SQLAlchemy - คู่มือฉบับย่อ
SQLAlchemy เป็นชุดเครื่องมือ SQL ยอดนิยมและ Object Relational Mapper. มันเขียนในPythonและมอบพลังและความยืดหยุ่นอย่างเต็มที่ของ SQL แก่นักพัฒนาแอปพลิเคชัน มันคือopen source และ cross-platform software เผยแพร่ภายใต้ใบอนุญาต MIT
SQLAlchemy มีชื่อเสียงในด้าน object-relational mapper (ORM) โดยใช้คลาสที่สามารถแมปกับฐานข้อมูลได้จึงทำให้โมเดลอ็อบเจ็กต์และสคีมาฐานข้อมูลสามารถพัฒนาได้อย่างแยกส่วนตั้งแต่ต้น
เนื่องจากขนาดและประสิทธิภาพของฐานข้อมูล SQL เริ่มมีความสำคัญจึงมีพฤติกรรมไม่เหมือนกับการรวบรวมวัตถุ ในทางกลับกันเนื่องจากสิ่งที่เป็นนามธรรมในคอลเลกชันวัตถุเริ่มมีความสำคัญพวกมันจะทำงานเหมือนตารางและแถวน้อยลง SQLAlchemy มีเป้าหมายเพื่อรองรับหลักการทั้งสองนี้
ด้วยเหตุนี้จึงได้นำไฟล์ data mapper pattern (like Hibernate) rather than the active record pattern used by a number of other ORMs. ฐานข้อมูลและ SQL จะถูกมองในมุมมองที่แตกต่างกันโดยใช้ SQLAlchemy
Michael Bayer เป็นผู้เขียนต้นฉบับของ SQLAlchemy เวอร์ชันเริ่มต้นเปิดตัวในเดือนกุมภาพันธ์ 2549 เวอร์ชันล่าสุดมีหมายเลข 1.2.7 ซึ่งเปิดตัวเมื่อเร็ว ๆ นี้ในเดือนเมษายน 2018
ORM คืออะไร?
ORM (Object Relational Mapping) เป็นเทคนิคการเขียนโปรแกรมสำหรับการแปลงข้อมูลระหว่างระบบชนิดที่เข้ากันไม่ได้ในภาษาโปรแกรมเชิงวัตถุ โดยปกติระบบ type ที่ใช้ในภาษา Object Oriented (OO) เช่น Python จะมีประเภทที่ไม่ใช่สเกลาร์ สิ่งเหล่านี้ไม่สามารถแสดงเป็นประเภทดั้งเดิมเช่นจำนวนเต็มและสตริง ดังนั้นโปรแกรมเมอร์ OO จึงต้องแปลงวัตถุในข้อมูลสเกลาร์เพื่อโต้ตอบกับฐานข้อมูลแบ็กเอนด์ อย่างไรก็ตามชนิดข้อมูลในผลิตภัณฑ์ฐานข้อมูลส่วนใหญ่เช่น Oracle, MySQL เป็นต้นเป็นประเภทข้อมูลหลัก
ในระบบ ORM แต่ละคลาสจะแมปกับตารางในฐานข้อมูลพื้นฐาน แทนที่จะเขียนโค้ดเชื่อมต่อฐานข้อมูลที่น่าเบื่อด้วยตัวคุณเอง ORM จะดูแลปัญหาเหล่านี้ให้คุณในขณะที่คุณสามารถมุ่งเน้นไปที่การเขียนโปรแกรมลอจิกของระบบ
SQLAlchemy - การตั้งค่าสภาพแวดล้อม
ให้เราหารือเกี่ยวกับการตั้งค่าสภาพแวดล้อมที่จำเป็นในการใช้ SQLAlchemy
Python ทุกเวอร์ชันที่สูงกว่า 2.7 จำเป็นต้องติดตั้ง SQLAlchemy วิธีที่ง่ายที่สุดในการติดตั้งคือใช้ Python Package Managerpip. ยูทิลิตี้นี้มาพร้อมกับการแจกแจงมาตรฐานของ Python
pip install sqlalchemyโดยใช้คำสั่งด้านบนเราสามารถดาวน์โหลดไฟล์ latest released versionของ SQLAlchemy จากpython.orgและติดตั้งลงในระบบของคุณ
ในกรณีที่มีการแจกจ่าย Python ของอนาคอนดาสามารถติดตั้ง SQLAlchemy ได้จากไฟล์ conda terminal โดยใช้คำสั่งด้านล่าง -
conda install -c anaconda sqlalchemyนอกจากนี้ยังสามารถติดตั้ง SQLAlchemy จากซอร์สโค้ดด้านล่าง -
python setup.py installSQLAlchemy ได้รับการออกแบบมาเพื่อทำงานร่วมกับการใช้งาน DBAPI ที่สร้างขึ้นสำหรับฐานข้อมูลเฉพาะ ใช้ระบบภาษาถิ่นเพื่อสื่อสารกับการใช้งาน DBAPI และฐานข้อมูลประเภทต่างๆ ภาษาถิ่นทั้งหมดต้องการให้ติดตั้งไดรเวอร์ DBAPI ที่เหมาะสม
ต่อไปนี้เป็นภาษาถิ่นรวม -
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Sybase
หากต้องการตรวจสอบว่า SQLAlchemy ได้รับการติดตั้งอย่างถูกต้องและต้องการทราบเวอร์ชันหรือไม่ให้ป้อนคำสั่งต่อไปนี้ในพรอมต์ Python -
>>> import sqlalchemy
>>>sqlalchemy.__version__
'1.2.7'SQLAlchemy core ประกอบด้วย SQL rendering engine, DBAPI integration, transaction integrationและ schema description services. SQLAlchemy core ใช้ SQL Expression Language ที่มีไฟล์schema-centric usage กระบวนทัศน์ในขณะที่ SQLAlchemy ORM เป็นไฟล์ domain-centric mode of usage.
SQL Expression Language นำเสนอระบบการแสดงโครงสร้างฐานข้อมูลเชิงสัมพันธ์และนิพจน์โดยใช้โครงสร้าง Python นำเสนอระบบการแสดงโครงสร้างดั้งเดิมของฐานข้อมูลเชิงสัมพันธ์โดยตรงโดยไม่มีความคิดเห็นซึ่งตรงกันข้ามกับ ORM ที่นำเสนอรูปแบบการใช้งานระดับสูงและนามธรรมซึ่งตัวเองเป็นตัวอย่างของการใช้นิพจน์ภาษาประยุกต์
Expression Language เป็นหนึ่งในองค์ประกอบหลักของ SQLAlchemy ช่วยให้โปรแกรมเมอร์ระบุคำสั่ง SQL ในโค้ด Python และใช้โดยตรงในแบบสอบถามที่ซับซ้อนมากขึ้น ภาษานิพจน์ไม่ขึ้นอยู่กับแบ็กเอนด์และครอบคลุมทุกแง่มุมของ SQL ดิบ ใกล้เคียงกับ SQL ดิบมากกว่าส่วนประกอบอื่น ๆ ใน SQLAlchemy
Expression Language แสดงถึงโครงสร้างดั้งเดิมของฐานข้อมูลเชิงสัมพันธ์โดยตรง เนื่องจาก ORM ขึ้นอยู่กับด้านบนของภาษา Expression แอปพลิเคชันฐานข้อมูล Python ทั่วไปอาจใช้ทั้งสองอย่างทับซ้อนกัน แอปพลิเคชันอาจใช้ภาษานิพจน์เพียงอย่างเดียวแม้ว่าจะต้องกำหนดระบบของตัวเองในการแปลแนวคิดแอปพลิเคชันเป็นแบบสอบถามฐานข้อมูลแต่ละรายการ
คำสั่งของภาษานิพจน์จะถูกแปลเป็นแบบสอบถาม SQL ดิบที่เกี่ยวข้องโดยเอ็นจิ้น SQLAlchemy ตอนนี้เราจะเรียนรู้วิธีสร้างเอ็นจิ้นและดำเนินการสืบค้น SQL ต่างๆด้วยความช่วยเหลือ
ในบทที่แล้วเราได้พูดถึงนิพจน์ภาษาใน SQLAlchemy ตอนนี้ให้เราดำเนินการตามขั้นตอนที่เกี่ยวข้องกับการเชื่อมต่อกับฐานข้อมูล
คลาสเครื่องยนต์เชื่อมต่อ Pool and Dialect together เพื่อจัดหาแหล่งฐานข้อมูล connectivity and behavior. อ็อบเจ็กต์ของคลาส Engine ถูกสร้างอินสแตนซ์โดยใช้create_engine() ฟังก์ชัน
ฟังก์ชัน create_engine () ใช้ฐานข้อมูลเป็นอาร์กิวเมนต์เดียว ไม่จำเป็นต้องกำหนดฐานข้อมูลที่ใดก็ได้ แบบฟอร์มการเรียกมาตรฐานต้องส่ง URL เป็นอาร์กิวเมนต์ตำแหน่งแรกโดยปกติจะเป็นสตริงที่ระบุภาษาถิ่นของฐานข้อมูลและอาร์กิวเมนต์การเชื่อมต่อ โดยใช้รหัสที่ระบุด้านล่างเราสามารถสร้างฐานข้อมูลได้
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///college.db', echo = True)สำหรับ MySQL databaseใช้คำสั่งด้านล่าง -
engine = create_engine("mysql://user:pwd@localhost/college",echo = True)ที่จะกล่าวถึงโดยเฉพาะ DB-API เพื่อใช้สำหรับการเชื่อมต่อไฟล์ URL string มีรูปแบบดังนี้ -
dialect[+driver]://user:password@host/dbnameตัวอย่างเช่นหากคุณใช้ไฟล์ PyMySQL driver with MySQLใช้คำสั่งต่อไปนี้ -
mysql+pymysql://<username>:<password>@<host>/<dbname>echo flagเป็นทางลัดในการตั้งค่าการบันทึก SQLAlchemy ซึ่งทำได้ผ่านโมดูลการบันทึกมาตรฐานของ Python ในบทต่อ ๆ ไปเราจะเรียนรู้ SQL ที่สร้างขึ้นทั้งหมด หากต้องการซ่อนเอาต์พุต verbose ให้ตั้งค่าแอตทริบิวต์ echo เป็นNone. อาร์กิวเมนต์อื่น ๆ ของฟังก์ชัน create_engine () อาจเป็นภาษาถิ่นเฉพาะ
ฟังก์ชัน create_engine () จะส่งกลับไฟล์ Engine object. วิธีการที่สำคัญบางประการของคลาส Engine ได้แก่ -
| ซีเนียร์ | วิธีการและคำอธิบาย |
|---|---|
| 1 | connect() ส่งคืนวัตถุการเชื่อมต่อ |
| 2 | execute() ดำเนินการสร้างคำสั่ง SQL |
| 3 | begin() ส่งกลับตัวจัดการบริบทที่ส่งการเชื่อมต่อกับธุรกรรมที่สร้างขึ้น เมื่อดำเนินการสำเร็จการทำธุรกรรมจะถูกผูกมัดมิฉะนั้นจะถูกย้อนกลับ |
| 4 | dispose() การจำหน่ายพูลการเชื่อมต่อที่ใช้โดยเครื่องยนต์ |
| 5 | driver() ชื่อไดรเวอร์ของภาษาถิ่นที่เครื่องยนต์ใช้ |
| 6 | table_names() ส่งกลับรายการชื่อตารางทั้งหมดที่มีอยู่ในฐานข้อมูล |
| 7 | transaction() เรียกใช้ฟังก์ชันที่กำหนดภายในขอบเขตธุรกรรม |
ตอนนี้ให้เราพูดถึงวิธีการใช้ฟังก์ชันสร้างตาราง
SQL Expression Language สร้างนิพจน์เทียบกับคอลัมน์ของตาราง SQLAlchemy Column object แทนไฟล์column ในตารางฐานข้อมูลซึ่งแทนด้วยไฟล์ Tableobject. ข้อมูลเมตาประกอบด้วยคำจำกัดความของตารางและวัตถุที่เกี่ยวข้องเช่นดัชนีมุมมองทริกเกอร์ ฯลฯ
ดังนั้นอ็อบเจ็กต์ของคลาส MetaData จาก SQLAlchemy Metadata คือคอลเล็กชันของวัตถุ Table และโครงสร้าง schema ที่เกี่ยวข้อง มันมีคอลเลกชันของวัตถุตารางเช่นเดียวกับการผูกทางเลือกกับเครื่องยนต์หรือการเชื่อมต่อ
from sqlalchemy import MetaData
meta = MetaData()Constructor ของคลาส MetaData สามารถมีพารามิเตอร์ bind และ schema ซึ่งเป็นค่าดีฟอลต์ None.
ต่อไปเราจะกำหนดตารางของเราทั้งหมดภายในแคตตาล็อกข้อมูลเมตาข้างต้นโดยใช้ the Table constructซึ่งคล้ายกับคำสั่ง SQL CREATE TABLE ปกติ
ออบเจ็กต์ของคลาส Table แทนตารางที่สอดคล้องกันในฐานข้อมูล ตัวสร้างรับพารามิเตอร์ต่อไปนี้ -
| ชื่อ | ชื่อของตาราง |
|---|---|
| ข้อมูลเมตา | MetaData วัตถุที่จะเก็บตารางนี้ |
| คอลัมน์ | ออบเจ็กต์อย่างน้อยหนึ่งรายการของคลาสคอลัมน์ |
วัตถุคอลัมน์แสดงถึงไฟล์ column ใน database table. ตัวสร้างใช้ชื่อประเภทและพารามิเตอร์อื่น ๆ เช่น primary_key การสร้างอัตโนมัติและข้อ จำกัด อื่น ๆ
SQLAlchemy จับคู่ข้อมูล Python กับประเภทข้อมูลคอลัมน์ทั่วไปที่ดีที่สุดที่กำหนดไว้ในนั้น ประเภทข้อมูลทั่วไปบางประเภท ได้แก่ -
- BigInteger
- Boolean
- Date
- DateTime
- Float
- Integer
- Numeric
- SmallInteger
- String
- Text
- Time
เพื่อสร้างไฟล์ students table ในฐานข้อมูลของวิทยาลัยใช้ตัวอย่างต่อไปนี้ -
from sqlalchemy import Table, Column, Integer, String, MetaData
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)ฟังก์ชัน create_all () ใช้เอนจินอ็อบเจ็กต์เพื่อสร้างอ็อบเจ็กต์ตารางที่กำหนดทั้งหมดและเก็บข้อมูลไว้ในเมทาดาทา
meta.create_all(engine)รหัสที่สมบูรณ์จะได้รับด้านล่างซึ่งจะสร้างฐานข้อมูล SQLite college.db โดยมีตารางนักเรียนอยู่
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
meta.create_all(engine)เนื่องจากคุณสมบัติ echo ของฟังก์ชัน create_engine () ถูกตั้งค่าเป็น Trueคอนโซลจะแสดงแบบสอบถาม SQL จริงสำหรับการสร้างตารางดังนี้ -
CREATE TABLE students (
id INTEGER NOT NULL,
name VARCHAR,
lastname VARCHAR,
PRIMARY KEY (id)
)college.db จะถูกสร้างขึ้นในไดเร็กทอรีการทำงานปัจจุบัน หากต้องการตรวจสอบว่ามีการสร้างตารางนักเรียนหรือไม่คุณสามารถเปิดฐานข้อมูลโดยใช้เครื่องมือ SQLite GUI เช่นSQLiteStudio.
