Genetic Algorithms - คู่มือฉบับย่อ
Genetic Algorithm (GA) เป็นเทคนิคการเพิ่มประสิทธิภาพตามการค้นหาตามหลักการของ Genetics and Natural Selection. มักใช้เพื่อค้นหาวิธีแก้ปัญหาที่ดีที่สุดหรือใกล้เคียงที่สุดสำหรับปัญหาที่ยากซึ่งอาจต้องใช้เวลาตลอดชีวิตในการแก้ไข มักใช้เพื่อแก้ปัญหาการเพิ่มประสิทธิภาพในการวิจัยและการเรียนรู้ของเครื่อง
ข้อมูลเบื้องต้นเกี่ยวกับการเพิ่มประสิทธิภาพ
การเพิ่มประสิทธิภาพเป็นกระบวนการของ making something better. ในกระบวนการใด ๆ เรามีชุดอินพุตและชุดเอาต์พุตดังแสดงในรูปต่อไปนี้

การเพิ่มประสิทธิภาพหมายถึงการค้นหาค่าของอินพุตในลักษณะที่เราได้รับค่าเอาต์พุตที่ "ดีที่สุด" คำจำกัดความของคำว่า“ ดีที่สุด” จะแตกต่างกันไปในแต่ละปัญหา แต่ในแง่คณิตศาสตร์หมายถึงการเพิ่มหรือลดฟังก์ชันวัตถุประสงค์อย่างน้อยหนึ่งฟังก์ชันโดยการเปลี่ยนพารามิเตอร์อินพุต
ชุดของโซลูชันหรือค่าที่เป็นไปได้ทั้งหมดซึ่งอินพุตสามารถใช้ประกอบเป็นพื้นที่ค้นหา ในพื้นที่การค้นหานี้มีจุดหรือชุดของจุดที่เป็นทางออกที่ดีที่สุด จุดมุ่งหมายของการเพิ่มประสิทธิภาพคือการค้นหาจุดนั้นหรือชุดของจุดนั้นในพื้นที่การค้นหา
Genetic Algorithms คืออะไร?
ธรรมชาติเป็นแหล่งที่มาของแรงบันดาลใจที่ดีสำหรับมวลมนุษยชาติ Genetic Algorithms (GAs) เป็นอัลกอริธึมที่ใช้การค้นหาตามแนวคิดของการคัดเลือกโดยธรรมชาติและพันธุศาสตร์ GAs เป็นชุดย่อยของสาขาการคำนวณที่ใหญ่กว่าที่เรียกว่าEvolutionary Computation.
GAs ได้รับการพัฒนาโดย John Holland และนักศึกษาและเพื่อนร่วมงานของเขาที่ University of Michigan โดยเฉพาะอย่างยิ่ง David E.
ใน GAs เรามีไฟล์ pool or a population of possible solutionsกับปัญหาที่กำหนด จากนั้นวิธีการแก้ปัญหาเหล่านี้จะผ่านการรวมตัวกันใหม่และการกลายพันธุ์ (เช่นเดียวกับในพันธุศาสตร์ตามธรรมชาติ) ผลิตลูกใหม่และกระบวนการนี้ซ้ำแล้วซ้ำอีกในชั่วอายุต่างๆ แต่ละคน (หรือวิธีการแก้ปัญหาของผู้สมัคร) จะได้รับการกำหนดค่าสมรรถภาพ (ตามค่าฟังก์ชันวัตถุประสงค์) และบุคคลที่มีความเหมาะสมจะได้รับโอกาสในการผสมพันธุ์และให้ผลตอบแทนที่สูงขึ้น ซึ่งสอดคล้องกับทฤษฎีดาร์วินเรื่อง“ Survival of the Fittest”
ด้วยวิธีนี้เราจะ“ พัฒนา” บุคคลหรือแนวทางแก้ไขที่ดีขึ้นเรื่อย ๆ มาหลายชั่วอายุคนจนกว่าจะถึงเกณฑ์ที่หยุดชะงัก
อัลกอริทึมทางพันธุกรรมมีการสุ่มอย่างเพียงพอในลักษณะ แต่ทำงานได้ดีกว่าการค้นหาในท้องถิ่นแบบสุ่ม (ซึ่งเราลองใช้วิธีการสุ่มแบบต่างๆเพื่อติดตามสิ่งที่ดีที่สุดจนถึงตอนนี้) เนื่องจากใช้ประโยชน์จากข้อมูลในอดีตเช่นกัน
ข้อดีของ GAs
GAs มีข้อดีหลายประการซึ่งทำให้พวกเขาได้รับความนิยมอย่างกว้างขวาง ซึ่ง ได้แก่ -
ไม่ต้องการข้อมูลอนุพันธ์ใด ๆ (ซึ่งอาจไม่มีให้สำหรับปัญหาในโลกแห่งความเป็นจริง)
เร็วขึ้นและมีประสิทธิภาพมากขึ้นเมื่อเทียบกับวิธีการแบบเดิม
มีความสามารถแบบขนานที่ดีมาก
ปรับฟังก์ชั่นทั้งแบบต่อเนื่องและไม่ต่อเนื่องและปัญหาหลายวัตถุประสงค์
แสดงรายการโซลูชันที่ "ดี" ไม่ใช่แค่โซลูชันเดียว
มักจะได้รับคำตอบสำหรับปัญหาซึ่งจะดีขึ้นเมื่อเวลาผ่านไป
มีประโยชน์เมื่อพื้นที่ค้นหามีขนาดใหญ่มากและมีพารามิเตอร์จำนวนมากที่เกี่ยวข้อง
ข้อ จำกัด ของ GAs
เช่นเดียวกับเทคนิคอื่น ๆ GAs ยังต้องทนทุกข์ทรมานจากข้อ จำกัด บางประการ ซึ่ง ได้แก่ -
GAs ไม่เหมาะกับทุกปัญหาโดยเฉพาะปัญหาที่เรียบง่ายและมีข้อมูลอนุพันธ์
ค่าฟิตเนสจะคำนวณซ้ำ ๆ ซึ่งอาจมีราคาแพงในการคำนวณสำหรับปัญหาบางอย่าง
การสุ่มตัวอย่างจะไม่มีการรับประกันเกี่ยวกับความเหมาะสมหรือคุณภาพของโซลูชัน
หากไม่ได้ติดตั้งอย่างถูกต้อง GA อาจไม่บรรจบกันเป็นโซลูชันที่เหมาะสมที่สุด
GA - แรงจูงใจ
อัลกอริทึมทางพันธุกรรมมีความสามารถในการนำเสนอโซลูชันที่ "ดีเพียงพอ" "เร็วพอ" สิ่งนี้ทำให้อัลกอริทึมทางพันธุกรรมน่าสนใจสำหรับใช้ในการแก้ปัญหาการเพิ่มประสิทธิภาพ เหตุผลที่ GAs จำเป็นมีดังต่อไปนี้ -
การแก้ปัญหาที่ยาก
ในวิทยาการคอมพิวเตอร์มีปัญหาชุดใหญ่ซึ่ง ได้แก่ NP-Hard. สิ่งนี้หมายความว่าโดยพื้นฐานแล้วแม้แต่ระบบคอมพิวเตอร์ที่ทรงพลังที่สุดก็ใช้เวลานานมาก (เป็นปี!) ในการแก้ปัญหานั้น ในสถานการณ์เช่นนี้ GAs พิสูจน์แล้วว่าเป็นเครื่องมือที่มีประสิทธิภาพในการจัดหาusable near-optimal solutions ในช่วงเวลาสั้น ๆ
ความล้มเหลวของวิธีการไล่ระดับสี
วิธีการที่ใช้แคลคูลัสแบบดั้งเดิมทำงานโดยเริ่มจากจุดสุ่มและโดยการเคลื่อนที่ไปตามทิศทางของการไล่ระดับสีจนกระทั่งเราไปถึงจุดสูงสุดของเนินเขา เทคนิคนี้มีประสิทธิภาพและใช้ได้ผลดีกับฟังก์ชันวัตถุประสงค์จุดยอดเดียวเช่นฟังก์ชันต้นทุนในการถดถอยเชิงเส้น แต่ในสถานการณ์จริงส่วนใหญ่เรามีปัญหาที่ซับซ้อนมากที่เรียกว่าภูมิประเทศซึ่งประกอบด้วยยอดเขาจำนวนมากและหุบเขาจำนวนมากซึ่งทำให้วิธีการดังกล่าวล้มเหลวเนื่องจากพวกเขาต้องทนทุกข์ทรมานจากแนวโน้มที่จะติดอยู่ที่ Optima ในพื้นที่ ดังแสดงในรูปต่อไปนี้

