Spark SQL - คู่มือฉบับย่อ
อุตสาหกรรมต่างๆใช้ Hadoop อย่างกว้างขวางเพื่อวิเคราะห์ชุดข้อมูลของตน เหตุผลก็คือ Hadoop framework เป็นไปตามรูปแบบการเขียนโปรแกรมอย่างง่าย (MapReduce) และช่วยให้สามารถแก้ปัญหาคอมพิวเตอร์ที่ปรับขนาดได้ยืดหยุ่นทนต่อข้อผิดพลาดและคุ้มค่า ที่นี่ข้อกังวลหลักคือการรักษาความเร็วในการประมวลผลชุดข้อมูลขนาดใหญ่ในแง่ของเวลารอระหว่างการสืบค้นและเวลารอเพื่อเรียกใช้โปรแกรม
Spark ได้รับการแนะนำโดย Apache Software Foundation เพื่อเร่งกระบวนการซอฟต์แวร์คอมพิวเตอร์คอมพิวเตอร์ Hadoop
ในทางตรงกันข้ามกับความเชื่อทั่วไป Spark is not a modified version of Hadoopและไม่ได้ขึ้นอยู่กับ Hadoop จริง ๆ เนื่องจากมีการจัดการคลัสเตอร์ของตัวเอง Hadoop เป็นเพียงวิธีหนึ่งในการนำ Spark ไปใช้
Spark ใช้ Hadoop ในสองวิธี - หนึ่งคือ storage และที่สองคือ processing. เนื่องจาก Spark มีการคำนวณการจัดการคลัสเตอร์ของตัวเองจึงใช้ Hadoop เพื่อการจัดเก็บเท่านั้น
Apache Spark
Apache Spark เป็นเทคโนโลยีการประมวลผลคลัสเตอร์ที่รวดเร็วปานสายฟ้าแลบออกแบบมาเพื่อการคำนวณที่รวดเร็ว มันขึ้นอยู่กับ Hadoop MapReduce และขยายโมเดล MapReduce เพื่อใช้อย่างมีประสิทธิภาพสำหรับการคำนวณประเภทอื่น ๆ ซึ่งรวมถึงการสืบค้นแบบโต้ตอบและการประมวลผลสตรีม คุณสมบัติหลักของ Spark คือin-memory cluster computing ที่เพิ่มความเร็วในการประมวลผลของแอปพลิเคชัน
Spark ได้รับการออกแบบมาเพื่อให้ครอบคลุมปริมาณงานที่หลากหลายเช่นแอปพลิเคชันแบตช์อัลกอริธึมซ้ำการสืบค้นแบบโต้ตอบและการสตรีม นอกเหนือจากการรองรับภาระงานทั้งหมดเหล่านี้ในระบบที่เกี่ยวข้องแล้วยังช่วยลดภาระการจัดการในการบำรุงรักษาเครื่องมือแยกต่างหาก
วิวัฒนาการของ Apache Spark
Spark เป็นหนึ่งในโครงการย่อยของ Hadoop ที่พัฒนาในปี 2009 ใน AMPLab ของ UC Berkeley โดย Matei Zaharia เป็น Open Sourced ในปี 2010 ภายใต้ใบอนุญาต BSD ได้รับการบริจาคให้กับมูลนิธิซอฟต์แวร์ Apache ในปี 2013 และตอนนี้ Apache Spark ได้กลายเป็นโครงการ Apache ระดับสูงสุดตั้งแต่เดือนกุมภาพันธ์ 2014
คุณสมบัติของ Apache Spark
Apache Spark มีคุณสมบัติดังต่อไปนี้
Speed- Spark ช่วยในการรันแอปพลิเคชันในคลัสเตอร์ Hadoop หน่วยความจำเร็วขึ้นสูงสุด 100 เท่าและเร็วขึ้น 10 เท่าเมื่อทำงานบนดิสก์ สามารถทำได้โดยการลดจำนวนการอ่าน / เขียนลงในดิสก์ เก็บข้อมูลการประมวลผลระดับกลางไว้ในหน่วยความจำ
Supports multiple languages- Spark มี API ในตัวใน Java, Scala หรือ Python ดังนั้นคุณสามารถเขียนแอปพลิเคชันในภาษาต่างๆ Spark มาพร้อมกับตัวดำเนินการระดับสูง 80 ตัวสำหรับการสืบค้นแบบโต้ตอบ
