TIKA - Hızlı Kılavuz
Apache Tika nedir?
Apache Tika, çeşitli dosya formatlarından belge türü algılama ve içerik çıkarma için kullanılan bir kitaplıktır.
Tika, verileri algılamak ve çıkarmak için dahili olarak mevcut çeşitli belge ayrıştırıcıları ve belge türü algılama tekniklerini kullanır.
Tika'yı kullanarak, hem yapılandırılmış metni hem de meta verileri elektronik tablolar, metin belgeleri, görüntüler, PDF'ler ve hatta multimedya giriş biçimleri gibi farklı türden belgelerden belirli bir dereceye kadar çıkarmak için evrensel bir tür algılayıcı ve içerik çıkarıcı geliştirilebilir.
Tika, farklı dosya formatlarını ayrıştırmak için tek bir genel API sağlar. Her belge türü için mevcut özel ayrıştırıcı kitaplıklarını kullanır.
Tüm bu ayrıştırıcı kitaplıkları, adı verilen tek bir arabirim altında toplanmıştır. Parser interface.

Neden Tika?
Filext.com'a göre, yaklaşık 15 bin ila 51 bin içerik türü var ve bu sayı her geçen gün artıyor. Veriler, metin belgeleri, Excel elektronik tablosu, PDF'ler, resimler ve multimedya dosyaları gibi çeşitli biçimlerde depolanmaktadır. Bu nedenle, arama motorları ve içerik yönetim sistemleri gibi uygulamalar, bu belge türlerinden verilerin kolayca çıkarılması için ek desteğe ihtiyaç duyar. Apache Tika, birden çok dosya biçiminden verileri bulmak ve çıkarmak için genel bir API sağlayarak bu amaca hizmet eder.
Apache Tika Uygulamaları
Apache Tika'yı kullanan çeşitli uygulamalar vardır. Burada, büyük ölçüde Apache Tika'ya bağlı olan birkaç önemli uygulamayı tartışacağız.
Arama motorları
Tika, dijital belgelerin metin içeriklerini indekslemek için arama motorlarını geliştirirken yaygın olarak kullanılmaktadır.
Arama motorları, Web'den bilgi ve indekslenmiş belgeleri aramak için tasarlanmış bilgi işleme sistemleridir.
Tarayıcı, bazı dizin oluşturma tekniklerini kullanarak dizine eklenecek belgeleri almak için Web'de gezinen bir arama motorunun önemli bir bileşenidir. Bundan sonra, tarayıcı bu dizine eklenen belgeleri bir çıkarma bileşenine aktarır.
Çıkarma bileşeninin görevi, belgeden metni ve meta verileri çıkarmaktır. Bu tür çıkarılan içerik ve meta veriler bir arama motoru için çok kullanışlıdır. Bu ekstraksiyon bileşeni Tika içerir.
Çıkarılan içerik daha sonra bir arama dizini oluşturmak için onu kullanan arama motorunun dizinleyicisine aktarılır. Bunun dışında arama motoru, çıkarılan içeriği başka birçok şekilde de kullanır.

Belge Analizi
Yapay zeka alanında, belgeleri otomatik olarak anlamsal düzeyde analiz etmek ve bunlardan her türlü veriyi çıkarmak için bazı araçlar bulunmaktadır.
Bu tür başvurularda belgeler, belgenin çıkarılan içeriğinde öne çıkan terimlere göre sınıflandırılır.
Bu araçlar, düz metinden dijital belgelere kadar değişen belgeleri analiz etmek için içerik çıkarma için Tika'yı kullanır.
Dijital Varlık Yönetimi
Bazı kuruluşlar, dijital varlık yönetimi (DAM) olarak bilinen özel bir uygulama kullanarak fotoğraf, e-kitap, çizim, müzik ve video gibi dijital varlıklarını yönetir.
Bu tür uygulamalar, çeşitli belgeleri sınıflandırmak için belge türü algılayıcılarından ve meta veri çıkarıcıdan yardım alır.
İçerik analizi
Amazon gibi web siteleri, web sitelerinin yeni yayınlanan içeriklerini ilgi alanlarına göre bireysel kullanıcılara tavsiye ediyor. Bunu yapmak için bu web siteleri takip edermachine learning techniquesveya Facebook gibi sosyal medya web sitelerinden kullanıcıların beğenileri ve ilgi alanları gibi gerekli bilgileri çıkarmak için yardım alın. Toplanan bu bilgiler html etiketleri veya daha fazla içerik türü tespiti ve çıkarımı gerektiren diğer formatlar biçiminde olacaktır.
Bir belgenin içerik analizi için, makine öğrenimi tekniklerini uygulayan teknolojilere sahibiz. UIMA ve Mahout. Bu teknolojiler, belgelerdeki verileri kümeleme ve analiz etmede kullanışlıdır.
Apache Mahoutbir bulut bilişim platformu olan Apache Hadoop'ta ML algoritmaları sağlayan bir çerçevedir. Mahout, belirli kümeleme ve filtreleme tekniklerini izleyerek bir mimari sağlar. Bu mimariyi takip ederek, programcılar çeşitli metin ve meta veri kombinasyonlarını alarak öneriler üretmek için kendi ML algoritmalarını yazabilirler. Bu algoritmalara girdi sağlamak için Mahout'un son sürümleri Tika'yı ikili içerikten metin ve meta veri çıkarmak için kullanıyor.
Apache UIMAçeşitli programlama dillerini analiz eder ve işler ve UIMA açıklamalarını üretir. Dahili olarak belge metnini ve meta verileri çıkarmak için Tika Annotator kullanır.
Tarih
| Yıl | Geliştirme |
|---|---|
| 2006 | Tika fikri, Lucene Proje Yönetim Komitesi önünde yansıtıldı. |
| 2006 | Tika kavramı ve Jackrabbit projesindeki kullanışlılığı tartışıldı. |
| 2007 | Tika, Apache kuluçka makinesine girdi. |
| 2008 | 0.1 ve 0.2 sürümleri yayınlandı ve Tika, inkübatörden Lucene alt projesine mezun oldu. |
| 2009 | 0.3, 0.4 ve 0.5 sürümleri yayınlandı. |
| 2010 | Sürüm 0.6 ve 0.7 yayınlandı ve Tika üst düzey Apache projesine mezun oldu. |
| 2011 | Tika 1.0 yayınlandı ve aynı yıl Tika "Tika in Action" kitabı da yayınlandı. |
Tika'nın Uygulama Düzeyinde Mimarisi
Uygulama programcıları, Tika'yı uygulamalarına kolayca entegre edebilir. Tika, kullanıcı dostu olması için bir Komut Satırı Arayüzü ve bir GUI sağlar.
Bu bölümde, Tika mimarisini oluşturan dört önemli modülü tartışacağız. Aşağıdaki çizim, dört modülüyle birlikte Tika'nın mimarisini göstermektedir -
- Dil algılama mekanizması.
- MIME algılama mekanizması.
- Ayrıştırıcı arabirimi.
- Tika Facade sınıfı.

Dil Algılama Mekanizması
Tika'ya bir metin belgesi her iletildiğinde, yazıldığı dili tespit edecektir. Dil ek açıklaması olmayan belgeleri kabul eder ve dili algılayarak bu bilgileri belgenin meta verilerine ekler.
Dil tanımlamasını desteklemek için Tika'nın adında bir sınıfı vardır Language Identifier paketin içinde org.apache.tika.languageve belirli bir metinden dil tespiti için algoritmalar içeren bir dil tanımlama havuzu. Tika, dil tespiti için dahili olarak N-gram algoritmasını kullanır.
MIME Tespit Mekanizması
Tika, belge türünü MIME standartlarına göre algılayabilir. Tika'da varsayılan MIME türü algılaması, org.apache.tika.mime.mimeTypes kullanılarak yapılır . İçerik türü algılamanın çoğu için org.apache.tika.detect.Detector arabirimini kullanır .
Dahili olarak Tika, dosya küreleri, içerik türü ipuçları, sihirli baytlar, karakter kodlamaları ve diğer birkaç teknik gibi çeşitli teknikler kullanır.
Ayrıştırıcı Arayüzü
Org.apache.tika.parser'ın ayrıştırıcı arabirimi, Tika'da belgeleri ayrıştırmak için anahtar arabirimdir. Bu Arayüz, bir belgeden metni ve meta verileri çıkarır ve ayrıştırıcı eklentileri yazmaya istekli olan harici kullanıcılar için bunları özetler.
Farklı belge türlerine özel farklı somut ayrıştırıcı sınıfları kullanan Tika, birçok belge biçimini destekler. Bu biçime özgü sınıflar, ya doğrudan ayrıştırıcı mantığını uygulayarak ya da harici ayrıştırıcı kitaplıkları kullanarak farklı belge biçimleri için destek sağlar.
Tika Cephe Sınıfı
Tika cephe sınıfını kullanmak, Java'dan Tika'yı çağırmanın en basit ve doğrudan yoludur ve cephe tasarım modelini takip eder. Tika cephe sınıfını Tika API'nin org.apache.tika paketinde bulabilirsiniz.
Tika, temel kullanım örneklerini uygulayarak bir peyzaj aracısı olarak hareket eder. MIME algılama mekanizması, ayrıştırıcı arabirimi ve dil algılama mekanizması gibi Tika kitaplığının temelindeki karmaşıklığı özetler ve kullanıcılara basit bir arabirim sağlar.
Tika'nın Özellikleri
Unified parser Interface- Tika, tüm üçüncü taraf ayrıştırıcı kitaplıklarını tek bir ayrıştırıcı arabirimi içinde kapsüller. Bu özellik sayesinde kullanıcı, uygun ayrıştırıcı kitaplığını seçme ve karşılaşılan dosya türüne göre kullanma yükünden kurtulur.
Low memory usage- Tika daha az bellek kaynağı tüketir, bu nedenle Java uygulamaları ile kolayca yerleştirilebilir. Tika'yı mobil PDA gibi daha az kaynağa sahip platformlarda çalışan uygulama içerisinde de kullanabiliriz.
Fast processing - Uygulamalardan hızlı içerik tespiti ve ayıklama beklenebilir.
Flexible metadata - Tika, dosyaları tanımlamak için kullanılan tüm meta veri modellerini anlar.
Parser integration - Tika, tek bir uygulamada her belge türü için mevcut olan çeşitli ayrıştırıcı kitaplıklarını kullanabilir.
MIME type detection - Tika, MIME standartlarında bulunan tüm ortam türlerinden içeriği algılayabilir ve çıkarabilir.
Language detection - Tika, dil tanımlama özelliği içerir, bu nedenle çok dilli web sitelerinde dil türüne göre belgelerde kullanılabilir.
Tika'nın İşlevleri
Tika çeşitli işlevleri destekler -
- Belge türü algılama
- İçerik çıkarma
- Meta veri çıkarma
- Dil algılama
Belge Türü Algılama
Tika, çeşitli tespit teknikleri kullanır ve kendisine verilen belgenin türünü tespit eder.