รับทางออกที่ดีอย่างรวดเร็ว
ปัญหาที่ยากบางอย่างเช่นปัญหาพนักงานขายในการเดินทาง (TSP) มีแอปพลิเคชันในโลกแห่งความเป็นจริงเช่นการค้นหาเส้นทางและการออกแบบ VLSI ลองนึกภาพว่าคุณกำลังใช้ระบบการนำทางด้วย GPS และใช้เวลาสองสามนาที (หรือสองสามชั่วโมง) ในการคำนวณเส้นทางที่ "เหมาะสมที่สุด" จากต้นทางไปยังปลายทาง ความล่าช้าในการใช้งานในโลกแห่งความเป็นจริงนั้นไม่สามารถยอมรับได้ดังนั้นโซลูชันที่ "ดีเพียงพอ" ซึ่งได้รับ "เร็ว" จึงเป็นสิ่งที่จำเป็น
ส่วนนี้จะแนะนำคำศัพท์พื้นฐานที่จำเป็นในการทำความเข้าใจ GAs นอกจากนี้โครงสร้างทั่วไปของ GAs ยังแสดงอยู่ในทั้งสองอย่างpseudo-code and graphical forms. ขอแนะนำให้ผู้อ่านทำความเข้าใจแนวคิดทั้งหมดที่แนะนำในส่วนนี้อย่างถูกต้องและควรคำนึงถึงแนวคิดเหล่านี้เมื่ออ่านส่วนอื่น ๆ ของบทช่วยสอนนี้ด้วย
คำศัพท์พื้นฐาน
ก่อนที่จะเริ่มการสนทนาเกี่ยวกับอัลกอริทึมทางพันธุกรรมจำเป็นอย่างยิ่งที่จะต้องทำความคุ้นเคยกับคำศัพท์พื้นฐานที่จะใช้ตลอดบทแนะนำนี้
Population- เป็นชุดย่อยของโซลูชัน (เข้ารหัส) ที่เป็นไปได้ทั้งหมดสำหรับปัญหาที่กำหนด ประชากรสำหรับ GA นั้นคล้ายคลึงกับประชากรสำหรับมนุษย์ยกเว้นว่าแทนที่จะเป็นมนุษย์เรามี Candidate Solutions ที่เป็นตัวแทนของมนุษย์
Chromosomes - โครโมโซมเป็นวิธีแก้ปัญหาที่กำหนด
Gene - ยีนเป็นตำแหน่งองค์ประกอบหนึ่งของโครโมโซม
Allele - เป็นค่าที่ยีนใช้สำหรับโครโมโซมเฉพาะ
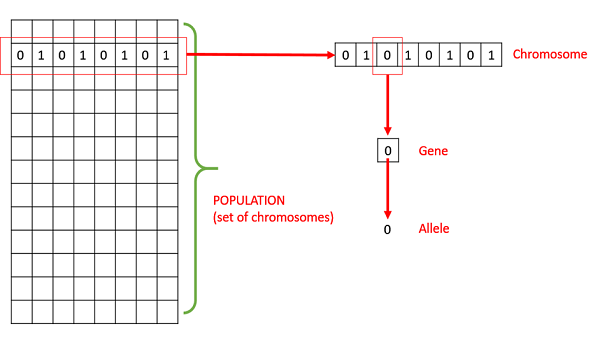
Genotype- จีโนไทป์คือประชากรในพื้นที่คำนวณ ในพื้นที่การคำนวณโซลูชันจะแสดงในลักษณะที่สามารถเข้าใจและจัดการได้ง่ายโดยใช้ระบบคอมพิวเตอร์
Phenotype - ฟีโนไทป์คือประชากรในพื้นที่โซลูชันในโลกแห่งความเป็นจริงที่มีการแสดงโซลูชันในลักษณะที่แสดงในสถานการณ์จริง
Decoding and Encoding - สำหรับปัญหาง่ายๆไฟล์ phenotype and genotypeช่องว่างเหมือนกัน อย่างไรก็ตามในกรณีส่วนใหญ่ฟีโนไทป์และจีโนไทป์จะแตกต่างกัน การถอดรหัสเป็นกระบวนการเปลี่ยนสารละลายจากจีโนไทป์ไปยังพื้นที่ฟีโนไทป์ในขณะที่การเข้ารหัสเป็นกระบวนการเปลี่ยนจากฟีโนไทป์เป็นพื้นที่จีโนไทป์ การถอดรหัสควรรวดเร็วเนื่องจากมีการดำเนินการซ้ำ ๆ ใน GA ระหว่างการคำนวณค่าสมรรถภาพ
ตัวอย่างเช่นพิจารณาปัญหา 0/1 เป้ ช่องว่างฟีโนไทป์ประกอบด้วยโซลูชันที่มีเพียงหมายเลขสินค้าของรายการที่จะเลือก
อย่างไรก็ตามในพื้นที่จีโนไทป์สามารถแสดงเป็นสตริงไบนารีของความยาว n (โดยที่ n คือจำนวนรายการ) ก0 at position x แสดงถึงสิ่งนั้น xthรายการจะถูกเลือกในขณะที่ 1 แทนการย้อนกลับ นี่เป็นกรณีที่ช่องว่างของจีโนไทป์และฟีโนไทป์แตกต่างกัน

Fitness Function- ฟังก์ชั่นฟิตเนสที่กำหนดไว้เพียงอย่างเดียวคือฟังก์ชันที่รับโซลูชันเป็นอินพุตและสร้างความเหมาะสมของโซลูชันเป็นเอาต์พุต ในบางกรณีฟังก์ชันฟิตเนสและฟังก์ชันวัตถุประสงค์อาจเหมือนกันในขณะที่ฟังก์ชันอื่นอาจแตกต่างกันไปตามปัญหา
Genetic Operators- สิ่งเหล่านี้เปลี่ยนแปลงองค์ประกอบทางพันธุกรรมของลูกหลาน ซึ่งรวมถึงการไขว้การกลายพันธุ์การคัดเลือก ฯลฯ
โครงสร้างพื้นฐาน
โครงสร้างพื้นฐานของ GA มีดังนี้ -
เราเริ่มต้นด้วยประชากรเริ่มต้น (ซึ่งอาจถูกสร้างขึ้นโดยการสุ่มหรือเพาะจากพฤติกรรมอื่น ๆ ) เลือกพ่อแม่จากประชากรกลุ่มนี้เพื่อผสมพันธุ์ ใช้ตัวดำเนินการครอสโอเวอร์และการกลายพันธุ์กับพ่อแม่เพื่อสร้างสปริงใหม่ และในที่สุดสิ่งเหล่านี้ก็เข้ามาแทนที่บุคคลที่มีอยู่ในประชากรและกระบวนการนี้ก็เกิดขึ้นซ้ำ ๆ ด้วยวิธีนี้ขั้นตอนวิธีทางพันธุกรรมพยายามที่จะเลียนแบบวิวัฒนาการของมนุษย์ในระดับหนึ่ง
แต่ละขั้นตอนต่อไปนี้ครอบคลุมเป็นบทที่แยกจากกันในบทช่วยสอนนี้

รหัสหลอกทั่วไปสำหรับ GA มีอธิบายไว้ในโปรแกรมต่อไปนี้ -
GA()
initialize population
find fitness of population
while (termination criteria is reached) do
parent selection
crossover with probability pc
mutation with probability pm
decode and fitness calculation
survivor selection
find best
return bestการตัดสินใจที่สำคัญที่สุดอย่างหนึ่งในขณะที่ใช้อัลกอริธึมทางพันธุกรรมคือการตัดสินใจเลือกตัวแทนที่เราจะใช้เพื่อแสดงโซลูชันของเรา มีการสังเกตว่าการนำเสนอที่ไม่เหมาะสมอาจทำให้ GA มีประสิทธิภาพต่ำ
ดังนั้นการเลือกการแสดงที่เหมาะสมการมีคำจำกัดความที่เหมาะสมของการแมประหว่างฟีโนไทป์และจีโนไทป์สเปซจึงเป็นสิ่งสำคัญสำหรับความสำเร็จของ GA
ในส่วนนี้เรานำเสนอการแสดงที่ใช้บ่อยที่สุดสำหรับอัลกอริทึมทางพันธุกรรม อย่างไรก็ตามการเป็นตัวแทนเป็นปัญหาที่เฉพาะเจาะจงมากและผู้อ่านอาจพบว่าการเป็นตัวแทนอื่นหรือการผสมผสานของตัวแทนที่กล่าวถึงในที่นี้อาจเหมาะกับปัญหาของเขา / เธอมากกว่า
การเป็นตัวแทนแบบไบนารี
นี่เป็นหนึ่งในการนำเสนอที่ง่ายที่สุดและใช้กันอย่างแพร่หลายใน GAs ในการแสดงประเภทนี้จีโนไทป์ประกอบด้วยสตริงบิต
สำหรับปัญหาบางอย่างเมื่อพื้นที่โซลูชันประกอบด้วยตัวแปรการตัดสินใจแบบบูลีนใช่หรือไม่ใช่การแสดงไบนารีนั้นเป็นไปตามธรรมชาติ ยกตัวอย่างเช่น 0/1 Knapsack Problem หากมี n รายการเราสามารถแทนคำตอบโดยสตริงไบนารีขององค์ประกอบ n โดยที่องค์ประกอบ x thจะบอกว่ารายการ x ถูกเลือก (1) หรือไม่ (0)

