ควาญช้าง - คู่มือฉบับย่อ
เราอยู่ในวันและอายุที่มีข้อมูลมากมาย ข้อมูลที่มากเกินไปได้ปรับขนาดให้สูงขึ้นจนบางครั้งการจัดการกล่องจดหมายเล็ก ๆ ของเราก็เป็นเรื่องยาก! ลองนึกภาพปริมาณข้อมูลและบันทึกเว็บไซต์ยอดนิยมบางแห่ง (เช่น Facebook, Twitter และ Youtube) ต้องรวบรวมและจัดการในแต่ละวัน ไม่ใช่เรื่องแปลกแม้แต่เว็บไซต์ที่รู้จักกันน้อยจะได้รับข้อมูลจำนวนมากในปริมาณมาก
โดยปกติเราจะใช้อัลกอริทึมการขุดข้อมูลเพื่อวิเคราะห์ข้อมูลจำนวนมากเพื่อระบุแนวโน้มและหาข้อสรุป อย่างไรก็ตามไม่มีอัลกอริธึมการขุดข้อมูลใดที่มีประสิทธิภาพเพียงพอที่จะประมวลผลชุดข้อมูลขนาดใหญ่มากและให้ผลลัพธ์ได้ในเวลารวดเร็วเว้นแต่งานคำนวณจะทำงานบนเครื่องหลายเครื่องที่กระจายอยู่บนคลาวด์
ขณะนี้เรามีเฟรมเวิร์กใหม่ที่ช่วยให้เราสามารถแบ่งงานคำนวณออกเป็นหลายส่วนและเรียกใช้แต่ละส่วนบนเครื่องอื่น Mahout เป็นกรอบการขุดข้อมูลที่ปกติจะทำงานควบคู่กับโครงสร้างพื้นฐาน Hadoop ที่พื้นหลังเพื่อจัดการข้อมูลจำนวนมหาศาล
Apache Mahout คืออะไร?
ควาญช้างเป็นหนึ่งที่ไดรฟ์ช้างเป็นเจ้านายของมัน ชื่อนี้มาจากความสัมพันธ์ใกล้ชิดกับ Apache Hadoop ซึ่งใช้ช้างเป็นโลโก้
Hadoop เป็นเฟรมเวิร์กโอเพ่นซอร์สจาก Apache ที่ช่วยให้สามารถจัดเก็บและประมวลผลข้อมูลขนาดใหญ่ในสภาพแวดล้อมแบบกระจายทั่วกลุ่มของคอมพิวเตอร์โดยใช้โมเดลการเขียนโปรแกรมอย่างง่าย
Apache Mahoutเป็นโครงการโอเพ่นซอร์สที่ใช้เป็นหลักในการสร้างอัลกอริทึมการเรียนรู้ของเครื่องที่ปรับขนาดได้ ใช้เทคนิคการเรียนรู้ของเครื่องยอดนิยมเช่น:
- Recommendation
- Classification
- Clustering
Apache Mahout เริ่มต้นเป็นโปรเจ็กต์ย่อยของ Apache's Lucene ในปี 2008 ในปี 2010 Mahout กลายเป็นโปรเจ็กต์ระดับบนสุดของ Apache
คุณสมบัติของควาญช้าง
คุณสมบัติดั้งเดิมของ Apache Mahout มีดังต่อไปนี้
อัลกอริทึมของ Mahout เขียนไว้ที่ด้านบนของ Hadoop ดังนั้นจึงทำงานได้ดีในสภาพแวดล้อมแบบกระจาย Mahout ใช้ไลบรารี Apache Hadoop เพื่อปรับขนาดอย่างมีประสิทธิภาพในระบบคลาวด์
Mahout นำเสนอเฟรมเวิร์กที่พร้อมใช้งานสำหรับการทำเหมืองข้อมูลกับข้อมูลจำนวนมากให้กับผู้เข้ารหัส
Mahout ช่วยให้แอปพลิเคชันสามารถวิเคราะห์ข้อมูลจำนวนมากได้อย่างมีประสิทธิภาพและรวดเร็ว
รวมการใช้งานคลัสเตอร์ MapReduce หลายอย่างเช่น k-mean, fuzzy k-mean, Canopy, Dirichlet และ Mean-Shift
รองรับการใช้งานการจำแนกประเภท Naive Bayes แบบกระจายและการใช้งานการจำแนกประเภท Naive Bayes เสริม
มาพร้อมกับความสามารถในการออกกำลังกายแบบกระจายสำหรับการเขียนโปรแกรมเชิงวิวัฒนาการ
รวมถึงเมทริกซ์และไลบรารีเวกเตอร์
การใช้งาน Mahout
บริษัท ต่างๆเช่น Adobe, Facebook, LinkedIn, Foursquare, Twitter และ Yahoo ใช้ Mahout เป็นการภายใน
Foursquare ช่วยคุณในการค้นหาสถานที่อาหารและความบันเทิงที่มีอยู่ในพื้นที่เฉพาะ ใช้เครื่องมือแนะนำของ Mahout
Twitter ใช้ Mahout สำหรับการสร้างแบบจำลองความสนใจของผู้ใช้
Yahoo! ใช้ Mahout สำหรับการขุดรูปแบบ
Apache Mahout เป็นไลบรารีการเรียนรู้ของเครื่องที่ปรับขนาดได้สูงซึ่งช่วยให้นักพัฒนาสามารถใช้อัลกอริทึมที่ปรับให้เหมาะสมได้ Mahout ใช้เทคนิคการเรียนรู้ของเครื่องที่เป็นที่นิยมเช่นการแนะนำการจัดประเภทและการจัดกลุ่ม ดังนั้นจึงควรมีส่วนสั้น ๆ เกี่ยวกับการเรียนรู้ของเครื่องก่อนที่เราจะก้าวต่อไป
Machine Learning คืออะไร?
การเรียนรู้ของเครื่องเป็นสาขาหนึ่งของวิทยาศาสตร์ที่เกี่ยวข้องกับการเขียนโปรแกรมระบบในลักษณะที่พวกเขาเรียนรู้และปรับปรุงโดยอัตโนมัติด้วยประสบการณ์ ในที่นี้การเรียนรู้หมายถึงการรับรู้และเข้าใจข้อมูลที่ป้อนเข้าและการตัดสินใจอย่างชาญฉลาดโดยพิจารณาจากข้อมูลที่ให้มา
เป็นเรื่องยากมากที่จะตอบสนองการตัดสินใจทั้งหมดโดยพิจารณาจากปัจจัยที่เป็นไปได้ทั้งหมด เพื่อแก้ไขปัญหานี้อัลกอริทึมได้รับการพัฒนา อัลกอริทึมเหล่านี้สร้างความรู้จากข้อมูลที่เฉพาะเจาะจงและประสบการณ์ในอดีตด้วยหลักการของสถิติทฤษฎีความน่าจะเป็นตรรกะการเพิ่มประสิทธิภาพเชิงผสมการค้นหาการเรียนรู้แบบเสริมแรงและทฤษฎีการควบคุม
อัลกอริทึมที่พัฒนาขึ้นเป็นพื้นฐานของแอพพลิเคชั่นต่างๆเช่น:
- การประมวลผลวิสัยทัศน์
- การประมวลผลภาษา
- การคาดการณ์ (เช่นแนวโน้มตลาดหุ้น)
- การจดจำรูปแบบ
- Games
- การขุดข้อมูล
- ระบบผู้เชี่ยวชาญ
- Robotics
แมชชีนเลิร์นนิงเป็นพื้นที่ที่กว้างขวางและอยู่นอกเหนือขอบเขตของบทช่วยสอนนี้ที่จะครอบคลุมคุณลักษณะทั้งหมด มีหลายวิธีในการใช้เทคนิคการเรียนรู้ของเครื่องอย่างไรก็ตามวิธีที่ใช้กันมากที่สุดคือsupervised และ unsupervised learning.