ภาพด้านล่างแสดงตารางนักเรียนที่สร้างในฐานข้อมูล -
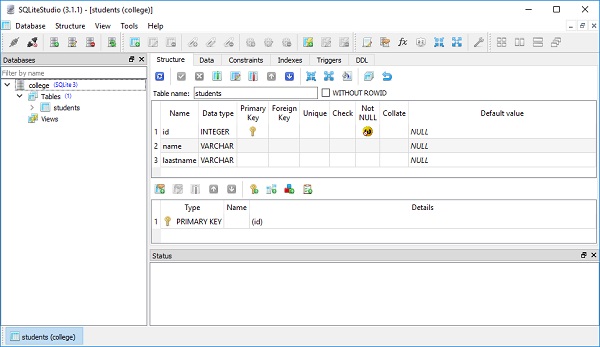
ในบทนี้เราจะเน้นสั้น ๆ เกี่ยวกับนิพจน์ SQL และฟังก์ชันต่างๆ
นิพจน์ SQL ถูกสร้างขึ้นโดยใช้วิธีการที่เกี่ยวข้องซึ่งสัมพันธ์กับวัตถุตารางเป้าหมาย ตัวอย่างเช่นคำสั่ง INSERT ถูกสร้างขึ้นโดยเรียกใช้เมธอด insert () ดังนี้ -
ins = students.insert()ผลลัพธ์ของวิธีการข้างต้นคือวัตถุแทรกที่สามารถตรวจสอบได้โดยใช้ str()ฟังก์ชัน โค้ดด้านล่างนี้จะใส่รายละเอียดเช่นรหัสนักศึกษาชื่อนามสกุล
'INSERT INTO students (id, name, lastname) VALUES (:id, :name, :lastname)'เป็นไปได้ที่จะแทรกค่าในฟิลด์เฉพาะโดย values()วิธีการแทรกวัตถุ รหัสสำหรับสิ่งเดียวกันได้รับด้านล่าง -
>>> ins = users.insert().values(name = 'Karan')
>>> str(ins)
'INSERT INTO users (name) VALUES (:name)'SQL ที่สะท้อนบนคอนโซล Python ไม่แสดงค่าจริง ('Karan' ในกรณีนี้) แต่ SQLALchemy จะสร้างพารามิเตอร์การผูกซึ่งสามารถมองเห็นได้ในรูปแบบที่คอมไพล์ของคำสั่ง
ins.compile().params
{'name': 'Karan'}ในทำนองเดียวกันวิธีการเช่น update(), delete() และ select()สร้างนิพจน์ UPDATE, DELETE และ SELECT ตามลำดับ เราจะเรียนรู้เกี่ยวกับพวกเขาในบทต่อ ๆ ไป
ในบทที่แล้วเราได้เรียนรู้ SQL Expressions ในบทนี้เราจะพิจารณาการดำเนินการของนิพจน์เหล่านี้
ในการดำเนินการกับนิพจน์ SQL ที่เป็นผลลัพธ์เราต้อง obtain a connection object representing an actively checked out DBAPI connection resource แล้ว feed the expression object ดังแสดงในโค้ดด้านล่าง
conn = engine.connect()สามารถใช้วัตถุแทรก () ต่อไปนี้สำหรับวิธีการดำเนินการ () -
ins = students.insert().values(name = 'Ravi', lastname = 'Kapoor')
result = conn.execute(ins)คอนโซลแสดงผลลัพธ์ของการดำเนินการของนิพจน์ SQL ดังต่อไปนี้ -
INSERT INTO students (name, lastname) VALUES (?, ?)
('Ravi', 'Kapoor')
COMMITต่อไปนี้เป็นส่วนย่อยทั้งหมดที่แสดงการดำเนินการของแบบสอบถาม INSERT โดยใช้เทคนิคหลักของ SQLAlchemy -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
ins = students.insert()
ins = students.insert().values(name = 'Ravi', lastname = 'Kapoor')
conn = engine.connect()
result = conn.execute(ins)ผลลัพธ์สามารถตรวจสอบได้โดยการเปิดฐานข้อมูลโดยใช้ SQLite Studio ดังที่แสดงในภาพหน้าจอด้านล่าง -

ตัวแปรผลลัพธ์เรียกว่าResultProxy object. คล้ายกับวัตถุเคอร์เซอร์ DBAPI เราสามารถรับข้อมูลเกี่ยวกับค่าคีย์หลักที่สร้างขึ้นจากคำสั่งของเราโดยใช้ResultProxy.inserted_primary_key ดังแสดงด้านล่าง -
result.inserted_primary_key
[1]ในการออกส่วนแทรกจำนวนมากโดยใช้เมธอด execute many () ของ DBAPI เราสามารถส่งรายการพจนานุกรมแต่ละรายการที่มีชุดพารามิเตอร์ที่แตกต่างกันเพื่อแทรก
conn.execute(students.insert(), [
{'name':'Rajiv', 'lastname' : 'Khanna'},
{'name':'Komal','lastname' : 'Bhandari'},
{'name':'Abdul','lastname' : 'Sattar'},
{'name':'Priya','lastname' : 'Rajhans'},
])สิ่งนี้สะท้อนให้เห็นในมุมมองข้อมูลของตารางดังแสดงในรูปต่อไปนี้ -
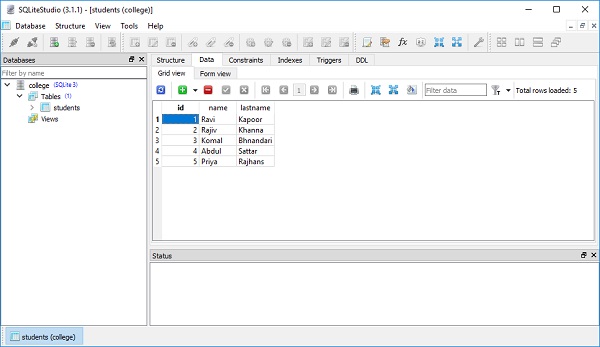
ในบทนี้เราจะพูดถึงแนวคิดในการเลือกแถวในวัตถุตาราง
วิธี select () ของวัตถุตารางช่วยให้เราสามารถ construct SELECT expression.
s = students.select()วัตถุที่เลือกจะแปลเป็น SELECT query by str(s) function ดังแสดงด้านล่าง -
'SELECT students.id, students.name, students.lastname FROM students'เราสามารถใช้วัตถุที่เลือกนี้เป็นพารามิเตอร์เพื่อดำเนินการ () วิธีการของวัตถุการเชื่อมต่อดังที่แสดงในโค้ดด้านล่าง -
result = conn.execute(s)เมื่อดำเนินการคำสั่งดังกล่าว Python shell จะสะท้อนตามนิพจน์ SQL ที่เทียบเท่า -
SELECT students.id, students.name, students.lastname
FROM studentsตัวแปรผลลัพธ์เทียบเท่าเคอร์เซอร์ใน DBAPI ตอนนี้เราสามารถดึงข้อมูลโดยใช้ไฟล์fetchone() method.
row = result.fetchone()แถวที่เลือกทั้งหมดในตารางสามารถพิมพ์ได้โดยไฟล์ for loop ตามที่ระบุด้านล่าง -
for row in result:
print (row)รหัสที่สมบูรณ์ในการพิมพ์แถวทั้งหมดจากตารางนักเรียนแสดงอยู่ด้านล่าง -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
s = students.select()
conn = engine.connect()
result = conn.execute(s)
for row in result:
print (row)ผลลัพธ์ที่แสดงใน Python shell มีดังนี้ -
(1, 'Ravi', 'Kapoor')
(2, 'Rajiv', 'Khanna')
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')คำสั่ง WHERE ของแบบสอบถาม SELECT สามารถนำไปใช้โดยใช้ Select.where(). ตัวอย่างเช่นหากเราต้องการแสดงแถวที่มี id> 2
s = students.select().where(students.c.id>2)
result = conn.execute(s)
for row in result:
print (row)ที่นี่ c attribute is an alias for column. ผลลัพธ์ต่อไปนี้จะแสดงบนเปลือก -
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')ที่นี่เราต้องทราบว่าวัตถุที่เลือกสามารถหาได้จากฟังก์ชัน select () ในโมดูล sqlalchemy.sql ฟังก์ชัน select () ต้องการวัตถุตารางเป็นอาร์กิวเมนต์
from sqlalchemy.sql import select
s = select([users])
result = conn.execute(s)SQLAlchemy ช่วยให้คุณใช้สตริงได้สำหรับกรณีเหล่านั้นเมื่อรู้จัก SQL แล้วและไม่จำเป็นต้องมีคำสั่งเพื่อรองรับคุณสมบัติไดนามิก โครงสร้าง text () ใช้ในการเขียนข้อความที่ส่งผ่านไปยังฐานข้อมูลโดยส่วนใหญ่ไม่มีการเปลี่ยนแปลง
มันสร้างไฟล์ TextClauseแทนสตริง SQL ที่เป็นข้อความโดยตรงดังที่แสดงในโค้ดด้านล่าง -
from sqlalchemy import text
t = text("SELECT * FROM students")
result = connection.execute(t)ข้อดี text() ให้มากกว่าสตริงธรรมดาคือ -
- การสนับสนุนแบ็กเอนด์เป็นกลางสำหรับพารามิเตอร์การผูก
- ตัวเลือกการดำเนินการต่อคำสั่ง
- ลักษณะการพิมพ์คอลัมน์ผลลัพธ์
ฟังก์ชัน text () ต้องการพารามิเตอร์ Bound ในรูปแบบโคลอนที่มีชื่อ มีความสอดคล้องกันโดยไม่คำนึงถึงแบ็กเอนด์ฐานข้อมูล ในการส่งค่าสำหรับพารามิเตอร์เราส่งผ่านเข้าไปในเมธอด execute () เป็นอาร์กิวเมนต์เพิ่มเติม
ตัวอย่างต่อไปนี้ใช้พารามิเตอร์ที่ถูกผูกไว้ใน SQL แบบข้อความ -
from sqlalchemy.sql import text
s = text("select students.name, students.lastname from students where students.name between :x and :y")
conn.execute(s, x = 'A', y = 'L').fetchall()ฟังก์ชัน text () สร้างนิพจน์ SQL ดังนี้ -
select students.name, students.lastname from students where students.name between ? and ?ค่าของ x = 'A' และ y = 'L' จะถูกส่งผ่านเป็นพารามิเตอร์ ผลลัพธ์คือรายการของแถวที่มีชื่ออยู่ระหว่าง 'A' และ 'L' -
[('Komal', 'Bhandari'), ('Abdul', 'Sattar')]โครงสร้าง text () รองรับค่าขอบเขตที่กำหนดไว้ล่วงหน้าโดยใช้เมธอด TextClause.bindparams () นอกจากนี้ยังสามารถพิมพ์พารามิเตอร์อย่างชัดเจนได้ดังนี้ -
stmt = text("SELECT * FROM students WHERE students.name BETWEEN :x AND :y")
stmt = stmt.bindparams(
bindparam("x", type_= String),
bindparam("y", type_= String)
)
result = conn.execute(stmt, {"x": "A", "y": "L"})
The text() function also be produces fragments of SQL within a select() object that
accepts text() objects as an arguments. The “geometry” of the statement is provided by
select() construct , and the textual content by text() construct. We can build a statement
without the need to refer to any pre-established Table metadata.
from sqlalchemy.sql import select
s = select([text("students.name, students.lastname from students")]).where(text("students.name between :x and :y"))
conn.execute(s, x = 'A', y = 'L').fetchall()คุณยังสามารถใช้ and_() ฟังก์ชันเพื่อรวมหลายเงื่อนไขในส่วนคำสั่ง WHERE ที่สร้างขึ้นด้วยความช่วยเหลือของฟังก์ชัน text ()
from sqlalchemy import and_
from sqlalchemy.sql import select
s = select([text("* from students")]) \
.where(
and_(
text("students.name between :x and :y"),
text("students.id>2")
)
)
conn.execute(s, x = 'A', y = 'L').fetchall()โค้ดด้านบนดึงข้อมูลแถวที่มีชื่อระหว่าง“ A” และ“ L” ที่มี id มากกว่า 2 ผลลัพธ์ของโค้ดได้รับด้านล่าง
[(3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar')]นามแฝงใน SQL สอดคล้องกับเวอร์ชัน "เปลี่ยนชื่อ" ของตารางหรือคำสั่ง SELECT ซึ่งเกิดขึ้นได้ทุกเมื่อที่คุณพูดว่า "SELECT * FROM table1 AS a" AS สร้างชื่อใหม่สำหรับตาราง นามแฝงอนุญาตให้อ้างอิงตารางหรือคิวรีย่อยด้วยชื่อเฉพาะ
ในกรณีของตารางจะทำให้สามารถตั้งชื่อตารางเดียวกันในส่วนคำสั่ง FROM ได้หลายครั้ง มีชื่อพาเรนต์สำหรับคอลัมน์ที่แสดงโดยคำสั่งซึ่งทำให้สามารถอ้างอิงได้โดยสัมพันธ์กับชื่อนี้
ใน SQLAlchemy ตารางใด ๆ เลือก () สร้างหรือวัตถุที่เลือกได้อื่น ๆ สามารถเปลี่ยนเป็นนามแฝงโดยใช้ From Clause.alias()วิธีการซึ่งสร้างโครงสร้างนามแฝง ฟังก์ชัน alias () ในโมดูล sqlalchemy.sql แสดงถึงนามแฝงโดยทั่วไปจะใช้กับตารางใด ๆ หรือเลือกย่อยภายในคำสั่ง SQL โดยใช้คีย์เวิร์ด AS
from sqlalchemy.sql import alias
st = students.alias("a")นามแฝงนี้สามารถใช้ในโครงสร้าง select () เพื่ออ้างถึงตารางนักเรียน -
s = select([st]).where(st.c.id>2)สิ่งนี้แปลเป็นนิพจน์ SQL ดังนี้ -
SELECT a.id, a.name, a.lastname FROM students AS a WHERE a.id > 2ตอนนี้เราสามารถเรียกใช้แบบสอบถาม SQL นี้ด้วยวิธี execute () ของวัตถุการเชื่อมต่อ รหัสที่สมบูรณ์มีดังนี้ -
from sqlalchemy.sql import alias, select
st = students.alias("a")
s = select([st]).where(st.c.id > 2)
conn.execute(s).fetchall()เมื่อดำเนินการบรรทัดด้านบนของรหัสจะสร้างผลลัพธ์ต่อไปนี้ -
[(3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar'), (5, 'Priya', 'Rajhans')]update() วิธีการบนวัตถุตารางเป้าหมายสร้างนิพจน์ UPDATE SQL ที่เทียบเท่า
table.update().where(conditions).values(SET expressions)values()วิธีการบนอ็อบเจ็กต์การอัพเดตผลลัพธ์ถูกใช้เพื่อระบุเงื่อนไข SET ของ UPDATE หากปล่อยไว้เป็นไม่มีเงื่อนไข SET จะถูกกำหนดจากพารามิเตอร์เหล่านั้นที่ส่งผ่านไปยังคำสั่งระหว่างการดำเนินการและ / หรือการรวบรวมคำสั่ง
where clause คือนิพจน์เสริมที่อธิบายเงื่อนไข WHERE ของคำสั่ง UPDATE
ข้อมูลโค้ดต่อไปนี้จะเปลี่ยนค่าของคอลัมน์ 'lastname' จาก 'Khanna' เป็น 'Kapoor' ในตารางนักเรียน -
stmt = students.update().where(students.c.lastname == 'Khanna').values(lastname = 'Kapoor')stmt object เป็นอ็อบเจกต์อัพเดตที่แปลเป็น -
'UPDATE students SET lastname = :lastname WHERE students.lastname = :lastname_1'พารามิเตอร์ที่ถูกผูกไว้ lastname_1 จะถูกเปลี่ยนตัวเมื่อ execute()เรียกใช้วิธีการ รหัสอัปเดตที่สมบูรณ์จะได้รับด้านล่าง -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students',
meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn = engine.connect()
stmt=students.update().where(students.c.lastname=='Khanna').values(lastname='Kapoor')
conn.execute(stmt)
s = students.select()
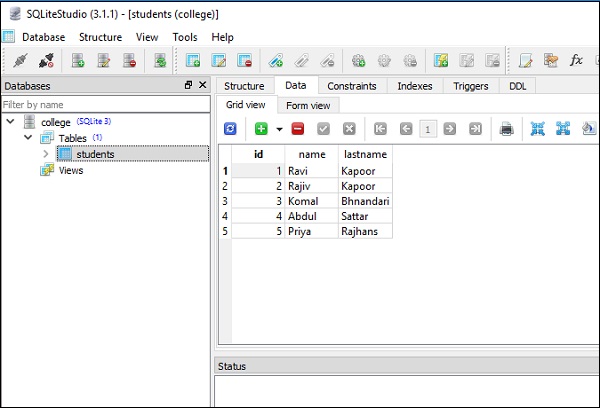
conn.execute(s).fetchall()โค้ดด้านบนจะแสดงผลลัพธ์ต่อไปนี้โดยมีแถวที่สองแสดงผลของการดำเนินการอัปเดตดังในภาพหน้าจอที่กำหนด -
[
(1, 'Ravi', 'Kapoor'),
(2, 'Rajiv', 'Kapoor'),
(3, 'Komal', 'Bhandari'),
(4, 'Abdul', 'Sattar'),
(5, 'Priya', 'Rajhans')
]
โปรดทราบว่าฟังก์ชันการทำงานที่คล้ายกันสามารถทำได้โดยใช้ update() ฟังก์ชันในโมดูล sqlalchemy.sql.expression ดังแสดงด้านล่าง -
from sqlalchemy.sql.expression import update
stmt = update(students).where(students.c.lastname == 'Khanna').values(lastname = 'Kapoor')ในบทที่แล้วเราได้เข้าใจแล้วว่าไฟล์ Updateนิพจน์ไม่ สำนวนต่อไปที่เราจะเรียนรู้คือDelete.