สำหรับปัญหาอื่น ๆ โดยเฉพาะผู้ที่เกี่ยวข้องกับตัวเลขเราสามารถแทนค่าตัวเลขด้วยการแทนค่าฐานสองได้ ปัญหาในการเข้ารหัสประเภทนี้คือบิตที่แตกต่างกันมีความสำคัญแตกต่างกันดังนั้นตัวดำเนินการการกลายพันธุ์และตัวดำเนินการครอสโอเวอร์อาจส่งผลที่ไม่ต้องการได้ สิ่งนี้สามารถแก้ไขได้ในระดับหนึ่งโดยใช้Gray Coding, เนื่องจากการเปลี่ยนแปลงในบิตเดียวจะไม่มีผลอย่างมากต่อการแก้ปัญหา
การเป็นตัวแทนที่มีคุณค่าอย่างแท้จริง
สำหรับปัญหาที่เราต้องการกำหนดยีนโดยใช้ตัวแปรแบบต่อเนื่องแทนที่จะเป็นแบบไม่ต่อเนื่องการแสดงมูลค่าที่แท้จริงนั้นเป็นธรรมชาติที่สุด อย่างไรก็ตามความแม่นยำของตัวเลขที่มีมูลค่าจริงหรือจุดลอยตัวเหล่านี้ถูก จำกัด ไว้ที่คอมพิวเตอร์

การแทนจำนวนเต็ม
สำหรับยีนที่มีมูลค่าไม่ต่อเนื่องเราไม่สามารถ จำกัด พื้นที่การแก้ปัญหาเป็นไบนารี 'ใช่' หรือ 'ไม่ใช่' ได้เสมอไป ตัวอย่างเช่นหากเราต้องการเข้ารหัสระยะทางทั้งสี่ - เหนือใต้ตะวันออกและตะวันตกเราสามารถเข้ารหัสเป็น{0,1,2,3}. ในกรณีเช่นนี้การแทนค่าจำนวนเต็มเป็นสิ่งที่พึงปรารถนา

การแสดงการเรียงสับเปลี่ยน
ในหลาย ๆ ปัญหาการแก้ปัญหาจะแสดงตามลำดับขององค์ประกอบ ในกรณีเช่นนี้การแสดงการเปลี่ยนแปลงจะเหมาะสมที่สุด
ตัวอย่างคลาสสิกของการนำเสนอนี้คือปัญหาพนักงานขายที่เดินทาง (TSP) ในการนี้พนักงานขายจะต้องทัวร์ชมเมืองทั้งหมดเยี่ยมชมเมืองแต่ละครั้งและกลับมาที่เมืองเริ่มต้น ต้องลดระยะทางทั้งหมดของทัวร์ การแก้ปัญหา TSP นี้เป็นการเรียงลำดับหรือการเปลี่ยนแปลงของเมืองทั้งหมดโดยธรรมชาติดังนั้นการใช้การแทนค่าการเปลี่ยนแปลงจึงเหมาะสมสำหรับปัญหานี้

ประชากรเป็นชุดย่อยของโซลูชันในยุคปัจจุบัน นอกจากนี้ยังสามารถกำหนดเป็นชุดของโครโมโซม มีหลายสิ่งที่ควรคำนึงถึงเมื่อจัดการกับประชากร GA -
ควรรักษาความหลากหลายของประชากรมิฉะนั้นอาจนำไปสู่การบรรจบกันก่อนวัยอันควร
ไม่ควรรักษาขนาดของประชากรให้ใหญ่มากเพราะอาจทำให้ GA ทำงานช้าลงในขณะที่ประชากรที่มีขนาดเล็กอาจไม่เพียงพอสำหรับการผสมพันธุ์ที่ดี ดังนั้นขนาดของประชากรที่เหมาะสมจึงต้องตัดสินใจโดยการลองผิดลองถูก
โดยปกติประชากรจะถูกกำหนดให้เป็นอาร์เรย์สองมิติของ - size population, size x, chromosome size.
การเริ่มต้นประชากร
มีสองวิธีหลักในการเริ่มต้นประชากรใน GA พวกเขาคือ -
Random Initialization - เติมประชากรเริ่มต้นด้วยวิธีการแก้ปัญหาแบบสุ่ม
Heuristic initialization - เติมประชากรเริ่มต้นโดยใช้ฮิวริสติกที่ทราบสำหรับปัญหา
มีการสังเกตว่าประชากรทั้งหมดไม่ควรเริ่มต้นโดยใช้ฮิวริสติกเนื่องจากอาจส่งผลให้ประชากรมีวิธีแก้ปัญหาที่คล้ายคลึงกันและมีความหลากหลายน้อยมาก มีการสังเกตในการทดลองว่าโซลูชันแบบสุ่มเป็นวิธีที่ขับเคลื่อนประชากรไปสู่การเพิ่มประสิทธิภาพ ดังนั้นด้วยการเริ่มต้นฮิวริสติกเราเพียงแค่เพาะเมล็ดประชากรด้วยวิธีแก้ปัญหาที่ดีสองสามวิธีเติมส่วนที่เหลือด้วยวิธีการแก้ปัญหาแบบสุ่มแทนที่จะเติมประชากรทั้งหมดด้วยโซลูชันตามฮิวริสติก
นอกจากนี้ยังมีข้อสังเกตว่าการเริ่มต้นฮิวริสติกในบางกรณีมีผลต่อสมรรถภาพเริ่มต้นของประชากรเท่านั้น แต่ในท้ายที่สุดความหลากหลายของวิธีการแก้ปัญหาซึ่งนำไปสู่การมองโลกในแง่ดี
แบบจำลองประชากร
มีการใช้แบบจำลองประชากรสองแบบ -
สถานะคงที่
ใน GA ที่คงที่เราจะสร้างออนสปริงหนึ่งหรือสองครั้งในการวนซ้ำแต่ละครั้งและแทนที่บุคคลหนึ่งหรือสองคนจากประชากร GA แบบคงที่เรียกอีกอย่างว่าIncremental GA.
Generational
ในแบบจำลองทั่วไปเราสร้าง 'n' ออฟสปริงโดยที่ n คือขนาดประชากรและประชากรทั้งหมดจะถูกแทนที่ด้วยค่าใหม่เมื่อสิ้นสุดการวนซ้ำ
ฟังก์ชั่นการออกกำลังกายที่กำหนดไว้เพียงอย่างเดียวคือฟังก์ชันที่ใช้เวลา a candidate solution to the problem as input and produces as output วิธีการ "เหมาะสม" ของเราวิธีแก้ "ดี" เกี่ยวกับปัญหาในการพิจารณา
การคำนวณค่าสมรรถภาพจะทำซ้ำ ๆ ใน GA ดังนั้นจึงควรเร็วเพียงพอ การคำนวณค่าสมรรถภาพทางกายที่ช้าอาจส่งผลเสียต่อ GA และทำให้ค่าการออกกำลังกายช้าเป็นพิเศษ
ในกรณีส่วนใหญ่ฟังก์ชันการออกกำลังกายและฟังก์ชันวัตถุประสงค์จะเหมือนกับวัตถุประสงค์คือเพื่อเพิ่มหรือลดฟังก์ชันวัตถุประสงค์ที่กำหนด อย่างไรก็ตามสำหรับปัญหาที่ซับซ้อนมากขึ้นโดยมีวัตถุประสงค์และข้อ จำกัด หลายประการไฟล์Algorithm Designer อาจเลือกใช้ฟังก์ชันการออกกำลังกายที่แตกต่างกัน
ฟังก์ชันการออกกำลังกายควรมีลักษณะดังต่อไปนี้ -
ฟังก์ชันฟิตเนสควรมีความเร็วเพียงพอในการคำนวณ
ต้องวัดในเชิงปริมาณว่าเหมาะสมกับโซลูชันที่กำหนดหรือเหมาะสมเพียงใดที่สามารถผลิตได้จากโซลูชันที่กำหนด
ในบางกรณีการคำนวณฟังก์ชันการออกกำลังกายโดยตรงอาจไม่สามารถทำได้เนื่องจากปัญหาที่ซับซ้อนโดยธรรมชาติ ในกรณีเช่นนี้เราจะทำการประเมินความเหมาะสมให้เหมาะกับความต้องการของเรา
ภาพต่อไปนี้แสดงการคำนวณความเหมาะสมสำหรับวิธีแก้ปัญหาของกระเป๋าเป้ 0/1 เป็นฟังก์ชั่นการออกกำลังกายที่เรียบง่ายซึ่งเพียงแค่รวมมูลค่ากำไรของสินค้าที่เลือก (ซึ่งมี 1) โดยจะสแกนองค์ประกอบจากซ้ายไปขวาจนกระเป๋าเป้เต็ม

