อัลกอริทึมแบบขนาน - คู่มือฉบับย่อ
อัน algorithmเป็นลำดับของขั้นตอนที่รับอินพุตจากผู้ใช้และหลังจากการคำนวณบางส่วนจะสร้างเอาต์พุต กparallel algorithm เป็นอัลกอริทึมที่สามารถดำเนินการคำสั่งหลายคำสั่งพร้อมกันบนอุปกรณ์การประมวลผลที่แตกต่างกันจากนั้นรวมเอาท์พุททั้งหมดเพื่อสร้างผลลัพธ์สุดท้าย
การประมวลผลพร้อมกัน
ความพร้อมใช้งานที่ง่ายดายของคอมพิวเตอร์พร้อมกับการเติบโตของอินเทอร์เน็ตได้เปลี่ยนวิธีที่เราจัดเก็บและประมวลผลข้อมูล เรากำลังอยู่ในวันและอายุที่มีข้อมูลมากมาย ทุกวันเราจัดการกับข้อมูลจำนวนมหาศาลที่ต้องใช้การประมวลผลที่ซับซ้อนและในเวลาอันรวดเร็ว บางครั้งเราจำเป็นต้องดึงข้อมูลจากเหตุการณ์ที่คล้ายกันหรือสัมพันธ์กันซึ่งเกิดขึ้นพร้อมกัน นี่คือที่ที่เราต้องการconcurrent processing ที่สามารถแบ่งงานที่ซับซ้อนและประมวลผลหลายระบบเพื่อสร้างผลลัพธ์ในเวลารวดเร็ว
การประมวลผลพร้อมกันเป็นสิ่งสำคัญที่งานเกี่ยวข้องกับการประมวลผลข้อมูลที่ซับซ้อนจำนวนมาก ตัวอย่าง ได้แก่ - การเข้าถึงฐานข้อมูลขนาดใหญ่การทดสอบเครื่องบินการคำนวณทางดาราศาสตร์ฟิสิกส์อะตอมและนิวเคลียร์การวิเคราะห์ทางชีวการแพทย์การวางแผนเศรษฐกิจการประมวลผลภาพหุ่นยนต์การพยากรณ์อากาศบริการบนเว็บเป็นต้น
Parallelism คืออะไร?
Parallelismเป็นกระบวนการประมวลผลชุดคำสั่งหลายชุดพร้อมกัน ช่วยลดเวลาในการคำนวณทั้งหมด ความเท่าเทียมกันสามารถทำได้โดยใช้parallel computers,คือคอมพิวเตอร์ที่มีโปรเซสเซอร์จำนวนมาก คอมพิวเตอร์แบบขนานต้องใช้อัลกอริทึมแบบขนานภาษาโปรแกรมคอมไพเลอร์และระบบปฏิบัติการที่รองรับการทำงานหลายอย่างพร้อมกัน
ในบทช่วยสอนนี้เราจะพูดถึงเฉพาะ parallel algorithms. ก่อนที่จะดำเนินการต่อไปให้เราพูดคุยเกี่ยวกับอัลกอริทึมและประเภทของอัลกอริทึมก่อน
อัลกอริทึมคืออะไร?
อัน algorithmเป็นลำดับของคำแนะนำตามเพื่อแก้ปัญหา ในขณะที่ออกแบบอัลกอริทึมเราควรพิจารณาสถาปัตยกรรมของคอมพิวเตอร์ที่จะใช้อัลกอริทึม ตามสถาปัตยกรรมมีคอมพิวเตอร์สองประเภท -
- คอมพิวเตอร์ตามลำดับ
- คอมพิวเตอร์แบบขนาน
ขึ้นอยู่กับสถาปัตยกรรมของคอมพิวเตอร์เรามีอัลกอริทึมสองประเภท -
Sequential Algorithm - อัลกอริทึมที่มีการดำเนินการขั้นตอนต่อเนื่องของคำสั่งตามลำดับเวลาเพื่อแก้ปัญหา
Parallel Algorithm- ปัญหาแบ่งออกเป็นปัญหาย่อยและดำเนินการควบคู่กันเพื่อให้ได้ผลลัพธ์แต่ละรายการ ต่อมาเอาต์พุตแต่ละรายการเหล่านี้จะถูกรวมเข้าด้วยกันเพื่อให้ได้ผลลัพธ์สุดท้ายที่ต้องการ
ไม่ใช่เรื่องง่ายที่จะแบ่งปัญหาใหญ่ออกเป็น sub-problems. ปัญหาย่อยอาจมีการพึ่งพาข้อมูลระหว่างกัน ดังนั้นหน่วยประมวลผลต้องสื่อสารกันเพื่อแก้ปัญหา
พบว่าเวลาที่โปรเซสเซอร์ต้องการในการสื่อสารระหว่างกันมากกว่าเวลาประมวลผลจริง ดังนั้นในขณะที่ออกแบบอัลกอริทึมแบบขนานควรพิจารณาการใช้งาน CPU ที่เหมาะสมเพื่อให้ได้อัลกอริทึมที่มีประสิทธิภาพ
ในการออกแบบอัลกอริทึมให้ถูกต้องเราต้องมีแนวคิดพื้นฐานที่ชัดเจน model of computation ในคอมพิวเตอร์แบบขนาน
แบบจำลองการคำนวณ
คอมพิวเตอร์ทั้งแบบเรียงลำดับและแบบขนานทำงานบนชุดคำสั่ง (สตรีม) ที่เรียกว่าอัลกอริทึม ชุดคำสั่ง (อัลกอริทึม) เหล่านี้จะสั่งคอมพิวเตอร์เกี่ยวกับสิ่งที่ต้องทำในแต่ละขั้นตอน
คอมพิวเตอร์สามารถแบ่งออกเป็นสี่ประเภททั้งนี้ขึ้นอยู่กับสตรีมคำสั่งและสตรีมข้อมูล
- สตรีมคำสั่งเดียวคอมพิวเตอร์สตรีมข้อมูลเดียว (SISD)
- สตรีมคำสั่งเดียวคอมพิวเตอร์หลายสตรีมข้อมูล (SIMD)
- สตรีมคำสั่งหลายเครื่องคอมพิวเตอร์สตรีมข้อมูลเดียว (MISD)
- สตรีมคำสั่งหลายเครื่องคอมพิวเตอร์หลายสตรีมข้อมูล (MIMD)
คอมพิวเตอร์ SISD
คอมพิวเตอร์ SISD ประกอบด้วย one control unit, one processing unit, และ one memory unit.

ในคอมพิวเตอร์ประเภทนี้โปรเซสเซอร์จะรับสตรีมคำสั่งเดียวจากชุดควบคุมและทำงานบนสตรีมข้อมูลเดียวจากหน่วยความจำ ระหว่างการคำนวณในแต่ละขั้นตอนโปรเซสเซอร์จะรับคำสั่งหนึ่งคำสั่งจากหน่วยควบคุมและดำเนินการกับข้อมูลเดียวที่ได้รับจากหน่วยความจำ
คอมพิวเตอร์ SIMD
คอมพิวเตอร์ SIMD ประกอบด้วย one control unit, multiple processing units, และ shared memory or interconnection network.
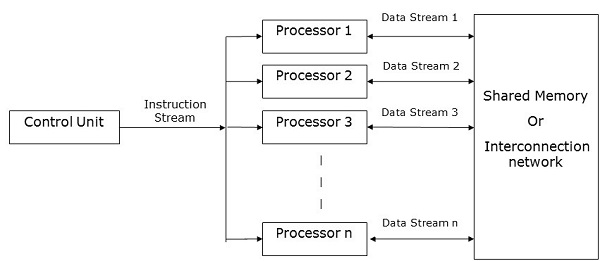
ที่นี่หน่วยควบคุมเดียวจะส่งคำสั่งไปยังหน่วยประมวลผลทั้งหมด ระหว่างการคำนวณในแต่ละขั้นตอนโปรเซสเซอร์ทั้งหมดจะได้รับคำสั่งชุดเดียวจากชุดควบคุมและดำเนินการกับชุดข้อมูลที่แตกต่างกันจากหน่วยความจำ
หน่วยประมวลผลแต่ละหน่วยมีหน่วยความจำภายในของตัวเองเพื่อเก็บทั้งข้อมูลและคำสั่ง ในคอมพิวเตอร์ SIMD โปรเซสเซอร์จำเป็นต้องสื่อสารกันเอง สิ่งนี้ทำได้โดยshared memory หรือโดย interconnection network.
ในขณะที่โปรเซสเซอร์บางตัวดำเนินการตามชุดคำสั่งโปรเซสเซอร์ที่เหลือจะรอคำสั่งชุดถัดไป คำแนะนำจากหน่วยควบคุมจะตัดสินใจว่าจะเป็นโปรเซสเซอร์ใดactive (ดำเนินการตามคำแนะนำ) หรือ inactive (รอคำแนะนำต่อไป)
คอมพิวเตอร์ MISD
ตามชื่อที่แนะนำคอมพิวเตอร์ MISD ประกอบด้วย multiple control units, multiple processing units, และ one common memory unit.

ที่นี่โปรเซสเซอร์แต่ละตัวมีหน่วยควบคุมของตัวเองและใช้หน่วยความจำร่วมกัน โปรเซสเซอร์ทั้งหมดได้รับคำสั่งแยกจากหน่วยควบคุมของตนเองและทำงานบนสตรีมข้อมูลเดียวตามคำแนะนำที่ได้รับจากหน่วยควบคุมที่เกี่ยวข้อง โปรเซสเซอร์นี้ทำงานพร้อมกัน
คอมพิวเตอร์ MIMD
คอมพิวเตอร์ MIMD มี multiple control units, multiple processing units, และก shared memory หรือ interconnection network.

