MapReduce - คู่มือฉบับย่อ
MapReduce เป็นรูปแบบการเขียนโปรแกรมสำหรับเขียนแอพพลิเคชั่นที่สามารถประมวลผล Big Data ควบคู่กันบนโหนดหลาย ๆ โหนด MapReduce ให้ความสามารถในการวิเคราะห์สำหรับการวิเคราะห์ข้อมูลที่ซับซ้อนจำนวนมหาศาล
Big Data คืออะไร?
Big Data คือชุดข้อมูลขนาดใหญ่ที่ไม่สามารถประมวลผลได้โดยใช้เทคนิคการคำนวณแบบดั้งเดิม ตัวอย่างเช่นปริมาณข้อมูลที่ Facebook หรือ Youtube จำเป็นต้องใช้ในการรวบรวมและจัดการในแต่ละวันอาจอยู่ในประเภทของ Big Data อย่างไรก็ตามข้อมูลขนาดใหญ่ไม่เพียง แต่เกี่ยวกับขนาดและปริมาตรเท่านั้น แต่ยังเกี่ยวข้องกับหนึ่งในด้านต่อไปนี้ด้วยเช่นความเร็วความหลากหลายปริมาณและความซับซ้อน
ทำไมต้อง MapReduce?
โดยปกติระบบองค์กรแบบดั้งเดิมจะมีเซิร์ฟเวอร์ส่วนกลางเพื่อจัดเก็บและประมวลผลข้อมูล ภาพประกอบต่อไปนี้แสดงให้เห็นถึงมุมมองแผนผังของระบบองค์กรแบบดั้งเดิม แบบจำลองดั้งเดิมไม่เหมาะสมอย่างแน่นอนในการประมวลผลข้อมูลจำนวนมากที่ปรับขนาดได้และไม่สามารถรองรับได้โดยเซิร์ฟเวอร์ฐานข้อมูลมาตรฐาน ยิ่งไปกว่านั้นระบบรวมศูนย์จะสร้างคอขวดมากเกินไปในขณะที่ประมวลผลไฟล์หลายไฟล์พร้อมกัน

Google แก้ไขปัญหาคอขวดนี้โดยใช้อัลกอริทึมที่เรียกว่า MapReduce MapReduce แบ่งงานออกเป็นส่วนเล็ก ๆ และกำหนดให้กับคอมพิวเตอร์หลายเครื่อง หลังจากนั้นผลลัพธ์จะถูกรวบรวมไว้ในที่เดียวและรวมเข้าด้วยกันเพื่อสร้างชุดข้อมูลผลลัพธ์

MapReduce ทำงานอย่างไร
อัลกอริทึม MapReduce ประกอบด้วยสองภารกิจที่สำคัญ ได้แก่ แผนที่และลด
งานแผนที่รับชุดข้อมูลและแปลงเป็นชุดข้อมูลอื่นโดยที่องค์ประกอบแต่ละรายการจะแบ่งออกเป็นสิ่งที่รวมกัน (คู่คีย์ - ค่า)
งานลดจะใช้เอาต์พุตจากแผนที่เป็นอินพุตและรวมสิ่งที่มีข้อมูลเหล่านั้น (คู่คีย์ - ค่า) เข้ากับทูเปิลชุดเล็ก ๆ
งานลดจะดำเนินการหลังงานแผนที่เสมอ
ตอนนี้ให้เราดูแต่ละขั้นตอนอย่างละเอียดและพยายามทำความเข้าใจความสำคัญของพวกเขา
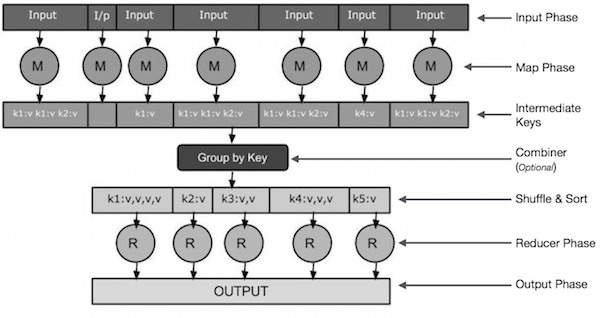
Input Phase - ที่นี่เรามีเครื่องอ่านบันทึกที่แปลแต่ละระเบียนในไฟล์อินพุตและส่งข้อมูลที่แยกวิเคราะห์ไปยังผู้ทำแผนที่ในรูปแบบของคู่คีย์ - ค่า
Map - แผนที่เป็นฟังก์ชันที่ผู้ใช้กำหนดเองซึ่งรับชุดของคู่คีย์ - ค่าและประมวลผลแต่ละคู่เพื่อสร้างคู่คีย์ - ค่าที่เป็นศูนย์หรือมากกว่า
Intermediate Keys - คู่คีย์ - ค่าที่สร้างโดยผู้ทำแผนที่เรียกว่าคีย์กลาง
Combiner- Combiner เป็นประเภทของ Reducer ในพื้นที่ที่จัดกลุ่มข้อมูลที่คล้ายกันจากเฟสแผนที่เป็นชุดที่ระบุได้ ใช้คีย์กลางจากผู้ทำแผนที่เป็นอินพุตและใช้โค้ดที่ผู้ใช้กำหนดเองเพื่อรวมค่าในขอบเขตเล็ก ๆ ของผู้ทำแผนที่เดียว ไม่ได้เป็นส่วนหนึ่งของอัลกอริทึม MapReduce หลัก เป็นทางเลือก
Shuffle and Sort- งาน Reducer เริ่มต้นด้วยขั้นตอนสุ่มและเรียงลำดับ จะดาวน์โหลดคู่คีย์ - ค่าที่จัดกลุ่มไว้บนเครื่องโลคัลซึ่งตัวลดกำลังทำงานอยู่ คู่คีย์ - ค่าแต่ละคู่จะเรียงตามคีย์ลงในรายการข้อมูลที่ใหญ่ขึ้น รายการข้อมูลจะจัดกลุ่มคีย์ที่เท่ากันเข้าด้วยกันเพื่อให้สามารถวนซ้ำค่าได้อย่างง่ายดายในงาน Reducer
Reducer- ตัวลดจะรับข้อมูลที่จับคู่คีย์ - ค่าที่จัดกลุ่มไว้เป็นอินพุตและเรียกใช้ฟังก์ชันลดสำหรับแต่ละรายการ ที่นี่ข้อมูลสามารถรวมกรองและรวมกันได้หลายวิธีและต้องใช้การประมวลผลที่หลากหลาย เมื่อการดำเนินการสิ้นสุดลงจะให้คู่คีย์ - ค่าเป็นศูนย์หรือมากกว่าในขั้นตอนสุดท้าย
Output Phase - ในเฟสเอาต์พุตเรามีตัวจัดรูปแบบเอาต์พุตที่แปลคู่คีย์ - ค่าสุดท้ายจากฟังก์ชัน Reducer และเขียนลงในไฟล์โดยใช้เครื่องบันทึก
ให้เราพยายามทำความเข้าใจทั้งสองงาน Map & f ลดด้วยความช่วยเหลือของแผนภาพขนาดเล็ก -

MapReduce- ตัวอย่าง
ให้เราใช้ตัวอย่างในโลกแห่งความเป็นจริงเพื่อทำความเข้าใจพลังของ MapReduce Twitter ได้รับประมาณ 500 ล้านทวีตต่อวันซึ่งเกือบ 3000 ทวีตต่อวินาที ภาพประกอบต่อไปนี้แสดงให้เห็นว่าทวีตเตอร์จัดการทวีตด้วยความช่วยเหลือของ MapReduce อย่างไร
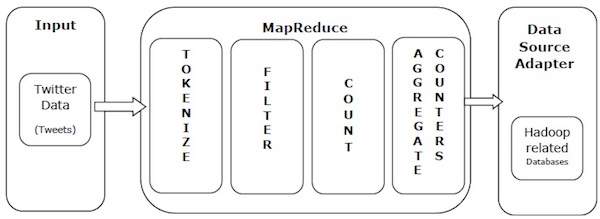
ดังที่แสดงในภาพประกอบอัลกอริทึม MapReduce ดำเนินการดังต่อไปนี้ -
Tokenize - แปลงทวีตลงในแผนที่ของโทเค็นและเขียนเป็นคู่คีย์ - ค่า
Filter - กรองคำที่ไม่ต้องการจากแผนที่ของโทเค็นและเขียนแผนที่ที่กรองแล้วเป็นคู่คีย์ - ค่า
Count - สร้างตัวนับโทเค็นต่อคำ
Aggregate Counters - เตรียมการรวมของค่าตัวนับที่คล้ายกันเป็นหน่วยที่จัดการได้ขนาดเล็ก
อัลกอริทึม MapReduce ประกอบด้วยสองภารกิจที่สำคัญ ได้แก่ แผนที่และลด
- ภารกิจแผนที่ทำได้โดยใช้ Mapper Class
- งานลดจะทำโดยวิธีการลดระดับ
คลาส Mapper รับอินพุตโทเค็นแมปและจัดเรียงข้อมูล เอาต์พุตของคลาส Mapper ถูกใช้เป็นอินพุตโดยคลาส Reducer ซึ่งจะค้นหาคู่ที่ตรงกันและลดลง

MapReduce ใช้อัลกอริทึมทางคณิตศาสตร์ที่หลากหลายเพื่อแบ่งงานออกเป็นส่วนเล็ก ๆ และกำหนดให้กับระบบต่างๆ ในแง่เทคนิคอัลกอริทึม MapReduce ช่วยในการส่งงานแผนที่และลดไปยังเซิร์ฟเวอร์ที่เหมาะสมในคลัสเตอร์
อัลกอริทึมทางคณิตศาสตร์เหล่านี้อาจรวมถึงสิ่งต่อไปนี้ -
- Sorting
- Searching
- Indexing
- TF-IDF
การเรียงลำดับ
การเรียงลำดับเป็นหนึ่งในอัลกอริทึม MapReduce พื้นฐานในการประมวลผลและวิเคราะห์ข้อมูล MapReduce ใช้อัลกอริทึมการเรียงลำดับเพื่อจัดเรียงคู่คีย์ - ค่าเอาต์พุตจากตัวแมปเปอร์ด้วยคีย์โดยอัตโนมัติ
วิธีการเรียงลำดับถูกนำไปใช้ในคลาส mapper เอง
ในเฟสสุ่มและเรียงลำดับหลังจากโทเค็นค่าในคลาส mapper แล้วไฟล์ Context คลาส (คลาสที่ผู้ใช้กำหนดเอง) รวบรวมคีย์มูลค่าที่ตรงกันเป็นคอลเลกชัน
ในการรวบรวมคู่คีย์ - ค่าที่คล้ายกัน (คีย์ระดับกลาง) คลาส Mapper จะช่วย RawComparator คลาสเพื่อจัดเรียงคู่คีย์ - ค่า
ชุดของคู่คีย์ - ค่าระดับกลางสำหรับตัวลดที่ระบุจะถูกจัดเรียงโดยอัตโนมัติโดย Hadoop เพื่อสร้างคีย์ - ค่า (K2, {V2, V2, …}) ก่อนที่จะนำเสนอต่อตัวลด
กำลังค้นหา
การค้นหามีบทบาทสำคัญในอัลกอริทึม MapReduce ช่วยในเฟส Combiner (ทางเลือก) และในเฟส Reducer ให้เราพยายามทำความเข้าใจว่า Searching ทำงานอย่างไรโดยใช้ตัวอย่าง
ตัวอย่าง
ตัวอย่างต่อไปนี้แสดงให้เห็นว่า MapReduce ใช้อัลกอริทึมการค้นหาเพื่อค้นหารายละเอียดของพนักงานที่ได้รับเงินเดือนสูงสุดในชุดข้อมูลพนักงานที่กำหนดอย่างไร
สมมติว่าเรามีข้อมูลพนักงานในสี่ไฟล์ที่แตกต่างกัน - A, B, C และ D นอกจากนี้เรายังถือว่ามีประวัติพนักงานที่ซ้ำกันในทั้งสี่ไฟล์เนื่องจากการนำเข้าข้อมูลพนักงานจากตารางฐานข้อมูลทั้งหมดซ้ำ ๆ ดูภาพประกอบต่อไปนี้

The Map phaseประมวลผลไฟล์อินพุตแต่ละไฟล์และจัดเตรียมข้อมูลพนักงานในคู่คีย์ - ค่า (<k, v>: <emp name, เงินเดือน>) ดูภาพประกอบต่อไปนี้

