PySpark - คู่มือฉบับย่อ
ในบทนี้เราจะทำความคุ้นเคยกับ Apache Spark คืออะไรและ PySpark ได้รับการพัฒนาอย่างไร
Spark - ภาพรวม
Apache Spark เป็นเฟรมเวิร์กการประมวลผลแบบเรียลไทม์ที่รวดเร็วทันใจ ทำการคำนวณในหน่วยความจำเพื่อวิเคราะห์ข้อมูลแบบเรียลไทม์ มันออกมาเป็นภาพApache Hadoop MapReduceกำลังดำเนินการประมวลผลชุดงานเท่านั้นและขาดคุณสมบัติการประมวลผลแบบเรียลไทม์ ดังนั้น Apache Spark จึงถูกนำมาใช้เนื่องจากสามารถประมวลผลสตรีมได้แบบเรียลไทม์และยังสามารถดูแลการประมวลผลแบบแบตช์ได้อีกด้วย
นอกเหนือจากการประมวลผลแบบเรียลไทม์และแบทช์แล้ว Apache Spark ยังรองรับการสอบถามแบบโต้ตอบและอัลกอริทึมซ้ำอีกด้วย Apache Spark มีตัวจัดการคลัสเตอร์ของตัวเองซึ่งสามารถโฮสต์แอปพลิเคชันได้ ใช้ประโยชน์จาก Apache Hadoop สำหรับทั้งการจัดเก็บและการประมวลผล มันใช้HDFS (Hadoop Distributed File system) สำหรับการจัดเก็บและสามารถเรียกใช้แอปพลิเคชัน Spark ได้ YARN เช่นกัน.
PySpark - ภาพรวม
Apache Spark เขียนด้วย Scala programming language. เพื่อรองรับ Python ด้วย Spark Apache Spark Community ได้เปิดตัวเครื่องมือ PySpark เมื่อใช้ PySpark คุณสามารถทำงานกับไฟล์RDDsในภาษาโปรแกรม Python ด้วย เป็นเพราะห้องสมุดที่เรียกว่าPy4j ว่าพวกเขาสามารถบรรลุเป้าหมายนี้ได้
ข้อเสนอของ PySpark PySpark Shellซึ่งเชื่อมโยง Python API กับแกนจุดประกายและเริ่มต้นบริบท Spark ปัจจุบันนักวิทยาศาสตร์ข้อมูลและผู้เชี่ยวชาญด้านการวิเคราะห์ส่วนใหญ่ใช้ Python เนื่องจากชุดไลบรารีที่สมบูรณ์ การรวม Python เข้ากับ Spark เป็นประโยชน์สำหรับพวกเขา
ในบทนี้เราจะเข้าใจการตั้งค่าสภาพแวดล้อมของ PySpark
Note - นี่เป็นการพิจารณาว่าคุณติดตั้ง Java และ Scala ไว้ในคอมพิวเตอร์ของคุณ
ให้เราดาวน์โหลดและตั้งค่า PySpark ตามขั้นตอนต่อไปนี้
Step 1- ไปที่หน้าดาวน์โหลด Apache Spark อย่างเป็นทางการและดาวน์โหลด Apache Spark เวอร์ชันล่าสุดที่มีอยู่ที่นั่น ในบทช่วยสอนนี้เรากำลังใช้ไฟล์spark-2.1.0-bin-hadoop2.7.
Step 2- ตอนนี้แตกไฟล์ Spark tar ที่ดาวน์โหลดมา โดยค่าเริ่มต้นจะดาวน์โหลดในไดเรกทอรีดาวน์โหลด
# tar -xvf Downloads/spark-2.1.0-bin-hadoop2.7.tgzมันจะสร้างไดเร็กทอรี spark-2.1.0-bin-hadoop2.7. ก่อนเริ่ม PySpark คุณต้องตั้งค่าสภาพแวดล้อมต่อไปนี้เพื่อตั้งค่าพา ธ Spark และไฟล์Py4j path.
export SPARK_HOME = /home/hadoop/spark-2.1.0-bin-hadoop2.7
export PATH = $PATH:/home/hadoop/spark-2.1.0-bin-hadoop2.7/bin
export PYTHONPATH = $SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH
export PATH = $SPARK_HOME/python:$PATHหรือหากต้องการตั้งค่าสภาพแวดล้อมข้างต้นทั่วโลกให้ใส่ไว้ในไฟล์ .bashrc file. จากนั้นรันคำสั่งต่อไปนี้เพื่อให้สภาพแวดล้อมทำงาน
# source .bashrcตอนนี้เราได้ตั้งค่าสภาพแวดล้อมทั้งหมดแล้วให้เราไปที่ไดเร็กทอรี Spark และเรียกใช้ PySpark shell โดยรันคำสั่งต่อไปนี้ -
# ./bin/pysparkสิ่งนี้จะเริ่มเชลล์ PySpark ของคุณ
Python 2.7.12 (default, Nov 19 2016, 06:48:10)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.1.0
/_/
Using Python version 2.7.12 (default, Nov 19 2016 06:48:10)
SparkSession available as 'spark'.