การเรียนรู้ภายใต้การดูแล
การเรียนรู้ภายใต้การดูแลเกี่ยวข้องกับการเรียนรู้ฟังก์ชันจากข้อมูลการฝึกอบรมที่มีอยู่ อัลกอริธึมการเรียนรู้ภายใต้การดูแลจะวิเคราะห์ข้อมูลการฝึกอบรมและสร้างฟังก์ชันที่สรุปได้ซึ่งสามารถใช้สำหรับการทำแผนที่ตัวอย่างใหม่ ตัวอย่างทั่วไปของการเรียนรู้ภายใต้การดูแล ได้แก่ :
- การจัดประเภทอีเมลว่าเป็นสแปม
- การติดป้ายกำกับหน้าเว็บตามเนื้อหาและ
- การจดจำเสียง
มีอัลกอริทึมการเรียนรู้ที่ได้รับการดูแลมากมายเช่นเครือข่ายประสาทเทียม Support Vector Machines (SVMs) และตัวแยกประเภท Naive Bayes ควาญช้างใช้ลักษณนาม Naive Bayes
การเรียนรู้ที่ไม่มีผู้ดูแล
การเรียนรู้ที่ไม่ได้รับการดูแลทำให้เข้าใจถึงข้อมูลที่ไม่มีป้ายกำกับโดยไม่ต้องมีชุดข้อมูลที่กำหนดไว้ล่วงหน้าสำหรับการฝึกอบรม การเรียนรู้ที่ไม่มีผู้ดูแลเป็นเครื่องมือที่มีประสิทธิภาพอย่างยิ่งสำหรับการวิเคราะห์ข้อมูลที่มีอยู่และมองหารูปแบบและแนวโน้ม มักใช้สำหรับการจัดกลุ่มอินพุตที่คล้ายกันไว้ในกลุ่มตรรกะ แนวทางทั่วไปในการเรียนรู้โดยไม่มีผู้ดูแล ได้แก่ :
- k-means
- แผนที่จัดระเบียบตนเองและ
- การจัดกลุ่มตามลำดับชั้น
คำแนะนำ
คำแนะนำเป็นเทคนิคยอดนิยมที่ให้คำแนะนำอย่างใกล้ชิดโดยอิงจากข้อมูลของผู้ใช้เช่นการซื้อครั้งก่อนการคลิกและการให้คะแนน
Amazon ใช้เทคนิคนี้เพื่อแสดงรายการแนะนำที่คุณอาจสนใจโดยวาดข้อมูลจากการกระทำในอดีตของคุณ มีเครื่องมือแนะนำที่ทำงานอยู่เบื้องหลัง Amazon เพื่อจับพฤติกรรมของผู้ใช้และแนะนำรายการที่เลือกตามการกระทำก่อนหน้านี้ของคุณ
Facebook ใช้เทคนิคผู้แนะนำเพื่อระบุและแนะนำ“ รายชื่อบุคคลที่คุณอาจรู้จัก”

การจำแนกประเภท
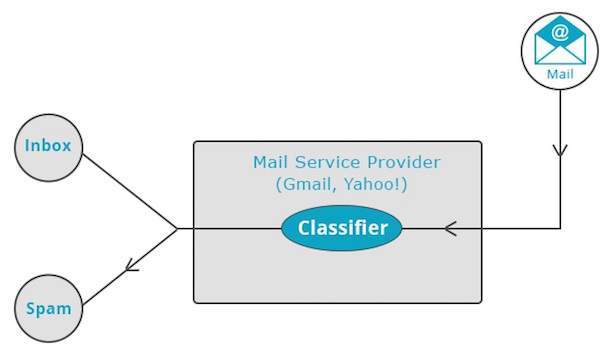
การจำแนกประเภทหรือที่เรียกว่า categorizationเป็นเทคนิคการเรียนรู้ของเครื่องที่ใช้ข้อมูลที่ทราบเพื่อกำหนดวิธีการจัดประเภทข้อมูลใหม่เป็นชุดของหมวดหมู่ที่มีอยู่ การจัดหมวดหมู่เป็นรูปแบบหนึ่งของการเรียนรู้ภายใต้การดูแล
ผู้ให้บริการจดหมายเช่น Yahoo! และ Gmail ใช้เทคนิคนี้ในการตัดสินใจว่าควรจัดประเภทอีเมลใหม่เป็นสแปมหรือไม่ อัลกอริธึมการจัดหมวดหมู่จะฝึกตัวเองโดยการวิเคราะห์พฤติกรรมของผู้ใช้ในการทำเครื่องหมายอีเมลบางฉบับว่าเป็นสแปม จากนั้นลักษณนามจะตัดสินใจว่าควรฝากอีเมลในอนาคตไว้ในกล่องจดหมายของคุณหรือในโฟลเดอร์จดหมายขยะ
แอปพลิเคชัน iTunes ใช้การจัดหมวดหมู่เพื่อจัดเตรียมรายการเพลง
การทำคลัสเตอร์
การทำคลัสเตอร์ใช้เพื่อสร้างกลุ่มหรือคลัสเตอร์ของข้อมูลที่คล้ายกันตามลักษณะทั่วไป การจัดกลุ่มเป็นรูปแบบหนึ่งของการเรียนรู้ที่ไม่มีผู้ดูแล
เครื่องมือค้นหาเช่น Google และ Yahoo! ใช้เทคนิคการจัดกลุ่มเพื่อจัดกลุ่มข้อมูลที่มีลักษณะคล้ายคลึงกัน
กลุ่มข่าวใช้เทคนิคการจัดกลุ่มเพื่อจัดกลุ่มบทความต่างๆตามหัวข้อที่เกี่ยวข้อง
กลไกการจัดกลุ่มจะส่งผ่านข้อมูลอินพุตอย่างสมบูรณ์และขึ้นอยู่กับลักษณะของข้อมูลโดยจะตัดสินใจว่าควรจัดกลุ่มคลัสเตอร์ใด ลองดูตัวอย่างต่อไปนี้
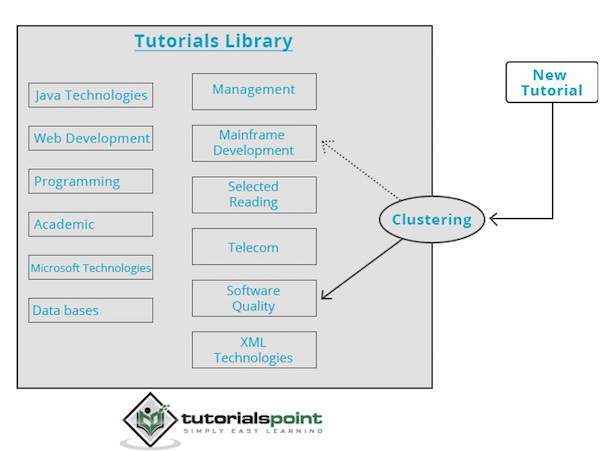
คลังบทเรียนของเราประกอบด้วยหัวข้อต่างๆ เมื่อเราได้รับบทช่วยสอนใหม่ที่ TutorialsPoint จะได้รับการประมวลผลโดยกลไกการทำคลัสเตอร์ที่ตัดสินใจโดยพิจารณาจากเนื้อหาที่ควรจัดกลุ่ม
บทนี้สอนวิธีตั้งค่าควาญช้าง Java และ Hadoop เป็นข้อกำหนดเบื้องต้นของควาญช้าง ด้านล่างนี้เป็นขั้นตอนในการดาวน์โหลดและติดตั้ง Java, Hadoop และ Mahout
การตั้งค่าก่อนการติดตั้ง
ก่อนติดตั้ง Hadoop ในสภาพแวดล้อม Linux เราต้องตั้งค่า Linux โดยใช้ ssh(Secure Shell) ทำตามขั้นตอนด้านล่างเพื่อตั้งค่าสภาพแวดล้อม Linux
การสร้างผู้ใช้
ขอแนะนำให้สร้างผู้ใช้แยกต่างหากสำหรับ Hadoop เพื่อแยกระบบไฟล์ Hadoop ออกจากระบบไฟล์ Unix ทำตามขั้นตอนด้านล่างเพื่อสร้างผู้ใช้:
เปิดรูทโดยใช้คำสั่ง“ su”
- สร้างผู้ใช้จากบัญชีรูทโดยใช้คำสั่ง “useradd username”.