The combiner phase(เทคนิคการค้นหา) จะรับอินพุตจากเฟสแผนที่เป็นคู่คีย์ - ค่าพร้อมชื่อพนักงานและเงินเดือน การใช้เทคนิคการค้นหาตัวรวมจะตรวจสอบเงินเดือนพนักงานทั้งหมดเพื่อค้นหาพนักงานที่ได้รับเงินเดือนสูงสุดในแต่ละไฟล์ ดูตัวอย่างต่อไปนี้
<k: employee name, v: salary>
Max= the salary of an first employee. Treated as max salary
if(v(second employee).salary > Max){
Max = v(salary);
}
else{
Continue checking;
}ผลที่คาดว่าจะได้รับมีดังนี้ -
|
Reducer phase- สร้างแต่ละไฟล์คุณจะพบพนักงานที่ได้รับเงินเดือนสูงสุด เพื่อหลีกเลี่ยงความซ้ำซ้อนให้ตรวจสอบคู่ <k, v> ทั้งหมดและกำจัดรายการที่ซ้ำกันถ้ามี ใช้อัลกอริทึมเดียวกันระหว่างคู่ <k, v> สี่คู่ซึ่งมาจากไฟล์อินพุตสี่ไฟล์ ผลลัพธ์สุดท้ายควรเป็นดังนี้ -
<gopal, 50000>การจัดทำดัชนี
โดยปกติการจัดทำดัชนีจะใช้เพื่อชี้ไปที่ข้อมูลเฉพาะและที่อยู่ ดำเนินการจัดทำดัชนีแบทช์ในไฟล์อินพุตสำหรับ Mapper เฉพาะ
เทคนิคการสร้างดัชนีที่ปกติใช้ใน MapReduce เรียกว่า inverted index.เครื่องมือค้นหาเช่น Google และ Bing ใช้เทคนิคการสร้างดัชนีกลับด้าน ให้เราพยายามทำความเข้าใจว่าการจัดทำดัชนีทำงานอย่างไรโดยใช้ตัวอย่างง่ายๆ
ตัวอย่าง
ข้อความต่อไปนี้เป็นข้อมูลสำหรับการจัดทำดัชนีกลับหัว ที่นี่ T [0], T [1] และ t [2] คือชื่อไฟล์และเนื้อหาอยู่ในเครื่องหมายอัญประกาศคู่
T[0] = "it is what it is"
T[1] = "what is it"
T[2] = "it is a banana"หลังจากใช้อัลกอริทึมการทำดัชนีเราจะได้ผลลัพธ์ต่อไปนี้ -
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}นี่คือ "a": {2} มีความหมายโดยนัยของคำว่า "a" ปรากฏในไฟล์ T [2] ในทำนองเดียวกัน "is": {0, 1, 2} แสดงนัยถึงคำว่า "is" ปรากฏในไฟล์ T [0], T [1] และ T [2]
TF-IDF
TF-IDF เป็นอัลกอริทึมการประมวลผลข้อความซึ่งย่อมาจาก Term Frequency - Inverse Document Frequency เป็นหนึ่งในอัลกอริทึมการวิเคราะห์เว็บทั่วไป ในที่นี้คำว่า 'ความถี่' หมายถึงจำนวนครั้งที่คำที่ปรากฏในเอกสาร
ระยะความถี่ (TF)
วัดผลว่าคำใดคำหนึ่งเกิดขึ้นบ่อยเพียงใดในเอกสาร คำนวณโดยจำนวนครั้งที่คำปรากฏในเอกสารหารด้วยจำนวนคำทั้งหมดในเอกสารนั้น
TF(the) = (Number of times term the ‘the’ appears in a document) / (Total number of terms in the document)ความถี่เอกสารผกผัน (IDF)
เป็นการวัดความสำคัญของคำศัพท์ คำนวณโดยจำนวนเอกสารในฐานข้อมูลข้อความหารด้วยจำนวนเอกสารที่มีคำเฉพาะปรากฏขึ้น
ในขณะที่คำนวณ TF คำศัพท์ทั้งหมดถือว่ามีความสำคัญเท่าเทียมกัน นั่นหมายความว่า TF จะนับความถี่ของคำศัพท์สำหรับคำปกติเช่น“ is”,“ a”,“ what” เป็นต้นดังนั้นเราจึงจำเป็นต้องทราบคำศัพท์ที่ใช้บ่อยในขณะที่ขยายคำที่หายากโดยคำนวณดังนี้ -
IDF(the) = log_e(Total number of documents / Number of documents with term ‘the’ in it).อัลกอริทึมอธิบายไว้ด้านล่างด้วยความช่วยเหลือของตัวอย่างเล็ก ๆ
ตัวอย่าง
พิจารณาเอกสารที่มีคำ 1,000 คำซึ่งคำนั้น hiveปรากฏ 50 ครั้ง TF สำหรับhive คือ (50/1000) = 0.05
ตอนนี้สมมติว่าเรามีเอกสาร 10 ล้านฉบับและคำว่า hiveปรากฏใน 1,000 รายการ จากนั้น IDF จะคำนวณเป็นบันทึก (10,000,000 / 1,000) = 4
น้ำหนัก TF-IDF เป็นผลคูณจากปริมาณเหล่านี้ - 0.05 × 4 = 0.20
MapReduce ใช้งานได้เฉพาะบนระบบปฏิบัติการที่ปรุงแต่งด้วย Linux และมาพร้อมกับ Hadoop Framework เราจำเป็นต้องทำตามขั้นตอนต่อไปนี้เพื่อติดตั้ง Hadoop framework
การตรวจสอบการติดตั้ง JAVA
ต้องติดตั้ง Java บนระบบของคุณก่อนที่จะติดตั้ง Hadoop ใช้คำสั่งต่อไปนี้เพื่อตรวจสอบว่าคุณติดตั้ง Java บนระบบของคุณหรือไม่
$ java –versionหากมีการติดตั้ง Java ในระบบของคุณแล้วคุณจะเห็นการตอบสนองต่อไปนี้ -
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)ในกรณีที่คุณไม่ได้ติดตั้ง Java ในระบบของคุณให้ทำตามขั้นตอนด้านล่าง
การติดตั้ง Java
ขั้นตอนที่ 1
ดาวน์โหลด Java เวอร์ชันล่าสุดจากลิงค์ต่อไปนี้ - ลิงค์นี้
หลังจากดาวน์โหลดคุณสามารถค้นหาไฟล์ได้ jdk-7u71-linux-x64.tar.gz ในโฟลเดอร์ดาวน์โหลดของคุณ
ขั้นตอนที่ 2
ใช้คำสั่งต่อไปนี้เพื่อแยกเนื้อหาของ jdk-7u71-linux-x64.gz
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzขั้นตอนที่ 3
เพื่อให้ผู้ใช้ทุกคนสามารถใช้งาน Java ได้คุณต้องย้ายไปยังตำแหน่ง“ / usr / local /” ไปที่รูทและพิมพ์คำสั่งต่อไปนี้ -
$ su
password:
# mv jdk1.7.0_71 /usr/local/java
# exitขั้นตอนที่ 4
สำหรับการตั้งค่าตัวแปร PATH และ JAVA_HOME ให้เพิ่มคำสั่งต่อไปนี้ในไฟล์ ~ / .bashrc
export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/binใช้การเปลี่ยนแปลงทั้งหมดกับระบบที่กำลังทำงานอยู่
$ source ~/.bashrcขั้นตอนที่ 5
ใช้คำสั่งต่อไปนี้เพื่อกำหนดค่าทางเลือก Java -
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarตอนนี้ตรวจสอบการติดตั้งโดยใช้คำสั่ง java -version จากขั้ว
การตรวจสอบการติดตั้ง Hadoop
ต้องติดตั้ง Hadoop บนระบบของคุณก่อนที่จะติดตั้ง MapReduce ให้เราตรวจสอบการติดตั้ง Hadoop โดยใช้คำสั่งต่อไปนี้ -
$ hadoop versionหาก Hadoop ได้รับการติดตั้งในระบบของคุณแล้วคุณจะได้รับคำตอบดังต่อไปนี้ -
Hadoop 2.4.1
--
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4หากไม่ได้ติดตั้ง Hadoop บนระบบของคุณให้ดำเนินการตามขั้นตอนต่อไปนี้
กำลังดาวน์โหลด Hadoop
ดาวน์โหลด Hadoop 2.4.1 จาก Apache Software Foundation และแยกเนื้อหาโดยใช้คำสั่งต่อไปนี้
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exitการติดตั้ง Hadoop ในโหมด Pseudo Distributed
ขั้นตอนต่อไปนี้ใช้เพื่อติดตั้ง Hadoop 2.4.1 ในโหมดกระจายหลอก
ขั้นตอนที่ 1 - การตั้งค่า Hadoop
คุณสามารถตั้งค่าตัวแปรสภาพแวดล้อม Hadoop ได้โดยต่อท้ายคำสั่งต่อไปนี้เข้ากับไฟล์ ~ / .bashrc
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binใช้การเปลี่ยนแปลงทั้งหมดกับระบบที่กำลังทำงานอยู่
$ source ~/.bashrcขั้นตอนที่ 2 - การกำหนดค่า Hadoop
คุณสามารถค้นหาไฟล์การกำหนดค่า Hadoop ทั้งหมดได้ในตำแหน่ง“ $ HADOOP_HOME / etc / hadoop” คุณต้องทำการเปลี่ยนแปลงที่เหมาะสมในไฟล์การกำหนดค่าเหล่านั้นตามโครงสร้างพื้นฐาน Hadoop ของคุณ
$ cd $HADOOP_HOME/etc/hadoopในการพัฒนาโปรแกรม Hadoop โดยใช้ Java คุณต้องรีเซ็ตตัวแปรสภาพแวดล้อม Java ใน hadoop-env.sh โดยแทนที่ค่า JAVA_HOME ด้วยตำแหน่งของ Java ในระบบของคุณ
export JAVA_HOME=/usr/local/javaคุณต้องแก้ไขไฟล์ต่อไปนี้เพื่อกำหนดค่า Hadoop -
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
core-site.xml มีข้อมูลต่อไปนี้
- หมายเลขพอร์ตที่ใช้สำหรับอินสแตนซ์ Hadoop
- หน่วยความจำที่จัดสรรสำหรับระบบไฟล์
- ขีด จำกัด หน่วยความจำสำหรับจัดเก็บข้อมูล
