KNIME - คู่มือฉบับย่อ
การพัฒนาโมเดลแมชชีนเลิร์นนิงถือเป็นเรื่องที่ท้าทายมากเนื่องจากมีลักษณะที่คลุมเครือ โดยทั่วไปในการพัฒนาแอปพลิเคชันการเรียนรู้ของเครื่องคุณต้องเป็นนักพัฒนาที่ดีและมีความเชี่ยวชาญในการพัฒนาที่ขับเคลื่อนด้วยคำสั่ง การเปิดตัว KNIME ได้นำมาซึ่งการพัฒนาโมเดล Machine Learning ในมุมมองของคนทั่วไป
KNIME มีอินเทอร์เฟซแบบกราฟิก (GUI ที่ใช้งานง่าย) สำหรับการพัฒนาทั้งหมด ใน KNIME คุณต้องกำหนดเวิร์กโฟลว์ระหว่างโหนดที่กำหนดไว้ล่วงหน้าต่างๆที่มีให้ในที่เก็บ KNIME มีส่วนประกอบที่กำหนดไว้ล่วงหน้าหลายรายการที่เรียกว่าโหนดสำหรับงานต่างๆเช่นการอ่านข้อมูลการใช้อัลกอริทึม ML ต่างๆและการแสดงข้อมูลในรูปแบบต่างๆ ดังนั้นสำหรับการทำงานกับ KNIME จึงไม่จำเป็นต้องมีความรู้ด้านการเขียนโปรแกรม นี่ไม่น่าตื่นเต้นเหรอ?
บทที่จะมาถึงของบทช่วยสอนนี้จะสอนวิธีการวิเคราะห์ข้อมูลโดยใช้อัลกอริทึม ML ที่ผ่านการทดสอบมาเป็นอย่างดี
KNIME Analytics Platform พร้อมใช้งานสำหรับ Windows, Linux และ MacOS ในบทนี้ให้เราดูขั้นตอนในการติดตั้งแพลตฟอร์มบนเครื่อง Mac หากคุณใช้ Windows หรือ Linux เพียงทำตามคำแนะนำในการติดตั้งที่ให้ไว้ในหน้าดาวน์โหลด KNIME การติดตั้งไบนารีสำหรับทั้งสามแพลตฟอร์มที่มีอยู่ในหน้าของ KNIME
การติดตั้ง Mac
ดาวน์โหลดการติดตั้งไบนารีจากเว็บไซต์ทางการของ KNIME ดับเบิลคลิกที่ไฟล์dmgเพื่อเริ่มการติดตั้ง เมื่อการติดตั้งเสร็จสิ้นให้ลากไอคอน KNIME ไปที่โฟลเดอร์ Applications ตามที่เห็นที่นี่ -


ดับเบิลคลิกที่ไอคอน KNIME เพื่อเริ่ม KNIME Analytics Platform ในขั้นต้นระบบจะขอให้คุณตั้งค่าโฟลเดอร์พื้นที่ทำงานเพื่อบันทึกงานของคุณ หน้าจอของคุณจะมีลักษณะดังต่อไปนี้ -
คุณสามารถตั้งค่าโฟลเดอร์ที่เลือกเป็นค่าเริ่มต้นและในครั้งต่อไปที่คุณเปิด KNIME โฟลเดอร์นั้นจะไม่ทำงาน

แสดงกล่องโต้ตอบนี้อีกครั้ง
หลังจากนั้นสักครู่แพลตฟอร์ม KNIME จะเริ่มต้นบนเดสก์ท็อปของคุณ นี่คือโต๊ะทำงานที่คุณจะดำเนินการวิเคราะห์ของคุณ ตอนนี้ให้เราดูส่วนต่างๆของโต๊ะทำงาน
เมื่อ KNIME เริ่มขึ้นคุณจะเห็นหน้าจอต่อไปนี้ -

ตามที่ได้ทำเครื่องหมายไว้ในภาพหน้าจอโต๊ะทำงานประกอบด้วยหลายมุมมอง มุมมองที่ใช้งานได้ทันทีสำหรับเรามีการทำเครื่องหมายไว้ในภาพหน้าจอและแสดงรายการด้านล่าง -
Workspace
Outline
ที่เก็บโหนด
KNIME Explorer
Console
Description
เมื่อเราก้าวไปข้างหน้าในบทนี้ขอให้เราเรียนรู้มุมมองเหล่านี้โดยละเอียด
มุมมองพื้นที่ทำงาน
มุมมองที่สำคัญที่สุดสำหรับเราคือ Workspaceดู. นี่คือที่ที่คุณจะสร้างโมเดลการเรียนรู้ของเครื่อง มุมมองพื้นที่ทำงานถูกเน้นในภาพหน้าจอด้านล่าง -

ภาพหน้าจอแสดงพื้นที่ทำงานที่เปิดอยู่ คุณจะได้เรียนรู้วิธีเปิดพื้นที่ทำงานที่มีอยู่ในไม่ช้า
แต่ละพื้นที่ทำงานมีโหนดอย่างน้อยหนึ่งโหนด คุณจะได้เรียนรู้ความสำคัญของโหนดเหล่านี้ในบทช่วยสอน โหนดเชื่อมต่อกันโดยใช้ลูกศร โดยทั่วไปโฟลว์ของโปรแกรมจะถูกกำหนดจากซ้ายไปขวาแม้ว่าจะไม่จำเป็นก็ตาม คุณสามารถย้ายแต่ละโหนดไปที่ใดก็ได้ในพื้นที่ทำงานได้อย่างอิสระ เส้นเชื่อมระหว่างทั้งสองจะเคลื่อนที่อย่างเหมาะสมเพื่อรักษาการเชื่อมต่อระหว่างโหนด คุณสามารถเพิ่ม / ลบการเชื่อมต่อระหว่างโหนดได้ตลอดเวลา สำหรับแต่ละโหนดอาจมีการเพิ่มคำอธิบายขนาดเล็กสำหรับแต่ละโหนด
มุมมองเค้าร่าง
มุมมองพื้นที่ทำงานอาจไม่สามารถแสดงเวิร์กโฟลว์ทั้งหมดให้คุณทราบได้ในแต่ละครั้ง นั่นคือเหตุผลที่มีให้มุมมองเค้าร่าง