การคัดเลือกผู้ปกครองเป็นกระบวนการในการคัดเลือกพ่อแม่ที่จะผสมพันธุ์และรวมตัวกันใหม่เพื่อสร้างสปริงสำหรับรุ่นต่อไป การเลือกผู้ปกครองมีความสำคัญอย่างยิ่งต่ออัตราการบรรจบกันของ GA เนื่องจากผู้ปกครองที่ดีจะผลักดันให้แต่ละบุคคลไปสู่โซลูชันที่ดีขึ้นและเหมาะสม
อย่างไรก็ตามควรใช้ความระมัดระวังเพื่อป้องกันไม่ให้โซลูชันที่เหมาะสมอย่างยิ่งอย่างหนึ่งเข้าครอบงำประชากรทั้งหมดในไม่กี่ชั่วอายุคนเนื่องจากสิ่งนี้นำไปสู่การแก้ปัญหาที่อยู่ใกล้กันในพื้นที่โซลูชันจึงนำไปสู่การสูญเสียความหลากหลาย Maintaining good diversityในประชากรมีความสำคัญอย่างยิ่งต่อความสำเร็จของ GA การรับประชากรทั้งหมดด้วยวิธีแก้ปัญหาที่เหมาะสมอย่างยิ่งนี้เรียกว่าpremature convergence และเป็นเงื่อนไขที่ไม่พึงปรารถนาใน GA
การเลือกสัดส่วนการออกกำลังกาย
Fitness Proportionate Selection เป็นวิธีการเลือกผู้ปกครองที่ได้รับความนิยมมากที่สุดวิธีหนึ่ง ในสิ่งนี้ทุกคนสามารถเป็นพ่อแม่ได้ด้วยความน่าจะเป็นซึ่งเป็นสัดส่วนกับความฟิตของตน ดังนั้นช่างฟิตจึงมีโอกาสที่จะผสมพันธุ์และขยายพันธุ์ไปยังรุ่นต่อไปได้ ดังนั้นกลยุทธ์การคัดเลือกดังกล่าวจึงใช้แรงกดดันในการเลือกกับบุคคลที่เหมาะสมกับประชากรมากขึ้นซึ่งจะพัฒนาบุคคลที่ดีขึ้นเมื่อเวลาผ่านไป
พิจารณาล้อทรงกลม ล้อแบ่งออกเป็นn piesโดยที่ n คือจำนวนบุคคลในประชากร แต่ละคนจะได้รับส่วนหนึ่งของวงกลมซึ่งเป็นสัดส่วนกับค่าการออกกำลังกาย
สามารถใช้การเลือกสัดส่วนการออกกำลังกายได้สองแบบ -
การเลือกวงล้อรูเล็ต
ในการเลือกวงล้อรูเล็ตวงล้อวงกลมจะถูกแบ่งออกตามที่อธิบายไว้ก่อนหน้านี้ มีการเลือกจุดคงที่บนเส้นรอบวงล้อตามที่แสดงและล้อจะหมุน พื้นที่ของวงล้อที่อยู่หน้าจุดคงที่จะถูกเลือกให้เป็นแม่ สำหรับผู้ปกครองคนที่สองกระบวนการเดียวกันซ้ำแล้วซ้ำอีก
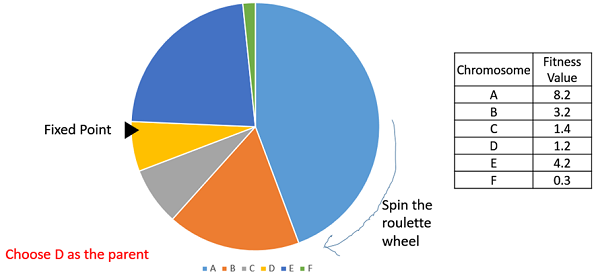
เป็นที่ชัดเจนว่าช่างฟิตแต่ละคนมีวงล้อที่มากขึ้นดังนั้นจึงมีโอกาสมากขึ้นที่จะลงจอดที่หน้าจุดคงที่เมื่อล้อหมุน ดังนั้นความน่าจะเป็นในการเลือกแต่ละบุคคลจึงขึ้นอยู่กับความเหมาะสมโดยตรง
การนำไปใช้อย่างชาญฉลาดเราใช้ขั้นตอนต่อไปนี้ -
คำนวณ S = ผลรวมของ finesses
สร้างตัวเลขสุ่มระหว่าง 0 ถึง S
เริ่มจากด้านบนสุดของประชากรให้เพิ่ม finesses ไปยังผลรวม P บางส่วนจนถึง P <S
บุคคลที่ P เกิน S คือบุคคลที่ถูกเลือก
Stochastic Universal Sampling (SUS)
Stochastic Universal Sampling ค่อนข้างคล้ายกับการเลือกวงล้อรูเล็ต แต่แทนที่จะมีจุดคงที่เพียงจุดเดียวเรามีจุดคงที่หลายจุดดังที่แสดงในภาพต่อไปนี้ ดังนั้นผู้ปกครองทุกคนจะได้รับการคัดเลือกในการหมุนวงล้อเพียงครั้งเดียว นอกจากนี้การตั้งค่าดังกล่าวสนับสนุนให้บุคคลที่มีรูปร่างเหมาะสมสูงได้รับเลือกอย่างน้อยหนึ่งครั้ง

เป็นที่น่าสังเกตว่าวิธีการเลือกสัดส่วนการออกกำลังกายไม่ได้ผลในกรณีที่ฟิตเนสสามารถรับค่าลบได้
การเลือกทัวร์นาเมนต์
ในการเลือกทัวร์นาเมนต์ K-Way เราเลือก K บุคคลจากประชากรโดยการสุ่มและเลือกสิ่งที่ดีที่สุดจากสิ่งเหล่านี้เพื่อเป็นผู้ปกครอง กระบวนการเดียวกันนี้ซ้ำแล้วซ้ำอีกสำหรับการเลือกพาเรนต์ถัดไป การเลือกทัวร์นาเมนต์ยังเป็นที่นิยมอย่างมากในวรรณกรรมเนื่องจากสามารถใช้กับค่าสมรรถภาพเชิงลบได้