- ขนาดของบัฟเฟอร์อ่าน / เขียน
เปิด core-site.xml และเพิ่มคุณสมบัติต่อไปนี้ระหว่างแท็ก <configuration> และ </configuration>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000 </value>
</property>
</configuration>hdfs-site.xml
hdfs-site.xml มีข้อมูลต่อไปนี้ -
- มูลค่าของข้อมูลการจำลองแบบ
- เส้นทาง Namenode
- พา ธ datanode ของระบบไฟล์โลคัลของคุณ (ที่ที่คุณต้องการเก็บ Hadoop อินฟาร์)
ให้เราสมมติข้อมูลต่อไปนี้
dfs.replication (data replication value) = 1
(In the following path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeเปิดไฟล์นี้และเพิ่มคุณสมบัติต่อไปนี้ระหว่างแท็ก <configuration>, </configuration>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>Note - ในไฟล์ด้านบนค่าคุณสมบัติทั้งหมดจะถูกกำหนดโดยผู้ใช้และคุณสามารถเปลี่ยนแปลงได้ตามโครงสร้างพื้นฐาน Hadoop ของคุณ
เส้นด้าย site.xml
ไฟล์นี้ใช้เพื่อกำหนดค่าเส้นด้ายใน Hadoop เปิดไฟล์ yarn-site.xml และเพิ่มคุณสมบัติต่อไปนี้ระหว่างแท็ก <configuration>, </configuration>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
ไฟล์นี้ใช้เพื่อระบุเฟรมเวิร์ก MapReduce ที่เราใช้ ตามค่าเริ่มต้น Hadoop จะมีเทมเพลตของ yarn-site.xml ก่อนอื่นคุณต้องคัดลอกไฟล์จาก mapred-site.xml.template ไปยังไฟล์ mapred-site.xml โดยใช้คำสั่งต่อไปนี้
$ cp mapred-site.xml.template mapred-site.xmlเปิดไฟล์ mapred-site.xml และเพิ่มคุณสมบัติต่อไปนี้ระหว่างแท็ก <configuration>, </configuration>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>การตรวจสอบการติดตั้ง Hadoop
ขั้นตอนต่อไปนี้ใช้เพื่อตรวจสอบการติดตั้ง Hadoop
ขั้นตอนที่ 1 - ตั้งชื่อโหนด
ตั้งค่า Namenode โดยใช้คำสั่ง“ hdfs namenode -format” ดังนี้ -
$ cd ~ $ hdfs namenode -formatผลที่คาดว่าจะได้รับมีดังนี้ -
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/ขั้นตอนที่ 2 - การตรวจสอบ Hadoop dfs
ดำเนินการคำสั่งต่อไปนี้เพื่อเริ่มระบบไฟล์ Hadoop ของคุณ
$ start-dfs.shผลลัพธ์ที่คาดหวังมีดังนี้ -
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]ขั้นตอนที่ 3 - ตรวจสอบสคริปต์เส้นด้าย
คำสั่งต่อไปนี้ใช้เพื่อเริ่มสคริปต์เส้นด้าย การดำเนินการคำสั่งนี้จะเริ่มต้นเส้นด้าย daemons ของคุณ
$ start-yarn.shผลลัพธ์ที่คาดหวังมีดังนี้ -
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting node manager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outขั้นตอนที่ 4 - การเข้าถึง Hadoop บนเบราว์เซอร์
หมายเลขพอร์ตเริ่มต้นในการเข้าถึง Hadoop คือ 50070 ใช้ URL ต่อไปนี้เพื่อรับบริการ Hadoop บนเบราว์เซอร์ของคุณ
http://localhost:50070/ภาพหน้าจอต่อไปนี้แสดงเบราว์เซอร์ Hadoop

ขั้นตอนที่ 5 - ตรวจสอบแอปพลิเคชันทั้งหมดของคลัสเตอร์
หมายเลขพอร์ตเริ่มต้นเพื่อเข้าถึงแอปพลิเคชันทั้งหมดของคลัสเตอร์คือ 8088 ใช้ URL ต่อไปนี้เพื่อใช้บริการนี้
http://localhost:8088/ภาพหน้าจอต่อไปนี้แสดงเบราว์เซอร์คลัสเตอร์ Hadoop

ในบทนี้เราจะดูอย่างละเอียดเกี่ยวกับคลาสและวิธีการที่เกี่ยวข้องกับการทำงานของโปรแกรม MapReduce เราจะให้ความสำคัญกับสิ่งต่อไปนี้เป็นหลัก -
- อินเทอร์เฟซ JobContext
- ชั้นงาน
- คลาส Mapper
- คลาสลด
อินเทอร์เฟซ JobContext
อินเทอร์เฟซ JobContext เป็นอินเทอร์เฟซขั้นสูงสำหรับทุกคลาสซึ่งกำหนดงานที่แตกต่างกันใน MapReduce ช่วยให้คุณมีมุมมองแบบอ่านอย่างเดียวของงานที่จัดเตรียมให้กับงานในขณะที่กำลังทำงานอยู่
ต่อไปนี้เป็นอินเทอร์เฟซย่อยของอินเทอร์เฟซ JobContext
| ส. | คำอธิบาย Subinterface |
|---|---|
| 1. | MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> กำหนดบริบทที่กำหนดให้กับ Mapper |
| 2. | ReduceContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> กำหนดบริบทที่ส่งผ่านไปยัง Reducer |
คลาสงานเป็นคลาสหลักที่ใช้อินเทอร์เฟซ JobContext
ชั้นงาน
คลาส Job เป็นคลาสที่สำคัญที่สุดใน MapReduce API ช่วยให้ผู้ใช้กำหนดค่างานส่งงานควบคุมการดำเนินการและสอบถามสถานะ วิธีการตั้งค่าจะใช้ได้เฉพาะจนกว่างานจะถูกส่งหลังจากนั้นพวกเขาจะโยน IllegalStateException
โดยปกติผู้ใช้จะสร้างแอปพลิเคชันอธิบายแง่มุมต่างๆของงานจากนั้นส่งงานและตรวจสอบความคืบหน้า
นี่คือตัวอย่างวิธีการส่งงาน -
// Create a new Job
Job job = new Job(new Configuration());
job.setJarByClass(MyJob.class);
// Specify various job-specific parameters
job.setJobName("myjob");
job.setInputPath(new Path("in"));
job.setOutputPath(new Path("out"));
job.setMapperClass(MyJob.MyMapper.class);
job.setReducerClass(MyJob.MyReducer.class);
// Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);ตัวสร้าง
ต่อไปนี้เป็นสรุปตัวสร้างของคลาส Job
| ส. เลขที่ | สรุปตัวสร้าง |
|---|---|
| 1 | Job() |
| 2 | Job(การกำหนดค่าคอนฟิก) |
| 3 | Job(Configuration Configuration, String jobName) |
วิธีการ
วิธีการที่สำคัญบางประการของ Job class มีดังนี้ -
| ส. เลขที่ | คำอธิบายวิธีการ |
|---|---|
| 1 | getJobName() ชื่องานที่ผู้ใช้ระบุ |
| 2 | getJobState() ส่งคืนสถานะปัจจุบันของงาน |
| 3 | isComplete() ตรวจสอบว่างานเสร็จสิ้นหรือไม่ |
| 4 | setInputFormatClass() ตั้งค่า InputFormat สำหรับงาน |
| 5 | setJobName(String name) ตั้งชื่องานที่ผู้ใช้ระบุ |
| 6 | setOutputFormatClass() ตั้งค่ารูปแบบเอาต์พุตสำหรับงาน |
| 7 | setMapperClass(Class) ตั้งค่า Mapper สำหรับงาน |
| 8 | setReducerClass(Class) ตั้งค่าตัวลดสำหรับงาน |
| 9 | setPartitionerClass(Class) ตั้งค่า Partitioner สำหรับงาน |
| 10 | setCombinerClass(Class) ตั้งค่า Combiner สำหรับงาน |
คลาส Mapper
คลาส Mapper กำหนดงานแผนที่ จับคู่คีย์ - ค่าป้อนข้อมูลให้กับชุดของคู่คีย์ - ค่าระดับกลาง แผนที่เป็นงานแต่ละรายการที่เปลี่ยนบันทึกข้อมูลเข้าเป็นระเบียนระดับกลาง ระเบียนระดับกลางที่แปลงแล้วไม่จำเป็นต้องเป็นประเภทเดียวกันกับระเบียนอินพุต คู่อินพุตที่ระบุอาจแมปกับคู่เอาต์พุตเป็นศูนย์หรือหลายคู่
วิธี
mapเป็นวิธีที่โดดเด่นที่สุดของคลาส Mapper ไวยากรณ์ถูกกำหนดไว้ด้านล่าง -
map(KEYIN key, VALUEIN value, org.apache.hadoop.mapreduce.Mapper.Context context)วิธีนี้เรียกหนึ่งครั้งสำหรับแต่ละคู่คีย์ - ค่าในการแยกอินพุต
คลาสลด
คลาส Reducer กำหนดงานลดใน MapReduce จะลดชุดของค่ากลางที่แบ่งคีย์ไปยังชุดค่าที่เล็กกว่า การใช้งานตัวลดสามารถเข้าถึงการกำหนดค่าสำหรับงานผ่านวิธี JobContext.getConfiguration () ตัวลดมีสามขั้นตอนหลัก - สุ่มเรียงลำดับและลด
