DAA - Hızlı Kılavuz
Algoritma, hesaplama, veri işleme ve otomatik akıl yürütme görevlerini gerçekleştiren bir problemi çözmek için bir dizi işlem adımından oluşur. Algoritma, sınırlı miktarda zaman ve mekan içinde ifade edilebilen verimli bir yöntemdir.
Algoritma, belirli bir sorunun çözümünü çok basit ve verimli bir şekilde temsil etmenin en iyi yoludur. Belirli bir problem için bir algoritmamız varsa, onu herhangi bir programlama dilinde uygulayabiliriz, yanialgorithm is independent from any programming languages.
Algoritma Tasarımı
Algoritma tasarımının önemli yönleri, minimum zaman ve alan kullanarak bir sorunu verimli bir şekilde çözmek için verimli bir algoritma oluşturmayı içerir.
Bir sorunu çözmek için farklı yaklaşımlar izlenebilir. Bazıları zaman tüketimi açısından verimli olabilirken, diğer yaklaşımlar hafıza açısından verimli olabilir. Ancak, hem zaman tüketiminin hem de bellek kullanımının aynı anda optimize edilemeyeceği unutulmamalıdır. Daha kısa sürede çalışacak bir algoritmaya ihtiyaç duyarsak, daha fazla belleğe yatırım yapmalıyız ve daha az bellekle çalışmak için bir algoritmaya ihtiyaç duyarsak, daha fazla zamana ihtiyacımız var.
Problem Geliştirme Adımları
Aşağıdaki adımlar hesaplama problemlerini çözmede yer almaktadır.
- Problem tanımı
- Bir modelin geliştirilmesi
- Bir Algoritmanın Tanımlanması
- Bir Algoritma Tasarlama
- Bir Algoritmanın doğruluğunu kontrol etme
- Bir Algoritmanın Analizi
- Bir Algoritmanın Uygulanması
- Program testi
- Documentation
Algoritmaların Özellikleri
Algoritmaların temel özellikleri aşağıdaki gibidir -
Algoritmaların benzersiz bir adı olmalıdır
Algoritmalar, açıkça tanımlanmış girdi ve çıktı kümelerine sahip olmalıdır
Algoritmalar, kesin işlemlerle iyi sıralanmıştır
Algoritmalar sınırlı bir süre içinde durur. Algoritmalar sonsuzluk için çalışmamalıdır, yani bir algoritma bir noktada bitmelidir
Sözde kod
Sözde kod, düz metinle ilişkili belirsizlik olmadan ve ayrıca belirli bir programlama dilinin sözdizimini bilmeye gerek kalmadan bir algoritmanın üst düzey tanımını verir.
Çalışma süresi, algoritmayı daha sonra sayılabilecek bir dizi temel işlemler olarak temsil etmek için Pseudocode kullanılarak daha genel bir şekilde tahmin edilebilir.
Algoritma ve Sözde Kod Arasındaki Fark
Algoritma, belirli bir görevi gerçekleştirmek için Turing-complete bilgisayar makinesi tarafından yürütülebilen bir işlemi tanımlayan bazı belirli özelliklere sahip resmi bir tanımdır. Genel olarak, "algoritma" kelimesi, bilgisayar bilimindeki herhangi bir üst düzey görevi tanımlamak için kullanılabilir.
Öte yandan, sözde kod, bir algoritmanın gayri resmi ve (genellikle ilkel) insan tarafından okunabilir bir açıklamasıdır ve birçok ayrıntılı ayrıntıyı bırakır. Bir sözde kod yazmanın stil kısıtlaması yoktur ve tek amacı, algoritmanın yüksek seviyeli adımlarını doğal dilde çok gerçekçi bir şekilde tanımlamaktır.
Örneğin, aşağıda Ekleme Sıralaması için bir algoritma verilmiştir.
Algorithm: Insertion-Sort
Input: A list L of integers of length n
Output: A sorted list L1 containing those integers present in L
Step 1: Keep a sorted list L1 which starts off empty
Step 2: Perform Step 3 for each element in the original list L
Step 3: Insert it into the correct position in the sorted list L1.
Step 4: Return the sorted list
Step 5: StopYukarıda Ekleme-Sıralama algoritmasında bahsedilen yüksek seviyeli soyut sürecin nasıl daha gerçekçi bir şekilde açıklanabileceğini açıklayan bir sözde kod.
for i <- 1 to length(A)
x <- A[i]
j <- i
while j > 0 and A[j-1] > x
A[j] <- A[j-1]
j <- j - 1
A[j] <- xBu eğitimde, algoritmalar, pek çok açıdan C, C ++, Java, Python ve diğer programlama dillerine benzeyen sözde kod biçiminde sunulacaktır.
Algoritmaların teorik analizinde, karmaşıklıklarını asimptotik anlamda tahmin etmek yaygındır, yani keyfi olarak büyük girdi için karmaşıklık fonksiyonunu tahmin etmek. Dönem"analysis of algorithms" Donald Knuth tarafından icat edildi.
Algoritma analizi, belirli bir hesaplama problemini çözmek için bir algoritmanın gerekli kaynakları için teorik tahmin sağlayan hesaplama karmaşıklığı teorisinin önemli bir parçasıdır. Çoğu algoritma, rastgele uzunluktaki girdilerle çalışmak üzere tasarlanmıştır. Algoritmaların analizi, onu yürütmek için gereken zaman ve alan kaynaklarının miktarının belirlenmesidir.
Genellikle, bir algoritmanın verimliliği veya çalışma süresi, giriş uzunluğunu adım sayısı ile ilişkilendiren bir fonksiyon olarak belirtilir. time complexityveya bellek hacmi olarak bilinir space complexity.
Analiz İhtiyacı
Bu bölümde, algoritmaların analizine olan ihtiyacı ve belirli bir problem için daha iyi bir algoritmanın nasıl seçileceğini tartışacağız çünkü bir hesaplama problemi farklı algoritmalarla çözülebilir.
Belirli bir problem için bir algoritma düşünerek, örüntü tanıma geliştirmeye başlayabiliriz, böylece benzer tipteki problemler bu algoritmanın yardımıyla çözülebilir.
Algoritmalar genellikle birbirinden oldukça farklıdır, ancak bu algoritmaların amacı aynıdır. Örneğin, farklı algoritmalar kullanılarak bir dizi sayının sıralanabileceğini biliyoruz. Bir algoritma tarafından gerçekleştirilen karşılaştırma sayısı, aynı girdi için diğerleriyle değişebilir. Bu nedenle, bu algoritmaların zaman karmaşıklığı farklılık gösterebilir. Aynı zamanda her algoritmanın gerektirdiği hafıza alanını da hesaplamamız gerekiyor.
Algoritmanın analizi, algoritmanın problem çözme yeteneğini gereken zaman ve boyut (uygulama sırasında depolama için bellek boyutu) açısından analiz etme sürecidir. Bununla birlikte, algoritmaların analizinin ana kaygısı, gerekli zaman veya performanstır. Genel olarak, aşağıdaki analiz türlerini gerçekleştiririz -
Worst-case - Herhangi bir boyut örneğinde atılan maksimum adım sayısı a.
Best-case - Herhangi bir boyut örneğinde atılan minimum adım sayısı a.
Average case - Herhangi bir boyut örneğinde atılan ortalama adım sayısı a.
Amortized - Boyut girdisine uygulanan bir dizi işlem a zaman içinde ortalama.
Bir sorunu çözmek için, program belleğin sınırlı olduğu ancak yeterli alanın mevcut olduğu veya bunun tersi olabilen bir sistemde çalışabileceğinden, zamanın yanı sıra alan karmaşıklığını da dikkate almalıyız. Bu bağlamda karşılaştırırsakbubble sort ve merge sort. Kabarcık sıralama ek bellek gerektirmez ancak birleştirme sıralaması ek alan gerektirir. Kabarcık sıralamanın zaman karmaşıklığı, birleştirerek sıralamaya kıyasla daha yüksek olsa da, programın belleğin çok sınırlı olduğu bir ortamda çalışması gerekiyorsa, balonlu sıralamayı uygulamamız gerekebilir.
Bir algoritmanın kaynak tüketimini ölçmek için, bu bölümde tartışıldığı gibi farklı stratejiler kullanılır.
Asimptotik Analiz
Bir fonksiyonun asimptotik davranışı f(n) büyümesini ifade eder f(n) gibi n genişliyor.
Genellikle küçük değerleri göz ardı ederiz n, çünkü genellikle programın büyük girdilerde ne kadar yavaş olacağını tahmin etmekle ilgileniyoruz.
İyi bir kural, asimptotik büyüme hızı ne kadar yavaşsa, algoritmanın o kadar iyi olmasıdır. Her zaman doğru olmasa da.
Örneğin, doğrusal bir algoritma $f(n) = d * n + k$ her zaman asimptotik olarak ikinci dereceden daha iyidir, $f(n) = c.n^2 + q$.
Tekrarlama Denklemlerini Çözme
Yineleme, bir işlevi daha küçük girdiler üzerindeki değeri açısından tanımlayan bir denklem veya eşitsizliktir. Yinelemeler genellikle böl ve yönet paradigmasında kullanılır.
Bir düşünelim T(n) boyut problemi için çalışma süresi olmak n.
Sorun boyutu yeterince küçükse n < c nerede c sabittir, basit çözüm sabit zaman alır ve şu şekilde yazılır: θ(1). Problemin bölünmesi, boyutla ilgili bir dizi alt problem ortaya çıkarırsa$\frac{n}{b}$.
Sorunu çözmek için gereken süre a.T(n/b). Bölünme için gereken süreyi düşünürsekD(n) ve alt problemlerin sonuçlarını birleştirmek için gereken süre C(n)yineleme ilişkisi şu şekilde temsil edilebilir -
$$T(n)=\begin{cases}\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\:\theta(1) & if\:n\leqslant c\\a T(\frac{n}{b})+D(n)+C(n) & otherwise\end{cases}$$
Bir tekrarlama ilişkisi aşağıdaki yöntemler kullanılarak çözülebilir -
Substitution Method - Bu yöntemde bir sınır tahmin ediyoruz ve matematiksel tümevarım kullanarak varsayımımızın doğru olduğunu kanıtlıyoruz.
Recursion Tree Method - Bu yöntemde, her düğümün maliyeti temsil ettiği bir yineleme ağacı oluşturulur.
Master’s Theorem - Bu, tekrarlama ilişkisinin karmaşıklığını bulmak için başka bir önemli tekniktir.
Amortize Analiz
Amortize edilmiş analiz genellikle bir dizi benzer işlemin gerçekleştirildiği belirli algoritmalar için kullanılır.
Amortize edilmiş analiz, işlem sırası maliyetini ayrı ayrı sınırlandırmak yerine, tüm dizinin gerçek maliyetine bir sınır sağlar.
Amortize edilmiş analiz, ortalama durum analizinden farklıdır; olasılık, amortize edilmiş analize dahil değildir. Amortize edilmiş analiz, en kötü durumda her işlemin ortalama performansını garanti eder.
Bu sadece analiz için bir araç değil, tasarım ve analiz yakından ilişkili olduğu için tasarım hakkında düşünmenin bir yolu.
Toplama Yöntemi
Birleştirme yöntemi, bir soruna genel bir bakış sağlar. Bu yöntemde, eğern operasyonlar en kötü zaman alır T(n)toplamda. Daha sonra her operasyonun amortize edilmiş maliyetiT(n)/n. Farklı işlemler farklı zaman alabilse de bu yöntemde değişen maliyetler ihmal edilir.
Muhasebe Yöntemi
Bu yöntemde, farklı işlemlere gerçek maliyetlerine göre farklı ücretler atanır. Bir işlemin amorti edilmiş maliyeti, gerçek maliyetini aşarsa, fark nesneye alacak olarak tayin edilir. Bu kredi, amortize edilmiş maliyetin gerçek maliyetten daha düşük olduğu sonraki operasyonlar için ödeme yapmaya yardımcı olur.
Fiili maliyet ve itfa edilmiş maliyet ith operasyon $c_{i}$ ve $\hat{c_{l}}$, sonra
$$\displaystyle\sum\limits_{i=1}^n \hat{c_{l}}\geqslant\displaystyle\sum\limits_{i=1}^n c_{i}$$
Potansiyel Yöntem
Bu yöntem, ön ödemeli çalışmayı kredi olarak değerlendirmek yerine, ön ödemeli işi potansiyel enerji olarak temsil eder. Bu enerji, gelecekteki operasyonlar için ödeme yapmak üzere serbest bırakılabilir.
Eğer gerçekleştirirsek n ilk veri yapısıyla başlayan işlemler D0. Bir düşünelim,ci gerçek maliyet olarak ve Di veri yapısı olarak ithoperasyon. Potansiyel fonksiyon Ф gerçek bir sayı ile eşleşir Ф (Di), ilişkili potansiyel Di. İtfa edilmiş maliyet$\hat{c_{l}}$ tarafından tanımlanabilir
$$\hat{c_{l}}=c_{i}+\Phi (D_{i})-\Phi (D_{i-1})$$
Dolayısıyla, toplam itfa edilmiş maliyet
$$\displaystyle\sum\limits_{i=1}^n \hat{c_{l}}=\displaystyle\sum\limits_{i=1}^n (c_{i}+\Phi (D_{i})-\Phi (D_{i-1}))=\displaystyle\sum\limits_{i=1}^n c_{i}+\Phi (D_{n})-\Phi (D_{0})$$
Dinamik Tablo
Tablo için ayrılan alan yeterli değilse, tabloyu daha büyük boyutlu bir tabloya kopyalamalıyız. Benzer şekilde, tablodan çok sayıda üye silinirse, tabloyu daha küçük boyutta yeniden tahsis etmek iyi bir fikirdir.
Amortize edilmiş analiz kullanarak, amortize edilmiş ekleme ve silme maliyetinin sabit olduğunu ve dinamik tablodaki kullanılmayan alanın hiçbir zaman toplam alanın sabit bir bölümünü aşmadığını gösterebiliriz.
Bu eğitimin bir sonraki bölümünde, Asimptotik Notasyonları kısaca tartışacağız.
Algoritmanın tasarımında, bir algoritmanın karmaşıklık analizi önemli bir husustur. Temel olarak, algoritmik karmaşıklık performansı, ne kadar hızlı veya yavaş çalıştığı ile ilgilidir.
Bir algoritmanın karmaşıklığı, verileri işlemek için gereken bellek miktarı ve işlem süresi açısından algoritmanın verimliliğini açıklar.
Bir algoritmanın karmaşıklığı iki açıdan analiz edilir: Time ve Space.
Zaman Karmaşıklığı
Girdinin boyutu açısından bir algoritmayı çalıştırmak için gereken süreyi açıklayan bir işlevdir. "Zaman", gerçekleştirilen bellek erişimlerinin sayısı, tamsayılar arasındaki karşılaştırma sayısı, bazı iç döngünün çalıştırılma sayısı veya algoritmanın alacağı gerçek zaman miktarıyla ilgili başka bir doğal birim anlamına gelebilir.
Uzay Karmaşıklığı
Bir algoritmanın aldığı bellek miktarını, algoritmaya girdi boyutu açısından tanımlayan bir işlevdir. Girdinin kendisini saklamak için gereken hafızayı hesaba katmadan, genellikle "ekstra" hafızadan söz ederiz. Yine, bunu ölçmek için doğal (ancak sabit uzunlukta) birimler kullanıyoruz.
Uzay karmaşıklığı bazen, kullanılan alan minimum ve / veya açık olduğu için göz ardı edilir, ancak bazen zaman kadar önemli bir konu haline gelir.
Asimptotik Gösterimler
Bir algoritmanın yürütme süresi komut setine, işlemci hızına, disk I / O hızına, vb. Bağlıdır. Dolayısıyla, bir algoritmanın verimliliğini asimptotik olarak tahmin ederiz.
Bir algoritmanın zaman fonksiyonu ile temsil edilir T(n), nerede n girdi boyutudur.
Bir algoritmanın karmaşıklığını temsil etmek için farklı asimptotik gösterimler kullanılır. Bir algoritmanın çalışma süresi karmaşıklığını hesaplamak için aşağıdaki asimptotik gösterimler kullanılır.
O - Büyük Oh
Ω - Büyük omega
θ - Büyük teta
o - Küçük Oh
ω - Küçük omega
O: Asimptotik Üst Sınır
'O' (Big Oh) en yaygın kullanılan notasyondur. Bir işlevf(n) temsil edilebilir sırası g(n) yani O(g(n)), pozitif bir tam sayı değeri varsa n gibi n0 ve pozitif bir sabit c öyle ki -
$f(n)\leqslant c.g(n)$ için $n > n_{0}$ her durumda
Dolayısıyla işlev g(n) fonksiyon için bir üst sınırdır f(n), gibi g(n) daha hızlı büyür f(n).