มุมมองเค้าร่างแสดงมุมมองขนาดเล็กของพื้นที่ทำงานทั้งหมด มีหน้าต่างซูมภายในมุมมองนี้ที่คุณสามารถเลื่อนเพื่อดูส่วนต่างๆของเวิร์กโฟลว์ในไฟล์Workspace ดู.
ที่เก็บโหนด
นี่คือมุมมองที่สำคัญถัดไปในโต๊ะทำงาน ที่เก็บโหนดจะแสดงรายการโหนดต่างๆที่พร้อมใช้งานสำหรับการวิเคราะห์ของคุณ ที่เก็บทั้งหมดได้รับการจัดหมวดหมู่อย่างสวยงามตามฟังก์ชันของโหนด คุณจะพบหมวดหมู่เช่น -
IO
Views
Analytics

ในแต่ละหมวดหมู่คุณจะพบตัวเลือกมากมาย เพียงขยายมุมมองแต่ละหมวดหมู่เพื่อดูสิ่งที่คุณมี ภายใต้IO คุณจะพบโหนดเพื่ออ่านข้อมูลของคุณในรูปแบบไฟล์ต่างๆเช่น ARFF, CSV, PMML, XLS เป็นต้น

ขึ้นอยู่กับรูปแบบข้อมูลแหล่งข้อมูลเข้าของคุณคุณจะเลือกโหนดที่เหมาะสมสำหรับการอ่านชุดข้อมูลของคุณ
ในตอนนี้คุณอาจเข้าใจจุดประสงค์ของโหนดแล้ว โหนดกำหนดฟังก์ชันบางประเภทที่คุณสามารถรวมไว้ในเวิร์กโฟลว์ของคุณได้
โหนด Analytics กำหนดอัลกอริทึมการเรียนรู้ของเครื่องต่างๆเช่น Bayes, Clustering, Decision Tree, Ensemble Learning และอื่น ๆ

การใช้อัลกอริทึม ML ต่างๆเหล่านี้มีให้ในโหนดเหล่านี้ หากต้องการใช้อัลกอริทึมใด ๆ ในการวิเคราะห์ของคุณเพียงแค่เลือกโหนดที่ต้องการจากที่เก็บและเพิ่มลงในพื้นที่ทำงานของคุณ เชื่อมต่อเอาต์พุตของโหนดตัวอ่านข้อมูลกับอินพุตของโหนด ML นี้และเวิร์กโฟลว์ของคุณจะถูกสร้างขึ้น
เราขอแนะนำให้คุณสำรวจโหนดต่างๆที่มีอยู่ในที่เก็บ
KNIME Explorer
มุมมองที่สำคัญถัดไปในโต๊ะทำงานคือไฟล์ Explorer ดูตามที่แสดงในภาพหน้าจอด้านล่าง -

สองประเภทแรกแสดงพื้นที่ทำงานที่กำหนดไว้บนเซิร์ฟเวอร์ KNIME ตัวเลือกที่สาม LOCAL ใช้สำหรับจัดเก็บพื้นที่ทำงานทั้งหมดที่คุณสร้างบนเครื่องของคุณ ลองขยายแท็บเหล่านี้เพื่อดูพื้นที่ทำงานที่กำหนดไว้ล่วงหน้าต่างๆ โดยเฉพาะอย่างยิ่งขยายแท็บ EXAMPLES
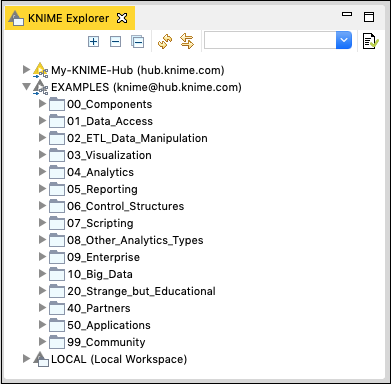
KNIME มีตัวอย่างมากมายเพื่อให้คุณเริ่มต้นใช้งานแพลตฟอร์ม ในบทถัดไปคุณจะใช้หนึ่งในตัวอย่างเหล่านี้เพื่อทำความคุ้นเคยกับแพลตฟอร์ม
มุมมองคอนโซล
ตามชื่อระบุไฟล์ Console view ให้มุมมองของข้อความคอนโซลต่างๆในขณะที่เรียกใช้เวิร์กโฟลว์ของคุณ

Console มุมมองมีประโยชน์ในการวินิจฉัยเวิร์กโฟลว์และตรวจสอบผลการวิเคราะห์
คำอธิบายดู
มุมมองสุดท้ายที่สำคัญซึ่งเกี่ยวข้องกับเราทันทีคือ Descriptionดู. มุมมองนี้ให้คำอธิบายของรายการที่เลือกในพื้นที่ทำงาน มุมมองทั่วไปแสดงอยู่ในภาพหน้าจอด้านล่าง -

มุมมองด้านบนแสดงคำอธิบายของไฟล์ File Readerโหนด เมื่อคุณเลือกไฟล์File Readerโหนดในพื้นที่ทำงานของคุณคุณจะเห็นคำอธิบายในมุมมองนี้ การคลิกที่โหนดอื่นจะแสดงคำอธิบายของโหนดที่เลือก ดังนั้นมุมมองนี้จะมีประโยชน์อย่างมากในขั้นตอนเริ่มต้นของการเรียนรู้เมื่อคุณไม่ทราบจุดประสงค์ของโหนดต่างๆในพื้นที่ทำงานและ / หรือที่เก็บโหนดอย่างแม่นยำ
แถบเครื่องมือ
นอกเหนือจากมุมมองที่อธิบายไว้ข้างต้นแล้วโต๊ะทำงานยังมีมุมมองอื่น ๆ เช่นแถบเครื่องมือ แถบเครื่องมือประกอบด้วยไอคอนต่างๆที่อำนวยความสะดวกในการดำเนินการอย่างรวดเร็ว ไอคอนถูกเปิด / ปิดขึ้นอยู่กับบริบท คุณสามารถดูการทำงานของแต่ละไอคอนได้โดยการวางเมาส์บนไอคอนนั้น หน้าจอต่อไปนี้แสดงการดำเนินการโดยConfigure ไอคอน.