Shuffle - Reducer คัดลอกเอาต์พุตที่เรียงลำดับจาก Mapper แต่ละตัวโดยใช้ HTTP ผ่านเครือข่าย
Sort- เฟรมเวิร์กผสาน - จัดเรียงอินพุต Reducer ด้วยคีย์ (เนื่องจาก Mappers ที่แตกต่างกันอาจมีเอาต์พุตคีย์เดียวกัน) ขั้นตอนการสับเปลี่ยนและการเรียงลำดับเกิดขึ้นพร้อมกันกล่าวคือในขณะที่กำลังดึงข้อมูลเอาต์พุตจะรวมเข้าด้วยกัน
Reduce - ในขั้นตอนนี้วิธีการลด (Object, Iterable, Context) ถูกเรียกใช้สำหรับแต่ละ <key, (collection of values)> ในอินพุตที่เรียงลำดับ
วิธี
reduceเป็นวิธีที่โดดเด่นที่สุดของคลาสลด ไวยากรณ์ถูกกำหนดไว้ด้านล่าง -
reduce(KEYIN key, Iterable<VALUEIN> values, org.apache.hadoop.mapreduce.Reducer.Context context)วิธีนี้เรียกหนึ่งครั้งสำหรับแต่ละคีย์บนคอลเลกชันของคู่คีย์ - ค่า
MapReduce เป็นเฟรมเวิร์กที่ใช้สำหรับการเขียนแอพพลิเคชั่นเพื่อประมวลผลข้อมูลจำนวนมหาศาลบนกลุ่มฮาร์ดแวร์สินค้าขนาดใหญ่ในลักษณะที่เชื่อถือได้ บทนี้จะนำคุณไปสู่การทำงานของ MapReduce ใน Hadoop framework โดยใช้ Java
อัลกอริทึม MapReduce
โดยทั่วไปกระบวนทัศน์ MapReduce จะขึ้นอยู่กับการส่งโปรแกรมลดแผนที่ไปยังคอมพิวเตอร์ที่มีข้อมูลจริงอยู่
ระหว่างงาน MapReduce Hadoop จะส่งแผนที่และงานลดไปยังเซิร์ฟเวอร์ที่เหมาะสมในคลัสเตอร์
เฟรมเวิร์กจัดการรายละเอียดทั้งหมดของการส่งผ่านข้อมูลเช่นการออกงานการตรวจสอบความสมบูรณ์ของงานและการคัดลอกข้อมูลรอบคลัสเตอร์ระหว่างโหนด
การประมวลผลส่วนใหญ่เกิดขึ้นบนโหนดที่มีข้อมูลบนดิสก์ภายในซึ่งช่วยลดปริมาณการใช้งานเครือข่าย
หลังจากเสร็จสิ้นภารกิจที่กำหนดคลัสเตอร์จะรวบรวมและลดข้อมูลเพื่อสร้างผลลัพธ์ที่เหมาะสมและส่งกลับไปยังเซิร์ฟเวอร์ Hadoop

อินพุตและเอาต์พุต (Java Perspective)
เฟรมเวิร์ก MapReduce ทำงานบนคู่คีย์ - ค่ากล่าวคือเฟรมเวิร์กดูอินพุตของงานเป็นชุดของคู่คีย์ - ค่าและสร้างชุดของคู่คีย์ - ค่าเป็นเอาต์พุตของงานซึ่งอาจเป็นประเภทต่างๆ
คลาสคีย์และค่าจะต้องทำให้เป็นอนุกรมได้ตามกรอบงานและด้วยเหตุนี้จึงจำเป็นต้องใช้อินเทอร์เฟซที่เขียนได้ นอกจากนี้คลาสหลักต้องใช้อินเทอร์เฟซ WritableComparable เพื่ออำนวยความสะดวกในการจัดเรียงตามกรอบงาน
ทั้งรูปแบบอินพุตและเอาต์พุตของงาน MapReduce อยู่ในรูปแบบของคู่คีย์ - ค่า -
(อินพุต) <k1, v1> -> แผนที่ -> <k2, v2> -> ลด -> <k3, v3> (เอาต์พุต)
| อินพุต | เอาต์พุต | |
|---|---|---|
| แผนที่ | <k1, v1> | รายการ (<k2, v2>) |
| ลด | <k2 รายการ (v2)> | รายการ (<k3, v3>) |
การใช้ MapReduce
ตารางต่อไปนี้แสดงข้อมูลเกี่ยวกับการใช้ไฟฟ้าขององค์กร ตารางประกอบด้วยปริมาณการใช้ไฟฟ้ารายเดือนและค่าเฉลี่ยรายปีเป็นเวลาห้าปีติดต่อกัน
| ม.ค. | ก.พ. | มี.ค. | เม.ย. | อาจ | มิ.ย. | ก.ค. | ส.ค. | ก.ย. | ต.ค. | พ.ย. | ธ.ค. | ค่าเฉลี่ย | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| พ.ศ. 2522 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| พ.ศ. 2523 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| พ.ศ. 2524 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| พ.ศ. 2527 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| พ.ศ. 2528 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
เราจำเป็นต้องเขียนแอปพลิเคชันเพื่อประมวลผลข้อมูลอินพุตในตารางที่กำหนดเพื่อค้นหาปีที่ใช้งานสูงสุดปีของการใช้งานขั้นต่ำและอื่น ๆ งานนี้เป็นเรื่องง่ายสำหรับโปรแกรมเมอร์ที่มีจำนวนบันทึก จำกัด เนื่องจากพวกเขาจะเขียนตรรกะเพื่อสร้างผลลัพธ์ที่ต้องการและส่งข้อมูลไปยังแอปพลิเคชันที่เขียนขึ้น
ตอนนี้ให้เราเพิ่มขนาดของข้อมูลอินพุต สมมติว่าเราต้องวิเคราะห์การใช้ไฟฟ้าของอุตสาหกรรมขนาดใหญ่ทั้งหมดของรัฐใดรัฐหนึ่ง เมื่อเราเขียนแอปพลิเคชันเพื่อประมวลผลข้อมูลจำนวนมากดังกล่าว
พวกเขาจะใช้เวลามากในการดำเนินการ
จะมีปริมาณการใช้งานเครือข่ายหนาแน่นเมื่อเราย้ายข้อมูลจากต้นทางไปยังเซิร์ฟเวอร์เครือข่าย
ในการแก้ปัญหาเหล่านี้เรามีกรอบ MapReduce
ป้อนข้อมูล
ข้อมูลข้างต้นถูกบันทึกเป็น sample.txtและกำหนดให้เป็นอินพุต ไฟล์อินพุตมีลักษณะดังที่แสดงด้านล่าง
| พ.ศ. 2522 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| พ.ศ. 2523 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| พ.ศ. 2524 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| พ.ศ. 2527 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| พ.ศ. 2528 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
ตัวอย่างโปรแกรม
โปรแกรมต่อไปนี้สำหรับข้อมูลตัวอย่างใช้กรอบ MapReduce
package hadoop;
import java.util.*;
import java.io.IOException;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class ProcessUnits
{
//Mapper class
public static class E_EMapper extends MapReduceBase implements
Mapper<LongWritable, /*Input key Type */
Text, /*Input value Type*/
Text, /*Output key Type*/
IntWritable> /*Output value Type*/
{
//Map function
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException
{
String line = value.toString();
String lasttoken = null;
StringTokenizer s = new StringTokenizer(line,"\t");
String year = s.nextToken();
while(s.hasMoreTokens()){
lasttoken=s.nextToken();
}
int avgprice = Integer.parseInt(lasttoken);
output.collect(new Text(year), new IntWritable(avgprice));
}
}
//Reducer class
public static class E_EReduce extends MapReduceBase implements
Reducer< Text, IntWritable, Text, IntWritable >
{
//Reduce function
public void reduce(Text key, Iterator <IntWritable> values, OutputCollector>Text, IntWritable> output, Reporter reporter) throws IOException
{
int maxavg=30;
int val=Integer.MIN_VALUE;
while (values.hasNext())
{
if((val=values.next().get())>maxavg)
{
output.collect(key, new IntWritable(val));
}
}
}
}
//Main function
public static void main(String args[])throws Exception
{
JobConf conf = new JobConf(Eleunits.class);
conf.setJobName("max_eletricityunits");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(E_EMapper.class);
conf.setCombinerClass(E_EReduce.class);
conf.setReducerClass(E_EReduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}บันทึกโปรแกรมข้างต้นลงใน ProcessUnits.java. การรวบรวมและการดำเนินการของโปรแกรมมีดังต่อไปนี้
การคอมไพล์และการดำเนินการของโปรแกรม ProcessUnits
สมมติว่าเราอยู่ในโฮมไดเร็กทอรีของผู้ใช้ Hadoop (เช่น / home / hadoop)