Misal
Verilen bir işlevi düşünelim, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
Düşünen $g(n) = n^3$,
$f(n)\leqslant 5.g(n)$ tüm değerleri için $n > 2$
Bu nedenle, karmaşıklığı f(n) olarak temsil edilebilir $O(g(n))$yani $O(n^3)$
Ω: Asimptotik Alt Sınır
Biz söylüyoruz $f(n) = \Omega (g(n))$ sabit olduğunda c o $f(n)\geqslant c.g(n)$ yeterince büyük bir değer için n. Burayanpozitif bir tamsayıdır. İşlev anlamına gelirg fonksiyon için alt sınırdır f; belli bir değerden sonran, f asla aşağı inmeyecek g.
Misal
Verilen bir işlevi düşünelim, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$.
Düşünen $g(n) = n^3$, $f(n)\geqslant 4.g(n)$ tüm değerleri için $n > 0$.
Bu nedenle, karmaşıklığı f(n) olarak temsil edilebilir $\Omega (g(n))$yani $\Omega (n^3)$
θ: Asimptotik Sıkı Bağlı
Biz söylüyoruz $f(n) = \theta(g(n))$ sabitler olduğunda c1 ve c2 o $c_{1}.g(n) \leqslant f(n) \leqslant c_{2}.g(n)$ yeterince büyük bir değer için n. Burayan pozitif bir tamsayıdır.
Bu işlev anlamına gelir g işlev için sıkı bir sınırdır f.
Misal
Verilen bir işlevi düşünelim, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
Düşünen $g(n) = n^3$, $4.g(n) \leqslant f(n) \leqslant 5.g(n)$ tüm büyük değerler için n.
Bu nedenle, karmaşıklığı f(n) olarak temsil edilebilir $\theta (g(n))$yani $\theta (n^3)$.
O - Gösterim
Asimptotik üst sınır tarafından sağlanan O-notationasimptotik olarak sıkı olabilir veya olmayabilir. Sınır$2.n^2 = O(n^2)$ asimptotik olarak sıkı, ancak bağlı $2.n = O(n^2)$ değil.
Kullanırız o-notation asimptotik olarak sıkı olmayan bir üst sınırı belirtmek için.
Resmen tanımlıyoruz o(g(n)) (küçük-oh g n) set olarak f(n) = o(g(n)) herhangi bir pozitif sabit için $c > 0$ ve bir değer var $n_{0} > 0$, öyle ki $0 \leqslant f(n) \leqslant c.g(n)$.
Sezgisel olarak, o-notation, işlev f(n) göre önemsiz hale gelir g(n) gibi nsonsuza yaklaşır; yani,
$$\lim_{n \rightarrow \infty}\left(\frac{f(n)}{g(n)}\right) = 0$$
Misal
Aynı işlevi düşünelim, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
Düşünen $g(n) = n^{4}$,
$$\lim_{n \rightarrow \infty}\left(\frac{4.n^3 + 10.n^2 + 5.n + 1}{n^4}\right) = 0$$
Bu nedenle, karmaşıklığı f(n) olarak temsil edilebilir $o(g(n))$yani $o(n^4)$.
ω - Gösterim
Kullanırız ω-notationasimptotik olarak sıkı olmayan bir alt sınırı belirtmek için. Resmi olarak, ancak biz tanımlarızω(g(n)) (küçük-omega g n) küme olarak f(n) = ω(g(n)) herhangi bir pozitif sabit için C > 0 ve bir değer var $n_{0} > 0$$ 0 \ leqslant cg (n) <f (n) $ olacak şekilde.
Örneğin, $\frac{n^2}{2} = \omega (n)$, fakat $\frac{n^2}{2} \neq \omega (n^2)$. İlişki$f(n) = \omega (g(n))$ aşağıdaki sınırın mevcut olduğunu ima eder
$$\lim_{n \rightarrow \infty}\left(\frac{f(n)}{g(n)}\right) = \infty$$
Yani, f(n) göre keyfi olarak büyük hale gelir g(n) gibi n sonsuza yaklaşır.
Misal
Aynı işlevi düşünelim, $f(n) = 4.n^3 + 10.n^2 + 5.n + 1$
Düşünen $g(n) = n^2$,
$$\lim_{n \rightarrow \infty}\left(\frac{4.n^3 + 10.n^2 + 5.n + 1}{n^2}\right) = \infty$$
Bu nedenle, karmaşıklığı f(n) olarak temsil edilebilir $o(g(n))$yani $\omega (n^2)$.
Apriori ve Apostiari Analizi
Apriori analizi, analizin belirli bir sistemde çalıştırılmadan önce yapılması anlamına gelir. Bu analiz, bir fonksiyonun bazı teorik modeller kullanılarak tanımlandığı bir aşamadır. Bu nedenle, bir algoritmanın zaman ve alan karmaşıklığını, onu farklı bir bellek, işlemci ve derleyiciye sahip belirli bir sistemde çalıştırmak yerine sadece algoritmaya bakarak belirleriz.
Bir algoritmanın apostiari analizi, bir algoritmanın analizini ancak onu bir sistemde çalıştırdıktan sonra gerçekleştirdiğimiz anlamına gelir. Doğrudan sisteme bağlıdır ve sistemden sisteme değişir.
Bir endüstride, yazılım genellikle anonim bir kullanıcı için yapıldığından ve onu endüstride mevcut olanlardan farklı bir sistemde çalıştırdığından Apostiari analizi yapamayız.
Apriori'de, bilgisayardan bilgisayara değiştikçe zaman ve mekan karmaşıklığını belirlemek için asimptotik gösterimler kullanmamızın nedeni budur; ancak, asimptotik olarak aynıdırlar.
Bu bölümde, hesaplama problemlerinin karmaşıklığını, bir algoritmanın gerektirdiği alan miktarına göre tartışacağız.
Uzay karmaşıklığı, zaman karmaşıklığının birçok özelliğini paylaşır ve problemleri hesaplama zorluklarına göre sınıflandırmanın başka bir yolu olarak hizmet eder.
Uzay Karmaşıklığı nedir?
Uzay karmaşıklığı, bir algoritmanın aldığı bellek miktarını (alan), algoritmaya girdi miktarı açısından tanımlayan bir işlevdir.
Sık sık konuşuyoruz extra memorygirişin kendisini saklamak için gereken hafızayı saymaz. Yine, bunu ölçmek için doğal (ancak sabit uzunlukta) birimler kullanıyoruz.
Bayt kullanabiliriz, ancak kullanımı daha kolaydır, örneğin kullanılan tamsayıların sayısı, sabit boyutlu yapıların sayısı vb.
Sonunda, bulduğumuz işlev, birimi temsil etmek için gereken gerçek bayt sayısından bağımsız olacaktır.
Uzay karmaşıklığı bazen, kullanılan alan minimum ve / veya açık olduğu için göz ardı edilir, ancak bazen zaman karmaşıklığı kadar önemli bir konu haline gelir
Tanım
İzin Vermek M belirleyici olmak Turing machine (TM)tüm girişlerde durur. Uzay karmaşıklığıM işlev $f \colon N \rightarrow N$, nerede f(n) maksimum bant hücre sayısıdır ve M herhangi bir uzunluk girdisini tarar M. Uzay karmaşıklığı iseM dır-dir f(n)bunu söyleyebiliriz M uzayda koşar f(n).
Turing makinesinin uzay karmaşıklığını asimptotik notasyon kullanarak tahmin ediyoruz.
İzin Vermek $f \colon N \rightarrow R^+$bir işlev olabilir. Uzay karmaşıklık sınıfları aşağıdaki gibi tanımlanabilir -
SPACE = {L | L is a language decided by an O(f(n)) space deterministic TM}
SPACE = {L | L is a language decided by an O(f(n)) space non-deterministic TM}
PSPACE deterministik bir Turing makinesinde polinom uzayda karar verilebilen diller sınıfıdır.
Başka bir deyişle, PSPACE = Uk SPACE (nk)
Savitch Teoremi
Uzay karmaşıklığıyla ilgili en eski teoremlerden biri Savitch teoremidir. Bu teoreme göre, deterministik bir makine, az miktarda alan kullanarak deterministik olmayan makineleri simüle edebilir.
Zaman karmaşıklığı için, böyle bir simülasyon zamanda üstel bir artış gerektiriyor gibi görünüyor. Uzay karmaşıklığı için bu teorem, kullanan herhangi bir deterministik olmayan Turing makinesininf(n) alan, kullanan deterministik bir TM'ye dönüştürülebilir f2(n) Uzay.
Bu nedenle, Savitch'in teoremi, herhangi bir fonksiyon için, $f \colon N \rightarrow R^+$, nerede $f(n) \geqslant n$
NSPACE(f(n)) ⊆ SPACE(f(n))
Karmaşıklık Sınıfları Arasındaki İlişki
Aşağıdaki diyagram, farklı karmaşıklık sınıfları arasındaki ilişkiyi göstermektedir.

Şimdiye kadar, bu eğitimde P ve NP sınıflarını tartışmadık. Bunlar daha sonra tartışılacaktır.
Çoğu algoritma, alt problemlerle özyinelemeli olarak ilgilenen belirli bir problemi çözmek için doğası gereği özyinelemelidir.
İçinde divide and conquer approachbir problem daha küçük problemlere bölünür, daha sonra daha küçük problemler bağımsız olarak çözülür ve son olarak daha küçük problemlerin çözümleri büyük problem için bir çözüm olarak birleştirilir.
Genel olarak böl ve yönet algoritmalarının üç bölümü vardır -
Divide the problem aynı sorunun daha küçük örnekleri olan bir dizi alt soruna.
Conquer the sub-problemsbunları yinelemeli olarak çözerek. Yeterince küçüklerse, alt problemleri temel durumlar olarak çözün.
Combine the solutions alt problemlere orijinal problemin çözümüne.
Böl ve Fethet Yaklaşımının artıları ve eksileri
Böl ve yönet yaklaşımı, alt problemler bağımsız olduğundan paralelliği destekler. Dolayısıyla bu teknik kullanılarak tasarlanan bir algoritma, çok işlemcili sistemde veya aynı anda farklı makinelerde çalışabilir.
Bu yaklaşımda, algoritmaların çoğu özyineleme kullanılarak tasarlanmıştır, bu nedenle bellek yönetimi çok yüksektir. Özyinelemeli işlev yığını için, işlev durumunun saklanması gerektiği yerde kullanılır.
Böl ve Fethet Yaklaşımının Uygulanması
Böl ve yönet yaklaşımı kullanılarak çözülen bazı problemler aşağıdadır.
- Bir sayı dizisinin maksimum ve minimumunu bulma
- Strassen'in matris çarpımı
- Sıralamayı birleştir
- Ikili arama
Böl ve yönet tekniği ile çözülebilecek basit bir problemi ele alalım.
Sorun bildirimi
Algoritma analizinde Max-Min Problemi, bir dizideki maksimum ve minimum değeri bulmaktır.
Çözüm
Belirli bir dizideki maksimum ve minimum sayıları bulmak için numbers[] boyut naşağıdaki algoritma kullanılabilir. Önce biz temsil ediyoruznaive method ve sonra sunacağız divide and conquer approach.
Naif Yöntem
Naif yöntem, herhangi bir sorunu çözmek için temel bir yöntemdir. Bu yöntemde maksimum ve minimum sayı ayrı ayrı bulunabilir. Maksimum ve minimum sayıları bulmak için aşağıdaki basit algoritma kullanılabilir.
Algorithm: Max-Min-Element (numbers[])
max := numbers[1]
min := numbers[1]
for i = 2 to n do
if numbers[i] > max then
max := numbers[i]
if numbers[i] < min then
min := numbers[i]
return (max, min)Analiz
Naive yönteminde karşılaştırma sayısı 2n - 2.
Böl ve yönet yaklaşımı kullanılarak karşılaştırma sayısı azaltılabilir. Aşağıdaki tekniktir.
Böl ve Fethet Yaklaşımı
Bu yaklaşımda, dizi ikiye bölünmüştür. Daha sonra özyinelemeli yaklaşım kullanılarak her yarıda maksimum ve minimum sayılar bulunur. Daha sonra, her bir yarının maksimum iki maksimumunu ve her bir yarının minimum iki minimumunu döndürün.
Bu verilen problemde, bir dizideki eleman sayısı $y - x + 1$, nerede y büyüktür veya eşittir x.
$\mathbf{\mathit{Max - Min(x, y)}}$ bir dizinin maksimum ve minimum değerlerini döndürür $\mathbf{\mathit{numbers[x...y]}}$.
Algorithm: Max - Min(x, y)
if y – x ≤ 1 then
return (max(numbers[x], numbers[y]), min((numbers[x], numbers[y]))
else
(max1, min1):= maxmin(x, ⌊((x + y)/2)⌋)
(max2, min2):= maxmin(⌊((x + y)/2) + 1)⌋,y)
return (max(max1, max2), min(min1, min2))Analiz
İzin Vermek T(n) tarafından yapılan karşılaştırma sayısı $\mathbf{\mathit{Max - Min(x, y)}}$, elemanların sayısı $n = y - x + 1$.
Eğer T(n) sayıları temsil ederse, tekrarlama ilişkisi şu şekilde temsil edilebilir:
$$T(n) = \begin{cases}T\left(\lfloor\frac{n}{2}\rfloor\right)+T\left(\lceil\frac{n}{2}\rceil\right)+2 & for\: n>2\\1 & for\:n = 2 \\0 & for\:n = 1\end{cases}$$
Farz edelim ki n güç biçimindedir 2. Dolayısıylan = 2k nerede k özyineleme ağacının yüksekliğidir.
Yani,
$$T(n) = 2.T (\frac{n}{2}) + 2 = 2.\left(\begin{array}{c}2.T(\frac{n}{4}) + 2\end{array}\right) + 2 ..... = \frac{3n}{2} - 2$$
Naif yöntemiyle karşılaştırıldığında böl ve yönet yaklaşımında karşılaştırma sayısı daha azdır. Ancak, asimptotik gösterimi kullanarak her iki yaklaşım da şu şekilde temsil edilir:O(n).
Bu bölümde, birleştirme sıralamasını tartışacağız ve karmaşıklığını analiz edeceğiz.
Sorun bildirimi
Bir sayılar listesini sıralama problemi, hemen bir böl ve yönet stratejisine dönüşür: listeyi iki yarıya bölün, her bir yarıyı tekrarlı olarak sıralayın ve sonra iki sıralı alt listeyi birleştirin.
Çözüm
Bu algoritmada, sayılar bir dizide saklanır numbers[]. Buraya,p ve q bir alt dizinin başlangıç ve bitiş dizinini temsil eder.
Algorithm: Merge-Sort (numbers[], p, r)
if p < r then
q = ⌊(p + r) / 2⌋
Merge-Sort (numbers[], p, q)
Merge-Sort (numbers[], q + 1, r)
Merge (numbers[], p, q, r)Function: Merge (numbers[], p, q, r)
n1 = q – p + 1
n2 = r – q
declare leftnums[1…n1 + 1] and rightnums[1…n2 + 1] temporary arrays
for i = 1 to n1
leftnums[i] = numbers[p + i - 1]
for j = 1 to n2
rightnums[j] = numbers[q+ j]
leftnums[n1 + 1] = ∞
rightnums[n2 + 1] = ∞
i = 1
j = 1
for k = p to r
if leftnums[i] ≤ rightnums[j]
numbers[k] = leftnums[i]
i = i + 1
else
numbers[k] = rightnums[j]
j = j + 1Analiz
Birleştirme-Sıralama işleminin çalışma süresini şöyle düşünelim: T(n). Dolayısıyla
$T(n)=\begin{cases}c & if\:n\leqslant 1\\2\:x\:T(\frac{n}{2})+d\:x\:n & otherwise\end{cases}$c ve d sabitler nerede
Bu nedenle, bu tekrarlama ilişkisini kullanarak,
$$T(n) = 2^i T(\frac{n}{2^i}) + i.d.n$$
Gibi, $i = log\:n,\: T(n) = 2^{log\:n} T(\frac{n}{2^{log\:n}}) + log\:n.d.n$
$=\:c.n + d.n.log\:n$
Bu nedenle, $T(n) = O(n\:log\:n)$
Misal
Aşağıdaki örnekte, Merge-Sort algoritmasını adım adım gösterdik. İlk olarak, her yineleme dizisi, alt dizi yalnızca bir öğe içerene kadar iki alt diziye bölünür. Bu alt diziler daha fazla bölünemediğinde, birleştirme işlemleri gerçekleştirilir.
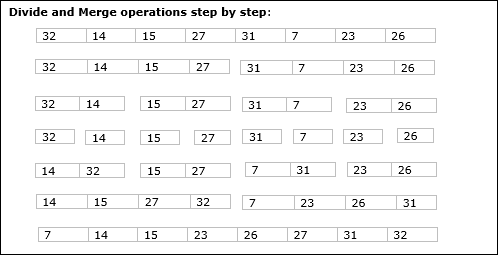
Bu bölümde, bölme ve yönetme yöntemine dayalı başka bir algoritmayı tartışacağız.
