MongoDB - คู่มือฉบับย่อ
MongoDB เป็นฐานข้อมูลที่เน้นเอกสารข้ามแพลตฟอร์มซึ่งมีประสิทธิภาพสูงพร้อมใช้งานสูงและปรับขนาดได้ง่าย MongoDB ทำงานเกี่ยวกับแนวคิดการรวบรวมและเอกสาร
ฐานข้อมูล
ฐานข้อมูลเป็นคอนเทนเนอร์ทางกายภาพสำหรับคอลเลกชัน แต่ละฐานข้อมูลจะได้รับชุดไฟล์ของตัวเองบนระบบไฟล์ โดยทั่วไปเซิร์ฟเวอร์ MongoDB เดียวจะมีฐานข้อมูลหลายฐานข้อมูล
คอลเลกชัน
คอลเล็กชันคือกลุ่มเอกสาร MongoDB มันเทียบเท่ากับตาราง RDBMS คอลเลกชันมีอยู่ในฐานข้อมูลเดียว คอลเล็กชันไม่บังคับใช้สคีมา เอกสารภายในคอลเลกชันอาจมีฟิลด์ที่แตกต่างกัน โดยทั่วไปเอกสารทั้งหมดในคอลเล็กชันจะมีวัตถุประสงค์ที่คล้ายกันหรือเกี่ยวข้องกัน
เอกสาร
เอกสารคือชุดของคู่คีย์ - ค่า เอกสารมีสคีมาแบบไดนามิก สคีมาแบบไดนามิกหมายความว่าเอกสารในคอลเล็กชันเดียวกันไม่จำเป็นต้องมีชุดของฟิลด์หรือโครงสร้างเดียวกันและฟิลด์ทั่วไปในเอกสารของคอลเล็กชันอาจมีข้อมูลประเภทต่างๆ
ตารางต่อไปนี้แสดงความสัมพันธ์ของคำศัพท์ RDBMS กับ MongoDB
| RDBMS | MongoDB |
|---|---|
| ฐานข้อมูล | ฐานข้อมูล |
| ตาราง | คอลเลกชัน |
| Tuple / แถว | เอกสาร |
| คอลัมน์ | ฟิลด์ |
| เข้าร่วมโต๊ะ | เอกสารที่ฝังตัว |
| คีย์หลัก | คีย์หลัก (คีย์เริ่มต้น _id ให้โดย mongodb เอง) |
| เซิร์ฟเวอร์ฐานข้อมูลและไคลเอนต์ | |
| Mysqld / Oracle | mongod |
| mysql / sqlplus | Mongo |
เอกสารตัวอย่าง
ตัวอย่างต่อไปนี้แสดงโครงสร้างเอกสารของไซต์บล็อกซึ่งเป็นเพียงคู่ค่าคีย์ที่คั่นด้วยจุลภาค
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2011,1,20,2,15),
like: 0
},
{
user:'user2',
message: 'My second comments',
dateCreated: new Date(2011,1,25,7,45),
like: 5
}
]
}_idเป็นเลขฐานสิบหก 12 ไบต์ซึ่งรับรองความเป็นเอกลักษณ์ของเอกสารทุกฉบับ คุณสามารถระบุ _id ขณะแทรกเอกสาร หากคุณไม่ได้ระบุ MongoDB จะให้รหัสเฉพาะสำหรับทุกเอกสาร 12 ไบต์ 4 ไบต์แรกเหล่านี้สำหรับการประทับเวลาปัจจุบัน 3 ไบต์ถัดไปสำหรับรหัสเครื่อง 2 ไบต์ถัดไปสำหรับรหัสกระบวนการของเซิร์ฟเวอร์ MongoDB และ 3 ไบต์ที่เหลือเป็น VALUE ที่เพิ่มขึ้นอย่างง่าย
ฐานข้อมูลเชิงสัมพันธ์ใด ๆ มีการออกแบบสคีมาทั่วไปที่แสดงจำนวนตารางและความสัมพันธ์ระหว่างตารางเหล่านี้ ในขณะที่ MongoDB ไม่มีแนวคิดเรื่องความสัมพันธ์
ข้อดีของ MongoDB มากกว่า RDBMS
Schema less- MongoDB เป็นฐานข้อมูลเอกสารที่คอลเลกชันหนึ่งเก็บเอกสารที่แตกต่างกัน จำนวนช่องเนื้อหาและขนาดของเอกสารอาจแตกต่างกันไปในแต่ละเอกสาร
โครงสร้างของวัตถุชิ้นเดียวชัดเจน
ไม่มีการรวมที่ซับซ้อน
ความสามารถในการสืบค้นลึก MongoDB รองรับการสืบค้นแบบไดนามิกบนเอกสารโดยใช้ภาษาคิวรีแบบเอกสารซึ่งมีประสิทธิภาพเกือบเท่ากับ SQL
Tuning.
Ease of scale-out - MongoDB นั้นปรับขนาดได้ง่าย
ไม่จำเป็นต้องมีการแปลง / การแม็พของแอ็พพลิเคชันอ็อบเจ็กต์เป็นอ็อบเจ็กต์ฐานข้อมูล
ใช้หน่วยความจำภายในสำหรับจัดเก็บชุดการทำงาน (หน้าต่าง) ทำให้สามารถเข้าถึงข้อมูลได้เร็วขึ้น
ทำไมต้องใช้ MongoDB
Document Oriented Storage - ข้อมูลถูกจัดเก็บในรูปแบบของเอกสารสไตล์ JSON
ดัชนีแอตทริบิวต์ใด ๆ
การจำลองแบบและความพร้อมใช้งานสูง
Auto-sharding
ข้อความค้นหาที่หลากหลาย
การอัปเดตในสถานที่อย่างรวดเร็ว
การสนับสนุนระดับมืออาชีพโดย MongoDB
ใช้ MongoDB ได้ที่ไหน?
- ข้อมูลใหญ่
- การจัดการเนื้อหาและการจัดส่ง
- โครงสร้างพื้นฐานมือถือและสังคม
- การจัดการข้อมูลผู้ใช้
- ฮับข้อมูล
ตอนนี้ให้เราดูวิธีการติดตั้ง MongoDB บน Windows
ติดตั้ง MongoDB บน Windows
ในการติดตั้ง MongoDB บน Windows ก่อนอื่นให้ดาวน์โหลด MongoDB รุ่นล่าสุดจาก https://www.mongodb.org/downloads. ตรวจสอบให้แน่ใจว่าคุณได้รับ MongoDB เวอร์ชันที่ถูกต้องขึ้นอยู่กับเวอร์ชัน Windows ของคุณ ในการรับเวอร์ชัน Windows ของคุณให้เปิดพรอมต์คำสั่งและดำเนินการคำสั่งต่อไปนี้
C:\>wmic os get osarchitecture
OSArchitecture
64-bit
C:\>MongoDB เวอร์ชัน 32 บิตรองรับเฉพาะฐานข้อมูลที่มีขนาดเล็กกว่า 2GB และเหมาะสำหรับการทดสอบและการประเมินเท่านั้น
ตอนนี้แตกไฟล์ที่ดาวน์โหลดไปยัง c: \ drive หรือตำแหน่งอื่น ๆ ตรวจสอบว่าชื่อของโฟลเดอร์ที่แตกออกมาคือ mongodb-win32-i386- [version] หรือ mongodb-win32-x86_64- [version] นี่คือ [เวอร์ชัน] คือเวอร์ชันดาวน์โหลด MongoDB
จากนั้นเปิดพรอมต์คำสั่งและเรียกใช้คำสั่งต่อไปนี้
C:\>move mongodb-win64-* mongodb
1 dir(s) moved.
C:\>ในกรณีที่คุณแยก MongoDB ในตำแหน่งอื่นให้ไปที่เส้นทางนั้นโดยใช้คำสั่ง cd FOLDER/DIR และตอนนี้เรียกใช้กระบวนการที่กำหนดข้างต้น
MongoDB ต้องการโฟลเดอร์ข้อมูลเพื่อจัดเก็บไฟล์ ตำแหน่งดีฟอลต์สำหรับไดเร็กทอรีข้อมูล MongoDB คือ c: \ data \ db ดังนั้นคุณต้องสร้างโฟลเดอร์นี้โดยใช้ Command Prompt ดำเนินการตามลำดับคำสั่งต่อไปนี้
C:\>md data
C:\md data\dbหากคุณต้องติดตั้ง MongoDB ในตำแหน่งอื่นคุณจะต้องระบุเส้นทางอื่นสำหรับ \data\db โดยการกำหนดเส้นทาง dbpath ใน mongod.exe. ในทำนองเดียวกันให้ใช้คำสั่งต่อไปนี้
ในพรอมต์คำสั่งไปที่ไดเร็กทอรี bin ที่อยู่ในโฟลเดอร์การติดตั้ง MongoDB สมมติว่าโฟลเดอร์การติดตั้งของฉันคือD:\set up\mongodb
C:\Users\XYZ>d:
D:\>cd "set up"
D:\set up>cd mongodb
D:\set up\mongodb>cd bin
D:\set up\mongodb\bin>mongod.exe --dbpath "d:\set up\mongodb\data"สิ่งนี้จะแสดง waiting for connections ข้อความบนเอาต์พุตคอนโซลซึ่งบ่งชี้ว่ากระบวนการ mongod.exe กำลังทำงานสำเร็จ
ตอนนี้ในการเรียกใช้ MongoDB คุณต้องเปิดพรอมต์คำสั่งอื่นและออกคำสั่งต่อไปนี้
D:\set up\mongodb\bin>mongo.exe
MongoDB shell version: 2.4.6
connecting to: test
>db.test.save( { a: 1 } )
>db.test.find()
{ "_id" : ObjectId(5879b0f65a56a454), "a" : 1 }
>นี่จะแสดงว่า MongoDB ได้รับการติดตั้งและรันสำเร็จ ครั้งต่อไปเมื่อคุณเรียกใช้ MongoDB คุณต้องออกคำสั่งเท่านั้น
D:\set up\mongodb\bin>mongod.exe --dbpath "d:\set up\mongodb\data"
D:\set up\mongodb\bin>mongo.exeติดตั้ง MongoDB บน Ubuntu
รันคำสั่งต่อไปนี้เพื่ออิมพอร์ตคีย์ MongoDB public GPG -
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10สร้างไฟล์ /etc/apt/sources.list.d/mongodb.list โดยใช้คำสั่งต่อไปนี้
echo 'deb http://downloads-distro.mongodb.org/repo/ubuntu-upstart dist 10gen'
| sudo tee /etc/apt/sources.list.d/mongodb.listตอนนี้ใช้คำสั่งต่อไปนี้เพื่ออัปเดตที่เก็บ -
sudo apt-get updateถัดไปติดตั้ง MongoDB โดยใช้คำสั่งต่อไปนี้ -
apt-get install mongodb-10gen = 2.2.3ในการติดตั้งข้างต้น 2.2.3 ออกเวอร์ชัน MongoDB ในปัจจุบัน ตรวจสอบให้แน่ใจว่าได้ติดตั้งเวอร์ชันล่าสุดเสมอ ตอนนี้ MongoDB ติดตั้งเรียบร้อยแล้ว
เริ่ม MongoDB
sudo service mongodb startหยุด MongoDB
sudo service mongodb stopรีสตาร์ท MongoDB
sudo service mongodb restartในการใช้ MongoDB ให้รันคำสั่งต่อไปนี้
mongoสิ่งนี้จะเชื่อมต่อคุณกับการรันอินสแตนซ์ MongoDB
MongoDB ช่วยเหลือ
หากต้องการรับรายการคำสั่งพิมพ์ db.help()ในไคลเอนต์ MongoDB ซึ่งจะให้รายการคำสั่งดังที่แสดงในภาพหน้าจอต่อไปนี้

MongoDB สถิติ
หากต้องการรับสถิติเกี่ยวกับเซิร์ฟเวอร์ MongoDB ให้พิมพ์คำสั่ง db.stats()ในไคลเอนต์ MongoDB ซึ่งจะแสดงชื่อฐานข้อมูลจำนวนคอลเลกชันและเอกสารในฐานข้อมูล ผลลัพธ์ของคำสั่งจะแสดงในภาพหน้าจอต่อไปนี้

ข้อมูลใน MongoDB มี schema.documents ที่ยืดหยุ่นในคอลเล็กชันเดียวกัน พวกเขาไม่จำเป็นต้องมีชุดของเขตข้อมูลหรือโครงสร้างเดียวกันและเขตข้อมูลทั่วไปในเอกสารของคอลเลกชันอาจมีข้อมูลประเภทต่างๆ
ข้อควรพิจารณาบางประการขณะออกแบบ Schema ใน MongoDB
ออกแบบสคีมาของคุณตามความต้องการของผู้ใช้
รวมวัตถุไว้ในเอกสารเดียวหากคุณจะใช้ร่วมกัน มิฉะนั้นให้แยกออก (แต่ตรวจสอบให้แน่ใจว่าไม่จำเป็นต้องมีการรวม)
ทำซ้ำข้อมูล (แต่มี จำกัด ) เนื่องจากเนื้อที่ดิสก์มีราคาถูกเมื่อเทียบกับเวลาในการคำนวณ
เข้าร่วมขณะเขียนไม่ใช่อ่าน
เพิ่มประสิทธิภาพสคีมาของคุณสำหรับกรณีการใช้งานที่พบบ่อยที่สุด
ทำการรวมที่ซับซ้อนในสคีมา
ตัวอย่าง
สมมติว่าลูกค้าต้องการการออกแบบฐานข้อมูลสำหรับบล็อก / เว็บไซต์และดูความแตกต่างระหว่างการออกแบบสคีมา RDBMS และ MongoDB เว็บไซต์มีข้อกำหนดดังต่อไปนี้
- ทุกโพสต์มีชื่อเรื่องคำอธิบายและ URL ที่ไม่ซ้ำกัน
- ทุกโพสต์สามารถมีแท็กได้ตั้งแต่หนึ่งแท็ก
- ทุกโพสต์มีชื่อผู้เผยแพร่และจำนวนการกดไลค์ทั้งหมด
- ทุกโพสต์มีความคิดเห็นจากผู้ใช้พร้อมทั้งชื่อข้อความเวลาข้อมูลและไลค์
- ในแต่ละโพสต์อาจมีความคิดเห็นเป็นศูนย์หรือมากกว่านั้นก็ได้
ในสคีมา RDBMS การออกแบบสำหรับข้อกำหนดข้างต้นจะมีตารางขั้นต่ำสามตาราง

ในขณะที่อยู่ใน MongoDB schema การออกแบบจะมีโพสต์คอลเลกชันหนึ่งรายการและโครงสร้างต่อไปนี้ -
{
_id: POST_ID
title: TITLE_OF_POST,
description: POST_DESCRIPTION,
by: POST_BY,
url: URL_OF_POST,
tags: [TAG1, TAG2, TAG3],
likes: TOTAL_LIKES,
comments: [
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
},
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
}
]
}ดังนั้นในขณะที่แสดงข้อมูลใน RDBMS คุณต้องเข้าร่วมสามตารางและใน MongoDB ข้อมูลจะแสดงจากคอลเล็กชันเดียวเท่านั้น
ในบทนี้เราจะดูวิธีสร้างฐานข้อมูลใน MongoDB
ใช้คำสั่ง
MongoDB use DATABASE_NAMEใช้ในการสร้างฐานข้อมูล คำสั่งจะสร้างฐานข้อมูลใหม่หากไม่มีอยู่มิฉะนั้นจะส่งคืนฐานข้อมูลที่มีอยู่
ไวยากรณ์
ไวยากรณ์พื้นฐานของ use DATABASE คำสั่งมีดังนี้ -
use DATABASE_NAMEตัวอย่าง
หากคุณต้องการใช้ฐานข้อมูลที่มีชื่อ <mydb>แล้ว use DATABASE คำสั่งจะเป็นดังนี้ -
>use mydb
switched to db mydbในการตรวจสอบฐานข้อมูลที่คุณเลือกในปัจจุบันให้ใช้คำสั่ง db
>db
mydbหากคุณต้องการตรวจสอบรายการฐานข้อมูลของคุณให้ใช้คำสั่ง show dbs.
>show dbs
local 0.78125GB
test 0.23012GBฐานข้อมูลที่คุณสร้างขึ้น (mydb) ไม่มีอยู่ในรายการ ในการแสดงฐานข้อมูลคุณต้องแทรกเอกสารอย่างน้อยหนึ่งเอกสารลงไป
>db.movie.insert({"name":"tutorials point"})
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GBในฐานข้อมูลเริ่มต้น MongoDB คือการทดสอบ หากคุณไม่ได้สร้างฐานข้อมูลคอลเลกชันจะถูกเก็บไว้ในฐานข้อมูลทดสอบ
ในบทนี้เราจะดูวิธีการวางฐานข้อมูลโดยใช้คำสั่ง MongoDB
dropDatabase () วิธีการ
MongoDB db.dropDatabase() คำสั่งใช้เพื่อวางฐานข้อมูลที่มีอยู่
ไวยากรณ์
ไวยากรณ์พื้นฐานของ dropDatabase() คำสั่งมีดังนี้ -
db.dropDatabase()การดำเนินการนี้จะลบฐานข้อมูลที่เลือก หากคุณไม่ได้เลือกฐานข้อมูลใดฐานข้อมูลจะลบฐานข้อมูล 'ทดสอบ' เริ่มต้น
ตัวอย่าง
ขั้นแรกให้ตรวจสอบรายการฐานข้อมูลที่มีโดยใช้คำสั่ง show dbs.