การเลือกอันดับ
การเลือกอันดับยังทำงานร่วมกับค่าสมรรถภาพเชิงลบและส่วนใหญ่จะใช้เมื่อบุคคลในประชากรมีค่าสมรรถภาพใกล้เคียงมาก (โดยปกติจะเกิดขึ้นเมื่อสิ้นสุดการวิ่ง) สิ่งนี้นำไปสู่แต่ละคนที่มีส่วนแบ่งของพายเกือบเท่ากัน (เช่นในกรณีของการเลือกสัดส่วนการออกกำลังกาย) ดังที่แสดงในภาพต่อไปนี้และด้วยเหตุนี้แต่ละคนไม่ว่าจะพอดีแค่ไหนเมื่อเทียบกันก็มีความเป็นไปได้ที่จะได้รับเลือกเป็น a ผู้ปกครอง. สิ่งนี้นำไปสู่การสูญเสียความกดดันในการเลือกที่มีต่อบุคคลช่างฟิตทำให้ GA ทำการเลือกผู้ปกครองที่ไม่ดีในสถานการณ์เช่นนี้
ด้วยเหตุนี้เราจึงลบแนวคิดของค่าสมรรถภาพขณะเลือกผู้ปกครอง อย่างไรก็ตามทุกคนในประชากรจะได้รับการจัดอันดับตามความเหมาะสม การเลือกผู้ปกครองขึ้นอยู่กับอันดับของแต่ละคนไม่ใช่ความฟิต บุคคลที่ได้รับการจัดอันดับสูงกว่าเป็นที่ต้องการมากกว่าบุคคลที่มีอันดับต่ำกว่า
| โครโมโซม | ค่าฟิตเนส | อันดับ |
|---|---|---|
| ก | 8.1 | 1 |
| ข | 8.0 | 4 |
| ค | 8.05 | 2 |
| ง | 7.95 | 6 |
| จ | 8.02 | 3 |
| ฉ | 7.99 | 5 |
การเลือกแบบสุ่ม
ในกลยุทธ์นี้เราสุ่มเลือกผู้ปกครองจากประชากรที่มีอยู่ ไม่มีแรงกดดันในการคัดเลือกต่อบุคคลช่างฟิตดังนั้นจึงมักหลีกเลี่ยงกลยุทธ์นี้
ในบทนี้เราจะพูดถึงสิ่งที่ Crossover Operator พร้อมกับโมดูลอื่น ๆ การใช้งานและประโยชน์ของพวกเขา
ข้อมูลเบื้องต้นเกี่ยวกับ Crossover
ตัวดำเนินการครอสโอเวอร์นั้นคล้ายคลึงกับการสืบพันธุ์และการผสมข้ามทางชีวภาพ ในนี้มีการเลือกพ่อแม่มากกว่าหนึ่งตัวและมีการผลิตนอกสปริงอย่างน้อยหนึ่งตัวโดยใช้สารพันธุกรรมของพ่อแม่ โดยทั่วไปจะใช้การครอสโอเวอร์ใน GA ที่มีความเป็นไปได้สูง -pc .
ตัวดำเนินการครอสโอเวอร์
ในส่วนนี้เราจะพูดถึงตัวดำเนินการครอสโอเวอร์ที่นิยมใช้กันมากที่สุด เป็นที่น่าสังเกตว่าตัวดำเนินการครอสโอเวอร์เหล่านี้มีลักษณะทั่วไปมากและผู้ออกแบบ GA อาจเลือกใช้ตัวดำเนินการครอสโอเวอร์เฉพาะปัญหาเช่นกัน
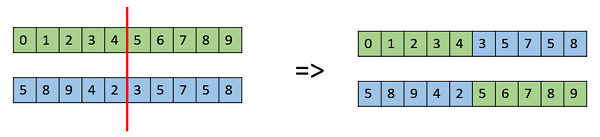
One Point Crossover
ในครอสโอเวอร์แบบจุดเดียวนี้จะมีการเลือกจุดครอสโอเวอร์แบบสุ่มและหางของพ่อแม่ทั้งสองจะถูกสลับกันเพื่อให้ได้สปริงใหม่
Multi Point Crossover
ครอสโอเวอร์แบบหลายจุดเป็นลักษณะทั่วไปของครอสโอเวอร์แบบจุดเดียวซึ่งจะมีการสลับส่วนสลับกันเพื่อให้ได้สปริงใหม่

ครอสโอเวอร์เครื่องแบบ
ในการไขว้แบบสม่ำเสมอเราจะไม่แบ่งโครโมโซมออกเป็นส่วน ๆ แต่เราปฏิบัติต่อยีนแต่ละยีนแยกกัน ในกรณีนี้เราจะพลิกเหรียญสำหรับโครโมโซมแต่ละอันเพื่อตัดสินใจว่าจะรวมอยู่ในสปริงหรือไม่ นอกจากนี้เรายังสามารถทำให้เหรียญมีอคติกับพ่อหรือแม่คนใดคนหนึ่งเพื่อให้มีสารพันธุกรรมในตัวเด็กจากพ่อแม่มากขึ้น

การรวมเลขคณิตทั้งหมด
สิ่งนี้มักใช้สำหรับการแทนค่าจำนวนเต็มและทำงานโดยการหาค่าเฉลี่ยถ่วงน้ำหนักของผู้ปกครองทั้งสองโดยใช้สูตรต่อไปนี้ -
- เด็ก 1 = α.x + (1-α) .y
- เด็ก 2 = α.x + (1-α) .y
เห็นได้ชัดว่าถ้าα = 0.5 ลูกทั้งสองจะเหมือนกันดังที่แสดงในภาพต่อไปนี้

Davis 'Order Crossover (OX1)
OX1 ใช้สำหรับการไขว้แบบเรียงสับเปลี่ยนโดยมีจุดประสงค์เพื่อส่งข้อมูลเกี่ยวกับการสั่งซื้อที่สัมพันธ์กับสปริง มันทำงานดังนี้ -
สร้างจุดครอสโอเวอร์แบบสุ่มสองจุดในพาเรนต์และคัดลอกเซ็กเมนต์ระหว่างพวกเขาจากพาเรนต์แรกไปยังออฟไลน์แรก
ตอนนี้เริ่มจากจุดครอสโอเวอร์ที่สองในพาเรนต์ที่สองคัดลอกตัวเลขที่ยังไม่ได้ใช้ที่เหลือจากพาเรนต์ที่สองไปยังลูกคนแรกโดยตัดรอบรายการ
ทำซ้ำสำหรับลูกคนที่สองโดยเปลี่ยนบทบาทของผู้ปกครอง

มีครอสโอเวอร์อื่น ๆ อีกมากมายเช่น Partially Mapped Crossover (PMX), ครอสโอเวอร์ตามลำดับ (OX2), ครอสโอเวอร์แบบสุ่ม, Ring Crossover เป็นต้น
รู้เบื้องต้นเกี่ยวกับการกลายพันธุ์
ในแง่ง่ายๆการกลายพันธุ์อาจถูกกำหนดให้เป็นการปรับแต่งแบบสุ่มเล็ก ๆ ในโครโมโซมเพื่อให้ได้โซลูชันใหม่ ใช้เพื่อรักษาและแนะนำความหลากหลายในประชากรทางพันธุกรรมและมักใช้กับความน่าจะเป็นต่ำ -pm. หากความน่าจะเป็นสูงมาก GA จะลดลงเป็นการค้นหาแบบสุ่ม
การกลายพันธุ์เป็นส่วนหนึ่งของ GA ซึ่งเกี่ยวข้องกับ "การสำรวจ" ของพื้นที่ค้นหา มีการสังเกตว่าการกลายพันธุ์มีความสำคัญต่อการบรรจบกันของ GA ในขณะที่ครอสโอเวอร์ไม่ใช่
ตัวดำเนินการกลายพันธุ์
ในส่วนนี้เราจะอธิบายตัวดำเนินการการกลายพันธุ์ที่ใช้บ่อยที่สุด เช่นเดียวกับตัวดำเนินการครอสโอเวอร์นี่ไม่ใช่รายการที่ละเอียดถี่ถ้วนและผู้ออกแบบ GA อาจพบว่าวิธีการเหล่านี้รวมกันหรือตัวดำเนินการกลายพันธุ์เฉพาะปัญหามีประโยชน์มากกว่า
การกลายพันธุ์พลิกบิต
ในการกลายพันธุ์ของการพลิกบิตนี้เราเลือกบิตแบบสุ่มอย่างน้อยหนึ่งบิตและพลิกมัน ใช้สำหรับ GAs ที่เข้ารหัสไบนารี

การรีเซ็ตแบบสุ่ม
Random Resetting เป็นส่วนขยายของการพลิกบิตสำหรับการแสดงจำนวนเต็ม ในสิ่งนี้ค่าสุ่มจากชุดค่าที่อนุญาตจะถูกกำหนดให้กับยีนที่เลือกแบบสุ่ม
สลับการกลายพันธุ์
ในการกลายพันธุ์ของสว็อปเราเลือกสองตำแหน่งบนโครโมโซมแบบสุ่มและเปลี่ยนค่า ซึ่งเป็นเรื่องปกติในการเข้ารหัสตามการเปลี่ยนแปลง

การกลายพันธุ์ของการแย่งชิง
การกลายพันธุ์ของการแย่งชิงยังเป็นที่นิยมในการแสดงการเปลี่ยนแปลง จากโครโมโซมทั้งหมดชุดย่อยของยีนจะถูกเลือกและค่าของมันจะถูกรบกวนหรือสับแบบสุ่ม