Sorun bildirimi
İkili arama, sıralı bir dizide gerçekleştirilebilir. Bu yaklaşımda, bir elemanın indeksixelemanın eleman listesine ait olup olmadığı belirlenir. Dizi sıralanmamışsa, konumu belirlemek için doğrusal arama kullanılır.
Çözüm
Bu algoritmada, elementin x bir dizide saklanan bir sayı kümesine aittir numbers[]. Neredel ve r arama işleminin gerçekleştirilmesi gereken bir alt dizinin sol ve sağ dizinini temsil eder.
Algorithm: Binary-Search(numbers[], x, l, r)
if l = r then
return l
else
m := ⌊(l + r) / 2⌋
if x ≤ numbers[m] then
return Binary-Search(numbers[], x, l, m)
else
return Binary-Search(numbers[], x, m+1, r)Analiz
Doğrusal arama çalışır O(n)zaman. İkili arama sonucu verirkenO(log n) zaman
İzin Vermek T(n) bir dizideki en kötü durumda karşılaştırmaların sayısı n elementler.
Dolayısıyla
$$T(n)=\begin{cases}0 & if\:n= 1\\T(\frac{n}{2})+1 & otherwise\end{cases}$$
Bu yineleme ilişkisini kullanma $T(n) = log\:n$.
Bu nedenle, ikili arama kullanır $O(log\:n)$ zaman.
Misal
Bu örnekte, 63 öğesini arayacağız.

Bu bölümde önce genel matris çarpma yöntemini, daha sonra Strassen'in matris çarpım algoritmasını tartışacağız.
Sorun bildirimi
İki matrisi düşünelim X ve Y. Ortaya çıkan matrisi hesaplamak istiyoruzZ çarparak X ve Y.
Naif Yöntem
İlk olarak, naif yöntemi ve karmaşıklığını tartışacağız. Burada hesaplıyoruzZ = X × Y. Naif yöntemini kullanarak, iki matris (X ve Y), bu matrislerin sırası ise çarpılabilir p × q ve q × r. Algoritma aşağıdadır.
Algorithm: Matrix-Multiplication (X, Y, Z)
for i = 1 to p do
for j = 1 to r do
Z[i,j] := 0
for k = 1 to q do
Z[i,j] := Z[i,j] + X[i,k] × Y[k,j]Karmaşıklık
Burada, tamsayı işlemlerinin O(1)zaman. Üç vardırfordöngüler bu algoritmada ve biri diğerinin içindedir. Bu nedenle, algoritmaO(n3) yürütme zamanı.
Strassen'in Matris Çarpma Algoritması
Bu bağlamda, Strassen'in Matrix çarpma algoritması kullanılarak, zaman tüketimi biraz iyileştirilebilir.
Strassen'in Matrix çarpımı yalnızca şu cihazlarda gerçekleştirilebilir: square matrices nerede n bir power of 2. Her iki matrisin sırasın × n.
Böl X, Y ve Z aşağıda gösterildiği gibi dört (n / 2) × (n / 2) matrise -
$Z = \begin{bmatrix}I & J \\K & L \end{bmatrix}$ $X = \begin{bmatrix}A & B \\C & D \end{bmatrix}$ ve $Y = \begin{bmatrix}E & F \\G & H \end{bmatrix}$
Strassen Algoritmasını kullanarak aşağıdakileri hesaplayın -
$$M_{1} \: \colon= (A+C) \times (E+F)$$
$$M_{2} \: \colon= (B+D) \times (G+H)$$
$$M_{3} \: \colon= (A-D) \times (E+H)$$
$$M_{4} \: \colon= A \times (F-H)$$
$$M_{5} \: \colon= (C+D) \times (E)$$
$$M_{6} \: \colon= (A+B) \times (H)$$
$$M_{7} \: \colon= D \times (G-E)$$
Sonra,
$$I \: \colon= M_{2} + M_{3} - M_{6} - M_{7}$$
$$J \: \colon= M_{4} + M_{6}$$
$$K \: \colon= M_{5} + M_{7}$$
$$L \: \colon= M_{1} - M_{3} - M_{4} - M_{5}$$
Analiz
$T(n)=\begin{cases}c & if\:n= 1\\7\:x\:T(\frac{n}{2})+d\:x\:n^2 & otherwise\end{cases}$c ve d sabitler nerede
Bu tekrarlama ilişkisini kullanarak, $T(n) = O(n^{log7})$
Dolayısıyla, Strassen'in matris çarpım algoritmasının karmaşıklığı şu şekildedir: $O(n^{log7})$.
Tüm algoritmik yaklaşımlar arasında en basit ve anlaşılır yaklaşım Greedy yöntemidir. Bu yaklaşımda, karar, mevcut kararın gelecekteki etkisinden endişe edilmeksizin mevcut mevcut bilgiler temelinde alınır.
Açgözlü algoritmalar, bir sonraki parçayı anında fayda sağlayacak şekilde seçerek parça parça bir çözüm oluşturur. Bu yaklaşım, daha önce alınan seçimleri asla yeniden değerlendirmez. Bu yaklaşım esas olarak optimizasyon problemlerini çözmek için kullanılır. Açgözlü yöntemin uygulanması kolaydır ve çoğu durumda oldukça etkilidir. Dolayısıyla, Greedy algoritmasının, global optimal çözümü bulma umuduyla her adımda yerel optimal seçimi takip eden sezgiselliğe dayalı algoritmik bir paradigma olduğunu söyleyebiliriz.
Pek çok problemde, makul bir sürede yaklaşık (optimuma yakın) bir çözüm verse de optimal bir çözüm üretmez.
Açgözlü Algoritmanın Bileşenleri
Açgözlü algoritmalar aşağıdaki beş bileşene sahiptir -
A candidate set - Bu setten bir çözüm oluşturulur.
A selection function - Çözüme eklenecek en iyi adayı seçmek için kullanılır.
A feasibility function - Bir adayın çözüme katkıda bulunmak için kullanılıp kullanılamayacağını belirlemek için kullanılır.
An objective function - Bir çözüme veya kısmi çözüme bir değer atamak için kullanılır.
A solution function - Tam bir çözüme ulaşılıp ulaşılmadığını belirtmek için kullanılır.
Uygulama alanları
Açgözlü yaklaşım, birçok sorunu çözmek için kullanılır.
Dijkstra algoritmasını kullanarak iki köşe arasındaki en kısa yolu bulmak.
Prim / Kruskal algoritması vb. Kullanarak bir grafikte minimum yayılma ağacını bulmak.
Açgözlü Yaklaşımın Başarısız Olduğu Yer
Pek çok problemde, Greedy algoritması en uygun çözümü bulamaz, dahası en kötü çözümü üretebilir. Seyahat Eden Satıcı ve Sırt Çantası gibi sorunlar bu yaklaşım kullanılarak çözülemez.
Açgözlü algoritma, Sırt Çantası problemi olarak adlandırılan iyi bilinen bir problemle çok iyi anlaşılabilir. Aynı problem diğer algoritmik yaklaşımlar kullanılarak çözülebilse de, Açgözlü yaklaşım, Kesirli Sırt Çantası problemini makul bir şekilde iyi bir zamanda çözer. Sırt çantası sorununu ayrıntılı olarak tartışalım.
Sırt Çantası Sorunu
Her biri bir ağırlık ve bir değere sahip bir öğe kümesi verildiğinde, toplam ağırlığın belirli bir sınırdan küçük veya ona eşit ve toplam değerin mümkün olduğunca büyük olması için bir koleksiyona dahil edilecek bir öğe alt kümesi belirleyin.
Sırt çantası problemi, kombinatoryal optimizasyon problemidir. Gerçek dünya problemlerinin birçok, daha karmaşık matematiksel modelinde bir alt problem olarak görünür. Zor problemlere genel bir yaklaşım, en kısıtlayıcı kısıtlamayı belirlemek, diğerlerini görmezden gelmek, bir sırt çantası problemini çözmek ve bir şekilde göz ardı edilen kısıtlamaları karşılamak için çözümü ayarlamaktır.
Uygulamalar
Çoğu durumda, bazı kısıtlamalarla birlikte kaynak tahsisi durumunda, sorun, Sırt Çantası problemine benzer bir şekilde türetilebilir. Aşağıda bir dizi örnek verilmiştir.
- Hammaddeleri kesmenin en az savurgan yolunu bulmak
- portföy optimizasyonu
- Stok sorunları kesme
Problem Senaryosu
Bir hırsız bir mağazayı soyuyor ve en fazla Wsırt çantasına. Mağazada mevcut n adet ürün var veith öğe wi ve karı pi. Hırsız hangi eşyaları almalı?
Bu bağlamda eşyalar, hırsızın maksimum kar elde edeceği eşyaları taşıyacak şekilde seçilmelidir. Dolayısıyla hırsızın amacı karı maksimize etmektir.
Ürünlerin doğasına göre Sırt Çantası sorunları şu şekilde kategorize edilir:
- Kesirli Sırt Çantası
- Knapsack
Kesirli Sırt Çantası
Bu durumda, parçalar daha küçük parçalara bölünebilir, dolayısıyla hırsız, parçaların parçalarını seçebilir.
Sorun açıklamasına göre,
Var n mağazadaki ürünler
Bayrağın ağırlığı ith eşya $w_{i} > 0$
Kar ith eşya $p_{i} > 0$ ve
Sırt Çantasının kapasitesi W
Sırt Çantası probleminin bu versiyonunda, eşyalar daha küçük parçalara bölünebilir. Yani hırsız sadece bir kısmını alabilirxi nın-nin ith öğe.
$$0 \leqslant x_{i} \leqslant 1$$
ith öğe ağırlığa katkıda bulunur $x_{i}.w_{i}$ sırt çantasındaki toplam ağırlığa ve kar $x_{i}.p_{i}$ toplam kâra.
Dolayısıyla, bu algoritmanın amacı
$$maximize\:\displaystyle\sum\limits_{n=1}^n (x_{i}.p_{}i)$$
kısıtlamaya tabi,
$$\displaystyle\sum\limits_{n=1}^n (x_{i}.w_{}i) \leqslant W$$
En uygun çözümün sırt çantasını tam olarak doldurması gerektiği açıktır, aksi takdirde kalan eşyalardan birinin bir kısmını ekleyebilir ve toplam kârı artırabiliriz.
Böylece optimal bir çözüm şu şekilde elde edilebilir:
$$\displaystyle\sum\limits_{n=1}^n (x_{i}.w_{}i) = W$$
Bu bağlamda, önce bu öğeleri değerine göre sıralamamız gerekir. $\frac{p_{i}}{w_{i}}$, Böylece $\frac{p_{i}+1}{w_{i}+1}$ ≤ $\frac{p_{i}}{w_{i}}$. Buraya,x öğelerin kesirlerini depolayan bir dizidir.
Algorithm: Greedy-Fractional-Knapsack (w[1..n], p[1..n], W)
for i = 1 to n
do x[i] = 0
weight = 0
for i = 1 to n
if weight + w[i] ≤ W then
x[i] = 1
weight = weight + w[i]
else
x[i] = (W - weight) / w[i]
weight = W
break
return xAnaliz
Sağlanan öğeler zaten azalan bir sırada sıralıysa $\mathbf{\frac{p_{i}}{w_{i}}}$, sonra yük biraz zaman alırken O(n); Bu nedenle sıralama dahil toplam süreO(n logn).
Misal
Sırt çantasının kapasitesinin W = 60 ve sağlanan öğelerin listesi aşağıdaki tabloda gösterilmektedir -
| Öğe | Bir | B | C | D |
|---|---|---|---|---|
| Kar | 280 | 100 | 120 | 120 |
| Ağırlık | 40 | 10 | 20 | 24 |
| Oran $(\frac{p_{i}}{w_{i}})$ | 7 | 10 | 6 | 5 |
Sağlanan öğeler şuna göre sıralanmadığından $\mathbf{\frac{p_{i}}{w_{i}}}$. Sıralamanın ardından öğeler aşağıdaki tabloda gösterildiği gibidir.
| Öğe | B | Bir | C | D |
|---|---|---|---|---|
| Kar | 100 | 280 | 120 | 120 |
| Ağırlık | 10 | 40 | 20 | 24 |
| Oran $(\frac{p_{i}}{w_{i}})$ | 10 | 7 | 6 | 5 |
Çözüm
Tüm öğeleri göre sıraladıktan sonra $\frac{p_{i}}{w_{i}}$. Öncelikle hepsiB ağırlığı olarak seçilir Bsırt çantasının kapasitesinden daha az. Sıradaki eşyaA Sırt çantasının mevcut kapasitesi, sırt çantasının ağırlığından daha büyük olduğu için seçilir. A. Şimdi,Csonraki öğe olarak seçilir. Bununla birlikte, sırt çantasının kalan kapasitesi,C.
Bu nedenle, fraksiyonu C (yani (60 - 50) / 20) seçilir.
Artık Sırt Çantasının kapasitesi seçilen eşyalara eşit. Bu nedenle, başka öğe seçilemez.
Seçilen öğelerin toplam ağırlığı 10 + 40 + 20 * (10/20) = 60
Ve toplam kâr 100 + 280 + 120 * (10/20) = 380 + 60 = 440
En uygun çözüm budur. Herhangi bir farklı öğe kombinasyonunu seçerek daha fazla kar elde edemeyiz.
Sorun bildirimi
İş sıralama probleminde amaç, süreleri içinde tamamlanan ve maksimum kar sağlayan bir dizi iş bulmaktır.
Çözüm
Bir dizi düşünelim nBir iş son teslim tarihine kadar tamamlanırsa, son teslim tarihleriyle ilişkili verilen işler ve kazanç elde edilir. Bu işler, maksimum kar sağlayacak şekilde sipariş edilmelidir.
Verilen tüm işlerin son teslim tarihleri içinde tamamlanamayabilir.
Varsayalım, son tarih ith iş Ji dır-dir di ve bu işten elde edilen kar pi. Bu nedenle, bu algoritmanın en uygun çözümü, maksimum kâr ile uygulanabilir bir çözümdür.
Böylece, $D(i) > 0$ için $1 \leqslant i \leqslant n$.
Başlangıçta, bu işler kara göre sıralanır, yani $p_{1} \geqslant p_{2} \geqslant p_{3} \geqslant \:... \: \geqslant p_{n}$.
Algorithm: Job-Sequencing-With-Deadline (D, J, n, k)
D(0) := J(0) := 0
k := 1
J(1) := 1 // means first job is selected
for i = 2 … n do
r := k
while D(J(r)) > D(i) and D(J(r)) ≠ r do
r := r – 1
if D(J(r)) ≤ D(i) and D(i) > r then
for l = k … r + 1 by -1 do
J(l + 1) := J(l)
J(r + 1) := i
k := k + 1Analiz
Bu algoritmada, biri diğerinin içinde olmak üzere iki döngü kullanıyoruz. Dolayısıyla, bu algoritmanın karmaşıklığı$O(n^2)$.
Misal
Aşağıdaki tabloda gösterildiği gibi verilen bir dizi işi ele alalım. Süreleri içinde tamamlanacak ve maksimum kar sağlayacak bir dizi iş bulmalıyız. Her iş bir son tarih ve kâr ile ilişkilidir.
| İş | J1 | J2 | J3 | J4 | J5 |
|---|---|---|---|---|---|
| Son tarih | 2 | 1 | 3 | 2 | 1 |
| Kar | 60 | 100 | 20 | 40 | 20 |
Çözüm
Bu sorunu çözmek için, verilen işler azalan bir sırada karlarına göre sıralanır. Bu nedenle, sıralamanın ardından işler aşağıdaki tabloda gösterildiği gibi sıralanır.
| İş | J2 | J1 | J4 | J3 | J5 |
|---|---|---|---|---|---|
| Son tarih | 1 | 2 | 2 | 3 | 1 |
| Kar | 100 | 60 | 40 | 20 | 20 |
Bu iş grubundan önce J2süresi içinde tamamlanabileceğinden ve maksimum kar sağladığından.
Sonraki, J1 göre daha fazla kar sağladığı için seçilir J4.
Sonraki saatte J4 son tarihi geçtiği için seçilemez, dolayısıyla J3 süresi içinde yürütülürken seçilir.
İş J5 süresi içinde yerine getirilemeyeceği için reddedilir.
Dolayısıyla çözüm, işler dizisidir (J2, J1, J3), süreleri içinde icra edilen ve maksimum kar sağlayan.
Bu dizinin toplam karı 100 + 60 + 20 = 180.
Farklı uzunluktaki bir dizi sıralı dosyayı tek bir sıralı dosyada birleştirin. Ortaya çıkan dosyanın minimum sürede oluşturulacağı optimum bir çözüm bulmamız gerekiyor.