İçerik Çıkarma
Tika, çeşitli belge biçimlerinin içeriğini ayrıştırıp çıkarabilen bir ayrıştırıcı kitaplığına sahiptir. Dokümanın türünü tespit ettikten sonra, ayrıştırıcı havuzundan uygun ayrıştırıcıyı seçer ve belgeyi iletir. Farklı Tika sınıfları, farklı belge biçimlerini ayrıştırma yöntemlerine sahiptir.

Meta Veri Çıkarma
Tika, içeriğin yanı sıra belgenin meta verilerini içerik çıkarma işlemiyle aynı prosedürle çıkarır. Bazı belge türleri için Tika, meta verileri çıkaracak sınıflara sahiptir.

Dil Algılama
Tika, dahili olarak şu algoritmaları izler: n-grambelirli bir belgedeki içeriğin dilini tespit etmek için. Tika aşağıdaki gibi sınıflara bağlıdırLanguageidentifier ve Profiler dil tanımlama için.

Bu bölüm, Apache Tika'yı Windows ve Linux'ta kurma sürecinde size yol gösterir. Apache Tika'yı yüklerken kullanıcı yönetimi gereklidir.
sistem gereksinimleri
| JDK | Java SE 2 JDK 1.6 veya üstü |
| Hafıza | 1 GB RAM (önerilen) |
| Disk alanı | Minimum gereklilik yok |
| İşletim Sistemi Sürümü | Windows XP veya üzeri, Linux |
Adım 1: Java Kurulumunu Doğrulama
Java kurulumunu doğrulamak için konsolu açın ve aşağıdakileri yürütün java komut.
| işletim sistemi | Görev | Komut |
|---|---|---|
| pencereler | Komut konsolunu aç | \> java –sürüm |
| Linux | Komut terminalini aç | $ java –version |
Java, sisteminize doğru bir şekilde yüklendiyse, üzerinde çalıştığınız platforma bağlı olarak aşağıdaki çıktılardan birini almalısınız.
| işletim sistemi | Çıktı |
|---|---|
| pencereler | Java sürümü "1.7.0_60"
Java (TM) SE Çalışma Zamanı Ortamı (derleme 1.7.0_60-b19) Java Hotspot (TM) 64-bit Sunucu VM (derleme 24.60-b09, karma mod) |
| Lunix | java sürümü "1.7.0_25" JDK Çalışma Zamanı Ortamını açın (rhel-2.3.10.4.el6_4-x86_64) JDK 64-Bit Sunucu VM'yi açın (23.7-b01 derleme, karma mod) |
Bu eğiticiye geçmeden önce bu eğiticinin okuyucularının sistemlerinde Java 1.7.0_60 yüklü olduğunu varsayıyoruz.
Java SDK'nız yoksa, mevcut sürümünü şuradan indirin: https://www.oracle.com/technetwork/java/javase/downloads/index.html and have it installed.
Adım 2: Java Ortamını Ayarlama
JAVA_HOME ortam değişkenini, Java'nın makinenizde kurulu olduğu temel dizin konumunu gösterecek şekilde ayarlayın. Örneğin,
| işletim sistemi | Çıktı |
|---|---|
| pencereler | Çevresel değişken JAVA_HOME'u C: \ ProgramFiles \ java \ jdk1.7.0_60 olarak ayarlayın |
| Linux | dışa aktar JAVA_HOME = / usr / local / java-current |
Java derleyici konumunun tam yolunu Sistem Yoluna ekleyin.
| işletim sistemi | Çıktı |
|---|---|
| pencereler | Dizeyi Ekle; C: \ Program Files \ Java \ jdk1.7.0_60 \ bin PATH sistem değişkeninin sonuna. |
| Linux | dışa aktar PATH = $ PATH: $ JAVA_HOME / bin / |
Yukarıda açıklandığı gibi komut isteminden java sürümü komutunu doğrulayın.
Adım 3: Apache Tika Ortamını Kurma
Programcılar, Apache Tika'yı ortamlarına entegre edebilirler.
- Komut satırı,
- Tika API,
- Tika'nın komut satırı arayüzü (CLI),
- Tika'nın Grafik Kullanıcı arabirimi (GUI) veya
- kaynak kodu.
Bu yaklaşımlardan herhangi biri için öncelikle Tika'nın kaynak kodunu indirmelisiniz.
Tika'nın kaynak kodunu şu adreste bulabilirsiniz: https://Tika.apache.org/download.html, iki bağlantı bulacaksınız -
apache-tika-1.6-src.zip - Tika'nın kaynak kodunu içerir ve
Tika -app-1.6.jar - Tika uygulamasını içeren bir jar dosyasıdır.
Bu iki dosyayı indirin. Tika'nın resmi web sitesinin bir anlık görüntüsü aşağıda gösterilmektedir.
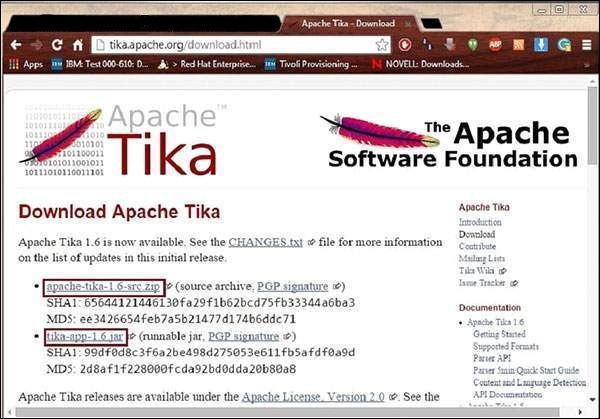
Dosyaları indirdikten sonra, jar dosyası için sınıf yolunu ayarlayın tika-app-1.6.jar. Aşağıdaki tabloda gösterildiği gibi jar dosyasının tam yolunu ekleyin.
| işletim sistemi | Çıktı |
|---|---|
| pencereler | "C: \ jars \ Tika-app-1.6.jar" dizesini CLASSPATH kullanıcı ortam değişkenine ekleyin |
| Linux | Dışa Aktar CLASSPATH = $ CLASSPATH - /usr/share/jars/Tika-app-1.6.tar - |
Apache, Eclipse kullanan bir Grafik Kullanıcı Arayüzü (GUI) uygulaması olan Tika uygulamasını sağlar.
Eclipse kullanarak Tika-Maven Build
Tutulmayı açın ve yeni bir proje oluşturun.
Eclipse'inizde Maven yoksa, verilen adımları izleyerek kurun.
Https://wiki.eclipse.org/M2E_updatesite_and_gittags bağlantısını açın . Orada m2e eklenti sürümlerini tablo biçiminde bulacaksınız.
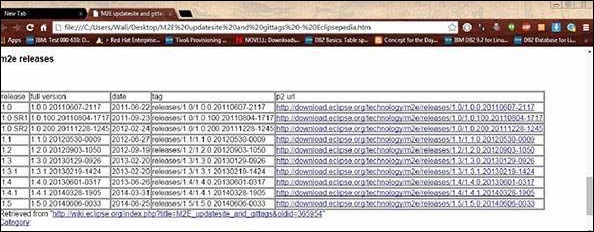
En son sürümü seçin ve url'nin yolunu p2 url sütununa kaydedin.
Şimdi tutulmayı tekrar ziyaret edin, menü çubuğunda Help, ve Seç Install New Software açılır menüden

Tıkla Adddüğmesine isteğe bağlı olduğundan istediğiniz adı yazın. Şimdi kaydedilen url'yi şuraya yapıştırın:Location alan.
Önceki adımda seçtiğiniz adla yeni bir eklenti eklenecek, önündeki onay kutusunu işaretleyin ve tıklayın Next.