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GB
>หากคุณต้องการลบฐานข้อมูลใหม่ <mydb>แล้ว dropDatabase() คำสั่งจะเป็นดังนี้ -
>use mydb
switched to db mydb
>db.dropDatabase()
>{ "dropped" : "mydb", "ok" : 1 }
>ตรวจสอบรายชื่อฐานข้อมูล
>show dbs
local 0.78125GB
test 0.23012GB
>ในบทนี้เราจะมาดูวิธีสร้างคอลเลกชันโดยใช้ MongoDB
createCollection () วิธีการ
MongoDB db.createCollection(name, options) ใช้ในการสร้างคอลเลกชัน
ไวยากรณ์
ไวยากรณ์พื้นฐานของ createCollection() คำสั่งมีดังนี้ -
db.createCollection(name, options)ในคำสั่ง name เป็นชื่อของคอลเลกชันที่จะสร้าง Options เป็นเอกสารและใช้เพื่อระบุการกำหนดค่าคอลเลกชัน
| พารามิเตอร์ | ประเภท | คำอธิบาย |
|---|---|---|
| ชื่อ | สตริง | ชื่อของคอลเล็กชันที่จะสร้าง |
| ตัวเลือก | เอกสาร | (ไม่บังคับ) ระบุตัวเลือกเกี่ยวกับขนาดหน่วยความจำและการจัดทำดัชนี |
พารามิเตอร์ตัวเลือกเป็นทางเลือกดังนั้นคุณต้องระบุเฉพาะชื่อของคอลเล็กชัน ต่อไปนี้เป็นรายการตัวเลือกที่คุณสามารถใช้ได้ -
| ฟิลด์ | ประเภท | คำอธิบาย |
|---|---|---|
| ต่อยอด | บูลีน | (ไม่บังคับ) หากเป็นจริงให้เปิดใช้คอลเล็กชันที่ต่อยอด คอลเลกชันที่ต่อยอดคือคอลเล็กชันขนาดคงที่ซึ่งจะเขียนทับรายการที่เก่าที่สุดโดยอัตโนมัติเมื่อถึงขนาดสูงสุดIf you specify true, you need to specify size parameter also. |
| autoIndexId | บูลีน | (ไม่บังคับ) หากเป็นจริงให้สร้างดัชนีบนฟิลด์ _id โดยอัตโนมัติค่าเริ่มต้นเป็นเท็จ |
| ขนาด | จำนวน | (ไม่บังคับ) ระบุขนาดสูงสุดเป็นไบต์สำหรับคอลเลกชันที่ต่อยอด If capped is true, then you need to specify this field also. |
| สูงสุด | จำนวน | (ไม่บังคับ) ระบุจำนวนเอกสารสูงสุดที่อนุญาตในคอลเล็กชันต่อยอด |
ในขณะที่แทรกเอกสาร MongoDB จะตรวจสอบฟิลด์ขนาดของคอลเลกชันที่ต่อยอดก่อนจากนั้นจะตรวจสอบฟิลด์สูงสุด
ตัวอย่าง
ไวยากรณ์พื้นฐานของ createCollection() วิธีการที่ไม่มีตัวเลือกมีดังนี้ -
>use test
switched to db test
>db.createCollection("mycollection")
{ "ok" : 1 }
>คุณสามารถตรวจสอบคอลเลกชันที่สร้างขึ้นโดยใช้คำสั่ง show collections.
>show collections
mycollection
system.indexesตัวอย่างต่อไปนี้แสดงไวยากรณ์ของ createCollection() วิธีการที่มีตัวเลือกที่สำคัญบางอย่าง -
>db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
{ "ok" : 1 }
>ใน MongoDB คุณไม่จำเป็นต้องสร้างคอลเล็กชัน MongoDB สร้างคอลเล็กชันโดยอัตโนมัติเมื่อคุณแทรกเอกสารบางอย่าง
>db.tutorialspoint.insert({"name" : "tutorialspoint"})
>show collections
mycol
mycollection
system.indexes
tutorialspoint
>ในบทนี้เราจะมาดูวิธีการวางคอลเลคชันโดยใช้ MongoDB
วิธีการลดลง ()
MongoDB ของ db.collection.drop() ใช้เพื่อวางคอลเล็กชันจากฐานข้อมูล
ไวยากรณ์
ไวยากรณ์พื้นฐานของ drop() คำสั่งมีดังนี้ -
db.COLLECTION_NAME.drop()ตัวอย่าง
ขั้นแรกตรวจสอบคอลเลกชันที่มีอยู่ในฐานข้อมูลของคุณ mydb.
>use mydb
switched to db mydb
>show collections
mycol
mycollection
system.indexes
tutorialspoint
>ตอนนี้ปล่อยคอลเลกชันที่มีชื่อ mycollection.
>db.mycollection.drop()
true
>ตรวจสอบรายการคอลเลกชันในฐานข้อมูลอีกครั้ง
>show collections
mycol
system.indexes
tutorialspoint
>drop () วิธีการจะคืนค่าจริงหากคอลเลกชันที่เลือกถูกทิ้งสำเร็จมิฉะนั้นจะส่งคืนเท็จ
MongoDB รองรับประเภทข้อมูลจำนวนมาก บางคนเป็น -
String- นี่คือประเภทข้อมูลที่ใช้กันมากที่สุดในการจัดเก็บข้อมูล สตริงใน MongoDB ต้องเป็น UTF-8 ที่ถูกต้อง
Integer- ประเภทนี้ใช้เพื่อเก็บค่าตัวเลข จำนวนเต็มอาจเป็น 32 บิตหรือ 64 บิตขึ้นอยู่กับเซิร์ฟเวอร์ของคุณ
Boolean - ประเภทนี้ใช้เพื่อเก็บค่าบูลีน (จริง / เท็จ)
Double - ประเภทนี้ใช้ในการจัดเก็บค่าทศนิยม
Min/ Max keys - ประเภทนี้ใช้เพื่อเปรียบเทียบค่ากับองค์ประกอบ BSON ต่ำสุดและสูงสุด
Arrays - ประเภทนี้ใช้เพื่อจัดเก็บอาร์เรย์หรือรายการหรือหลายค่าไว้ในคีย์เดียว
Timestamp- ctimestamp สิ่งนี้สามารถช่วยในการบันทึกเมื่อมีการแก้ไขหรือเพิ่มเอกสาร
Object - ประเภทข้อมูลนี้ใช้สำหรับเอกสารแบบฝัง
Null - ประเภทนี้ใช้เพื่อเก็บค่า Null
Symbol- ประเภทข้อมูลนี้ใช้เหมือนกับสตริง อย่างไรก็ตามโดยทั่วไปจะสงวนไว้สำหรับภาษาที่ใช้สัญลักษณ์เฉพาะประเภท
Date - ประเภทข้อมูลนี้ใช้เพื่อจัดเก็บวันที่หรือเวลาปัจจุบันในรูปแบบเวลา UNIX คุณสามารถระบุวันเวลาของคุณเองได้โดยสร้างวัตถุของวันที่และวันเดือนปีที่ผ่านไป
Object ID - ประเภทข้อมูลนี้ใช้เพื่อจัดเก็บ ID ของเอกสาร
Binary data - ประเภทข้อมูลนี้ใช้เพื่อจัดเก็บข้อมูลไบนารี
Code - ประเภทข้อมูลนี้ใช้เพื่อจัดเก็บโค้ด JavaScript ลงในเอกสาร
Regular expression - ประเภทข้อมูลนี้ใช้เพื่อจัดเก็บนิพจน์ทั่วไป
ในบทนี้เราจะเรียนรู้วิธีแทรกเอกสารในคอลเลคชัน MongoDB
วิธีแทรก ()
ในการแทรกข้อมูลลงในคอลเลกชัน MongoDB คุณต้องใช้ MongoDB insert() หรือ save() วิธี.
ไวยากรณ์
ไวยากรณ์พื้นฐานของ insert() คำสั่งมีดังนี้ -
>db.COLLECTION_NAME.insert(document)ตัวอย่าง
>db.mycol.insert({
_id: ObjectId(7df78ad8902c),
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})ที่นี่ mycolคือชื่อคอลเลกชันของเราตามที่สร้างไว้ในบทก่อนหน้า หากไม่มีคอลเล็กชันในฐานข้อมูล MongoDB จะสร้างคอลเล็กชันนี้จากนั้นแทรกเอกสารเข้าไป
ในเอกสารที่แทรกหากเราไม่ระบุพารามิเตอร์ _id ดังนั้น MongoDB จะกำหนด ObjectId เฉพาะสำหรับเอกสารนี้
_id เป็นเลขฐานสิบหก 12 ไบต์ที่ไม่ซ้ำกันสำหรับทุกเอกสารในคอลเล็กชัน 12 ไบต์แบ่งดังนี้ -
_id: ObjectId(4 bytes timestamp, 3 bytes machine id, 2 bytes process id,
3 bytes incrementer)ในการแทรกเอกสารหลายชุดในแบบสอบถามเดียวคุณสามารถส่งอาร์เรย์ของเอกสารในคำสั่ง insert ()
ตัวอย่าง
>db.post.insert([
{
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
title: 'NoSQL Database',
description: "NoSQL database doesn't have tables",
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 20,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2013,11,10,2,35),
like: 0
}
]
}
])ในการแทรกเอกสารคุณสามารถใช้ได้ db.post.save(document)ด้วย. หากคุณไม่ระบุ_id ในเอกสารแล้ว save() วิธีการจะทำงานเช่นเดียวกับ insert()วิธี. หากคุณระบุ _id ระบบจะแทนที่ข้อมูลทั้งหมดของเอกสารที่มี _id ตามที่ระบุในเมธอด save ()
ในบทนี้เราจะเรียนรู้วิธีการสืบค้นเอกสารจาก MongoDB collection
วิธีค้นหา ()
ในการสืบค้นข้อมูลจากคอลเลกชัน MongoDB คุณต้องใช้ MongoDB's find() วิธี.
ไวยากรณ์
ไวยากรณ์พื้นฐานของ find() วิธีการมีดังนี้ -
>db.COLLECTION_NAME.find()find() วิธีการจะแสดงเอกสารทั้งหมดในลักษณะที่ไม่มีโครงสร้าง
วิธีสวย ๆ ()
หากต้องการแสดงผลลัพธ์ในรูปแบบคุณสามารถใช้ pretty() วิธี.
ไวยากรณ์
>db.mycol.find().pretty()ตัวอย่าง
>db.mycol.find().pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>นอกจากวิธี find () แล้วยังมี findOne() วิธีการที่ส่งคืนเอกสารเพียงชุดเดียว
RDBMS โดยที่ Clause Equivalents ใน MongoDB
ในการสืบค้นเอกสารตามเงื่อนไขบางประการคุณสามารถใช้การดำเนินการต่อไปนี้
| การดำเนินการ | ไวยากรณ์ | ตัวอย่าง | RDBMS เทียบเท่า |
|---|---|---|---|
| ความเท่าเทียมกัน | {<key>: <value>} | db.mycol.find ({"by": "tutorials point"}) สวย () | โดย = 'tutorials point' |
| น้อยกว่า | {<key>: {$ lt: <value>}} | db.mycol.find ({"ไลค์": {$ lt: 50}}) สวย () | ชอบที่ไหน <50 |
| น้อยกว่าเท่ากับ | {<key>: {$ lte: <value>}} | db.mycol.find ({"ไลค์": {$ lte: 50}}) สวย () | ชอบที่ไหน <= 50 |
| มากกว่า | {<key>: {$ gt: <value>}} | db.mycol.find ({"ไลค์": {$ gt: 50}}) สวย () | ชอบที่ไหน> 50 |
| มากกว่าที่เท่าเทียมกัน | {<key>: {$ gte: <value>}} | db.mycol.find ({"ชอบ": {$ gte: 50}}) สวย () | ที่ชอบ> = 50 |
| ไม่เท่ากับ | {<key>: {$ ne: <value>}} | db.mycol.find ({"ไลค์": {$ ne: 50}}) สวย () | ชอบที่ไหน! = 50 |
และใน MongoDB
ไวยากรณ์
ใน find() วิธีการหากคุณส่งผ่านหลายคีย์โดยคั่นด้วย '' MongoDB จะถือว่าเป็น ANDเงื่อนไข. ต่อไปนี้เป็นไวยากรณ์พื้นฐานของAND -
>db.mycol.find(
{
$and: [
{key1: value1}, {key2:value2}
]
}
).pretty()ตัวอย่าง
ตัวอย่างต่อไปนี้จะแสดงบทช่วยสอนทั้งหมดที่เขียนโดย 'จุดช่วยสอน' และมีชื่อว่า 'MongoDB Overview'
>db.mycol.find({$and:[{"by":"tutorials point"},{"title": "MongoDB Overview"}]}).pretty() {
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}สำหรับตัวอย่างที่กำหนดข้างต้นเทียบเท่ากับที่ประโยคจะเป็น ' where by = 'tutorials point' AND title = 'MongoDB Overview' '. คุณสามารถส่งคีย์คู่ค่าจำนวนเท่าใดก็ได้ใน find clause
หรือใน MongoDB
ไวยากรณ์
ในการสืบค้นเอกสารตามเงื่อนไข OR คุณต้องใช้ $orคำสำคัญ. ต่อไปนี้เป็นไวยากรณ์พื้นฐานของOR -
>db.mycol.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()ตัวอย่าง
ตัวอย่างต่อไปนี้จะแสดงบทช่วยสอนทั้งหมดที่เขียนโดย 'จุดสอน' หรือที่มีชื่อว่า 'ภาพรวม MongoDB'
>db.mycol.find({$or:[{"by":"tutorials point"},{"title": "MongoDB Overview"}]}).pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>การใช้ AND และ OR ร่วมกัน
ตัวอย่าง
ตัวอย่างต่อไปนี้จะแสดงเอกสารที่มีจำนวนไลค์มากกว่า 10 และมีชื่อเป็น 'MongoDB Overview' หรือโดยเป็น 'tutorials point' SQL ที่เทียบเท่าโดยที่ประโยคคือ'where likes>10 AND (by = 'tutorials point' OR title = 'MongoDB Overview')'
>db.mycol.find({"likes": {$gt:10}, $or: [{"by": "tutorials point"},
{"title": "MongoDB Overview"}]}).pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>MongoDB ของ update() และ save()วิธีการใช้เพื่ออัปเดตเอกสารลงในคอลเล็กชัน วิธีการ update () จะอัปเดตค่าในเอกสารที่มีอยู่ในขณะที่เมธอด save () แทนที่เอกสารที่มีอยู่ด้วยเอกสารที่ส่งผ่านด้วยวิธี save ()
MongoDB Update () วิธีการ
วิธี update () จะอัพเดตค่าในเอกสารที่มีอยู่
ไวยากรณ์
ไวยากรณ์พื้นฐานของ update() วิธีการมีดังนี้ -
>db.COLLECTION_NAME.update(SELECTION_CRITERIA, UPDATED_DATA)ตัวอย่าง
พิจารณาคอลเลกชัน mycol มีข้อมูลต่อไปนี้
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}ตัวอย่างต่อไปนี้จะตั้งชื่อเรื่องใหม่ 'New MongoDB Tutorial' ของเอกสารที่มีชื่อว่า 'MongoDB Overview'
>db.mycol.update({'title':'MongoDB Overview'},{$set:{'title':'New MongoDB Tutorial'}})
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"New MongoDB Tutorial"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>ตามค่าเริ่มต้น MongoDB จะอัปเดตเพียงเอกสารเดียว หากต้องการอัปเดตเอกสารหลายชุดคุณต้องตั้งค่าพารามิเตอร์ "หลาย" เป็นจริง
>db.mycol.update({'title':'MongoDB Overview'},
{$set:{'title':'New MongoDB Tutorial'}},{multi:true})MongoDB Save () วิธีการ
save() วิธีการแทนที่เอกสารที่มีอยู่ด้วยเอกสารใหม่ที่ส่งผ่านในเมธอด save ()
ไวยากรณ์
ไวยากรณ์พื้นฐานของ MongoDB save() วิธีการแสดงด้านล่าง -
>db.COLLECTION_NAME.save({_id:ObjectId(),NEW_DATA})ตัวอย่าง
ตัวอย่างต่อไปนี้จะแทนที่เอกสารด้วย _id '5983548781331adf45ec5'
>db.mycol.save(
{
"_id" : ObjectId(5983548781331adf45ec5), "title":"Tutorials Point New Topic",
"by":"Tutorials Point"
}
)
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"Tutorials Point New Topic",
"by":"Tutorials Point"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>ในบทนี้เราจะเรียนรู้วิธีการลบเอกสารโดยใช้ MongoDB
วิธีลบ ()
MongoDB ของ remove()วิธีนี้ใช้เพื่อลบเอกสารออกจากคอลเลกชัน ลบ () วิธีการยอมรับสองพารามิเตอร์ หนึ่งคือเกณฑ์การลบและอันดับสองคือแฟล็ก justOne
deletion criteria - (ไม่บังคับ) เกณฑ์การลบตามเอกสารจะถูกลบออก
justOne - (ไม่บังคับ) หากตั้งค่าเป็นจริงหรือ 1 ให้ลบเอกสารเพียงชุดเดียว
ไวยากรณ์
ไวยากรณ์พื้นฐานของ remove() วิธีการมีดังนี้ -
>db.COLLECTION_NAME.remove(DELLETION_CRITTERIA)ตัวอย่าง
พิจารณาคอลเลกชัน mycol มีข้อมูลต่อไปนี้
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}ตัวอย่างต่อไปนี้จะลบเอกสารทั้งหมดที่มีชื่อว่า 'MongoDB Overview'
>db.mycol.remove({'title':'MongoDB Overview'})
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>ลบเพียงหนึ่งเดียว
หากมีหลายระเบียนและคุณต้องการลบเฉพาะระเบียนแรกให้ตั้งค่า justOne พารามิเตอร์ใน remove() วิธี.