Sıralanan dosyaların sayısı belirtilmişse, bunları tek bir sıralı dosyada birleştirmenin birçok yolu vardır. Bu birleştirme, çift olarak gerçekleştirilebilir. Bu nedenle, bu tür bir birleştirme,2-way merge patterns.
Farklı eşlemeler farklı miktarlarda zaman gerektirdiğinden, bu stratejide birçok dosyayı bir araya getirmenin en uygun yolunu belirlemek istiyoruz. Her adımda, en kısa iki dizi birleştirilir.
Birleştirmek için p-record file ve bir q-record file muhtemelen gerektirir p + q kayıt hareketleri, bariz seçim, her adımda en küçük iki dosyayı birleştirmektir.
İki yönlü birleştirme desenleri, ikili birleştirme ağaçları ile temsil edilebilir. Bir dizi düşünelimn sıralanmış dosyalar {f1, f2, f3, …, fn}. Başlangıçta, bunun her bir öğesi tek düğümlü ikili ağaç olarak kabul edilir. Bu en uygun çözümü bulmak için aşağıdaki algoritma kullanılır.
Algorithm: TREE (n)
for i := 1 to n – 1 do
declare new node
node.leftchild := least (list)
node.rightchild := least (list)
node.weight) := ((node.leftchild).weight) + ((node.rightchild).weight)
insert (list, node);
return least (list);Bu algoritmanın sonunda, kök düğümün ağırlığı optimum maliyeti temsil eder.
Misal
Sırasıyla 20, 30, 10, 5 ve 30 elemanlı verilen f 1 , f 2 , f 3 , f 4 ve f 5 dosyalarını ele alalım .
Birleştirme işlemleri sağlanan sıraya göre gerçekleştirilirse,
M1 = merge f1 and f2 => 20 + 30 = 50
M2 = merge M1 and f3 => 50 + 10 = 60
M3 = merge M2 and f4 => 60 + 5 = 65
M4 = merge M3 and f5 => 65 + 30 = 95
Bu nedenle, toplam işlem sayısı
50 + 60 + 65 + 95 = 270
Şimdi, soru ortaya çıkıyor daha iyi bir çözüm var mı?
Sayıları boyutlarına göre artan sırada sıralayarak aşağıdaki sırayı elde ederiz -
f4, f3, f1, f2, f5
Bu nedenle, birleştirme işlemleri bu sıra üzerinde gerçekleştirilebilir
M1 = merge f4 and f3 => 5 + 10 = 15
M2 = merge M1 and f1 => 15 + 20 = 35
M3 = merge M2 and f2 => 35 + 30 = 65
M4 = merge M3 and f5 => 65 + 30 = 95
Bu nedenle, toplam işlem sayısı
15 + 35 + 65 + 95 = 210
Açıkçası, bu öncekinden daha iyi.
Bu bağlamda, şimdi bu algoritmayı kullanarak sorunu çözeceğiz.
İlk Set

Aşama 1
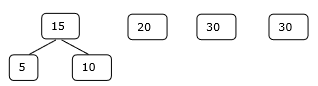
Adım 2
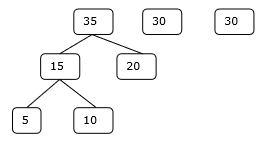
Aşama 3
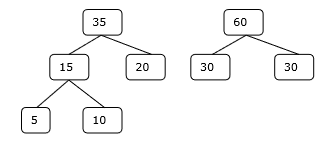
Adım 4
Bu nedenle, çözüm 15 + 35 + 60 + 95 = 205 sayıda karşılaştırma gerektirir.
Optimizasyon problemlerinde Dinamik Programlama da kullanılmaktadır. Böl ve yönet yöntemi gibi, Dinamik Programlama da alt problemlerin çözümlerini birleştirerek problemleri çözer. Dahası, Dinamik Programlama algoritması her bir alt problemi sadece bir kez çözer ve ardından cevabını bir tabloya kaydederek, her seferinde cevabı yeniden hesaplama işinden kaçınır.
Bir problemin iki ana özelliği, verilen problemin Dinamik Programlama kullanılarak çözülebileceğini gösterir. Bu özellikleroverlapping sub-problems and optimal substructure.
Örtüşen Alt Problemler
Böl ve Yönet yaklaşımına benzer şekilde Dinamik Programlama, alt problemlere yönelik çözümleri de birleştirir. Çoğunlukla bir alt problemin çözümüne tekrar tekrar ihtiyaç duyulduğunda kullanılır. Hesaplanan çözümler bir tabloda saklanır, böylece bunların yeniden hesaplanması gerekmez. Bu nedenle, çakışan alt problemin olduğu yerlerde bu tekniğe ihtiyaç vardır.
Örneğin, İkili Arama, çakışan alt soruna sahip değildir. Oysa Fibonacci sayılarının özyinelemeli programının birçok çakışan alt problemi vardır.
Optimal Alt Yapı
Verilen problemin optimal çözümü, alt problemlerinin optimal çözümleri kullanılarak elde edilebiliyorsa, belirli bir problem Optimal Alt Yapı Özelliğine sahiptir.
Örneğin, En Kısa Yol problemi aşağıdaki optimal alt yapı özelliğine sahiptir -
Eğer bir düğüm x bir kaynak düğümden gelen en kısa yolda yatıyor u hedef düğüme v, sonra en kısa yol u -e v en kısa yolun birleşimidir u -e xve en kısa yol x -e v.
Floyd-Warshall ve Bellman-Ford gibi standart All Pair En Kısa Yol algoritmaları, Dinamik Programlamanın tipik örnekleridir.
Dinamik Programlama Yaklaşımının Adımları
Dinamik Programlama algoritması aşağıdaki dört adım kullanılarak tasarlanmıştır -
- Optimal bir çözümün yapısını karakterize edin.
- En uygun çözümün değerini yinelemeli olarak tanımlayın.
- En uygun çözümün değerini, genellikle aşağıdan yukarıya bir şekilde hesaplayın.
- Hesaplanan bilgilerden optimal bir çözüm oluşturun.
Dinamik Programlama Yaklaşımının Uygulamaları
- Matris Zinciri Çarpımı
- En Uzun Ortak Sonuç
- Seyahat Eden Satıcı Problemi
Bu eğitimde, daha önce Greedy yaklaşımını kullanarak Kesirli Sırt Çantası problemini tartışmıştık. Açgözlü yaklaşımın Kesirli Sırt Çantası için en uygun çözümü verdiğini gösterdik. Bununla birlikte, bu bölüm 0-1 Sırt Çantası problemini ve analizini kapsayacaktır.
0-1 Sırt Çantasında, eşyalar kırılamaz, bu da hırsızın eşyayı bir bütün olarak alması veya bırakması gerektiği anlamına gelir. 0-1 Sırt Çantası olarak adlandırılmasının nedeni budur.
Dolayısıyla, 0-1 Sırt Çantası durumunda, değeri xi herhangi biri olabilir 0 veya 1, diğer kısıtlamaların aynı kaldığı durumlarda.
0-1 Sırt Çantası Açgözlü yaklaşımı ile çözülemez. Açgözlü yaklaşım, optimal bir çözüm sağlamaz. Çoğu durumda, Açgözlü yaklaşım optimal bir çözüm sağlayabilir.
Aşağıdaki örnekler ifademizi oluşturacaktır.
Örnek 1
Sırt çantasının kapasitesinin W = 25 olduğunu ve eşyaların aşağıdaki tabloda gösterildiği gibi olduğunu düşünelim.
| Öğe | Bir | B | C | D |
|---|---|---|---|---|
| Kar | 24 | 18 | 18 | 10 |
| Ağırlık | 24 | 10 | 10 | 7 |
Birim ağırlık başına kar dikkate alınmadan (pi/wi), bu sorunu çözmek için Açgözlü yaklaşımı uygularsak, ilk madde Ao maksimum katkıda bulunacak şekilde seçilecektir i tüm unsurları arasında anne karı.
Öğeyi seçtikten sonra A, başka öğe seçilmeyecek. Bu nedenle, bu belirli ürün grubu için toplam kâr24. Oysa en uygun çözüme ürün seçilerek ulaşılabilir,B ve toplam kârın 18 + 18 = 36 olduğu C.
Örnek-2
Maddeleri genel faydaya göre seçmek yerine, bu örnekte maddeler p i / w i oranına göre seçilmiştir . Sırt çantasının kapasitesinin W = 60 olduğunu ve eşyaların aşağıdaki tabloda gösterildiği gibi olduğunu düşünelim .
| Öğe | Bir | B | C |
|---|---|---|---|
| Fiyat | 100 | 280 | 120 |
| Ağırlık | 10 | 40 | 20 |
| Oran | 10 | 7 | 6 |
Açgözlü yaklaşımı kullanarak, ilk madde Aseçildi. Sonra bir sonraki öğeBseçilmiş. Dolayısıyla, toplam kâr100 + 280 = 380. Bununla birlikte, bu örneğin en uygun çözümü, öğeleri seçerek elde edilebilir,B ve C, toplam kâr nerede 280 + 120 = 400.
Dolayısıyla, Açgözlü yaklaşımın optimal bir çözüm vermeyebileceği sonucuna varılabilir.
0-1 Sırt Çantasını çözmek için Dinamik Programlama yaklaşımı gereklidir.
Sorun bildirimi
Bir hırsız bir mağaza soyarak ve maksimum taşıyabilen i arasında mal ağırlığıWsırt çantasına. Varn öğeleri ve ağırlığı ith öğe wi ve bu öğeyi seçmenin karı pi. Hırsız hangi eşyaları almalı?
Dinamik Programlama Yaklaşımı
İzin Vermek i en uygun çözümde en yüksek numaralı öğe olmak S için Wdolar. SonraS' = S - {i} için en uygun çözümdür W - wi dolar ve çözümün değeri S dır-dir Vi artı alt problemin değeri.
Bu gerçeği aşağıdaki formülde ifade edebiliriz: c[i, w] öğeler için çözüm olmak 1,2, … , ive maksimum i mum ağırlıkw.
Algoritma aşağıdaki girdileri alır
Maksimum i mum ağırlıkW
Öğe sayısı n
İki dizi v = <v1, v2, …, vn> ve w = <w1, w2, …, wn>
Dynamic-0-1-knapsack (v, w, n, W)
for w = 0 to W do
c[0, w] = 0
for i = 1 to n do
c[i, 0] = 0
for w = 1 to W do
if wi ≤ w then
if vi + c[i-1, w-wi] then
c[i, w] = vi + c[i-1, w-wi]
else c[i, w] = c[i-1, w]
else
c[i, w] = c[i-1, w]Alınacak öğe seti, tablodan başlayarak çıkarılabilir. c[n, w] ve optimum değerlerin geldiği yeri geriye doğru izlemek.
Eğer c [i, W] = C [i-1, a] , daha sonra ürüni çözümün bir parçası değil ve izlemeye devam ediyoruz c[i-1, w]. Aksi takdirde öğei çözümün bir parçası ve izlemeye devam ediyoruz c[i-1, w-W].
Analiz
Bu algoritma, c tablosunda ( n + 1). ( W + 1) girişleri olduğu için entry ( n , w ) kez alır , burada her girişin hesaplanması (1) süre gerektirir.
En uzun ortak alt dizi problemi, verilen dizelerin her ikisinde de var olan en uzun diziyi bulmaktır.
Sonraki
S = <s 1 , s 2 , s 3 , s 4 ,…, s n > dizisini ele alalım .
Z = <z 1 , z 2 , z 3 , z 4 ,…, z m > üzerinden S dizisine , ancak ve ancak bazı elemanların S silinmesinden türetilebiliyorsa, S'nin bir alt dizisi denir.
Ortak Sonrası
Varsayalım, X ve Ysonlu bir öğe kümesi üzerinde iki dizidir. Bunu söyleyebilirizZ ortak bir alt dizisidir X ve Y, Eğer Z her ikisinin alt dizisidir X ve Y.
En Uzun Ortak Sonuç
Bir dizi dizisi verilirse, en uzun ortak alt dizi problemi, maksimum uzunluktaki tüm dizilerin ortak bir alt dizisini bulmaktır.
En uzun ortak alt dizi problemi, klasik bir bilgisayar bilimi problemidir, diff-yarar gibi veri karşılaştırma programlarının temelini oluşturur ve biyoinformatikte uygulamaları vardır. Ayrıca, revizyon kontrollü bir dosya koleksiyonunda yapılan birden çok değişikliği uzlaştırmak için SVN ve Git gibi revizyon kontrol sistemleri tarafından yaygın olarak kullanılır.
Naif Yöntem
İzin Vermek X uzunluk dizisi olmak m ve Y bir dizi uzunluk n. Her alt dizisini kontrol edinX alt dizisi olup olmadığı Yve bulunan en uzun ortak alt diziyi döndürür.
Var 2m alt dizileri X. Bir alt dizisi olsun ya da olmasın dizileri test etmeY alır O(n)zaman. Bu nedenle, saf algoritmaO(n2m) zaman.
Dinamik program
Let , X = <x 1 x 2 , x 3 , ..., x m > ve Y = <y 1 , y 2 , y 3 , ..., Y , n > dizileri. Bir elemanın uzunluğunu hesaplamak için aşağıdaki algoritma kullanılır.
Bu prosedürde tablo C[m, n] satır ana sırasına göre ve başka bir tabloda hesaplanır B[m,n] optimal çözümü oluşturmak için hesaplanır.
Algorithm: LCS-Length-Table-Formulation (X, Y)
m := length(X)
n := length(Y)
for i = 1 to m do
C[i, 0] := 0
for j = 1 to n do
C[0, j] := 0
for i = 1 to m do
for j = 1 to n do
if xi = yj
C[i, j] := C[i - 1, j - 1] + 1
B[i, j] := ‘D’
else
if C[i -1, j] ≥ C[i, j -1]
C[i, j] := C[i - 1, j] + 1
B[i, j] := ‘U’
else
C[i, j] := C[i, j - 1]
B[i, j] := ‘L’
return C and BAlgorithm: Print-LCS (B, X, i, j)
if i = 0 and j = 0
return
if B[i, j] = ‘D’
Print-LCS(B, X, i-1, j-1)
Print(xi)
else if B[i, j] = ‘U’
Print-LCS(B, X, i-1, j)
else
Print-LCS(B, X, i, j-1)Bu algoritma, en uzun ortak alt dizisini yazdıracaktır. X ve Y.
Analiz
Tabloyu doldurmak için dış for döngü yinelenir m zamanlar ve iç for döngü yinelenir nzamanlar. Dolayısıyla, algoritmanın karmaşıklığı O (m, n) 'dir , buradam ve n iki dizenin uzunluğudur.
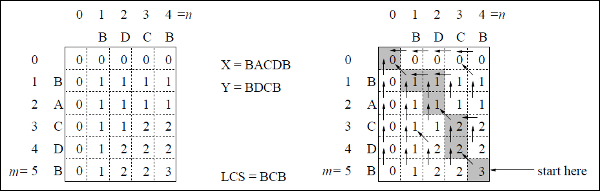
Misal
Bu örnekte, iki dizimiz var X = BACDB ve Y = BDCB en uzun ortak alt diziyi bulmak için.
LCS-Uzunluk-Tablo-Formülasyon algoritmasını (yukarıda belirtildiği gibi) izleyerek, C tablosunu (sol tarafta gösterilmiştir) ve B tablosunu (sağ tarafta gösterilmiştir) hesapladık.
Tablo B'de 'D', 'L' ve 'U' yerine sırasıyla çapraz ok, sol ok ve yukarı ok kullanıyoruz. Tablo B'yi oluşturduktan sonra, LCS, LCS-Yazdırma işlevi tarafından belirlenir. Sonuç BCB'dir.
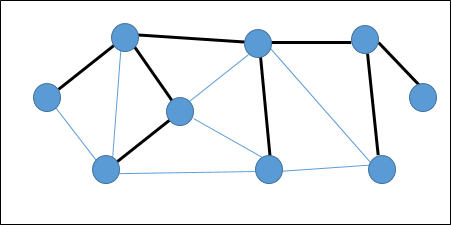
Bir spanning tree Tüm köşeleri minimum sayıda kenarla birbirine bağlayan yönsüz bir Grafiğin bir alt kümesidir.
Tüm köşeler bir grafiğe bağlıysa, en az bir kapsayan ağaç vardır. Bir grafikte birden fazla yayılan ağaç olabilir.
Özellikleri
- Kapsayan bir ağacın herhangi bir döngüsü yoktur.
- Herhangi bir tepe noktasına başka herhangi bir tepe noktasından ulaşılabilir.
Misal
Aşağıdaki grafikte, vurgulanan kenarlar bir kapsayan ağaç oluşturur.
Az yer kaplayan ağaç
Bir Minimum Spanning Tree (MST)tüm köşeleri mümkün olan minimum toplam kenar ağırlığıyla birbirine bağlayan bağlı ağırlıklı yönsüz grafiğin kenarlarının bir alt kümesidir. Bir MST türetmek için Prim'in algoritması veya Kruskal'ın algoritması kullanılabilir. Bu nedenle, Prim'in algoritmasını bu bölümde tartışacağız.
