MapReduce - Hızlı Kılavuz
MapReduce, Büyük Verileri birden çok düğümde paralel olarak işleyebilen uygulamalar yazmak için bir programlama modelidir. MapReduce, büyük hacimli karmaşık verileri analiz etmek için analitik yetenekler sağlar.
Büyük Veri nedir?
Büyük Veri, geleneksel hesaplama teknikleri kullanılarak işlenemeyen büyük veri kümelerinin bir koleksiyonudur. Örneğin, Facebook veya Youtube'un günlük olarak toplanması ve yönetmesi için ihtiyaç duyduğu veri hacmi Büyük Veri kategorisine girebilir. Bununla birlikte, Büyük Veri yalnızca ölçek ve hacimle ilgili değildir, aynı zamanda aşağıdaki yönlerden bir veya daha fazlasını içerir - Hız, Çeşitlilik, Hacim ve Karmaşıklık.
Neden MapReduce?
Geleneksel Kurumsal Sistemler, verileri depolamak ve işlemek için normalde merkezi bir sunucuya sahiptir. Aşağıdaki çizim, geleneksel bir kurumsal sistemin şematik bir görünümünü tasvir etmektedir. Geleneksel model, büyük hacimlerde ölçeklenebilir veriyi işlemek için kesinlikle uygun değildir ve standart veritabanı sunucuları tarafından barındırılamaz. Dahası, merkezi sistem aynı anda birden fazla dosyayı işlerken çok fazla darboğaz yaratır.

Google, bu darboğaz sorununu MapReduce adlı bir algoritma kullanarak çözdü. MapReduce, bir görevi küçük parçalara böler ve bunları birçok bilgisayara atar. Daha sonra sonuçlar tek bir yerde toplanır ve sonuç veri setini oluşturmak için entegre edilir.

MapReduce Nasıl Çalışır?
MapReduce algoritması, Map ve Reduce olmak üzere iki önemli görev içerir.
Harita görevi, bir veri kümesini alır ve bunları, tek tek öğelerin demetlere (anahtar-değer çiftleri) bölündüğü başka bir veri kümesine dönüştürür.
Azaltma görevi, Harita'daki çıktıyı bir girdi olarak alır ve bu veri gruplarını (anahtar-değer çiftleri) daha küçük bir grup kümesinde birleştirir.
Azaltma görevi her zaman harita işinden sonra gerçekleştirilir.
Şimdi aşamaların her birine yakından bakalım ve bunların önemini anlamaya çalışalım.
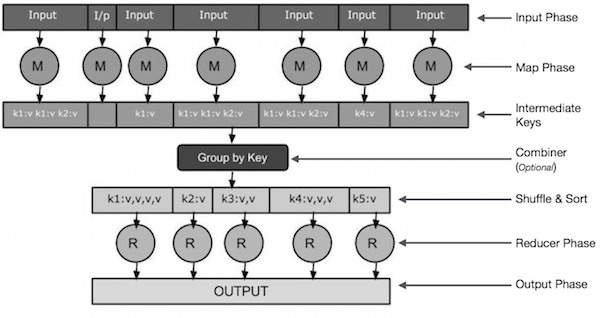
Input Phase - Burada, bir girdi dosyasındaki her kaydı çeviren ve ayrıştırılmış verileri eşleştiriciye anahtar-değer çiftleri biçiminde gönderen bir Kayıt Okuyucumuz var.
Map - Harita, bir dizi anahtar-değer çifti alan ve sıfır veya daha fazla anahtar-değer çifti oluşturmak için her birini işleyen kullanıcı tanımlı bir işlevdir.
Intermediate Keys - Eşleştirici tarafından oluşturulan anahtar / değer çiftleri ara anahtarlar olarak bilinir.
Combiner- Birleştirici, benzer verileri harita aşamasından tanımlanabilir setler halinde gruplayan bir tür yerel Redüktördür. Ara anahtarları eşleyiciden girdi olarak alır ve değerleri bir eşleyicinin küçük bir kapsamında toplamak için kullanıcı tanımlı bir kod uygular. Ana MapReduce algoritmasının bir parçası değildir; isteğe bağlıdır.
Shuffle and Sort- Azaltıcı görevi, Karıştır ve Sırala adımıyla başlar. Gruplanmış anahtar / değer çiftlerini Redüktörün çalıştığı yerel makineye indirir. Ayrı anahtar / değer çiftleri, anahtara göre daha büyük bir veri listesi halinde sıralanır. Veri listesi, eşdeğer anahtarları bir arada gruplandırır, böylece değerleri Reducer görevinde kolayca yinelenebilir.
Reducer- İndirgeyici, gruplanmış anahtar-değer eşleştirilmiş verilerini girdi olarak alır ve her birinde bir Düşürücü işlevi çalıştırır. Burada veriler toplanabilir, filtrelenebilir ve çeşitli şekillerde birleştirilebilir ve geniş bir işlem yelpazesi gerektirir. Yürütme bittikten sonra, son adıma sıfır veya daha fazla anahtar-değer çifti verir.
Output Phase - Çıktı aşamasında, son anahtar-değer çiftlerini Reducer işlevinden çeviren ve bunları bir kayıt yazıcı kullanarak bir dosyaya yazan bir çıktı biçimlendiricimiz var.
Küçük bir diyagram yardımıyla Map & f Reduce iki görevi anlamaya çalışalım -

MapReduce-Örnek
MapReduce'un gücünü anlamak için gerçek dünyadan bir örnek alalım. Twitter günde yaklaşık 500 milyon tweet alıyor, bu da saniyede yaklaşık 3000 tweet anlamına geliyor. Aşağıdaki çizim, Tweeter'ın tweet'lerini MapReduce yardımıyla nasıl yönettiğini göstermektedir.
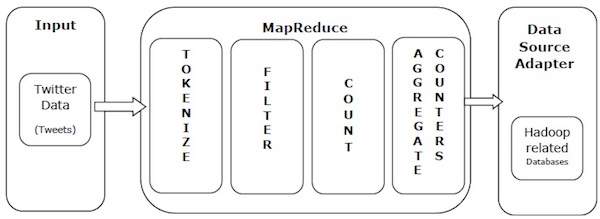
Çizimde gösterildiği gibi, MapReduce algoritması aşağıdaki eylemleri gerçekleştirir -
Tokenize - Tweet'leri jeton haritalarına dönüştürür ve bunları anahtar-değer çiftleri olarak yazar.
Filter - Belirteç haritalarından istenmeyen sözcükleri filtreler ve filtrelenmiş haritaları anahtar-değer çiftleri olarak yazar.
Count - Kelime başına bir simge sayacı oluşturur.
Aggregate Counters - Küçük yönetilebilir birimlere benzer sayaç değerleri toplamı hazırlar.
MapReduce algoritması, Map ve Reduce olmak üzere iki önemli görev içerir.
- Harita görevi Mapper Class aracılığıyla yapılır
- İndirgeme görevi Redüktör Sınıfı ile yapılır.
Mapper sınıfı girdiyi alır, belirteçlere ayırır, eşler ve sıralar. Mapper sınıfının çıktısı, karşılık gelen çiftleri arayan ve onları azaltan Reducer sınıfı tarafından girdi olarak kullanılır.

MapReduce, bir görevi küçük parçalara ayırmak ve bunları birden çok sisteme atamak için çeşitli matematiksel algoritmalar uygular. Teknik açıdan, MapReduce algoritması, Harita ve Azaltma görevlerinin bir kümedeki uygun sunuculara gönderilmesine yardımcı olur.
Bu matematiksel algoritmalar şunları içerebilir:
- Sorting
- Searching
- Indexing
- TF-IDF
Sıralama
Sıralama, verileri işlemek ve analiz etmek için temel MapReduce algoritmalarından biridir. MapReduce, eşleştiriciden çıktı anahtar-değer çiftlerini anahtarlarına göre otomatik olarak sıralamak için sıralama algoritması uygular.
