Apache MXNet - Hướng dẫn nhanh
Chương này nêu bật các tính năng của Apache MXNet và nói về phiên bản mới nhất của khung phần mềm học sâu này.
MXNet là gì?
Apache MXNet là một công cụ khung phần mềm học sâu mã nguồn mở mạnh mẽ giúp các nhà phát triển xây dựng, đào tạo và triển khai các mô hình Học sâu. Trong vài năm qua, từ chăm sóc sức khỏe đến giao thông vận tải đến sản xuất và trên thực tế, trong mọi khía cạnh của cuộc sống hàng ngày của chúng ta, tác động của học sâu đã trở nên phổ biến. Ngày nay, học sâu được các công ty tìm kiếm để giải quyết một số vấn đề khó khăn như Nhận dạng khuôn mặt, phát hiện đối tượng, Nhận dạng ký tự quang học (OCR), Nhận dạng giọng nói và Dịch máy.
Đó là lý do Apache MXNet được hỗ trợ bởi:
Một số công ty lớn như Intel, Baidu, Microsoft, Wolfram Research, v.v.
Các nhà cung cấp đám mây công cộng bao gồm Amazon Web Services (AWS) và Microsoft Azure
Một số viện nghiên cứu lớn như Carnegie Mellon, MIT, Đại học Washington, và Đại học Khoa học & Công nghệ Hồng Kông.
Tại sao sử dụng Apache MXNet?
Có rất nhiều nền tảng học sâu khác nhau như Torch7, Caffe, Theano, TensorFlow, Keras, Bộ công cụ nhận thức của Microsoft, v.v. tồn tại và bạn có thể thắc mắc tại sao Apache MXNet? Hãy cùng kiểm tra một số lý do đằng sau nó:
Apache MXNet giải quyết một trong những vấn đề lớn nhất của các nền tảng học sâu hiện có. Vấn đề là để sử dụng các nền tảng học sâu, người ta phải học một hệ thống khác để có một hương vị lập trình khác.
Với sự trợ giúp của Apache MXNet các nhà phát triển có thể khai thác hết khả năng của GPU cũng như điện toán đám mây.
Apache MXNet có thể tăng tốc bất kỳ tính toán số nào và đặc biệt chú trọng vào việc tăng tốc độ phát triển và triển khai DNN quy mô lớn (mạng nơ ron sâu).
Nó cung cấp cho người dùng khả năng của cả lập trình mệnh lệnh và biểu tượng.
Các tính năng khác nhau
Nếu bạn đang tìm kiếm một thư viện học sâu linh hoạt để nhanh chóng phát triển nghiên cứu học sâu tiên tiến hoặc một nền tảng mạnh mẽ để đẩy khối lượng công việc sản xuất, tìm kiếm của bạn sẽ kết thúc tại Apache MXNet. Đó là vì các tính năng sau của nó:
Đào tạo phân tán
Cho dù đó là đào tạo đa gpu hay đa máy chủ với hiệu quả mở rộng gần tuyến tính, Apache MXNet cho phép các nhà phát triển tận dụng tối đa phần cứng của họ. MXNet cũng hỗ trợ tích hợp với Horovod, một khung học sâu phân tán mã nguồn mở được tạo ra tại Uber.
Đối với tích hợp này, sau đây là một số API phân phối phổ biến được xác định trong Horovod:
horovod.broadcast()
horovod.allgather()
horovod.allgather()
Về vấn đề này, MXNet cung cấp cho chúng tôi các khả năng sau:
Device Placement - Với sự trợ giúp của MXNet, chúng ta có thể dễ dàng chỉ định từng cấu trúc dữ liệu (DS).
Automatic Differentiation - Apache MXNet tự động hóa phân biệt tức là tính toán đạo hàm.
Multi-GPU training - MXNet cho phép chúng tôi đạt được hiệu quả mở rộng với số lượng GPU có sẵn.
Optimized Predefined Layers - Chúng tôi có thể mã hóa các lớp của riêng mình trong MXNet cũng như tối ưu hóa các lớp được xác định trước để tăng tốc độ.
Lai ghép
Apache MXNet cung cấp cho người dùng một giao diện người dùng kết hợp. Với sự trợ giúp của API Gluon Python, nó có thể thu hẹp khoảng cách giữa khả năng bắt buộc và biểu tượng của nó. Nó có thể được thực hiện bằng cách gọi nó là chức năng hybridize.
Tính toán nhanh hơn
Các phép toán tuyến tính như hàng chục hoặc hàng trăm phép nhân ma trận là nút thắt cổ chai tính toán cho các mạng nơron sâu. Để giải quyết nút thắt cổ chai này, MXNet cung cấp:
Tính toán số được tối ưu hóa cho GPU
Tính toán số được tối ưu hóa cho hệ sinh thái phân tán
Tự động hóa các quy trình công việc chung với sự trợ giúp của NN tiêu chuẩn có thể được diễn đạt ngắn gọn.
Ràng buộc ngôn ngữ
MXNet có khả năng tích hợp sâu vào các ngôn ngữ cấp cao như Python và R. Nó cũng cung cấp hỗ trợ cho các ngôn ngữ lập trình khác như-
Scala
Julia
Clojure
Java
C/C++
Perl
Chúng tôi không cần phải học bất kỳ ngôn ngữ lập trình mới nào thay vào đó MXNet, kết hợp với tính năng lai tạo, cho phép chuyển đổi đặc biệt trơn tru từ Python sang triển khai bằng ngôn ngữ lập trình mà chúng tôi lựa chọn.
Phiên bản mới nhất MXNet 1.6.0
Apache Software Foundation (ASF) đã phát hành phiên bản ổn định 1.6.0 của Apache MXNet vào ngày 21 tháng 2 năm 2020 theo Giấy phép Apache 2.0. Đây là bản phát hành MXNet cuối cùng hỗ trợ Python 2 vì cộng đồng MXNet đã bỏ phiếu không hỗ trợ Python 2 trong các bản phát hành tiếp theo. Hãy để chúng tôi kiểm tra một số tính năng mới mà bản phát hành này mang lại cho người dùng.
Giao diện tương thích NumPy
Do tính linh hoạt và tính tổng quát của nó, NumPy đã được sử dụng rộng rãi bởi các nhà thực hành Máy học, nhà khoa học và sinh viên. Nhưng như chúng ta biết rằng, những bộ tăng tốc phần cứng ngày nay như Bộ xử lý đồ họa (GPU) ngày càng được đồng hóa với nhiều bộ công cụ Học máy (ML) khác nhau, người dùng NumPy, để tận dụng tốc độ của GPU, cần phải chuyển sang các khuôn khổ mới với các cú pháp khác nhau.
Với MXNet 1.6.0, Apache MXNet đang hướng tới trải nghiệm lập trình tương thích với NumPy. Giao diện mới cung cấp khả năng sử dụng tương đương cũng như tính biểu cảm cho những người thực hành quen thuộc với cú pháp NumPy. Cùng với đó, MXNet 1.6.0 cũng cho phép hệ thống Numpy hiện có sử dụng các bộ tăng tốc phần cứng như GPU để tăng tốc các phép tính quy mô lớn.
Tích hợp với Apache TVM
Apache TVM, một ngăn xếp trình biên dịch học sâu mã nguồn mở end-to-end dành cho phần cứng-phụ trợ như CPU, GPU và các bộ tăng tốc chuyên dụng, nhằm mục đích lấp đầy khoảng cách giữa khung học sâu tập trung vào năng suất và phần cứng phụ trợ phần cứng theo định hướng hiệu suất . Với bản phát hành mới nhất MXNet 1.6.0, người dùng có thể tận dụng Apache (đang ấp ủ) TVM để triển khai các hạt nhân toán tử hiệu suất cao bằng ngôn ngữ lập trình Python. Hai ưu điểm chính của tính năng mới này là:
Đơn giản hóa quy trình phát triển dựa trên C ++ trước đây.
Cho phép chia sẻ cùng một triển khai trên nhiều phần cứng phần cứng như CPU, GPU, v.v.
Cải tiến các tính năng hiện có
Ngoài các tính năng được liệt kê ở trên của MXNet 1.6.0, nó cũng cung cấp một số cải tiến so với các tính năng hiện có. Các cải tiến như sau:
Phân nhóm hoạt động khôn ngoan cho GPU
Như chúng ta biết hiệu suất của các hoạt động khôn ngoan là băng thông bộ nhớ và đó là lý do, việc xâu chuỗi các hoạt động đó có thể làm giảm hiệu suất tổng thể. Apache MXNet 1.6.0 thực hiện sự kết hợp hoạt động khôn ngoan của phần tử, thực sự tạo ra các hoạt động được hợp nhất đúng lúc và khi có thể. Sự kết hợp hoạt động khôn ngoan như vậy cũng làm giảm nhu cầu lưu trữ và cải thiện hiệu suất tổng thể.
Đơn giản hóa các biểu thức phổ biến
MXNet 1.6.0 loại bỏ các biểu thức thừa và đơn giản hóa các biểu thức phổ biến. Việc tăng cường như vậy cũng cải thiện việc sử dụng bộ nhớ và tổng thời gian thực thi.
Tối ưu hóa
MXNet 1.6.0 cũng cung cấp các tối ưu hóa khác nhau cho các tính năng và toán tử hiện có, như sau:
Độ chính xác hỗn hợp tự động
API Gluon Fit
MKL-DNN
Hỗ trợ căng thẳng lớn
TensorRT hội nhập
Hỗ trợ gradient bậc cao hơn
Operators
Hồ sơ hiệu suất của người vận hành
Nhập / xuất ONNX
Cải tiến đối với API Gluon
Cải tiến đối với API biểu tượng
Hơn 100 bản sửa lỗi
Để bắt đầu với MXNet, điều đầu tiên chúng ta cần làm là cài đặt nó trên máy tính của mình. Apache MXNet hoạt động trên hầu hết các nền tảng có sẵn, bao gồm Windows, Mac và Linux.
Hệ điều hành Linux
Chúng ta có thể cài đặt MXNet trên HĐH Linux theo các cách sau:
Bộ xử lý đồ họa (GPU)
Ở đây, chúng tôi sẽ sử dụng các phương pháp khác nhau cụ thể là Pip, Docker và Nguồn để cài đặt MXNet khi chúng tôi đang sử dụng GPU để xử lý -
Bằng cách sử dụng phương pháp Pip
Bạn có thể sử dụng lệnh sau để cài đặt MXNet trên Hệ điều hành Linus của mình -
pip install mxnetApache MXNet cũng cung cấp gói pip MKL, nhanh hơn nhiều khi chạy trên phần cứng intel. Ví dụ ở đâymxnet-cu101mkl có nghĩa là -
Gói được xây dựng bằng CUDA / cuDNN
Gói được bật MKL-DNN
Phiên bản CUDA là 10.1
Đối với tùy chọn khác, bạn cũng có thể tham khảo https://pypi.org/project/mxnet/.
Bằng cách sử dụng Docker
Bạn có thể tìm hình ảnh docker bằng MXNet tại DockerHub, có sẵn tại https://hub.docker.com/u/mxnet Hãy để chúng tôi kiểm tra các bước dưới đây để cài đặt MXNet bằng cách sử dụng Docker với GPU -
Step 1- Đầu tiên, bằng cách làm theo hướng dẫn cài đặt docker có sẵn tại https://docs.docker.com/engine/install/ubuntu/. Chúng tôi cần cài đặt Docker trên máy của mình.
Step 2- Để cho phép sử dụng GPU từ bộ chứa docker, tiếp theo chúng ta cần cài đặt nvidia-docker-plugin. Bạn có thể làm theo hướng dẫn cài đặt được cung cấp tạihttps://github.com/NVIDIA/nvidia-docker/wiki.
Step 3- Bằng cách sử dụng lệnh sau, bạn có thể kéo hình ảnh bộ đế MXNet -
$ sudo docker pull mxnet/python:gpuBây giờ để xem liệu việc kéo hình ảnh docker mxnet / python có thành công hay không, chúng ta có thể liệt kê các hình ảnh docker như sau:
$ sudo docker imagesĐể có tốc độ suy luận nhanh nhất với MXNet, bạn nên sử dụng MXNet mới nhất với Intel MKL-DNN. Kiểm tra các lệnh bên dưới -
$ sudo docker pull mxnet/python:1.3.0_cpu_mkl $ sudo docker imagesTừ nguồn
Để xây dựng thư viện chia sẻ MXNet từ nguồn với GPU, trước tiên chúng ta cần thiết lập môi trường cho CUDA và cuDNN như sau−
Tải xuống và cài đặt bộ công cụ CUDA, tại đây khuyến nghị sử dụng CUDA 9.2.
Tiếp theo tải về cuDNN 7.1.4.
Bây giờ chúng ta cần giải nén tệp. Nó cũng được yêu cầu để thay đổi thư mục gốc cuDNN. Đồng thời di chuyển tiêu đề và thư viện vào thư mục Bộ công cụ CUDA cục bộ như sau:
tar xvzf cudnn-9.2-linux-x64-v7.1
sudo cp -P cuda/include/cudnn.h /usr/local/cuda/include
sudo cp -P cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
sudo ldconfigSau khi thiết lập môi trường cho CUDA và cuDNN, hãy làm theo các bước bên dưới để xây dựng thư viện được chia sẻ MXNet từ nguồn -
Step 1- Đầu tiên, chúng ta cần cài đặt các gói tiên quyết. Các phụ thuộc này được yêu cầu trên Ubuntu phiên bản 16.04 trở lên.
sudo apt-get update
sudo apt-get install -y build-essential git ninja-build ccache libopenblas-dev
libopencv-dev cmakeStep 2- Ở bước này, chúng ta sẽ tải mã nguồn MXNet và cấu hình. Trước tiên, hãy để chúng tôi sao chép kho lưu trữ bằng cách sử dụng lệnh sau
git clone –recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux_gpu.cmake #for build with CUDAStep 3- Bằng cách sử dụng các lệnh sau, bạn có thể xây dựng thư viện chia sẻ lõi MXNet
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .Two important points regarding the above step is as follows−
Nếu bạn muốn tạo phiên bản Gỡ lỗi, hãy chỉ định như sau:
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..Để đặt số lượng công việc biên dịch song song, hãy chỉ định như sau:
cmake --build . --parallel NSau khi bạn xây dựng thành công thư viện chia sẻ lõi MXNet, trong build thư mục trong của bạn MXNet project root, Bạn sẽ thấy libmxnet.so được yêu cầu để cài đặt ràng buộc ngôn ngữ (tùy chọn).
Bộ phận xử lý trung tâm (CPU)
Ở đây, chúng tôi sẽ sử dụng các phương pháp khác nhau cụ thể là Pip, Docker và Nguồn để cài đặt MXNet khi chúng tôi đang sử dụng CPU để xử lý -
Bằng cách sử dụng phương pháp Pip
Bạn có thể sử dụng lệnh sau để cài đặt MXNet trên Linus OS−
pip install mxnetApache MXNet cũng cung cấp các gói pip hỗ trợ MKL-DNN nhanh hơn nhiều khi chạy trên phần cứng intel.
pip install mxnet-mklBằng cách sử dụng Docker
Bạn có thể tìm hình ảnh docker bằng MXNet tại DockerHub, có sẵn tại https://hub.docker.com/u/mxnet. Hãy để chúng tôi kiểm tra các bước dưới đây để cài đặt MXNet bằng cách sử dụng Docker với CPU -
Step 1- Đầu tiên, bằng cách làm theo hướng dẫn cài đặt docker có sẵn tại https://docs.docker.com/engine/install/ubuntu/. Chúng tôi cần cài đặt Docker trên máy của mình.
Step 2- Bằng cách sử dụng lệnh sau, bạn có thể kéo hình ảnh bộ đế MXNet:
$ sudo docker pull mxnet/pythonBây giờ, để xem liệu việc kéo hình ảnh docker mxnet / python có thành công hay không, chúng ta có thể liệt kê các hình ảnh docker như sau:
$ sudo docker imagesĐể có tốc độ suy luận nhanh nhất với MXNet, bạn nên sử dụng MXNet mới nhất với Intel MKL-DNN.
Kiểm tra các lệnh bên dưới -
$ sudo docker pull mxnet/python:1.3.0_cpu_mkl $ sudo docker imagesTừ nguồn
Để xây dựng thư viện được chia sẻ MXNet từ nguồn với CPU, hãy làm theo các bước bên dưới:
Step 1- Đầu tiên, chúng ta cần cài đặt các gói tiên quyết. Các phụ thuộc này được yêu cầu trên Ubuntu phiên bản 16.04 trở lên.
sudo apt-get update
sudo apt-get install -y build-essential git ninja-build ccache libopenblas-dev libopencv-dev cmakeStep 2- Ở bước này chúng ta sẽ tải mã nguồn MXNet và cấu hình. Trước tiên, chúng ta hãy sao chép kho lưu trữ bằng cách sử dụng lệnh sau:
git clone –recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux.cmake config.cmakeStep 3- Bằng cách sử dụng các lệnh sau, bạn có thể xây dựng thư viện chia sẻ lõi MXNet:
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .Two important points regarding the above step is as follows−
Nếu bạn muốn xây dựng phiên bản Gỡ lỗi, hãy chỉ định như sau:
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..Để đặt số lượng công việc biên dịch song song, hãy chỉ định như sau:
cmake --build . --parallel NSau khi bạn xây dựng thành công thư viện chia sẻ lõi MXNet, trong build trong thư mục gốc dự án MXNet của bạn, bạn sẽ tìm thấy libmxnet.so, được yêu cầu để cài đặt ràng buộc ngôn ngữ (tùy chọn).
Hệ điều hành Mac
Chúng tôi có thể cài đặt MXNet trên MacOS theo những cách sau
Bộ xử lý đồ họa (GPU)
Nếu bạn định xây dựng MXNet trên MacOS với GPU, thì KHÔNG có sẵn phương pháp Pip và Docker. Phương pháp duy nhất trong trường hợp này là xây dựng nó từ nguồn.
Từ nguồn
Để xây dựng thư viện chia sẻ MXNet từ nguồn với GPU, trước tiên chúng ta cần thiết lập môi trường cho CUDA và cuDNN. Bạn cần làm theoNVIDIA CUDA Installation Guide có sẵn tại https://docs.nvidia.com và cuDNN Installation Guide, có sẵn tại https://docs.nvidia.com/deeplearning cho mac OS.
Xin lưu ý rằng vào năm 2019 CUDA đã ngừng hỗ trợ macOS. Trên thực tế, các phiên bản CUDA trong tương lai cũng có thể không hỗ trợ macOS.
Sau khi bạn thiết lập môi trường cho CUDA và cuDNN, hãy làm theo các bước dưới đây để cài đặt MXNet từ nguồn trên OS X (Mac) -
Step 1- Vì chúng ta cần một số phụ thuộc vào OS x, Đầu tiên, chúng ta cần cài đặt các gói tiên quyết.
xcode-select –-install #Install OS X Developer Tools
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" #Install Homebrew
brew install cmake ninja ccache opencv # Install dependenciesChúng tôi cũng có thể xây dựng MXNet mà không cần OpenCV vì opencv là một phụ thuộc tùy chọn.
Step 2- Ở bước này chúng ta sẽ tải mã nguồn MXNet và cấu hình. Trước tiên, hãy để chúng tôi sao chép kho lưu trữ bằng cách sử dụng lệnh sau
git clone –-recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux.cmake config.cmakeĐối với một GPU hỗ trợ, trước tiên cần phải cài đặt các phụ thuộc CUDA bởi vì khi một người cố gắng tạo một bản dựng hỗ trợ GPU trên một máy không có GPU, bản dựng MXNet không thể tự động phát hiện kiến trúc GPU của bạn. Trong những trường hợp như vậy MXNet sẽ nhắm mục tiêu tất cả các kiến trúc GPU có sẵn.
Step 3- Bằng cách sử dụng các lệnh sau, bạn có thể xây dựng thư viện chia sẻ lõi MXNet
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .Hai điểm quan trọng liên quan đến bước trên như sau:
Nếu bạn muốn tạo phiên bản Gỡ lỗi, hãy chỉ định như sau:
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..Để đặt số lượng công việc biên dịch song song, hãy chỉ định như sau:
cmake --build . --parallel NSau khi bạn xây dựng thành công thư viện chia sẻ lõi MXNet, trong build thư mục trong của bạn MXNet project root, Bạn sẽ thấy libmxnet.dylib, được yêu cầu để cài đặt ràng buộc ngôn ngữ (tùy chọn).
Bộ phận xử lý trung tâm (CPU)
Ở đây, chúng tôi sẽ sử dụng các phương pháp khác nhau cụ thể là Pip, Docker và Nguồn để cài đặt MXNet khi chúng tôi đang sử dụng CPU để xử lý−
Bằng cách sử dụng phương pháp Pip
Bạn có thể sử dụng lệnh sau để cài đặt MXNet trên Hệ điều hành Linus của mình
pip install mxnetBằng cách sử dụng Docker
Bạn có thể tìm hình ảnh docker bằng MXNet tại DockerHub, có sẵn tại https://hub.docker.com/u/mxnet. Hãy để chúng tôi kiểm tra các bước dưới đây để cài đặt MXNet bằng cách sử dụng Docker với CPU−
Step 1- Đầu tiên, bằng cách làm theo docker installation instructions có sẵn tại https://docs.docker.com/docker-for-mac chúng ta cần cài đặt Docker trên máy của mình.
Step 2- Bằng cách sử dụng lệnh sau, bạn có thể kéo hình ảnh bộ đế MXNet
$ docker pull mxnet/pythonBây giờ để xem liệu việc kéo hình ảnh docker mxnet / python có thành công hay không, chúng ta có thể liệt kê các hình ảnh docker như sau−
$ docker imagesĐể có tốc độ suy luận nhanh nhất với MXNet, bạn nên sử dụng MXNet mới nhất với Intel MKL-DNN. Kiểm tra các lệnh bên dưới−
$ docker pull mxnet/python:1.3.0_cpu_mkl
$ docker imagesTừ nguồn
Làm theo các bước dưới đây để cài đặt MXNet từ nguồn trên OS X (Mac) -
Step 1- Vì chúng ta cần một số phụ thuộc vào OS x, trước tiên, chúng ta cần cài đặt các gói điều kiện tiên quyết.
xcode-select –-install #Install OS X Developer Tools
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" #Install Homebrew
brew install cmake ninja ccache opencv # Install dependenciesChúng tôi cũng có thể xây dựng MXNet mà không cần OpenCV vì opencv là một phụ thuộc tùy chọn.
Step 2- Ở bước này chúng ta sẽ tải mã nguồn MXNet và cấu hình. Trước tiên, chúng ta hãy sao chép kho lưu trữ bằng cách sử dụng lệnh sau
git clone –-recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux.cmake config.cmakeStep 3- Bằng cách sử dụng các lệnh sau, bạn có thể xây dựng thư viện chia sẻ lõi MXNet:
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .Two important points regarding the above step is as follows−
Nếu bạn muốn tạo phiên bản Gỡ lỗi, hãy chỉ định như sau:
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..Để đặt số lượng công việc biên dịch song song, hãy chỉ định như sau:
cmake --build . --parallel NSau khi bạn xây dựng thành công thư viện chia sẻ lõi MXNet, trong build thư mục trong của bạn MXNet project root, Bạn sẽ thấy libmxnet.dylib, được yêu cầu để cài đặt ràng buộc ngôn ngữ (tùy chọn).
HĐH Windows
Để cài đặt MXNet trên Windows, sau đây là các điều kiện tiên quyết−
Yêu cầu hệ thống tối thiểu
Windows 7, 10, Server 2012 R2 hoặc Server 2016
Visual Studio 2015 hoặc 2017 (bất kỳ loại nào)
Python 2.7 hoặc 3.6
pip
Yêu cầu hệ thống được đề xuất
Windows 10, Server 2012 R2 hoặc Server 2016
Visual Studio 2017
Ít nhất một GPU hỗ trợ NVIDIA CUDA
CPU hỗ trợ MKL: bộ xử lý Intel® Xeon®, dòng bộ xử lý Intel® Core ™, bộ xử lý Intel Atom® hoặc bộ xử lý Intel® Xeon Phi ™
Python 2.7 hoặc 3.6
pip
Bộ xử lý đồ họa (GPU)
Bằng cách sử dụng phương pháp Pip−
Nếu bạn định xây dựng MXNet trên Windows với GPU NVIDIA, có hai tùy chọn để cài đặt MXNet có hỗ trợ CUDA với gói Python−
Cài đặt với Hỗ trợ CUDA
Dưới đây là các bước với sự trợ giúp của chúng, chúng ta có thể thiết lập MXNet với CUDA.
Step 1- Trước tiên hãy cài đặt Microsoft Visual Studio 2017 hoặc Microsoft Visual Studio 2015.
Step 2- Tiếp theo, tải và cài đặt NVIDIA CUDA. Bạn nên sử dụng CUDA phiên bản 9.2 hoặc 9.0 vì một số vấn đề với CUDA 9.1 đã được xác định trong quá khứ.
Step 3- Bây giờ, tải xuống và cài đặt NVIDIA_CUDA_DNN.
Step 4- Cuối cùng, bằng cách sử dụng lệnh pip sau, cài đặt MXNet với CUDA−
pip install mxnet-cu92Cài đặt với Hỗ trợ CUDA và MKL
Dưới đây là các bước với sự trợ giúp của chúng, chúng ta có thể thiết lập MXNet với CUDA và MKL.
Step 1- Trước tiên hãy cài đặt Microsoft Visual Studio 2017 hoặc Microsoft Visual Studio 2015.
Step 2- Tiếp theo, tải và cài đặt intel MKL
Step 3- Bây giờ, tải xuống và cài đặt NVIDIA CUDA.
Step 4- Bây giờ, tải xuống và cài đặt NVIDIA_CUDA_DNN.
Step 5- Cuối cùng, bằng cách sử dụng lệnh pip sau, cài đặt MXNet với MKL.
pip install mxnet-cu92mklTừ nguồn
Để xây dựng thư viện lõi MXNet từ nguồn với GPU, chúng tôi có hai tùy chọn sau:
Option 1− Build with Microsoft Visual Studio 2017
Để tự xây dựng và cài đặt MXNet bằng Microsoft Visual Studio 2017, bạn cần có các phụ thuộc sau.
Install/update Microsoft Visual Studio.
Nếu Microsoft Visual Studio chưa được cài đặt trên máy của bạn, trước tiên hãy tải xuống và cài đặt nó.
Nó sẽ nhắc về việc cài đặt Git. Cài đặt nó cũng được.
Nếu Microsoft Visual Studio đã được cài đặt trên máy của bạn nhưng bạn muốn cập nhật nó thì hãy tiến hành bước tiếp theo để sửa đổi cài đặt của bạn. Tại đây, bạn cũng sẽ có cơ hội cập nhật Microsoft Visual Studio.
Làm theo hướng dẫn để mở Trình cài đặt Visual Studio có sẵn tại https://docs.microsoft.com/en-us để sửa đổi các thành phần riêng lẻ.
Trong ứng dụng Visual Studio Installer, cập nhật theo yêu cầu. Sau đó tìm kiếm và kiểm traVC++ 2017 version 15.4 v14.11 toolset và bấm vào Modify.
Bây giờ bằng cách sử dụng lệnh sau, hãy thay đổi phiên bản của Microsoft VS2017 thành v14.11−
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat" -vcvars_ver=14.11Tiếp theo, bạn cần tải xuống và cài đặt CMake có sẵn tại https://cmake.org/download/ Nó được khuyến khích sử dụng CMake v3.12.2 có sẵn tại https://cmake.org/download/ vì nó được thử nghiệm với MXNet.
Bây giờ, tải xuống và chạy OpenCV gói có sẵn tại https://sourceforge.net/projects/opencvlibrary/sẽ giải nén một số tệp. Bạn có muốn đặt chúng vào thư mục khác hay không là tùy thuộc vào bạn. Ở đây, chúng ta sẽ sử dụng đường dẫnC:\utils(mkdir C:\utils) làm đường dẫn mặc định của chúng tôi.
Tiếp theo, chúng ta cần đặt biến môi trường OpenCV_DIR trỏ đến thư mục xây dựng OpenCV mà chúng ta vừa giải nén. Đối với dấu nhắc lệnh mở này và nhậpset OpenCV_DIR=C:\utils\opencv\build.
Một điểm quan trọng là nếu bạn chưa cài đặt Intel MKL (Math Kernel Library), bạn có thể cài đặt nó.
Một gói mã nguồn mở khác mà bạn có thể sử dụng là OpenBLAS. Tại đây để biết thêm các hướng dẫn, chúng tôi giả định rằng bạn đang sử dụngOpenBLAS.
Vì vậy, hãy tải xuống OpenBlas gói có sẵn tại https://sourceforge.net và giải nén tệp, đổi tên nó thành OpenBLAS và đặt nó dưới C:\utils.
Tiếp theo, chúng ta cần đặt biến môi trường OpenBLAS_HOME để trỏ đến thư mục OpenBLAS có chứa include và libcác thư mục. Đối với dấu nhắc lệnh mở này và nhậpset OpenBLAS_HOME=C:\utils\OpenBLAS.
Bây giờ, tải xuống và cài đặt CUDA có sẵn tại https://developer.nvidia.com. Lưu ý rằng, nếu bạn đã có CUDA, sau đó đã cài đặt Microsoft VS2017, bạn cần cài đặt lại CUDA ngay bây giờ để có thể nhận các thành phần bộ công cụ CUDA cho tích hợp Microsoft VS2017.
Tiếp theo, bạn cần tải xuống và cài đặt cuDNN.
Tiếp theo, bạn cần tải xuống và cài đặt git tại https://gitforwindows.org/ cũng thế.
Khi bạn đã cài đặt tất cả các phần phụ thuộc bắt buộc, hãy làm theo các bước được cung cấp bên dưới để tạo mã nguồn MXNet−
Step 1- Mở dấu nhắc lệnh trong cửa sổ.
