Apache Spark - Çekirdek Programlama
Spark Core, tüm projenin temelidir. Dağıtılmış görev dağıtımı, zamanlama ve temel G / Ç işlevleri sağlar. Spark, makineler arasında bölümlere ayrılmış mantıksal bir veri koleksiyonu olan RDD (Esnek Dağıtılmış Veri Kümeleri) olarak bilinen özel bir temel veri yapısı kullanır. RDD'ler iki şekilde oluşturulabilir; bunlardan biri, harici depolama sistemlerindeki veri setlerine referans vermek ve ikincisi, mevcut RDD'lere dönüşümler (ör. harita, filtre, azaltıcı, birleştirme) uygulamaktır.
RDD soyutlaması, dil ile entegre bir API aracılığıyla gösterilir. Bu, programlama karmaşıklığını basitleştirir, çünkü uygulamaların RDD'leri işleme biçimi yerel veri koleksiyonlarını değiştirmeye benzer.
Kıvılcım Kabuğu
Spark, verileri etkileşimli olarak analiz etmek için güçlü bir araç olan etkileşimli bir kabuk sağlar. Scala veya Python dilinde mevcuttur. Spark'ın birincil soyutlaması, Esnek Dağıtılmış Veri Kümesi (RDD) adı verilen dağıtılmış bir öğe koleksiyonudur. RDD'ler, Hadoop Giriş Biçimlerinden (HDFS dosyaları gibi) veya diğer RDD'leri dönüştürerek oluşturulabilir.
Spark Shell'i Aç
Aşağıdaki komut Spark kabuğunu açmak için kullanılır.
$ spark-shellBasit RDD oluşturun
Metin dosyasından basit bir RDD oluşturalım. Basit bir RDD oluşturmak için aşağıdaki komutu kullanın.
scala> val inputfile = sc.textFile(“input.txt”)Yukarıdaki komutun çıktısı
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12Spark RDD API, birkaç Transformations ve birkaç Actions RDD'yi değiştirmek için.
RDD Dönüşümleri
RDD dönüşümleri, yeni RDD'ye işaretçi döndürür ve RDD'ler arasında bağımlılıklar oluşturmanıza izin verir. Bağımlılık zincirindeki (Bağımlılıklar Dizisi) her RDD, verilerini hesaplamak için bir işleve sahiptir ve üst RDD'sine bir gösterici (bağımlılık) vardır.
Spark tembeldir, bu nedenle iş yaratma ve yürütmeyi tetikleyecek bir dönüşüm veya eylem çağırmadığınız sürece hiçbir şey yürütülmez. Sözcük sayısı örneğinin aşağıdaki parçacığına bakın.
Bu nedenle, RDD dönüşümü bir veri kümesi değildir, bir programda (tek adım olabilir) Spark'a verileri nasıl alacağını ve onunla ne yapacağını söyleyen bir adımdır.
Aşağıda RDD dönüşümlerinin bir listesi verilmiştir.
| S.No | Dönüşümler ve Anlam |
|---|---|
| 1 | map(func) Kaynağın her bir öğesini bir işlevden geçirerek oluşturulmuş yeni bir dağıtılmış veri kümesi döndürür func. |
| 2 | filter(func) Kaynağın üzerinde bulunduğu öğeleri seçerek oluşturulan yeni bir veri kümesi döndürür. func true döndürür. |
| 3 | flatMap(func) Eşlemeye benzer, ancak her girdi öğesi 0 veya daha fazla çıktı öğesiyle eşlenebilir (bu nedenle func , tek bir öğe yerine bir Seq döndürmelidir). |
| 4 | mapPartitions(func) Haritaya benzer, ancak RDD'nin her bölümünde (blok) ayrı ayrı çalışır, bu nedenle func T tipinde bir RDD üzerinde çalışırken Iterator <T> ⇒ Iterator <U> türünde olmalıdır. |
| 5 | mapPartitionsWithIndex(func) Harita Bölümlerine benzer, ancak aynı zamanda func bölümün dizinini temsil eden bir tamsayı değeriyle, bu nedenle func T türünde bir RDD üzerinde çalışırken (Int, Iterator <T>) ⇒ Iterator <U> türünde olmalıdır. |
| 6 | sample(withReplacement, fraction, seed) Örnek a fraction Verilerin, değiştirilerek veya değiştirilmeden, belirli bir rasgele sayı üreteci tohum kullanarak. |
| 7 | union(otherDataset) Kaynak veri kümesindeki öğelerin birleşimini ve bağımsız değişkeni içeren yeni bir veri kümesi döndürür. |