ที่นี่โปรเซสเซอร์แต่ละตัวจะมีหน่วยควบคุมหน่วยความจำภายในและหน่วยเลขคณิตและตรรกะของตัวเอง พวกเขาได้รับชุดคำสั่งที่แตกต่างกันจากหน่วยควบคุมตามลำดับและดำเนินการกับชุดข้อมูลที่แตกต่างกัน
บันทึก
คอมพิวเตอร์ MIMD ที่แชร์หน่วยความจำทั่วไปเรียกว่า multiprocessors, ในขณะที่ผู้ที่ใช้เครือข่ายเชื่อมต่อจะเรียกว่า multicomputers.
ตามระยะทางกายภาพของโปรเซสเซอร์มัลติคอมพิวเตอร์มีสองประเภท -
Multicomputer - เมื่อโปรเซสเซอร์ทั้งหมดอยู่ใกล้กันมาก (เช่นในห้องเดียวกัน)
Distributed system - เมื่อโปรเซสเซอร์ทั้งหมดอยู่ห่างไกลจากกัน (เช่น - ในเมืองต่างๆ)
การวิเคราะห์อัลกอริทึมช่วยให้เราทราบว่าอัลกอริทึมมีประโยชน์หรือไม่ โดยทั่วไปอัลกอริทึมจะถูกวิเคราะห์ตามเวลาดำเนินการ(Time Complexity) และจำนวนพื้นที่ (Space Complexity) มันต้องการ.
เนื่องจากเรามีอุปกรณ์หน่วยความจำที่ซับซ้อนในราคาที่สมเหตุสมผลพื้นที่จัดเก็บข้อมูลจึงไม่ใช่ปัญหาอีกต่อไป ดังนั้นความซับซ้อนของพื้นที่จึงไม่ได้รับความสำคัญมากนัก
อัลกอริทึมแบบขนานได้รับการออกแบบมาเพื่อปรับปรุงความเร็วในการคำนวณของคอมพิวเตอร์ สำหรับการวิเคราะห์อัลกอริทึมแบบขนานโดยปกติเราจะพิจารณาพารามิเตอร์ต่อไปนี้ -
- ความซับซ้อนของเวลา (Execution Time)
- จำนวนโปรเซสเซอร์ทั้งหมดที่ใช้และ
- ค่าใช้จ่ายทั้งหมด.
ความซับซ้อนของเวลา
เหตุผลหลักที่อยู่เบื้องหลังการพัฒนาอัลกอริทึมแบบขนานคือการลดเวลาในการคำนวณของอัลกอริทึม ดังนั้นการประเมินเวลาดำเนินการของอัลกอริทึมจึงมีความสำคัญอย่างยิ่งในการวิเคราะห์ประสิทธิภาพ
เวลาดำเนินการวัดตามเวลาที่อัลกอริทึมใช้ในการแก้ปัญหา เวลาในการดำเนินการทั้งหมดคำนวณจากช่วงเวลาที่อัลกอริทึมเริ่มดำเนินการจนถึงช่วงเวลาที่หยุดทำงาน หากโปรเซสเซอร์ทั้งหมดไม่เริ่มทำงานหรือสิ้นสุดการดำเนินการพร้อมกันเวลาดำเนินการทั้งหมดของอัลกอริทึมคือช่วงเวลาที่โปรเซสเซอร์ตัวแรกเริ่มต้นการดำเนินการจนถึงช่วงเวลาที่โปรเซสเซอร์ตัวสุดท้ายหยุดการดำเนินการ
ความซับซ้อนของเวลาของอัลกอริทึมสามารถแบ่งออกเป็นสามประเภท
Worst-case complexity - เมื่อระยะเวลาที่อัลกอริทึมต้องการสำหรับอินพุตที่กำหนดคือ maximum.
Average-case complexity - เมื่อระยะเวลาที่อัลกอริทึมต้องการสำหรับอินพุตที่กำหนดคือ average.
Best-case complexity - เมื่อระยะเวลาที่อัลกอริทึมต้องการสำหรับอินพุตที่กำหนดคือ minimum.
การวิเคราะห์ Asymptotic
ความซับซ้อนหรือประสิทธิภาพของอัลกอริทึมคือจำนวนขั้นตอนที่ดำเนินการโดยอัลกอริทึมเพื่อให้ได้ผลลัพธ์ที่ต้องการ การวิเคราะห์ Asymptotic ทำขึ้นเพื่อคำนวณความซับซ้อนของอัลกอริทึมในการวิเคราะห์เชิงทฤษฎี ในการวิเคราะห์แบบไม่แสดงอาการจะใช้อินพุตที่มีความยาวมากเพื่อคำนวณฟังก์ชันความซับซ้อนของอัลกอริทึม
Note - Asymptoticเป็นเงื่อนไขที่เส้นมีแนวโน้มที่จะพบกับเส้นโค้ง แต่ไม่ตัดกัน ที่นี่เส้นและเส้นโค้งเป็นแบบไม่แสดงอาการซึ่งกันและกัน
สัญกรณ์ Asymptotic เป็นวิธีที่ง่ายที่สุดในการอธิบายเวลาดำเนินการที่เร็วและช้าที่สุดสำหรับอัลกอริทึมที่ใช้ขอบเขตสูงและขอบเขตความเร็วต่ำ สำหรับสิ่งนี้เราใช้สัญกรณ์ต่อไปนี้ -
- สัญกรณ์ O ขนาดใหญ่
- สัญกรณ์โอเมก้า
- สัญกรณ์เธต้า
สัญกรณ์ O ขนาดใหญ่
ในทางคณิตศาสตร์สัญกรณ์ Big O ใช้เพื่อแสดงถึงลักษณะที่ไม่แสดงอาการของฟังก์ชัน แสดงถึงพฤติกรรมของฟังก์ชันสำหรับอินพุตขนาดใหญ่ในวิธีการที่ง่ายและถูกต้อง เป็นวิธีการแสดงขอบเขตบนของเวลาดำเนินการของอัลกอริทึม แสดงถึงระยะเวลาที่ยาวนานที่สุดที่อัลกอริทึมสามารถใช้เพื่อดำเนินการให้เสร็จสิ้น ฟังก์ชั่น -
f (n) = O (g (n))
iff มีค่าคงที่เป็นบวก c และ n0 ดังนั้น f(n) ≤ c * g(n) เพื่อทุกสิ่ง n ที่ไหน n ≥ n0.
สัญกรณ์โอเมก้า
สัญกรณ์ Omega เป็นวิธีการแสดงขอบเขตล่างของเวลาดำเนินการของอัลกอริทึม ฟังก์ชั่น -
ฉ (n) = Ω (g (n))
iff มีค่าคงที่เป็นบวก c และ n0 ดังนั้น f(n) ≥ c * g(n) เพื่อทุกสิ่ง n ที่ไหน n ≥ n0.
สัญลักษณ์ Theta
สัญกรณ์ทีต้าเป็นวิธีการแสดงทั้งขอบเขตล่างและขอบเขตบนของเวลาดำเนินการของอัลกอริทึม ฟังก์ชั่น -
ฉ (n) = θ (g (n))
iff มีค่าคงที่เป็นบวก c1, c2, และ n0 เช่น c1 * g (n) ≤ f (n) ≤ c2 * g (n) สำหรับทุกคน n ที่ไหน n ≥ n0.
เร่งความเร็วของอัลกอริทึม
ประสิทธิภาพของอัลกอริทึมแบบขนานถูกกำหนดโดยการคำนวณ speedup. Speedup ถูกกำหนดให้เป็นอัตราส่วนของเวลาในการดำเนินการกรณีที่เลวร้ายที่สุดของอัลกอริธึมแบบลำดับที่รู้จักกันเร็วที่สุดสำหรับปัญหาเฉพาะกับเวลาดำเนินการกรณีที่เลวร้ายที่สุดของอัลกอริทึมแบบขนาน
จำนวนโปรเซสเซอร์ที่ใช้
จำนวนโปรเซสเซอร์ที่ใช้เป็นปัจจัยสำคัญในการวิเคราะห์ประสิทธิภาพของอัลกอริทึมแบบขนาน คำนวณค่าใช้จ่ายในการซื้อบำรุงรักษาและใช้งานคอมพิวเตอร์ จำนวนโปรเซสเซอร์ที่อัลกอริทึมใช้ในการแก้ปัญหามีจำนวนมากขึ้นผลที่ได้รับจะมีราคาแพงกว่า
ค่าใช้จ่ายทั้งหมด
ต้นทุนทั้งหมดของอัลกอริทึมแบบขนานคือผลคูณของความซับซ้อนของเวลาและจำนวนตัวประมวลผลที่ใช้ในอัลกอริทึมนั้น ๆ
ต้นทุนรวม = ความซับซ้อนของเวลา×จำนวนโปรเซสเซอร์ที่ใช้
ดังนั้นไฟล์ efficiency ของอัลกอริทึมแบบขนานคือ -
แบบจำลองของอัลกอริทึมแบบคู่ขนานได้รับการพัฒนาโดยพิจารณาถึงกลยุทธ์ในการแบ่งข้อมูลและวิธีการประมวลผลและใช้กลยุทธ์ที่เหมาะสมเพื่อลดการโต้ตอบ ในบทนี้เราจะพูดถึงโมเดลอัลกอริทึมแบบคู่ขนานต่อไปนี้ -
- แบบจำลองข้อมูลแบบขนาน
- โมเดลกราฟงาน
- แบบจำลองสระว่ายน้ำ
- นายแบบทาส
- ผู้บริโภคของผู้ผลิตหรือรูปแบบไปป์ไลน์
- รุ่นไฮบริด
ข้อมูลแบบขนาน
ในแบบจำลองข้อมูลแบบขนานงานจะถูกกำหนดให้กับกระบวนการและแต่ละงานจะดำเนินการประเภทเดียวกันกับข้อมูลที่ต่างกัน Data parallelism เป็นผลมาจากการดำเนินการเดียวที่ถูกนำไปใช้กับรายการข้อมูลหลายรายการ
แบบจำลองข้อมูลขนานสามารถนำไปใช้กับพื้นที่ที่อยู่ที่ใช้ร่วมกันและกระบวนทัศน์การส่งผ่านข้อความ ในแบบจำลองข้อมูลคู่ขนานค่าใช้จ่ายในการโต้ตอบสามารถลดลงได้โดยการเลือกพื้นที่ที่รักษาการสลายตัวโดยใช้รูทีนการโต้ตอบร่วมที่เหมาะสมที่สุดหรือโดยการคำนวณและการโต้ตอบที่ทับซ้อนกัน
ลักษณะสำคัญของปัญหาแบบจำลองข้อมูลคู่ขนานคือความเข้มของความขนานของข้อมูลจะเพิ่มขึ้นตามขนาดของปัญหาซึ่งจะทำให้สามารถใช้กระบวนการมากขึ้นเพื่อแก้ปัญหาที่ใหญ่ขึ้น
Example - การคูณเมทริกซ์หนาแน่น