การกลายพันธุ์ผกผัน
ในการกลายพันธุ์แบบผกผันเราเลือกชุดย่อยของยีนเช่นในการกลายพันธุ์ช่วงชิง แต่แทนที่จะสับชุดย่อยเราเพียงแค่สลับสตริงทั้งหมดในชุดย่อย

นโยบายการคัดเลือกผู้รอดชีวิตกำหนดว่าบุคคลใดบ้างที่จะถูกไล่ออกและจะถูกเก็บไว้ในรุ่นต่อไป เป็นสิ่งสำคัญอย่างยิ่งที่ควรทำให้แน่ใจว่าบุคคลช่างฟิตจะไม่ถูกไล่ออกจากประชากรในขณะเดียวกันก็ควรรักษาความหลากหลายในประชากรไว้ด้วย
GAs บางคนใช้ Elitism. พูดง่ายๆก็คือสมาชิกที่เหมาะสมที่สุดในปัจจุบันจะแพร่กระจายไปยังคนรุ่นต่อไปเสมอ ดังนั้นจึงไม่สามารถแทนที่สมาชิกที่เหมาะสมที่สุดของประชากรปัจจุบันได้ไม่ว่าในกรณีใด
นโยบายที่ง่ายที่สุดคือการไล่สมาชิกแบบสุ่มออกจากประชากร แต่แนวทางดังกล่าวมักมีปัญหาการบรรจบกันดังนั้นจึงมีการใช้กลยุทธ์ต่อไปนี้อย่างกว้างขวาง
การเลือกตามอายุ
ในการเลือกตามอายุเราไม่มีความคิดเรื่องฟิตเนส ตั้งอยู่บนสมมติฐานที่ว่าบุคคลแต่ละคนได้รับอนุญาตในประชากรสำหรับรุ่นที่ จำกัด ซึ่งได้รับอนุญาตให้ทำซ้ำหลังจากนั้นจะถูกไล่ออกจากประชากรไม่ว่าจะมีสมรรถภาพดีเพียงใดก็ตาม
ตัวอย่างเช่นในตัวอย่างต่อไปนี้อายุคือจำนวนรุ่นที่บุคคลนั้นอยู่ในประชากร สมาชิกที่เก่าแก่ที่สุดของประชากร ได้แก่ P4 และ P7 ถูกไล่ออกจากประชากรและอายุของสมาชิกที่เหลือจะเพิ่มขึ้นทีละคน

การเลือกตามฟิตเนส
ในการเลือกตามการออกกำลังกายนี้เด็ก ๆ มักจะแทนที่บุคคลที่พอดีน้อยที่สุดในประชากร การเลือกบุคคลที่เหมาะสมน้อยที่สุดอาจทำได้โดยใช้รูปแบบของนโยบายการคัดเลือกใด ๆ ที่อธิบายไว้ก่อนหน้านี้เช่นการเลือกทัวร์นาเมนต์การเลือกสัดส่วนการออกกำลังกายเป็นต้น
ตัวอย่างเช่นในภาพต่อไปนี้เด็ก ๆ จะแทนที่บุคคลที่พอดีน้อยที่สุด P1 และ P10 ของประชากร เป็นที่น่าสังเกตว่าเนื่องจาก P1 และ P9 มีค่าสมรรถภาพเท่ากันการตัดสินใจที่จะลบบุคคลใดออกจากประชากรจึงเป็นไปตามอำเภอใจ

เงื่อนไขการสิ้นสุดของอัลกอริทึมทางพันธุกรรมมีความสำคัญในการพิจารณาว่าการทำงานของ GA จะสิ้นสุดเมื่อใด เป็นที่สังเกตว่าในขั้นต้น GA ดำเนินไปอย่างรวดเร็วโดยมีโซลูชันที่ดีขึ้นในทุกๆการทำซ้ำสองสามครั้ง แต่สิ่งนี้มีแนวโน้มที่จะอิ่มตัวในระยะหลังซึ่งการปรับปรุงมีน้อยมาก โดยปกติเราต้องการเงื่อนไขการยุติเพื่อให้โซลูชันของเราใกล้เคียงกับที่เหมาะสมที่สุดเมื่อสิ้นสุดการทำงาน
โดยปกติเราจะรักษาเงื่อนไขการยกเลิกข้อใดข้อหนึ่งดังต่อไปนี้ -
- เมื่อไม่มีการปรับปรุงประชากรสำหรับการทำซ้ำ X
- เมื่อเรามาถึงรุ่นที่แน่นอน
- เมื่อค่าฟังก์ชันวัตถุประสงค์ถึงค่าที่กำหนดไว้ล่วงหน้า
ตัวอย่างเช่นในอัลกอริธึมทางพันธุกรรมเรามีตัวนับซึ่งติดตามรุ่นที่ประชากรไม่มีการปรับปรุง เริ่มแรกเราตั้งค่าตัวนับนี้เป็นศูนย์ ทุกครั้งที่เราไม่สร้างสิ่งที่ดีกว่าคนในประชากรเราจะเพิ่มตัวนับ
อย่างไรก็ตามหากความฟิตของสปริงใด ๆ ดีขึ้นเราจะรีเซ็ตตัวนับเป็นศูนย์ อัลกอริทึมจะสิ้นสุดเมื่อตัวนับถึงค่าที่กำหนดไว้ล่วงหน้า
เช่นเดียวกับพารามิเตอร์อื่น ๆ ของ GA เงื่อนไขการยกเลิกยังเป็นปัญหาที่เฉพาะเจาะจงสูงและผู้ออกแบบ GA ควรลองใช้ตัวเลือกต่างๆเพื่อดูว่าอะไรเหมาะสมกับปัญหาเฉพาะของเขามากที่สุด
จนถึงตอนนี้ในบทช่วยสอนนี้สิ่งที่เราได้พูดคุยนั้นสอดคล้องกับแบบจำลองวิวัฒนาการของดาร์วิน - การคัดเลือกโดยธรรมชาติและการเปลี่ยนแปลงทางพันธุกรรมผ่านการรวมตัวกันใหม่และการกลายพันธุ์ โดยธรรมชาติแล้วเฉพาะข้อมูลที่มีอยู่ในจีโนไทป์ของแต่ละบุคคลเท่านั้นที่สามารถถ่ายทอดไปยังคนรุ่นต่อไปได้ นี่คือแนวทางที่เราได้ติดตามในบทช่วยสอนจนถึงตอนนี้
อย่างไรก็ตามรุ่นอื่น ๆ ของการปรับอายุการใช้งาน - Lamarckian Model และ Baldwinian Modelยังมีอยู่ เป็นที่น่าสังเกตว่าแบบจำลองใดดีที่สุดเปิดให้มีการอภิปรายและผลที่ได้รับจากนักวิจัยแสดงให้เห็นว่าทางเลือกของการปรับตัวตลอดชีวิตเป็นปัญหาที่เฉพาะเจาะจง
บ่อยครั้งที่เราผสม GA กับการค้นหาในพื้นที่เช่นเดียวกับใน Memetic Algorithms ในกรณีเช่นนี้เราอาจเลือกใช้ Lamarckian หรือ Baldwinian Model เพื่อตัดสินใจว่าจะทำอย่างไรกับบุคคลที่สร้างขึ้นหลังจากการค้นหาในท้องถิ่น
Lamarckian รุ่น
โดยพื้นฐานแล้วแบบจำลอง Lamarckian กล่าวว่าคุณลักษณะที่บุคคลได้รับในช่วงชีวิตของเขา / เธอสามารถส่งต่อไปยังลูกหลานได้ ได้รับการตั้งชื่อตาม Jean-Baptiste Lamarck นักชีววิทยาชาวฝรั่งเศส
แม้ว่าชีววิทยาตามธรรมชาติจะไม่สนใจ Lamarckism อย่างสิ้นเชิงเนื่องจากเราทุกคนรู้ว่ามีเพียงข้อมูลในจีโนไทป์เท่านั้นที่สามารถถ่ายทอดได้ อย่างไรก็ตามจากมุมมองของการคำนวณแสดงให้เห็นว่าการใช้โมเดล Lamarckian ให้ผลลัพธ์ที่ดีสำหรับปัญหาบางอย่าง
ในแบบจำลอง Lamarckian ตัวดำเนินการค้นหาในพื้นที่จะตรวจสอบพื้นที่ใกล้เคียง (การได้รับลักษณะใหม่) และหากพบโครโมโซมที่ดีกว่าก็จะกลายเป็นลูกหลาน
Baldwinian Model
แบบจำลอง Baldwinian เป็นแนวคิดระดับกลางที่ตั้งชื่อตาม James Mark Baldwin (1896) ในแบบจำลองบอลด์วินโครโมโซมสามารถเข้ารหัสแนวโน้มของการเรียนรู้พฤติกรรมที่เป็นประโยชน์ ซึ่งหมายความว่าแตกต่างจากแบบจำลอง Lamarckian เราจะไม่ถ่ายทอดลักษณะที่ได้รับไปยังรุ่นต่อไปและเราก็ไม่ได้เพิกเฉยต่อลักษณะที่ได้มาอย่างสิ้นเชิงเช่นในแบบจำลองดาร์วิน
Baldwin Model อยู่ตรงกลางของสองขั้วนี้ซึ่งแนวโน้มของบุคคลที่จะได้รับลักษณะบางอย่างจะถูกเข้ารหัสมากกว่าลักษณะที่เป็นตัวของตัวเอง
ใน Baldwinian Model นี้ผู้ดำเนินการค้นหาในพื้นที่จะตรวจสอบพื้นที่ใกล้เคียง (การได้รับลักษณะใหม่ ๆ ) และหากพบโครโมโซมที่ดีขึ้นก็จะกำหนดเฉพาะโครโมโซมที่ดีขึ้นและไม่ได้ปรับเปลี่ยนโครโมโซมเอง การเปลี่ยนแปลงในความแข็งแรงแสดงให้เห็นถึงความสามารถของโครโมโซมในการ "ได้รับลักษณะ" แม้ว่าจะไม่ได้ส่งต่อไปยังคนรุ่นต่อไปโดยตรง
GAs มีลักษณะทั่วไปมากและเพียงแค่นำไปใช้กับปัญหาการเพิ่มประสิทธิภาพใด ๆ ก็ไม่ได้ให้ผลลัพธ์ที่ดี ในส่วนนี้เราจะอธิบายประเด็นบางประการที่จะช่วยและช่วยเหลือนักออกแบบ GA หรือผู้ติดตั้ง GA ในการทำงานของพวกเขา
แนะนำความรู้เกี่ยวกับโดเมนเฉพาะปัญหา
เป็นที่สังเกตว่าความรู้เกี่ยวกับโดเมนเฉพาะปัญหามากขึ้นที่เรารวมไว้ใน GA; ค่าวัตถุประสงค์ที่ดีกว่าที่เราได้รับ การเพิ่มข้อมูลเฉพาะของปัญหาสามารถทำได้โดยใช้ตัวดำเนินการครอสโอเวอร์เฉพาะปัญหาหรือตัวดำเนินการการกลายพันธุ์การแทนค่าแบบกำหนดเอง ฯลฯ
ภาพต่อไปนี้แสดงมุมมองของ Michalewicz (1990) เกี่ยวกับ EA -