ทำตามขั้นตอนด้านล่างเพื่อคอมไพล์และรันโปรแกรมข้างต้น
Step 1 - ใช้คำสั่งต่อไปนี้เพื่อสร้างไดเร็กทอรีเพื่อจัดเก็บคลาส java ที่คอมไพล์
$ mkdir unitsStep 2- ดาวน์โหลด Hadoop-core-1.2.1.jar ซึ่งใช้ในการคอมไพล์และรันโปรแกรม MapReduce ดาวน์โหลดขวดจากmvnrepository.com ให้เราถือว่าโฟลเดอร์ดาวน์โหลดคือ / home / hadoop /
Step 3 - คำสั่งต่อไปนี้ใช้เพื่อรวบรวมไฟล์ ProcessUnits.java โปรแกรมและสร้าง jar สำหรับโปรแกรม
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java
$ jar -cvf units.jar -C units/ .Step 4 - คำสั่งต่อไปนี้ใช้เพื่อสร้างไดเร็กทอรีอินพุตใน HDFS
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirStep 5 - คำสั่งต่อไปนี้ใช้เพื่อคัดลอกไฟล์อินพุตที่ชื่อ sample.txt ในไดเร็กทอรีอินพุตของ HDFS
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dirStep 6 - คำสั่งต่อไปนี้ใช้เพื่อตรวจสอบไฟล์ในไดเร็กทอรีอินพุต
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 7 - คำสั่งต่อไปนี้ใช้เพื่อรันแอปพลิเคชัน Eleunit_max โดยรับไฟล์อินพุตจากไดเร็กทอรีอินพุต
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dirรอสักครู่จนกว่าไฟล์จะถูกเรียกใช้งาน หลังจากดำเนินการแล้วผลลัพธ์จะมีการแยกอินพุตจำนวนหนึ่งงานแผนที่งานลดและอื่น ๆ
INFO mapreduce.Job: Job job_1414748220717_0002
completed successfully
14/10/31 06:02:52
INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=61
FILE: Number of bytes written=279400
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=546
HDFS: Number of bytes written=40
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2 Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=146137
Total time spent by all reduces in occupied slots (ms)=441
Total time spent by all map tasks (ms)=14613
Total time spent by all reduce tasks (ms)=44120
Total vcore-seconds taken by all map tasks=146137
Total vcore-seconds taken by all reduce tasks=44120
Total megabyte-seconds taken by all map tasks=149644288
Total megabyte-seconds taken by all reduce tasks=45178880
Map-Reduce Framework
Map input records=5
Map output records=5
Map output bytes=45
Map output materialized bytes=67
Input split bytes=208
Combine input records=5
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=6
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=948
CPU time spent (ms)=5160
Physical memory (bytes) snapshot=47749120
Virtual memory (bytes) snapshot=2899349504
Total committed heap usage (bytes)=277684224
File Output Format Counters
Bytes Written=40Step 8 - คำสั่งต่อไปนี้ใช้เพื่อตรวจสอบไฟล์ผลลัพธ์ในโฟลเดอร์ผลลัพธ์
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Step 9 - คำสั่งต่อไปนี้ใช้เพื่อดูผลลัพธ์ใน Part-00000ไฟล์. ไฟล์นี้สร้างโดย HDFS
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000ต่อไปนี้เป็นผลลัพธ์ที่สร้างโดยโปรแกรม MapReduce -
| พ.ศ. 2524 | 34 |
| พ.ศ. 2527 | 40 |
| พ.ศ. 2528 | 45 |
Step 10 - คำสั่งต่อไปนี้ใช้เพื่อคัดลอกโฟลเดอร์ผลลัพธ์จาก HDFS ไปยังระบบไฟล์ภายในเครื่อง
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs -get output_dir /home/hadoopพาร์ติชันเนอร์ทำงานเหมือนเงื่อนไขในการประมวลผลชุดข้อมูลอินพุต เฟสพาร์ติชันเกิดขึ้นหลังจากเฟสแผนที่และก่อนเฟสลด
จำนวนพาร์ติชันเท่ากับจำนวนตัวลด นั่นหมายความว่าพาร์ติชันเนอร์จะแบ่งข้อมูลตามจำนวนตัวลด ดังนั้นข้อมูลที่ส่งผ่านจากพาร์ติชันเดียวจะถูกประมวลผลโดยตัวลดขนาดเดียว
พาร์ทิชันเนอร์
พาร์ติชันเนอร์พาร์ติชันคู่คีย์ - ค่าของแม็พเอาต์พุตระดับกลาง แบ่งพาร์ติชันข้อมูลโดยใช้เงื่อนไขที่ผู้ใช้กำหนดซึ่งทำงานเหมือนกับฟังก์ชันแฮช จำนวนพาร์ติชันทั้งหมดเท่ากับจำนวนงานลดสำหรับงาน ให้เรายกตัวอย่างเพื่อทำความเข้าใจว่าพาร์ติชันทำงานอย่างไร
การติดตั้ง MapReduce Partitioner
เพื่อความสะดวกสมมติว่าเรามีตารางขนาดเล็กที่เรียกว่าพนักงานพร้อมข้อมูลต่อไปนี้ เราจะใช้ข้อมูลตัวอย่างนี้เป็นชุดข้อมูลอินพุตของเราเพื่อสาธิตการทำงานของพาร์ติชันเนอร์
| Id | ชื่อ | อายุ | เพศ | เงินเดือน |
|---|---|---|---|---|
| 1201 | โกปาล | 45 | ชาย | 50,000 |
| 1202 | มานิชา | 40 | หญิง | 50,000 |
| 1203 | คาลิล | 34 | ชาย | 30,000 |
| 1204 | พระสันต | 30 | ชาย | 30,000 |
| 1205 | คีรัน | 20 | ชาย | 40,000 |
| 1206 | ลักษมี | 25 | หญิง | 35,000 |
| 1207 | ภควา | 20 | หญิง | 15,000 |
| 1208 | reshma | 19 | หญิง | 15,000 |
| 1209 | กระท้อน | 22 | ชาย | 22,000 |
| 1210 | Satish | 24 | ชาย | 25,000 |
| 1211 | กฤษณะ | 25 | ชาย | 25,000 |
| 1212 | Arshad | 28 | ชาย | 20,000 |
| 1213 | Lavanya | 18 | หญิง | 8,000 |
เราต้องเขียนแอปพลิเคชันเพื่อประมวลผลชุดข้อมูลอินพุตเพื่อค้นหาพนักงานที่ได้รับเงินเดือนสูงสุดตามเพศในกลุ่มอายุต่างๆ (เช่นอายุต่ำกว่า 20 ปีระหว่าง 21 ถึง 30 และสูงกว่า 30)
ป้อนข้อมูล
ข้อมูลข้างต้นถูกบันทึกเป็น input.txt ในไดเร็กทอรี“ / home / hadoop / hadoopPartitioner” และกำหนดให้เป็นอินพุต
| 1201 | โกปาล | 45 | ชาย | 50000 |
| 1202 | มานิชา | 40 | หญิง | 51000 |
| 1203 | khaleel | 34 | ชาย | 30000 |
| 1204 | พระสันต | 30 | ชาย | 31000 |
| 1205 | คีรัน | 20 | ชาย | 40000 |
| 1206 | ลักษมี | 25 | หญิง | 35000 |
| 1207 | ภควา | 20 | หญิง | 15000 |
| 1208 | reshma | 19 | หญิง | 14000 |
| 1209 | กระท้อน | 22 | ชาย | 22000 |
| 1210 | Satish | 24 | ชาย | 25000 |
| 1211 | กฤษณะ | 25 | ชาย | 26000 |
| 1212 | Arshad | 28 | ชาย | 20000 |
| 1213 | Lavanya | 18 | หญิง | 8000 |
ขึ้นอยู่กับอินพุตที่กำหนดต่อไปนี้เป็นคำอธิบายอัลกอริทึมของโปรแกรม
งานแผนที่
งานแผนที่ยอมรับคู่คีย์ - ค่าเป็นอินพุตในขณะที่เรามีข้อมูลข้อความในไฟล์ข้อความ อินพุตสำหรับงานแผนที่นี้มีดังนี้ -
Input - คีย์จะเป็นรูปแบบเช่น "คีย์พิเศษใด ๆ + ชื่อไฟล์ + หมายเลขบรรทัด" (ตัวอย่าง: key = @ input1) และค่าจะเป็นข้อมูลในบรรทัดนั้น (ตัวอย่าง: value = 1201 \ t gopal \ t 45 \ ชาย \ t 50000)
Method - การดำเนินงานของแผนที่นี้มีดังต่อไปนี้ -
อ่าน value (บันทึกข้อมูล) ซึ่งมาเป็นค่าอินพุตจากรายการอาร์กิวเมนต์ในสตริง
ใช้ฟังก์ชันแยกแยกเพศและจัดเก็บในตัวแปรสตริง
String[] str = value.toString().split("\t", -3);
String gender=str[3];ส่งข้อมูลเพศและข้อมูลบันทึก value เป็นคู่คีย์ - ค่าเอาต์พุตจากงานแผนที่ไปยัง partition task.