Sıralama yöntemleri, mapper sınıfının kendisinde uygulanır.
Shuffle and Sort aşamasında, mapper sınıfındaki değerleri tokenize ettikten sonra, Context class (kullanıcı tanımlı sınıf), eşleşen değerli anahtarları bir koleksiyon olarak toplar.
Benzer anahtar-değer çiftlerini (ara anahtarlar) toplamak için Mapper sınıfı şunlardan yardım alır: RawComparator anahtar / değer çiftlerini sıralamak için sınıf.
Belirli bir İndirgeyici için ara anahtar / değer çifti kümesi, Düşürücüye sunulmadan önce anahtar / değer çiftleri (K2, {V2, V2,…}) oluşturmak için otomatik olarak Hadoop tarafından sıralanır.
Aranıyor
Arama, MapReduce algoritmasında önemli bir rol oynar. Birleştirici aşamasında (isteğe bağlı) ve Redüktör aşamasında yardımcı olur. Bir örnek yardımıyla Aramanın nasıl çalıştığını anlamaya çalışalım.
Misal
Aşağıdaki örnek, MapReduce'un belirli bir çalışan veri kümesinde en yüksek maaşı alan çalışanın ayrıntılarını bulmak için Arama algoritmasını nasıl kullandığını gösterir.
Çalışan verilerinin A, B, C ve D olmak üzere dört farklı dosyada olduğunu varsayalım. Çalışan verilerini tüm veritabanı tablolarından tekrar tekrar içe aktardığımız için dört dosyanın hepsinde de yinelenen çalışan kayıtları olduğunu varsayalım. Aşağıdaki resme bakın.

The Map phaseher girdi dosyasını işler ve çalışan verilerini anahtar-değer çiftleri halinde sağlar (<k, v>: <emp adı, maaş>). Aşağıdaki resme bakın.

The combiner phase(arama tekniği), Harita aşamasından gelen girdiyi, çalışan adı ve maaşıyla birlikte bir anahtar-değer çifti olarak kabul edecektir. Arama tekniğini kullanarak birleştirici, her dosyadaki en yüksek maaşlı çalışanı bulmak için tüm çalışan maaşını kontrol edecektir. Aşağıdaki parçaya bakın.
<k: employee name, v: salary>
Max= the salary of an first employee. Treated as max salary
if(v(second employee).salary > Max){
Max = v(salary);
}
else{
Continue checking;
}Beklenen sonuç aşağıdaki gibidir -
|
Reducer phase- Her dosyayı oluşturun, en yüksek maaşlı çalışanı bulacaksınız. Fazlalıktan kaçınmak için, tüm <k, v> çiftlerini kontrol edin ve varsa yinelenen girişleri eleyin. Aynı algoritma, dört girdi dosyasından gelen dört <k, v> çifti arasında kullanılır. Nihai çıktı aşağıdaki gibi olmalıdır -
<gopal, 50000>Endeksleme
Normalde indeksleme, belirli bir veriyi ve adresini göstermek için kullanılır. Belirli bir Eşleştirici için girdi dosyaları üzerinde toplu indeksleme gerçekleştirir.
Normalde MapReduce'da kullanılan indeksleme tekniği olarak bilinir inverted index.Google ve Bing gibi arama motorları tersine çevrilmiş indeksleme tekniğini kullanır. Basit bir örnek yardımıyla İndekslemenin nasıl çalıştığını anlamaya çalışalım.
Misal
Aşağıdaki metin, tersine çevrilmiş indeksleme için girdidir. Burada T [0], T [1] ve t [2] dosya adlarıdır ve içerikleri çift tırnak içindedir.
T[0] = "it is what it is"
T[1] = "what is it"
T[2] = "it is a banana"İndeksleme algoritmasını uyguladıktan sonra aşağıdaki çıktıyı alıyoruz -
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}Burada "a": {2} "a" teriminin T [2] dosyasında göründüğünü belirtir. Benzer şekilde, "eşittir": {0, 1, 2} "eşittir" teriminin T [0], T [1] ve T [2] dosyalarında göründüğünü belirtir.
TF-IDF
TF-IDF, Terim Frekansı - Ters Belge Frekansı'nın kısaltması olan bir metin işleme algoritmasıdır. Yaygın web analiz algoritmalarından biridir. Burada, 'sıklık' terimi, bir terimin bir belgede kaç kez göründüğünü ifade eder.
Dönem Frekansı (TF)
Bir belgede belirli bir terimin ne sıklıkla geçtiğini ölçer. Bir kelimenin bir belgedeki görünme sayısının o belgedeki toplam kelime sayısına bölünmesiyle hesaplanır.
TF(the) = (Number of times term the ‘the’ appears in a document) / (Total number of terms in the document)Ters Belge Frekansı (IDF)
Bir terimin önemini ölçer. Metin veritabanındaki belge sayısının belirli bir terimin göründüğü belge sayısına bölünmesiyle hesaplanır.
TF'yi hesaplarken, tüm terimler eşit derecede önemli kabul edilir. Bu, TF'nin "eşittir", "a", "ne" gibi normal kelimeler için terim sıklığını saydığı anlamına gelir. Bu nedenle, aşağıdakileri hesaplayarak nadir terimleri ölçeklendirirken sık kullanılan terimleri bilmemiz gerekir -
IDF(the) = log_e(Total number of documents / Number of documents with term ‘the’ in it).Algoritma aşağıda küçük bir örnek yardımıyla açıklanmıştır.
Misal
1000 kelimelik bir belge düşünün, burada kelime hive50 kez görünür. TF içinhive (50/1000) = 0,05 olur.
Şimdi, 10 milyon belgemiz olduğunu ve hivebunların 1000'inde görünür. Daha sonra IDF, log (10.000.000 / 1.000) = 4 olarak hesaplanır.
TF-IDF ağırlığı, bu miktarların ürünüdür - 0,05 × 4 = 0,20.
MapReduce yalnızca Linux aromalı işletim sistemlerinde çalışır ve bir Hadoop Çerçevesi ile birlikte gelir. Hadoop çerçevesini kurmak için aşağıdaki adımları gerçekleştirmemiz gerekiyor.
JAVA Kurulumunu Doğrulama
Hadoop'u kurmadan önce sisteminize Java yüklenmiş olmalıdır. Sisteminizde Java yüklü olup olmadığını kontrol etmek için aşağıdaki komutu kullanın.
$ java –versionJava sisteminizde zaten yüklüyse, aşağıdaki yanıtı görürsünüz -
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Sisteminizde Java kurulu değilse, aşağıda verilen adımları izleyin.
Java yükleme
Aşama 1
Java'nın en son sürümünü aşağıdaki bağlantıdan indirin - bu bağlantı .
İndirdikten sonra dosyayı bulabilirsiniz jdk-7u71-linux-x64.tar.gz İndirilenler klasörünüzde.
Adım 2
Jdk-7u71-linux-x64.gz'nin içeriğini çıkarmak için aşağıdaki komutları kullanın.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzAşama 3
Java'yı tüm kullanıcılar için kullanılabilir hale getirmek için, onu "/ usr / local /" konumuna taşımalısınız. Köke gidin ve aşağıdaki komutları yazın -
$ su
password:
# mv jdk1.7.0_71 /usr/local/java
# exit4. adım
PATH ve JAVA_HOME değişkenlerini ayarlamak için aşağıdaki komutları ~ / .bashrc dosyasına ekleyin.
export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/binTüm değişiklikleri mevcut çalışan sisteme uygulayın.
$ source ~/.bashrcAdım 5
Java alternatiflerini yapılandırmak için aşağıdaki komutları kullanın -
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarŞimdi komutu kullanarak kurulumu doğrulayın java -version terminalden.
Hadoop Kurulumunu Doğrulama
MapReduce'u kurmadan önce Hadoop sisteminize kurulmalıdır. Aşağıdaki komutu kullanarak Hadoop kurulumunu doğrulayalım -
$ hadoop versionHadoop sisteminize zaten yüklüyse, aşağıdaki yanıtı alırsınız -
Hadoop 2.4.1
--
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4Sisteminizde Hadoop yüklü değilse, aşağıdaki adımlarla devam edin.