Kuruluma devam edin. Tamamlandığında, Eclipse'i yeniden başlatın.
Şimdi projeye sağ tıklayın ve configure seçenek seçin convert to maven project.
Yeni bir pom oluşturmak için yeni bir sihirbaz belirir. Grup Kimliğini org.apache.tika olarak girin, Tika'nın en son sürümünü girin,packaging kavanoz olarak ve tıklayın Finish.
Maven projesi başarıyla yüklendi ve projeniz Maven'e dönüştürüldü. Şimdi pom.xml dosyasını yapılandırmanız gerekiyor.
XML Dosyasını Yapılandırın
Tika maven bağımlılığını buradan alınhttps://mvnrepository.com/artifact/org.apache.tika
Aşağıda, Apache Tika'nın tam Maven bağımlılığı gösterilmektedir.
<dependency>
<groupId>org.apache.Tika</groupId>
<artifactId>Tika-core</artifactId>
<version>1.6</version>
<groupId>org.apache.Tika</groupId>
<artifactId> Tika-parsers</artifactId>
<version> 1.6</version>
<groupId> org.apache.Tika</groupId>
<artifactId>Tika</artifactId>
<version>1.6</version>
<groupId>org.apache.Tika</groupId>
< artifactId>Tika-serialization</artifactId>
< version>1.6< /version>
< groupId>org.apache.Tika< /groupId>
< artifactId>Tika-app< /artifactId>
< version>1.6< /version>
<groupId>org.apache.Tika</groupId>
<artifactId>Tika-bundle</artifactId>
<version>1.6</version>
</dependency>Kullanıcılar, Tika cephe sınıfını kullanarak uygulamalarına Tika'yı yerleştirebilirler. Tika'nın tüm işlevlerini keşfetme yöntemlerine sahiptir. Bir cephe sınıfı olduğu için Tika, işlevlerinin ardındaki karmaşıklığı özetler. Buna ek olarak, kullanıcılar uygulamalarında çeşitli Tika sınıflarını da kullanabilirler.
Tika Sınıfı (cephe)
Bu, Tika kütüphanesinin en öne çıkan sınıfıdır ve cephe tasarım modelini takip eder. Bu nedenle, tüm dahili uygulamaları özetler ve Tika işlevlerine erişmek için basit yöntemler sağlar. Aşağıdaki tablo, bu sınıfın yapıcılarını açıklamalarıyla birlikte listeler.
package - org.apache.tika
class - Tika
| Sr.No. | Oluşturucu ve Açıklama |
|---|---|
| 1 | Tika () Varsayılan konfigürasyonu kullanır ve Tika sınıfını oluşturur. |
| 2 | Tika (Detector detector) Dedektör örneğini parametre olarak kabul ederek bir Tika cephesi oluşturur |
| 3 | Tika (Detector detector, Parser parser) Dedektör ve ayrıştırıcı örneklerini parametre olarak kabul ederek bir Tika cephesi oluşturur. |
| 4 | Tika (Detector detector, Parser parser, Translator translator) Detektörü, ayrıştırıcıyı ve çevirmen örneğini parametre olarak kabul ederek bir Tika cephesi oluşturur. |
| 5 | Tika (TikaConfig config) TikaConfig sınıfının nesnesini parametre olarak kabul ederek bir Tika cephesi oluşturur. |
Yöntemler ve Açıklama
Aşağıdakiler Tika cephe sınıfının önemli yöntemleridir -
| Sr.No. | Yöntemler ve Açıklama |
|---|---|
| 1 | ayrıştırmakToString (File dosya) Bu yöntem ve tüm türevleri, parametre olarak iletilen dosyayı ayrıştırır ve çıkarılan metin içeriğini String biçiminde döndürür. Varsayılan olarak, bu dize parametresinin uzunluğu sınırlıdır. |
| 2 | int getMaxStringLength () ParseToString yöntemleri tarafından döndürülen dizelerin maksimum uzunluğunu döndürür. |
| 3 | geçersiz setMaxStringLength (int maxStringLength) ParseToString yöntemleri tarafından döndürülen maksimum dize uzunluğunu ayarlar. |
| 4 | Okuyucu parse (File dosya) Bu yöntem ve tüm türevleri, parametre olarak iletilen dosyayı ayrıştırır ve çıkarılan metin içeriğini java.io.reader nesnesi biçiminde döndürür. |
| 5 | Dize detect (InputStream Akış, Metadata meta veriler) Bu yöntem ve tüm varyantları, bir InputStream nesnesini ve bir Metadata nesnesini parametre olarak kabul eder, verilen belgenin türünü algılar ve belge türü adını String nesnesi olarak döndürür. Bu yöntem, Tika tarafından kullanılan tespit mekanizmalarını özetler. |
| 6 | Dize translate (InputStream Metin, String hedef dil) Bu yöntem ve tüm türevleri, InputStream nesnesini ve metnimizin çevrilmesini istediğimiz dili temsil eden bir String'i kabul eder ve kaynak dili otomatik olarak algılamaya çalışarak verilen metni istenen dile çevirir. |
Ayrıştırıcı Arayüzü
Bu, Tika paketinin tüm ayrıştırıcı sınıfları tarafından uygulanan arabirimdir.
package - org.apache.tika.parser
Interface - Ayrıştırıcı
Yöntemler ve Açıklama
Tika Parser arayüzünün önemli yöntemi aşağıdadır -
| Sr.No. | Yöntemler ve Açıklama |
|---|---|
| 1 | parse (InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) Bu yöntem, verilen belgeyi bir XHTML ve SAX olayları dizisine ayrıştırır. Ayrıştırdıktan sonra, çıkarılan belge içeriğini ContentHandler sınıfının nesnesine ve meta verileri Metadata sınıfının nesnesine yerleştirir. |
Meta Veri Sınıfı
Bu sınıf, çeşitli veri modellerini desteklemek için CreativeCommons, Geographic, HttpHeaders, Message, MSOffice, ClimateForcast, TIFF, TikaMetadataKeys, TikaMimeKeys, Serializable gibi çeşitli arabirimleri uygular. Aşağıdaki tablolar, bu sınıfın yapıcılarını ve yöntemlerini açıklamalarıyla birlikte listeler.
package - org.apache.tika.metadata
class - Meta veriler
| Sr.No. | Oluşturucu ve Açıklama |
|---|---|
| 1 | Metadata() Yeni, boş bir meta veri oluşturur. |
| Sr.No. | Yöntemler ve Açıklama |
|---|---|
| 1 | add (Property property, String value) Belirli bir belgeye bir meta veri özelliği / değer eşlemesi ekler. Bu işlevi kullanarak değeri bir özelliğe ayarlayabiliriz. |
| 2 | add (String name, String value) Belirli bir belgeye bir meta veri özelliği / değer eşlemesi ekler. Bu yöntemi kullanarak, bir belgenin mevcut meta verilerine yeni bir ad değeri ayarlayabiliriz. |
| 3 | String get (Property property) Verilen meta veri özelliğinin değerini (varsa) döndürür. |
| 4 | String get (String name) Verilen meta veri adının değerini (varsa) döndürür. |
| 5 | Date getDate (Property property) Date meta veri özelliğinin değerini döndürür. |
| 6 | String[] getValues (Property property) Bir meta veri özelliğinin tüm değerlerini döndürür. |
| 7 | String[] getValues (String name) Belirli bir meta veri adının tüm değerlerini döndürür. |
| 8 | String[] names() Bir meta veri nesnesindeki tüm meta veri öğelerinin adlarını döndürür. |
| 9 | set (Property property, Date date) Verilen meta veri özelliğinin tarih değerini ayarlar |
| 10 | set(Property property, String[] values) Birden çok değeri bir meta veri özelliğine ayarlar. |
Dil Tanımlayıcı Sınıfı
Bu sınıf, verilen içeriğin dilini tanımlar. Aşağıdaki tablolarda bu sınıfın kurucuları açıklamalarıyla birlikte listelenmektedir.
package - org.apache.tika.language
class - Dil Tanımlayıcı
| Sr.No. | Oluşturucu ve Açıklama |
|---|---|
| 1 | LanguageIdentifier (LanguageProfile profile) Dil tanımlayıcısını somutlaştırır. Burada bir LanguageProfile nesnesini parametre olarak iletmelisiniz. |
| 2 | LanguageIdentifier (String content) Bu yapıcı, metin içeriğinden bir Dize geçirerek bir dil tanımlayıcısını başlatabilir. |
| Sr.No. | Yöntemler ve Açıklama |
|---|---|
| 1 | String getLanguage () Geçerli LanguageIdentifier nesnesine verilen dili döndürür. |
Tika Tarafından Desteklenen Dosya Biçimleri
Aşağıdaki tablo Tika'nın desteklediği dosya formatlarını göstermektedir.
| Dosya formatı | Paket Kitaplığı | Tika Sınıfı |
|---|---|---|
| XML | org.apache.tika.parser.xml | XMLParser |
| HTML | org.apache.tika.parser.html ve Tagsoup Kitaplığı kullanır | HtmlParser |
| MS-Office bileşik belgesi Ole2 2007'ye kadar ooxml 2007'den itibaren | org.apache.tika.parser.microsoft org.apache.tika.parser.microsoft.ooxml ve Apache Poi kitaplığını kullanır |
OfficeParser (ole2) OOXMLParser (ooxml) |
| OpenDocument Biçimi openoffice | org.apache.tika.parser.odf | OpenOfficeParser |
| taşınabilir Belge Biçimi (PDF) | org.apache.tika.parser.pdf ve bu paket Apache PdfBox kitaplığını kullanır | PDFParser |
| Elektronik Yayın Formatı (dijital kitaplar) | org.apache.tika.parser.epub | EpubParser |
| Zengin metin formatı | org.apache.tika.parser.rtf | RTFParser |
| Sıkıştırma ve paketleme formatları | org.apache.tika.parser.pkg ve bu paket Ortak sıkıştırma kitaplığını kullanır | PackageParser ve CompressorParser ve alt sınıfları |
| Metin formatı | org.apache.tika.parser.txt | TXTParser |
| Besleme ve sendikasyon biçimleri | org.apache.tika.parser.feed | FeedParser |
| Ses formatları | org.apache.tika.parser.audio ve org.apache.tika.parser.mp3 | AudioParser MidiParser Mp3- mp3parser için |
| Görüntü ayırıcılar | org.apache.tika.parser.jpeg | JpegParser-için jpeg görüntüleri |
| Video biçimleri | org.apache.tika.parser.mp4 ve org.apache.tika.parser.video bu ayrıştırıcı, flash video formatlarını ayrıştırmak için dahili olarak Basit Algoritma kullanır | Mp4parser FlvParser |
| java sınıf dosyaları ve jar dosyaları | org.apache.tika.parser.asm | ClassParser CompressorParser |
| Mobxformat (e-posta mesajları) | org.apache.tika.parser.mbox | MobXParser |
| Cad formatları | org.apache.tika.parser.dwg | DWGParser |
| FontFormats | org.apache.tika.parser.font | TrueTypeParser |
| çalıştırılabilir programlar ve kitaplıklar | org.apache.tika.parser.executable | ExecutableParser |
MIME Standartları
Çok Amaçlı İnternet Posta Uzantıları (MIME) standartları, belge türlerini belirlemek için mevcut en iyi standartlardır. Bu standartların bilgisi, dahili etkileşimler sırasında tarayıcıya yardımcı olur.
Tarayıcı bir medya dosyasıyla her karşılaştığında, içeriğini görüntülemek için onunla uyumlu bir yazılım seçer. Belirli bir medya dosyasını çalıştırmak için uygun herhangi bir uygulamaya sahip olmaması durumunda, kullanıcıya onun için uygun eklenti yazılımını almasını önerir.
Tika'da Tip Algılama
Tika, MIME'de sağlanan tüm İnternet medya belge türlerini destekler. Bir dosya Tika'dan her geçirildiğinde, dosyayı ve belge türünü algılar. Ortam türlerini tespit etmek için Tika dahili olarak aşağıdaki mekanizmaları kullanır.
Dosya uzantıları
Dosya uzantılarını kontrol etmek, bir dosyanın biçimini tespit etmek için en basit ve en yaygın kullanılan yöntemdir. Birçok uygulama ve işletim sistemi bu uzantılar için destek sağlar. Aşağıda, bilinen birkaç dosya türünün uzantısı gösterilmektedir.
| Dosya adı | Uzantı |
|---|---|
| görüntü | .jpg |
| ses | .mp3 |
| java arşiv dosyası | .jar |
| java sınıf dosyası | .sınıf |
İçerik Türü İpuçları
Veritabanından bir dosya aldığınızda veya başka bir belgeye eklediğinizde, dosyanın adını veya uzantısını kaybedebilirsiniz. Bu gibi durumlarda, dosya ile birlikte sağlanan meta veriler, dosya uzantısını tespit etmek için kullanılır.
Sihirli Bayt
Bir dosyanın ham baytlarını inceleyerek, her dosya için bazı benzersiz karakter desenleri bulabilirsiniz. Bazı dosyaların özel bayt önekleri vardır.magic bytes dosya türünü belirlemek amacıyla özel olarak yapılmış ve bir dosyaya eklenmiş
Örneğin, bir java dosyasında CA FE BA BE (onaltılık format) ve bir pdf dosyasında% PDF (ASCII formatı) bulabilirsiniz. Tika, bu bilgileri bir dosyanın ortam türünü belirlemek için kullanır.
Karakter Kodlamaları
Düz metin içeren dosyalar, farklı karakter kodlaması türleri kullanılarak kodlanır. Buradaki ana zorluk, dosyalarda kullanılan karakter kodlama türünü belirlemektir. Tika, aşağıdaki gibi karakter kodlama tekniklerini takip eder:Bom markers ve Byte Frequencies düz metin içeriği tarafından kullanılan kodlama sistemini tanımlamak için.
XML Kök Karakterleri
XML belgelerini algılamak için Tika, xml belgelerini ayrıştırır ve dosyaların gerçek ortam türünün bulunabileceği kök öğeler, ad alanları ve başvurulan şemalar gibi bilgileri çıkarır.
Cephe Sınıfı kullanarak Tip Algılama
detect()Doküman türünü tespit etmek için cephe sınıfı yöntemi kullanılır. Bu yöntem, bir dosyayı girdi olarak kabul eder. Aşağıda gösterilen, Tika cephe sınıfı ile belge tipi tespiti için örnek bir programdır.
import java.io.File;
import org.apache.tika.Tika;
public class Typedetection {
public static void main(String[] args) throws Exception {
//assume example.mp3 is in your current directory
File file = new File("example.mp3");//
//Instantiating tika facade class
Tika tika = new Tika();
//detecting the file type using detect method
String filetype = tika.detect(file);
System.out.println(filetype);
}
}Yukarıdaki kodu TypeDetection.java olarak kaydedin ve aşağıdaki komutları kullanarak komut isteminden çalıştırın -
javac TypeDetection.java
java TypeDetection
audio/mpegTika, belirli ayrıştırıcılardan içerik çıkarmak için çeşitli ayrıştırıcı kitaplıkları kullanır. Verilen belge türünü çıkarmak için doğru ayrıştırıcıyı seçer.
Belgeleri ayrıştırmak için genellikle Tika cephe sınıfının parseToString () yöntemi kullanılır. Aşağıda, ayrıştırma sürecine dahil olan adımlar gösterilmektedir ve bunlar Tika ParsertoString () yöntemi ile soyutlanmıştır.