Step 2- Bây giờ, bằng cách sử dụng lệnh sau, tải xuống mã nguồn MXNet từ GitHub:
cd C:\
git clone https://github.com/apache/incubator-mxnet.git --recursiveStep 3- Tiếp theo, xác minh những điều sau−
DCUDNN_INCLUDE and DCUDNN_LIBRARY các biến môi trường đang trỏ đến include thư mục và cudnn.lib tệp vị trí đã cài đặt CUDA của bạn
C:\incubator-mxnet là vị trí của mã nguồn bạn vừa sao chép ở bước trước.
Step 4- Tiếp theo bằng cách sử dụng lệnh sau, tạo một bản dựng directory và cũng đi đến thư mục, chẳng hạn như
mkdir C:\incubator-mxnet\build
cd C:\incubator-mxnet\buildStep 5- Bây giờ, bằng cách sử dụng cmake, hãy biên dịch mã nguồn MXNet như sau−
cmake -G "Visual Studio 15 2017 Win64" -T cuda=9.2,host=x64 -DUSE_CUDA=1 -DUSE_CUDNN=1 -DUSE_NVRTC=1 -DUSE_OPENCV=1 -DUSE_OPENMP=1 -DUSE_BLAS=open -DUSE_LAPACK=1 -DUSE_DIST_KVSTORE=0 -DCUDA_ARCH_LIST=Common -DCUDA_TOOLSET=9.2 -DCUDNN_INCLUDE=C:\cuda\include -DCUDNN_LIBRARY=C:\cuda\lib\x64\cudnn.lib "C:\incubator-mxnet"Step 6- Sau khi CMake hoàn tất thành công, hãy sử dụng lệnh sau để biên dịch mã nguồn MXNet
msbuild mxnet.sln /p:Configuration=Release;Platform=x64 /maxcpucountOption 2: Build with Microsoft Visual Studio 2015
Để tự xây dựng và cài đặt MXNet bằng Microsoft Visual Studio 2015, bạn cần có các phụ thuộc sau.
Cài đặt / cập nhật Microsoft Visual Studio 2015. Yêu cầu tối thiểu để xây dựng MXnet từ nguồn là Cập nhật 3 của Microsoft Visual Studio 2015. Bạn có thể sử dụng Tools -> Extensions and Updates... | Product Updates để nâng cấp nó.
Tiếp theo, bạn cần tải xuống và cài đặt CMake có sẵn tại https://cmake.org/download/. Nó được khuyến khích sử dụngCMake v3.12.2 đó là ở https://cmake.org/download/, bởi vì nó được thử nghiệm với MXNet.
Bây giờ, hãy tải xuống và chạy gói OpenCV có sẵn tại https://excellmedia.dl.sourceforge.netsẽ giải nén một số tệp. Bạn có muốn đặt chúng vào thư mục khác hay không.
Tiếp theo, chúng ta cần đặt biến môi trường OpenCV_DIR để chỉ vào OpenCVxây dựng thư mục mà chúng tôi vừa giải nén. Đối với điều này, hãy mở dấu nhắc lệnh và nhập setOpenCV_DIR=C:\opencv\build\x64\vc14\bin.
Một điểm quan trọng là nếu bạn chưa cài đặt Intel MKL (Math Kernel Library), bạn có thể cài đặt nó.
Một gói mã nguồn mở khác mà bạn có thể sử dụng là OpenBLAS. Tại đây để biết thêm các hướng dẫn, chúng tôi giả định rằng bạn đang sử dụngOpenBLAS.
Vì vậy, hãy tải xuống OpenBLAS gói có sẵn tại https://excellmedia.dl.sourceforge.net và giải nén tệp, đổi tên tệp thành OpenBLAS và đặt nó dưới C: \ utils.
Tiếp theo, chúng ta cần thiết lập biến môi trường OpenBLAS_HOME trỏ đến thư mục OpenBLAS có chứa thư mục include và lib. Bạn có thể tìm thấy thư mục trongC:\Program files (x86)\OpenBLAS\
Lưu ý rằng, nếu bạn đã có CUDA, sau đó đã cài đặt Microsoft VS2015, bạn cần cài đặt lại CUDA ngay bây giờ để có thể nhận các thành phần bộ công cụ CUDA để tích hợp Microsoft VS2017.
Tiếp theo, bạn cần tải xuống và cài đặt cuDNN.
Bây giờ, chúng ta cần Đặt biến môi trường CUDACXX trỏ đến CUDA Compiler(C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.1\bin\nvcc.exe ví dụ).
Tương tự, chúng ta cũng cần đặt biến môi trường CUDNN_ROOT để chỉ vào cuDNN thư mục chứa include, lib và bin thư mục (C:\Downloads\cudnn-9.1-windows7-x64-v7\cuda ví dụ).
Khi bạn đã cài đặt tất cả các phần phụ thuộc bắt buộc, hãy làm theo các bước được cung cấp bên dưới để tạo mã nguồn MXNet−
Step 1- Đầu tiên, tải xuống mã nguồn MXNet từ GitHub−
cd C:\
git clone https://github.com/apache/incubator-mxnet.git --recursiveStep 2- Tiếp theo, sử dụng CMake để tạo Visual Studio trong ./build.
Step 3- Bây giờ, trong Visual Studio, chúng ta cần mở tệp giải pháp,.slnvà biên dịch nó. Các lệnh này sẽ tạo ra một thư viện có tên làmxnet.dll bên trong ./build/Release/ or ./build/Debug thư mục
Step 4- Sau khi CMake hoàn tất thành công, hãy sử dụng lệnh sau để biên dịch mã nguồn MXNet
msbuild mxnet.sln /p:Configuration=Release;Platform=x64 /maxcpucountBộ phận xử lý trung tâm (CPU)
Ở đây, chúng tôi sẽ sử dụng các phương pháp khác nhau cụ thể là Pip, Docker và Nguồn để cài đặt MXNet khi chúng tôi đang sử dụng CPU để xử lý−
Bằng cách sử dụng phương pháp Pip
Nếu bạn định xây dựng MXNet trên Windows với CPU, có hai tùy chọn để cài đặt MXNet bằng gói Python−
Install with CPUs
Sử dụng lệnh sau để cài đặt MXNet với CPU với Python−
pip install mxnetInstall with Intel CPUs
Như đã thảo luận ở trên, MXNet có hỗ trợ thử nghiệm cho Intel MKL cũng như MKL-DNN. Sử dụng lệnh sau để cài đặt MXNet với CPU Intel với Python−
pip install mxnet-mklBằng cách sử dụng Docker
Bạn có thể tìm thấy hình ảnh docker với MXNet tại DockerHub, có sẵn tại https://hub.docker.com/u/mxnet Hãy để chúng tôi kiểm tra các bước bên dưới, để cài đặt MXNet bằng cách sử dụng Docker với CPU−
Step 1- Đầu tiên, bằng cách làm theo hướng dẫn cài đặt docker có thể đọc tại https://docs.docker.com/docker-for-mac/install. Chúng tôi cần cài đặt Docker trên máy của mình.
Step 2- Bằng cách sử dụng lệnh sau, bạn có thể kéo hình ảnh bộ đế MXNet
$ docker pull mxnet/pythonBây giờ để xem liệu việc kéo hình ảnh docker mxnet / python có thành công hay không, chúng ta có thể liệt kê các hình ảnh docker như sau−
$ docker imagesĐể có tốc độ suy luận nhanh nhất với MXNet, bạn nên sử dụng MXNet mới nhất với Intel MKL-DNN.
Kiểm tra các lệnh bên dưới−
$ docker pull mxnet/python:1.3.0_cpu_mkl $ docker imagesCài đặt MXNet trên đám mây và thiết bị
Phần này nêu bật cách cài đặt Apache MXNet trên Đám mây và trên các thiết bị. Chúng ta hãy bắt đầu bằng cách tìm hiểu về cách cài đặt MXNet trên đám mây.
Cài đặt MXNet trên đám mây
Bạn cũng có thể tải Apache MXNet trên một số nhà cung cấp đám mây với Graphical Processing Unit (GPU)ủng hộ. Hai loại hỗ trợ khác mà bạn có thể tìm thấy như sau:
- Hỗ trợ kết hợp giữa GPU / CPU cho các trường hợp sử dụng như suy luận có thể mở rộng.
- Hỗ trợ GPU giai thừa với AWS Elastic Inference.
Sau đây là các nhà cung cấp đám mây cung cấp hỗ trợ GPU với máy ảo khác nhau cho Apache MXNet−
Bảng điều khiển Alibaba
Bạn có thể tạo NVIDIA GPU Cloud Virtual Machine (VM) có sẵn tại https://docs.nvidia.com/ngc với Bảng điều khiển Alibaba và sử dụng Apache MXNet.
Dịch vụ web của Amazon
Nó cũng cung cấp hỗ trợ GPU và cung cấp các dịch vụ sau cho Apache MXNet−
Amazon SageMaker
Nó quản lý đào tạo và triển khai các mô hình Apache MXNet.
AWS Deep Learning AMI
Nó cung cấp môi trường Conda được cài đặt sẵn cho cả Python 2 và Python 3 với Apache MXNet, CUDA, cuDNN, MKL-DNN và AWS Elastic Inference.
Đào tạo động trên AWS
Nó cung cấp đào tạo để thiết lập EC2 thủ công thử nghiệm cũng như thiết lập CloudFormation bán tự động.
Bạn có thể dùng NVIDIA VM có sẵn tại https://aws.amazon.com với các dịch vụ web của Amazon.
Nền tảng đám mây của Google
Google cũng đang cung cấp NVIDIA GPU cloud image có sẵn tại https://console.cloud.google.com để làm việc với Apache MXNet.
Microsoft Azure
Microsoft Azure Marketplace cũng đang cung cấp NVIDIA GPU cloud image có sẵn tại https://azuremarketplace.microsoft.com để làm việc với Apache MXNet.
Đám mây Oracle
Oracle cũng đang cung cấp NVIDIA GPU cloud image có sẵn tại https://docs.cloud.oracle.com để làm việc với Apache MXNet.
Bộ phận xử lý trung tâm (CPU)
Apache MXNet hoạt động trên mọi phiên bản chỉ dành cho CPU của nhà cung cấp đám mây. Có nhiều phương pháp khác nhau để cài đặt như
Hướng dẫn cài đặt pip trong Python.
Hướng dẫn Docker.
Tùy chọn cài đặt sẵn như Amazon Web Services cung cấp AWS Deep Learning AMI (có môi trường Conda được cài đặt sẵn cho cả Python 2 và Python 3 với MXNet và MKL-DNN).
Cài đặt MXNet trên thiết bị
Hãy để chúng tôi tìm hiểu cách cài đặt MXNet trên các thiết bị.
Raspberry Pi
Bạn cũng có thể chạy Apache MXNet trên các thiết bị Raspberry Pi 3B vì MXNet cũng hỗ trợ Hệ điều hành dựa trên ARM Respbian. Để chạy MXNet trơn tru trên Raspberry Pi3, bạn nên trang bị thiết bị có RAM hơn 1 GB và thẻ SD với ít nhất 4GB dung lượng trống.
Sau đây là các cách với sự trợ giúp mà bạn có thể xây dựng MXNet cho Raspberry Pi và cài đặt các liên kết Python cho thư viện
Cài đặt nhanh chóng
Bánh xe Python được tạo sẵn có thể được sử dụng trên Raspberry Pi 3B với tính năng Stretch để cài đặt nhanh chóng. Một trong những vấn đề quan trọng với phương pháp này là chúng ta cần cài đặt một số phụ thuộc để Apache MXNet hoạt động.
Cài đặt Docker
Bạn có thể làm theo hướng dẫn cài đặt docker, có sẵn tại https://docs.docker.com/engine/install/ubuntu/để cài đặt Docker trên máy của bạn. Vì mục đích này, chúng tôi cũng có thể cài đặt và sử dụng Phiên bản Cộng đồng (CE).
Bản dựng gốc (từ nguồn)
Để cài đặt MXNet từ nguồn, chúng ta cần làm theo hai bước sau:
Bước 1
Build the shared library from the Apache MXNet C++ source code
Để xây dựng thư viện được chia sẻ trên phiên bản Raspberry Wheezy trở lên, chúng ta cần các phụ thuộc sau:
Git- Bắt buộc phải lấy mã từ GitHub.
Libblas- Nó được yêu cầu cho các phép toán đại số tuyến tính.
Libopencv- Nó được yêu cầu cho các hoạt động liên quan đến thị giác máy tính. Tuy nhiên, nó là tùy chọn nếu bạn muốn tiết kiệm RAM và Dung lượng đĩa của mình.
C++ Compiler- Yêu cầu biên dịch và xây dựng mã nguồn MXNet. Sau đây là các trình biên dịch được hỗ trợ hỗ trợ C ++ 11−
G ++ (phiên bản 4.8 trở lên)
Clang(3.9-6)
Sử dụng các lệnh sau để cài đặt các phần phụ thuộc nêu trên−
sudo apt-get update
sudo apt-get -y install git cmake ninja-build build-essential g++-4.9 c++-4.9 liblapack*
libblas* libopencv*
libopenblas* python3-dev python-dev virtualenvTiếp theo, chúng ta cần sao chép kho mã nguồn MXNet. Đối với điều này, hãy sử dụng lệnh git sau trong thư mục chính của bạn−
git clone https://github.com/apache/incubator-mxnet.git --recursive
cd incubator-mxnetBây giờ, với sự trợ giúp của các lệnh sau, hãy xây dựng thư viện được chia sẻ:
mkdir -p build && cd build
cmake \
-DUSE_SSE=OFF \
-DUSE_CUDA=OFF \
-DUSE_OPENCV=ON \
-DUSE_OPENMP=ON \
-DUSE_MKL_IF_AVAILABLE=OFF \
-DUSE_SIGNAL_HANDLER=ON \
-DCMAKE_BUILD_TYPE=Release \
-GNinja ..
ninja -j$(nproc)Sau khi bạn thực hiện các lệnh trên, nó sẽ bắt đầu quá trình xây dựng sẽ mất vài giờ để hoàn thành. Bạn sẽ nhận được một tệp có tênlibmxnet.so trong thư mục xây dựng.
Bước 2
Install the supported language-specific packages for Apache MXNet
Trong bước này, chúng tôi sẽ cài đặt các ràng buộc MXNet Pythin. Để làm như vậy, chúng ta cần chạy lệnh sau trong thư mục MXNet−
cd python
pip install --upgrade pip
pip install -e .Ngoài ra, với lệnh sau, bạn cũng có thể tạo whl package có thể cài đặt với pip-
ci/docker/runtime_functions.sh build_wheel python/ $(realpath build)Thiết bị NVIDIA Jetson
Bạn cũng có thể chạy Apache MXNet trên Thiết bị NVIDIA Jetson, chẳng hạn như TX2 hoặc là Nanovì MXNet cũng hỗ trợ HĐH dựa trên Ubuntu Arch64. Để chạy mượt mà MXNet trên Thiết bị NVIDIA Jetson, bạn cần phải cài đặt CUDA trên thiết bị Jetson của mình.
Sau đây là các cách với sự trợ giúp mà bạn có thể tạo MXNet cho các thiết bị NVIDIA Jetson:
Bằng cách sử dụng bánh xe pip Jetson MXNet để phát triển Python
Từ nguồn
Tuy nhiên, trước khi xây dựng MXNet từ bất kỳ cách nào được đề cập ở trên, bạn cần cài đặt các phần phụ thuộc sau trên thiết bị Jetson của mình−
Sự phụ thuộc Python
Để sử dụng API Python, chúng ta cần có các phụ thuộc sau:
sudo apt update
sudo apt -y install \
build-essential \
git \
graphviz \
libatlas-base-dev \
libopencv-dev \
python-pip
sudo pip install --upgrade \
pip \
setuptools
sudo pip install \
graphviz==0.8.4 \
jupyter \
numpy==1.15.2Sao chép kho lưu trữ mã nguồn MXNet
Bằng cách sử dụng lệnh git sau trong thư mục chính của bạn, sao chép kho lưu trữ mã nguồn MXNet−
git clone --recursive https://github.com/apache/incubator-mxnet.git mxnetThiết lập các biến môi trường
Thêm phần sau vào của bạn .profile tập tin trong thư mục chính của bạn
export PATH=/usr/local/cuda/bin:$PATH export MXNET_HOME=$HOME/mxnet/
export PYTHONPATH=$MXNET_HOME/python:$PYTHONPATHBây giờ, hãy áp dụng thay đổi ngay lập tức bằng lệnh sau
source .profileĐịnh cấu hình CUDA
Trước khi định cấu hình CUDA, với nvcc, bạn cần kiểm tra phiên bản CUDA đang chạy
nvcc --versionGiả sử, nếu nhiều phiên bản CUDA được cài đặt trên thiết bị hoặc máy tính của bạn và bạn muốn chuyển đổi phiên bản CUDA, hãy sử dụng cách sau và thay thế liên kết tượng trưng thành phiên bản bạn muốn−
sudo rm /usr/local/cuda
sudo ln -s /usr/local/cuda-10.0 /usr/local/cudaLệnh trên sẽ chuyển sang CUDA 10.0, được cài đặt sẵn trên thiết bị NVIDIA Jetson Nano.
Sau khi thực hiện xong các điều kiện tiên quyết nêu trên, bây giờ bạn có thể cài đặt MXNet trên Thiết bị NVIDIA Jetson. Vì vậy, hãy để chúng tôi hiểu các cách mà bạn có thể cài đặt MXNet−
By using a Jetson MXNet pip wheel for Python development- Nếu bạn muốn sử dụng bánh xe Python đã chuẩn bị, hãy tải phần sau xuống Jetson của bạn và chạy nó−
MXNet 1.4.0 (cho Python 3) có sẵn tại https://docs.docker.com
MXNet 1.4.0 (cho Python 2) có sẵn tại https://docs.docker.com
Bản dựng gốc (từ nguồn)
Để cài đặt MXNet từ nguồn, chúng ta cần làm theo hai bước sau:
Bước 1
Build the shared library from the Apache MXNet C++ source code
Để xây dựng thư viện được chia sẻ từ mã nguồn Apache MXNet C ++, bạn có thể sử dụng phương pháp Docker hoặc thực hiện theo cách thủ công−
Phương pháp Docker
Trong phương pháp này, trước tiên bạn cần cài đặt Docker và có thể chạy nó mà không cần sudo (cũng được giải thích trong các bước trước). Sau khi hoàn tất, hãy chạy phần sau để thực hiện biên dịch chéo qua Docker−
$MXNET_HOME/ci/build.py -p jetsonThủ công
Trong phương pháp này, bạn cần chỉnh sửa Makefile (với lệnh bên dưới) để cài đặt MXNet với các ràng buộc CUDA để tận dụng các đơn vị Xử lý Đồ họa (GPU) trên các thiết bị NVIDIA Jetson:
cp $MXNET_HOME/make/crosscompile.jetson.mk config.mkSau khi chỉnh sửa Makefile, bạn cần chỉnh sửa tệp config.mk để thực hiện một số thay đổi bổ sung cho thiết bị NVIDIA Jetson.
Đối với điều này, hãy cập nhật các cài đặt sau
Cập nhật đường dẫn CUDA: USE_CUDA_PATH = / usr / local / cuda
Thêm -gencode Arch = compute-63, code = sm_62 vào cài đặt CUDA_ARCH.
Cập nhật cài đặt NVCC: NVCCFLAGS: = -m64
Bật OpenCV: USE_OPENCV = 1
Bây giờ để đảm bảo rằng MXNet xây dựng với khả năng tăng tốc chính xác thấp ở cấp phần cứng của Pascal, chúng ta cần chỉnh sửa Mshadow Makefile như sau:
MSHADOW_CFLAGS += -DMSHADOW_USE_PASCAL=1Cuối cùng, với sự trợ giúp của lệnh sau, bạn có thể tạo thư viện Apache MXNet hoàn chỉnh−
cd $MXNET_HOME make -j $(nproc)Sau khi bạn thực hiện các lệnh trên, nó sẽ bắt đầu quá trình xây dựng sẽ mất vài giờ để hoàn thành. Bạn sẽ nhận được một tệp có tênlibmxnet.so bên trong mxnet/lib directory.
Bước 2
Install the Apache MXNet Python Bindings
Trong bước này, chúng tôi sẽ cài đặt các liên kết MXNet Python. Để làm như vậy, chúng ta cần chạy lệnh sau trong thư mục MXNet−
cd $MXNET_HOME/python
sudo pip install -e .Sau khi thực hiện xong các bước trên, bây giờ bạn đã sẵn sàng chạy MXNet trên các thiết bị NVIDIA Jetson TX2 hoặc Nano của mình. Nó có thể được xác minh bằng lệnh sau
import mxnet
mxnet.__version__Nó sẽ trả về số phiên bản nếu mọi thứ hoạt động bình thường.
Để hỗ trợ việc nghiên cứu và phát triển các ứng dụng Deep Learning trên nhiều lĩnh vực, Apache MXNet cung cấp cho chúng ta một hệ sinh thái phong phú gồm các bộ công cụ, thư viện và nhiều hơn nữa. Hãy để chúng tôi khám phá chúng -
Bộ dụng cụ
Sau đây là một số bộ công cụ quan trọng và được sử dụng nhiều nhất do MXNet cung cấp -
GluonCV
Như tên của nó GluonCV là một bộ công cụ Gluon dành cho thị giác máy tính được cung cấp bởi MXNet. Nó cung cấp việc triển khai các thuật toán DL (Deep Learning) hiện đại nhất trong thị giác máy tính (CV). Với sự trợ giúp của các kỹ sư, nhà nghiên cứu và sinh viên của bộ công cụ GluonCV có thể xác nhận các ý tưởng mới và tìm hiểu CV một cách dễ dàng.
Dưới đây là một số features of GluonCV -
Nó đào tạo các tập lệnh để tái tạo các kết quả hiện đại được báo cáo trong nghiên cứu mới nhất.
Hơn 170+ mô hình chất lượng cao.
Nắm bắt mô hình phát triển linh hoạt.
GluonCV rất dễ tối ưu hóa. Chúng tôi có thể triển khai nó mà không cần giữ lại khung DL nặng.
Nó cung cấp các API được thiết kế cẩn thận giúp giảm bớt sự phức tạp khi triển khai.
Sự đóng góp cho cộng đồng.
Cách triển khai dễ hiểu.
Sau đây là supported applications bởi bộ công cụ GluonCV:
Phân loại hình ảnh
Phát hiện đối tượng
Phân đoạn ngữ nghĩa
Phân đoạn phiên bản
Ước tính tư thế
Nhận dạng hành động video
Chúng ta có thể cài đặt GluonCV bằng cách sử dụng pip như sau:
pip install --upgrade mxnet gluoncvGluonNLP
Như tên của nó, GluonNLP là một bộ công cụ Gluon để xử lý ngôn ngữ tự nhiên (NLP) được cung cấp bởi MXNet. Nó cung cấp việc triển khai các mô hình DL (Học sâu) tiên tiến trong NLP.
Với sự trợ giúp của các kỹ sư, nhà nghiên cứu và sinh viên bộ công cụ GluonNLP có thể xây dựng các khối cho mô hình và đường ống dẫn dữ liệu văn bản. Dựa trên các mô hình này, họ có thể nhanh chóng tạo mẫu cho các ý tưởng và sản phẩm nghiên cứu.
Dưới đây là một số tính năng của GluonNLP:
Nó đào tạo các tập lệnh để tái tạo các kết quả hiện đại được báo cáo trong nghiên cứu mới nhất.
Tập hợp các mô hình được đào tạo trước cho các nhiệm vụ NLP phổ biến.
Nó cung cấp các API được thiết kế cẩn thận giúp giảm bớt sự phức tạp khi triển khai.
Sự đóng góp cho cộng đồng.
Nó cũng cung cấp các hướng dẫn để giúp bạn bắt đầu với các nhiệm vụ NLP mới.
Sau đây là các tác vụ NLP mà chúng ta có thể thực hiện với bộ công cụ GluonNLP -
Nhúng từ
Mô hình ngôn ngữ
Dịch máy
Phân loại văn bản
Phân tích cảm xúc
Suy luận ngôn ngữ tự nhiên
Tạo văn bản
Phân tích cú pháp phụ thuộc
Nhận dạng đối tượng được đặt tên
Phân loại ý định và ghi nhãn vị trí
Chúng ta có thể cài đặt GluonNLP bằng cách sử dụng pip như sau:
pip install --upgrade mxnet gluonnlpGluonTS
Như tên của nó, GluonTS là một bộ công cụ Gluon để Lập mô hình chuỗi thời gian xác suất được cung cấp bởi MXNet.
Nó cung cấp các tính năng sau:
Các mô hình học sâu hiện đại (SOTA) sẵn sàng được đào tạo.
Các tiện ích để tải cũng như lặp qua các tập dữ liệu chuỗi thời gian.
Các khối xây dựng để xác định mô hình của riêng bạn.
Với sự trợ giúp của các kỹ sư bộ công cụ GluonTS, các nhà nghiên cứu và sinh viên có thể đào tạo và đánh giá bất kỳ mô hình tích hợp nào trên dữ liệu của riêng họ, nhanh chóng thử nghiệm các giải pháp khác nhau và đưa ra giải pháp cho các nhiệm vụ chuỗi thời gian của họ.
Họ cũng có thể sử dụng các khối xây dựng và trừu tượng được cung cấp để tạo các mô hình chuỗi thời gian tùy chỉnh và nhanh chóng đánh giá chúng theo các thuật toán cơ sở.
Chúng ta có thể cài đặt GluonTS bằng cách sử dụng pip như sau:
pip install gluontsGluonFR
Như tên của nó, nó là một bộ công cụ Apache MXNet Gluon cho FR (Nhận dạng khuôn mặt). Nó cung cấp các tính năng sau:
Mô hình học sâu hiện đại (SOTA) trong nhận dạng khuôn mặt.
Việc triển khai SoftmaxCrossEntropyLoss, ArcLoss, TripletLoss, RingLoss, CosLoss / AMsoftmax, L2-Softmax, A-Softmax, CenterLoss, ContrastiveLoss và LGM Loss, v.v.
Để cài đặt Gluon Face, chúng ta cần Python 3.5 trở lên. Trước tiên, chúng ta cũng cần cài đặt GluonCV và MXNet như sau:
pip install gluoncv --pre
pip install mxnet-mkl --pre --upgrade
pip install mxnet-cuXXmkl --pre –upgrade # if cuda XX is installedKhi bạn đã cài đặt các phụ thuộc, bạn có thể sử dụng lệnh sau để cài đặt GluonFR:
From Source
pip install git+https://github.com/THUFutureLab/gluon-face.git@masterPip
pip install gluonfrHệ sinh thái
Bây giờ chúng ta hãy khám phá các thư viện, gói và khuôn khổ phong phú của MXNet -
Huấn luyện viên RL
Coach, một khung học tập củng cố Python (RL) được tạo bởi phòng thí nghiệm AI của Intel. Nó cho phép thử nghiệm dễ dàng với các thuật toán RL hiện đại. Coach RL hỗ trợ Apache MXNet như một phần mềm hỗ trợ và cho phép tích hợp đơn giản môi trường mới để giải quyết.
Để mở rộng và sử dụng lại các thành phần hiện có một cách dễ dàng, Coach RL đã tách rất tốt các thành phần học tăng cường cơ bản như thuật toán, môi trường, kiến trúc NN, chính sách khám phá.
Sau đây là các tác nhân và thuật toán được hỗ trợ cho khung Coach RL:
Đại lý tối ưu hóa giá trị
Mạng Q sâu (DQN)
Mạng Double Deep Q (DDQN)
Dueling Q Mạng
Monte Carlo hỗn hợp (MMC)
Học tập lợi thế liên tục (PAL)
Mạng Q sâu Categorical (C51)
Hồi quy lượng tử Deep Q Network (QR-DQN)
Học N-Step Q
Kiểm soát giai đoạn thần kinh (NEC)
Chức năng lợi thế chuẩn hóa (NAF)
Rainbow
Đại lý tối ưu hóa chính sách
Thành viên chính sách (PG)
Diễn viên-phê bình lợi thế không đồng bộ (A3C)
Trọng tài chính sách xác định sâu (DDPG)
Tối ưu hóa chính sách gần (PPO)
Tối ưu hóa chính sách gần đã được cắt bớt (CPPO)
Ước tính lợi thế chung (GAE)
Mẫu-Phê bình diễn viên hiệu quả với phát lại kinh nghiệm (ACER)
Diễn viên mềm-Phê bình (SAC)
Dốc chính sách xác định sâu đôi bị trì hoãn (TD3)
Tổng đại lý
Dự đoán tương lai trực tiếp (DFP)
Đại lý học bắt chước
Nhân bản hành vi (BC)
Học bắt chước có điều kiện
Tác nhân học tập củng cố thứ bậc
Nhà phê bình diễn viên phân cấp (HAC)
Thư viện đồ thị sâu
Thư viện đồ thị sâu (DGL), được phát triển bởi nhóm NYU và AWS, Thượng Hải, là một gói Python cung cấp các triển khai dễ dàng của Mạng thần kinh đồ thị (GNN) trên MXNet. Nó cũng cung cấp khả năng triển khai GNN dễ dàng trên các thư viện học sâu hiện có khác như PyTorch, Gluon, v.v.
Thư viện Deep Graph là một phần mềm miễn phí. Nó có sẵn trên tất cả các bản phân phối Linux sau Ubuntu 16.04, macOS X và Windows 7 trở lên. Nó cũng yêu cầu phiên bản Python 3.5 trở lên.
Sau đây là các tính năng của DGL -
No Migration cost - Không có chi phí di chuyển khi sử dụng DGL vì nó được xây dựng trên các khuôn khổ DL phổ biến.
Message Passing- DGL cung cấp khả năng truyền thông điệp và nó có khả năng kiểm soát linh hoạt đối với nó. Việc truyền thông báo có phạm vi từ các hoạt động cấp thấp như gửi dọc theo các cạnh đã chọn đến kiểm soát cấp cao như cập nhật tính năng trên toàn đồ thị.
Smooth Learning Curve - Nó khá dễ dàng để học và sử dụng DGL vì các chức năng mạnh mẽ do người dùng định nghĩa rất linh hoạt cũng như dễ sử dụng.