โมเดลกราฟงาน
ในโมเดลกราฟงานความขนานจะแสดงโดย a task graph. กราฟงานอาจเป็นเรื่องเล็กน้อยหรือไม่สำคัญก็ได้ ในรูปแบบนี้ความสัมพันธ์ระหว่างงานถูกนำมาใช้เพื่อส่งเสริมความเป็นท้องถิ่นหรือเพื่อลดต้นทุนในการโต้ตอบ แบบจำลองนี้ถูกบังคับใช้เพื่อแก้ปัญหาที่ปริมาณข้อมูลที่เกี่ยวข้องกับงานนั้นมีมากเมื่อเทียบกับจำนวนการคำนวณที่เกี่ยวข้อง งานได้รับมอบหมายเพื่อช่วยปรับปรุงต้นทุนของการเคลื่อนย้ายข้อมูลระหว่างงาน
Examples - การเรียงลำดับอย่างรวดเร็วแบบคู่ขนานการแยกตัวประกอบเมทริกซ์แบบกระจัดกระจายและอัลกอริทึมแบบขนานที่ได้มาจากวิธีการหารและพิชิต
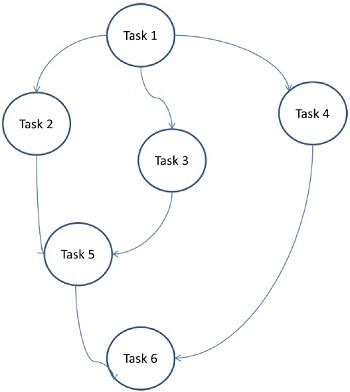
ที่นี่ปัญหาจะแบ่งออกเป็นงานปรมาณูและดำเนินการเป็นกราฟ แต่ละงานเป็นหน่วยงานอิสระที่มีการพึ่งพางานก่อนหน้าอย่างน้อยหนึ่งงาน หลังจากเสร็จสิ้นภารกิจผลลัพธ์ของงานก่อนหน้าจะถูกส่งผ่านไปยังงานที่ต้องพึ่งพา งานที่มีภารกิจก่อนหน้าจะเริ่มดำเนินการก็ต่อเมื่องานก่อนหน้าทั้งหมดเสร็จสิ้น ผลลัพธ์สุดท้ายของกราฟจะได้รับเมื่องานที่ต้องพึ่งพาสุดท้ายเสร็จสิ้น (ภารกิจที่ 6 ในรูปด้านบน)
แบบจำลองสระว่ายน้ำ
ในโมเดลพูลงานงานจะถูกกำหนดแบบไดนามิกให้กับกระบวนการสำหรับการปรับสมดุลของโหลด ดังนั้นกระบวนการใด ๆ อาจดำเนินการงานใด ๆ แบบจำลองนี้ใช้เมื่อปริมาณข้อมูลที่เกี่ยวข้องกับงานมีขนาดค่อนข้างเล็กกว่าการคำนวณที่เกี่ยวข้องกับงาน
ไม่มีการกำหนดงานล่วงหน้าที่ต้องการในกระบวนการ การมอบหมายงานจะรวมศูนย์หรือกระจายอำนาจ ตัวชี้ไปที่งานจะถูกบันทึกไว้ในรายการที่ใช้ร่วมกันทางกายภาพในคิวลำดับความสำคัญหรือในตารางแฮชหรือโครงสร้างหรืออาจถูกบันทึกไว้ในโครงสร้างข้อมูลแบบกระจายทางกายภาพ
งานอาจพร้อมใช้งานในช่วงเริ่มต้นหรืออาจสร้างแบบไดนามิก หากงานถูกสร้างขึ้นแบบไดนามิกและการมอบหมายงานแบบกระจายอำนาจเสร็จสิ้นแล้วจำเป็นต้องมีอัลกอริธึมการตรวจจับการยุติเพื่อให้กระบวนการทั้งหมดสามารถตรวจจับความสมบูรณ์ของโปรแกรมทั้งหมดได้จริงและหยุดมองหางานเพิ่มเติม
Example - ค้นหาต้นไม้คู่ขนาน

แบบจำลอง Master-Slave
ในโมเดลต้นแบบทาสกระบวนการหลักอย่างน้อยหนึ่งกระบวนการสร้างงานและจัดสรรให้กับกระบวนการทาส งานอาจได้รับการจัดสรรล่วงหน้าถ้า -
- ต้นแบบสามารถประมาณปริมาณของงานหรือ
- การมอบหมายแบบสุ่มสามารถทำงานที่น่าพอใจในการปรับสมดุลภาระหรือ
- ทาสได้รับมอบหมายงานชิ้นเล็ก ๆ ในเวลาที่ต่างกัน
รุ่นนี้มีความเหมาะสมเท่าเทียมกันกับ shared-address-space หรือ message-passing paradigms, เนื่องจากการโต้ตอบมีสองวิธีตามธรรมชาติ
ในบางกรณีงานอาจต้องทำให้เสร็จเป็นขั้นตอนและงานในแต่ละขั้นตอนจะต้องเสร็จสิ้นก่อนที่จะสามารถสร้างงานในขั้นตอนถัดไปได้ โมเดลต้นแบบทาสสามารถกำหนดให้เป็นhierarchical หรือ multi-level master-slave model ซึ่งมาสเตอร์ระดับบนสุดจะป้อนงานส่วนใหญ่ให้กับมาสเตอร์ระดับสองซึ่งจะแบ่งงานระหว่างทาสของตัวเองและอาจดำเนินการบางส่วนของงานนั้นเอง
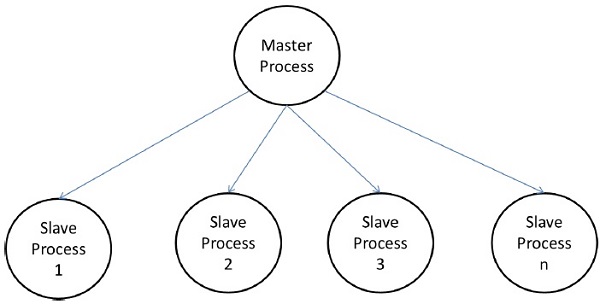
ข้อควรระวังในการใช้โมเดลต้นแบบทาส
ควรใช้ความระมัดระวังเพื่อให้มั่นใจว่าต้นแบบจะไม่กลายเป็นจุดแออัด อาจเกิดขึ้นได้หากงานมีขนาดเล็กเกินไปหรือคนงานค่อนข้างเร็ว
ควรเลือกงานในลักษณะที่ค่าใช้จ่ายในการปฏิบัติงานมีส่วนเหนือต้นทุนการสื่อสารและค่าใช้จ่ายในการซิงโครไนซ์
การโต้ตอบแบบอะซิงโครนัสอาจช่วยให้การโต้ตอบซ้อนทับกันและการคำนวณที่เกี่ยวข้องกับการสร้างงานโดยผู้เชี่ยวชาญ
แบบจำลองท่อ
เป็นที่รู้จักกันในชื่อ producer-consumer model. ที่นี่ชุดข้อมูลจะถูกส่งต่อผ่านชุดของกระบวนการซึ่งแต่ละกระบวนการทำงานบางอย่าง ที่นี่การมาถึงของข้อมูลใหม่ทำให้เกิดการดำเนินการของงานใหม่โดยกระบวนการในคิว กระบวนการสามารถสร้างคิวในรูปของอาร์เรย์เชิงเส้นหรือหลายมิติต้นไม้หรือกราฟทั่วไปที่มีหรือไม่มีรอบ
โมเดลนี้เป็นห่วงโซ่ของผู้ผลิตและผู้บริโภค แต่ละกระบวนการในคิวถือได้ว่าเป็นผู้บริโภคของลำดับรายการข้อมูลสำหรับกระบวนการที่อยู่ข้างหน้าในคิวและในฐานะผู้ผลิตข้อมูลสำหรับกระบวนการที่ตามมาในคิว คิวไม่จำเป็นต้องเป็นโซ่เชิงเส้น มันสามารถเป็นกราฟกำกับ เทคนิคการย่อขนาดปฏิสัมพันธ์ที่พบบ่อยที่สุดที่ใช้กับโมเดลนี้คือการโต้ตอบซ้อนทับกับการคำนวณ
Example - อัลกอริธึมการแยกตัวประกอบ LU แบบขนาน

รุ่นไฮบริด
ต้องใช้โมเดลอัลกอริธึมแบบไฮบริดเมื่ออาจต้องใช้โมเดลมากกว่าหนึ่งแบบในการแก้ปัญหา
โมเดลไฮบริดอาจประกอบด้วยโมเดลหลายแบบที่ใช้ตามลำดับชั้นหรือหลายโมเดลที่ใช้ตามลำดับกับขั้นตอนต่างๆของอัลกอริทึมแบบขนาน
Example - เรียงลำดับอย่างรวดเร็วแบบขนาน
Parallel Random Access Machines (PRAM)เป็นแบบจำลองซึ่งถือเป็นส่วนใหญ่ของอัลกอริทึมแบบขนาน ที่นี่โปรเซสเซอร์หลายตัวจะเชื่อมต่อกับหน่วยความจำบล็อกเดียว แบบจำลอง PRAM ประกอบด้วย -
ชุดของโปรเซสเซอร์ประเภทเดียวกัน
โปรเซสเซอร์ทั้งหมดใช้หน่วยความจำร่วมกัน โปรเซสเซอร์สามารถสื่อสารระหว่างกันผ่านหน่วยความจำแบบแบ่งใช้เท่านั้น
หน่วยการเข้าถึงหน่วยความจำ (MAU) เชื่อมต่อโปรเซสเซอร์กับหน่วยความจำที่ใช้ร่วมกันเดียว

ที่นี่ n จำนวนโปรเซสเซอร์ที่สามารถดำเนินการอิสระได้ nจำนวนข้อมูลในหน่วยเวลาหนึ่ง ๆ ซึ่งอาจส่งผลให้มีการเข้าถึงตำแหน่งหน่วยความจำเดียวกันพร้อมกันโดยโปรเซสเซอร์ที่แตกต่างกัน
เพื่อแก้ปัญหานี้ได้มีการบังคับใช้ข้อ จำกัด ต่อไปนี้กับโมเดล PRAM -
Exclusive Read Exclusive Write (EREW) - ที่นี่ไม่อนุญาตให้โปรเซสเซอร์สองตัวอ่านหรือเขียนไปยังตำแหน่งหน่วยความจำเดียวกันในเวลาเดียวกัน
Exclusive Read Concurrent Write (ERCW) - ที่นี่ไม่อนุญาตให้โปรเซสเซอร์สองตัวอ่านจากตำแหน่งหน่วยความจำเดียวกันในเวลาเดียวกัน แต่ได้รับอนุญาตให้เขียนไปยังตำแหน่งหน่วยความจำเดียวกันในเวลาเดียวกัน
Concurrent Read Exclusive Write (CREW) - ที่นี่โปรเซสเซอร์ทั้งหมดได้รับอนุญาตให้อ่านจากตำแหน่งหน่วยความจำเดียวกันในเวลาเดียวกัน แต่ไม่ได้รับอนุญาตให้เขียนไปยังตำแหน่งหน่วยความจำเดียวกันในเวลาเดียวกัน
Concurrent Read Concurrent Write (CRCW) - โปรเซสเซอร์ทั้งหมดได้รับอนุญาตให้อ่านหรือเขียนไปยังตำแหน่งหน่วยความจำเดียวกันในเวลาเดียวกัน
มีหลายวิธีในการปรับใช้โมเดล PRAM แต่วิธีที่โดดเด่นที่สุดคือ -
- โมเดลหน่วยความจำที่ใช้ร่วมกัน
- แบบจำลองการส่งข้อความ
- แบบจำลองข้อมูลแบบขนาน
โมเดลหน่วยความจำที่ใช้ร่วมกัน
หน่วยความจำที่ใช้ร่วมกันเน้นบน control parallelism กว่าใน data parallelism. ในโมเดลหน่วยความจำแบบแบ่งใช้กระบวนการต่างๆจะดำเนินการบนโปรเซสเซอร์ที่แตกต่างกันอย่างอิสระ แต่จะใช้พื้นที่หน่วยความจำร่วมกัน เนื่องจากกิจกรรมของตัวประมวลผลใด ๆ หากมีการเปลี่ยนแปลงในตำแหน่งหน่วยความจำใด ๆ โปรเซสเซอร์ที่เหลือจะมองเห็นได้
เนื่องจากโปรเซสเซอร์หลายตัวเข้าถึงตำแหน่งหน่วยความจำเดียวกันอาจเกิดขึ้นได้ในช่วงเวลาใดเวลาหนึ่งโปรเซสเซอร์มากกว่าหนึ่งตัวกำลังเข้าถึงตำแหน่งหน่วยความจำเดียวกัน สมมติว่าคนหนึ่งกำลังอ่านตำแหน่งนั้นและอีกคนกำลังเขียนตำแหน่งนั้น มันอาจสร้างความสับสน เพื่อหลีกเลี่ยงปัญหานี้กลไกการควบคุมบางอย่างเช่นlock / semaphore, ดำเนินการเพื่อให้แน่ใจว่ามีการยกเว้นซึ่งกันและกัน

