Apache Spark - Hızlı Kılavuz
Sektörler, veri setlerini analiz etmek için yoğun bir şekilde Hadoop'u kullanıyor. Bunun nedeni, Hadoop çerçevesinin basit bir programlama modeline (MapReduce) dayanması ve ölçeklenebilir, esnek, hataya dayanıklı ve uygun maliyetli bir hesaplama çözümü sağlamasıdır. Burada asıl mesele, sorgular arasındaki bekleme süresi ve programı çalıştırmak için bekleme süresi açısından büyük veri kümelerini işlemede hızı korumaktır.
Spark, Hadoop hesaplamalı bilgi işlem yazılımı sürecini hızlandırmak için Apache Software Foundation tarafından tanıtıldı.
Ortak bir inanca karşı, Spark is not a modified version of Hadoopve kendi küme yönetimine sahip olduğu için Hadoop'a gerçekten bağımlı değildir. Hadoop, Spark'ı uygulamanın yollarından yalnızca biridir.
Spark, Hadoop'u iki şekilde kullanır - biri storage ve ikincisi processing. Spark kendi küme yönetimi hesaplamasına sahip olduğundan, Hadoop'u yalnızca depolama amacıyla kullanır.
Apache Spark
Apache Spark, hızlı hesaplama için tasarlanmış, ışık hızında bir küme bilgi işlem teknolojisidir. Hadoop MapReduce'a dayanır ve MapReduce modelini, etkileşimli sorgular ve akış işlemeyi içeren daha fazla hesaplama türü için verimli bir şekilde kullanmak üzere genişletir. Spark'ın ana özelliği,in-memory cluster computing bu, bir uygulamanın işlem hızını artırır.
Spark, toplu uygulamalar, yinelemeli algoritmalar, etkileşimli sorgular ve akış gibi çok çeşitli iş yüklerini kapsayacak şekilde tasarlanmıştır. Tüm bu iş yükünü ilgili bir sistemde desteklemenin yanı sıra, ayrı araçları korumanın yönetim yükünü azaltır.
Apache Spark'ın Evrimi
Spark, Matei Zaharia tarafından UC Berkeley'in AMPLab'ında 2009 yılında geliştirilen Hadoop'un alt projelerinden biridir. 2010 yılında bir BSD lisansı altında Açık Kaynaklıdır. 2013'te Apache yazılım vakfına bağışlandı ve şimdi Apache Spark, Şubat-2014'ten itibaren üst düzey bir Apache projesi haline geldi.
Apache Spark'ın Özellikleri
Apache Spark aşağıdaki özelliklere sahiptir.
Speed- Spark, bir uygulamanın Hadoop kümesinde, bellekte 100 kata kadar ve diskte çalışırken 10 kat daha hızlı çalıştırılmasına yardımcı olur. Bu, diske yapılan okuma / yazma işlemlerinin sayısını azaltarak mümkündür. Ara işlem verilerini bellekte depolar.
Supports multiple languages- Spark, Java, Scala veya Python'da yerleşik API'ler sağlar. Bu nedenle, farklı dillerde uygulama yazabilirsiniz. Spark, etkileşimli sorgulama için 80 üst düzey operatör ile birlikte gelir.
Advanced Analytics- Spark yalnızca 'Harita'yı ve' azalt'ı desteklemez. Ayrıca SQL sorgularını, Akış verilerini, Makine öğrenimini (ML) ve Grafik algoritmalarını destekler.
Spark, Hadoop'ta Oluşturuldu
Aşağıdaki diyagram, Spark'ın Hadoop bileşenleriyle nasıl oluşturulabileceğinin üç yolunu gösterir.

Aşağıda açıklandığı gibi Spark dağıtımının üç yolu vardır.
Standalone- Spark Bağımsız dağıtım, Spark'ın HDFS (Hadoop Dağıtılmış Dosya Sistemi) üzerindeki yeri işgal ettiği ve HDFS için açık bir şekilde yer ayrıldığı anlamına gelir. Burada, Spark ve MapReduce, kümedeki tüm kıvılcım işlerini kapsayacak şekilde yan yana çalışacaktır.
Hadoop Yarn- Hadoop Yarn dağıtımı, herhangi bir ön kurulum veya kök erişimi gerekmeden Yarn üzerinde basitçe kıvılcım çalışmaları anlamına gelir. Spark'ı Hadoop ekosistemine veya Hadoop yığınına entegre etmeye yardımcı olur. Diğer bileşenlerin yığının en üstünde çalışmasına izin verir.
Spark in MapReduce (SIMR)- MapReduce'ta Spark, bağımsız dağıtıma ek olarak kıvılcım işi başlatmak için kullanılır. SIMR ile kullanıcı Spark'ı başlatabilir ve kabuğunu herhangi bir yönetici erişimi olmadan kullanabilir.
Spark Bileşenleri
Aşağıdaki çizim, Spark'ın farklı bileşenlerini tasvir etmektedir.

Apache Spark Çekirdeği
Spark Core, diğer tüm işlevlerin üzerine inşa edildiği kıvılcım platformunun temelini oluşturan genel yürütme motorudur. Bellek içi bilgi işlem ve harici depolama sistemlerinde referans veri kümeleri sağlar.
Spark SQL
Spark SQL, yapılandırılmış ve yarı yapılandırılmış veriler için destek sağlayan SchemaRDD adlı yeni bir veri soyutlaması sunan Spark Core'un üzerinde bir bileşendir.
Kıvılcım Akışı
Spark Streaming, akış analizi gerçekleştirmek için Spark Core'un hızlı programlama özelliğinden yararlanır. Verileri mini gruplar halinde alır ve bu mini veri yığınları üzerinde RDD (Esnek Dağıtılmış Veri Kümeleri) dönüşümleri gerçekleştirir.
MLlib (Makine Öğrenimi Kitaplığı)
MLlib, dağıtılmış bellek tabanlı Spark mimarisi nedeniyle Spark'ın üzerinde dağıtılmış bir makine öğrenimi çerçevesidir. Karşılaştırmalara göre, MLlib geliştiricileri tarafından Alternating En Küçük Kareler (ALS) uygulamalarına karşı yapılır. Spark MLlib, Hadoop disk tabanlı sürümünden dokuz kat daha hızlıdır.Apache Mahout (Mahout bir Spark arayüzü kazanmadan önce).