การเปิด / ปิดการใช้งานมุมมอง
มุมมองต่างๆที่คุณเห็นจนถึงตอนนี้สามารถเปิด / ปิดได้อย่างง่ายดาย คลิกไอคอนปิดในมุมมองจะcloseมุมมอง. หากต้องการคืนสถานะมุมมองให้ไปที่ไฟล์Viewตัวเลือกเมนูและเลือกมุมมองที่ต้องการ มุมมองที่เลือกจะถูกเพิ่มไปยังโต๊ะทำงาน

ตอนนี้เมื่อคุณคุ้นเคยกับโต๊ะทำงานแล้วฉันจะแสดงวิธีเรียกใช้เวิร์กโฟลว์และศึกษาการวิเคราะห์ที่ดำเนินการ
KNIME ได้จัดเตรียมเวิร์กโฟลว์ที่ดีไว้มากมายเพื่อความสะดวกในการเรียนรู้ ในบทนี้เราจะเลือกหนึ่งในขั้นตอนการทำงานที่มีให้ในการติดตั้งเพื่ออธิบายคุณสมบัติต่างๆและพลังของแพลตฟอร์มการวิเคราะห์ เราจะใช้ลักษณนามอย่างง่ายตามไฟล์Decision Tree สำหรับการศึกษาของเรา
กำลังโหลดลักษณนามทรีการตัดสินใจ
ใน KNIME Explorer ให้ค้นหาเวิร์กโฟลว์ต่อไปนี้ -
LOCAL / Example Workflows / Basic Examples / Building a Simple Classifierนอกจากนี้ยังแสดงในภาพหน้าจอด้านล่างสำหรับการอ้างอิงอย่างรวดเร็วของคุณ -

ดับเบิลคลิกที่รายการที่เลือกเพื่อเปิดเวิร์กโฟลว์ สังเกตมุมมองพื้นที่ทำงาน คุณจะเห็นเวิร์กโฟลว์ที่มีหลายโหนด จุดประสงค์ของเวิร์กโฟลว์นี้คือการทำนายกลุ่มรายได้จากคุณลักษณะที่เป็นประชาธิปไตยของชุดข้อมูลสำหรับผู้ใหญ่ที่นำมาจาก UCI Machine Learning Repository หน้าที่ของโมเดล ML นี้คือการจำแนกคนในภูมิภาคเฉพาะว่ามีรายได้มากกว่าหรือน้อยกว่า 50K
Workspace มุมมองพร้อมกับโครงร่างจะแสดงในภาพหน้าจอด้านล่าง -

สังเกตว่ามีหลายโหนดที่ดึงมาจากไฟล์ Nodesที่เก็บและเชื่อมต่อในเวิร์กโฟลว์ด้วยลูกศร การเชื่อมต่อระบุว่าเอาต์พุตของโหนดหนึ่งถูกป้อนเข้ากับอินพุตของโหนดถัดไป ก่อนที่เราจะเรียนรู้การทำงานของแต่ละโหนดในเวิร์กโฟลว์ให้เราดำเนินการเวิร์กโฟลว์ทั้งหมดก่อน
กำลังดำเนินการเวิร์กโฟลว์
ก่อนที่เราจะตรวจสอบการดำเนินการของเวิร์กโฟลว์สิ่งสำคัญคือต้องเข้าใจรายงานสถานะของแต่ละโหนด ตรวจสอบโหนดใด ๆ ในเวิร์กโฟลว์ ที่ด้านล่างของแต่ละโหนดคุณจะพบไฟแสดงสถานะที่มีวงกลมสามวง โหนด Decision Tree Learner แสดงในภาพหน้าจอด้านล่าง -

ไฟแสดงสถานะเป็นสีแดงแสดงว่าโหนดนี้ยังไม่ได้ดำเนินการ ในระหว่างการประหารชีวิตวงกลมตรงกลางซึ่งมีสีเหลืองจะสว่างขึ้น เมื่อดำเนินการสำเร็จวงกลมสุดท้ายจะเปลี่ยนเป็นสีเขียว มีตัวบ่งชี้เพิ่มเติมเพื่อให้ข้อมูลสถานะแก่คุณในกรณีที่เกิดข้อผิดพลาด คุณจะได้เรียนรู้เมื่อเกิดข้อผิดพลาดในการประมวลผล
โปรดทราบว่าขณะนี้อินดิเคเตอร์บนโหนดทั้งหมดเป็นสีแดงแสดงว่ายังไม่มีการดำเนินการโหนดใด ๆ ในการเรียกใช้โหนดทั้งหมดให้คลิกที่รายการเมนูต่อไปนี้ -
Node → Execute All
หลังจากนั้นไม่นานคุณจะพบว่าตัวบ่งชี้สถานะแต่ละโหนดเปลี่ยนเป็นสีเขียวแสดงว่าไม่มีข้อผิดพลาด
ในบทต่อไปเราจะสำรวจการทำงานของโหนดต่างๆในเวิร์กโฟลว์
หากคุณตรวจสอบโหนดในเวิร์กโฟลว์คุณจะเห็นว่ามีสิ่งต่อไปนี้ -
โปรแกรมอ่านไฟล์
ผู้จัดการสี
Partitioning
ผู้เรียนต้นไม้แห่งการตัดสินใจ
ตัวทำนายต้นไม้ตัดสินใจ
Score
ตารางโต้ตอบ
พล็อตกระจาย
Statistics
สิ่งเหล่านี้สามารถมองเห็นได้ง่ายในไฟล์ Outline ดูตามที่แสดงไว้ที่นี่ -