Transparent Speed Optimization - DGL cung cấp tối ưu hóa tốc độ minh bạch bằng cách thực hiện các phép tính tự động và nhân ma trận thưa thớt.
High performance - Để đạt được hiệu quả tối đa, DGL tự động đào tạo hàng loạt DNN (mạng nơ ron sâu) trên một hoặc nhiều đồ thị với nhau.
Easy & friendly interface - DGL cung cấp cho chúng ta giao diện dễ dàng và thân thiện để truy cập tính năng cạnh cũng như thao tác cấu trúc đồ thị.
InsightFace
InsightFace, Bộ công cụ học sâu dành cho Phân tích khuôn mặt cung cấp việc triển khai thuật toán phân tích khuôn mặt SOTA (hiện đại) trong thị giác máy tính do MXNet cung cấp. Nó cung cấp -
Bộ mô hình lớn chất lượng cao được đào tạo trước.
Các kịch bản đào tạo hiện đại (SOTA).
InsightFace rất dễ tối ưu hóa. Chúng tôi có thể triển khai nó mà không cần giữ lại khung DL nặng.
Nó cung cấp các API được thiết kế cẩn thận giúp giảm bớt sự phức tạp khi triển khai.
Các khối xây dựng để xác định mô hình của riêng bạn.
Chúng ta có thể cài đặt InsightFace bằng cách sử dụng pip như sau:
pip install --upgrade insightfaceXin lưu ý rằng trước khi cài đặt InsightFace, hãy cài đặt đúng gói MXNet theo cấu hình hệ thống của bạn.
Keras-MXNet
Như chúng ta biết rằng Keras là một API Mạng Nơ-ron (NN) cấp cao được viết bằng Python, Keras-MXNet cung cấp cho chúng ta một hỗ trợ phụ trợ cho Keras. Nó có thể chạy trên khung công tác Apache MXNet DL hiệu suất cao và có thể mở rộng.
Các tính năng của Keras-MXNet được đề cập dưới đây:
Cho phép người dùng tạo mẫu dễ dàng, mượt mà và nhanh chóng. Tất cả đều xảy ra thông qua tính thân thiện với người dùng, tính mô-đun và khả năng mở rộng.
Hỗ trợ cả CNN (Mạng thần kinh chuyển đổi) và RNN (Mạng thần kinh định kỳ) cũng như sự kết hợp của cả hai.
Chạy hoàn hảo trên cả Bộ xử lý trung tâm (CPU) và Bộ xử lý đồ họa (GPU).
Có thể chạy trên một hoặc nhiều GPU.
Để làm việc với chương trình phụ trợ này, trước tiên bạn cần cài đặt keras-mxnet như sau:
pip install keras-mxnetBây giờ, nếu bạn đang sử dụng GPU, hãy cài đặt MXNet với hỗ trợ CUDA 9 như sau:
pip install mxnet-cu90Nhưng nếu bạn chỉ sử dụng CPU thì hãy cài đặt MXNet cơ bản như sau:
pip install mxnetMXBoard
MXBoard là công cụ ghi nhật ký, được viết bằng Python, được sử dụng để ghi lại các khung dữ liệu MXNet và hiển thị trong TensorBoard. Nói cách khác, MXBoard có nghĩa là tuân theo API tensorboard-pytorch. Nó hỗ trợ hầu hết các kiểu dữ liệu trong TensorBoard.
Một số trong số chúng được đề cập dưới đây -
Graph
Scalar
Histogram
Embedding
Image
Text
Audio
Đường cong thu hồi chính xác
MXFusion
MXFusion là một thư viện lập trình xác suất theo mô-đun với tính năng học sâu. MXFusion cho phép chúng tôi khai thác triệt để tính mô-đun, đây là một tính năng chính của thư viện học sâu, để lập trình xác suất. Nó đơn giản để sử dụng và cung cấp cho người dùng một giao diện thuận tiện để thiết kế các mô hình xác suất và áp dụng chúng vào các bài toán trong thế giới thực.
MXFusion được xác minh trên Python phiên bản 3.4 trở lên trên MacOS và Linux OS. Để cài đặt MXFusion, trước tiên chúng ta cần cài đặt các phần phụ thuộc sau:
MXNet> = 1,3
Networkx> = 2.1
Với sự trợ giúp của lệnh pip sau, bạn có thể cài đặt MXFusion -
pip install mxfusionTVM
Apache TVM, một ngăn xếp trình biên dịch học sâu mã nguồn mở end-to-end dành cho phần cứng-phụ trợ như CPU, GPU và các bộ tăng tốc chuyên dụng, nhằm mục đích lấp đầy khoảng cách giữa khung học sâu tập trung vào năng suất và phần cứng phụ trợ phần cứng theo định hướng hiệu suất . Với bản phát hành mới nhất MXNet 1.6.0, người dùng có thể tận dụng Apache (đang ấp ủ) TVM để triển khai các hạt nhân toán tử hiệu suất cao bằng ngôn ngữ lập trình Python.
Apache TVM thực sự bắt đầu như một dự án nghiên cứu tại nhóm SAMPL của Trường Khoa học Máy tính & Kỹ thuật Paul G. Allen, Đại học Washington và bây giờ nó là một nỗ lực đang được ấp ủ tại Tổ chức Phần mềm Apache (ASF) được điều hành bởi một OSC ( cộng đồng mã nguồn mở) liên quan đến nhiều ngành cũng như các tổ chức học thuật theo cách Apache.
Sau đây là các tính năng chính của Apache (ươm tạo) TVM:
Đơn giản hóa quy trình phát triển dựa trên C ++ trước đây.
Cho phép chia sẻ cùng một triển khai trên nhiều phần cứng phụ trợ như CPU, GPU, v.v.
TVM cung cấp việc biên dịch các mô hình DL trong nhiều khuôn khổ khác nhau như Kears, MXNet, PyTorch, Tensorflow, CoreML, DarkNet thành các mô-đun có thể triển khai tối thiểu trên các phần cứng phụ trợ đa dạng.
Nó cũng cung cấp cho chúng tôi cơ sở hạ tầng để tự động tạo và tối ưu hóa các nhà khai thác tensor với hiệu suất tốt hơn.
XFer
Xfer, một khung học tập chuyển giao, được viết bằng Python. Về cơ bản, nó cần có một mô hình MXNet và đào tạo một mô hình meta hoặc sửa đổi mô hình cho một tập dữ liệu mục tiêu mới.
Nói một cách dễ hiểu, Xfer là một thư viện Python cho phép người dùng truyền nhanh chóng và dễ dàng kiến thức được lưu trữ trong DNN (mạng nơ ron sâu).
Xfer có thể được sử dụng -
Đối với việc phân loại dữ liệu có định dạng số tùy ý.
Đối với các trường hợp phổ biến của hình ảnh hoặc dữ liệu văn bản.
Là một đường ống gửi thư rác từ việc trích xuất các tính năng để đào tạo một repurposer (một đối tượng thực hiện phân loại trong nhiệm vụ đích).
Sau đây là các tính năng của Xfer:
Hiệu quả tài nguyên
Hiệu quả dữ liệu
Dễ dàng truy cập vào mạng nơ-ron
Mô hình không chắc chắn
Tạo mẫu nhanh
Các tiện ích để trích xuất tính năng từ NN
Chương này sẽ giúp bạn hiểu về kiến trúc hệ thống MXNet. Chúng ta hãy bắt đầu bằng cách tìm hiểu về Mô-đun MXNet.
Mô-đun MXNet
Sơ đồ dưới đây là kiến trúc hệ thống MXNet và nó cho thấy các mô-đun và thành phần chính của MXNet modules and their interaction.

Trong sơ đồ trên -
Các mô-đun trong hộp màu xanh lam là User Facing Modules.
Các mô-đun trong hộp màu xanh lá cây là System Modules.
Mũi tên đặc thể hiện sự phụ thuộc cao, tức là phụ thuộc nhiều vào giao diện.
Mũi tên chấm biểu thị sự phụ thuộc ánh sáng, tức là Cấu trúc dữ liệu được sử dụng để thuận tiện và nhất quán giao diện. Trong thực tế, nó có thể được thay thế bằng các lựa chọn thay thế.
Hãy để chúng tôi thảo luận thêm về mô-đun hệ thống và giao diện người dùng.
Mô-đun giao diện người dùng
Các mô-đun hướng tới người dùng như sau:
NDArray- Nó cung cấp các chương trình mệnh lệnh linh hoạt cho Apache MXNet. Chúng là mảng n chiều động và không đồng bộ.
KVStore- Nó hoạt động như một giao diện để đồng bộ tham số hiệu quả. Trong KVStore, KV là viết tắt của Key-Value. Vì vậy, nó là một giao diện cửa hàng khóa-giá trị.
Data Loading (IO) - Mô-đun hướng về người dùng này được sử dụng để tải và tăng dữ liệu phân tán hiệu quả.
Symbol Execution- Nó là một trình thực thi đồ thị biểu tượng tĩnh. Nó cung cấp hiệu quả thực thi và tối ưu hóa đồ thị biểu tượng.
Symbol Construction - Mô-đun hướng về người dùng này cung cấp cho người dùng một cách để xây dựng một đồ thị tính toán tức là cấu hình mạng.
Mô-đun hệ thống
Các mô-đun hệ thống như sau:
Storage Allocator - Mô-đun hệ thống này, như tên cho thấy, phân bổ và tái chế các khối bộ nhớ một cách hiệu quả trên máy chủ, tức là CPU và các thiết bị khác nhau tức là GPU.
Runtime Dependency Engine - Lịch trình mô-đun công cụ phụ thuộc thời gian chạy cũng như thực hiện các hoạt động theo sự phụ thuộc đọc / ghi của chúng.
Resource Manager - Mô-đun hệ thống Quản lý tài nguyên (RM) quản lý các tài nguyên toàn cầu như trình tạo số ngẫu nhiên và không gian thời gian.
Operator - Mô-đun hệ thống toán tử bao gồm tất cả các toán tử xác định tính toán chuyển tiếp và gradient tĩnh tức là sự lan truyền ngược.
Tại đây, các thành phần hệ thống trong Apache MXNet được giải thích chi tiết. Đầu tiên, chúng ta sẽ nghiên cứu về công cụ thực thi trong MXNet.
Công cụ thực thi
Công cụ thực thi của Apache MXNet rất linh hoạt. Chúng tôi có thể sử dụng nó cho việc học sâu cũng như bất kỳ vấn đề nào về miền cụ thể: thực thi một loạt các hàm theo sau sự phụ thuộc của chúng. Nó được thiết kế theo cách mà các hàm có phụ thuộc được tuần tự hóa trong khi các hàm không có phụ thuộc có thể được thực thi song song.
Giao diện cốt lõi
API được cung cấp bên dưới là giao diện cốt lõi cho công cụ thực thi của Apache MXNet -
virtual void PushSync(Fn exec_fun, Context exec_ctx,
std::vector<VarHandle> const& const_vars,
std::vector<VarHandle> const& mutate_vars) = 0;API trên có những điều sau:
exec_fun - API giao diện cốt lõi của MXNet cho phép chúng ta đẩy hàm có tên là execute_fun, cùng với thông tin ngữ cảnh và các phụ thuộc của nó, tới công cụ thực thi.
exec_ctx - Thông tin ngữ cảnh mà trong đó hàm execute_fun nói trên sẽ được thực thi.
const_vars - Đây là các biến mà hàm đọc từ đó.
mutate_vars - Đây là những biến sẽ được sửa đổi.
Công cụ thực thi cung cấp cho người dùng sự đảm bảo rằng việc thực thi bất kỳ hai hàm nào sửa đổi một biến chung được tuần tự hóa theo thứ tự đẩy của chúng.
Chức năng
Sau đây là loại chức năng của công cụ thực thi của Apache MXNet:
using Fn = std::function<void(RunContext)>;Trong hàm trên, RunContextchứa thông tin thời gian chạy. Thông tin thời gian chạy phải được xác định bởi công cụ thực thi. Cú pháp củaRunContext như sau
struct RunContext {
// stream pointer which could be safely cast to
// cudaStream_t* type
void *stream;
};Dưới đây là một số điểm quan trọng về các chức năng của công cụ thực thi:
Tất cả các chức năng được thực thi bởi các luồng nội bộ của công cụ thực thi MXNet.
Sẽ không tốt nếu đẩy chức năng chặn đến công cụ thực thi vì cùng với đó, chức năng sẽ chiếm luồng thực thi và cũng sẽ làm giảm tổng thông lượng.
Đối với MXNet này, cung cấp một hàm không đồng bộ khác như sau:
using Callback = std::function<void()>;
using AsyncFn = std::function<void(RunContext, Callback)>;Trong này AsyncFn hàm, chúng ta có thể chuyển phần nặng của các luồng của chúng ta, nhưng bộ máy thực thi không coi hàm đã hoàn thành cho đến khi chúng ta gọi callback chức năng.
Bối cảnh
Trong Context, chúng ta có thể chỉ định ngữ cảnh của hàm sẽ được thực thi bên trong. Điều này thường bao gồm những điều sau:
Cho dù chức năng sẽ được chạy trên CPU hay GPU.
Nếu chúng tôi chỉ định GPU trong Ngữ cảnh, thì GPU nào sẽ sử dụng.
Có một sự khác biệt rất lớn giữa Context và RunContext. Ngữ cảnh có loại thiết bị và id thiết bị, trong khi RunContext có thông tin chỉ có thể được quyết định trong thời gian chạy.
VarHandle
VarHandle, được sử dụng để chỉ định các phụ thuộc của các hàm, giống như một mã thông báo (đặc biệt được cung cấp bởi công cụ thực thi) mà chúng ta có thể sử dụng để đại diện cho các tài nguyên bên ngoài mà hàm có thể sửa đổi hoặc sử dụng.
Nhưng câu hỏi đặt ra, tại sao chúng ta cần sử dụng VarHandle? Đó là bởi vì, công cụ Apache MXNet được thiết kế để tách khỏi các mô-đun MXNet khác.
Sau đây là một số điểm quan trọng về VarHandle -
Nó nhẹ, do đó, để tạo, xóa hoặc sao chép một biến sẽ tốn ít chi phí vận hành.
Chúng ta cần chỉ định các biến bất biến, tức là các biến sẽ được sử dụng trong const_vars.
Chúng ta cần chỉ định các biến có thể thay đổi, tức là các biến sẽ được sửa đổi trong mutate_vars.
Quy tắc được sử dụng bởi công cụ thực thi để giải quyết sự phụ thuộc giữa các hàm là việc thực thi hai hàm bất kỳ khi một trong số chúng sửa đổi ít nhất một biến chung được tuần tự hóa theo thứ tự đẩy của chúng.
Để tạo một biến mới, chúng ta có thể sử dụng NewVar() API.
Để xóa một biến, chúng ta có thể sử dụng PushDelete API.
Hãy để chúng tôi hiểu cách hoạt động của nó với một ví dụ đơn giản -
Giả sử nếu ta có hai hàm là F1 và F2 và chúng đều đồng biến là V2. Trong trường hợp đó, F2 được đảm bảo thực hiện sau F1 nếu F2 được đẩy sau F1. Mặt khác, nếu F1 và F2 đều sử dụng V2 thì thứ tự thực hiện thực tế của chúng có thể là ngẫu nhiên.
Đẩy và chờ
Push và wait là hai API hữu ích hơn của công cụ thực thi.
Sau đây là hai tính năng quan trọng của Push API:
Tất cả các API đẩy là không đồng bộ, có nghĩa là lệnh gọi API ngay lập tức trả về bất kể chức năng được đẩy đã kết thúc hay chưa.
API đẩy không an toàn cho luồng, có nghĩa là chỉ một luồng nên thực hiện lệnh gọi API công cụ tại một thời điểm.
Bây giờ nếu chúng ta nói về Wait API, các điểm sau thể hiện nó:
Nếu người dùng muốn đợi một chức năng cụ thể kết thúc, họ nên bao gồm một hàm gọi lại trong bao đóng. Sau khi được bao gồm, hãy gọi hàm ở cuối hàm.
Mặt khác, nếu người dùng muốn đợi tất cả các hàm liên quan đến một biến nào đó kết thúc, họ nên sử dụng WaitForVar(var) API.
Nếu ai đó muốn đợi tất cả các chức năng được đẩy kết thúc, hãy sử dụng WaitForAll () API.
Được sử dụng để chỉ định các phụ thuộc của các hàm, giống như một mã thông báo.
Các nhà khai thác
Toán tử trong Apache MXNet là một lớp chứa logic tính toán thực tế cũng như thông tin bổ trợ và hỗ trợ hệ thống thực hiện tối ưu hóa.
Giao diện điều hành
Forward là giao diện toán tử cốt lõi có cú pháp như sau:
virtual void Forward(const OpContext &ctx,
const std::vector<TBlob> &in_data,
const std::vector<OpReqType> &req,
const std::vector<TBlob> &out_data,
const std::vector<TBlob> &aux_states) = 0;Cấu trúc của OpContext, được định nghĩa trong Forward() là như sau:
struct OpContext {
int is_train;
RunContext run_ctx;
std::vector<Resource> requested;
}Các OpContextmô tả trạng thái của người vận hành (cho dù đang trong giai đoạn chạy tàu hay chạy thử), thiết bị nào mà người vận hành nên được chạy và cả các tài nguyên được yêu cầu. hai API hữu ích hơn của công cụ thực thi.
Từ trên Forward giao diện cốt lõi, chúng ta có thể hiểu các tài nguyên được yêu cầu như sau:
in_data và out_data đại diện cho đầu vào và đầu ra tensors.
req biểu thị cách kết quả tính toán được ghi vào out_data.
Các OpReqType có thể được định nghĩa là -
enum OpReqType {
kNullOp,
kWriteTo,
kWriteInplace,
kAddTo
};Như thể là Forward , chúng tôi có thể tùy chọn triển khai Backward giao diện như sau -
virtual void Backward(const OpContext &ctx,
const std::vector<TBlob> &out_grad,
const std::vector<TBlob> &in_data,
const std::vector<TBlob> &out_data,
const std::vector<OpReqType> &req,
const std::vector<TBlob> &in_grad,
const std::vector<TBlob> &aux_states);Các nhiệm vụ khác nhau
Operator giao diện cho phép người dùng thực hiện các tác vụ sau:
Người dùng có thể chỉ định các bản cập nhật tại chỗ và có thể giảm chi phí phân bổ bộ nhớ
Để làm cho nó rõ ràng hơn, người dùng có thể ẩn một số đối số nội bộ khỏi Python.
Người dùng có thể xác định mối quan hệ giữa các tensor và tensors đầu ra.
Để thực hiện tính toán, người dùng có thể có thêm không gian tạm thời từ hệ thống.
Thuộc tính nhà điều hành
Như chúng ta đã biết rằng trong mạng nơ-ron hợp hiến (CNN), một tích chập có một số cách triển khai. Để đạt được hiệu suất tốt nhất từ chúng, chúng tôi có thể muốn chuyển đổi giữa một số phức hợp đó.
Đó là lý do, Apache MXNet tách giao diện ngữ nghĩa của nhà điều hành khỏi giao diện thực thi. Sự tách biệt này được thực hiện dưới dạngOperatorProperty lớp bao gồm các lớp sau
InferShape - Giao diện InferShape có hai mục đích như dưới đây:
Mục đích đầu tiên là cho hệ thống biết kích thước của mỗi tensor đầu vào và đầu ra để không gian có thể được phân bổ trước Forward và Backward gọi.
Mục đích thứ hai là thực hiện kiểm tra kích thước để đảm bảo rằng không có lỗi trước khi chạy.
Cú pháp được đưa ra dưới đây:
virtual bool InferShape(mxnet::ShapeVector *in_shape,
mxnet::ShapeVector *out_shape,
mxnet::ShapeVector *aux_shape) const = 0;Request Resource- Điều gì sẽ xảy ra nếu hệ thống của bạn có thể quản lý không gian làm việc tính toán cho các hoạt động như cudnnConvolutionForward? Hệ thống của bạn có thể thực hiện các tối ưu hóa chẳng hạn như tái sử dụng không gian và nhiều hơn nữa. Ở đây, MXNet dễ dàng đạt được điều này với sự trợ giúp của hai giao diện sau:
virtual std::vector<ResourceRequest> ForwardResource(
const mxnet::ShapeVector &in_shape) const;
virtual std::vector<ResourceRequest> BackwardResource(
const mxnet::ShapeVector &in_shape) const;Nhưng, điều gì sẽ xảy ra nếu ForwardResource và BackwardResourcetrả về mảng không trống? Trong trường hợp đó, hệ thống cung cấp các tài nguyên tương ứng thông quactx tham số trong Forward và Backward giao diện của Operator.
Backward dependency - Apache MXNet có hai chữ ký toán tử khác nhau sau đây để đối phó với sự phụ thuộc ngược -
void FullyConnectedForward(TBlob weight, TBlob in_data, TBlob out_data);
void FullyConnectedBackward(TBlob weight, TBlob in_data, TBlob out_grad, TBlob in_grad);
void PoolingForward(TBlob in_data, TBlob out_data);
void PoolingBackward(TBlob in_data, TBlob out_data, TBlob out_grad, TBlob in_grad);Ở đây, hai điểm quan trọng cần lưu ý -
Dữ liệu out_data trong CompleteConnectedForward không được sử dụng bởi FullConnectedBackward và
PoolingBackward yêu cầu tất cả các đối số của PoolingForward.
Đó là lý do tại sao FullyConnectedForward, các out_datatensor một khi được tiêu thụ có thể được giải phóng an toàn vì hàm lùi sẽ không cần đến nó. Với sự trợ giúp của hệ thống này có thể thu thập một số tensors rác càng sớm càng tốt.
In place Option- Apache MXNet cung cấp một giao diện khác cho người dùng để tiết kiệm chi phí cấp phát bộ nhớ. Giao diện thích hợp cho các hoạt động khôn ngoan trong đó cả bộ căng đầu vào và đầu ra có hình dạng giống nhau.
Sau đây là cú pháp để chỉ định cập nhật tại chỗ:
Ví dụ để tạo một toán tử
Với sự trợ giúp của OperatorProperty, chúng ta có thể tạo một toán tử. Để làm như vậy, hãy làm theo các bước dưới đây:
virtual std::vector<std::pair<int, void*>> ElewiseOpProperty::ForwardInplaceOption(
const std::vector<int> &in_data,
const std::vector<void*> &out_data)
const {
return { {in_data[0], out_data[0]} };
}
virtual std::vector<std::pair<int, void*>> ElewiseOpProperty::BackwardInplaceOption(
const std::vector<int> &out_grad,
const std::vector<int> &in_data,
const std::vector<int> &out_data,
const std::vector<void*> &in_grad)
const {
return { {out_grad[0], in_grad[0]} }
}Bước 1
Create Operator
Đầu tiên hãy triển khai giao diện sau trong OperatorProperty:
virtual Operator* CreateOperator(Context ctx) const = 0;Ví dụ được đưa ra dưới đây -
class ConvolutionOp {
public:
void Forward( ... ) { ... }
void Backward( ... ) { ... }
};
class ConvolutionOpProperty : public OperatorProperty {
public:
Operator* CreateOperator(Context ctx) const {
return new ConvolutionOp;
}
};Bước 2
Parameterize Operator
Nếu bạn định triển khai toán tử tích chập, bạn bắt buộc phải biết kích thước hạt nhân, kích thước bước sóng, kích thước phần đệm, v.v. Tại sao, vì các tham số này phải được chuyển cho nhà điều hành trước khi gọi bất kỳForward hoặc là backward giao diện.
Đối với điều này, chúng ta cần xác định ConvolutionParam cấu trúc như bên dưới -
#include <dmlc/parameter.h>
struct ConvolutionParam : public dmlc::Parameter<ConvolutionParam> {
mxnet::TShape kernel, stride, pad;
uint32_t num_filter, num_group, workspace;
bool no_bias;
};Bây giờ, chúng ta cần đưa cái này vào ConvolutionOpProperty và chuyển nó cho nhà điều hành như sau:
class ConvolutionOp {
public:
ConvolutionOp(ConvolutionParam p): param_(p) {}
void Forward( ... ) { ... }
void Backward( ... ) { ... }
private:
ConvolutionParam param_;
};
class ConvolutionOpProperty : public OperatorProperty {
public:
void Init(const vector<pair<string, string>& kwargs) {
// initialize param_ using kwargs
}
Operator* CreateOperator(Context ctx) const {
return new ConvolutionOp(param_);
}
private:
ConvolutionParam param_;
};Bước 3
Register the Operator Property Class and the Parameter Class to Apache MXNet
Cuối cùng, chúng ta cần đăng ký Lớp thuộc tính toán tử và Lớp tham số cho MXNet. Nó có thể được thực hiện với sự trợ giúp của các macro sau:
DMLC_REGISTER_PARAMETER(ConvolutionParam);
MXNET_REGISTER_OP_PROPERTY(Convolution, ConvolutionOpProperty);Trong macro trên, đối số đầu tiên là chuỗi tên và đối số thứ hai là tên lớp thuộc tính.
Chương này cung cấp thông tin về giao diện lập trình ứng dụng điều hành hợp nhất (API) trong Apache MXNet.
SimpleOp
SimpleOp là một API toán tử hợp nhất mới hợp nhất các quy trình gọi khác nhau. Sau khi được gọi, nó quay trở lại các phần tử cơ bản của các toán tử. Toán tử hợp nhất được thiết kế đặc biệt cho các phép toán đơn phân cũng như nhị phân. Đó là bởi vì hầu hết các toán tử toán học tham gia vào một hoặc hai toán hạng và nhiều toán hạng hơn làm cho việc tối ưu hóa, liên quan đến phụ thuộc, hữu ích.
Chúng ta sẽ hiểu toán tử hợp nhất SimpleOp của nó hoạt động với sự trợ giúp của một ví dụ. Trong ví dụ này, chúng tôi sẽ tạo một toán tử hoạt động như mộtsmooth l1 loss, là hỗn hợp mất đi l1 và l2. Chúng ta có thể xác định và viết khoản lỗ như dưới đây:
loss = outside_weight .* f(inside_weight .* (data - label))
grad = outside_weight .* inside_weight .* f'(inside_weight .* (data - label))Đây, trong ví dụ trên,
. * là viết tắt của phép nhân theo nguyên tố
f, f’ là hàm mất mát l1 mượt mà chúng ta đang giả định là mshadow.
Có vẻ như không thể thực hiện sự mất mát cụ thể này dưới dạng toán tử một ngôi hoặc nhị phân nhưng MXNet cung cấp cho người dùng sự khác biệt tự động trong việc thực thi ký hiệu giúp đơn giản hóa sự mất mát đối với f và f 'một cách trực tiếp. Đó là lý do tại sao chúng tôi chắc chắn có thể thực hiện lỗ cụ thể này với tư cách là toán tử một ngôi.
Xác định hình dạng
Như chúng ta biết MXNet's mshadow libraryyêu cầu phân bổ bộ nhớ rõ ràng do đó chúng tôi cần cung cấp tất cả các hình dạng dữ liệu trước khi bất kỳ phép tính nào xảy ra. Trước khi xác định các hàm và gradient, chúng ta cần cung cấp tính nhất quán của hình dạng đầu vào và hình dạng đầu ra như sau:
typedef mxnet::TShape (*UnaryShapeFunction)(const mxnet::TShape& src,
const EnvArguments& env);
typedef mxnet::TShape (*BinaryShapeFunction)(const mxnet::TShape& lhs,
const mxnet::TShape& rhs,
const EnvArguments& env);Hàm mxnet :: Tshape được sử dụng để kiểm tra hình dạng dữ liệu đầu vào và hình dạng dữ liệu đầu ra được chỉ định. Trong trường hợp, nếu bạn không xác định hàm này thì hình dạng đầu ra mặc định sẽ giống như hình dạng đầu vào. Ví dụ, trong trường hợp toán tử nhị phân, hình dạng của lhs và rhs theo mặc định được kiểm tra là giống nhau.
Bây giờ chúng ta hãy chuyển sang smooth l1 loss example. Đối với điều này, chúng ta cần xác định XPU thành cpu hoặc gpu trong triển khai tiêu đề smooth_l1_unary-inl.h. Lý do là sử dụng lại cùng một mã trong smooth_l1_unary.cc và smooth_l1_unary.cu.