GraphX
GraphX, Spark'ın üzerinde dağıtılmış bir grafik işleme çerçevesidir. Pregel soyutlama API'sini kullanarak kullanıcı tanımlı grafikleri modelleyebilen grafik hesaplamasını ifade etmek için bir API sağlar. Ayrıca bu soyutlama için optimize edilmiş bir çalışma zamanı sağlar.
Esnek Dağıtılmış Veri Kümeleri
Esnek Dağıtılmış Veri Kümeleri (RDD), Spark'ın temel bir veri yapısıdır. Değişmez dağıtılmış nesneler koleksiyonudur. RDD'deki her veri kümesi, kümenin farklı düğümlerinde hesaplanabilen mantıksal bölümlere bölünmüştür. RDD'ler, kullanıcı tanımlı sınıflar dahil her tür Python, Java veya Scala nesnesini içerebilir.
Resmi olarak, bir RDD salt okunur, bölümlenmiş bir kayıt koleksiyonudur. RDD'ler, kararlı depolamadaki veriler veya diğer RDD'lerdeki deterministik işlemler yoluyla oluşturulabilir. RDD, paralel olarak çalıştırılabilen hataya dayanıklı bir öğe koleksiyonudur.
RDD oluşturmanın iki yolu vardır - parallelizing sürücü programınızda mevcut bir koleksiyon veya referencing a dataset paylaşılan bir dosya sistemi, HDFS, HBase veya bir Hadoop Giriş Formatı sunan herhangi bir veri kaynağı gibi harici bir depolama sisteminde.
Spark, daha hızlı ve verimli MapReduce işlemleri elde etmek için RDD konseptini kullanır. Öncelikle MapReduce işlemlerinin nasıl gerçekleştiğini ve neden bu kadar verimli olmadığını tartışalım.
MapReduce'da Veri Paylaşımı Yavaş
MapReduce, bir küme üzerinde paralel, dağıtılmış bir algoritma ile büyük veri kümelerini işlemek ve oluşturmak için yaygın olarak benimsenmiştir. Kullanıcıların, iş dağıtımı ve hata toleransı konusunda endişelenmelerine gerek kalmadan bir dizi üst düzey operatör kullanarak paralel hesaplamalar yazmasına olanak tanır.
Ne yazık ki, mevcut çerçevelerin çoğunda, hesaplamalar arasında verileri yeniden kullanmanın tek yolu (Örn - iki MapReduce işi arasında), verileri harici bir kararlı depolama sistemine (Ex - HDFS) yazmaktır. Bu çerçeve, bir kümenin hesaplama kaynaklarına erişim için çok sayıda soyutlama sağlasa da, kullanıcılar yine de daha fazlasını istiyor.
Her ikisi de Iterative ve Interactiveuygulamalar, paralel işler arasında daha hızlı veri paylaşımı gerektirir. MapReduce'ta veri paylaşımı yavaşreplication, serialization, ve disk IO. Depolama sistemi ile ilgili olarak, Hadoop uygulamalarının çoğu, zamanın% 90'ından fazlasını HDFS okuma-yazma işlemlerine harcıyorlar.
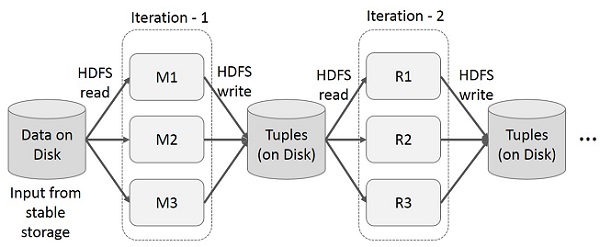
MapReduce'da Yinelemeli İşlemler
Çok aşamalı uygulamalarda birden çok hesaplamada ara sonuçları yeniden kullanın. Aşağıdaki çizim, MapReduce üzerinde yinelemeli işlemleri yaparken mevcut çerçevenin nasıl çalıştığını açıklamaktadır. Bu, sistemi yavaşlatan veri çoğaltma, disk G / Ç ve serileştirme nedeniyle önemli ek yüklere neden olur.
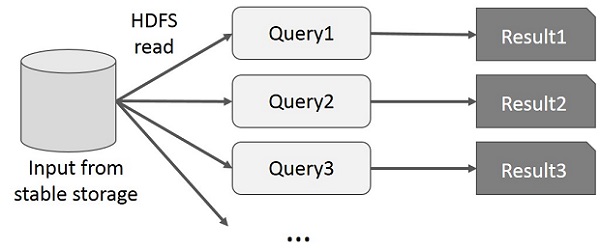
MapReduce'da Etkileşimli İşlemler
Kullanıcı, aynı veri alt kümesinde anlık sorgular çalıştırır. Her sorgu, uygulama yürütme süresine hakim olabilecek sabit depolama alanında disk G / Ç işlemini gerçekleştirecektir.
Aşağıdaki çizim, MapReduce üzerinde etkileşimli sorgular yaparken mevcut çerçevenin nasıl çalıştığını açıklamaktadır.
Spark RDD kullanarak Veri Paylaşımı
MapReduce'ta veri paylaşımı yavaş replication, serialization, ve disk IO. Hadoop uygulamalarının çoğu, zamanın% 90'ından fazlasını HDFS okuma-yazma işlemleri yaparak geçirirler.
Bu sorunu fark eden araştırmacılar, Apache Spark adlı özel bir çerçeve geliştirdiler. Kıvılcımın ana fikriResrarengiz Dpaylaştırılmış Datasetler (RDD); bellek içi işlem hesaplamasını destekler. Bu, bellek durumunu işler arasında bir nesne olarak depoladığı ve nesnenin bu işler arasında paylaşılabildiği anlamına gelir. Bellekteki veri paylaşımı, ağ ve Diskten 10 ila 100 kat daha hızlıdır.
Şimdi Spark RDD'de yinelemeli ve etkileşimli işlemlerin nasıl gerçekleştiğini bulmaya çalışalım.
Spark RDD'de Yinelemeli İşlemler
Aşağıda verilen çizim, Spark RDD üzerindeki yinelemeli işlemleri gösterir. Ara sonuçları Kararlı depolama (Disk) yerine dağıtılmış bir bellekte depolayacak ve sistemi daha hızlı hale getirecektir.
Note - Dağıtılmış bellek (RAM), ara sonuçları (JOB Durumu) depolamak için yeterliyse, bu sonuçları diskte depolar.

Spark RDD'de Etkileşimli İşlemler
Bu çizim, Spark RDD üzerindeki etkileşimli işlemleri gösterir. Aynı veri kümesi üzerinde tekrar tekrar farklı sorgular çalıştırılırsa, bu belirli veriler daha iyi yürütme süreleri için bellekte tutulabilir.

