ควาญช้าง - การรวมกลุ่ม
การทำคลัสเตอร์เป็นขั้นตอนในการจัดองค์ประกอบหรือรายการของคอลเลกชันที่กำหนดให้เป็นกลุ่มตามความคล้ายคลึงกันระหว่างรายการ ตัวอย่างเช่นแอปพลิเคชันที่เกี่ยวข้องกับการเผยแพร่ข่าวออนไลน์จัดกลุ่มบทความข่าวโดยใช้การทำคลัสเตอร์
การประยุกต์ใช้การทำคลัสเตอร์
การทำคลัสเตอร์ใช้กันอย่างแพร่หลายในหลาย ๆ แอปพลิเคชันเช่นการวิจัยตลาดการจดจำรูปแบบการวิเคราะห์ข้อมูลและการประมวลผลภาพ
การทำคลัสเตอร์สามารถช่วยให้นักการตลาดค้นพบกลุ่มที่แตกต่างกันตามฐานลูกค้าของตน และสามารถกำหนดลักษณะกลุ่มลูกค้าได้ตามรูปแบบการซื้อ
ในสาขาชีววิทยาสามารถใช้เพื่อหาอนุกรมวิธานของพืชและสัตว์จัดหมวดหมู่ยีนที่มีฟังก์ชันการทำงานที่คล้ายคลึงกันและได้รับข้อมูลเชิงลึกเกี่ยวกับโครงสร้างที่มีอยู่ในประชากร
การจัดกลุ่มช่วยในการระบุพื้นที่ที่มีการใช้ประโยชน์ที่ดินในลักษณะเดียวกันในฐานข้อมูลการสังเกตการณ์บนพื้นโลก
การจัดกลุ่มยังช่วยในการจัดประเภทเอกสารบนเว็บสำหรับการค้นหาข้อมูล
การทำคลัสเตอร์ใช้ในแอปพลิเคชันการตรวจจับค่าผิดปกติเช่นการตรวจจับการฉ้อโกงบัตรเครดิต
ในฐานะฟังก์ชั่นการขุดข้อมูล Cluster Analysis ทำหน้าที่เป็นเครื่องมือในการทำความเข้าใจเกี่ยวกับการกระจายข้อมูลเพื่อสังเกตลักษณะของแต่ละคลัสเตอร์
การใช้ Mahout ทำให้เราสามารถจัดกลุ่มข้อมูลที่กำหนดได้ ขั้นตอนที่จำเป็นมีดังต่อไปนี้:
Algorithm คุณต้องเลือกอัลกอริทึมการจัดกลุ่มที่เหมาะสมเพื่อจัดกลุ่มองค์ประกอบของคลัสเตอร์
Similarity and Dissimilarity คุณต้องมีกฎเพื่อตรวจสอบความคล้ายคลึงกันระหว่างองค์ประกอบที่พบใหม่และองค์ประกอบในกลุ่ม
Stopping Condition ต้องมีเงื่อนไขการหยุดเพื่อกำหนดจุดที่ไม่จำเป็นต้องทำคลัสเตอร์
ขั้นตอนการทำคลัสเตอร์
ในการจัดกลุ่มข้อมูลที่คุณต้องการ -
เริ่มเซิร์ฟเวอร์ Hadoop สร้างไดเร็กทอรีที่จำเป็นสำหรับการจัดเก็บไฟล์ใน Hadoop File System (สร้างไดเร็กทอรีสำหรับอินพุตไฟล์ไฟล์ลำดับและเอาต์พุตคลัสเตอร์ในกรณีของ canopy)