ตอนนี้คุณสามารถเปิดบัญชีผู้ใช้ที่มีอยู่โดยใช้คำสั่ง “su username”.
เปิดเทอร์มินัล Linux และพิมพ์คำสั่งต่อไปนี้เพื่อสร้างผู้ใช้
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdการตั้งค่า SSH และการสร้างคีย์
จำเป็นต้องมีการตั้งค่า SSH เพื่อดำเนินการต่างๆบนคลัสเตอร์เช่นการเริ่มต้นการหยุดและการดำเนินการเชลล์ daemon แบบกระจาย ในการรับรองความถูกต้องของผู้ใช้ Hadoop ที่แตกต่างกันจำเป็นต้องให้คู่คีย์สาธารณะ / ส่วนตัวสำหรับผู้ใช้ Hadoop และแชร์กับผู้ใช้รายอื่น
คำสั่งต่อไปนี้ใช้เพื่อสร้างคู่ค่าคีย์โดยใช้ SSH คัดลอกคีย์สาธารณะในรูปแบบ id_rsa.pub ไปยัง Authorized_keys และให้สิทธิ์เจ้าของอ่านและเขียนไปยังไฟล์ Author_keys ตามลำดับ
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keysกำลังตรวจสอบ ssh
ssh localhostการติดตั้ง Java
Java เป็นข้อกำหนดเบื้องต้นหลักสำหรับ Hadoop และ HBase ก่อนอื่นคุณควรตรวจสอบการมีอยู่ของ Java ในระบบของคุณโดยใช้ "java -version" ไวยากรณ์ของคำสั่งเวอร์ชัน Java แสดงไว้ด้านล่าง
$ java -versionควรให้ผลลัพธ์ดังต่อไปนี้
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)หากคุณไม่ได้ติดตั้ง Java ในระบบของคุณให้ทำตามขั้นตอนด้านล่างเพื่อติดตั้ง Java
Step 1
ดาวน์โหลด java (JDK <เวอร์ชันล่าสุด> - X64.tar.gz) โดยไปที่ลิงค์ต่อไปนี้: Oracle
แล้ว jdk-7u71-linux-x64.tar.gz is downloaded เข้าสู่ระบบของคุณ
Step 2
โดยทั่วไปคุณจะพบไฟล์ Java ที่ดาวน์โหลดมาในโฟลเดอร์ดาวน์โหลด ตรวจสอบและแตกไฟล์jdk-7u71-linux-x64.gz ไฟล์โดยใช้คำสั่งต่อไปนี้
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzStep 3
เพื่อให้ผู้ใช้ทุกคนสามารถใช้งาน Java ได้คุณต้องย้ายไปยังตำแหน่ง“ / usr / local /” เปิดรูทและพิมพ์คำสั่งต่อไปนี้
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitStep 4
สำหรับการตั้งค่า PATH และ JAVA_HOME ตัวแปรเพิ่มคำสั่งต่อไปนี้ ~/.bashrc file.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH= $PATH:$JAVA_HOME/binตอนนี้ตรวจสอบไฟล์ java -version คำสั่งจากเทอร์มินัลตามที่อธิบายไว้ข้างต้น
กำลังดาวน์โหลด Hadoop
หลังจากติดตั้ง Java คุณต้องติดตั้ง Hadoop ในขั้นต้น ตรวจสอบการมีอยู่ของ Hadoop โดยใช้คำสั่ง“ Hadoop version” ตามที่แสดงด้านล่าง
hadoop versionควรสร้างผลลัพธ์ต่อไปนี้:
Hadoop 2.6.0
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoopcommon-2.6.0.jarหากระบบของคุณไม่พบ Hadoop ให้ดาวน์โหลด Hadoop และติดตั้งลงในระบบของคุณ ทำตามคำสั่งด้านล่างเพื่อดำเนินการดังกล่าว
ดาวน์โหลดและแยก hadoop-2.6.0 จากพื้นฐานซอฟต์แวร์ apache โดยใช้คำสั่งต่อไปนี้
$ su
password:
# cd /usr/local
# wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop-
2.6.0/hadoop-2.6.0-src.tar.gz
# tar xzf hadoop-2.6.0-src.tar.gz
# mv hadoop-2.6.0/* hadoop/
# exitการติดตั้ง Hadoop
ติดตั้ง Hadoop ในโหมดที่ต้องการ ที่นี่เรากำลังสาธิตการทำงานของ HBase ในโหมดหลอกกระจายดังนั้นจึงติดตั้ง Hadoop ในโหมดหลอกกระจาย
ทำตามขั้นตอนด้านล่างเพื่อติดตั้ง Hadoop 2.4.1 ในระบบของคุณ
ขั้นตอนที่ 1: การตั้งค่า Hadoop
คุณสามารถตั้งค่าตัวแปรสภาพแวดล้อม Hadoop ได้โดยต่อท้ายคำสั่งต่อไปนี้ ~/.bashrc ไฟล์.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOMEตอนนี้ใช้การเปลี่ยนแปลงทั้งหมดในระบบที่กำลังทำงานอยู่
$ source ~/.bashrcขั้นตอนที่ 2: การกำหนดค่า Hadoop
คุณสามารถค้นหาไฟล์การกำหนดค่า Hadoop ทั้งหมดได้ที่ตำแหน่ง“ $ HADOOP_HOME / etc / hadoop” จำเป็นต้องทำการเปลี่ยนแปลงในไฟล์การกำหนดค่าเหล่านั้นตามโครงสร้างพื้นฐาน Hadoop ของคุณ
$ cd $HADOOP_HOME/etc/hadoopในการพัฒนาโปรแกรม Hadoop ใน Java คุณต้องรีเซ็ตตัวแปรสภาพแวดล้อม Java ใน hadoop-env.sh ไฟล์โดยแทนที่ไฟล์ JAVA_HOME ค่ากับตำแหน่งของ Java ในระบบของคุณ
export JAVA_HOME=/usr/local/jdk1.7.0_71ด้านล่างนี้คือรายการไฟล์ที่คุณต้องแก้ไขเพื่อกำหนดค่า Hadoop
core-site.xml
core-site.xml ไฟล์มีข้อมูลเช่นหมายเลขพอร์ตที่ใช้สำหรับอินสแตนซ์ Hadoop หน่วยความจำที่จัดสรรสำหรับระบบไฟล์ขีด จำกัด หน่วยความจำสำหรับจัดเก็บข้อมูลและขนาดของบัฟเฟอร์อ่าน / เขียน
เปิด core-site.xml และเพิ่มคุณสมบัติต่อไปนี้ระหว่างแท็ก <configuration>, </configuration>:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xm
