตัวเลข 5 จะแสดงเป็น [0,0,0,0,0,1,0,0,0 , 0]
เข้ารหัสข้อมูลโดยใช้รหัสต่อไปนี้ -
n_classes = 10
Y_train = np_utils.to_categorical(y_train, n_classes)คุณสามารถตรวจสอบผลลัพธ์ของการเข้ารหัสได้โดยพิมพ์ 5 องค์ประกอบแรกของเวกเตอร์ Y_train ที่จัดหมวดหมู่
ใช้รหัสต่อไปนี้เพื่อพิมพ์เวกเตอร์ 5 ตัวแรก -
for i in range(5):
print (Y_train[i])คุณจะเห็นผลลัพธ์ต่อไปนี้ -
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]องค์ประกอบแรกแสดงถึงหลัก 5 ส่วนที่สองหมายถึงเลข 0 และอื่น ๆ
สุดท้ายคุณจะต้องจัดหมวดหมู่ข้อมูลการทดสอบด้วยซึ่งทำได้โดยใช้คำสั่งต่อไปนี้ -
Y_test = np_utils.to_categorical(y_test, n_classes)ในขั้นตอนนี้ข้อมูลของคุณได้รับการเตรียมอย่างสมบูรณ์สำหรับป้อนเข้าสู่เครือข่าย
ถัดไปเป็นส่วนที่สำคัญที่สุดนั่นคือการฝึกอบรมรูปแบบเครือข่ายของเรา
การฝึกโมเดลทำได้ในวิธีการเดียวที่เรียกว่า fit ซึ่งใช้พารามิเตอร์ไม่กี่ตัวดังที่เห็นในโค้ดด้านล่าง -
history = model.fit(X_train, Y_train,
batch_size=128, epochs=20,
verbose=2,
validation_data=(X_test, Y_test)))พารามิเตอร์สองตัวแรกของวิธีการพอดีระบุคุณลักษณะและผลลัพธ์ของชุดข้อมูลการฝึกอบรม
epochsถูกตั้งค่าเป็น 20; เราถือว่าการฝึกอบรมจะมาบรรจบกันใน 20 ยุคสูงสุดนั่นคือการทำซ้ำ แบบจำลองที่ผ่านการฝึกอบรมได้รับการตรวจสอบความถูกต้องของข้อมูลการทดสอบตามที่ระบุไว้ในพารามิเตอร์สุดท้าย
ผลลัพธ์บางส่วนของการรันคำสั่งดังกล่าวแสดงไว้ที่นี่ -
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
- 9s - loss: 0.2488 - acc: 0.9252 - val_loss: 0.1059 - val_acc: 0.9665
Epoch 2/20
- 9s - loss: 0.1004 - acc: 0.9688 - val_loss: 0.0850 - val_acc: 0.9715
Epoch 3/20
- 9s - loss: 0.0723 - acc: 0.9773 - val_loss: 0.0717 - val_acc: 0.9765
Epoch 4/20
- 9s - loss: 0.0532 - acc: 0.9826 - val_loss: 0.0665 - val_acc: 0.9795
Epoch 5/20
- 9s - loss: 0.0457 - acc: 0.9856 - val_loss: 0.0695 - val_acc: 0.9792ภาพหน้าจอของผลลัพธ์แสดงไว้ด้านล่างสำหรับการอ้างอิงอย่างรวดเร็วของคุณ -

ขณะนี้โมเดลได้รับการฝึกอบรมเกี่ยวกับข้อมูลการฝึกของเราเราจะประเมินประสิทธิภาพของโมเดลนั้น
ในการประเมินประสิทธิภาพของโมเดลเราโทร evaluate วิธีการดังนี้ -
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)ในการประเมินประสิทธิภาพของโมเดลเราโทร evaluate วิธีการดังนี้ -
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)เราจะพิมพ์การสูญเสียและความถูกต้องโดยใช้สองข้อความต่อไปนี้ -
print("Test Loss", loss_and_metrics[0])