Varsayılan olarak, dönüştürülen her RDD, üzerinde bir eylemi her çalıştırdığınızda yeniden hesaplanabilir. Ancak şunları da yapabilirsiniz:persistBellekte bir RDD, bu durumda Spark, bir dahaki sefere sorguladığınızda çok daha hızlı erişim için öğeleri kümede tutacaktır. Diskte kalıcı RDD'ler veya birden çok düğümde çoğaltılması için destek de vardır.
Spark, Hadoop'un alt projesidir. Bu nedenle, Spark'ı Linux tabanlı bir sisteme kurmak daha iyidir. Aşağıdaki adımlar Apache Spark'ın nasıl kurulacağını gösterir.
Adım 1: Java Kurulumunu Doğrulama
Java yüklemesi, Spark'ı kurarken zorunlu olan şeylerden biridir. JAVA sürümünü doğrulamak için aşağıdaki komutu deneyin.
$java -versionJava sisteminizde zaten yüklüyse, aşağıdaki yanıtı görürsünüz -
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Sisteminizde Java yüklü değilse, sonraki adıma geçmeden önce Java'yı yükleyin.
2. Adım: Scala kurulumunu doğrulama
Spark'ı uygulamak için Scala dilini kullanmalısınız. Öyleyse aşağıdaki komutu kullanarak Scala kurulumunu doğrulayalım.
$scala -versionScala sisteminize zaten yüklüyse, aşağıdaki yanıtı görürsünüz -
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLSisteminizde Scala kurulu değilse, Scala kurulumu için bir sonraki adıma geçin.
3. Adım: Scala'yı İndirme
Scala İndir bağlantısını ziyaret ederek en son Scala sürümünü indirin . Bu eğitim için scala-2.11.6 sürümünü kullanıyoruz. İndirdikten sonra, Scala tar dosyasını indirme klasöründe bulacaksınız.
Adım 4: Scala'yı Kurma
Scala'yı kurmak için aşağıda verilen adımları izleyin.
Scala tar dosyasını çıkarın
Scala tar dosyasını çıkarmak için aşağıdaki komutu yazın.
$ tar xvf scala-2.11.6.tgzScala yazılım dosyalarını taşıyın
Scala yazılım dosyalarını ilgili dizine taşımak için aşağıdaki komutları kullanın (/usr/local/scala).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv scala-2.11.6 /usr/local/scala
# exitScala için PATH ayarla
Scala için PATH ayarlamak için aşağıdaki komutu kullanın.
$ export PATH = $PATH:/usr/local/scala/binScala Kurulumunu Doğrulama
Kurulumdan sonra doğrulamak daha iyidir. Scala kurulumunu doğrulamak için aşağıdaki komutu kullanın.
$scala -versionScala sisteminize zaten yüklüyse, aşağıdaki yanıtı görürsünüz -
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLAdım 5: Apache Spark'ı İndirme
Aşağıdaki Spark'ı İndir bağlantısını ziyaret ederek Spark'ın en son sürümünü indirin . Bu eğitim için kullanıyoruzspark-1.3.1-bin-hadoop2.6versiyon. İndirdikten sonra, Spark tar dosyasını indirme klasöründe bulacaksınız.
Adım 6: Spark'ı Yükleme
Spark'ı kurmak için aşağıda verilen adımları izleyin.
Kıvılcım katranının çıkarılması
Spark tar dosyasını çıkarmak için aşağıdaki komut.
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgzSpark yazılım dosyalarını taşıma
Spark yazılım dosyalarını ilgili dizine taşımak için aşağıdaki komutlar (/usr/local/spark).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark
# exitSpark için ortamı kurma
Aşağıdaki satırı ~ 'a ekleyin/.bashrcdosya. PATH değişkenine spark yazılım dosyasının bulunduğu konumu eklemek anlamına gelir.
export PATH=$PATH:/usr/local/spark/bin~ / .Bashrc dosyasını kaynak bulmak için aşağıdaki komutu kullanın.
$ source ~/.bashrc7. Adım: Spark Kurulumunu Doğrulama
Spark kabuğunu açmak için aşağıdaki komutu yazın.
$spark-shellKıvılcım başarıyla takılırsa, aşağıdaki çıktıyı bulacaksınız.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>Spark Core, tüm projenin temelidir. Dağıtılmış görev dağıtımı, zamanlama ve temel G / Ç işlevleri sağlar. Spark, makineler arasında bölümlere ayrılmış mantıksal bir veri koleksiyonu olan RDD (Esnek Dağıtılmış Veri Kümeleri) olarak bilinen özel bir temel veri yapısı kullanır. RDD'ler iki şekilde oluşturulabilir; bunlardan biri, harici depolama sistemlerindeki veri setlerine referans vermek ve ikincisi, mevcut RDD'lere dönüşümler (örneğin, harita, filtre, azaltıcı, birleştirme) uygulamaktır.
RDD soyutlaması, dil ile entegre bir API aracılığıyla gösterilir. Bu, programlama karmaşıklığını basitleştirir, çünkü uygulamaların RDD'leri işleme biçimi yerel veri koleksiyonlarını değiştirmeye benzer.
Kıvılcım Kabuğu
Spark, verileri etkileşimli olarak analiz etmek için güçlü bir araç olan etkileşimli bir kabuk sağlar. Scala veya Python dilinde mevcuttur. Spark'ın birincil soyutlaması, Esnek Dağıtılmış Veri Kümesi (RDD) adı verilen dağıtılmış bir öğe koleksiyonudur. RDD'ler, Hadoop Girdi Biçimlerinden (HDFS dosyaları gibi) veya diğer RDD'leri dönüştürerek oluşturulabilir.
Spark Shell'i Aç
Aşağıdaki komut Spark kabuğunu açmak için kullanılır.
$ spark-shellBasit RDD oluşturun
Metin dosyasından basit bir RDD oluşturalım. Basit bir RDD oluşturmak için aşağıdaki komutu kullanın.
scala> val inputfile = sc.textFile(“input.txt”)Yukarıdaki komutun çıktısı
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12Spark RDD API, birkaç Transformations ve birkaç Actions RDD'yi değiştirmek için.
RDD Dönüşümleri
RDD dönüşümleri, yeni RDD'ye işaretçi döndürür ve RDD'ler arasında bağımlılıklar oluşturmanıza izin verir. Bağımlılık zincirindeki (Bağımlılıklar Dizesi) her RDD, verilerini hesaplamak için bir işleve sahiptir ve üst RDD'sine bir gösterici (bağımlılık) vardır.