ลดความแออัด
ความแออัดเกิดขึ้นเมื่อโครโมโซมที่มีความพอดีสูงได้รับการสืบพันธุ์เป็นจำนวนมากและในอีกไม่กี่ชั่วอายุคนประชากรทั้งหมดจะเต็มไปด้วยโซลูชันที่คล้ายคลึงกันซึ่งมีความเหมาะสมเหมือนกัน ซึ่งจะช่วยลดความหลากหลายซึ่งเป็นองค์ประกอบที่สำคัญมากในการรับรองความสำเร็จของ GA มีหลายวิธีในการ จำกัด ฝูงชน บางคนเป็น -
Mutation เพื่อแนะนำความหลากหลาย
กำลังเปลี่ยนไปใช้ rank selection และ tournament selection ซึ่งมีความกดดันในการเลือกมากกว่าการเลือกตามสัดส่วนการออกกำลังกายสำหรับบุคคลที่มีสมรรถภาพใกล้เคียงกัน
Fitness Sharing - ในเรื่องนี้ความฟิตของแต่ละบุคคลจะลดลงหากประชากรมีบุคคลที่คล้ายคลึงกันอยู่แล้ว
การสุ่มช่วย!
มีการทดลองพบว่าวิธีแก้ปัญหาที่ดีที่สุดนั้นขับเคลื่อนด้วยโครโมโซมแบบสุ่มเนื่องจากให้ความหลากหลายแก่ประชากร ผู้ติดตั้ง GA ควรระมัดระวังเพื่อให้มีการสุ่มตัวอย่างและความหลากหลายในจำนวนที่เพียงพอเพื่อให้ได้ผลลัพธ์ที่ดีที่สุด
ผสม GA กับการค้นหาในท้องถิ่น
การค้นหาในพื้นที่หมายถึงการตรวจสอบโซลูชันในพื้นที่ใกล้เคียงของโซลูชันที่กำหนดเพื่อค้นหาค่าวัตถุประสงค์ที่ดีขึ้น
บางครั้งอาจเป็นประโยชน์ในการผสม GA กับการค้นหาในท้องถิ่น ภาพต่อไปนี้แสดงสถานที่ต่างๆที่สามารถนำการค้นหาในท้องถิ่นมาใช้ใน GA

การเปลี่ยนแปลงของพารามิเตอร์และเทคนิค
ในอัลกอริทึมทางพันธุกรรมไม่มี“ ขนาดเดียวที่เหมาะกับทุกคน” หรือสูตรมหัศจรรย์ที่ใช้ได้กับทุกปัญหา แม้ว่า GA เริ่มต้นจะพร้อมแล้ว แต่ก็ยังต้องใช้เวลาและความพยายามอย่างมากในการเล่นกับพารามิเตอร์ต่างๆเช่นขนาดของประชากรการกลายพันธุ์และความน่าจะเป็นแบบครอสโอเวอร์เป็นต้นเพื่อค้นหาค่าที่เหมาะสมกับปัญหานั้น ๆ
ในส่วนนี้เราจะแนะนำหัวข้อขั้นสูงใน Genetic Algorithms ผู้อ่านที่ต้องการข้อมูลเบื้องต้นเกี่ยวกับ GAs อาจเลือกที่จะข้ามส่วนนี้ไป
ปัญหาการเพิ่มประสิทธิภาพที่ จำกัด
ปัญหาการเพิ่มประสิทธิภาพที่มีข้อ จำกัด คือปัญหาในการเพิ่มประสิทธิภาพที่เราต้องเพิ่มหรือลดค่าฟังก์ชันวัตถุประสงค์ที่กำหนดซึ่งอยู่ภายใต้ข้อ จำกัด บางประการ ดังนั้นผลลัพธ์ทั้งหมดในพื้นที่โซลูชันจะไม่เป็นไปได้และพื้นที่โซลูชันมีขอบเขตที่เป็นไปได้ดังที่แสดงในภาพต่อไปนี้

ในสถานการณ์เช่นนี้ตัวดำเนินการครอสโอเวอร์และการกลายพันธุ์อาจให้วิธีแก้ปัญหาแก่เราซึ่งเป็นไปไม่ได้ ดังนั้นจึงต้องใช้กลไกเพิ่มเติมใน GA เมื่อจัดการกับปัญหาการเพิ่มประสิทธิภาพที่มีข้อ จำกัด
วิธีที่ใช้บ่อยที่สุดคือ -
การใช้ penalty functions ซึ่งช่วยลดความเหมาะสมของโซลูชันที่ไม่สามารถทำได้โดยเฉพาะอย่างยิ่งเพื่อให้ความฟิตลดลงตามสัดส่วนด้วยจำนวนข้อ จำกัด ที่ละเมิดหรือระยะห่างจากพื้นที่ที่เป็นไปได้
การใช้ repair functions ซึ่งใช้วิธีแก้ปัญหาที่ไม่สามารถทำได้และแก้ไขเพื่อให้ข้อ จำกัด ที่ละเมิดได้รับความพึงพอใจ
Not allowing infeasible solutions เพื่อเข้าสู่ประชากรเลย
ใช้ special representation or decoder functions ที่รับรองความเป็นไปได้ของโซลูชัน
ความเป็นมาทางทฤษฎีพื้นฐาน
ในส่วนนี้เราจะพูดถึงทฤษฎีบทสคีมาและเอ็นเอฟแอลพร้อมกับสมมติฐานการสร้างบล็อค
Schema Theorem
นักวิจัยพยายามค้นหาคณิตศาสตร์ที่อยู่เบื้องหลังการทำงานของอัลกอริธึมทางพันธุกรรมและ Schema Theorem ของฮอลแลนด์เป็นขั้นตอนในทิศทางนั้น ในช่วงหลายปีที่ผ่านมาได้มีการปรับปรุงและข้อเสนอแนะต่างๆของ Schema Theorem เพื่อให้ครอบคลุมมากขึ้น
ในส่วนนี้เราไม่ได้เจาะลึกเกี่ยวกับคณิตศาสตร์ของ Schema Theorem แต่เราพยายามที่จะพัฒนาความเข้าใจพื้นฐานเกี่ยวกับสิ่งที่ Schema Theorem คือ คำศัพท์พื้นฐานที่ควรทราบมีดังนี้ -
ก Schemaคือ "แม่แบบ" ตามปกติจะเป็นสตริงที่ทับตัวอักษร = {0,1, *},
โดยที่ * ไม่สนใจและสามารถใช้ค่าใดก็ได้
ดังนั้น * 10 * 1 อาจหมายถึง 01001, 01011, 11001 หรือ 11011
ในทางเรขาคณิตสคีมาคือไฮเปอร์ระนาบในพื้นที่ค้นหาโซลูชัน
Order สคีมาคือจำนวนตำแหน่งคงที่ที่ระบุในยีน