Advanced Analytics- Spark ไม่เพียง แต่รองรับ 'แผนที่' และ 'ลด' นอกจากนี้ยังรองรับการสืบค้น SQL ข้อมูลสตรีมมิ่งแมชชีนเลิร์นนิง (ML) และอัลกอริทึมกราฟ
Spark สร้างขึ้นบน Hadoop
แผนภาพต่อไปนี้แสดงสามวิธีในการสร้าง Spark ด้วยส่วนประกอบ Hadoop
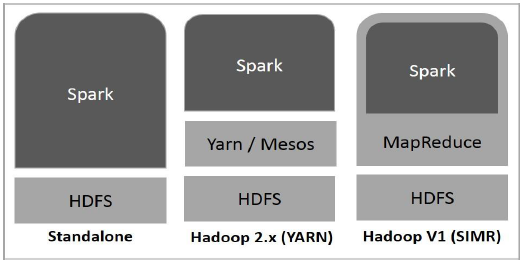
การปรับใช้ Spark มีสามวิธีดังที่อธิบายไว้ด้านล่าง
Standalone- การใช้งาน Spark แบบสแตนด์อโลนหมายความว่า Spark ครอบครองตำแหน่งที่อยู่ด้านบนของ HDFS (Hadoop Distributed File System) และมีการจัดสรรพื้นที่สำหรับ HDFS อย่างชัดเจน ที่นี่ Spark และ MapReduce จะทำงานเคียงข้างกันเพื่อครอบคลุมงานจุดประกายทั้งหมดในคลัสเตอร์
Hadoop Yarn- การปรับใช้ Hadoop Yarn หมายถึงเพียงแค่จุดประกายทำงานบน Yarn โดยไม่ต้องติดตั้งล่วงหน้าหรือเข้าถึงรูท ช่วยในการรวม Spark เข้ากับระบบนิเวศ Hadoop หรือ Hadoop stack ช่วยให้ส่วนประกอบอื่น ๆ ทำงานบนสแต็กได้
Spark in MapReduce (SIMR)- Spark ใน MapReduce ใช้เพื่อเปิดงานจุดประกายนอกเหนือจากการใช้งานแบบสแตนด์อโลน ด้วย SIMR ผู้ใช้สามารถเริ่ม Spark และใช้เชลล์ได้โดยไม่ต้องมีสิทธิ์เข้าถึงระดับผู้ดูแลระบบ
ส่วนประกอบของ Spark
ภาพประกอบต่อไปนี้แสดงให้เห็นถึงส่วนประกอบต่างๆของ Spark
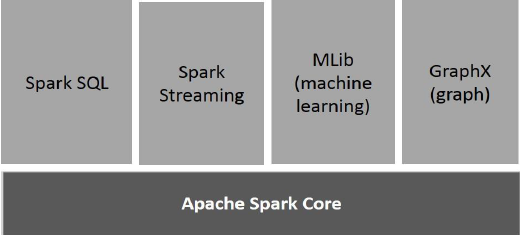
Apache Spark Core
Spark Core เป็นเครื่องมือประมวลผลทั่วไปที่เป็นพื้นฐานสำหรับแพลตฟอร์มจุดประกายที่มีการสร้างฟังก์ชันอื่น ๆ ทั้งหมด มีการประมวลผลในหน่วยความจำและการอ้างอิงชุดข้อมูลในระบบจัดเก็บข้อมูลภายนอก
Spark SQL
Spark SQL เป็นส่วนประกอบที่อยู่ด้านบนของ Spark Core ซึ่งนำเสนอข้อมูลนามธรรมใหม่ที่เรียกว่า SchemaRDD ซึ่งให้การสนับสนุนข้อมูลที่มีโครงสร้างและกึ่งโครงสร้าง
Spark Streaming
Spark Streaming ใช้ประโยชน์จากความสามารถในการตั้งเวลาที่รวดเร็วของ Spark Core เพื่อทำการวิเคราะห์สตรีมมิ่ง นำเข้าข้อมูลเป็นชุดย่อยและดำเนินการแปลง RDD (Resilient Distributed Datasets) บนชุดข้อมูลขนาดเล็กเหล่านั้น
MLlib (ไลบรารีการเรียนรู้ของเครื่อง)
MLlib เป็นเฟรมเวิร์กการเรียนรู้ของเครื่องที่กระจายอยู่เหนือ Spark เนื่องจากสถาปัตยกรรม Spark ที่ใช้หน่วยความจำแบบกระจาย เป็นไปตามเกณฑ์มาตรฐานที่ทำโดยนักพัฒนา MLlib กับการใช้งาน Alternating Least Squares (ALS) Spark MLlib เร็วกว่ารุ่นที่ใช้ดิสก์ Hadoop ถึงเก้าเท่าApache Mahout (ก่อนที่ Mahout จะได้รับอินเทอร์เฟซ Spark)
GraphX
GraphX เป็นเฟรมเวิร์กการประมวลผลกราฟแบบกระจายที่ด้านบนของ Spark มี API สำหรับการแสดงการคำนวณกราฟที่สามารถจำลองกราฟที่ผู้ใช้กำหนดโดยใช้ Pregel Abstraction API นอกจากนี้ยังมีรันไทม์ที่ปรับให้เหมาะสมสำหรับสิ่งที่เป็นนามธรรมนี้
ชุดข้อมูลแบบกระจายที่ยืดหยุ่น
