PySpark - SparkContext
SparkContext เป็นจุดเริ่มต้นของฟังก์ชันจุดประกายใด ๆ เมื่อเราเรียกใช้แอปพลิเคชัน Spark ใด ๆ โปรแกรมควบคุมจะเริ่มทำงานซึ่งมีฟังก์ชันหลักและ SparkContext ของคุณจะเริ่มต้นที่นี่ จากนั้นโปรแกรมไดรเวอร์จะรันการดำเนินการภายในตัวดำเนินการบนโหนดของผู้ปฏิบัติงาน
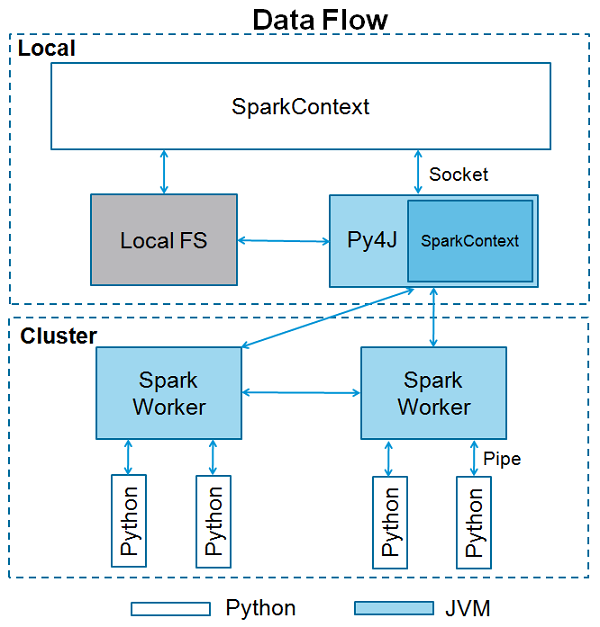
SparkContext ใช้ Py4J เพื่อเปิดไฟล์ JVM และสร้างไฟล์ JavaSparkContext. โดยค่าเริ่มต้น PySpark มี SparkContext พร้อมใช้งานในรูปแบบ‘sc’ดังนั้นการสร้าง SparkContext ใหม่จะไม่ทำงาน
บล็อกโค้ดต่อไปนี้มีรายละเอียดของคลาส PySpark และพารามิเตอร์ซึ่ง SparkContext สามารถรับได้
class pyspark.SparkContext (
master = None,
appName = None,
sparkHome = None,
pyFiles = None,
environment = None,
batchSize = 0,
serializer = PickleSerializer(),
conf = None,
gateway = None,
jsc = None,
profiler_cls = <class 'pyspark.profiler.BasicProfiler'>
)พารามิเตอร์
ต่อไปนี้เป็นพารามิเตอร์ของ SparkContext
Master - เป็น URL ของคลัสเตอร์ที่เชื่อมต่อ
appName - ชื่องานของคุณ
sparkHome - ไดเร็กทอรีการติดตั้ง Spark
pyFiles - ไฟล์. zip หรือ. py เพื่อส่งไปยังคลัสเตอร์และเพิ่มลงใน PYTHONPATH
Environment - ตัวแปรสภาพแวดล้อมโหนดของผู้ปฏิบัติงาน
batchSize- จำนวนวัตถุ Python ที่แสดงเป็นวัตถุ Java เดียว ตั้งค่า 1 เพื่อปิดใช้งานแบทช์ 0 เพื่อเลือกขนาดแบทช์โดยอัตโนมัติตามขนาดอ็อบเจ็กต์หรือ -1 เพื่อใช้ขนาดแบตช์ที่ไม่ จำกัด
Serializer - เครื่องอนุกรม RDD
Conf - วัตถุของ L {SparkConf} เพื่อตั้งค่าคุณสมบัติ Spark ทั้งหมด
Gateway - ใช้เกตเวย์และ JVM ที่มีอยู่มิฉะนั้นจะเริ่มต้น JVM ใหม่
JSC - อินสแตนซ์ JavaSparkContext
profiler_cls - คลาสของ Profiler แบบกำหนดเองที่ใช้ในการทำโปรไฟล์ (ค่าเริ่มต้นคือ pyspark.profiler.BasicProfiler)
ท่ามกลางพารามิเตอร์ข้างต้น master และ appnameส่วนใหญ่จะใช้ สองบรรทัดแรกของโปรแกรม PySpark มีลักษณะดังที่แสดงด้านล่าง -
from pyspark import SparkContext
sc = SparkContext("local", "First App")ตัวอย่าง SparkContext - PySpark Shell
ตอนนี้คุณรู้เพียงพอเกี่ยวกับ SparkContext แล้วให้เรารันตัวอย่างง่ายๆบน PySpark shell ในตัวอย่างนี้เราจะนับจำนวนบรรทัดที่มีอักขระ 'a' หรือ 'b' ในไฟล์README.mdไฟล์. ดังนั้นให้เราบอกว่าหากไฟล์มี 5 บรรทัดและ 3 บรรทัดมีอักขระ 'a' ผลลัพธ์จะเป็น→Line with a: 3. จะทำเช่นเดียวกันสำหรับอักขระ 'b'
Note- เราไม่ได้สร้างออบเจ็กต์ SparkContext ในตัวอย่างต่อไปนี้เนื่องจากโดยค่าเริ่มต้น Spark จะสร้างออบเจ็กต์ SparkContext ชื่อ sc โดยอัตโนมัติเมื่อ PySpark เชลล์เริ่ม ในกรณีที่คุณพยายามสร้างออบเจ็กต์ SparkContext อื่นคุณจะได้รับข้อผิดพลาดต่อไปนี้ -"ValueError: Cannot run multiple SparkContexts at once".

<<< logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
<<< logData = sc.textFile(logFile).cache()
<<< numAs = logData.filter(lambda s: 'a' in s).count()
<<< numBs = logData.filter(lambda s: 'b' in s).count()
<<< print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
Lines with a: 62, lines with b: 30ตัวอย่าง SparkContext - โปรแกรม Python
ให้เราเรียกใช้ตัวอย่างเดียวกันโดยใช้โปรแกรม Python สร้างไฟล์ Python ที่เรียกว่าfirstapp.py และป้อนรหัสต่อไปนี้ในไฟล์นั้น
----------------------------------------firstapp.py---------------------------------------
from pyspark import SparkContext
logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
sc = SparkContext("local", "first app")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
----------------------------------------firstapp.py---------------------------------------จากนั้นเราจะดำเนินการคำสั่งต่อไปนี้ในเทอร์มินัลเพื่อเรียกใช้ไฟล์ Python นี้ เราจะได้ผลลัพธ์เดียวกันกับด้านบน
$SPARK_HOME/bin/spark-submit firstapp.py
Output: Lines with a: 62, lines with b: 30