Defining length คือระยะห่างระหว่างสัญลักษณ์คงที่ที่ไกลที่สุดสองตัวในยีน

ทฤษฎีบทสคีมาระบุว่าสคีมานี้ที่มีสมรรถภาพสูงกว่าค่าเฉลี่ยความยาวที่กำหนดสั้นและลำดับที่ต่ำกว่ามีแนวโน้มที่จะอยู่รอดแบบครอสโอเวอร์และการกลายพันธุ์
สมมติฐานการสร้างบล็อค
Building Blocks เป็นสคีมาตาที่มีความยาวต่ำและมีความยาวต่ำโดยมีค่าความเหมาะสมเฉลี่ยข้างต้น สมมติฐานสำเร็จรูปกล่าวว่าหน่วยการสร้างดังกล่าวทำหน้าที่เป็นรากฐานสำหรับความสำเร็จของ GAs และการปรับตัวใน GAs เมื่อดำเนินไปโดยการระบุและรวม "แบบสำเร็จรูป" ดังกล่าวอย่างต่อเนื่อง
ทฤษฎีบทไม่มีอาหารกลางวันฟรี (NFL)
Wolpert และ Macready ในปี 1997 ตีพิมพ์บทความเรื่อง No Free Lunch Theorems for Optimization โดยพื้นฐานแล้วระบุว่าถ้าเราเฉลี่ยในพื้นที่ของปัญหาที่เป็นไปได้ทั้งหมดอัลกอริทึมกล่องดำที่ไม่ได้ตรวจสอบซ้ำทั้งหมดจะแสดงประสิทธิภาพเดียวกัน
หมายความว่ายิ่งเราเข้าใจปัญหามากขึ้น GA ของเราก็ยิ่งมีปัญหาเฉพาะเจาะจงมากขึ้นและให้ประสิทธิภาพที่ดีขึ้น แต่ก็ชดเชยได้ด้วยการดำเนินการไม่ดีสำหรับปัญหาอื่น ๆ
การเรียนรู้ของเครื่องตาม GA
Genetic Algorithms ยังพบแอปพลิเคชันใน Machine Learning Classifier systems เป็นรูปแบบของ genetics-based machine learning(GBML) ระบบที่ใช้บ่อยในด้านการเรียนรู้ของเครื่อง วิธี GBML เป็นแนวทางเฉพาะสำหรับการเรียนรู้ของเครื่อง
ระบบ GBML มีสองประเภท -
The Pittsburg Approach - ในแนวทางนี้โครโมโซมหนึ่งชุดได้เข้ารหัสหนึ่งโซลูชันดังนั้นความเหมาะสมจึงถูกกำหนดให้กับโซลูชัน
The Michigan Approach - โดยทั่วไปแล้วโซลูชันหนึ่งจะแสดงด้วยโครโมโซมจำนวนมากดังนั้นความเหมาะสมจึงถูกกำหนดให้กับโซลูชันบางส่วน
ควรจำไว้ว่าปัญหามาตรฐานเช่นครอสโอเวอร์การกลายพันธุ์ Lamarckian หรือ Darwinian เป็นต้นก็มีอยู่ในระบบ GBML เช่นกัน
Genetic Algorithms ส่วนใหญ่จะใช้ในปัญหาการเพิ่มประสิทธิภาพประเภทต่าง ๆ แต่มักใช้ในแอปพลิเคชันอื่น ๆ เช่นกัน
ในส่วนนี้เราจะแสดงรายการบางส่วนที่มักใช้ Genetic Algorithms เหล่านี้คือ -
Optimization- Genetic Algorithms มักใช้ในปัญหาการเพิ่มประสิทธิภาพซึ่งเราต้องเพิ่มหรือลดค่าฟังก์ชันวัตถุประสงค์ที่กำหนดให้มากที่สุดภายใต้ชุดข้อ จำกัด ที่กำหนด แนวทางในการแก้ปัญหาการเพิ่มประสิทธิภาพได้รับการเน้นตลอดบทช่วยสอน
Economics - GAs ยังใช้เพื่อกำหนดลักษณะของโมเดลทางเศรษฐกิจต่างๆเช่นแบบจำลองใยแมงมุมการแก้ปัญหาดุลยภาพของทฤษฎีเกมการกำหนดราคาสินทรัพย์เป็นต้น
Neural Networks - GAs ยังใช้ในการฝึกเครือข่ายประสาทโดยเฉพาะอย่างยิ่งเครือข่ายประสาทที่เกิดซ้ำ
Parallelization - GAs ยังมีความสามารถแบบคู่ขนานที่ดีมากและพิสูจน์แล้วว่ามีประสิทธิภาพมากในการแก้ปัญหาบางอย่างและยังเป็นพื้นที่ที่ดีสำหรับการวิจัย
Image Processing - GAs ใช้สำหรับงานการประมวลผลภาพดิจิทัล (DIP) ต่างๆเช่นเดียวกับการจับคู่พิกเซลที่หนาแน่น
Vehicle routing problems - ด้วยหน้าต่าง soft time หลาย ๆ คลังหลายคลังและกองเรือที่แตกต่างกัน
Scheduling applications - GAs ใช้ในการแก้ปัญหาการตั้งเวลาต่างๆเช่นกันโดยเฉพาะปัญหาการจัดตารางเวลา
Machine Learning - ตามที่ได้กล่าวไปแล้วการเรียนรู้ของเครื่องตามพันธุศาสตร์ (GBML) เป็นพื้นที่เฉพาะในการเรียนรู้ของเครื่อง
Robot Trajectory Generation - GAs ถูกนำมาใช้เพื่อวางแผนเส้นทางที่แขนหุ่นยนต์ใช้โดยการเคลื่อนที่จากจุดหนึ่งไปยังอีกจุดหนึ่ง
Parametric Design of Aircraft - GAs ถูกนำมาใช้เพื่อออกแบบเครื่องบินโดยเปลี่ยนพารามิเตอร์และพัฒนาโซลูชันที่ดีขึ้น
DNA Analysis - มีการใช้ GAs เพื่อกำหนดโครงสร้างของ DNA โดยใช้ข้อมูลสเปกโตรเมตริกเกี่ยวกับตัวอย่าง
Multimodal Optimization - เห็นได้ชัดว่า GAs เป็นแนวทางที่ดีมากสำหรับการเพิ่มประสิทธิภาพแบบหลายรูปแบบซึ่งเราต้องหาโซลูชันที่เหมาะสมหลายอย่าง
Traveling salesman problem and its applications - GAs ถูกนำมาใช้เพื่อแก้ปัญหา TSP ซึ่งเป็นปัญหาที่รู้จักกันดีโดยใช้กลยุทธ์การไขว้และการบรรจุแบบใหม่
หนังสือต่อไปนี้สามารถอ้างอิงได้เพื่อเพิ่มพูนความรู้ของผู้อ่านเกี่ยวกับอัลกอริทึมทางพันธุกรรมและการคำนวณเชิงวิวัฒนาการโดยทั่วไป -
อัลกอริทึมทางพันธุกรรมในการค้นหาการเพิ่มประสิทธิภาพและการเรียนรู้ของเครื่องโดย David E. Goldberg.
อัลกอริทึมทางพันธุกรรม + โครงสร้างข้อมูล = โปรแกรมวิวัฒนาการโดย Zbigniew Michalewicz.
อัลกอริธึมทางพันธุกรรมในทางปฏิบัติโดย Randy L. Haupt และ Sue Ellen Haupt.
Multi Objective Optimization โดยใช้ Evolutionary Algorithms โดย Kalyanmoy Deb.