แต่ละโหนดมีฟังก์ชันเฉพาะในเวิร์กโฟลว์ ตอนนี้เราจะดูวิธีกำหนดค่าโหนดเหล่านี้เพื่อให้ตรงตามฟังก์ชันที่ต้องการ โปรดทราบว่าเราจะพูดถึงเฉพาะโหนดที่เกี่ยวข้องกับเราในบริบทปัจจุบันของการสำรวจเวิร์กโฟลว์
โปรแกรมอ่านไฟล์
โหนด File Reader แสดงอยู่ในภาพหน้าจอด้านล่าง -

มีคำอธิบายบางอย่างที่ด้านบนของหน้าต่างที่ผู้สร้างเวิร์กโฟลว์ให้ไว้ เป็นการบอกว่าโหนดนี้อ่านชุดข้อมูลสำหรับผู้ใหญ่ ชื่อของไฟล์คือadult.csvดังที่เห็นจากคำอธิบายด้านล่างสัญลักษณ์โหนด File Reader มีสองเอาต์พุต - หนึ่งไปที่ Color Manager โหนดและอีกอันหนึ่งไปที่ Statistics โหนด
หากคุณคลิกขวาที่ไฟล์ File Managerเมนูป๊อปอัพจะปรากฏขึ้นดังนี้ -

Configureตัวเลือกเมนูช่วยให้สามารถกำหนดค่าโหนดได้ Executeเมนูเรียกใช้โหนด โปรดทราบว่าหากโหนดถูกเรียกใช้แล้วและหากอยู่ในสถานะสีเขียวเมนูนี้จะปิดใช้งาน นอกจากนี้โปรดสังเกตการมีอยู่ของEdit Note Descriptionตัวเลือกเมนู สิ่งนี้ช่วยให้คุณสามารถเขียนคำอธิบายสำหรับโหนดของคุณ
ตอนนี้เลือก Configure ตัวเลือกเมนูจะแสดงหน้าจอที่มีข้อมูลจากไฟล์ adult.csv ดังที่เห็นในภาพหน้าจอที่นี่ -

เมื่อคุณรันโหนดนี้ข้อมูลจะถูกโหลดในหน่วยความจำ รหัสโปรแกรมโหลดข้อมูลทั้งหมดถูกซ่อนจากผู้ใช้ ตอนนี้คุณสามารถชื่นชมประโยชน์ของโหนดดังกล่าว - ไม่จำเป็นต้องเข้ารหัส
โหนดถัดไปของเราคือ Color Manager.
ผู้จัดการสี
เลือกไฟล์ Color Managerและไปที่การกำหนดค่าโดยคลิกขวาที่มัน กล่องโต้ตอบการตั้งค่าสีจะปรากฏขึ้น เลือกไฟล์income คอลัมน์จากรายการแบบเลื่อนลง
หน้าจอของคุณจะมีลักษณะดังต่อไปนี้ -

สังเกตว่ามีข้อ จำกัด สองข้อ หากรายได้น้อยกว่า 50K ดาต้าพอยต์จะได้รับสีเขียวและหากมีมากขึ้นก็จะได้รับสีแดง คุณจะเห็นการแมปจุดข้อมูลเมื่อเราดูพล็อตการกระจายในบทนี้
การแบ่งพาร์ติชัน
ในการเรียนรู้ของเครื่องเรามักจะแบ่งข้อมูลที่มีอยู่ทั้งหมดออกเป็นสองส่วน ส่วนที่ใหญ่กว่าจะใช้ในการฝึกโมเดลในขณะที่ส่วนที่เล็กกว่าจะใช้สำหรับการทดสอบ มีกลยุทธ์ที่แตกต่างกันที่ใช้ในการแบ่งพาร์ติชันข้อมูล
ในการกำหนดการแบ่งพาร์ติชันที่ต้องการให้คลิกขวาที่ไฟล์ Partitioning โหนดและเลือกไฟล์ Configureตัวเลือก คุณจะเห็นหน้าจอต่อไปนี้ -

ในกรณีนี้ System modeller ได้ใช้ไฟล์ Relative(%) และข้อมูลจะถูกแบ่งในอัตราส่วน 80:20 ในขณะที่ทำการแยกจุดข้อมูลจะถูกสุ่มเลือก เพื่อให้แน่ใจว่าข้อมูลการทดสอบของคุณอาจไม่เอนเอียง ในกรณีของการสุ่มตัวอย่างเชิงเส้นข้อมูลที่เหลืออีก 20% ที่ใช้ในการทดสอบอาจแสดงข้อมูลการฝึกอบรมไม่ถูกต้องเนื่องจากอาจมีความเอนเอียงทั้งหมดในระหว่างการรวบรวม
หากคุณแน่ใจว่าในระหว่างการรวบรวมข้อมูลจะรับประกันการสุ่มคุณสามารถเลือกการสุ่มตัวอย่างเชิงเส้นได้ เมื่อข้อมูลของคุณพร้อมสำหรับการฝึกโมเดลแล้วให้ป้อนข้อมูลไปยังโหนดถัดไปซึ่งก็คือไฟล์Decision Tree Learner.
ผู้เรียนต้นไม้แห่งการตัดสินใจ
Decision Tree Learnerโหนดตามชื่อที่แนะนำใช้ข้อมูลการฝึกอบรมและสร้างแบบจำลอง ตรวจสอบการกำหนดค่าของโหนดนี้ซึ่งแสดงในภาพหน้าจอด้านล่าง -