การเขียนโปรแกรมหน่วยความจำแบบแบ่งใช้ถูกนำไปใช้ดังต่อไปนี้ -
Thread libraries- ไลบรารีเธรดอนุญาตให้มีเธรดการควบคุมหลายเธรดที่ทำงานพร้อมกันในตำแหน่งหน่วยความจำเดียวกัน ไลบรารีเธรดจัดเตรียมอินเทอร์เฟซที่สนับสนุนมัลติเธรดผ่านไลบรารีของรูทีนย่อย มันมีรูทีนย่อยสำหรับ
- การสร้างและทำลายเธรด
- การจัดกำหนดการดำเนินการเธรด
- การส่งผ่านข้อมูลและข้อความระหว่างเธรด
- การบันทึกและการกู้คืนบริบทเธรด
ตัวอย่างของเธรดไลบรารี ได้แก่ - เธรด Solaris ™สำหรับ Solaris เธรด POSIX ที่ใช้งานใน Linux เธรด Win32 ที่มีอยู่ใน Windows NT และ Windows 2000 และเธรด Java ™ซึ่งเป็นส่วนหนึ่งของ Java ™ Development Kit (JDK) มาตรฐาน
Distributed Shared Memory (DSM) Systems- ระบบ DSM สร้างส่วนที่เป็นนามธรรมของหน่วยความจำที่ใช้ร่วมกันบนสถาปัตยกรรมคู่แบบหลวม ๆ เพื่อใช้การเขียนโปรแกรมหน่วยความจำแบบแบ่งใช้โดยไม่ต้องรองรับฮาร์ดแวร์ พวกเขาใช้ไลบรารีมาตรฐานและใช้คุณสมบัติการจัดการหน่วยความจำระดับผู้ใช้ขั้นสูงที่มีอยู่ในระบบปฏิบัติการสมัยใหม่ ตัวอย่างเช่น Tread Marks System, Munin, IVY, Shasta, Brazos และ Cashmere
Program Annotation Packages- ใช้กับสถาปัตยกรรมที่มีลักษณะการเข้าถึงหน่วยความจำแบบเดียวกัน ตัวอย่างที่โดดเด่นที่สุดของแพ็คเกจคำอธิบายประกอบโปรแกรมคือ OpenMP OpenMP ใช้ฟังก์ชันการทำงานแบบขนาน ส่วนใหญ่มุ่งเน้นไปที่การขนานของลูป
แนวคิดของหน่วยความจำที่ใช้ร่วมกันให้การควบคุมระบบหน่วยความจำแบบแบ่งใช้ในระดับต่ำ แต่มีแนวโน้มที่จะน่าเบื่อและผิดพลาด เหมาะสำหรับการเขียนโปรแกรมระบบมากกว่าการเขียนโปรแกรมประยุกต์
ข้อดีของการเขียนโปรแกรมหน่วยความจำร่วม
พื้นที่ที่อยู่ส่วนกลางให้แนวทางการเขียนโปรแกรมที่ใช้งานง่ายสำหรับหน่วยความจำ
เนื่องจากความใกล้ชิดของหน่วยความจำกับ CPU การแบ่งปันข้อมูลระหว่างกระบวนการต่างๆจึงรวดเร็วและสม่ำเสมอ
ไม่จำเป็นต้องระบุการสื่อสารข้อมูลระหว่างกระบวนการอย่างชัดเจน
ค่าใช้จ่ายในการสื่อสารในกระบวนการมีความสำคัญเล็กน้อย
มันง่ายมากที่จะเรียนรู้
ข้อด้อยของการเขียนโปรแกรมหน่วยความจำร่วม
- ไม่สามารถพกพาได้
- การจัดการพื้นที่ข้อมูลเป็นเรื่องยากมาก
รูปแบบการส่งข้อความ
การส่งผ่านข้อความเป็นวิธีการเขียนโปรแกรมแบบขนานที่ใช้กันมากที่สุดในระบบหน่วยความจำแบบกระจาย ที่นี่โปรแกรมเมอร์จะต้องกำหนดความขนาน ในรุ่นนี้โปรเซสเซอร์ทั้งหมดมีหน่วยความจำภายในของตนเองและแลกเปลี่ยนข้อมูลผ่านเครือข่ายการสื่อสาร