hdfs-site.xmlไฟล์มีข้อมูลเช่นค่าของข้อมูลการจำลอง, พา ธ namenode และพา ธ datanode ของระบบไฟล์โลคัลของคุณ หมายถึงสถานที่ที่คุณต้องการจัดเก็บโครงสร้างพื้นฐาน Hadoop
ให้เราสมมติข้อมูลต่อไปนี้:
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeเปิดไฟล์นี้และเพิ่มคุณสมบัติต่อไปนี้ระหว่างแท็ก <configuration>, </configuration> ในไฟล์นี้
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note:ในไฟล์ด้านบนค่าคุณสมบัติทั้งหมดถูกกำหนดโดยผู้ใช้ คุณสามารถเปลี่ยนแปลงได้ตามโครงสร้างพื้นฐาน Hadoop ของคุณ
mapred-site.xml
ไฟล์นี้ใช้เพื่อกำหนดค่าเส้นด้ายใน Hadoop เปิดไฟล์ mapred-site.xml และเพิ่มคุณสมบัติต่อไปนี้ระหว่างแท็ก <configuration>, </configuration> ในไฟล์นี้
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
ไฟล์นี้ใช้เพื่อระบุเฟรมเวิร์ก MapReduce ที่เราใช้อยู่ โดยค่าเริ่มต้น Hadoop มีเทมเพลตของ mapred-site.xml ก่อนอื่นต้องคัดลอกไฟล์จากไฟล์mapred-site.xml.template ถึง mapred-site.xml ไฟล์โดยใช้คำสั่งต่อไปนี้
$ cp mapred-site.xml.template mapred-site.xmlเปิด mapred-site.xml ไฟล์และเพิ่มคุณสมบัติต่อไปนี้ระหว่างแท็ก <configuration>, </configuration> ในไฟล์นี้
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>การตรวจสอบการติดตั้ง Hadoop
ขั้นตอนต่อไปนี้ใช้เพื่อตรวจสอบการติดตั้ง Hadoop
ขั้นตอนที่ 1: ตั้งชื่อโหนด
ตั้งค่า Namenode โดยใช้คำสั่ง“ hdfs namenode -format” ดังนี้:
$ cd ~
$ hdfs namenode -formatผลลัพธ์ที่คาดหวังมีดังนี้:
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain
1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/ขั้นตอนที่ 2: การตรวจสอบ Hadoop dfs
คำสั่งต่อไปนี้ใช้เพื่อเริ่ม dfs คำสั่งนี้เริ่มระบบไฟล์ Hadoop ของคุณ
$ start-dfs.shผลลัพธ์ที่คาดหวังมีดังนี้:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]ขั้นตอนที่ 3: การตรวจสอบสคริปต์เส้นด้าย
คำสั่งต่อไปนี้ใช้เพื่อเริ่มสคริปต์เส้นด้าย การดำเนินการคำสั่งนี้จะเริ่มปีศาจเส้นด้ายของคุณ
$ start-yarn.shผลลัพธ์ที่คาดหวังมีดังนี้:
starting yarn daemons
starting resource manager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-
hadoop-resourcemanager-localhost.out
localhost: starting node manager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outขั้นตอนที่ 4: การเข้าถึง Hadoop บนเบราว์เซอร์
หมายเลขพอร์ตเริ่มต้นในการเข้าถึง hadoop คือ 50070 ใช้ URL ต่อไปนี้เพื่อรับบริการ Hadoop บนเบราว์เซอร์ของคุณ
http://localhost:50070/
ขั้นตอนที่ 5: ตรวจสอบแอปพลิเคชันทั้งหมดสำหรับคลัสเตอร์
หมายเลขพอร์ตเริ่มต้นเพื่อเข้าถึงแอปพลิเคชันทั้งหมดของคลัสเตอร์คือ 8088 ใช้ URL ต่อไปนี้เพื่อเยี่ยมชมบริการนี้
http://localhost:8088/
กำลังดาวน์โหลด Mahout
ควาญช้างที่มีอยู่ในเว็บไซต์ของควาญช้าง ดาวน์โหลด Mahout จากลิงค์ที่ให้ไว้ในเว็บไซต์ นี่คือภาพหน้าจอของเว็บไซต์

ขั้นตอนที่ 1
ดาวน์โหลด Apache mahout จากลิงค์ http://mirror.nexcess.net/apache/mahout/ โดยใช้คำสั่งต่อไปนี้
[Hadoop@localhost ~]$ wget
http://mirror.nexcess.net/apache/mahout/0.9/mahout-distribution-0.9.tar.gzแล้ว mahout-distribution-0.9.tar.gz จะถูกดาวน์โหลดในระบบของคุณ
ขั้นตอนที่ 2
เรียกดูโฟลเดอร์ที่ mahout-distribution-0.9.tar.gz จะถูกจัดเก็บและแตกไฟล์ jar ที่ดาวน์โหลดมาดังแสดงด้านล่าง
[Hadoop@localhost ~]$ tar zxvf mahout-distribution-0.9.tar.gzพื้นที่เก็บข้อมูล Maven
ด้านล่างคือ pom.xml สำหรับสร้าง Apache Mahout โดยใช้ Eclipse
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>0.9</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-math</artifactId>
<version>${mahout.version}</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-integration</artifactId>
<version>${mahout.version}</version>
</dependency>บทนี้ครอบคลุมเทคนิคการเรียนรู้ของเครื่องยอดนิยมที่เรียกว่า recommendation, กลไกและวิธีการเขียนแอปพลิเคชันตามคำแนะนำของควาญช้าง
คำแนะนำ
เคยสงสัยบ้างไหมว่า Amazon จัดทำรายการแนะนำเพื่อดึงดูดความสนใจของคุณไปยังผลิตภัณฑ์เฉพาะที่คุณอาจสนใจได้อย่างไร!