Spark tembeldir, bu nedenle, iş yaratma ve yürütmeyi tetikleyecek bir dönüşüm veya eylem çağırmadıkça hiçbir şey yürütülmez. Sözcük sayısı örneğinin aşağıdaki parçacığına bakın.
Bu nedenle, RDD dönüşümü bir veri kümesi değil, Spark'a verileri nasıl alacağını ve onunla ne yapacağını söyleyen bir programdaki (tek adım olabilir) bir adımdır.
| S.No | Dönüşümler ve Anlam |
|---|---|
| 1 | map(func) Kaynağın her bir öğesini bir işlevden geçirerek oluşturulmuş yeni bir dağıtılmış veri kümesi döndürür func. |
| 2 | filter(func) Kaynağın üzerinde bulunduğu öğeleri seçerek oluşturulmuş yeni bir veri kümesi döndürür. func true döndürür. |
| 3 | flatMap(func) Eşlemeye benzer, ancak her girdi öğesi 0 veya daha fazla çıktı öğesiyle eşlenebilir (bu nedenle func , tek bir öğe yerine bir Seq döndürmelidir). |
| 4 | mapPartitions(func) Haritaya benzer, ancak RDD'nin her bölümünde (blok) ayrı ayrı çalışır, bu nedenle func T tipinde bir RDD üzerinde çalışırken Iterator <T> ⇒ Iterator <U> türünde olmalıdır. |
| 5 | mapPartitionsWithIndex(func) Harita Bölümlerine benzer, ancak aynı zamanda func bölümün dizinini temsil eden bir tamsayı değeri ile func T türünde bir RDD üzerinde çalışırken (Int, Iterator <T>) ⇒ Iterator <U> türünde olmalıdır. |
| 6 | sample(withReplacement, fraction, seed) Örnek a fraction Verilerin, değiştirilerek veya değiştirilmeden, belirli bir rasgele sayı üreteci tohumunu kullanarak. |
| 7 | union(otherDataset) Kaynak veri kümesindeki öğelerin birleşimini ve bağımsız değişkeni içeren yeni bir veri kümesi döndürür. |
| 8 | intersection(otherDataset) Kaynak veri kümesindeki öğelerin ve bağımsız değişkenin kesişimini içeren yeni bir RDD döndürür. |
| 9 | distinct([numTasks]) Kaynak veri kümesinin farklı öğelerini içeren yeni bir veri kümesi döndürür. |
| 10 | groupByKey([numTasks]) (K, V) çiftlerinden oluşan bir veri kümesinde çağrıldığında, (K, Yinelenebilir <V>) çiftlerinden oluşan bir veri kümesi döndürür. Note - Her anahtar üzerinde bir toplama (bir toplam veya ortalama gibi) gerçekleştirmek için gruplama yapıyorsanız, lessByKey veya aggregateByKey kullanmak çok daha iyi performans sağlayacaktır. |
| 11 | reduceByKey(func, [numTasks]) (K, V) çiftlerinin bir veri kümesi üzerinde çağrıldığında, her bir anahtar değerleri azaltmak verilen fonksiyon kullanılarak bir araya getirilmiştir (K, V) çiftlerinin bir veri kümesi döner fonk tipi (V, V) sahip olmalıdır, ⇒ V GroupByKey'de olduğu gibi, azaltma görevlerinin sayısı isteğe bağlı bir ikinci bağımsız değişken aracılığıyla yapılandırılabilir. |
| 12 | aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) (K, V) çiftlerinden oluşan bir veri kümesinde çağrıldığında, her anahtarın değerlerinin verilen birleştirme işlevleri ve nötr bir "sıfır" değeri kullanılarak toplandığı (K, U) çiftlerinden oluşan bir veri kümesi döndürür. Gereksiz ayırmalardan kaçınırken, giriş değeri türünden farklı bir toplanmış değer türüne izin verir. GroupByKey'de olduğu gibi, azaltma görevlerinin sayısı isteğe bağlı bir ikinci bağımsız değişken aracılığıyla yapılandırılabilir. |
| 13 | sortByKey([ascending], [numTasks]) K'nin Sıralı'yı uyguladığı (K, V) çiftlerinden oluşan bir veri kümesinde çağrıldığında, Boole artan bağımsız değişkeninde belirtildiği gibi, anahtarlara göre artan veya azalan sırada sıralanmış (K, V) çiftlerinden oluşan bir veri kümesi döndürür. |
| 14 | join(otherDataset, [numTasks]) (K, V) ve (K, W) türündeki veri kümelerinde çağrıldığında, her anahtar için tüm öğe çiftleriyle (K, (V, W)) çiftlerinden oluşan bir veri kümesi döndürür. Dış birleşimler leftOuterJoin, rightOuterJoin ve fullOuterJoin ile desteklenir. |
| 15 | cogroup(otherDataset, [numTasks]) (K, V) ve (K, W) türündeki veri kümeleri çağrıldığında, (K, (Yinelenebilir <V>, Yinelenebilir <W>)) demetlerinin bir veri kümesi döndürür. Bu işlem aynı zamanda Grup olarak da adlandırılır. |
| 16 | cartesian(otherDataset) T ve U türlerinin veri kümelerinde çağrıldığında, (T, U) çiftlerinden (tüm öğe çiftleri) oluşan bir veri kümesi döndürür. |
| 17 | pipe(command, [envVars]) RDD'nin her bölümünü bir kabuk komutu, örneğin bir Perl veya bash betiği aracılığıyla yönlendirin. RDD öğeleri sürecin standart çıkışına yazılır ve standart çıkışına giden satırlar, dizelerin RDD'si olarak döndürülür. |
| 18 | coalesce(numPartitions) RDD'deki bölümlerin sayısını numPartitions'a düşürün. Büyük bir veri kümesini filtreledikten sonra işlemleri daha verimli çalıştırmak için kullanışlıdır. |
| 19 | repartition(numPartitions) Daha fazla veya daha az bölüm oluşturmak ve bunlar arasında dengelemek için RDD'deki verileri rastgele yeniden karıştırın. Bu her zaman ağ üzerindeki tüm verileri karıştırır. |