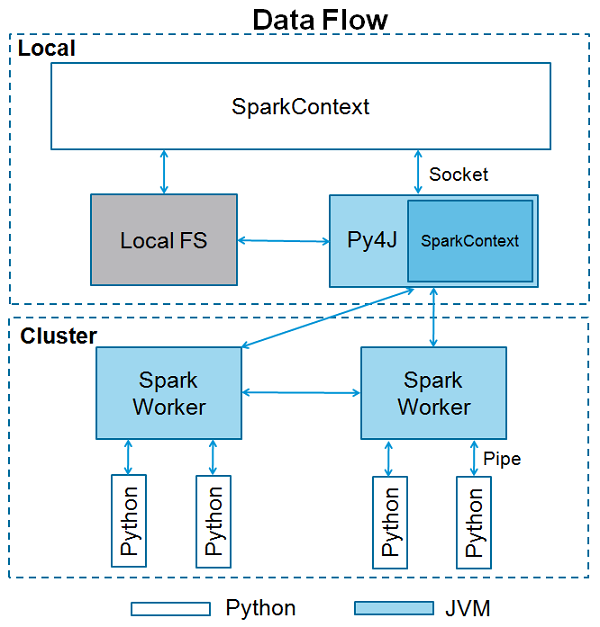
<<<SparkContext เป็นจุดเริ่มต้นของฟังก์ชันจุดประกายใด ๆ เมื่อเราเรียกใช้แอปพลิเคชัน Spark ใด ๆ โปรแกรมควบคุมจะเริ่มทำงานซึ่งมีฟังก์ชันหลักและ SparkContext ของคุณจะเริ่มต้นที่นี่ จากนั้นโปรแกรมไดรเวอร์จะรันการดำเนินการภายในตัวดำเนินการบนโหนดของผู้ปฏิบัติงาน
SparkContext ใช้ Py4J เพื่อเปิดไฟล์ JVM และสร้างไฟล์ JavaSparkContext. โดยค่าเริ่มต้น PySpark มี SparkContext พร้อมใช้งานในรูปแบบ‘sc’ดังนั้นการสร้าง SparkContext ใหม่จะไม่ทำงาน
บล็อกโค้ดต่อไปนี้มีรายละเอียดของคลาส PySpark และพารามิเตอร์ซึ่ง SparkContext สามารถรับได้
class pyspark.SparkContext (
master = None,
appName = None,
sparkHome = None,
pyFiles = None,
environment = None,
batchSize = 0,
serializer = PickleSerializer(),
conf = None,
gateway = None,
jsc = None,
profiler_cls = <class 'pyspark.profiler.BasicProfiler'>
)พารามิเตอร์
ต่อไปนี้เป็นพารามิเตอร์ของ SparkContext
Master - เป็น URL ของคลัสเตอร์ที่เชื่อมต่อ
appName - ชื่องานของคุณ
sparkHome - ไดเร็กทอรีการติดตั้ง Spark
pyFiles - ไฟล์. zip หรือ. py เพื่อส่งไปยังคลัสเตอร์และเพิ่มลงใน PYTHONPATH
Environment - ตัวแปรสภาพแวดล้อมโหนดของผู้ปฏิบัติงาน
batchSize- จำนวนวัตถุ Python ที่แสดงเป็นวัตถุ Java เดียว ตั้งค่า 1 เพื่อปิดใช้งานแบทช์ 0 เพื่อเลือกขนาดแบทช์โดยอัตโนมัติตามขนาดอ็อบเจ็กต์หรือ -1 เพื่อใช้ขนาดแบตช์ที่ไม่ จำกัด
Serializer - เครื่องอนุกรม RDD
Conf - วัตถุของ L {SparkConf} เพื่อตั้งค่าคุณสมบัติ Spark ทั้งหมด
Gateway - ใช้เกตเวย์และ JVM ที่มีอยู่มิฉะนั้นจะเริ่มต้น JVM ใหม่
JSC - อินสแตนซ์ JavaSparkContext
profiler_cls - คลาสของ Profiler แบบกำหนดเองที่ใช้ในการทำโปรไฟล์ (ค่าเริ่มต้นคือ pyspark.profiler.BasicProfiler)
ท่ามกลางพารามิเตอร์ข้างต้น master และ appnameส่วนใหญ่จะใช้ สองบรรทัดแรกของโปรแกรม PySpark มีลักษณะดังที่แสดงด้านล่าง -
from pyspark import SparkContext
sc = SparkContext("local", "First App")ตัวอย่าง SparkContext - PySpark Shell
ตอนนี้คุณรู้เพียงพอเกี่ยวกับ SparkContext แล้วให้เรารันตัวอย่างง่ายๆบน PySpark shell ในตัวอย่างนี้เราจะนับจำนวนบรรทัดที่มีอักขระ "a" หรือ "b" ในไฟล์README.mdไฟล์. ดังนั้นให้เราบอกว่าถ้าไฟล์มี 5 บรรทัดและ 3 บรรทัดมีอักขระ 'a' ผลลัพธ์จะเป็น→Line with a: 3. จะทำเช่นเดียวกันสำหรับอักขระ 'b'
Note- เราไม่ได้สร้างออบเจ็กต์ SparkContext ในตัวอย่างต่อไปนี้เนื่องจากโดยค่าเริ่มต้น Spark จะสร้างออบเจ็กต์ SparkContext ชื่อ sc โดยอัตโนมัติเมื่อ PySpark เชลล์เริ่มทำงาน ในกรณีที่คุณพยายามสร้างวัตถุ SparkContext อื่นคุณจะได้รับข้อผิดพลาดต่อไปนี้ -"ValueError: Cannot run multiple SparkContexts at once".