Ayrıştırma sürecinin soyutlanması -
Başlangıçta Tika'ya bir belge ilettiğimizde, onunla birlikte bulunan uygun bir tür algılama mekanizması kullanır ve belge türünü algılar.
Belge türü bilindiğinde, ayrıştırıcı deposundan uygun bir ayrıştırıcı seçer. Ayrıştırıcı deposu, harici kitaplıklardan yararlanan sınıfları içerir.
Ardından belge, içeriği ayrıştıracak, metni çıkaracak ve ayrıca okunamayan biçimler için istisnalar atacak ayrıştırıcıyı seçmek için iletilir.
Tika kullanarak İçerik Çıkarma
Aşağıda, Tika cephe sınıfını kullanarak bir dosyadan metin çıkarma programı verilmiştir -
import java.io.File;
import java.io.IOException;
import org.apache.tika.Tika;
import org.apache.tika.exception.TikaException;
import org.xml.sax.SAXException;
public class TikaExtraction {
public static void main(final String[] args) throws IOException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//Instantiating Tika facade class
Tika tika = new Tika();
String filecontent = tika.parseToString(file);
System.out.println("Extracted Content: " + filecontent);
}
}Yukarıdaki kodu TikaExtraction.java olarak kaydedin ve komut isteminden çalıştırın -
javac TikaExtraction.java
java TikaExtractionAşağıda, sample.txt'nin içeriği verilmiştir.
Hi students welcome to tutorialspointSize şu çıktıyı verir -
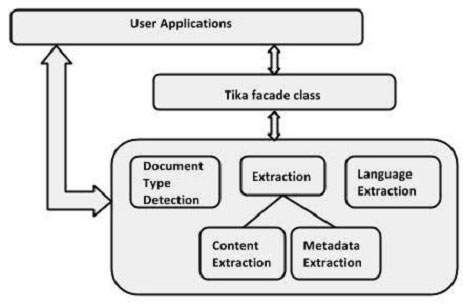
Extracted Content: Hi students welcome to tutorialspointAyrıştırıcı Arayüzü kullanarak İçerik Çıkarma
Tika'nın ayrıştırıcı paketi, bir metin belgesini ayrıştırabileceğimiz çeşitli arayüzler ve sınıflar sağlar. Aşağıda verilen blok diyagramıdır.org.apache.tika.parser paketi.

