Hive - บทนำ
คำว่า 'ข้อมูลขนาดใหญ่' ใช้สำหรับการรวบรวมชุดข้อมูลขนาดใหญ่ที่มีปริมาณมากความเร็วสูงและข้อมูลหลากหลายที่เพิ่มขึ้นในแต่ละวัน การใช้ระบบจัดการข้อมูลแบบดั้งเดิมทำให้การประมวลผลข้อมูลขนาดใหญ่ทำได้ยาก ดังนั้น Apache Software Foundation จึงนำเสนอกรอบงานที่เรียกว่า Hadoop เพื่อแก้ปัญหาการจัดการข้อมูลขนาดใหญ่และความท้าทายในการประมวลผล
Hadoop
Hadoop เป็นเฟรมเวิร์กโอเพนซอร์สเพื่อจัดเก็บและประมวลผลข้อมูลขนาดใหญ่ในสภาพแวดล้อมแบบกระจาย ประกอบด้วยโมดูลสองโมดูลหนึ่งคือ MapReduce และอีกโมดูลคือ Hadoop Distributed File System (HDFS)
MapReduce: เป็นรูปแบบการเขียนโปรแกรมแบบขนานสำหรับการประมวลผลข้อมูลที่มีโครงสร้างกึ่งโครงสร้างและไม่มีโครงสร้างจำนวนมากบนกลุ่มสินค้าฮาร์ดแวร์ขนาดใหญ่
HDFS:Hadoop Distributed File System เป็นส่วนหนึ่งของ Hadoop framework ที่ใช้ในการจัดเก็บและประมวลผลชุดข้อมูล จัดเตรียมระบบไฟล์ที่ทนต่อความผิดพลาดเพื่อรันบนฮาร์ดแวร์สินค้าโภคภัณฑ์
ระบบนิเวศ Hadoop ประกอบด้วยโปรเจ็กต์ย่อยต่างๆ (เครื่องมือ) เช่น Sqoop, Pig และ Hive ที่ใช้เพื่อช่วยโมดูล Hadoop
Sqoop: ใช้เพื่อนำเข้าและส่งออกข้อมูลระหว่าง HDFS และ RDBMS
Pig: เป็นแพลตฟอร์มภาษาขั้นตอนที่ใช้ในการพัฒนาสคริปต์สำหรับการดำเนินการ MapReduce
Hive: เป็นแพลตฟอร์มที่ใช้ในการพัฒนาสคริปต์ประเภท SQL เพื่อดำเนินการ MapReduce
Note: มีหลายวิธีในการดำเนินการ MapReduce:
- แนวทางดั้งเดิมโดยใช้โปรแกรม Java MapReduce สำหรับข้อมูลที่มีโครงสร้างกึ่งโครงสร้างและไม่มีโครงสร้าง
- แนวทางการเขียนสคริปต์สำหรับ MapReduce เพื่อประมวลผลข้อมูลที่มีโครงสร้างและกึ่งโครงสร้างโดยใช้ Pig
- Hive Query Language (HiveQL หรือ HQL) สำหรับ MapReduce เพื่อประมวลผลข้อมูลที่มีโครงสร้างโดยใช้ Hive
Hive คืออะไร
Hive เป็นเครื่องมือโครงสร้างพื้นฐานคลังข้อมูลสำหรับประมวลผลข้อมูลที่มีโครงสร้างใน Hadoop มันอยู่ด้านบนของ Hadoop เพื่อสรุปข้อมูลขนาดใหญ่และทำให้การสืบค้นและวิเคราะห์เป็นเรื่องง่าย
เริ่มแรก Hive ได้รับการพัฒนาโดย Facebook ต่อมา Apache Software Foundation ได้นำมันขึ้นมาและพัฒนาต่อไปในฐานะโอเพ่นซอร์สภายใต้ชื่อ Apache Hive ใช้โดย บริษัท ต่างๆ ตัวอย่างเช่น Amazon ใช้ใน Amazon Elastic MapReduce
ไฮฟ์ไม่ได้
- ฐานข้อมูลเชิงสัมพันธ์
- การออกแบบสำหรับการประมวลผลธุรกรรมออนไลน์ (OLTP)
- ภาษาสำหรับการสืบค้นแบบเรียลไทม์และการอัปเดตระดับแถว
คุณสมบัติของ Hive
- เก็บสคีมาในฐานข้อมูลและประมวลผลข้อมูลเป็น HDFS
- ออกแบบมาสำหรับ OLAP
- มีภาษาประเภท SQL สำหรับการสืบค้นที่เรียกว่า HiveQL หรือ HQL
- เป็นที่คุ้นเคยรวดเร็วปรับขนาดได้และขยายได้
สถาปัตยกรรมของ Hive
แผนภาพส่วนประกอบต่อไปนี้แสดงให้เห็นถึงสถาปัตยกรรมของ Hive:

แผนภาพส่วนประกอบนี้ประกอบด้วยหน่วยต่างๆ ตารางต่อไปนี้อธิบายแต่ละหน่วย:
| ชื่อหน่วย | การดำเนินการ |
|---|---|
| หน้าจอผู้ใช้ | Hive เป็นซอฟต์แวร์โครงสร้างพื้นฐานคลังข้อมูลที่สามารถสร้างปฏิสัมพันธ์ระหว่างผู้ใช้และ HDFS อินเทอร์เฟซผู้ใช้ที่ Hive รองรับ ได้แก่ Hive Web UI, Hive command line และ Hive HD Insight (ในเซิร์ฟเวอร์ Windows) |
| Meta Store | Hive เลือกเซิร์ฟเวอร์ฐานข้อมูลตามลำดับเพื่อจัดเก็บสคีมาหรือข้อมูลเมตาของตารางฐานข้อมูลคอลัมน์ในตารางชนิดข้อมูลและการแมป HDFS |
| HiveQL Process Engine | HiveQL คล้ายกับ SQL สำหรับการค้นหาข้อมูลสคีมาบน Metastore เป็นหนึ่งในการแทนที่แนวทางดั้งเดิมสำหรับโปรแกรม MapReduce แทนที่จะเขียนโปรแกรม MapReduce ใน Java เราสามารถเขียนแบบสอบถามสำหรับงาน MapReduce และดำเนินการได้ |
| Execution Engine | การทำงานร่วมกันของ HiveQL process Engine และ MapReduce คือ Hive Execution Engine กลไกการดำเนินการประมวลผลแบบสอบถามและสร้างผลลัพธ์เช่นเดียวกับผลลัพธ์ MapReduce ใช้รสชาติของ MapReduce |
| HDFS หรือ HBASE | Hadoop ระบบไฟล์แบบกระจายหรือ HBASE เป็นเทคนิคการจัดเก็บข้อมูลเพื่อจัดเก็บข้อมูลลงในระบบไฟล์ |
การทำงานของ Hive
แผนภาพต่อไปนี้แสดงให้เห็นถึงขั้นตอนการทำงานระหว่าง Hive และ Hadoop
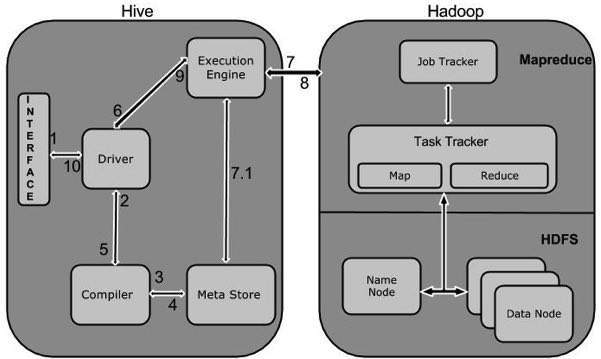
ตารางต่อไปนี้กำหนดวิธีที่ Hive โต้ตอบกับ Hadoop framework:
| ขั้นตอนที่ | การดำเนินการ |
|---|---|
| 1 | Execute Query อินเทอร์เฟซ Hive เช่น Command Line หรือ Web UI จะส่งแบบสอบถามไปยัง Driver (ไดรเวอร์ฐานข้อมูลใด ๆ เช่น JDBC, ODBC เป็นต้น) เพื่อดำเนินการ |
| 2 | Get Plan โปรแกรมควบคุมใช้ความช่วยเหลือของคอมไพเลอร์แบบสอบถามที่แยกวิเคราะห์แบบสอบถามเพื่อตรวจสอบไวยากรณ์และแผนการสืบค้นหรือความต้องการของแบบสอบถาม |
| 3 | Get Metadata คอมไพเลอร์ส่งคำขอข้อมูลเมตาไปยัง Metastore (ฐานข้อมูลใด ๆ ) |
| 4 | Send Metadata Metastore ส่งข้อมูลเมตาเป็นการตอบสนองไปยังคอมไพเลอร์ |
| 5 | Send Plan คอมไพลเลอร์จะตรวจสอบข้อกำหนดและส่งแผนไปยังไดรเวอร์อีกครั้ง ที่นี่การแยกวิเคราะห์และการรวบรวมแบบสอบถามเสร็จสมบูรณ์ |
| 6 | Execute Plan โปรแกรมควบคุมจะส่งแผนการดำเนินการไปยังเครื่องมือดำเนินการ |
| 7 | Execute Job ภายในกระบวนการดำเนินงานคืองาน MapReduce เอ็นจิ้นการดำเนินการส่งงานไปยัง JobTracker ซึ่งอยู่ใน Name node และจะกำหนดงานนี้ให้กับ TaskTracker ซึ่งอยู่ใน Data node ที่นี่แบบสอบถามเรียกใช้งาน MapReduce |
| 7.1 | Metadata Ops ในระหว่างการดำเนินการโปรแกรมการดำเนินการสามารถเรียกใช้การดำเนินการเมทาดาทาด้วย Metastore |
| 8 | Fetch Result เอ็นจินการดำเนินการรับผลลัพธ์จากโหนดข้อมูล |
| 9 | Send Results โปรแกรมเรียกใช้งานจะส่งค่าผลลัพธ์เหล่านั้นไปยังไดรเวอร์ |
| 10 | Send Results โปรแกรมควบคุมจะส่งผลลัพธ์ไปยัง Hive Interfaces |