อย่างที่คุณเห็นไฟล์ Class คือ income. ดังนั้นต้นไม้จะถูกสร้างขึ้นตามคอลัมน์รายได้และนั่นคือสิ่งที่เราพยายามทำให้สำเร็จในโมเดลนี้ เราต้องการแยกคนที่มีรายได้มากกว่าหรือน้อยกว่า 50K
หลังจากโหนดนี้ทำงานสำเร็จโมเดลของคุณจะพร้อมสำหรับการทดสอบ
ตัวทำนายต้นไม้ตัดสินใจ
โหนด Decision Tree Predictor ใช้โมเดลที่พัฒนาแล้วกับชุดข้อมูลทดสอบและผนวกการคาดคะเนแบบจำลอง

เอาต์พุตของตัวทำนายถูกป้อนไปยังโหนดที่แตกต่างกันสองโหนด - Scorer และ Scatter Plot. ต่อไปเราจะตรวจสอบผลลัพธ์ของการทำนาย
ผู้ทำประตู
โหนดนี้สร้างไฟล์ confusion matrix. หากต้องการดูให้คลิกขวาที่โหนด คุณจะเห็นเมนูป๊อปอัปต่อไปนี้ -

คลิก View: Confusion Matrix ตัวเลือกเมนูและเมทริกซ์จะปรากฏขึ้นในหน้าต่างแยกต่างหากดังที่แสดงในภาพหน้าจอที่นี่ -
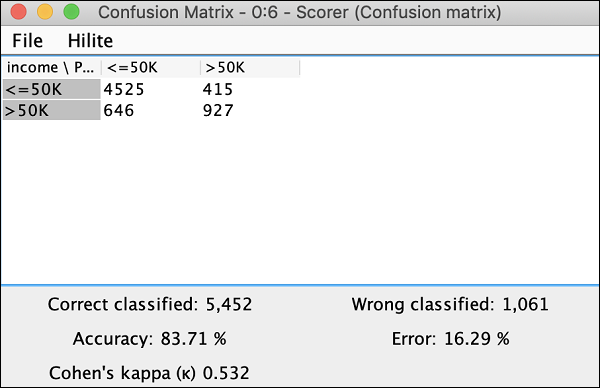
แสดงว่าความแม่นยำของแบบจำลองที่เราพัฒนาคือ 83.71% หากคุณไม่พอใจกับสิ่งนี้คุณอาจลองใช้พารามิเตอร์อื่น ๆ ในการสร้างแบบจำลองโดยเฉพาะอย่างยิ่งคุณอาจต้องการทบทวนและล้างข้อมูลของคุณ
พล็อตกระจาย
หากต้องการดูแผนภูมิกระจายของการกระจายข้อมูลให้คลิกขวาที่ไฟล์ Scatter Plot โหนดและเลือกตัวเลือกเมนู Interactive View: Scatter Plot. คุณจะเห็นพล็อตต่อไปนี้ -

พล็อตนี้ให้การกระจายของกลุ่มคนที่มีรายได้แตกต่างกันตามเกณฑ์ 50K ในสองจุดสีที่แตกต่างกัน - สีแดงและสีน้ำเงิน เหล่านี้เป็นสีที่กำหนดไว้ในColor Managerโหนด การแจกแจงจะสัมพันธ์กับอายุตามที่พล็อตบนแกน x คุณสามารถเลือกคุณสมบัติอื่นสำหรับแกน x ได้โดยเปลี่ยนการกำหนดค่าของโหนด
กล่องโต้ตอบการกำหนดค่าจะแสดงที่นี่ซึ่งเราได้เลือกไฟล์ marital-status เป็นคุณสมบัติสำหรับแกน x
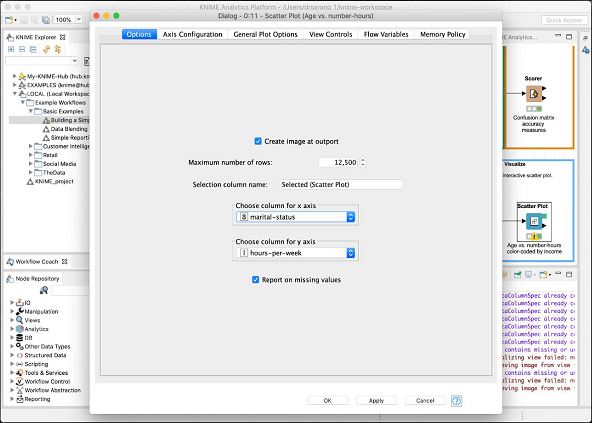
นี่เป็นการเสร็จสิ้นการสนทนาของเราเกี่ยวกับแบบจำลองที่กำหนดไว้ล่วงหน้าจาก KNIME เราขอแนะนำให้คุณใช้อีกสองโหนด (สถิติและตารางเชิงโต้ตอบ) ในแบบจำลองสำหรับการศึกษาด้วยตนเองของคุณ
ตอนนี้ให้เราไปยังส่วนที่สำคัญที่สุดของบทช่วยสอนนั่นคือการสร้างโมเดลของคุณเอง
ในบทนี้คุณจะสร้างโมเดลแมชชีนเลิร์นนิงของคุณเองเพื่อจัดหมวดหมู่พืชตามคุณสมบัติที่สังเกตได้ เราจะใช้ที่รู้จักกันดีiris ชุดข้อมูลจาก UCI Machine Learning Repositoryเพื่อจุดประสงค์นี้. ชุดข้อมูลประกอบด้วยพืชสามประเภทที่แตกต่างกัน เราจะฝึกโมเดลของเราเพื่อจำแนกพืชที่ไม่รู้จักออกเป็นหนึ่งในสามคลาสนี้
เราจะเริ่มต้นด้วยการสร้างเวิร์กโฟลว์ใหม่ใน KNIME เพื่อสร้างโมเดลแมชชีนเลิร์นนิงของเรา
การสร้างเวิร์กโฟลว์
ในการสร้างเวิร์กโฟลว์ใหม่ให้เลือกตัวเลือกเมนูต่อไปนี้ใน KNIME workbench
File → Newคุณจะเห็นหน้าจอต่อไปนี้ -