İlgili belgeleri ayrı ayrı ayrıştırmak için çeşitli ayrıştırıcı sınıfları vardır, örneğin pdf ayrıştırıcı, Mp3Passer, OfficeParser, vb. Tüm bu sınıflar ayrıştırıcı arabirimini uygular.
CompositeParser
Verilen diyagram, Tika'nın genel amaçlı ayrıştırıcı sınıflarını gösterir: CompositeParser ve AutoDetectParser. CompositeParser sınıfı bileşik tasarım desenini takip ettiğinden, bir grup ayrıştırıcı örneğini tek bir ayrıştırıcı olarak kullanabilirsiniz. CompositeParser sınıfı ayrıca ayrıştırıcı arabirimini uygulayan tüm sınıflara erişim sağlar.
AutoDetectParser
Bu, CompositeParser'ın bir alt sınıfıdır ve otomatik tip algılama sağlar. AutoDetectParser, bu işlevi kullanarak, gelen belgeleri bileşik metodolojiyi kullanarak uygun ayrıştırıcı sınıflarına otomatik olarak gönderir.
parse () yöntemi
ParseToString () ile birlikte, ayrıştırıcı Arayüzünün parse () yöntemini de kullanabilirsiniz. Bu yöntemin prototipi aşağıda gösterilmiştir.
parse(InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context)Aşağıdaki tablo, parametre olarak kabul ettiği dört nesneyi listeler.
| Sr.No. | Nesne ve Açıklama |
|---|---|
| 1 | InputStream stream Dosyanın içeriğini içeren herhangi bir Inputstream nesnesi |
| 2 | ContentHandler handler Tika, belgeyi XHTML içeriği olarak bu işleyiciye iletir, ardından belge SAX API kullanılarak işlenir. Bir belgedeki içeriklerin verimli bir şekilde sonradan işlenmesini sağlar. |
| 3 | Metadata metadata Meta veri nesnesi hem kaynak hem de belge meta verilerinin hedefi olarak kullanılır. |
| 4 | ParseContext context Bu nesne, istemci uygulamasının ayrıştırma sürecini özelleştirmek istediği durumlarda kullanılır. |
Misal
Aşağıda, parse () yönteminin nasıl kullanıldığını gösteren bir örnek verilmiştir.
Step 1 -
Ayrıştırıcı arabiriminin parse () yöntemini kullanmak için, bu arabirim için uygulama sağlayan sınıflardan herhangi birini somutlaştırın.
PDFParser, OfficeParser, XMLParser, vb. Gibi ayrı ayrı ayrıştırıcı sınıfları vardır. Bu ayrı belge ayrıştırıcılardan herhangi birini kullanabilirsiniz. Alternatif olarak, dahili olarak tüm ayrıştırıcı sınıflarını kullanan ve uygun bir ayrıştırıcı kullanarak bir belgenin içeriğini çıkaran CompositeParser veya AutoDetectParser'ı kullanabilirsiniz.
Parser parser = new AutoDetectParser();
(or)
Parser parser = new CompositeParser();
(or)
object of any individual parsers given in Tika LibraryStep 2 -
Bir işleyici sınıfı nesnesi oluşturun. Aşağıda üç içerik işleyicisi verilmiştir -
| Sr.No. | Sınıf ve Açıklama |
|---|---|
| 1 | BodyContentHandler Bu sınıf, XHTML çıktısının gövde bölümünü seçer ve bu içeriği çıktı yazıcıya veya çıktı akışına yazar. Daha sonra XHTML içeriğini başka bir içerik işleyici örneğine yeniden yönlendirir. |
| 2 | LinkContentHandler Bu sınıf, XHTML belgesinin tüm H-Ref etiketlerini algılar ve seçer ve bunları web tarayıcıları gibi araçların kullanımı için iletir. |
| 3 | TeeContentHandler Bu sınıf aynı anda birden fazla aracı kullanmanıza yardımcı olur. |
Hedefimiz metin içeriğini bir belgeden çıkarmak olduğundan, BodyContentHandler'ı aşağıda gösterildiği gibi somutlaştırın -
BodyContentHandler handler = new BodyContentHandler( );Step 3 -
Metadata nesnesini aşağıda gösterildiği gibi oluşturun -
Metadata metadata = new Metadata();Step 4 -
Giriş akışı nesnelerinden herhangi birini oluşturun ve çıkarılması gereken dosyanızı ona aktarın.
FileInputstream
Dosya yolunu parametre olarak ileterek bir dosya nesnesinin örneğini oluşturun ve bu nesneyi FileInputStream sınıfı yapıcısına iletin.
Note - Dosya nesnesine iletilen yol boşluk içermemelidir.
Bu giriş akışı sınıflarıyla ilgili sorun, bazı dosya formatlarını verimli bir şekilde işlemek için gerekli olan rastgele erişim okumalarını desteklememeleridir. Bu sorunu çözmek için Tika, TikaInputStream sağlar.
File file = new File(filepath)
FileInputStream inputstream = new FileInputStream(file);
(or)
InputStream stream = TikaInputStream.get(new File(filename));Step 5 -
Aşağıda gösterildiği gibi bir ayrıştırma bağlam nesnesi oluşturun -
ParseContext context =new ParseContext();Step 6 -
Ayrıştırıcı nesnesini örnekleyin, ayrıştırma yöntemini çağırın ve aşağıdaki prototipte gösterildiği gibi gerekli tüm nesneleri iletin -
parser.parse(inputstream, handler, metadata, context);Aşağıda, ayrıştırıcı arabirimini kullanarak içerik çıkarma programı verilmiştir -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class ParserExtraction {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//parse method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the file
parser.parse(inputstream, handler, metadata, context);
System.out.println("File content : " + Handler.toString());
}
}Yukarıdaki kodu ParserExtraction.java olarak kaydedin ve komut isteminden çalıştırın -
javac ParserExtraction.java
java ParserExtractionAşağıda verilen sample.txt içeriğidir
Hi students welcome to tutorialspointYukarıdaki programı çalıştırırsanız, size aşağıdaki çıktıyı verecektir -
File content : Hi students welcome to tutorialspointTika, içeriğin yanı sıra meta verileri bir dosyadan da çıkarır. Meta veriler, bir dosya ile sağlanan ek bilgilerden başka bir şey değildir. Bir ses dosyası düşünürsek, sanatçı adı, albüm adı, başlık meta verilerin altında gelir.
XMP Standartları
Genişletilebilir Meta Veri Platformu (XMP), bir dosyanın içeriğiyle ilgili bilgileri işlemek ve depolamak için bir standarttır. Adobe Systems Inc tarafından oluşturulmuştur . XMP, meta verilerin tanımlanması, oluşturulması ve işlenmesi için standartlar sağlar . Bu standardı PDF , JPEG , JPEG , GIF , jpg , HTML vb. Gibi çeşitli dosya formatlarına gömebilirsiniz .
Emlak Sınıfı
Tika, XMP özellik tanımını takip etmek için Property sınıfını kullanır. Bir meta verilerin adını ve değerini yakalamak için PropertyType ve ValueType numaralandırmalarını sağlar.
Meta Veri Sınıfı
Bu sınıf , çeşitli meta veri modellerine destek sağlamak için ClimateForcast , CativeCommons, Geographic , TIFF vb. Gibi çeşitli arabirimleri uygular . Ek olarak, bu sınıf, içeriği bir dosyadan çıkarmak için çeşitli yöntemler sağlar.
Meta Veri Adları
Bir dosyanın tüm meta veri adlarının listesini, yöntem adlarını () kullanarak meta veri nesnesinden çıkarabiliriz . Tüm isimleri bir dizge dizisi olarak döndürür. Meta verinin adını kullanarak değeri,get()yöntem. Bir meta veri adı alır ve onunla ilişkili bir değer döndürür.
String[] metadaNames = metadata.names();
String value = metadata.get(name);Ayrıştırma Yöntemini Kullanarak Meta Verileri Çıkarma
Parse () kullanarak bir dosyayı ayrıştırdığımızda, parametrelerden biri olarak boş bir meta veri nesnesi geçiririz. Bu yöntem, verilen dosyanın meta verilerini (bu dosya varsa) çıkarır ve bunları meta veri nesnesine yerleştirir. Bu nedenle, dosyayı parse () kullanarak ayrıştırdıktan sonra, meta verileri o nesneden çıkarabiliriz.
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata(); //empty metadata object
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
parser.parse(inputstream, handler, metadata, context);
// now this metadata object contains the extracted metadata of the given file.
metadata.metadata.names();Aşağıda, bir metin dosyasından meta verileri çıkarmak için eksiksiz bir program verilmiştir.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class GetMetadata {
public static void main(final String[] args) throws IOException, TikaException {
//Assume that boy.jpg is in your current directory
File file = new File("boy.jpg");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
parser.parse(inputstream, handler, metadata, context);
System.out.println(handler.toString());
//getting the list of all meta data elements
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Yukarıdaki kodu GetMetadata.java olarak kaydedin ve aşağıdaki komutları kullanarak komut isteminden çalıştırın -
javac GetMetadata .java
java GetMetadataBoy.jpg'nin anlık görüntüsü aşağıda verilmiştir.