โปรเซสเซอร์ใช้ไลบรารีการส่งผ่านข้อความเพื่อการสื่อสารระหว่างกัน พร้อมกับข้อมูลที่กำลังส่งข้อความประกอบด้วยส่วนประกอบต่อไปนี้ -
ที่อยู่ของโปรเซสเซอร์ที่จะส่งข้อความ
ที่อยู่เริ่มต้นของตำแหน่งหน่วยความจำของข้อมูลในโปรเซสเซอร์ที่ส่ง
ประเภทข้อมูลของข้อมูลที่ส่ง
ขนาดข้อมูลของข้อมูลที่ส่ง
ที่อยู่ของโปรเซสเซอร์ที่ข้อความกำลังถูกส่ง
ที่อยู่เริ่มต้นของตำแหน่งหน่วยความจำสำหรับข้อมูลในโปรเซสเซอร์ที่รับ
โปรเซสเซอร์สามารถสื่อสารกันได้โดยวิธีใดวิธีหนึ่งดังต่อไปนี้ -
- การสื่อสารแบบจุดต่อจุด
- การสื่อสารโดยรวม
- อินเทอร์เฟซการส่งข้อความ
การสื่อสารแบบจุดต่อจุด
การสื่อสารแบบจุดต่อจุดเป็นรูปแบบการส่งผ่านข้อความที่ง่ายที่สุด ที่นี่ข้อความสามารถส่งจากโปรเซสเซอร์ที่ส่งไปยังโปรเซสเซอร์ที่รับได้โดยใช้โหมดการถ่ายโอนใด ๆ ต่อไปนี้ -
Synchronous mode - ข้อความถัดไปจะถูกส่งหลังจากได้รับการยืนยันว่ามีการส่งข้อความก่อนหน้านี้แล้วเท่านั้นเพื่อรักษาลำดับของข้อความ
Asynchronous mode - ในการส่งข้อความถัดไปไม่จำเป็นต้องได้รับการยืนยันการส่งข้อความก่อนหน้านี้
การสื่อสารโดยรวม
การสื่อสารโดยรวมเกี่ยวข้องกับโปรเซสเซอร์มากกว่าสองตัวสำหรับการส่งผ่านข้อความ โหมดต่อไปนี้อนุญาตให้มีการสื่อสารร่วมกัน -
Barrier - โหมด Barrier เป็นไปได้หากโปรเซสเซอร์ทั้งหมดที่รวมอยู่ในการสื่อสารเรียกใช้ bock เฉพาะ (เรียกว่า barrier block) สำหรับการส่งข้อความ
Broadcast - การออกอากาศมีสองประเภท -
One-to-all - ที่นี่โปรเซสเซอร์หนึ่งตัวที่มีการดำเนินการเดียวจะส่งข้อความเดียวกันไปยังโปรเซสเซอร์อื่น ๆ ทั้งหมด
All-to-all - ที่นี่โปรเซสเซอร์ทั้งหมดจะส่งข้อความไปยังโปรเซสเซอร์อื่น ๆ ทั้งหมด
ข้อความที่ออกอากาศอาจมีสามประเภท -
Personalized - ข้อความที่ไม่ซ้ำกันจะถูกส่งไปยังโปรเซสเซอร์ปลายทางอื่น ๆ ทั้งหมด
Non-personalized - โปรเซสเซอร์ปลายทางทั้งหมดได้รับข้อความเดียวกัน
Reduction - ในการลดการออกอากาศโปรเซสเซอร์หนึ่งตัวในกลุ่มจะรวบรวมข้อความทั้งหมดจากโปรเซสเซอร์อื่น ๆ ทั้งหมดในกลุ่มและรวมเป็นข้อความเดียวซึ่งโปรเซสเซอร์อื่น ๆ ทั้งหมดในกลุ่มสามารถเข้าถึงได้
ข้อดีของการส่งข้อความ
- ให้การควบคุมความขนานในระดับต่ำ
- เป็นแบบพกพา
- เกิดข้อผิดพลาดน้อยลง
- ค่าใช้จ่ายน้อยลงในการซิงโครไนซ์แบบขนานและการกระจายข้อมูล
ข้อด้อยของการส่งข้อความ
เมื่อเทียบกับรหัสหน่วยความจำแบบแบ่งใช้แบบขนานโดยทั่วไปแล้วรหัสการส่งผ่านข้อความจะต้องใช้ซอฟต์แวร์มากกว่า
ข้อความผ่านไลบรารี
มีไลบรารีการส่งผ่านข้อความจำนวนมาก ในที่นี้เราจะพูดถึงไลบรารีการส่งผ่านข้อความที่ใช้มากที่สุดสองไลบรารี -
- อินเทอร์เฟซการส่งข้อความ (MPI)
- เครื่องเสมือนแบบขนาน (PVM)
อินเทอร์เฟซการส่งข้อความ (MPI)
เป็นมาตรฐานสากลในการสื่อสารระหว่างกระบวนการที่เกิดขึ้นพร้อมกันทั้งหมดในระบบหน่วยความจำแบบกระจาย แพลตฟอร์มคอมพิวเตอร์คู่ขนานที่ใช้กันทั่วไปส่วนใหญ่มีการใช้งานอินเทอร์เฟซการส่งข้อความอย่างน้อยหนึ่งรายการ มีการใช้งานเป็นชุดของฟังก์ชันที่กำหนดไว้ล่วงหน้าที่เรียกว่าlibrary และสามารถเรียกได้จากภาษาต่างๆเช่น C, C ++, Fortran เป็นต้น MPI นั้นทั้งรวดเร็วและพกพาได้เมื่อเทียบกับไลบรารีที่ส่งผ่านข้อความอื่น ๆ
Merits of Message Passing Interface
รันบนสถาปัตยกรรมหน่วยความจำแบบแบ่งใช้หรือสถาปัตยกรรมหน่วยความจำแบบกระจายเท่านั้น
โปรเซสเซอร์แต่ละตัวมีตัวแปรท้องถิ่นของตัวเอง
เมื่อเทียบกับคอมพิวเตอร์หน่วยความจำที่ใช้ร่วมกันขนาดใหญ่คอมพิวเตอร์หน่วยความจำแบบกระจายมีราคาไม่แพง
Demerits of Message Passing Interface
- จำเป็นต้องมีการเปลี่ยนแปลงโปรแกรมเพิ่มเติมสำหรับอัลกอริทึมแบบขนาน
- บางครั้งยากที่จะแก้ไขข้อบกพร่อง และ
- ทำงานได้ไม่ดีในเครือข่ายการสื่อสารระหว่างโหนด
เครื่องเสมือนแบบขนาน (PVM)
PVM เป็นระบบส่งข้อความแบบพกพาที่ออกแบบมาเพื่อเชื่อมต่อเครื่องโฮสต์ที่แตกต่างกันเพื่อสร้างเครื่องเสมือนเครื่องเดียว เป็นทรัพยากรคอมพิวเตอร์แบบขนานที่จัดการได้เพียงแหล่งเดียว ปัญหาการคำนวณขนาดใหญ่เช่นการศึกษาความเป็นตัวนำยิ่งยวดการจำลองพลวัตของโมเลกุลและอัลกอริทึมเมทริกซ์สามารถแก้ไขได้อย่างคุ้มค่ามากขึ้นโดยใช้หน่วยความจำและพลังรวมของคอมพิวเตอร์หลายเครื่อง จัดการการกำหนดเส้นทางข้อความการแปลงข้อมูลการจัดตารางงานในเครือข่ายของสถาปัตยกรรมคอมพิวเตอร์ที่เข้ากันไม่ได้
Features of PVM
- ติดตั้งและกำหนดค่าได้ง่ายมาก
- ผู้ใช้หลายคนสามารถใช้ PVM ในเวลาเดียวกัน
- ผู้ใช้หนึ่งคนสามารถเรียกใช้งานหลายแอป
- เป็นแพ็คเกจขนาดเล็ก
- รองรับ C, C ++, Fortran;
- สำหรับการรันโปรแกรม PVM ที่กำหนดผู้ใช้สามารถเลือกกลุ่มของเครื่อง
- เป็นรูปแบบการส่งข้อความ
- การคำนวณตามกระบวนการ
- รองรับสถาปัตยกรรมที่แตกต่างกัน
การเขียนโปรแกรมข้อมูลแบบขนาน
จุดเน้นหลักของรูปแบบการเขียนโปรแกรมแบบขนานข้อมูลคือการดำเนินการกับชุดข้อมูลพร้อมกัน ชุดข้อมูลถูกจัดเป็นโครงสร้างบางอย่างเช่นอาร์เรย์ไฮเปอร์คิวบ์ ฯลฯ โปรเซสเซอร์ดำเนินการร่วมกันบนโครงสร้างข้อมูลเดียวกัน แต่ละงานจะดำเนินการบนพาร์ติชันที่แตกต่างกันของโครงสร้างข้อมูลเดียวกัน
มีข้อ จำกัด เนื่องจากไม่สามารถระบุอัลกอริทึมทั้งหมดในแง่ของความขนานของข้อมูลได้ นี่คือเหตุผลว่าทำไมความขนานของข้อมูลจึงไม่เป็นสากล
ภาษาคู่ขนานของข้อมูลช่วยในการระบุการย่อยสลายข้อมูลและการแม็ปไปยังโปรเซสเซอร์ นอกจากนี้ยังรวมถึงคำสั่งการกระจายข้อมูลที่ช่วยให้โปรแกรมเมอร์สามารถควบคุมข้อมูลได้ตัวอย่างเช่นข้อมูลใดจะไปที่โปรเซสเซอร์ใดเพื่อลดปริมาณการสื่อสารภายในโปรเซสเซอร์
ในการใช้อัลกอริทึมใด ๆ อย่างถูกต้องคุณต้องเลือกโครงสร้างข้อมูลที่เหมาะสม เป็นเพราะการดำเนินการเฉพาะที่ดำเนินการกับโครงสร้างข้อมูลอาจใช้เวลามากกว่าเมื่อเทียบกับการดำเนินการเดียวกันกับโครงสร้างข้อมูลอื่น
Example- ในการเข้าถึงองค์ประกอบi thในชุดโดยใช้อาร์เรย์อาจใช้เวลาคงที่ แต่เมื่อใช้รายการที่เชื่อมโยงเวลาที่ต้องใช้ในการดำเนินการเดียวกันอาจกลายเป็นพหุนาม
ดังนั้นการเลือกโครงสร้างข้อมูลจะต้องพิจารณาจากสถาปัตยกรรมและประเภทของการดำเนินการที่จะดำเนินการ
โครงสร้างข้อมูลต่อไปนี้มักใช้ในการเขียนโปรแกรมแบบขนาน -
- รายการที่เชื่อมโยง
- Arrays
- Hypercube Network
รายการที่เชื่อมโยง
รายการที่เชื่อมโยงคือโครงสร้างข้อมูลที่มีโหนดหรือมากกว่าที่เชื่อมต่อกันด้วยตัวชี้ โหนดอาจใช้ตำแหน่งหน่วยความจำติดต่อกันหรือไม่ก็ได้ แต่ละโหนดมีสองหรือสามส่วน - หนึ่งdata part ที่เก็บข้อมูลและอีกสองรายการคือ link fieldsที่เก็บแอดเดรสของโหนดก่อนหน้าหรือถัดไป แอดเดรสของโหนดแรกจะถูกเก็บไว้ในตัวชี้ภายนอกที่เรียกว่าhead. โหนดสุดท้ายเรียกว่าtail, โดยทั่วไปไม่มีที่อยู่ใด ๆ
รายการที่เชื่อมโยงมีสามประเภท -
- รายการที่เชื่อมโยงเดี่ยว
- รายการที่เชื่อมโยงเป็นทวีคูณ
- รายการที่เชื่อมโยงแบบวงกลม
รายการที่เชื่อมโยงเดี่ยว
โหนดของรายการที่เชื่อมโยงเดี่ยวมีข้อมูลและที่อยู่ของโหนดถัดไป ตัวชี้ภายนอกเรียกว่าhead เก็บที่อยู่ของโหนดแรก

รายการที่เชื่อมโยงเป็นทวีคูณ
โหนดของรายการที่เชื่อมโยงแบบทวีคูณประกอบด้วยข้อมูลและที่อยู่ของทั้งโหนดก่อนหน้าและโหนดถัดไป ตัวชี้ภายนอกเรียกว่าhead เก็บที่อยู่ของโหนดแรกและตัวชี้ภายนอกที่เรียกว่า tail เก็บที่อยู่ของโหนดสุดท้าย

รายการที่เชื่อมโยงแบบวงกลม
รายการที่เชื่อมโยงแบบวงกลมมีความคล้ายคลึงกับรายการที่เชื่อมโยงเดี่ยวมากยกเว้นข้อเท็จจริงที่ว่าโหนดสุดท้ายบันทึกที่อยู่ของโหนดแรก

อาร์เรย์
อาร์เรย์เป็นโครงสร้างข้อมูลที่เราสามารถจัดเก็บข้อมูลประเภทเดียวกันได้ อาจเป็นมิติเดียวหรือหลายมิติ อาร์เรย์สามารถสร้างแบบคงที่หรือแบบไดนามิก
ใน statically declared arrays, มิติข้อมูลและขนาดของอาร์เรย์เป็นที่ทราบกันดีในขณะคอมไพล์
ใน dynamically declared arrays, มิติข้อมูลและขนาดของอาร์เรย์เป็นที่รู้จักในขณะรันไทม์
สำหรับการเขียนโปรแกรมหน่วยความจำแบบแบ่งใช้อาร์เรย์สามารถใช้เป็นหน่วยความจำทั่วไปและสำหรับการเขียนโปรแกรมข้อมูลแบบขนานสามารถใช้โดยแบ่งพาร์ติชันเป็นอาร์เรย์ย่อย
Hypercube Network
สถาปัตยกรรม Hypercube มีประโยชน์สำหรับอัลกอริทึมแบบขนานที่แต่ละงานต้องสื่อสารกับงานอื่น ๆ โทโพโลยี Hypercube สามารถฝังโทโพโลยีอื่น ๆ เช่นวงแหวนและตาข่ายได้อย่างง่ายดาย เป็นที่รู้จักกันในนาม n-ก้อนโดยที่nคือจำนวนมิติข้อมูล ไฮเปอร์คิวบ์สามารถสร้างแบบวนซ้ำได้