Resilient Distributed Datasets (RDD) เป็นโครงสร้างข้อมูลพื้นฐานของ Spark มันเป็นคอลเลกชันของวัตถุที่กระจายไม่เปลี่ยนรูป ชุดข้อมูลแต่ละชุดใน RDD จะแบ่งออกเป็นโลจิคัลพาร์ติชันซึ่งอาจคำนวณจากโหนดต่าง ๆ ของคลัสเตอร์ RDD สามารถมีออบเจ็กต์ Python, Java หรือ Scala ประเภทใดก็ได้รวมถึงคลาสที่ผู้ใช้กำหนดเอง
ตามปกติแล้ว RDD คือคอลเล็กชันเรกคอร์ดแบบอ่านอย่างเดียวที่แบ่งพาร์ติชัน RDD สามารถสร้างขึ้นได้จากการดำเนินการที่กำหนดบนข้อมูลบนพื้นที่จัดเก็บที่เสถียรหรือ RDD อื่น ๆ RDD คือชุดขององค์ประกอบที่ทนต่อความผิดพลาดซึ่งสามารถทำงานแบบขนานได้
มีสองวิธีในการสร้าง RDD - parallelizing คอลเลกชันที่มีอยู่ในโปรแกรมไดรเวอร์ของคุณหรือ referencing a dataset ในระบบจัดเก็บข้อมูลภายนอกเช่นระบบไฟล์ที่ใช้ร่วมกัน HDFS HBase หรือแหล่งข้อมูลใด ๆ ที่เสนอรูปแบบอินพุต Hadoop
Spark ใช้แนวคิดของ RDD เพื่อให้การดำเนินการ MapReduce เร็วขึ้นและมีประสิทธิภาพ ก่อนอื่นให้เราคุยกันก่อนว่าการดำเนินการ MapReduce เกิดขึ้นได้อย่างไรและเหตุใดจึงไม่มีประสิทธิภาพ
การแบ่งปันข้อมูลทำได้ช้าใน MapReduce
MapReduce ถูกนำมาใช้อย่างกว้างขวางสำหรับการประมวลผลและสร้างชุดข้อมูลขนาดใหญ่ด้วยอัลกอริธึมแบบกระจายแบบขนานบนคลัสเตอร์ ช่วยให้ผู้ใช้สามารถเขียนการคำนวณแบบขนานโดยใช้ชุดตัวดำเนินการระดับสูงโดยไม่ต้องกังวลเกี่ยวกับการกระจายงานและการยอมรับข้อผิดพลาด
น่าเสียดายที่ในเฟรมเวิร์กปัจจุบันส่วนใหญ่วิธีเดียวที่จะใช้ข้อมูลซ้ำระหว่างการคำนวณ (เช่นระหว่างงาน MapReduce สองงาน) คือการเขียนลงในระบบจัดเก็บข้อมูลภายนอกที่มีเสถียรภาพ (เช่น HDFS) แม้ว่าเฟรมเวิร์กนี้จะจัดเตรียมสิ่งที่เป็นนามธรรมมากมายสำหรับการเข้าถึงทรัพยากรการคำนวณของคลัสเตอร์ แต่ผู้ใช้ก็ยังต้องการมากกว่านี้
ทั้งสอง Iterative และ Interactiveแอปพลิเคชันต้องการการแบ่งปันข้อมูลที่เร็วขึ้นระหว่างงานคู่ขนาน การแบ่งปันข้อมูลใน MapReduce ช้าเนื่องจากreplication, serializationและ disk IO. เกี่ยวกับระบบจัดเก็บข้อมูลแอพพลิเคชั่น Hadoop ส่วนใหญ่ใช้เวลามากกว่า 90% ในการดำเนินการอ่านเขียน HDFS
การดำเนินการซ้ำบน MapReduce
นำผลลัพธ์ระดับกลางมาใช้ซ้ำในการคำนวณหลายรายการในแอปพลิเคชันหลายขั้นตอน ภาพประกอบต่อไปนี้อธิบายวิธีการทำงานของเฟรมเวิร์กปัจจุบันในขณะที่ดำเนินการซ้ำบน MapReduce สิ่งนี้ก่อให้เกิดค่าใช้จ่ายจำนวนมากเนื่องจากการจำลองข้อมูลดิสก์ I / O และการทำให้เป็นอนุกรมซึ่งทำให้ระบบทำงานช้า
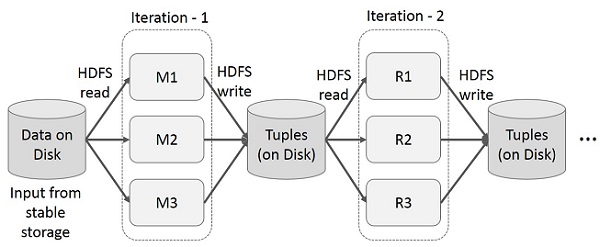
การทำงานแบบโต้ตอบบน MapReduce
ผู้ใช้เรียกใช้การสืบค้นแบบเฉพาะกิจในชุดข้อมูลย่อยเดียวกัน แบบสอบถามแต่ละรายการจะทำดิสก์ I / O บนที่เก็บข้อมูลที่เสถียรซึ่งสามารถครอบงำเวลาในการดำเนินการของแอปพลิเคชันได้