<<< logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
<<< logData = sc.textFile(logFile).cache()
<<< numAs = logData.filter(lambda s: 'a' in s).count()
<<< numBs = logData.filter(lambda s: 'b' in s).count()
<<< print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
Lines with a: 62, lines with b: 30ตัวอย่าง SparkContext - โปรแกรม Python
ให้เราเรียกใช้ตัวอย่างเดียวกันโดยใช้โปรแกรม Python สร้างไฟล์ Python ที่เรียกว่าfirstapp.py และป้อนรหัสต่อไปนี้ในไฟล์นั้น
----------------------------------------firstapp.py---------------------------------------
from pyspark import SparkContext
logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
sc = SparkContext("local", "first app")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
----------------------------------------firstapp.py---------------------------------------จากนั้นเราจะดำเนินการคำสั่งต่อไปนี้ในเทอร์มินัลเพื่อเรียกใช้ไฟล์ Python นี้ เราจะได้ผลลัพธ์เดียวกันกับด้านบน
$SPARK_HOME/bin/spark-submit firstapp.py
Output: Lines with a: 62, lines with b: 30ตอนนี้เราได้ติดตั้งและกำหนดค่า PySpark บนระบบของเราแล้วเราสามารถตั้งโปรแกรมใน Python บน Apache Spark ได้ อย่างไรก็ตามก่อนที่จะทำเช่นนั้นให้เราเข้าใจแนวคิดพื้นฐานใน Spark - RDD
RDD ย่อมาจาก Resilient Distributed Datasetนี่คือองค์ประกอบที่รันและดำเนินการบนหลายโหนดเพื่อทำการประมวลผลแบบขนานบนคลัสเตอร์ RDD เป็นองค์ประกอบที่ไม่เปลี่ยนรูปซึ่งหมายความว่าเมื่อคุณสร้าง RDD แล้วคุณจะไม่สามารถเปลี่ยนแปลงได้ RDD สามารถทนต่อความผิดพลาดได้เช่นกันดังนั้นในกรณีที่เกิดความล้มเหลวใด ๆ พวกเขาจะกู้คืนโดยอัตโนมัติ คุณสามารถใช้การดำเนินการหลายอย่างกับ RDD เหล่านี้เพื่อให้บรรลุภารกิจบางอย่าง
ในการใช้การดำเนินการกับ RDD เหล่านี้มีสองวิธี -
- การเปลี่ยนแปลงและ
- Action
ให้เราเข้าใจสองวิธีนี้โดยละเอียด
Transformation- นี่คือการดำเนินการซึ่งใช้กับ RDD เพื่อสร้าง RDD ใหม่ ตัวกรอง groupBy และแผนที่เป็นตัวอย่างของการเปลี่ยนแปลง
Action - นี่คือการดำเนินการที่ใช้กับ RDD ซึ่งสั่งให้ Spark ทำการคำนวณและส่งผลลัพธ์กลับไปยังไดรเวอร์
ในการใช้การดำเนินการใด ๆ ใน PySpark เราจำเป็นต้องสร้างไฟล์ PySpark RDDอันดับแรก. บล็อกโค้ดต่อไปนี้มีรายละเอียดของคลาส PySpark RDD -
class pyspark.RDD (
jrdd,
ctx,
jrdd_deserializer = AutoBatchedSerializer(PickleSerializer())
)ให้เราดูวิธีเรียกใช้การดำเนินการพื้นฐานบางอย่างโดยใช้ PySpark รหัสต่อไปนี้ในไฟล์ Python จะสร้างคำ RDD ซึ่งเก็บชุดคำที่กล่าวถึง
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)ตอนนี้เราจะดำเนินการสองสามคำ
นับ()
จำนวนองค์ประกอบใน RDD จะถูกส่งกลับ
----------------------------------------count.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "count app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
counts = words.count()
print "Number of elements in RDD -> %i" % (counts)
----------------------------------------count.py---------------------------------------Command - คำสั่งสำหรับ count () คือ -
$SPARK_HOME/bin/spark-submit count.pyOutput - ผลลัพธ์สำหรับคำสั่งดังกล่าวคือ -
Number of elements in RDD → 8เก็บ()
องค์ประกอบทั้งหมดใน RDD จะถูกส่งกลับ
----------------------------------------collect.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Collect app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