#include <mxnet/operator_util.h>
#if defined(__CUDACC__)
#define XPU gpu
#else
#define XPU cpu
#endifNhư trong của chúng tôi smooth l1 loss example,đầu ra có cùng hình dạng với nguồn, chúng ta có thể sử dụng hành vi mặc định. Nó có thể được viết như sau:
inline mxnet::TShape SmoothL1Shape_(const mxnet::TShape& src,const EnvArguments& env) {
return mxnet::TShape(src);
}Xác định chức năng
Chúng ta có thể tạo một hàm đơn phân hoặc nhị phân với một đầu vào như sau:
typedef void (*UnaryFunction)(const TBlob& src,
const EnvArguments& env,
TBlob* ret,
OpReqType req,
RunContext ctx);
typedef void (*BinaryFunction)(const TBlob& lhs,
const TBlob& rhs,
const EnvArguments& env,
TBlob* ret,
OpReqType req,
RunContext ctx);Sau đây là RunContext ctx struct chứa thông tin cần thiết trong thời gian chạy để thực thi -
struct RunContext {
void *stream; // the stream of the device, can be NULL or Stream<gpu>* in GPU mode
template<typename xpu> inline mshadow::Stream<xpu>* get_stream() // get mshadow stream from Context
} // namespace mxnetBây giờ, hãy xem cách chúng ta có thể viết kết quả tính toán trong ret.
enum OpReqType {
kNullOp, // no operation, do not write anything
kWriteTo, // write gradient to provided space
kWriteInplace, // perform an in-place write
kAddTo // add to the provided space
};Bây giờ, hãy chuyển sang smooth l1 loss example. Đối với điều này, chúng tôi sẽ sử dụng UnaryFunction để xác định chức năng của toán tử này như sau:
template<typename xpu>
void SmoothL1Forward_(const TBlob& src,
const EnvArguments& env,
TBlob *ret,
OpReqType req,
RunContext ctx) {
using namespace mshadow;
using namespace mshadow::expr;
mshadow::Stream<xpu> *s = ctx.get_stream<xpu>();
real_t sigma2 = env.scalar * env.scalar;
MSHADOW_TYPE_SWITCH(ret->type_flag_, DType, {
mshadow::Tensor<xpu, 2, DType> out = ret->get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> in = src.get<xpu, 2, DType>(s);
ASSIGN_DISPATCH(out, req,
F<mshadow_op::smooth_l1_loss>(in, ScalarExp<DType>(sigma2)));
});
}Định nghĩa Gradients
Ngoại trừ Input, TBlob, và OpReqTypeđược nhân đôi, các hàm Gradients của toán tử nhị phân có cấu trúc tương tự. Hãy kiểm tra bên dưới, nơi chúng tôi đã tạo một hàm gradient với nhiều kiểu đầu vào:
// depending only on out_grad
typedef void (*UnaryGradFunctionT0)(const OutputGrad& out_grad,
const EnvArguments& env,
TBlob* in_grad,
OpReqType req,
RunContext ctx);
// depending only on out_value
typedef void (*UnaryGradFunctionT1)(const OutputGrad& out_grad,
const OutputValue& out_value,
const EnvArguments& env,
TBlob* in_grad,
OpReqType req,
RunContext ctx);
// depending only on in_data
typedef void (*UnaryGradFunctionT2)(const OutputGrad& out_grad,
const Input0& in_data0,
const EnvArguments& env,
TBlob* in_grad,
OpReqType req,
RunContext ctx);Như đã định nghĩa ở trên Input0, Input, OutputValue, và OutputGrad tất cả đều chia sẻ cấu trúc của GradientFunctionArgument. Nó được định nghĩa như sau:
struct GradFunctionArgument {
TBlob data;
}Bây giờ chúng ta hãy chuyển sang smooth l1 loss example. Đối với điều này để kích hoạt quy tắc chuỗi của gradient, chúng ta cần nhânout_grad từ đầu đến kết quả của in_grad.
template<typename xpu>
void SmoothL1BackwardUseIn_(const OutputGrad& out_grad, const Input0& in_data0,
const EnvArguments& env,
TBlob *in_grad,
OpReqType req,
RunContext ctx) {
using namespace mshadow;
using namespace mshadow::expr;
mshadow::Stream<xpu> *s = ctx.get_stream<xpu>();
real_t sigma2 = env.scalar * env.scalar;
MSHADOW_TYPE_SWITCH(in_grad->type_flag_, DType, {
mshadow::Tensor<xpu, 2, DType> src = in_data0.data.get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> ograd = out_grad.data.get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> igrad = in_grad->get<xpu, 2, DType>(s);
ASSIGN_DISPATCH(igrad, req,
ograd * F<mshadow_op::smooth_l1_gradient>(src, ScalarExp<DType>(sigma2)));
});
}Đăng ký SimpleOp với MXNet
Khi chúng ta đã tạo hình dạng, hàm và độ dốc, chúng ta cần khôi phục chúng thành cả toán tử NDArray cũng như thành toán tử tượng trưng. Đối với điều này, chúng ta có thể sử dụng macro đăng ký như sau:
MXNET_REGISTER_SIMPLE_OP(Name, DEV)
.set_shape_function(Shape)
.set_function(DEV::kDevMask, Function<XPU>, SimpleOpInplaceOption)
.set_gradient(DEV::kDevMask, Gradient<XPU>, SimpleOpInplaceOption)
.describe("description");Các SimpleOpInplaceOption có thể được định nghĩa như sau:
enum SimpleOpInplaceOption {
kNoInplace, // do not allow inplace in arguments
kInplaceInOut, // allow inplace in with out (unary)
kInplaceOutIn, // allow inplace out_grad with in_grad (unary)
kInplaceLhsOut, // allow inplace left operand with out (binary)
kInplaceOutLhs // allow inplace out_grad with lhs_grad (binary)
};Bây giờ chúng ta hãy chuyển sang smooth l1 loss example. Đối với điều này, chúng ta có một hàm gradient dựa vào dữ liệu đầu vào để hàm không thể được viết tại chỗ.
MXNET_REGISTER_SIMPLE_OP(smooth_l1, XPU)
.set_function(XPU::kDevMask, SmoothL1Forward_<XPU>, kNoInplace)
.set_gradient(XPU::kDevMask, SmoothL1BackwardUseIn_<XPU>, kInplaceOutIn)
.set_enable_scalar(true)
.describe("Calculate Smooth L1 Loss(lhs, scalar)");SimpleOp trên EnvArguments
Như chúng ta biết một số thao tác có thể cần những điều sau:
Một đại lượng vô hướng như đầu vào chẳng hạn như thang độ dốc
Một tập hợp các đối số từ khóa kiểm soát hành vi
Một không gian tạm thời để tăng tốc độ tính toán.
Lợi ích của việc sử dụng EnvArguments là nó cung cấp các đối số và tài nguyên bổ sung để làm cho các phép tính có thể mở rộng và hiệu quả hơn.
Thí dụ
Đầu tiên, hãy xác định cấu trúc như bên dưới:
struct EnvArguments {
real_t scalar; // scalar argument, if enabled
std::vector<std::pair<std::string, std::string> > kwargs; // keyword arguments
std::vector<Resource> resource; // pointer to the resources requested
};Tiếp theo, chúng tôi cần yêu cầu các tài nguyên bổ sung như mshadow::Random<xpu> và không gian bộ nhớ tạm thời từ EnvArguments.resource. Nó có thể được thực hiện như sau:
struct ResourceRequest {
enum Type { // Resource type, indicating what the pointer type is
kRandom, // mshadow::Random<xpu> object
kTempSpace // A dynamic temp space that can be arbitrary size
};
Type type; // type of resources
};Bây giờ, đăng ký sẽ yêu cầu yêu cầu tài nguyên được khai báo từ mxnet::ResourceManager. Sau đó, nó sẽ đặt các tài nguyên vào std::vector<Resource> resource in EnvAgruments.
Chúng tôi có thể truy cập các tài nguyên với sự trợ giúp của mã sau:
auto tmp_space_res = env.resources[0].get_space(some_shape, some_stream);
auto rand_res = env.resources[0].get_random(some_stream);Nếu bạn thấy trong ví dụ về mất mát l1 trơn tru của chúng tôi, thì cần có một đầu vào vô hướng để đánh dấu bước ngoặt của một hàm lỗ. Đó là lý do tại sao trong quá trình đăng ký, chúng tôi sử dụngset_enable_scalar(true)và env.scalar trong khai báo hàm và gradient.
Xây dựng hoạt động Tensor
Ở đây câu hỏi đặt ra rằng tại sao chúng ta cần phải tạo ra các hoạt động tensor? Lý do như sau:
Tính toán sử dụng thư viện mshadow và đôi khi chúng tôi không có sẵn các chức năng.
Nếu một hoạt động không được thực hiện theo cách khôn ngoan như mất softmax và gradient.
Thí dụ
Ở đây, chúng tôi đang sử dụng ví dụ mất mát l1 mịn ở trên. Chúng tôi sẽ tạo hai ánh xạ cụ thể là các trường hợp vô hướng của mất l1 mịn và gradient:
namespace mshadow_op {
struct smooth_l1_loss {
// a is x, b is sigma2
MSHADOW_XINLINE static real_t Map(real_t a, real_t b) {
if (a > 1.0f / b) {
return a - 0.5f / b;
} else if (a < -1.0f / b) {
return -a - 0.5f / b;
} else {
return 0.5f * a * a * b;
}
}
};
}Chương này nói về đào tạo phân tán trong Apache MXNet. Chúng ta hãy bắt đầu bằng cách hiểu các chế độ tính toán trong MXNet là gì.
Các phương thức tính toán
MXNet, một thư viện ML đa ngôn ngữ, cung cấp cho người dùng hai chế độ tính toán sau:
Chế độ mệnh lệnh
Chế độ tính toán này cho thấy một giao diện giống như API NumPy. Ví dụ: trong MXNet, hãy sử dụng mã bắt buộc sau để tạo một hàng chục số không trên cả CPU cũng như GPU -
import mxnet as mx
tensor_cpu = mx.nd.zeros((100,), ctx=mx.cpu())
tensor_gpu= mx.nd.zeros((100,), ctx=mx.gpu(0))Như chúng ta thấy trong đoạn mã trên, MXNets chỉ định vị trí để giữ tensor, trong thiết bị CPU hoặc GPU. Trong ví dụ trên, nó nằm ở vị trí 0. MXNet đạt được hiệu suất sử dụng thiết bị đáng kinh ngạc, bởi vì tất cả các tính toán diễn ra một cách lười biếng thay vì tức thì.
Chế độ tượng trưng
Mặc dù chế độ mệnh lệnh khá hữu ích, nhưng một trong những hạn chế của chế độ này là tính cứng nhắc của nó, tức là tất cả các phép tính cần được biết trước cùng với cấu trúc dữ liệu được xác định trước.
Mặt khác, chế độ Symbolic hiển thị một đồ thị tính toán như TensorFlow. Nó loại bỏ nhược điểm của API bắt buộc bằng cách cho phép MXNet làm việc với các ký hiệu hoặc biến thay vì cấu trúc dữ liệu cố định / được xác định trước. Sau đó, các ký hiệu có thể được hiểu như một tập hợp các thao tác như sau:
import mxnet as mx
x = mx.sym.Variable(“X”)
y = mx.sym.Variable(“Y”)
z = (x+y)
m = z/100Các loại song song
Apache MXNet hỗ trợ đào tạo phân tán. Nó cho phép chúng tôi sử dụng nhiều máy để luyện tập nhanh hơn cũng như hiệu quả.
Sau đây là hai cách, chúng tôi có thể phân phối khối lượng công việc đào tạo NN trên nhiều thiết bị, thiết bị CPU hoặc GPU -
Song song dữ liệu
Trong kiểu song song này, mỗi thiết bị lưu trữ một bản sao hoàn chỉnh của mô hình và hoạt động với một phần khác nhau của tập dữ liệu. Các thiết bị cũng cập nhật chung một mô hình được chia sẻ. Chúng tôi có thể định vị tất cả các thiết bị trên một máy hoặc trên nhiều máy.
Mô hình song song
Đó là một kiểu song song khác, có ích khi các mô hình quá lớn đến mức chúng không vừa với bộ nhớ thiết bị. Trong mô hình song song, các thiết bị khác nhau được giao nhiệm vụ học các phần khác nhau của mô hình. Điểm quan trọng cần lưu ý ở đây là Apache MXNet chỉ hỗ trợ mô hình song song trong một máy duy nhất.
Làm việc của đào tạo phân tán
Các khái niệm được đưa ra dưới đây là chìa khóa để hiểu hoạt động của đào tạo phân tán trong Apache MXNet -
Các loại quy trình
Các quá trình giao tiếp với nhau để hoàn thành việc đào tạo một mô hình. Apache MXNet có ba quy trình sau:
Công nhân
Công việc của nút công nhân là thực hiện đào tạo trên một loạt các mẫu đào tạo. Các nút Worker sẽ kéo trọng số từ máy chủ trước khi xử lý từng đợt. Các nút Worker sẽ gửi các gradient đến máy chủ, khi lô được xử lý.
Người phục vụ
MXNet có thể có nhiều máy chủ để lưu trữ các thông số của mô hình và giao tiếp với các nút công nhân.
Người lập kế hoạch
Vai trò của bộ lập lịch là thiết lập cụm, bao gồm việc chờ đợi các thông báo mà mỗi nút gửi đến và cổng nào nút đang lắng nghe. Sau khi thiết lập cụm, bộ lập lịch cho phép tất cả các quy trình biết về mọi nút khác trong cụm. Đó là bởi vì các quá trình có thể giao tiếp với nhau. Chỉ có một công cụ lập lịch.
Cửa hàng KV
KV cửa hàng là viết tắt của Key-Valuecửa hàng. Nó là thành phần quan trọng được sử dụng để đào tạo đa thiết bị. Điều quan trọng là bởi vì, việc truyền thông số giữa các thiết bị trên một máy cũng như trên nhiều máy được truyền qua một hoặc nhiều máy chủ có KVStore cho các tham số. Chúng ta hãy hiểu hoạt động của KVStore với sự trợ giúp của các điểm sau:
Mỗi giá trị trong KVStore được đại diện bởi một key và một value.
Mỗi mảng tham số trong mạng được gán một key và trọng số của mảng tham số đó được tham chiếu bởi value.
Sau đó, các nút công nhân pushgradient sau khi xử lý một mẻ. Họ cũngpull cập nhật trọng lượng trước khi xử lý một lô mới.
Khái niệm về máy chủ KVStore chỉ tồn tại trong quá trình đào tạo phân tán và chế độ phân tán của nó được kích hoạt bằng cách gọi mxnet.kvstore.create hàm với một đối số chuỗi có chứa từ dist -
kv = mxnet.kvstore.create(‘dist_sync’)Phân phối các phím
Không nhất thiết là tất cả các máy chủ lưu trữ tất cả các mảng hoặc khóa tham số, nhưng chúng được phân phối trên các máy chủ khác nhau. Việc phân phối khóa như vậy trên các máy chủ khác nhau được KVStore xử lý minh bạch và quyết định máy chủ nào lưu trữ khóa cụ thể được đưa ra ngẫu nhiên.
KVStore, như đã thảo luận ở trên, đảm bảo rằng bất cứ khi nào khóa được kéo, yêu cầu của nó sẽ được gửi đến máy chủ đó, có giá trị tương ứng. Điều gì xảy ra nếu giá trị của một số khóa lớn? Trong trường hợp đó, nó có thể được chia sẻ trên các máy chủ khác nhau.
Tách dữ liệu đào tạo
Là người dùng, chúng tôi muốn mỗi máy làm việc trên các phần khác nhau của tập dữ liệu, đặc biệt, khi chạy đào tạo phân tán ở chế độ song song dữ liệu. Chúng tôi biết rằng, để chia một loạt các mẫu được cung cấp bởi trình lặp dữ liệu để đào tạo song song dữ liệu trên một nhân viên, chúng tôi có thể sử dụngmxnet.gluon.utils.split_and_load và sau đó, tải từng phần của lô vào thiết bị sẽ xử lý thêm.
Mặt khác, trong trường hợp đào tạo phân tán, lúc đầu chúng ta cần chia tập dữ liệu thành ncác bộ phận khác nhau để mỗi công nhân nhận được một bộ phận khác nhau. Sau khi có, mỗi công nhân có thể sử dụngsplit_and_loadđể chia lại phần đó của tập dữ liệu cho các thiết bị khác nhau trên một máy duy nhất. Tất cả điều này xảy ra thông qua trình lặp dữ liệu.mxnet.io.MNISTIterator và mxnet.io.ImageRecordIter là hai trình vòng lặp như vậy trong MXNet hỗ trợ tính năng này.
Đang cập nhật trọng lượng
Để cập nhật trọng số, KVStore hỗ trợ hai chế độ sau:
Phương pháp đầu tiên tổng hợp các gradient và cập nhật trọng số bằng cách sử dụng các gradient đó.
Trong phương pháp thứ hai, máy chủ chỉ tổng hợp các gradient.
Nếu bạn đang sử dụng Gluon, có một tùy chọn để chọn giữa các phương pháp đã nêu ở trên bằng cách chuyển update_on_kvstoreBiến đổi. Hãy hiểu nó bằng cách tạotrainer đối tượng như sau -
trainer = gluon.Trainer(net.collect_params(), optimizer='sgd',
optimizer_params={'learning_rate': opt.lr,
'wd': opt.wd,
'momentum': opt.momentum,
'multi_precision': True},
kvstore=kv,
update_on_kvstore=True)Các phương thức đào tạo phân tán
Nếu chuỗi tạo KVStore chứa từ dist, điều đó có nghĩa là đào tạo phân tán đã được kích hoạt. Sau đây là các phương thức đào tạo phân tán khác nhau có thể được kích hoạt bằng cách sử dụng các loại KVStore khác nhau:
dist_sync
Như tên của nó, nó biểu thị đào tạo phân tán đồng bộ. Trong trường hợp này, tất cả công nhân sử dụng cùng một bộ thông số mô hình được đồng bộ hóa giống nhau vào đầu mỗi lô.
Hạn chế của chế độ này là, sau mỗi đợt, máy chủ phải đợi để nhận gradient từ mỗi worker trước khi cập nhật các thông số mô hình. Điều này có nghĩa là nếu một công nhân gặp sự cố, nó sẽ cản trở tiến độ của tất cả công nhân.
dist_async
Như tên của nó, nó biểu thị đào tạo phân tán đồng bộ. Trong trường hợp này, máy chủ nhận gradient từ một công nhân và ngay lập tức cập nhật cửa hàng của nó. Máy chủ sử dụng cửa hàng cập nhật để phản hồi bất kỳ lần kéo nào khác.
Lợi thế, so với dist_sync mode, là một công nhân kết thúc quá trình xử lý một lô có thể kéo các tham số hiện tại từ máy chủ và bắt đầu lô tiếp theo. Công nhân có thể làm như vậy, ngay cả khi công nhân kia vẫn chưa xử lý xong lô trước đó. Nó cũng nhanh hơn chế độ dist_sync bởi vì, có thể mất nhiều kỷ nguyên hơn để hội tụ mà không tốn bất kỳ chi phí đồng bộ hóa nào.
dist_sync_device
Chế độ này giống như dist_syncchế độ. Sự khác biệt duy nhất là, khi có nhiều GPU được sử dụng trên mỗi nútdist_sync_device tổng hợp các độ dốc và cập nhật trọng số trên GPU trong khi, dist_sync tổng hợp các độ dốc và cập nhật trọng số trên bộ nhớ CPU.
Nó làm giảm giao tiếp đắt tiền giữa GPU và CPU. Đó là lý do tại sao, nó nhanh hơndist_sync. Hạn chế là nó làm tăng mức sử dụng bộ nhớ trên GPU.
dist_async_device
Chế độ này hoạt động giống như dist_sync_device nhưng ở chế độ không đồng bộ.
Trong chương này, chúng ta sẽ tìm hiểu về các Gói Python có sẵn trong Apache MXNet.
Các gói Python MXNet quan trọng
MXNet có các gói Python quan trọng sau đây mà chúng ta sẽ thảo luận từng gói một:
Autograd (Phân biệt tự động)
NDArray
KVStore
Gluon
Visualization
Đầu tiên chúng ta hãy bắt đầu với Autograd Gói Python cho Apache MXNet.
Autograd
Autograd viết tắt của automatic differentiationđược sử dụng để sao chép các gradient từ chỉ số tổn thất trở lại từng tham số. Cùng với sự lan truyền ngược, nó sử dụng phương pháp lập trình động để tính toán hiệu quả các độ dốc. Nó còn được gọi là chế độ phân biệt tự động đảo ngược. Kỹ thuật này rất hiệu quả trong các tình huống 'fan-in' trong đó, nhiều tham số ảnh hưởng đến một chỉ số tổn thất duy nhất.
Gradient là gì?
Gradients là những nguyên tắc cơ bản cho quá trình đào tạo mạng nơ-ron. Về cơ bản, chúng cho chúng ta biết cách thay đổi các thông số của mạng để cải thiện hiệu suất của mạng.
Như chúng ta đã biết, mạng nơron (NN) bao gồm các toán tử như tổng, tích, chập, v.v ... Các toán tử này, để tính toán, sử dụng các tham số như trọng số trong nhân chập. Chúng ta phải tìm các giá trị tối ưu cho các tham số này và độ dốc chỉ cho chúng ta thấy con đường và dẫn chúng ta đến giải pháp.
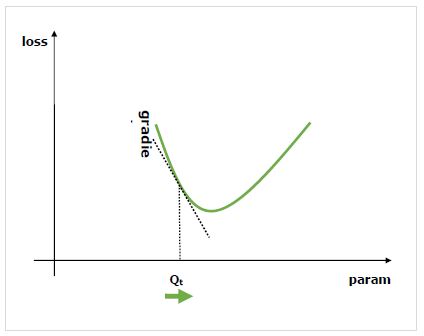
Chúng tôi quan tâm đến ảnh hưởng của việc thay đổi một tham số đối với hiệu suất của mạng và độ dốc cho chúng tôi biết, một biến nhất định tăng hoặc giảm bao nhiêu khi chúng tôi thay đổi một biến mà nó phụ thuộc vào. Hiệu suất thường được xác định bằng cách sử dụng số liệu tổn thất mà chúng tôi cố gắng giảm thiểu. Ví dụ: đối với hồi quy, chúng tôi có thể cố gắng giảm thiểuL2 mất mát giữa dự đoán của chúng tôi và giá trị chính xác, trong khi đối với phân loại, chúng tôi có thể giảm thiểu cross-entropy loss.
Khi chúng tôi tính toán gradient của từng tham số có tham chiếu đến tổn thất, sau đó chúng tôi có thể sử dụng một công cụ tối ưu hóa, chẳng hạn như descent gradient ngẫu nhiên.
Làm thế nào để tính toán gradient?
Chúng tôi có các tùy chọn sau để tính toán độ dốc -
Symbolic Differentiation- Tùy chọn đầu tiên là Symbolic Differentiation, tính toán các công thức cho mỗi gradient. Hạn chế của phương pháp này là nó sẽ nhanh chóng dẫn đến các công thức cực kỳ dài khi mạng ngày càng sâu và các nhà khai thác ngày càng phức tạp hơn.
Finite Differencing- Một tùy chọn khác là sử dụng tính khác biệt hữu hạn để thử các khác biệt nhỏ trên từng tham số và xem chỉ số tổn thất phản ứng như thế nào. Hạn chế của phương pháp này là nó sẽ tốn kém về mặt tính toán và có thể có độ chính xác số kém.
Automatic differentiation- Giải pháp cho những hạn chế của các phương pháp trên là sử dụng phân biệt tự động để ghép ngược các gradient từ chỉ số tổn thất trở lại từng tham số. Sự lan truyền cho phép chúng ta một cách tiếp cận lập trình động để tính toán hiệu quả các độ dốc. Phương pháp này còn được gọi là chế độ phân biệt tự động đảo ngược.
Phân biệt tự động (autograd)
Sau đây, chúng ta sẽ hiểu chi tiết về hoạt động của autograd. Về cơ bản nó hoạt động theo hai giai đoạn:
Stage 1 - Giai đoạn này được gọi là ‘Forward Pass’đào tạo. Như tên của nó, trong giai đoạn này, nó tạo ra bản ghi của nhà điều hành được mạng sử dụng để đưa ra dự đoán và tính toán số liệu tổn thất.
Stage 2 - Giai đoạn này được gọi là ‘Backward Pass’đào tạo. Như tên của nó, trong giai đoạn này, nó hoạt động ngược lại thông qua bản ghi này. Quay ngược lại, nó đánh giá các đạo hàm riêng của từng nhà khai thác, tất cả các cách trở lại tham số mạng.
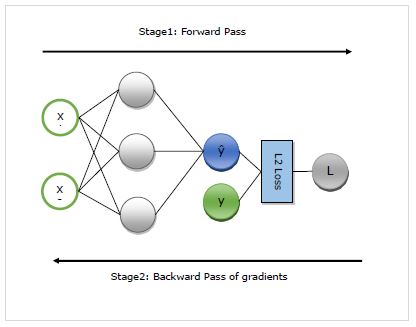
Ưu điểm của autograd
Sau đây là những ưu điểm của việc sử dụng Phân biệt tự động (autograd) -
Flexible- Tính linh hoạt mà nó mang lại cho chúng tôi khi xác định mạng của chúng tôi, là một trong những lợi ích to lớn của việc sử dụng autograd. Chúng tôi có thể thay đổi các hoạt động trên mỗi lần lặp. Chúng được gọi là đồ thị động, phức tạp hơn nhiều để triển khai trong các khuôn khổ yêu cầu đồ thị tĩnh. Autograd, ngay cả trong những trường hợp như vậy, vẫn có thể sao chép các gradient một cách chính xác.
Automatic- Autograd là tự động, tức là những phức tạp của thủ tục nhân giống ngược sẽ được nó giải quyết cho bạn. Chúng tôi chỉ cần xác định những gradient mà chúng tôi muốn tính toán.
Efficient - Autogard tính toán độ dốc rất hiệu quả.
Can use native Python control flow operators- Chúng ta có thể sử dụng các toán tử luồng điều khiển Python nguyên bản như if điều kiện và vòng lặp while. Autograd sẽ vẫn có thể sao chép các gradient một cách hiệu quả và chính xác.
Sử dụng autograd trong MXNet Gluon
Ở đây, với sự trợ giúp của một ví dụ, chúng ta sẽ thấy cách chúng ta có thể sử dụng autograd trong MXNet Gluon.
Ví dụ triển khai
Trong ví dụ sau, chúng ta sẽ thực hiện mô hình hồi quy có hai lớp. Sau khi triển khai, chúng tôi sẽ sử dụng autograd để tự động tính toán độ dốc của tổn thất với tham chiếu đến từng thông số trọng lượng -
Đầu tiên nhập autogrard và các gói bắt buộc khác như sau:
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2LossBây giờ, chúng ta cần xác định mạng như sau:
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()Bây giờ chúng ta cần xác định khoản lỗ như sau:
loss_function = L2Loss()Tiếp theo, chúng ta cần tạo dữ liệu giả như sau:
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])Bây giờ, chúng tôi đã sẵn sàng cho lần chuyển tiếp đầu tiên của chúng tôi qua mạng. Chúng tôi muốn autograd ghi lại đồ thị tính toán để chúng tôi có thể tính toán độ dốc. Đối với điều này, chúng tôi cần chạy mã mạng trong phạm viautograd.record ngữ cảnh như sau -
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)Bây giờ, chúng ta đã sẵn sàng cho quá trình chuyển ngược, mà chúng ta bắt đầu bằng cách gọi phương pháp lùi về số lượng quan tâm. Vấn đề quan tâm trong ví dụ của chúng tôi là tổn thất bởi vì chúng tôi đang cố gắng tính toán độ dốc của tổn thất có tham chiếu đến các tham số -
loss.backward()Bây giờ, chúng ta có gradient cho từng tham số của mạng, sẽ được sử dụng bởi trình tối ưu hóa để cập nhật giá trị tham số nhằm cải thiện hiệu suất. Hãy kiểm tra các gradient của lớp thứ nhất như sau:
N_net[0].weight.grad()Output
Kết quả như sau:
[[-0.00470527 -0.00846948]
[-0.03640365 -0.06552657]
[ 0.00800354 0.01440637]]
<NDArray 3x2 @cpu(0)>Hoàn thành ví dụ triển khai
Dưới đây là ví dụ triển khai đầy đủ.
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Loss
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()
loss_function = L2Loss()
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)
loss.backward()
N_net[0].weight.grad()Trong chương này, chúng ta sẽ thảo luận về định dạng mảng đa chiều của MXNet được gọi là ndarray.
Xử lý dữ liệu với NDArray
Đầu tiên, chúng ta sẽ xem cách chúng ta có thể xử lý dữ liệu với NDArray. Sau đây là các điều kiện tiên quyết cho cùng một -
Điều kiện tiên quyết
Để hiểu cách chúng tôi có thể xử lý dữ liệu với định dạng mảng đa chiều này, chúng tôi cần đáp ứng các điều kiện tiên quyết sau:
MXNet được cài đặt trong môi trường Python
Python 2.7.x hoặc Python 3.x
Ví dụ triển khai
Hãy để chúng tôi hiểu chức năng cơ bản với sự trợ giúp của một ví dụ dưới đây:
Đầu tiên, chúng ta cần nhập MXNet và ndarray từ MXNet như sau:
import mxnet as mx
from mxnet import ndKhi chúng tôi nhập các thư viện cần thiết, chúng tôi sẽ đi với các chức năng cơ bản sau:
Mảng 1-D đơn giản với danh sách python
Example
x = nd.array([1,2,3,4,5,6,7,8,9,10])
print(x)Output
Đầu ra như được đề cập bên dưới -
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
<NDArray 10 @cpu(0)>Mảng 2-D với danh sách python
Example
y = nd.array([[1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10]])
print(y)Output
Đầu ra như được nêu bên dưới -
[[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]]
<NDArray 3x10 @cpu(0)>Tạo NDArray mà không cần bất kỳ khởi tạo nào
Ở đây, chúng ta sẽ tạo một ma trận với 3 hàng và 4 cột bằng cách sử dụng .emptychức năng. Chúng tôi cũng sẽ sử dụng.full hàm này sẽ nhận thêm một toán tử cho giá trị bạn muốn điền vào mảng.
Example
x = nd.empty((3, 4))
print(x)
x = nd.full((3,4), 8)
print(x)Output
Đầu ra được đưa ra dưới đây -
[[0.000e+00 0.000e+00 0.000e+00 0.000e+00]
[0.000e+00 0.000e+00 2.887e-42 0.000e+00]
[0.000e+00 0.000e+00 0.000e+00 0.000e+00]]
<NDArray 3x4 @cpu(0)>
[[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]]
<NDArray 3x4 @cpu(0)>Ma trận của tất cả các số không với hàm .zeros
Example
x = nd.zeros((3, 8))
print(x)Output
Kết quả như sau:
[[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]]
<NDArray 3x8 @cpu(0)>Ma trận của tất cả những cái có chức năng .ones
Example
x = nd.ones((3, 8))
print(x)Output
Đầu ra được đề cập bên dưới -
[[1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1.]]
<NDArray 3x8 @cpu(0)>Tạo mảng có các giá trị được lấy mẫu ngẫu nhiên
Example
y = nd.random_normal(0, 1, shape=(3, 4))
print(y)Output
Đầu ra được đưa ra dưới đây -
[[ 1.2673576 -2.0345826 -0.32537818 -1.4583491 ]
[-0.11176403 1.3606371 -0.7889914 -0.17639421]
[-0.2532185 -0.42614475 -0.12548696 1.4022992 ]]
<NDArray 3x4 @cpu(0)>Tìm thứ nguyên của mỗi NDArray
Example
y.shapeOutput
Kết quả như sau:
(3, 4)Tìm kích thước của từng NDArray
Example
y.sizeOutput
12Tìm kiểu dữ liệu của mỗi NDArray
Example
y.dtypeOutput
numpy.float32Hoạt động NDArray
Trong phần này, chúng tôi sẽ giới thiệu cho bạn các thao tác với mảng của MXNet. NDArray hỗ trợ một số lượng lớn các phép toán tiêu chuẩn cũng như tại chỗ.