Hadoop'u indirme
Apache Software Foundation'dan Hadoop 2.4.1'i indirin ve aşağıdaki komutları kullanarak içeriğini çıkarın.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exitHadoop'u Sözde Dağıtılmış modda yükleme
Aşağıdaki adımlar Hadoop 2.4.1'i sözde dağıtılmış modda kurmak için kullanılır.
Adım 1 - Hadoop'u Kurma
Aşağıdaki komutları ~ / .bashrc dosyasına ekleyerek Hadoop ortam değişkenlerini ayarlayabilirsiniz.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binTüm değişiklikleri mevcut çalışan sisteme uygulayın.
$ source ~/.bashrcAdım 2 - Hadoop Yapılandırması
Tüm Hadoop yapılandırma dosyalarını “$ HADOOP_HOME / etc / hadoop” konumunda bulabilirsiniz. Hadoop altyapınıza göre bu yapılandırma dosyalarında uygun değişiklikleri yapmanız gerekir.
$ cd $HADOOP_HOME/etc/hadoopJava kullanarak Hadoop programları geliştirmek için, Java ortam değişkenlerini sıfırlamanız gerekir. hadoop-env.sh JAVA_HOME değerini sisteminizdeki Java konumuyla değiştirerek.
export JAVA_HOME=/usr/local/javaHadoop'u yapılandırmak için aşağıdaki dosyaları düzenlemelisiniz -
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
core-site.xml
core-site.xml aşağıdaki bilgileri içerir−
- Hadoop örneği için kullanılan bağlantı noktası numarası
- Dosya sistemi için ayrılan bellek
- Verileri saklamak için hafıza sınırı
- Okuma / Yazma tamponlarının boyutu
Core-site.xml dosyasını açın ve aşağıdaki özellikleri <configuration> ve </configuration> etiketleri arasına ekleyin.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000 </value>
</property>
</configuration>hdfs-site.xml
hdfs-site.xml aşağıdaki bilgileri içerir -
- Çoğaltma verilerinin değeri
- Ad kodu yolu
- Yerel dosya sistemlerinizin datanode yolu (Hadoop infra'sını depolamak istediğiniz yer)
Aşağıdaki verileri varsayalım.
dfs.replication (data replication value) = 1
(In the following path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeBu dosyayı açın ve <configuration>, </configuration> etiketleri arasına aşağıdaki özellikleri ekleyin.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>Note - Yukarıdaki dosyada tüm özellik değerleri kullanıcı tanımlıdır ve Hadoop altyapınıza göre değişiklik yapabilirsiniz.
iplik-site.xml
Bu dosya, ipliği Hadoop'ta yapılandırmak için kullanılır. İplik-site.xml dosyasını açın ve aşağıdaki özellikleri <configuration>, </configuration> etiketleri arasına ekleyin.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Bu dosya, kullandığımız MapReduce çerçevesini belirtmek için kullanılır. Varsayılan olarak, Hadoop bir iplik-site.xml şablonu içerir. Öncelikle, aşağıdaki komutu kullanarak dosyayı mapred-site.xml.template'den mapred-site.xml dosyasına kopyalamanız gerekir.
$ cp mapred-site.xml.template mapred-site.xmlMapred-site.xml dosyasını açın ve aşağıdaki özellikleri <configuration>, </configuration> etiketleri arasına ekleyin.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Hadoop Kurulumunu Doğrulama
Aşağıdaki adımlar Hadoop kurulumunu doğrulamak için kullanılır.
Adım 1 - Ad Düğümü Kurulumu
“Hdfs namenode -format” komutunu kullanarak ad kodunu aşağıdaki gibi ayarlayın -
$ cd ~ $ hdfs namenode -formatBeklenen sonuç aşağıdaki gibidir -
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Adım 2 - Hadoop dfs'yi doğrulama
Hadoop dosya sisteminizi başlatmak için aşağıdaki komutu yürütün.
$ start-dfs.shBeklenen çıktı aşağıdaki gibidir -
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Adım 3 - İplik Komut Dosyasını Doğrulama
İplik betiğini başlatmak için aşağıdaki komut kullanılır. Bu komutun yürütülmesi iplik daemonlarınızı başlatacaktır.
$ start-yarn.shBeklenen çıktı aşağıdaki gibidir -
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting node manager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outAdım 4 - Tarayıcıda Hadoop'a Erişim
Hadoop'a erişmek için varsayılan bağlantı noktası numarası 50070'tir. Tarayıcınızda Hadoop hizmetlerini almak için aşağıdaki URL'yi kullanın.
http://localhost:50070/Aşağıdaki ekran görüntüsü Hadoop tarayıcısını göstermektedir.

Adım 5 - Bir Kümenin Tüm Uygulamalarını Doğrulayın
Bir kümenin tüm uygulamalarına erişmek için varsayılan bağlantı noktası numarası 8088'dir. Bu hizmeti kullanmak için aşağıdaki URL'yi kullanın.
http://localhost:8088/Aşağıdaki ekran görüntüsü bir Hadoop küme tarayıcısını göstermektedir.

Bu bölümde, MapReduce programlama işlemlerinde yer alan sınıflara ve yöntemlerine yakından bakacağız. Öncelikle aşağıdakilere odaklanmaya devam edeceğiz -
- JobContext Arayüzü
- İş Sınıfı
- Eşleyici Sınıfı
- Redüktör Sınıfı
JobContext Arayüzü
JobContext arabirimi, MapReduce'ta farklı işleri tanımlayan tüm sınıflar için süper arabirimdir. Görevler çalışırken onlara sağlanan işin salt okunur bir görünümünü verir.
Aşağıdakiler, JobContext arayüzünün alt arayüzleridir.
| S.No. | Alt Arayüz Tanımı |
|---|---|
| 1. | MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> Eşleştiriciye verilen bağlamı tanımlar. |
| 2. | ReduceContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> Redüktöre aktarılan bağlamı tanımlar. |
Job sınıfı, JobContext arayüzünü uygulayan ana sınıftır.
İş Sınıfı
Job sınıfı, MapReduce API'deki en önemli sınıftır. Kullanıcının işi yapılandırmasına, göndermesine, yürütülmesini kontrol etmesine ve durumu sorgulamasına olanak tanır. Ayar yöntemleri yalnızca iş gönderilinceye kadar çalışır, daha sonra bir IllegalStateException oluşturur.
Normalde, kullanıcı uygulamayı oluşturur, işin çeşitli yönlerini tanımlar ve ardından işi gönderir ve ilerlemesini izler.
İşte bir işin nasıl gönderileceğine dair bir örnek -
// Create a new Job
Job job = new Job(new Configuration());
job.setJarByClass(MyJob.class);
// Specify various job-specific parameters
job.setJobName("myjob");
job.setInputPath(new Path("in"));
job.setOutputPath(new Path("out"));
job.setMapperClass(MyJob.MyMapper.class);
job.setReducerClass(MyJob.MyReducer.class);
// Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);İnşaatçılar
Aşağıda Job sınıfının yapıcı özeti bulunmaktadır.
| S.No | Yapıcı Özeti |
|---|---|
| 1 | Job() |
| 2 | Job(Yapılandırma konf.) |
| 3 | Job(Konfigürasyon conf, String jobName) |
Yöntemler
Job sınıfının önemli yöntemlerinden bazıları aşağıdaki gibidir -
| S.No | Yöntem Açıklama |
|---|---|
| 1 | getJobName() Kullanıcı tarafından belirlenen iş adı. |
| 2 | getJobState() İşin mevcut durumunu döndürür. |
| 3 | isComplete() İşin bitip bitmediğini kontrol eder. |
| 4 | setInputFormatClass() İş için InputFormat'ı ayarlar. |
| 5 | setJobName(String name) Kullanıcı tarafından belirlenen iş adını ayarlar. |
| 6 | setOutputFormatClass() İş için Çıktı Formatını ayarlar. |
| 7 | setMapperClass(Class) İş için Eşleştiriciyi ayarlar. |
| 8 | setReducerClass(Class) İş için Redüktörü ayarlar. |
| 9 | setPartitionerClass(Class) İş için Partitioner'ı ayarlar. |
| 10 | setCombinerClass(Class) İş için Birleştiriciyi ayarlar. |
Eşleyici Sınıfı
Mapper sınıfı, Map işini tanımlar. Giriş anahtar / değer çiftlerini bir dizi ara anahtar / değer çiftiyle eşler. Haritalar, giriş kayıtlarını ara kayıtlara dönüştüren bağımsız görevlerdir. Dönüştürülen ara kayıtların girdi kayıtlarıyla aynı türde olması gerekmez. Verilen bir girdi çifti, sıfır veya birçok çıktı çifti ile eşleşebilir.