coll = words.collect()
print "Elements in RDD -> %s" % (coll)
----------------------------------------collect.py---------------------------------------Command - คำสั่งสำหรับการรวบรวม () คือ -
$SPARK_HOME/bin/spark-submit collect.pyOutput - ผลลัพธ์สำหรับคำสั่งดังกล่าวคือ -
Elements in RDD -> [
'scala',
'java',
'hadoop',
'spark',
'akka',
'spark vs hadoop',
'pyspark',
'pyspark and spark'
]foreach (ฉ)
ส่งคืนเฉพาะองค์ประกอบที่ตรงตามเงื่อนไขของฟังก์ชันภายใน foreach ในตัวอย่างต่อไปนี้เราเรียกฟังก์ชันการพิมพ์ใน foreach ซึ่งจะพิมพ์องค์ประกอบทั้งหมดใน RDD
----------------------------------------foreach.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "ForEach app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
def f(x): print(x)
fore = words.foreach(f)
----------------------------------------foreach.py---------------------------------------Command - คำสั่งสำหรับ foreach (f) คือ -
$SPARK_HOME/bin/spark-submit foreach.pyOutput - ผลลัพธ์สำหรับคำสั่งดังกล่าวคือ -
scala
java
hadoop
spark
akka
spark vs hadoop
pyspark
pyspark and sparkตัวกรอง (f)
RDD ใหม่จะถูกส่งคืนซึ่งมีองค์ประกอบซึ่งตรงตามฟังก์ชันภายในตัวกรอง ในตัวอย่างต่อไปนี้เรากรองสตริงที่มี "" spark "ออก
----------------------------------------filter.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Filter app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words_filter = words.filter(lambda x: 'spark' in x)
filtered = words_filter.collect()
print "Fitered RDD -> %s" % (filtered)
----------------------------------------filter.py----------------------------------------Command - คำสั่งสำหรับตัวกรอง (f) คือ -
$SPARK_HOME/bin/spark-submit filter.pyOutput - ผลลัพธ์สำหรับคำสั่งดังกล่าวคือ -
Fitered RDD -> [
'spark',
'spark vs hadoop',
'pyspark',
'pyspark and spark'
]แผนที่ (f, preservesPartitioning = False)
RDD ใหม่จะถูกส่งคืนโดยใช้ฟังก์ชันกับแต่ละองค์ประกอบใน RDD ในตัวอย่างต่อไปนี้เราสร้างคู่ค่าคีย์และแมปทุกสตริงด้วยค่า 1
----------------------------------------map.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Map app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words_map = words.map(lambda x: (x, 1))
mapping = words_map.collect()
print "Key value pair -> %s" % (mapping)
----------------------------------------map.py---------------------------------------Command - คำสั่งสำหรับแผนที่ (f, preservesPartitioning = False) คือ -
$SPARK_HOME/bin/spark-submit map.pyOutput - ผลลัพธ์ของคำสั่งดังกล่าวคือ -
Key value pair -> [
('scala', 1),
('java', 1),
('hadoop', 1),
('spark', 1),
('akka', 1),
('spark vs hadoop', 1),
('pyspark', 1),
('pyspark and spark', 1)
]ลด (f)
หลังจากดำเนินการดำเนินการไบนารีการสับเปลี่ยนและเชื่อมโยงที่ระบุองค์ประกอบใน RDD จะถูกส่งกลับ ในตัวอย่างต่อไปนี้เรากำลังนำเข้าแพ็กเกจเพิ่มจากตัวดำเนินการและใช้กับ 'num' เพื่อดำเนินการเพิ่มอย่างง่าย
----------------------------------------reduce.py---------------------------------------
from pyspark import SparkContext
from operator import add
sc = SparkContext("local", "Reduce app")
nums = sc.parallelize([1, 2, 3, 4, 5])
adding = nums.reduce(add)
print "Adding all the elements -> %i" % (adding)