context.write(new Text(gender), new Text(value));ทำซ้ำขั้นตอนข้างต้นทั้งหมดสำหรับระเบียนทั้งหมดในไฟล์ข้อความ
Output - คุณจะได้รับข้อมูลเพศและค่าข้อมูลบันทึกเป็นคู่คีย์ - ค่า
งาน Partitioner
งาน partitioner ยอมรับคู่คีย์ - ค่าจากงานแผนที่เป็นอินพุต พาร์ติชันหมายถึงการแบ่งข้อมูลออกเป็นเซ็กเมนต์ ตามเกณฑ์เงื่อนไขที่กำหนดของพาร์ติชันข้อมูลที่จับคู่คีย์ - ค่าอินพุตสามารถแบ่งออกเป็นสามส่วนตามเกณฑ์อายุ
Input - ข้อมูลทั้งหมดในชุดของคู่คีย์ - ค่า
คีย์ = ค่าฟิลด์เพศในเรกคอร์ด
value = ค่าข้อมูลบันทึกทั้งหมดของเพศนั้น
Method - กระบวนการของลอจิกพาร์ติชันทำงานดังนี้
- อ่านค่าฟิลด์อายุจากคู่คีย์ - ค่าอินพุต
String[] str = value.toString().split("\t");
int age = Integer.parseInt(str[2]);ตรวจสอบค่าอายุด้วยเงื่อนไขต่อไปนี้
- อายุน้อยกว่าหรือเท่ากับ 20
- อายุมากกว่า 20 และน้อยกว่าหรือเท่ากับ 30
- อายุมากกว่า 30 ปี
if(age<=20)
{
return 0;
}
else if(age>20 && age<=30)
{
return 1 % numReduceTasks;
}
else
{
return 2 % numReduceTasks;
}Output- ข้อมูลทั้งหมดของคู่คีย์ - ค่าแบ่งออกเป็นสามคอลเลกชันของคู่คีย์ - ค่า Reducer ทำงานแยกกันในแต่ละคอลเลกชัน
Reduce Tasks
The number of partitioner tasks is equal to the number of reducer tasks. Here we have three partitioner tasks and hence we have three Reducer tasks to be executed.
Input − The Reducer will execute three times with different collection of key-value pairs.
key = gender field value in the record.
value = the whole record data of that gender.
Method − The following logic will be applied on each collection.
- Read the Salary field value of each record.
String [] str = val.toString().split("\t", -3);
Note: str[4] have the salary field value.Check the salary with the max variable. If str[4] is the max salary, then assign str[4] to max, otherwise skip the step.
if(Integer.parseInt(str[4])>max)
{
max=Integer.parseInt(str[4]);
}Repeat Steps 1 and 2 for each key collection (Male & Female are the key collections). After executing these three steps, you will find one max salary from the Male key collection and one max salary from the Female key collection.
context.write(new Text(key), new IntWritable(max));Output − Finally, you will get a set of key-value pair data in three collections of different age groups. It contains the max salary from the Male collection and the max salary from the Female collection in each age group respectively.
After executing the Map, the Partitioner, and the Reduce tasks, the three collections of key-value pair data are stored in three different files as the output.
All the three tasks are treated as MapReduce jobs. The following requirements and specifications of these jobs should be specified in the Configurations −
- Job name
- Input and Output formats of keys and values
- Individual classes for Map, Reduce, and Partitioner tasks
Configuration conf = getConf();
//Create Job
Job job = new Job(conf, "topsal");
job.setJarByClass(PartitionerExample.class);
// File Input and Output paths
FileInputFormat.setInputPaths(job, new Path(arg[0]));
FileOutputFormat.setOutputPath(job,new Path(arg[1]));
//Set Mapper class and Output format for key-value pair.
job.setMapperClass(MapClass.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//set partitioner statement
job.setPartitionerClass(CaderPartitioner.class);
//Set Reducer class and Input/Output format for key-value pair.
job.setReducerClass(ReduceClass.class);
//Number of Reducer tasks.
job.setNumReduceTasks(3);
//Input and Output format for data
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);ตัวอย่างโปรแกรม
โปรแกรมต่อไปนี้แสดงวิธีการใช้งานพาร์ติชันสำหรับเกณฑ์ที่กำหนดในโปรแกรม MapReduce
package partitionerexample;
import java.io.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
import org.apache.hadoop.util.*;
public class PartitionerExample extends Configured implements Tool
{
//Map class
public static class MapClass extends Mapper<LongWritable,Text,Text,Text>
{
public void map(LongWritable key, Text value, Context context)
{
try{
String[] str = value.toString().split("\t", -3);
String gender=str[3];
context.write(new Text(gender), new Text(value));
}
catch(Exception e)
{
System.out.println(e.getMessage());
}
}
}
//Reducer class
public static class ReduceClass extends Reducer<Text,Text,Text,IntWritable>
{
public int max = -1;
public void reduce(Text key, Iterable <Text> values, Context context) throws IOException, InterruptedException
{
max = -1;
for (Text val : values)
{
String [] str = val.toString().split("\t", -3);
if(Integer.parseInt(str[4])>max)
max=Integer.parseInt(str[4]);
}
context.write(new Text(key), new IntWritable(max));
}
}
//Partitioner class
public static class CaderPartitioner extends
Partitioner < Text, Text >
{
@Override
public int getPartition(Text key, Text value, int numReduceTasks)
{
String[] str = value.toString().split("\t");
int age = Integer.parseInt(str[2]);
if(numReduceTasks == 0)
{
return 0;
}
if(age<=20)
{
return 0;
}
else if(age>20 && age<=30)
{
return 1 % numReduceTasks;
}
else
{
return 2 % numReduceTasks;
}
}
}
@Override
public int run(String[] arg) throws Exception
{
Configuration conf = getConf();
Job job = new Job(conf, "topsal");
job.setJarByClass(PartitionerExample.class);
FileInputFormat.setInputPaths(job, new Path(arg[0]));
FileOutputFormat.setOutputPath(job,new Path(arg[1]));
job.setMapperClass(MapClass.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//set partitioner statement
job.setPartitionerClass(CaderPartitioner.class);
job.setReducerClass(ReduceClass.class);
job.setNumReduceTasks(3);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true)? 0 : 1);
return 0;
}
public static void main(String ar[]) throws Exception
{
int res = ToolRunner.run(new Configuration(), new PartitionerExample(),ar);
System.exit(0);
}
}บันทึกรหัสด้านบนเป็น PartitionerExample.javaใน“ / home / hadoop / hadoopPartitioner” การรวบรวมและการดำเนินการของโปรแกรมมีดังต่อไปนี้