การดำเนินการลบสามารถทำได้โดยการรันเมธอด delete () บนวัตถุตารางเป้าหมายตามที่ระบุในคำสั่งต่อไปนี้ -
stmt = students.delete()ในกรณีของตารางนักเรียนบรรทัดด้านบนของโค้ดจะสร้างนิพจน์ SQL ดังต่อไปนี้ -
'DELETE FROM students'อย่างไรก็ตามการดำเนินการนี้จะลบแถวทั้งหมดในตารางนักเรียน โดยปกติการสอบถาม DELETE จะเชื่อมโยงกับนิพจน์เชิงตรรกะที่ระบุโดยคำสั่ง WHERE คำสั่งต่อไปนี้แสดงที่พารามิเตอร์ -
stmt = students.delete().where(students.c.id > 2)นิพจน์ SQL ที่เป็นผลลัพธ์จะมีพารามิเตอร์ที่ถูกผูกไว้ซึ่งจะถูกแทนที่ในรันไทม์เมื่อคำสั่งถูกดำเนินการ
'DELETE FROM students WHERE students.id > :id_1'ตัวอย่างโค้ดต่อไปนี้จะลบแถวเหล่านั้นออกจากตารางนักเรียนที่มีนามสกุลเป็น 'คันนา' -
from sqlalchemy.sql.expression import update
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn = engine.connect()
stmt = students.delete().where(students.c.lastname == 'Khanna')
conn.execute(stmt)
s = students.select()
conn.execute(s).fetchall()ในการตรวจสอบผลลัพธ์ให้รีเฟรชมุมมองข้อมูลของตารางนักเรียนใน SQLiteStudio
คุณสมบัติที่สำคัญอย่างหนึ่งของ RDBMS คือการสร้างความสัมพันธ์ระหว่างตาราง การดำเนินการ SQL เช่น SELECT, UPDATE และ DELETE สามารถทำได้บนตารางที่เกี่ยวข้อง ส่วนนี้อธิบายการดำเนินการเหล่านี้โดยใช้ SQLAlchemy
เพื่อจุดประสงค์นี้ตารางสองตารางจะถูกสร้างขึ้นในฐานข้อมูล SQLite ของเรา (college.db) ตารางนักเรียนมีโครงสร้างเหมือนกับที่ให้ไว้ในส่วนก่อนหน้า ในขณะที่ตารางที่อยู่มีst_id คอลัมน์ที่แมปกับ id column in students table โดยใช้ข้อ จำกัด ของคีย์ต่างประเทศ
รหัสต่อไปนี้จะสร้างสองตารางใน college.db -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey
engine = create_engine('sqlite:///college.db', echo=True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer, ForeignKey('students.id')),
Column('postal_add', String),
Column('email_add', String))
meta.create_all(engine)โค้ดด้านบนจะแปลเป็นแบบสอบถาม CREATE TABLE สำหรับนักเรียนและตารางที่อยู่ดังต่อไปนี้ -
CREATE TABLE students (
id INTEGER NOT NULL,
name VARCHAR,
lastname VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE addresses (
id INTEGER NOT NULL,
st_id INTEGER,
postal_add VARCHAR,
email_add VARCHAR,
PRIMARY KEY (id),
FOREIGN KEY(st_id) REFERENCES students (id)
)ภาพหน้าจอต่อไปนี้แสดงรหัสข้างต้นอย่างชัดเจน -
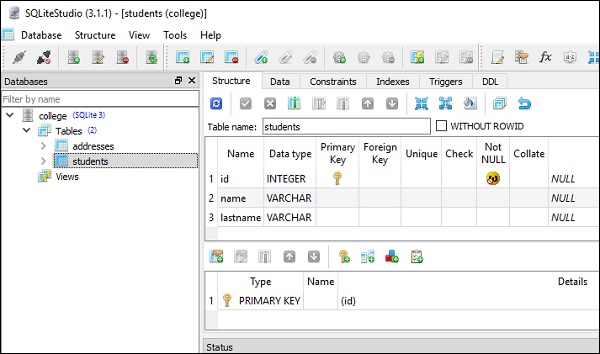
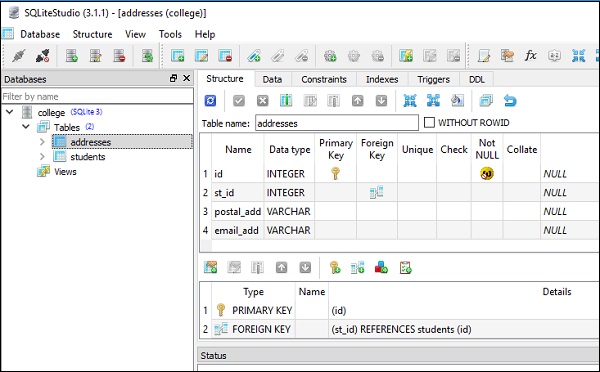
ตารางเหล่านี้ถูกเติมด้วยข้อมูลโดยการดำเนินการ insert() methodของวัตถุตาราง ในการแทรก 5 แถวในตารางนักเรียนคุณสามารถใช้รหัสที่ระบุด้านล่าง -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn.execute(students.insert(), [
{'name':'Ravi', 'lastname':'Kapoor'},
{'name':'Rajiv', 'lastname' : 'Khanna'},
{'name':'Komal','lastname' : 'Bhandari'},
{'name':'Abdul','lastname' : 'Sattar'},
{'name':'Priya','lastname' : 'Rajhans'},
])Rows จะถูกเพิ่มในตารางที่อยู่ด้วยความช่วยเหลือของรหัสต่อไปนี้ -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer),
Column('postal_add', String),
Column('email_add', String)
)
conn.execute(addresses.insert(), [
{'st_id':1, 'postal_add':'Shivajinagar Pune', 'email_add':'[email protected]'},
{'st_id':1, 'postal_add':'ChurchGate Mumbai', 'email_add':'[email protected]'},
{'st_id':3, 'postal_add':'Jubilee Hills Hyderabad', 'email_add':'[email protected]'},
{'st_id':5, 'postal_add':'MG Road Bangaluru', 'email_add':'[email protected]'},
{'st_id':2, 'postal_add':'Cannought Place new Delhi', 'email_add':'[email protected]'},
])โปรดสังเกตว่าคอลัมน์ st_id ในตารางที่อยู่หมายถึงคอลัมน์ id ในตารางนักเรียน ตอนนี้เราสามารถใช้ความสัมพันธ์นี้เพื่อดึงข้อมูลจากทั้งสองตาราง เราต้องการดึงข้อมูลname และ lastname จากตารางนักเรียนที่ตรงกับ st_id ในตารางที่อยู่
from sqlalchemy.sql import select
s = select([students, addresses]).where(students.c.id == addresses.c.st_id)
result = conn.execute(s)
for row in result:
print (row)อ็อบเจ็กต์ที่เลือกจะแปลเป็นนิพจน์ SQL ต่อไปนี้อย่างมีประสิทธิภาพโดยรวมสองตารางบนความสัมพันธ์ทั่วไป -
SELECT students.id,
students.name,
students.lastname,
addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM students, addresses
WHERE students.id = addresses.st_idสิ่งนี้จะให้ผลลัพธ์ที่ดึงข้อมูลที่เกี่ยวข้องจากทั้งสองตารางดังนี้ -
(1, 'Ravi', 'Kapoor', 1, 1, 'Shivajinagar Pune', '[email protected]')
(1, 'Ravi', 'Kapoor', 2, 1, 'ChurchGate Mumbai', '[email protected]')
(3, 'Komal', 'Bhandari', 3, 3, 'Jubilee Hills Hyderabad', '[email protected]')
(5, 'Priya', 'Rajhans', 4, 5, 'MG Road Bangaluru', '[email protected]')
(2, 'Rajiv', 'Khanna', 5, 2, 'Cannought Place new Delhi', '[email protected]')ในบทที่แล้วเราได้กล่าวถึงวิธีการใช้ตารางหลายตาราง ดังนั้นเราจึงดำเนินการต่อไปและเรียนรู้multiple table updates ในบทนี้.
การใช้วัตถุตารางของ SQLAlchemy สามารถระบุตารางได้มากกว่าหนึ่งตารางใน WHERE clause of update () method PostgreSQL และ Microsoft SQL Server สนับสนุนคำสั่ง UPDATE ที่อ้างถึงหลายตาราง การดำเนินการนี้“UPDATE FROM”ไวยากรณ์ซึ่งอัปเดตทีละตาราง อย่างไรก็ตามตารางเพิ่มเติมสามารถอ้างอิงได้ในส่วนคำสั่ง“ FROM” เพิ่มเติมในส่วนคำสั่ง WHERE โดยตรง โค้ดบรรทัดต่อไปนี้อธิบายแนวคิดของmultiple table updates ชัดเจน.
stmt = students.update().\
values({
students.c.name:'xyz',
addresses.c.email_add:'[email protected]'
}).\
where(students.c.id == addresses.c.id)อ็อบเจ็กต์อัพเดตเทียบเท่ากับเคียวรี UPDATE ต่อไปนี้ -
UPDATE students
SET email_add = :addresses_email_add, name = :name
FROM addresses
WHERE students.id = addresses.idเท่าที่เกี่ยวข้องกับภาษา MySQL ตารางหลายตารางสามารถฝังลงในคำสั่ง UPDATE เดียวโดยคั่นด้วยเครื่องหมายจุลภาคตามที่ระบุด้านล่าง -
stmt = students.update().\
values(name = 'xyz').\
where(students.c.id == addresses.c.id)รหัสต่อไปนี้แสดงถึงการค้นหา UPDATE ที่เป็นผลลัพธ์ -
'UPDATE students SET name = :name
FROM addresses
WHERE students.id = addresses.id'ภาษา SQLite ไม่สนับสนุนเกณฑ์หลายตารางภายใน UPDATE และแสดงข้อผิดพลาดต่อไปนี้ -
NotImplementedError: This backend does not support multiple-table criteria within UPDATEแบบสอบถาม UPDATE ของ SQL ดิบมีส่วนคำสั่ง SET แสดงผลโดยโครงสร้าง update () โดยใช้ลำดับคอลัมน์ที่กำหนดในออบเจ็กต์ Table ต้นทาง ดังนั้นคำสั่ง UPDATE เฉพาะกับคอลัมน์ใดคอลัมน์หนึ่งจะแสดงผลเหมือนกันทุกครั้ง เนื่องจากพารามิเตอร์เองถูกส่งไปยังเมธอด Update.values () เป็นคีย์พจนานุกรม Python จึงไม่มีคำสั่งคงที่อื่น ๆ
ในบางกรณีลำดับของพารามิเตอร์ที่แสดงในประโยค SET มีความสำคัญ ใน MySQL การให้การอัปเดตค่าคอลัมน์จะขึ้นอยู่กับค่าของคอลัมน์อื่น ๆ
ผลลัพธ์ของคำสั่งต่อไปนี้ -
UPDATE table1 SET x = y + 10, y = 20จะมีผลลัพธ์ที่แตกต่างจาก -
UPDATE table1 SET y = 20, x = y + 10ประโยค SET ใน MySQL ได้รับการประเมินตามมูลค่าและไม่ได้คำนวณตามแต่ละแถว เพื่อจุดประสงค์นี้ไฟล์preserve_parameter_orderถูกนำมาใช้. รายการ Python ของ 2-tuples ถูกกำหนดให้เป็นอาร์กิวเมนต์ของไฟล์Update.values() วิธีการ -
stmt = table1.update(preserve_parameter_order = True).\
values([(table1.c.y, 20), (table1.c.x, table1.c.y + 10)])วัตถุรายการจะคล้ายกับพจนานุกรมยกเว้นว่าจะได้รับคำสั่ง เพื่อให้แน่ใจว่าส่วนคำสั่ง SET ของคอลัมน์“ y” จะแสดงผลก่อนจากนั้นจึงใช้คำสั่ง SET ของคอลัมน์“ x”
ในบทนี้เราจะดูนิพจน์การลบตารางหลายรายการซึ่งคล้ายกับการใช้ฟังก์ชันการอัปเดตตารางหลายรายการ
สามารถอ้างถึงตารางมากกว่าหนึ่งตารางใน WHERE clause ของ DELETE ในภาษาถิ่น DBMS สำหรับ PG และ MySQL จะใช้ไวยากรณ์“ DELETE USING” และสำหรับ SQL Server การใช้นิพจน์ "DELETE FROM" หมายถึงตารางมากกว่าหนึ่งตาราง SQLAlchemydelete() โครงสร้างรองรับทั้งสองโหมดนี้โดยปริยายโดยระบุหลายตารางในส่วนคำสั่ง WHERE ดังต่อไปนี้ -
stmt = users.delete().\
where(users.c.id == addresses.c.id).\
where(addresses.c.email_address.startswith('xyz%'))
conn.execute(stmt)บนแบ็กเอนด์ PostgreSQL SQL ที่เป็นผลลัพธ์จากคำสั่งด้านบนจะแสดงผลเป็น -
DELETE FROM users USING addresses
WHERE users.id = addresses.id
AND (addresses.email_address LIKE %(email_address_1)s || '%%')หากใช้วิธีนี้กับฐานข้อมูลที่ไม่รองรับลักษณะการทำงานนี้คอมไพลเลอร์จะเพิ่ม NotImplementedError
ในบทนี้เราจะเรียนรู้วิธีการใช้ Joins ใน SQLAlchemy
ผลของการเข้าร่วมทำได้โดยการวางตารางสองตารางในไฟล์ columns clause หรือ where clauseของโครงสร้าง select () ตอนนี้เราใช้เมธอด join () และ outerjoin ()
วิธี join () ส่งคืนอ็อบเจ็กต์การรวมจากอ็อบเจ็กต์ตารางหนึ่งไปยังอีก
join(right, onclause = None, isouter = False, full = False)ฟังก์ชันของพารามิเตอร์ที่กล่าวถึงในโค้ดข้างต้นมีดังนี้ -
right- ด้านขวาของการเข้าร่วม นี่คือวัตถุตารางใด ๆ
onclause- นิพจน์ SQL ที่แสดงถึงส่วนคำสั่ง ON ของการเข้าร่วม หากปล่อยไว้ที่ไม่มีก็จะพยายามรวมตารางทั้งสองตามความสัมพันธ์ของคีย์ต่างประเทศ
isouter - ถ้าเป็นจริงให้แสดงการเข้าร่วมด้านนอกด้านซ้ายแทนการเข้าร่วม
full - ถ้าเป็นจริงจะแสดงการเข้าร่วมภายนอกแบบเต็มแทนที่จะเป็น LEFT OUTER JOIN
ตัวอย่างเช่นการใช้เมธอด join () ต่อไปนี้จะส่งผลให้เข้าร่วมโดยอัตโนมัติตามคีย์ต่างประเทศ
>>> print(students.join(addresses))สิ่งนี้เทียบเท่ากับนิพจน์ SQL ต่อไปนี้ -
students JOIN addresses ON students.id = addresses.st_idคุณสามารถพูดถึงเกณฑ์การเข้าร่วมอย่างชัดเจนดังต่อไปนี้ -
j = students.join(addresses, students.c.id == addresses.c.st_id)หากตอนนี้เราสร้างโครงสร้างเลือกด้านล่างโดยใช้การเข้าร่วมนี้เป็น -
stmt = select([students]).select_from(j)สิ่งนี้จะส่งผลให้เกิดนิพจน์ SQL ต่อไปนี้ -
SELECT students.id, students.name, students.lastname
FROM students JOIN addresses ON students.id = addresses.st_idหากคำสั่งนี้ดำเนินการโดยใช้การเชื่อมต่อที่เป็นตัวแทนของเอ็นจินข้อมูลที่เป็นของคอลัมน์ที่เลือกจะแสดงขึ้น รหัสที่สมบูรณ์มีดังนี้ -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer,ForeignKey('students.id')),
Column('postal_add', String),
Column('email_add', String)
)
from sqlalchemy import join
from sqlalchemy.sql import select
j = students.join(addresses, students.c.id == addresses.c.st_id)
stmt = select([students]).select_from(j)
result = conn.execute(stmt)
result.fetchall()ต่อไปนี้เป็นผลลัพธ์ของโค้ดด้านบน -
[
(1, 'Ravi', 'Kapoor'),
(1, 'Ravi', 'Kapoor'),
(3, 'Komal', 'Bhandari'),
(5, 'Priya', 'Rajhans'),
(2, 'Rajiv', 'Khanna')
]คำสันธานเป็นฟังก์ชันในโมดูล SQLAlchemy ที่ใช้ตัวดำเนินการเชิงสัมพันธ์ที่ใช้ใน WHERE clause ของนิพจน์ SQL ตัวดำเนินการ AND, OR, NOT ฯลฯ ถูกใช้เพื่อสร้างนิพจน์สารประกอบที่รวมนิพจน์ตรรกะสองนิพจน์ ตัวอย่างง่ายๆของการใช้ AND ในคำสั่ง SELECT มีดังนี้ -