>db.COLLECTION_NAME.remove(DELETION_CRITERIA,1)ลบเอกสารทั้งหมด
หากคุณไม่ระบุเกณฑ์การลบ MongoDB จะลบเอกสารทั้งหมดออกจากคอลเล็กชัน This is equivalent of SQL's truncate command.
>db.mycol.remove({})
>db.mycol.find()
>ใน MongoDB การฉายภาพหมายถึงการเลือกเฉพาะข้อมูลที่จำเป็นแทนที่จะเลือกข้อมูลทั้งหมดของเอกสาร หากเอกสารมี 5 ช่องและคุณต้องแสดงเพียง 3 ช่องให้เลือกเพียง 3 ช่องจากนั้น
วิธีค้นหา ()
MongoDB ของ find()วิธีการอธิบายในMongoDB Query Documentยอมรับพารามิเตอร์ทางเลือกที่สองซึ่งเป็นรายการของฟิลด์ที่คุณต้องการดึงข้อมูล ใน MongoDB เมื่อคุณรันไฟล์find()จากนั้นจะแสดงทุกฟิลด์ของเอกสาร ในการ จำกัด สิ่งนี้คุณต้องตั้งค่ารายการของเขตข้อมูลที่มีค่า 1 หรือ 0 1 ใช้เพื่อแสดงเขตข้อมูลในขณะที่ใช้ 0 เพื่อซ่อนเขตข้อมูล
ไวยากรณ์
ไวยากรณ์พื้นฐานของ find() วิธีการฉายภาพมีดังนี้ -
>db.COLLECTION_NAME.find({},{KEY:1})ตัวอย่าง
พิจารณาคอลเลกชัน mycol มีข้อมูลต่อไปนี้ -
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}ตัวอย่างต่อไปนี้จะแสดงชื่อของเอกสารในขณะที่ค้นหาเอกสาร
>db.mycol.find({},{"title":1,_id:0})
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
{"title":"Tutorials Point Overview"}
>โปรดทราบ _id ฟิลด์จะปรากฏขึ้นเสมอขณะดำเนินการ find() วิธีการถ้าคุณไม่ต้องการฟิลด์นี้คุณต้องตั้งค่าเป็น 0
ในบทนี้เราจะเรียนรู้วิธี จำกัด ระเบียนโดยใช้ MongoDB
วิธีการ จำกัด ()
ในการ จำกัด ระเบียนใน MongoDB คุณต้องใช้ limit()วิธี. เมธอดยอมรับอาร์กิวเมนต์ประเภทตัวเลขหนึ่งรายการซึ่งเป็นจำนวนเอกสารที่คุณต้องการให้แสดง
ไวยากรณ์
ไวยากรณ์พื้นฐานของ limit() วิธีการมีดังนี้ -
>db.COLLECTION_NAME.find().limit(NUMBER)ตัวอย่าง
พิจารณาว่าคอลเลกชัน myycol มีข้อมูลดังต่อไปนี้
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}ตัวอย่างต่อไปนี้จะแสดงเอกสารเพียงสองชุดในขณะที่สืบค้นเอกสาร
>db.mycol.find({},{"title":1,_id:0}).limit(2)
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
>หากคุณไม่ระบุอาร์กิวเมนต์ตัวเลขใน limit() จากนั้นจะแสดงเอกสารทั้งหมดจากคอลเล็กชัน
MongoDB ข้าม () วิธีการ
นอกเหนือจากวิธี limit () แล้วยังมีอีกหนึ่งวิธี skip() ซึ่งยอมรับอาร์กิวเมนต์ประเภทตัวเลขและใช้เพื่อข้ามจำนวนเอกสาร
ไวยากรณ์
ไวยากรณ์พื้นฐานของ skip() วิธีการมีดังนี้ -
>db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)ตัวอย่าง
ตัวอย่างต่อไปนี้จะแสดงเฉพาะเอกสารที่สอง
>db.mycol.find({},{"title":1,_id:0}).limit(1).skip(1)
{"title":"NoSQL Overview"}
>โปรดทราบว่าค่าเริ่มต้นในรูปแบบ skip() วิธีการคือ 0
ในบทนี้เราจะเรียนรู้วิธีการจัดเรียงระเบียนใน MongoDB
วิธีการเรียงลำดับ ()
ในการจัดเรียงเอกสารใน MongoDB คุณต้องใช้ sort()วิธี. วิธีนี้ยอมรับเอกสารที่มีรายการเขตข้อมูลพร้อมกับลำดับการเรียงลำดับ ในการระบุลำดับการจัดเรียง 1 และ -1 จะใช้ 1 ใช้สำหรับการเรียงลำดับจากน้อยไปมากในขณะที่ -1 ใช้สำหรับลำดับจากมากไปหาน้อย
ไวยากรณ์
ไวยากรณ์พื้นฐานของ sort() วิธีการมีดังนี้ -
>db.COLLECTION_NAME.find().sort({KEY:1})ตัวอย่าง
พิจารณาว่าคอลเลกชัน myycol มีข้อมูลดังต่อไปนี้
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}ตัวอย่างต่อไปนี้จะแสดงเอกสารที่เรียงตามชื่อเรื่องในลำดับจากมากไปหาน้อย
>db.mycol.find({},{"title":1,_id:0}).sort({"title":-1})
{"title":"Tutorials Point Overview"}
{"title":"NoSQL Overview"}
{"title":"MongoDB Overview"}
>โปรดทราบว่าหากคุณไม่ได้ระบุการตั้งค่าการเรียงลำดับ sort() วิธีการจะแสดงเอกสารจากน้อยไปมาก
ดัชนีสนับสนุนการแก้ปัญหาที่มีประสิทธิภาพของแบบสอบถาม MongoDB ต้องสแกนเอกสารทุกชุดเพื่อเลือกเอกสารที่ตรงกับคำสั่งแบบสอบถาม การสแกนนี้ไม่มีประสิทธิภาพสูงและต้องใช้ MongoDB ในการประมวลผลข้อมูลจำนวนมาก
ดัชนีเป็นโครงสร้างข้อมูลพิเศษที่จัดเก็บข้อมูลส่วนเล็ก ๆ ไว้ในรูปแบบที่ง่ายต่อการสำรวจ ดัชนีจะเก็บค่าของเขตข้อมูลหรือชุดของเขตข้อมูลเฉพาะโดยเรียงลำดับตามค่าของเขตข้อมูลตามที่ระบุไว้ในดัชนี
วิธีการ sureIndex ()
ในการสร้างดัชนีคุณต้องใช้เมธอด sureIndex () ของ MongoDB
ไวยากรณ์
ไวยากรณ์พื้นฐานของ ensureIndex() วิธีการดังต่อไปนี้ ().
>db.COLLECTION_NAME.ensureIndex({KEY:1})คีย์ต่อไปนี้คือชื่อของฟิลด์ที่คุณต้องการสร้างดัชนีและ 1 สำหรับจากน้อยไปหามาก ในการสร้างดัชนีจากมากไปหาน้อยคุณต้องใช้ -1
ตัวอย่าง
>db.mycol.ensureIndex({"title":1})
>ใน ensureIndex() วิธีการที่คุณสามารถส่งหลายฟิลด์เพื่อสร้างดัชนีในหลายฟิลด์
>db.mycol.ensureIndex({"title":1,"description":-1})
>ensureIndex()วิธีนี้ยังยอมรับรายการตัวเลือก (ซึ่งเป็นทางเลือก) ต่อไปนี้เป็นรายการ -
| พารามิเตอร์ | ประเภท | คำอธิบาย |
|---|---|---|
| พื้นหลัง | บูลีน | สร้างดัชนีในพื้นหลังเพื่อให้การสร้างดัชนีไม่บล็อกกิจกรรมฐานข้อมูลอื่น ๆ ระบุ true เพื่อสร้างในพื้นหลัง ค่าเริ่มต้นคือfalse. |
| ไม่เหมือนใคร | บูลีน | สร้างดัชนีเฉพาะเพื่อที่คอลเลกชันจะไม่ยอมรับการแทรกเอกสารที่คีย์ดัชนีหรือคีย์ตรงกับค่าที่มีอยู่ในดัชนี ระบุ true เพื่อสร้างดัชนีเฉพาะ ค่าเริ่มต้นคือfalse. |
| ชื่อ | สตริง | ชื่อของดัชนี หากไม่ระบุ MongoDB จะสร้างชื่อดัชนีโดยการต่อชื่อของเขตข้อมูลที่จัดทำดัชนีและลำดับการจัดเรียง |
| dropDups | บูลีน | สร้างดัชนีเฉพาะบนฟิลด์ที่อาจมีข้อมูลซ้ำกัน MongoDB ทำดัชนีเฉพาะการเกิดขึ้นครั้งแรกของคีย์และลบเอกสารทั้งหมดออกจากคอลเล็กชันที่มีการเกิดขึ้นของคีย์นั้นในภายหลัง ระบุ true เพื่อสร้างดัชนีเฉพาะ ค่าเริ่มต้นคือfalse. |
| เบาบาง | บูลีน | หากเป็นจริงดัชนีจะอ้างอิงเฉพาะเอกสารที่มีฟิลด์ที่ระบุ ดัชนีเหล่านี้ใช้พื้นที่น้อยกว่า แต่ทำงานแตกต่างกันในบางสถานการณ์ (โดยเฉพาะประเภทต่างๆ) ค่าเริ่มต้นคือfalse. |
| expireAfterSeconds | จำนวนเต็ม | ระบุค่าเป็นวินาทีเป็น TTL เพื่อควบคุมระยะเวลาที่ MongoDB เก็บรักษาเอกสารในคอลเล็กชันนี้ |
| v | เวอร์ชันดัชนี | หมายเลขเวอร์ชันดัชนี เวอร์ชันดัชนีเริ่มต้นขึ้นอยู่กับเวอร์ชันของ MongoDB ที่ทำงานเมื่อสร้างดัชนี |
| น้ำหนัก | เอกสาร | น้ำหนักคือตัวเลขตั้งแต่ 1 ถึง 99,999 และแสดงถึงความสำคัญของฟิลด์ที่สัมพันธ์กับฟิลด์อื่น ๆ ที่จัดทำดัชนีในแง่ของคะแนน |
| default_language | สตริง | สำหรับดัชนีข้อความภาษาที่กำหนดรายการคำหยุดและกฎสำหรับตัวเริ่มต้นและโทเค็นไนเซอร์ ค่าเริ่มต้นคือenglish. |
| language_override | สตริง | สำหรับดัชนีข้อความให้ระบุชื่อของเขตข้อมูลในเอกสารที่มีภาษาที่จะแทนที่ภาษาเริ่มต้น ค่าเริ่มต้นคือภาษา |
การดำเนินการรวมประมวลผลบันทึกข้อมูลและส่งคืนผลลัพธ์ที่คำนวณ ค่ากลุ่มการดำเนินการรวมจากเอกสารหลายชุดเข้าด้วยกันและสามารถดำเนินการต่างๆกับข้อมูลที่จัดกลุ่มเพื่อส่งคืนผลลัพธ์เดียว ใน SQL count (*) และด้วย group by เท่ากับการรวม mongodb
วิธีการรวม ()
สำหรับการรวมใน MongoDB คุณควรใช้ aggregate() วิธี.
ไวยากรณ์
ไวยากรณ์พื้นฐานของ aggregate() วิธีการมีดังนี้ -
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)ตัวอย่าง
ในคอลเล็กชันคุณมีข้อมูลต่อไปนี้ -
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
},จากคอลเล็กชันด้านบนหากคุณต้องการแสดงรายการที่ระบุจำนวนบทช่วยสอนที่เขียนโดยผู้ใช้แต่ละคนคุณจะใช้สิ่งต่อไปนี้ aggregate() วิธีการ -
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{
"result" : [
{
"_id" : "tutorials point",
"num_tutorial" : 2
},
{
"_id" : "Neo4j",
"num_tutorial" : 1
}
],
"ok" : 1
}
>แบบสอบถามเทียบเท่า SQL สำหรับกรณีการใช้งานข้างต้นจะเป็น select by_user, count(*) from mycol group by by_user.
ในตัวอย่างข้างต้นเราได้จัดกลุ่มเอกสารตามเขตข้อมูล by_userและในแต่ละครั้งของ by_user ค่าก่อนหน้าของผลรวมจะเพิ่มขึ้น ต่อไปนี้เป็นรายการนิพจน์การรวมที่พร้อมใช้งาน
| นิพจน์ | คำอธิบาย | ตัวอย่าง |
|---|---|---|
| $ sum | รวมค่าที่กำหนดจากเอกสารทั้งหมดในคอลเล็กชัน | db.mycol.aggregate ([{$ group: {_id: "$by_user", num_tutorial : {$ผลรวม: "$ likes"}}}]) |
| $ เฉลี่ย | คำนวณค่าเฉลี่ยของค่าที่กำหนดทั้งหมดจากเอกสารทั้งหมดในคอลเล็กชัน | db.mycol.aggregate ([{$group : {_id : "$by_user ", num_tutorial: {$avg : "$ชอบ "}}}]) |
| $ นาที | รับค่าต่ำสุดของค่าที่เกี่ยวข้องจากเอกสารทั้งหมดในคอลเล็กชัน | db.mycol.aggregate ([{$ group: {_id: "$by_user", num_tutorial : {$นาที: "$ likes"}}}]) |
| สูงสุด $ | รับค่าสูงสุดที่สอดคล้องกันจากเอกสารทั้งหมดในคอลเล็กชัน | db.mycol.aggregate ([{$group : {_id : "$by_user ", num_tutorial: {$max : "$ชอบ "}}}]) |
| $ ดัน | แทรกค่าให้กับอาร์เรย์ในเอกสารผลลัพธ์ | db.mycol.aggregate ([{$ group: {_id: "$by_user", url : {$ดัน: "$ url"}}}]) |
| $ addToSet | แทรกค่าให้กับอาร์เรย์ในเอกสารผลลัพธ์ แต่ไม่สร้างรายการที่ซ้ำกัน | db.mycol.aggregate ([{$group : {_id : "$by_user ", url: {$addToSet : "$url "}}}]) |
| $ แรก | รับเอกสารแรกจากเอกสารต้นทางตามการจัดกลุ่ม โดยทั่วไปแล้วสิ่งนี้จะเข้ากันได้กับเวที“ $ sort” ที่ใช้ก่อนหน้านี้เท่านั้น | db.mycol.aggregate ([{$group : {_id : "$by_user ", first_url: {$first : "$url "}}}]) |
| $ last | รับเอกสารล่าสุดจากเอกสารต้นทางตามการจัดกลุ่ม โดยทั่วไปแล้วสิ่งนี้จะเข้ากันได้กับเวที“ $ sort” ที่ใช้ก่อนหน้านี้เท่านั้น | db.mycol.aggregate ([{$group : {_id : "$by_user ", last_url: {$last : "$url "}}}]) |
แนวคิดท่อ
ในคำสั่ง UNIX เชลล์ไปป์ไลน์หมายถึงความเป็นไปได้ในการดำเนินการกับอินพุตบางส่วนและใช้เอาต์พุตเป็นอินพุตสำหรับคำสั่งถัดไปเป็นต้น MongoDB ยังสนับสนุนแนวคิดเดียวกันในกรอบการรวม มีชุดของขั้นตอนที่เป็นไปได้และแต่ละขั้นตอนจะถูกนำมาเป็นชุดของเอกสารเป็นอินพุตและสร้างชุดเอกสารที่เป็นผลลัพธ์ (หรือเอกสาร JSON ที่เป็นผลลัพธ์สุดท้ายที่ส่วนท้ายของไปป์ไลน์) จากนั้นจะสามารถใช้สำหรับขั้นตอนต่อไปและอื่น ๆ
ต่อไปนี้เป็นขั้นตอนที่เป็นไปได้ในกรอบการรวม -
$project - ใช้เพื่อเลือกฟิลด์เฉพาะบางฟิลด์จากคอลเลกชัน
$match - นี่คือการดำเนินการกรองและทำให้สามารถลดจำนวนเอกสารที่กำหนดให้เป็นข้อมูลป้อนเข้าในขั้นตอนต่อไป
$group - นี่เป็นการรวมจริงตามที่กล่าวไว้ข้างต้น
$sort - จัดเรียงเอกสาร
$skip - ด้วยวิธีนี้คุณสามารถข้ามไปข้างหน้าในรายการเอกสารสำหรับจำนวนเอกสารที่กำหนดได้
$limit - สิ่งนี้จะ จำกัด จำนวนเอกสารที่จะดูโดยจำนวนที่กำหนดเริ่มต้นจากตำแหน่งปัจจุบัน
$unwind- ใช้เพื่อคลายเอกสารที่ใช้อาร์เรย์ เมื่อใช้อาร์เรย์ข้อมูลจะถูกรวมไว้ล่วงหน้าและการดำเนินการนี้จะถูกยกเลิกเพื่อให้มีเอกสารแต่ละชุดอีกครั้ง ดังนั้นในขั้นตอนนี้เราจะเพิ่มจำนวนเอกสารสำหรับขั้นตอนต่อไป
การจำลองแบบเป็นกระบวนการซิงโครไนซ์ข้อมูลระหว่างเซิร์ฟเวอร์หลายเครื่อง การจำลองแบบให้ความซ้ำซ้อนและเพิ่มความพร้อมของข้อมูลด้วยสำเนาข้อมูลหลายชุดบนเซิร์ฟเวอร์ฐานข้อมูลที่แตกต่างกัน การจำลองแบบช่วยปกป้องฐานข้อมูลจากการสูญหายของเซิร์ฟเวอร์เดียว การจำลองแบบยังช่วยให้คุณสามารถกู้คืนจากความล้มเหลวของฮาร์ดแวร์และการหยุดชะงักของบริการ ด้วยสำเนาข้อมูลเพิ่มเติมคุณสามารถมอบข้อมูลให้กับการกู้คืนระบบรายงานหรือสำรองข้อมูลได้
ทำไมต้องจำลองแบบ?