Yöntem
mapMapper sınıfının en belirgin yöntemidir. Sözdizimi aşağıda tanımlanmıştır -
map(KEYIN key, VALUEIN value, org.apache.hadoop.mapreduce.Mapper.Context context)Bu yöntem, giriş bölümündeki her anahtar / değer çifti için bir kez çağrılır.
Redüktör Sınıfı
Reducer sınıfı, MapReduce'ta Reduce işini tanımlar. Bir anahtarı paylaşan bir dizi ara değeri daha küçük bir değer kümesine indirger. İndirgeyici uygulamaları JobContext.getConfiguration () yöntemi aracılığıyla bir işin Yapılandırmasına erişebilir. Bir Redüktörün üç ana aşaması vardır - Shuffle, Sort ve Reduce.
Shuffle - Reducer, ağ üzerinde HTTP kullanarak her Eşleştiriciden sıralanmış çıktıları kopyalar.
Sort- Çerçeve, Reducer girişlerini anahtarlara göre birleştirerek sıralar (çünkü farklı Mappers aynı anahtarı çıkarmış olabilir). Karıştırma ve sıralama aşamaları eşzamanlı olarak gerçekleşir, yani çıktılar getirilirken birleştirilirler.
Reduce - Bu aşamada, sıralanmış girdilerdeki her <anahtar, (değerler koleksiyonu)> için azaltma (Nesne, Yinelenebilir, Bağlam) yöntemi çağrılır.
Yöntem
reduceReducer sınıfının en öne çıkan yöntemidir. Sözdizimi aşağıda tanımlanmıştır -
reduce(KEYIN key, Iterable<VALUEIN> values, org.apache.hadoop.mapreduce.Reducer.Context context)Bu yöntem, anahtar / değer çiftleri koleksiyonundaki her anahtar için bir kez çağrılır.
MapReduce, büyük hacimli verileri geniş ticari donanım kümelerinde güvenilir bir şekilde işlemek için uygulamalar yazmak için kullanılan bir çerçevedir. Bu bölüm, Java kullanarak Hadoop çerçevesinde MapReduce'un çalıştırılmasına götürür.
MapReduce Algoritması
Genel olarak MapReduce paradigması, gerçek verilerin bulunduğu bilgisayarlara harita azaltma programları göndermeye dayanır.
Bir MapReduce işi sırasında Hadoop, Eşleme ve Azaltma görevlerini kümedeki uygun sunuculara gönderir.
Çerçeve, görevler yayınlama, görev tamamlamayı doğrulama ve düğümler arasındaki küme etrafındaki verileri kopyalama gibi veri aktarımının tüm ayrıntılarını yönetir.
Hesaplamanın çoğu, ağ trafiğini azaltan yerel disklerdeki verilerle düğümlerde gerçekleşir.
Verilen bir görevi tamamladıktan sonra, küme verileri toplar ve uygun bir sonuç oluşturmak için küçültür ve Hadoop sunucusuna geri gönderir.

Girdiler ve Çıktılar (Java Perspective)
MapReduce çerçevesi anahtar-değer çiftleri üzerinde çalışır, yani çerçeve işin girdisini bir anahtar-değer çifti kümesi olarak görür ve işin çıktısı olarak, muhtemelen farklı tiplerde bir dizi anahtar-değer çifti üretir.
Anahtar ve değer sınıflarının çerçeve tarafından serileştirilebilir olması gerekir ve bu nedenle Yazılabilir arabirimi uygulamak gerekir. Ek olarak, anahtar sınıfların çerçeveye göre sıralamayı kolaylaştırmak için WritableComparable arabirimini uygulaması gerekir.
Bir MapReduce işinin hem girdi hem de çıktı biçimi anahtar / değer çiftleri biçimindedir -
(Giriş) <k1, v1> -> harita -> <k2, v2> -> azalt -> <k3, v3> (Çıkış).
| Giriş | Çıktı | |
|---|---|---|
| Harita | <k1, v1> | liste (<k2, v2>) |
| Azalt | <k2, liste (v2)> | liste (<k3, v3>) |
MapReduce Uygulaması
Aşağıdaki tablo, bir kuruluşun elektrik tüketimi ile ilgili verileri göstermektedir. Tablo, aylık elektrik tüketimini ve arka arkaya beş yıl için yıllık ortalamayı içermektedir.
| Oca | Şubat | Mar | Nis | Mayıs | Haz | Tem | Ağu | Eylül | Ekim | Kasım | Aralık | Ort. | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Maksimum kullanım yılını, minimum kullanım yılını vb. Bulmak için verilen tablodaki giriş verilerini işlemek için uygulamalar yazmamız gerekir. Bu görev, gerekli çıktıyı üretmek için mantığı yazacakları ve verileri yazılı uygulamaya geçirecekleri için, sınırlı sayıda kaydı olan programcılar için kolaydır.
Şimdi giriş verilerinin ölçeğini yükseltelim. Belirli bir eyaletteki tüm büyük ölçekli endüstrilerin elektrik tüketimini analiz etmemiz gerektiğini varsayalım. Bu tür toplu verileri işlemek için uygulamalar yazdığımızda,
Yürütmek çok zaman alacak.
Verileri kaynaktan ağ sunucusuna taşıdığımızda yoğun ağ trafiği olacaktır.
Bu sorunları çözmek için MapReduce çerçevesine sahibiz.
Giriş Verileri
Yukarıdaki veriler şu şekilde kaydedilir: sample.txtve girdi olarak verilir. Girdi dosyası aşağıda gösterildiği gibi görünür.
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
Örnek Program
Örnek veriler için aşağıdaki program MapReduce çerçevesini kullanır.
package hadoop;
import java.util.*;
import java.io.IOException;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class ProcessUnits
{
//Mapper class
public static class E_EMapper extends MapReduceBase implements
Mapper<LongWritable, /*Input key Type */
Text, /*Input value Type*/
Text, /*Output key Type*/
IntWritable> /*Output value Type*/
{
//Map function
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException
{
String line = value.toString();
String lasttoken = null;
StringTokenizer s = new StringTokenizer(line,"\t");
String year = s.nextToken();
while(s.hasMoreTokens()){
lasttoken=s.nextToken();
}
int avgprice = Integer.parseInt(lasttoken);
output.collect(new Text(year), new IntWritable(avgprice));
}
}
//Reducer class
public static class E_EReduce extends MapReduceBase implements
Reducer< Text, IntWritable, Text, IntWritable >
{
//Reduce function
public void reduce(Text key, Iterator <IntWritable> values, OutputCollector>Text, IntWritable> output, Reporter reporter) throws IOException
{
int maxavg=30;
int val=Integer.MIN_VALUE;
while (values.hasNext())
{
if((val=values.next().get())>maxavg)
{
output.collect(key, new IntWritable(val));
}
}
}
}
//Main function
public static void main(String args[])throws Exception
{
JobConf conf = new JobConf(Eleunits.class);
conf.setJobName("max_eletricityunits");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(E_EMapper.class);
conf.setCombinerClass(E_EReduce.class);
conf.setReducerClass(E_EReduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}Yukarıdaki programı şuraya kaydedin: ProcessUnits.java. Programın derlenmesi ve çalıştırılması aşağıda verilmiştir.