Yukarıdaki programı çalıştırırsanız, size aşağıdaki çıktıyı verecektir -
X-Parsed-By: org.apache.tika.parser.DefaultParser
Resolution Units: inch
Compression Type: Baseline
Data Precision: 8 bits
Number of Components: 3
tiff:ImageLength: 3000
Component 2: Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert
Component 1: Y component: Quantization table 0, Sampling factors 2 horiz/2 vert
Image Height: 3000 pixels
X Resolution: 300 dots
Original Transmission Reference:
53616c7465645f5f2368da84ca932841b336ac1a49edb1a93fae938b8db2cb3ec9cc4dc28d7383f1
Image Width: 4000 pixels
IPTC-NAA record: 92 bytes binary data
Component 3: Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert
tiff:BitsPerSample: 8
Application Record Version: 4
tiff:ImageWidth: 4000
Content-Type: image/jpeg
Y Resolution: 300 dotsİstediğimiz meta veri değerlerimizi de alabiliriz.
Yeni Meta Veri Değerleri Ekleme
Metadata sınıfının add () yöntemini kullanarak yeni meta veri değerleri ekleyebiliriz. Aşağıda bu yöntemin sözdizimi verilmiştir. Burada yazar adını ekliyoruz.
metadata.add(“author”,”Tutorials point”);Metadata sınıfı, çeşitli veri modellerini desteklemek için ClimateForcast , CativeCommons, Geographic vb. Sınıflardan miras alınan özellikler dahil olmak üzere önceden tanımlanmış özelliklere sahiptir . Aşağıda, TIFF görüntü formatları için XMP meta veri standartlarını takip etmek için Tika tarafından uygulanan TIFF arayüzünden miras alınan YAZILIM veri türünün kullanımı gösterilmektedir.
metadata.add(Metadata.SOFTWARE,"ms paint");Aşağıda, belirli bir dosyaya meta veri değerlerinin nasıl ekleneceğini gösteren eksiksiz program verilmiştir. Burada, metadata öğelerinin listesi, yeni değerler ekledikten sonra listedeki değişikliği gözlemleyebilmeniz için çıktıda görüntülenir.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Arrays;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class AddMetadata {
public static void main(final String[] args) throws IOException, SAXException, TikaException {
//create a file object and assume sample.txt is in your current directory
File file = new File("Example.txt");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the document
parser.parse(inputstream, handler, metadata, context);
//list of meta data elements before adding new elements
System.out.println( " metadata elements :" +Arrays.toString(metadata.names()));
//adding new meta data name value pair
metadata.add("Author","Tutorials Point");
System.out.println(" metadata name value pair is successfully added");
//printing all the meta data elements after adding new elements
System.out.println("Here is the list of all the metadata
elements after adding new elements");
System.out.println( Arrays.toString(metadata.names()));
}
}Yukarıdaki kodu AddMetadata.java sınıfı olarak kaydedin ve komut isteminden çalıştırın -
javac AddMetadata .java
java AddMetadataAşağıda, Example.txt'nin içeriği verilmiştir
Hi students welcome to tutorialspointYukarıdaki programı çalıştırırsanız, size aşağıdaki çıktıyı verecektir -
metadata elements of the given file :
[Content-Encoding, Content-Type]
enter the number of metadata name value pairs to be added 1
enter metadata1name:
Author enter metadata1value:
Tutorials point metadata name value pair is successfully added
Here is the list of all the metadata elements after adding new elements
[Content-Encoding, Author, Content-Type]Mevcut Meta Veri Öğelerine Değer Ayarlama
Set () yöntemini kullanarak değerleri mevcut meta veri öğelerine ayarlayabilirsiniz. Set () yöntemini kullanarak date özelliğini ayarlamanın sözdizimi aşağıdaki gibidir -
metadata.set(Metadata.DATE, new Date());Set () yöntemini kullanarak özelliklere birden çok değer de ayarlayabilirsiniz. Set () yöntemini kullanarak Author özelliğine birden çok değer ayarlama sözdizimi aşağıdaki gibidir -
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");Aşağıda set () yöntemini gösteren eksiksiz program verilmiştir.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Date;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class SetMetadata {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Create a file object and assume example.txt is in your current directory
File file = new File("example.txt");
//parameters of parse() method
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//Parsing the given file
parser.parse(inputstream, handler, metadata, context);
//list of meta data elements elements
System.out.println( " metadata elements and values of the given file :");
String[] metadataNamesb4 = metadata.names();
for(String name : metadataNamesb4) {
System.out.println(name + ": " + metadata.get(name));
}
//setting date meta data
metadata.set(Metadata.DATE, new Date());
//setting multiple values to author property
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");
//printing all the meta data elements with new elements
System.out.println("List of all the metadata elements after adding new elements ");
String[] metadataNamesafter = metadata.names();
for(String name : metadataNamesafter) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Yukarıdaki kodu SetMetadata.java olarak kaydedin ve komut isteminden çalıştırın -
javac SetMetadata.java
java SetMetadataAşağıda örnek.txt'nin içeriği verilmiştir.
Hi students welcome to tutorialspointYukarıdaki programı çalıştırırsanız, size aşağıdaki çıktıyı verecektir. Çıktıda, yeni eklenen meta veri öğelerini gözlemleyebilirsiniz.
metadata elements and values of the given file :
Content-Encoding: ISO-8859-1
Content-Type: text/plain; charset = ISO-8859-1
Here is the list of all the metadata elements after adding new elements
date: 2014-09-24T07:01:32Z
Content-Encoding: ISO-8859-1
Author: ram, raheem, robin
Content-Type: text/plain; charset = ISO-8859-1Dil Algılama İhtiyacı
Belgelerin çok dilli bir web sitesinde yazıldıkları dile göre sınıflandırılması için bir dil algılama aracına ihtiyaç vardır. Bu araç, dil ek açıklaması (meta veriler) içermeyen belgeleri kabul etmeli ve dili algılayarak bu bilgileri belgenin meta verilerine eklemelidir.
Corpus Profilleme Algoritmaları
Corpus nedir?
Bir belgenin dilini tespit etmek için bir dil profili oluşturulur ve bilinen dillerin profiliyle karşılaştırılır. Bu bilinen dillerin metin kümesi, bircorpus.
Bir külliyat, dilin gerçek durumlarda nasıl kullanıldığını açıklayan bir yazılı dilin metinlerinin bir koleksiyonudur.
Derleme kitaplardan, transkriptlerden ve İnternet gibi diğer veri kaynaklarından geliştirilmiştir. Derlemenin doğruluğu, derlemeyi çerçevelemek için kullandığımız profil oluşturma algoritmasına bağlıdır.
Profil Oluşturma Algoritmaları nelerdir?
Dilleri tespit etmenin yaygın yolu sözlük kullanmaktır. Belirli bir metin parçasında kullanılan sözcükler, sözlüklerde bulunan sözcüklerle eşleştirilecektir.
Bir dilde yaygın olarak kullanılan kelimelerin listesi, belirli bir dili, örneğin makaleleri tespit etmek için en basit ve etkili külliyat olacaktır. a, an, the İngilizcede.
Kelime Kümelerini Derlem olarak Kullanma
Sözcük kümeleri kullanılarak, iki cisim arasındaki mesafeyi bulmak için basit bir algoritma çerçevelenir; bu, eşleşen kelimelerin frekansları arasındaki farkların toplamına eşit olacaktır.
Bu tür algoritmalar aşağıdaki sorunlardan muzdariptir -
Eşleşen kelimelerin sıklığı çok daha az olduğu için algoritma az cümle içeren küçük metinlerle verimli bir şekilde çalışamaz. Doğru eşleşme için çok fazla metne ihtiyaç vardır.
Bileşik cümleleri olan diller ve boşluklar veya noktalama işaretleri gibi kelime bölücüler içermeyen diller için kelime sınırlarını tespit edemez.
Sözcük kümelerini külliyat olarak kullanmadaki bu zorluklar nedeniyle, tek tek karakterler veya karakter grupları dikkate alınır.
Karakter Kümelerini Derlem Olarak Kullanma
Bir dilde yaygın olarak kullanılan karakterler sayı olarak sonlu olduğundan, karakterlerden ziyade kelime frekanslarına dayalı bir algoritma uygulamak kolaydır. Bu algoritma, bir veya birkaç dilde belirli karakter kümelerinin kullanılması durumunda daha da iyi çalışır.
Bu algoritma aşağıdaki dezavantajlardan muzdariptir -
Benzer karakter frekanslarına sahip iki dili ayırt etmek zordur.
Bir dili, birden çok dil tarafından kullanılan karakter kümesinin yardımıyla (külliyat olarak) özel olarak tanımlamak için belirli bir araç veya algoritma yoktur.
N-gram Algoritması
Yukarıda belirtilen dezavantajlar, belirli bir uzunluktaki karakter dizilerini korpusu profillemek için kullanma konusunda yeni bir yaklaşıma yol açtı. Bu tür karakter dizileri genel olarak N-gram olarak adlandırılır; burada N, karakter dizisinin uzunluğunu temsil eder.
N-gram algoritması, özellikle İngilizce gibi Avrupa dilleri söz konusu olduğunda, dil algılama için etkili bir yaklaşımdır.
Bu algoritma kısa metinlerle iyi çalışıyor.
Daha çekici özelliklere sahip çok dilli bir belgede birden çok dili algılamak için gelişmiş dil profili oluşturma algoritmaları olsa da, Tika çoğu pratik durumda uygun olduğu için 3 gramlık algoritmayı kullanır.
Tika'da Dil Algılama
ISO 639-1 tarafından standartlaştırılan 184 standart dil arasında Tika, 18 dili algılayabilir. Tika'da dil tespiti,getLanguage() yöntemi LanguageIdentifiersınıf. Bu yöntem, dilin kod adını String biçiminde döndürür. Aşağıda, Tika tarafından tespit edilen 18 dil kodu çiftinin listesi verilmiştir -
| da — Danca | de — Almanca | et — Estonca | el — Yunanca |
| en — İngilizce | es - İspanyolca | fi - Fince | fr - Fransızca |
| hu — Macar | İzlandaca | o - İtalyanca | nl — Hollandaca |
| hayır - Norveççe | pl — Lehçe | pt — Portekizce | ru — Rusça |
| sv — İsveççe | th - Tayca |
Örneklenirken LanguageIdentifier sınıf, ayıklanacak içeriğin String formatını veya bir LanguageProfile sınıf nesnesi.
LanguageIdentifier object = new LanguageIdentifier(“this is english”);Aşağıda, Tika'da Dil algılama için örnek program verilmiştir.
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.language.LanguageIdentifier;
import org.xml.sax.SAXException;
public class LanguageDetection {
public static void main(String args[])throws IOException, SAXException, TikaException {
LanguageIdentifier identifier = new LanguageIdentifier("this is english ");
String language = identifier.getLanguage();
System.out.println("Language of the given content is : " + language);
}
}Yukarıdaki kodu farklı kaydedin LanguageDetection.java ve aşağıdaki komutları kullanarak komut isteminden çalıştırın -
javac LanguageDetection.java
java LanguageDetectionYukarıdaki programı çalıştırırsanız aşağıdaki çıktıyı verir gives
Language of the given content is : enBir Belgenin Dil Algılama
Belirli bir belgenin dilini tespit etmek için, parse () yöntemini kullanarak ayrıştırmanız gerekir. Parse () yöntemi, içeriği ayrıştırır ve argümanlardan biri olarak kendisine iletilen işleyici nesnesinde depolar. İşleyici nesnesinin String formatını,LanguageIdentifier aşağıda gösterildiği gibi sınıf -
parser.parse(inputstream, handler, metadata, context);
LanguageIdentifier object = new LanguageIdentifier(handler.toString());Aşağıda verilen bir belgenin dilinin nasıl tespit edileceğini gösteren eksiksiz bir program verilmiştir -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.language.*;
import org.xml.sax.SAXException;
public class DocumentLanguageDetection {
public static void main(final String[] args) throws IOException, SAXException, TikaException {
//Instantiating a file object
File file = new File("Example.txt");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream content = new FileInputStream(file);
//Parsing the given document
parser.parse(content, handler, metadata, new ParseContext());
LanguageIdentifier object = new LanguageIdentifier(handler.toString());
System.out.println("Language name :" + object.getLanguage());
}
}Yukarıdaki kodu SetMetadata.java olarak kaydedin ve komut isteminden çalıştırın -
javac SetMetadata.java
java SetMetadataAşağıda, Example.txt'nin içeriği verilmiştir.
Hi students welcome to tutorialspointYukarıdaki programı çalıştırırsanız, size aşağıdaki çıktıyı verecektir -
Language name :enTika jar ile birlikte Tika, bir Grafik Kullanıcı Arayüzü uygulaması (GUI) ve Komut Satırı Arayüzü (CLI) uygulaması sağlar. Bir Tika uygulamasını da diğer Java uygulamaları gibi komut isteminden çalıştırabilirsiniz.
Grafik Kullanıcı Arayüzü (GUI)
Tika, aşağıdaki bağlantıda kaynak koduyla birlikte bir jar dosyası sağlar. https://tika.apache.org/download.html.
Her iki dosyayı da indirin, jar dosyası için sınıf yolunu ayarlayın.
Kaynak kodu zip klasörünü çıkarın, tika-app klasörünü açın.
"Tika-1.6 \ tika-app \ src \ main \ java \ org \ apache \ Tika \ gui" konumundaki çıkartılan klasörde iki sınıf dosyası göreceksiniz: ParsingTransferHandler.java ve TikaGUI.java.
Hem sınıf dosyalarını derleyin hem de TikaGUI.java sınıf dosyasını çalıştırın, aşağıdaki pencereyi açar.