| 20 | repartitionAndSortWithinPartitions(partitioner) RDD'yi verilen bölümleyiciye göre yeniden bölümleyin ve ortaya çıkan her bölüm içinde kayıtları anahtarlarına göre sıralayın. Bu, yeniden bölümleme çağırmaktan ve ardından her bölüm içinde sıralamaktan daha etkilidir çünkü sıralamayı karıştırma makinesine doğru itebilir. |
Hareketler
| S.No | Eylem ve Anlam |
|---|---|
| 1 | reduce(func) Veri kümesinin öğelerini bir işlev kullanarak toplayın func(iki bağımsız değişken alır ve bir döndürür). Fonksiyon, paralel olarak doğru bir şekilde hesaplanabilmesi için değişmeli ve ilişkisel olmalıdır. |
| 2 | collect() Veri kümesinin tüm öğelerini sürücü programında bir dizi olarak döndürür. Bu genellikle, verilerin yeterince küçük bir alt kümesini döndüren bir filtre veya başka bir işlemden sonra yararlıdır. |
| 3 | count() Veri kümesindeki öğelerin sayısını döndürür. |
| 4 | first() Veri kümesinin ilk öğesini döndürür (take (1) 'e benzer). |
| 5 | take(n) İlkini içeren bir dizi verir n veri kümesinin öğeleri. |
| 6 | takeSample (withReplacement,num, [seed]) Rastgele örneklemi olan bir dizi döndürür: num veri kümesinin öğeleri, değiştirilerek veya değiştirilmeden, isteğe bağlı olarak bir rastgele sayı üreteci tohumunu önceden belirleyerek. |
| 7 | takeOrdered(n, [ordering]) İlkini verir n RDD'nin öğeleri doğal sıralarını veya özel bir karşılaştırıcıyı kullanarak. |
| 8 | saveAsTextFile(path) Veri kümesinin öğelerini yerel dosya sisteminde, HDFS'de veya Hadoop tarafından desteklenen başka herhangi bir dosya sisteminde belirli bir dizinde bir metin dosyası (veya metin dosyaları kümesi) olarak yazar. Spark, dosyadaki bir metin satırına dönüştürmek için her öğe için toString'i çağırır. |
| 9 | saveAsSequenceFile(path) (Java and Scala) Veri kümesinin öğelerini yerel dosya sisteminde, HDFS'de veya Hadoop tarafından desteklenen başka bir dosya sisteminde belirli bir yolda Hadoop SequenceFile olarak yazar. Bu, Hadoop'un Yazılabilir arayüzünü uygulayan anahtar-değer çiftlerinin RDD'lerinde mevcuttur. Scala'da, örtülü olarak Yazılabilir'e dönüştürülebilen türlerde de mevcuttur (Spark, Int, Double, String, vb. Gibi temel türler için dönüştürmeleri içerir). |
| 10 | saveAsObjectFile(path) (Java and Scala) Veri kümesinin öğelerini, daha sonra SparkContext.objectFile () kullanılarak yüklenebilen Java serileştirmeyi kullanarak basit bir biçimde yazar. |
| 11 | countByKey() Yalnızca (K, V) tipi RDD'lerde mevcuttur. Her anahtarın sayısıyla (K, Int) çiftlerinden oluşan bir hashmap döndürür. |
| 12 | foreach(func) Bir işlevi çalıştırır funcveri kümesinin her bir öğesi üzerinde. Bu genellikle, bir Akümülatörü güncelleme veya harici depolama sistemleriyle etkileşim gibi yan etkiler için yapılır. Note- Foreach () dışında Accumulators dışındaki değişkenleri değiştirmek tanımsız davranışa neden olabilir. Daha fazla ayrıntı için Kapanışları anlama konusuna bakın. |
RDD ile programlama
RDD programlamasında birkaç RDD dönüşümünün ve eyleminin uygulamalarını bir örnek yardımıyla görelim.
Misal
Bir kelime sayısı örneği düşünün - Bir belgede görünen her kelimeyi sayar. Aşağıdaki metni bir giriş olarak düşünün ve birinput.txt ev dizinindeki dosya.
input.txt - girdi dosyası.
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.Verilen örneği yürütmek için aşağıda verilen prosedürü izleyin.
Spark-Shell'i açın
Aşağıdaki komut kıvılcım kabuğunu açmak için kullanılır. Genellikle kıvılcım Scala kullanılarak oluşturulur. Bu nedenle, bir Spark programı Scala ortamında çalışır.
$ spark-shellSpark kabuğu başarıyla açılırsa, aşağıdaki çıktıyı bulacaksınız. "Spark bağlamı sc olarak kullanılabilir" çıktısının son satırına bakın, Spark kabının otomatik olarak bu adla kıvılcım bağlam nesnesi oluşturduğu anlamına gelir.sc. Bir programın ilk adımına başlamadan önce, SparkContext nesnesi oluşturulmalıdır.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>RDD oluştur
Öncelikle girdi dosyasını Spark-Scala API kullanarak okumalı ve bir RDD oluşturmalıyız.
Aşağıdaki komut, verilen konumdan bir dosyayı okumak için kullanılır. Burada, inputfile adıyla yeni RDD oluşturulur. TextFile (“”) yönteminde argüman olarak verilen String, girdi dosyası adı için mutlak yoldur. Ancak, sadece dosya adı verilmişse, bu, giriş dosyasının mevcut konumda olduğu anlamına gelir.
scala> val inputfile = sc.textFile("input.txt")Kelime Sayımı Dönüşümünü Yürüt
Amacımız bir dosyadaki kelimeleri saymaktır. Her satırı kelimelere ayırmak için düz bir harita oluşturun (flatMap(line ⇒ line.split(“ ”)).
Ardından, her kelimeyi bir değer içeren bir anahtar olarak okuyun ‘1’ (<anahtar, değer> = <kelime, 1>) harita işlevini kullanarak (map(word ⇒ (word, 1)).
Son olarak, benzer anahtarların değerlerini ekleyerek bu anahtarları azaltın (reduceByKey(_+_)).