เลือกไฟล์ New KNIME Workflow และคลิกที่ไฟล์ Nextปุ่ม. ในหน้าจอถัดไประบบจะถามชื่อที่ต้องการสำหรับเวิร์กโฟลว์และโฟลเดอร์ปลายทางเพื่อบันทึก ป้อนข้อมูลตามต้องการแล้วคลิกFinish เพื่อสร้างพื้นที่ทำงานใหม่
พื้นที่ทำงานใหม่ที่มีชื่อที่กำหนดจะถูกเพิ่มลงในไฟล์ Workspace ดูตามที่เห็นนี้ -
ตอนนี้คุณจะเพิ่มโหนดต่างๆในพื้นที่ทำงานนี้เพื่อสร้างโมเดลของคุณ ก่อนหน้านี้คุณจะเพิ่มโหนดคุณต้องดาวน์โหลดและเตรียมไฟล์iris ชุดข้อมูลสำหรับการใช้งานของเรา
กำลังเตรียมชุดข้อมูล
ดาวน์โหลดชุดม่านตาจาก UCI เครื่องเรียนรู้ Repository เว็บไซต์ดาวน์โหลด Iris ชุดข้อมูล ไฟล์ iris.data ที่ดาวน์โหลดมาอยู่ในรูปแบบ CSV เราจะทำการเปลี่ยนแปลงบางอย่างเพื่อเพิ่มชื่อคอลัมน์
เปิดไฟล์ที่ดาวน์โหลดในโปรแกรมแก้ไขข้อความที่คุณชื่นชอบและเพิ่มบรรทัดต่อไปนี้ที่จุดเริ่มต้น
sepal length, petal length, sepal width, petal width, classเมื่อ File Reader โหนดอ่านไฟล์นี้โดยอัตโนมัติจะใช้ฟิลด์ด้านบนเป็นชื่อคอลัมน์
ตอนนี้คุณจะเริ่มเพิ่มโหนดต่างๆ
การเพิ่มโปรแกรมอ่านไฟล์
ไปที่ไฟล์ Node Repository ดูพิมพ์ "ไฟล์" ในช่องค้นหาเพื่อค้นหาไฟล์ File Readerโหนด สิ่งนี้จะเห็นในภาพหน้าจอด้านล่าง -

เลือกและดับเบิลคลิกที่ไฟล์ File Readerเพื่อเพิ่มโหนดลงในพื้นที่ทำงาน หรือคุณอาจใช้คุณลักษณะลาก n วางเพื่อเพิ่มโหนดลงในพื้นที่ทำงาน หลังจากเพิ่มโหนดแล้วคุณจะต้องกำหนดค่า คลิกขวาที่โหนดและเลือกไฟล์Configureตัวเลือกเมนู คุณได้ทำสิ่งนี้ในบทเรียนก่อนหน้านี้แล้ว
หน้าจอการตั้งค่าจะมีลักษณะดังต่อไปนี้หลังจากโหลดดาต้าไฟล์แล้ว

ในการโหลดชุดข้อมูลของคุณคลิกที่ไฟล์ Browseและเลือกตำแหน่งของไฟล์ iris.data ของคุณ โหนดจะโหลดเนื้อหาของไฟล์ซึ่งแสดงในส่วนล่างของกล่องกำหนดค่า เมื่อคุณพอใจว่าดาต้าไฟล์อยู่ในตำแหน่งที่ถูกต้องและโหลดแล้วให้คลิกที่ไฟล์OK เพื่อปิดกล่องโต้ตอบการกำหนดค่า
ตอนนี้คุณจะเพิ่มคำอธิบายประกอบให้กับโหนดนี้ คลิกขวาที่โหนดแล้วเลือกNew Workflow Annotationตัวเลือกเมนู กล่องคำอธิบายประกอบจะปรากฏบนหน้าจอดังที่แสดงในภาพหน้าจอที่นี่:
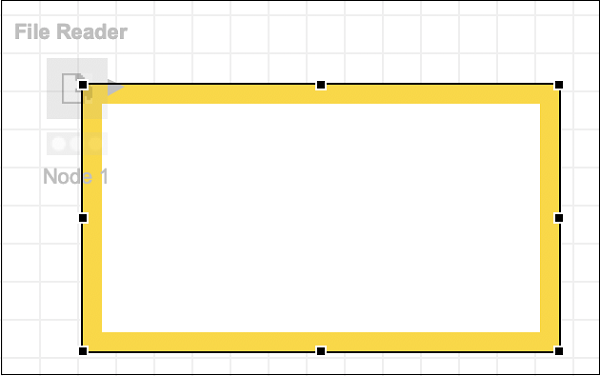
คลิกภายในกล่องและเพิ่มคำอธิบายประกอบต่อไปนี้ -
Reads iris.dataคลิกที่ใดก็ได้นอกกรอบเพื่อออกจากโหมดแก้ไข ปรับขนาดและวางกล่องรอบโหนดตามต้องการ สุดท้ายดับเบิลคลิกที่ไฟล์Node 1 ข้อความใต้โหนดเพื่อเปลี่ยนสตริงนี้เป็นดังต่อไปนี้ -
Loads dataณ จุดนี้หน้าจอของคุณจะมีลักษณะดังต่อไปนี้ -
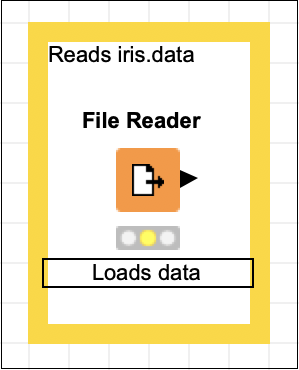
ตอนนี้เราจะเพิ่มโหนดใหม่สำหรับการแบ่งชุดข้อมูลที่โหลดลงในการฝึกอบรมและการทดสอบ
การเพิ่ม Partitioning Node
ใน Node Repository หน้าต่างค้นหาพิมพ์อักขระสองสามตัวเพื่อค้นหาไฟล์ Partitioning โหนดดังที่เห็นในภาพหน้าจอด้านล่าง -
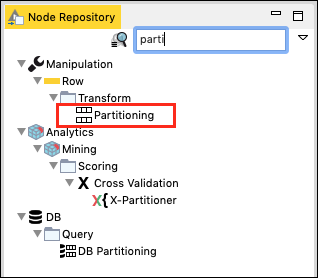
เพิ่มโหนดในพื้นที่ทำงานของเรา ตั้งค่าการกำหนดค่าดังนี้ -
Relative (%) : 95
Draw Randomlyภาพหน้าจอต่อไปนี้แสดงพารามิเตอร์การกำหนดค่า

