อนุกรมเวลา - คู่มือฉบับย่อ
อนุกรมเวลาคือลำดับของการสังเกตในช่วงเวลาหนึ่ง อนุกรมเวลาแบบไม่แปรผันประกอบด้วยค่าที่นำมาจากตัวแปรเดียวในอินสแตนซ์เวลาเป็นช่วง ๆ ในช่วงเวลาหนึ่งและอนุกรมเวลาหลายตัวแปรประกอบด้วยค่าที่นำมาจากตัวแปรหลายตัวในช่วงเวลาเดียวกันในช่วงเวลาเดียวกัน ตัวอย่างที่ง่ายที่สุดของอนุกรมเวลาที่เราทุกคนเจอในแต่ละวันคือการเปลี่ยนแปลงของอุณหภูมิตลอดทั้งวันหรือสัปดาห์หรือเดือนหรือปี
การวิเคราะห์ข้อมูลชั่วคราวสามารถให้ข้อมูลเชิงลึกที่เป็นประโยชน์แก่เราเกี่ยวกับการเปลี่ยนแปลงของตัวแปรเมื่อเวลาผ่านไปหรือขึ้นอยู่กับการเปลี่ยนแปลงค่าของตัวแปรอื่นอย่างไร ความสัมพันธ์ของตัวแปรกับค่าก่อนหน้านี้และ / หรือตัวแปรอื่น ๆ สามารถวิเคราะห์ได้สำหรับการพยากรณ์อนุกรมเวลาและมีการใช้งานมากมายในปัญญาประดิษฐ์
ความเข้าใจพื้นฐานเกี่ยวกับภาษาโปรแกรมเป็นสิ่งสำคัญสำหรับผู้ใช้ในการทำงานกับหรือพัฒนาปัญหาการเรียนรู้ของเครื่อง รายชื่อภาษาโปรแกรมที่ต้องการสำหรับทุกคนที่ต้องการทำงานเกี่ยวกับแมชชีนเลิร์นนิงมีให้ด้านล่าง -
Python
เป็นภาษาการเขียนโปรแกรมที่มีการตีความระดับสูงรวดเร็วและง่ายต่อการเขียนโค้ด Python สามารถทำตามกระบวนทัศน์การเขียนโปรแกรมเชิงขั้นตอนหรือเชิงวัตถุ การมีห้องสมุดที่หลากหลายทำให้การดำเนินการตามขั้นตอนที่ซับซ้อนง่ายขึ้น ในบทช่วยสอนนี้เราจะเขียนโค้ดใน Python และไลบรารีที่เกี่ยวข้องที่มีประโยชน์สำหรับการสร้างแบบจำลองอนุกรมเวลาจะกล่าวถึงในบทต่อ ๆ ไป
ร
เช่นเดียวกับ Python R เป็นภาษาที่มีการตีความหลายกระบวนทัศน์ซึ่งรองรับการคำนวณทางสถิติและกราฟิก แพ็กเกจที่หลากหลายช่วยให้ใช้งานโมเดลแมชชีนเลิร์นนิงใน R ได้ง่ายขึ้น
Java
เป็นภาษาการเขียนโปรแกรมเชิงวัตถุที่มีการตีความซึ่งมีชื่อเสียงอย่างกว้างขวางในด้านความพร้อมใช้งานของแพคเกจที่หลากหลายและเทคนิคการสร้างภาพข้อมูลที่ซับซ้อน
C / C ++
ภาษาเหล่านี้เป็นภาษาคอมไพล์และภาษาโปรแกรมที่เก่าแก่ที่สุดสองภาษา ภาษาเหล่านี้มักนิยมนำความสามารถของ ML มาใช้ในแอปพลิเคชันที่มีอยู่แล้วเนื่องจากช่วยให้คุณปรับแต่งการใช้อัลกอริทึม ML ได้อย่างง่ายดาย
MATLAB
MATrix LAB สนับสนุนเป็นภาษาหลายกระบวนทัศน์ซึ่งให้การทำงานทำงานกับเมทริกซ์ ช่วยให้การดำเนินการทางคณิตศาสตร์สำหรับปัญหาที่ซับซ้อน ส่วนใหญ่จะใช้สำหรับการดำเนินการเชิงตัวเลข แต่บางแพ็คเกจยังอนุญาตให้มีการจำลองแบบหลายโดเมนแบบกราฟิกและการออกแบบตามโมเดล
ภาษาโปรแกรมอื่น ๆ ที่ต้องการสำหรับปัญหาการเรียนรู้ของเครื่อง ได้แก่ JavaScript, LISP, Prolog, SQL, Scala, Julia, SAS เป็นต้น
Python ได้รับความนิยมเป็นอย่างมากในหมู่บุคคลที่ดำเนินการเรียนรู้ของเครื่องเนื่องจากโครงสร้างโค้ดที่เขียนง่ายและเข้าใจง่ายรวมถึงไลบรารีโอเพนซอร์สที่หลากหลาย ไลบรารีโอเพนซอร์สบางส่วนที่เราจะใช้ในบทต่อ ๆ ไปได้รับการแนะนำด้านล่าง
NumPy
Numerical Python เป็นไลบรารีที่ใช้สำหรับการคำนวณทางวิทยาศาสตร์ มันทำงานบนวัตถุอาร์เรย์ N มิติและมีฟังก์ชันพื้นฐานทางคณิตศาสตร์เช่นขนาดรูปร่างค่าเฉลี่ยส่วนเบี่ยงเบนมาตรฐานค่าต่ำสุดสูงสุดรวมทั้งฟังก์ชันที่ซับซ้อนมากขึ้นเช่นฟังก์ชันพีชคณิตเชิงเส้นและการแปลงฟูริเยร์ คุณจะได้เรียนรู้เพิ่มเติมเกี่ยวกับสิ่งเหล่านี้เมื่อเราดำเนินการต่อในบทช่วยสอนนี้
หมีแพนด้า
ไลบรารีนี้มีโครงสร้างข้อมูลที่มีประสิทธิภาพสูงและใช้งานง่ายเช่นอนุกรมดาต้าเฟรมและพาเนล ได้ปรับปรุงฟังก์ชันการทำงานของ Python ตั้งแต่การรวบรวมและเตรียมข้อมูลไปจนถึงการวิเคราะห์ข้อมูล ทั้งสองไลบรารี Pandas และ NumPy ทำให้การดำเนินการใด ๆ กับชุดข้อมูลขนาดเล็กถึงขนาดใหญ่เป็นเรื่องง่ายมาก หากต้องการทราบข้อมูลเพิ่มเติมเกี่ยวกับฟังก์ชันเหล่านี้โปรดทำตามบทแนะนำนี้
SciPy
Science Python เป็นไลบรารีที่ใช้สำหรับการคำนวณทางวิทยาศาสตร์และทางเทคนิค มีฟังก์ชันสำหรับการเพิ่มประสิทธิภาพการประมวลผลสัญญาณและภาพการรวมการแก้ไขและพีชคณิตเชิงเส้น ไลบรารีนี้มีประโยชน์ขณะดำเนินการเรียนรู้ของเครื่อง เราจะพูดถึงฟังก์ชันเหล่านี้เมื่อเราดำเนินการต่อในบทช่วยสอนนี้
เรียนวิทย์
ไลบรารีนี้เป็น SciPy Toolkit ที่ใช้กันอย่างแพร่หลายสำหรับการสร้างแบบจำลองทางสถิติการเรียนรู้ของเครื่องและการเรียนรู้เชิงลึกเนื่องจากมีรูปแบบการถดถอยการจำแนกและการจัดกลุ่มที่ปรับแต่งได้หลายแบบ ใช้งานได้ดีกับ Numpy, Pandas และไลบรารีอื่น ๆ ซึ่งทำให้ใช้งานได้ง่ายขึ้น
สถิติ
เช่นเดียวกับ Scikit Learn ไลบรารีนี้ใช้สำหรับการสำรวจข้อมูลทางสถิติและการสร้างแบบจำลองทางสถิติ นอกจากนี้ยังทำงานได้ดีกับไลบรารี Python อื่น ๆ
Matplotlib
ไลบรารีนี้ใช้สำหรับการแสดงข้อมูลในรูปแบบต่างๆเช่นพล็อตเส้นกราฟแท่งแผนที่ความร้อนแผนภาพการกระจายฮิสโตแกรมเป็นต้นประกอบด้วยฟังก์ชันที่เกี่ยวข้องกับกราฟทั้งหมดที่จำเป็นตั้งแต่การลงจุดไปจนถึงการติดฉลาก เราจะพูดถึงฟังก์ชันเหล่านี้เมื่อเราดำเนินการต่อในบทช่วยสอนนี้
ไลบรารีเหล่านี้มีความสำคัญมากในการเริ่มต้นด้วยการเรียนรู้ของเครื่องด้วยข้อมูลประเภทใดก็ได้
นอกเหนือจากที่กล่าวไว้ข้างต้นห้องสมุดอีกแห่งที่สำคัญอย่างยิ่งในการจัดการกับอนุกรมเวลาคือ -
วันเวลา
ไลบรารีนี้มีสองโมดูล - วันที่และเวลาและปฏิทินจัดเตรียมฟังก์ชันวันที่และเวลาที่จำเป็นทั้งหมดสำหรับการอ่านการจัดรูปแบบและการจัดการเวลา
เราจะใช้ห้องสมุดเหล่านี้ในบทต่อ ๆ ไป
อนุกรมเวลาคือลำดับของการสังเกตที่จัดทำดัชนีในช่วงเวลาที่เว้นระยะห่างเท่ากัน ดังนั้นควรรักษาลำดับและความต่อเนื่องในอนุกรมเวลาใด ๆ
ชุดข้อมูลที่เราจะใช้เป็นอนุกรมเวลาแบบหลายรูปแบบซึ่งมีข้อมูลรายชั่วโมงเป็นเวลาประมาณหนึ่งปีสำหรับคุณภาพอากาศในเมืองอิตาลีที่มีมลพิษอย่างมาก สามารถดาวน์โหลดชุดข้อมูลได้จากลิงค์ด้านล่าง -https://archive.ics.uci.edu/ml/datasets/air+quality.