print("Test Accuracy", loss_and_metrics[1])เมื่อคุณเรียกใช้ข้อความข้างต้นคุณจะเห็นผลลัพธ์ต่อไปนี้ -
Test Loss 0.08041584826191042
Test Accuracy 0.9837นี่แสดงให้เห็นถึงความแม่นยำในการทดสอบ 98% ซึ่งเราควรจะยอมรับได้ ความหมายสำหรับเราที่ใน 2% ของกรณีตัวเลขที่เขียนด้วยลายมือจะไม่ถูกจัดประเภทอย่างถูกต้อง นอกจากนี้เราจะพล็อตเมตริกความแม่นยำและการสูญเสียเพื่อดูว่าโมเดลทำงานอย่างไรกับข้อมูลทดสอบ
การพล็อตเมตริกความแม่นยำ
เราใช้ไฟล์ historyในระหว่างการฝึกอบรมเพื่อรับพล็อตเมตริกความแม่นยำ รหัสต่อไปนี้จะพล็อตความถูกต้องในแต่ละยุค เราเลือกความแม่นยำของข้อมูลการฝึกอบรม (“ acc”) และความถูกต้องของข้อมูลการตรวจสอบความถูกต้อง (“ val_acc”) สำหรับการลงจุด
plot.subplot(2,1,1)
plot.plot(history.history['acc'])
plot.plot(history.history['val_acc'])
plot.title('model accuracy')
plot.ylabel('accuracy')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='lower right')พล็อตเอาต์พุตแสดงด้านล่าง -

ดังที่คุณเห็นในแผนภาพความแม่นยำจะเพิ่มขึ้นอย่างรวดเร็วในสองยุคแรกซึ่งบ่งชี้ว่าเครือข่ายกำลังเรียนรู้อย่างรวดเร็ว หลังจากนั้นเส้นโค้งจะแบนแสดงว่าไม่จำเป็นต้องมียุคมากเกินไปในการฝึกโมเดลต่อไป โดยทั่วไปหากความแม่นยำของข้อมูลการฝึกอบรม (“ acc”) ดีขึ้นเรื่อย ๆ ในขณะที่ความถูกต้องของข้อมูลการตรวจสอบความถูกต้อง (“ val_acc”) แย่ลงแสดงว่าคุณกำลังพบปัญหาการฟิตติ้งมากเกินไป แสดงว่าโมเดลกำลังเริ่มจดจำข้อมูล
เราจะวางแผนเมตริกการสูญเสียเพื่อตรวจสอบประสิทธิภาพของโมเดลของเราด้วย
การวางแผนเมตริกการสูญเสีย
อีกครั้งเราวางแผนการสูญเสียทั้งข้อมูลการฝึกอบรม (“ การสูญเสีย”) และการทดสอบ (“ val_loss”) ทำได้โดยใช้รหัสต่อไปนี้ -
plot.subplot(2,1,2)
plot.plot(history.history['loss'])
plot.plot(history.history['val_loss'])
plot.title('model loss')
plot.ylabel('loss')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='upper right')ผลลัพธ์ของรหัสนี้แสดงไว้ด้านล่าง -

ดังที่คุณเห็นในแผนภาพการสูญเสียชุดฝึกจะลดลงอย่างรวดเร็วในสองยุคแรก สำหรับชุดทดสอบการสูญเสียไม่ได้ลดลงในอัตราเดียวกับชุดฝึก แต่ยังคงเกือบจะคงที่สำหรับหลายยุค ซึ่งหมายความว่าโมเดลของเรามีการสรุปข้อมูลที่มองไม่เห็นได้เป็นอย่างดี
ตอนนี้เราจะใช้แบบจำลองที่ได้รับการฝึกฝนของเราเพื่อทำนายตัวเลขในข้อมูลทดสอบของเรา
การทำนายตัวเลขในข้อมูลที่มองไม่เห็นทำได้ง่ายมาก คุณต้องโทรไปที่ไฟล์predict_classes วิธีการของ model โดยส่งต่อไปยังเวกเตอร์ที่ประกอบด้วยจุดข้อมูลที่คุณไม่รู้จัก
predictions = model.predict_classes(X_test)การเรียกเมธอดจะส่งคืนการคาดการณ์ในเวกเตอร์ที่สามารถทดสอบได้สำหรับ 0 และ 1 เทียบกับค่าจริง ทำได้โดยใช้สองคำสั่งต่อไปนี้ -