- เพื่อให้ข้อมูลของคุณปลอดภัย
- ความพร้อมใช้งานของข้อมูลสูง (24 * 7)
- การกู้คืนระบบ
- ไม่มีการหยุดทำงานสำหรับการบำรุงรักษา (เช่นการสำรองข้อมูลการสร้างดัชนีการบดอัด)
- อ่านมาตราส่วน (สำเนาเพิ่มเติมเพื่ออ่าน)
- ชุดจำลองมีความโปร่งใสต่อแอปพลิเคชัน
การจำลองแบบทำงานอย่างไรใน MongoDB
MongoDB ประสบความสำเร็จในการจำลองแบบโดยใช้ชุดแบบจำลอง ชุดจำลองคือกลุ่มของmongodอินสแตนซ์ที่โฮสต์ชุดข้อมูลเดียวกัน ในการจำลองโหนดหนึ่งเป็นโหนดหลักที่รับการดำเนินการเขียนทั้งหมด อินสแตนซ์อื่น ๆ ทั้งหมดเช่นวินาทีจะใช้การดำเนินการจากหลักเพื่อให้มีชุดข้อมูลเดียวกัน ชุดการจำลองสามารถมีโหนดหลักได้เพียงโหนดเดียว
ชุดการจำลองคือกลุ่มของโหนดตั้งแต่สองโหนดขึ้นไป (โดยทั่วไปต้องมีโหนดอย่างน้อย 3 โหนด)
ในชุดการจำลองโหนดหนึ่งเป็นโหนดหลักและโหนดที่เหลือเป็นโหนดรอง
ข้อมูลทั้งหมดจำลองจากโหนดหลักไปยังโหนดรอง
ในช่วงเวลาของการเฟลโอเวอร์หรือการบำรุงรักษาโดยอัตโนมัติการเลือกตั้งจะสร้างขึ้นสำหรับโหนดหลักและมีการเลือกโหนดหลักใหม่
หลังจากการกู้คืนโหนดที่ล้มเหลวโหนดนั้นจะเข้าร่วมชุดการจำลองอีกครั้งและทำงานเป็นโหนดรอง
แผนภาพทั่วไปของการจำลองแบบ MongoDB จะแสดงซึ่งไคลเอ็นต์แอ็พพลิเคชันโต้ตอบกับโหนดหลักเสมอจากนั้นโหนดหลักจะจำลองข้อมูลไปยังโหนดรอง

คุณสมบัติชุดจำลอง
- คลัสเตอร์ของโหนด N
- โหนดใดโหนดหนึ่งสามารถเป็นโหนดหลักได้
- การดำเนินการเขียนทั้งหมดไปที่ขั้นต้น
- เฟลโอเวอร์อัตโนมัติ
- การกู้คืนอัตโนมัติ
- ฉันทามติการเลือกตั้งขั้นต้น
ตั้งค่าชุดการจำลอง
ในบทช่วยสอนนี้เราจะแปลงอินสแตนซ์ MongoDB แบบสแตนด์อโลนเป็นชุดจำลอง ในการแปลงเป็นชุดแบบจำลองให้ทำตามขั้นตอนต่อไปนี้ -
ปิดเครื่องแล้วรันเซิร์ฟเวอร์ MongoDB
เริ่มเซิร์ฟเวอร์ MongoDB โดยระบุ - replSet option ต่อไปนี้เป็นไวยากรณ์พื้นฐานของ --replSet -
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"ตัวอย่าง
mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0มันจะเริ่มต้นอินสแตนซ์ mongod ด้วยชื่อ rs0 บนพอร์ต 27017
ตอนนี้เริ่มพรอมต์คำสั่งและเชื่อมต่อกับอินสแตนซ์ mongod นี้
ในไคลเอนต์ Mongo ให้ออกคำสั่ง rs.initiate() เพื่อเริ่มชุดการจำลองใหม่
ในการตรวจสอบการกำหนดค่าชุดข้อมูลจำลองให้ออกคำสั่ง rs.conf(). ในการตรวจสอบสถานะของชุดข้อมูลจำลองให้ออกคำสั่งrs.status().
เพิ่มสมาชิกใน Replica Set
ในการเพิ่มสมาชิกในชุดการจำลองให้เริ่มอินสแตนซ์ mongod บนเครื่องหลายเครื่อง ตอนนี้เริ่มต้นไคลเอนต์ mongo และออกคำสั่งrs.add().
ไวยากรณ์
ไวยากรณ์พื้นฐานของ rs.add() คำสั่งมีดังนี้ -
>rs.add(HOST_NAME:PORT)ตัวอย่าง
สมมติว่าชื่ออินสแตนซ์ mongod ของคุณคือ mongod1.net และกำลังทำงานบนพอร์ต 27017. หากต้องการเพิ่มอินสแตนซ์นี้ในชุดข้อมูลจำลองให้ออกคำสั่งrs.add() ในลูกค้า Mongo
>rs.add("mongod1.net:27017")
>คุณสามารถเพิ่มอินสแตนซ์ mongod ในการจำลองชุดเฉพาะเมื่อคุณเชื่อมต่อกับโหนดหลัก หากต้องการตรวจสอบว่าคุณเชื่อมต่อกับอุปกรณ์หลักหรือไม่ให้ออกคำสั่งdb.isMaster() ในลูกค้า mongo
Sharding เป็นกระบวนการจัดเก็บบันทึกข้อมูลในหลาย ๆ เครื่องและเป็นแนวทางของ MongoDB ในการตอบสนองความต้องการของการเติบโตของข้อมูล เมื่อขนาดของข้อมูลเพิ่มขึ้นเครื่องเดียวอาจไม่เพียงพอที่จะจัดเก็บข้อมูลหรือให้ปริมาณงานอ่านและเขียนที่ยอมรับได้ Sharding แก้ปัญหาด้วยการปรับขนาดแนวนอน ด้วยการชาร์ดคุณสามารถเพิ่มเครื่องจักรเพื่อรองรับการเติบโตของข้อมูลและความต้องการในการอ่านและเขียน
ทำไมต้อง Sharding?
- ในการจำลองแบบการเขียนทั้งหมดจะไปที่โหนดหลัก
- คำค้นหาที่ละเอียดอ่อนในเวลาแฝงยังคงเป็นข้อมูลหลัก
- ชุดการจำลองเดี่ยวมีข้อ จำกัด 12 โหนด
- หน่วยความจำต้องไม่ใหญ่พอเมื่อชุดข้อมูลที่ใช้งานมีขนาดใหญ่
- โลคัลดิสก์ไม่ใหญ่พอ
- การขูดหินปูนในแนวตั้งมีราคาแพงเกินไป
Sharding ใน MongoDB
แผนภาพต่อไปนี้แสดงการชาร์ดใน MongoDB โดยใช้คลัสเตอร์ Sharded

ในแผนภาพต่อไปนี้มีองค์ประกอบหลักสามส่วน -
Shards- Shards ใช้ในการจัดเก็บข้อมูล มีความพร้อมใช้งานและความสอดคล้องของข้อมูลสูง ในสภาพแวดล้อมการผลิตแต่ละชิ้นส่วนจะเป็นชุดแบบจำลองแยกต่างหาก
Config Servers- เซิร์ฟเวอร์กำหนดค่าจัดเก็บข้อมูลเมตาของคลัสเตอร์ ข้อมูลนี้มีการแมปชุดข้อมูลของคลัสเตอร์กับเศษ เราเตอร์แบบสอบถามใช้ข้อมูลเมตานี้เพื่อกำหนดเป้าหมายการดำเนินการไปยังชิ้นส่วนที่เฉพาะเจาะจง ในสภาพแวดล้อมการใช้งานจริงคลัสเตอร์แบบชาร์ดมีเซิร์ฟเวอร์กำหนดค่า 3 เซิร์ฟเวอร์
Query Routers- เราเตอร์ Query นั้นโดยทั่วไปแล้วอินสแตนซ์ mongo ส่วนต่อประสานกับแอปพลิเคชันไคลเอนต์และการดำเนินการโดยตรงไปยังส่วนที่เหมาะสม เราเตอร์เคียวรีจะประมวลผลและกำหนดเป้าหมายการดำเนินการเป็นเศษจากนั้นส่งกลับผลลัพธ์ไปยังไคลเอนต์ คลัสเตอร์ Sharded สามารถมีเราเตอร์แบบสอบถามมากกว่าหนึ่งตัวเพื่อแบ่งโหลดคำขอของไคลเอ็นต์ ไคลเอนต์ส่งคำขอไปยังเราเตอร์แบบสอบถามหนึ่งตัว โดยทั่วไปคลัสเตอร์ที่แยกส่วนจะมีเราเตอร์แบบสอบถามจำนวนมาก
ในบทนี้เราจะดูวิธีสร้างข้อมูลสำรองใน MongoDB
ถ่ายโอนข้อมูล MongoDB
ในการสร้างการสำรองฐานข้อมูลใน MongoDB คุณควรใช้ mongodumpคำสั่ง คำสั่งนี้จะถ่ายโอนข้อมูลทั้งหมดของเซิร์ฟเวอร์ของคุณไปยังไดเร็กทอรีดัมพ์ มีตัวเลือกมากมายที่คุณสามารถ จำกัด ปริมาณข้อมูลหรือสร้างการสำรองข้อมูลของเซิร์ฟเวอร์ระยะไกลของคุณได้
ไวยากรณ์
ไวยากรณ์พื้นฐานของ mongodump คำสั่งมีดังนี้ -
>mongodumpตัวอย่าง
เริ่มเซิร์ฟเวอร์ mongod ของคุณ สมมติว่าเซิร์ฟเวอร์ mongod ของคุณกำลังทำงานบน localhost และพอร์ต 27017 ให้เปิดพรอมต์คำสั่งและไปที่ไดเร็กทอรี bin ของอินสแตนซ์ mongodb ของคุณและพิมพ์คำสั่งmongodump
พิจารณาคอลเลกชัน mycol มีข้อมูลต่อไปนี้
>mongodumpคำสั่งจะเชื่อมต่อกับเซิร์ฟเวอร์ที่ทำงานอยู่ที่ 127.0.0.1 และพอร์ต 27017 และสำรองข้อมูลทั้งหมดของเซิร์ฟเวอร์ไปยังไดเร็กทอรี /bin/dump/. ต่อไปนี้เป็นผลลัพธ์ของคำสั่ง -

ต่อไปนี้เป็นรายการตัวเลือกที่สามารถใช้ได้กับไฟล์ mongodump คำสั่ง
| ไวยากรณ์ | คำอธิบาย | ตัวอย่าง |
|---|---|---|
| mongodump - โฮสต์ HOST_NAME - พอร์ต PORT_NUMBER | คำสั่งนี้จะสำรองฐานข้อมูลทั้งหมดของอินสแตนซ์ mongod ที่ระบุ | mongodump --host tutorialspoint.com - พอร์ต 27017 |
| mongodump --dbpath DB_PATH - ออก BACKUP_DIRECTORY | คำสั่งนี้จะสำรองเฉพาะฐานข้อมูลที่ระบุตามเส้นทางที่ระบุ | mongodump --dbpath / data / db / --out / data / backup / |
| mongodump - คอลเลกชัน COLLECTION --db DB_NAME | คำสั่งนี้จะสำรองข้อมูลเฉพาะคอลเลกชันที่ระบุของฐานข้อมูลที่ระบุ | mongodump --collection mycol - การทดสอบ db |
กู้คืนข้อมูล
ในการกู้คืนข้อมูลสำรองของ MongoDB mongorestoreใช้คำสั่ง คำสั่งนี้กู้คืนข้อมูลทั้งหมดจากไดเร็กทอรีสำรอง
ไวยากรณ์
ไวยากรณ์พื้นฐานของ mongorestore คำสั่งคือ -
>mongorestoreต่อไปนี้เป็นผลลัพธ์ของคำสั่ง -

เมื่อคุณกำลังเตรียมการปรับใช้ MongoDB คุณควรพยายามทำความเข้าใจว่าแอปพลิเคชันของคุณจะดำเนินต่อไปอย่างไรในการใช้งานจริง เป็นความคิดที่ดีที่จะพัฒนาแนวทางที่สอดคล้องและทำซ้ำได้ในการจัดการสภาพแวดล้อมการปรับใช้ของคุณเพื่อให้คุณสามารถลดความประหลาดใจเมื่อคุณอยู่ในขั้นตอนการผลิต
แนวทางที่ดีที่สุดประกอบด้วยการสร้างต้นแบบการตั้งค่าการทดสอบโหลดการตรวจสอบเมตริกหลักและการใช้ข้อมูลดังกล่าวเพื่อปรับขนาดการตั้งค่าของคุณ ส่วนสำคัญของแนวทางนี้คือการตรวจสอบระบบทั้งหมดของคุณในเชิงรุกซึ่งจะช่วยให้คุณเข้าใจว่าระบบการผลิตของคุณจะทำงานได้อย่างไรก่อนที่จะปรับใช้และกำหนดตำแหน่งที่คุณจะต้องเพิ่มกำลังการผลิต ตัวอย่างเช่นการมีข้อมูลเชิงลึกเกี่ยวกับการเพิ่มขึ้นอย่างรวดเร็วที่อาจเกิดขึ้นในการใช้หน่วยความจำของคุณสามารถช่วยดับไฟการเขียนล็อกก่อนที่จะเริ่ม
ในการตรวจสอบการปรับใช้ MongoDB มีคำสั่งต่อไปนี้ -
mongostat
คำสั่งนี้ตรวจสอบสถานะของอินสแตนซ์ mongod ที่รันอยู่ทั้งหมดและส่งคืนตัวนับการดำเนินการฐานข้อมูล ตัวนับเหล่านี้ประกอบด้วยส่วนแทรกคิวรีอัปเดตลบและเคอร์เซอร์ คำสั่งยังแสดงเมื่อคุณกดปุ่มข้อบกพร่องของหน้าและแสดงเปอร์เซ็นต์การล็อกของคุณ ซึ่งหมายความว่าคุณมีหน่วยความจำเหลือน้อยกดขีดความสามารถในการเขียนหรือมีปัญหาด้านประสิทธิภาพ
ในการรันคำสั่งให้เริ่มอินสแตนซ์ mongod ของคุณ ในพรอมต์คำสั่งอื่นไปที่bin ไดเร็กทอรีของการติดตั้งและประเภท mongodb ของคุณ mongostat.
