TIKA - HTML Dokümanı Çıkarma
Aşağıda, bir HTML belgesinden içerik ve meta veri çıkarma programı verilmiştir.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.html.HtmlParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class HtmlParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.html"));
ParseContext pcontext = new ParseContext();
//Html parser
HtmlParser htmlparser = new HtmlParser();
htmlparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Yukarıdaki kodu farklı kaydedin HtmlParse.javave aşağıdaki komutları kullanarak komut isteminden derleyin -
javac HtmlParse.java
java HtmlParseAşağıda, example.txt dosyasının anlık görüntüsü verilmiştir.
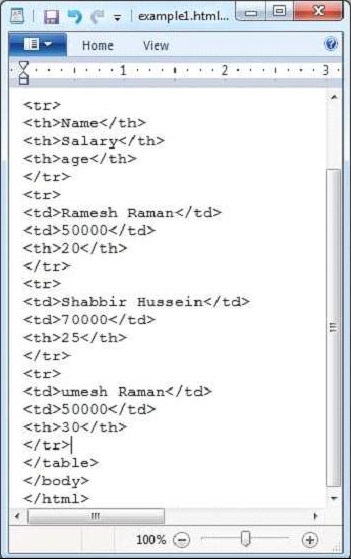
HTML belgesi aşağıdaki özelliklere sahiptir−

Yukarıdaki programı çalıştırırsanız, size aşağıdaki çıktıyı verecektir.
Output -
Contents of the document:
Name Salary age
Ramesh Raman 50000 20
Shabbir Hussein 70000 25
Umesh Raman 50000 30
Somesh 50000 35
Metadata of the document:
title: HTML Table Header
Content-Encoding: windows-1252
Content-Type: text/html; charset = windows-1252
dc:title: HTML Table Header