| 8 | intersection(otherDataset) Kaynak veri kümesindeki öğelerin ve bağımsız değişkenin kesişimini içeren yeni bir RDD döndürür. |
| 9 | distinct([numTasks]) Kaynak veri kümesinin farklı öğelerini içeren yeni bir veri kümesi döndürür. |
| 10 | groupByKey([numTasks]) (K, V) çiftlerinden oluşan bir veri kümesinde çağrıldığında, (K, Yinelenebilir <V>) çiftlerinden oluşan bir veri kümesi döndürür. Note - Her anahtar üzerinde bir toplama (toplam veya ortalama gibi) gerçekleştirmek için gruplama yapıyorsanız, lessByKey veya aggregateByKey kullanmak çok daha iyi performans sağlayacaktır. |
| 11 | reduceByKey(func, [numTasks]) (K, V) çiftlerinin bir veri kümesi üzerinde çağrıldığında, her bir anahtar değerleri azaltmak verilen fonksiyon kullanılarak bir araya getirilmiştir (K, V) çiftlerinin bir veri kümesi döner fonk tipi (V, V) sahip olmalıdır, ⇒ V GroupByKey'de olduğu gibi, azaltma görevlerinin sayısı isteğe bağlı bir ikinci bağımsız değişken aracılığıyla yapılandırılabilir. |
| 12 | aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) (K, V) çiftlerinden oluşan bir veri kümesinde çağrıldığında, her anahtarın değerlerinin verilen birleştirme işlevleri ve nötr bir "sıfır" değeri kullanılarak toplandığı (K, U) çiftlerinden oluşan bir veri kümesi döndürür. Gereksiz ayırmalardan kaçınırken, giriş değeri türünden farklı bir toplanmış değer türüne izin verir. GroupByKey'de olduğu gibi, azaltma görevlerinin sayısı isteğe bağlı bir ikinci bağımsız değişken aracılığıyla yapılandırılabilir. |
| 13 | sortByKey([ascending], [numTasks]) K'nin Sıralı'yı uyguladığı (K, V) çiftlerinden oluşan bir veri kümesinde çağrıldığında, Boole artan bağımsız değişkeninde belirtildiği gibi, anahtarlara göre artan veya azalan sırada sıralanmış (K, V) çiftlerinden oluşan bir veri kümesi döndürür. |
| 14 | join(otherDataset, [numTasks]) (K, V) ve (K, W) türündeki veri kümeleri çağrıldığında, her anahtar için tüm öğe çiftleriyle (K, (V, W)) çiftlerinden oluşan bir veri kümesi döndürür. Dış birleşimler leftOuterJoin, rightOuterJoin ve fullOuterJoin aracılığıyla desteklenir. |
| 15 | cogroup(otherDataset, [numTasks]) (K, V) ve (K, W) türündeki veri kümeleri çağrıldığında, (K, (Yinelenebilir <V>, Yinelenebilir <W>)) demetlerinden oluşan bir veri kümesi döndürür. Bu işlem aynı zamanda Grup olarak da adlandırılır. |
| 16 | cartesian(otherDataset) T ve U türlerinin veri kümelerinde çağrıldığında, (T, U) çiftlerinden (tüm öğe çiftleri) oluşan bir veri kümesi döndürür. |
| 17 | pipe(command, [envVars]) RDD'nin her bölümünü bir kabuk komutu, örneğin bir Perl veya bash betiği aracılığıyla yönlendirin. RDD öğeleri sürecin standart çıkışına yazılır ve standart çıkışına giden satırlar, dizelerin RDD'si olarak döndürülür. |
| 18 | coalesce(numPartitions) RDD'deki bölümlerin sayısını numPartitions'a düşürün. Büyük bir veri kümesini filtreledikten sonra işlemleri daha verimli çalıştırmak için kullanışlıdır. |
| 19 | repartition(numPartitions) Daha fazla veya daha az bölüm oluşturmak ve bunlar arasında dengelemek için RDD'deki verileri rastgele yeniden karıştırın. Bu her zaman ağ üzerindeki tüm verileri karıştırır. |
| 20 | repartitionAndSortWithinPartitions(partitioner) RDD'yi verilen bölümleyiciye göre yeniden bölümleyin ve ortaya çıkan her bölüm içinde kayıtları anahtarlarına göre sıralayın. Bu, yeniden bölümleme çağırmaktan ve ardından her bölüm içinde sıralamaktan daha etkilidir, çünkü sıralamayı karıştırma makinesine doğru itebilir. |
Hareketler
Aşağıdaki tablo, değerleri döndüren Eylemlerin bir listesini verir.