SELECT * from EMPLOYEE WHERE salary>10000 AND age>30ฟังก์ชัน SQLAlchemy และ _ () หรือ_ () และ not_ () ใช้ตัวดำเนินการ AND, OR และ NOT ตามลำดับ
and_ () ฟังก์ชัน
มันสร้างการรวมกันของนิพจน์ที่เข้าร่วมโดย AND ตัวอย่างมีให้ด้านล่างเพื่อความเข้าใจที่ดีขึ้น -
from sqlalchemy import and_
print(
and_(
students.c.name == 'Ravi',
students.c.id <3
)
)แปลว่า -
students.name = :name_1 AND students.id < :id_1ในการใช้ and_ () ในโครงสร้าง select () บนโต๊ะนักเรียนให้ใช้โค้ดบรรทัดต่อไปนี้ -
stmt = select([students]).where(and_(students.c.name == 'Ravi', students.c.id <3))คำสั่ง SELECT ของลักษณะต่อไปนี้จะถูกสร้างขึ้น -
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.name = :name_1 AND students.id < :id_1รหัสทั้งหมดที่แสดงผลลัพธ์ของแบบสอบถาม SELECT ด้านบนมีดังนี้ -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey, select
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
from sqlalchemy import and_, or_
stmt = select([students]).where(and_(students.c.name == 'Ravi', students.c.id <3))
result = conn.execute(stmt)
print (result.fetchall())แถวต่อไปนี้จะถูกเลือกโดยสมมติว่าตารางนักเรียนมีข้อมูลที่ใช้ในตัวอย่างก่อนหน้านี้ -
[(1, 'Ravi', 'Kapoor')]or_ () ฟังก์ชัน
มันสร้างการรวมกันของนิพจน์ที่เข้าร่วมโดย OR เราจะแทนที่วัตถุ stmt ในตัวอย่างข้างต้นด้วยสิ่งต่อไปนี้โดยใช้ or_ ()
stmt = select([students]).where(or_(students.c.name == 'Ravi', students.c.id <3))ซึ่งจะมีประสิทธิภาพเทียบเท่ากับแบบสอบถาม SELECT ต่อไปนี้ -
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.name = :name_1
OR students.id < :id_1เมื่อคุณทำการแทนที่และรันโค้ดด้านบนผลลัพธ์จะเป็นสองแถวที่อยู่ในเงื่อนไข OR -
[(1, 'Ravi', 'Kapoor'),
(2, 'Rajiv', 'Khanna')]asc () ฟังก์ชัน
มันสร้างคำสั่งจากน้อยไปหามาก ฟังก์ชันนำคอลัมน์ไปใช้ฟังก์ชันเป็นพารามิเตอร์
from sqlalchemy import asc
stmt = select([students]).order_by(asc(students.c.name))คำสั่งดำเนินการตามนิพจน์ SQL -
SELECT students.id,
students.name,
students.lastname
FROM students
ORDER BY students.name ASCรหัสต่อไปนี้แสดงรายการระเบียนทั้งหมดในตารางนักเรียนตามลำดับคอลัมน์ชื่อจากน้อยไปหามาก -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey, select
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
from sqlalchemy import asc
stmt = select([students]).order_by(asc(students.c.name))
result = conn.execute(stmt)
for row in result:
print (row)โค้ดด้านบนสร้างผลลัพธ์ต่อไปนี้ -
(4, 'Abdul', 'Sattar')
(3, 'Komal', 'Bhandari')
(5, 'Priya', 'Rajhans')
(2, 'Rajiv', 'Khanna')
(1, 'Ravi', 'Kapoor')desc () ฟังก์ชัน
ในทำนองเดียวกันฟังก์ชัน desc () สร้างจากมากไปหาน้อยตามคำสั่งดังต่อไปนี้ -
from sqlalchemy import desc
stmt = select([students]).order_by(desc(students.c.lastname))นิพจน์ SQL ที่เทียบเท่าคือ -
SELECT students.id,
students.name,
students.lastname
FROM students
ORDER BY students.lastname DESCและผลลัพธ์ของโค้ดด้านบนคือ -
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')
(2, 'Rajiv', 'Khanna')
(1, 'Ravi', 'Kapoor')
(3, 'Komal', 'Bhandari')ระหว่าง () ฟังก์ชัน
สร้างประโยคเพรดิเคตระหว่างกัน โดยทั่วไปจะใช้เพื่อตรวจสอบว่าค่าของคอลัมน์ใดคอลัมน์หนึ่งอยู่ระหว่างช่วง ตัวอย่างเช่นโค้ดต่อไปนี้จะเลือกแถวที่คอลัมน์ id อยู่ระหว่าง 2 ถึง 4 -
from sqlalchemy import between
stmt = select([students]).where(between(students.c.id,2,4))
print (stmt)นิพจน์ SQL ที่ได้มีลักษณะคล้ายกับ -
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.id
BETWEEN :id_1 AND :id_2และผลลัพธ์เป็นดังนี้ -
(2, 'Rajiv', 'Khanna')
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')ฟังก์ชันสำคัญบางอย่างที่ใช้ใน SQLAlchemy จะกล่าวถึงในบทนี้
Standard SQL ได้แนะนำฟังก์ชันมากมายที่ใช้โดยภาษาถิ่นส่วนใหญ่ โดยส่งคืนค่าเดียวตามอาร์กิวเมนต์ที่ส่งไป ฟังก์ชัน SQL บางฟังก์ชันใช้คอลัมน์เป็นอาร์กิวเมนต์ในขณะที่บางฟังก์ชันเป็นแบบทั่วไปThefunc keyword in SQLAlchemy API is used to generate these functions.
ใน SQL ตอนนี้ () เป็นฟังก์ชันทั่วไป ข้อความต่อไปนี้แสดงฟังก์ชัน now () โดยใช้ func -
from sqlalchemy.sql import func
result = conn.execute(select([func.now()]))
print (result.fetchone())ตัวอย่างผลลัพธ์ของโค้ดด้านบนอาจเป็นดังที่แสดงด้านล่าง -
(datetime.datetime(2018, 6, 16, 6, 4, 40),)ในทางกลับกันฟังก์ชัน count () ซึ่งส่งคืนจำนวนแถวที่เลือกจากตารางจะแสดงผลโดยใช้ฟังก์ชันต่อไปนี้ -
from sqlalchemy.sql import func
result = conn.execute(select([func.count(students.c.id)]))
print (result.fetchone())จากโค้ดด้านบนจะมีการดึงข้อมูลจำนวนแถวในตารางนักเรียน
ฟังก์ชัน SQL ในตัวบางอย่างจะแสดงโดยใช้ตารางพนักงานพร้อมข้อมูลต่อไปนี้ -
| ID | ชื่อ | เครื่องหมาย |
|---|---|---|
| 1 | คามาล | 56 |
| 2 | เฟอร์นันเดซ | 85 |
| 3 | Sunil | 62 |
| 4 | บาสการ์ | 76 |
ฟังก์ชั่น max () ถูกนำไปใช้โดยการใช้ func จาก SQLAlchemy ซึ่งจะส่งผลให้ได้ 85 คะแนนสูงสุดทั้งหมดที่ได้รับ -
from sqlalchemy.sql import func
result = conn.execute(select([func.max(employee.c.marks)]))
print (result.fetchone())ในทำนองเดียวกันฟังก์ชัน min () ที่จะส่งกลับ 56 เครื่องหมายต่ำสุดจะแสดงผลโดยรหัสต่อไปนี้ -
from sqlalchemy.sql import func
result = conn.execute(select([func.min(employee.c.marks)]))
print (result.fetchone())ดังนั้นฟังก์ชัน AVG () จึงสามารถใช้งานได้โดยใช้รหัสด้านล่าง -
from sqlalchemy.sql import func
result = conn.execute(select([func.avg(employee.c.marks)]))
print (result.fetchone())
Functions are normally used in the columns clause of a select statement.
They can also be given label as well as a type. A label to function allows the result
to be targeted in a result row based on a string name, and a type is required when
you need result-set processing to occur.from sqlalchemy.sql import func
result = conn.execute(select([func.max(students.c.lastname).label('Name')]))
print (result.fetchone())ในบทที่แล้วเราได้เรียนรู้เกี่ยวกับฟังก์ชั่นต่างๆเช่น max (), min (), count () ฯลฯ ที่นี่เราจะเรียนรู้เกี่ยวกับการใช้งานชุดและการใช้งาน
การตั้งค่าการดำเนินการเช่น UNION และ INTERSECT ได้รับการสนับสนุนโดย SQL มาตรฐานและภาษาถิ่นส่วนใหญ่ SQLAlchemy ดำเนินการด้วยความช่วยเหลือของฟังก์ชันต่อไปนี้ -
สหภาพ ()
ในขณะที่รวมผลลัพธ์ของคำสั่ง SELECT สองรายการขึ้นไป UNION จะกำจัดรายการที่ซ้ำกันออกจากชุดผลลัพธ์ จำนวนคอลัมน์และประเภทข้อมูลต้องเหมือนกันทั้งสองตาราง
ฟังก์ชัน union () ส่งคืนวัตถุ CompoundSelect จากหลายตาราง ตัวอย่างต่อไปนี้แสดงให้เห็นถึงการใช้งาน -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, union
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer),
Column('postal_add', String),
Column('email_add', String)
)
u = union(addresses.select().where(addresses.c.email_add.like('%@gmail.com addresses.select().where(addresses.c.email_add.like('%@yahoo.com'))))
result = conn.execute(u)
result.fetchall()โครงสร้างสหภาพแปลเป็นนิพจน์ SQL ต่อไปนี้ -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? UNION SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ?จากตารางที่อยู่ของเราแถวต่อไปนี้แสดงถึงการดำเนินการร่วมกัน -
[
(1, 1, 'Shivajinagar Pune', '[email protected]'),
(2, 1, 'ChurchGate Mumbai', '[email protected]'),
(3, 3, 'Jubilee Hills Hyderabad', '[email protected]'),
(4, 5, 'MG Road Bangaluru', '[email protected]')
]union_all ()
การดำเนินการ UNION ALL ไม่สามารถลบรายการที่ซ้ำกันและไม่สามารถเรียงลำดับข้อมูลในชุดผลลัพธ์ได้ ตัวอย่างเช่นในข้อความค้นหาด้านบน UNION จะถูกแทนที่ด้วย UNION ALL เพื่อดูเอฟเฟกต์
u = union_all(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.email_add.like('%@yahoo.com')))นิพจน์ SQL ที่เกี่ยวข้องมีดังนี้ -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? UNION ALL SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ?ยกเว้น_()
SQL EXCEPTอนุประโยค / ตัวดำเนินการใช้เพื่อรวมสองคำสั่ง SELECT และส่งคืนแถวจากคำสั่ง SELECT แรกที่ไม่ถูกส่งกลับโดยคำสั่ง SELECT ที่สอง ฟังก์ชัน except_ () สร้างนิพจน์ SELECT ที่มีส่วนคำสั่ง EXCEPT
ในตัวอย่างต่อไปนี้ฟังก์ชัน except_ () จะส่งคืนเฉพาะระเบียนเหล่านั้นจากตารางที่อยู่ที่มี "gmail.com" ในช่อง email_add แต่จะไม่รวมรายการที่มี "ปูน" เป็นส่วนหนึ่งของช่อง Postal_add
u = except_(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.postal_add.like('%Pune')))ผลลัพธ์ของโค้ดด้านบนคือนิพจน์ SQL ต่อไปนี้ -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? EXCEPT SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.postal_add LIKE ?สมมติว่าตารางที่อยู่มีข้อมูลที่ใช้ในตัวอย่างก่อนหน้านี้จะแสดงผลลัพธ์ต่อไปนี้ -
[(2, 1, 'ChurchGate Mumbai', '[email protected]'),
(3, 3, 'Jubilee Hills Hyderabad', '[email protected]')]ตัด()
การใช้ตัวดำเนินการ INTERSECT SQL จะแสดงแถวทั่วไปจากทั้งคำสั่ง SELECT ฟังก์ชัน intersect () ใช้พฤติกรรมนี้
ในตัวอย่างต่อไปนี้โครงสร้าง SELECT สองรายการคือพารามิเตอร์เพื่อตัดกัน () ฟังก์ชัน หนึ่งส่งคืนแถวที่มี "gmail.com" เป็นส่วนหนึ่งของคอลัมน์ email_add และแถวอื่น ๆ จะแสดงผลที่มี "Pune" เป็นส่วนหนึ่งของคอลัมน์ Postal_add ผลลัพธ์จะเป็นแถวทั่วไปจากทั้งสองชุดผลลัพธ์
u = intersect(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.postal_add.like('%Pune')))มีผลเทียบเท่ากับคำสั่ง SQL ต่อไปนี้ -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? INTERSECT SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.postal_add LIKE ?พารามิเตอร์สองตัวที่ถูกผูกไว้ '% gmail.com' และ '% Pune' สร้างแถวเดียวจากข้อมูลต้นฉบับในตารางที่อยู่ดังที่แสดงด้านล่าง -
[(1, 1, 'Shivajinagar Pune', '[email protected]')]วัตถุประสงค์หลักของ Object Relational Mapper API ของ SQLAlchemy คือเพื่ออำนวยความสะดวกในการเชื่อมโยงคลาส Python ที่ผู้ใช้กำหนดกับตารางฐานข้อมูลและอ็อบเจ็กต์ของคลาสเหล่านั้นกับแถวในตารางที่เกี่ยวข้อง การเปลี่ยนแปลงสถานะของวัตถุและแถวจะจับคู่กันแบบซิงโครนัส SQLAlchemy เปิดใช้งานการแสดงแบบสอบถามฐานข้อมูลในแง่ของคลาสที่ผู้ใช้กำหนดและความสัมพันธ์ที่กำหนดไว้
ORM สร้างขึ้นที่ด้านบนของ SQL Expression Language เป็นรูปแบบการใช้งานระดับสูงและเป็นนามธรรม ในความเป็นจริง ORM คือการใช้งาน Expression Language
แม้ว่าแอปพลิเคชันที่ประสบความสำเร็จอาจสร้างขึ้นโดยใช้ Object Relational Mapper เท่านั้นบางครั้งแอปพลิเคชันที่สร้างด้วย ORM อาจใช้ Expression Language โดยตรงซึ่งจำเป็นต้องมีการโต้ตอบกับฐานข้อมูล