----------------------------------------reduce.py---------------------------------------Command - คำสั่งสำหรับลด (f) คือ -
$SPARK_HOME/bin/spark-submit reduce.pyOutput - ผลลัพธ์ของคำสั่งดังกล่าวคือ -
Adding all the elements -> 15เข้าร่วม (อื่น ๆ numPartitions = ไม่มี)
ส่งคืน RDD พร้อมกับคู่ขององค์ประกอบที่มีคีย์ที่ตรงกันและค่าทั้งหมดสำหรับคีย์นั้น ๆ ในตัวอย่างต่อไปนี้มีสองคู่ขององค์ประกอบในสอง RDD ที่แตกต่างกัน หลังจากเข้าร่วม RDD ทั้งสองนี้เราได้รับ RDD ที่มีองค์ประกอบที่มีคีย์และค่าที่ตรงกัน
----------------------------------------join.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Join app")
x = sc.parallelize([("spark", 1), ("hadoop", 4)])
y = sc.parallelize([("spark", 2), ("hadoop", 5)])
joined = x.join(y)
final = joined.collect()
print "Join RDD -> %s" % (final)
----------------------------------------join.py---------------------------------------Command - คำสั่งสำหรับการเข้าร่วม (อื่น ๆ , numPartitions = ไม่มี) คือ -
$SPARK_HOME/bin/spark-submit join.pyOutput - ผลลัพธ์สำหรับคำสั่งดังกล่าวคือ -
Join RDD -> [
('spark', (1, 2)),
('hadoop', (4, 5))
]แคช ()
คง RDD นี้ด้วยระดับการจัดเก็บเริ่มต้น (MEMORY_ONLY) คุณยังสามารถตรวจสอบว่า RDD ถูกแคชไว้หรือไม่
----------------------------------------cache.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Cache app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words.cache()
caching = words.persist().is_cached
print "Words got chached > %s" % (caching)
----------------------------------------cache.py---------------------------------------Command - คำสั่งสำหรับ cache () คือ -
$SPARK_HOME/bin/spark-submit cache.pyOutput - ผลลัพธ์ของโปรแกรมข้างต้นคือ -
Words got cached -> Trueนี่คือการดำเนินการที่สำคัญที่สุดบางส่วนที่ทำบน PySpark RDD
สำหรับการประมวลผลแบบขนาน Apache Spark ใช้ตัวแปรที่ใช้ร่วมกัน สำเนาของตัวแปรที่ใช้ร่วมกันจะไปที่แต่ละโหนดของคลัสเตอร์เมื่อไดรเวอร์ส่งงานไปยังตัวดำเนินการบนคลัสเตอร์เพื่อให้สามารถใช้ในการปฏิบัติงานได้
มีตัวแปรที่ใช้ร่วมกันสองประเภทที่รองรับโดย Apache Spark -
- Broadcast
- Accumulator
ให้เราเข้าใจโดยละเอียด
ออกอากาศ
ตัวแปรบรอดคาสต์ถูกใช้เพื่อบันทึกสำเนาของข้อมูลในทุกโหนด ตัวแปรนี้ถูกแคชบนเครื่องทั้งหมดและไม่ถูกส่งไปยังเครื่องที่มีงาน บล็อกโค้ดต่อไปนี้มีรายละเอียดของคลาส Broadcast สำหรับ PySpark
class pyspark.Broadcast (
sc = None,
value = None,
pickle_registry = None,
path = None
)ตัวอย่างต่อไปนี้แสดงวิธีการใช้ตัวแปร Broadcast ตัวแปร Broadcast มีแอตทริบิวต์ที่เรียกว่า value ซึ่งเก็บข้อมูลและใช้เพื่อส่งคืนค่าที่ออกอากาศ
----------------------------------------broadcast.py--------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Broadcast app")
words_new = sc.broadcast(["scala", "java", "hadoop", "spark", "akka"])
data = words_new.value
print "Stored data -> %s" % (data)
elem = words_new.value[2]
print "Printing a particular element in RDD -> %s" % (elem)
----------------------------------------broadcast.py--------------------------------------Command - คำสั่งสำหรับตัวแปรออกอากาศมีดังนี้ -
$SPARK_HOME/bin/spark-submit broadcast.pyOutput - ผลลัพธ์สำหรับคำสั่งต่อไปนี้ได้รับด้านล่าง
Stored data -> [
'scala',
'java',
'hadoop',
'spark',
'akka'
]