ภาพประกอบต่อไปนี้อธิบายวิธีการทำงานของเฟรมเวิร์กปัจจุบันในขณะที่ทำแบบสอบถามแบบโต้ตอบบน MapReduce
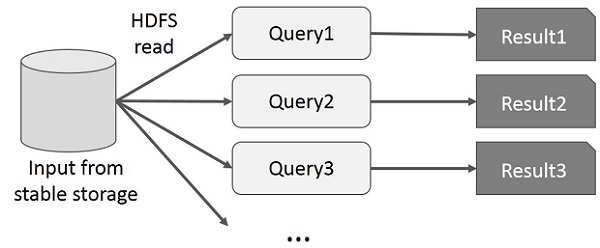
การแบ่งปันข้อมูลโดยใช้ Spark RDD
การแบ่งปันข้อมูลใน MapReduce ช้าเนื่องจาก replication, serializationและ disk IO. แอปพลิเคชัน Hadoop ส่วนใหญ่ใช้เวลามากกว่า 90% ในการดำเนินการอ่าน - เขียน HDFS
เมื่อตระหนักถึงปัญหานี้นักวิจัยได้พัฒนากรอบงานเฉพาะที่เรียกว่า Apache Spark แนวคิดสำคัญของการจุดประกายคือRฉลาด Dมีที่มา Datasets (RDD); รองรับการคำนวณการประมวลผลในหน่วยความจำ ซึ่งหมายความว่าจะจัดเก็บสถานะของหน่วยความจำเป็นวัตถุในงานและวัตถุสามารถแบ่งปันได้ระหว่างงานเหล่านั้น การแชร์ข้อมูลในหน่วยความจำเร็วกว่าเครือข่ายและดิสก์ 10 ถึง 100 เท่า
ตอนนี้ให้เราลองค้นหาว่าการดำเนินการซ้ำและโต้ตอบเกิดขึ้นใน Spark RDD อย่างไร
การดำเนินการซ้ำบน Spark RDD
ภาพประกอบด้านล่างแสดงการดำเนินการซ้ำบน Spark RDD มันจะเก็บผลลัพธ์ระดับกลางไว้ในหน่วยความจำแบบกระจายแทนที่จะเป็น Stable storage (Disk) และทำให้ระบบเร็วขึ้น
Note - หากหน่วยความจำแบบกระจาย (RAM) เพียงพอที่จะจัดเก็บผลลัพธ์ระดับกลาง (สถานะของงาน) ก็จะเก็บผลลัพธ์เหล่านั้นไว้ในดิสก์
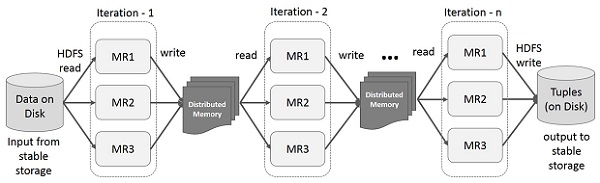
การทำงานแบบโต้ตอบบน Spark RDD
ภาพประกอบนี้แสดงการทำงานแบบโต้ตอบบน Spark RDD หากมีการเรียกใช้แบบสอบถามที่แตกต่างกันในชุดข้อมูลเดียวกันซ้ำ ๆ ข้อมูลเฉพาะนี้จะถูกเก็บไว้ในหน่วยความจำเพื่อให้มีเวลาดำเนินการที่ดีขึ้น

ตามค่าเริ่มต้น RDD ที่แปลงแล้วแต่ละรายการอาจได้รับการคำนวณใหม่ทุกครั้งที่คุณดำเนินการกับมัน อย่างไรก็ตามคุณอาจpersistRDD ในหน่วยความจำซึ่งในกรณีนี้ Spark จะเก็บองค์ประกอบต่างๆไว้ในคลัสเตอร์เพื่อให้เข้าถึงได้เร็วขึ้นในครั้งต่อไปที่คุณสอบถาม นอกจากนี้ยังมีการสนับสนุนสำหรับ RDD ที่มีอยู่บนดิสก์หรือจำลองแบบในหลายโหนด
Spark เป็นโครงการย่อยของ Hadoop ดังนั้นจึงควรติดตั้ง Spark ลงในระบบที่ใช้ Linux ขั้นตอนต่อไปนี้แสดงวิธีการติดตั้ง Apache Spark
ขั้นตอนที่ 1: การตรวจสอบการติดตั้ง Java
การติดตั้ง Java เป็นสิ่งที่จำเป็นอย่างหนึ่งในการติดตั้ง Spark ลองใช้คำสั่งต่อไปนี้เพื่อตรวจสอบเวอร์ชัน JAVA
$java -versionหากมีการติดตั้ง Java ไว้แล้วในระบบของคุณคุณจะเห็นคำตอบต่อไปนี้ -
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)ในกรณีที่คุณไม่ได้ติดตั้ง Java บนระบบของคุณให้ติดตั้ง Java ก่อนดำเนินการขั้นตอนถัดไป
ขั้นตอนที่ 2: การตรวจสอบการติดตั้ง Scala
คุณควรใช้ภาษาสกาล่าเพื่อใช้งาน Spark ดังนั้นให้เราตรวจสอบการติดตั้ง Scala โดยใช้คำสั่งต่อไปนี้
$scala -versionหากติดตั้ง Scala ในระบบของคุณแล้วคุณจะเห็นคำตอบต่อไปนี้ -