สมมติว่าคุณต้องการซื้อหนังสือ“ Mahout in Action” จาก Amazon:
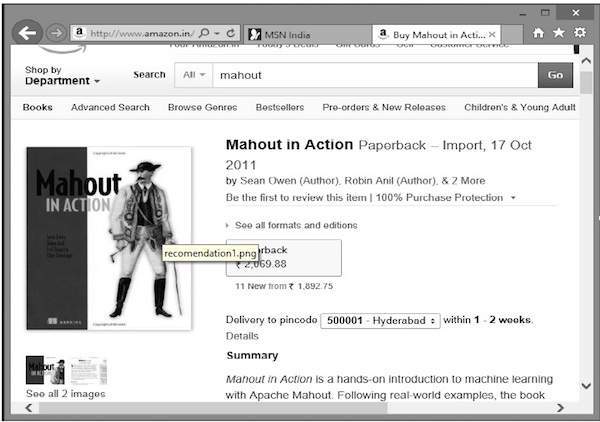
นอกเหนือจากผลิตภัณฑ์ที่เลือกแล้ว Amazon ยังแสดงรายการแนะนำที่เกี่ยวข้องดังที่แสดงด้านล่าง

รายการคำแนะนำดังกล่าวจัดทำขึ้นด้วยความช่วยเหลือของ recommender engines. Mahout มีเครื่องมือแนะนำหลายประเภทเช่น:
- ผู้แนะนำตามผู้ใช้
- ผู้แนะนำตามรายการและ
- อัลกอริทึมอื่น ๆ อีกมากมาย
เครื่องมือแนะนำ Mahout
Mahout มีเอ็นจิ้นผู้แนะนำแบบไม่แจกจ่ายและไม่อิงตาม Hadoop คุณควรส่งเอกสารข้อความที่มีการกำหนดลักษณะของผู้ใช้สำหรับรายการต่างๆ และผลลัพธ์ของเอ็นจิ้นนี้จะเป็นค่ากำหนดโดยประมาณของผู้ใช้เฉพาะสำหรับรายการอื่น ๆ
ตัวอย่าง
พิจารณาเว็บไซต์ที่ขายสินค้าอุปโภคบริโภคเช่นโทรศัพท์มือถือแกดเจ็ตและอุปกรณ์เสริม หากเราต้องการใช้คุณสมบัติของ Mahout ในไซต์ดังกล่าวเราสามารถสร้างเครื่องมือแนะนำได้ เครื่องมือนี้จะวิเคราะห์ข้อมูลการซื้อในอดีตของผู้ใช้และแนะนำผลิตภัณฑ์ใหม่ตามนั้น
ส่วนประกอบที่ Mahout จัดหาให้เพื่อสร้างเอ็นจิ้นผู้แนะนำมีดังนี้:
- DataModel
- UserSimilarity
- ItemSimilarity
- UserNeighborhood
- Recommender
จากที่เก็บข้อมูลโมเดลข้อมูลจะถูกจัดเตรียมและถูกส่งผ่านเป็นอินพุตไปยังเอ็นจินผู้แนะนำ เครื่องมือแนะนำจะสร้างคำแนะนำสำหรับผู้ใช้เฉพาะ ด้านล่างนี้เป็นสถาปัตยกรรมของเครื่องมือแนะนำ
สถาปัตยกรรมของเครื่องมือแนะนำ

การสร้างผู้แนะนำโดยใช้ Mahout
ขั้นตอนในการพัฒนาผู้แนะนำง่ายๆมีดังนี้
ขั้นตอนที่ 1: สร้าง DataModel Object
ตัวสร้างของ PearsonCorrelationSimilarityคลาสต้องการอ็อบเจ็กต์โมเดลข้อมูลซึ่งเก็บไฟล์ที่มีรายละเอียดผู้ใช้ไอเท็มและค่ากำหนดของผลิตภัณฑ์ นี่คือไฟล์โมเดลข้อมูลตัวอย่าง:
1,00,1.0
1,01,2.0
1,02,5.0
1,03,5.0
1,04,5.0
2,00,1.0
2,01,2.0
2,05,5.0
2,06,4.5
2,02,5.0
3,01,2.5
3,02,5.0
3,03,4.0
3,04,3.0
4,00,5.0
4,01,5.0
4,02,5.0
4,03,0.0DataModelอ็อบเจ็กต์ต้องการอ็อบเจ็กต์ไฟล์ซึ่งมีพา ธ ของอินพุตไฟล์ สร้างไฟล์DataModel วัตถุดังที่แสดงด้านล่าง
DataModel datamodel = new FileDataModel(new File("input file"));ขั้นตอนที่ 2: สร้าง UserSimilarity Object
สร้าง UserSimilarity วัตถุโดยใช้ PearsonCorrelationSimilarity คลาสดังแสดงด้านล่าง:
UserSimilarity similarity = new PearsonCorrelationSimilarity(datamodel);ขั้นตอนที่ 3: สร้างวัตถุ UserNeighborhood
วัตถุนี้คำนวณ "พื้นที่ใกล้เคียง" ของผู้ใช้เช่นเดียวกับผู้ใช้ที่ระบุ ย่านใกล้เคียงมีสองประเภท:
NearestNUserNeighborhood- คลาสนี้คำนวณย่านที่ประกอบด้วยผู้ใช้n ที่ใกล้ที่สุดกับผู้ใช้ที่ระบุ "ใกล้ที่สุด" ถูกกำหนดโดย UserSimilarity ที่กำหนด
ThresholdUserNeighborhood- คลาสนี้คำนวณพื้นที่ใกล้เคียงซึ่งประกอบด้วยผู้ใช้ทั้งหมดที่มีความคล้ายคลึงกับผู้ใช้ที่กำหนดตรงตามหรือเกินเกณฑ์ที่กำหนด ความคล้ายคลึงกันถูกกำหนดโดย UserSimilarity ที่กำหนด
ที่นี่เรากำลังใช้ ThresholdUserNeighborhood และตั้งค่าขีด จำกัด ของการตั้งค่าเป็น 3.0
UserNeighborhood neighborhood = new ThresholdUserNeighborhood(3.0, similarity, model);ขั้นตอนที่ 4: สร้างวัตถุผู้แนะนำ
สร้าง UserbasedRecomenderวัตถุ. ส่งผ่านวัตถุที่สร้างข้างต้นทั้งหมดไปยังตัวสร้างดังที่แสดงด้านล่าง
UserBasedRecommender recommender = new GenericUserBasedRecommender(model, neighborhood, similarity);ขั้นตอนที่ 5: แนะนำรายการให้กับผู้ใช้
แนะนำผลิตภัณฑ์ให้กับผู้ใช้โดยใช้วิธีการแนะนำ () ของ Recommenderอินเตอร์เฟซ. วิธีนี้ต้องใช้สองพารามิเตอร์ อันแรกแสดงถึงรหัสผู้ใช้ของผู้ใช้ที่เราต้องส่งคำแนะนำและอันที่สองหมายถึงจำนวนคำแนะนำที่จะส่ง นี่คือการใช้งานของrecommender() วิธี:
List<RecommendedItem> recommendations = recommender.recommend(2, 3);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}Example Program
ด้านล่างเป็นโปรแกรมตัวอย่างในการตั้งค่าคำแนะนำ เตรียมคำแนะนำสำหรับผู้ใช้ด้วยรหัสผู้ใช้ 2
import java.io.File;
import java.util.List;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.ThresholdUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.UserBasedRecommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
public class Recommender {
public static void main(String args[]){
try{
//Creating data model
DataModel datamodel = new FileDataModel(new File("data")); //data
//Creating UserSimilarity object.
