MapReduce - Birleştiriciler
Birleştirici, aynı zamanda bir semi-reducer, Map sınıfından gelen girdileri kabul ederek ve ardından çıktı anahtar / değer çiftlerini Reducer sınıfına geçirerek çalışan isteğe bağlı bir sınıftır.
Bir Birleştiricinin ana işlevi, harita çıktı kayıtlarını aynı anahtarla özetlemektir. Birleştiricinin çıktısı (anahtar-değer koleksiyonu), girdi olarak ağ üzerinden gerçek Düşürücü görevine gönderilecektir.
Birleştirici
Combiner sınıfı, Map ve Reduce arasındaki veri aktarım hacmini azaltmak için Map sınıfı ile Reduce sınıfı arasında kullanılır. Genellikle, harita görevinin çıktısı büyüktür ve azaltma görevine aktarılan veriler yüksektir.
Aşağıdaki MapReduce görev diyagramı BİRLEŞTİRİCİ AŞAMASINI gösterir.
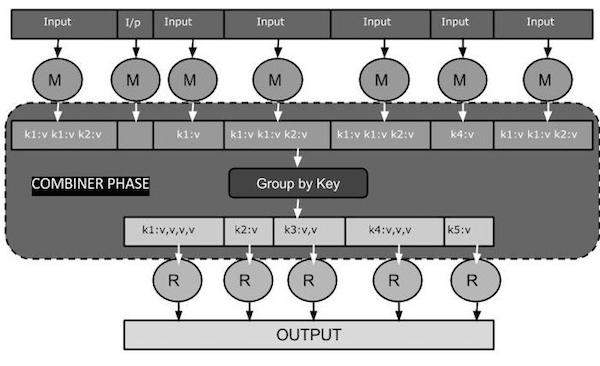
Combiner Nasıl Çalışır?
İşte MapReduce Combiner'ın nasıl çalıştığına dair kısa bir özet -
Bir birleştiricinin önceden tanımlanmış bir arabirimi yoktur ve Reducer arabiriminin azaltma () yöntemini uygulaması gerekir.
Her harita çıkış anahtarı üzerinde bir birleştirici çalışır. Reducer sınıfıyla aynı çıkış anahtar-değer türlerine sahip olmalıdır.
Bir birleştirici, orijinal Harita çıktısının yerini aldığı için büyük bir veri kümesinden özet bilgi üretebilir.
Combiner isteğe bağlı olmasına rağmen, Verileri Azaltma aşaması için birden çok gruba ayırmaya yardımcı olur ve bu da işlenmesini kolaylaştırır.
MapReduce Combiner Uygulaması
Aşağıdaki örnek, birleştiriciler hakkında teorik bir fikir sağlar. Aşağıdaki giriş metin dosyasına sahip olduğumuzu varsayalıminput.txt MapReduce için.
What do you mean by Object
What do you know about Java
What is Java Virtual Machine
How Java enabled High PerformanceCombiner ile MapReduce programının önemli aşamaları aşağıda tartışılmaktadır.
Kayıt Okuyucu
Bu, Kayıt Okuyucusunun giriş metin dosyasındaki her satırı metin olarak okuduğu ve anahtar-değer çiftleri olarak çıktı verdiği MapReduce'un ilk aşamasıdır.
Input - Giriş dosyasından satır satır metin.
Output- Anahtar / değer çiftlerini oluşturur. Aşağıda, beklenen anahtar / değer çiftleri kümesi verilmiştir.
<1, What do you mean by Object>
<2, What do you know about Java>
<3, What is Java Virtual Machine>
<4, How Java enabled High Performance>Harita Aşaması
Harita aşaması, Kayıt Okuyucusundan girdi alır, işler ve çıktıyı başka bir anahtar-değer çifti kümesi olarak üretir.
Input - Aşağıdaki anahtar / değer çifti, Kayıt Okuyucusundan alınan giriştir.
<1, What do you mean by Object>
<2, What do you know about Java>
<3, What is Java Virtual Machine>
<4, How Java enabled High Performance>Harita aşaması her bir anahtar-değer çiftini okur, her kelimeyi değerden StringTokenizer kullanarak böler, her kelimeyi anahtar ve bu kelimenin sayısını değer olarak ele alır. Aşağıdaki kod parçacığı, Mapper sınıfını ve harita işlevini gösterir.
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}Output - Beklenen çıktı aşağıdaki gibidir -
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1>
<What,1> <do,1> <you,1> <know,1> <about,1> <Java,1>
<What,1> <is,1> <Java,1> <Virtual,1> <Machine,1>
<How,1> <Java,1> <enabled,1> <High,1> <Performance,1>Birleştirici Faz
Birleştirici aşaması, her bir anahtar / değer çiftini Harita aşamasından alır, işler ve çıktıyı şu şekilde üretir: key-value collection çiftler.