Các phép toán chuẩn
Sau đây là các phép toán tiêu chuẩn được hỗ trợ bởi NDArray:
Bổ sung nguyên tố khôn ngoan
Đầu tiên, chúng ta cần nhập MXNet và ndarray từ MXNet như sau:
import mxnet as mx
from mxnet import nd
x = nd.ones((3, 5))
y = nd.random_normal(0, 1, shape=(3, 5))
print('x=', x)
print('y=', y)
x = x + y
print('x = x + y, x=', x)Output
Đầu ra được cung cấp kèm theo:
x=
[[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]]
<NDArray 3x5 @cpu(0)>
y=
[[-1.0554522 -1.3118273 -0.14674698 0.641493 -0.73820823]
[ 2.031364 0.5932667 0.10228804 1.179526 -0.5444829 ]
[-0.34249446 1.1086396 1.2756858 -1.8332436 -0.5289873 ]]
<NDArray 3x5 @cpu(0)>
x = x + y, x=
[[-0.05545223 -0.3118273 0.853253 1.6414931 0.26179177]
[ 3.031364 1.5932667 1.102288 2.1795259 0.4555171 ]
[ 0.6575055 2.1086397 2.2756858 -0.8332436 0.4710127 ]]
<NDArray 3x5 @cpu(0)>Phép nhân khôn ngoan
Example
x = nd.array([1, 2, 3, 4])
y = nd.array([2, 2, 2, 1])
x * yOutput
Bạn sẽ thấy kết quả sau
[2. 4. 6. 4.]
<NDArray 4 @cpu(0)>Luỹ thừa
Example
nd.exp(x)Output
Khi bạn chạy mã, bạn sẽ thấy kết quả sau:
[ 2.7182817 7.389056 20.085537 54.59815 ]
<NDArray 4 @cpu(0)>Chuyển đổi ma trận để tính tích ma trận-ma trận
Example
nd.dot(x, y.T)Output
Dưới đây là đầu ra của mã:
[16.]
<NDArray 1 @cpu(0)>Hoạt động tại chỗ
Mỗi lần, trong ví dụ trên, chúng tôi chạy một hoạt động, chúng tôi cấp phát một bộ nhớ mới để lưu trữ kết quả của nó.
Ví dụ, nếu chúng ta viết A = A + B, chúng ta sẽ bỏ tham chiếu đến ma trận mà A đã dùng để trỏ tới và thay vào đó trỏ nó vào bộ nhớ mới được cấp phát. Hãy để chúng tôi hiểu nó với ví dụ được đưa ra bên dưới, sử dụng hàm id () của Python -
print('y=', y)
print('id(y):', id(y))
y = y + x
print('after y=y+x, y=', y)
print('id(y):', id(y))Output
Khi thực hiện, bạn sẽ nhận được kết quả sau:
y=
[2. 2. 2. 1.]
<NDArray 4 @cpu(0)>
id(y): 2438905634376
after y=y+x, y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)>
id(y): 2438905685664Trên thực tế, chúng ta cũng có thể gán kết quả cho một mảng đã được cấp phát trước đó như sau:
print('x=', x)
z = nd.zeros_like(x)
print('z is zeros_like x, z=', z)
print('id(z):', id(z))
print('y=', y)
z[:] = x + y
print('z[:] = x + y, z=', z)
print('id(z) is the same as before:', id(z))Output
Đầu ra được hiển thị bên dưới -
x=
[1. 2. 3. 4.]
<NDArray 4 @cpu(0)>
z is zeros_like x, z=
[0. 0. 0. 0.]
<NDArray 4 @cpu(0)>
id(z): 2438905790760
y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)>
z[:] = x + y, z=
[4. 6. 8. 9.]
<NDArray 4 @cpu(0)>
id(z) is the same as before: 2438905790760Từ kết quả trên, chúng ta có thể thấy rằng x + y vẫn sẽ cấp phát một bộ đệm tạm thời để lưu trữ kết quả trước khi sao chép nó vào z. Vì vậy, bây giờ, chúng ta có thể thực hiện các hoạt động tại chỗ để sử dụng bộ nhớ tốt hơn và tránh bộ đệm tạm thời. Để làm điều này, chúng tôi sẽ chỉ định đối số từ khóa out mà mọi toán tử hỗ trợ như sau:
print('x=', x, 'is in id(x):', id(x))
print('y=', y, 'is in id(y):', id(y))
print('z=', z, 'is in id(z):', id(z))
nd.elemwise_add(x, y, out=z)
print('after nd.elemwise_add(x, y, out=z), x=', x, 'is in id(x):', id(x))
print('after nd.elemwise_add(x, y, out=z), y=', y, 'is in id(y):', id(y))
print('after nd.elemwise_add(x, y, out=z), z=', z, 'is in id(z):', id(z))Output
Khi thực hiện chương trình trên, bạn sẽ nhận được kết quả sau:
x=
[1. 2. 3. 4.]
<NDArray 4 @cpu(0)> is in id(x): 2438905791152
y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)> is in id(y): 2438905685664
z=
[4. 6. 8. 9.]
<NDArray 4 @cpu(0)> is in id(z): 2438905790760
after nd.elemwise_add(x, y, out=z), x=
[1. 2. 3. 4.]
<NDArray 4 @cpu(0)> is in id(x): 2438905791152
after nd.elemwise_add(x, y, out=z), y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)> is in id(y): 2438905685664
after nd.elemwise_add(x, y, out=z), z=
[4. 6. 8. 9.]
<NDArray 4 @cpu(0)> is in id(z): 2438905790760NDArray Contexts
Trong Apache MXNet, mỗi mảng có một ngữ cảnh và một ngữ cảnh có thể là CPU, trong khi các ngữ cảnh khác có thể là một số GPU. Mọi thứ thậm chí có thể trở nên tồi tệ nhất, khi chúng tôi triển khai công việc trên nhiều máy chủ. Đó là lý do tại sao, chúng ta cần gán các mảng cho các ngữ cảnh một cách thông minh. Nó sẽ giảm thiểu thời gian truyền dữ liệu giữa các thiết bị.
Ví dụ, hãy thử khởi tạo một mảng như sau:
from mxnet import nd
z = nd.ones(shape=(3,3), ctx=mx.cpu(0))
print(z)Output
Khi bạn thực thi đoạn mã trên, bạn sẽ thấy kết quả sau:
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
<NDArray 3x3 @cpu(0)>Chúng ta có thể sao chép NDArray đã cho từ ngữ cảnh này sang ngữ cảnh khác bằng cách sử dụng phương thức copyto () như sau:
x_gpu = x.copyto(gpu(0))
print(x_gpu)Mảng NumPy so với NDArray
Tất cả chúng ta đều quen thuộc với mảng NumPy nhưng Apache MXNet cung cấp triển khai mảng riêng có tên là NDArray. Trên thực tế, ban đầu nó được thiết kế tương tự như NumPy nhưng có một điểm khác biệt chính:
Sự khác biệt chính là cách tính toán được thực hiện trong NumPy và NDArray. Mọi thao tác NDArray trong MXNet đều được thực hiện theo cách không đồng bộ và không chặn, có nghĩa là khi chúng ta viết mã như c = a * b, hàm được đẩy đếnExecution Engine, sẽ bắt đầu tính toán.
Ở đây, a và b đều là NDArrays. Lợi ích của việc sử dụng nó là, hàm ngay lập tức trả về trở lại và luồng người dùng có thể tiếp tục thực thi mặc dù thực tế là phép tính trước đó có thể chưa được hoàn thành.
Hoạt động của công cụ thực thi
Nếu chúng ta nói về hoạt động của bộ máy thực thi, nó sẽ xây dựng đồ thị tính toán. Biểu đồ tính toán có thể sắp xếp lại hoặc kết hợp một số phép tính, nhưng nó luôn tuân theo thứ tự phụ thuộc.
Ví dụ: nếu có các thao tác khác với 'X' được thực hiện sau này trong mã lập trình, Công cụ thực thi sẽ bắt đầu thực hiện chúng sau khi có kết quả của 'X'. Công cụ thực thi sẽ xử lý một số công việc quan trọng đối với người dùng, chẳng hạn như viết các lệnh gọi lại để bắt đầu thực thi mã tiếp theo.
Trong Apache MXNet, với sự trợ giúp của NDArray, để có được kết quả tính toán, chúng ta chỉ cần truy cập vào biến kết quả. Dòng mã sẽ bị chặn cho đến khi kết quả tính toán được gán cho biến kết quả. Bằng cách này, nó làm tăng hiệu suất mã trong khi vẫn hỗ trợ chế độ lập trình mệnh lệnh.
Chuyển đổi NDArray thành NumPy Array
Hãy để chúng tôi tìm hiểu cách chuyển NDArray thành NumPy Array trong MXNet.
Combining higher-level operator with the help of few lower-level operators
Đôi khi, chúng ta có thể tập hợp toán tử cấp cao hơn bằng cách sử dụng các toán tử hiện có. Một trong những ví dụ tốt nhất về điều này là,np.full_like()toán tử này không có trong API NDArray. Nó có thể dễ dàng được thay thế bằng sự kết hợp của các toán tử hiện có như sau:
from mxnet import nd
import numpy as np
np_x = np.full_like(a=np.arange(7, dtype=int), fill_value=15)
nd_x = nd.ones(shape=(7,)) * 15
np.array_equal(np_x, nd_x.asnumpy())Output
Chúng ta sẽ nhận được kết quả tương tự như sau:
TrueFinding similar operator with different name and/or signature
Trong số tất cả các toán tử, một số trong số chúng có tên hơi khác nhau, nhưng chúng giống nhau về chức năng. Một ví dụ về điều này lànd.ravel_index() với np.ravel()chức năng. Theo cách tương tự, một số toán tử có thể có tên tương tự, nhưng chúng có chữ ký khác nhau. Một ví dụ về điều này lànp.split() và nd.split() tương tự nhau.
Hãy hiểu nó với ví dụ lập trình sau:
def pad_array123(data, max_length):
data_expanded = data.reshape(1, 1, 1, data.shape[0])
data_padded = nd.pad(data_expanded,
mode='constant',
pad_width=[0, 0, 0, 0, 0, 0, 0, max_length - data.shape[0]],
constant_value=0)
data_reshaped_back = data_padded.reshape(max_length)
return data_reshaped_back
pad_array123(nd.array([1, 2, 3]), max_length=10)Output
Đầu ra được nêu dưới đây -
[1. 2. 3. 0. 0. 0. 0. 0. 0. 0.]
<NDArray 10 @cpu(0)>Giảm thiểu tác động của việc chặn cuộc gọi
Trong một số trường hợp, chúng ta phải sử dụng .asnumpy() hoặc là .asscalar()nhưng điều này sẽ buộc MXNet phải chặn việc thực thi, cho đến khi kết quả có thể được truy xuất. Chúng tôi có thể giảm thiểu tác động của việc chặn cuộc gọi bằng cách gọi.asnumpy() hoặc là .asscalar() tại thời điểm này, khi chúng tôi nghĩ rằng việc tính toán giá trị này đã được thực hiện.
Ví dụ triển khai
Example
from __future__ import print_function
import mxnet as mx
from mxnet import gluon, nd, autograd
from mxnet.ndarray import NDArray
from mxnet.gluon import HybridBlock
import numpy as np
class LossBuffer(object):
"""
Simple buffer for storing loss value
"""
def __init__(self):
self._loss = None
def new_loss(self, loss):
ret = self._loss
self._loss = loss
return ret
@property
def loss(self):
return self._loss
net = gluon.nn.Dense(10)
ce = gluon.loss.SoftmaxCELoss()
net.initialize()
data = nd.random.uniform(shape=(1024, 100))
label = nd.array(np.random.randint(0, 10, (1024,)), dtype='int32')
train_dataset = gluon.data.ArrayDataset(data, label)
train_data = gluon.data.DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=2)
trainer = gluon.Trainer(net.collect_params(), optimizer='sgd')
loss_buffer = LossBuffer()
for data, label in train_data:
with autograd.record():
out = net(data)
# This call saves new loss and returns previous loss
prev_loss = loss_buffer.new_loss(ce(out, label))
loss_buffer.loss.backward()
trainer.step(data.shape[0])
if prev_loss is not None:
print("Loss: {}".format(np.mean(prev_loss.asnumpy())))Output
Kết quả được trích dẫn dưới đây:
Loss: 2.3373236656188965
Loss: 2.3656985759735107
Loss: 2.3613128662109375
Loss: 2.3197104930877686
Loss: 2.3054862022399902
Loss: 2.329197406768799
Loss: 2.318927526473999Một gói MXNet Python quan trọng nhất khác là Gluon. Trong chương này, chúng ta sẽ thảo luận về gói này. Gluon cung cấp một API rõ ràng, ngắn gọn và đơn giản cho các dự án DL. Nó cho phép Apache MXNet tạo mẫu, xây dựng và đào tạo các mô hình DL mà không làm giảm tốc độ đào tạo.
Khối
Các khối tạo thành cơ sở của các thiết kế mạng phức tạp hơn. Trong mạng nơ-ron, khi độ phức tạp của mạng nơ-ron tăng lên, chúng ta cần chuyển từ thiết kế từng lớp nơ-ron đơn lẻ sang toàn bộ lớp. Ví dụ: thiết kế NN như ResNet-152 có mức độ đều đặn rất công bằng bằng cách bao gồmblocks của các lớp lặp lại.
Thí dụ
Trong ví dụ dưới đây, chúng ta sẽ viết mã một khối đơn giản, cụ thể là khối cho perceptron nhiều lớp.
from mxnet import nd
from mxnet.gluon import nn
x = nd.random.uniform(shape=(2, 20))
N_net = nn.Sequential()
N_net.add(nn.Dense(256, activation='relu'))
N_net.add(nn.Dense(10))
N_net.initialize()
N_net(x)Output
Điều này tạo ra kết quả sau:
[[ 0.09543004 0.04614332 -0.00286655 -0.07790346 -0.05130241 0.02942038
0.08696645 -0.0190793 -0.04122177 0.05088576]
[ 0.0769287 0.03099706 0.00856576 -0.044672 -0.06926838 0.09132431
0.06786592 -0.06187843 -0.03436674 0.04234696]]
<NDArray 2x10 @cpu(0)>Các bước cần thiết để đi từ xác định các lớp đến xác định các khối của một hoặc nhiều lớp -
Step 1 - Khối lấy dữ liệu làm đầu vào.
Step 2- Bây giờ, các khối sẽ lưu trữ trạng thái dưới dạng tham số. Ví dụ, trong ví dụ mã hóa ở trên, khối chứa hai lớp ẩn và chúng ta cần một nơi để lưu trữ các tham số cho nó.
Step 3- Khối tiếp theo sẽ gọi hàm forward để thực hiện quá trình truyền tiến. Nó còn được gọi là tính toán chuyển tiếp. Là một phần của lệnh gọi chuyển tiếp đầu tiên, các khối khởi tạo các tham số theo kiểu lười biếng.
Step 4- Cuối cùng, các khối sẽ gọi hàm lùi và tính toán độ dốc với tham chiếu đến đầu vào của chúng. Thông thường, bước này được thực hiện tự động.
Khối tuần tự
Khối tuần tự là một loại khối đặc biệt, trong đó dữ liệu chảy qua một chuỗi các khối. Trong đó, mỗi khối được áp dụng cho đầu ra của một khối trước đó với khối đầu tiên được áp dụng cho chính dữ liệu đầu vào.
Hãy để chúng tôi xem làm thế nào sequential tác phẩm của lớp -
from mxnet import nd
from mxnet.gluon import nn
class MySequential(nn.Block):
def __init__(self, **kwargs):
super(MySequential, self).__init__(**kwargs)
def add(self, block):
self._children[block.name] = block
def forward(self, x):
for block in self._children.values():
x = block(x)
return x
x = nd.random.uniform(shape=(2, 20))
N_net = MySequential()
N_net.add(nn.Dense(256, activation
='relu'))
N_net.add(nn.Dense(10))
N_net.initialize()
N_net(x)Output
Đầu ra được cung cấp kèm theo:
[[ 0.09543004 0.04614332 -0.00286655 -0.07790346 -0.05130241 0.02942038
0.08696645 -0.0190793 -0.04122177 0.05088576]
[ 0.0769287 0.03099706 0.00856576 -0.044672 -0.06926838 0.09132431
0.06786592 -0.06187843 -0.03436674 0.04234696]]
<NDArray 2x10 @cpu(0)>Khối tùy chỉnh
Chúng ta có thể dễ dàng vượt ra ngoài phép nối với khối tuần tự như đã định nghĩa ở trên. Nhưng, nếu chúng tôi muốn thực hiện các tùy chỉnh thìBlocklớp cũng cung cấp cho chúng tôi các chức năng cần thiết. Lớp khối có một phương thức tạo mô hình được cung cấp trong mô-đun nn. Chúng ta có thể kế thừa hàm tạo mô hình đó để định nghĩa mô hình mà chúng ta muốn.
Trong ví dụ sau, MLP class ghi đè lên __init__ và các chức năng chuyển tiếp của lớp Block.
Hãy để chúng tôi xem nó hoạt động như thế nào.
class MLP(nn.Block):
def __init__(self, **kwargs):
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Dense(256, activation='relu') # Hidden layer
self.output = nn.Dense(10) # Output layer
def forward(self, x):
hidden_out = self.hidden(x)
return self.output(hidden_out)
x = nd.random.uniform(shape=(2, 20))
N_net = MLP()
N_net.initialize()
N_net(x)Output
Khi bạn chạy mã, bạn sẽ thấy kết quả sau:
[[ 0.07787763 0.00216403 0.01682201 0.03059879 -0.00702019 0.01668715
0.04822846 0.0039432 -0.09300035 -0.04494302]
[ 0.08891078 -0.00625484 -0.01619131 0.0380718 -0.01451489 0.02006172
0.0303478 0.02463485 -0.07605448 -0.04389168]]
<NDArray 2x10 @cpu(0)>Lớp tùy chỉnh
API Gluon của Apache MXNet đi kèm với một số lượng khiêm tốn các lớp được xác định trước. Nhưng vẫn còn ở một số điểm, chúng ta có thể thấy rằng một lớp mới là cần thiết. Chúng ta có thể dễ dàng thêm một lớp mới trong API Gluon. Trong phần này, chúng ta sẽ xem cách chúng ta có thể tạo một lớp mới từ đầu.
Lớp tùy chỉnh đơn giản nhất
Để tạo một lớp mới trong API Gluon, chúng ta phải tạo một lớp kế thừa từ lớp Block cung cấp chức năng cơ bản nhất. Chúng ta có thể kế thừa tất cả các lớp được xác định trước từ nó trực tiếp hoặc thông qua các lớp con khác.
Để tạo lớp mới, phương thức phiên bản duy nhất cần được triển khai là forward (self, x). Phương thức này xác định, chính xác lớp của chúng ta sẽ làm gì trong quá trình truyền chuyển tiếp. Như đã thảo luận trước đó, quá trình truyền ngược cho các khối sẽ được chính Apache MXNet thực hiện tự động.
Thí dụ
Trong ví dụ dưới đây, chúng tôi sẽ xác định một lớp mới. Chúng tôi cũng sẽ thực hiệnforward() phương pháp chuẩn hóa dữ liệu đầu vào bằng cách phù hợp với phạm vi [0, 1].
from __future__ import print_function
import mxnet as mx
from mxnet import nd, gluon, autograd
from mxnet.gluon.nn import Dense
mx.random.seed(1)
class NormalizationLayer(gluon.Block):
def __init__(self):
super(NormalizationLayer, self).__init__()
def forward(self, x):
return (x - nd.min(x)) / (nd.max(x) - nd.min(x))
x = nd.random.uniform(shape=(2, 20))
N_net = NormalizationLayer()
N_net.initialize()
N_net(x)Output
Khi thực hiện chương trình trên, bạn sẽ nhận được kết quả sau:
[[0.5216355 0.03835821 0.02284337 0.5945146 0.17334817 0.69329053
0.7782702 1. 0.5508242 0. 0.07058554 0.3677264
0.4366546 0.44362497 0.7192635 0.37616986 0.6728799 0.7032008
0.46907538 0.63514024]
[0.9157533 0.7667402 0.08980197 0.03593295 0.16176797 0.27679572
0.07331014 0.3905285 0.6513384 0.02713427 0.05523694 0.12147208
0.45582628 0.8139887 0.91629887 0.36665893 0.07873632 0.78268915
0.63404864 0.46638715]]
<NDArray 2x20 @cpu(0)>Lai hóa
Nó có thể được định nghĩa là một quá trình được Apache MXNet's sử dụng để tạo một biểu đồ tượng trưng của một phép tính chuyển tiếp. Hybridisation cho phép MXNet nâng cao hiệu suất tính toán bằng cách tối ưu hóa đồ thị biểu tượng tính toán. Thay vì kế thừa trực tiếp từBlock, trên thực tế, chúng tôi có thể thấy rằng trong khi triển khai các lớp hiện có, một khối kế thừa từ HybridBlock.
Sau đây là những lý do cho điều này -
Allows us to write custom layers: HybridBlock cho phép chúng ta viết các lớp tùy chỉnh có thể được sử dụng trong cả lập trình mệnh lệnh và biểu tượng.
Increase computation performance- HybridBlock tối ưu hóa đồ thị biểu tượng tính toán cho phép MXNet tăng hiệu suất tính toán.
Thí dụ
Trong ví dụ này, chúng tôi sẽ viết lại lớp mẫu của chúng tôi, được tạo ở trên, bằng cách sử dụng HybridBlock:
class NormalizationHybridLayer(gluon.HybridBlock):
def __init__(self):
super(NormalizationHybridLayer, self).__init__()
def hybrid_forward(self, F, x):
return F.broadcast_div(F.broadcast_sub(x, F.min(x)), (F.broadcast_sub(F.max(x), F.min(x))))
layer_hybd = NormalizationHybridLayer()
layer_hybd(nd.array([1, 2, 3, 4, 5, 6], ctx=mx.cpu()))Output
Đầu ra được nêu dưới đây:
[0. 0.2 0.4 0.6 0.8 1. ]
<NDArray 6 @cpu(0)>Lai hóa không liên quan gì đến tính toán trên GPU và người ta có thể đào tạo các mạng lai cũng như không lai trên cả CPU và GPU.
Sự khác biệt giữa Block và HybridBlock
Nếu chúng ta sẽ so sánh Block Lớp và HybridBlock, chúng ta sẽ thấy rằng HybridBlock đã có nó forward() phương pháp thực hiện. HybridBlock xác định một hybrid_forward()phương pháp cần được thực hiện trong khi tạo các lớp. Đối số F tạo ra sự khác biệt chính giữaforward() và hybrid_forward(). Trong cộng đồng MXNet, đối số F được gọi là phụ trợ. F có thể tham khảomxnet.ndarray API (được sử dụng cho lập trình mệnh lệnh) hoặc mxnet.symbol API (dùng cho lập trình Symbolic).
Làm cách nào để thêm lớp tùy chỉnh vào mạng?
Thay vì sử dụng các lớp tùy chỉnh riêng biệt, các lớp này được sử dụng với các lớp được xác định trước. Chúng ta có thể sử dụngSequential hoặc là HybridSequentialvùng chứa từ một mạng nơ-ron tuần tự. Như đã thảo luận trước đó,Sequential kế thừa vùng chứa từ Block và HybridSequential Kế thừa từ HybridBlock tương ứng.
Thí dụ
Trong ví dụ dưới đây, chúng ta sẽ tạo một mạng nơ-ron đơn giản với một lớp tùy chỉnh. Đầu ra từDense (5) lớp sẽ là đầu vào của NormalizationHybridLayer. Đầu ra củaNormalizationHybridLayer sẽ trở thành đầu vào của Dense (1) lớp.
net = gluon.nn.HybridSequential()
with net.name_scope():
net.add(Dense(5))
net.add(NormalizationHybridLayer())
net.add(Dense(1))
net.initialize(mx.init.Xavier(magnitude=2.24))
net.hybridize()
input = nd.random_uniform(low=-10, high=10, shape=(10, 2))
net(input)Output
Bạn sẽ thấy kết quả sau:
[[-1.1272651]
[-1.2299833]
[-1.0662932]
[-1.1805027]
[-1.3382034]
[-1.2081106]
[-1.1263978]
[-1.2524893]
[-1.1044774]
[-1.316593 ]]
<NDArray 10x1 @cpu(0)>Thông số lớp tùy chỉnh
Trong mạng nơron, một lớp có một tập hợp các tham số được liên kết với nó. Đôi khi chúng tôi gọi chúng là trọng số, là trạng thái bên trong của một lớp. Các thông số này đóng các vai trò khác nhau -
Đôi khi đây là những thứ mà chúng ta muốn học trong bước nhân giống ngược.
Đôi khi đây chỉ là những hằng số chúng ta muốn sử dụng trong quá trình chuyển tiếp.
Nếu chúng ta nói về khái niệm lập trình, các tham số này (trọng số) của một khối được lưu trữ và truy cập thông qua ParameterDict lớp giúp khởi tạo, cập nhật, lưu và tải chúng.
Thí dụ
Trong ví dụ dưới đây, chúng tôi sẽ xác định hai bộ tham số sau:
Parameter weights- Đây là loại cây có thể huấn luyện được, và hình dạng của nó không được biết trong giai đoạn xây dựng. Nó sẽ được suy ra trong lần truyền chuyển tiếp đầu tiên.
Parameter scale- Đây là một hằng số có giá trị không thay đổi. Ngược lại với trọng số tham số, hình dạng của nó được xác định trong quá trình xây dựng.
class NormalizationHybridLayer(gluon.HybridBlock):
def __init__(self, hidden_units, scales):
super(NormalizationHybridLayer, self).__init__()
with self.name_scope():
self.weights = self.params.get('weights',
shape=(hidden_units, 0),
allow_deferred_init=True)
self.scales = self.params.get('scales',
shape=scales.shape,
init=mx.init.Constant(scales.asnumpy()),
differentiable=False)
def hybrid_forward(self, F, x, weights, scales):
normalized_data = F.broadcast_div(F.broadcast_sub(x, F.min(x)),
(F.broadcast_sub(F.max(x), F.min(x))))
weighted_data = F.FullyConnected(normalized_data, weights, num_hidden=self.weights.shape[0], no_bias=True)
scaled_data = F.broadcast_mul(scales, weighted_data)
return scaled_dataChương này đề cập đến các gói python KVStore và trực quan hóa.
Gói KVStore
Cửa hàng KV là viết tắt của Key-Value store. Nó là thành phần quan trọng được sử dụng để đào tạo đa thiết bị. Điều quan trọng là bởi vì, việc truyền thông số giữa các thiết bị trên một máy cũng như trên nhiều máy được truyền qua một hoặc nhiều máy chủ có KVStore cho các tham số.
Hãy để chúng tôi hiểu hoạt động của KVStore với sự trợ giúp của các điểm sau:
Mỗi giá trị trong KVStore được đại diện bởi một key và một value.
Mỗi mảng tham số trong mạng được gán một key và trọng số của mảng tham số đó được tham chiếu bởi value.
Sau đó, các nút công nhân pushgradient sau khi xử lý một mẻ. Họ cũngpull cập nhật trọng lượng trước khi xử lý một lô mới.
Nói một cách dễ hiểu, chúng ta có thể nói KVStore là nơi chia sẻ dữ liệu, nơi mỗi thiết bị có thể đẩy dữ liệu vào và kéo dữ liệu ra.
Dữ liệu đẩy vào và kéo ra
KVStore có thể được coi là một đối tượng được chia sẻ trên các thiết bị khác nhau như GPU & máy tính, nơi mỗi thiết bị có thể đẩy dữ liệu vào và lấy dữ liệu ra.
Sau đây là các bước triển khai mà các thiết bị cần phải tuân theo để đẩy dữ liệu vào và kéo dữ liệu ra:
Các bước thực hiện
Initialisation- Bước đầu tiên là khởi tạo các giá trị. Ví dụ ở đây, chúng ta sẽ khởi tạo một cặp (int, NDArray) vào KVStrore và sau đó kéo các giá trị ra -
import mxnet as mx
kv = mx.kv.create('local') # create a local KVStore.
shape = (3,3)
kv.init(3, mx.nd.ones(shape)*2)
a = mx.nd.zeros(shape)
kv.pull(3, out = a)
print(a.asnumpy())Output
Điều này tạo ra kết quả sau:
[[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]]Push, Aggregate, and Update - Sau khi khởi tạo, chúng ta có thể đẩy một giá trị mới vào KVStore có cùng hình dạng với khóa -
kv.push(3, mx.nd.ones(shape)*8)
kv.pull(3, out = a)
print(a.asnumpy())Output
Đầu ra được đưa ra dưới đây -
[[8. 8. 8.]
[8. 8. 8.]
[8. 8. 8.]]Dữ liệu được sử dụng để đẩy có thể được lưu trữ trên bất kỳ thiết bị nào như GPU hoặc máy tính. Chúng tôi cũng có thể đẩy nhiều giá trị vào cùng một khóa. Trong trường hợp này, KVStore trước tiên sẽ tính tổng tất cả các giá trị này và sau đó đẩy giá trị tổng hợp như sau:
contexts = [mx.cpu(i) for i in range(4)]
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.push(3, b)
kv.pull(3, out = a)
print(a.asnumpy())Output
Bạn sẽ thấy kết quả sau:
[[4. 4. 4.]
[4. 4. 4.]
[4. 4. 4.]]Đối với mỗi lần đẩy bạn đã áp dụng, KVStore sẽ kết hợp giá trị được đẩy với giá trị đã được lưu trữ. Nó sẽ được thực hiện với sự trợ giúp của một trình cập nhật. Ở đây, trình cập nhật mặc định là ASSIGN.
def update(key, input, stored):
print("update on key: %d" % key)
stored += input * 2
kv.set_updater(update)
kv.pull(3, out=a)
print(a.asnumpy())Output
Khi bạn thực thi đoạn mã trên, bạn sẽ thấy kết quả sau:
[[4. 4. 4.]