UserSimilarity usersimilarity = new PearsonCorrelationSimilarity(datamodel);
//Creating UserNeighbourHHood object.
UserNeighborhood userneighborhood = new ThresholdUserNeighborhood(3.0, usersimilarity, datamodel);
//Create UserRecomender
UserBasedRecommender recommender = new GenericUserBasedRecommender(datamodel, userneighborhood, usersimilarity);
List<RecommendedItem> recommendations = recommender.recommend(2, 3);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
}catch(Exception e){}
}
}คอมไพล์โปรแกรมโดยใช้คำสั่งต่อไปนี้:
javac Recommender.java
java Recommenderควรสร้างผลลัพธ์ต่อไปนี้:
RecommendedItem [item:3, value:4.5]
RecommendedItem [item:4, value:4.0]การทำคลัสเตอร์เป็นขั้นตอนในการจัดองค์ประกอบหรือรายการของคอลเลกชันที่กำหนดให้เป็นกลุ่มตามความคล้ายคลึงกันระหว่างรายการ ตัวอย่างเช่นแอปพลิเคชันที่เกี่ยวข้องกับการเผยแพร่ข่าวออนไลน์จัดกลุ่มบทความข่าวโดยใช้การทำคลัสเตอร์
การประยุกต์ใช้การทำคลัสเตอร์
การทำคลัสเตอร์ใช้กันอย่างแพร่หลายในหลาย ๆ แอปพลิเคชันเช่นการวิจัยตลาดการจดจำรูปแบบการวิเคราะห์ข้อมูลและการประมวลผลภาพ
การทำคลัสเตอร์สามารถช่วยให้นักการตลาดค้นพบกลุ่มที่แตกต่างกันตามฐานลูกค้าของตน และสามารถกำหนดลักษณะกลุ่มลูกค้าได้ตามรูปแบบการซื้อ
ในสาขาชีววิทยาสามารถใช้เพื่อหาอนุกรมวิธานของพืชและสัตว์จัดหมวดหมู่ยีนที่มีฟังก์ชันการทำงานที่คล้ายคลึงกันและได้รับข้อมูลเชิงลึกเกี่ยวกับโครงสร้างที่มีอยู่ในประชากร
การจัดกลุ่มช่วยในการระบุพื้นที่ที่มีการใช้ประโยชน์ที่ดินในลักษณะเดียวกันในฐานข้อมูลการสังเกตการณ์บนพื้นโลก
การจัดกลุ่มยังช่วยในการจัดประเภทเอกสารบนเว็บสำหรับการค้นหาข้อมูล
การทำคลัสเตอร์ใช้ในแอปพลิเคชันการตรวจจับค่าผิดปกติเช่นการตรวจจับการฉ้อโกงบัตรเครดิต
ในฐานะฟังก์ชั่นการขุดข้อมูล Cluster Analysis ทำหน้าที่เป็นเครื่องมือในการทำความเข้าใจเกี่ยวกับการกระจายข้อมูลเพื่อสังเกตลักษณะของแต่ละคลัสเตอร์
การใช้ Mahout ทำให้เราสามารถจัดกลุ่มข้อมูลที่กำหนดได้ ขั้นตอนที่จำเป็นมีดังต่อไปนี้:
Algorithm คุณต้องเลือกอัลกอริทึมการจัดกลุ่มที่เหมาะสมเพื่อจัดกลุ่มองค์ประกอบของคลัสเตอร์
Similarity and Dissimilarity คุณต้องมีกฎเพื่อตรวจสอบความคล้ายคลึงกันระหว่างองค์ประกอบที่พบใหม่และองค์ประกอบในกลุ่ม
Stopping Condition ต้องมีเงื่อนไขการหยุดเพื่อกำหนดจุดที่ไม่จำเป็นต้องทำคลัสเตอร์
ขั้นตอนการทำคลัสเตอร์
ในการจัดกลุ่มข้อมูลที่คุณต้องการ -
เริ่มเซิร์ฟเวอร์ Hadoop สร้างไดเร็กทอรีที่จำเป็นสำหรับการจัดเก็บไฟล์ใน Hadoop File System (สร้างไดเร็กทอรีสำหรับอินพุตไฟล์ไฟล์ลำดับและเอาต์พุตคลัสเตอร์ในกรณีของ canopy)
คัดลอกไฟล์อินพุตไปยังระบบ Hadoop File จากระบบไฟล์ Unix
เตรียมไฟล์ลำดับจากข้อมูลอินพุต
เรียกใช้อัลกอริทึมการทำคลัสเตอร์ใด ๆ ที่มีอยู่
รับข้อมูลคลัสเตอร์
เริ่ม Hadoop
Mahout ทำงานร่วมกับ Hadoop ดังนั้นตรวจสอบให้แน่ใจว่าเซิร์ฟเวอร์ Hadoop พร้อมใช้งานแล้ว
$ cd HADOOP_HOME/bin
$ start-all.shการเตรียมไดเร็กทอรีไฟล์อินพุต
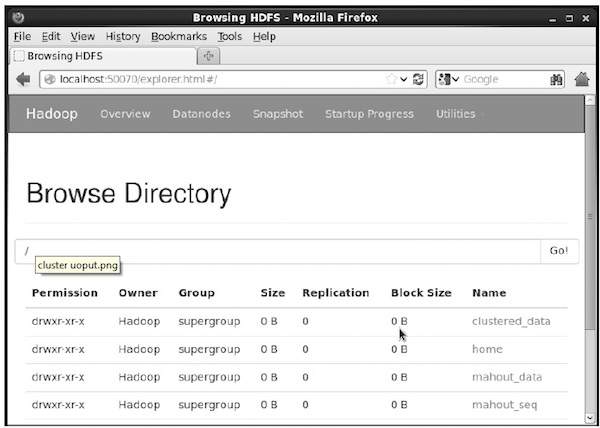
สร้างไดเร็กทอรีในระบบไฟล์ Hadoop เพื่อเก็บไฟล์อินพุตไฟล์ลำดับและข้อมูลคลัสเตอร์โดยใช้คำสั่งต่อไปนี้:
$ hadoop fs -p mkdir /mahout_data
$ hadoop fs -p mkdir /clustered_data
$ hadoop fs -p mkdir /mahout_seqคุณสามารถตรวจสอบว่าไดเร็กทอรีถูกสร้างโดยใช้เว็บอินเตอร์เฟส hadoop ใน URL ต่อไปนี้ - http://localhost:50070/
ให้ผลลัพธ์ดังที่แสดงด้านล่าง:
การคัดลอกไฟล์อินพุตเป็น HDFS
ตอนนี้คัดลอกไฟล์ข้อมูลอินพุตจากระบบไฟล์ Linux ไปยังไดเร็กทอรี mahout_data ใน Hadoop File System ดังที่แสดงด้านล่าง สมมติว่าไฟล์อินพุตของคุณคือ mydata.txt และอยู่ในไดเร็กทอรี / home / Hadoop / data /
$ hadoop fs -put /home/Hadoop/data/mydata.txt /mahout_data/กำลังเตรียมไฟล์ลำดับ
Mahout มียูทิลิตี้ในการแปลงไฟล์อินพุตที่กำหนดให้เป็นรูปแบบไฟล์ลำดับ ยูทิลิตี้นี้ต้องการพารามิเตอร์สองตัว
- ไดเร็กทอรีไฟล์อินพุตที่มีข้อมูลต้นฉบับอยู่
- ไดเร็กทอรีไฟล์เอาต์พุตที่จะจัดเก็บข้อมูลคลัสเตอร์
ด้านล่างเป็นคำแนะนำช่วยเหลือของควาญช้าง seqdirectory ยูทิลิตี้
Step 1:เรียกดูโฮมไดเร็กทอรีของ Mahout คุณสามารถขอความช่วยเหลือจากยูทิลิตี้ดังที่แสดงด้านล่าง:
[Hadoop@localhost bin]$ ./mahout seqdirectory --help
Job-Specific Options:
--input (-i) input Path to job input directory.