Input - Aşağıdaki anahtar / değer çifti, Harita aşamasından alınan girdidir.
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1>
<What,1> <do,1> <you,1> <know,1> <about,1> <Java,1>
<What,1> <is,1> <Java,1> <Virtual,1> <Machine,1>
<How,1> <Java,1> <enabled,1> <High,1> <Performance,1>Birleştirici aşaması, her bir anahtar / değer çiftini okur, ortak kelimeleri anahtar olarak ve değerleri koleksiyon olarak birleştirir. Genellikle, bir Birleştiricinin kodu ve işlemi, bir Redüktörünkine benzer. Mapper, Combiner ve Reducer sınıf bildirimi için kod parçacığı aşağıdadır.
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);Output - Beklenen çıktı aşağıdaki gibidir -
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,1,1,1>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>Redüktör Faz
İndirgeyici aşaması, her bir anahtar / değer toplama çiftini Birleştirici aşamasından alır, işler ve çıkışı anahtar / değer çiftleri olarak geçirir. Combiner işlevinin Redüktör ile aynı olduğuna dikkat edin.
Input - Aşağıdaki anahtar / değer çifti, Birleştirici aşamasından alınan girdidir.
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,1,1,1>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>Düşürücü aşaması, her bir anahtar / değer çiftini okur. Birleştirici için kod parçacığı aşağıdadır.
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}Output - Redüktör aşamasından beklenen çıktı aşağıdaki gibidir -
<What,3> <do,2> <you,2> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,3>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>Kayıt Yazarı
Bu, Kayıt Yazıcısının Reducer aşamasından her anahtar / değer çiftini yazdığı ve çıktıyı metin olarak gönderdiği MapReduce'un son aşamasıdır.
Input - Çıktı biçimiyle birlikte Azaltıcı aşamasındaki her bir anahtar / değer çifti.
Output- Size metin biçiminde anahtar / değer çiftleri verir. Beklenen çıktı aşağıdadır.
What 3
do 2
you 2
mean 1
by 1
Object 1
know 1
about 1
Java 3
is 1
Virtual 1
Machine 1
How 1
enabled 1
High 1
Performance 1Örnek Program
Aşağıdaki kod bloğu, bir programdaki kelimelerin sayısını sayar.
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Yukarıdaki programı farklı kaydedin WordCount.java. Programın derlenmesi ve çalıştırılması aşağıda verilmiştir.
Derleme ve Yürütme
Hadoop kullanıcısının ana dizininde olduğumuzu varsayalım (örneğin, / home / hadoop).
Yukarıdaki programı derlemek ve yürütmek için aşağıda verilen adımları izleyin.
Step 1 - Derlenmiş java sınıflarını depolamak için bir dizin oluşturmak için aşağıdaki komutu kullanın.
$ mkdir unitsStep 2- MapReduce programını derlemek ve yürütmek için kullanılan Hadoop-core-1.2.1.jar dosyasını indirin. Kavanozu mvnrepository.com adresinden indirebilirsiniz .
İndirilen klasörün / home / hadoop / olduğunu varsayalım.
Step 3 - Aşağıdaki komutları kullanarak WordCount.java program ve program için bir jar oluşturun.
$ javac -classpath hadoop-core-1.2.1.jar -d units WordCount.java
$ jar -cvf units.jar -C units/ .Step 4 - HDFS'de bir giriş dizini oluşturmak için aşağıdaki komutu kullanın.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirStep 5 - adlı giriş dosyasını kopyalamak için aşağıdaki komutu kullanın input.txt HDFS'nin giriş dizininde.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/input.txt input_dirStep 6 - Giriş dizinindeki dosyaları doğrulamak için aşağıdaki komutu kullanın.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 7 - Giriş dizininden giriş dosyalarını alarak Word sayımı uygulamasını çalıştırmak için aşağıdaki komutu kullanın.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dirDosya yürütülene kadar bir süre bekleyin. Yürütmeden sonra, çıktı bir dizi giriş bölümü, Harita görevleri ve İndirgeyici görevleri içerir.
Step 8 - Çıktı klasöründe ortaya çıkan dosyaları doğrulamak için aşağıdaki komutu kullanın.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Step 9 - Çıktıyı görmek için aşağıdaki komutu kullanın Part-00000dosya. Bu dosya HDFS tarafından oluşturulmuştur.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000MapReduce programı tarafından üretilen çıktı aşağıdadır.
What 3
do 2
you 2
mean 1
by 1
Object 1
know 1
about 1
Java 3
is 1
Virtual 1
Machine 1
How 1
enabled 1
High 1
Performance 1