ประกาศการแมป
ประการแรกฟังก์ชัน create_engine () ถูกเรียกเพื่อตั้งค่าอ็อบเจ็กต์เอ็นจินซึ่งจะใช้ในการดำเนินการ SQL ในภายหลัง ฟังก์ชันมีสองอาร์กิวเมนต์หนึ่งคือชื่อของฐานข้อมูลและอื่น ๆ เป็นพารามิเตอร์ echo เมื่อตั้งค่าเป็น True จะสร้างบันทึกกิจกรรม หากไม่มีอยู่ฐานข้อมูลจะถูกสร้างขึ้น ในตัวอย่างต่อไปนี้ฐานข้อมูล SQLite ถูกสร้างขึ้น
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)Engine จะสร้างการเชื่อมต่อ DBAPI จริงกับฐานข้อมูลเมื่อมีการเรียกใช้เมธอดเช่น Engine.execute () หรือ Engine.connect () จากนั้นจะใช้เพื่อปล่อย SQLORM ซึ่งไม่ได้ใช้ Engine โดยตรง ORM ใช้อยู่เบื้องหลังแทน
ในกรณีของ ORM กระบวนการกำหนดค่าเริ่มต้นด้วยการอธิบายตารางฐานข้อมูลจากนั้นกำหนดคลาสที่จะแมปกับตารางเหล่านั้น ใน SQLAlchemy งานทั้งสองนี้จะดำเนินการร่วมกัน สามารถทำได้โดยใช้ระบบ Declarative คลาสที่สร้างขึ้นมีคำสั่งเพื่ออธิบายตารางฐานข้อมูลจริงที่แมป
คลาสฐานเก็บ catlog ของคลาสและตารางที่แมปไว้ในระบบ Declarative สิ่งนี้เรียกว่าเป็นคลาสฐานที่ประกาศ โดยปกติจะมีเพียงหนึ่งอินสแตนซ์ของฐานนี้ในโมดูลที่นำเข้าโดยทั่วไป ฟังก์ชัน declarative_base () ใช้เพื่อสร้างคลาสพื้นฐาน ฟังก์ชันนี้กำหนดไว้ในโมดูล sqlalchemy.ext.declarative
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()เมื่อประกาศคลาสพื้นฐานแล้วสามารถกำหนดคลาสที่แมปจำนวนเท่าใดก็ได้ในแง่ของคลาสนั้น รหัสต่อไปนี้กำหนดคลาสของลูกค้า ประกอบด้วยตารางที่จะแมปและชื่อและประเภทข้อมูลของคอลัมน์ในนั้น
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)คลาสใน Declarative ต้องมี __tablename__ แอตทริบิวต์และอย่างน้อยหนึ่งรายการ Columnซึ่งเป็นส่วนหนึ่งของคีย์หลัก Declarative แทนที่ไฟล์Column วัตถุที่มีตัวเข้าถึง Python พิเศษที่เรียกว่า descriptors. กระบวนการนี้เรียกว่าเครื่องมือวัดซึ่งให้วิธีการอ้างถึงตารางในบริบท SQL และเปิดใช้งานการคงอยู่และโหลดค่าของคอลัมน์จากฐานข้อมูล
คลาสที่แมปนี้เหมือนกับคลาส Python ทั่วไปมีคุณสมบัติและวิธีการตามความต้องการ
ข้อมูลเกี่ยวกับคลาสในระบบ Declarative เรียกว่าเป็นข้อมูลเมตาของตาราง SQLAlchemy ใช้วัตถุ Table เพื่อแสดงข้อมูลนี้สำหรับตารางเฉพาะที่สร้างโดย Declarative วัตถุ Table ถูกสร้างขึ้นตามข้อกำหนดและเชื่อมโยงกับคลาสโดยสร้างอ็อบเจ็กต์ Mapper อ็อบเจ็กต์การทำแผนที่นี้ไม่ได้ใช้โดยตรง แต่ใช้ภายในเป็นส่วนต่อประสานระหว่างคลาสที่แมปและตาราง
วัตถุ Table แต่ละชิ้นเป็นสมาชิกของคอลเลกชันขนาดใหญ่ที่เรียกว่า MetaData และวัตถุนี้พร้อมใช้งานโดยใช้ไฟล์ .metadataแอตทริบิวต์ของคลาสฐานที่เปิดเผย MetaData.create_all()วิธีการคือการส่งผ่านใน Engine ของเราเป็นแหล่งที่มาของการเชื่อมต่อฐานข้อมูล สำหรับตารางทั้งหมดที่ยังไม่ได้สร้างจะออกคำสั่ง CREATE TABLE ไปยังฐานข้อมูล
Base.metadata.create_all(engine)สคริปต์ที่สมบูรณ์ในการสร้างฐานข้อมูลและตารางและการแมปคลาส Python ได้รับด้านล่าง -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
Base.metadata.create_all(engine)เมื่อดำเนินการ Python console จะสะท้อนหลังจากการดำเนินการนิพจน์ SQL -
CREATE TABLE customers (
id INTEGER NOT NULL,
name VARCHAR,
address VARCHAR,
email VARCHAR,
PRIMARY KEY (id)
)หากเราเปิด Sales.db โดยใช้เครื่องมือกราฟิก SQLiteStudio จะแสดงตารางลูกค้าที่อยู่ข้างในพร้อมด้วยโครงสร้างที่กล่าวถึงข้างต้น

ในการโต้ตอบกับฐานข้อมูลเราจำเป็นต้องได้รับหมายเลขอ้างอิง วัตถุเซสชันเป็นตัวจัดการฐานข้อมูล คลาสเซสชันถูกกำหนดโดยใช้ sessionmaker () - เมธอดโรงงานเซสชันที่กำหนดค่าได้ซึ่งถูกผูกไว้กับอ็อบเจ็กต์เอ็นจินที่สร้างขึ้นก่อนหน้านี้
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)จากนั้นวัตถุเซสชันจะถูกตั้งค่าโดยใช้ตัวสร้างเริ่มต้นดังนี้ -
session = Session()วิธีการบางอย่างของคลาสเซสชันที่จำเป็นต้องใช้บ่อยมีดังต่อไปนี้ -
| ซีเนียร์ | วิธีการและคำอธิบาย |
|---|---|
| 1 | begin() เริ่มต้นธุรกรรมในเซสชันนี้ |
| 2 | add() วางวัตถุในเซสชัน สถานะของมันยังคงอยู่ในฐานข้อมูลในการดำเนินการล้างครั้งต่อไป |
| 3 | add_all() เพิ่มคอลเลกชันของวัตถุในเซสชัน |
| 4 | commit() ล้างรายการทั้งหมดและธุรกรรมที่อยู่ระหว่างดำเนินการ |
| 5 | delete() ทำเครื่องหมายธุรกรรมว่าถูกลบ |
| 6 | execute() เรียกใช้นิพจน์ SQL |
| 7 | expire() ทำเครื่องหมายแอตทริบิวต์ของอินสแตนซ์ว่าล้าสมัย |
| 8 | flush() ล้างการเปลี่ยนแปลงวัตถุทั้งหมดไปยังฐานข้อมูล |
| 9 | invalidate() ปิดเซสชันโดยใช้การยกเลิกการเชื่อมต่อ |
| 10 | rollback() ย้อนกลับธุรกรรมปัจจุบันที่อยู่ระหว่างดำเนินการ |
| 11 | close() ปิดเซสชันปัจจุบันโดยการล้างรายการทั้งหมดและสิ้นสุดธุรกรรมที่อยู่ระหว่างดำเนินการ |
ในบทก่อนหน้าของ SQLAlchemy ORM เราได้เรียนรู้วิธีการประกาศการแมปและสร้างเซสชัน ในบทนี้เราจะเรียนรู้วิธีการเพิ่มวัตถุลงในตาราง
เราได้ประกาศคลาสลูกค้าที่แมปกับตารางลูกค้าแล้ว เราต้องประกาศออบเจ็กต์ของคลาสนี้และเพิ่มลงในตารางอย่างต่อเนื่องโดยวิธีการ add () ของวัตถุเซสชัน
c1 = Sales(name = 'Ravi Kumar', address = 'Station Road Nanded', email = '[email protected]')
session.add(c1)โปรดทราบว่าธุรกรรมนี้กำลังรอดำเนินการจนกว่าจะมีการล้างข้อมูลโดยใช้วิธีการกระทำ ()
session.commit()ต่อไปนี้เป็นสคริปต์ที่สมบูรณ์เพื่อเพิ่มบันทึกในตารางลูกค้า -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
c1 = Customers(name = 'Ravi Kumar', address = 'Station Road Nanded', email = '[email protected]')
session.add(c1)
session.commit()เราสามารถใช้ไฟล์ add_all() วิธีการของคลาสเซสชัน
session.add_all([
Customers(name = 'Komal Pande', address = 'Koti, Hyderabad', email = '[email protected]'),
Customers(name = 'Rajender Nath', address = 'Sector 40, Gurgaon', email = '[email protected]'),
Customers(name = 'S.M.Krishna', address = 'Budhwar Peth, Pune', email = '[email protected]')]
)
session.commit()มุมมองตารางของ SQLiteStudio แสดงว่ามีการเพิ่มระเบียนอย่างต่อเนื่องในตารางลูกค้า ภาพต่อไปนี้แสดงผลลัพธ์ -
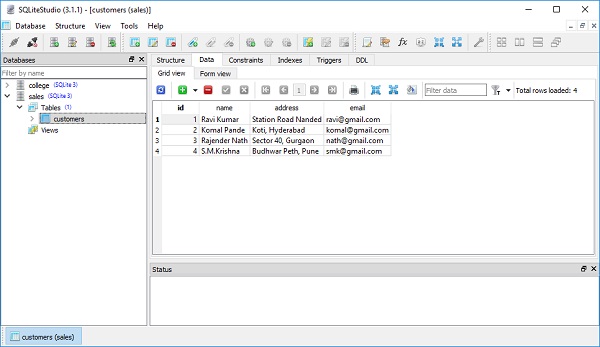
คำสั่ง SELECT ทั้งหมดที่สร้างโดย SQLAlchemy ORM สร้างโดย Query object มันมีอินเทอร์เฟซแบบกำเนิดดังนั้นการเรียกที่ต่อเนื่องจะส่งคืนอ็อบเจ็กต์ Query ใหม่สำเนาของเดิมพร้อมเกณฑ์และตัวเลือกเพิ่มเติมที่เกี่ยวข้อง
เริ่มแรกวัตถุแบบสอบถามถูกสร้างขึ้นโดยใช้เมธอด query () ของ Session ดังต่อไปนี้ -
q = session.query(mapped class)คำสั่งต่อไปนี้เทียบเท่ากับข้อความข้างต้น -
q = Query(mappedClass, session)ออบเจ็กต์คิวรีมีเมธอด all () ซึ่งส่งคืนชุดผลลัพธ์ในรูปแบบของรายการวัตถุ หากเราดำเนินการบนโต๊ะลูกค้าของเรา -
result = session.query(Customers).all()คำสั่งนี้มีประสิทธิภาพเทียบเท่ากับนิพจน์ SQL ต่อไปนี้ -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customersอ็อบเจ็กต์ผลลัพธ์สามารถข้ามผ่านได้โดยใช้ For loop ด้านล่างเพื่อรับเร็กคอร์ดทั้งหมดในตารางลูกค้าอ้างอิง นี่คือรหัสที่สมบูรณ์เพื่อแสดงบันทึกทั้งหมดในตารางลูกค้า -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
result = session.query(Customers).all()
for row in result:
print ("Name: ",row.name, "Address:",row.address, "Email:",row.email)Python console แสดงรายการบันทึกดังต่อไปนี้ -
Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
Name: Komal Pande Address: Koti, Hyderabad Email: [email protected]
Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]วัตถุ Query ยังมีวิธีการที่มีประโยชน์ดังต่อไปนี้ -
| ซีเนียร์ | วิธีการและคำอธิบาย |
|---|---|
| 1 | add_columns() จะเพิ่มนิพจน์คอลัมน์อย่างน้อยหนึ่งรายการในรายการคอลัมน์ผลลัพธ์ที่จะส่งคืน |
| 2 | add_entity() เพิ่มเอนทิตีที่แมปลงในรายการคอลัมน์ผลลัพธ์ที่จะส่งคืน |
| 3 | count() ส่งคืนจำนวนแถวที่ Query นี้จะส่งคืน |
| 4 | delete() ดำเนินการค้นหาลบจำนวนมาก ลบแถวที่ตรงกับแบบสอบถามนี้จากฐานข้อมูล |
| 5 | distinct() ใช้ส่วนคำสั่ง DISTINCT กับแบบสอบถามและส่งคืนแบบสอบถามที่เป็นผลลัพธ์ใหม่ |
| 6 | filter() ใช้เกณฑ์การกรองที่กำหนดกับสำเนาของแบบสอบถามนี้โดยใช้นิพจน์ SQL |
| 7 | first() จะส่งคืนผลลัพธ์แรกของแบบสอบถามนี้หรือไม่มีหากผลลัพธ์ไม่มีแถวใด ๆ |
| 8 | get() ส่งคืนอินสแตนซ์ตามตัวระบุคีย์หลักที่กำหนดซึ่งให้การเข้าถึงโดยตรงไปยังแผนที่ข้อมูลประจำตัวของเซสชันที่เป็นเจ้าของ |
| 9 | group_by() ใช้เกณฑ์ GROUP BY อย่างน้อยหนึ่งรายการกับแบบสอบถามและส่งคืนแบบสอบถามที่เป็นผลลัพธ์ใหม่ |
| 10 | join() สร้างการเข้าร่วม SQL กับเกณฑ์ของวัตถุแบบสอบถามนี้และใช้โดยกำเนิดโดยส่งคืนแบบสอบถามที่เป็นผลลัพธ์ใหม่ |
| 11 | one() จะส่งกลับผลลัพธ์เดียวหรือเพิ่มข้อยกเว้น |
| 12 | order_by() ใช้เกณฑ์ ORDER BY อย่างน้อยหนึ่งรายการกับแบบสอบถามและส่งคืนแบบสอบถามที่เป็นผลลัพธ์ใหม่ |
| 13 | update() ดำเนินการแบบสอบถามการอัปเดตจำนวนมากและอัปเดตแถวที่ตรงกับแบบสอบถามนี้ในฐานข้อมูล |
ในบทนี้เราจะดูวิธีแก้ไขหรือปรับปรุงตารางด้วยค่าที่ต้องการ
ในการแก้ไขข้อมูลของแอตทริบิวต์บางอย่างของวัตถุใด ๆ เราต้องกำหนดค่าใหม่ให้กับมันและยอมรับการเปลี่ยนแปลงเพื่อให้การเปลี่ยนแปลงคงอยู่
ให้เราดึงวัตถุจากตารางที่มีตัวระบุคีย์หลักในตารางลูกค้าของเราด้วย ID = 2 เราสามารถใช้ get () method ของ session ได้ดังนี้ -
x = session.query(Customers).get(2)เราสามารถแสดงเนื้อหาของวัตถุที่เลือกด้วยรหัสที่กำหนดด้านล่าง -
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)จากตารางลูกค้าของเราควรแสดงผลลัพธ์ต่อไปนี้ -
Name: Komal Pande Address: Koti, Hyderabad Email: [email protected]ตอนนี้เราต้องอัปเดตช่องที่อยู่โดยกำหนดค่าใหม่ตามที่ระบุด้านล่าง -
x.address = 'Banjara Hills Secunderabad'
session.commit()การเปลี่ยนแปลงจะปรากฏในฐานข้อมูลอย่างต่อเนื่อง ตอนนี้เราดึงวัตถุที่ตรงกับแถวแรกในตารางโดยใช้first() method ดังต่อไปนี้ -
x = session.query(Customers).first()สิ่งนี้จะเรียกใช้นิพจน์ SQL ต่อไปนี้ -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
LIMIT ? OFFSET ?พารามิเตอร์ที่ถูกผูกไว้จะเป็น LIMIT = 1 และ OFFSET = 0 ตามลำดับซึ่งหมายความว่าจะเลือกแถวแรก
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)ตอนนี้ผลลัพธ์สำหรับโค้ดด้านบนที่แสดงแถวแรกมีดังนี้ -
Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]ตอนนี้เปลี่ยนแอตทริบิวต์ชื่อและแสดงเนื้อหาโดยใช้รหัสด้านล่าง -
x.name = 'Ravi Shrivastava'
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)ผลลัพธ์ของโค้ดด้านบนคือ -
Name: Ravi Shrivastava Address: Station Road Nanded Email: [email protected]แม้ว่าการเปลี่ยนแปลงจะปรากฏขึ้น แต่ก็ไม่ได้มุ่งมั่น คุณสามารถรักษาตำแหน่งถาวรก่อนหน้านี้ได้โดยใช้rollback() method ด้วยรหัสด้านล่าง
session.rollback()
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)เนื้อหาต้นฉบับของบันทึกแรกจะปรากฏขึ้น
สำหรับการอัปเดตจำนวนมากเราจะใช้เมธอด update () ของ Query object ให้เราลองใส่คำนำหน้าว่า 'Mr. ' เพื่อตั้งชื่อในแต่ละแถว (ยกเว้น ID = 2) คำสั่ง update () ที่เกี่ยวข้องมีดังนี้ -
session.query(Customers).filter(Customers.id! = 2).