D:\set up\mongodb\bin>mongostatต่อไปนี้เป็นผลลัพธ์ของคำสั่ง -

mongotop
คำสั่งนี้ติดตามและรายงานกิจกรรมการอ่านและเขียนของอินสแตนซ์ MongoDB บนพื้นฐานการรวบรวม โดยค่าเริ่มต้น,mongotopส่งคืนข้อมูลในแต่ละวินาทีซึ่งคุณสามารถเปลี่ยนแปลงได้ตามนั้น คุณควรตรวจสอบว่ากิจกรรมการอ่านและเขียนนี้ตรงกับความตั้งใจของแอปพลิเคชันของคุณและคุณไม่ได้ทำการเขียนข้อมูลไปยังฐานข้อมูลครั้งละมากเกินไปอ่านบ่อยเกินไปจากดิสก์หรือเกินขนาดชุดการทำงานของคุณ
ในการรันคำสั่งให้เริ่มอินสแตนซ์ mongod ของคุณ ในพรอมต์คำสั่งอื่นไปที่bin ไดเร็กทอรีของการติดตั้งและประเภท mongodb ของคุณ mongotop.
D:\set up\mongodb\bin>mongotopต่อไปนี้เป็นผลลัพธ์ของคำสั่ง -
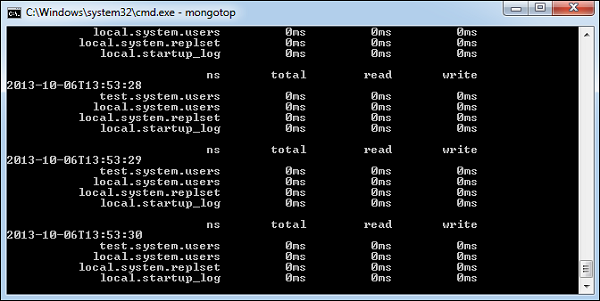
เพื่อเปลี่ยนแปลง mongotop คำสั่งเพื่อส่งคืนข้อมูลให้น้อยลงให้ระบุหมายเลขเฉพาะหลังคำสั่ง mongotop
D:\set up\mongodb\bin>mongotop 30ตัวอย่างข้างต้นจะคืนค่าทุกๆ 30 วินาที
นอกเหนือจากเครื่องมือ MongoDB แล้ว 10gen ยังมีบริการตรวจสอบโฮสต์ฟรี MongoDB Management Service (MMS) ซึ่งมีแดชบอร์ดและให้มุมมองของเมตริกจากคลัสเตอร์ทั้งหมดของคุณ
ในบทนี้เราจะเรียนรู้วิธีการตั้งค่าไดรเวอร์ MongoDB JDBC
การติดตั้ง
ก่อนที่คุณจะเริ่มใช้ MongoDB ในโปรแกรม Java ของคุณคุณต้องแน่ใจว่าคุณได้ติดตั้งไดรเวอร์ MongoDB JDBC และ Java ไว้ในเครื่องแล้ว คุณสามารถตรวจสอบบทช่วยสอน Java สำหรับการติดตั้ง Java บนเครื่องของคุณ ตอนนี้ให้เราตรวจสอบวิธีการตั้งค่าไดรเวอร์ MongoDB JDBC
คุณจะต้องดาวน์โหลดขวดจากเส้นทางดาวน์โหลด mongo.jar อย่าลืมดาวน์โหลดรุ่นล่าสุด
คุณต้องรวม mongo.jar ลงใน classpath ของคุณ
เชื่อมต่อกับฐานข้อมูล
ในการเชื่อมต่อฐานข้อมูลคุณต้องระบุชื่อฐานข้อมูลหากไม่มีฐานข้อมูล MongoDB จะสร้างขึ้นโดยอัตโนมัติ
ต่อไปนี้เป็นข้อมูลโค้ดเพื่อเชื่อมต่อกับฐานข้อมูล -
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class ConnectToDB {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
System.out.println("Credentials ::"+ credential);
}
}ตอนนี้เรามารวบรวมและเรียกใช้โปรแกรมด้านบนเพื่อสร้างฐานข้อมูล myDb ตามที่แสดงด้านล่าง
$javac ConnectToDB.java
$java ConnectToDBในการดำเนินการโปรแกรมข้างต้นจะให้ผลลัพธ์ดังต่อไปนี้
Connected to the database successfully
Credentials ::MongoCredential{
mechanism = null,
userName = 'sampleUser',
source = 'myDb',
password = <hidden>,
mechanismProperties = {}
}สร้างคอลเล็กชัน
ในการสร้างคอลเลกชัน createCollection() วิธีการของ com.mongodb.client.MongoDatabase ใช้คลาส
ต่อไปนี้เป็นข้อมูลโค้ดเพื่อสร้างคอลเลกชัน -
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class CreatingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
//Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
//Creating a collection
database.createCollection("sampleCollection");
System.out.println("Collection created successfully");
}
}ในการคอมไพล์โปรแกรมข้างต้นจะให้ผลลัพธ์ดังต่อไปนี้ -
Connected to the database successfully
Collection created successfullyการรับ / เลือกคอลเลคชัน
ในการรับ / เลือกคอลเลกชันจากฐานข้อมูล getCollection() วิธีการของ com.mongodb.client.MongoDatabase ใช้คลาส
ต่อไปนี้เป็นโปรแกรมรับ / เลือกคอลเลกชัน -
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class selectingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Creating a collection
System.out.println("Collection created successfully");
// Retieving a collection
MongoCollection<Document> collection = database.getCollection("myCollection");
System.out.println("Collection myCollection selected successfully");
}
}ในการคอมไพล์โปรแกรมข้างต้นจะให้ผลลัพธ์ดังต่อไปนี้ -
Connected to the database successfully
Collection created successfully
Collection myCollection selected successfullyแทรกเอกสาร
ในการแทรกเอกสารลงใน MongoDB insert() วิธีการของ com.mongodb.client.MongoCollection ใช้คลาส
ต่อไปนี้เป็นข้อมูลโค้ดเพื่อแทรกเอกสาร -
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class InsertingDocument {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
Document document = new Document("title", "MongoDB")
.append("id", 1)
.append("description", "database")
.append("likes", 100)
.append("url", "http://www.tutorialspoint.com/mongodb/")
.append("by", "tutorials point");
collection.insertOne(document);
System.out.println("Document inserted successfully");
}
}ในการคอมไพล์โปรแกรมข้างต้นจะให้ผลลัพธ์ดังต่อไปนี้ -
Connected to the database successfully
Collection sampleCollection selected successfully
Document inserted successfullyดึงเอกสารทั้งหมด
ในการเลือกเอกสารทั้งหมดจากคอลเล็กชัน find() วิธีการของ com.mongodb.client.MongoCollectionใช้คลาส วิธีนี้ส่งคืนเคอร์เซอร์ดังนั้นคุณต้องวนเคอร์เซอร์นี้ซ้ำ
ต่อไปนี้เป็นโปรแกรมสำหรับเลือกเอกสารทั้งหมด -
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class RetrievingAllDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println(it.next());
i++;
}
}
}ในการคอมไพล์โปรแกรมข้างต้นจะให้ผลลัพธ์ดังต่อไปนี้ -
Document{{
_id = 5967745223993a32646baab8,
title = MongoDB,
id = 1,
description = database,
likes = 100,
url = http://www.tutorialspoint.com/mongodb/, by = tutorials point
}}
Document{{
_id = 7452239959673a32646baab8,
title = RethinkDB,
id = 2,
description = database,
likes = 200,
url = http://www.tutorialspoint.com/rethinkdb/, by = tutorials point
}}อัปเดตเอกสาร
ในการอัปเดตเอกสารจากคอลเล็กชัน updateOne() วิธีการของ com.mongodb.client.MongoCollection ใช้คลาส
ต่อไปนี้เป็นโปรแกรมสำหรับเลือกเอกสารแรก -
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.model.Filters;
import com.mongodb.client.model.Updates;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class UpdatingDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection myCollection selected successfully");
collection.updateOne(Filters.eq("id", 1), Updates.set("likes", 150));
System.out.println("Document update successfully...");
// Retrieving the documents after updation
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println(it.next());
i++;
}
}
}ในการคอมไพล์โปรแกรมข้างต้นจะให้ผลลัพธ์ดังต่อไปนี้ -
Document update successfully...
Document {{
_id = 5967745223993a32646baab8,
title = MongoDB,
id = 1,
description = database,
likes = 150,
url = http://www.tutorialspoint.com/mongodb/, by = tutorials point
}}ลบเอกสาร
ในการลบเอกสารออกจากคอลเล็กชันคุณต้องใช้ไฟล์ deleteOne() วิธีการของ com.mongodb.client.MongoCollection ชั้นเรียน.
ต่อไปนี้เป็นโปรแกรมลบเอกสาร -
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.model.Filters;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class DeletingDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
// Deleting the documents
collection.deleteOne(Filters.eq("id", 1));
System.out.println("Document deleted successfully...");
// Retrieving the documents after updation
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println("Inserted Document: "+i);
System.out.println(it.next());
i++;
}
}
}ในการคอมไพล์โปรแกรมข้างต้นจะให้ผลลัพธ์ดังต่อไปนี้ -
Connected to the database successfully
Collection sampleCollection selected successfully
Document deleted successfully...การทิ้งคอลเลคชัน
ในการวางคอลเล็กชันจากฐานข้อมูลคุณต้องใช้ไฟล์ drop() วิธีการของ com.mongodb.client.MongoCollection ชั้นเรียน.
ต่อไปนี้เป็นโปรแกรมสำหรับลบคอลเล็กชัน -
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class DropingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Creating a collection
System.out.println("Collections created successfully");
// Retieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
// Dropping a Collection
collection.drop();
System.out.println("Collection dropped successfully");
}
}ในการคอมไพล์โปรแกรมข้างต้นจะให้ผลลัพธ์ดังต่อไปนี้ -
Connected to the database successfully
Collection sampleCollection selected successfully
Collection dropped successfullyการแสดงรายการคอลเล็กชันทั้งหมด
ในการแสดงรายการคอลเลกชันทั้งหมดในฐานข้อมูลคุณต้องใช้ไฟล์ listCollectionNames() วิธีการของ com.mongodb.client.MongoDatabase ชั้นเรียน.
ต่อไปนี้เป็นโปรแกรมแสดงรายการคอลเลกชันทั้งหมดของฐานข้อมูล -
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class ListOfCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
System.out.println("Collection created successfully");
for (String name : database.listCollectionNames()) {
System.out.println(name);
}
}
}ในการคอมไพล์โปรแกรมข้างต้นจะให้ผลลัพธ์ดังต่อไปนี้ -
Connected to the database successfully
Collection created successfully
myCollection
myCollection1
myCollection5วิธี MongoDB ที่เหลืออยู่ save(), limit(), skip(), sort() ฯลฯ ทำงานเหมือนกับที่อธิบายไว้ในบทช่วยสอนที่ตามมา
ในการใช้ MongoDB กับ PHP คุณต้องใช้ไดรเวอร์ MongoDB PHP ดาวน์โหลดไดรเวอร์จาก URL ที่ไดร์เวอร์ดาวน์โหลด PHP อย่าลืมดาวน์โหลดรุ่นล่าสุด ตอนนี้คลายซิปไฟล์เก็บถาวรและใส่ php_mongo.dll ในไดเร็กทอรีส่วนขยาย PHP ของคุณ ("ext" ตามค่าเริ่มต้น) และเพิ่มบรรทัดต่อไปนี้ในไฟล์ php.ini ของคุณ -
extension = php_mongo.dllทำการเชื่อมต่อและเลือกฐานข้อมูล
ในการเชื่อมต่อคุณต้องระบุชื่อฐานข้อมูลหากไม่มีฐานข้อมูล MongoDB จะสร้างขึ้นโดยอัตโนมัติ
ต่อไปนี้เป็นข้อมูลโค้ดเพื่อเชื่อมต่อกับฐานข้อมูล -
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
?>เมื่อโปรแกรมทำงานโปรแกรมจะให้ผลลัพธ์ดังต่อไปนี้ -
Connection to database successfully
Database mydb selectedสร้างคอลเล็กชัน
ต่อไปนี้เป็นข้อมูลโค้ดเพื่อสร้างคอลเลกชัน -
<?php
// connect to mongodb
$m = new MongoClient(); echo "Connection to database successfully"; // select a database $db = $m->mydb; echo "Database mydb selected"; $collection = $db->createCollection("mycol");
echo "Collection created succsessfully";
?>เมื่อโปรแกรมทำงานโปรแกรมจะให้ผลลัพธ์ดังต่อไปนี้ -
Connection to database successfully
Database mydb selected
Collection created succsessfullyแทรกเอกสาร
ในการแทรกเอกสารลงใน MongoDB insert() ใช้วิธีการ
ต่อไปนี้เป็นข้อมูลโค้ดเพื่อแทรกเอกสาร -
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
$document = array( "title" => "MongoDB", "description" => "database", "likes" => 100, "url" => "http://www.tutorialspoint.com/mongodb/", "by" => "tutorials point" ); $collection->insert($document);
echo "Document inserted successfully";
?>เมื่อโปรแกรมทำงานโปรแกรมจะให้ผลลัพธ์ดังต่อไปนี้ -
Connection to database successfully
Database mydb selected
Collection selected succsessfully
Document inserted successfullyค้นหาเอกสารทั้งหมด
ในการเลือกเอกสารทั้งหมดจากคอลเล็กชันให้ใช้เมธอด find ()
ต่อไปนี้เป็นข้อมูลโค้ดเพื่อเลือกเอกสารทั้งหมด -
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
$cursor = $collection->find();
// iterate cursor to display title of documents
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>เมื่อโปรแกรมทำงานโปรแกรมจะให้ผลลัพธ์ดังต่อไปนี้ -
Connection to database successfully
Database mydb selected
Collection selected succsessfully {
"title": "MongoDB"
}อัปเดตเอกสาร
ในการอัปเดตเอกสารคุณต้องใช้เมธอด update ()
ในตัวอย่างต่อไปนี้เราจะอัปเดตชื่อของเอกสารที่แทรกเป็น MongoDB Tutorial. ต่อไปนี้เป็นข้อมูลโค้ดสำหรับอัปเดตเอกสาร -
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
// now update the document
$collection->update(array("title"=>"MongoDB"), array('$set'=>array("title"=>"MongoDB Tutorial")));
echo "Document updated successfully";
// now display the updated document
$cursor = $collection->find();
// iterate cursor to display title of documents
echo "Updated document";
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>เมื่อโปรแกรมทำงานโปรแกรมจะให้ผลลัพธ์ดังต่อไปนี้ -
Connection to database successfully
Database mydb selected
Collection selected succsessfully
Document updated successfully
Updated document {
"title": "MongoDB Tutorial"
}ลบเอกสาร
ในการลบเอกสารคุณต้องใช้เมธอด remove ()
ในตัวอย่างต่อไปนี้เราจะลบเอกสารที่มีชื่อเรื่อง MongoDB Tutorial. ต่อไปนี้เป็นข้อมูลโค้ดเพื่อลบเอกสาร -
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
// now remove the document
$collection->remove(array("title"=>"MongoDB Tutorial"),false); echo "Documents deleted successfully"; // now display the available documents $cursor = $collection->find(); // iterate cursor to display title of documents echo "Updated document"; foreach ($cursor as $document) { echo $document["title"] . "\n";
}
?>เมื่อโปรแกรมทำงานโปรแกรมจะให้ผลลัพธ์ดังต่อไปนี้ -
Connection to database successfully
Database mydb selected
Collection selected succsessfully
Documents deleted successfullyในตัวอย่างข้างต้นพารามิเตอร์ที่สองคือประเภทบูลีนและใช้สำหรับ justOne ที่ดินของ remove() วิธี.