Tartıştığımız gibi, bir grafiğin birden fazla kapsayan ağacı olabilir. Eğer varsan köşe sayısı, yayılan ağacın sahip olması gereken n - 1kenar sayısı. Bu bağlamda, grafiğin her kenarı bir ağırlıkla ilişkilendirilmişse ve birden fazla yayılan ağaç varsa, grafiğin minimum kapsayan ağacını bulmamız gerekir.
Üstelik, herhangi bir yinelenen ağırlıklı kenar varsa, grafik birden çok minimum yayılma ağacına sahip olabilir.
Yukarıdaki grafikte, minimum yayılma ağacı olmasa da bir kapsayan ağaç gösterdik. Bu genişleyen ağacın maliyeti (5 + 7 + 3 + 3 + 5 + 8 + 3 + 4) = 38'dir.
Minimum yayılma ağacını bulmak için Prim'in algoritmasını kullanacağız.
Prim Algoritması
Prim'in algoritması, minimum yayılma ağacını bulmak için açgözlü bir yaklaşımdır. Bu algoritmada, bir MST oluşturmak için keyfi bir tepe noktasından başlayabiliriz.
Algorithm: MST-Prim’s (G, w, r)
for each u є G.V
u.key = ∞
u.∏ = NIL
r.key = 0
Q = G.V
while Q ≠ Ф
u = Extract-Min (Q)
for each v є G.adj[u]
if each v є Q and w(u, v) < v.key
v.∏ = u
v.key = w(u, v)Ayıkla-Min işlevi, minimum kenar maliyetiyle tepe noktasını döndürür. Bu işlev min-heap üzerinde çalışır.
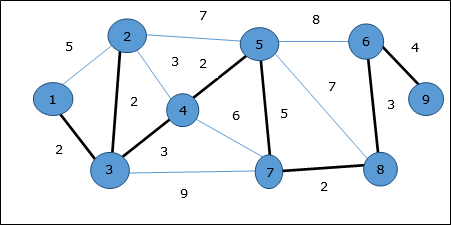
Misal
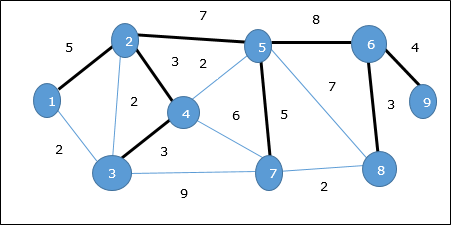
Prim'in algoritmasını kullanarak herhangi bir tepe noktasından başlayabiliriz, tepe noktasından başlayalım 1.
Köşe 3 tepe noktasına bağlı 1 minimum kenar maliyetiyle, dolayısıyla kenar (1, 2) kapsayan ağaca eklenir.
Sonra, kenar (2, 3) bu kenarlar arasında minimum olduğu için {(1, 2), (2, 3), (3, 4), (3, 7)}.
Bir sonraki adımda avantaj elde ederiz (3, 4) ve (2, 4)minimum maliyetle. Kenar(3, 4) rastgele seçilir.
Benzer şekilde, kenarlar (4, 5), (5, 7), (7, 8), (6, 8) ve (6, 9)seçildi. Tüm köşeler ziyaret edildiğinde artık algoritma durur.
Kapsayan ağacın maliyeti (2 + 2 + 3 + 2 + 5 + 2 + 3 + 4) = 23'tür. Bu grafikte daha düşük maliyetli yayılan ağaç yoktur. 23.
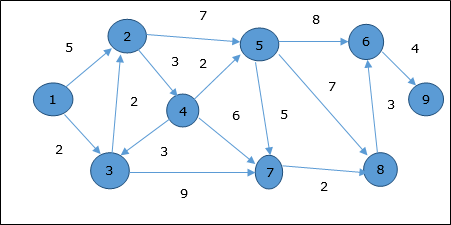
Dijkstra Algoritması
Bir yönlendirilmiş ağırlıklı grafikte Dijkstra algoritması çözer tek kaynaklı kısa-yolları sorunu G = (V, E) bütün kenarları olmayan negatif (yani olan, ağırlık (u, v) ≥ 0, her kenar için (u, v ) Є E ).
Aşağıdaki algoritmada bir işlev kullanacağız Extract-Min(), düğümü en küçük anahtarla çıkarır.
Algorithm: Dijkstra’s-Algorithm (G, w, s)
for each vertex v Є G.V
v.d := ∞
v.∏ := NIL
s.d := 0
S := Ф
Q := G.V
while Q ≠ Ф
u := Extract-Min (Q)
S := S U {u}
for each vertex v Є G.adj[u]
if v.d > u.d + w(u, v)
v.d := u.d + w(u, v)
v.∏ := uAnaliz
Bu algoritmanın karmaşıklığı tamamen Min Ayıklama işlevinin uygulanmasına bağlıdır. Çıkarım min fonksiyonu doğrusal arama kullanılarak uygulanırsa, bu algoritmanın karmaşıklığı şu şekildedir:O(V2 + E).
Bu algoritmada, min-heap kullanırsak Extract-Min() işlev düğümü döndürmek için çalışır Q en küçük anahtar ile bu algoritmanın karmaşıklığı daha da azaltılabilir.
Misal
Tepe noktasını düşünelim 1 ve 9sırasıyla başlangıç ve hedef köşe noktası olarak. Başlangıçta, başlangıç köşesi dışındaki tüm köşeler ∞ ile işaretlenir ve başlangıç köşesi ile işaretlenir0.
| Köşe | İlk | Adım 1 V 1 | Adım2 V 3 | Adım3 V 2 | Adım4 V 4 | Adım5 V 5 | Adım6 V 7 | Adım7 V 8 | Adım8 V 6 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | ∞ | 5 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| 3 | ∞ | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 4 | ∞ | ∞ | ∞ | 7 | 7 | 7 | 7 | 7 | 7 |
| 5 | ∞ | ∞ | ∞ | 11 | 9 | 9 | 9 | 9 | 9 |
| 6 | ∞ | ∞ | ∞ | ∞ | ∞ | 17 | 17 | 16 | 16 |
| 7 | ∞ | ∞ | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| 8 | ∞ | ∞ | ∞ | ∞ | ∞ | 16 | 13 | 13 | 13 |
| 9 | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | ∞ | 20 |
Bu nedenle, minimum tepe mesafesi 9 tepe noktasından 1 dır-dir 20. Ve yol
1 → 3 → 7 → 8 → 6 → 9
Bu yol, önceki bilgilere göre belirlenir.
Bellman Ford Algoritması
Bu algoritma, yönlendirilmiş bir grafiğin tek kaynaklı en kısa yol problemini çözer G = (V, E)kenar ağırlıklarının negatif olabileceği. Ayrıca, negatif ağırlıklı döngü yoksa bu algoritma en kısa yolu bulmak için de uygulanabilir.
Algorithm: Bellman-Ford-Algorithm (G, w, s)
for each vertex v Є G.V
v.d := ∞
v.∏ := NIL
s.d := 0
for i = 1 to |G.V| - 1
for each edge (u, v) Є G.E
if v.d > u.d + w(u, v)
v.d := u.d +w(u, v)
v.∏ := u
for each edge (u, v) Є G.E
if v.d > u.d + w(u, v)
return FALSE
return TRUEAnaliz
İlk for döngü, başlatma için kullanılır. O(V)zamanlar. Sonrakifor döngü çalışmaları |V - 1| alan kenarları üzerinden geçerO(E) zamanlar.
Dolayısıyla, Bellman-Ford algoritması O(V, E) zaman.
Misal
Aşağıdaki örnek Bellman-Ford algoritmasının adım adım nasıl çalıştığını göstermektedir. Bu grafiğin negatif bir kenarı vardır, ancak herhangi bir negatif döngüsü yoktur, bu nedenle problem bu teknik kullanılarak çözülebilir.
Başlatma sırasında, kaynak dışındaki tüm köşeler ∞ ile işaretlenir ve kaynak 0.
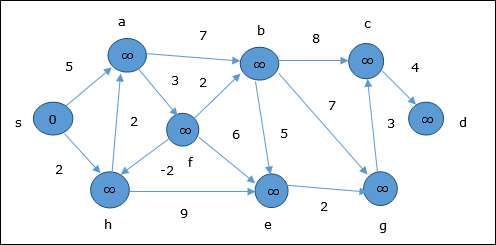
İlk adımda kaynaktan ulaşılabilen tüm köşeler minimum maliyetle güncellenir. Dolayısıyla, köşelera ve h güncellenir.
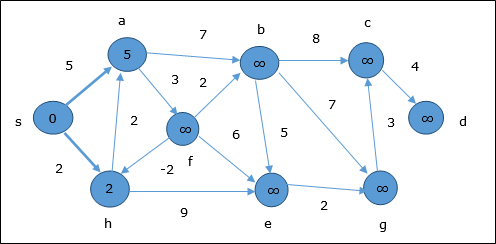
Bir sonraki adımda, köşeler a, b, f ve e güncellenir.
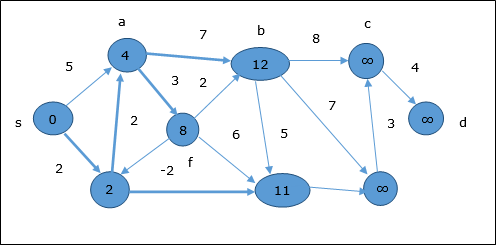
Aynı mantığı takip ederek, bu adımda köşeler b, f, c ve g güncellenir.
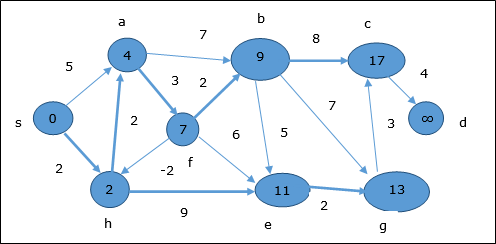
Burada, köşeler c ve d güncellenir.
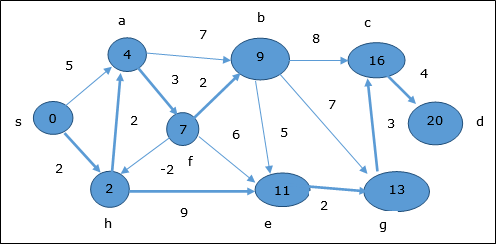
Bu nedenle, tepe noktası arasındaki minimum mesafe s ve tepe d dır-dir 20.
Önceki bilgilere dayanarak, yol s → h → e → g → c → d şeklindedir
Çok aşamalı bir grafik G = (V, E) köşelerin bölündüğü yönlendirilmiş bir grafiktir. k (nerede k > 1) ayrık alt kümelerin sayısı S = {s1,s2,…,sk}öyle ki kenar (u, v) E içindedir , sonra bölümdeki bazı alt kümeler için u Є s i ve v Є s 1 + 1 ve |s1| = |sk| = 1.
Tepe s Є s1 denir source ve tepe t Є sk denir sink.
Ggenellikle ağırlıklı bir grafik olduğu varsayılır. Bu grafikte, bir kenarın (i, j) maliyeti c (i, j) ile temsil edilmektedir . Bu nedenle, kaynaktan gelen yolun maliyetis batmak t bu yoldaki her kenarın maliyetlerinin toplamıdır.
Çok aşamalı grafik problemi, kaynaktan minimum maliyetle yolu bulmaktır. s batmak t.
Misal
Çok aşamalı grafik kavramını anlamak için aşağıdaki örneği düşünün.
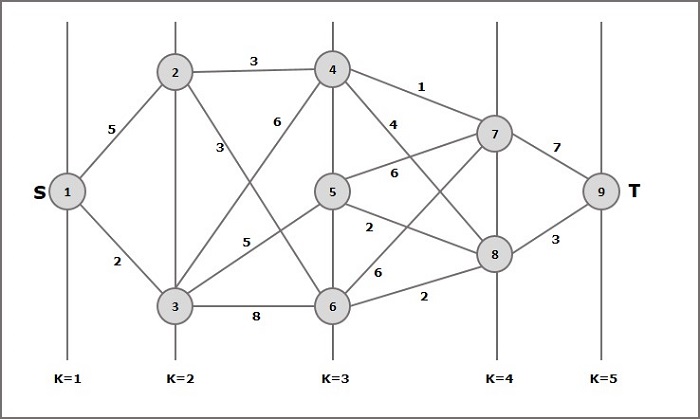
Formüle göre maliyeti hesaplamalıyız (i, j) aşağıdaki adımları kullanarak
Adım-1: Maliyet (K-2, j)
Bu adımda, üç düğüm (düğüm 4, 5. 6) şu şekilde seçilir: j. Dolayısıyla, bu adımda minimum maliyeti seçmek için üç seçeneğimiz var.
Maliyet (3, 4) = min {c (4, 7) + Maliyet (7, 9), c (4, 8) + Maliyet (8, 9)} = 7
Maliyet (3, 5) = min {c (5, 7) + Maliyet (7, 9), c (5, 8) + Maliyet (8, 9)} = 5
Maliyet (3, 6) = min {c (6, 7) + Maliyet (7, 9), c (6, 8) + Maliyet (8, 9)} = 5
Adım-2: Maliyet (K-3, j)
J olarak iki düğüm seçilir çünkü k - 3 = 2 aşamasında iki düğüm vardır, 2 ve 3. Yani, i = 2 ve j = 2 ve 3 değeri.
Maliyet (2, 2) = min {c (2, 4) + Maliyet (4, 8) + Maliyet (8, 9), c (2, 6) +
Maliyet (6, 8) + Maliyet (8, 9)} = 8
Maliyet (2, 3) = {c (3, 4) + Maliyet (4, 8) + Maliyet (8, 9), c (3, 5) + Maliyet (5, 8) + Maliyet (8, 9), c (3, 6) + Maliyet (6, 8) + Maliyet (8, 9)} = 10
Adım-3: Maliyet (K-4, j)
Maliyet (1, 1) = {c (1, 2) + Maliyet (2, 6) + Maliyet (6, 8) + Maliyet (8, 9), c (1, 3) + Maliyet (3, 5) + Maliyet (5, 8) + Maliyet (8, 9))} = 12
c (1, 3) + Maliyet (3, 6) + Maliyet (6, 8 + Maliyet (8, 9))} = 13
Bu nedenle, minimum maliyete sahip yol 1→ 3→ 5→ 8→ 9.
Sorun bildirimi
Bir gezginin, tüm şehirler arasındaki mesafelerin bilindiği ve her şehrin yalnızca bir kez ziyaret edilmesi gereken bir listeden tüm şehirleri ziyaret etmesi gerekir. Her şehri tam olarak bir kez ziyaret edip asıl şehre geri döndüğü en kısa rota nedir?
Çözüm
Seyahat eden satıcı problemi, en kötü şöhretli hesaplama problemidir. Olası her turu değerlendirmek ve en iyisini seçmek için kaba kuvvet yaklaşımını kullanabiliriz. İçinn number of vertices in a graph, there are (n - 1)! number of possibilities.
Instead of brute-force using dynamic programming approach, the solution can be obtained in lesser time, though there is no polynomial time algorithm.
Let us consider a graph G = (V, E), where V is a set of cities and E is a set of weighted edges. An edge e(u, v) represents that vertices u and v are connected. Distance between vertex u and v is d(u, v), which should be non-negative.
Suppose we have started at city 1 and after visiting some cities now we are in city j. Hence, this is a partial tour. We certainly need to know j, since this will determine which cities are most convenient to visit next. We also need to know all the cities visited so far, so that we don't repeat any of them. Hence, this is an appropriate sub-problem.
For a subset of cities S Є {1, 2, 3, ... , n} that includes 1, and j Є S, let C(S, j) be the length of the shortest path visiting each node in S exactly once, starting at 1 and ending at j.
When |S| > 1, we define C(S, 1) = ∝ since the path cannot start and end at 1.
Now, let express C(S, j) in terms of smaller sub-problems. We need to start at 1 and end at j. We should select the next city in such a way that
$$C(S, j) = min \:C(S - \lbrace j \rbrace, i) + d(i, j)\:where\: i\in S \: and\: i \neq jc(S, j) = minC(s- \lbrace j \rbrace, i)+ d(i,j) \:where\: i\in S \: and\: i \neq j $$
Algorithm: Traveling-Salesman-Problem
C ({1}, 1) = 0
for s = 2 to n do
for all subsets S Є {1, 2, 3, … , n} of size s and containing 1
C (S, 1) = ∞
for all j Є S and j ≠ 1
C (S, j) = min {C (S – {j}, i) + d(i, j) for i Є S and i ≠ j}
Return minj C ({1, 2, 3, …, n}, j) + d(j, i)Analysis
There are at the most $2^n.n$ sub-problems and each one takes linear time to solve. Therefore, the total running time is $O(2^n.n^2)$.