การรวบรวมและการดำเนินการ
สมมติว่าเราอยู่ในโฮมไดเร็กทอรีของผู้ใช้ Hadoop (ตัวอย่างเช่น / home / hadoop)
ทำตามขั้นตอนด้านล่างเพื่อคอมไพล์และรันโปรแกรมข้างต้น
Step 1- ดาวน์โหลด Hadoop-core-1.2.1.jar ซึ่งใช้ในการคอมไพล์และรันโปรแกรม MapReduce คุณสามารถดาวน์โหลดขวดจากmvnrepository.com
ให้เราถือว่าโฟลเดอร์ที่ดาวน์โหลดคือ“ / home / hadoop / hadoopPartitioner”
Step 2 - คำสั่งต่อไปนี้ใช้สำหรับการคอมไพล์โปรแกรม PartitionerExample.java และสร้าง jar สำหรับโปรแกรม
$ javac -classpath hadoop-core-1.2.1.jar -d ProcessUnits.java $ jar -cvf PartitionerExample.jar -C .Step 3 - ใช้คำสั่งต่อไปนี้เพื่อสร้างไดเร็กทอรีอินพุตใน HDFS
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirStep 4 - ใช้คำสั่งต่อไปนี้เพื่อคัดลอกไฟล์อินพุตที่ชื่อ input.txt ในไดเร็กทอรีอินพุตของ HDFS
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/hadoopPartitioner/input.txt input_dirStep 5 - ใช้คำสั่งต่อไปนี้เพื่อตรวจสอบไฟล์ในไดเร็กทอรีอินพุต
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 6 - ใช้คำสั่งต่อไปนี้เพื่อเรียกใช้แอปพลิเคชันเงินเดือนสูงสุดโดยรับไฟล์อินพุตจากไดเร็กทอรีอินพุต
$HADOOP_HOME/bin/hadoop jar PartitionerExample.jar partitionerexample.PartitionerExample input_dir/input.txt output_dirรอสักครู่จนกว่าไฟล์จะถูกเรียกใช้งาน หลังจากดำเนินการแล้วเอาต์พุตจะมีการแยกอินพุตงานแผนที่และงานลดจำนวน
15/02/04 15:19:51 INFO mapreduce.Job: Job job_1423027269044_0021 completed successfully
15/02/04 15:19:52 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=467
FILE: Number of bytes written=426777
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=480
HDFS: Number of bytes written=72
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=6
Job Counters
Launched map tasks=1
Launched reduce tasks=3
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=8212
Total time spent by all reduces in occupied slots (ms)=59858
Total time spent by all map tasks (ms)=8212
Total time spent by all reduce tasks (ms)=59858
Total vcore-seconds taken by all map tasks=8212
Total vcore-seconds taken by all reduce tasks=59858
Total megabyte-seconds taken by all map tasks=8409088
Total megabyte-seconds taken by all reduce tasks=61294592
Map-Reduce Framework
Map input records=13
Map output records=13
Map output bytes=423
Map output materialized bytes=467
Input split bytes=119
Combine input records=0
Combine output records=0
Reduce input groups=6
Reduce shuffle bytes=467
Reduce input records=13
Reduce output records=6
Spilled Records=26
Shuffled Maps =3
Failed Shuffles=0
Merged Map outputs=3
GC time elapsed (ms)=224
CPU time spent (ms)=3690
Physical memory (bytes) snapshot=553816064
Virtual memory (bytes) snapshot=3441266688
Total committed heap usage (bytes)=334102528
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=361
File Output Format Counters
Bytes Written=72Step 7 - ใช้คำสั่งต่อไปนี้เพื่อตรวจสอบไฟล์ผลลัพธ์ในโฟลเดอร์ผลลัพธ์
$HADOOP_HOME/bin/hadoop fs -ls output_dir/คุณจะพบผลลัพธ์ในสามไฟล์เนื่องจากคุณใช้พาร์ติชันสามตัวและตัวลดสามตัวในโปรแกรมของคุณ
Step 8 - ใช้คำสั่งต่อไปนี้เพื่อดูผลลัพธ์ในรูปแบบ Part-00000ไฟล์. ไฟล์นี้สร้างโดย HDFS
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000Output in Part-00000
Female 15000
Male 40000ใช้คำสั่งต่อไปนี้เพื่อดูผลลัพธ์ใน Part-00001 ไฟล์.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00001Output in Part-00001
Female 35000
Male 31000ใช้คำสั่งต่อไปนี้เพื่อดูผลลัพธ์ใน Part-00002 ไฟล์.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00002Output in Part-00002
Female 51000
Male 50000Combiner หรือที่เรียกว่า semi-reducer, เป็นคลาสทางเลือกที่ดำเนินการโดยรับอินพุตจากคลาส Map และหลังจากนั้นส่งคู่คีย์ - ค่าเอาต์พุตไปยังคลาส Reducer
หน้าที่หลักของ Combiner คือการสรุปเร็กคอร์ดผลลัพธ์แผนที่ด้วยคีย์เดียวกัน เอาต์พุต (การรวบรวมคีย์ - ค่า) ของตัวรวมจะถูกส่งผ่านเครือข่ายไปยังงานลดที่แท้จริงเป็นอินพุต
Combiner
คลาส Combiner ใช้ระหว่างคลาสแผนที่และคลาสลดเพื่อลดปริมาณการถ่ายโอนข้อมูลระหว่างแผนที่และลด โดยปกติผลลัพธ์ของงานแผนที่จะมีขนาดใหญ่และข้อมูลที่ถ่ายโอนไปยังงานลดจะสูง
แผนผังงาน MapReduce ต่อไปนี้แสดง COMBINER PHASE
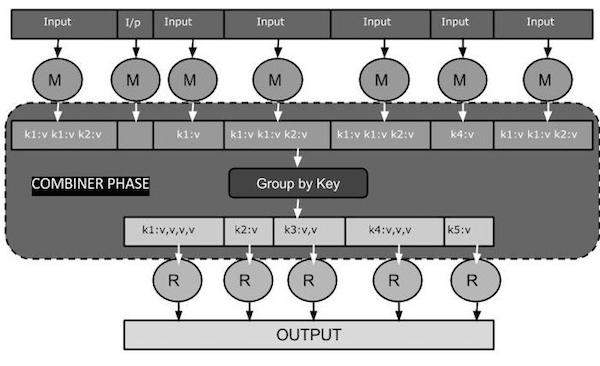
Combiner ทำงานอย่างไร?
นี่คือสรุปสั้น ๆ เกี่ยวกับวิธีการทำงานของ MapReduce Combiner -
Combiner ไม่มีอินเทอร์เฟซที่กำหนดไว้ล่วงหน้าและต้องใช้วิธีการลด () ของส่วนต่อประสาน Reducer
Combiner ทำงานบนคีย์เอาต์พุตแต่ละแผนที่ ต้องมีประเภทคีย์ - ค่าเอาต์พุตเดียวกันกับคลาส Reducer
Combiner สามารถสร้างข้อมูลสรุปจากชุดข้อมูลขนาดใหญ่ได้เนื่องจากแทนที่เอาต์พุตแผนที่ดั้งเดิม
แม้ว่า Combiner จะเป็นทางเลือก แต่ก็ช่วยแยกข้อมูลออกเป็นหลายกลุ่มสำหรับ Reduce phase ซึ่งทำให้ประมวลผลได้ง่ายขึ้น
การใช้งาน MapReduce Combiner
ตัวอย่างต่อไปนี้ให้แนวคิดเชิงทฤษฎีเกี่ยวกับตัวผสม สมมติว่าเรามีไฟล์ข้อความอินพุตต่อไปนี้ชื่อinput.txt สำหรับ MapReduce
What do you mean by Object
What do you know about Java
What is Java Virtual Machine
How Java enabled High Performanceขั้นตอนที่สำคัญของโปรแกรม MapReduce กับ Combiner จะกล่าวถึงด้านล่าง
ผู้อ่านบันทึก
นี่เป็นเฟสแรกของ MapReduce ที่ตัวอ่านบันทึกอ่านทุกบรรทัดจากไฟล์ข้อความอินพุตเป็นข้อความและให้ผลลัพธ์เป็นคู่คีย์ - ค่า
Input - ข้อความทีละบรรทัดจากไฟล์อินพุต
Output- สร้างคู่คีย์ - ค่า ต่อไปนี้คือชุดของคู่คีย์ - ค่าที่คาดไว้
<1, What do you mean by Object>
<2, What do you know about Java>
<3, What is Java Virtual Machine>
<4, How Java enabled High Performance>แผนที่เฟส
เฟสแผนที่รับอินพุตจากเครื่องอ่านบันทึกประมวลผลและสร้างเอาต์พุตเป็นชุดคู่คีย์ - ค่าอื่น
Input - คู่คีย์ - ค่าต่อไปนี้คืออินพุตที่นำมาจากเครื่องอ่านบันทึก
<1, What do you mean by Object>
<2, What do you know about Java>
<3, What is Java Virtual Machine>
<4, How Java enabled High Performance>เฟสแผนที่อ่านคู่คีย์ - ค่าแต่ละคู่แบ่งแต่ละคำออกจากค่าโดยใช้ StringTokenizer ถือว่าแต่ละคำเป็นคีย์และนับคำนั้นเป็นค่า ข้อมูลโค้ดต่อไปนี้แสดงคลาส Mapper และฟังก์ชันแผนที่
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}Output - ผลลัพธ์ที่คาดหวังมีดังนี้ -
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1>