Printing a particular element in RDD -> hadoopตัวสะสม
ตัวแปร Accumulator ใช้สำหรับการรวบรวมข้อมูลผ่านการดำเนินการเชื่อมโยงและการสับเปลี่ยน ตัวอย่างเช่นคุณสามารถใช้ตัวสะสมสำหรับการดำเนินการรวมหรือตัวนับ (ใน MapReduce) บล็อกโค้ดต่อไปนี้มีรายละเอียดของคลาส Accumulator สำหรับ PySpark
class pyspark.Accumulator(aid, value, accum_param)ตัวอย่างต่อไปนี้แสดงวิธีการใช้ตัวแปร Accumulator ตัวแปร Accumulator มีแอตทริบิวต์ที่เรียกว่าค่าที่คล้ายกับตัวแปรที่ออกอากาศ จัดเก็บข้อมูลและใช้เพื่อส่งคืนค่าของตัวสะสม แต่สามารถใช้ได้เฉพาะในโปรแกรมไดรเวอร์เท่านั้น
ในตัวอย่างนี้ผู้ปฏิบัติงานหลายคนใช้ตัวแปรตัวสะสมและส่งคืนค่าสะสม
----------------------------------------accumulator.py------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Accumulator app")
num = sc.accumulator(10)
def f(x):
global num
num+=x
rdd = sc.parallelize([20,30,40,50])
rdd.foreach(f)
final = num.value
print "Accumulated value is -> %i" % (final)
----------------------------------------accumulator.py------------------------------------Command - คำสั่งสำหรับตัวแปรตัวสะสมมีดังนี้ -
$SPARK_HOME/bin/spark-submit accumulator.pyOutput - ผลลัพธ์สำหรับคำสั่งดังกล่าวแสดงไว้ด้านล่าง
Accumulated value is -> 150ในการเรียกใช้แอปพลิเคชัน Spark บนโลคัล / คลัสเตอร์คุณต้องตั้งค่าการกำหนดค่าและพารามิเตอร์บางอย่างซึ่งเป็นสิ่งที่ SparkConf ช่วยได้ มีการกำหนดค่าเพื่อเรียกใช้แอปพลิเคชัน Spark บล็อกโค้ดต่อไปนี้มีรายละเอียดของคลาส SparkConf สำหรับ PySpark
class pyspark.SparkConf (
loadDefaults = True,
_jvm = None,
_jconf = None
)ในขั้นต้นเราจะสร้างวัตถุ SparkConf ด้วย SparkConf () ซึ่งจะโหลดค่าจาก spark.*คุณสมบัติของระบบ Java เช่นกัน ตอนนี้คุณสามารถตั้งค่าพารามิเตอร์ต่างๆโดยใช้ออบเจ็กต์ SparkConf และพารามิเตอร์จะมีลำดับความสำคัญเหนือคุณสมบัติของระบบ
ในคลาส SparkConf มีเมธอด setter ซึ่งรองรับการผูกมัด ตัวอย่างเช่นคุณสามารถเขียนconf.setAppName(“PySpark App”).setMaster(“local”). เมื่อเราส่งออบเจ็กต์ SparkConf ไปยัง Apache Spark แล้วผู้ใช้คนใดก็ไม่สามารถแก้ไขได้
ต่อไปนี้เป็นคุณลักษณะที่ใช้บ่อยที่สุดของ SparkConf -
set(key, value) - เพื่อตั้งค่าคุณสมบัติการกำหนดค่า
setMaster(value) - ในการตั้งค่า URL หลัก
setAppName(value) - ในการตั้งชื่อแอปพลิเคชัน
get(key, defaultValue=None) - เพื่อรับค่าการกำหนดค่าของคีย์
setSparkHome(value) - เพื่อกำหนดเส้นทางการติดตั้ง Spark บนโหนดของผู้ปฏิบัติงาน
ให้เราพิจารณาตัวอย่างต่อไปนี้ของการใช้ SparkConf ในโปรแกรม PySpark ในตัวอย่างนี้เรากำลังตั้งชื่อแอปพลิเคชัน spark เป็นPySpark App และตั้งค่า URL หลักสำหรับแอปพลิเคชัน spark เป็น→ spark://master:7077.
บล็อกโค้ดต่อไปนี้มีบรรทัดเมื่อเพิ่มเข้าไปในไฟล์ Python จะตั้งค่าการกำหนดค่าพื้นฐานสำหรับการรันแอ็พพลิเคชัน PySpark
---------------------------------------------------------------------------------------
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("PySpark App").setMaster("spark://master:7077")
sc = SparkContext(conf=conf)
---------------------------------------------------------------------------------------ใน Apache Spark คุณสามารถอัปโหลดไฟล์โดยใช้ไฟล์ sc.addFile (sc คือ SparkContext เริ่มต้นของคุณ) และรับเส้นทางบนผู้ปฏิบัติงานโดยใช้ไฟล์ SparkFiles.get. ดังนั้น SparkFiles จึงแก้ไขเส้นทางไปยังไฟล์ที่เพิ่มผ่านSparkContext.addFile().