| S.No | Eylem ve Anlam |
|---|---|
| 1 | reduce(func) Veri kümesinin öğelerini bir işlev kullanarak toplayın func(iki bağımsız değişken alır ve bir döndürür). Fonksiyon, paralel olarak doğru şekilde hesaplanabilmesi için değişmeli ve ilişkisel olmalıdır. |
| 2 | collect() Veri kümesinin tüm öğelerini sürücü programında bir dizi olarak döndürür. Bu genellikle, verilerin yeterince küçük bir alt kümesini döndüren bir filtre veya başka bir işlemden sonra yararlıdır. |
| 3 | count() Veri kümesindeki öğelerin sayısını döndürür. |
| 4 | first() Veri kümesinin ilk öğesini döndürür (take (1) 'e benzer). |
| 5 | take(n) İlkine sahip bir dizi verir n veri kümesinin öğeleri. |
| 6 | takeSample (withReplacement,num, [seed]) Rastgele örneklemi olan bir dizi döndürür: num veri kümesinin öğeleri, değiştirilerek veya değiştirilmeden, isteğe bağlı olarak bir rastgele sayı üreteci tohumunu önceden belirleyerek. |
| 7 | takeOrdered(n, [ordering]) İlkini verir n RDD'nin öğeleri doğal sıralarını veya özel bir karşılaştırıcıyı kullanarak. |
| 8 | saveAsTextFile(path) Veri kümesinin öğelerini, yerel dosya sisteminde, HDFS'de veya Hadoop tarafından desteklenen başka herhangi bir dosya sisteminde belirli bir dizinde bir metin dosyası (veya metin dosyaları kümesi) olarak yazar. Spark, dosyadaki bir metin satırına dönüştürmek için her öğe için toString'i çağırır. |
| 9 | saveAsSequenceFile(path) (Java and Scala) Veri kümesinin öğelerini yerel dosya sisteminde, HDFS'de veya Hadoop tarafından desteklenen başka herhangi bir dosya sisteminde belirli bir yolda Hadoop SequenceFile olarak yazar. Bu, Hadoop'un Yazılabilir arayüzünü uygulayan anahtar-değer çiftlerinin RDD'lerinde mevcuttur. Scala'da, örtülü olarak Yazılabilir'e dönüştürülebilen türlerde de mevcuttur (Spark, Int, Double, String, vb. Gibi temel türler için dönüştürmeleri içerir). |
| 10 | saveAsObjectFile(path) (Java and Scala) Veri kümesinin öğelerini, daha sonra SparkContext.objectFile () kullanılarak yüklenebilen Java serileştirmeyi kullanarak basit bir biçimde yazar. |
| 11 | countByKey() Yalnızca (K, V) tipi RDD'lerde mevcuttur. Her anahtarın sayısıyla (K, Int) çiftlerinden oluşan bir hashmap döndürür. |
| 12 | foreach(func) Bir işlevi çalıştırır funcveri kümesinin her bir öğesi üzerinde. Bu genellikle, bir Biriktiriciyi güncelleme veya harici depolama sistemleriyle etkileşim gibi yan etkiler için yapılır. Note- Foreach () dışında Accumulators dışındaki değişkenleri değiştirmek tanımsız davranışa neden olabilir. Daha fazla ayrıntı için Kapanışları anlama konusuna bakın. |
RDD ile programlama
RDD programlamasında birkaç RDD dönüşümünün ve eyleminin uygulamalarını bir örnek yardımıyla görelim.
Misal
Bir kelime sayısı örneği düşünün - Bir belgede görünen her kelimeyi sayar. Aşağıdaki metni bir giriş olarak düşünün ve birinput.txt ev dizinindeki dosya.
input.txt - girdi dosyası.
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.Verilen örneği yürütmek için aşağıda verilen prosedürü izleyin.
Spark-Shell'i açın
Aşağıdaki komut kıvılcım kabuğunu açmak için kullanılır. Genellikle kıvılcım Scala kullanılarak oluşturulur. Bu nedenle, bir Spark programı Scala ortamında çalışır.
$ spark-shellSpark kabuğu başarılı bir şekilde açılırsa, aşağıdaki çıktıyı bulacaksınız. "Spark bağlamı sc olarak kullanılabilir" çıktısının son satırına bakın, Kıvılcım kabının otomatik olarak bu adla kıvılcım bağlam nesnesi oluşturduğu anlamına gelir.sc. Bir programın ilk adımına başlamadan önce, SparkContext nesnesi oluşturulmalıdır.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>RDD oluştur
İlk olarak, girdi dosyasını Spark-Scala API kullanarak okumalı ve bir RDD oluşturmalıyız.
Aşağıdaki komut, verilen konumdan bir dosyayı okumak için kullanılır. Burada, inputfile adıyla yeni RDD oluşturulur. TextFile (“”) yönteminde argüman olarak verilen String, girdi dosyası adı için mutlak yoldur. Ancak, sadece dosya adı verilmişse, bu, giriş dosyasının mevcut konumda olduğu anlamına gelir.
scala> val inputfile = sc.textFile("input.txt")Kelime Sayımı Dönüşümünü Yürüt
Amacımız bir dosyadaki kelimeleri saymaktır. Her satırı kelimelere ayırmak için düz bir harita oluşturun (flatMap(line ⇒ line.split(“ ”)).