<What,1> <do,1> <you,1> <know,1> <about,1> <Java,1>
<What,1> <is,1> <Java,1> <Virtual,1> <Machine,1>
<How,1> <Java,1> <enabled,1> <High,1> <Performance,1>Combiner เฟส
เฟส Combiner ใช้คู่คีย์ - ค่าแต่ละคู่จากเฟสแผนที่ประมวลผลและสร้างเอาต์พุตเป็น key-value collection คู่
Input - คู่คีย์ - ค่าต่อไปนี้คืออินพุตที่นำมาจากเฟสแผนที่
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1>
<What,1> <do,1> <you,1> <know,1> <about,1> <Java,1>
<What,1> <is,1> <Java,1> <Virtual,1> <Machine,1>
<How,1> <Java,1> <enabled,1> <High,1> <Performance,1>เฟส Combiner อ่านคู่คีย์ - ค่าแต่ละคู่รวมคำทั่วไปเป็นคีย์และค่าเป็นคอลเลกชัน โดยปกติรหัสและการทำงานของ Combiner จะคล้ายกับตัวลด ต่อไปนี้เป็นข้อมูลโค้ดสำหรับการประกาศคลาส Mapper, Combiner และ Reducer
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);Output - ผลลัพธ์ที่คาดหวังมีดังนี้ -
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,1,1,1>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>เฟสลด
เฟส Reducer นำคู่การรวบรวมคีย์ - ค่าแต่ละคู่จากเฟส Combiner ประมวลผลและส่งเอาต์พุตเป็นคู่คีย์ - ค่า โปรดทราบว่าการทำงานของ Combiner เหมือนกับตัวลด
Input - คู่คีย์ - ค่าต่อไปนี้คืออินพุตที่นำมาจากเฟส Combiner
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,1,1,1>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>เฟสลดอ่านแต่ละคู่คีย์ - ค่า ต่อไปนี้เป็นข้อมูลโค้ดสำหรับ Combiner
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}Output - ผลลัพธ์ที่คาดหวังจากเฟส Reducer มีดังนี้ -
<What,3> <do,2> <you,2> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,3>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>ผู้เขียนบันทึก
นี่คือเฟสสุดท้ายของ MapReduce ที่ Record Writer เขียนทุกคู่คีย์ - ค่าจากเฟส Reducer และส่งเอาต์พุตเป็นข้อความ
Input - แต่ละคู่คีย์ - ค่าจากเฟสลดพร้อมกับรูปแบบเอาต์พุต
Output- ให้คู่คีย์ - ค่าในรูปแบบข้อความ ต่อไปนี้คือผลลัพธ์ที่คาดหวัง
What 3
do 2
you 2
mean 1
by 1
Object 1
know 1
about 1
Java 3
is 1
Virtual 1
Machine 1
How 1
enabled 1
High 1
Performance 1ตัวอย่างโปรแกรม
บล็อกรหัสต่อไปนี้จะนับจำนวนคำในโปรแกรม
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}บันทึกโปรแกรมข้างต้นเป็น WordCount.java. การรวบรวมและการดำเนินการของโปรแกรมมีดังต่อไปนี้
การรวบรวมและการดำเนินการ
สมมติว่าเราอยู่ในโฮมไดเร็กทอรีของผู้ใช้ Hadoop (ตัวอย่างเช่น / home / hadoop)
ทำตามขั้นตอนด้านล่างเพื่อคอมไพล์และรันโปรแกรมข้างต้น
Step 1 - ใช้คำสั่งต่อไปนี้เพื่อสร้างไดเร็กทอรีเพื่อจัดเก็บคลาส java ที่คอมไพล์
$ mkdir unitsStep 2- ดาวน์โหลด Hadoop-core-1.2.1.jar ซึ่งใช้ในการคอมไพล์และรันโปรแกรม MapReduce คุณสามารถดาวน์โหลดขวดจากmvnrepository.com
ให้เราถือว่าโฟลเดอร์ที่ดาวน์โหลดคือ / home / hadoop /
Step 3 - ใช้คำสั่งต่อไปนี้เพื่อรวบรวมไฟล์ WordCount.java โปรแกรมและสร้าง jar สำหรับโปรแกรม
$ javac -classpath hadoop-core-1.2.1.jar -d units WordCount.java
$ jar -cvf units.jar -C units/ .Step 4 - ใช้คำสั่งต่อไปนี้เพื่อสร้างไดเร็กทอรีอินพุตใน HDFS
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirStep 5 - ใช้คำสั่งต่อไปนี้เพื่อคัดลอกไฟล์อินพุตที่ชื่อ input.txt ในไดเร็กทอรีอินพุตของ HDFS
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/input.txt input_dirStep 6 - ใช้คำสั่งต่อไปนี้เพื่อตรวจสอบไฟล์ในไดเร็กทอรีอินพุต
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 7 - ใช้คำสั่งต่อไปนี้เพื่อเรียกใช้แอปพลิเคชัน Word count โดยรับไฟล์อินพุตจากไดเร็กทอรีอินพุต
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dirรอสักครู่จนกว่าไฟล์จะถูกเรียกใช้งาน หลังจากดำเนินการแล้วเอาต์พุตจะมีการแยกอินพุตงานแผนที่และงานลดจำนวน
Step 8 - ใช้คำสั่งต่อไปนี้เพื่อตรวจสอบไฟล์ผลลัพธ์ในโฟลเดอร์ผลลัพธ์
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Step 9 - ใช้คำสั่งต่อไปนี้เพื่อดูผลลัพธ์ในรูปแบบ Part-00000ไฟล์. ไฟล์นี้สร้างโดย HDFS
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000ต่อไปนี้เป็นผลลัพธ์ที่สร้างโดยโปรแกรม MapReduce
What 3
do 2
you 2
mean 1
by 1
Object 1
know 1
about 1
Java 3
is 1
Virtual 1
Machine 1
How 1
enabled 1
High 1
Performance 1บทนี้อธิบายการดูแลระบบ Hadoop ซึ่งรวมถึงการดูแลระบบ HDFS และ MapReduce
การดูแลระบบ HDFS รวมถึงการตรวจสอบโครงสร้างไฟล์ HDFS ตำแหน่งและไฟล์ที่อัพเดต
การดูแลระบบ MapReduce รวมถึงการตรวจสอบรายการแอปพลิเคชันการกำหนดค่าโหนดสถานะของแอปพลิเคชัน ฯลฯ
การตรวจสอบ HDFS
HDFS (Hadoop Distributed File System) ประกอบด้วยไดเร็กทอรีผู้ใช้ไฟล์อินพุตและไฟล์เอาต์พุต ใช้คำสั่ง MapReduceput และ get, สำหรับจัดเก็บและเรียกค้น
หลังจากเริ่มใช้ Hadoop framework (daemons) โดยส่งคำสั่ง“ start-all.sh” บน“ / $ HADOOP_HOME / sbin” ให้ส่ง URL ต่อไปนี้ไปยังเบราว์เซอร์“ http: // localhost: 50070” คุณควรเห็นหน้าจอต่อไปนี้บนเบราว์เซอร์ของคุณ
ภาพหน้าจอต่อไปนี้แสดงวิธีเรียกดู HDFS เรียกดู

ภาพหน้าจอต่อไปนี้แสดงโครงสร้างไฟล์ของ HDFS จะแสดงไฟล์ในไดเร็กทอรี“ / user / hadoop”

ภาพหน้าจอต่อไปนี้แสดงข้อมูล Datanode ในคลัสเตอร์ ที่นี่คุณจะพบหนึ่งโหนดที่มีการกำหนดค่าและความจุ

MapReduce การตรวจสอบงาน
แอปพลิเคชัน MapReduce คือชุดของงาน (งานแผนที่, Combiner, Partitioner และลดงาน) จำเป็นต้องตรวจสอบและบำรุงรักษาสิ่งต่อไปนี้ -
- การกำหนดค่า datanode ที่เหมาะสมกับแอปพลิเคชัน
- จำนวนรหัสข้อมูลและทรัพยากรที่ใช้ต่อแอปพลิเคชัน
ในการตรวจสอบสิ่งเหล่านี้เราจำเป็นต้องมีส่วนต่อประสานกับผู้ใช้ หลังจากเริ่มใช้งาน Hadoop framework โดยส่งคำสั่ง“ start-all.sh” บน“ / $ HADOOP_HOME / sbin” ให้ส่ง URL ต่อไปนี้ไปยังเบราว์เซอร์“ http: // localhost: 8080” คุณควรเห็นหน้าจอต่อไปนี้บนเบราว์เซอร์ของคุณ

ในภาพหน้าจอด้านบนตัวชี้มือจะอยู่บนรหัสแอปพลิเคชัน เพียงคลิกเพื่อค้นหาหน้าจอต่อไปนี้บนเบราว์เซอร์ของคุณ อธิบายสิ่งต่อไปนี้ -
แอปพลิเคชันปัจจุบันกำลังทำงานกับผู้ใช้
ชื่อแอปพลิเคชัน
ประเภทของแอปพลิเคชันนั้น
สถานะปัจจุบันสถานะสุดท้าย
เวลาเริ่มต้นของแอปพลิเคชันเวลาที่ผ่านไป (เวลาที่เสร็จสมบูรณ์) หากเสร็จสมบูรณ์ในเวลาที่ตรวจสอบ
ประวัติของแอปพลิเคชันนี้ ได้แก่ ข้อมูลบันทึก
และสุดท้ายข้อมูลโหนดคือโหนดที่เข้าร่วมในการรันแอปพลิเคชัน
ภาพหน้าจอต่อไปนี้แสดงรายละเอียดของแอปพลิเคชันเฉพาะ -

ภาพหน้าจอต่อไปนี้อธิบายข้อมูลโหนดที่กำลังทำงานอยู่ ที่นี่ภาพหน้าจอมีเพียงโหนดเดียว ตัวชี้มือแสดงที่อยู่ localhost ของโหนดที่กำลังทำงานอยู่