correct_predictions = np.nonzero(predictions == y_test)[0]
incorrect_predictions = np.nonzero(predictions != y_test)[0]สุดท้ายเราจะพิมพ์จำนวนการคาดการณ์ที่ถูกต้องและไม่ถูกต้องโดยใช้คำสั่งโปรแกรมสองรายการต่อไปนี้ -
print(len(correct_predictions)," classified correctly")
print(len(incorrect_predictions)," classified incorrectly")เมื่อคุณรันโค้ดคุณจะได้ผลลัพธ์ดังต่อไปนี้ -
9837 classified correctly
163 classified incorrectlyขณะนี้เมื่อคุณได้ฝึกฝนโมเดลเป็นที่พอใจแล้วเราจะบันทึกไว้เพื่อใช้ในอนาคต
เราจะบันทึกโมเดลที่ผ่านการฝึกอบรมไว้ในไดรฟ์ภายในเครื่องของเราในโฟลเดอร์ Models ในไดเร็กทอรีการทำงานปัจจุบันของเรา ในการบันทึกโมเดลให้เรียกใช้รหัสต่อไปนี้ -
directory = "./models/"
name = 'handwrittendigitrecognition.h5'
path = os.path.join(save_dir, name)
model.save(path)
print('Saved trained model at %s ' % path)ผลลัพธ์หลังจากรันโค้ดดังแสดงด้านล่าง -

ขณะนี้เมื่อคุณบันทึกโมเดลที่ได้รับการฝึกฝนแล้วคุณสามารถใช้ในภายหลังเพื่อประมวลผลข้อมูลที่คุณไม่รู้จัก
ในการคาดเดาข้อมูลที่มองไม่เห็นก่อนอื่นคุณต้องโหลดแบบจำลองที่ได้รับการฝึกฝนลงในหน่วยความจำ ทำได้โดยใช้คำสั่งต่อไปนี้ -
model = load_model ('./models/handwrittendigitrecognition.h5')โปรดทราบว่าเรากำลังโหลดไฟล์. h5 ลงในหน่วยความจำ สิ่งนี้จะตั้งค่าเครือข่ายประสาทเทียมทั้งหมดในหน่วยความจำพร้อมกับน้ำหนักที่กำหนดให้กับแต่ละเลเยอร์
ตอนนี้ในการคาดเดาข้อมูลที่มองไม่เห็นให้โหลดข้อมูลปล่อยให้เป็นรายการอย่างน้อยหนึ่งรายการลงในหน่วยความจำ ประมวลผลข้อมูลล่วงหน้าเพื่อให้เป็นไปตามข้อกำหนดการป้อนข้อมูลของโมเดลของเราเช่นเดียวกับสิ่งที่คุณทำกับข้อมูลการฝึกอบรมและการทดสอบด้านบน หลังจากประมวลผลล่วงหน้าแล้วให้ฟีดเข้ากับเครือข่ายของคุณ โมเดลจะแสดงผลการทำนาย
Keras มี API ระดับสูงสำหรับการสร้างโครงข่ายประสาทเทียมระดับลึก ในบทช่วยสอนนี้คุณได้เรียนรู้การสร้างเครือข่ายประสาทเทียมที่ได้รับการฝึกฝนมาเพื่อค้นหาตัวเลขในข้อความที่เขียนด้วยลายมือ เครือข่ายหลายชั้นถูกสร้างขึ้นเพื่อจุดประสงค์นี้ Keras ช่วยให้คุณกำหนดฟังก์ชันการเปิดใช้งานที่คุณเลือกในแต่ละเลเยอร์ ใช้การไล่ระดับสีเครือข่ายได้รับการฝึกอบรมเกี่ยวกับข้อมูลการฝึกอบรม ความแม่นยำของเครือข่ายที่ได้รับการฝึกฝนในการทำนายข้อมูลที่มองไม่เห็นได้รับการทดสอบกับข้อมูลการทดสอบ คุณเรียนรู้ที่จะพล็อตเมตริกความแม่นยำและข้อผิดพลาด หลังจากที่เครือข่ายได้รับการฝึกอบรมอย่างสมบูรณ์คุณได้บันทึกโมเดลเครือข่ายเพื่อใช้ในอนาคต