ProcessUnits Programının Derlenmesi ve Yürütülmesi
Hadoop kullanıcısının ana dizininde olduğumuzu varsayalım (örneğin / home / hadoop).
Yukarıdaki programı derlemek ve yürütmek için aşağıda verilen adımları izleyin.
Step 1 - Derlenmiş java sınıflarını depolamak için bir dizin oluşturmak için aşağıdaki komutu kullanın.
$ mkdir unitsStep 2- MapReduce programını derlemek ve yürütmek için kullanılan Hadoop-core-1.2.1.jar dosyasını indirin. Kavanozu mvnrepository.com adresinden indirin . İndirme klasörünün / home / hadoop / olduğunu varsayalım.
Step 3 - Aşağıdaki komutlar, ProcessUnits.java program ve program için bir jar oluşturun.
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java
$ jar -cvf units.jar -C units/ .Step 4 - Aşağıdaki komut, HDFS'de bir giriş dizini oluşturmak için kullanılır.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirStep 5 - Aşağıdaki komut, adlı giriş dosyasını kopyalamak için kullanılır sample.txt HDFS'nin giriş dizininde.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dirStep 6 - Giriş dizinindeki dosyaları doğrulamak için aşağıdaki komut kullanılır
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 7 - Aşağıdaki komut, girdi dosyalarını girdi dizininden alarak Eleunit_max uygulamasını çalıştırmak için kullanılır.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dirDosya yürütülene kadar bir süre bekleyin. Yürütmeden sonra, çıktı bir dizi girdi bölmesi, Harita görevleri, İndirgeyici görevleri vb. İçerir.
INFO mapreduce.Job: Job job_1414748220717_0002
completed successfully
14/10/31 06:02:52
INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=61
FILE: Number of bytes written=279400
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=546
HDFS: Number of bytes written=40
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2 Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=146137
Total time spent by all reduces in occupied slots (ms)=441
Total time spent by all map tasks (ms)=14613
Total time spent by all reduce tasks (ms)=44120
Total vcore-seconds taken by all map tasks=146137
Total vcore-seconds taken by all reduce tasks=44120
Total megabyte-seconds taken by all map tasks=149644288
Total megabyte-seconds taken by all reduce tasks=45178880
Map-Reduce Framework
Map input records=5
Map output records=5
Map output bytes=45
Map output materialized bytes=67
Input split bytes=208
Combine input records=5
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=6
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=948
CPU time spent (ms)=5160
Physical memory (bytes) snapshot=47749120
Virtual memory (bytes) snapshot=2899349504
Total committed heap usage (bytes)=277684224
File Output Format Counters
Bytes Written=40Step 8 - Aşağıdaki komut, çıktı klasöründe ortaya çıkan dosyaları doğrulamak için kullanılır.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Step 9 - Aşağıdaki komut, çıktıyı görmek için kullanılır. Part-00000dosya. Bu dosya HDFS tarafından oluşturulmuştur.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000MapReduce programı tarafından üretilen çıktı aşağıdadır -
| 1981 | 34 |
| 1984 | 40 |
| 1985 | 45 |
Step 10 - Aşağıdaki komut, çıktı klasörünü HDFS'den yerel dosya sistemine kopyalamak için kullanılır.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs -get output_dir /home/hadoopBir bölümleyici, bir giriş veri kümesini işlemede bir koşul gibi çalışır. Bölme aşaması, Harita aşamasından sonra ve Azaltma aşamasından önce gerçekleşir.
Bölme sayısı, redüktör sayısına eşittir. Bu, bir bölümleyicinin verileri redüktör sayısına göre böleceği anlamına gelir. Bu nedenle, tek bir bölümleyiciden aktarılan veriler tek bir Redüktör tarafından işlenir.
Bölümleyici
Bir bölümleyici, ara Harita çıktılarının anahtar-değer çiftlerini bölümler. Karma işlevi gibi çalışan, kullanıcı tanımlı bir koşul kullanarak verileri bölümler. Toplam bölüm sayısı, iş için Reducer görevlerinin sayısıyla aynıdır. Bölümleyicinin nasıl çalıştığını anlamak için bir örnek alalım.
MapReduce Partitioner Uygulaması
Kolaylık olması açısından, aşağıdaki verileri içeren Çalışan adında küçük bir tablomuz olduğunu varsayalım. Bu örnek verileri, bölümleyicinin nasıl çalıştığını göstermek için girdi veri kümemiz olarak kullanacağız.
| İD | İsim | Yaş | Cinsiyet | Maaş |
|---|---|---|---|---|
| 1201 | gopal | 45 | Erkek | 50.000 |
| 1202 | Manisha | 40 | Kadın | 50.000 |
| 1203 | Khalil | 34 | Erkek | 30.000 |
| 1204 | prasant | 30 | Erkek | 30.000 |
| 1205 | Kiran | 20 | Erkek | 40.000 |
| 1206 | Laxmi | 25 | Kadın | 35.000 |
| 1207 | Bhavya | 20 | Kadın | 15.000 |
| 1208 | reshma | 19 | Kadın | 15.000 |
| 1209 | Kranthi | 22 | Erkek | 22.000 |
| 1210 | Satish | 24 | Erkek | 25.000 |
| 1211 | Krishna | 25 | Erkek | 25.000 |
| 1212 | Arshad | 28 | Erkek | 20.000 |
| 1213 | Lavanya | 18 | Kadın | 8.000 |
Farklı yaş gruplarında cinsiyete göre en yüksek maaşlı çalışanı bulmak için girdi veri setini işlemek için bir uygulama yazmalıyız (örneğin, 20'nin altı, 21-30 arası, 30'un üstü).
Giriş Verileri
Yukarıdaki veriler şu şekilde kaydedilir: input.txt "/ home / hadoop / hadoopPartitioner" dizininde ve girdi olarak verilir.
| 1201 | gopal | 45 | Erkek | 50000 |
| 1202 | Manisha | 40 | Kadın | 51000 |
| 1203 | Khaleel | 34 | Erkek | 30000 |
| 1204 | prasant | 30 | Erkek | 31000 |
| 1205 | Kiran | 20 | Erkek | 40000 |
| 1206 | Laxmi | 25 | Kadın | 35.000 |
| 1207 | Bhavya | 20 | Kadın | 15.000 |
| 1208 | reshma | 19 | Kadın | 14.000 |
| 1209 | Kranthi | 22 | Erkek | 22.000 |
| 1210 | Satish | 24 | Erkek | 25.000 |
| 1211 | Krishna | 25 | Erkek | 26.000 |
| 1212 | Arshad | 28 | Erkek | 20.000 |
| 1213 | Lavanya | 18 | Kadın | 8000 |
Verilen girdiye bağlı olarak, programın algoritmik açıklaması aşağıdadır.
Harita Görevleri
Harita görevi, metin verisini bir metin dosyasında tuttuğumuzda, anahtar-değer çiftlerini girdi olarak kabul eder. Bu harita görevinin girdisi aşağıdaki gibidir -
Input - Anahtar, "herhangi bir özel anahtar + dosya adı + satır numarası" (örnek: anahtar = @ girdi1) gibi bir kalıp olur ve değer, bu satırdaki veriler olur (örnek: değer = 1201 \ t gopal \ t 45 \ t Erkek \ t 50000).
Method - Bu harita görevinin çalışması aşağıdaki gibidir -
Okumak value (veri kaydı), bir dizedeki bağımsız değişken listesinden giriş değeri olarak gelir.
Bölme işlevini kullanarak cinsiyeti ayırın ve bir dize değişkeninde saklayın.
String[] str = value.toString().split("\t", -3);
String gender=str[3];Cinsiyet bilgilerini ve kayıt verilerini gönderin value eşleme görevinden anahtar / değer çifti çıktısı olarak partition task.
context.write(new Text(gender), new Text(value));Metin dosyasındaki tüm kayıtlar için yukarıdaki tüm adımları tekrarlayın.