จำเป็นต้องตรวจสอบให้แน่ใจว่า -
อนุกรมเวลามีระยะห่างเท่า ๆ กันและ
ไม่มีค่าซ้ำซ้อนหรือช่องว่างในนั้น
ในกรณีที่อนุกรมเวลาไม่ต่อเนื่องเราสามารถเพิ่มหรือลดตัวอย่างได้
กำลังแสดง df.head ()
ใน [122]:
import pandasใน [123]:
df = pandas.read_csv("AirQualityUCI.csv", sep = ";", decimal = ",")
df = df.iloc[ : , 0:14]ใน [124]:
len(df)ออก [124]:
9471ใน [125]:
df.head()ออก [125]:

สำหรับการประมวลผลอนุกรมเวลาล่วงหน้าเราตรวจสอบให้แน่ใจว่าไม่มีค่า NaN (NULL) ในชุดข้อมูล ถ้ามีเราสามารถแทนที่ด้วยค่า 0 หรือค่าเฉลี่ยหรือค่านำหน้าหรือสำเร็จ การเปลี่ยนเป็นทางเลือกที่ต้องการมากกว่าการลดลงเพื่อให้คงความต่อเนื่องของอนุกรมเวลาไว้ อย่างไรก็ตามในชุดข้อมูลของเราค่าสองสามค่าสุดท้ายดูเหมือนจะเป็นโมฆะดังนั้นการลดลงจะไม่ส่งผลต่อความต่อเนื่อง
การลด NaN (ไม่ใช่ตัวเลข)
ใน [126]:
df.isna().sum()
Out[126]:
Date 114
Time 114
CO(GT) 114
PT08.S1(CO) 114
NMHC(GT) 114
C6H6(GT) 114
PT08.S2(NMHC) 114
NOx(GT) 114
PT08.S3(NOx) 114
NO2(GT) 114
PT08.S4(NO2) 114
PT08.S5(O3) 114
T 114
RH 114
dtype: int64ใน [127]:
df = df[df['Date'].notnull()]ใน [128]:
df.isna().sum()ออก [128]:
Date 0
Time 0
CO(GT) 0
PT08.S1(CO) 0
NMHC(GT) 0
C6H6(GT) 0
PT08.S2(NMHC) 0
NOx(GT) 0
PT08.S3(NOx) 0
NO2(GT) 0
PT08.S4(NO2) 0
PT08.S5(O3) 0
T 0
RH 0
dtype: int64อนุกรมเวลามักจะพล็อตเป็นกราฟเส้นเทียบกับเวลา ในตอนนี้เราจะรวมคอลัมน์วันที่และเวลาและแปลงเป็นวัตถุวันที่และเวลาจากสตริง ซึ่งสามารถทำได้โดยใช้ไลบรารีวันที่และเวลา
การแปลงเป็นวัตถุ datetime
ใน [129]:
df['DateTime'] = (df.Date) + ' ' + (df.Time)
print (type(df.DateTime[0]))<class 'str'>
ใน [130]:
import datetime
df.DateTime = df.DateTime.apply(lambda x: datetime.datetime.strptime(x, '%d/%m/%Y %H.%M.%S'))
print (type(df.DateTime[0]))<class 'pandas._libs.tslibs.timestamps.Timestamp'>
ให้เราดูว่าตัวแปรบางอย่างเช่นอุณหภูมิเปลี่ยนแปลงไปตามเวลาที่เปลี่ยนแปลงอย่างไร
กำลังแสดงพล็อต
ใน [131]:
df.index = df.DateTimeใน [132]:
import matplotlib.pyplot as plt
plt.plot(df['T'])ออก [132]:
[<matplotlib.lines.Line2D at 0x1eaad67f780>]
ใน [208]:
plt.plot(df['C6H6(GT)'])ออก [208]:
[<matplotlib.lines.Line2D at 0x1eaaeedff28>]Box-plot เป็นกราฟอีกประเภทที่มีประโยชน์ซึ่งช่วยให้คุณสามารถย่อข้อมูลจำนวนมากเกี่ยวกับชุดข้อมูลลงในกราฟเดียว แสดงค่าเฉลี่ยควอร์ไทล์ 25% และ 75% และค่าผิดปกติของตัวแปรเดียวหรือหลายตัวแปร ในกรณีที่จำนวนค่าผิดปกติมีน้อยและอยู่ห่างจากค่าเฉลี่ยมากเราสามารถกำจัดค่าผิดปกติได้โดยตั้งค่าเป็นค่าเฉลี่ยหรือค่าควอไทล์ 75%
กำลังแสดง Boxplots
ใน [134]:
plt.boxplot(df[['T','C6H6(GT)']].values)ออก [134]:
{'whiskers': [<matplotlib.lines.Line2D at 0x1eaac16de80>,
<matplotlib.lines.Line2D at 0x1eaac16d908>,
<matplotlib.lines.Line2D at 0x1eaac177a58>,
<matplotlib.lines.Line2D at 0x1eaac177cf8>],
'caps': [<matplotlib.lines.Line2D at 0x1eaac16d2b0>,
<matplotlib.lines.Line2D at 0x1eaac16d588>,
<matplotlib.lines.Line2D at 0x1eaac1a69e8>,
<matplotlib.lines.Line2D at 0x1eaac1a64a8>],
'boxes': [<matplotlib.lines.Line2D at 0x1eaac16dc50>,
<matplotlib.lines.Line2D at 0x1eaac1779b0>],
'medians': [<matplotlib.lines.Line2D at 0x1eaac16d4a8>,
<matplotlib.lines.Line2D at 0x1eaac1a6c50>],
'fliers': [<matplotlib.lines.Line2D at 0x1eaac177dd8>,
<matplotlib.lines.Line2D at 0x1eaac1a6c18>],'means': []
}
บทนำ
อนุกรมเวลามี 4 องค์ประกอบตามที่ระบุด้านล่าง -
Level - เป็นค่าเฉลี่ยที่อนุกรมแตกต่างกันไป
Trend - เป็นพฤติกรรมที่เพิ่มขึ้นหรือลดลงของตัวแปรตามเวลา
Seasonality - เป็นพฤติกรรมแบบวนรอบของอนุกรมเวลา
Noise - เป็นข้อผิดพลาดในการสังเกตการณ์ที่เพิ่มเข้ามาเนื่องจากปัจจัยแวดล้อม
เทคนิคการสร้างแบบจำลองอนุกรมเวลา
ในการจับภาพส่วนประกอบเหล่านี้มีเทคนิคการสร้างแบบจำลองอนุกรมเวลาที่เป็นที่นิยมหลายประการ ส่วนนี้จะให้คำแนะนำสั้น ๆ เกี่ยวกับแต่ละเทคนิคอย่างไรก็ตามเราจะพูดถึงพวกเขาโดยละเอียดในบทต่อ ๆ ไป -
วิธีไร้เดียงสา
เทคนิคเหล่านี้เป็นเทคนิคการประมาณอย่างง่ายเช่นค่าที่คาดการณ์จะได้รับค่าเท่ากับค่าเฉลี่ยของค่าก่อนหน้าของตัวแปรตามเวลาหรือค่าจริงก่อนหน้า สิ่งเหล่านี้ใช้เพื่อเปรียบเทียบกับเทคนิคการสร้างแบบจำลองที่ซับซ้อน
การถดถอยอัตโนมัติ
การถดถอยอัตโนมัติจะทำนายค่าของช่วงเวลาในอนาคตโดยเป็นฟังก์ชันของค่าในช่วงเวลาก่อนหน้า การคาดการณ์การถดถอยอัตโนมัติอาจเข้ากับข้อมูลได้ดีกว่าวิธีการไร้เดียงสา แต่อาจไม่สามารถอธิบายถึงฤดูกาลได้
โมเดล ARIMA
แบบจำลองค่าเฉลี่ยเคลื่อนที่แบบบูรณาการแบบถดถอยอัตโนมัติจะจำลองค่าของตัวแปรเป็นฟังก์ชันเชิงเส้นของค่าก่อนหน้าและข้อผิดพลาดที่เหลือในขั้นตอนเวลาก่อนหน้าของชุดเวลาที่หยุดนิ่ง อย่างไรก็ตามข้อมูลในโลกแห่งความเป็นจริงอาจไม่อยู่นิ่งและมีฤดูกาลดังนั้น Seasonal-ARIMA และ Fractional-ARIMA จึงถูกพัฒนาขึ้น ARIMA ทำงานกับอนุกรมเวลาที่ไม่แปรผันเพื่อจัดการกับตัวแปรหลายตัว VARIMA ถูกนำมาใช้
การปรับให้เรียบแบบเอ็กซ์โปเนนเชียล
มันจำลองค่าของตัวแปรเป็นฟังก์ชันเชิงเส้นแบบถ่วงน้ำหนักเลขชี้กำลังของค่าก่อนหน้า แบบจำลองทางสถิตินี้สามารถจัดการกับแนวโน้มและฤดูกาลได้เช่นกัน
LSTM
แบบจำลองหน่วยความจำระยะสั้นยาว (LSTM) เป็นเครือข่ายประสาทที่เกิดซ้ำซึ่งใช้สำหรับอนุกรมเวลาเพื่อพิจารณาการอ้างอิงระยะยาว สามารถฝึกกับข้อมูลจำนวนมากเพื่อจับแนวโน้มของอนุกรมเวลาที่มีหลายรูปแบบ
เทคนิคการสร้างแบบจำลองดังกล่าวใช้สำหรับการถดถอยอนุกรมเวลา ในบทที่จะมาถึงตอนนี้ให้เราสำรวจทั้งหมดนี้ทีละคน
บทนำ