Şimdi Tika GUI'den nasıl yararlanacağımızı görelim.
GUI'de aç'a tıklayın, çıkartılacak bir dosyaya göz atın ve seçin veya pencerenin beyaz alanına sürükleyin.
Tika dosyaların içeriğini çıkarır ve beş farklı biçimde görüntüler, yani. meta veriler, biçimlendirilmiş metin, düz metin, ana içerik ve yapılandırılmış metin. İstediğiniz formatlardan herhangi birini seçebilirsiniz.
Aynı şekilde, CLI sınıfını da “tika-1.6 \ tikaapp \ src \ main \ java \ org \ apache \ tika \ cli” klasöründe bulacaksınız.
Aşağıdaki çizim Tika'nın neler yapabileceğini göstermektedir. Görüntüyü GUI'ye bıraktığımızda, Tika meta verilerini çıkarır ve görüntüler.
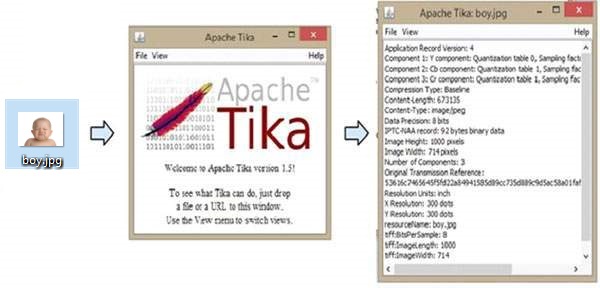
Aşağıda, bir PDF'den içerik ve meta veri çıkarma programı verilmiştir.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.pdf.PDFParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class PdfParse {
public static void main(final String[] args) throws IOException,TikaException {
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.pdf"));
ParseContext pcontext = new ParseContext();
//parsing the document using PDF parser
PDFParser pdfparser = new PDFParser();
pdfparser.parse(inputstream, handler, metadata,pcontext);
//getting the content of the document
System.out.println("Contents of the PDF :" + handler.toString());
//getting metadata of the document
System.out.println("Metadata of the PDF:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name+ " : " + metadata.get(name));
}
}
}Yukarıdaki kodu farklı kaydedin PdfParse.javave aşağıdaki komutları kullanarak komut isteminden derleyin -
javac PdfParse.java
java PdfParseAşağıda örnek.pdf'nin anlık görüntüsü verilmiştir.

Geçtiğimiz PDF aşağıdaki özelliklere sahiptir -

Programı derledikten sonra çıktıyı aşağıda gösterildiği gibi alacaksınız.
Output -
Contents of the PDF:
Apache Tika is a framework for content type detection and content extraction
which was designed by Apache software foundation. It detects and extracts metadata
and structured text content from different types of documents such as spreadsheets,
text documents, images or PDFs including audio or video input formats to certain extent.
Metadata of the PDF:
dcterms:modified : 2014-09-28T12:31:16Z
meta:creation-date : 2014-09-28T12:31:16Z
meta:save-date : 2014-09-28T12:31:16Z
dc:creator : Krishna Kasyap
pdf:PDFVersion : 1.5
Last-Modified : 2014-09-28T12:31:16Z
Author : Krishna Kasyap
dcterms:created : 2014-09-28T12:31:16Z
date : 2014-09-28T12:31:16Z
modified : 2014-09-28T12:31:16Z
creator : Krishna Kasyap
xmpTPg:NPages : 1
Creation-Date : 2014-09-28T12:31:16Z
pdf:encrypted : false
meta:author : Krishna Kasyap
created : Sun Sep 28 05:31:16 PDT 2014
dc:format : application/pdf; version = 1.5
producer : Microsoft® Word 2013
Content-Type : application/pdf
xmp:CreatorTool : Microsoft® Word 2013
Last-Save-Date : 2014-09-28T12:31:16ZAşağıda, Open Office Document Format (ODF) 'den içerik ve meta veri çıkarma programı verilmiştir.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.odf.OpenDocumentParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class OpenDocumentParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example_open_document_presentation.odp"));
ParseContext pcontext = new ParseContext();
//Open Document Parser
OpenDocumentParser openofficeparser = new OpenDocumentParser ();
openofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}Yukarıdaki kodu farklı kaydedin OpenDocumentParse.javave aşağıdaki komutları kullanarak komut isteminde derleyin -
javac OpenDocumentParse.java
java OpenDocumentParseAşağıda, example_open_document_presentation.odp dosyasının anlık görüntüsü verilmiştir.

Bu belge aşağıdaki özelliklere sahiptir -
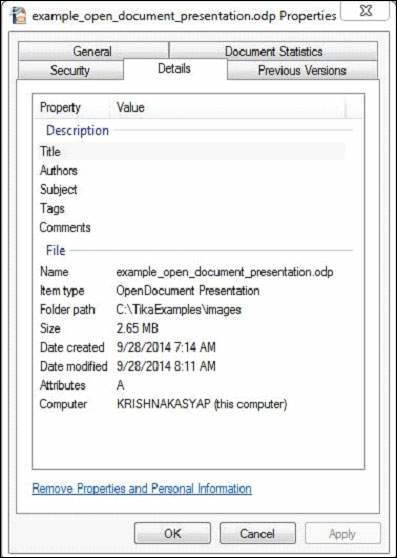
Programı derledikten sonra aşağıdaki çıktıyı alacaksınız.
Output -
Contents of the document:
Apache Tika
Apache Tika is a framework for content type detection and content extraction which was designed
by Apache software foundation. It detects and extracts metadata and structured text content from
different types of documents such as spreadsheets, text documents, images or PDFs including audio
or video input formats to certain extent.
Metadata of the document:
editing-cycles: 4
meta:creation-date: 2009-04-16T11:32:32.86
dcterms:modified: 2014-09-28T07:46:13.03
meta:save-date: 2014-09-28T07:46:13.03
Last-Modified: 2014-09-28T07:46:13.03
dcterms:created: 2009-04-16T11:32:32.86
date: 2014-09-28T07:46:13.03
modified: 2014-09-28T07:46:13.03
nbObject: 36
Edit-Time: PT32M6S
Creation-Date: 2009-04-16T11:32:32.86
Object-Count: 36
meta:object-count: 36
generator: OpenOffice/4.1.0$Win32 OpenOffice.org_project/410m18$Build-9764
Content-Type: application/vnd.oasis.opendocument.presentation
Last-Save-Date: 2014-09-28T07:46:13.03Aşağıda, bir Microsoft Office Belgesinden içerik ve meta veri çıkarma programı verilmiştir.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.microsoft.ooxml.OOXMLParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class MSExcelParse {
public static void main(final String[] args) throws IOException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example_msExcel.xlsx"));
ParseContext pcontext = new ParseContext();
//OOXml parser
OOXMLParser msofficeparser = new OOXMLParser ();
msofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Yukarıdaki kodu farklı kaydedin MSExelParse.javave aşağıdaki komutları kullanarak komut isteminden derleyin -
javac MSExcelParse.java
java MSExcelParseBurada aşağıdaki örnek Excel dosyasını geçiyoruz.
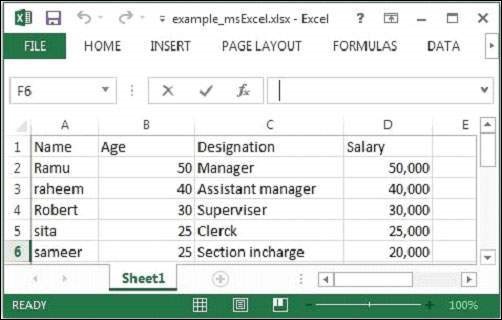
Verilen Excel dosyası aşağıdaki özelliklere sahiptir -

Yukarıdaki programı çalıştırdıktan sonra aşağıdaki çıktıyı alacaksınız.
Output -
Contents of the document:
Sheet1
Name Age Designation Salary
Ramu 50 Manager 50,000
Raheem 40 Assistant manager 40,000
Robert 30 Superviser 30,000
sita 25 Clerk 25,000
sameer 25 Section in-charge 20,000
Metadata of the document:
meta:creation-date: 2006-09-16T00:00:00Z
dcterms:modified: 2014-09-28T15:18:41Z
meta:save-date: 2014-09-28T15:18:41Z
Application-Name: Microsoft Excel
extended-properties:Company:
dcterms:created: 2006-09-16T00:00:00Z
Last-Modified: 2014-09-28T15:18:41Z
Application-Version: 15.0300
date: 2014-09-28T15:18:41Z
publisher:
modified: 2014-09-28T15:18:41Z
Creation-Date: 2006-09-16T00:00:00Z
extended-properties:AppVersion: 15.0300
protected: false
dc:publisher:
extended-properties:Application: Microsoft Excel
Content-Type: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
Last-Save-Date: 2014-09-28T15:18:41ZAşağıda, bir Metin belgesinden içerik ve meta veri çıkarma programı verilmiştir -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.parser.txt.TXTParser;
import org.xml.sax.SAXException;
public class TextParser {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.txt"));
ParseContext pcontext=new ParseContext();
//Text document parser
TXTParser TexTParser = new TXTParser();
TexTParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}Yukarıdaki kodu farklı kaydedin TextParser.javave aşağıdaki komutları kullanarak komut isteminden derleyin -
javac TextParser.java
java TextParserAşağıda, sample.txt dosyasının anlık görüntüsü verilmiştir -
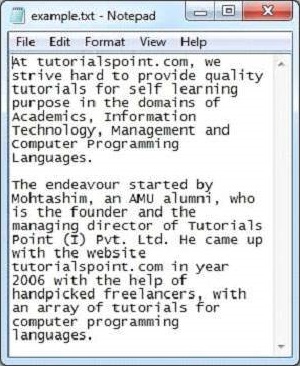
Metin belgesi aşağıdaki özelliklere sahiptir -