Output - Cinsiyet verilerini ve kayıt veri değerini anahtar / değer çiftleri olarak alacaksınız.
Partitioner Görevi
Bölümleyici görevi, eşleme görevindeki anahtar-değer çiftlerini girdi olarak kabul eder. Bölümleme, verilerin bölümlere ayrılması anlamına gelir. Bölümlerin verilen koşullu kriterlerine göre, giriş anahtar-değer eşleştirilmiş verileri yaş kriterine göre üç bölüme ayrılabilir.
Input - Anahtar / değer çiftlerinden oluşan bir koleksiyondaki verilerin tamamı.
key = Kayıttaki cinsiyet alanı değeri.
değer = Bu cinsiyetin tüm kayıt veri değeri.
Method - Bölümleme mantığı süreci aşağıdaki gibi çalışır.
- Giriş anahtar / değer çiftinden yaş alanı değerini okuyun.
String[] str = value.toString().split("\t");
int age = Integer.parseInt(str[2]);Yaş değerini aşağıdaki koşullarla kontrol edin.
- 20'den küçük veya eşit yaş
- Yaş 20'den büyük ve 30'dan küçük veya 30'a eşit.
- Yaş 30'dan büyük.
if(age<=20)
{
return 0;
}
else if(age>20 && age<=30)
{
return 1 % numReduceTasks;
}
else
{
return 2 % numReduceTasks;
}Output- Anahtar / değer çiftlerinin tüm verileri, anahtar / değer çiftlerinin üç koleksiyonuna bölünür. Redüktör, her koleksiyonda ayrı ayrı çalışır.
Görevleri Azaltın
Bölme görevlerinin sayısı, düşürücü görevlerin sayısına eşittir. Burada üç bölümleyici görevimiz var ve dolayısıyla gerçekleştirilecek üç Redüktör görevimiz var.
Input - İndirgeyici, farklı anahtar / değer çiftleri koleksiyonuyla üç kez çalıştırılır.
kayıttaki anahtar = cinsiyet alanı değeri.
değer = o cinsiyetin tüm kayıt verileri.
Method - Her koleksiyona aşağıdaki mantık uygulanacaktır.
- Her kaydın Maaş alanı değerini okuyun.
String [] str = val.toString().split("\t", -3);
Note: str[4] have the salary field value.Maaşı maksimum değişkenle kontrol edin. Eğer str [4] maksimum maaş ise, str [4] 'ü max'a atayın, aksi takdirde adımı atlayın.
if(Integer.parseInt(str[4])>max)
{
max=Integer.parseInt(str[4]);
}Her anahtar teslimi için Adım 1 ve 2'yi tekrarlayın (Erkek ve Kadın anahtar koleksiyonlarıdır). Bu üç adımı uyguladıktan sonra, Erkek anahtar koleksiyonundan bir maksimum maaş ve Kadın anahtar koleksiyonundan bir maksimum maaş bulacaksınız.
context.write(new Text(key), new IntWritable(max));Output- Son olarak, farklı yaş gruplarından oluşan üç koleksiyonda bir dizi anahtar / değer çifti verisi alacaksınız. Her yaş grubunda sırasıyla Erkek koleksiyonundan maksimum maaşı ve Kadın koleksiyonundan maksimum maaşı içerir.
Map, Partitioner ve Reduce görevlerini çalıştırdıktan sonra, anahtar-değer çifti verilerinin üç koleksiyonu çıktı olarak üç farklı dosyada depolanır.
Üç görevin tümü MapReduce işleri olarak değerlendirilir. Bu işlerin aşağıdaki gereksinimleri ve özellikleri Konfigürasyonlarda belirtilmelidir -
- İş adı
- Anahtarların ve değerlerin giriş ve çıkış formatları
- Map, Reduce ve Partitioner görevleri için ayrı sınıflar
Configuration conf = getConf();
//Create Job
Job job = new Job(conf, "topsal");
job.setJarByClass(PartitionerExample.class);
// File Input and Output paths
FileInputFormat.setInputPaths(job, new Path(arg[0]));
FileOutputFormat.setOutputPath(job,new Path(arg[1]));
//Set Mapper class and Output format for key-value pair.
job.setMapperClass(MapClass.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//set partitioner statement
job.setPartitionerClass(CaderPartitioner.class);
//Set Reducer class and Input/Output format for key-value pair.
job.setReducerClass(ReduceClass.class);
//Number of Reducer tasks.
job.setNumReduceTasks(3);
//Input and Output format for data
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);Örnek Program
Aşağıdaki program, bir MapReduce programında verilen kriterler için bölümleyicilerin nasıl uygulanacağını gösterir.
package partitionerexample;
import java.io.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
import org.apache.hadoop.util.*;
public class PartitionerExample extends Configured implements Tool
{
//Map class
public static class MapClass extends Mapper<LongWritable,Text,Text,Text>
{
public void map(LongWritable key, Text value, Context context)
{
try{
String[] str = value.toString().split("\t", -3);
String gender=str[3];
context.write(new Text(gender), new Text(value));
}
catch(Exception e)
{
System.out.println(e.getMessage());
}
}
}
//Reducer class
public static class ReduceClass extends Reducer<Text,Text,Text,IntWritable>
{
public int max = -1;
public void reduce(Text key, Iterable <Text> values, Context context) throws IOException, InterruptedException
{
max = -1;
for (Text val : values)
{
String [] str = val.toString().split("\t", -3);
if(Integer.parseInt(str[4])>max)
max=Integer.parseInt(str[4]);
}
context.write(new Text(key), new IntWritable(max));
}
}
//Partitioner class
public static class CaderPartitioner extends
Partitioner < Text, Text >
{
@Override
public int getPartition(Text key, Text value, int numReduceTasks)
{
String[] str = value.toString().split("\t");
int age = Integer.parseInt(str[2]);
if(numReduceTasks == 0)
{
return 0;
}
if(age<=20)
{
return 0;
}
else if(age>20 && age<=30)
{
return 1 % numReduceTasks;
}
else
{
return 2 % numReduceTasks;
}
}
}
@Override
public int run(String[] arg) throws Exception
{
Configuration conf = getConf();
Job job = new Job(conf, "topsal");
job.setJarByClass(PartitionerExample.class);
FileInputFormat.setInputPaths(job, new Path(arg[0]));
FileOutputFormat.setOutputPath(job,new Path(arg[1]));
job.setMapperClass(MapClass.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//set partitioner statement
job.setPartitionerClass(CaderPartitioner.class);
job.setReducerClass(ReduceClass.class);
job.setNumReduceTasks(3);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true)? 0 : 1);
return 0;
}
public static void main(String ar[]) throws Exception
{
int res = ToolRunner.run(new Configuration(), new PartitionerExample(),ar);
System.exit(0);
}
}Yukarıdaki kodu farklı kaydedin PartitionerExample.java"/ home / hadoop / hadoopPartitioner" içinde. Programın derlenmesi ve çalıştırılması aşağıda verilmiştir.
Derleme ve Yürütme
Hadoop kullanıcısının ana dizininde olduğumuzu varsayalım (örneğin, / home / hadoop).
Yukarıdaki programı derlemek ve yürütmek için aşağıda verilen adımları izleyin.
Step 1- MapReduce programını derlemek ve yürütmek için kullanılan Hadoop-core-1.2.1.jar dosyasını indirin. Kavanozu mvnrepository.com adresinden indirebilirsiniz .
İndirilen klasörün "/ home / hadoop / hadoopPartitioner" olduğunu varsayalım
Step 2 - Programı derlemek için aşağıdaki komutlar kullanılır PartitionerExample.java ve program için bir kavanoz oluşturmak.