Example
In the following example, we will illustrate the steps to solve the travelling salesman problem.

From the above graph, the following table is prepared.
| 1 | 2 | 3 | 4 | |
| 1 | 0 | 10 | 15 | 20 |
| 2 | 5 | 0 | 9 | 10 |
| 3 | 6 | 13 | 0 | 12 |
| 4 | 8 | 8 | 9 | 0 |
S = Φ
$$\small Cost (2,\Phi,1) = d (2,1) = 5\small Cost(2,\Phi,1)=d(2,1)=5$$
$$\small Cost (3,\Phi,1) = d (3,1) = 6\small Cost(3,\Phi,1)=d(3,1)=6$$
$$\small Cost (4,\Phi,1) = d (4,1) = 8\small Cost(4,\Phi,1)=d(4,1)=8$$
S = 1
$$\small Cost (i,s) = min \lbrace Cost (j,s – (j)) + d [i,j]\rbrace\small Cost (i,s)=min \lbrace Cost (j,s)-(j))+ d [i,j]\rbrace$$
$$\small Cost (2,\lbrace 3 \rbrace,1) = d [2,3] + Cost (3,\Phi,1) = 9 + 6 = 15cost(2,\lbrace3 \rbrace,1)=d[2,3]+cost(3,\Phi ,1)=9+6=15$$
$$\small Cost (2,\lbrace 4 \rbrace,1) = d [2,4] + Cost (4,\Phi,1) = 10 + 8 = 18cost(2,\lbrace4 \rbrace,1)=d[2,4]+cost(4,\Phi,1)=10+8=18$$
$$\small Cost (3,\lbrace 2 \rbrace,1) = d [3,2] + Cost (2,\Phi,1) = 13 + 5 = 18cost(3,\lbrace2 \rbrace,1)=d[3,2]+cost(2,\Phi,1)=13+5=18$$
$$\small Cost (3,\lbrace 4 \rbrace,1) = d [3,4] + Cost (4,\Phi,1) = 12 + 8 = 20cost(3,\lbrace4 \rbrace,1)=d[3,4]+cost(4,\Phi,1)=12+8=20$$
$$\small Cost (4,\lbrace 3 \rbrace,1) = d [4,3] + Cost (3,\Phi,1) = 9 + 6 = 15cost(4,\lbrace3 \rbrace,1)=d[4,3]+cost(3,\Phi,1)=9+6=15$$
$$\small Cost (4,\lbrace 2 \rbrace,1) = d [4,2] + Cost (2,\Phi,1) = 8 + 5 = 13cost(4,\lbrace2 \rbrace,1)=d[4,2]+cost(2,\Phi,1)=8+5=13$$
S = 2
$$\small Cost(2, \lbrace 3, 4 \rbrace, 1)=\begin{cases}d[2, 3] + Cost(3, \lbrace 4 \rbrace, 1) = 9 + 20 = 29\\d[2, 4] + Cost(4, \lbrace 3 \rbrace, 1) = 10 + 15 = 25=25\small Cost (2,\lbrace 3,4 \rbrace,1)\\\lbrace d[2,3]+ \small cost(3,\lbrace4\rbrace,1)=9+20=29d[2,4]+ \small Cost (4,\lbrace 3 \rbrace ,1)=10+15=25\end{cases}= 25$$
$$\small Cost(3, \lbrace 2, 4 \rbrace, 1)=\begin{cases}d[3, 2] + Cost(2, \lbrace 4 \rbrace, 1) = 13 + 18 = 31\\d[3, 4] + Cost(4, \lbrace 2 \rbrace, 1) = 12 + 13 = 25=25\small Cost (3,\lbrace 2,4 \rbrace,1)\\\lbrace d[3,2]+ \small cost(2,\lbrace4\rbrace,1)=13+18=31d[3,4]+ \small Cost (4,\lbrace 2 \rbrace ,1)=12+13=25\end{cases}= 25$$
$$\small Cost(4, \lbrace 2, 3 \rbrace, 1)=\begin{cases}d[4, 2] + Cost(2, \lbrace 3 \rbrace, 1) = 8 + 15 = 23\\d[4, 3] + Cost(3, \lbrace 2 \rbrace, 1) = 9 + 18 = 27=23\small Cost (4,\lbrace 2,3 \rbrace,1)\\\lbrace d[4,2]+ \small cost(2,\lbrace3\rbrace,1)=8+15=23d[4,3]+ \small Cost (3,\lbrace 2 \rbrace ,1)=9+18=27\end{cases}= 23$$
S = 3
$$\small Cost(1, \lbrace 2, 3, 4 \rbrace, 1)=\begin{cases}d[1, 2] + Cost(2, \lbrace 3, 4 \rbrace, 1) = 10 + 25 = 35\\d[1, 3] + Cost(3, \lbrace 2, 4 \rbrace, 1) = 15 + 25 = 40\\d[1, 4] + Cost(4, \lbrace 2, 3 \rbrace, 1) = 20 + 23 = 43=35 cost(1,\lbrace 2,3,4 \rbrace),1)\\d[1,2]+cost(2,\lbrace 3,4 \rbrace,1)=10+25=35\\d[1,3]+cost(3,\lbrace 2,4 \rbrace,1)=15+25=40\\d[1,4]+cost(4,\lbrace 2,3 \rbrace ,1)=20+23=43=35\end{cases}$$
The minimum cost path is 35.
Start from cost {1, {2, 3, 4}, 1}, we get the minimum value for d [1, 2]. When s = 3, select the path from 1 to 2 (cost is 10) then go backwards. When s = 2, we get the minimum value for d [4, 2]. Select the path from 2 to 4 (cost is 10) then go backwards.
When s = 1, we get the minimum value for d [4, 3]. Selecting path 4 to 3 (cost is 9), then we shall go to then go to s = Φ step. We get the minimum value for d [3, 1] (cost is 6).

A Binary Search Tree (BST) is a tree where the key values are stored in the internal nodes. The external nodes are null nodes. The keys are ordered lexicographically, i.e. for each internal node all the keys in the left sub-tree are less than the keys in the node, and all the keys in the right sub-tree are greater.
When we know the frequency of searching each one of the keys, it is quite easy to compute the expected cost of accessing each node in the tree. An optimal binary search tree is a BST, which has minimal expected cost of locating each node
Search time of an element in a BST is O(n), whereas in a Balanced-BST search time is O(log n). Again the search time can be improved in Optimal Cost Binary Search Tree, placing the most frequently used data in the root and closer to the root element, while placing the least frequently used data near leaves and in leaves.
Here, the Optimal Binary Search Tree Algorithm is presented. First, we build a BST from a set of provided n number of distinct keys < k1, k2, k3, ... kn >. Here we assume, the probability of accessing a key Ki is pi. Some dummy keys (d0, d1, d2, ... dn) are added as some searches may be performed for the values which are not present in the Key set K. We assume, for each dummy key di probability of access is qi.
Optimal-Binary-Search-Tree(p, q, n)
e[1…n + 1, 0…n],
w[1…n + 1, 0…n],
root[1…n + 1, 0…n]
for i = 1 to n + 1 do
e[i, i - 1] := qi - 1
w[i, i - 1] := qi - 1
for l = 1 to n do
for i = 1 to n – l + 1 do
j = i + l – 1 e[i, j] := ∞
w[i, i] := w[i, i -1] + pj + qj
for r = i to j do
t := e[i, r - 1] + e[r + 1, j] + w[i, j]
if t < e[i, j]
e[i, j] := t
root[i, j] := r
return e and rootAnalysis
The algorithm requires O (n3) time, since three nested for loops are used. Each of these loops takes on at most n values.
Example
Considering the following tree, the cost is 2.80, though this is not an optimal result.
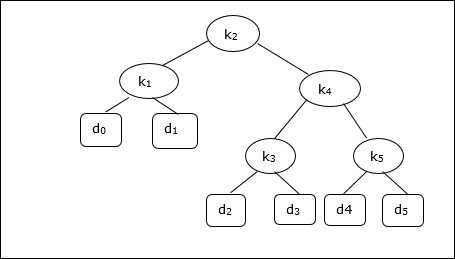
| Node | Depth | Probability | Contribution |
|---|---|---|---|
| k1 | 1 | 0.15 | 0.30 |
| k2 | 0 | 0.10 | 0.10 |
| k3 | 2 | 0.05 | 0.15 |
| k4 | 1 | 0.10 | 0.20 |
| k5 | 2 | 0.20 | 0.60 |
| d0 | 2 | 0.05 | 0.15 |
| d1 | 2 | 0.10 | 0.30 |
| d2 | 3 | 0.05 | 0.20 |
| d3 | 3 | 0.05 | 0.20 |
| d4 | 3 | 0.05 | 0.20 |
| d5 | 3 | 0.10 | 0.40 |
| Total | 2.80 |
To get an optimal solution, using the algorithm discussed in this chapter, the following tables are generated.
In the following tables, column index is i and row index is j.
| e | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 5 | 2.75 | 2.00 | 1.30 | 0.90 | 0.50 | 0.10 |
| 4 | 1.75 | 1.20 | 0.60 | 0.30 | 0.05 | |
| 3 | 1.25 | 0.70 | 0.25 | 0.05 | ||
| 2 | 0.90 | 0.40 | 0.05 | |||
| 1 | 0.45 | 0.10 | ||||
| 0 | 0.05 |
| w | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 5 | 1.00 | 0.80 | 0.60 | 0.50 | 0.35 | 0.10 |
| 4 | 0.70 | 0.50 | 0.30 | 0.20 | 0.05 | |
| 3 | 0.55 | 0.35 | 0.15 | 0.05 | ||
| 2 | 0.45 | 0.25 | 0.05 | |||
| 1 | 0.30 | 0.10 | ||||
| 0 | 0.05 |
| root | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 5 | 2 | 4 | 5 | 5 | 5 |
| 4 | 2 | 2 | 4 | 4 | |
| 3 | 2 | 2 | 3 | ||
| 2 | 1 | 2 | |||
| 1 | 1 |
From these tables, the optimal tree can be formed.
There are several types of heaps, however in this chapter, we are going to discuss binary heap. A binary heap is a data structure, which looks similar to a complete binary tree. Heap data structure obeys ordering properties discussed below. Generally, a Heap is represented by an array. In this chapter, we are representing a heap by H.
As the elements of a heap is stored in an array, considering the starting index as 1, the position of the parent node of ith element can be found at ⌊ i/2 ⌋ . Left child and right child of ith node is at position 2i and 2i + 1.
A binary heap can be classified further as either a max-heap or a min-heap based on the ordering property.
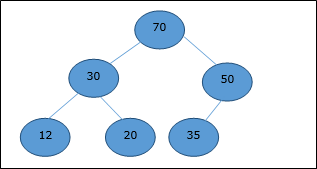
Max-Heap
In this heap, the key value of a node is greater than or equal to the key value of the highest child.
Hence, H[Parent(i)] ≥ H[i]
Min-Heap
In mean-heap, the key value of a node is lesser than or equal to the key value of the lowest child.
Hence, H[Parent(i)] ≤ H[i]
In this context, basic operations are shown below with respect to Max-Heap. Insertion and deletion of elements in and from heaps need rearrangement of elements. Hence, Heapify function needs to be called.
Array Representation
A complete binary tree can be represented by an array, storing its elements using level order traversal.
Let us consider a heap (as shown below) which will be represented by an array H.
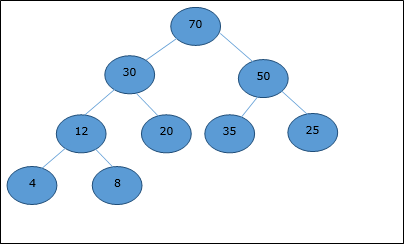
Considering the starting index as 0, using level order traversal, the elements are being kept in an array as follows.
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ... |
| elements | 70 | 30 | 50 | 12 | 20 | 35 | 25 | 4 | 8 | ... |
In this context, operations on heap are being represented with respect to Max-Heap.
To find the index of the parent of an element at index i, the following algorithm Parent (numbers[], i) is used.
Algorithm: Parent (numbers[], i)
if i == 1
return NULL
else
[i / 2]The index of the left child of an element at index i can be found using the following algorithm, Left-Child (numbers[], i).
Algorithm: Left-Child (numbers[], i)
If 2 * i ≤ heapsize
return [2 * i]
else
return NULLThe index of the right child of an element at index i can be found using the following algorithm, Right-Child(numbers[], i).
Algorithm: Right-Child (numbers[], i)
if 2 * i < heapsize
return [2 * i + 1]
else
return NULLTo insert an element in a heap, the new element is initially appended to the end of the heap as the last element of the array.
After inserting this element, heap property may be violated, hence the heap property is repaired by comparing the added element with its parent and moving the added element up a level, swapping positions with the parent. This process is called percolation up.
The comparison is repeated until the parent is larger than or equal to the percolating element.
Algorithm: Max-Heap-Insert (numbers[], key)
heapsize = heapsize + 1
numbers[heapsize] = -∞
i = heapsize
numbers[i] = key
while i > 1 and numbers[Parent(numbers[], i)] < numbers[i]
exchange(numbers[i], numbers[Parent(numbers[], i)])
i = Parent (numbers[], i)Analysis
Initially, an element is being added at the end of the array. If it violates the heap property, the element is exchanged with its parent. The height of the tree is log n. Maximum log n number of operations needs to be performed.
Hence, the complexity of this function is O(log n).
Example
Let us consider a max-heap, as shown below, where a new element 5 needs to be added.
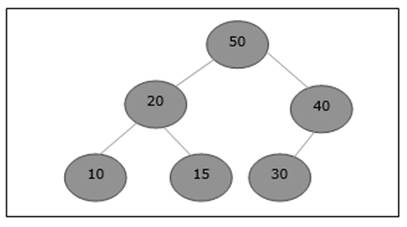
Initially, 55 will be added at the end of this array.
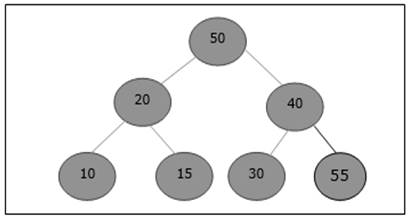
After insertion, it violates the heap property. Hence, the element needs to swap with its parent. After swap, the heap looks like the following.
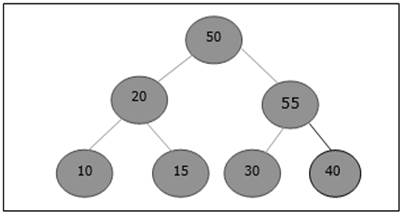
Again, the element violates the property of heap. Hence, it is swapped with its parent.
Now, we have to stop.
Heapify method rearranges the elements of an array where the left and right sub-tree of ith element obeys the heap property.
Algorithm: Max-Heapify(numbers[], i)
leftchild := numbers[2i]
rightchild := numbers [2i + 1]
if leftchild ≤ numbers[].size and numbers[leftchild] > numbers[i]
largest := leftchild
else
largest := i
if rightchild ≤ numbers[].size and numbers[rightchild] > numbers[largest]
largest := rightchild
if largest ≠ i
swap numbers[i] with numbers[largest]
Max-Heapify(numbers, largest)When the provided array does not obey the heap property, Heap is built based on the following algorithm Build-Max-Heap (numbers[]).
Algorithm: Build-Max-Heap(numbers[])
numbers[].size := numbers[].length
fori = ⌊ numbers[].length/2 ⌋ to 1 by -1
Max-Heapify (numbers[], i)Extract method is used to extract the root element of a Heap. Following is the algorithm.
Algorithm: Heap-Extract-Max (numbers[])
max = numbers[1]
numbers[1] = numbers[heapsize]
heapsize = heapsize – 1
Max-Heapify (numbers[], 1)
return maxExample
Let us consider the same example discussed previously. Now we want to extract an element. This method will return the root element of the heap.
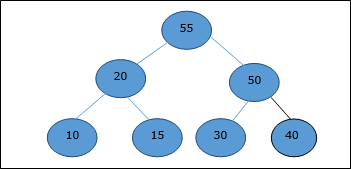
After deletion of the root element, the last element will be moved to the root position.
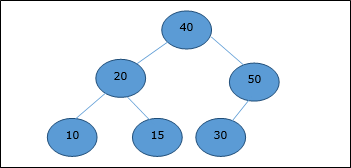
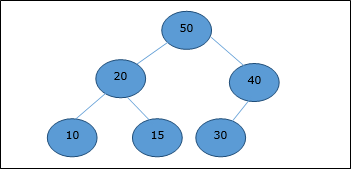
Now, Heapify function will be called. After Heapify, the following heap is generated.
Bubble Sort is an elementary sorting algorithm, which works by repeatedly exchanging adjacent elements, if necessary. When no exchanges are required, the file is sorted.
This is the simplest technique among all sorting algorithms.