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLในกรณีที่คุณไม่ได้ติดตั้ง Scala ในระบบของคุณให้ทำตามขั้นตอนต่อไปสำหรับการติดตั้ง Scala
ขั้นตอนที่ 3: การดาวน์โหลด Scala
ดาวน์โหลดรุ่นล่าสุดของสกาล่าโดยการเยี่ยมชมลิงค์ต่อไปนี้ดาวน์โหลดสกาล่า สำหรับบทช่วยสอนนี้เรากำลังใช้เวอร์ชัน scala-2.11.6 หลังจากดาวน์โหลดคุณจะพบไฟล์ Scala tar ในโฟลเดอร์ดาวน์โหลด
ขั้นตอนที่ 4: การติดตั้ง Scala
ทำตามขั้นตอนด้านล่างสำหรับการติดตั้ง Scala
แตกไฟล์ Scala tar
พิมพ์คำสั่งต่อไปนี้สำหรับการแตกไฟล์ Scala tar
$ tar xvf scala-2.11.6.tgzย้ายไฟล์ซอฟต์แวร์ Scala
ใช้คำสั่งต่อไปนี้เพื่อย้ายไฟล์ซอฟต์แวร์ Scala ไปยังไดเร็กทอรีที่เกี่ยวข้อง (/usr/local/scala).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv scala-2.11.6 /usr/local/scala
# exitตั้งค่า PATH สำหรับ Scala
ใช้คำสั่งต่อไปนี้สำหรับการตั้งค่า PATH สำหรับ Scala
$ export PATH = $PATH:/usr/local/scala/binกำลังตรวจสอบการติดตั้ง Scala
หลังจากการติดตั้งจะเป็นการดีกว่าที่จะตรวจสอบ ใช้คำสั่งต่อไปนี้เพื่อตรวจสอบการติดตั้ง Scala
$scala -versionหากติดตั้ง Scala ในระบบของคุณแล้วคุณจะเห็นคำตอบต่อไปนี้ -
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLขั้นตอนที่ 5: ดาวน์โหลด Apache Spark
ดาวน์โหลดรุ่นล่าสุดของ Spark โดยไปที่การเชื่อมโยงต่อไปนี้ดาวน์โหลด Spark สำหรับบทช่วยสอนนี้เรากำลังใช้spark-1.3.1-bin-hadoop2.6รุ่น. หลังจากดาวน์โหลดแล้วคุณจะพบไฟล์ Spark tar ในโฟลเดอร์ดาวน์โหลด
ขั้นตอนที่ 6: การติดตั้ง Spark
ทำตามขั้นตอนด้านล่างเพื่อติดตั้ง Spark
สกัดน้ำมัน Spark
คำสั่งต่อไปนี้สำหรับการแตกไฟล์ spark tar
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgzการย้ายไฟล์ซอฟต์แวร์ Spark
คำสั่งต่อไปนี้สำหรับการย้ายไฟล์ซอฟต์แวร์ Spark ไปยังไดเร็กทอรีที่เกี่ยวข้อง (/usr/local/spark).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark
# exitการตั้งค่าสภาพแวดล้อมสำหรับ Spark
เพิ่มบรรทัดต่อไปนี้ใน ~/.bashrcไฟล์. หมายถึงการเพิ่มตำแหน่งที่ไฟล์ซอฟต์แวร์ spark อยู่ในตัวแปร PATH
export PATH = $PATH:/usr/local/spark/binใช้คำสั่งต่อไปนี้เพื่อจัดหาไฟล์ ~ / .bashrc
$ source ~/.bashrcขั้นตอนที่ 7: การตรวจสอบการติดตั้ง Spark
เขียนคำสั่งต่อไปนี้เพื่อเปิด Spark shell
$spark-shellหากติดตั้ง spark สำเร็จคุณจะพบผลลัพธ์ต่อไปนี้
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>Spark แนะนำโมดูลการเขียนโปรแกรมสำหรับการประมวลผลข้อมูลที่มีโครงสร้างที่เรียกว่า Spark SQL มีสิ่งที่เป็นนามธรรมการเขียนโปรแกรมที่เรียกว่า DataFrame และสามารถทำหน้าที่เป็นเอ็นจิ้นการสืบค้น SQL แบบกระจาย
คุณสมบัติของ Spark SQL
ต่อไปนี้เป็นคุณสมบัติของ Spark SQL -