[4. 4. 4.]
[4. 4. 4.]]Example
kv.push(3, mx.nd.ones(shape))
kv.pull(3, out=a)
print(a.asnumpy())Output
Dưới đây là đầu ra của mã:
update on key: 3
[[6. 6. 6.]
[6. 6. 6.]
[6. 6. 6.]]Pull - Giống như Push, chúng ta cũng có thể kéo giá trị lên một số thiết bị bằng một lệnh gọi như sau:
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.pull(3, out = b)
print(b[1].asnumpy())Output
Đầu ra được nêu dưới đây -
[[6. 6. 6.]
[6. 6. 6.]
[6. 6. 6.]]Hoàn thành ví dụ triển khai
Dưới đây là ví dụ triển khai đầy đủ -
import mxnet as mx
kv = mx.kv.create('local')
shape = (3,3)
kv.init(3, mx.nd.ones(shape)*2)
a = mx.nd.zeros(shape)
kv.pull(3, out = a)
print(a.asnumpy())
kv.push(3, mx.nd.ones(shape)*8)
kv.pull(3, out = a) # pull out the value
print(a.asnumpy())
contexts = [mx.cpu(i) for i in range(4)]
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.push(3, b)
kv.pull(3, out = a)
print(a.asnumpy())
def update(key, input, stored):
print("update on key: %d" % key)
stored += input * 2
kv._set_updater(update)
kv.pull(3, out=a)
print(a.asnumpy())
kv.push(3, mx.nd.ones(shape))
kv.pull(3, out=a)
print(a.asnumpy())
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.pull(3, out = b)
print(b[1].asnumpy())Xử lý các cặp khóa-giá trị
Tất cả các hoạt động chúng tôi đã triển khai ở trên liên quan đến một khóa duy nhất, nhưng KVStore cũng cung cấp một giao diện cho a list of key-value pairs -
Đối với một thiết bị duy nhất
Sau đây là một ví dụ để hiển thị giao diện KVStore cho danh sách các cặp khóa-giá trị cho một thiết bị duy nhất:
keys = [5, 7, 9]
kv.init(keys, [mx.nd.ones(shape)]*len(keys))
kv.push(keys, [mx.nd.ones(shape)]*len(keys))
b = [mx.nd.zeros(shape)]*len(keys)
kv.pull(keys, out = b)
print(b[1].asnumpy())Output
Bạn sẽ nhận được kết quả sau:
update on key: 5
update on key: 7
update on key: 9
[[3. 3. 3.]
[3. 3. 3.]
[3. 3. 3.]]Đối với nhiều thiết bị
Sau đây là một ví dụ để hiển thị giao diện KVStore cho danh sách các cặp khóa-giá trị cho nhiều thiết bị -
b = [[mx.nd.ones(shape, ctx) for ctx in contexts]] * len(keys)
kv.push(keys, b)
kv.pull(keys, out = b)
print(b[1][1].asnumpy())Output
Bạn sẽ thấy kết quả sau:
update on key: 5
update on key: 7
update on key: 9
[[11. 11. 11.]
[11. 11. 11.]
[11. 11. 11.]]Gói hình ảnh hóa
Gói trực quan hóa là gói Apache MXNet được sử dụng để biểu diễn mạng nơ-ron (NN) dưới dạng đồ thị tính toán bao gồm các nút và cạnh.
Trực quan hóa mạng thần kinh
Trong ví dụ dưới đây, chúng tôi sẽ sử dụng mx.viz.plot_networkđể hình dung mạng nơ-ron. Theo dõi là điều kiện tiên quyết cho điều này -
Prerequisites
Sổ ghi chép Jupyter
Thư viện Graphviz
Ví dụ triển khai
Trong ví dụ dưới đây, chúng ta sẽ hình dung một NN mẫu để phân tích nhân tử ma trận tuyến tính -
import mxnet as mx
user = mx.symbol.Variable('user')
item = mx.symbol.Variable('item')
score = mx.symbol.Variable('score')
# Set the dummy dimensions
k = 64
max_user = 100
max_item = 50
# The user feature lookup
user = mx.symbol.Embedding(data = user, input_dim = max_user, output_dim = k)
# The item feature lookup
item = mx.symbol.Embedding(data = item, input_dim = max_item, output_dim = k)
# predict by the inner product and then do sum
N_net = user * item
N_net = mx.symbol.sum_axis(data = N_net, axis = 1)
N_net = mx.symbol.Flatten(data = N_net)
# Defining the loss layer
N_net = mx.symbol.LinearRegressionOutput(data = N_net, label = score)
# Visualize the network
mx.viz.plot_network(N_net)Chương này giải thích thư viện ndarray có sẵn trong Apache MXNet.
Mxnet.ndarray
Thư viện NDArray của Apache MXNet xác định DS (cấu trúc dữ liệu) cốt lõi cho tất cả các phép tính toán học. Hai công việc cơ bản của NDArray như sau:
Nó hỗ trợ thực thi nhanh chóng trên nhiều loại cấu hình phần cứng.
Nó tự động song song nhiều hoạt động trên phần cứng có sẵn.
Ví dụ dưới đây cho thấy cách người ta có thể tạo NDArray bằng cách sử dụng 'mảng' 1-D và 2-D từ danh sách Python thông thường -
import mxnet as mx
from mxnet import nd
x = nd.array([1,2,3,4,5,6,7,8,9,10])
print(x)Output
Đầu ra được đưa ra dưới đây:
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
<NDArray 10 @cpu(0)>Example
y = nd.array([[1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10]])
print(y)Output
Điều này tạo ra kết quả sau:
[[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]]
<NDArray 3x10 @cpu(0)>Bây giờ chúng ta hãy thảo luận chi tiết về các lớp, hàm và tham số của API ndarray của MXNet.
Các lớp học
Bảng sau bao gồm các lớp API ndarray của MXNet:
| Lớp học | Định nghĩa |
|---|---|
| CachedOp (sym [, flags]) | Nó được sử dụng cho bộ điều khiển được lưu trong bộ nhớ cache. |
| NDArray (xử lý [, có thể ghi]) | Nó được sử dụng như một đối tượng mảng đại diện cho một mảng đa chiều, đồng nhất của các mục có kích thước cố định. |
Các chức năng và thông số của chúng
Sau đây là một số hàm quan trọng và các tham số của chúng được bao phủ bởi API mxnet.ndarray:
| Chức năng và các thông số của nó | Định nghĩa |
|---|---|
| Activation([data, act_type, out, name]) | Nó áp dụng một phần tử chức năng kích hoạt khôn ngoan cho đầu vào. Nó hỗ trợ các chức năng kích hoạt relu, sigmoid, tanh, softrelu, softsign. |
| BatchNorm([data, gamma, beta, moving_mean,…]) | Nó được sử dụng để chuẩn hóa hàng loạt. Hàm này chuẩn hóa một lô dữ liệu theo giá trị trung bình và phương sai. Nó áp dụng gamma quy mô và beta bù đắp. |
| BilinearSampler([dữ liệu, lưới, cudnn_off,…]) | Chức năng này áp dụng lấy mẫu song tuyến cho bản đồ tính năng đầu vào. Trên thực tế, nó là chìa khóa của “Mạng lưới biến áp không gian”. Nếu bạn đã quen với chức năng remap trong OpenCV thì cách sử dụng chức năng này cũng tương tự như vậy. Sự khác biệt duy nhất là nó có đường chuyền ngược. |
| BlockGrad ([data, out, name]) | Như tên chỉ định, hàm này dừng tính toán gradient. Về cơ bản, nó ngăn không cho gradient tích lũy của các đầu vào chảy qua toán tử này theo hướng ngược lại. |
| ép kiểu ([data, dtype, out, name]) | Hàm này sẽ chuyển tất cả các phần tử của đầu vào sang một kiểu mới. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng ta sẽ sử dụng hàm BilinierSampler () để thu nhỏ dữ liệu hai lần và dịch chuyển dữ liệu theo chiều ngang -1 pixel -
import mxnet as mx
from mxnet import nd
data = nd.array([[[[2, 5, 3, 6],
[1, 8, 7, 9],
[0, 4, 1, 8],
[2, 0, 3, 4]]]])
affine_matrix = nd.array([[2, 0, 0],
[0, 2, 0]])
affine_matrix = nd.reshape(affine_matrix, shape=(1, 6))
grid = nd.GridGenerator(data=affine_matrix, transform_type='affine', target_shape=(4, 4))
output = nd.BilinearSampler(data, grid)Output
Khi bạn thực thi đoạn mã trên, bạn sẽ thấy kết quả sau:
[[[[0. 0. 0. 0. ]
[0. 4.0000005 6.25 0. ]
[0. 1.5 4. 0. ]
[0. 0. 0. 0. ]]]]
<NDArray 1x1x4x4 @cpu(0)>Kết quả trên hiển thị việc thu phóng dữ liệu hai lần.
Ví dụ về việc dịch chuyển dữ liệu theo -1 pixel như sau:
import mxnet as mx
from mxnet import nd
data = nd.array([[[[2, 5, 3, 6],
[1, 8, 7, 9],
[0, 4, 1, 8],
[2, 0, 3, 4]]]])
warp_matrix = nd.array([[[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]],
[[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]]]])
grid = nd.GridGenerator(data=warp_matrix, transform_type='warp')
output = nd.BilinearSampler(data, grid)Output
Đầu ra được nêu dưới đây -
[[[[5. 3. 6. 0.]
[8. 7. 9. 0.]
[4. 1. 8. 0.]
[0. 3. 4. 0.]]]]
<NDArray 1x1x4x4 @cpu(0)>Tương tự, ví dụ sau cho thấy việc sử dụng hàm cast () -
nd.cast(nd.array([300, 10.1, 15.4, -1, -2]), dtype='uint8')Output
Khi thực hiện, bạn sẽ nhận được kết quả sau:
[ 44 10 15 255 254]
<NDArray 5 @cpu(0)>ndarray.contrib
API Contrib NDArray được định nghĩa trong gói ndarray.contrib. Nó thường cung cấp nhiều API thử nghiệm hữu ích cho các tính năng mới. API này hoạt động như một nơi dành cho cộng đồng, nơi họ có thể thử các tính năng mới. Người đóng góp tính năng cũng sẽ nhận được phản hồi.
Các chức năng và thông số của chúng
Sau đây là một số chức năng quan trọng và các tham số của chúng được bao hàm bởi mxnet.ndarray.contrib API -
| Chức năng và các thông số của nó | Định nghĩa |
|---|---|
| rand_zipfian(true_classes, num_sampled,…) | Hàm này lấy mẫu ngẫu nhiên từ phân phối Zipfian gần đúng. Phân phối cơ sở của chức năng này là phân phối Zipfian. Hàm này lấy mẫu ngẫu nhiên các ứng cử viên num_sampled và các phần tử của mẫu_candidate được lấy từ phân phối cơ sở đã cho ở trên. |
| foreach(body, data, init_states) | Như tên của nó, hàm này chạy một vòng lặp for với tính toán do người dùng xác định qua NDArrays trên thứ nguyên 0. Hàm này mô phỏng một vòng lặp for và phần thân có tính toán cho một lần lặp lại của vòng lặp for. |
| while_loop (cond, func, loop_vars [,…]) | Như tên của nó, hàm này chạy một vòng lặp while với điều kiện tính toán và vòng lặp do người dùng xác định. Hàm này mô phỏng một vòng lặp while thực hiện tính toán tùy chỉnh một cách thành thạo nếu điều kiện được thỏa mãn. |
| cond(pred, then_func, else_func) | Như tên của nó, hàm này chạy if-then-else bằng cách sử dụng tính toán và điều kiện do người dùng xác định. Hàm này mô phỏng một nhánh if-like chọn thực hiện một trong hai phép tính tùy chỉnh theo điều kiện đã chỉ định. |
| isinf(dữ liệu) | Hàm này thực hiện kiểm tra phần tử khôn ngoan để xác định xem NDArray có chứa phần tử vô hạn hay không. |
| getnnz([dữ liệu, trục, ra, tên]) | Hàm này cung cấp cho chúng ta số lượng giá trị được lưu trữ cho một tensor thưa thớt. Nó cũng bao gồm các số không rõ ràng. Nó chỉ hỗ trợ ma trận CSR trên CPU. |
| yêu cầu ([data, min_range, max_range,…]) | Hàm này yêu cầu dữ liệu đã cho được lượng hóa trong int32 và các ngưỡng tương ứng, vào int8 bằng cách sử dụng ngưỡng tối thiểu và tối đa được tính toán trong thời gian chạy hoặc từ hiệu chuẩn. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng tôi sẽ sử dụng hàm rand_zipfian để vẽ các mẫu ngẫu nhiên từ phân phối Zipfian gần đúng -
import mxnet as mx
from mxnet import nd
trueclass = mx.nd.array([2])
samples, exp_count_true, exp_count_sample = mx.nd.contrib.rand_zipfian(trueclass, 3, 4)
samplesOutput
Bạn sẽ thấy kết quả sau:
[0 0 1]
<NDArray 3 @cpu(0)>Example
exp_count_trueOutput
Đầu ra được đưa ra dưới đây:
[0.53624076]
<NDArray 1 @cpu(0)>Example
exp_count_sampleOutput
Điều này tạo ra kết quả sau:
[1.29202967 1.29202967 0.75578891]
<NDArray 3 @cpu(0)>Trong ví dụ dưới đây, chúng ta sẽ sử dụng hàm while_loop để chạy vòng lặp while cho tính toán do người dùng xác định và điều kiện vòng lặp:
cond = lambda i, s: i <= 7
func = lambda i, s: ([i + s], [i + 1, s + i])
loop_var = (mx.nd.array([0], dtype="int64"), mx.nd.array([1], dtype="int64"))
outputs, states = mx.nd.contrib.while_loop(cond, func, loop_vars, max_iterations=10)
outputsOutput
Đầu ra được hiển thị bên dưới -
[
[[ 1]
[ 2]
[ 4]
[ 7]
[ 11]
[ 16]
[ 22]
[ 29]
[3152434450384]
[ 257]]
<NDArray 10x1 @cpu(0)>]Example
StatesOutput
Điều này tạo ra kết quả sau:
[
[8]
<NDArray 1 @cpu(0)>,
[29]
<NDArray 1 @cpu(0)>]ndarray.image
API Image NDArray được định nghĩa trong gói ndarray.image. Như tên của nó, nó thường được sử dụng cho hình ảnh và các tính năng của chúng.
Các chức năng và thông số của chúng
Sau đây là một số chức năng quan trọng và các tham số của chúng được bao hàm bởi mxnet.ndarray.image API-
| Chức năng và các thông số của nó | Định nghĩa |
|---|---|
| adjust_lighting([dữ liệu, alpha, out, name]) | Như tên của nó, chức năng này điều chỉnh mức độ chiếu sáng của đầu vào. Nó tuân theo phong cách AlexNet. |
| crop([dữ liệu, x, y, width, height, out, name]) | Với sự trợ giúp của chức năng này, chúng ta có thể cắt ảnh NDArray có hình dạng (H x W x C) hoặc (N x H x W x C) theo kích thước do người dùng đưa ra. |
| normalize([data, mean, std, out, name]) | Nó sẽ chuẩn hóa một tensor hình dạng (C x H x W) hoặc (N x C x H x W) với mean và standard deviation(SD). |
| random_crop ([dữ liệu, xrange, yrange, width,…]) | Tương tự như crop (), nó cắt ngẫu nhiên một NDArray hình ảnh có hình dạng (H x W x C) hoặc (N x H x W x C) theo kích thước do người dùng đưa ra. Nó sẽ lấy mẫu kết quả nếu src nhỏ hơn kích thước. |
| random_lighting([dữ liệu, alpha_std, out, name]) | Như tên của nó, chức năng này thêm nhiễu PCA một cách ngẫu nhiên. Nó cũng tuân theo phong cách AlexNet. |
| random_resized_crop([dữ liệu, xrange, yrange,…]) | Nó cũng cắt ảnh một cách ngẫu nhiên NDArray có hình dạng (H x W x C) hoặc (N x H x W x C) theo kích thước đã cho. Nó sẽ lấy mẫu kết quả, nếu src nhỏ hơn kích thước. Nó cũng sẽ ngẫu nhiên hóa diện tích và khẩu phần. |
| resize([data, size, keep_ratio, interp,…]) | Như tên của nó, chức năng này sẽ thay đổi kích thước một NDArray hình ảnh có hình dạng (H x W x C) hoặc (N x H x W x C) thành kích thước do người dùng cung cấp. |
| to_tensor([dữ liệu, ngoài, tên]) | Nó chuyển đổi một NDArray hình ảnh có hình dạng (H x W x C) hoặc (N x H x W x C) với các giá trị trong phạm vi [0, 255] thành một tensor NDArray có hình dạng (C x H x W) hoặc ( N x C x H x W) với các giá trị trong khoảng [0, 1]. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng tôi sẽ sử dụng hàm to_tensor để chuyển đổi NDArray hình ảnh có dạng (H x W x C) hoặc (N x H x W x C) với các giá trị trong phạm vi [0, 255] thành tensor NDArray của shape (C x H x W) hoặc (N x C x H x W) với các giá trị trong khoảng [0, 1].
import numpy as np
img = mx.nd.random.uniform(0, 255, (4, 2, 3)).astype(dtype=np.uint8)
mx.nd.image.to_tensor(img)Output
Bạn sẽ thấy kết quả sau:
[[[0.972549 0.5058824 ]
[0.6039216 0.01960784]
[0.28235295 0.35686275]
[0.11764706 0.8784314 ]]
[[0.8745098 0.9764706 ]
[0.4509804 0.03529412]
[0.9764706 0.29411766]
[0.6862745 0.4117647 ]]
[[0.46666667 0.05490196]
[0.7372549 0.4392157 ]
[0.11764706 0.47843137]
[0.31764707 0.91764706]]]
<NDArray 3x4x2 @cpu(0)>Example
img = mx.nd.random.uniform(0, 255, (2, 4, 2, 3)).astype(dtype=np.uint8)
mx.nd.image.to_tensor(img)Output
Khi bạn chạy mã, bạn sẽ thấy kết quả sau:
[[[[0.0627451 0.5647059 ]
[0.2627451 0.9137255 ]
[0.57254905 0.27450982]
[0.6666667 0.64705884]]
[[0.21568628 0.5647059 ]
[0.5058824 0.09019608]
[0.08235294 0.31764707]
[0.8392157 0.7137255 ]]
[[0.6901961 0.8627451 ]
[0.52156866 0.91764706]
[0.9254902 0.00784314]
[0.12941177 0.8392157 ]]]
[[[0.28627452 0.39607844]
[0.01960784 0.36862746]
[0.6745098 0.7019608 ]
[0.9607843 0.7529412 ]]
[[0.2627451 0.58431375]
[0.16470589 0.00392157]
[0.5686275 0.73333335]
[0.43137255 0.57254905]]
[[0.18039216 0.54901963]
[0.827451 0.14509805]
[0.26666668 0.28627452]
[0.24705882 0.39607844]]]]
<NDArgt;ray 2x3x4x2 @cpu(0)>Trong ví dụ dưới đây, chúng ta sẽ sử dụng hàm normalize để chuẩn hóa một tensor hình dạng (C x H x W) hoặc (N x C x H x W) với mean và standard deviation(SD).
img = mx.nd.random.uniform(0, 1, (3, 4, 2))
mx.nd.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
Điều này tạo ra kết quả sau:
[[[ 0.29391178 0.3218054 ]
[ 0.23084386 0.19615503]
[ 0.24175143 0.21988946]
[ 0.16710812 0.1777354 ]]
[[-0.02195817 -0.3847335 ]
[-0.17800489 -0.30256534]
[-0.28807247 -0.19059572]
[-0.19680339 -0.26256624]]
[[-1.9808068 -1.5298678 ]
[-1.6984252 -1.2839255 ]
[-1.3398265 -1.712009 ]
[-1.7099224 -1.6165378 ]]]
<NDArray 3x4x2 @cpu(0)>Example
img = mx.nd.random.uniform(0, 1, (2, 3, 4, 2))
mx.nd.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
Khi bạn thực thi đoạn mã trên, bạn sẽ thấy kết quả sau:
[[[[ 2.0600514e-01 2.4972327e-01]
[ 1.4292289e-01 2.9281738e-01]
[ 4.5158025e-02 3.4287784e-02]
[ 9.9427439e-02 3.0791296e-02]]
[[-2.1501756e-01 -3.2297665e-01]
[-2.0456362e-01 -2.2409186e-01]
[-2.1283737e-01 -4.8318747e-01]
[-1.7339960e-01 -1.5519112e-02]]
[[-1.3478968e+00 -1.6790028e+00]
[-1.5685816e+00 -1.7787373e+00]
[-1.1034534e+00 -1.8587360e+00]
[-1.6324382e+00 -1.9027401e+00]]]
[[[ 1.4528830e-01 3.2801408e-01]
[ 2.9730779e-01 8.6780310e-02]
[ 2.6873133e-01 1.7900752e-01]
[ 2.3462953e-01 1.4930873e-01]]
[[-4.4988656e-01 -4.5021546e-01]
[-4.0258706e-02 -3.2384416e-01]
[-1.4287934e-01 -2.6537544e-01]
[-5.7649612e-04 -7.9429924e-02]]
[[-1.8505517e+00 -1.0953522e+00]
[-1.1318740e+00 -1.9624406e+00]
[-1.8375070e+00 -1.4916846e+00]
[-1.3844404e+00 -1.8331525e+00]]]]
<NDArray 2x3x4x2 @cpu(0)>ndarray.random
API NDArray ngẫu nhiên được định nghĩa trong gói ndarray.random. Như tên của nó, nó là API NDArray của trình tạo phân phối ngẫu nhiên của MXNet.
Các chức năng và thông số của chúng
Sau đây là một số chức năng quan trọng và các tham số của chúng được bao hàm bởi mxnet.ndarray.random API -
| Chức năng và các tham số của nó | Định nghĩa |
|---|---|
| đồng nhất ([thấp, cao, hình dạng, loại, ctx, ngoài]) | Nó tạo ra các mẫu ngẫu nhiên từ một phân phối đồng đều. |
| bình thường ([loc, scale, shape, dtype, ctx, out]) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối chuẩn (Gaussian). |
| randn (* hình dạng, ** kwargs) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối chuẩn (Gaussian). |
| hàm mũ ([scale, shape, dtype, ctx, out]) | Nó tạo ra các mẫu từ phân phối hàm mũ. |
| gamma ([alpha, beta, shape, dtype, ctx, out]) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối gamma. |
| đa thức (data [, shape, get_prob, out, dtype]) | Nó tạo ra lấy mẫu đồng thời từ nhiều phân phối đa thức. |
| negative_binomial ([k, p, shape, dtype, ctx, out]) | Nó tạo ra các mẫu ngẫu nhiên từ một phân phối nhị thức âm. |
| general_negative_binomial ([mu, alpha,…]) | Nó tạo ra các mẫu ngẫu nhiên từ một phân phối nhị thức âm tổng quát. |
| xáo trộn (dữ liệu, ** kwargs) | Nó xáo trộn các phần tử một cách ngẫu nhiên. |
| randint (thấp, cao [, shape, dtype, ctx, out]) | Nó tạo ra các mẫu ngẫu nhiên từ một phân bố đồng đều rời rạc. |
| exponential_like ([data, lam, out, name]) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối hàm mũ theo hình dạng mảng đầu vào. |
| gamma_like ([dữ liệu, alpha, beta, out, name]) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối gamma theo hình dạng mảng đầu vào. |
| general_negative_binomial_like ([dữ liệu,…]) | Nó tạo ra các mẫu ngẫu nhiên từ một phân phối nhị thức âm tổng quát, theo hình dạng mảng đầu vào. |
| negative_binomial_like ([data, k, p, out, name]) | Nó tạo các mẫu ngẫu nhiên từ phân phối nhị thức âm, theo hình dạng mảng đầu vào. |
| normal_like ([data, loc, scale, out, name]) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối chuẩn (Gaussian), theo hình dạng mảng đầu vào. |
| poisson_like ([data, lam, out, name]) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối Poisson, theo hình dạng mảng đầu vào. |
| Uniform_like ([dữ liệu, thấp, cao, ngoài, tên]) | Nó tạo ra các mẫu ngẫu nhiên từ một phân phối đồng nhất, theo hình dạng mảng đầu vào. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng ta sẽ vẽ các mẫu ngẫu nhiên từ một phân phối đồng đều. Đối với điều này sẽ được sử dụng chức nănguniform().
mx.nd.random.uniform(0, 1)Output
Đầu ra được đề cập bên dưới -
[0.12381998]
<NDArray 1 @cpu(0)>Example
mx.nd.random.uniform(-1, 1, shape=(2,))Output
Đầu ra được đưa ra dưới đây -
[0.558102 0.69601643]
<NDArray 2 @cpu(0)>Example
low = mx.nd.array([1,2,3])
high = mx.nd.array([2,3,4])
mx.nd.random.uniform(low, high, shape=2)Output
Bạn sẽ thấy kết quả sau:
[[1.8649333 1.8073189]
[2.4113967 2.5691009]
[3.1399727 3.4071832]]
<NDArray 3x2 @cpu(0)>Trong ví dụ dưới đây, chúng ta sẽ vẽ các mẫu ngẫu nhiên từ một phân phối nhị thức âm tổng quát. Đối với điều này, chúng tôi sẽ sử dụng hàmgeneralized_negative_binomial().
mx.nd.random.generalized_negative_binomial(10, 0.5)Output
Khi bạn thực thi đoạn mã trên, bạn sẽ thấy kết quả sau:
[1.]
<NDArray 1 @cpu(0)>Example
mx.nd.random.generalized_negative_binomial(10, 0.5, shape=(2,))Output
Đầu ra được cung cấp kèm theo:
[16. 23.]
<NDArray 2 @cpu(0)>Example
mu = mx.nd.array([1,2,3])
alpha = mx.nd.array([0.2,0.4,0.6])
mx.nd.random.generalized_negative_binomial(mu, alpha, shape=2)Output
Dưới đây là đầu ra của mã:
[[0. 0.]
[4. 1.]
[9. 3.]]
<NDArray 3x2 @cpu(0)>ndarray.utils
API NDArray tiện ích được định nghĩa trong gói ndarray.utils. Như tên của nó, nó cung cấp các chức năng tiện ích cho NDArray và BaseSparseNDArray.
Các chức năng và thông số của chúng
Sau đây là một số chức năng quan trọng và các tham số của chúng được bao hàm bởi mxnet.ndarray.utils API -
| Chức năng và các tham số của nó | Định nghĩa |
|---|---|
| số không (shape [, ctx, dtype, stype]) | Hàm này sẽ trả về một mảng mới có hình dạng và kiểu đã cho, chứa đầy các số không. |
| trống (shape [, ctx, dtype, stype]) | Nó sẽ trả về một mảng mới có hình dạng và kiểu đã cho mà không cần khởi tạo các mục nhập. |
| mảng (source_array [, ctx, dtype]) | Như tên của nó, hàm này sẽ tạo một mảng từ bất kỳ đối tượng nào có giao diện mảng. |
| tải (fname) | Nó sẽ tải một mảng từ tệp. |
| load_frombuffer (buf) | Như tên của nó, hàm này sẽ tải một từ điển mảng hoặc danh sách từ một bộ đệm |
| lưu (tên, dữ liệu) | Hàm này sẽ lưu danh sách các mảng hoặc một lệnh của mảng str-> vào tệp. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng ta sẽ trả về một mảng mới có hình dạng và kiểu đã cho, chứa đầy các số không. Đối với điều này, chúng tôi sẽ sử dụng hàmzeros().
mx.nd.zeros((1,2), mx.cpu(), stype='csr')Output
Điều này tạo ra kết quả sau:
<CSRNDArray 1x2 @cpu(0)>Example
mx.nd.zeros((1,2), mx.cpu(), 'float16', stype='row_sparse').asnumpy()Output
Bạn sẽ nhận được kết quả sau:
array([[0., 0.]], dtype=float16)Trong ví dụ dưới đây, chúng ta sẽ lưu một danh sách các mảng và một từ điển các chuỗi. Đối với điều này, chúng tôi sẽ sử dụng hàmsave().
Example
x = mx.nd.zeros((2,3))
y = mx.nd.ones((1,4))
mx.nd.save('list', [x,y])
mx.nd.save('dict', {'x':x, 'y':y})
mx.nd.load('list')Output
Khi thực hiện, bạn sẽ nhận được kết quả sau:
[
[[0. 0. 0.]
[0. 0. 0.]]
<NDArray 2x3 @cpu(0)>,
[[1. 1. 1. 1.]]
<NDArray 1x4 @cpu(0)>]Example
mx.nd.load('my_dict')Output
Đầu ra được hiển thị bên dưới -
{'x':
[[0. 0. 0.]
[0. 0. 0.]]
<NDArray 2x3 @cpu(0)>, 'y':
[[1. 1. 1. 1.]]
<NDArray 1x4 @cpu(0)>}Như chúng ta đã thảo luận trong các chương trước rằng, MXNet Gluon cung cấp một API rõ ràng, ngắn gọn và đơn giản cho các dự án DL. Nó cho phép Apache MXNet tạo mẫu, xây dựng và đào tạo các mô hình DL mà không làm giảm tốc độ đào tạo.
Mô-đun cốt lõi
Hãy cùng chúng tôi tìm hiểu các mô-đun cốt lõi của giao diện lập trình ứng dụng Apache MXNet Python (API) gluon.
gluon.nn
Gluon cung cấp một số lượng lớn các lớp NN tích hợp trong mô-đun gluon.nn. Đó là lý do nó được gọi là mô-đun lõi.