Algorithm: Sequential-Bubble-Sort (A)
fori← 1 to length [A] do
for j ← length [A] down-to i +1 do
if A[A] < A[j - 1] then
Exchange A[j] ↔ A[j-1]Implementation
voidbubbleSort(int numbers[], intarray_size) {
inti, j, temp;
for (i = (array_size - 1); i >= 0; i--)
for (j = 1; j <= i; j++)
if (numbers[j - 1] > numbers[j]) {
temp = numbers[j-1];
numbers[j - 1] = numbers[j];
numbers[j] = temp;
}
}Analysis
Here, the number of comparisons are
1 + 2 + 3 +...+ (n - 1) = n(n - 1)/2 = O(n2)
Clearly, the graph shows the n2 nature of the bubble sort.
In this algorithm, the number of comparison is irrespective of the data set, i.e. whether the provided input elements are in sorted order or in reverse order or at random.
Memory Requirement
From the algorithm stated above, it is clear that bubble sort does not require extra memory.
Example
Unsorted list: |
|
1st iteration:
5 > 2 swap |
|
|||||||
5 > 1 swap |
|
|||||||
5 > 4 swap |
|
|||||||
5 > 3 swap |
|
|||||||
5 < 7 no swap |
|
|||||||
7 > 6 swap |
|
2nd iteration:
2 > 1 swap |
|
|||||||
2 < 4 no swap |
|
|||||||
4 > 3 swap |
|
|||||||
4 < 5 no swap |
|
|||||||
5 < 6 no swap |
|
There is no change in 3rd, 4th, 5th and 6th iteration.
Finally,
the sorted list is |
|
Insertion sort is a very simple method to sort numbers in an ascending or descending order. This method follows the incremental method. It can be compared with the technique how cards are sorted at the time of playing a game.
The numbers, which are needed to be sorted, are known as keys. Here is the algorithm of the insertion sort method.
Algorithm: Insertion-Sort(A)
for j = 2 to A.length
key = A[j]
i = j – 1
while i > 0 and A[i] > key
A[i + 1] = A[i]
i = i -1
A[i + 1] = keyAnalysis
Run time of this algorithm is very much dependent on the given input.
If the given numbers are sorted, this algorithm runs in O(n) time. If the given numbers are in reverse order, the algorithm runs in O(n2) time.
Example
Unsorted list: |
|
1st iteration:
Key = a[2] = 13
a[1] = 2 < 13
Swap, no swap |
|
2nd iteration:
Key = a[3] = 5
a[2] = 13 > 5
Swap 5 and 13 |
|
Next, a[1] = 2 < 13
Swap, no swap |
|
3rd iteration:
Key = a[4] = 18
a[3] = 13 < 18,
a[2] = 5 < 18,
a[1] = 2 < 18
Swap, no swap |
|
4th iteration:
Key = a[5] = 14
a[4] = 18 > 14
Swap 18 and 14 |
|
Next, a[3] = 13 < 14,
a[2] = 5 < 14,
a[1] = 2 < 14
So, no swap |
|
Finally,
the sorted list is |
|
This type of sorting is called Selection Sort as it works by repeatedly sorting elements. It works as follows: first find the smallest in the array and exchange it with the element in the first position, then find the second smallest element and exchange it with the element in the second position, and continue in this way until the entire array is sorted.
Algorithm: Selection-Sort (A)
fori ← 1 to n-1 do
min j ← i;
min x ← A[i]
for j ←i + 1 to n do
if A[j] < min x then
min j ← j
min x ← A[j]
A[min j] ← A [i]
A[i] ← min xSelection sort is among the simplest of sorting techniques and it works very well for small files. It has a quite important application as each item is actually moved at the most once.
Section sort is a method of choice for sorting files with very large objects (records) and small keys. The worst case occurs if the array is already sorted in a descending order and we want to sort them in an ascending order.
Nonetheless, the time required by selection sort algorithm is not very sensitive to the original order of the array to be sorted: the test if A[j] < min x is executed exactly the same number of times in every case.
Selection sort spends most of its time trying to find the minimum element in the unsorted part of the array. It clearly shows the similarity between Selection sort and Bubble sort.
Bubble sort selects the maximum remaining elements at each stage, but wastes some effort imparting some order to an unsorted part of the array.
Selection sort is quadratic in both the worst and the average case, and requires no extra memory.
For each i from 1 to n - 1, there is one exchange and n - i comparisons, so there is a total of n - 1 exchanges and
(n − 1) + (n − 2) + ...+ 2 + 1 = n(n − 1)/2 comparisons.
These observations hold, no matter what the input data is.
In the worst case, this could be quadratic, but in the average case, this quantity is O(n log n). It implies that the running time of Selection sort is quite insensitive to the input.
Implementation
Void Selection-Sort(int numbers[], int array_size) {
int i, j;
int min, temp;
for (i = 0; I < array_size-1; i++) {
min = i;
for (j = i+1; j < array_size; j++)
if (numbers[j] < numbers[min])
min = j;
temp = numbers[i];
numbers[i] = numbers[min];
numbers[min] = temp;
}
}Example
Unsorted list: |
|
1st iteration:
Smallest = 5
2 < 5, smallest = 2
1 < 2, smallest = 1
4 > 1, smallest = 1
3 > 1, smallest = 1
Swap 5 and 1 |
|
2nd iteration:
Smallest = 2
2 < 5, smallest = 2
2 < 4, smallest = 2
2 < 3, smallest = 2
No Swap |
|
3rd iteration:
Smallest = 5
4 < 5, smallest = 4
3 < 4, smallest = 3
Swap 5 and 3 |
|
4th iteration:
Smallest = 4
4 < 5, smallest = 4
No Swap |
|
Finally,
the sorted list is |
|
It is used on the principle of divide-and-conquer. Quick sort is an algorithm of choice in many situations as it is not difficult to implement. It is a good general purpose sort and it consumes relatively fewer resources during execution.
Advantages
It is in-place since it uses only a small auxiliary stack.
It requires only n (log n) time to sort n items.
It has an extremely short inner loop.
This algorithm has been subjected to a thorough mathematical analysis, a very precise statement can be made about performance issues.
Disadvantages
It is recursive. Especially, if recursion is not available, the implementation is extremely complicated.
It requires quadratic (i.e., n2) time in the worst-case.
It is fragile, i.e. a simple mistake in the implementation can go unnoticed and cause it to perform badly.
Quick sort works by partitioning a given array A[p ... r] into two non-empty sub array A[p ... q] and A[q+1 ... r] such that every key in A[p ... q] is less than or equal to every key in A[q+1 ... r].
Then, the two sub-arrays are sorted by recursive calls to Quick sort. The exact position of the partition depends on the given array and index q is computed as a part of the partitioning procedure.
Algorithm: Quick-Sort (A, p, r)
if p < r then
q Partition (A, p, r)
Quick-Sort (A, p, q)
Quick-Sort (A, q + r, r)Note that to sort the entire array, the initial call should be Quick-Sort (A, 1, length[A])
As a first step, Quick Sort chooses one of the items in the array to be sorted as pivot. Then, the array is partitioned on either side of the pivot. Elements that are less than or equal to pivot will move towards the left, while the elements that are greater than or equal to pivot will move towards the right.
Partitioning the Array
Partitioning procedure rearranges the sub-arrays in-place.
Function: Partition (A, p, r)
x ← A[p]
i ← p-1
j ← r+1
while TRUE do
Repeat j ← j - 1
until A[j] ≤ x
Repeat i← i+1
until A[i] ≥ x
if i < j then
exchange A[i] ↔ A[j]
else
return jAnalysis
The worst case complexity of Quick-Sort algorithm is O(n2). However using this technique, in average cases generally we get the output in O(n log n) time.
Radix sort is a small method that many people intuitively use when alphabetizing a large list of names. Specifically, the list of names is first sorted according to the first letter of each name, that is, the names are arranged in 26 classes.
Intuitively, one might want to sort numbers on their most significant digit. However, Radix sort works counter-intuitively by sorting on the least significant digits first. On the first pass, all the numbers are sorted on the least significant digit and combined in an array. Then on the second pass, the entire numbers are sorted again on the second least significant digits and combined in an array and so on.
Algorithm: Radix-Sort (list, n)
shift = 1
for loop = 1 to keysize do
for entry = 1 to n do
bucketnumber = (list[entry].key / shift) mod 10
append (bucket[bucketnumber], list[entry])
list = combinebuckets()
shift = shift * 10Analiz
Her tuş, en uzun tuşun her basamağı (veya tuşlar alfabetikse harf) için bir kerede bakılır. Dolayısıyla, en uzun anahtara sahipsem rakamlar ve var n anahtarlar, radix sıralama düzeni vardır O(m.n).
Ancak bu iki değere bakarsak, anahtarların sayısı ile karşılaştırıldığında anahtarların boyutları nispeten küçük olacaktır. Örneğin, altı basamaklı anahtarlarımız varsa, milyonlarca farklı kaydımız olabilir.
Burada, anahtarların boyutunun önemli olmadığını ve bu algoritmanın doğrusal karmaşıklıkta olduğunu görüyoruz. O(n).
Misal
Aşağıdaki örnek, Radix sıralamanın yedi 3 basamaklı sayı üzerinde nasıl çalıştığını göstermektedir.
| Giriş | 1 st Geçiş | 2 nd Geçiş | 3 rd Geçiş |
|---|---|---|---|
| 329 | 720 | 720 | 329 |
| 457 | 355 | 329 | 355 |
| 657 | 436 | 436 | 436 |
| 839 | 457 | 839 | 457 |
| 436 | 657 | 355 | 657 |
| 720 | 329 | 457 | 720 |
| 355 | 839 | 657 | 839 |
Yukarıdaki örnekte, ilk sütun girdidir. Kalan sütunlar, gittikçe önem kazanan basamak konumlarına göre ardışık sıralamalardan sonra listeyi gösterir. Radix sıralama kodu, bir dizideki her öğeninA nın-nin n elemanlar var d rakamlar, nerede rakam 1 en düşük dereceden rakamdır ve d en yüksek dereceden rakamdır.
Sınıfı anlamak için P ve NPönce hesaplama modelini bilmeliyiz. Bu nedenle, bu bölümde iki önemli hesaplama modelini tartışacağız.
Deterministik Hesaplama ve P Sınıfı
Deterministik Turing Makinesi
Bu modellerden biri deterministik tek bantlı Turing makinesidir. Bu makine, sonlu bir durum kontrolü, bir okuma-yazma kafası ve sonsuz sıralı iki yönlü bir banttan oluşur.
Aşağıda deterministik tek bantlı bir Turing makinesinin şematik diyagramı verilmiştir.
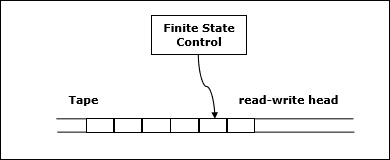
Belirleyici bir Turing makinesi için bir program aşağıdaki bilgileri belirtir -
- Sonlu bir bant sembolleri kümesi (giriş sembolleri ve boş bir sembol)
- Sonlu bir durum kümesi
- Bir geçiş işlevi
Algoritmik analizde, eğer bir problem tek şeritli deterministik bir Turing makinesi ile polinom zamanında çözülebilir ise problem P sınıfına aittir.
Belirsiz Hesaplama ve Sınıf NP
Belirsiz Turing Makinesi
Hesaplama problemini çözmek için başka bir model, deterministik Olmayan Turing Makinesi'dir (NDTM). NDTM'nin yapısı DTM'ye benzer, ancak burada, bir salt yazılır kafayla ilişkili, tahmin modülü olarak bilinen bir ek modülümüz var.
Şematik diyagram aşağıdadır.
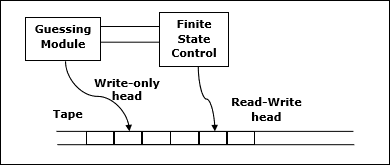
Problem deterministik olmayan bir Turing makinesi ile polinom zamanda çözülebilir ise problem NP sınıfına aittir.
Yönlendirilmemiş bir grafikte cliqueverilen grafiğin tam bir alt grafiğidir. Tam alt grafik, bu alt grafiğin tüm köşelerinin bu alt grafiğin diğer tüm köşelerine bağlı olduğu anlamına gelir.
Max-Clique problemi, grafiğin maksimum kliğini bulmanın hesaplama problemidir. Max clique birçok gerçek dünya probleminde kullanılır.
Köşelerin insanların profilini temsil ettiği ve kenarların bir grafikte karşılıklı tanışmayı temsil ettiği bir sosyal ağ uygulamasını düşünelim. Bu grafikte bir klik, birbirini tanıyan bir grup insanı temsil ediyor.
Bir maksimum kliği bulmak için, sistematik olarak tüm alt kümeler incelenebilir, ancak bu tür kaba kuvvet araması, birkaç düzineden fazla köşeden oluşan ağlar için çok zaman alıcıdır.
Algorithm: Max-Clique (G, n, k)
S := Φ
for i = 1 to k do
t := choice (1…n)
if t Є S then
return failure
S := S ∪ t
for all pairs (i, j) such that i Є S and j Є S and i ≠ j do
if (i, j) is not a edge of the graph then
return failure
return successAnaliz
Max-Clique problemi, deterministik olmayan bir algoritmadır. Bu algoritmada, önce bir dizi belirlemeye çalışıyoruzk farklı köşeler ve sonra bu köşelerin tam bir grafik oluşturup oluşturmadığını test etmeye çalışıyoruz.
Bu problemi çözmek için polinom zaman belirleyici bir algoritma yoktur. Bu sorun NP-Complete.
Misal
Aşağıdaki grafiğe bir göz atın. Burada, 2, 3, 4 ve 6 köşelerini içeren alt grafik tam bir grafik oluşturur. Dolayısıyla, bu alt grafik birclique. Bu, sağlanan grafiğin maksimum tam alt grafiği olduğundan,4-Clique.

Yönlendirilmemiş bir grafiğin tepe noktası G = (V, E) köşelerin bir alt kümesidir V' ⊆ V öyle ki kenar (u, v) bir kenarı G, O zaman ya u içinde V veya v içinde V' ya da her ikisi de.
Yönlendirilmemiş bir grafikte maksimum boyutta bir tepe noktası bulun. Bu optimal köşe kapağı, NP-complete probleminin optimizasyon versiyonudur. Bununla birlikte, optimuma yakın bir tepe noktası bulmak çok da zor değildir.
APPROX-VERTEX_COVER (G: Graph) c ← { } E' ← E[G]
while E' is not empty do
Let (u, v) be an arbitrary edge of E' c ← c U {u, v}
Remove from E' every edge incident on either u or v
return cMisal
Verilen grafiğin kenar seti -
{(1,6),(1,2),(1,4),(2,3),(2,4),(6,7),(4,7),(7,8),(3,8),(3,5),(8,5)}
Şimdi keyfi bir kenar (1,6) seçerek başlıyoruz. Tepe 1 veya 6'ya gelen tüm kenarları ortadan kaldırıyoruz ve örtmek için kenar (1,6) ekliyoruz.
Bir sonraki adımda, rastgele başka bir kenar (2,3) seçtik
Şimdi başka bir kenar (4,7) seçiyoruz.
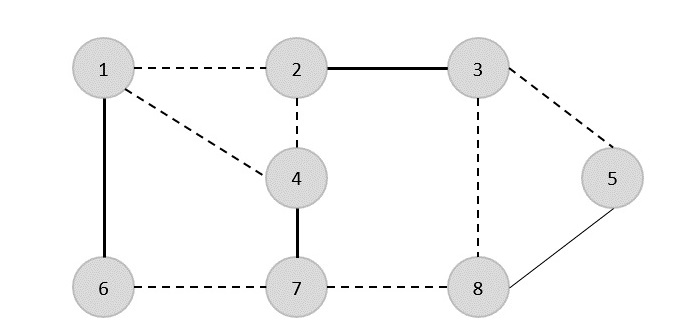
Başka bir kenar (8,5) seçiyoruz.
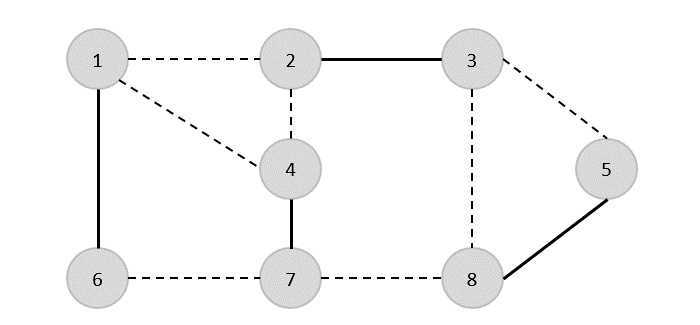
Bu nedenle, bu grafiğin tepe noktası {1,2,4,5} 'dir.
Analiz
Bu algoritmanın çalışma süresinin O(V + E), temsil etmek için bitişik listesi kullanarak E'.