SparkFiles มีวิธีการเรียนดังต่อไปนี้ -
- get(filename)
- getrootdirectory()
ให้เราเข้าใจโดยละเอียด
รับ (ชื่อไฟล์)
ระบุเส้นทางของไฟล์ที่เพิ่มผ่าน SparkContext.addFile ()
getrootdirectory ()
ระบุพา ธ ไปยังไดเร็กทอรี root ซึ่งมีไฟล์ที่เพิ่มผ่าน SparkContext.addFile ()
----------------------------------------sparkfile.py------------------------------------
from pyspark import SparkContext
from pyspark import SparkFiles
finddistance = "/home/hadoop/examples_pyspark/finddistance.R"
finddistancename = "finddistance.R"
sc = SparkContext("local", "SparkFile App")
sc.addFile(finddistance)
print "Absolute Path -> %s" % SparkFiles.get(finddistancename)
----------------------------------------sparkfile.py------------------------------------Command - คำสั่งมีดังนี้ -
$SPARK_HOME/bin/spark-submit sparkfiles.pyOutput - ผลลัพธ์สำหรับคำสั่งดังกล่าวคือ -
Absolute Path ->
/tmp/spark-f1170149-af01-4620-9805-f61c85fecee4/userFiles-641dfd0f-240b-4264-a650-4e06e7a57839/finddistance.RStorageLevel เป็นตัวกำหนดว่าควรจัดเก็บ RDD อย่างไร ใน Apache Spark StorageLevel จะตัดสินใจว่าควรเก็บ RDD ไว้ในหน่วยความจำหรือควรเก็บไว้ในดิสก์หรือทั้งสองอย่าง นอกจากนี้ยังตัดสินใจว่าจะทำให้ RDD เป็นอนุกรมหรือไม่และจะจำลองพาร์ติชัน RDD หรือไม่
บล็อกโค้ดต่อไปนี้มีนิยามคลาสของ StorageLevel -
class pyspark.StorageLevel(useDisk, useMemory, useOffHeap, deserialized, replication = 1)ตอนนี้ในการตัดสินใจจัดเก็บ RDD มีระดับการจัดเก็บที่แตกต่างกันซึ่งแสดงไว้ด้านล่าง -
DISK_ONLY = StorageLevel (จริงเท็จเท็จเท็จ 1)
DISK_ONLY_2 = StorageLevel (จริงเท็จเท็จเท็จ 2)
MEMORY_AND_DISK = StorageLevel (จริงจริงเท็จเท็จ 1)
MEMORY_AND_DISK_2 = StorageLevel (จริงจริงเท็จเท็จ 2)
MEMORY_AND_DISK_SER = StorageLevel (จริงจริงเท็จเท็จ 1)
MEMORY_AND_DISK_SER_2 = StorageLevel (จริงจริงเท็จเท็จ 2)
MEMORY_ONLY = StorageLevel (เท็จจริงเท็จเท็จ 1)
MEMORY_ONLY_2 = StorageLevel (เท็จจริงเท็จเท็จ 2)
MEMORY_ONLY_SER = StorageLevel (เท็จจริงเท็จเท็จ 1)
MEMORY_ONLY_SER_2 = StorageLevel (เท็จจริงเท็จเท็จ 2)
OFF_HEAP = StorageLevel (True, True, True, False, 1)
ให้เราพิจารณาตัวอย่างต่อไปนี้ของ StorageLevel ที่เราใช้ระดับการจัดเก็บ MEMORY_AND_DISK_2, ซึ่งหมายความว่าพาร์ติชัน RDD จะมีการจำลองแบบ 2
------------------------------------storagelevel.py-------------------------------------
from pyspark import SparkContext
import pyspark
sc = SparkContext (
"local",
"storagelevel app"
)
rdd1 = sc.parallelize([1,2])
rdd1.persist( pyspark.StorageLevel.MEMORY_AND_DISK_2 )
rdd1.getStorageLevel()
print(rdd1.getStorageLevel())
------------------------------------storagelevel.py-------------------------------------Command - คำสั่งมีดังนี้ -
$SPARK_HOME/bin/spark-submit storagelevel.pyOutput - ผลลัพธ์สำหรับคำสั่งดังกล่าวแสดงไว้ด้านล่าง -
Disk Memory Serialized 2x ReplicatedApache Spark นำเสนอ Machine Learning API ที่เรียกว่า MLlib. PySpark มี API การเรียนรู้ของเครื่องนี้ใน Python เช่นกัน สนับสนุนอัลกอริทึมประเภทต่างๆซึ่งมีการระบุไว้ด้านล่าง -
mllib.classification - spark.mllibแพคเกจสนับสนุนวิธีการต่างๆสำหรับการจำแนกไบนารีการจำแนกประเภทหลายชั้นและการวิเคราะห์การถดถอย อัลกอริทึมที่ได้รับความนิยมมากที่สุดในการจำแนกประเภท ได้แก่Random Forest, Naive Bayes, Decision Treeฯลฯ
mllib.clustering - การจัดกลุ่มเป็นปัญหาการเรียนรู้ที่ไม่ได้รับการดูแลโดยคุณตั้งเป้าหมายที่จะจัดกลุ่มส่วนย่อยของเอนทิตีเข้าด้วยกันตามแนวคิดเกี่ยวกับความคล้ายคลึงกัน
mllib.fpm- การจับคู่รูปแบบที่พบบ่อยคือการขุดไอเท็มชุดรายการลำดับต่อมาหรือโครงสร้างย่อยอื่น ๆ ที่มักจะเป็นขั้นตอนแรกในการวิเคราะห์ชุดข้อมูลขนาดใหญ่ นี่เป็นหัวข้อการวิจัยที่กระตือรือร้นในการขุดข้อมูลมาหลายปีแล้ว
mllib.linalg - ยูทิลิตี้ MLlib สำหรับพีชคณิตเชิงเส้น
mllib.recommendation- การกรองร่วมกันมักใช้สำหรับระบบผู้แนะนำ เทคนิคเหล่านี้มีจุดมุ่งหมายเพื่อเติมเต็มรายการที่ขาดหายไปของเมทริกซ์การเชื่อมโยงรายการผู้ใช้
spark.mllib- ปัจจุบันสนับสนุนการกรองการทำงานร่วมกันตามแบบจำลองซึ่งผู้ใช้และผลิตภัณฑ์ได้รับการอธิบายโดยปัจจัยแฝงเล็กน้อยที่สามารถใช้ในการคาดเดารายการที่ขาดหายไป spark.mllib ใช้อัลกอริทึม Alternating Least Squares (ALS) เพื่อเรียนรู้ปัจจัยแฝงเหล่านี้
mllib.regression- การถดถอยเชิงเส้นเป็นของตระกูลของอัลกอริทึมการถดถอย เป้าหมายของการถดถอยคือการค้นหาความสัมพันธ์และการพึ่งพาระหว่างตัวแปร อินเทอร์เฟซสำหรับการทำงานกับแบบจำลองการถดถอยเชิงเส้นและการสรุปแบบจำลองจะคล้ายกับกรณีการถดถอยโลจิสติก
มีอัลกอริทึมคลาสและฟังก์ชันอื่น ๆ ที่เป็นส่วนหนึ่งของแพ็คเกจ mllib ด้วย ณ ตอนนี้ให้เราเข้าใจการสาธิตบนpyspark.mllib.