วิธี MongoDB ที่เหลืออยู่ findOne(), save(), limit(), skip(), sort() ฯลฯ ทำงานเหมือนกับที่อธิบายไว้ข้างต้น
ความสัมพันธ์ใน MongoDB แสดงให้เห็นว่าเอกสารต่างๆมีความสัมพันธ์กันอย่างไร ความสัมพันธ์สามารถจำลองได้ผ่านEmbedded และ Referencedแนวทาง ความสัมพันธ์ดังกล่าวอาจเป็น 1: 1, 1: N, N: 1 หรือ N: N
ให้เราพิจารณากรณีการจัดเก็บที่อยู่สำหรับผู้ใช้ ดังนั้นผู้ใช้หนึ่งคนสามารถมีหลายที่อยู่ทำให้เป็นความสัมพันธ์แบบ 1: N
ต่อไปนี้เป็นโครงสร้างเอกสารตัวอย่างของ user เอกสาร -
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"name": "Tom Hanks",
"contact": "987654321",
"dob": "01-01-1991"
}ต่อไปนี้เป็นโครงสร้างเอกสารตัวอย่างของ address เอกสาร -
{
"_id":ObjectId("52ffc4a5d85242602e000000"),
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
}การสร้างแบบจำลองความสัมพันธ์แบบฝัง
ในวิธีการฝังเราจะฝังเอกสารที่อยู่ไว้ในเอกสารผู้ใช้
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address": [
{
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
},
{
"building": "170 A, Acropolis Apt",
"pincode": 456789,
"city": "Chicago",
"state": "Illinois"
}
]
}วิธีนี้จะเก็บรักษาข้อมูลที่เกี่ยวข้องทั้งหมดไว้ในเอกสารเดียวซึ่งทำให้ง่ายต่อการดึงและบำรุงรักษา เอกสารทั้งหมดสามารถเรียกดูได้ในแบบสอบถามเดียวเช่น -
>db.users.findOne({"name":"Tom Benzamin"},{"address":1})โปรดทราบว่าในข้อความค้นหาด้านบน db และ users เป็นฐานข้อมูลและการรวบรวมตามลำดับ
ข้อเสียเปรียบคือหากเอกสารที่ฝังไว้มีขนาดใหญ่เกินไปอาจส่งผลกระทบต่อประสิทธิภาพการอ่าน / เขียน
การสร้างแบบจำลองความสัมพันธ์ที่อ้างอิง
นี่คือแนวทางของการออกแบบความสัมพันธ์แบบปกติ ในแนวทางนี้ทั้งเอกสารผู้ใช้และที่อยู่จะได้รับการดูแลแยกกัน แต่เอกสารผู้ใช้จะมีฟิลด์ที่อ้างอิงเอกสารที่อยู่id ฟิลด์
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address_ids": [
ObjectId("52ffc4a5d85242602e000000"),
ObjectId("52ffc4a5d85242602e000001")
]
}ดังที่แสดงไว้ด้านบนเอกสารผู้ใช้ประกอบด้วยฟิลด์อาร์เรย์ address_idsซึ่งมี ObjectIds ของที่อยู่ที่เกี่ยวข้อง การใช้ ObjectIds เหล่านี้เราสามารถสืบค้นเอกสารที่อยู่และรับรายละเอียดที่อยู่ได้จากที่นั่น ด้วยวิธีการนี้เราจะต้องมีสองแบบสอบถาม: อันดับแรกเพื่อดึงไฟล์address_ids ฟิลด์จาก user เอกสารและวินาทีเพื่อดึงข้อมูลที่อยู่เหล่านี้จาก address คอลเลกชัน
>var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1})
>var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})ดังที่เห็นในบทสุดท้ายของความสัมพันธ์ MongoDB ในการใช้โครงสร้างฐานข้อมูลปกติใน MongoDB เราใช้แนวคิดของ Referenced Relationships เรียกอีกอย่างว่า Manual Referencesซึ่งเราจัดเก็บ id ของเอกสารที่อ้างอิงไว้ในเอกสารอื่นด้วยตนเอง อย่างไรก็ตามในกรณีที่เอกสารมีการอ้างอิงจากคอลเล็กชันที่แตกต่างกันเราสามารถใช้MongoDB DBRefs.
DBRefs เทียบกับการอ้างอิงด้วยตนเอง
ดังตัวอย่างสถานการณ์ที่เราจะใช้ DBRef แทนการอ้างอิงด้วยตนเองให้พิจารณาฐานข้อมูลที่เราจัดเก็บที่อยู่ประเภทต่างๆ (บ้านที่ทำงานการส่งจดหมาย ฯลฯ ) ในคอลเลกชันที่แตกต่างกัน (address_home, address_office, address_mailing ฯลฯ ) ตอนนี้เมื่อกuserเอกสารของคอลเลกชันอ้างอิงที่อยู่นอกจากนี้ยังต้องระบุว่าคอลเล็กชันใดที่จะค้นหาตามประเภทที่อยู่ ในสถานการณ์เช่นนี้ที่เอกสารอ้างอิงเอกสารจากคอลเลกชันจำนวนมากเราควรใช้ DBRef
ใช้ DBRefs
มีสามฟิลด์ใน DBRefs -
$ref - ฟิลด์นี้ระบุคอลเล็กชันของเอกสารที่อ้างอิง
$id - ฟิลด์นี้ระบุฟิลด์ _id ของเอกสารอ้างอิง
$db - นี่เป็นช่องทางเลือกและมีชื่อของฐานข้อมูลที่เอกสารอ้างอิงอยู่
พิจารณาเอกสารผู้ใช้ตัวอย่างที่มีฟิลด์ DBRef address ดังที่แสดงในข้อมูลโค้ด -
{
"_id":ObjectId("53402597d852426020000002"),
"address": {
"$ref": "address_home", "$id": ObjectId("534009e4d852427820000002"),
"$db": "tutorialspoint"},
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin"
}address ฟิลด์ DBRef ที่นี่ระบุว่าเอกสารที่อยู่ที่อ้างอิงอยู่ใน address_home คอลเลกชันภายใต้ tutorialspoint ฐานข้อมูลและมีรหัส 534009e4d852427820000002
รหัสต่อไปนี้จะดูแบบไดนามิกในคอลเล็กชันที่ระบุโดย $ref พารามิเตอร์ (address_home ในกรณีของเรา) สำหรับเอกสารที่มี id ตามที่ระบุโดย $id พารามิเตอร์ใน DBRef
>var user = db.users.findOne({"name":"Tom Benzamin"})
>var dbRef = user.address
>db[dbRef.$ref].findOne({"_id":(dbRef.$id)})รหัสด้านบนส่งคืนเอกสารที่อยู่ต่อไปนี้ที่มีอยู่ใน address_home คอลเลกชัน -
{
"_id" : ObjectId("534009e4d852427820000002"),
"building" : "22 A, Indiana Apt",
"pincode" : 123456,
"city" : "Los Angeles",
"state" : "California"
}ในบทนี้เราจะเรียนรู้เกี่ยวกับแบบสอบถามที่ครอบคลุม
Covered Query คืออะไร?
ตามเอกสารอย่างเป็นทางการของ MongoDB แบบสอบถามที่ครอบคลุมคือข้อความค้นหาที่ -
- ฟิลด์ทั้งหมดในแบบสอบถามเป็นส่วนหนึ่งของดัชนี
- เขตข้อมูลทั้งหมดที่ส่งคืนในแบบสอบถามอยู่ในดัชนีเดียวกัน
เนื่องจากฟิลด์ทั้งหมดที่มีอยู่ในแบบสอบถามเป็นส่วนหนึ่งของดัชนี MongoDB จึงจับคู่เงื่อนไขการสืบค้นและส่งคืนผลลัพธ์โดยใช้ดัชนีเดียวกันโดยไม่ต้องเข้าไปดูในเอกสารจริงๆ เนื่องจากดัชนีมีอยู่ใน RAM การดึงข้อมูลจากดัชนีจึงเร็วกว่ามากเมื่อเทียบกับการดึงข้อมูลโดยการสแกนเอกสาร
การใช้แบบสอบถามที่ครอบคลุม
หากต้องการทดสอบคำค้นหาที่ครอบคลุมให้พิจารณาเอกสารต่อไปนี้ในไฟล์ users คอลเลกชัน -
{
"_id": ObjectId("53402597d852426020000002"),
"contact": "987654321",
"dob": "01-01-1991",
"gender": "M",
"name": "Tom Benzamin",
"user_name": "tombenzamin"
}ก่อนอื่นเราจะสร้างดัชนีสารประกอบสำหรับ users คอลเลกชันบนฟิลด์ gender และ user_name โดยใช้แบบสอบถามต่อไปนี้ -
>db.users.ensureIndex({gender:1,user_name:1})ตอนนี้ดัชนีนี้จะครอบคลุมแบบสอบถามต่อไปนี้ -
>db.users.find({gender:"M"},{user_name:1,_id:0})กล่าวคือสำหรับข้อความค้นหาข้างต้น MongoDB จะไม่เข้าไปค้นหาเอกสารฐานข้อมูล แต่จะดึงข้อมูลที่ต้องการจากข้อมูลที่จัดทำดัชนีซึ่งรวดเร็วมาก
เนื่องจากดัชนีของเราไม่รวม _idเราได้แยกออกจากชุดผลลัพธ์ของแบบสอบถามของเราอย่างชัดเจนเนื่องจาก MongoDB จะส่งคืนฟิลด์ _id ในทุกการสืบค้น ดังนั้นข้อความค้นหาต่อไปนี้จะไม่ครอบคลุมอยู่ในดัชนีที่สร้างขึ้นด้านบน -
>db.users.find({gender:"M"},{user_name:1})สุดท้ายโปรดจำไว้ว่าดัชนีไม่สามารถครอบคลุมข้อความค้นหาได้หาก -
- ฟิลด์ใด ๆ ที่จัดทำดัชนีคืออาร์เรย์
- ฟิลด์ใด ๆ ที่จัดทำดัชนีเป็นเอกสารย่อย
การวิเคราะห์แบบสอบถามเป็นสิ่งที่สำคัญมากในการวัดประสิทธิภาพของฐานข้อมูลและการออกแบบดัชนี เราจะเรียนรู้เกี่ยวกับการใช้งานบ่อย$explain และ $hint แบบสอบถาม
ใช้ $ อธิบาย
$explainตัวดำเนินการให้ข้อมูลเกี่ยวกับแบบสอบถามดัชนีที่ใช้ในแบบสอบถามและสถิติอื่น ๆ มีประโยชน์มากเมื่อวิเคราะห์ว่าดัชนีของคุณได้รับการปรับให้เหมาะสมเพียงใด
ในบทสุดท้ายเราได้สร้างดัชนีสำหรับไฟล์ users คอลเลกชันในฟิลด์ gender และ user_name โดยใช้แบบสอบถามต่อไปนี้ -
>db.users.ensureIndex({gender:1,user_name:1})ตอนนี้เราจะใช้ $explain ในแบบสอบถามต่อไปนี้ -
>db.users.find({gender:"M"},{user_name:1,_id:0}).explain()แบบสอบถามอธิบาย () ข้างต้นส่งคืนผลลัพธ์ที่วิเคราะห์ต่อไปนี้ -
{
"cursor" : "BtreeCursor gender_1_user_name_1",
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 0,
"nscanned" : 1,
"nscannedObjectsAllPlans" : 0,
"nscannedAllPlans" : 1,
"scanAndOrder" : false,
"indexOnly" : true,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"gender" : [
[
"M",
"M"
]
],
"user_name" : [
[
{
"$minElement" : 1 }, { "$maxElement" : 1
}
]
]
}
}ตอนนี้เราจะดูฟิลด์ในชุดผลลัพธ์นี้ -
มูลค่าที่แท้จริงของ indexOnly บ่งชี้ว่าแบบสอบถามนี้ใช้การสร้างดัชนี
cursorฟิลด์ระบุประเภทของเคอร์เซอร์ที่ใช้ ประเภท BTreeCursor ระบุว่ามีการใช้ดัชนีและให้ชื่อของดัชนีที่ใช้ด้วย BasicCursor ระบุว่าทำการสแกนแบบเต็มโดยไม่ต้องใช้ดัชนีใด ๆ
n ระบุจำนวนเอกสารที่ส่งคืน
nscannedObjects ระบุจำนวนเอกสารทั้งหมดที่สแกน
nscanned ระบุจำนวนเอกสารหรือรายการดัชนีทั้งหมดที่สแกน
ใช้คำใบ้ $
$hintตัวดำเนินการบังคับให้เครื่องมือเพิ่มประสิทธิภาพการสืบค้นใช้ดัชนีที่ระบุเพื่อเรียกใช้แบบสอบถาม สิ่งนี้มีประโยชน์อย่างยิ่งเมื่อคุณต้องการทดสอบประสิทธิภาพของแบบสอบถามด้วยดัชนีที่แตกต่างกัน ตัวอย่างเช่นแบบสอบถามต่อไปนี้ระบุดัชนีในฟิลด์gender และ user_name ที่จะใช้สำหรับแบบสอบถามนี้ -
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1})ในการวิเคราะห์แบบสอบถามข้างต้นโดยใช้ $ อธิบาย -
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1}).explain()ข้อมูลแบบจำลองสำหรับปฏิบัติการปรมาณู
แนวทางที่แนะนำในการรักษาความเป็นอะตอมคือการเก็บข้อมูลที่เกี่ยวข้องทั้งหมดซึ่งมักจะได้รับการอัปเดตร่วมกันในเอกสารเดียวโดยใช้ embedded documents. สิ่งนี้จะทำให้แน่ใจว่าการอัปเดตทั้งหมดสำหรับเอกสารเดียวนั้นเป็นแบบปรมาณู
พิจารณาเอกสารผลิตภัณฑ์ต่อไปนี้ -
{
"_id":1,
"product_name": "Samsung S3",
"category": "mobiles",
"product_total": 5,
"product_available": 3,
"product_bought_by": [
{
"customer": "john",
"date": "7-Jan-2014"
},
{
"customer": "mark",
"date": "8-Jan-2014"
}
]
}ในเอกสารนี้เราได้ฝังข้อมูลของลูกค้าที่ซื้อผลิตภัณฑ์ไว้ในไฟล์ product_bought_byฟิลด์ ตอนนี้เมื่อใดก็ตามที่ลูกค้าใหม่ซื้อผลิตภัณฑ์เราจะตรวจสอบก่อนว่าผลิตภัณฑ์ยังคงมีจำหน่ายอยู่หรือไม่product_availableฟิลด์ หากมีเราจะลดค่าของฟิลด์ product_available รวมทั้งแทรกเอกสารที่ฝังของลูกค้าใหม่ในฟิลด์ product_bought_by เราจะใช้findAndModify คำสั่งสำหรับฟังก์ชันนี้เนื่องจากค้นหาและอัปเดตเอกสารในคราวเดียวกัน
>db.products.findAndModify({
query:{_id:2,product_available:{$gt:0}},
update:{
$inc:{product_available:-1}, $push:{product_bought_by:{customer:"rob",date:"9-Jan-2014"}}
}
})แนวทางของเราเกี่ยวกับเอกสารฝังตัวและการใช้แบบสอบถาม findAndModify ทำให้แน่ใจว่าข้อมูลการซื้อผลิตภัณฑ์จะได้รับการอัปเดตเฉพาะในกรณีที่มีผลิตภัณฑ์ และธุรกรรมทั้งหมดนี้อยู่ในแบบสอบถามเดียวกันคือ atomic
ในทางตรงกันข้ามให้พิจารณาสถานการณ์ที่เราอาจเก็บความพร้อมจำหน่ายสินค้าและข้อมูลว่าใครเป็นผู้ซื้อผลิตภัณฑ์แยกต่างหาก ในกรณีนี้เราจะตรวจสอบก่อนว่ามีผลิตภัณฑ์หรือไม่โดยใช้แบบสอบถามแรก จากนั้นในแบบสอบถามที่สองเราจะอัปเดตข้อมูลการซื้อ อย่างไรก็ตามเป็นไปได้ว่าระหว่างการดำเนินการของคำค้นหาทั้งสองนี้ผู้ใช้รายอื่นบางรายได้ซื้อผลิตภัณฑ์และไม่สามารถใช้งานได้อีกต่อไป โดยไม่ทราบสิ่งนี้แบบสอบถามที่สองของเราจะอัปเดตข้อมูลการซื้อตามผลลัพธ์ของการสืบค้นแรกของเรา สิ่งนี้จะทำให้ฐานข้อมูลไม่สอดคล้องกันเนื่องจากเราได้ขายผลิตภัณฑ์ที่ไม่มีจำหน่าย
พิจารณาเอกสารต่อไปนี้ของ users คอลเลกชัน -
{
"address": {
"city": "Los Angeles",
"state": "California",
"pincode": "123"
},
"tags": [
"music",
"cricket",
"blogs"
],
"name": "Tom Benzamin"
}เอกสารด้านบนประกอบด้วยไฟล์ address sub-document และก tags array.