Các phương thức và tham số của chúng
Sau đây là một số phương pháp quan trọng và các tham số của chúng được mxnet.gluon.nn mô-đun cốt lõi -
| Các phương thức và các tham số của nó | Định nghĩa |
|---|---|
| Kích hoạt (kích hoạt, ** kwargs) | Như tên của nó, phương pháp này áp dụng một chức năng kích hoạt cho đầu vào. |
| AvgPool1D ([pool_size, strides, padding,…]) | Đây là hoạt động gộp trung bình cho dữ liệu tạm thời. |
| AvgPool2D ([pool_size, strides, padding,…]) | Đây là hoạt động gộp trung bình cho dữ liệu không gian. |
| AvgPool3D ([pool_size, strides, padding,…]) | Đây là hoạt động gộp trung bình cho dữ liệu 3D. Dữ liệu có thể là không gian hoặc không gian-thời gian. |
| BatchNorm ([trục, động lượng, epsilon, tâm,…]) | Nó đại diện cho lớp chuẩn hóa hàng loạt. |
| BatchNormReLU ([trục, động lượng, epsilon,…]) | Nó cũng đại diện cho lớp chuẩn hóa hàng loạt nhưng với chức năng kích hoạt Relu. |
| Khối ([tiền tố, thông số]) | Nó cung cấp lớp cơ sở cho tất cả các lớp và mô hình mạng nơron. |
| Conv1D (kênh, kernel_size [, strides,…]) | Phương pháp này được sử dụng cho lớp chập 1-D. Ví dụ, tích chập theo thời gian. |
| Conv1DTranspose (kênh, kernel_size [,…]) | Phương pháp này được sử dụng cho lớp tích chập 1D được vận chuyển. |
| Conv2D (kênh, kernel_size [, strides,…]) | Phương pháp này được sử dụng cho lớp tích chập 2D. Ví dụ, tích chập không gian trên hình ảnh). |
| Conv2DTranspose (kênh, kernel_size [,…]) | Phương pháp này được sử dụng cho lớp tích chập 2D được vận chuyển. |
| Conv3D (kênh, kernel_size [, strides,…]) | Phương pháp này được sử dụng cho lớp tích chập 3D. Ví dụ, tích chập không gian trên khối lượng. |
| Conv3DTranspose (kênh, kernel_size [,…]) | Phương pháp này được sử dụng cho lớp tích chập 3D Transposed. |
| Mật độ (đơn vị [, kích hoạt, use_bias,…]) | Phương thức này đại diện cho lớp NN được kết nối dày đặc thường xuyên của bạn. |
| Bỏ học (tỷ lệ [, số trục]) | Như tên của nó, phương pháp áp dụng Dropout cho đầu vào. |
| ELU ([alpha]) | Phương pháp này được sử dụng cho Đơn vị tuyến tính hàm mũ (ELU). |
| Nhúng (input_dim, output_dim [, dtype,…]) | Nó biến các số nguyên không âm thành các vectơ dày đặc có kích thước cố định. |
| Làm phẳng (** kwargs) | Phương thức này làm phẳng đầu vào thành 2-D. |
| GELU (** kwargs) | Phương pháp này được sử dụng cho Đơn vị tuyến tính hàm mũ Gaussian (GELU). |
| GlobalAvgPool1D ([bố cục]) | Với sự trợ giúp của phương pháp này, chúng ta có thể thực hiện hoạt động gộp trung bình toàn cầu cho dữ liệu tạm thời. |
| GlobalAvgPool2D ([bố cục]) | Với sự trợ giúp của phương pháp này, chúng ta có thể thực hiện hoạt động gộp trung bình toàn cầu cho dữ liệu không gian. |
| GlobalAvgPool3D ([bố cục]) | Với sự trợ giúp của phương pháp này, chúng tôi có thể thực hiện hoạt động gộp trung bình toàn cầu cho dữ liệu 3-D. |
| GlobalMaxPool1D ([bố cục]) | Với sự trợ giúp của phương pháp này, chúng tôi có thể thực hiện hoạt động tổng hợp tối đa toàn cầu cho dữ liệu 1-D. |
| GlobalMaxPool2D ([bố cục]) | Với sự trợ giúp của phương pháp này, chúng tôi có thể thực hiện hoạt động tổng hợp tối đa toàn cầu cho dữ liệu 2-D. |
| GlobalMaxPool3D ([bố cục]) | Với sự trợ giúp của phương pháp này, chúng tôi có thể thực hiện hoạt động tổng hợp tối đa toàn cầu cho dữ liệu 3-D. |
| GroupNorm ([num_groups, epsilon, center,…]) | Phương thức này áp dụng chuẩn hóa nhóm cho mảng đầu vào nD. |
| HybridBlock ([tiền tố, tham số]) | Phương pháp này hỗ trợ chuyển tiếp với cả hai Symbol và NDArray. |
| HybridLambda(hàm [, tiền tố]) | Với sự trợ giúp của phương thức này, chúng ta có thể bọc một toán tử hoặc một biểu thức dưới dạng một đối tượng HybridBlock. |
| HybridSequential ([tiền tố, tham số]) | Nó sắp xếp các HybridBlocks một cách tuần tự. |
| InstanceNorm ([trục, epsilon, trung tâm, tỷ lệ,…]) | Phương thức này áp dụng chuẩn hóa phiên bản cho mảng đầu vào nD. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng ta sẽ sử dụng Block () để cung cấp lớp cơ sở cho tất cả các lớp và mô hình mạng nơ-ron.
from mxnet.gluon import Block, nn
class Model(Block):
def __init__(self, **kwargs):
super(Model, self).__init__(**kwargs)
# use name_scope to give child Blocks appropriate names.
with self.name_scope():
self.dense0 = nn.Dense(20)
self.dense1 = nn.Dense(20)
def forward(self, x):
x = mx.nd.relu(self.dense0(x))
return mx.nd.relu(self.dense1(x))
model = Model()
model.initialize(ctx=mx.cpu(0))
model(mx.nd.zeros((5, 5), ctx=mx.cpu(0)))Output
Bạn sẽ thấy kết quả sau:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
<NDArray 5x20 @cpu(0)*gt;Trong ví dụ dưới đây, chúng ta sẽ sử dụng HybridBlock () hỗ trợ chuyển tiếp với cả Symbol và NDArray.
import mxnet as mx
from mxnet.gluon import HybridBlock, nn
class Model(HybridBlock):
def __init__(self, **kwargs):
super(Model, self).__init__(**kwargs)
# use name_scope to give child Blocks appropriate names.
with self.name_scope():
self.dense0 = nn.Dense(20)
self.dense1 = nn.Dense(20)
def forward(self, x):
x = nd.relu(self.dense0(x))
return nd.relu(self.dense1(x))
model = Model()
model.initialize(ctx=mx.cpu(0))
model.hybridize()
model(mx.nd.zeros((5, 5), ctx=mx.cpu(0)))Output
Đầu ra được đề cập bên dưới -
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
<NDArray 5x20 @cpu(0)>gluon.rnn
Gluon cung cấp một số lượng lớn cài sẵn recurrent neural network(RNN) các lớp trong mô-đun gluon.rnn. Đó là lý do, nó được gọi là mô-đun lõi.
Các phương thức và tham số của chúng
Sau đây là một số phương pháp quan trọng và các tham số của chúng được mxnet.gluon.nn mô-đun cốt lõi:
| Các phương thức và các tham số của nó | Định nghĩa |
|---|---|
| Hai chiềuCell (l_cell, r_cell [,…]) | Nó được sử dụng cho ô Mạng thần kinh tái phát hai chiều (RNN). |
| DropoutCell (tỷ lệ [, trục, tiền tố, thông số]) | Phương pháp này sẽ áp dụng bỏ học đối với đầu vào đã cho. |
| GRU (hidden_size [, num_layers, layout,…]) | Nó áp dụng RNN đơn vị định kỳ nhiều lớp (GRU) cho một chuỗi đầu vào nhất định. |
| GRUCell (hidden_size [,…]) | Nó được sử dụng cho tế bào mạng Gated Rectified Unit (GRU). |
| HybridRecurrentCell ([tiền tố, tham số]) | Phương pháp này hỗ trợ hybridize. |
| HybridSequentialRNNCell ([tiền tố, tham số]) | Với sự trợ giúp của phương pháp này, chúng ta có thể xếp chồng nhiều ô HybridRNN một cách tuần tự. |
| LSTM (hidden_size [, num_layers, layout,…]) 0 | Nó áp dụng RNN bộ nhớ ngắn hạn (LSTM) nhiều lớp cho một chuỗi đầu vào nhất định. |
| LSTMCell (hidden_size [,…]) | Nó được sử dụng cho ô mạng Bộ nhớ Dài hạn (LSTM). |
| ModifierCell (base_cell) | Nó là lớp Cơ sở cho các ô bổ trợ. |
| RNN (hidden_size [, num_layers, kích hoạt,…]) | Nó áp dụng Elman RNN nhiều lớp với tanh hoặc là ReLU không tuyến tính đối với một chuỗi đầu vào nhất định. |
| RNNCell (hidden_size [, kích hoạt,…]) | Nó được sử dụng cho tế bào mạng nơ-ron lặp lại Elman RNN. |
| RecurrentCell ([tiền tố, thông số]) | Nó đại diện cho lớp cơ sở trừu tượng cho các ô RNN. |
| SequentialRNNCell ([tiền tố, thông số]) | Với sự trợ giúp của phương pháp này, chúng ta có thể xếp chồng nhiều ô RNN một cách tuần tự. |
| ZoneoutCell (base_cell [, zoneout_outputs,…]) | Phương pháp này áp dụng Zoneout trên ô cơ sở. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng ta sẽ sử dụng GRU () áp dụng RNN đơn vị định kỳ nhiều lớp (GRU) cho một chuỗi đầu vào nhất định.
layer = mx.gluon.rnn.GRU(100, 3)
layer.initialize()
input_seq = mx.nd.random.uniform(shape=(5, 3, 10))
out_seq = layer(input_seq)
h0 = mx.nd.random.uniform(shape=(3, 3, 100))
out_seq, hn = layer(input_seq, h0)
out_seqOutput
Điều này tạo ra kết quả sau:
[[[ 1.50152072e-01 5.19012511e-01 1.02390535e-01 ... 4.35803324e-01
1.30406499e-01 3.30152437e-02]
[ 2.91542172e-01 1.02243155e-01 1.73325196e-01 ... 5.65296151e-02
1.76546033e-02 1.66693389e-01]
[ 2.22257316e-01 3.76294643e-01 2.11277917e-01 ... 2.28903517e-01
3.43954474e-01 1.52770668e-01]]
[[ 1.40634328e-01 2.93247789e-01 5.50393537e-02 ... 2.30207980e-01
6.61415309e-02 2.70989928e-02]
[ 1.11081995e-01 7.20834285e-02 1.08342394e-01 ... 2.28330195e-02
6.79589901e-03 1.25501186e-01]
[ 1.15944080e-01 2.41565228e-01 1.18612610e-01 ... 1.14908054e-01
1.61080107e-01 1.15969211e-01]]
………………………….Example
hnOutput
Điều này tạo ra kết quả sau:
[[[-6.08105101e-02 3.86217088e-02 6.64453954e-03 8.18805695e-02
3.85607071e-02 -1.36945639e-02 7.45836645e-03 -5.46515081e-03
9.49622393e-02 6.39371723e-02 -6.37890724e-03 3.82240303e-02
9.11015049e-02 -2.01375950e-02 -7.29381144e-02 6.93765879e-02
2.71829776e-02 -6.64435029e-02 -8.45306814e-02 -1.03075653e-01
6.72040805e-02 -7.06537142e-02 -3.93818803e-02 5.16211614e-03
-4.79770005e-02 1.10734522e-01 1.56721435e-02 -6.93409378e-03
1.16915874e-01 -7.95962065e-02 -3.06530762e-02 8.42394680e-02
7.60370195e-02 2.17055440e-01 9.85361822e-03 1.16660878e-01
4.08297703e-02 1.24978097e-02 8.25245082e-02 2.28673983e-02
-7.88266212e-02 -8.04114193e-02 9.28791538e-02 -5.70827350e-03
-4.46166918e-02 -6.41122833e-02 1.80885363e-02 -2.37745279e-03
4.37298454e-02 1.28888980e-01 -3.07202265e-02 2.50503756e-02
4.00907174e-02 3.37077095e-03 -1.78839862e-02 8.90695080e-02
6.30150884e-02 1.11416787e-01 2.12221760e-02 -1.13236710e-01
5.39616570e-02 7.80710578e-02 -2.28817668e-02 1.92073174e-02
………………………….Trong ví dụ dưới đây, chúng ta sẽ sử dụng LSTM () áp dụng một bộ nhớ ngắn hạn (LSTM) RNN cho một chuỗi đầu vào nhất định.
layer = mx.gluon.rnn.LSTM(100, 3)
layer.initialize()
input_seq = mx.nd.random.uniform(shape=(5, 3, 10))
out_seq = layer(input_seq)
h0 = mx.nd.random.uniform(shape=(3, 3, 100))
c0 = mx.nd.random.uniform(shape=(3, 3, 100))
out_seq, hn = layer(input_seq,[h0,c0])
out_seqOutput
Đầu ra được đề cập bên dưới -
[[[ 9.00025964e-02 3.96071747e-02 1.83841765e-01 ... 3.95872220e-02
1.25569820e-01 2.15555862e-01]
[ 1.55962542e-01 -3.10300849e-02 1.76772922e-01 ... 1.92474753e-01
2.30574399e-01 2.81707942e-02]
[ 7.83204585e-02 6.53361529e-03 1.27262697e-01 ... 9.97719541e-02
1.28254429e-01 7.55299702e-02]]
[[ 4.41036932e-02 1.35250352e-02 9.87644792e-02 ... 5.89378644e-03
5.23949116e-02 1.00922674e-01]
[ 8.59075040e-02 -1.67027581e-02 9.69351009e-02 ... 1.17763653e-01
9.71239135e-02 2.25218050e-02]
[ 4.34580036e-02 7.62207608e-04 6.37005866e-02 ... 6.14888743e-02
5.96345589e-02 4.72368896e-02]]
……………Example
hnOutput
Khi bạn chạy mã, bạn sẽ thấy kết quả sau:
[
[[[ 2.21408084e-02 1.42750628e-02 9.53067932e-03 -1.22849066e-02
1.78788435e-02 5.99269159e-02 5.65306023e-02 6.42553642e-02
6.56616641e-03 9.80876666e-03 -1.15729487e-02 5.98640442e-02
-7.21173314e-03 -2.78371759e-02 -1.90690923e-02 2.21447181e-02
8.38765781e-03 -1.38521893e-02 -9.06938594e-03 1.21346042e-02
6.06449470e-02 -3.77471633e-02 5.65885007e-02 6.63008019e-02
-7.34188128e-03 6.46054149e-02 3.19911093e-02 4.11194898e-02
4.43960279e-02 4.92892228e-02 1.74766723e-02 3.40303481e-02
-5.23341820e-03 2.68163737e-02 -9.43402853e-03 -4.11836170e-02
1.55221792e-02 -5.05655073e-02 4.24557598e-03 -3.40388380e-02
……………………Mô-đun đào tạo
Các mô-đun đào tạo ở Gluon như sau:
gluon.loss
Trong mxnet.gluon.lossmô-đun, Gluon cung cấp chức năng mất mát được xác định trước. Về cơ bản, nó có những tổn thất cho việc đào tạo mạng nơ-ron. Đó là lý do nó được gọi là mô-đun đào tạo.
Các phương thức và tham số của chúng
Sau đây là một số phương pháp quan trọng và các tham số của chúng được mxnet.gluon.loss mô-đun đào tạo:
| Các phương thức và các tham số của nó | Định nghĩa |
|---|---|
| Giảm (trọng lượng, mẻ_axis, ** kwargs) | Điều này hoạt động như lớp cơ sở cho sự mất mát. |
| L2Loss ([trọng lượng, batch_axis]) | Nó tính toán sai số bình phương trung bình (MSE) giữa label và prediction(pred). |
| L1Loss ([trọng lượng, batch_axis]) | Nó tính toán sai số tuyệt đối trung bình (MAE) giữa label và pred. |
| SigmoidBinaryCrossEntropyLoss ([…]) | Phương pháp này được sử dụng cho tổn thất entropy chéo để phân loại nhị phân. |
| SigmoidBCELoss | Phương pháp này được sử dụng cho tổn thất entropy chéo để phân loại nhị phân. |
| SoftmaxCrossEntropyLoss ([trục,…]) | Nó tính toán tổn thất entropy chéo softmax (CEL). |
| SoftmaxCELoss | Nó cũng tính toán tổn thất entropy chéo softmax. |
| KLDivLoss ([from_logits, axis, weight,…]) | Nó được sử dụng cho tổn thất phân kỳ Kullback-Leibler. |
| CTCLoss ([layout, label_layout, weight]) | Nó được sử dụng cho Tổn thất phân loại theo thời gian kết nối (TCL). |
| HuberLoss ([rho, trọng lượng, batch_axis]) | Nó tính toán tổn thất L1 được làm mịn. Suy hao L1 được làm mịn sẽ bằng tổn hao L1 nếu sai số tuyệt đối vượt quá rho nhưng bằng với tổn thất L2 nếu ngược lại. |
| HingeLoss ([margin, weight, batch_axis]) | Phương pháp này tính toán hàm mất bản lề thường được sử dụng trong SVM: |
| SquaredHingeLoss ([margin, weight, batch_axis]) | Phương pháp này tính toán hàm tổn thất ký quỹ mềm được sử dụng trong SVM: |
| LogisticLoss ([trọng lượng, batch_axis, label_format]) | Phương pháp này tính toán tổn thất logistic. |
| TripletLoss ([margin, weight, batch_axis]) | Phương pháp này tính toán tổn thất ba lần với ba bộ căng đầu vào và một biên dương. |
| PoissonNLLLoss ([trọng lượng, from_logits,…]) | Hàm tính toán khả năng mất Nhật ký Phủ định. |
| CosineEmbeddingLoss ([weight, batch_axis, margin]) | Hàm tính khoảng cách cosin giữa các vectơ. |
| SDMLLoss ([Smoothhing_parameter, weight,…]) | Phương pháp này tính toán Suy hao theo số liệu sâu được làm mượt theo từng đợt (SDML) dựa trên hai bộ căng đầu vào và giảm SDM trọng lượng làm mịn. Nó tìm hiểu sự tương đồng giữa các mẫu được ghép đôi bằng cách sử dụng các mẫu chưa được ghép nối trong minibatch làm ví dụ tiêu cực tiềm năng. |
Thí dụ
Như chúng ta biết rằng mxnet.gluon.loss.losssẽ tính toán MSE (Mean Squared Error) giữa nhãn và dự đoán (trước). Nó được thực hiện với sự trợ giúp của công thức sau:

gluon.parameter
mxnet.gluon.parameter là một vùng chứa chứa các tham số tức là trọng lượng của các Khối.
Các phương thức và tham số của chúng
Sau đây là một số phương pháp quan trọng và các tham số của chúng được mxnet.gluon.parameter mô-đun đào tạo -
| Các phương thức và các tham số của nó | Định nghĩa |
|---|---|
| cast (dtype) | Phương thức này sẽ truyền dữ liệu và gradient của Tham số này sang một kiểu dữ liệu mới. |
| dữ liệu ([ctx]) | Phương thức này sẽ trả về một bản sao của tham số này trên một ngữ cảnh. |
| grad ([ctx]) | Phương thức này sẽ trả về một bộ đệm gradient cho tham số này trên một ngữ cảnh. |
| khởi tạo ([init, ctx, default_init,…]) | Phương thức này sẽ khởi tạo mảng tham số và độ dốc. |
| list_ctx () | Phương thức này sẽ trả về một danh sách các ngữ cảnh mà tham số này được khởi tạo. |
| list_data () | Phương thức này sẽ trả về các bản sao của tham số này trên tất cả các ngữ cảnh. Nó sẽ được thực hiện theo thứ tự như khi tạo. |
| list_grad () | Phương thức này sẽ trả về bộ đệm gradient trên tất cả các ngữ cảnh. Điều này sẽ được thực hiện theo thứ tự nhưvalues(). |
| list_row_sparse_data (row_id) | Phương thức này sẽ trả về các bản sao của tham số 'row_sparse' trên tất cả các ngữ cảnh. Điều này sẽ được thực hiện theo thứ tự giống như tạo. |
| reset_ctx (ctx) | Phương thức này sẽ gán lại Tham số cho các ngữ cảnh khác. |
| row_sparse_data (row_id) | Phương thức này sẽ trả về một bản sao của tham số 'row_sparse' trên cùng ngữ cảnh với row_id's. |
| set_data (dữ liệu) | Phương thức này sẽ đặt giá trị của tham số này trên tất cả các ngữ cảnh. |
| var () | Phương thức này sẽ trả về một ký hiệu đại diện cho tham số này. |
| zero_grad () | Phương pháp này sẽ đặt bộ đệm gradient trên tất cả các ngữ cảnh thành 0. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng ta sẽ khởi tạo các tham số và mảng gradient bằng cách sử dụng phương thức khởi tạo () như sau:
weight = mx.gluon.Parameter('weight', shape=(2, 2))
weight.initialize(ctx=mx.cpu(0))
weight.data()Output
Đầu ra được đề cập bên dưới -
[[-0.0256899 0.06511251]
[-0.00243821 -0.00123186]]
<NDArray 2x2 @cpu(0)>Example
weight.grad()Output
Đầu ra được đưa ra dưới đây -
[[0. 0.]
[0. 0.]]
<NDArray 2x2 @cpu(0)>Example
weight.initialize(ctx=[mx.gpu(0), mx.gpu(1)])
weight.data(mx.gpu(0))Output
Bạn sẽ thấy kết quả sau:
[[-0.00873779 -0.02834515]
[ 0.05484822 -0.06206018]]
<NDArray 2x2 @gpu(0)>Example
weight.data(mx.gpu(1))Output
Khi bạn thực thi đoạn mã trên, bạn sẽ thấy kết quả sau:
[[-0.00873779 -0.02834515]
[ 0.05484822 -0.06206018]]
<NDArray 2x2 @gpu(1)>gluon.trainer
mxnet.gluon.trainer áp dụng Trình tối ưu hóa trên một tập hợp các tham số. Nó nên được sử dụng cùng với autograd.
Các phương thức và tham số của chúng
Sau đây là một số phương pháp quan trọng và các tham số của chúng được mxnet.gluon.trainer mô-đun đào tạo -
| Các phương thức và các tham số của nó | Định nghĩa |
|---|---|
| allreduce_grads () | Phương pháp này sẽ giảm độ dốc từ các ngữ cảnh khác nhau cho từng tham số (trọng số). |
| load_states (fname) | Như tên của nó, phương pháp này sẽ tải trạng thái của trình huấn luyện. |
| save_states (fname) | Như tên của nó, phương pháp này sẽ lưu trạng thái của người huấn luyện. |
| set_learning_rate (lr) | Phương pháp này sẽ đặt tốc độ học tập mới của trình tối ưu hóa. |
| step (batch_size [, ignore_stale_grad]) | Phương thức này sẽ thực hiện một bước cập nhật tham số. Nó nên được gọi sauautograd.backward() và bên ngoài record() phạm vi. |
| cập nhật (batch_size [, ignore_stale_grad]) | Phương thức này cũng sẽ thực hiện một bước cập nhật tham số. Nó nên được gọi sauautograd.backward() và bên ngoài record() phạm vi và sau trình đào tạo.update (). |
Mô-đun dữ liệu
Các mô-đun dữ liệu của Gluon được giải thích bên dưới:
gluon.data
Gluon cung cấp một số lượng lớn các tiện ích tập dữ liệu tích hợp trong mô-đun gluon.data. Đó là lý do nó được gọi là mô-đun dữ liệu.
Các lớp và tham số của chúng
Sau đây là một số phương thức quan trọng và các thông số của chúng được mô-đun lõi mxnet.gluon.data bao phủ. Các phương pháp này thường liên quan đến Tập dữ liệu, Lấy mẫu và Trình tải dữ liệu.
Dataset| Các phương thức và các tham số của nó | Định nghĩa |
|---|---|
| ArrayDataset (* args) | Phương thức này đại diện cho một tập dữ liệu kết hợp hai hoặc nhiều hơn hai đối tượng giống như tập dữ liệu. Ví dụ: Tập dữ liệu, danh sách, mảng, v.v. |
| BatchSampler (lấy mẫu, batch_size [, last_batch]) | Phương pháp này bao trùm lên phương pháp khác Sampler. Sau khi bọc nó sẽ trả về các lô mẫu nhỏ. |
| DataLoader (tập dữ liệu [, batch_size, shuffle,…]) | Tương tự như BatchSampler nhưng phương pháp này tải dữ liệu từ một tập dữ liệu. Sau khi được tải, nó sẽ trả về các lô dữ liệu nhỏ. |
| Điều này đại diện cho lớp tập dữ liệu trừu tượng. | |
| FilterSampler (fn, tập dữ liệu) | Phương thức này đại diện cho các phần tử mẫu từ Tập dữ liệu mà fn (hàm) trả về True. |
| RandomSampler (chiều dài) | Phương pháp này đại diện cho các phần tử mẫu từ [0, chiều dài) một cách ngẫu nhiên mà không cần thay thế. |
| RecordFileDataset (tên tệp) | Nó đại diện cho một tập dữ liệu gói trên một tệp RecordIO. Phần mở rộng của tệp là.rec. |
| Người lấy mẫu | Đây là lớp cơ sở cho người lấy mẫu. |
| SequentialSampler (length [, start]) | Nó đại diện cho các phần tử mẫu từ tập hợp [bắt đầu, bắt đầu + chiều dài) một cách tuần tự. |
| Nó đại diện cho các phần tử mẫu từ tập hợp [bắt đầu, bắt đầu + chiều dài) một cách tuần tự. | Điều này đại diện cho trình bao bọc Tập dữ liệu đơn giản, đặc biệt cho danh sách và mảng. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng tôi sẽ sử dụng gluon.data.BatchSampler()API, bao bọc trên một trình lấy mẫu khác. Nó trả về các lô mẫu nhỏ.
import mxnet as mx
from mxnet.gluon import data
sampler = mx.gluon.data.SequentialSampler(15)
batch_sampler = mx.gluon.data.BatchSampler(sampler, 4, 'keep')
list(batch_sampler)Output
Đầu ra được đề cập bên dưới -
[[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14]]gluon.data.vision.datasets
Gluon cung cấp một số lượng lớn các chức năng tập dữ liệu thị lực được xác định trước trong gluon.data.vision.datasets mô-đun.
Các lớp và tham số của chúng
MXNet cung cấp cho chúng ta các tập dữ liệu hữu ích và quan trọng, có các lớp và tham số được đưa ra bên dưới:
| Các lớp và các thông số của nó | Định nghĩa |
|---|---|
| MNIST ([gốc, đào tạo, biến đổi]) | Đây là một tập dữ liệu hữu ích cung cấp cho chúng ta các chữ số viết tay. Url cho tập dữ liệu MNIST là http://yann.lecun.com/exdb/mnist |
| FashionMNIST ([gốc, đào tạo, biến đổi]) | Tập dữ liệu này bao gồm các hình ảnh bài viết của Zalando bao gồm các sản phẩm thời trang. Nó là bản thay thế tập dữ liệu MNIST ban đầu. Bạn có thể lấy bộ dữ liệu này từ https://github.com/zalandoresearch/fashion-mnist |
| CIFAR10 ([gốc, đào tạo, biến đổi]) | Đây là tập dữ liệu phân loại hình ảnh từ https://www.cs.toronto.edu/~kriz/cifar.html. Trong tập dữ liệu này, mỗi mẫu là một hình ảnh có hình dạng (32, 32, 3). |
| CIFAR100 ([root, fine_label, train, convert]) | Đây là tập dữ liệu phân loại hình ảnh CIFAR100 từ https://www.cs.toscape.edu/~kriz/cifar.html. Nó cũng có mỗi mẫu là một hình ảnh với hình dạng (32, 32, 3). |
| ImageRecordDataset (tên tệp [, cờ, biến đổi]) | Tập dữ liệu này bao bọc bên ngoài tệp RecordIO có chứa hình ảnh. Trong mỗi mẫu này là một hình ảnh có nhãn tương ứng. |
| ImageFolderDataset (root [, cờ, biến đổi]) | Đây là tập dữ liệu để tải các tệp hình ảnh được lưu trữ trong cấu trúc thư mục. |
| ImageListDataset ([root, imglist, flag]) | Đây là tập dữ liệu để tải các tệp hình ảnh được chỉ định bởi danh sách các mục nhập. |
Thí dụ
Trong ví dụ dưới đây, chúng tôi sẽ cho thấy việc sử dụng ImageListDataset (), được sử dụng để tải các tệp hình ảnh được chỉ định bởi danh sách các mục -
# written to text file *.lst
0 0 root/cat/0001.jpg
1 0 root/cat/xxxa.jpg
2 0 root/cat/yyyb.jpg
3 1 root/dog/123.jpg
4 1 root/dog/023.jpg
5 1 root/dog/wwww.jpg
# A pure list, each item is a list [imagelabel: float or list of float, imgpath]
[[0, root/cat/0001.jpg]
[0, root/cat/xxxa.jpg]
[0, root/cat/yyyb.jpg]
[1, root/dog/123.jpg]
[1, root/dog/023.jpg]
[1, root/dog/wwww.jpg]]Mô-đun tiện ích
Các mô-đun tiện ích trong Gluon như sau:
gluon.utils
Gluon cung cấp một số lượng lớn công cụ tối ưu hóa tiện ích song song tích hợp trong mô-đun gluon.utils. Nó cung cấp nhiều tiện ích cho việc đào tạo. Đó là lý do nó được gọi là mô-đun tiện ích.