Aşağıdaki komut, kelime sayısı mantığını yürütmek için kullanılır. Bunu gerçekleştirdikten sonra herhangi bir çıktı bulamayacaksınız çünkü bu bir eylem değil, bu bir dönüşümdür; yeni bir RDD'yi işaret edin veya kıvılcıma verilen verilerle ne yapılacağını söyleyin)
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);Mevcut RDD
RDD ile çalışırken, mevcut RDD hakkında bilgi edinmek istiyorsanız, aşağıdaki komutu kullanın. Size mevcut RDD ve hata ayıklama için bağımlılıkları hakkında açıklama gösterecektir.
scala> counts.toDebugStringDönüşümleri Önbelleğe Alma
Kalıcı bir RDD'yi, üzerindeki persist () veya cache () yöntemlerini kullanarak işaretleyebilirsiniz. Bir eylemde ilk kez hesaplandığında, düğümlerde bellekte tutulacaktır. Ara dönüşümleri bellekte saklamak için aşağıdaki komutu kullanın.
scala> counts.cache()Eylemi Uygulama
Tüm dönüşümleri, sonuçları bir metin dosyasına kaydetmek gibi bir eylem uygulamak. SaveAsTextFile (“”) yöntemi için String argümanı, çıktı klasörünün mutlak yoludur. Çıkışı bir metin dosyasına kaydetmek için aşağıdaki komutu deneyin. Aşağıdaki örnekte, 'çıktı' klasörü mevcut konumdadır.
scala> counts.saveAsTextFile("output")Çıkışın Kontrol Edilmesi
Ana dizine gitmek için başka bir terminal açın (diğer terminalde spark çalıştırıldığı yer). Çıkış dizinini kontrol etmek için aşağıdaki komutları kullanın.
[hadoop@localhost ~]$ cd output/
[hadoop@localhost output]$ ls -1
part-00000
part-00001
_SUCCESSAşağıdaki komut, aşağıdaki komuttan çıktıyı görmek için kullanılır. Part-00000 Dosyalar.
[hadoop@localhost output]$ cat part-00000Çıktı
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)Aşağıdaki komut, aşağıdaki komuttan çıktıyı görmek için kullanılır. Part-00001 Dosyalar.
[hadoop@localhost output]$ cat part-00001Çıktı
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)BM Depolamaya Devam Ediyor
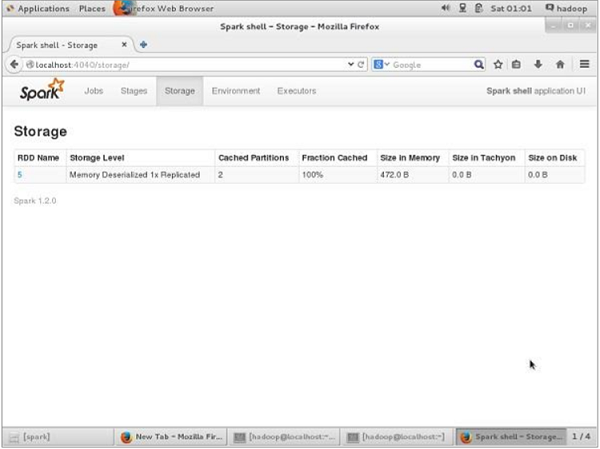
BM-kalıcı olmadan önce, bu uygulama için kullanılan depolama alanını görmek istiyorsanız, tarayıcınızda aşağıdaki URL'yi kullanın.
http://localhost:4040Spark kabuğunda çalışan uygulama için kullanılan depolama alanını gösteren aşağıdaki ekranı göreceksiniz.

Belirli RDD'nin depolama alanını UN-kalıcı hale getirmek istiyorsanız, aşağıdaki komutu kullanın.
Scala> counts.unpersist()Çıkışı aşağıdaki gibi göreceksiniz -
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list
15/06/27 00:57:33 INFO BlockManager: Removing RDD 9
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810)
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106)
res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14Tarayıcıdaki depolama alanını doğrulamak için aşağıdaki URL'yi kullanın.
http://localhost:4040/Aşağıdaki ekranı göreceksiniz. Spark kabuğunda çalışan uygulama için kullanılan depolama alanını gösterir.
Spark-submit kullanan Spark uygulaması, Spark uygulamasını bir kümeye dağıtmak için kullanılan bir kabuk komutudur. Tek tip bir arayüz aracılığıyla tüm ilgili küme yöneticilerini kullanır. Bu nedenle, uygulamanızı her biri için yapılandırmanız gerekmez.
Misal
Kabuk komutlarını kullanarak daha önce kullandığımız aynı kelime sayımı örneğini ele alalım. Burada aynı örneği kıvılcım uygulaması olarak ele alıyoruz.
Örnek Giriş
Aşağıdaki metin giriş verileridir ve adlı dosya in.txt.
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.Aşağıdaki programa bakın -
SparkWordCount.scala
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark._
object SparkWordCount {
def main(args: Array[String]) {
val sc = new SparkContext( "local", "Word Count", "/usr/local/spark", Nil, Map(), Map())
/* local = master URL; Word Count = application name; */
/* /usr/local/spark = Spark Home; Nil = jars; Map = environment */
/* Map = variables to work nodes */
/*creating an inputRDD to read text file (in.txt) through Spark context*/
val input = sc.textFile("in.txt")
/* Transform the inputRDD into countRDD */
val count = input.flatMap(line ⇒ line.split(" "))
.map(word ⇒ (word, 1))
.reduceByKey(_ + _)
/* saveAsTextFile method is an action that effects on the RDD */
count.saveAsTextFile("outfile")
System.out.println("OK");
}
}Yukarıdaki programı adlı bir dosyaya kaydedin. SparkWordCount.scala ve bunu adında kullanıcı tanımlı bir dizine yerleştirin spark-application.
Note - inputRDD'yi countRDD'ye dönüştürürken, satırları (metin dosyasından) kelimelere belirtmek için flatMap (), kelime sıklığını saymak için map () yöntemi ve her kelime tekrarını saymak için lessByKey () yöntemini kullanıyoruz.
Bu başvuruyu göndermek için aşağıdaki adımları kullanın. Tüm adımları yürütünspark-application terminal üzerinden rehber.
1. Adım: Spark Ja'yı indirin
Derleme için Spark core jar gereklidir, bu nedenle aşağıdaki Spark core jar bağlantısından spark-core_2.10-1.3.0.jar dosyasını indirin ve jar dosyasını indirme dizinindenspark-application dizin.
Adım 2: Programı derleyin
Aşağıda verilen komutu kullanarak yukarıdaki programı derleyin. Bu komut, spark-application dizininden çalıştırılmalıdır. Buraya,/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar Spark kitaplığından alınan bir Hadoop destek kavanozudur.