การจัดทำดัชนีฟิลด์อาร์เรย์
สมมติว่าเราต้องการค้นหาเอกสารผู้ใช้ตามแท็กของผู้ใช้ สำหรับสิ่งนี้เราจะสร้างดัชนีบนอาร์เรย์แท็กในคอลเล็กชัน
การสร้างดัชนีบนอาร์เรย์จะสร้างรายการดัชนีแยกกันสำหรับแต่ละฟิลด์ ดังนั้นในกรณีของเราเมื่อเราสร้างดัชนีบนอาร์เรย์แท็กดัชนีแยกต่างหากจะถูกสร้างขึ้นสำหรับเพลงค่าคริกเก็ตและบล็อก
ในการสร้างดัชนีบนอาร์เรย์แท็กให้ใช้รหัสต่อไปนี้ -
>db.users.ensureIndex({"tags":1})หลังจากสร้างดัชนีเราสามารถค้นหาในฟิลด์แท็กของคอลเลกชันเช่นนี้ -
>db.users.find({tags:"cricket"})ในการตรวจสอบว่ามีการใช้การจัดทำดัชนีที่ถูกต้องให้ใช้ดังต่อไปนี้ explain คำสั่ง -
>db.users.find({tags:"cricket"}).explain()คำสั่งดังกล่าวทำให้เกิด "cursor": "BtreeCursor tags_1" ซึ่งยืนยันว่ามีการใช้การจัดทำดัชนีที่เหมาะสม
การจัดทำดัชนีฟิลด์เอกสารย่อย
สมมติว่าเราต้องการค้นหาเอกสารตามเขตข้อมูลเมืองรัฐและรหัสพินโคด เนื่องจากฟิลด์ทั้งหมดเหล่านี้เป็นส่วนหนึ่งของฟิลด์เอกสารย่อยที่อยู่เราจะสร้างดัชนีในทุกฟิลด์ของเอกสารย่อย
สำหรับการสร้างดัชนีในทั้งสามฟิลด์ของเอกสารย่อยให้ใช้รหัสต่อไปนี้ -
>db.users.ensureIndex({"address.city":1,"address.state":1,"address.pincode":1})เมื่อสร้างดัชนีแล้วเราสามารถค้นหาฟิลด์เอกสารย่อยใดก็ได้โดยใช้ดัชนีนี้ดังนี้ -
>db.users.find({"address.city":"Los Angeles"})โปรดจำไว้ว่านิพจน์เคียวรีต้องเป็นไปตามลำดับของดัชนีที่ระบุ ดังนั้นดัชนีที่สร้างขึ้นข้างต้นจะรองรับคำค้นหาต่อไปนี้ -
>db.users.find({"address.city":"Los Angeles","address.state":"California"})นอกจากนี้ยังรองรับแบบสอบถามต่อไปนี้ -
>db.users.find({"address.city":"LosAngeles","address.state":"California",
"address.pincode":"123"})ในบทนี้เราจะเรียนรู้เกี่ยวกับข้อ จำกัด การจัดทำดัชนีและส่วนประกอบอื่น ๆ
ค่าโสหุ้ยพิเศษ
ทุกดัชนีใช้พื้นที่บางส่วนรวมทั้งทำให้เกิดค่าใช้จ่ายในการแทรกอัปเดตและลบแต่ละครั้ง ดังนั้นหากคุณไม่ค่อยใช้คอลเลกชันของคุณในการดำเนินการอ่านก็ควรที่จะไม่ใช้ดัชนี
การใช้ RAM
เนื่องจากดัชนีถูกเก็บไว้ใน RAM คุณควรตรวจสอบให้แน่ใจว่าขนาดทั้งหมดของดัชนีไม่เกินขีด จำกัด RAM หากขนาดรวมเพิ่มขนาด RAM ก็จะเริ่มลบดัชนีบางตัวทำให้สูญเสียประสิทธิภาพการทำงาน
ข้อ จำกัด การสืบค้น
ไม่สามารถใช้การจัดทำดัชนีในแบบสอบถามที่ใช้ -
- นิพจน์ทั่วไปหรือตัวดำเนินการปฏิเสธเช่น $nin, $ไม่ ฯลฯ
- ตัวดำเนินการเลขคณิตเช่น $ mod เป็นต้น
- $ where clause
ดังนั้นขอแนะนำให้ตรวจสอบการใช้ดัชนีสำหรับคำถามของคุณเสมอ
ขีด จำกัด คีย์ดัชนี
ตั้งแต่เวอร์ชัน 2.6 MongoDB จะไม่สร้างดัชนีหากค่าของฟิลด์ดัชนีที่มีอยู่เกินขีด จำกัด คีย์ดัชนี
การแทรกเอกสารเกินขีด จำกัด คีย์ดัชนี
MongoDB จะไม่แทรกเอกสารใด ๆ ลงในคอลเล็กชันที่จัดทำดัชนีหากค่าฟิลด์ที่จัดทำดัชนีของเอกสารนี้เกินขีด จำกัด คีย์ดัชนี เช่นเดียวกันกับ mongorestore และ mongoimport ยูทิลิตี้
ช่วงสูงสุด
- คอลเล็กชันต้องมีดัชนีไม่เกิน 64 รายการ
- ความยาวของชื่อดัชนีต้องมีความยาวไม่เกิน 125 อักขระ
- ดัชนีผสมสามารถมีดัชนีได้สูงสุด 31 ฟิลด์
เราใช้ MongoDB Object Id ในทุกบทก่อนหน้านี้ ในบทนี้เราจะเข้าใจโครงสร้างของ ObjectId
อัน ObjectId เป็นประเภท BSON ขนาด 12 ไบต์ที่มีโครงสร้างดังนี้ -
- 4 ไบต์แรกแทนวินาทีนับตั้งแต่ยุคยูนิกซ์
- 3 ไบต์ถัดไปคือตัวระบุเครื่อง
- 2 ไบต์ถัดไปประกอบด้วย process id
- 3 ไบต์สุดท้ายเป็นค่าตัวนับแบบสุ่ม
MongoDB ใช้ ObjectIds เป็นค่าเริ่มต้นของ _idของแต่ละเอกสารซึ่งสร้างขึ้นในขณะที่สร้างเอกสารใด ๆ การรวมกันที่ซับซ้อนของ ObjectId ทำให้ฟิลด์ _id ทั้งหมดไม่ซ้ำกัน
การสร้าง ObjectId ใหม่
ในการสร้าง ObjectId ใหม่ให้ใช้รหัสต่อไปนี้ -
>newObjectId = ObjectId()ข้อความข้างต้นส่งคืน id ที่สร้างขึ้นโดยเฉพาะต่อไปนี้ -
ObjectId("5349b4ddd2781d08c09890f3")แทนที่จะให้ MongoDB สร้าง ObjectId คุณยังสามารถระบุรหัส 12 ไบต์ -
>myObjectId = ObjectId("5349b4ddd2781d08c09890f4")การสร้างการประทับเวลาของเอกสาร
เนื่องจาก _id ObjectId โดยค่าเริ่มต้นจะเก็บการประทับเวลา 4 ไบต์ในกรณีส่วนใหญ่คุณไม่จำเป็นต้องจัดเก็บเวลาในการสร้างเอกสารใด ๆ คุณสามารถดึงเวลาสร้างเอกสารโดยใช้เมธอด getTimestamp -
>ObjectId("5349b4ddd2781d08c09890f4").getTimestamp()การดำเนินการนี้จะคืนเวลาสร้างเอกสารนี้ในรูปแบบวันที่ ISO -
ISODate("2014-04-12T21:49:17Z")การแปลง ObjectId เป็น String
ในบางกรณีคุณอาจต้องการค่า ObjectId ในรูปแบบสตริง ในการแปลง ObjectId ในสตริงให้ใช้รหัสต่อไปนี้ -
>newObjectId.strโค้ดด้านบนจะส่งคืนรูปแบบสตริงของ Guid -
5349b4ddd2781d08c09890f3ตามเอกสาร MongoDB Map-reduceเป็นกระบวนทัศน์การประมวลผลข้อมูลสำหรับการกลั่นข้อมูลจำนวนมากให้กลายเป็นผลลัพธ์รวมที่มีประโยชน์ MongoDB ใช้mapReduceคำสั่งสำหรับการดำเนินการลดแผนที่ โดยทั่วไป MapReduce จะใช้สำหรับการประมวลผลชุดข้อมูลขนาดใหญ่
คำสั่ง MapReduce
ต่อไปนี้เป็นไวยากรณ์ของคำสั่ง mapReduce พื้นฐาน -
>db.collection.mapReduce(
function() {emit(key,value);}, //map function
function(key,values) {return reduceFunction}, { //reduce function
out: collection,
query: document,
sort: document,
limit: number
}
)ฟังก์ชันลดแผนที่จะค้นหาคอลเล็กชันก่อนจากนั้นแมปเอกสารผลลัพธ์เพื่อปล่อยคู่คีย์ - ค่าซึ่งจะลดลงตามคีย์ที่มีหลายค่า
ในไวยากรณ์ข้างต้น -
map เป็นฟังก์ชันจาวาสคริปต์ที่จับคู่ค่ากับคีย์และส่งคู่คีย์ - ค่าออกมา
reduce เป็นฟังก์ชันจาวาสคริปต์ที่ลดหรือจัดกลุ่มเอกสารทั้งหมดที่มีคีย์เดียวกัน
out ระบุตำแหน่งของผลลัพธ์แบบสอบถามลดแผนที่
query ระบุเกณฑ์การเลือกทางเลือกสำหรับการเลือกเอกสาร
sort ระบุเกณฑ์การจัดเรียงที่เป็นทางเลือก
limit ระบุจำนวนเอกสารสูงสุดที่เป็นทางเลือกที่จะส่งคืน
ใช้ MapReduce
พิจารณาโครงสร้างเอกสารต่อไปนี้ที่จัดเก็บโพสต์ของผู้ใช้ เอกสารจัดเก็บ user_name ของผู้ใช้และสถานะของโพสต์
{
"post_text": "tutorialspoint is an awesome website for tutorials",
"user_name": "mark",
"status":"active"
}ตอนนี้เราจะใช้ฟังก์ชัน mapReduce บนไฟล์ posts คอลเล็กชันเพื่อเลือกโพสต์ที่ใช้งานอยู่ทั้งหมดจัดกลุ่มตาม user_name จากนั้นนับจำนวนโพสต์โดยผู้ใช้แต่ละรายโดยใช้รหัสต่อไปนี้
>db.posts.mapReduce(
function() { emit(this.user_id,1); },
function(key, values) {return Array.sum(values)}, {
query:{status:"active"},
out:"post_total"
}
)แบบสอบถาม mapReduce ด้านบนแสดงผลลัพธ์ต่อไปนี้ -
{
"result" : "post_total",
"timeMillis" : 9,
"counts" : {
"input" : 4,
"emit" : 4,
"reduce" : 2,
"output" : 2
},
"ok" : 1,
}ผลลัพธ์แสดงให้เห็นว่าเอกสารทั้งหมด 4 รายการตรงกับข้อความค้นหา (สถานะ: "ใช้งานอยู่") ฟังก์ชั่นแผนที่แสดงเอกสาร 4 ชุดพร้อมคู่คีย์ - ค่าและในที่สุดฟังก์ชันลดฟังก์ชันที่จัดกลุ่มเอกสารที่มีคีย์เดียวกันเป็น 2
หากต้องการดูผลลัพธ์ของแบบสอบถาม mapReduce นี้ให้ใช้ตัวดำเนินการค้นหา -
>db.posts.mapReduce(
function() { emit(this.user_id,1); },
function(key, values) {return Array.sum(values)}, {
query:{status:"active"},
out:"post_total"
}
).find()แบบสอบถามข้างต้นให้ผลลัพธ์ต่อไปนี้ซึ่งบ่งชี้ว่าผู้ใช้ทั้งสอง tom และ mark มีสองโพสต์ในสถานะที่ใช้งานอยู่ -
{ "_id" : "tom", "value" : 2 }
{ "_id" : "mark", "value" : 2 }ในลักษณะเดียวกันแบบสอบถาม MapReduce สามารถใช้เพื่อสร้างคิวรีการรวมที่ซับซ้อนขนาดใหญ่ การใช้ฟังก์ชัน Javascript ที่กำหนดเองใช้ประโยชน์จาก MapReduce ซึ่งมีความยืดหยุ่นและมีประสิทธิภาพมาก
เริ่มตั้งแต่เวอร์ชัน 2.4 MongoDB เริ่มรองรับดัชนีข้อความเพื่อค้นหาเนื้อหาสตริง Text Search ใช้เทคนิคการสร้างต้นกำเนิดเพื่อค้นหาคำที่ระบุในช่องสตริงโดยการวางคำหยุดการสร้างคำเช่น a, an, the, เป็นต้นปัจจุบัน MongoDB รองรับประมาณ 15 ภาษา
การเปิดใช้งานการค้นหาข้อความ
ในขั้นต้นการค้นหาข้อความเป็นคุณลักษณะทดลอง แต่เริ่มตั้งแต่เวอร์ชัน 2.6 การกำหนดค่าจะเปิดใช้งานโดยค่าเริ่มต้น แต่ถ้าคุณใช้ MongoDB เวอร์ชันก่อนหน้าคุณต้องเปิดใช้งานการค้นหาข้อความด้วยรหัสต่อไปนี้ -
>db.adminCommand({setParameter:true,textSearchEnabled:true})การสร้างดัชนีข้อความ
พิจารณาเอกสารต่อไปนี้ภายใต้ posts คอลเลกชันที่มีข้อความโพสต์และแท็ก -
{
"post_text": "enjoy the mongodb articles on tutorialspoint",
"tags": [
"mongodb",
"tutorialspoint"
]
}เราจะสร้างดัชนีข้อความในฟิลด์ post_text เพื่อให้เราสามารถค้นหาภายในข้อความของโพสต์ของเรา -
>db.posts.ensureIndex({post_text:"text"})ใช้ดัชนีข้อความ
ตอนนี้เราได้สร้างดัชนีข้อความในฟิลด์ post_text แล้วเราจะค้นหาโพสต์ทั้งหมดที่มีคำว่า tutorialspoint ในข้อความของพวกเขา
>db.posts.find({$text:{$search:"tutorialspoint"}})คำสั่งดังกล่าวส่งคืนเอกสารผลลัพธ์ต่อไปนี้ที่มีคำ tutorialspoint ในข้อความโพสต์ -
{
"_id" : ObjectId("53493d14d852429c10000002"),
"post_text" : "enjoy the mongodb articles on tutorialspoint",
"tags" : [ "mongodb", "tutorialspoint" ]
}
{
"_id" : ObjectId("53493d1fd852429c10000003"),
"post_text" : "writing tutorials on mongodb",
"tags" : [ "mongodb", "tutorial" ]
}หากคุณใช้ MongoDB เวอร์ชันเก่าคุณต้องใช้คำสั่งต่อไปนี้ -
>db.posts.runCommand("text",{search:" tutorialspoint "})การใช้ Text Search ช่วยเพิ่มประสิทธิภาพในการค้นหาอย่างมากเมื่อเทียบกับการค้นหาปกติ
การลบดัชนีข้อความ
ในการลบดัชนีข้อความที่มีอยู่ก่อนอื่นให้ค้นหาชื่อของดัชนีโดยใช้แบบสอบถามต่อไปนี้ -
>db.posts.getIndexes()หลังจากได้รับชื่อดัชนีของคุณจากแบบสอบถามด้านบนแล้วให้รันคำสั่งต่อไปนี้ ที่นี่post_text_text คือชื่อของดัชนี
>db.posts.dropIndex("post_text_text")Regular Expressions มักใช้ในทุกภาษาเพื่อค้นหารูปแบบหรือคำในสตริงใด ๆ MongoDB ยังมีฟังก์ชันการทำงานของนิพจน์ทั่วไปสำหรับการจับคู่รูปแบบสตริงโดยใช้$regexตัวดำเนินการ MongoDB ใช้ PCRE (Perl Compatible Regular Expression) เป็นภาษานิพจน์ทั่วไป
ไม่เหมือนกับการค้นหาข้อความเราไม่จำเป็นต้องกำหนดค่าหรือคำสั่งใด ๆ เพื่อใช้นิพจน์ทั่วไป
พิจารณาโครงสร้างเอกสารต่อไปนี้ภายใต้ posts คอลเลกชันที่มีข้อความโพสต์และแท็ก -
{
"post_text": "enjoy the mongodb articles on tutorialspoint",
"tags": [
"mongodb",
"tutorialspoint"
]
}ใช้นิพจน์นิพจน์ทั่วไป
คำค้นหา regex ต่อไปนี้ค้นหาโพสต์ทั้งหมดที่มีสตริง tutorialspoint ในนั้น -
>db.posts.find({post_text:{$regex:"tutorialspoint"}})แบบสอบถามเดียวกันสามารถเขียนเป็น -
>db.posts.find({post_text:/tutorialspoint/})การใช้นิพจน์นิพจน์ทั่วไปที่ไม่คำนึงถึงตัวพิมพ์เล็กและใหญ่
เพื่อให้การค้นหาไม่คำนึงถึงตัวพิมพ์ใหญ่เราใช้ไฟล์ $options พารามิเตอร์ที่มีค่า $i. คำสั่งต่อไปนี้จะค้นหาสตริงที่มีคำtutorialspointโดยไม่คำนึงถึงตัวพิมพ์เล็กหรือใหญ่ -
>db.posts.find({post_text:{$regex:"tutorialspoint",$options:"$i"}})หนึ่งในผลลัพธ์ที่ส่งกลับจากแบบสอบถามนี้คือเอกสารต่อไปนี้ซึ่งมีคำ tutorialspoint ในกรณีที่แตกต่างกัน -
{
"_id" : ObjectId("53493d37d852429c10000004"),
"post_text" : "hey! this is my post on TutorialsPoint",
"tags" : [ "tutorialspoint" ]
}การใช้ regex สำหรับ Array Elements
เรายังสามารถใช้แนวคิดของ regex บนฟิลด์อาร์เรย์ สิ่งนี้มีความสำคัญอย่างยิ่งเมื่อเราใช้ฟังก์ชันของแท็ก ดังนั้นหากคุณต้องการค้นหาโพสต์ทั้งหมดที่มีแท็กเริ่มต้นจากคำว่าบทช่วยสอน (ไม่ว่าจะเป็นบทช่วยสอนหรือแบบฝึกหัดหรือ Tutorialpoint หรือ Tutorialphp) คุณสามารถใช้รหัสต่อไปนี้ -
>db.posts.find({tags:{$regex:"tutorial"}})การเพิ่มประสิทธิภาพแบบสอบถามนิพจน์ทั่วไป
หากฟิลด์เอกสารเป็น indexedแบบสอบถามจะใช้ประโยชน์จากค่าที่จัดทำดัชนีเพื่อให้ตรงกับนิพจน์ทั่วไป ทำให้การค้นหารวดเร็วมากเมื่อเทียบกับนิพจน์ทั่วไปที่สแกนคอลเลคชันทั้งหมด
ถ้านิพจน์ทั่วไปคือ prefix expressionการจับคู่ทั้งหมดหมายถึงการเริ่มต้นด้วยอักขระสตริงบางตัว ตัวอย่างเช่นถ้านิพจน์ regex คือ^tutจากนั้นข้อความค้นหาจะต้องค้นหาเฉพาะสตริงที่ขึ้นต้นด้วย tut.