การเลือกเทคนิคการออกแบบที่เหมาะสมสำหรับอัลกอริทึมคู่ขนานเป็นงานที่ยากและสำคัญที่สุด ปัญหาการเขียนโปรแกรมแบบขนานส่วนใหญ่อาจมีวิธีแก้ปัญหามากกว่าหนึ่งวิธี ในบทนี้เราจะพูดถึงเทคนิคการออกแบบต่อไปนี้สำหรับอัลกอริทึมแบบขนาน -
- แบ่งและพิชิต
- วิธีโลภ
- การเขียนโปรแกรมแบบไดนามิก
- Backtracking
- สาขา & ผูกพัน
- การเขียนโปรแกรมเชิงเส้น
วิธีหารและพิชิต
ในแนวทางแบ่งแยกและพิชิตปัญหาแบ่งออกเป็นปัญหาย่อยย่อย ๆ หลายปัญหา จากนั้นปัญหาย่อยจะถูกแก้ไขซ้ำแล้วซ้ำอีกและรวมกันเพื่อหาทางออกของปัญหาเดิม
แนวทางการแบ่งแยกและพิชิตเกี่ยวข้องกับขั้นตอนต่อไปนี้ในแต่ละระดับ -
Divide - ปัญหาเดิมแบ่งเป็นปัญหาย่อย
Conquer - ปัญหาย่อยได้รับการแก้ไขแบบวนซ้ำ
Combine - การแก้ปัญหาย่อยจะถูกรวมเข้าด้วยกันเพื่อหาทางออกของปัญหาเดิม
แนวทางการแบ่งและพิชิตถูกนำไปใช้ในอัลกอริทึมต่อไปนี้ -
- การค้นหาแบบไบนารี
- จัดเรียงด่วน
- ผสานการจัดเรียง
- การคูณจำนวนเต็ม
- การผกผันของเมทริกซ์
- การคูณเมทริกซ์
วิธีโลภ
ในอัลกอริธึมโลภของการเพิ่มประสิทธิภาพโซลูชันโซลูชันที่ดีที่สุดจะถูกเลือกในทุกขณะ อัลกอริทึมโลภเป็นเรื่องง่ายมากที่จะนำไปใช้กับปัญหาที่ซับซ้อน เป็นการตัดสินใจว่าขั้นตอนใดจะให้คำตอบที่ถูกต้องที่สุดในขั้นตอนต่อไป
อัลกอริทึมนี้เรียกว่า greedyเนื่องจากเมื่อมีการจัดหาโซลูชันที่ดีที่สุดสำหรับอินสแตนซ์ขนาดเล็กอัลกอริทึมจะไม่พิจารณาโปรแกรมทั้งหมดโดยรวม เมื่อพิจารณาวิธีแก้ปัญหาแล้วอัลกอริทึมโลภจะไม่พิจารณาวิธีแก้ปัญหาเดิมอีก
อัลกอริทึมโลภทำงานซ้ำเพื่อสร้างกลุ่มของวัตถุจากชิ้นส่วนส่วนประกอบที่เล็กที่สุดที่เป็นไปได้ การเรียกซ้ำเป็นขั้นตอนในการแก้ปัญหาซึ่งการแก้ปัญหาเฉพาะจะขึ้นอยู่กับการแก้ปัญหาของอินสแตนซ์ที่เล็กกว่าของปัญหานั้น
การเขียนโปรแกรมแบบไดนามิก
การเขียนโปรแกรมแบบไดนามิกเป็นเทคนิคการเพิ่มประสิทธิภาพซึ่งแบ่งปัญหาออกเป็นปัญหาย่อยที่เล็กกว่าและหลังจากแก้ปัญหาย่อยแต่ละปัญหาแล้วการเขียนโปรแกรมแบบไดนามิกจะรวมโซลูชันทั้งหมดเข้าด้วยกันเพื่อให้ได้โซลูชันที่ดีที่สุด ซึ่งแตกต่างจากวิธีการแบ่งและพิชิตการเขียนโปรแกรมแบบไดนามิกจะใช้วิธีแก้ปัญหาย่อยซ้ำหลายครั้ง
อัลกอริทึมแบบเรียกซ้ำสำหรับ Fibonacci Series เป็นตัวอย่างของการเขียนโปรแกรมแบบไดนามิก
Backtracking Algorithm
การย้อนรอยเป็นเทคนิคการเพิ่มประสิทธิภาพเพื่อแก้ปัญหาที่เกิดร่วมกัน ใช้กับปัญหาทั้งแบบเป็นโปรแกรมและในชีวิตจริง ปัญหาแปดราชินีปริศนาซูโดกุและการเดินผ่านเขาวงกตเป็นตัวอย่างยอดนิยมที่ใช้อัลกอริธึมการย้อนรอย
ในการย้อนรอยเราเริ่มต้นด้วยวิธีแก้ปัญหาที่เป็นไปได้ซึ่งตรงตามเงื่อนไขที่กำหนดทั้งหมด จากนั้นเราจะย้ายไปยังระดับถัดไปและหากระดับนั้นไม่ได้ผลลัพธ์ที่น่าพอใจเราจะคืนกลับหนึ่งระดับและเริ่มต้นด้วยตัวเลือกใหม่
สาขาและขอบเขต
อัลกอริทึมสาขาและขอบเขตเป็นเทคนิคการเพิ่มประสิทธิภาพเพื่อให้ได้วิธีการแก้ปัญหาที่เหมาะสมที่สุด มองหาทางออกที่ดีที่สุดสำหรับปัญหาที่กำหนดในพื้นที่ทั้งหมดของโซลูชัน ขอบเขตในฟังก์ชันที่จะปรับให้เหมาะสมจะรวมเข้ากับมูลค่าของโซลูชันที่ดีที่สุดล่าสุด ช่วยให้อัลกอริทึมสามารถค้นหาส่วนต่างๆของพื้นที่โซลูชันได้อย่างสมบูรณ์
จุดประสงค์ของสาขาและการค้นหาที่ถูกผูกไว้คือการรักษาเส้นทางที่มีต้นทุนต่ำที่สุดไปยังเป้าหมาย เมื่อพบวิธีแก้ปัญหาแล้วก็สามารถปรับปรุงโซลูชันได้ต่อไป การค้นหาสาขาและขอบเขตถูกนำไปใช้ในการค้นหาขอบเขตเชิงลึกและการค้นหาเชิงลึกเป็นครั้งแรก
การเขียนโปรแกรมเชิงเส้น
การเขียนโปรแกรมเชิงเส้นอธิบายถึงงานการเพิ่มประสิทธิภาพระดับกว้างโดยที่ทั้งเกณฑ์การปรับให้เหมาะสมและข้อ จำกัด เป็นฟังก์ชันเชิงเส้น เป็นเทคนิคเพื่อให้ได้ผลลัพธ์ที่ดีที่สุดเช่นกำไรสูงสุดเส้นทางที่สั้นที่สุดหรือต้นทุนต่ำสุด
ในการเขียนโปรแกรมนี้เรามีชุดของตัวแปรและเราต้องกำหนดค่าสัมบูรณ์ให้กับตัวแปรเหล่านั้นเพื่อให้เป็นไปตามชุดของสมการเชิงเส้นและเพื่อเพิ่มหรือลดฟังก์ชันวัตถุประสงค์เชิงเส้นที่กำหนด
เมทริกซ์คือชุดข้อมูลที่เป็นตัวเลขและไม่ใช่ตัวเลขที่จัดเรียงเป็นจำนวนแถวและคอลัมน์คงที่ การคูณเมทริกซ์เป็นการออกแบบการคูณที่สำคัญในการคำนวณแบบขนาน ในที่นี้เราจะพูดถึงการใช้การคูณเมทริกซ์บนเครือข่ายการสื่อสารต่างๆเช่นเมชและไฮเปอร์คิวบ์ Mesh และ Hypercube มีการเชื่อมต่อเครือข่ายที่สูงกว่าดังนั้นจึงอนุญาตให้ใช้อัลกอริทึมที่เร็วกว่าเครือข่ายอื่น ๆ เช่นเครือข่ายวงแหวน
เครือข่ายตาข่าย
โทโพโลยีที่ชุดของโหนดเป็นกริด p มิติเรียกว่าโทโพโลยีแบบตาข่าย ที่นี่ขอบทั้งหมดขนานกับแกนกริดและโหนดที่อยู่ติดกันทั้งหมดสามารถสื่อสารกันเองได้
จำนวนโหนดทั้งหมด = (จำนวนโหนดในแถว) × (จำนวนโหนดในคอลัมน์)
เครือข่ายตาข่ายสามารถประเมินได้โดยใช้ปัจจัยต่อไปนี้ -
- Diameter
- ความกว้าง Bisection
Diameter - ในเครือข่ายตาข่ายยาวที่สุด distanceระหว่างสองโหนดคือเส้นผ่านศูนย์กลาง เครือข่ายตาข่าย p มิติที่มีkP โหนดมีเส้นผ่านศูนย์กลาง p(k–1).
Bisection width - Bisection width คือจำนวนขอบขั้นต่ำที่จำเป็นในการลบออกจากเครือข่ายเพื่อแบ่งเครือข่ายตาข่ายออกเป็นสองส่วน
การคูณเมทริกซ์โดยใช้เครือข่ายตาข่าย
เราได้พิจารณาแบบจำลอง SIMD เครือข่ายตาข่าย 2 มิติที่มีการเชื่อมต่อที่ครอบคลุม เราจะออกแบบอัลกอริทึมเพื่อคูณอาร์เรย์ n × n สองอาร์เรย์โดยใช้โปรเซสเซอร์n 2ในระยะเวลาหนึ่ง
เมทริกซ์ A และ B มีองค์ประกอบเป็นijและ b ijตามลำดับ การประมวลผลองค์ประกอบ PE IJหมายถึงIJและขIJ จัดเรียงเมทริกซ์ A และ B ในลักษณะที่โปรเซสเซอร์ทุกตัวมีคู่ขององค์ประกอบที่จะคูณ องค์ประกอบของเมทริกซ์ A จะเคลื่อนที่ไปในทิศทางซ้ายและองค์ประกอบของเมทริกซ์ B จะเคลื่อนที่ในทิศทางขึ้น การเปลี่ยนแปลงตำแหน่งขององค์ประกอบในเมทริกซ์ A และ B เหล่านี้จะนำเสนอองค์ประกอบการประมวลผลแต่ละรายการ PE ซึ่งเป็นคู่ค่าใหม่ที่จะคูณ
ขั้นตอนในอัลกอริทึม
- ซวนเซสองเมทริกซ์
- คำนวณผลิตภัณฑ์ทั้งหมด a ik × b kj
- คำนวณผลรวมเมื่อขั้นตอนที่ 2 เสร็จสมบูรณ์
อัลกอริทึม
Procedure MatrixMulti
Begin
for k = 1 to n-1
for all Pij; where i and j ranges from 1 to n
ifi is greater than k then
rotate a in left direction
end if
if j is greater than k then
rotate b in the upward direction
end if
for all Pij ; where i and j lies between 1 and n
compute the product of a and b and store it in c
for k= 1 to n-1 step 1
for all Pi;j where i and j ranges from 1 to n
rotate a in left direction
rotate b in the upward direction
c=c+aXb
EndHypercube Network
ไฮเปอร์คิวบ์คือโครงสร้าง n มิติที่ขอบตั้งฉากกันเองและมีความยาวเท่ากัน ไฮเปอร์คิวบ์ n มิติเรียกอีกอย่างว่า n-cube หรือคิวบ์ n มิติ
คุณสมบัติของ Hypercube ที่มีโหนด2 k
- เส้นผ่านศูนย์กลาง = k
- ความกว้างทวิ = 2 k – 1
- จำนวนขอบ = k
การคูณเมทริกซ์โดยใช้ Hypercube Network
ข้อกำหนดทั่วไปของเครือข่าย Hypercube -
ปล่อย N = 2mเป็นจำนวนโปรเซสเซอร์ทั้งหมด ให้การประมวลผลเป็น P 0, P 1 ... ..P N-1
ให้ i และ i bเป็นจำนวนเต็ม 2 จำนวน 0 <i, i b <N-1 และการแทนค่าฐานสองจะแตกต่างกันเฉพาะในตำแหน่ง b, 0 <b <k – 1
ให้เราพิจารณาเมทริกซ์ n × n สองเมทริกซ์ A และเมทริกซ์บี
Step 1- องค์ประกอบของเมทริกซ์ A และ B เมทริกซ์ได้รับมอบหมายให้ที่ n 3โปรเซสเซอร์ประมวลผลดังกล่าวว่าในฐานะที่ฉัน j, k จะมีjiและขIK
Step 2 - โปรเซสเซอร์ทั้งหมดในตำแหน่ง (i, j, k) คำนวณผลิตภัณฑ์
C (i, j, k) = A (i, j, k) × B (i, j, k)
Step 3 - ผลรวม C (0, j, k) = ΣC (i, j, k) สำหรับ 0 ≤ i ≤ n-1 โดยที่ 0 ≤ j, k <n – 1
บล็อกเมทริกซ์
Block Matrix หรือเมทริกซ์แบ่งพาร์ติชันคือเมทริกซ์ที่แต่ละองค์ประกอบแสดงถึงเมทริกซ์แต่ละรายการ แต่ละส่วนเหล่านี้เรียกว่าไฟล์block หรือ sub-matrix.
ตัวอย่าง