จากนั้นทำการเชื่อมต่อระหว่างสองโหนด โดยคลิกที่ผลลัพธ์ของไฟล์File Reader คลิกปุ่มเมาส์ค้างไว้จะมีแถบยางปรากฏขึ้นลากไปที่อินพุตของ Partitioningปล่อยปุ่มเมาส์ ขณะนี้มีการสร้างการเชื่อมต่อระหว่างสองโหนด
เพิ่มคำอธิบายประกอบเปลี่ยนคำอธิบายวางตำแหน่งโหนดและมุมมองคำอธิบายประกอบตามต้องการ หน้าจอของคุณควรมีลักษณะดังต่อไปนี้ในขั้นตอนนี้ -

ต่อไปเราจะเพิ่มไฟล์ k-Means โหนด
การเพิ่ม k-mean Node
เลือกไฟล์ k-Meansโหนดจากที่เก็บและเพิ่มลงในพื้นที่ทำงาน หากคุณต้องการรีเฟรชความรู้ของคุณเกี่ยวกับอัลกอริทึม k-Means เพียงแค่ค้นหาคำอธิบายในมุมมองคำอธิบายของโต๊ะทำงาน สิ่งนี้แสดงในภาพหน้าจอด้านล่าง -

อนึ่งคุณอาจค้นหาคำอธิบายของอัลกอริทึมต่างๆในหน้าต่างคำอธิบายก่อนที่จะตัดสินใจขั้นสุดท้ายว่าจะใช้อัลกอริทึมใด
เปิดกล่องโต้ตอบการกำหนดค่าสำหรับโหนด เราจะใช้ค่าเริ่มต้นสำหรับทุกฟิลด์ดังที่แสดงไว้ที่นี่ -

คลิก OK เพื่อยอมรับค่าเริ่มต้นและปิดกล่องโต้ตอบ
ตั้งค่าคำอธิบายประกอบและคำอธิบายดังต่อไปนี้ -
คำอธิบายประกอบ: จัดประเภทคลัสเตอร์
คำอธิบาย: ดำเนินการจัดกลุ่ม
เชื่อมต่อเอาต์พุตด้านบนของไฟล์ Partitioning โหนดไปยังอินพุตของ k-Meansโหนด จัดตำแหน่งรายการของคุณใหม่และหน้าจอของคุณควรมีลักษณะดังนี้ -

ต่อไปเราจะเพิ่มไฟล์ Cluster Assigner โหนด
การเพิ่ม Cluster Assigner
Cluster Assignerกำหนดข้อมูลใหม่ให้กับชุดต้นแบบที่มีอยู่ ใช้อินพุตสองอินพุต - โมเดลต้นแบบและดาต้าเบสที่มีข้อมูลอินพุต ค้นหาคำอธิบายของโหนดในหน้าต่างคำอธิบายซึ่งแสดงในภาพหน้าจอด้านล่าง -

ดังนั้นสำหรับโหนดนี้คุณต้องทำการเชื่อมต่อสองครั้ง -
เอาต์พุต PMML Cluster Model ของ Partitioning โหนด→ต้นแบบอินพุตของ Cluster Assigner
เอาต์พุตพาร์ติชันที่สองของ Partitioning โหนด→ข้อมูลอินพุตของ Cluster Assigner
การเชื่อมต่อทั้งสองนี้แสดงในภาพหน้าจอด้านล่าง -

Cluster Assignerไม่จำเป็นต้องมีการกำหนดค่าพิเศษใด ๆ เพียงแค่ยอมรับค่าเริ่มต้น
ตอนนี้เพิ่มคำอธิบายประกอบและคำอธิบายลงในโหนดนี้ จัดเรียงโหนดของคุณใหม่ หน้าจอของคุณควรมีลักษณะดังต่อไปนี้ -

ณ จุดนี้การทำคลัสเตอร์ของเราเสร็จสมบูรณ์ เราจำเป็นต้องเห็นภาพผลลัพธ์ในรูปแบบกราฟิก สำหรับสิ่งนี้เราจะเพิ่มพล็อตกระจาย เราจะกำหนดสีและรูปทรงสำหรับสามคลาสให้แตกต่างกันในพล็อตกระจาย ดังนั้นเราจะกรองผลลัพธ์ของไฟล์k-Means โหนดแรกผ่านไฟล์ Color Manager โหนดแล้วผ่าน Shape Manager โหนด
การเพิ่มตัวจัดการสี
ค้นหาไฟล์ Color Managerโหนดในที่เก็บ เพิ่มลงในพื้นที่ทำงาน ปล่อยให้การกำหนดค่าเป็นค่าเริ่มต้น โปรดทราบว่าคุณต้องเปิดกล่องโต้ตอบการกำหนดค่าและกดOKเพื่อยอมรับค่าเริ่มต้น ตั้งค่าข้อความอธิบายสำหรับโหนด
ทำการเชื่อมต่อจากเอาต์พุตของ k-Means ไปยังอินพุตของ Color Manager. หน้าจอของคุณจะมีลักษณะดังต่อไปนี้ในขั้นตอนนี้ -

