Seaborn - İstatistiksel Tahmin
Çoğu durumda, verilerin tüm dağılımının tahminleriyle ilgileniriz. Ancak, merkezi eğilim tahmini söz konusu olduğunda, dağılımı özetlemek için belirli bir yola ihtiyacımız var. Ortalama ve medyan, dağılımın merkezi eğilimini tahmin etmek için en sık kullanılan tekniklerdir.
Yukarıdaki bölümde öğrendiğimiz tüm parsellerde tüm dağılımın görselleştirmesini yaptık. Şimdi, dağılımın merkezi eğilimini tahmin edebileceğimiz arsaları tartışalım.
Bar Grafiği
barplot()kategorik bir değişken ile sürekli bir değişken arasındaki ilişkiyi gösterir. Veriler, çubuğun uzunluğunun o kategorideki verilerin oranını temsil ettiği dikdörtgen çubuklarla temsil edilir.
Çubuk grafiği, merkezi eğilim tahminini temsil eder. Çubuk grafiklerini öğrenmek için 'titanik' veri kümesini kullanalım.
Misal
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.barplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()Çıktı
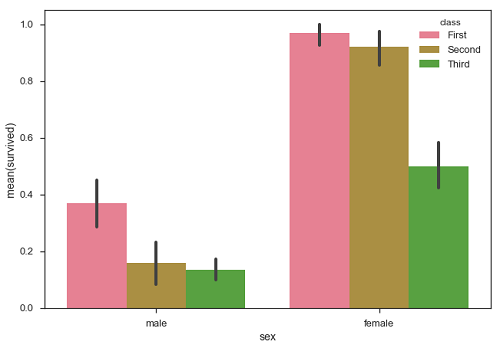
Yukarıdaki örnekte, her sınıftaki erkek ve dişi hayatta kalanların ortalama sayısını görebiliriz. Olay örgüsünden, erkeklerden daha fazla sayıda kadının hayatta kaldığını anlayabiliriz. Hem erkeklerde hem de kadınlarda hayatta kalanların sayısı daha fazla birinci sınıftır.
Barplotta özel bir durum, ikinci bir değişken için bir istatistik hesaplamaktan ziyade her kategorideki gözlemlerin sayısını göstermektir. Bunun için kullanıyoruzcountplot().
Misal
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.countplot(x = " class ", data = df, palette = "Blues");
plt.show()Çıktı
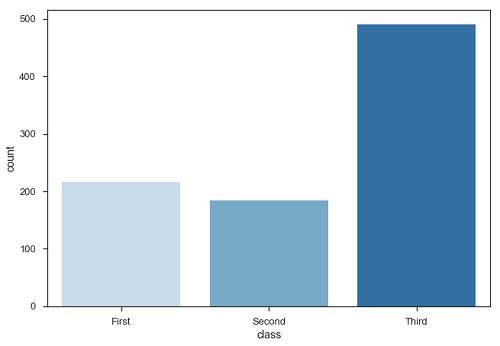
Plot, üçüncü sınıftaki yolcu sayısının birinci ve ikinci sınıfa göre daha fazla olduğunu söylüyor.
Nokta Grafikleri
Nokta grafikleri çubuk grafiklerle aynıdır, ancak farklı bir tarzda. Dolu çubuktan ziyade, tahminin değeri, diğer eksende belirli bir yükseklikteki nokta ile temsil edilir.
Misal
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.pointplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()Çıktı