update({Customers.name:"Mr."+Customers.name}, synchronize_session = False)The update() method requires two parameters as follows −
พจนานุกรมของคีย์ - ค่าที่มีคีย์เป็นแอตทริบิวต์ที่จะอัปเดตและค่าเป็นเนื้อหาใหม่ของแอตทริบิวต์
synchronize_session แอตทริบิวต์ที่กล่าวถึงกลยุทธ์ในการอัปเดตแอตทริบิวต์ในเซสชัน ค่าที่ถูกต้องเป็นเท็จ: สำหรับการไม่ซิงโครไนซ์เซสชันการดึงข้อมูล: ดำเนินการเคียวรีแบบเลือกก่อนการอัพเดตเพื่อค้นหาอ็อบเจ็กต์ที่ตรงกับคิวรีอัพเดต และประเมิน: ประเมินเกณฑ์เกี่ยวกับวัตถุในเซสชัน
สามใน 4 แถวในตารางจะมีชื่อขึ้นต้นด้วย 'Mr. ' อย่างไรก็ตามการเปลี่ยนแปลงจะไม่เกิดขึ้นและจะไม่ปรากฏในมุมมองตารางของ SQLiteStudio จะรีเฟรชเมื่อเราคอมมิตเซสชันเท่านั้น
ในบทนี้เราจะพูดถึงวิธีการใช้ตัวกรองและการดำเนินการกรองบางอย่างพร้อมกับรหัส
ชุดผลลัพธ์ที่แสดงโดยวัตถุแบบสอบถามสามารถอยู่ภายใต้เกณฑ์บางอย่างโดยใช้วิธีการกรอง () การใช้วิธีการกรองโดยทั่วไปมีดังนี้ -
session.query(class).filter(criteria)ในตัวอย่างต่อไปนี้ผลลัพธ์ที่ได้จากแบบสอบถาม SELECT ในตารางลูกค้าจะถูกกรองโดยเงื่อนไข (ID> 2) -
result = session.query(Customers).filter(Customers.id>2)คำสั่งนี้จะแปลเป็นนิพจน์ SQL ต่อไปนี้ -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ?เนื่องจากพารามิเตอร์ที่ถูกผูกไว้ (?) ถูกกำหนดให้เป็น 2 จะแสดงเฉพาะแถวที่มีคอลัมน์ ID> 2 เท่านั้น รหัสที่สมบูรณ์ได้รับด้านล่าง -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
result = session.query(Customers).filter(Customers.id>2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)ผลลัพธ์ที่แสดงในคอนโซล Python มีดังต่อไปนี้ -
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]ตอนนี้เราจะเรียนรู้การดำเนินการกรองด้วยรหัสและเอาต์พุตตามลำดับ
เท่ากับ
ตัวดำเนินการปกติที่ใช้คือ == และใช้เกณฑ์เพื่อตรวจสอบความเท่าเทียมกัน
result = session.query(Customers).filter(Customers.id == 2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)SQLAlchemy จะส่งนิพจน์ SQL ต่อไปนี้ -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?ผลลัพธ์สำหรับโค้ดด้านบนมีดังนี้ -
ID: 2 Name: Komal Pande Address: Banjara Hills Secunderabad Email: [email protected]ไม่เท่ากับ
ตัวดำเนินการที่ใช้ไม่เท่ากับคือ! = และให้ค่าไม่เท่ากับเกณฑ์
result = session.query(Customers).filter(Customers.id! = 2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)นิพจน์ SQL ที่ได้คือ -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id != ?ผลลัพธ์สำหรับบรรทัดด้านบนของโค้ดมีดังนี้ -
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]ชอบ
like () method สร้างเกณฑ์ LIKE สำหรับ WHERE clause ในนิพจน์ SELECT
result = session.query(Customers).filter(Customers.name.like('Ra%'))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)เหนือโค้ด SQLAlchemy เทียบเท่ากับนิพจน์ SQL ต่อไปนี้ -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name LIKE ?และผลลัพธ์สำหรับโค้ดด้านบนคือ -
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]ใน
ตัวดำเนินการนี้ตรวจสอบว่าค่าคอลัมน์เป็นของคอลเลกชันของรายการในรายการหรือไม่ จัดทำโดย in_ () วิธีการ
result = session.query(Customers).filter(Customers.id.in_([1,3]))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)ที่นี่นิพจน์ SQL ที่ประเมินโดยเอ็นจิ้น SQLite จะเป็นดังนี้ -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id IN (?, ?)ผลลัพธ์สำหรับโค้ดด้านบนมีดังนี้ -
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]และ
การเชื่อมต่อนี้สร้างขึ้นโดย putting multiple commas separated criteria in the filter or using and_() method ตามที่ระบุด้านล่าง -
result = session.query(Customers).filter(Customers.id>2, Customers.name.like('Ra%'))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)from sqlalchemy import and_
result = session.query(Customers).filter(and_(Customers.id>2, Customers.name.like('Ra%')))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)ทั้งสองวิธีข้างต้นทำให้เกิดนิพจน์ SQL ที่คล้ายกัน -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ? AND customers.name LIKE ?ผลลัพธ์สำหรับบรรทัดด้านบนของโค้ดคือ -
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]หรือ
การเชื่อมต่อนี้ดำเนินการโดย or_() method.
from sqlalchemy import or_
result = session.query(Customers).filter(or_(Customers.id>2, Customers.name.like('Ra%')))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)เป็นผลให้เอ็นจิ้น SQLite ได้รับตามนิพจน์ SQL ที่เทียบเท่า -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ? OR customers.name LIKE ?ผลลัพธ์สำหรับโค้ดด้านบนมีดังนี้ -
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]มีหลายวิธีของวัตถุแบบสอบถามที่ออก SQL ทันทีและส่งคืนค่าที่มีผลลัพธ์ฐานข้อมูลที่โหลด
นี่คือสรุปสั้น ๆ ของรายการส่งคืนและสเกลาร์ -
ทั้งหมด()
ส่งคืนรายการ ระบุไว้ด้านล่างคือบรรทัดของรหัสสำหรับฟังก์ชัน all ()
session.query(Customers).all()คอนโซล Python แสดงนิพจน์ SQL ที่ปล่อยออกมา -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customersแรก ()
ใช้ขีด จำกัด หนึ่งรายการและส่งคืนผลลัพธ์แรกเป็นสเกลาร์
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
LIMIT ? OFFSET ?พารามิเตอร์ที่ถูกผูกไว้สำหรับ LIMIT คือ 1 และสำหรับ OFFSET คือ 0
หนึ่ง()
คำสั่งนี้ดึงข้อมูลแถวทั้งหมดอย่างสมบูรณ์และหากไม่มีข้อมูลประจำตัวของอ็อบเจ็กต์หรือแถวคอมโพสิตที่ปรากฏอยู่ในผลลัพธ์จะทำให้เกิดข้อผิดพลาด
session.query(Customers).one()พบหลายแถว -
MultipleResultsFound: Multiple rows were found for one()ไม่พบแถว -
NoResultFound: No row was found for one()วิธี one () มีประโยชน์สำหรับระบบที่คาดว่าจะจัดการ“ ไม่พบรายการ” กับ“ พบหลายรายการ” แตกต่างกัน
สเกลาร์ ()
มันเรียกใช้เมธอด one () และเมื่อสำเร็จจะส่งกลับคอลัมน์แรกของแถวดังนี้ -
session.query(Customers).filter(Customers.id == 3).scalar()สิ่งนี้สร้างคำสั่ง SQL ต่อไปนี้ -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?ก่อนหน้านี้ข้อความ SQL ที่ใช้ฟังก์ชัน text () ได้รับการอธิบายจากมุมมองของภาษานิพจน์หลักของ SQLAlchemy ตอนนี้เราจะพูดคุยจากมุมมองของ ORM
สตริงตัวอักษรสามารถใช้ได้อย่างยืดหยุ่นกับวัตถุ Query โดยระบุการใช้งานด้วยโครงสร้าง text () วิธีการที่ใช้ได้ส่วนใหญ่ยอมรับ ตัวอย่างเช่น filter () และ order_by ()
ในตัวอย่างด้านล่างนี้วิธีการ filter () จะแปลสตริง“ id <3” เป็น WHERE id <3
from sqlalchemy import text
for cust in session.query(Customers).filter(text("id<3")):
print(cust.name)นิพจน์ SQL ดิบที่สร้างขึ้นแสดงการแปลงตัวกรองเป็นส่วนคำสั่ง WHERE พร้อมรหัสที่แสดงด้านล่าง -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE id<3จากข้อมูลตัวอย่างของเราในตารางลูกค้าจะมีการเลือกสองแถวและคอลัมน์ชื่อจะถูกพิมพ์ดังนี้ -
Ravi Kumar
Komal Pandeในการระบุพารามิเตอร์การผูกด้วย SQL แบบสตริงให้ใช้โคลอนและเพื่อระบุค่าให้ใช้เมธอด params ()
cust = session.query(Customers).filter(text("id = :value")).params(value = 1).one()SQL ที่มีประสิทธิภาพที่แสดงบนคอนโซล Python จะเป็นดังที่ระบุด้านล่าง -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE id = ?ในการใช้คำสั่งแบบสตริงทั้งหมดข้อความ () สร้างแทนคำสั่งที่สมบูรณ์สามารถส่งผ่านไปยัง from_statement ()
session.query(Customers).from_statement(text("SELECT * FROM customers")).all()ผลลัพธ์ของโค้ดด้านบนจะเป็นคำสั่ง SELECT พื้นฐานตามที่ระบุด้านล่าง -
SELECT * FROM customersเห็นได้ชัดว่าระเบียนทั้งหมดในตารางลูกค้าจะถูกเลือก
โครงสร้าง text () ช่วยให้เราสามารถเชื่อมโยง SQL ที่เป็นข้อความกับนิพจน์คอลัมน์ Core หรือ ORM ที่แมปได้ในตำแหน่ง เราสามารถบรรลุสิ่งนี้ได้โดยส่งนิพจน์คอลัมน์เป็นอาร์กิวเมนต์ตำแหน่งไปยังเมธอด TextClause.columns ()
stmt = text("SELECT name, id, name, address, email FROM customers")
stmt = stmt.columns(Customers.id, Customers.name)
session.query(Customers.id, Customers.name).from_statement(stmt).all()คอลัมน์ id และชื่อของแถวทั้งหมดจะถูกเลือกแม้ว่าเอ็นจิ้น SQLite จะเรียกใช้นิพจน์ต่อไปนี้ที่สร้างโดยโค้ดด้านบนจะแสดงคอลัมน์ทั้งหมดในเมธอด text () -
SELECT name, id, name, address, email FROM customersเซสชันนี้อธิบายถึงการสร้างตารางอื่นซึ่งเกี่ยวข้องกับตารางที่มีอยู่แล้วในฐานข้อมูลของเรา ตารางลูกค้ามีข้อมูลหลักของลูกค้า ตอนนี้เราจำเป็นต้องสร้างตารางใบแจ้งหนี้ซึ่งอาจมีใบแจ้งหนี้จำนวนเท่าใดก็ได้ที่เป็นของลูกค้า นี่เป็นกรณีของความสัมพันธ์แบบหนึ่งถึงหลาย ๆ
โดยใช้การประกาศเรากำหนดตารางนี้พร้อมกับคลาสที่แมปใบแจ้งหนี้ตามที่ระบุด้านล่าง -
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = 'invoices'
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey('customers.id'))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")
Base.metadata.create_all(engine)สิ่งนี้จะส่งแบบสอบถาม CREATE TABLE ไปยังเครื่องมือ SQLite ดังต่อไปนี้ -
CREATE TABLE invoices (
id INTEGER NOT NULL,
custid INTEGER,
invno INTEGER,
amount INTEGER,
PRIMARY KEY (id),
FOREIGN KEY(custid) REFERENCES customers (id)
)เราสามารถตรวจสอบได้ว่าตารางใหม่ถูกสร้างขึ้นใน sales.db ด้วยความช่วยเหลือของเครื่องมือ SQLiteStudio
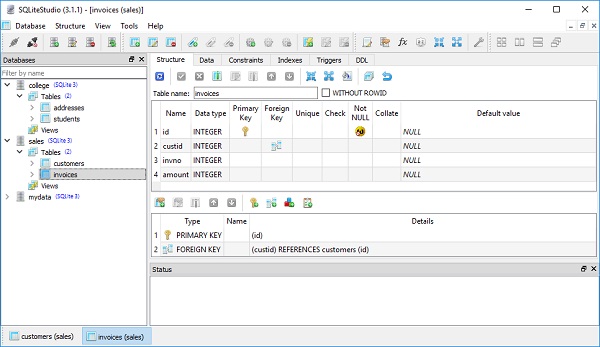
คลาสใบแจ้งหนี้ใช้โครงสร้าง ForeignKey บนแอตทริบิวต์ custid คำสั่งนี้ระบุว่าค่าในคอลัมน์นี้ควรถูก จำกัด ให้เป็นค่าที่มีอยู่ในคอลัมน์รหัสในตารางลูกค้า นี่เป็นคุณสมบัติหลักของฐานข้อมูลเชิงสัมพันธ์และเป็น "กาว" ที่เปลี่ยนชุดตารางที่ไม่เชื่อมต่อให้มีความสัมพันธ์ที่ทับซ้อนกัน
คำสั่งที่สองเรียกว่า relationship () บอก ORM ว่าคลาส Invoice ควรเชื่อมโยงกับคลาส Customer โดยใช้แอตทริบิวต์ Invoice.customer ความสัมพันธ์ () ใช้ความสัมพันธ์ของคีย์ต่างประเทศระหว่างสองตารางเพื่อกำหนดลักษณะของการเชื่อมโยงนี้โดยพิจารณาว่าเป็นแบบหลายต่อหนึ่ง
คำสั่งความสัมพันธ์เพิ่มเติม () วางอยู่บนคลาสที่แมปลูกค้าภายใต้แอตทริบิวต์ Customer.invoices พารามิเตอร์ relationship.back_populate ถูกกำหนดให้อ้างถึงชื่อแอตทริบิวต์เสริมเพื่อให้แต่ละความสัมพันธ์ () สามารถตัดสินใจได้อย่างชาญฉลาดเกี่ยวกับความสัมพันธ์เดียวกันโดยแสดงในสิ่งที่ตรงกันข้าม ในด้านหนึ่งใบแจ้งหนี้ลูกค้าหมายถึงอินสแตนซ์ใบแจ้งหนี้และอีกด้านหนึ่ง Customer.invoices หมายถึงรายการอินสแตนซ์ของลูกค้า
ฟังก์ชันความสัมพันธ์เป็นส่วนหนึ่งของ Relationship API ของแพ็คเกจ SQLAlchemy ORM มีความสัมพันธ์ระหว่างคลาสที่แมปสองคลาส สิ่งนี้สอดคล้องกับความสัมพันธ์ของตารางแม่ลูกหรือตารางการเชื่อมโยง
ต่อไปนี้เป็นรูปแบบความสัมพันธ์พื้นฐานที่พบ -
หนึ่งต่อหลาย
ความสัมพันธ์แบบหนึ่งต่อกลุ่มหมายถึงผู้ปกครองโดยใช้คีย์ต่างประเทศบนตารางรอง จากนั้นจะระบุความสัมพันธ์ () บนพาเรนต์โดยอ้างถึงคอลเล็กชันของไอเท็มที่แสดงโดยเด็ก พารามิเตอร์ relationship.back_populate ใช้เพื่อสร้างความสัมพันธ์แบบสองทิศทางแบบหนึ่งต่อกลุ่มโดยที่ด้าน "ย้อนกลับ" เป็นแบบหลายต่อหนึ่ง
หลายต่อหนึ่ง
ในทางกลับกันความสัมพันธ์แบบ Many to One จะวางคีย์ต่างประเทศในตารางหลักเพื่ออ้างถึงเด็ก ความสัมพันธ์ () ถูกประกาศบนพาเรนต์ซึ่งจะมีการสร้างแอตทริบิวต์การถือสเกลาร์ใหม่ ที่นี่อีกครั้งใช้พารามิเตอร์ relationship.back_populate สำหรับ Bidirectionalbehaviour
หนึ่งต่อหนึ่ง
ความสัมพันธ์แบบวันทูวันเป็นความสัมพันธ์แบบสองทิศทางโดยธรรมชาติ ค่าสถานะ uselist ระบุตำแหน่งของแอตทริบิวต์สเกลาร์แทนที่จะเป็นคอลเลกชันที่ด้าน "จำนวนมาก" ของความสัมพันธ์ ในการแปลงหนึ่งต่อกลุ่มเป็นความสัมพันธ์ประเภทหนึ่งต่อหนึ่งให้ตั้งค่าพารามิเตอร์ uselist เป็น false
หลายต่อหลายคน
ความสัมพันธ์แบบกลุ่มต่อกลุ่มมากถูกสร้างขึ้นโดยการเพิ่มตารางการเชื่อมโยงที่เกี่ยวข้องกับสองคลาสโดยการกำหนดคุณสมบัติด้วยคีย์ต่างประเทศ มันถูกระบุโดยอาร์กิวเมนต์รองกับความสัมพันธ์ () โดยปกติตารางจะใช้ออบเจ็กต์ MetaData ที่เชื่อมโยงกับคลาสฐานที่ประกาศเพื่อให้คำสั่ง ForeignKey สามารถค้นหาตารางระยะไกลที่จะเชื่อมโยง พารามิเตอร์ relationship.back_populate สำหรับแต่ละความสัมพันธ์ () สร้างความสัมพันธ์แบบสองทิศทาง ทั้งสองด้านของความสัมพันธ์ประกอบด้วยคอลเลกชัน
ในบทนี้เราจะเน้นที่วัตถุที่เกี่ยวข้องใน SQLAlchemy ORM
ตอนนี้เมื่อเราสร้างวัตถุของลูกค้าคอลเลกชันใบแจ้งหนี้เปล่าจะปรากฏในรูปแบบของ Python List
c1 = Customer(name = "Gopal Krishna", address = "Bank Street Hydarebad", email = "[email protected]")แอตทริบิวต์ใบแจ้งหนี้ของ c1.invoices จะเป็นรายการว่างเปล่า เราสามารถกำหนดรายการในรายการเป็น -
c1.invoices = [Invoice(invno = 10, amount = 15000), Invoice(invno = 14, amount = 3850)]ให้เราส่งวัตถุนี้ไปยังฐานข้อมูลโดยใช้วัตถุเซสชันดังนี้ -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
session.add(c1)
session.commit()สิ่งนี้จะสร้างคำค้นหา INSERT สำหรับลูกค้าและตารางใบแจ้งหนี้โดยอัตโนมัติ -
INSERT INTO customers (name, address, email) VALUES (?, ?, ?)