การเพิ่ม Shape Manager
ค้นหาไฟล์ Shape Managerในที่เก็บและเพิ่มลงในพื้นที่ทำงาน ปล่อยให้การกำหนดค่าเป็นค่าเริ่มต้น เช่นเดียวกับก่อนหน้านี้คุณต้องเปิดกล่องโต้ตอบการกำหนดค่าและกดOKเพื่อตั้งค่าเริ่มต้น สร้างการเชื่อมต่อจากเอาต์พุตของColor Manager ไปยังอินพุตของ Shape Manager. ตั้งค่าคำอธิบายสำหรับโหนด
หน้าจอของคุณควรมีลักษณะดังต่อไปนี้ -
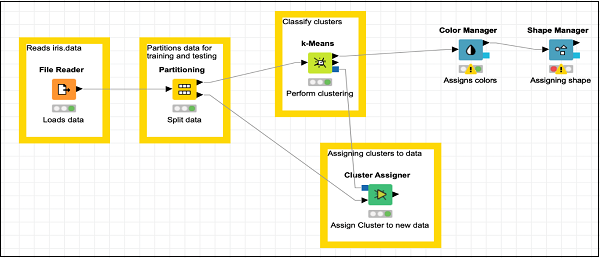
ตอนนี้คุณจะเพิ่มโหนดสุดท้ายในโมเดลของเราและนั่นคือพล็อตกระจาย
การเพิ่ม Scatter Plot
ค้นหา Scatter Plotโหนดในที่เก็บและเพิ่มลงในพื้นที่ทำงาน เชื่อมต่อเอาต์พุตของShape Manager ไปยังอินพุตของ Scatter Plot. ปล่อยให้การกำหนดค่าเป็นค่าเริ่มต้น ตั้งค่าคำอธิบาย
สุดท้ายเพิ่มคำอธิบายประกอบกลุ่มไปยังสามโหนดที่เพิ่งเพิ่ม
คำอธิบายประกอบ: การแสดงภาพ
จัดตำแหน่งโหนดใหม่ตามต้องการ หน้าจอของคุณควรมีลักษณะดังต่อไปนี้ในขั้นตอนนี้
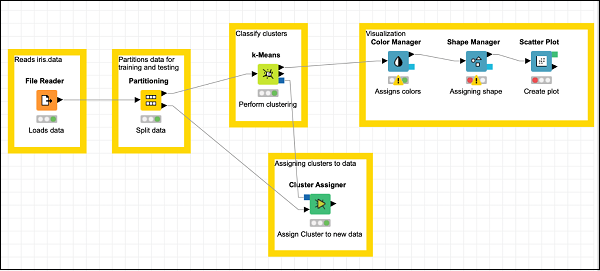
เสร็จสิ้นภารกิจการสร้างแบบจำลอง
ในการทดสอบโมเดลให้ดำเนินการตามตัวเลือกเมนูต่อไปนี้: Node → Execute All
หากทุกอย่างถูกต้องสัญญาณสถานะที่ด้านล่างของแต่ละโหนดจะเปลี่ยนเป็นสีเขียว ถ้าไม่คุณจะต้องค้นหาไฟล์Console ดูข้อผิดพลาดแก้ไขและเรียกใช้เวิร์กโฟลว์ใหม่
ตอนนี้คุณพร้อมที่จะเห็นภาพผลลัพธ์ที่คาดการณ์ไว้ของโมเดลแล้ว สำหรับสิ่งนี้ให้คลิกขวาที่ไฟล์Scatter Plot โหนดและเลือกตัวเลือกเมนูต่อไปนี้: Interactive View: Scatter Plot
สิ่งนี้แสดงในภาพหน้าจอด้านล่าง -

คุณจะเห็นพล็อตการกระจายบนหน้าจอดังที่แสดงไว้ที่นี่ -

คุณสามารถเรียกใช้การแสดงภาพที่แตกต่างกันได้โดยการเปลี่ยนแกน x และ y โดยคลิกที่เมนูการตั้งค่าที่มุมขวาบนของพล็อตกระจาย เมนูป๊อปอัพจะปรากฏขึ้นตามที่แสดงในภาพหน้าจอด้านล่าง -

คุณสามารถตั้งค่าพารามิเตอร์ต่างๆสำหรับพล็อตบนหน้าจอนี้เพื่อแสดงภาพข้อมูลจากหลายแง่มุม
เสร็จสิ้นภารกิจการสร้างแบบจำลองของเรา
KNIME มีเครื่องมือกราฟิกสำหรับสร้างโมเดล Machine Learning ในบทช่วยสอนนี้คุณได้เรียนรู้วิธีดาวน์โหลดและติดตั้ง KNIME บนเครื่องของคุณ
สรุป
คุณได้เรียนรู้มุมมองต่างๆที่มีให้ในโต๊ะทำงาน KNIME KNIME มีเวิร์กโฟลว์ที่กำหนดไว้ล่วงหน้าหลายขั้นตอนสำหรับการเรียนรู้ของคุณ เราใช้ขั้นตอนการทำงานดังกล่าวเพื่อเรียนรู้ความสามารถของ KNIME KNIME มีโหนดที่ตั้งโปรแกรมไว้ล่วงหน้าหลายโหนดสำหรับการอ่านข้อมูลในรูปแบบต่างๆการวิเคราะห์ข้อมูลโดยใช้อัลกอริทึม ML หลายแบบและในที่สุดก็แสดงภาพข้อมูลในรูปแบบต่างๆ ในตอนท้ายของบทช่วยสอนคุณได้สร้างโมเดลของคุณเองโดยเริ่มตั้งแต่ต้น เราใช้ชุดข้อมูลไอริสที่รู้จักกันดีในการจำแนกพืชโดยใช้อัลกอริทึม k-mean
ตอนนี้คุณพร้อมที่จะใช้เทคนิคเหล่านี้สำหรับการวิเคราะห์ของคุณเองแล้ว
งานในอนาคต
หากคุณเป็นนักพัฒนาและต้องการใช้ส่วนประกอบ KNIME ในแอปพลิเคชันการเขียนโปรแกรมของคุณคุณจะดีใจที่ทราบว่า KNIME ทำงานร่วมกับภาษาโปรแกรมที่หลากหลายเช่น Java, R, Python และอื่น ๆ อีกมากมาย