ในรูป (a) X คือเมทริกซ์บล็อกโดยที่ A, B, C, D เป็นเมทริกซ์เอง รูป (f) แสดงเมทริกซ์ทั้งหมด
การคูณบล็อกเมทริกซ์
เมื่อเมทริกซ์บล็อกสองเมทริกซ์เป็นเมทริกซ์กำลังสองพวกมันจะถูกคูณด้วยวิธีที่เราทำการคูณเมทริกซ์อย่างง่าย ตัวอย่างเช่น,

การเรียงลำดับเป็นกระบวนการจัดเรียงองค์ประกอบในกลุ่มตามลำดับเฉพาะกล่าวคือเรียงลำดับจากน้อยไปหามากลำดับจากมากไปหาน้อยลำดับตัวอักษร ฯลฯ ในที่นี้จะกล่าวถึงสิ่งต่อไปนี้ -
- เรียงลำดับการแจงนับ
- การเรียงลำดับคี่ - คู่
- เรียงลำดับการผสานแบบขนาน
- จัดเรียงด่วนอย่างรวดเร็ว
การจัดเรียงรายการองค์ประกอบเป็นการดำเนินการที่พบบ่อยมาก อัลกอริทึมการจัดเรียงตามลำดับอาจไม่มีประสิทธิภาพเพียงพอเมื่อเราต้องจัดเรียงข้อมูลจำนวนมาก ดังนั้นจึงใช้อัลกอริทึมแบบขนานในการเรียงลำดับ
เรียงลำดับการแจงนับ
การเรียงลำดับการแจงนับเป็นวิธีการจัดเรียงองค์ประกอบทั้งหมดในรายการโดยการค้นหาตำแหน่งสุดท้ายของแต่ละองค์ประกอบในรายการที่เรียงลำดับ ทำได้โดยการเปรียบเทียบแต่ละองค์ประกอบกับองค์ประกอบอื่น ๆ ทั้งหมดและค้นหาจำนวนองค์ประกอบที่มีค่าน้อยกว่า
ดังนั้นสำหรับการใด ๆ สององค์ประกอบที่ฉันและเจหนึ่งในกรณีดังต่อไปนี้ต้องเป็นจริง -
- ฉัน <a J
- กi > a j
- a ผม = a j
อัลกอริทึม
procedure ENUM_SORTING (n)
begin
for each process P1,j do
C[j] := 0;
for each process Pi, j do
if (A[i] < A[j]) or A[i] = A[j] and i < j) then
C[j] := 1;
else
C[j] := 0;
for each process P1, j do
A[C[j]] := A[j];
end ENUM_SORTINGการเรียงลำดับคี่ - คู่
Odd-Even Transposition Sort ขึ้นอยู่กับเทคนิค Bubble Sort จะเปรียบเทียบตัวเลขสองตัวที่อยู่ติดกันและสลับตัวเลขหากตัวเลขแรกมากกว่าตัวเลขที่สองเพื่อให้ได้รายการลำดับจากน้อยไปมาก กรณีตรงกันข้ามใช้กับลำดับจากมากไปหาน้อย การเรียงลำดับการขนย้ายคี่ - คู่ทำงานในสองขั้นตอน -odd phase และ even phase. ในทั้งสองเฟสประมวลผลการแลกเปลี่ยนหมายเลขกับหมายเลขที่อยู่ติดกันทางด้านขวา
อัลกอริทึม
procedure ODD-EVEN_PAR (n)
begin
id := process's label
for i := 1 to n do
begin
if i is odd and id is odd then
compare-exchange_min(id + 1);
else
compare-exchange_max(id - 1);
if i is even and id is even then
compare-exchange_min(id + 1);
else
compare-exchange_max(id - 1);
end for
end ODD-EVEN_PARเรียงลำดับการผสานแบบขนาน
การเรียงลำดับขั้นแรกจะแบ่งรายการที่ไม่ได้เรียงลำดับออกเป็นรายการย่อยที่เล็กที่สุดเท่าที่จะเป็นไปได้เปรียบเทียบกับรายการที่อยู่ติดกันและรวมเข้าด้วยกันตามลำดับที่เรียง มันใช้ความเท่าเทียมกันอย่างดีเยี่ยมโดยทำตามขั้นตอนวิธีการแบ่งและพิชิต

อัลกอริทึม
procedureparallelmergesort(id, n, data, newdata)
begin
data = sequentialmergesort(data)
for dim = 1 to n
data = parallelmerge(id, dim, data)
endfor
newdata = data
endจัดเรียงด่วนอย่างรวดเร็ว
Hyper quick sort คือการนำการจัดเรียงอย่างรวดเร็วไปใช้บนไฮเปอร์คิวบ์ ขั้นตอนมีดังนี้ -
- แบ่งรายการที่ไม่เรียงลำดับระหว่างแต่ละโหนด
- จัดเรียงแต่ละโหนดในเครื่อง
- จากโหนด 0 ออกอากาศค่ากลาง
- แยกแต่ละรายการในเครื่องจากนั้นแลกเปลี่ยนครึ่งหนึ่งในมิติสูงสุด
- ทำซ้ำขั้นตอนที่ 3 และ 4 พร้อมกันจนกว่าขนาดจะถึง 0
อัลกอริทึม
procedure HYPERQUICKSORT (B, n)
begin
id := process’s label;
for i := 1 to d do
begin
x := pivot;
partition B into B1 and B2 such that B1 ≤ x < B2;
if ith bit is 0 then
begin
send B2 to the process along the ith communication link;
C := subsequence received along the ith communication link;
B := B1 U C;
endif
else
send B1 to the process along the ith communication link;
C := subsequence received along the ith communication link;
B := B2 U C;
end else
end for
sort B using sequential quicksort;
end HYPERQUICKSORTการค้นหาเป็นหนึ่งในปฏิบัติการพื้นฐานในวิทยาการคอมพิวเตอร์ มันถูกใช้ในทุกแอปพลิเคชันที่เราต้องการค้นหาว่ามีองค์ประกอบอยู่ในรายการที่กำหนดหรือไม่ ในบทนี้เราจะพูดถึงอัลกอริทึมการค้นหาต่อไปนี้ -
- แบ่งและพิชิต
- การค้นหาเชิงลึก - แรก
- การค้นหาแบบกว้าง - แรก
- Best-First Search
แบ่งและพิชิต
ในแนวทางแบ่งแยกและพิชิตปัญหาแบ่งออกเป็นปัญหาย่อยย่อย ๆ จากนั้นปัญหาย่อยจะถูกแก้ไขซ้ำแล้วซ้ำอีกและรวมกันเพื่อหาทางออกของปัญหาเดิม
แนวทางการแบ่งแยกและพิชิตเกี่ยวข้องกับขั้นตอนต่อไปนี้ในแต่ละระดับ -
Divide - ปัญหาเดิมแบ่งเป็นปัญหาย่อย
Conquer - ปัญหาย่อยได้รับการแก้ไขแบบวนซ้ำ
Combine - การแก้ปัญหาของปัญหาย่อยจะถูกรวมเข้าด้วยกันเพื่อหาทางออกของปัญหาเดิม
การค้นหาแบบไบนารีเป็นตัวอย่างของอัลกอริทึมการแบ่งและพิชิต
รหัสเทียม
Binarysearch(a, b, low, high)
if low < high then
return NOT FOUND
else
mid ← (low+high) / 2
if b = key(mid) then
return key(mid)
else if b < key(mid) then
return BinarySearch(a, b, low, mid−1)
else
return BinarySearch(a, b, mid+1, high)การค้นหาเชิงลึก - แรก
Depth-First Search (หรือ DFS) คืออัลกอริทึมสำหรับการค้นหาต้นไม้หรือโครงสร้างข้อมูลกราฟที่ไม่มีทิศทาง ที่นี่แนวคิดคือการเริ่มต้นจากโหนดเริ่มต้นที่เรียกว่าrootและสำรวจให้ไกลที่สุดในสาขาเดียวกัน หากเราได้โหนดที่ไม่มีโหนดตัวต่อเราจะส่งคืนและดำเนินการต่อด้วยจุดยอดซึ่งยังไม่มีการเยี่ยมชม
ขั้นตอนของการค้นหาความลึก - แรก
พิจารณาโหนด (รูท) ที่ไม่ได้เยี่ยมชมก่อนหน้านี้และทำเครื่องหมายว่าเยี่ยมชมแล้ว
ไปที่โหนดตัวต่อแรกที่อยู่ติดกันและทำเครื่องหมายว่าเยี่ยมแล้ว
หากโหนดตัวต่อทั้งหมดของโหนดที่พิจารณาถูกเยี่ยมชมแล้วหรือไม่มีโหนดตัวต่อให้กลับไปที่โหนดหลัก
รหัสเทียม
ปล่อย v เป็นจุดยอดที่การค้นหาเริ่มต้นในกราฟ G.
DFS(G,v)
Stack S := {};
for each vertex u, set visited[u] := false;
push S, v;
while (S is not empty) do
u := pop S;
if (not visited[u]) then
visited[u] := true;
for each unvisited neighbour w of u
push S, w;
end if
end while
END DFS()การค้นหาแบบกว้าง - แรก
Breadth-First Search (หรือ BFS) เป็นอัลกอริทึมสำหรับการค้นหาต้นไม้หรือโครงสร้างข้อมูลกราฟที่ไม่ได้กำหนดทิศทาง ที่นี่เราเริ่มต้นด้วยโหนดจากนั้นไปที่โหนดที่อยู่ติดกันทั้งหมดในระดับเดียวกันจากนั้นย้ายไปยังโหนดตัวต่อที่อยู่ติดกันในระดับถัดไป นี้เรียกอีกอย่างว่าlevel-by-level search.
ขั้นตอนของการค้นหาแบบกว้าง - แรก
- เริ่มต้นด้วยโหนดรูททำเครื่องหมายว่าเยี่ยมแล้ว
- เนื่องจากโหนดรูทไม่มีโหนดในระดับเดียวกันให้ไปที่ระดับถัดไป
- เยี่ยมชมโหนดที่อยู่ติดกันทั้งหมดและทำเครื่องหมายว่าเยี่ยมชมแล้ว
- ไปที่ระดับถัดไปและไปที่โหนดที่อยู่ติดกันที่ไม่ได้เข้าชมทั้งหมด
- ดำเนินขั้นตอนนี้ต่อไปจนกว่าจะมีการเยี่ยมชมโหนดทั้งหมด
รหัสเทียม
ปล่อย v เป็นจุดยอดที่การค้นหาเริ่มต้นในกราฟ G.
BFS(G,v)
Queue Q := {};
for each vertex u, set visited[u] := false;
insert Q, v;
while (Q is not empty) do
u := delete Q;
if (not visited[u]) then
visited[u] := true;
for each unvisited neighbor w of u
insert Q, w;
end if
end while
END BFS()Best-First Search
Best-First Search คืออัลกอริทึมที่สำรวจกราฟเพื่อไปยังเป้าหมายในเส้นทางที่สั้นที่สุด ซึ่งแตกต่างจาก BFS และ DFS การค้นหาที่ดีที่สุดจะทำตามฟังก์ชันการประเมินเพื่อพิจารณาว่าโหนดใดเหมาะสมที่สุดในการสำรวจถัดไป
ขั้นตอนของการค้นหาที่ดีที่สุดเป็นอันดับแรก
- เริ่มต้นด้วยโหนดรูททำเครื่องหมายว่าเยี่ยมแล้ว
- ค้นหาโหนดถัดไปที่เหมาะสมและทำเครื่องหมายว่าเยี่ยมชมแล้ว
- ไปที่ระดับถัดไปและค้นหาโหนดที่เหมาะสมและทำเครื่องหมายว่าเยี่ยมชมแล้ว
- ทำตามขั้นตอนนี้ต่อไปจนกว่าจะถึงเป้าหมาย
รหัสเทียม
BFS( m )
Insert( m.StartNode )
Until PriorityQueue is empty
c ← PriorityQueue.DeleteMin
If c is the goal
Exit
Else
Foreach neighbor n of c
If n "Unvisited"
Mark n "Visited"
Insert( n )
Mark c "Examined"
End procedureกราฟคือสัญกรณ์นามธรรมที่ใช้แสดงการเชื่อมต่อระหว่างคู่ของวัตถุ กราฟประกอบด้วย -
Vertices- วัตถุที่เชื่อมต่อกันในกราฟเรียกว่าจุดยอด จุดยอดเรียกอีกอย่างว่าnodes.
Edges - ขอบคือลิงค์ที่เชื่อมต่อจุดยอด
กราฟมีสองประเภท -
Directed graph - ในกราฟกำกับขอบมีทิศทางกล่าวคือขอบจะเปลี่ยนจากจุดยอดหนึ่งไปยังอีกจุดยอดหนึ่ง
Undirected graph - ในกราฟที่ไม่มีทิศทางขอบจะไม่มีทิศทาง
การระบายสีกราฟ
การระบายสีกราฟเป็นวิธีการกำหนดสีให้กับจุดยอดของกราฟเพื่อไม่ให้จุดยอดสองจุดที่อยู่ติดกันมีสีเหมือนกัน ปัญหาการระบายสีกราฟคือ -
Vertex coloring - วิธีการระบายสีจุดยอดของกราฟเพื่อไม่ให้จุดยอดสองจุดที่อยู่ติดกันมีสีเดียวกัน
Edge Coloring - เป็นวิธีการกำหนดสีให้กับแต่ละขอบเพื่อไม่ให้ขอบสองด้านที่อยู่ติดกันมีสีเดียวกัน
Face coloring - กำหนดสีให้กับแต่ละใบหน้าหรือภูมิภาคของกราฟระนาบเพื่อไม่ให้สองใบหน้าที่มีขอบเขตร่วมกันมีสีเดียวกัน
Chromatic Number
Chromatic number คือจำนวนสีขั้นต่ำที่ต้องใช้ในการระบายสีกราฟ ตัวอย่างเช่นจำนวนสีของกราฟต่อไปนี้คือ 3