โมเดลทางสถิติหรือแมชชีนเลิร์นนิงใด ๆ มีพารามิเตอร์บางอย่างที่มีผลอย่างมากต่อวิธีการสร้างโมเดลข้อมูล ตัวอย่างเช่น ARIMA มีค่า p, d, q พารามิเตอร์เหล่านี้จะต้องถูกตัดสินเพื่อให้ข้อผิดพลาดระหว่างค่าจริงและค่าที่จำลองเป็นค่าต่ำสุด การปรับเทียบพารามิเตอร์เป็นงานที่สำคัญและใช้เวลานานที่สุดในการปรับตั้งโมเดล ดังนั้นจึงจำเป็นอย่างยิ่งที่เราจะต้องเลือกพารามิเตอร์ที่เหมาะสมที่สุด
วิธีการสอบเทียบพารามิเตอร์
มีหลายวิธีในการปรับเทียบพารามิเตอร์ ส่วนนี้พูดถึงรายละเอียดบางส่วน
ตีแล้วลอง
วิธีการทั่วไปในการสอบเทียบแบบจำลองวิธีหนึ่งคือการปรับเทียบด้วยมือโดยคุณเริ่มต้นด้วยการแสดงอนุกรมเวลาและลองใช้ค่าพารามิเตอร์บางค่าอย่างสังหรณ์ใจและเปลี่ยนแปลงซ้ำแล้วซ้ำเล่าจนกว่าคุณจะได้ขนาดที่ดีพอ ต้องมีความเข้าใจที่ดีเกี่ยวกับโมเดลที่เรากำลังพยายาม สำหรับโมเดล ARIMA การปรับเทียบด้วยมือทำได้โดยใช้พล็อตความสัมพันธ์อัตโนมัติสำหรับพารามิเตอร์ 'p' พล็อตความสัมพันธ์อัตโนมัติบางส่วนสำหรับพารามิเตอร์ 'q' และการทดสอบ ADF เพื่อยืนยันความสม่ำเสมอของอนุกรมเวลาและการตั้งค่าพารามิเตอร์ 'd' . เราจะพูดถึงรายละเอียดทั้งหมดนี้ในบทต่อ ๆ ไป
ค้นหาตาราง
อีกวิธีหนึ่งในการปรับเทียบโมเดลคือการค้นหาแบบกริดซึ่งโดยพื้นฐานแล้วหมายความว่าคุณลองสร้างแบบจำลองสำหรับชุดค่าผสมที่เป็นไปได้ทั้งหมดของพารามิเตอร์และเลือกแบบที่มีข้อผิดพลาดน้อยที่สุด สิ่งนี้ใช้เวลานานและด้วยเหตุนี้จึงมีประโยชน์เมื่อจำนวนพารามิเตอร์ที่จะปรับเทียบและช่วงของค่าที่ใช้มีน้อยลงเนื่องจากเกี่ยวข้องกับการซ้อนกันหลายรายการสำหรับลูป
อัลกอริทึมทางพันธุกรรม
อัลกอริธึมทางพันธุกรรมทำงานบนหลักการทางชีววิทยาซึ่งในที่สุดทางออกที่ดีจะพัฒนาไปสู่โซลูชันที่ 'เหมาะสมที่สุด' ที่สุด มันใช้การดำเนินการทางชีวภาพของการกลายพันธุ์การข้ามและการคัดเลือกเพื่อไปสู่ทางออกที่ดีที่สุดในที่สุด
สำหรับความรู้เพิ่มเติมคุณสามารถอ่านเกี่ยวกับเทคนิคการเพิ่มประสิทธิภาพพารามิเตอร์อื่น ๆ เช่นการเพิ่มประสิทธิภาพแบบเบย์และการเพิ่มประสิทธิภาพ Swarm
บทนำ
วิธีการที่ไร้เดียงสาเช่นสมมติว่าค่าที่คาดการณ์ไว้ในเวลา 't' เป็นค่าจริงของตัวแปรในเวลา 't-1' หรือค่าเฉลี่ยของอนุกรมจะใช้เพื่อชั่งน้ำหนักว่าแบบจำลองทางสถิติและแบบจำลองการเรียนรู้ของเครื่องสามารถทำงานได้ดีเพียงใด และเน้นความต้องการของพวกเขา
ในบทนี้ให้เราลองใช้โมเดลเหล่านี้กับคุณสมบัติของข้อมูลอนุกรมเวลาของเรา
อันดับแรกเราจะเห็นค่าเฉลี่ยของคุณสมบัติ 'อุณหภูมิ' ของข้อมูลของเราและค่าเบี่ยงเบนรอบ ๆ นอกจากนี้ยังมีประโยชน์ในการดูค่าอุณหภูมิสูงสุดและต่ำสุด เราสามารถใช้ฟังก์ชันของไลบรารี numpy ได้ที่นี่
กำลังแสดงสถิติ
ใน [135]:
import numpy
print (
'Mean: ',numpy.mean(df['T']), ';
Standard Deviation: ',numpy.std(df['T']),';
\nMaximum Temperature: ',max(df['T']),';
Minimum Temperature: ',min(df['T'])
)เรามีสถิติสำหรับการสังเกตการณ์ทั้งหมด 9357 ครั้งในไทม์ไลน์ที่เว้นระยะห่างเท่ากันซึ่งเป็นประโยชน์สำหรับเราในการทำความเข้าใจข้อมูล
ตอนนี้เราจะลองวิธีไร้เดียงสาแรกตั้งค่าที่คาดการณ์ไว้ในเวลาปัจจุบันเท่ากับค่าจริงในเวลาก่อนหน้าและคำนวณข้อผิดพลาดค่าเฉลี่ยกำลังสองราก (RMSE) เพื่อหาปริมาณประสิทธิภาพของวิธีนี้
แสดง 1 เซนต์วิธีไร้เดียงสา
ใน [136]:
df['T']
df['T_t-1'] = df['T'].shift(1)ใน [137]:
df_naive = df[['T','T_t-1']][1:]ใน [138]:
from sklearn import metrics
from math import sqrt
true = df_naive['T']
prediction = df_naive['T_t-1']
error = sqrt(metrics.mean_squared_error(true,prediction))
print ('RMSE for Naive Method 1: ', error)RMSE สำหรับวิธีไร้เดียงสา 1: 12.901140576492974
ให้เราดูวิธีการไร้เดียงสาต่อไปโดยที่ค่าที่คาดการณ์ในเวลาปัจจุบันจะเท่ากับค่าเฉลี่ยของช่วงเวลาที่อยู่ก่อนหน้านั้น เราจะคำนวณ RMSE สำหรับวิธีนี้ด้วย
กำลังแสดงวิธีไร้เดียงสา2 ครั้ง
ใน [139]:
df['T_rm'] = df['T'].rolling(3).mean().shift(1)
df_naive = df[['T','T_rm']].dropna()ใน [140]:
true = df_naive['T']
prediction = df_naive['T_rm']
error = sqrt(metrics.mean_squared_error(true,prediction))
print ('RMSE for Naive Method 2: ', error)RMSE for Naive Method 2: 14.957633272839242
ที่นี่คุณสามารถทดลองกับช่วงเวลาก่อนหน้าต่างๆที่เรียกว่า 'ล่าช้า' ที่คุณต้องการพิจารณาซึ่งจะเก็บไว้เป็น 3 ที่นี่ ในข้อมูลนี้จะเห็นได้ว่าเมื่อคุณเพิ่มจำนวนความล่าช้าและข้อผิดพลาดที่เพิ่มขึ้น หากความล่าช้าถูกเก็บไว้ 1 จะกลายเป็นวิธีเดียวกับวิธีไร้เดียงสาที่ใช้ก่อนหน้านี้
Points to Note
คุณสามารถเขียนฟังก์ชันที่ง่ายมากสำหรับการคำนวณข้อผิดพลาดค่าเฉลี่ยกำลังสองราก ที่นี่เราได้ใช้ฟังก์ชันข้อผิดพลาดกำลังสองเฉลี่ยจากแพ็กเกจ 'sklearn' จากนั้นจึงนำสแควร์รูท
ในแพนด้า df ['column_name'] ยังสามารถเขียนเป็น df.column_name ได้อย่างไรก็ตามสำหรับชุดข้อมูลนี้ df.T จะไม่ทำงานเหมือนกับ df ['T'] เนื่องจาก df.T เป็นฟังก์ชันสำหรับการย้ายดาต้าเฟรม ดังนั้นใช้เฉพาะ df ['T'] หรือพิจารณาเปลี่ยนชื่อคอลัมน์นี้ก่อนใช้ไวยากรณ์อื่น
สำหรับอนุกรมเวลาที่หยุดนิ่งแบบจำลองการถดถอยอัตโนมัติจะเห็นค่าของตัวแปรที่เวลา "t" เป็นฟังก์ชันเชิงเส้นของขั้นตอนเวลาของค่า "p" ที่อยู่ข้างหน้า ในทางคณิตศาสตร์สามารถเขียนเป็น -
$$y_{t} = \:C+\:\phi_{1}y_{t-1}\:+\:\phi_{2}Y_{t-2}+...+\phi_{p}y_{t-p}+\epsilon_{t}$$
โดยที่'p' คือพารามิเตอร์แนวโน้มถอยหลังอัตโนมัติ
$\epsilon_{t}$ คือเสียงสีขาวและ
$y_{t-1}, y_{t-2}\:\: ...y_{t-p}$ แสดงถึงค่าของตัวแปรในช่วงเวลาก่อนหน้า
ค่าของ p สามารถปรับเทียบได้โดยใช้วิธีการต่างๆ วิธีหนึ่งในการหาค่า apt ของ 'p' คือการวางพล็อตความสัมพันธ์อัตโนมัติ
Note- เราควรแยกข้อมูลออกเป็นแบบฝึกและทดสอบที่อัตราส่วน 8: 2 ของข้อมูลทั้งหมดที่มีอยู่ก่อนทำการวิเคราะห์ข้อมูลเนื่องจากข้อมูลการทดสอบเป็นเพียงเพื่อค้นหาความถูกต้องของแบบจำลองเท่านั้นและข้อสันนิษฐานของเรานั้นไม่มีให้สำหรับเรา จนกว่าจะมีการทำนาย ในกรณีของอนุกรมเวลาลำดับของจุดข้อมูลมีความสำคัญมากดังนั้นอย่าลืมลำดับระหว่างการแบ่งข้อมูล
