MapReduce - Combiners
Combiner หรือที่เรียกว่า semi-reducer, เป็นคลาสทางเลือกที่ดำเนินการโดยรับอินพุตจากคลาส Map และหลังจากนั้นส่งคู่คีย์ - ค่าเอาต์พุตไปยังคลาส Reducer
หน้าที่หลักของ Combiner คือการสรุปบันทึกผลลัพธ์แผนที่ด้วยคีย์เดียวกัน เอาต์พุต (การรวบรวมคีย์ - ค่า) ของตัวรวมจะถูกส่งผ่านเครือข่ายไปยังงานลดจริงเป็นอินพุต
Combiner
คลาส Combiner ใช้ระหว่างคลาสแผนที่และคลาสลดเพื่อลดปริมาณการถ่ายโอนข้อมูลระหว่างแผนที่และลด โดยปกติผลลัพธ์ของงานแผนที่จะมีขนาดใหญ่และข้อมูลที่ถ่ายโอนไปยังงานลดจะสูง
แผนผังงาน MapReduce ต่อไปนี้แสดง COMBINER PHASE
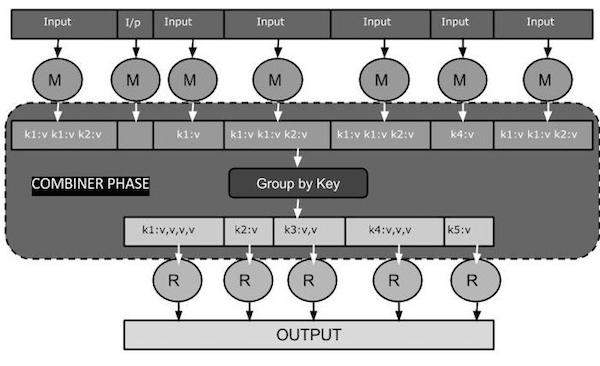
Combiner ทำงานอย่างไร?
นี่คือสรุปสั้น ๆ เกี่ยวกับวิธีการทำงานของ MapReduce Combiner -
Combiner ไม่มีอินเทอร์เฟซที่กำหนดไว้ล่วงหน้าและต้องใช้วิธีการลด () ของส่วนต่อประสาน Reducer
Combiner ทำงานบนคีย์เอาต์พุตแต่ละแผนที่ ต้องมีประเภทคีย์ - ค่าเอาต์พุตเดียวกันกับคลาส Reducer
Combiner สามารถสร้างข้อมูลสรุปจากชุดข้อมูลขนาดใหญ่ได้เนื่องจากแทนที่เอาต์พุตแผนที่ดั้งเดิม
แม้ว่า Combiner จะเป็นทางเลือก แต่ก็ช่วยแยกข้อมูลออกเป็นหลายกลุ่มสำหรับ Reduce phase ซึ่งทำให้ประมวลผลได้ง่ายขึ้น
การใช้งาน MapReduce Combiner
ตัวอย่างต่อไปนี้ให้แนวคิดเชิงทฤษฎีเกี่ยวกับตัวผสม สมมติว่าเรามีไฟล์ข้อความอินพุตต่อไปนี้ชื่อinput.txt สำหรับ MapReduce
What do you mean by Object
What do you know about Java
What is Java Virtual Machine
How Java enabled High Performanceขั้นตอนที่สำคัญของโปรแกรม MapReduce กับ Combiner จะกล่าวถึงด้านล่าง
ผู้อ่านบันทึก
นี่เป็นเฟสแรกของ MapReduce ที่ตัวอ่านบันทึกอ่านทุกบรรทัดจากไฟล์ข้อความอินพุตเป็นข้อความและให้ผลลัพธ์เป็นคู่คีย์ - ค่า
Input - ข้อความทีละบรรทัดจากไฟล์อินพุต
Output- สร้างคู่คีย์ - ค่า ต่อไปนี้คือชุดของคู่คีย์ - ค่าที่คาดไว้
<1, What do you mean by Object>
<2, What do you know about Java>
<3, What is Java Virtual Machine>
<4, How Java enabled High Performance>แผนที่เฟส
เฟสแผนที่รับอินพุตจากเครื่องอ่านบันทึกประมวลผลและสร้างเอาต์พุตเป็นชุดคู่คีย์ - ค่าอื่น
Input - คู่คีย์ - ค่าต่อไปนี้คืออินพุตที่นำมาจากเครื่องอ่านบันทึก
<1, What do you mean by Object>
<2, What do you know about Java>
<3, What is Java Virtual Machine>
<4, How Java enabled High Performance>เฟสแผนที่อ่านคู่คีย์ - ค่าแต่ละคู่แบ่งแต่ละคำออกจากค่าโดยใช้ StringTokenizer ถือว่าแต่ละคำเป็นคีย์และนับคำนั้นเป็นค่า ข้อมูลโค้ดต่อไปนี้แสดงคลาส Mapper และฟังก์ชันแผนที่
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}Output - ผลลัพธ์ที่คาดหวังมีดังนี้ -
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1>
<What,1> <do,1> <you,1> <know,1> <about,1> <Java,1>
<What,1> <is,1> <Java,1> <Virtual,1> <Machine,1>
<How,1> <Java,1> <enabled,1> <High,1> <Performance,1>เฟส Combiner
เฟส Combiner รับคู่คีย์ - ค่าแต่ละคู่จากเฟสแผนที่ประมวลผลและสร้างเอาต์พุตเป็น key-value collection คู่
Input - คู่คีย์ - ค่าต่อไปนี้คืออินพุตที่นำมาจากเฟสแผนที่
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1>
<What,1> <do,1> <you,1> <know,1> <about,1> <Java,1>
<What,1> <is,1> <Java,1> <Virtual,1> <Machine,1>
<How,1> <Java,1> <enabled,1> <High,1> <Performance,1>เฟส Combiner อ่านคู่คีย์ - ค่าแต่ละคู่รวมคำทั่วไปเป็นคีย์และค่าเป็นคอลเลกชัน โดยปกติรหัสและการทำงานของ Combiner จะคล้ายกับตัวลด ต่อไปนี้เป็นข้อมูลโค้ดสำหรับการประกาศคลาส Mapper, Combiner และ Reducer