Ardından, her kelimeyi bir değer içeren bir anahtar olarak okuyun ‘1’ (<anahtar, değer> = <kelime, 1>) harita işlevini kullanarak (map(word ⇒ (word, 1)).
Son olarak, benzer anahtarların değerlerini ekleyerek bu anahtarları azaltın (reduceByKey(_+_)).
Sözcük sayımı mantığını yürütmek için aşağıdaki komut kullanılır. Bunu yaptıktan sonra herhangi bir çıktı bulamayacaksınız çünkü bu bir eylem değil, bu bir dönüşümdür; yeni bir RDD'yi işaret edin veya kıvılcıma verilen verilerle ne yapılacağını söyleyin)
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);Mevcut RDD
RDD ile çalışırken, mevcut RDD hakkında bilgi edinmek istiyorsanız, aşağıdaki komutu kullanın. Size mevcut RDD ve hata ayıklama için bağımlılıkları hakkında açıklama gösterecektir.
scala> counts.toDebugStringDönüşümleri Önbelleğe Alma
Kalıcı bir RDD'yi, üzerindeki persist () veya cache () yöntemlerini kullanarak işaretleyebilirsiniz. Bir eylemde ilk kez hesaplandığında, düğümlerde bellekte tutulacaktır. Ara dönüşümleri bellekte saklamak için aşağıdaki komutu kullanın.
scala> counts.cache()Eylemi Uygulama
Tüm dönüşümleri, sonuçları bir metin dosyasına kaydetmek gibi bir eylem uygulamak. SaveAsTextFile (“”) yöntemi için String argümanı, çıktı klasörünün mutlak yoludur. Çıkışı bir metin dosyasına kaydetmek için aşağıdaki komutu deneyin. Aşağıdaki örnekte, 'çıktı' klasörü mevcut konumdadır.
scala> counts.saveAsTextFile("output")Çıkışın Kontrol Edilmesi
Ana dizine gitmek için başka bir terminal açın (diğer terminalde spark çalıştırıldığı yer). Çıkış dizinini kontrol etmek için aşağıdaki komutları kullanın.
[hadoop@localhost ~]$ cd output/
[hadoop@localhost output]$ ls -1
part-00000
part-00001
_SUCCESSAşağıdaki komut, aşağıdaki komuttan çıktıyı görmek için kullanılır. Part-00000 Dosyalar.
[hadoop@localhost output]$ cat part-00000Çıktı
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)Aşağıdaki komut, aşağıdaki komuttan çıktıyı görmek için kullanılır. Part-00001 Dosyalar.
[hadoop@localhost output]$ cat part-00001Çıktı
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)BM Depolamaya Devam Ediyor
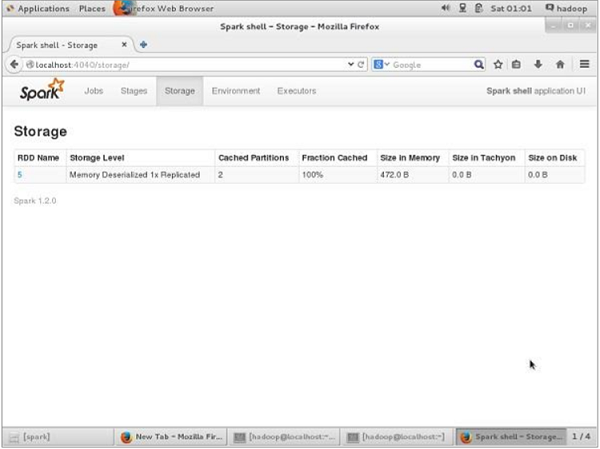
BM-kalıcı olmadan önce, bu uygulama için kullanılan depolama alanını görmek istiyorsanız, tarayıcınızda aşağıdaki URL'yi kullanın.
http://localhost:4040Spark kabuğunda çalışan uygulama için kullanılan depolama alanını gösteren aşağıdaki ekranı göreceksiniz.

Belirli RDD'nin depolama alanını UN-kalıcı hale getirmek istiyorsanız, aşağıdaki komutu kullanın.
Scala> counts.unpersist()Çıkışı aşağıdaki gibi göreceksiniz -
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list
15/06/27 00:57:33 INFO BlockManager: Removing RDD 9
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810)
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106)
res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14Tarayıcıdaki depolama alanını doğrulamak için aşağıdaki URL'yi kullanın.
http://localhost:4040/Aşağıdaki ekranı göreceksiniz. Spark kabuğunda çalışan uygulama için kullanılan depolama alanını gösterir.