คัดลอกไฟล์อินพุตไปยังระบบ Hadoop File จากระบบไฟล์ Unix
เตรียมไฟล์ลำดับจากข้อมูลอินพุต
เรียกใช้อัลกอริทึมการทำคลัสเตอร์ใด ๆ ที่มีอยู่
รับข้อมูลคลัสเตอร์
เริ่ม Hadoop
Mahout ทำงานร่วมกับ Hadoop ดังนั้นตรวจสอบให้แน่ใจว่าเซิร์ฟเวอร์ Hadoop พร้อมใช้งานแล้ว
$ cd HADOOP_HOME/bin
$ start-all.shการเตรียมไดเร็กทอรีไฟล์อินพุต
สร้างไดเร็กทอรีในระบบไฟล์ Hadoop เพื่อเก็บไฟล์อินพุตไฟล์ลำดับและข้อมูลคลัสเตอร์โดยใช้คำสั่งต่อไปนี้:
$ hadoop fs -p mkdir /mahout_data
$ hadoop fs -p mkdir /clustered_data
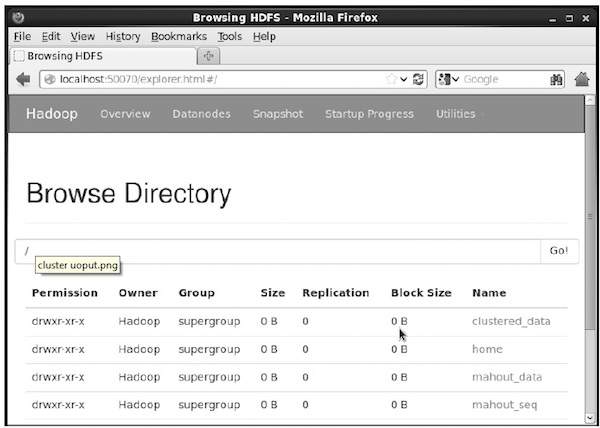
$ hadoop fs -p mkdir /mahout_seqคุณสามารถตรวจสอบว่าไดเร็กทอรีถูกสร้างโดยใช้เว็บอินเตอร์เฟส hadoop ใน URL ต่อไปนี้ - http://localhost:50070/
ให้ผลลัพธ์ดังที่แสดงด้านล่าง:
การคัดลอกไฟล์อินพุตเป็น HDFS
ตอนนี้คัดลอกไฟล์ข้อมูลอินพุตจากระบบไฟล์ Linux ไปยังไดเร็กทอรี mahout_data ใน Hadoop File System ดังที่แสดงด้านล่าง สมมติว่าไฟล์อินพุตของคุณคือ mydata.txt และอยู่ในไดเร็กทอรี / home / Hadoop / data /
$ hadoop fs -put /home/Hadoop/data/mydata.txt /mahout_data/กำลังเตรียมไฟล์ลำดับ
Mahout มียูทิลิตี้ในการแปลงไฟล์อินพุตที่กำหนดให้เป็นรูปแบบไฟล์ลำดับ ยูทิลิตี้นี้ต้องการพารามิเตอร์สองตัว
- ไดเร็กทอรีไฟล์อินพุตที่มีข้อมูลต้นฉบับอยู่
- ไดเร็กทอรีไฟล์เอาต์พุตที่จะจัดเก็บข้อมูลคลัสเตอร์
ด้านล่างเป็นคำแนะนำช่วยเหลือของควาญช้าง seqdirectory ยูทิลิตี้
Step 1:เรียกดูโฮมไดเร็กทอรีของ Mahout คุณสามารถขอความช่วยเหลือจากยูทิลิตี้ดังที่แสดงด้านล่าง:
[Hadoop@localhost bin]$ ./mahout seqdirectory --help
Job-Specific Options:
--input (-i) input Path to job input directory.
--output (-o) output The directory pathname for output.