$ scalac -classpath "spark-core_2.10-1.3.0.jar:/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar" SparkPi.scala3. Adım: Bir JAR oluşturun
Aşağıdaki komutu kullanarak kıvılcım uygulamasının bir jar dosyasını oluşturun. Buraya,wordcount jar dosyasının dosya adıdır.
jar -cvf wordcount.jar SparkWordCount*.class spark-core_2.10-1.3.0.jar/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar4. Adım: Kıvılcım uygulamasını gönderin
Kıvılcım uygulamasını aşağıdaki komutu kullanarak gönderin -
spark-submit --class SparkWordCount --master local wordcount.jarBaşarıyla yürütülürse, aşağıda verilen çıktıyı bulacaksınız. OKAşağıdaki çıktıya izin verilmesi kullanıcı kimliği içindir ve bu programın son satırıdır. Aşağıdaki çıktıyı dikkatlice okursanız, farklı şeyler bulacaksınız:
- 42954 numaralı bağlantı noktasında "sparkDriver" hizmeti başarıyla başlatıldı
- MemoryStore 267,3 MB kapasite ile başladı
- SparkUI'yi http://192.168.1.217:4040 adresinde başlattı
- JAR dosyası eklendi: /home/hadoop/piapplication/count.jar
- Sonuç Aşaması 1 (SparkPi.scala'da saveAsTextFile: 11) 0,566 saniyede tamamlandı
- Spark web kullanıcı arayüzü http://192.168.1.217:4040 adresinde durduruldu
- MemoryStore temizlendi
15/07/08 13:56:04 INFO Slf4jLogger: Slf4jLogger started
15/07/08 13:56:04 INFO Utils: Successfully started service 'sparkDriver' on port 42954.
15/07/08 13:56:04 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:42954]
15/07/08 13:56:04 INFO MemoryStore: MemoryStore started with capacity 267.3 MB
15/07/08 13:56:05 INFO HttpServer: Starting HTTP Server
15/07/08 13:56:05 INFO Utils: Successfully started service 'HTTP file server' on port 56707.
15/07/08 13:56:06 INFO SparkUI: Started SparkUI at http://192.168.1.217:4040
15/07/08 13:56:07 INFO SparkContext: Added JAR file:/home/hadoop/piapplication/count.jar at http://192.168.1.217:56707/jars/count.jar with timestamp 1436343967029
15/07/08 13:56:11 INFO Executor: Adding file:/tmp/spark-45a07b83-42ed-42b3b2c2-823d8d99c5af/userFiles-df4f4c20-a368-4cdd-a2a7-39ed45eb30cf/count.jar to class loader
15/07/08 13:56:11 INFO HadoopRDD: Input split: file:/home/hadoop/piapplication/in.txt:0+54
15/07/08 13:56:12 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2001 bytes result sent to driver
(MapPartitionsRDD[5] at saveAsTextFile at SparkPi.scala:11), which is now runnable
15/07/08 13:56:12 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[5] at saveAsTextFile at SparkPi.scala:11)
15/07/08 13:56:13 INFO DAGScheduler: ResultStage 1 (saveAsTextFile at SparkPi.scala:11) finished in 0.566 s
15/07/08 13:56:13 INFO DAGScheduler: Job 0 finished: saveAsTextFile at SparkPi.scala:11, took 2.892996 s
OK
15/07/08 13:56:13 INFO SparkContext: Invoking stop() from shutdown hook
15/07/08 13:56:13 INFO SparkUI: Stopped Spark web UI at http://192.168.1.217:4040
15/07/08 13:56:13 INFO DAGScheduler: Stopping DAGScheduler
15/07/08 13:56:14 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
15/07/08 13:56:14 INFO Utils: path = /tmp/spark-45a07b83-42ed-42b3-b2c2823d8d99c5af/blockmgr-ccdda9e3-24f6-491b-b509-3d15a9e05818, already present as root for deletion.
15/07/08 13:56:14 INFO MemoryStore: MemoryStore cleared
15/07/08 13:56:14 INFO BlockManager: BlockManager stopped
15/07/08 13:56:14 INFO BlockManagerMaster: BlockManagerMaster stopped
15/07/08 13:56:14 INFO SparkContext: Successfully stopped SparkContext
15/07/08 13:56:14 INFO Utils: Shutdown hook called
15/07/08 13:56:14 INFO Utils: Deleting directory /tmp/spark-45a07b83-42ed-42b3b2c2-823d8d99c5af
15/07/08 13:56:14 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!Adım 5: Çıktı kontrol ediliyor
Programın başarılı bir şekilde yürütülmesinden sonra, adlı dizini bulacaksınız. outfile spark-application dizininde.
Aşağıdaki komutlar, outfile dizinindeki dosyaların listesini açmak ve kontrol etmek için kullanılır.
$ cd outfile
$ ls
Part-00000 part-00001 _SUCCESSÇıkış kontrolü için komutlar part-00000 dosya -
$ cat part-00000
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)Part-00001 dosyasındaki çıktıyı kontrol etme komutları şunlardır:
$ cat part-00001
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)'Spark-submit' komutu hakkında daha fazla bilgi edinmek için aşağıdaki bölümden geçin.