Yukarıdaki programı çalıştırırsanız, size aşağıdaki çıktıyı verecektir.
Output -
Contents of the document:
At tutorialspoint.com, we strive hard to provide quality tutorials for self-learning
purpose in the domains of Academics, Information Technology, Management and Computer
Programming Languages.
The endeavour started by Mohtashim, an AMU alumni, who is the founder and the managing
director of Tutorials Point (I) Pvt. Ltd. He came up with the website tutorialspoint.com
in year 2006 with the help of handpicked freelancers, with an array of tutorials for
computer programming languages.
Metadata of the document:
Content-Encoding: windows-1252
Content-Type: text/plain; charset = windows-1252Aşağıda, bir HTML belgesinden içerik ve meta veri çıkarma programı verilmiştir.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.html.HtmlParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class HtmlParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.html"));
ParseContext pcontext = new ParseContext();
//Html parser
HtmlParser htmlparser = new HtmlParser();
htmlparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Yukarıdaki kodu farklı kaydedin HtmlParse.javave aşağıdaki komutları kullanarak komut isteminden derleyin -
javac HtmlParse.java
java HtmlParseAşağıda, example.txt dosyasının anlık görüntüsü verilmiştir.
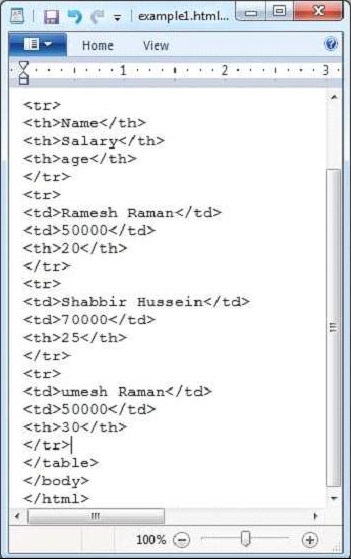
HTML belgesi aşağıdaki özelliklere sahiptir−

Yukarıdaki programı çalıştırırsanız, size aşağıdaki çıktıyı verecektir.
Output -
Contents of the document:
Name Salary age
Ramesh Raman 50000 20
Shabbir Hussein 70000 25
Umesh Raman 50000 30
Somesh 50000 35
Metadata of the document:
title: HTML Table Header
Content-Encoding: windows-1252
Content-Type: text/html; charset = windows-1252
dc:title: HTML Table HeaderAşağıda, bir XML belgesinden içerik ve meta veri çıkarma programı verilmiştir -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.xml.XMLParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class XmlParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("pom.xml"));
ParseContext pcontext = new ParseContext();
//Xml parser
XMLParser xmlparser = new XMLParser();
xmlparser.parse(inputstream, handler, metadata, pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Yukarıdaki kodu farklı kaydedin XmlParse.javave aşağıdaki komutları kullanarak komut isteminden derleyin -
javac XmlParse.java
java XmlParseAşağıda, example.xml dosyasının anlık görüntüsü verilmiştir.
Bu belge aşağıdaki özelliklere sahiptir -

Yukarıdaki programı çalıştırırsanız, size aşağıdaki çıktıyı verecektir -
Output -
Contents of the document:
4.0.0
org.apache.tika
tika
1.6
org.apache.tika
tika-core
1.6
org.apache.tika
tika-parsers
1.6
src
maven-compiler-plugin
3.1
1.7
1.7
Metadata of the document:
Content-Type: application/xmlAşağıda, bir .class dosyasından içerik ve meta veri ayıklama programı verilmiştir.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.asm.ClassParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class JavaClassParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.class"));
ParseContext pcontext = new ParseContext();
//Html parser
ClassParser ClassParser = new ClassParser();
ClassParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}Yukarıdaki kodu farklı kaydedin JavaClassParse.javave aşağıdaki komutları kullanarak komut isteminden derleyin -
javac JavaClassParse.java
java JavaClassParseAşağıda verilen anlık görüntüsüdür Example.java derlemeden sonra Example.class oluşturacaktır.

Example.class dosya aşağıdaki özelliklere sahiptir -
Yukarıdaki programı çalıştırdıktan sonra aşağıdaki çıktıyı alacaksınız.
Output -
Contents of the document:
package tutorialspoint.tika.examples;
public synchronized class Example {
public void Example();
public static void main(String[]);
}
Metadata of the document:
title: Example
resourceName: Example.class
dc:title: ExampleAşağıda, bir Java Arşivi (jar) dosyasından içerik ve meta veri çıkarma programı verilmiştir -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.parser.pkg.PackageParser;
import org.xml.sax.SAXException;
public class PackageParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.jar"));
ParseContext pcontext = new ParseContext();
//Package parser
PackageParser packageparser = new PackageParser();
packageparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document: " + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Yukarıdaki kodu farklı kaydedin PackageParse.javave aşağıdaki komutları kullanarak komut isteminden derleyin -
javac PackageParse.java
java PackageParseAşağıda verilen, paketin içinde bulunan Example.java'nın anlık görüntüsüdür.

Jar dosyası aşağıdaki özelliklere sahiptir -

Yukarıdaki programı çalıştırdıktan sonra, size aşağıdaki çıktıyı verecektir -
Output -
Contents of the document:
META-INF/MANIFEST.MF
tutorialspoint/tika/examples/Example.class
Metadata of the document:
Content-Type: application/zipAşağıda, bir JPEG görüntüsünden içerik ve meta veri çıkarma programı verilmiştir.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.jpeg.JpegParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class JpegParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("boy.jpg"));
ParseContext pcontext = new ParseContext();
//Jpeg Parse
JpegParser JpegParser = new JpegParser();
JpegParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Yukarıdaki kodu farklı kaydedin JpegParse.javave aşağıdaki komutları kullanarak komut isteminden derleyin -
javac JpegParse.java
java JpegParseAşağıda, Example.jpeg'in anlık görüntüsü verilmiştir -

JPEG dosyası aşağıdaki özelliklere sahiptir -
Programı çalıştırdıktan sonra aşağıdaki çıktıyı alacaksınız.
Output −
Contents of the document:
Meta data of the document:
Resolution Units: inch
Compression Type: Baseline
Data Precision: 8 bits
Number of Components: 3
tiff:ImageLength: 3000
Component 2: Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert
Component 1: Y component: Quantization table 0, Sampling factors 2 horiz/2 vert
Image Height: 3000 pixels
X Resolution: 300 dots
Original Transmission Reference: 53616c7465645f5f2368da84ca932841b336ac1a49edb1a93fae938b8db2cb3ec9cc4dc28d7383f1
Image Width: 4000 pixels
IPTC-NAA record: 92 bytes binary data
Component 3: Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert
tiff:BitsPerSample: 8
Application Record Version: 4
tiff:ImageWidth: 4000
Y Resolution: 300 dotsAşağıda, mp4 dosyalarından içerik ve meta veri çıkarma programı verilmiştir -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.mp4.MP4Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class Mp4Parse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.mp4"));
ParseContext pcontext = new ParseContext();
//Html parser
MP4Parser MP4Parser = new MP4Parser();
MP4Parser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document: :" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Yukarıdaki kodu JpegParse.java olarak kaydedin ve aşağıdaki komutları kullanarak komut isteminden derleyin -
javac Mp4Parse.java
java Mp4ParseAşağıda, Example.mp4 dosyasının özelliklerinin anlık görüntüsü verilmiştir.

Yukarıdaki programı çalıştırdıktan sonra, aşağıdaki çıktıyı alacaksınız -
Output -
Contents of the document:
Metadata of the document:
dcterms:modified: 2014-01-06T12:10:27Z
meta:creation-date: 1904-01-01T00:00:00Z
meta:save-date: 2014-01-06T12:10:27Z
Last-Modified: 2014-01-06T12:10:27Z
dcterms:created: 1904-01-01T00:00:00Z
date: 2014-01-06T12:10:27Z
tiff:ImageLength: 360
modified: 2014-01-06T12:10:27Z
Creation-Date: 1904-01-01T00:00:00Z
tiff:ImageWidth: 640
Content-Type: video/mp4
Last-Save-Date: 2014-01-06T12:10:27ZAşağıda, mp3 dosyalarından içerik ve meta veri çıkarma programı verilmiştir -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.mp3.LyricsHandler;
import org.apache.tika.parser.mp3.Mp3Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class Mp3Parse {
public static void main(final String[] args) throws Exception, IOException, SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.mp3"));
ParseContext pcontext = new ParseContext();
//Mp3 parser
Mp3Parser Mp3Parser = new Mp3Parser();
Mp3Parser.parse(inputstream, handler, metadata, pcontext);
LyricsHandler lyrics = new LyricsHandler(inputstream,handler);
while(lyrics.hasLyrics()) {
System.out.println(lyrics.toString());
}
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Yukarıdaki kodu farklı kaydedin JpegParse.javave aşağıdaki komutları kullanarak komut isteminden derleyin -
javac Mp3Parse.java
java Mp3ParseExample.mp3 dosyası aşağıdaki özelliklere sahiptir -
Programı çalıştırdıktan sonra aşağıdaki çıktıyı alacaksınız. Verilen dosyada herhangi bir şarkı sözü varsa, uygulamamız bunu çıktıyla birlikte yakalayıp görüntüler.
Output -
Contents of the document:
Kanulanu Thaake
Arijit Singh
Manam (2014), track 01/06
2014
Soundtrack
30171.65
eng -
DRGM
Arijit Singh
Manam (2014), track 01/06
2014
Soundtrack
30171.65
eng -
DRGM
Metadata of the document:
xmpDM:releaseDate: 2014
xmpDM:duration: 30171.650390625
xmpDM:audioChannelType: Stereo
dc:creator: Arijit Singh
xmpDM:album: Manam (2014)
Author: Arijit Singh
xmpDM:artist: Arijit Singh
channels: 2
xmpDM:audioSampleRate: 44100
xmpDM:logComment: eng -
DRGM
xmpDM:trackNumber: 01/06
version: MPEG 3 Layer III Version 1
creator: Arijit Singh
xmpDM:composer: Music : Anoop Rubens | Lyrics : Vanamali
xmpDM:audioCompressor: MP3
title: Kanulanu Thaake
samplerate: 44100
meta:author: Arijit Singh
xmpDM:genre: Soundtrack
Content-Type: audio/mpeg
xmpDM:albumArtist: Manam (2014)
dc:title: Kanulanu Thaake