พล็อตความสัมพันธ์อัตโนมัติหรือ Correlogram แสดงความสัมพันธ์ของตัวแปรกับตัวมันเองในขั้นตอนก่อนหน้านี้ ใช้ประโยชน์จากสหสัมพันธ์ของเพียร์สันและแสดงความสัมพันธ์ภายในช่วงความเชื่อมั่น 95% มาดูกันว่าตัวแปร 'อุณหภูมิ' ของข้อมูลของเราเป็นอย่างไร
กำลังแสดง ACP
ใน [141]:
split = len(df) - int(0.2*len(df))
train, test = df['T'][0:split], df['T'][split:]ใน [142]:
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(train, lags = 100)
plt.show()
ค่าความล่าช้าทั้งหมดที่อยู่นอกพื้นที่สีฟ้าที่แรเงาจะถือว่ามีความสัมพันธ์กัน
สำหรับอนุกรมเวลาที่หยุดนิ่งแบบจำลองค่าเฉลี่ยเคลื่อนที่จะเห็นค่าของตัวแปร ณ เวลา 't' เป็นฟังก์ชันเชิงเส้นของข้อผิดพลาดที่เหลือจากขั้นตอนเวลา 'q' ที่อยู่ข้างหน้า ข้อผิดพลาดที่เหลือคำนวณโดยการเปรียบเทียบค่าในเวลา 't' กับค่าเฉลี่ยเคลื่อนที่ของค่าที่อยู่ข้างหน้า
ในทางคณิตศาสตร์สามารถเขียนเป็น -
$$y_{t} = c\:+\:\epsilon_{t}\:+\:\theta_{1}\:\epsilon_{t-1}\:+\:\theta_{2}\:\epsilon_{t-2}\:+\:...+:\theta_{q}\:\epsilon_{t-q}\:$$
โดยที่'q' คือพารามิเตอร์แนวโน้มค่าเฉลี่ยเคลื่อนที่
$\epsilon_{t}$ คือเสียงสีขาวและ
$\epsilon_{t-1}, \epsilon_{t-2}...\epsilon_{t-q}$ เป็นเงื่อนไขข้อผิดพลาดในช่วงเวลาก่อนหน้า
ค่าของ 'q' สามารถปรับเทียบได้โดยใช้วิธีการต่างๆ วิธีหนึ่งในการหาค่า apt ของ 'q' คือการวางพล็อตความสัมพันธ์อัตโนมัติบางส่วน
พล็อตความสัมพันธ์อัตโนมัติบางส่วนแสดงความสัมพันธ์ของตัวแปรกับตัวมันเองในขั้นตอนก่อนหน้าโดยลบความสัมพันธ์ทางอ้อมซึ่งแตกต่างจากพล็อตความสัมพันธ์อัตโนมัติซึ่งแสดงความสัมพันธ์โดยตรงและโดยอ้อมมาดูกันว่าตัวแปร 'อุณหภูมิ' ของเรามีลักษณะอย่างไร ข้อมูล.
กำลังแสดง PACP
ใน [143]:
from statsmodels.graphics.tsaplots import plot_pacf
plot_pacf(train, lags = 100)
plt.show()
ความสัมพันธ์อัตโนมัติบางส่วนถูกอ่านในลักษณะเดียวกับ correlogram
เราเข้าใจแล้วว่าสำหรับอนุกรมเวลาที่หยุดนิ่งตัวแปรที่เวลา 't' เป็นฟังก์ชันเชิงเส้นของการสังเกตก่อนหน้านี้หรือข้อผิดพลาดที่เหลือ ดังนั้นถึงเวลาแล้วที่เราจะรวมทั้งสองอย่างเข้าด้วยกันและมีโมเดลค่าเฉลี่ยเคลื่อนที่ถอยหลัง (ARMA) โดยอัตโนมัติ
อย่างไรก็ตามในบางครั้งอนุกรมเวลาจะไม่อยู่นิ่งนั่นคือคุณสมบัติทางสถิติของอนุกรมเช่นค่าเฉลี่ยความแปรปรวนเปลี่ยนแปลงตลอดเวลา และแบบจำลองทางสถิติที่เราศึกษาจนถึงตอนนี้ถือว่าอนุกรมเวลาเป็นแบบนิ่งดังนั้นเราจึงสามารถรวมขั้นตอนก่อนการประมวลผลของการแยกอนุกรมเวลาเพื่อทำให้มันนิ่งได้ ตอนนี้เป็นเรื่องสำคัญที่เราจะต้องค้นหาว่าอนุกรมเวลาที่เรากำลังดำเนินการอยู่นั้นหยุดนิ่งหรือไม่
วิธีการต่างๆในการค้นหาความสม่ำเสมอของอนุกรมเวลากำลังมองหาฤดูกาลหรือแนวโน้มในพล็อตของอนุกรมเวลาการตรวจสอบความแตกต่างของค่าเฉลี่ยและความแปรปรวนสำหรับช่วงเวลาต่างๆการทดสอบ Augmented Dickey-Fuller (ADF) การทดสอบ KPSS การยกกำลังเฮิร์สต์ .
ให้เราดูว่าตัวแปร 'อุณหภูมิ' ของชุดข้อมูลของเราเป็นอนุกรมเวลาที่หยุดนิ่งหรือไม่โดยใช้การทดสอบ ADF
ใน [74]:
from statsmodels.tsa.stattools import adfuller
result = adfuller(train)
print('ADF Statistic: %f' % result[0])
print('p-value: %f' % result[1])
print('Critical Values:')
for key, value In result[4].items()
print('\t%s: %.3f' % (key, value))สถิติ ADF: -10.406056
ค่า p: 0.000000
ค่าวิกฤต:
1%: -3.431
5%: -2.862
10%: -2.567
ตอนนี้เราได้ทำการทดสอบ ADF แล้วให้เราแปลผล ก่อนอื่นเราจะเปรียบเทียบสถิติของ ADF กับค่าวิกฤตค่าวิกฤตที่ต่ำกว่าจะบอกเราว่าซีรีส์ส่วนใหญ่มักไม่อยู่นิ่ง ต่อไปเราจะเห็นค่า p ค่า p ที่มากกว่า 0.05 ยังแสดงให้เห็นว่าอนุกรมเวลาไม่หยุดนิ่ง
หรืออีกวิธีหนึ่งคือค่า p น้อยกว่าหรือเท่ากับ 0.05 หรือสถิติ ADF น้อยกว่าค่าวิกฤตแนะนำให้อนุกรมเวลาหยุดนิ่ง
ดังนั้นอนุกรมเวลาที่เรากำลังดำเนินการจึงหยุดนิ่งอยู่แล้ว ในกรณีของอนุกรมเวลาที่หยุดนิ่งเราตั้งค่าพารามิเตอร์ 'd' เป็น 0
นอกจากนี้เรายังสามารถยืนยันความสม่ำเสมอของอนุกรมเวลาโดยใช้เฮิร์สต์เอ็กซ์โปเนนต์
ใน [75]:
import hurst
H, c,data = hurst.compute_Hc(train)
print("H = {:.4f}, c = {:.4f}".format(H,c))H = 0.1660, c = 5.0740
ค่า H <0.5 แสดงพฤติกรรมต่อต้านต่อเนื่องและ H> 0.5 แสดงพฤติกรรมต่อเนื่องหรือซีรี่ส์ที่กำลังมาแรง H = 0.5 แสดงการเดินแบบสุ่ม / การเคลื่อนไหวแบบ Brownian ค่า H <0.5 ยืนยันว่าซีรีส์ของเราหยุดนิ่ง
สำหรับอนุกรมเวลาที่ไม่อยู่นิ่งเราตั้งค่าพารามิเตอร์ 'd' เป็น 1 นอกจากนี้ค่าของพารามิเตอร์แนวโน้มถอยหลังอัตโนมัติ 'p' และพารามิเตอร์แนวโน้มค่าเฉลี่ยเคลื่อนที่ 'q' จะคำนวณจากอนุกรมเวลาที่หยุดนิ่งเช่นโดยการพล็อต ACP และ PACP หลังจากทำให้อนุกรมเวลาต่างกัน
แบบจำลอง ARIMA ซึ่งมีลักษณะเป็น 3 พารามิเตอร์ (p, d, q) นั้นชัดเจนสำหรับเราแล้วดังนั้นให้เราจำลองอนุกรมเวลาของเราและทำนายค่าอุณหภูมิในอนาคต
ใน [156]:
from statsmodels.tsa.arima_model import ARIMA
model = ARIMA(train.values, order=(5, 0, 2))
model_fit = model.fit(disp=False)ใน [157]:
predictions = model_fit.predict(len(test))
test_ = pandas.DataFrame(test)
test_['predictions'] = predictions[0:1871]ใน [158]:
plt.plot(df['T'])
plt.plot(test_.predictions)
plt.show()
ใน [167]:
error = sqrt(metrics.mean_squared_error(test.values,predictions[0:1871]))
print ('Test RMSE for ARIMA: ', error)ทดสอบ RMSE สำหรับ ARIMA: 43.21252940234892
ในบทที่แล้วตอนนี้เราได้เห็นวิธีการทำงานของโมเดล ARIMA และข้อ จำกัด ที่ไม่สามารถจัดการข้อมูลตามฤดูกาลหรืออนุกรมเวลาหลายตัวแปรได้และด้วยเหตุนี้โมเดลใหม่จึงถูกนำมาใช้เพื่อรวมคุณสมบัติเหล่านี้