Integrated- ผสมแบบสอบถาม SQL กับโปรแกรม Spark ได้อย่างราบรื่น Spark SQL ช่วยให้คุณสืบค้นข้อมูลที่มีโครงสร้างเป็นชุดข้อมูลแบบกระจาย (RDD) ใน Spark พร้อมด้วย API แบบรวมใน Python, Scala และ Java การรวมที่แน่นหนานี้ทำให้ง่ายต่อการเรียกใช้การสืบค้น SQL ควบคู่ไปกับอัลกอริทึมการวิเคราะห์ที่ซับซ้อน
Unified Data Access- โหลดและสืบค้นข้อมูลจากแหล่งต่างๆ Schema-RDD มีอินเทอร์เฟซเดียวสำหรับการทำงานกับข้อมูลที่มีโครงสร้างอย่างมีประสิทธิภาพรวมถึงตาราง Apache Hive ไฟล์ปาร์เก้และไฟล์ JSON
Hive Compatibility- เรียกใช้การสืบค้น Hive ที่ไม่ได้แก้ไขในคลังสินค้าที่มีอยู่ Spark SQL นำส่วนหน้าของ Hive และ MetaStore มาใช้ใหม่ทำให้คุณสามารถใช้งานร่วมกับข้อมูล Hive แบบสอบถามและ UDF ที่มีอยู่ได้ เพียงติดตั้งควบคู่ไปกับ Hive
Standard Connectivity- เชื่อมต่อผ่าน JDBC หรือ ODBC Spark SQL มีโหมดเซิร์ฟเวอร์ที่มีการเชื่อมต่อ JDBC และ ODBC มาตรฐานอุตสาหกรรม
Scalability- ใช้เอ็นจิ้นเดียวกันสำหรับทั้งแบบสอบถามแบบโต้ตอบและแบบยาว Spark SQL ใช้ประโยชน์จากโมเดล RDD เพื่อรองรับความทนทานต่อข้อผิดพลาดกลางเคียวรีทำให้สามารถปรับขนาดเป็นงานขนาดใหญ่ได้เช่นกัน ไม่ต้องกังวลเกี่ยวกับการใช้เครื่องมืออื่นสำหรับข้อมูลในอดีต
สถาปัตยกรรม Spark SQL
ภาพประกอบต่อไปนี้อธิบายถึงสถาปัตยกรรมของ Spark SQL -
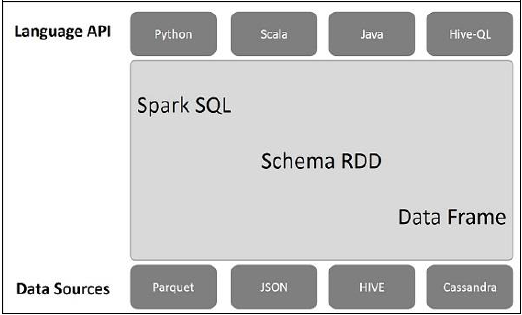
สถาปัตยกรรมนี้ประกอบด้วยสามชั้น ได้แก่ Language API, Schema RDD และ Data Sources
Language API- Spark เข้ากันได้กับภาษาต่างๆและ Spark SQL นอกจากนี้ยังรองรับโดยภาษาเหล่านี้ - API (python, scala, java, HiveQL)
Schema RDD- Spark Core ได้รับการออกแบบด้วยโครงสร้างข้อมูลพิเศษที่เรียกว่า RDD โดยทั่วไป Spark SQL จะทำงานบนสกีมาตารางและระเบียน ดังนั้นเราสามารถใช้ Schema RDD เป็นตารางชั่วคราว เราสามารถเรียก Schema RDD นี้ว่า Data Frame
Data Sources- โดยปกติแล้วแหล่งข้อมูลสำหรับ spark-core คือไฟล์ข้อความไฟล์ Avro เป็นต้นอย่างไรก็ตามแหล่งข้อมูลสำหรับ Spark SQL นั้นแตกต่างกัน ไฟล์เหล่านี้คือไฟล์ Parquet เอกสาร JSON ตาราง HIVE และฐานข้อมูล Cassandra
เราจะพูดคุยเพิ่มเติมเกี่ยวกับสิ่งเหล่านี้ในบทต่อ ๆ ไป
DataFrame คือชุดข้อมูลแบบกระจายซึ่งจัดเป็นคอลัมน์ที่มีชื่อ ตามแนวคิดแล้วมันเทียบเท่ากับตารางเชิงสัมพันธ์ที่มีเทคนิคการเพิ่มประสิทธิภาพที่ดี
DataFrame สามารถสร้างขึ้นจากอาร์เรย์ของแหล่งที่มาต่างๆเช่นตาราง Hive ไฟล์ข้อมูลที่มีโครงสร้างฐานข้อมูลภายนอกหรือ RDD ที่มีอยู่ API นี้ออกแบบมาสำหรับแอปพลิเคชัน Big Data และ Data Science ที่ทันสมัยโดยได้รับแรงบันดาลใจDataFrame in R Programming และ Pandas in Python.