--output (-o) output The directory pathname for output.
--overwrite (-ow) If present, overwrite the output directoryสร้างไฟล์ลำดับโดยใช้ยูทิลิตี้โดยใช้ไวยากรณ์ต่อไปนี้:
mahout seqdirectory -i <input file path> -o <output directory>Example
mahout seqdirectory
-i hdfs://localhost:9000/mahout_seq/
-o hdfs://localhost:9000/clustered_data/อัลกอริทึมการทำคลัสเตอร์
Mahout รองรับอัลกอริทึมหลักสองแบบสำหรับการทำคลัสเตอร์ ได้แก่ :
- การจัดกลุ่มหลังคา
- K-mean clustering
การจัดกลุ่มหลังคา
การจัดกลุ่ม Canopy เป็นเทคนิคที่ง่ายและรวดเร็วที่ Mahout ใช้เพื่อจุดประสงค์ในการจัดกลุ่ม วัตถุจะถือว่าเป็นจุดในพื้นที่ธรรมดา เทคนิคนี้มักใช้เป็นขั้นตอนเริ่มต้นในเทคนิคการทำคลัสเตอร์อื่น ๆ เช่น k-mean clustering คุณสามารถรันงาน Canopy โดยใช้ไวยากรณ์ต่อไปนี้:
mahout canopy -i <input vectors directory>
-o <output directory>
-t1 <threshold value 1>
-t2 <threshold value 2>งาน Canopy ต้องการไดเร็กทอรีไฟล์อินพุตที่มีไฟล์ลำดับและไดเร็กทอรีเอาต์พุตที่จะจัดเก็บข้อมูลคลัสเตอร์
Example
mahout canopy -i hdfs://localhost:9000/mahout_seq/mydata.seq
-o hdfs://localhost:9000/clustered_data
-t1 20
-t2 30คุณจะได้รับข้อมูลคลัสเตอร์ที่สร้างขึ้นในไดเร็กทอรีเอาต์พุตที่กำหนด
K-mean Clustering
K-mean clustering เป็นอัลกอริธึมการทำคลัสเตอร์ที่สำคัญ k ในอัลกอริทึมการทำคลัสเตอร์ k หมายถึงจำนวนคลัสเตอร์ที่จะแบ่งข้อมูลออกเป็น ตัวอย่างเช่นค่า k ที่ระบุในอัลกอริทึมนี้ถูกเลือกเป็น 3 อัลกอริทึมจะแบ่งข้อมูลออกเป็น 3 คลัสเตอร์
แต่ละวัตถุจะแสดงเป็นเวกเตอร์ในอวกาศ จุดเริ่มต้น k จะถูกเลือกโดยอัลกอริทึมแบบสุ่มและถือว่าเป็นจุดศูนย์กลางวัตถุทุกชิ้นที่อยู่ใกล้กับแต่ละจุดศูนย์กลางมากที่สุดจะรวมกลุ่มกัน มีหลายอัลกอริทึมสำหรับการวัดระยะทางและผู้ใช้ควรเลือกอันที่ต้องการ
Creating Vector Files
ซึ่งแตกต่างจากอัลกอริทึม Canopy อัลกอริทึม k-mean ต้องการไฟล์เวกเตอร์เป็นอินพุตดังนั้นคุณต้องสร้างไฟล์เวกเตอร์
ในการสร้างไฟล์เวกเตอร์จากรูปแบบไฟล์ลำดับ Mahout ให้ไฟล์ seq2parse ยูทิลิตี้
ด้านล่างนี้เป็นตัวเลือกบางส่วนของ seq2parseยูทิลิตี้ สร้างไฟล์เวกเตอร์โดยใช้ตัวเลือกเหล่านี้
$MAHOUT_HOME/bin/mahout seq2sparse
--analyzerName (-a) analyzerName The class name of the analyzer
--chunkSize (-chunk) chunkSize The chunkSize in MegaBytes.
--output (-o) output The directory pathname for o/p
--input (-i) input Path to job input directory.หลังจากสร้างเวกเตอร์แล้วให้ใช้อัลกอริทึม k-mean ไวยากรณ์ในการรัน k-mean job มีดังนี้:
mahout kmeans -i <input vectors directory>
-c <input clusters directory>
-o <output working directory>
-dm <Distance Measure technique>
-x <maximum number of iterations>
-k <number of initial clusters>งานคลัสเตอร์ K-mean ต้องการไดเร็กทอรีเวกเตอร์อินพุตไดเร็กทอรีคลัสเตอร์เอาต์พุตการวัดระยะทางจำนวนการทำซ้ำสูงสุดที่จะดำเนินการและค่าจำนวนเต็มแทนจำนวนคลัสเตอร์ที่ข้อมูลอินพุตจะถูกแบ่งออกเป็น
Classification คืออะไร?