--overwrite (-ow) If present, overwrite the output directoryสร้างไฟล์ลำดับโดยใช้ยูทิลิตี้โดยใช้ไวยากรณ์ต่อไปนี้:
mahout seqdirectory -i <input file path> -o <output directory>Example
mahout seqdirectory
-i hdfs://localhost:9000/mahout_seq/
-o hdfs://localhost:9000/clustered_data/อัลกอริทึมการทำคลัสเตอร์
Mahout รองรับอัลกอริทึมหลักสองแบบสำหรับการทำคลัสเตอร์ ได้แก่ :
- การจัดกลุ่มหลังคา
- K-mean clustering
การจัดกลุ่มหลังคา
การจัดกลุ่ม Canopy เป็นเทคนิคที่ง่ายและรวดเร็วที่ Mahout ใช้เพื่อจุดประสงค์ในการจัดกลุ่ม วัตถุจะถือว่าเป็นจุดในพื้นที่ธรรมดา เทคนิคนี้มักใช้เป็นขั้นตอนเริ่มต้นในเทคนิคการทำคลัสเตอร์อื่น ๆ เช่น k-mean clustering คุณสามารถรันงาน Canopy โดยใช้ไวยากรณ์ต่อไปนี้:
mahout canopy -i <input vectors directory>
-o <output directory>
-t1 <threshold value 1>
-t2 <threshold value 2>งาน Canopy ต้องการไดเร็กทอรีไฟล์อินพุตที่มีไฟล์ลำดับและไดเร็กทอรีเอาต์พุตที่จะจัดเก็บข้อมูลคลัสเตอร์
Example
mahout canopy -i hdfs://localhost:9000/mahout_seq/mydata.seq
-o hdfs://localhost:9000/clustered_data
-t1 20
-t2 30คุณจะได้รับข้อมูลคลัสเตอร์ที่สร้างขึ้นในไดเร็กทอรีเอาต์พุตที่กำหนด
K-mean Clustering
K-mean clustering เป็นอัลกอริธึมการทำคลัสเตอร์ที่สำคัญ k ในอัลกอริทึมการทำคลัสเตอร์ k หมายถึงจำนวนคลัสเตอร์ที่จะแบ่งข้อมูลออกเป็น ตัวอย่างเช่นค่า k ที่ระบุในอัลกอริทึมนี้ถูกเลือกเป็น 3 อัลกอริทึมจะแบ่งข้อมูลออกเป็น 3 คลัสเตอร์
แต่ละวัตถุจะแสดงเป็นเวกเตอร์ในอวกาศ จุดเริ่มต้น k จะถูกเลือกโดยอัลกอริทึมแบบสุ่มและถือว่าเป็นจุดศูนย์กลางวัตถุทุกชิ้นที่อยู่ใกล้กับแต่ละจุดศูนย์กลางมากที่สุดจะรวมกลุ่มกัน มีหลายอัลกอริทึมสำหรับการวัดระยะทางและผู้ใช้ควรเลือกอันที่ต้องการ
Creating Vector Files
ซึ่งแตกต่างจากอัลกอริทึม Canopy อัลกอริทึม k-mean ต้องการไฟล์เวกเตอร์เป็นอินพุตดังนั้นคุณต้องสร้างไฟล์เวกเตอร์
ในการสร้างไฟล์เวกเตอร์จากรูปแบบไฟล์ลำดับ Mahout ให้ไฟล์ seq2parse ยูทิลิตี้
ด้านล่างนี้เป็นตัวเลือกบางส่วนของ seq2parseยูทิลิตี้ สร้างไฟล์เวกเตอร์โดยใช้ตัวเลือกเหล่านี้
$MAHOUT_HOME/bin/mahout seq2sparse
--analyzerName (-a) analyzerName The class name of the analyzer
--chunkSize (-chunk) chunkSize The chunkSize in MegaBytes.
--output (-o) output The directory pathname for o/p
--input (-i) input Path to job input directory.หลังจากสร้างเวกเตอร์แล้วให้ใช้อัลกอริทึม k-mean ไวยากรณ์ในการรัน k-mean job มีดังนี้:
mahout kmeans -i <input vectors directory>
-c <input clusters directory>
-o <output working directory>
-dm <Distance Measure technique>
-x <maximum number of iterations>
-k <number of initial clusters>งานคลัสเตอร์ K-mean ต้องการไดเร็กทอรีเวกเตอร์อินพุตไดเร็กทอรีคลัสเตอร์เอาต์พุตการวัดระยะทางจำนวนการทำซ้ำสูงสุดที่จะดำเนินการและค่าจำนวนเต็มแทนจำนวนคลัสเตอร์ที่ข้อมูลอินพุตจะถูกแบ่งออกเป็น