RockMongo เป็นเครื่องมือดูแลระบบ MongoDB ที่คุณสามารถจัดการเซิร์ฟเวอร์ฐานข้อมูลคอลเลกชันเอกสารดัชนีและอื่น ๆ อีกมากมาย เป็นวิธีที่ใช้งานง่ายมากสำหรับการอ่านเขียนและสร้างเอกสาร มันคล้ายกับเครื่องมือ PHPMyAdmin สำหรับ PHP และ MySQL
กำลังดาวน์โหลด RockMongo
คุณสามารถดาวน์โหลด RockMongo เวอร์ชันล่าสุดได้จากที่นี่: https://github.com/iwind/rockmongo
การติดตั้ง RockMongo
เมื่อดาวน์โหลดแล้วคุณสามารถคลายซิปแพคเกจในโฟลเดอร์รูทเซิร์ฟเวอร์ของคุณและเปลี่ยนชื่อโฟลเดอร์ที่แตกแล้วเป็น rockmongo. เปิดเว็บเบราว์เซอร์และเข้าถึงไฟล์index.phpเพจจากโฟลเดอร์ rockmongo ป้อน admin / admin เป็นชื่อผู้ใช้ / รหัสผ่านตามลำดับ
ทำงานกับ RockMongo
ตอนนี้เราจะมาดูการใช้งานพื้นฐานบางอย่างที่คุณสามารถทำได้ด้วย RockMongo
การสร้างฐานข้อมูลใหม่
ในการสร้างฐานข้อมูลใหม่คลิก Databasesแท็บ คลิกCreate New Database. ในหน้าจอถัดไประบุชื่อฐานข้อมูลใหม่และคลิกที่Create. คุณจะเห็นฐานข้อมูลใหม่ถูกเพิ่มในแผงด้านซ้าย
การสร้างคอลเล็กชันใหม่
หากต้องการสร้างคอลเล็กชันใหม่ภายในฐานข้อมูลให้คลิกที่ฐานข้อมูลนั้นจากแผงด้านซ้าย คลิกที่New Collectionลิงค์ด้านบน ระบุชื่อที่ต้องการของคอลเล็กชัน ไม่ต้องกังวลกับฟิลด์อื่น ๆ ของ Is Capped, Size และ Max คลิกที่Create. คอลเล็กชันใหม่จะถูกสร้างขึ้นและคุณจะเห็นได้ในแผงด้านซ้าย
การสร้างเอกสารใหม่
ในการสร้างเอกสารใหม่ให้คลิกที่คอลเลกชันที่คุณต้องการเพิ่มเอกสาร เมื่อคุณคลิกที่คอลเลกชันคุณจะสามารถดูเอกสารทั้งหมดภายในคอลเล็กชันนั้นที่แสดงอยู่ในนั้น ในการสร้างเอกสารใหม่ให้คลิกที่ไฟล์Insertลิงก์ที่ด้านบน คุณสามารถป้อนข้อมูลของเอกสารในรูปแบบ JSON หรืออาร์เรย์แล้วคลิกที่Save.
ส่งออก / นำเข้าข้อมูล
ในการนำเข้า / ส่งออกข้อมูลของคอลเลกชันใด ๆ ให้คลิกที่คอลเลกชันนั้นจากนั้นคลิกที่ Export/Importลิงค์ที่แผงด้านบน ทำตามคำแนะนำถัดไปเพื่อส่งออกข้อมูลของคุณในรูปแบบ zip จากนั้นนำเข้าไฟล์ zip เดียวกันเพื่อนำเข้าข้อมูลกลับ
GridFSเป็นข้อกำหนดของ MongoDB สำหรับจัดเก็บและเรียกไฟล์ขนาดใหญ่เช่นรูปภาพไฟล์เสียงไฟล์วิดีโอเป็นต้นเป็นระบบไฟล์ที่ใช้จัดเก็บไฟล์ แต่ข้อมูลจะถูกเก็บไว้ในคอลเลคชัน MongoDB GridFS มีความสามารถในการจัดเก็บไฟล์ที่มากกว่าขีด จำกัด ขนาดเอกสารที่ 16MB
GridFS แบ่งไฟล์ออกเป็นชิ้น ๆ และจัดเก็บข้อมูลแต่ละชิ้นในเอกสารแยกกันโดยแต่ละไฟล์มีขนาดสูงสุด 255k
โดยค่าเริ่มต้น GridFS ใช้สองคอลเลกชัน fs.files และ fs.chunksเพื่อจัดเก็บข้อมูลเมตาของไฟล์และชิ้นส่วน แต่ละกลุ่มถูกระบุโดยฟิลด์ _id ObjectId ที่ไม่ซ้ำกัน fs.files ทำหน้าที่เป็นเอกสารหลัก files_id ฟิลด์ในเอกสาร fs.chunks จะเชื่อมโยงกลุ่มกับพาเรนต์
ต่อไปนี้เป็นเอกสารตัวอย่างของการรวบรวม fs.files -
{
"filename": "test.txt",
"chunkSize": NumberInt(261120),
"uploadDate": ISODate("2014-04-13T11:32:33.557Z"),
"md5": "7b762939321e146569b07f72c62cca4f",
"length": NumberInt(646)
}เอกสารระบุชื่อไฟล์ขนาดชิ้นวันที่อัปโหลดและความยาว
ต่อไปนี้เป็นเอกสารตัวอย่างของเอกสาร fs.chunks -
{
"files_id": ObjectId("534a75d19f54bfec8a2fe44b"),
"n": NumberInt(0),
"data": "Mongo Binary Data"
}การเพิ่มไฟล์ลงใน GridFS
ตอนนี้เราจะจัดเก็บไฟล์ mp3 โดยใช้ GridFS โดยใช้ไฟล์ putคำสั่ง สำหรับสิ่งนี้เราจะใช้ไฟล์mongofiles.exe ยูทิลิตี้อยู่ในโฟลเดอร์ bin ของโฟลเดอร์การติดตั้ง MongoDB
เปิดพร้อมรับคำสั่งของคุณไปที่ mongofiles.exe ในโฟลเดอร์ bin ของโฟลเดอร์การติดตั้ง MongoDB และพิมพ์รหัสต่อไปนี้ -
>mongofiles.exe -d gridfs put song.mp3ที่นี่ gridfsคือชื่อของฐานข้อมูลที่จะจัดเก็บไฟล์ หากไม่มีฐานข้อมูล MongoDB จะสร้างเอกสารใหม่โดยอัตโนมัติทันที Song.mp3 คือชื่อไฟล์ที่อัพโหลด หากต้องการดูเอกสารของไฟล์ในฐานข้อมูลคุณสามารถใช้การค้นหา -
>db.fs.files.find()คำสั่งดังกล่าวส่งคืนเอกสารต่อไปนี้ -
{
_id: ObjectId('534a811bf8b4aa4d33fdf94d'),
filename: "song.mp3",
chunkSize: 261120,
uploadDate: new Date(1397391643474), md5: "e4f53379c909f7bed2e9d631e15c1c41",
length: 10401959
}นอกจากนี้เรายังสามารถดูชิ้นส่วนทั้งหมดที่มีอยู่ในคอลเล็กชัน fs.chunks ที่เกี่ยวข้องกับไฟล์ที่จัดเก็บด้วยรหัสต่อไปนี้โดยใช้รหัสเอกสารที่ส่งคืนในแบบสอบถามก่อนหน้านี้ -
>db.fs.chunks.find({files_id:ObjectId('534a811bf8b4aa4d33fdf94d')})ในกรณีของฉันแบบสอบถามส่งคืนเอกสาร 40 ฉบับซึ่งหมายความว่าเอกสาร mp3 ทั้งหมดถูกแบ่งออกเป็น 40 ส่วนของข้อมูล
Capped collectionsคือคอลเลกชันวงกลมขนาดคงที่ซึ่งเป็นไปตามลำดับการแทรกเพื่อรองรับประสิทธิภาพสูงสำหรับการสร้างอ่านและลบการดำเนินการ โดยวงกลมหมายความว่าเมื่อขนาดคงที่ที่จัดสรรให้กับคอลเลกชันหมดลงจะเริ่มลบเอกสารที่เก่าที่สุดในคอลเล็กชันโดยไม่ต้องให้คำสั่งที่ชัดเจนใด ๆ
คอลเลกชันที่ต่อยอด จำกัด การอัปเดตเอกสารหากการอัปเดตส่งผลให้ขนาดเอกสารเพิ่มขึ้น เนื่องจากคอลเลกชันที่ต่อยอดจะจัดเก็บเอกสารตามลำดับของที่จัดเก็บดิสก์จึงทำให้มั่นใจได้ว่าขนาดเอกสารจะไม่เพิ่มขนาดที่จัดสรรบนดิสก์ คอลเลกชันที่ต่อยอดเหมาะที่สุดสำหรับการจัดเก็บข้อมูลบันทึกข้อมูลแคชหรือข้อมูลปริมาณมากอื่น ๆ
การสร้างคอลเลกชันที่ต่อยอด
ในการสร้างคอลเลกชันที่ต่อยอดเราใช้คำสั่ง createCollection ปกติ แต่มี capped ตัวเลือกเป็น true และระบุขนาดสูงสุดของคอลเลกชันเป็นไบต์
>db.createCollection("cappedLogCollection",{capped:true,size:10000})นอกจากขนาดคอลเลกชันแล้วเรายังสามารถ จำกัด จำนวนเอกสารในคอลเลกชันโดยใช้ไฟล์ max พารามิเตอร์ -
>db.createCollection("cappedLogCollection",{capped:true,size:10000,max:1000})หากคุณต้องการตรวจสอบว่าคอลเลกชันถูกต่อยอดหรือไม่ให้ใช้สิ่งต่อไปนี้ isCapped คำสั่ง -
>db.cappedLogCollection.isCapped()หากมีคอลเล็กชันที่มีอยู่ซึ่งคุณกำลังวางแผนที่จะแปลงเป็นต่อยอดคุณสามารถทำได้โดยใช้รหัสต่อไปนี้ -
>db.runCommand({"convertToCapped":"posts",size:10000})รหัสนี้จะแปลงคอลเล็กชันที่มีอยู่ของเรา posts ไปยังคอลเลกชันที่ต่อยอด
กำลังค้นหาคอลเล็กชันที่มีการปิดทับ
ตามค่าเริ่มต้นค้นหาแบบสอบถามในคอลเลกชันที่มีการต่อยอดจะแสดงผลลัพธ์ตามลำดับการแทรก แต่ถ้าคุณต้องการดึงเอกสารในลำดับย้อนกลับให้ใช้ไฟล์sort คำสั่งดังแสดงในรหัสต่อไปนี้ -
>db.cappedLogCollection.find().sort({$natural:-1})มีประเด็นสำคัญอื่น ๆ อีกเล็กน้อยเกี่ยวกับคอลเลกชั่นที่ควรทราบ -
เราไม่สามารถลบเอกสารจากคอลเลกชันที่ต่อยอดได้
ไม่มีดัชนีเริ่มต้นอยู่ในคอลเลกชันที่ต่อยอดแม้แต่ในฟิลด์ _id
ในขณะที่ใส่เอกสารใหม่ MongoDB ไม่จำเป็นต้องมองหาสถานที่เพื่อรองรับเอกสารใหม่บนดิสก์ สามารถแทรกเอกสารใหม่ที่ส่วนท้ายของคอลเล็กชันแบบสุ่มสี่สุ่มห้า สิ่งนี้ทำให้การแทรกในคอลเลกชันที่ต่อยอดทำได้รวดเร็วมาก
ในทำนองเดียวกันในขณะที่อ่านเอกสาร MongoDB จะส่งคืนเอกสารในลำดับเดียวกับที่แสดงบนดิสก์ ทำให้การดำเนินการอ่านรวดเร็วมาก
MongoDB ไม่มีฟังก์ชันการเพิ่มอัตโนมัติแบบสำเร็จรูปเช่นฐานข้อมูล SQL โดยค่าเริ่มต้นจะใช้ ObjectId ขนาด 12 ไบต์สำหรับไฟล์_idฟิลด์เป็นคีย์หลักเพื่อระบุเอกสารโดยไม่ซ้ำกัน อย่างไรก็ตามอาจมีสถานการณ์ที่เราอาจต้องการให้ฟิลด์ _id มีค่าที่เพิ่มขึ้นโดยอัตโนมัตินอกเหนือจาก ObjectId
เนื่องจากนี่ไม่ใช่คุณสมบัติเริ่มต้นใน MongoDB เราจะบรรลุฟังก์ชันนี้โดยใช้โปรแกรมโดยใช้ไฟล์ counters คอลเลกชันตามที่แนะนำโดยเอกสาร MongoDB
ใช้ Counter Collection
พิจารณาสิ่งต่อไปนี้ productsเอกสาร. เราต้องการให้ฟิลด์ _id เป็นไฟล์auto-incremented integer sequence เริ่มตั้งแต่ 1,2,3,4 ถึง n.
{
"_id":1,
"product_name": "Apple iPhone",
"category": "mobiles"
}สำหรับสิ่งนี้ให้สร้างไฟล์ counters คอลเลกชันซึ่งจะติดตามค่าลำดับสุดท้ายสำหรับฟิลด์ลำดับทั้งหมด
>db.createCollection("counters")ตอนนี้เราจะแทรกเอกสารต่อไปนี้ในคอลเลกชันตัวนับด้วย productid เป็นกุญแจสำคัญ -
{
"_id":"productid",
"sequence_value": 0
}สนาม sequence_value ติดตามค่าสุดท้ายของลำดับ
ใช้รหัสต่อไปนี้เพื่อแทรกเอกสารลำดับนี้ในคอลเลกชันตัวนับ -
>db.counters.insert({_id:"productid",sequence_value:0})การสร้างฟังก์ชัน Javascript
ตอนนี้เราจะสร้างฟังก์ชัน getNextSequenceValueซึ่งจะใช้ชื่อลำดับเป็นอินพุตเพิ่มหมายเลขลำดับทีละ 1 และส่งคืนหมายเลขลำดับที่อัปเดต ในกรณีของเราชื่อลำดับคือproductid.
>function getNextSequenceValue(sequenceName){
var sequenceDocument = db.counters.findAndModify({
query:{_id: sequenceName },
update: {$inc:{sequence_value:1}},
new:true
});
return sequenceDocument.sequence_value;
}การใช้ฟังก์ชัน Javascript
ตอนนี้เราจะใช้ฟังก์ชัน getNextSequenceValue ในขณะที่สร้างเอกสารใหม่และกำหนดค่าลำดับที่ส่งคืนเป็นฟิลด์ _id ของเอกสาร
แทรกเอกสารตัวอย่างสองชุดโดยใช้รหัสต่อไปนี้ -
>db.products.insert({
"_id":getNextSequenceValue("productid"),
"product_name":"Apple iPhone",
"category":"mobiles"
})
>db.products.insert({
"_id":getNextSequenceValue("productid"),
"product_name":"Samsung S3",
"category":"mobiles"
})อย่างที่คุณเห็นเราได้ใช้ฟังก์ชัน getNextSequenceValue เพื่อกำหนดค่าสำหรับฟิลด์ _id
ในการตรวจสอบการทำงานให้เราดึงเอกสารโดยใช้คำสั่ง find -
>db.products.find()ข้อความค้นหาข้างต้นส่งคืนเอกสารต่อไปนี้ที่มีฟิลด์ _id ที่เพิ่มขึ้นอัตโนมัติ -
{ "_id" : 1, "product_name" : "Apple iPhone", "category" : "mobiles"}
{ "_id" : 2, "product_name" : "Samsung S3", "category" : "mobiles" }