Apache MXNet - Các gói Python
Trong chương này, chúng ta sẽ tìm hiểu về các Gói Python có sẵn trong Apache MXNet.
Các gói Python MXNet quan trọng
MXNet có các gói Python quan trọng sau đây mà chúng ta sẽ thảo luận từng cái một -
Autograd (Tự động phân biệt)
NDArray
KVStore
Gluon
Visualization
Đầu tiên chúng ta hãy bắt đầu với Autograd Gói Python cho Apache MXNet.
Autograd
Autograd viết tắt của automatic differentiationđược sử dụng để sao chép các gradient từ chỉ số tổn thất trở lại từng tham số. Cùng với sự lan truyền ngược, nó sử dụng phương pháp lập trình động để tính toán hiệu quả các gradient. Nó còn được gọi là chế độ phân biệt tự động đảo ngược. Kỹ thuật này rất hiệu quả trong các tình huống 'fan-in' trong đó, nhiều tham số ảnh hưởng đến một chỉ số tổn thất duy nhất.
Gradient là gì?
Gradients là nền tảng cơ bản của quá trình đào tạo mạng nơ-ron. Về cơ bản, chúng cho chúng ta biết cách thay đổi các thông số của mạng để cải thiện hiệu suất của mạng.
Như chúng ta đã biết, mạng nơ-ron (NN) bao gồm các toán tử như tổng, tích, chập, v.v. Những toán tử này, để tính toán, sử dụng các tham số như trọng số trong nhân chập. Chúng ta phải tìm ra các giá trị tối ưu cho các tham số này và độ dốc chỉ cho chúng ta thấy con đường và dẫn chúng ta đến giải pháp.
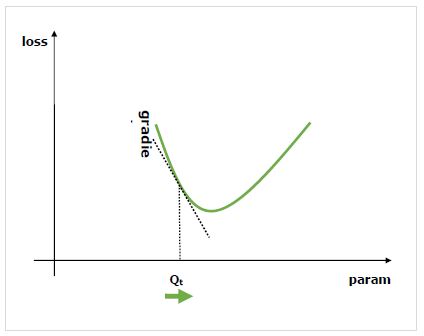
Chúng tôi quan tâm đến ảnh hưởng của việc thay đổi một tham số đối với hiệu suất của mạng và độ dốc cho chúng tôi biết, một biến nhất định tăng hoặc giảm bao nhiêu khi chúng tôi thay đổi một biến mà nó phụ thuộc vào. Hiệu suất thường được xác định bằng cách sử dụng số liệu tổn thất mà chúng tôi cố gắng giảm thiểu. Ví dụ: đối với hồi quy, chúng tôi có thể cố gắng giảm thiểuL2 mất mát giữa dự đoán của chúng tôi và giá trị chính xác, trong khi đối với phân loại, chúng tôi có thể giảm thiểu cross-entropy loss.
Khi chúng tôi tính toán gradient của mỗi tham số có tham chiếu đến tổn thất, sau đó chúng tôi có thể sử dụng một công cụ tối ưu hóa, chẳng hạn như descent gradient ngẫu nhiên.
Làm thế nào để tính toán gradient?
Chúng tôi có các tùy chọn sau để tính toán độ dốc -
Symbolic Differentiation- Tùy chọn đầu tiên là Symbolic Differentiation, tính toán các công thức cho mỗi gradient. Hạn chế của phương pháp này là nó sẽ nhanh chóng dẫn đến các công thức cực kỳ dài khi mạng ngày càng sâu và các nhà khai thác phức tạp hơn.
Finite Differencing- Một tùy chọn khác là, sử dụng sai lệch hữu hạn để thử các khác biệt nhỏ trên từng tham số và xem chỉ số tổn thất phản ứng như thế nào. Hạn chế của phương pháp này là nó sẽ tốn kém về mặt tính toán và có thể có độ chính xác số kém.
Automatic differentiation- Giải pháp cho những hạn chế của các phương pháp trên là sử dụng phân biệt tự động để ghép ngược các gradient từ số liệu tổn thất trở lại từng tham số. Sự lan truyền cho phép chúng tôi một cách tiếp cận lập trình động để tính toán hiệu quả các gradient. Phương pháp này còn được gọi là chế độ phân biệt tự động đảo ngược.