แนวคิดของการระบายสีกราฟถูกนำไปใช้ในการเตรียมตารางเวลาการกำหนดความถี่วิทยุมือถือ Suduku การจัดสรรการลงทะเบียนและการระบายสีแผนที่
ขั้นตอนในการระบายสีกราฟ
ตั้งค่าเริ่มต้นของโปรเซสเซอร์แต่ละตัวในอาร์เรย์ n มิติเป็น 1
ตอนนี้ในการกำหนดสีเฉพาะให้กับจุดยอดให้พิจารณาว่าสีนั้นถูกกำหนดให้กับจุดยอดที่อยู่ติดกันแล้วหรือไม่
หากโปรเซสเซอร์ตรวจพบสีเดียวกันในจุดยอดที่อยู่ติดกันโปรเซสเซอร์จะตั้งค่าในอาร์เรย์เป็น 0
หลังจากทำการเปรียบเทียบn 2แล้วหากองค์ประกอบใด ๆ ของอาร์เรย์เป็น 1 แสดงว่าเป็นสีที่ถูกต้อง
Pseudocode สำหรับการระบายสีกราฟ
begin
create the processors P(i0,i1,...in-1) where 0_iv < m, 0 _ v < n
status[i0,..in-1] = 1
for j varies from 0 to n-1 do
begin
for k varies from 0 to n-1 do
begin
if aj,k=1 and ij=ikthen
status[i0,..in-1] =0
end
end
ok = ΣStatus
if ok > 0, then display valid coloring exists
else
display invalid coloring
endต้นไม้ที่มีระยะน้อยที่สุด
ต้นไม้ทอดที่มีผลรวมของน้ำหนัก (หรือความยาว) ของขอบทั้งหมดน้อยกว่าต้นไม้ที่ทอดเป็นไปได้อื่น ๆ ทั้งหมดของกราฟ G เรียกว่า a minimal spanning tree หรือ minimum cost spanningต้นไม้. รูปต่อไปนี้แสดงกราฟที่เชื่อมต่อแบบถ่วงน้ำหนัก

แผนภูมิด้านบนที่เป็นไปได้บางส่วนแสดงอยู่ด้านล่าง -



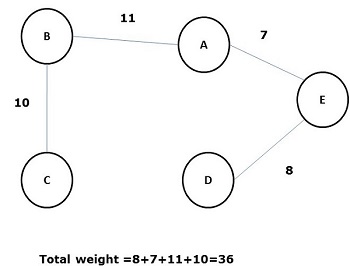



ในบรรดาต้นไม้ที่ทอดยาวข้างต้นรูปที่ (d) คือต้นไม้ที่มีระยะทอดน้อยที่สุด แนวคิดของต้นทุนขั้นต่ำที่ครอบคลุมต้นไม้ถูกนำไปใช้ในปัญหาพนักงานขายในการเดินทางการออกแบบวงจรอิเล็กทรอนิกส์การออกแบบเครือข่ายที่มีประสิทธิภาพและการออกแบบอัลกอริทึมการกำหนดเส้นทางที่มีประสิทธิภาพ
ในการใช้งานโครงสร้างต้นทุนขั้นต่ำจะใช้สองวิธีต่อไปนี้ -
- อัลกอริทึมของ Prim
- อัลกอริทึมของ Kruskal
อัลกอริทึมของ Prim
อัลกอริทึมของ Prim เป็นอัลกอริธึมแบบละโมบซึ่งช่วยให้เราค้นหาโครงสร้างสแปนนิงขั้นต่ำสำหรับกราฟที่ไม่ได้กำหนดทิศทางแบบถ่วงน้ำหนัก เลือกจุดยอดก่อนและหาขอบที่มีน้ำหนักต่ำสุดที่จุดยอดนั้น
ขั้นตอนของอัลกอริทึมของ Prim
เลือกจุดยอดใด ๆ พูดว่า v 1ของกราฟ G
เลือกขอบพูดว่า e 1ของ G เช่นว่า1 = v 1 v 2และ v 1 ≠ v 2และ e 1มีน้ำหนักต่ำสุดระหว่างขอบที่เกิดขึ้นบน v 1ในกราฟ G
ตอนนี้ดังต่อไปนี้ขั้นตอนที่ 2 เลือกขั้นต่ำถ่วงน้ำหนักเหตุการณ์ที่เกิดขึ้นที่ขอบบนโวลต์2
ดำเนินการต่อไปจนกว่าจะเลือกขอบ n – 1 ที่นี่n คือจำนวนจุดยอด

ต้นไม้ที่ทอดน้อยที่สุดคือ -

อัลกอริทึมของ Kruskal
อัลกอริทึมของ Kruskal เป็นอัลกอริธึมแบบละโมบซึ่งช่วยให้เราค้นหาโครงสร้างสแปนนิงขั้นต่ำสำหรับกราฟถ่วงน้ำหนักที่เชื่อมต่อโดยเพิ่มส่วนโค้งต้นทุนที่เพิ่มขึ้นในแต่ละขั้นตอน มันเป็นอัลกอริธึมต้นไม้ที่มีระยะห่างขั้นต่ำที่หาขอบของน้ำหนักที่น้อยที่สุดที่เป็นไปได้ที่เชื่อมต่อต้นไม้สองต้นในป่า
ขั้นตอนของอัลกอริทึมของ Kruskal
เลือกขอบของน้ำหนักขั้นต่ำ พูดว่า e 1ของ Graph G และ e 1ไม่ใช่การวนซ้ำ
เลือกต่ำสุดขอบถ่วงน้ำหนักถัดไปเชื่อมต่อกับ e 1
ดำเนินการต่อไปจนกว่าจะเลือกขอบ n – 1 ที่นี่n คือจำนวนจุดยอด

ต้นไม้ระยะต่ำสุดของกราฟด้านบนคือ -
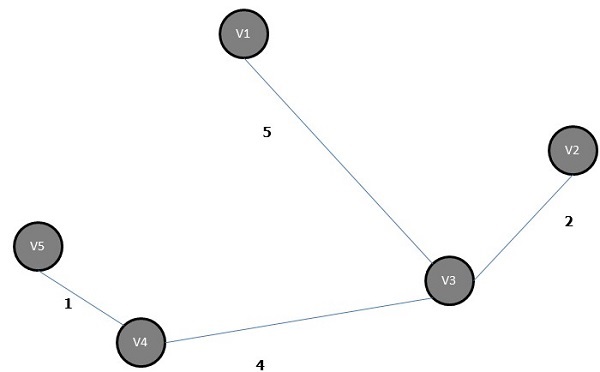
อัลกอริทึมเส้นทางที่สั้นที่สุด
อัลกอริทึมเส้นทางที่สั้นที่สุดคือวิธีการค้นหาเส้นทางที่มีต้นทุนน้อยที่สุดจากโหนดต้นทาง (S) ไปยังโหนดปลายทาง (D) ในที่นี้เราจะพูดถึงอัลกอริทึมของ Moore หรือที่เรียกว่า Breadth First Search Algorithm
อัลกอริทึมของมัวร์
ติดป้ายจุดยอดต้นทาง S และติดป้ายกำกับ i และตั้งค่า i=0.
ค้นหาจุดยอดที่ไม่มีป้ายกำกับทั้งหมดที่อยู่ติดกับจุดยอดที่มีป้ายกำกับ i. หากไม่มีจุดยอดเชื่อมต่อกับจุดยอด S แล้วจุดยอด D จะไม่เชื่อมต่อกับ S หากมีจุดยอดเชื่อมต่อกับ S ให้ติดป้ายกำกับi+1.
หากมีป้ายกำกับ D ให้ไปที่ขั้นตอนที่ 4 มิฉะนั้นไปที่ขั้นตอนที่ 2 เพื่อเพิ่ม i = i + 1
หยุดหลังจากพบความยาวของเส้นทางที่สั้นที่สุด