คุณสมบัติของ DataFrame
นี่คือชุดคุณลักษณะเฉพาะบางประการของ DataFrame -
ความสามารถในการประมวลผลข้อมูลในขนาด Kilobytes ถึง Petabytes บนคลัสเตอร์โหนดเดียวไปจนถึงคลัสเตอร์ขนาดใหญ่
รองรับรูปแบบข้อมูลที่แตกต่างกัน (Avro, csv, การค้นหาแบบยืดหยุ่นและ Cassandra) และระบบจัดเก็บข้อมูล (HDFS, ตาราง HIVE, mysql ฯลฯ )
การเพิ่มประสิทธิภาพที่ทันสมัยและการสร้างโค้ดผ่านเครื่องมือเพิ่มประสิทธิภาพ Spark SQL Catalyst (กรอบการแปลงร่างต้นไม้)
สามารถรวมเข้ากับเครื่องมือและเฟรมเวิร์ก Big Data ทั้งหมดได้อย่างง่ายดายผ่าน Spark-Core
จัดเตรียม API สำหรับ Python, Java, Scala และ R Programming
SQLC บริบท
SQLContext เป็นคลาสและใช้สำหรับการเริ่มต้นฟังก์ชันการทำงานของ Spark SQL วัตถุคลาส SparkContext (sc) เป็นสิ่งจำเป็นสำหรับการเตรียมใช้งานวัตถุคลาส SQLContext
คำสั่งต่อไปนี้ใช้สำหรับการเตรียมใช้งาน SparkContext ผ่าน spark-shell
$ spark-shellตามค่าเริ่มต้นวัตถุ SparkContext จะเริ่มต้นด้วยชื่อ sc เมื่อประกายไฟเริ่มต้น
ใช้คำสั่งต่อไปนี้เพื่อสร้าง SQLContext
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)ตัวอย่าง
ให้เราพิจารณาตัวอย่างของบันทึกพนักงานในไฟล์ JSON ที่ชื่อ employee.json. ใช้คำสั่งต่อไปนี้เพื่อสร้าง DataFrame (df) และอ่านเอกสาร JSON ที่ชื่อemployee.json โดยมีเนื้อหาดังต่อไปนี้
employee.json - วางไฟล์นี้ในไดเร็กทอรีที่เป็นไฟล์ scala> ตัวชี้ตั้งอยู่
{
{"id" : "1201", "name" : "satish", "age" : "25"}
{"id" : "1202", "name" : "krishna", "age" : "28"}
{"id" : "1203", "name" : "amith", "age" : "39"}
{"id" : "1204", "name" : "javed", "age" : "23"}
{"id" : "1205", "name" : "prudvi", "age" : "23"}
}การดำเนินการ DataFrame
DataFrame จัดเตรียมภาษาเฉพาะโดเมนสำหรับการจัดการข้อมูลที่มีโครงสร้าง ในที่นี้เรารวมตัวอย่างพื้นฐานของการประมวลผลข้อมูลที่มีโครงสร้างโดยใช้ DataFrames
ทำตามขั้นตอนด้านล่างเพื่อดำเนินการกับ DataFrame -
อ่านเอกสาร JSON
ก่อนอื่นเราต้องอ่านเอกสาร JSON จากสิ่งนี้สร้าง DataFrame ชื่อ (dfs)
ใช้คำสั่งต่อไปนี้เพื่ออ่านเอกสาร JSON ที่ชื่อ employee.json. ข้อมูลจะแสดงเป็นตารางพร้อมด้วยฟิลด์ - id, name และ age
scala> val dfs = sqlContext.read.json("employee.json")Output - ชื่อฟิลด์จะถูกนำมาโดยอัตโนมัติ employee.json.