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);Output - ผลลัพธ์ที่คาดหวังมีดังนี้ -
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,1,1,1>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>เฟสลด
เฟส Reducer นำคู่การรวบรวมคีย์ - ค่าแต่ละคู่จากเฟส Combiner ประมวลผลและส่งเอาต์พุตเป็นคู่คีย์ - ค่า โปรดทราบว่าการทำงานของ Combiner เหมือนกับตัวลด
Input - คู่คีย์ - ค่าต่อไปนี้คืออินพุตที่นำมาจากเฟส Combiner
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,1,1,1>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>เฟส Reducer จะอ่านคู่คีย์ - ค่าแต่ละคู่ ต่อไปนี้เป็นข้อมูลโค้ดสำหรับ Combiner
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}Output - ผลลัพธ์ที่คาดหวังจากเฟส Reducer มีดังนี้ -
<What,3> <do,2> <you,2> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,3>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>ผู้เขียนบันทึก
นี่คือเฟสสุดท้ายของ MapReduce ที่ Record Writer เขียนทุกคู่คีย์ - ค่าจากเฟส Reducer และส่งเอาต์พุตเป็นข้อความ
Input - แต่ละคู่คีย์ - ค่าจากเฟสลดพร้อมกับรูปแบบเอาต์พุต
Output- ให้คู่คีย์ - ค่าในรูปแบบข้อความ ต่อไปนี้คือผลลัพธ์ที่คาดหวัง
What 3
do 2
you 2
mean 1
by 1
Object 1
know 1
about 1
Java 3
is 1
Virtual 1
Machine 1
How 1
enabled 1
High 1
Performance 1ตัวอย่างโปรแกรม
บล็อกโค้ดต่อไปนี้จะนับจำนวนคำในโปรแกรม
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}บันทึกโปรแกรมข้างต้นเป็น WordCount.java. การรวบรวมและการดำเนินการของโปรแกรมมีดังต่อไปนี้
การรวบรวมและการดำเนินการ
สมมติว่าเราอยู่ในโฮมไดเร็กทอรีของผู้ใช้ Hadoop (ตัวอย่างเช่น / home / hadoop)
ทำตามขั้นตอนด้านล่างเพื่อคอมไพล์และรันโปรแกรมข้างต้น
Step 1 - ใช้คำสั่งต่อไปนี้เพื่อสร้างไดเร็กทอรีเพื่อจัดเก็บคลาส java ที่คอมไพล์
$ mkdir unitsStep 2- ดาวน์โหลด Hadoop-core-1.2.1.jar ซึ่งใช้ในการคอมไพล์และรันโปรแกรม MapReduce คุณสามารถดาวน์โหลดขวดจากmvnrepository.com
ให้เราถือว่าโฟลเดอร์ที่ดาวน์โหลดคือ / home / hadoop /
Step 3 - ใช้คำสั่งต่อไปนี้เพื่อรวบรวมไฟล์ WordCount.java โปรแกรมและสร้าง jar สำหรับโปรแกรม
$ javac -classpath hadoop-core-1.2.1.jar -d units WordCount.java
$ jar -cvf units.jar -C units/ .Step 4 - ใช้คำสั่งต่อไปนี้เพื่อสร้างไดเร็กทอรีอินพุตใน HDFS
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirStep 5 - ใช้คำสั่งต่อไปนี้เพื่อคัดลอกไฟล์อินพุตที่ชื่อ input.txt ในไดเร็กทอรีอินพุตของ HDFS
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/input.txt input_dirStep 6 - ใช้คำสั่งต่อไปนี้เพื่อตรวจสอบไฟล์ในไดเร็กทอรีอินพุต
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 7 - ใช้คำสั่งต่อไปนี้เพื่อเรียกใช้แอปพลิเคชัน Word count โดยรับไฟล์อินพุตจากไดเร็กทอรีอินพุต
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dirรอสักครู่จนกว่าไฟล์จะถูกเรียกใช้งาน หลังจากดำเนินการแล้วเอาต์พุตจะมีการแยกอินพุตงานแผนที่และงานลดจำนวน
Step 8 - ใช้คำสั่งต่อไปนี้เพื่อตรวจสอบไฟล์ผลลัพธ์ในโฟลเดอร์ผลลัพธ์
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Step 9 - ใช้คำสั่งต่อไปนี้เพื่อดูผลลัพธ์ในรูปแบบ Part-00000ไฟล์. ไฟล์นี้สร้างโดย HDFS
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000ต่อไปนี้เป็นผลลัพธ์ที่สร้างโดยโปรแกรม MapReduce
What 3
do 2
you 2
mean 1
by 1
Object 1
know 1
about 1
Java 3
is 1
Virtual 1
Machine 1
How 1
enabled 1
High 1
Performance 1