Spark-submit Sözdizimi
spark-submit [options] <app jar | python file> [app arguments]Seçenekler
| S.No | Seçenek | Açıklama |
|---|---|---|
| 1 | --usta | spark: // ana bilgisayar: bağlantı noktası, mesos: // ana bilgisayar: bağlantı noktası, iplik veya yerel. |
| 2 | --deploy modu | Sürücü programının yerel olarak mı ("istemci") yoksa kümedeki çalışan makinelerden birinde mi ("küme") (Varsayılan: istemci) başlatılacağı. |
| 3 | --sınıf | Uygulamanızın ana sınıfı (Java / Scala uygulamaları için). |
| 4 | --name | Başvurunuzun adı. |
| 5 | - kavanoz | Sürücü ve uygulayıcı sınıf yollarına eklenecek yerel kavanozların virgülle ayrılmış listesi. |
| 6 | - paketler | Sürücü ve uygulayıcı sınıf yollarına dahil edilecek kavanozların maven koordinatlarının virgülle ayrılmış listesi. |
| 7 | --repositories | --Packages ile verilen maven koordinatlarını aramak için ek uzak depoların virgülle ayrılmış listesi. |
| 8 | --py-dosyaları | Python uygulamaları için PYTHON PATH'ına yerleştirilecek .zip, .egg veya .py dosyalarının virgülle ayrılmış listesi. |
| 9 | --Dosyalar | Her yürütücünün çalışma dizinine yerleştirilecek dosyaların virgülle ayrılmış listesi. |
| 10 | --conf (prop = val) | Keyfi Spark yapılandırma özelliği. |
| 11 | --özellikler-dosya | Ekstra özelliklerin yükleneceği dosyanın yolu. Belirtilmezse, bu conf / spark-default'ları arayacaktır. |
| 12 | - sürücü belleği | Sürücü için bellek (örneğin 1000M, 2G) (Varsayılan: 512M). |
| 13 | --driver-java-seçenekleri | Sürücüye geçmek için ekstra Java seçenekleri. |
| 14 | --driver-library-path | Sürücüye iletilecek ekstra kitaplık yolu girişleri. |
| 15 | --driver-sınıf-yolu | Sürücüye iletilecek ekstra sınıf yolu girişleri. --Jars ile eklenen kavanozların otomatik olarak sınıf yoluna dahil edildiğini unutmayın. |
| 16 | - yürütücü-hafıza | Yürütücü başına bellek (örn. 1000M, 2G) (Varsayılan: 1G). |
| 17 | --proxy-user | Başvuruyu gönderirken kullanıcının kimliğine bürünmesi. |
| 18 | --yardım, -h | Bu yardım mesajını göster ve çık. |
| 19 | --verbose, -v | Ek hata ayıklama çıktısı yazdırın. |
| 20 | --version | Mevcut Spark sürümünü yazdırın. |
| 21 | --driver çekirdekler NUM | Sürücü için çekirdekler (Varsayılan: 1). |
| 22 | - denetim | Verilirse, hata durumunda sürücüyü yeniden başlatır. |
| 23 | --öldürmek | Verilirse, belirtilen sürücüyü öldürür. |
| 24 | --durum | Verilirse, belirtilen sürücünün durumunu ister. |
| 25 | --total-executor-cores | Tüm yöneticiler için toplam çekirdek. |
| 26 | - yürütücü-çekirdekler | Yürütücü başına çekirdek sayısı. (Varsayılan: YARN modunda 1 veya bağımsız modda çalışan üzerinde mevcut tüm çekirdekler). |
Spark, iki farklı türde paylaşılan değişken içerir - biri broadcast variables ve ikincisi accumulators.
Broadcast variables - büyük değerleri verimli bir şekilde dağıtmak için kullanılır.
Accumulators - belirli bir koleksiyona ait bilgileri toplamak için kullanılır.
Yayın Değişkenleri
Yayın değişkenleri, programcının salt okunur bir değişkeni görevlerle birlikte bir kopyasını göndermek yerine her makinede önbelleğe almasını sağlar. Örneğin, her düğüme, büyük bir giriş veri kümesinin bir kopyasını verimli bir şekilde vermek için kullanılabilirler. Spark ayrıca, iletişim maliyetini düşürmek için verimli yayın algoritmaları kullanarak yayın değişkenlerini dağıtmaya çalışır.
Kıvılcım eylemleri, dağıtılmış "karıştırma" işlemleriyle ayrılmış bir dizi aşamada yürütülür. Spark, her aşamadaki görevlerin ihtiyaç duyduğu ortak verileri otomatik olarak yayınlar.
Bu şekilde yayınlanan veriler, serileştirilmiş biçimde önbelleğe alınır ve her bir görevi çalıştırmadan önce serileştirmesi kaldırılır. Bu, açıkça yayın değişkenleri oluşturmanın, yalnızca birden çok aşamadaki görevler aynı verilere ihtiyaç duyduğunda veya verileri serileştirilmemiş biçimde önbelleğe almak önemli olduğunda yararlı olduğu anlamına gelir.
Yayın değişkenleri bir değişkenden oluşturulur v arayarak SparkContext.broadcast(v). Yayın değişkeni bir sarmalayıcıdırvve değerine şu aranarak erişilebilir: valueyöntem. Aşağıda verilen kod bunu göstermektedir -
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))Output -
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)Yayın değişkeni oluşturulduktan sonra, değer yerine kullanılmalıdır v küme üzerinde çalışan herhangi bir işlevde vdüğümlere birden fazla gönderilmez. Ek olarak, nesnev Tüm düğümlerin yayın değişkeninin aynı değerini almasını sağlamak için yayınlandıktan sonra değiştirilmemelidir.
Akümülatörler
Akümülatörler, yalnızca ilişkisel bir işlem yoluyla "eklenen" ve bu nedenle paralel olarak verimli bir şekilde desteklenebilen değişkenlerdir. Sayaçları (MapReduce'ta olduğu gibi) veya toplamları uygulamak için kullanılabilirler. Spark, sayısal türdeki toplayıcıları yerel olarak destekler ve programcılar yeni türler için destek ekleyebilir. Akümülatörler bir adla oluşturulursa,Spark’s UI. Bu, çalışan aşamaların ilerlemesini anlamak için yararlı olabilir (NOT - bu henüz Python'da desteklenmemektedir).
Bir başlangıç değerinden bir akümülatör oluşturulur v arayarak SparkContext.accumulator(v). Küme üzerinde çalışan görevler daha sonraaddyöntem veya + = operatörü (Scala ve Python'da). Ancak değerini okuyamazlar. Akümülatörün değerini sadece sürücü programı kullanarak okuyabilir.value yöntem.
Aşağıda verilen kod, bir dizinin öğelerini toplamak için kullanılan bir toplayıcıyı göstermektedir -
scala> val accum = sc.accumulator(0)
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)Yukarıdaki kodun çıktısını görmek istiyorsanız, aşağıdaki komutu kullanın -
scala> accum.valueÇıktı
res2: Int = 10Sayısal RDD İşlemleri
Spark, önceden tanımlanmış API yöntemlerinden birini kullanarak sayısal veriler üzerinde farklı işlemler yapmanızı sağlar. Spark'ın sayısal işlemleri, her seferinde bir öğe olmak üzere modeli oluşturmaya izin veren bir akış algoritması ile gerçekleştirilir.
Bu işlemler hesaplanır ve bir StatusCounter çağırarak nesne status() yöntem.
| S.No | Yöntemler ve Anlam |
|---|---|
| 1 | count() RDD'deki eleman sayısı. |
| 2 | Mean() RDD'deki öğelerin ortalaması. |
| 3 | Sum() RDD'deki öğelerin toplam değeri. |
| 4 | Max() RDD'deki tüm öğeler arasında maksimum değer. |
| 5 | Min() RDD'deki tüm öğeler arasında minimum değer. |
| 6 | Variance() Elemanların varyansı. |
| 7 | Stdev() Standart sapma. |
Bu yöntemlerden yalnızca birini kullanmak istiyorsanız, ilgili yöntemi doğrudan RDD üzerinden çağırabilirsiniz.