ภาพรวมของรุ่นใหม่เหล่านี้มีให้ที่นี่ -
เวกเตอร์การถดถอยอัตโนมัติ (VAR)
เป็นรุ่นทั่วไปของแบบจำลองการถดถอยอัตโนมัติสำหรับอนุกรมเวลาที่หยุดนิ่งหลายตัวแปร มีลักษณะเป็นพารามิเตอร์ 'p'
ค่าเฉลี่ยเคลื่อนที่เวกเตอร์ (VMA)
เป็นรุ่นทั่วไปของแบบจำลองค่าเฉลี่ยเคลื่อนที่สำหรับอนุกรมเวลาแบบคงที่หลายตัวแปร มีลักษณะเป็นพารามิเตอร์ 'q'
เวกเตอร์อัตโนมัติถดถอยเฉลี่ยเคลื่อนที่ (VARMA)
เป็นการผสมผสานระหว่าง VAR และ VMA และแบบจำลอง ARMA สำหรับอนุกรมเวลาแบบคงที่หลายตัวแปร มีลักษณะเป็นพารามิเตอร์ 'p' และ 'q' เช่นเดียวกับ ARMA สามารถทำหน้าที่เหมือนโมเดล AR ได้โดยตั้งค่าพารามิเตอร์ 'q' เป็น 0 และในรูปแบบ MA โดยการตั้งค่าพารามิเตอร์ 'p' เป็น 0 VARMA ยังสามารถทำหน้าที่เหมือนโมเดล VAR ได้โดยการตั้งค่าพารามิเตอร์ 'q' เป็น 0 และเป็นโมเดล VMA โดยตั้งค่าพารามิเตอร์ 'p' เป็น 0
ใน [209]:
df_multi = df[['T', 'C6H6(GT)']]
split = len(df) - int(0.2*len(df))
train_multi, test_multi = df_multi[0:split], df_multi[split:]ใน [211]:
from statsmodels.tsa.statespace.varmax import VARMAX
model = VARMAX(train_multi, order = (2,1))
model_fit = model.fit()
c:\users\naveksha\appdata\local\programs\python\python37\lib\site-packages\statsmodels\tsa\statespace\varmax.py:152:
EstimationWarning: Estimation of VARMA(p,q) models is not generically robust,
due especially to identification issues.
EstimationWarning)
c:\users\naveksha\appdata\local\programs\python\python37\lib\site-packages\statsmodels\tsa\base\tsa_model.py:171:
ValueWarning: No frequency information was provided, so inferred frequency H will be used.
% freq, ValueWarning)
c:\users\naveksha\appdata\local\programs\python\python37\lib\site-packages\statsmodels\base\model.py:508:
ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
"Check mle_retvals", ConvergenceWarning)ใน [213]:
predictions_multi = model_fit.forecast( steps=len(test_multi))
c:\users\naveksha\appdata\local\programs\python\python37\lib\site-packages\statsmodels\tsa\base\tsa_model.py:320:
FutureWarning: Creating a DatetimeIndex by passing range endpoints is deprecated. Use `pandas.date_range` instead.
freq = base_index.freq)
c:\users\naveksha\appdata\local\programs\python\python37\lib\site-packages\statsmodels\tsa\statespace\varmax.py:152:
EstimationWarning: Estimation of VARMA(p,q) models is not generically robust, due especially to identification issues.
EstimationWarning)ใน [231]:
plt.plot(train_multi['T'])
plt.plot(test_multi['T'])
plt.plot(predictions_multi.iloc[:,0:1], '--')
plt.show()
plt.plot(train_multi['C6H6(GT)'])
plt.plot(test_multi['C6H6(GT)'])
plt.plot(predictions_multi.iloc[:,1:2], '--')
plt.show()

โค้ดด้านบนแสดงวิธีใช้โมเดล VARMA เพื่อสร้างแบบจำลองอนุกรมเวลาหลายตัวแปรแม้ว่าโมเดลนี้อาจไม่เหมาะสมที่สุดกับข้อมูลของเรา
VARMA พร้อมตัวแปรภายนอก (VARMAX)
เป็นส่วนขยายของโมเดล VARMA ที่ใช้ตัวแปรพิเศษที่เรียกว่าโควาเรียตเพื่อสร้างแบบจำลองตัวแปรหลักที่เราสนใจ
ค่าเฉลี่ยเคลื่อนที่แบบรวมถอยหลังอัตโนมัติตามฤดูกาล (SARIMA)
นี่คือส่วนขยายของโมเดล ARIMA เพื่อจัดการกับข้อมูลตามฤดูกาล โดยแบ่งข้อมูลออกเป็นส่วนประกอบตามฤดูกาลและไม่เป็นไปตามฤดูกาลและสร้างแบบจำลองในลักษณะที่คล้ายกัน มีลักษณะเป็นพารามิเตอร์ 7 ตัวสำหรับพารามิเตอร์ส่วนที่ไม่ใช่ฤดูกาล (p, d, q) เช่นเดียวกับแบบจำลอง ARIMA และสำหรับพารามิเตอร์ส่วนตามฤดูกาล (P, D, Q, m) โดยที่ 'm' คือจำนวนช่วงเวลาตามฤดูกาลและ P, D, Q คล้ายกับพารามิเตอร์ของโมเดล ARIMA พารามิเตอร์เหล่านี้สามารถปรับเทียบได้โดยใช้การค้นหาแบบกริดหรือขั้นตอนวิธีทางพันธุกรรม
SARIMA ที่มีตัวแปรภายนอก (SARIMAX)
นี่คือส่วนขยายของโมเดล SARIMA เพื่อรวมตัวแปรภายนอกซึ่งช่วยให้เราสามารถสร้างแบบจำลองตัวแปรที่เราสนใจได้
อาจเป็นประโยชน์ในการวิเคราะห์ความสัมพันธ์ร่วมกับตัวแปรก่อนที่จะวางเป็นตัวแปรภายนอก
ใน [251]:
from scipy.stats.stats import pearsonr
x = train_multi['T'].values
y = train_multi['C6H6(GT)'].values
corr , p = pearsonr(x,y)
print ('Corelation Coefficient =', corr,'\nP-Value =',p)
Corelation Coefficient = 0.9701173437269858
P-Value = 0.0ความสัมพันธ์ของเพียร์สันแสดงความสัมพันธ์เชิงเส้นระหว่าง 2 ตัวแปรในการตีความผลลัพธ์อันดับแรกเราจะดูที่ค่า p ถ้าน้อยกว่า 0.05 แสดงว่าค่าสัมประสิทธิ์มีนัยสำคัญมิฉะนั้นค่าสัมประสิทธิ์จะไม่มีนัยสำคัญ สำหรับค่า p ที่มีนัยสำคัญค่าสัมประสิทธิ์สหสัมพันธ์ที่เป็นบวกแสดงถึงความสัมพันธ์เชิงบวกและค่าลบบ่งบอกถึงความสัมพันธ์เชิงลบ
ดังนั้นสำหรับข้อมูลของเรา 'อุณหภูมิ' และ 'C6H6' ดูเหมือนจะมีความสัมพันธ์ในเชิงบวกอย่างมาก ดังนั้นเราจะ
ใน [297]:
from statsmodels.tsa.statespace.sarimax import SARIMAX
model = SARIMAX(x, exog = y, order = (2, 0, 2), seasonal_order = (2, 0, 1, 1), enforce_stationarity=False, enforce_invertibility = False)
model_fit = model.fit(disp = False)
c:\users\naveksha\appdata\local\programs\python\python37\lib\site-packages\statsmodels\base\model.py:508:
ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
"Check mle_retvals", ConvergenceWarning)ใน [298]:
y_ = test_multi['C6H6(GT)'].values
predicted = model_fit.predict(exog=y_)
test_multi_ = pandas.DataFrame(test)
test_multi_['predictions'] = predicted[0:1871]ใน [299]:
plt.plot(train_multi['T'])
plt.plot(test_multi_['T'])
plt.plot(test_multi_.predictions, '--')ออก [299]:
[<matplotlib.lines.Line2D at 0x1eab0191c18>]การคาดการณ์ที่นี่ดูเหมือนจะมีรูปแบบที่หลากหลายกว่าในขณะนี้เมื่อเทียบกับการสร้างแบบจำลอง ARIMA ที่ไม่แปรผัน
ไม่จำเป็นต้องพูดว่า SARIMAX สามารถใช้เป็นโมเดล ARX, MAX, ARMAX หรือ ARIMAX ได้โดยตั้งค่าเฉพาะพารามิเตอร์ที่เกี่ยวข้องเป็นค่าที่ไม่ใช่ศูนย์
Fractional Auto Regressive Integrated Moving Average (FARIMA)
ในบางครั้งอาจเกิดขึ้นได้ว่าซีรีส์ของเราไม่ได้อยู่นิ่ง แต่การแตกต่างกับพารามิเตอร์ 'd' ที่ใช้ค่า 1 อาจแตกต่างกันมากเกินไป ดังนั้นเราต้องแตกต่างของอนุกรมเวลาโดยใช้ค่าเศษส่วน
ในโลกของวิทยาศาสตร์ข้อมูลไม่มีโมเดลที่เหนือกว่าแบบจำลองที่ทำงานกับข้อมูลของคุณขึ้นอยู่กับชุดข้อมูลของคุณเป็นอย่างมาก ความรู้เกี่ยวกับแบบจำลองต่างๆช่วยให้เราสามารถเลือกรูปแบบที่ทำงานกับข้อมูลของเราและทดลองใช้โมเดลนั้นเพื่อให้ได้ผลลัพธ์ที่ดีที่สุด และผลลัพธ์ควรถูกมองว่าเป็นพล็อตเช่นเดียวกับเมตริกข้อผิดพลาดในบางครั้งข้อผิดพลาดเล็กน้อยก็อาจไม่ดีด้วยเหตุนี้การวางแผนและการแสดงผลลัพธ์จึงเป็นสิ่งสำคัญ
ในบทต่อไปเราจะมาดูแบบจำลองทางสถิติอีกแบบคือการปรับให้เรียบแบบเอ็กซ์โปเนนเชียล
ในบทนี้เราจะพูดถึงเทคนิคที่เกี่ยวข้องกับการปรับอนุกรมเวลาให้เรียบแบบเลขชี้กำลัง
เรียบง่ายเลขชี้กำลัง
Exponential Smoothing เป็นเทคนิคในการทำให้อนุกรมเวลาที่ไม่แปรผันอย่างราบรื่นโดยการกำหนดน้ำหนักที่ลดลงแบบเอ็กซ์โพเนนเชียลให้กับข้อมูลในช่วงเวลาหนึ่ง
ในทางคณิตศาสตร์ค่าของตัวแปรในเวลา 't + 1' ค่าที่กำหนดในเวลา t, y_ (t + 1 | t) ถูกกำหนดเป็น -
$$y_{t+1|t}\:=\:\alpha y_{t}\:+\:\alpha\lgroup1 -\alpha\rgroup y_{t-1}\:+\alpha\lgroup1-\alpha\rgroup^{2}\:y_{t-2}\:+\:...+y_{1}$$
ที่ไหน$0\leq\alpha \leq1$ คือพารามิเตอร์การปรับให้เรียบและ
$y_{1},....,y_{t}$ คือค่าก่อนหน้าของการรับส่งข้อมูลเครือข่ายที่คูณ 1, 2, 3, …, t
นี่เป็นวิธีง่ายๆในการสร้างแบบจำลองอนุกรมเวลาโดยไม่มีแนวโน้มหรือฤดูกาลที่ชัดเจน แต่การปรับให้เรียบแบบเอ็กซ์โพเนนเชียลยังสามารถใช้กับอนุกรมเวลาที่มีแนวโน้มและฤดูกาลได้
Triple Exponential Smoothing
Triple Exponential Smoothing (TES) หรือวิธี Winter ของ Holt ใช้การปรับให้เรียบแบบเอ็กซ์โปเนนเชียลสามครั้ง - การปรับระดับให้เรียบ $l_{t}$เทรนด์เรียบ $b_{t}$และการปั่นตามฤดูกาล $S_{t}$กับ $\alpha$, $\beta^{*}$ และ $\gamma$ เป็นพารามิเตอร์ที่ทำให้เรียบโดยมี 'm' เป็นความถี่ของฤดูกาลเช่นจำนวนฤดูกาลในหนึ่งปี
ตามลักษณะขององค์ประกอบตามฤดูกาล TES มีสองประเภท -
Holt-Winter's Additive Method - เมื่อฤดูกาลเป็นสิ่งที่เติมแต่งในธรรมชาติ
Holt-Winter’s Multiplicative Method - เมื่อฤดูกาลทวีคูณตามธรรมชาติ
สำหรับอนุกรมเวลาที่ไม่ใช่ฤดูกาลเรามีเพียงการปรับให้เรียบตามแนวโน้มและการปรับระดับให้เรียบเท่านั้นซึ่งเรียกว่าวิธีเชิงเส้นของโฮลท์
ลองใช้การปรับให้เรียบแบบเลขชี้กำลังสามเท่ากับข้อมูลของเรา
ใน [316]:
from statsmodels.tsa.holtwinters import ExponentialSmoothing
model = ExponentialSmoothing(train.values, trend= )
model_fit = model.fit()ใน [322]:
predictions_ = model_fit.predict(len(test))ใน [325]:
plt.plot(test.values)
plt.plot(predictions_[1:1871])ออก [325]:
[<matplotlib.lines.Line2D at 0x1eab00f1cf8>]
ที่นี่เราได้ฝึกโมเดลหนึ่งครั้งด้วยชุดฝึกจากนั้นเราก็ทำการคาดเดาต่อไป แนวทางที่เป็นจริงมากขึ้นคือการฝึกโมเดลใหม่หลังจากผ่านไปหนึ่งขั้นตอนหรือมากกว่านั้น เมื่อเราได้รับการทำนายเวลา 't + 1' จากข้อมูลการฝึก 'til time' t 'การทำนายครั้งต่อไปสำหรับเวลา' t + 2 'สามารถทำได้โดยใช้ข้อมูลการฝึกอบรม' til time 't + 1' ตามความเป็นจริง ค่าที่ "t + 1" จะทราบแล้ว วิธีการนี้ในการคาดการณ์สำหรับขั้นตอนในอนาคตอย่างน้อยหนึ่งขั้นตอนจากนั้นฝึกอบรมแบบจำลองใหม่เรียกว่าการคาดการณ์แบบหมุนหรือการตรวจสอบความถูกต้องของการเดิน
ในการสร้างแบบจำลองอนุกรมเวลาการคาดการณ์เมื่อเวลาผ่านไปจะมีความแม่นยำน้อยลงเรื่อย ๆ และด้วยเหตุนี้จึงเป็นแนวทางที่เป็นจริงมากขึ้นในการฝึกโมเดลใหม่ด้วยข้อมูลจริงเมื่อมีการคาดการณ์เพิ่มเติม เนื่องจากการฝึกอบรมแบบจำลองทางสถิติไม่ใช้เวลานานการตรวจสอบความถูกต้องโดยการเดินไปข้างหน้าจึงเป็นทางออกที่ดีที่สุดเพื่อให้ได้ผลลัพธ์ที่แม่นยำที่สุด
ให้เราใช้การตรวจสอบความถูกต้องของข้อมูลของเราในขั้นตอนเดียวและเปรียบเทียบกับผลลัพธ์ที่เราได้รับก่อนหน้านี้
ใน [333]:
prediction = []
data = train.values
for t In test.values:
model = (ExponentialSmoothing(data).fit())
y = model.predict()
prediction.append(y[0])
data = numpy.append(data, t)ใน [335]:
test_ = pandas.DataFrame(test)
test_['predictionswf'] = predictionใน [341]:
plt.plot(test_['T'])
plt.plot(test_.predictionswf, '--')
plt.show()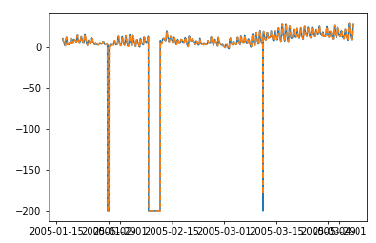
ใน [340]:
error = sqrt(metrics.mean_squared_error(test.values,prediction))
print ('Test RMSE for Triple Exponential Smoothing with Walk-Forward Validation: ', error)
Test RMSE for Triple Exponential Smoothing with Walk-Forward Validation: 11.787532205759442เราจะเห็นได้ว่าโมเดลของเราทำงานได้ดีขึ้นอย่างมากในตอนนี้ ในความเป็นจริงแนวโน้มจะถูกติดตามอย่างใกล้ชิดจนการคาดคะเนของพล็อตทับซ้อนกับค่าจริง คุณสามารถลองใช้การตรวจสอบการเดินไปข้างหน้ากับโมเดล ARIMA ได้เช่นกัน
ในปี 2560 เฟซบุ๊กโอเพ่นซอร์สได้สร้างโมเดลศาสดาพยากรณ์ซึ่งสามารถสร้างแบบจำลองอนุกรมเวลาที่มีหลายฤดูกาลที่แข็งแกร่งในระดับวันระดับสัปดาห์ระดับปี ฯลฯ และแนวโน้ม มีพารามิเตอร์ที่ใช้งานง่ายซึ่งนักวิทยาศาสตร์ข้อมูลที่ไม่เชี่ยวชาญสามารถปรับแต่งเพื่อการคาดการณ์ที่ดีขึ้นได้ ที่แกนหลักคือแบบจำลองการถอยหลังแบบเสริมซึ่งสามารถตรวจจับจุดเปลี่ยนแปลงเพื่อจำลองอนุกรมเวลาได้
ศาสดาย่อยสลายอนุกรมเวลาเป็นส่วนประกอบของแนวโน้ม $g_{t}$, ฤดูกาล $S_{t}$ และวันหยุด $h_{t}$.