การจัดหมวดหมู่เป็นเทคนิคการเรียนรู้ของเครื่องที่ใช้ข้อมูลที่ทราบเพื่อพิจารณาว่าข้อมูลใหม่ควรถูกจัดประเภทเป็นชุดของหมวดหมู่ที่มีอยู่อย่างไร ตัวอย่างเช่น,
แอปพลิเคชัน iTunes ใช้การจัดหมวดหมู่เพื่อจัดเตรียมรายการเพลง
ผู้ให้บริการจดหมายเช่น Yahoo! และ Gmail ใช้เทคนิคนี้ในการตัดสินใจว่าควรจัดประเภทอีเมลใหม่เป็นสแปมหรือไม่ อัลกอริธึมการจัดหมวดหมู่จะฝึกตัวเองโดยการวิเคราะห์พฤติกรรมของผู้ใช้ในการทำเครื่องหมายอีเมลบางฉบับว่าเป็นสแปม จากนั้นลักษณนามจะตัดสินใจว่าควรฝากอีเมลในอนาคตไว้ในกล่องจดหมายของคุณหรือในโฟลเดอร์จดหมายขยะ
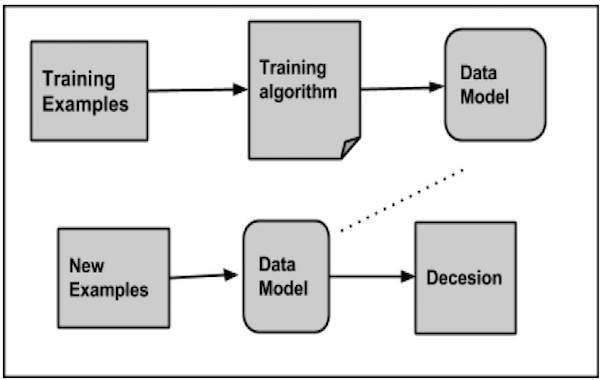
การจำแนกประเภททำงานอย่างไร
ในขณะที่จำแนกชุดข้อมูลที่กำหนดระบบลักษณนามจะดำเนินการดังต่อไปนี้:
- ในขั้นต้นแบบจำลองข้อมูลใหม่จัดทำขึ้นโดยใช้อัลกอริทึมการเรียนรู้ใด ๆ
- จากนั้นจึงทดสอบแบบจำลองข้อมูลที่เตรียมไว้
- หลังจากนั้นแบบจำลองข้อมูลนี้จะถูกใช้เพื่อประเมินข้อมูลใหม่และกำหนดคลาส
การประยุกต์ใช้การจำแนกประเภท
Credit card fraud detection- กลไกการจำแนกประเภทใช้เพื่อทำนายการฉ้อโกงบัตรเครดิต การใช้ข้อมูลในอดีตของการฉ้อโกงครั้งก่อนลักษณนามสามารถคาดเดาได้ว่าธุรกรรมใดในอนาคตอาจกลายเป็นการฉ้อโกง
Spam e-mails - ขึ้นอยู่กับลักษณะของสแปมเมลก่อนหน้าตัวจำแนกจะกำหนดว่าควรส่งอีเมลที่พบใหม่ไปยังโฟลเดอร์สแปมหรือไม่
ลักษณนาม Naive Bayes
Mahout ใช้อัลกอริธึมลักษณนาม Naive Bayes ใช้สองการใช้งาน:
- การจำแนกประเภท Naive Bayes แบบกระจาย
- การจำแนกประเภท Naive Bayes เสริม
Naive Bayes เป็นเทคนิคง่ายๆในการสร้างลักษณนาม ไม่ใช่อัลกอริทึมเดียวสำหรับการฝึกตัวแยกประเภทดังกล่าว แต่เป็นกลุ่มของอัลกอริทึม ลักษณนาม Bayes สร้างโมเดลเพื่อจำแนกอินสแตนซ์ของปัญหา การจำแนกประเภทเหล่านี้จัดทำขึ้นโดยใช้ข้อมูลที่มีอยู่
ข้อได้เปรียบของบาเยสที่ไร้เดียงสาคือต้องใช้ข้อมูลการฝึกอบรมเพียงเล็กน้อยเพื่อประมาณค่าพารามิเตอร์ที่จำเป็นสำหรับการจำแนกประเภท
สำหรับแบบจำลองความน่าจะเป็นบางประเภทตัวแยกประเภทของ Bayes ที่ไร้เดียงสาสามารถฝึกได้อย่างมีประสิทธิภาพในสภาพแวดล้อมการเรียนรู้ภายใต้การดูแล
แม้จะมีสมมติฐานที่เข้าใจง่าย แต่ลักษณนามของ Bayes ที่ไร้เดียงสาก็ทำงานได้ดีในสถานการณ์จริงที่ซับซ้อนหลายอย่าง
ขั้นตอนการจัดหมวดหมู่
ต้องปฏิบัติตามขั้นตอนต่อไปนี้เพื่อใช้การจำแนกประเภท:
- สร้างข้อมูลตัวอย่าง
- สร้างไฟล์ลำดับจากข้อมูล
- แปลงไฟล์ลำดับเป็นเวกเตอร์
- ฝึกเวกเตอร์
- ทดสอบเวกเตอร์
ขั้นที่ 1: สร้างข้อมูลตัวอย่าง
สร้างหรือดาวน์โหลดข้อมูลที่จะจัดประเภท ตัวอย่างเช่นคุณจะได้รับไฟล์ 20 newsgroups ตัวอย่างข้อมูลจากลิงค์ต่อไปนี้: http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz
สร้างไดเร็กทอรีสำหรับจัดเก็บข้อมูลอินพุต ดาวน์โหลดตัวอย่างตามภาพด้านล่าง
$ mkdir classification_example
$ cd classification_example
$tar xzvf 20news-bydate.tar.gz
wget http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gzขั้นตอนที่ 2: สร้างไฟล์ลำดับ
สร้างไฟล์ลำดับจากตัวอย่างโดยใช้ seqdirectoryยูทิลิตี้ ไวยากรณ์ในการสร้างลำดับได้รับด้านล่าง:
mahout seqdirectory -i <input file path> -o <output directory>ขั้นตอนที่ 3: แปลงไฟล์ลำดับเป็นเวกเตอร์
สร้างไฟล์เวกเตอร์จากไฟล์ลำดับโดยใช้ seq2parseยูทิลิตี้ ตัวเลือกของ seq2parse ยูทิลิตี้ได้รับด้านล่าง:
$MAHOUT_HOME/bin/mahout seq2sparse
--analyzerName (-a) analyzerName The class name of the analyzer
--chunkSize (-chunk) chunkSize The chunkSize in MegaBytes.
--output (-o) output The directory pathname for o/p
--input (-i) input Path to job input directory.ขั้นตอนที่ 4: ฝึกเวกเตอร์
ฝึกเวกเตอร์ที่สร้างขึ้นโดยใช้ trainnbยูทิลิตี้ ตัวเลือกที่จะใช้trainnb ยูทิลิตี้ได้รับด้านล่าง:
mahout trainnb
-i ${PATH_TO_TFIDF_VECTORS}
-el
-o ${PATH_TO_MODEL}/model
-li ${PATH_TO_MODEL}/labelindex
-ow
-cขั้นตอนที่ 5: ทดสอบเวกเตอร์
ทดสอบเวกเตอร์โดยใช้ testnbยูทิลิตี้ ตัวเลือกที่จะใช้testnb ยูทิลิตี้ได้รับด้านล่าง:
mahout testnb
-i ${PATH_TO_TFIDF_TEST_VECTORS}
-m ${PATH_TO_MODEL}/model
-l ${PATH_TO_MODEL}/labelindex
-ow
-o ${PATH_TO_OUTPUT}
-c
-seq