Bilgisayar Biliminde, hedefin bazı değerleri maksimize etmek veya en aza indirmek olduğu birçok sorun çözülür, oysa diğer problemlerde bir çözüm olup olmadığını bulmaya çalışırız. Dolayısıyla sorunlar aşağıdaki şekilde kategorize edilebilir:
Optimizasyon Sorunu
Optimizasyon problemleri, amacı bazı değerleri maksimize etmek veya en aza indirmek olan problemlerdir. Örneğin,
Belirli bir grafiği renklendirmek için gereken minimum renk sayısını bulmak.
Bir grafikteki iki köşe arasındaki en kısa yolu bulmak.
Karar Problemi
Cevabın Evet veya Hayır olduğu birçok sorun vardır. Bu tür sorunlar olarak bilinir. decision problems. Örneğin,
Belirli bir grafiğin yalnızca 4 renkle renklendirilip renklendirilemeyeceği.
Hamilton döngüsünü bir grafikte bulmak bir karar problemi değildir, oysa bir grafiğin kontrol edilmesi bir karar problemidir.
Dil nedir?
Her karar sorunun sadece iki cevabı olabilir, evet veya hayır. Dolayısıyla, belirli bir girdi için 'evet' yanıtı veriyorsa, bir karar problemi bir dile ait olabilir. Bir dil, cevabı Evet olan girdilerin toplamıdır. Önceki bölümlerde tartışılan algoritmaların çoğupolynomial time algorithms.
Giriş boyutu için n, bir algoritmanın en kötü durumda zaman karmaşıklığı ise O(nk), nerede k bir sabittir, algoritma bir polinom zaman algoritmasıdır.
Matris Zinciri Çarpımı, Tek Kaynaklı En Kısa Yol, Tüm Çiftler En Kısa Yol, Minimum Yayılma Ağacı, vb. Gibi algoritmalar polinom zamanda çalışır. Bununla birlikte, seyyar satıcı, optimal grafik renklendirme, Hamilton döngüleri, bir grafikte en uzun yolu bulma ve hiçbir polinom zaman algoritmasının bilinmediği bir Boole formülünü karşılama gibi birçok sorun vardır. Bu sorunlar ilginç bir sorun sınıfına aittir.NP-Complete durumu bilinmeyen sorunlar.
Bu bağlamda sorunları şu şekilde sınıflandırabiliriz -
P-Sınıfı
P sınıfı, polinom zamanda çözülebilen problemlerden oluşur, yani bu problemler zaman içinde çözülebilir. O(nk) en kötü durumda, nerede k sabittir.
Bu sorunlara tractablediğerleri çağrılırken intractable or superpolynomial.
Resmi olarak, bir algoritma polinom zaman algoritmasıdır, eğer bir polinom varsa p(n) algoritma herhangi bir boyut örneğini çözebilecek şekilde n bir süre içinde O(p(n)).
Gerektiren sorun Ω(n50) çözme süresi esasen büyük n. En çok bilinen polinom zaman algoritması zamanda çalışırO(nk) oldukça düşük değer için k.
Polinom zamanlı algoritmalar sınıfını dikkate almanın avantajları, tümünün makul olmasıdır. deterministic single processor model of computation en fazla bir polinom yavaş-d ile birbirleri üzerinde simüle edilebilir
NP Sınıfı
NP sınıfı, polinom zamanında doğrulanabilen problemlerden oluşur. NP, iddia edilen bir cevabın doğruluğunu biraz fazladan bilgi yardımıyla kontrol etmenin kolay olduğu karar problemleri sınıfıdır. Bu nedenle, bir çözüm bulmanın bir yolunu değil, yalnızca iddia edilen bir çözümün gerçekten doğru olduğunu doğrulamak istiyoruz.
Bu sınıftaki her problem, kapsamlı arama kullanılarak üstel zamanda çözülebilir.
P ve NP
Bir deterministik polinom zaman algoritması ile çözülebilen her karar problemi, aynı zamanda, bir polinom zamanlı deterministik olmayan algoritma ile de çözülebilir.
P'deki tüm problemler polinom zaman algoritmaları ile çözülebilirken, NP - P'deki tüm problemler çözülemez.
Bilinmemektedir P = NP. Bununla birlikte, NP'de, eğer P'ye aitlerse, P = NP olduğu ispatlanabilir özelliğiyle bilinen birçok problem bilinmektedir.
Eğer P ≠ NPNP'de ne P'de ne de NP-Complete'de olmayan sorunlar vardır.
Sorun sınıfa ait Psorun için bir çözüm bulmak kolaysa. Sorun şuna aitNP, bulmak çok sıkıcı olabilecek bir çözümü kontrol etmek kolaysa.
Stephen Cook, "The Complexity of Theorem Proving Procedures" adlı makalesinde dört teorem sundu. Bu teoremler aşağıda belirtilmiştir. Bu bölümde birçok bilinmeyen terimin kullanıldığını anlıyoruz, ancak her şeyi ayrıntılı olarak tartışmak için herhangi bir kapsamımız yok.
Stephen Cook'un dört teoremi aşağıdadır -
Teorem-1
Eğer bir set S Polinom zaman içinde bazı deterministik olmayan Turing makinesi tarafından kabul edilir, sonra S {DNF tautolojileri} için P-indirgenebilir.
Teorem-2
Aşağıdaki kümeler çiftler halinde birbirlerine P-indirgenebilirdir (ve dolayısıyla her biri aynı polinom zorluk derecesine sahiptir): {tautolojiler}, {DNF tautolojileri}, D3, {alt grafik çiftleri}.
Teorem-3
Herhangi TQ(k) tip Q, $\mathbf{\frac{T_{Q}(k)}{\frac{\sqrt{k}}{(log\:k)^2}}}$ sınırsız
Var TQ(k) tip Q öyle ki $T_{Q}(k)\leqslant 2^{k(log\:k)^2}$
Teorem-4
Dize kümeleri zaman içinde deterministik olmayan bir makine tarafından kabul edilirse T(n) = 2n, ve eğer TQ(k) dürüst (yani gerçek zamanlı sayılabilir) bir tür işlevdir Q, o zaman bir sabit K, yani S zaman içinde deterministik bir makine tarafından tanınabilir TQ(K8n).
İlk olarak, polinom zaman indirgenebilirliğinin önemini vurguladı. Bir problemden diğerine bir polinom zaman indirgememiz varsa, bu, ikinci problemdeki herhangi bir polinom zaman algoritmasının ilk problem için karşılık gelen bir polinom zaman algoritmasına dönüştürülebilmesini sağlar.
İkinci olarak, deterministik olmayan bir bilgisayar tarafından polinom zamanında çözülebilen karar problemlerinin NP sınıfına odaklandı. İnatçı problemlerin çoğu bu sınıfa, NP'ye aittir.
Üçüncüsü, NP'deki belirli bir sorunun NP'deki diğer her sorunun polinomik olarak ona indirgenebileceği özelliğine sahip olduğunu kanıtladı. Tatmin edilebilirlik problemi bir polinom zaman algoritması ile çözülebiliyorsa, NP'deki her problem polinom zamanda da çözülebilir. NP'deki herhangi bir problem çözülemezse, tatmin edici problem çözülemez olmalıdır. Dolayısıyla, tatmin problemi NP'deki en zor problemdir.
Dördüncüsü, Cook, NP'deki diğer sorunların, NP'nin en zor üyesi olma özelliğini tatmin etme sorunu ile paylaşabileceğini öne sürdü.
NP'de ise ve aşağıdaki gibi ise, NPC sınıfında bir problem vardır. hardNP'deki herhangi bir sorun gibi. Bir problemNP-hard NP'deki tüm problemler, NP'nin kendisinde olmasa bile, polinom zamana indirgenebilirse.
Bu problemlerden herhangi biri için bir polinom zaman algoritması mevcutsa, NP'deki tüm problemler polinom zamanda çözülebilir olacaktır. Bu sorunlaraNP-complete. NP-tamlık olgusu hem teorik hem de pratik nedenlerle önemlidir.
NP-Tamlığın Tanımı
Dil B dır-dir NP-complete iki koşulu karşılarsa
B NP'de
Her A NP'de polinom zamandır B.
Bir dil ikinci özelliği karşılıyorsa, ancak ilki olmasa da, dil B olarak bilinir NP-Hard. Gayri resmi olarak, bir arama sorunuB dır-dir NP-Hard eğer varsa NP-Complete sorun A Turing'in B.
NP-Hard'daki problem polinom zamanında çözülemez. P = NP. Bir sorunun NPC olduğu kanıtlanırsa, bunun için verimli bir algoritma bulmaya çalışmakla zaman kaybetmeye gerek yoktur. Bunun yerine, tasarım yaklaştırma algoritmasına odaklanabiliriz.
NP-Tam Sorunlar
Aşağıdakiler, polinom zaman algoritmasının bilinmediği bazı NP-Tam problemlerdir.
- Bir grafiğin Hamilton döngüsüne sahip olup olmadığını belirleme
- Bir Boole formülünün tatmin edici olup olmadığının belirlenmesi vb.
NP-Zor Problemler
Aşağıdaki sorunlar NP-Hard'dır
- Devre tatmin problemi
- Kapağı Ayarla
- Köşe Kapağı
- Seyahat Eden Satıcı Problemi
Bu bağlamda, şimdi TSP'nin NP-Complete olduğunu tartışacağız.
TSP NP-Tamamlandı
Gezici satıcı sorunu, bir satıcı ve bir dizi şehirden oluşur. Satıcı, belirli bir şehirden başlayıp aynı şehre geri dönen şehirlerin her birini ziyaret etmek zorundadır. Sorunun zorluğu, seyahat eden satıcının seyahatin toplam uzunluğunu en aza indirmek istemesidir.
Kanıt
Kanıtlamak TSP is NP-Completeönce bunu kanıtlamalıyız TSP belongs to NP. TSP'de bir tur buluruz ve turun her bir tepe noktasını bir kez içerdiğini kontrol ederiz. Ardından turun kenarlarının toplam maliyeti hesaplanır. Son olarak, maliyetin minimum olup olmadığını kontrol ediyoruz. Bu, polinom zamanda tamamlanabilir. BöyleceTSP belongs to NP.
İkincisi, bunu kanıtlamalıyız TSP is NP-hard. Bunu kanıtlamanın bir yolu bunu göstermektir.Hamiltonian cycle ≤p TSP (Hamilton döngü probleminin NP-tamamlandığını bildiğimiz gibi).
Varsaymak G = (V, E) Hamilton döngüsünün bir örneği.
Bu nedenle, bir TSP örneği oluşturulur. Tam grafiği oluşturuyoruzG' = (V, E'), nerede
$$E^{'}=\lbrace(i, j)\colon i, j \in V \:\:and\:i\neq j$$
Böylece, maliyet fonksiyonu aşağıdaki gibi tanımlanır -
$$t(i,j)=\begin{cases}0 & if\: (i, j)\: \in E\\1 & otherwise\end{cases}$$
Şimdi, bir Hamilton döngüsünün h var G. Her bir kenarın maliyetininh dır-dir 0 içinde G' her kenar ait olduğu gibi E. Bu nedenle,h maliyeti var 0 içinde G'. Böylece, eğer grafikG Hamilton döngüsüne sahiptir, sonra grafik G' turu var 0 maliyet.
Tersine, varsayıyoruz ki G' tur var h' en fazla maliyet 0. Kenarların maliyetiE' vardır 0 ve 1tanım olarak. Bu nedenle, her kenarın bir maliyeti olmalıdır0 maliyeti olarak h' dır-dir 0. Bu nedenle şu sonuca varıyoruz:h' sadece kenarları içerir E.
Böylece kanıtladık ki G Hamilton döngüsüne sahiptir, ancak ve ancak G' en fazla maliyet turu var 0. TSP, NP-tamamlandı.
Önceki bölümlerde tartışılan algoritmalar sistematik olarak çalışır. Hedefe ulaşmak için, çözüme giden önceden keşfedilmiş bir veya daha fazla yolun en uygun çözümü bulmak için saklanması gerekir.
Birçok sorun için hedefe giden yol önemsizdir. Örneğin, N-Queens probleminde, kraliçelerin son konfigürasyonunu ve kraliçelerin hangi sırayla eklendiğini önemsememize gerek yoktur.
Tepe Tırmanışı
Tepe Tırmanışı, belirli optimizasyon problemlerini çözmek için kullanılan bir tekniktir. Bu teknikte, optimal olmayan bir çözümle başlıyoruz ve çözüm, bazı koşullar en üst düzeye çıkarılana kadar tekrar tekrar geliştiriliyor.
Optimal olmayan bir çözümle başlama fikri, tepenin tabanından başlamakla, çözümü iyileştirmek tepeye tırmanmakla ve nihayet bazı koşulları en üst düzeye çıkarmak tepenin tepesine ulaşmakla karşılaştırılır.
Bu nedenle, tepe tırmanma tekniği aşağıdaki aşamalar olarak düşünülebilir -
- Problemin kısıtlamalarına uyarak optimal altı bir çözüm oluşturmak
- Çözümü adım adım iyileştirme
- Daha fazla iyileştirme mümkün olmayana kadar çözümü iyileştirmek
Tepe Tırmanma tekniği temel olarak hesaplama açısından zor problemleri çözmek için kullanılır. Yalnızca mevcut duruma ve yakın gelecekteki duruma bakar. Bu nedenle, bu teknik, bir arama ağacını korumadığı için bellek açısından verimlidir.
Algorithm: Hill Climbing
Evaluate the initial state.
Loop until a solution is found or there are no new operators left to be applied:
- Select and apply a new operator
- Evaluate the new state:
goal -→ quit
better than current state -→ new current stateYinelemeli İyileştirme
Yinelemeli iyileştirme yönteminde, her yinelemede en uygun çözüme doğru ilerleme kaydedilerek optimum çözüme ulaşılır. Ancak, bu teknik yerel maksimumlarla karşılaşabilir. Bu durumda, daha iyi bir çözüm için yakın bir devlet yoktur.
Bu problem farklı yöntemlerle önlenebilir. Bu yöntemlerden biri tavlama simülasyonudur.
Rastgele Yeniden Başlatma
Bu, yerel optima problemini çözmenin başka bir yöntemidir. Bu teknik bir dizi araştırma yürütür. Her seferinde, rastgele oluşturulmuş bir başlangıç durumundan başlar. Böylece, yapılan aramaların çözümlerini karşılaştırarak optimum veya neredeyse optimal çözüm elde edilebilir.
Tepe Tırmanma Tekniğinin Sorunları
Yerel Maxima
Sezgisel yöntem dışbükey değilse, Tepe Tırmanışı global maksimumlar yerine yerel maksimumlara yakınsayabilir.
Sırtlar ve Sokaklar
Hedef işlev dar bir sırt oluşturuyorsa, tırmanıcı yalnızca sırtı tırmanabilir veya zig-zag yaparak geçidi alçaltabilir. Bu senaryoda, tırmanıcı hedefe ulaşmak için daha fazla zaman gerektiren çok küçük adımlar atmalıdır.
Plato
Arama alanı düz olduğunda veya makine tarafından değerini temsil etmek için kullanılan hassasiyet nedeniyle hedef fonksiyon tarafından döndürülen değerin yakındaki bölgeler için döndürülen değerden ayırt edilemeyeceği kadar düz olduğunda bir plato ile karşılaşılır.
Tepe Tırmanma Tekniğinin Karmaşıklığı
Bu teknik, yalnızca mevcut duruma baktığı için uzayla ilgili sorunlardan muzdarip değildir. Daha önce keşfedilen yollar depolanmaz.
Rastgele yeniden başlatılan Tepe Tırmanma tekniğindeki problemlerin çoğu için, polinom zamanda optimal bir çözüm elde edilebilir. Bununla birlikte, NP-Complete problemleri için, hesaplama süresi yerel maksimumların sayısına bağlı olarak üstel olabilir.
Tepe Tırmanma Tekniği Uygulamaları
Tepe Tırmanma tekniği, mevcut durumun Network-Flow, Traveling Salesman problemi, 8-Queens problemi, Entegre Devre tasarımı gibi doğru bir değerlendirme fonksiyonuna izin verdiği birçok problemi çözmek için kullanılabilir.
Hill Climbing, endüktif öğrenme yöntemlerinde de kullanılmaktadır. Bu teknik, robotikte bir ekipteki birden fazla robot arasında koordinasyon için kullanılır. Bu tekniğin kullanıldığı birçok başka problem vardır.
Misal
Bu teknik, seyyar satıcı problemini çözmek için uygulanabilir. Öncelikle tüm şehirleri tam olarak bir kez ziyaret eden bir ilk çözüm belirlenir. Bu nedenle, bu ilk çözüm çoğu durumda optimal değildir. Bu çözüm bile çok zayıf olabilir. Hill Climbing algoritması böyle bir ilk çözümle başlar ve yinelemeli bir şekilde iyileştirmeler yapar. Sonunda, çok daha kısa bir rota elde edilmesi muhtemeldir.