$$y_{t}=g_{t}+s_{t}+h_{t}+\epsilon_{t}$$
ที่ไหน $\epsilon_{t}$ คือเงื่อนไขข้อผิดพลาด
แพ็คเกจที่คล้ายกันสำหรับการพยากรณ์อนุกรมเวลาเช่นผลกระทบเชิงสาเหตุและการตรวจจับความผิดปกติได้รับการแนะนำใน R โดย google และ twitter ตามลำดับ
ตอนนี้เราคุ้นเคยกับการสร้างแบบจำลองทางสถิติเกี่ยวกับอนุกรมเวลา แต่การเรียนรู้ของเครื่องเป็นสิ่งที่น่าสนใจในตอนนี้ดังนั้นจึงจำเป็นอย่างยิ่งที่จะต้องทำความคุ้นเคยกับโมเดลการเรียนรู้ของเครื่องด้วย เราจะเริ่มต้นด้วยโมเดลยอดนิยมในโดเมนอนุกรมเวลา - โมเดลหน่วยความจำระยะสั้นระยะยาว
LSTM เป็นเครือข่ายประสาทที่เกิดซ้ำ ดังนั้นก่อนที่เราจะข้ามไปยัง LSTM จำเป็นอย่างยิ่งที่จะต้องเข้าใจเครือข่ายประสาทเทียมและเครือข่ายประสาทที่เกิดซ้ำ
โครงข่ายประสาท
โครงข่ายประสาทเทียมเป็นโครงสร้างชั้นของเซลล์ประสาทที่เชื่อมต่อซึ่งได้รับแรงบันดาลใจจากโครงข่ายประสาททางชีววิทยา ไม่ใช่อัลกอริทึมเดียว แต่เป็นการรวมกันของอัลกอริทึมต่างๆซึ่งช่วยให้เราดำเนินการที่ซับซ้อนกับข้อมูลได้
เครือข่ายประสาทที่กำเริบ
เป็นเครือข่ายประสาทเทียมระดับหนึ่งที่ออกแบบมาเพื่อจัดการกับข้อมูลชั่วคราว เซลล์ประสาทของ RNN มีสถานะเซลล์ / หน่วยความจำและอินพุตจะถูกประมวลผลตามสถานะภายในนี้ซึ่งทำได้ด้วยความช่วยเหลือของลูปในเครือข่ายประสาทเทียม มีโมดูลที่เกิดซ้ำของเลเยอร์ 'tanh' ใน RNN ที่ช่วยให้สามารถเก็บรักษาข้อมูลได้ อย่างไรก็ตามไม่นานเราจึงต้องการรุ่น LSTM
LSTM
เป็นโครงข่ายประสาทที่เกิดซ้ำแบบพิเศษที่สามารถเรียนรู้การพึ่งพาข้อมูลในระยะยาวได้ สิ่งนี้เกิดขึ้นได้เนื่องจากโมดูลที่เกิดซ้ำของแบบจำลองมีการรวมกันของสี่ชั้นที่โต้ตอบซึ่งกันและกัน

ภาพด้านบนแสดงเลเยอร์เครือข่ายประสาทเทียมสี่ชั้นในกล่องสีเหลืองชี้ตัวดำเนินการที่ชาญฉลาดในวงกลมสีเขียวป้อนข้อมูลในวงกลมสีเหลืองและสถานะของเซลล์ในวงกลมสีน้ำเงิน โมดูล LSTM มีสถานะเซลล์และประตูสามประตูซึ่งให้อำนาจในการเลือกเรียนรู้ไม่เรียนรู้หรือเก็บรักษาข้อมูลจากแต่ละหน่วย สถานะเซลล์ใน LSTM ช่วยให้ข้อมูลไหลผ่านหน่วยต่างๆโดยไม่ถูกเปลี่ยนแปลงโดยอนุญาตให้มีปฏิสัมพันธ์เชิงเส้นเพียงไม่กี่ครั้ง แต่ละหน่วยมีอินพุตเอาต์พุตและประตูลืมซึ่งสามารถเพิ่มหรือลบข้อมูลไปยังสถานะเซลล์ได้ ประตูการลืมจะตัดสินใจว่าข้อมูลใดจากสถานะเซลล์ก่อนหน้านี้ที่ควรลืมซึ่งใช้ฟังก์ชัน sigmoid ประตูอินพุตควบคุมการไหลของข้อมูลไปยังสถานะเซลล์ปัจจุบันโดยใช้การดำเนินการคูณแบบชี้จุดของ 'sigmoid' และ 'tanh' ตามลำดับ สุดท้ายประตูเอาต์พุตจะตัดสินใจว่าข้อมูลใดควรถูกส่งต่อไปยังสถานะที่ซ่อนอยู่ถัดไป
ตอนนี้เราเข้าใจการทำงานภายในของโมเดล LSTM แล้วให้เรานำไปใช้ เพื่อทำความเข้าใจการใช้งาน LSTM เราจะเริ่มต้นด้วยตัวอย่างง่ายๆ - เส้นตรง ให้เราดูว่า LSTM สามารถเรียนรู้ความสัมพันธ์ของเส้นตรงและทำนายได้หรือไม่
ขั้นแรกให้เราสร้างชุดข้อมูลที่แสดงเส้นตรง
ใน [402]:
x = numpy.arange (1,500,1)
y = 0.4 * x + 30
plt.plot(x,y)ออก [402]:
[<matplotlib.lines.Line2D at 0x1eab9d3ee10>]
ใน [403]:
trainx, testx = x[0:int(0.8*(len(x)))], x[int(0.8*(len(x))):]
trainy, testy = y[0:int(0.8*(len(y)))], y[int(0.8*(len(y))):]
train = numpy.array(list(zip(trainx,trainy)))
test = numpy.array(list(zip(trainx,trainy)))ตอนนี้ข้อมูลถูกสร้างขึ้นและแยกออกเป็นรถไฟและทดสอบ เรามาแปลงข้อมูลอนุกรมเวลาให้อยู่ในรูปแบบของข้อมูลการเรียนรู้ภายใต้การดูแลตามค่าของระยะเวลามองย้อนกลับซึ่งโดยพื้นฐานแล้วคือจำนวนความล่าช้าที่เห็นเพื่อทำนายค่าในเวลา 't'
อนุกรมเวลาแบบนี้ -
time variable_x
t1 x1
t2 x2
: :
: :
T xTเมื่อระยะเวลามองย้อนกลับเป็น 1 จะถูกแปลงเป็น -
x1 x2
x2 x3
: :
: :
xT-1 xTใน [404]:
def create_dataset(n_X, look_back):
dataX, dataY = [], []
for i in range(len(n_X)-look_back):
a = n_X[i:(i+look_back), ]
dataX.append(a)
dataY.append(n_X[i + look_back, ])
return numpy.array(dataX), numpy.array(dataY)ใน [405]:
look_back = 1
trainx,trainy = create_dataset(train, look_back)
testx,testy = create_dataset(test, look_back)
trainx = numpy.reshape(trainx, (trainx.shape[0], 1, 2))
testx = numpy.reshape(testx, (testx.shape[0], 1, 2))ตอนนี้เราจะฝึกโมเดลของเรา
ข้อมูลการฝึกอบรมกลุ่มเล็ก ๆ จะแสดงให้กับเครือข่ายการรันหนึ่งครั้งเมื่อข้อมูลการฝึกอบรมทั้งหมดแสดงต่อโมเดลเป็นชุดและคำนวณข้อผิดพลาดเรียกว่า epoch ยุคจะถูกเรียกใช้จนกว่าข้อผิดพลาดจะลดลง
ใน []:
from keras.models import Sequential
from keras.layers import LSTM, Dense
model = Sequential()
model.add(LSTM(256, return_sequences = True, input_shape = (trainx.shape[1], 2)))
model.add(LSTM(128,input_shape = (trainx.shape[1], 2)))
model.add(Dense(2))
model.compile(loss = 'mean_squared_error', optimizer = 'adam')
model.fit(trainx, trainy, epochs = 2000, batch_size = 10, verbose = 2, shuffle = False)
model.save_weights('LSTMBasic1.h5')ใน [407]:
model.load_weights('LSTMBasic1.h5')
predict = model.predict(testx)ตอนนี้เรามาดูกันว่าการคาดการณ์ของเรามีลักษณะอย่างไร
ใน [408]:
plt.plot(testx.reshape(398,2)[:,0:1], testx.reshape(398,2)[:,1:2])
plt.plot(predict[:,0:1], predict[:,1:2])ออก [408]:
[<matplotlib.lines.Line2D at 0x1eac792f048>]
ตอนนี้เราควรลองสร้างแบบจำลองคลื่นไซน์หรือโคไซน์ในลักษณะที่คล้ายกัน คุณสามารถรันโค้ดที่ระบุด้านล่างและเล่นกับพารามิเตอร์โมเดลเพื่อดูว่าผลลัพธ์เปลี่ยนแปลงไปอย่างไร
ใน [409]:
x = numpy.arange (1,500,1)
y = numpy.sin(x)
plt.plot(x,y)ออก [409]:
[<matplotlib.lines.Line2D at 0x1eac7a0b3c8>]
ใน [410]:
trainx, testx = x[0:int(0.8*(len(x)))], x[int(0.8*(len(x))):]
trainy, testy = y[0:int(0.8*(len(y)))], y[int(0.8*(len(y))):]
train = numpy.array(list(zip(trainx,trainy)))