$ javac -classpath hadoop-core-1.2.1.jar -d ProcessUnits.java $ jar -cvf PartitionerExample.jar -C .Step 3 - HDFS'de bir giriş dizini oluşturmak için aşağıdaki komutu kullanın.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirStep 4 - adlı giriş dosyasını kopyalamak için aşağıdaki komutu kullanın input.txt HDFS'nin giriş dizininde.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/hadoopPartitioner/input.txt input_dirStep 5 - Giriş dizinindeki dosyaları doğrulamak için aşağıdaki komutu kullanın.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 6 - Giriş dosyalarını giriş dizininden alarak En yüksek maaş uygulamasını çalıştırmak için aşağıdaki komutu kullanın.
$HADOOP_HOME/bin/hadoop jar PartitionerExample.jar partitionerexample.PartitionerExample input_dir/input.txt output_dirDosya yürütülene kadar bir süre bekleyin. Yürütmeden sonra, çıktı bir dizi girdi bölmesi, harita görevleri ve İndirgeyici görevleri içerir.
15/02/04 15:19:51 INFO mapreduce.Job: Job job_1423027269044_0021 completed successfully
15/02/04 15:19:52 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=467
FILE: Number of bytes written=426777
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=480
HDFS: Number of bytes written=72
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=6
Job Counters
Launched map tasks=1
Launched reduce tasks=3
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=8212
Total time spent by all reduces in occupied slots (ms)=59858
Total time spent by all map tasks (ms)=8212
Total time spent by all reduce tasks (ms)=59858
Total vcore-seconds taken by all map tasks=8212
Total vcore-seconds taken by all reduce tasks=59858
Total megabyte-seconds taken by all map tasks=8409088
Total megabyte-seconds taken by all reduce tasks=61294592
Map-Reduce Framework
Map input records=13
Map output records=13
Map output bytes=423
Map output materialized bytes=467
Input split bytes=119
Combine input records=0
Combine output records=0
Reduce input groups=6
Reduce shuffle bytes=467
Reduce input records=13
Reduce output records=6
Spilled Records=26
Shuffled Maps =3
Failed Shuffles=0
Merged Map outputs=3
GC time elapsed (ms)=224
CPU time spent (ms)=3690
Physical memory (bytes) snapshot=553816064
Virtual memory (bytes) snapshot=3441266688
Total committed heap usage (bytes)=334102528
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=361
File Output Format Counters
Bytes Written=72Step 7 - Çıktı klasöründe ortaya çıkan dosyaları doğrulamak için aşağıdaki komutu kullanın.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Çıktıyı üç dosyada bulacaksınız çünkü programınızda üç bölümleyici ve üç Redüktör kullanıyorsunuz.
Step 8 - Çıktıyı görmek için aşağıdaki komutu kullanın Part-00000dosya. Bu dosya HDFS tarafından oluşturulmuştur.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000Output in Part-00000
Female 15000
Male 40000Çıktıyı görmek için aşağıdaki komutu kullanın. Part-00001 dosya.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00001Output in Part-00001
Female 35000
Male 31000Çıktıyı görmek için aşağıdaki komutu kullanın. Part-00002 dosya.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00002Output in Part-00002
Female 51000
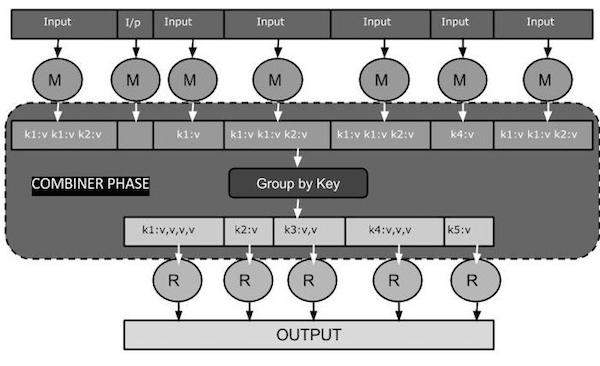
Male 50000Bir birleştirici, aynı zamanda bir semi-reducer, Map sınıfından gelen girdileri kabul ederek ve ardından çıktı anahtar / değer çiftlerini Reducer sınıfına geçirerek çalışan isteğe bağlı bir sınıftır.
Bir Birleştiricinin ana işlevi, harita çıktı kayıtlarını aynı anahtarla özetlemektir. Birleştiricinin çıktısı (anahtar-değer koleksiyonu) girdi olarak ağ üzerinden gerçek İndirgeyici görevine gönderilecektir.
Birleştirici
Combiner sınıfı, Map ve Reduce arasındaki veri aktarım hacmini azaltmak için Map sınıfı ile Reduce sınıfı arasında kullanılır. Genellikle, harita görevinin çıktısı büyüktür ve azaltma görevine aktarılan veriler yüksektir.
Aşağıdaki MapReduce görev diyagramı BİRLEŞTİRİCİ AŞAMASINI gösterir.
Combiner Nasıl Çalışır?
MapReduce Combiner'ın nasıl çalıştığına dair kısa bir özet:
Bir birleştiricinin önceden tanımlanmış bir arabirimi yoktur ve Reducer arabiriminin azaltma () yöntemini uygulaması gerekir.
Her harita çıkış anahtarı üzerinde bir birleştirici çalışır. Reducer sınıfıyla aynı çıkış anahtar-değer türlerine sahip olmalıdır.
Bir birleştirici, orijinal Harita çıktısının yerini aldığı için büyük bir veri kümesinden özet bilgi üretebilir.
Combiner isteğe bağlı olmasına rağmen, Verileri Azaltma aşaması için birden fazla gruba ayırmaya yardımcı olur ve bu da işlenmesini kolaylaştırır.
MapReduce Combiner Uygulaması
Aşağıdaki örnek, birleştiriciler hakkında teorik bir fikir sağlar. Aşağıdaki giriş metin dosyasına sahip olduğumuzu varsayalıminput.txt MapReduce için.
What do you mean by Object
What do you know about Java
What is Java Virtual Machine
How Java enabled High PerformanceCombiner ile MapReduce programının önemli aşamaları aşağıda tartışılmaktadır.
Kayıt Okuyucu
Bu, Kayıt Okuyucunun giriş metin dosyasındaki her satırı metin olarak okuduğu ve çıktıyı anahtar-değer çiftleri olarak verdiği MapReduce'un ilk aşamasıdır.
Input - Giriş dosyasından satır satır metin.
Output- Anahtar / değer çiftlerini oluşturur. Aşağıda, beklenen anahtar / değer çiftleri kümesi verilmiştir.
<1, What do you mean by Object>
<2, What do you know about Java>
<3, What is Java Virtual Machine>
<4, How Java enabled High Performance>Harita Aşaması
Harita aşaması, Kayıt Okuyucusundan girdi alır, işler ve çıktıyı başka bir anahtar-değer çifti kümesi olarak üretir.
Input - Aşağıdaki anahtar / değer çifti, Kayıt Okuyucusundan alınan giriştir.
<1, What do you mean by Object>
<2, What do you know about Java>
<3, What is Java Virtual Machine>
<4, How Java enabled High Performance>Harita aşaması her bir anahtar-değer çiftini okur, her kelimeyi değerden StringTokenizer kullanarak böler, her kelimeyi anahtar ve bu kelimenin sayısını değer olarak ele alır. Aşağıdaki kod parçacığı, Mapper sınıfını ve harita işlevini gösterir.
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}Output - Beklenen çıktı aşağıdaki gibidir -
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1>
<What,1> <do,1> <you,1> <know,1> <about,1> <Java,1>
<What,1> <is,1> <Java,1> <Virtual,1> <Machine,1>
<How,1> <Java,1> <enabled,1> <High,1> <Performance,1>Birleştirici Faz
Birleştirici aşaması, her bir anahtar / değer çiftini Harita aşamasından alır, işler ve çıktıyı şu şekilde üretir: key-value collection çiftler.
Input - Aşağıdaki anahtar / değer çifti, Harita aşamasından alınan girdidir.
