Spark SQL - บทนำ
Spark แนะนำโมดูลการเขียนโปรแกรมสำหรับการประมวลผลข้อมูลที่มีโครงสร้างที่เรียกว่า Spark SQL มีสิ่งที่เป็นนามธรรมการเขียนโปรแกรมที่เรียกว่า DataFrame และสามารถทำหน้าที่เป็นเอ็นจิ้นการสืบค้น SQL แบบกระจาย
คุณสมบัติของ Spark SQL
ต่อไปนี้เป็นคุณสมบัติของ Spark SQL -
Integrated- ผสมแบบสอบถาม SQL กับโปรแกรม Spark ได้อย่างราบรื่น Spark SQL ช่วยให้คุณสืบค้นข้อมูลที่มีโครงสร้างเป็นชุดข้อมูลแบบกระจาย (RDD) ใน Spark พร้อมด้วย API แบบรวมใน Python, Scala และ Java การผสานรวมที่แน่นหนานี้ทำให้ง่ายต่อการเรียกใช้การสืบค้น SQL ควบคู่ไปกับอัลกอริธึมการวิเคราะห์ที่ซับซ้อน
Unified Data Access- โหลดและสืบค้นข้อมูลจากแหล่งต่างๆ Schema-RDD มีอินเทอร์เฟซเดียวสำหรับการทำงานกับข้อมูลที่มีโครงสร้างอย่างมีประสิทธิภาพรวมถึงตาราง Apache Hive ไฟล์ปาร์เก้และไฟล์ JSON
Hive Compatibility- เรียกใช้การสืบค้น Hive ที่ไม่ได้แก้ไขในคลังสินค้าที่มีอยู่ Spark SQL นำส่วนหน้าของ Hive และ MetaStore มาใช้ใหม่ทำให้คุณสามารถใช้งานร่วมกับข้อมูล Hive แบบสอบถามและ UDF ที่มีอยู่ได้อย่างสมบูรณ์ เพียงติดตั้งควบคู่ไปกับ Hive
Standard Connectivity- เชื่อมต่อผ่าน JDBC หรือ ODBC Spark SQL มีโหมดเซิร์ฟเวอร์ที่มีการเชื่อมต่อ JDBC และ ODBC มาตรฐานอุตสาหกรรม
Scalability- ใช้เอ็นจิ้นเดียวกันสำหรับทั้งแบบสอบถามแบบโต้ตอบและแบบยาว Spark SQL ใช้ประโยชน์จากโมเดล RDD เพื่อรองรับความทนทานต่อข้อผิดพลาดกลางเคียวรีทำให้สามารถปรับขนาดเป็นงานขนาดใหญ่ได้เช่นกัน ไม่ต้องกังวลเกี่ยวกับการใช้เครื่องมืออื่นสำหรับข้อมูลในอดีต
สถาปัตยกรรม Spark SQL
ภาพประกอบต่อไปนี้อธิบายถึงสถาปัตยกรรมของ Spark SQL -
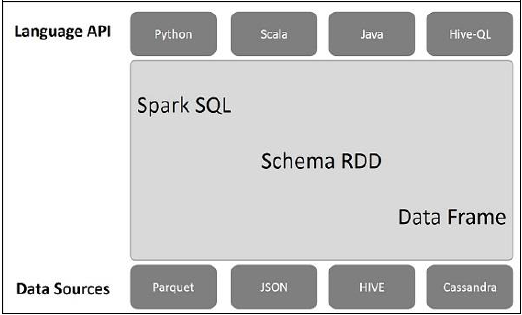
สถาปัตยกรรมนี้มีสามชั้น ได้แก่ Language API, Schema RDD และ Data Sources
Language API- Spark เข้ากันได้กับภาษาต่างๆและ Spark SQL นอกจากนี้ยังรองรับโดยภาษาเหล่านี้ - API (python, scala, java, HiveQL)
Schema RDD- Spark Core ได้รับการออกแบบด้วยโครงสร้างข้อมูลพิเศษที่เรียกว่า RDD โดยทั่วไป Spark SQL จะทำงานบนสกีมาตารางและระเบียน ดังนั้นเราสามารถใช้ Schema RDD เป็นตารางชั่วคราว เราสามารถเรียก Schema RDD นี้ว่า Data Frame
Data Sources- โดยปกติแหล่งข้อมูลสำหรับ spark-core คือไฟล์ข้อความไฟล์ Avro ฯลฯ อย่างไรก็ตามแหล่งข้อมูลสำหรับ Spark SQL นั้นแตกต่างกัน ไฟล์เหล่านี้คือไฟล์ Parquet เอกสาร JSON ตาราง HIVE และฐานข้อมูล Cassandra
เราจะพูดคุยเพิ่มเติมเกี่ยวกับสิ่งเหล่านี้ในบทต่อ ๆ ไป