test = numpy.array(list(zip(trainx,trainy)))ใน [411]:
look_back = 1
trainx,trainy = create_dataset(train, look_back)
testx,testy = create_dataset(test, look_back)
trainx = numpy.reshape(trainx, (trainx.shape[0], 1, 2))
testx = numpy.reshape(testx, (testx.shape[0], 1, 2))ใน []:
model = Sequential()
model.add(LSTM(512, return_sequences = True, input_shape = (trainx.shape[1], 2)))
model.add(LSTM(256,input_shape = (trainx.shape[1], 2)))
model.add(Dense(2))
model.compile(loss = 'mean_squared_error', optimizer = 'adam')
model.fit(trainx, trainy, epochs = 2000, batch_size = 10, verbose = 2, shuffle = False)
model.save_weights('LSTMBasic2.h5')ใน [413]:
model.load_weights('LSTMBasic2.h5')
predict = model.predict(testx)ใน [415]:
plt.plot(trainx.reshape(398,2)[:,0:1], trainx.reshape(398,2)[:,1:2])
plt.plot(predict[:,0:1], predict[:,1:2])ออก [415]:
[<matplotlib.lines.Line2D at 0x1eac7a1f550>]
ตอนนี้คุณพร้อมที่จะไปยังชุดข้อมูลใด ๆ
เป็นสิ่งสำคัญสำหรับเราในการหาปริมาณประสิทธิภาพของแบบจำลองเพื่อใช้เป็นข้อเสนอแนะและการเปรียบเทียบ ในบทช่วยสอนนี้เราได้ใช้หนึ่งในข้อผิดพลาดเมตริกรูทค่าเฉลี่ยข้อผิดพลาดกำลังสองที่เป็นที่นิยมมากที่สุด มีเมตริกข้อผิดพลาดอื่น ๆ อีกมากมาย บทนี้จะกล่าวถึงโดยสังเขป
Mean Square Error
เป็นค่าเฉลี่ยของกำลังสองของความแตกต่างระหว่างค่าที่ทำนายและค่าที่แท้จริง Sklearn จัดให้เป็นฟังก์ชัน มีหน่วยเดียวกับค่าจริงและค่าที่คาดการณ์กำลังสองและเป็นค่าบวกเสมอ
$$MSE = \frac{1}{n} \displaystyle\sum\limits_{t=1}^n \lgroup y'_{t}\:-y_{t}\rgroup^{2}$$
ที่ไหน $y'_{t}$ คือค่าทำนาย
$y_{t}$ คือค่าจริงและ
n คือจำนวนค่าทั้งหมดในชุดทดสอบ
เห็นได้ชัดจากสมการว่า MSE มีโทษมากกว่าสำหรับข้อผิดพลาดที่ใหญ่กว่าหรือค่าผิดปกติ
ข้อผิดพลาดค่าเฉลี่ยกำลังสองราก
มันคือรากที่สองของข้อผิดพลาดกำลังสองเฉลี่ย นอกจากนี้ยังเป็นค่าบวกเสมอและอยู่ในช่วงของข้อมูล
$$RMSE = \sqrt{\frac{1}{n} \displaystyle\sum\limits_{t=1}^n \lgroup y'_{t}-y_{t}\rgroup ^2}$$
ที่ไหน $y'_{t}$ คือค่าที่คาดการณ์
$y_{t}$ คือมูลค่าจริงและ
n คือจำนวนค่าทั้งหมดในชุดทดสอบ
มันอยู่ในพลังของความสามัคคีและด้วยเหตุนี้จึงตีความได้มากกว่าเมื่อเทียบกับ MSE RMSE ยังให้โทษมากกว่าสำหรับข้อผิดพลาดที่ใหญ่กว่า เราใช้เมตริก RMSE ในบทช่วยสอนของเราแล้ว
หมายถึงข้อผิดพลาดสัมบูรณ์
เป็นค่าเฉลี่ยของความแตกต่างที่แน่นอนระหว่างค่าที่ทำนายและค่าที่แท้จริง มีหน่วยเดียวกับค่าที่ทำนายและเป็นจริงและเป็นค่าบวกเสมอ
$$MAE = \frac{1}{n}\displaystyle\sum\limits_{t=1}^{t=n} | y'{t}-y_{t}\lvert$$
ที่ไหน $y'_{t}$ คือค่าที่คาดการณ์
$y_{t}$ คือมูลค่าจริงและ
n คือจำนวนค่าทั้งหมดในชุดทดสอบ
ค่าเฉลี่ยเปอร์เซ็นต์ผิดพลาด
เป็นเปอร์เซ็นต์ของค่าเฉลี่ยของความแตกต่างที่แน่นอนระหว่างค่าที่ทำนายและค่าจริงหารด้วยค่าจริง
$$MAPE = \frac{1}{n}\displaystyle\sum\limits_{t=1}^n\frac{y'_{t}-y_{t}}{y_{t}}*100\: \%$$
ที่ไหน $y'_{t}$ คือค่าที่คาดการณ์
$y_{t}$ คือค่าจริงและ n คือจำนวนค่าทั้งหมดในชุดทดสอบ
อย่างไรก็ตามข้อเสียของการใช้ข้อผิดพลาดนี้คือข้อผิดพลาดเชิงบวกและข้อผิดพลาดเชิงลบสามารถหักล้างกันได้ ดังนั้นจึงใช้ข้อผิดพลาดเปอร์เซ็นต์สัมบูรณ์
ค่าเฉลี่ยข้อผิดพลาดเปอร์เซ็นต์สัมบูรณ์
เป็นเปอร์เซ็นต์ของค่าเฉลี่ยของความแตกต่างที่แน่นอนระหว่างค่าที่ทำนายและค่าจริงหารด้วยค่าจริง
$$MAPE = \frac{1}{n}\displaystyle\sum\limits_{t=1}^n\frac{|y'_{t}-y_{t}\lvert}{y_{t}}*100\: \%$$
ที่ไหน $y'_{t}$ คือค่าที่คาดการณ์
$y_{t}$ คือมูลค่าจริงและ
n คือจำนวนค่าทั้งหมดในชุดทดสอบ
เราได้พูดถึงการวิเคราะห์อนุกรมเวลาในบทช่วยสอนนี้ซึ่งทำให้เราเข้าใจว่าแบบจำลองอนุกรมเวลาจะรับรู้แนวโน้มและฤดูกาลจากการสังเกตที่มีอยู่ก่อนแล้วจึงคาดการณ์มูลค่าตามแนวโน้มและฤดูกาลนี้ การวิเคราะห์ดังกล่าวมีประโยชน์ในด้านต่างๆเช่น -
Financial Analysis - รวมถึงการพยากรณ์ยอดขายการวิเคราะห์สินค้าคงคลังการวิเคราะห์ตลาดหุ้นการประมาณราคา
Weather Analysis - รวมถึงการประมาณอุณหภูมิการเปลี่ยนแปลงสภาพภูมิอากาศการรับรู้การเปลี่ยนแปลงตามฤดูกาลการพยากรณ์อากาศ
Network Data Analysis - รวมถึงการทำนายการใช้งานเครือข่ายการตรวจจับความผิดปกติหรือการบุกรุกการบำรุงรักษาเชิงคาดการณ์
Healthcare Analysis - รวมถึงการทำนายสำมะโนประชากรการทำนายผลประโยชน์การประกันการตรวจสอบผู้ป่วย
แมชชีนเลิร์นนิงเกี่ยวข้องกับปัญหาต่างๆ ในความเป็นจริงเกือบทุกช่องมีขอบเขตที่จะทำให้เป็นอัตโนมัติหรือปรับปรุงด้วยความช่วยเหลือของแมชชีนเลิร์นนิง ปัญหาดังกล่าวบางประการที่ต้องดำเนินการจำนวนมากดังต่อไปนี้
ข้อมูลอนุกรมเวลา
นี่คือข้อมูลที่เปลี่ยนแปลงไปตามเวลาและด้วยเหตุนี้เวลาจึงมีบทบาทสำคัญในนั้นซึ่งส่วนใหญ่เราจะพูดถึงในบทช่วยสอนนี้
ข้อมูลอนุกรมที่ไม่ใช่เวลา
เป็นข้อมูลที่ไม่ขึ้นกับเวลาและปัญหา ML ส่วนใหญ่เกิดจากข้อมูลอนุกรมที่ไม่ใช่เวลา เพื่อความง่ายเราจะจัดหมวดหมู่เพิ่มเติมเป็น -
Numerical Data - คอมพิวเตอร์ไม่เหมือนมนุษย์เท่านั้นที่เข้าใจตัวเลขดังนั้นข้อมูลทุกชนิดจะถูกแปลงเป็นข้อมูลตัวเลขสำหรับการเรียนรู้ของเครื่องในที่สุดเช่นข้อมูลภาพจะถูกแปลงเป็นค่า (r, b, g) ตัวอักษรจะถูกแปลงเป็นรหัส ASCII หรือคำ ถูกจัดทำดัชนีเป็นตัวเลขข้อมูลคำพูดจะถูกแปลงเป็นไฟล์ mfcc ที่มีข้อมูลตัวเลข
Image Data - วิสัยทัศน์ของคอมพิวเตอร์ได้ปฏิวัติโลกของคอมพิวเตอร์มีการใช้งานที่หลากหลายในด้านการแพทย์การถ่ายภาพจากดาวเทียมเป็นต้น
Text Data- Natural Language Processing (NLP) ใช้สำหรับการจำแนกประเภทข้อความการตรวจหาการถอดความและการสรุปภาษา นี่คือสิ่งที่ทำให้ Google และ Facebook ฉลาดขึ้น
Speech Data- การประมวลผลคำพูดเกี่ยวข้องกับการรู้จำเสียงและการเข้าใจความรู้สึก มีบทบาทสำคัญในการให้คอมพิวเตอร์มีคุณสมบัติเหมือนมนุษย์