Phân biệt tự động (autograd)
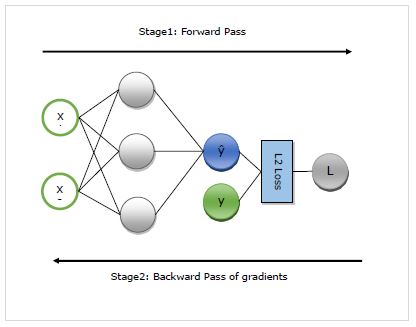
Sau đây, chúng ta sẽ hiểu chi tiết về hoạt động của autograd. Về cơ bản, nó hoạt động theo hai giai đoạn sau:
Stage 1 - Giai đoạn này được gọi là ‘Forward Pass’đào tạo. Như tên của nó, trong giai đoạn này, nó tạo ra bản ghi của nhà điều hành được mạng sử dụng để đưa ra dự đoán và tính toán số liệu tổn thất.
Stage 2 - Giai đoạn này được gọi là ‘Backward Pass’đào tạo. Như tên của nó, trong giai đoạn này, nó hoạt động ngược lại thông qua bản ghi này. Quay ngược lại, nó đánh giá các đạo hàm riêng của mỗi nhà khai thác, tất cả các cách trở lại tham số mạng.
Ưu điểm của autograd
Sau đây là những ưu điểm của việc sử dụng Phân biệt tự động (autograd) -
Flexible- Tính linh hoạt mà nó mang lại cho chúng tôi khi xác định mạng của chúng tôi, là một trong những lợi ích to lớn của việc sử dụng autograd. Chúng tôi có thể thay đổi các hoạt động trên mỗi lần lặp lại. Chúng được gọi là đồ thị động, phức tạp hơn nhiều để triển khai trong các khuôn khổ yêu cầu đồ thị tĩnh. Autograd, ngay cả trong những trường hợp như vậy, vẫn có thể sao chép các gradient một cách chính xác.
Automatic- Autograd là tự động, tức là những phức tạp của thủ tục nhân giống ngược sẽ được nó giải quyết cho bạn. Chúng ta chỉ cần xác định những gradient mà chúng ta muốn tính toán.
Efficient - Autogard tính toán độ dốc rất hiệu quả.
Can use native Python control flow operators- Chúng ta có thể sử dụng các toán tử luồng điều khiển Python nguyên bản như if điều kiện và vòng lặp while. Autograd sẽ vẫn có thể sao chép các gradient một cách hiệu quả và chính xác.
Sử dụng autograd trong MXNet Gluon
Ở đây, với sự trợ giúp của một ví dụ, chúng ta sẽ thấy cách chúng ta có thể sử dụng autograd trong MXNet Gluon.
Ví dụ triển khai
Trong ví dụ sau, chúng ta sẽ triển khai mô hình hồi quy có hai lớp. Sau khi triển khai, chúng tôi sẽ sử dụng autograd để tự động tính toán độ dốc của tổn thất có tham chiếu đến từng tham số trọng lượng -
Đầu tiên nhập autogrard và các gói bắt buộc khác như sau:
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2LossBây giờ, chúng ta cần xác định mạng như sau:
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()Bây giờ chúng ta cần xác định khoản lỗ như sau:
loss_function = L2Loss()Tiếp theo, chúng ta cần tạo dữ liệu giả như sau:
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])Bây giờ, chúng tôi đã sẵn sàng cho lần chuyển tiếp đầu tiên của chúng tôi qua mạng. Chúng tôi muốn autograd ghi lại đồ thị tính toán để chúng tôi có thể tính toán độ dốc. Đối với điều này, chúng tôi cần chạy mã mạng trong phạm viautograd.record ngữ cảnh như sau -
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)Bây giờ, chúng ta đã sẵn sàng cho quá trình chuyển lùi, mà chúng ta bắt đầu bằng cách gọi phương pháp lùi về số lượng quan tâm. Mối quan tâm trong ví dụ của chúng tôi là tổn thất vì chúng tôi đang cố gắng tính toán độ dốc của tổn thất có tham chiếu đến các tham số -
loss.backward()Bây giờ, chúng ta có gradient cho từng tham số của mạng, sẽ được sử dụng bởi trình tối ưu hóa để cập nhật giá trị tham số nhằm cải thiện hiệu suất. Hãy kiểm tra các gradient của lớp thứ nhất như sau:
N_net[0].weight.grad()Output
Kết quả như sau:
[[-0.00470527 -0.00846948]
[-0.03640365 -0.06552657]
[ 0.00800354 0.01440637]]
<NDArray 3x2 @cpu(0)>Hoàn thành ví dụ triển khai
Dưới đây là ví dụ triển khai đầy đủ.
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Loss
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()
loss_function = L2Loss()
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)
loss.backward()
N_net[0].weight.grad()