<What,1> <do,1> <you,1> <mean,1> <by,1> <Object,1>
<What,1> <do,1> <you,1> <know,1> <about,1> <Java,1>
<What,1> <is,1> <Java,1> <Virtual,1> <Machine,1>
<How,1> <Java,1> <enabled,1> <High,1> <Performance,1>Birleştirici aşaması, her bir anahtar / değer çiftini okur, ortak kelimeleri anahtar olarak ve değerleri koleksiyon olarak birleştirir. Genellikle, bir Birleştiricinin kodu ve çalışması, bir Redüktörünkine benzer. Aşağıda Mapper, Combiner ve Reducer sınıf bildirimi için kod parçacığı verilmiştir.
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);Output - Beklenen çıktı aşağıdaki gibidir -
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,1,1,1>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>Redüktör Faz
İndirgeyici aşaması, her bir anahtar / değer toplama çiftini Birleştirici aşamasından alır, işler ve çıkışı anahtar / değer çiftleri olarak geçirir. Combiner işlevinin Redüktör ile aynı olduğuna dikkat edin.
Input - Aşağıdaki anahtar / değer çifti, Birleştirici aşamasından alınan girdidir.
<What,1,1,1> <do,1,1> <you,1,1> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,1,1,1>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>Azaltıcı aşaması, her bir anahtar / değer çiftini okur. Birleştirici için kod parçacığı aşağıdadır.
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}Output - Redüktör aşamasından beklenen çıktı aşağıdaki gibidir -
<What,3> <do,2> <you,2> <mean,1> <by,1> <Object,1>
<know,1> <about,1> <Java,3>
<is,1> <Virtual,1> <Machine,1>
<How,1> <enabled,1> <High,1> <Performance,1>Kayıt Yazarı
Bu, Kayıt Yazıcısının Reducer aşamasından her anahtar / değer çiftini yazdığı ve çıktıyı metin olarak gönderdiği MapReduce'un son aşamasıdır.
Input - Çıktı biçimiyle birlikte Azaltıcı aşamasındaki her bir anahtar / değer çifti.
Output- Size metin biçiminde anahtar / değer çiftleri verir. Beklenen çıktı aşağıdadır.
What 3
do 2
you 2
mean 1
by 1
Object 1
know 1
about 1
Java 3
is 1
Virtual 1
Machine 1
How 1
enabled 1
High 1
Performance 1Örnek Program
Aşağıdaki kod bloğu, bir programdaki kelimelerin sayısını sayar.
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>
{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Yukarıdaki programı farklı kaydedin WordCount.java. Programın derlenmesi ve çalıştırılması aşağıda verilmiştir.
Derleme ve Yürütme
Hadoop kullanıcısının ana dizininde olduğumuzu varsayalım (örneğin, / home / hadoop).
Yukarıdaki programı derlemek ve yürütmek için aşağıda verilen adımları izleyin.
Step 1 - Derlenmiş java sınıflarını depolamak için bir dizin oluşturmak için aşağıdaki komutu kullanın.
$ mkdir unitsStep 2- MapReduce programını derlemek ve yürütmek için kullanılan Hadoop-core-1.2.1.jar dosyasını indirin. Kavanozu mvnrepository.com adresinden indirebilirsiniz .
İndirilen klasörün / home / hadoop / olduğunu varsayalım.
Step 3 - Aşağıdaki komutları kullanarak WordCount.java program ve program için bir jar oluşturun.
$ javac -classpath hadoop-core-1.2.1.jar -d units WordCount.java
$ jar -cvf units.jar -C units/ .Step 4 - HDFS'de bir giriş dizini oluşturmak için aşağıdaki komutu kullanın.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dirStep 5 - adlı giriş dosyasını kopyalamak için aşağıdaki komutu kullanın input.txt HDFS'nin giriş dizininde.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/input.txt input_dirStep 6 - Giriş dizinindeki dosyaları doğrulamak için aşağıdaki komutu kullanın.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 7 - Giriş dizininden giriş dosyalarını alarak Word sayımı uygulamasını çalıştırmak için aşağıdaki komutu kullanın.
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dirDosya yürütülene kadar bir süre bekleyin. Yürütmeden sonra, çıktı bir dizi girdi bölmesi, Harita görevleri ve İndirgeyici görevleri içerir.
Step 8 - Çıktı klasöründe ortaya çıkan dosyaları doğrulamak için aşağıdaki komutu kullanın.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Step 9 - Çıktıyı görmek için aşağıdaki komutu kullanın Part-00000dosya. Bu dosya HDFS tarafından oluşturulmuştur.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000MapReduce programı tarafından üretilen çıktı aşağıdadır.
What 3
do 2
you 2
mean 1
by 1
Object 1
know 1
about 1
Java 3
is 1
Virtual 1
Machine 1
How 1
enabled 1
High 1
Performance 1Bu bölüm, hem HDFS hem de MapReduce yönetimini içeren Hadoop yönetimini açıklamaktadır.
HDFS yönetimi, HDFS dosya yapısının, konumlarının ve güncellenmiş dosyaların izlenmesini içerir.
MapReduce yönetimi, uygulamaların listesini, düğümlerin yapılandırmasını, uygulama durumunu vb. İzlemeyi içerir.
HDFS İzleme
HDFS (Hadoop Dağıtılmış Dosya Sistemi), kullanıcı dizinlerini, giriş dosyalarını ve çıktı dosyalarını içerir. MapReduce komutlarını kullanın,put ve get, saklamak ve almak için.
"/ $ HADOOP_HOME / sbin" üzerinde "start-all.sh" komutunu ileterek Hadoop çerçevesini (arka plan programı) başlattıktan sonra, aşağıdaki URL'yi "http: // localhost: 50070" tarayıcısına iletin. Tarayıcınızda aşağıdaki ekranı görmelisiniz.
Aşağıdaki ekran görüntüsü, göz atma HDFS'sine nasıl göz atılacağını gösterir.

Aşağıdaki ekran görüntüsü HDFS'nin dosya yapısını göstermektedir. "/ User / hadoop" dizinindeki dosyaları gösterir.

Aşağıdaki ekran görüntüsü, bir kümedeki Datanode bilgilerini gösterir. Burada konfigürasyonları ve kapasiteleri ile bir düğüm bulabilirsiniz.

MapReduce İş İzleme
MapReduce uygulaması, işlerin bir koleksiyonudur (Map job, Combiner, Partitioner ve Reduce işi). Aşağıdakileri izlemek ve sürdürmek zorunludur -
- Uygulamanın uygun olduğu datanode konfigürasyonu.
- Uygulama başına kullanılan veri ve kaynakların sayısı.
Tüm bunları izlemek için, bir kullanıcı arayüzüne sahip olmamız zorunludur. "/ $ HADOOP_HOME / sbin" üzerinde "start-all.sh" komutunu ileterek Hadoop çerçevesini başlattıktan sonra, aşağıdaki URL'yi "http: // localhost: 8080" tarayıcısına iletin. Tarayıcınızda aşağıdaki ekranı görmelisiniz.

Yukarıdaki ekran görüntüsünde, el işaretçisi uygulama kimliğindedir. Tarayıcınızda aşağıdaki ekranı bulmak için üzerine tıklamanız yeterlidir. Aşağıdakileri açıklar -
Geçerli uygulamanın hangi kullanıcı üzerinde çalıştığı
Uygulama adı
Bu uygulamanın türü
Mevcut durum, Son durum
İzleme sırasında tamamlanmışsa, uygulama başlama zamanı, geçen (tamamlanan zaman)
Bu uygulamanın geçmişi, yani günlük bilgileri
Ve son olarak, düğüm bilgileri, yani uygulamanın çalıştırılmasına katılan düğümler.
Aşağıdaki ekran görüntüsü belirli bir uygulamanın ayrıntılarını gösterir -

Aşağıdaki ekran görüntüsü şu anda çalışan düğüm bilgilerini açıklamaktadır. Burada, ekran görüntüsü yalnızca bir düğüm içerir. Bir el işaretçisi, çalışan düğümün localhost adresini gösterir.