dfs: org.apache.spark.sql.DataFrame = [age: string, id: string, name: string]แสดงข้อมูล
หากคุณต้องการดูข้อมูลใน DataFrame ให้ใช้คำสั่งต่อไปนี้
scala> dfs.show()Output - คุณสามารถดูข้อมูลพนักงานในรูปแบบตาราง
<console>:22, took 0.052610 s
+----+------+--------+
|age | id | name |
+----+------+--------+
| 25 | 1201 | satish |
| 28 | 1202 | krishna|
| 39 | 1203 | amith |
| 23 | 1204 | javed |
| 23 | 1205 | prudvi |
+----+------+--------+ใช้วิธี printSchema
หากคุณต้องการดูโครงสร้าง (Schema) ของ DataFrame ให้ใช้คำสั่งต่อไปนี้
scala> dfs.printSchema()Output
root
|-- age: string (nullable = true)
|-- id: string (nullable = true)
|-- name: string (nullable = true)ใช้ Select Method
ใช้คำสั่งต่อไปนี้เพื่อดึงข้อมูล name- คอลัมน์ระหว่างสามคอลัมน์จาก DataFrame
scala> dfs.select("name").show()Output - คุณสามารถดูค่าของไฟล์ name คอลัมน์.
<console>:22, took 0.044023 s
+--------+
| name |
+--------+
| satish |
| krishna|
| amith |
| javed |
| prudvi |
+--------+ใช้ตัวกรองอายุ
ใช้คำสั่งต่อไปนี้เพื่อค้นหาพนักงานที่มีอายุมากกว่า 23 ปี (อายุ> 23 ปี)
scala> dfs.filter(dfs("age") > 23).show()Output
<console>:22, took 0.078670 s
+----+------+--------+
|age | id | name |
+----+------+--------+
| 25 | 1201 | satish |
| 28 | 1202 | krishna|
| 39 | 1203 | amith |
+----+------+--------+ใช้วิธี groupBy
ใช้คำสั่งต่อไปนี้สำหรับการนับจำนวนพนักงานที่มีอายุเท่ากัน
scala> dfs.groupBy("age").count().show()Output - พนักงานสองคนมีอายุ 23 ปี
<console>:22, took 5.196091 s
+----+-----+
|age |count|
+----+-----+
| 23 | 2 |
| 25 | 1 |
| 28 | 1 |
| 39 | 1 |
+----+-----+เรียกใช้ SQL Queries โดยทางโปรแกรม
SQLContext ช่วยให้แอปพลิเคชันสามารถเรียกใช้การสืบค้น SQL โดยทางโปรแกรมในขณะที่เรียกใช้ฟังก์ชัน SQL และส่งคืนผลลัพธ์เป็น DataFrame
โดยทั่วไปในเบื้องหลัง SparkSQL สนับสนุนสองวิธีที่แตกต่างกันสำหรับการแปลง RDD ที่มีอยู่เป็น DataFrames -
| ซีเนียร์ไม่มี | วิธีการและคำอธิบาย |
|---|---|
| 1 | การอ้างอิงสคีมาโดยใช้การสะท้อนกลับ วิธีนี้ใช้การสะท้อนเพื่อสร้างสคีมาของ RDD ที่มีวัตถุบางประเภท |
| 2 | การระบุสคีมาโดยทางโปรแกรม วิธีที่สองในการสร้าง DataFrame คือการใช้อินเทอร์เฟซแบบเป็นโปรแกรมที่ให้คุณสร้างสคีมาจากนั้นนำไปใช้กับ RDD ที่มีอยู่ |
อินเทอร์เฟซ DataFrame ช่วยให้แหล่งข้อมูลที่แตกต่างกันทำงานบน Spark SQL เป็นโต๊ะชั่วคราวและสามารถใช้งานได้ตามปกติ RDD การลงทะเบียน DataFrame เป็นตารางช่วยให้คุณสามารถเรียกใช้การสืบค้น SQL ผ่านข้อมูลได้
ในบทนี้เราจะอธิบายวิธีการทั่วไปในการโหลดและบันทึกข้อมูลโดยใช้ Spark DataSources ที่แตกต่างกัน หลังจากนั้นเราจะพูดถึงรายละเอียดเกี่ยวกับตัวเลือกเฉพาะที่พร้อมใช้งานสำหรับแหล่งข้อมูลในตัว
มีแหล่งข้อมูลหลายประเภทที่มีอยู่ใน SparkSQL ซึ่งบางแหล่งมีการระบุไว้ด้านล่าง -
| ซีเนียร์ไม่มี | แหล่งข้อมูล |
|---|---|
| 1 | ชุดข้อมูล JSON Spark SQL สามารถจับสคีมาของชุดข้อมูล JSON โดยอัตโนมัติและโหลดเป็น DataFrame |
| 2 | ตารางไฮฟ์ Hive มาพร้อมกับไลบรารี Spark เป็น HiveContext ซึ่งสืบทอดมาจาก SQLContext |
| 3 | ไฟล์ไม้ปาร์เก้ ไม้ปาร์เก้เป็นรูปแบบเสาซึ่งรองรับโดยระบบประมวลผลข้อมูลจำนวนมาก |