('Gopal Krishna', 'Bank Street Hydarebad', '[email protected]')
INSERT INTO invoices (custid, invno, amount) VALUES (?, ?, ?)
(2, 10, 15000)
INSERT INTO invoices (custid, invno, amount) VALUES (?, ?, ?)
(2, 14, 3850)ตอนนี้ให้เราดูเนื้อหาของตารางลูกค้าและตารางใบแจ้งหนี้ในมุมมองตารางของ SQLiteStudio -

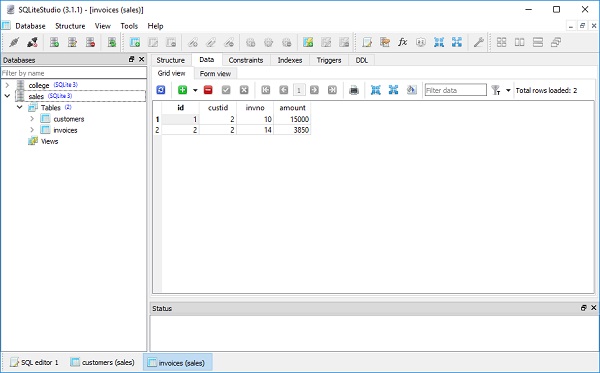
คุณสามารถสร้างออบเจ็กต์ของลูกค้าโดยระบุแอตทริบิวต์ที่แมปของใบแจ้งหนี้ในตัวสร้างเองโดยใช้คำสั่งด้านล่าง -
c2 = [
Customer(
name = "Govind Pant",
address = "Gulmandi Aurangabad",
email = "[email protected]",
invoices = [Invoice(invno = 3, amount = 10000),
Invoice(invno = 4, amount = 5000)]
)
]หรือรายการวัตถุที่จะเพิ่มโดยใช้ฟังก์ชัน add_all () ของวัตถุเซสชันดังแสดงด้านล่าง -
rows = [
Customer(
name = "Govind Kala",
address = "Gulmandi Aurangabad",
email = "[email protected]",
invoices = [Invoice(invno = 7, amount = 12000), Invoice(invno = 8, amount = 18500)]),
Customer(
name = "Abdul Rahman",
address = "Rohtak",
email = "[email protected]",
invoices = [Invoice(invno = 9, amount = 15000),
Invoice(invno = 11, amount = 6000)
])
]
session.add_all(rows)
session.commit()ตอนนี้เรามีสองตารางแล้วเราจะดูวิธีสร้างแบบสอบถามบนทั้งสองตารางในเวลาเดียวกัน ในการสร้างการรวมโดยนัยอย่างง่ายระหว่างลูกค้าและใบแจ้งหนี้เราสามารถใช้ Query.filter () เพื่อนำคอลัมน์ที่เกี่ยวข้องมารวมกัน ด้านล่างนี้เราโหลดเอนทิตีลูกค้าและใบแจ้งหนี้พร้อมกันโดยใช้วิธีนี้ -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for c, i in session.query(Customer, Invoice).filter(Customer.id == Invoice.custid).all():
print ("ID: {} Name: {} Invoice No: {} Amount: {}".format(c.id,c.name, i.invno, i.amount))นิพจน์ SQL ที่ปล่อยออกมาโดย SQLAlchemy มีดังนี้ -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email, invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM customers, invoices
WHERE customers.id = invoices.custidและผลลัพธ์ของบรรทัดข้างต้นของโค้ดมีดังนี้ -
ID: 2 Name: Gopal Krishna Invoice No: 10 Amount: 15000
ID: 2 Name: Gopal Krishna Invoice No: 14 Amount: 3850
ID: 3 Name: Govind Pant Invoice No: 3 Amount: 10000
ID: 3 Name: Govind Pant Invoice No: 4 Amount: 5000
ID: 4 Name: Govind Kala Invoice No: 7 Amount: 12000
ID: 4 Name: Govind Kala Invoice No: 8 Amount: 8500
ID: 5 Name: Abdul Rahman Invoice No: 9 Amount: 15000
ID: 5 Name: Abdul Rahman Invoice No: 11 Amount: 6000ไวยากรณ์ของ SQL JOIN จริงสามารถทำได้อย่างง่ายดายโดยใช้เมธอด Query.join () ดังต่อไปนี้ -
session.query(Customer).join(Invoice).filter(Invoice.amount == 8500).all()นิพจน์ SQL สำหรับการเข้าร่วมจะแสดงบนคอนโซล -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers JOIN invoices ON customers.id = invoices.custid
WHERE invoices.amount = ?เราสามารถวนซ้ำผลลัพธ์โดยใช้ for loop -
result = session.query(Customer).join(Invoice).filter(Invoice.amount == 8500)
for row in result:
for inv in row.invoices:
print (row.id, row.name, inv.invno, inv.amount)ด้วย 8500 เป็นพารามิเตอร์การผูกเอาต์พุตต่อไปนี้จะปรากฏขึ้น -
4 Govind Kala 8 8500Query.join () รู้วิธีเข้าร่วมระหว่างตารางเหล่านี้เนื่องจากมีคีย์ต่างประเทศเพียงหนึ่งคีย์ระหว่างกัน หากไม่มีคีย์ต่างประเทศหรือคีย์ต่างประเทศมากกว่า Query.join () จะทำงานได้ดีขึ้นเมื่อใช้รูปแบบใดรูปแบบหนึ่งต่อไปนี้ -
| query.join (ใบแจ้งหนี้ id == Address.custid) | เงื่อนไขที่ชัดเจน |
| query.join (Customer.invoices) | ระบุความสัมพันธ์จากซ้ายไปขวา |
| query.join (ใบแจ้งหนี้ Customer.invoices) | เหมือนกันกับเป้าหมายที่ชัดเจน |
| query.join ('ใบแจ้งหนี้') | เหมือนกันโดยใช้สตริง |
ฟังก์ชัน outerjoin () ในทำนองเดียวกันพร้อมใช้งานเพื่อให้ได้การรวมภายนอกด้านซ้าย
query.outerjoin(Customer.invoices)subquery () method สร้างนิพจน์ SQL ที่แสดงคำสั่ง SELECT ที่ฝังอยู่ภายในนามแฝง
from sqlalchemy.sql import func
stmt = session.query(
Invoice.custid, func.count('*').label('invoice_count')
).group_by(Invoice.custid).subquery()วัตถุ stmt จะมีคำสั่ง SQL ดังต่อไปนี้ -
SELECT invoices.custid, count(:count_1) AS invoice_count FROM invoices GROUP BY invoices.custidเมื่อเรามีคำสั่งของเรามันจะทำงานเหมือนการสร้างตาราง คอลัมน์ในคำสั่งสามารถเข้าถึงได้ผ่านแอตทริบิวต์ที่เรียกว่า c ดังที่แสดงในโค้ดด้านล่าง -
for u, count in session.query(Customer, stmt.c.invoice_count).outerjoin(stmt, Customer.id == stmt.c.custid).order_by(Customer.id):
print(u.name, count)ด้านบนสำหรับการวนรอบแสดงจำนวนใบแจ้งหนี้ตามชื่อดังนี้ -
Arjun Pandit None
Gopal Krishna 2
Govind Pant 2
Govind Kala 2
Abdul Rahman 2ในบทนี้เราจะพูดถึงตัวดำเนินการที่สร้างความสัมพันธ์
__eq __ ()
ตัวดำเนินการข้างต้นเป็นการเปรียบเทียบแบบ "เท่ากับ" แบบหลายต่อหนึ่ง บรรทัดรหัสสำหรับตัวดำเนินการนี้มีดังที่แสดงด้านล่าง -
s = session.query(Customer).filter(Invoice.invno.__eq__(12))แบบสอบถาม SQL ที่เทียบเท่าสำหรับบรรทัดด้านบนของโค้ดคือ -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers, invoices
WHERE invoices.invno = ?__ne __ ()
ตัวดำเนินการนี้เป็นการเปรียบเทียบแบบ "ไม่เท่ากับ" แบบหลายต่อหนึ่ง บรรทัดรหัสสำหรับตัวดำเนินการนี้มีดังที่แสดงด้านล่าง -
s = session.query(Customer).filter(Invoice.custid.__ne__(2))แบบสอบถาม SQL ที่เทียบเท่าสำหรับบรรทัดด้านบนของโค้ดได้รับด้านล่าง -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers, invoices
WHERE invoices.custid != ?ประกอบด้วย ()
ตัวดำเนินการนี้ใช้สำหรับคอลเลกชันแบบหนึ่งต่อหลายและระบุไว้ด้านล่างคือรหัสสำหรับมี () -
s = session.query(Invoice).filter(Invoice.invno.contains([3,4,5]))แบบสอบถาม SQL ที่เทียบเท่าสำหรับบรรทัดด้านบนของโค้ดคือ -
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE (invoices.invno LIKE '%' + ? || '%')ใด ๆ ()
ตัวดำเนินการใด ๆ () ใช้สำหรับคอลเลกชันดังที่แสดงด้านล่าง -
s = session.query(Customer).filter(Customer.invoices.any(Invoice.invno==11))แบบสอบถาม SQL ที่เทียบเท่าสำหรับบรรทัดด้านบนของโค้ดแสดงไว้ด้านล่าง -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE EXISTS (
SELECT 1
FROM invoices
WHERE customers.id = invoices.custid
AND invoices.invno = ?)มี ()
ตัวดำเนินการนี้ใช้สำหรับการอ้างอิงแบบสเกลาร์ดังนี้ -
s = session.query(Invoice).filter(Invoice.customer.has(name = 'Arjun Pandit'))แบบสอบถาม SQL ที่เทียบเท่าสำหรับบรรทัดด้านบนของโค้ดคือ -
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE EXISTS (
SELECT 1
FROM customers
WHERE customers.id = invoices.custid
AND customers.name = ?)การโหลดที่กระตือรือร้นช่วยลดจำนวนการสืบค้น SQLAlchemy นำเสนอฟังก์ชันการโหลดที่กระตือรือร้นที่เรียกใช้ผ่านตัวเลือกการสืบค้นซึ่งให้คำแนะนำเพิ่มเติมแก่แบบสอบถาม ตัวเลือกเหล่านี้กำหนดวิธีการโหลดแอตทริบิวต์ต่างๆผ่านเมธอด Query.options ()
โหลดแบบสอบถามย่อย
เราต้องการให้ Customer.invoices โหลดอย่างกระตือรือร้น อ็อพชัน orm.subqueryload () ให้คำสั่ง SELECT ที่สองที่โหลดคอลเลกชันที่เกี่ยวข้องกับผลลัพธ์ที่เพิ่งโหลดอย่างสมบูรณ์ ชื่อ“ เคียวรีย่อย” ทำให้คำสั่ง SELECT ถูกสร้างขึ้นโดยตรงผ่านคิวรีที่ใช้ซ้ำและฝังเป็นเคียวรีย่อยลงใน SELECT เทียบกับตารางที่เกี่ยวข้อง
from sqlalchemy.orm import subqueryload
c1 = session.query(Customer).options(subqueryload(Customer.invoices)).filter_by(name = 'Govind Pant').one()ผลลัพธ์ในสองนิพจน์ SQL ต่อไปนี้ -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?
('Govind Pant',)
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount, anon_1.customers_id
AS anon_1_customers_id
FROM (
SELECT customers.id
AS customers_id
FROM customers
WHERE customers.name = ?)
AS anon_1
JOIN invoices
ON anon_1.customers_id = invoices.custid
ORDER BY anon_1.customers_id, invoices.id 2018-06-25 18:24:47,479
INFO sqlalchemy.engine.base.Engine ('Govind Pant',)ในการเข้าถึงข้อมูลจากสองตารางเราสามารถใช้โปรแกรมด้านล่าง -
print (c1.name, c1.address, c1.email)
for x in c1.invoices:
print ("Invoice no : {}, Amount : {}".format(x.invno, x.amount))ผลลัพธ์ของโปรแกรมข้างต้นมีดังนี้ -
Govind Pant Gulmandi Aurangabad [email protected]
Invoice no : 3, Amount : 10000
Invoice no : 4, Amount : 5000เข้าร่วมโหลด
ฟังก์ชันอื่นเรียกว่า orm.joinedload () สิ่งนี้ส่งการเข้าร่วมด้านนอกด้านซ้าย วัตถุตะกั่วและวัตถุที่เกี่ยวข้องหรือคอลเลกชันถูกโหลดในขั้นตอนเดียว
from sqlalchemy.orm import joinedload
c1 = session.query(Customer).options(joinedload(Customer.invoices)).filter_by(name='Govind Pant').one()สิ่งนี้ส่งออกนิพจน์ต่อไปนี้โดยให้เอาต์พุตเช่นเดียวกับด้านบน -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email, invoices_1.id
AS invoices_1_id, invoices_1.custid
AS invoices_1_custid, invoices_1.invno
AS invoices_1_invno, invoices_1.amount
AS invoices_1_amount
FROM customers
LEFT OUTER JOIN invoices
AS invoices_1
ON customers.id = invoices_1.custid
WHERE customers.name = ? ORDER BY invoices_1.id
('Govind Pant',)OUTER JOIN ส่งผลให้เกิดแถวสองแถว แต่ให้ลูกค้ากลับมาหนึ่งอินสแตนซ์ เนื่องจาก Query ใช้กลยุทธ์ "uniquing" ตามเอกลักษณ์ของวัตถุกับเอนทิตีที่ส่งคืน สามารถใช้การโหลดร่วมอย่างกระตือรือร้นได้โดยไม่ส่งผลต่อผลลัพธ์การค้นหา
subqueryload () เหมาะสมกว่าสำหรับการโหลดคอลเลกชันที่เกี่ยวข้องในขณะที่ joinload () เหมาะกว่าสำหรับความสัมพันธ์แบบหลายต่อหนึ่ง
ง่ายต่อการดำเนินการลบบนตารางเดียว สิ่งที่คุณต้องทำคือลบอ็อบเจ็กต์ของคลาสที่แมปออกจากเซสชันและคอมมิตการดำเนินการ อย่างไรก็ตามการดำเนินการลบบนตารางที่เกี่ยวข้องหลายตารางนั้นยุ่งยากเล็กน้อย
ในฐานข้อมูล sales.db ของเราคลาสลูกค้าและใบแจ้งหนี้จะถูกแมปกับลูกค้าและตารางใบแจ้งหนี้ที่มีความสัมพันธ์แบบหนึ่งต่อหลายประเภท เราจะพยายามลบวัตถุของลูกค้าและดูผลลัพธ์
เพื่อเป็นข้อมูลอ้างอิงอย่างรวดเร็วด้านล่างนี้คือคำจำกัดความของคลาสลูกค้าและใบแจ้งหนี้ -
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = 'invoices'
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey('customers.id'))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")เราตั้งค่าเซสชันและรับวัตถุของลูกค้าโดยการค้นหาด้วยรหัสหลักโดยใช้โปรแกรมด้านล่าง -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
x = session.query(Customer).get(2)ในตารางตัวอย่างของเรา x.name เป็น 'Gopal Krishna' ให้เราลบ x นี้ออกจากเซสชันและนับการเกิดชื่อนี้
session.delete(x)
session.query(Customer).filter_by(name = 'Gopal Krishna').count()นิพจน์ SQL ที่ได้จะส่งกลับ 0
SELECT count(*)
AS count_1
FROM (
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?)