ตัวอย่างต่อไปนี้เป็นการกรองร่วมกันโดยใช้อัลกอริทึม ALS เพื่อสร้างแบบจำลองคำแนะนำและประเมินข้อมูลการฝึกอบรม
Dataset used - test.data
1,1,5.0
1,2,1.0
1,3,5.0
1,4,1.0
2,1,5.0
2,2,1.0
2,3,5.0
2,4,1.0
3,1,1.0
3,2,5.0
3,3,1.0
3,4,5.0
4,1,1.0
4,2,5.0
4,3,1.0
4,4,5.0--------------------------------------recommend.py----------------------------------------
from __future__ import print_function
from pyspark import SparkContext
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel, Rating
if __name__ == "__main__":
sc = SparkContext(appName="Pspark mllib Example")
data = sc.textFile("test.data")
ratings = data.map(lambda l: l.split(','))\
.map(lambda l: Rating(int(l[0]), int(l[1]), float(l[2])))
# Build the recommendation model using Alternating Least Squares
rank = 10
numIterations = 10
model = ALS.train(ratings, rank, numIterations)
# Evaluate the model on training data
testdata = ratings.map(lambda p: (p[0], p[1]))
predictions = model.predictAll(testdata).map(lambda r: ((r[0], r[1]), r[2]))
ratesAndPreds = ratings.map(lambda r: ((r[0], r[1]), r[2])).join(predictions)
MSE = ratesAndPreds.map(lambda r: (r[1][0] - r[1][1])**2).mean()
print("Mean Squared Error = " + str(MSE))
# Save and load model
model.save(sc, "target/tmp/myCollaborativeFilter")
sameModel = MatrixFactorizationModel.load(sc, "target/tmp/myCollaborativeFilter")
--------------------------------------recommend.py----------------------------------------Command - คำสั่งจะเป็นดังนี้ -
$SPARK_HOME/bin/spark-submit recommend.pyOutput - ผลลัพธ์ของคำสั่งดังกล่าวจะเป็น -
Mean Squared Error = 1.20536041839e-05Serialization ใช้สำหรับการปรับแต่งประสิทธิภาพบน Apache Spark ข้อมูลทั้งหมดที่ส่งผ่านเครือข่ายหรือเขียนลงดิสก์หรือคงอยู่ในหน่วยความจำควรเป็นแบบอนุกรม การทำให้เป็นอนุกรมมีบทบาทสำคัญในการดำเนินการที่มีค่าใช้จ่ายสูง
PySpark รองรับ Serializers ที่กำหนดเองสำหรับการปรับแต่งประสิทธิภาพ PySpark รองรับ Serializers สองตัวต่อไปนี้ -
MarshalSerializer
ทำให้วัตถุเป็นอนุกรมโดยใช้ Marshal Serializer ของ Python Serializer นี้เร็วกว่า PickleSerializer แต่รองรับประเภทข้อมูลน้อยกว่า
class pyspark.MarshalSerializerPickleSerializer
ทำให้วัตถุเป็นอนุกรมโดยใช้ Pickle Serializer ของ Python Serializer นี้รองรับออบเจ็กต์ Python เกือบทุกชนิด แต่อาจไม่เร็วเท่ากับ serializers เฉพาะทาง
class pyspark.PickleSerializerให้เราดูตัวอย่างใน PySpark serialization ที่นี่เราจัดลำดับข้อมูลโดยใช้ MarshalSerializer
--------------------------------------serializing.py-------------------------------------
from pyspark.context import SparkContext
from pyspark.serializers import MarshalSerializer
sc = SparkContext("local", "serialization app", serializer = MarshalSerializer())
print(sc.parallelize(list(range(1000))).map(lambda x: 2 * x).take(10))
sc.stop()
--------------------------------------serializing.py-------------------------------------Command - คำสั่งมีดังนี้ -
$SPARK_HOME/bin/spark-submit serializing.pyOutput - ผลลัพธ์ของคำสั่งดังกล่าวคือ -
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]