AS anon_1('Gopal Krishna',) 0อย่างไรก็ตามออบเจ็กต์ใบแจ้งหนี้ที่เกี่ยวข้องของ x ยังคงอยู่ที่นั่น สามารถตรวจสอบได้ด้วยรหัสต่อไปนี้ -
session.query(Invoice).filter(Invoice.invno.in_([10,14])).count()ในที่นี้ 10 และ 14 เป็นหมายเลขใบแจ้งหนี้ของลูกค้า Gopal Krishna ผลลัพธ์ของแบบสอบถามข้างต้นคือ 2 ซึ่งหมายความว่าวัตถุที่เกี่ยวข้องยังไม่ถูกลบ
SELECT count(*)
AS count_1
FROM (
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE invoices.invno IN (?, ?))
AS anon_1(10, 14) 2เนื่องจาก SQLAlchemy ไม่ถือว่าการลบ cascade; เราต้องให้คำสั่งเพื่อลบมัน
ในการเปลี่ยนลักษณะการทำงานเรากำหนดค่าตัวเลือกการเรียงซ้อนบนความสัมพันธ์ User.addresses ให้เราปิดเซสชันที่กำลังดำเนินอยู่ใช้ new declarative_base () และประกาศคลาสผู้ใช้อีกครั้งโดยเพิ่มความสัมพันธ์ที่อยู่รวมถึงการกำหนดค่าแบบเรียงซ้อน
แอ็ตทริบิวต์ cascade ในฟังก์ชันความสัมพันธ์คือรายการกฎการเรียงลำดับที่คั่นด้วยเครื่องหมายจุลภาคซึ่งกำหนดว่าการดำเนินการของเซสชันควร "เรียงซ้อน" จากระดับบนไปยังลูกอย่างไร โดยค่าเริ่มต้นจะเป็น False ซึ่งหมายความว่า "บันทึกอัปเดตผสาน"
น้ำตกที่มีอยู่มีดังนี้ -
- save-update
- merge
- expunge
- delete
- delete-orphan
- refresh-expire
ตัวเลือกที่มักใช้คือ "all, delete-orphan" เพื่อระบุว่าอ็อบเจ็กต์ที่เกี่ยวข้องควรตามมาพร้อมกับอ็อบเจ็กต์พาเรนต์ในทุกกรณีและจะถูกลบเมื่อยกเลิกการเชื่อมโยง
ดังนั้นคลาสลูกค้าที่ประกาศใหม่ดังแสดงด้านล่าง -
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
invoices = relationship(
"Invoice",
order_by = Invoice.id,
back_populates = "customer",
cascade = "all,
delete, delete-orphan"
)ให้เราลบลูกค้าที่มีชื่อ Gopal Krishna โดยใช้โปรแกรมด้านล่างและดูจำนวนวัตถุใบแจ้งหนี้ที่เกี่ยวข้อง -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
x = session.query(Customer).get(2)
session.delete(x)
session.query(Customer).filter_by(name = 'Gopal Krishna').count()
session.query(Invoice).filter(Invoice.invno.in_([10,14])).count()ตอนนี้จำนวนเป็น 0 พร้อมด้วย SQL ต่อไปนี้ที่ปล่อยออกมาโดยสคริปต์ด้านบน -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?
(2,)
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE ? = invoices.custid
ORDER BY invoices.id (2,)
DELETE FROM invoices
WHERE invoices.id = ? ((1,), (2,))
DELETE FROM customers
WHERE customers.id = ? (2,)
SELECT count(*)
AS count_1
FROM (
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?)
AS anon_1('Gopal Krishna',)
SELECT count(*)
AS count_1
FROM (
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE invoices.invno IN (?, ?))
AS anon_1(10, 14)
0Many to Many relationshipระหว่างสองตารางทำได้โดยการเพิ่มตารางการเชื่อมโยงเพื่อให้มีคีย์ต่างประเทศสองคีย์ - หนึ่งคีย์จากคีย์หลักของแต่ละตาราง ยิ่งไปกว่านั้นการแมปคลาสกับสองตารางยังมีแอ็ตทริบิวต์ที่มีคอลเลกชันของอ็อบเจ็กต์ของตารางการเชื่อมโยงอื่น ๆ ที่กำหนดให้เป็นแอ็ตทริบิวต์รองของฟังก์ชันความสัมพันธ์ ()
เพื่อจุดประสงค์นี้เราจะสร้างฐานข้อมูล SQLite (mycollege.db) โดยมีสองตาราง - แผนกและพนักงาน ในที่นี้เราถือว่าพนักงานเป็นส่วนหนึ่งของแผนกมากกว่าหนึ่งแผนกและแผนกหนึ่งมีพนักงานมากกว่าหนึ่งคน สิ่งนี้ถือเป็นความสัมพันธ์แบบกลุ่มต่อกลุ่ม
คำจำกัดความของคลาสพนักงานและแผนกที่แมปกับแผนกและตารางพนักงานมีดังนี้ -
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///mycollege.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Department(Base):
__tablename__ = 'department'
id = Column(Integer, primary_key = True)
name = Column(String)
employees = relationship('Employee', secondary = 'link')
class Employee(Base):
__tablename__ = 'employee'
id = Column(Integer, primary_key = True)
name = Column(String)
departments = relationship(Department,secondary='link')ตอนนี้เรากำหนดคลาสลิงค์ มีการเชื่อมโยงกับตารางลิงก์และมีแอตทริบิวต์ department_id และ employee_id ตามลำดับโดยอ้างอิงถึงคีย์หลักของแผนกและตารางพนักงาน
class Link(Base):
__tablename__ = 'link'
department_id = Column(
Integer,
ForeignKey('department.id'),
primary_key = True)
employee_id = Column(
Integer,
ForeignKey('employee.id'),
primary_key = True)ที่นี่เราต้องจดบันทึกไว้ว่าแผนกชั้นมีคุณลักษณะของพนักงานที่เกี่ยวข้องกับระดับพนักงาน แอตทริบิวต์รองของฟังก์ชันความสัมพันธ์ได้รับการกำหนดลิงก์เป็นค่า
ในทำนองเดียวกันระดับพนักงานมีแอตทริบิวต์ของแผนกที่เกี่ยวข้องกับระดับแผนก แอตทริบิวต์รองของฟังก์ชันความสัมพันธ์ได้รับการกำหนดลิงก์เป็นค่า
ตารางทั้งสามนี้ถูกสร้างขึ้นเมื่อดำเนินการคำสั่งต่อไปนี้ -
Base.metadata.create_all(engine)คอนโซล Python ส่งเสียงตามคำสั่ง CREATE TABLE -
CREATE TABLE department (
id INTEGER NOT NULL,
name VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE employee (
id INTEGER NOT NULL,
name VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE link (
department_id INTEGER NOT NULL,
employee_id INTEGER NOT NULL,
PRIMARY KEY (department_id, employee_id),
FOREIGN KEY(department_id) REFERENCES department (id),
FOREIGN KEY(employee_id) REFERENCES employee (id)
)ตรวจสอบได้โดยเปิด mycollege.db โดยใช้ SQLiteStudio ดังที่แสดงในภาพหน้าจอด้านล่าง -
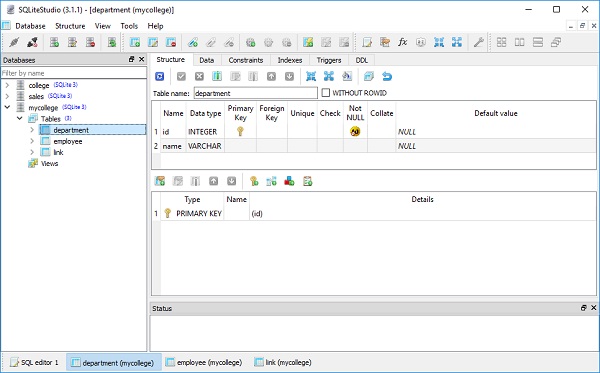
ต่อไปเราจะสร้างออบเจ็กต์สามชิ้นของคลาสแผนกและสามอ็อบเจกต์ของคลาสพนักงานดังที่แสดงด้านล่าง -
d1 = Department(name = "Accounts")
d2 = Department(name = "Sales")
d3 = Department(name = "Marketing")
e1 = Employee(name = "John")
e2 = Employee(name = "Tony")
e3 = Employee(name = "Graham")แต่ละตารางมีแอตทริบิวต์คอลเลกชันที่มีเมธอด append () เราสามารถเพิ่มวัตถุพนักงานในคอลเลกชันของพนักงานของวัตถุแผนก ในทำนองเดียวกันเราสามารถเพิ่มวัตถุแผนกไปยังแผนกรวบรวมแอตทริบิวต์ของวัตถุพนักงาน
e1.departments.append(d1)
e2.departments.append(d3)
d1.employees.append(e3)
d2.employees.append(e2)
d3.employees.append(e1)
e3.departments.append(d2)สิ่งที่เราต้องทำตอนนี้คือการตั้งค่าวัตถุเซสชันเพิ่มวัตถุทั้งหมดลงในวัตถุนั้นและทำการเปลี่ยนแปลงดังที่แสดงด้านล่าง -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
session.add(e1)
session.add(e2)
session.add(d1)
session.add(d2)
session.add(d3)
session.add(e3)
session.commit()คำสั่ง SQL ต่อไปนี้จะถูกปล่อยออกมาบนคอนโซล Python -
INSERT INTO department (name) VALUES (?) ('Accounts',)
INSERT INTO department (name) VALUES (?) ('Sales',)
INSERT INTO department (name) VALUES (?) ('Marketing',)
INSERT INTO employee (name) VALUES (?) ('John',)
INSERT INTO employee (name) VALUES (?) ('Graham',)
INSERT INTO employee (name) VALUES (?) ('Tony',)
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 2), (3, 1), (2, 3))
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 1), (2, 2), (3, 3))ในการตรวจสอบผลของการดำเนินการข้างต้นให้ใช้ SQLiteStudio และดูข้อมูลในแผนกพนักงานและตารางลิงค์ -
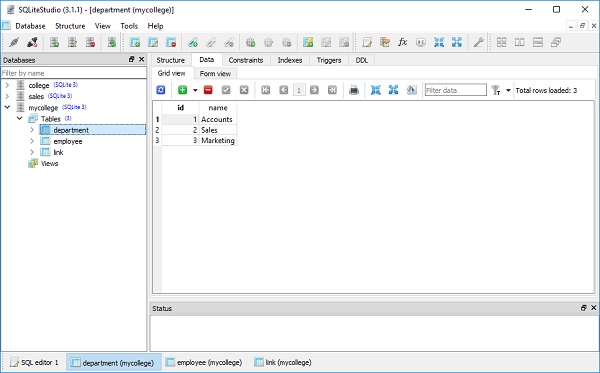
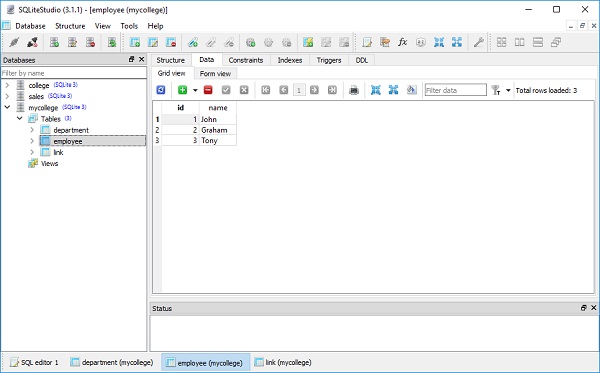
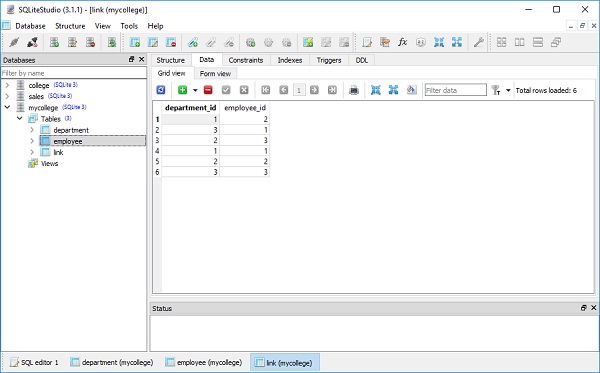
ในการแสดงข้อมูลให้เรียกใช้คำสั่งแบบสอบถามต่อไปนี้ -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for x in session.query( Department, Employee).filter(Link.department_id == Department.id,
Link.employee_id == Employee.id).order_by(Link.department_id).all():
print ("Department: {} Name: {}".format(x.Department.name, x.Employee.name))ตามข้อมูลที่เติมในตัวอย่างของเราผลลัพธ์จะแสดงดังต่อไปนี้ -
Department: Accounts Name: John
Department: Accounts Name: Graham
Department: Sales Name: Graham
Department: Sales Name: Tony
Department: Marketing Name: John
Department: Marketing Name: TonySQLAlchemy ใช้ระบบภาษาถิ่นเพื่อสื่อสารกับฐานข้อมูลประเภทต่างๆ แต่ละฐานข้อมูลมีตัวห่อ DBAPI ที่สอดคล้องกัน ภาษาถิ่นทั้งหมดต้องการให้ติดตั้งไดรเวอร์ DBAPI ที่เหมาะสม
ภาษาถิ่นต่อไปนี้รวมอยู่ใน SQLAlchemy API -
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQL
- Sybase
อ็อบเจ็กต์ Engine ตาม URL ถูกสร้างขึ้นโดยฟังก์ชัน create_engine () URL เหล่านี้อาจรวมถึงชื่อผู้ใช้รหัสผ่านชื่อโฮสต์และชื่อฐานข้อมูล อาจมีอาร์กิวเมนต์คำหลักที่เป็นทางเลือกสำหรับการกำหนดค่าเพิ่มเติม ในบางกรณีเส้นทางของไฟล์ได้รับการยอมรับและในบางกรณี "ชื่อแหล่งข้อมูล" จะแทนที่ส่วนของ "โฮสต์" และ "ฐานข้อมูล" รูปแบบทั่วไปของ URL ฐานข้อมูลมีดังนี้ -
dialect+driver://username:password@host:port/databasePostgreSQL
ภาษา PostgreSQL ใช้ psycopg2เป็น DBAPI เริ่มต้น นอกจากนี้ pg8000 ยังสามารถใช้แทน Pure-Python ได้ดังที่แสดงด้านล่าง:
# default
engine = create_engine('postgresql://scott:tiger@localhost/mydatabase')
# psycopg2
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')
# pg8000
engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')MySQL
ภาษา MySQL ใช้ mysql-pythonเป็น DBAPI เริ่มต้น มี MySQL DBAPI มากมายเช่น MySQL-connector-python ดังนี้ -
# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysql-python
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# MySQL-connector-python
engine = create_engine('mysql+mysqlconnector://scott:tiger@localhost/foo')Oracle
ภาษา Oracle ใช้ cx_oracle เป็น DBAPI ดีฟอลต์ดังนี้ -
engine = create_engine('oracle://scott:[email protected]:1521/sidname')
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')Microsoft SQL Server
ภาษา SQL Server ใช้ pyodbcเป็น DBAPI เริ่มต้น pymssql ก็มี
# pyodbc
engine = create_engine('mssql+pyodbc://scott:tiger@mydsn')
# pymssql
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname')SQLite
SQLite เชื่อมต่อกับฐานข้อมูลแบบไฟล์โดยใช้โมดูลในตัว Python sqlite3โดยค่าเริ่มต้น. เนื่องจาก SQLite เชื่อมต่อกับไฟล์ในเครื่องรูปแบบ URL จึงแตกต่างกันเล็กน้อย ส่วน "ไฟล์" ของ URL คือชื่อไฟล์ของฐานข้อมูล สำหรับเส้นทางไฟล์สัมพัทธ์ต้องใช้เครื่องหมายทับสามตัวดังที่แสดงด้านล่าง -
engine = create_engine('sqlite:///foo.db')และสำหรับเส้นทางไฟล์สัมบูรณ์เครื่องหมายทับสามตัวจะตามด้วยพา ธ สัมบูรณ์ดังที่ระบุด้านล่าง -
engine = create_engine('sqlite:///C:\\path\\to\\foo.db')ในการใช้ฐานข้อมูล SQLite: memory: ระบุ URL ว่างตามที่ระบุด้านล่าง -
engine = create_engine('sqlite://')สรุป
ในส่วนแรกของบทช่วยสอนนี้เราได้เรียนรู้วิธีใช้ Expression Language เพื่อดำเนินการคำสั่ง SQL ภาษานิพจน์ฝังโครงสร้าง SQL ในโค้ด Python ในส่วนที่สองเราได้กล่าวถึงความสามารถในการทำแผนที่ความสัมพันธ์ของวัตถุของ SQLAlchemy ORM API แมปตาราง SQL กับคลาส Python