Các chức năng và thông số của chúng
Sau đây là các chức năng và tham số của chúng bao gồm trong mô-đun tiện ích này có tên gluon.utils −
| Các chức năng và các thông số của nó | Định nghĩa |
|---|---|
| split_data (dữ liệu, num_slice [, batch_axis,…]) | Chức năng này thường được sử dụng cho dữ liệu song song và mỗi lát cắt được gửi đến một thiết bị tức là GPU. Nó chia một NDArray thànhnum_slice lát dọc batch_axis. |
| split_and_load (dữ liệu, ctx_list [, batch_axis,…]) | Hàm này chia một NDArray thành len(ctx_list) lát dọc batch_axis. Sự khác biệt duy nhất so với hàm split_data () ở trên là, nó cũng tải từng lát vào một ngữ cảnh trong ctx_list. |
| clip_global_norm (mảng, max_norm [,…]) | Công việc của chức năng này là bán lại các NDArrays theo cách sao cho tổng 2 chuẩn của chúng nhỏ hơn max_norm. |
| check_sha1 (tên tệp, sha1_hash) | Hàm này sẽ kiểm tra xem băm sha1 của nội dung tệp có khớp với băm mong đợi hay không. |
| tải xuống (url [, đường dẫn, ghi đè, sha1_hash,…]) | Như tên chỉ định, chức năng này sẽ tải xuống một URL nhất định. |
| Replace_file (src, dst) | Hàm này sẽ thực hiện nguyên tử os.replace. nó sẽ được thực hiện với Linux và OSX. |
Chương này đề cập đến autograd và API khởi tạo trong MXNet.
mxnet.autograd
Đây là API tự động của MXNet cho NDArray. Nó có lớp sau:
Lớp: Hàm ()
Nó được sử dụng để phân biệt tùy chỉnh trong autograd. Nó có thể được viết làmxnet.autograd.Function. Nếu vì bất kỳ lý do gì, người dùng không muốn sử dụng các gradient được tính toán theo quy tắc chuỗi mặc định, thì họ có thể sử dụng lớp Hàm của mxnet.autograd để tùy chỉnh sự khác biệt cho tính toán. Nó có hai phương thức là Forward () và Backward ().
Hãy để chúng tôi hiểu hoạt động của lớp này với sự trợ giúp của các điểm sau:
Đầu tiên, chúng ta cần xác định tính toán của chúng ta trong phương pháp chuyển tiếp.
Sau đó, chúng ta cần cung cấp sự khác biệt tùy chỉnh trong phương pháp lạc hậu.
Bây giờ trong quá trình tính toán gradient, thay vì hàm lùi do người dùng xác định, mxnet.autograd sẽ sử dụng hàm lùi do người dùng xác định. Chúng ta cũng có thể ép kiểu sang mảng numpy và lùi lại đối với một số thao tác tiến cũng như lùi.
Example
Trước khi sử dụng lớp mxnet.autograd. Chức năng, hãy xác định một hàm sigmoid ổn định với các phương thức lùi và chuyển tiếp như sau:
class sigmoid(mx.autograd.Function):
def forward(self, x):
y = 1 / (1 + mx.nd.exp(-x))
self.save_for_backward(y)
return y
def backward(self, dy):
y, = self.saved_tensors
return dy * y * (1-y)Bây giờ, lớp hàm có thể được sử dụng như sau:
func = sigmoid()
x = mx.nd.random.uniform(shape=(10,))
x.attach_grad()
with mx.autograd.record():
m = func(x)
m.backward()
dx_grad = x.grad.asnumpy()
dx_gradOutput
Khi bạn chạy mã, bạn sẽ thấy kết quả sau:
array([0.21458015, 0.21291625, 0.23330082, 0.2361367 , 0.23086983,
0.24060014, 0.20326573, 0.21093895, 0.24968489, 0.24301809],
dtype=float32)Các phương thức và tham số của chúng
Sau đây là các phương thức và tham số của chúng của lớp mxnet.autogard. Chức năng:
| Các phương thức và các tham số của nó | Định nghĩa |
|---|---|
| chuyển tiếp (đầu [, head_grads, giữ lại_graph,…]) | Phương pháp này được sử dụng để tính toán chuyển tiếp. |
| lùi (đầu [, head_grads, giữ lại_graph,…]) | Phương pháp này được sử dụng để tính toán ngược. Nó tính toán độ dốc của phần đầu đối với các biến được đánh dấu trước đó. Phương pháp này sử dụng nhiều đầu vào như đầu ra của kỳ hạn. Nó cũng trả về nhiều NDArray như đầu vào của phía trước. |
| get_symbol (x) | Phương pháp này được sử dụng để truy xuất lịch sử tính toán được ghi lại dưới dạng Symbol. |
| grad (đầu, biến [, head_grads,…]) | Phương pháp này tính toán gradient của phần đầu đối với các biến. Sau khi được tính toán, thay vì lưu trữ vào variable.grad, gradient sẽ được trả về dưới dạng NDArrays mới. |
| is_recording () | Với sự trợ giúp của phương pháp này, chúng tôi có thể nhận được trạng thái ghi và không ghi. |
| Đó là hành trình() | Với sự trợ giúp của phương pháp này, chúng tôi có thể nhận được trạng thái đào tạo và dự đoán. |
| mark_variables (biến, gradient [, grad_reqs]) | Phương thức này sẽ đánh dấu NDArrays là các biến để tính toán gradient cho autograd. Phương thức này giống như hàm .attach_grad () trong một biến nhưng sự khác biệt duy nhất là với lệnh gọi này, chúng ta có thể đặt gradient thành bất kỳ giá trị nào. |
| tạm dừng ([train_mode]) | Phương thức này trả về một ngữ cảnh phạm vi được sử dụng trong câu lệnh 'with' cho các mã không cần tính toán độ dốc. |
| Pred_mode () | Phương thức này trả về một ngữ cảnh phạm vi được sử dụng trong câu lệnh 'with' trong đó hành vi chuyển tiếp được đặt thành chế độ suy luận và điều đó không thay đổi trạng thái ghi. |
| bản ghi ([train_mode]) | Nó sẽ trả về một autograd ghi lại ngữ cảnh phạm vi sẽ được sử dụng trong câu lệnh 'with' và nắm bắt mã cần được tính toán độ dốc. |
| set_recording (is_recording) | Tương tự như is_recoring (), với sự trợ giúp của phương thức này, chúng ta có thể nhận được trạng thái ghi và không ghi. |
| set_training (is_training) | Tương tự như is_traininig (), với sự trợ giúp của phương thức này, chúng ta có thể đặt trạng thái thành huấn luyện hoặc dự đoán. |
| train_mode () | Phương thức này sẽ trả về một ngữ cảnh phạm vi được sử dụng trong câu lệnh 'with' trong đó hành vi chuyển tiếp được đặt thành chế độ huấn luyện và điều đó không thay đổi trạng thái ghi. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng tôi sẽ sử dụng phương thức mxnet.autograd.grad () để tính toán gradient của head liên quan đến các biến -
x = mx.nd.ones((2,))
x.attach_grad()
with mx.autograd.record():
z = mx.nd.elemwise_add(mx.nd.exp(x), x)
dx_grad = mx.autograd.grad(z, [x], create_graph=True)
dx_gradOutput
Đầu ra được đề cập bên dưới -
[
[3.7182817 3.7182817]
<NDArray 2 @cpu(0)>]Chúng ta có thể sử dụng phương thức mxnet.autograd.posystem_mode () để trả về một phạm vi được sử dụng trong câu lệnh 'with' -
with mx.autograd.record():
y = model(x)
with mx.autograd.predict_mode():
y = sampling(y)
backward([y])mxnet.intializer
Đây là API của MXNet cho bộ khởi tạo cân. Nó có các lớp sau:
Các lớp và tham số của chúng
Sau đây là các phương thức và tham số của chúng mxnet.autogard.function lớp học:
| Các lớp và các thông số của nó | Định nghĩa |
|---|---|
| Bilinear () | Với sự trợ giúp của lớp này, chúng ta có thể khởi tạo trọng lượng cho các lớp lấy mẫu lên. |
| Giá trị hiện có) | Lớp này khởi tạo các trọng số thành một giá trị nhất định. Giá trị có thể là một đại lượng vô hướng cũng như NDArray phù hợp với hình dạng của tham số được đặt. |
| FusedRNN (init, num_hiised, num_layers, mode) | Như tên của nó, lớp này khởi tạo các tham số cho các lớp Mạng thần kinh tái tạo (RNN) được hợp nhất. |
| InitDesc | Nó hoạt động như bộ mô tả cho mẫu khởi tạo. |
| Bộ khởi tạo (** kwargs) | Đây là lớp cơ sở của bộ khởi tạo. |
| LSTMBias ([quên_bias]) | Lớp này khởi tạo tất cả các thành kiến của một LSTMCell thành 0,0 nhưng ngoại trừ cổng quên có thiên vị được đặt thành giá trị tùy chỉnh. |
| Tải (param [, default_init, verbose]) | Lớp này khởi tạo các biến bằng cách tải dữ liệu từ tệp hoặc từ điển. |
| MSRAPrelu ([loại_số_lượng, độ dốc]) | Như tên của nó, lớp này Khởi tạo trọng lượng theo giấy MSRA. |
| Hỗn hợp (mẫu, bộ khởi tạo) | Nó khởi tạo các tham số bằng nhiều bộ khởi tạo. |
| Bình thường ([sigma]) | Lớp Normal () khởi tạo các trọng số với các giá trị ngẫu nhiên được lấy mẫu từ phân phối chuẩn với giá trị trung bình bằng 0 và độ lệch chuẩn (SD) là sigma. |
| Một() | Nó khởi tạo các trọng số của tham số thành một. |
| Trực giao ([scale, rand_type]) | Như tên của nó, lớp này khởi tạo trọng số dưới dạng ma trận trực giao. |
| Đồng phục ([quy mô]) | Nó khởi tạo các trọng số với các giá trị ngẫu nhiên được lấy mẫu đồng nhất từ một phạm vi nhất định. |
| Xavier ([rnd_type, factor_type, độ lớn]) | Nó thực sự trả về một trình khởi tạo thực hiện khởi tạo “Xavier” cho các trọng số. |
| Số không() | Nó khởi tạo các trọng số của tham số bằng không. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng ta sẽ sử dụng lớp mxnet.init.Normal () để tạo một trình khởi tạo và truy xuất các tham số của nó -
init = mx.init.Normal(0.8)
init.dumps()Output
Đầu ra được đưa ra dưới đây -
'["normal", {"sigma": 0.8}]'Example
init = mx.init.Xavier(factor_type="in", magnitude=2.45)
init.dumps()Output
Đầu ra được hiển thị bên dưới -
'["xavier", {"rnd_type": "uniform", "factor_type": "in", "magnitude": 2.45}]'Trong ví dụ dưới đây, chúng ta sẽ sử dụng lớp mxnet.initializer.Mixed () để khởi tạo các tham số bằng nhiều trình khởi tạo -
init = mx.initializer.Mixed(['bias', '.*'], [mx.init.Zero(),
mx.init.Uniform(0.1)])
module.init_params(init)
for dictionary in module.get_params():
for key in dictionary:
print(key)
print(dictionary[key].asnumpy())Output
Đầu ra được hiển thị bên dưới -
fullyconnected1_weight
[[ 0.0097627 0.01856892 0.04303787]]
fullyconnected1_bias
[ 0.]Trong chương này, chúng ta sẽ tìm hiểu về một giao diện trong MXNet được gọi là Symbol.
Mxnet.ndarray
API biểu tượng của Apache MXNet là một giao diện để lập trình tượng trưng. API biểu tượng có các tính năng sử dụng sau:
Đồ thị tính toán
Giảm sử dụng bộ nhớ
Tối ưu hóa chức năng trước khi sử dụng
Ví dụ dưới đây cho thấy cách người ta có thể tạo một biểu thức đơn giản bằng cách sử dụng API biểu tượng của MXNet -
Một NDArray bằng cách sử dụng 'mảng' 1-D và 2-D từ danh sách Python thông thường -
import mxnet as mx
# Two placeholders namely x and y will be created with mx.sym.variable
x = mx.sym.Variable('x')
y = mx.sym.Variable('y')
# The symbol here is constructed using the plus ‘+’ operator.
z = x + yOutput
Bạn sẽ thấy kết quả sau:
<Symbol _plus0>Example
(x, y, z)Output
Đầu ra được đưa ra dưới đây -
(<Symbol x>, <Symbol y>, <Symbol _plus0>)Bây giờ chúng ta hãy thảo luận chi tiết về các lớp, hàm và tham số của API ndarray của MXNet.
Các lớp học
Bảng sau bao gồm các lớp của API Symbol của MXNet:
| Lớp học | Định nghĩa |
|---|---|
| Biểu tượng (tay cầm) | Biểu tượng cụ thể của lớp này là biểu đồ tượng trưng của Apache MXNet. |
Các chức năng và thông số của chúng
Sau đây là một số hàm quan trọng và các tham số của chúng được bao phủ bởi mxnet. API biểu tượng -
| Chức năng và các tham số của nó | Định nghĩa |
|---|---|
| Kích hoạt ([data, act_type, out, name]) | Nó áp dụng một phần tử chức năng kích hoạt khôn ngoan cho đầu vào. Nó hỗ trợrelu, sigmoid, tanh, softrelu, softsign các chức năng kích hoạt. |
| BatchNorm ([data, gamma, beta, moving_mean,…]) | Nó được sử dụng để chuẩn hóa hàng loạt. Hàm này chuẩn hóa một lô dữ liệu theo giá trị trung bình và phương sai. Nó áp dụng một thang điểmgamma và bù đắp beta. |
| BilinearSampler ([dữ liệu, lưới, cudnn_off,…]) | Chức năng này áp dụng lấy mẫu song tuyến cho bản đồ tính năng đầu vào. Trên thực tế, nó là chìa khóa của “Mạng lưới biến áp không gian”. Nếu bạn đã quen với chức năng remap trong OpenCV thì cách sử dụng chức năng này cũng tương tự như vậy. Sự khác biệt duy nhất là nó có đường chuyền ngược. |
| BlockGrad ([data, out, name]) | Như tên chỉ định, hàm này dừng tính toán gradient. Về cơ bản, nó ngăn không cho gradient tích lũy của các đầu vào chảy qua toán tử này theo hướng ngược lại. |
| ép kiểu ([data, dtype, out, name]) | Hàm này sẽ chuyển tất cả các phần tử của đầu vào sang một kiểu mới. |
| Hàm này sẽ chuyển tất cả các phần tử của đầu vào sang một kiểu mới. | Hàm này, như tên đã chỉ định, trả về một biểu tượng mới có hình dạng và kiểu đã cho, chứa đầy các số không. |
| cái (shape [, dtype]) | Hàm này, như tên đã chỉ định, trả về một biểu tượng mới có hình dạng và kiểu đã cho, chứa đầy các ký hiệu. |
| đầy đủ (shape, val [, dtype]) | Hàm này, như tên đã chỉ định trả về một mảng mới có hình dạng và kiểu đã cho, chứa đầy giá trị đã cho val. |
| arange (bắt đầu [, dừng, bước, lặp lại,…]) | Nó sẽ trả về các giá trị cách đều nhau trong một khoảng thời gian nhất định. Các giá trị được tạo trong khoảng thời gian nửa mở [bắt đầu, dừng) có nghĩa là khoảng đó bao gồmstart nhưng loại trừ stop. |
| linspace (bắt đầu, dừng, num [, điểm cuối, tên,…]) | Nó sẽ trả về các số cách đều nhau trong một khoảng thời gian xác định. Tương tự như hàm sắp xếp (), các giá trị được tạo trong khoảng thời gian nửa mở [bắt đầu, dừng lại) có nghĩa là khoảng đó bao gồmstart nhưng loại trừ stop. |
| biểu đồ (a [, thùng, dải]) | Như tên của nó, hàm này sẽ tính toán biểu đồ của dữ liệu đầu vào. |
| sức mạnh (cơ sở, điểm kinh nghiệm) | Như tên của nó, hàm này sẽ trả về kết quả theo phần tử của base phần tử được nâng lên thành quyền lực từ expthành phần. Cả hai đầu vào tức là cơ sở và điểm kinh nghiệm, có thể là Biểu tượng hoặc vô hướng. Ở đây lưu ý rằng không được phép phát sóng. Bạn có thể dùngbroadcast_pow nếu bạn muốn sử dụng tính năng phát sóng. |
| SoftmaxActivation ([data, mode, name, attr, out]) | Chức năng này áp dụng kích hoạt softmax cho đầu vào. Nó dành cho các lớp bên trong. Nó thực sự không được dùng nữa, chúng ta có thể sử dụngsoftmax() thay thế. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng tôi sẽ sử dụng hàm power() sẽ trả về kết quả theo phần tử của phần tử cơ sở được nâng lên thành lũy thừa từ phần tử exp:
import mxnet as mx
mx.sym.power(3, 5)Output
Bạn sẽ thấy kết quả sau:
243Example
x = mx.sym.Variable('x')
y = mx.sym.Variable('y')
z = mx.sym.power(x, 3)
z.eval(x=mx.nd.array([1,2]))[0].asnumpy()Output
Điều này tạo ra kết quả sau:
array([1., 8.], dtype=float32)Example
z = mx.sym.power(4, y)
z.eval(y=mx.nd.array([2,3]))[0].asnumpy()Output
Khi bạn thực thi đoạn mã trên, bạn sẽ thấy kết quả sau:
array([16., 64.], dtype=float32)Example
z = mx.sym.power(x, y)
z.eval(x=mx.nd.array([4,5]), y=mx.nd.array([2,3]))[0].asnumpy()Output
Đầu ra được đề cập bên dưới -
array([ 16., 125.], dtype=float32)Trong ví dụ dưới đây, chúng ta sẽ sử dụng hàm SoftmaxActivation() (or softmax()) sẽ được áp dụng cho đầu vào và dành cho các lớp bên trong.
input_data = mx.nd.array([[2., 0.9, -0.5, 4., 8.], [4., -.7, 9., 2., 0.9]])
soft_max_act = mx.nd.softmax(input_data)
print (soft_max_act.asnumpy())Output
Bạn sẽ thấy kết quả sau:
[[2.4258138e-03 8.0748333e-04 1.9912292e-04 1.7924475e-02 9.7864312e-01]
[6.6843745e-03 6.0796250e-05 9.9204916e-01 9.0463174e-04 3.0112563e-04]]Symbol.contrib
API Contrib NDArray được định nghĩa trong gói Symbol.contrib. Nó thường cung cấp nhiều API thử nghiệm hữu ích cho các tính năng mới. API này hoạt động như một nơi dành cho cộng đồng, nơi họ có thể thử các tính năng mới. Người đóng góp tính năng cũng sẽ nhận được phản hồi.
Các chức năng và thông số của chúng
Sau đây là một số chức năng quan trọng và các tham số của chúng được bao hàm bởi mxnet.symbol.contrib API -
| Chức năng và các tham số của nó | Định nghĩa |
|---|---|
| rand_zipfian (true_classes, num_sampled,…) | Hàm này lấy mẫu ngẫu nhiên từ phân phối Zipfian gần đúng. Phân phối cơ sở của chức năng này là phân phối Zipfian. Hàm này lấy mẫu ngẫu nhiên các ứng cử viên num_sampled và các phần tử của mẫu_candidate được lấy từ phân phối cơ sở đã cho ở trên. |
| foreach (body, data, init_states) | Như tên của nó, hàm này chạy một vòng lặp với tính toán do người dùng xác định qua NDArrays trên thứ nguyên 0. Hàm này mô phỏng một vòng lặp for và phần thân có tính toán cho một lần lặp lại của vòng lặp for. |
| while_loop (cond, func, loop_vars [,…]) | Như tên của nó, hàm này chạy một vòng lặp while với điều kiện tính toán và vòng lặp do người dùng xác định. Hàm này mô phỏng một vòng lặp while thực hiện tính toán tùy chỉnh một cách thành thạo nếu điều kiện được thỏa mãn. |
| cond (pred, then_func, else_func) | Như tên của nó, hàm này chạy if-then-else bằng cách sử dụng tính toán và điều kiện do người dùng xác định. Hàm này mô phỏng một nhánh if-like chọn thực hiện một trong hai phép tính tùy chỉnh theo điều kiện đã chỉ định. |
| getnnz ([dữ liệu, trục, ra, tên]) | Hàm này cung cấp cho chúng ta số lượng giá trị được lưu trữ cho một tensor thưa thớt. Nó cũng bao gồm các số không rõ ràng. Nó chỉ hỗ trợ ma trận CSR trên CPU. |
| yêu cầu ([data, min_range, max_range,…]) | Hàm này yêu cầu dữ liệu đã cho được lượng tử hóa trong int32 và các ngưỡng tương ứng, thành int8 bằng cách sử dụng ngưỡng tối thiểu và tối đa được tính toán trong thời gian chạy hoặc từ hiệu chuẩn. |
| index_copy ([old_tensor, index_vector,…]) | Hàm này sao chép các phần tử của một new_tensor into the old_tensor by selecting the indices in the order given in index. The output of this operator will be a new tensor that contains the rest elements of old tensor and the copied elements of new tensor. |
| interleaved_matmul_encdec_qk ([truy vấn,…]) | Toán tử này tính toán phép nhân ma trận giữa các phép chiếu của truy vấn và khóa trong việc sử dụng sự chú ý nhiều đầu làm bộ mã hóa-giải mã. Điều kiện là các đầu vào phải là hàng chục phép chiếu của các truy vấn tuân theo bố cục: (seq_length, batch_size, num_heads *, head_dim). |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng tôi sẽ sử dụng hàm rand_zipfian để vẽ các mẫu ngẫu nhiên từ một phân phối Zipfian gần đúng -
import mxnet as mx
true_cls = mx.sym.Variable('true_cls')
samples, exp_count_true, exp_count_sample = mx.sym.contrib.rand_zipfian(true_cls, 5, 6)
samples.eval(true_cls=mx.nd.array([3]))[0].asnumpy()Output
Bạn sẽ thấy kết quả sau:
array([4, 0, 2, 1, 5], dtype=int64)Example
exp_count_true.eval(true_cls=mx.nd.array([3]))[0].asnumpy()Output
Đầu ra được đề cập bên dưới -
array([0.57336551])Example
exp_count_sample.eval(true_cls=mx.nd.array([3]))[0].asnumpy()Output
Bạn sẽ thấy kết quả sau:
array([1.78103594, 0.46847373, 1.04183923, 0.57336551, 1.04183923])Trong ví dụ dưới đây, chúng tôi sẽ sử dụng hàm while_loop để chạy vòng lặp while cho tính toán do người dùng xác định và điều kiện vòng lặp -
cond = lambda i, s: i <= 7
func = lambda i, s: ([i + s], [i + 1, s + i])
loop_vars = (mx.sym.var('i'), mx.sym.var('s'))
outputs, states = mx.sym.contrib.while_loop(cond, func, loop_vars, max_iterations=10)
print(outputs)Output
Đầu ra được đưa ra dưới đây:
[<Symbol _while_loop0>]Example
Print(States)Output
Điều này tạo ra kết quả sau:
[<Symbol _while_loop0>, <Symbol _while_loop0>]Trong ví dụ dưới đây, chúng tôi sẽ sử dụng hàm index_copy sao chép các phần tử của new_tensor vào old_tensor.
import mxnet as mx
a = mx.nd.zeros((6,3))
b = mx.nd.array([[1,2,3],[4,5,6],[7,8,9]])
index = mx.nd.array([0,4,2])
mx.nd.contrib.index_copy(a, index, b)Output
Khi bạn thực thi đoạn mã trên, bạn sẽ thấy kết quả sau:
[[1. 2. 3.]
[0. 0. 0.]
[7. 8. 9.]
[0. 0. 0.]
[4. 5. 6.]
[0. 0. 0.]]
<NDArray 6x3 @cpu(0)>biểu tượng.image
API biểu tượng hình ảnh được định nghĩa trong gói biểu tượng.image. Như tên của nó, nó thường được sử dụng cho hình ảnh và các tính năng của chúng.
Các chức năng và thông số của chúng
Sau đây là một số chức năng quan trọng và các tham số của chúng được bao hàm bởi mxnet.symbol.image API -
| Chức năng và các tham số của nó | Định nghĩa |
|---|---|
| Adjust_lighting ([dữ liệu, alpha, out, name]) | Như tên của nó, chức năng này điều chỉnh mức độ chiếu sáng của đầu vào. Nó tuân theo phong cách AlexNet. |
| crop ([dữ liệu, x, y, width, height, out, name]) | Với sự trợ giúp của chức năng này, chúng ta có thể cắt ảnh NDArray có hình dạng (H x W x C) hoặc (N x H x W x C) theo kích thước do người dùng đưa ra. |
| chuẩn hóa ([data, mean, std, out, name]) | Nó sẽ chuẩn hóa một tensor hình dạng (C x H x W) hoặc (N x C x H x W) với mean và standard deviation(SD). |
| random_crop ([dữ liệu, xrange, yrange, width,…]) | Tương tự như crop (), nó cắt ngẫu nhiên một NDArray hình ảnh có hình dạng (H x W x C) hoặc (N x H x W x C) theo kích thước do người dùng đưa ra. Nó sẽ làm mẫu kết quả nếusrc nhỏ hơn size. |
| random_lighting([dữ liệu, alpha_std, out, name]) | Như tên của nó, chức năng này thêm nhiễu PCA một cách ngẫu nhiên. Nó cũng tuân theo phong cách AlexNet. |
| random_resized_crop ([dữ liệu, xrange, yrange,…]) | Nó cũng cắt ảnh một cách ngẫu nhiên NDArray có hình dạng (H x W x C) hoặc (N x H x W x C) theo kích thước đã cho. Nó sẽ lấy mẫu kết quả nếu src nhỏ hơn kích thước. Nó cũng sẽ ngẫu nhiên hóa khu vực và khẩu phần. |
| thay đổi kích thước ([data, size, keep_ratio, interp,…]) | Như tên của nó, chức năng này sẽ thay đổi kích thước một NDArray hình ảnh có hình dạng (H x W x C) hoặc (N x H x W x C) thành kích thước do người dùng cung cấp. |
| to_tensor ([data, out, name]) | Nó chuyển đổi một NDArray hình ảnh có hình dạng (H x W x C) hoặc (N x H x W x C) với các giá trị trong phạm vi [0, 255] thành một tensor NDArray có hình dạng (C x H x W) hoặc ( N x C x H x W) với các giá trị trong khoảng [0, 1]. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng tôi sẽ sử dụng hàm to_tensor để chuyển đổi NDArray hình ảnh có dạng (H x W x C) hoặc (N x H x W x C) với các giá trị trong phạm vi [0, 255] thành tensor NDArray của shape (C x H x W) hoặc (N x C x H x W) với các giá trị trong khoảng [0, 1].
import numpy as np
img = mx.sym.random.uniform(0, 255, (4, 2, 3)).astype(dtype=np.uint8)
mx.sym.image.to_tensor(img)Output
Đầu ra được nêu dưới đây -
<Symbol to_tensor4>Example
img = mx.sym.random.uniform(0, 255, (2, 4, 2, 3)).astype(dtype=np.uint8)
mx.sym.image.to_tensor(img)Output
Đầu ra được đề cập dưới đây:
<Symbol to_tensor5>Trong ví dụ dưới đây, chúng ta sẽ sử dụng hàm normalize () để chuẩn hóa một tensor của hình dạng (C x H x W) hoặc (N x C x H x W) với mean và standard deviation(SD).
img = mx.sym.random.uniform(0, 1, (3, 4, 2))
mx.sym.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
Dưới đây là đầu ra của mã:
<Symbol normalize0>Example
img = mx.sym.random.uniform(0, 1, (2, 3, 4, 2))
mx.sym.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
Đầu ra được hiển thị bên dưới -
<Symbol normalize1>Symbol.random
API ký hiệu ngẫu nhiên được định nghĩa trong gói Symbol.random. Như tên của nó, nó là API Symbol của trình tạo phân phối ngẫu nhiên của MXNet.
Các chức năng và thông số của chúng
Sau đây là một số chức năng quan trọng và các tham số của chúng được bao hàm bởi mxnet.symbol.random API -
| Chức năng và các tham số của nó | Định nghĩa |
|---|---|
| đồng nhất ([thấp, cao, hình dạng, loại, ctx, ngoài]) | Nó tạo ra các mẫu ngẫu nhiên từ một phân phối đồng đều. |
| bình thường ([loc, scale, shape, dtype, ctx, out]) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối chuẩn (Gaussian). |
| randn (* hình dạng, ** kwargs) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối chuẩn (Gaussian). |
| poisson ([lam, shape, dtype, ctx, out]) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối Poisson. |
| hàm mũ ([scale, shape, dtype, ctx, out]) | Nó tạo ra các mẫu từ phân phối hàm mũ. |
| gamma ([alpha, beta, shape, dtype, ctx, out]) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối gamma. |
| đa thức (data [, shape, get_prob, out, dtype]) | Nó tạo ra lấy mẫu đồng thời từ nhiều phân phối đa thức. |
| negative_binomial ([k, p, shape, dtype, ctx, out]) | Nó tạo ra các mẫu ngẫu nhiên từ một phân phối nhị thức âm. |
| general_negative_binomial ([mu, alpha,…]) | Nó tạo ra các mẫu ngẫu nhiên từ một phân phối nhị thức âm tổng quát. |
| xáo trộn (dữ liệu, ** kwargs) | Nó xáo trộn các phần tử một cách ngẫu nhiên. |
| randint (thấp, cao [, shape, dtype, ctx, out]) | Nó tạo ra các mẫu ngẫu nhiên từ một phân bố đồng đều rời rạc. |
| exponential_like ([data, lam, out, name]) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối hàm mũ theo hình dạng mảng đầu vào. |
| gamma_like ([dữ liệu, alpha, beta, out, name]) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối gamma theo hình dạng mảng đầu vào. |
| general_negative_binomial_like ([dữ liệu,…]) | Nó tạo ra các mẫu ngẫu nhiên từ một phân phối nhị thức âm tổng quát theo hình dạng mảng đầu vào. |
| negative_binomial_like ([data, k, p, out, name]) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối nhị thức âm theo hình dạng mảng đầu vào. |
| normal_like ([data, loc, scale, out, name]) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối chuẩn (Gaussian) theo hình dạng mảng đầu vào. |
| poisson_like ([data, lam, out, name]) | Nó tạo ra các mẫu ngẫu nhiên từ phân phối Poisson theo hình dạng mảng đầu vào. |
| Uniform_like ([dữ liệu, thấp, cao, ngoài, tên]) | Nó tạo ra các mẫu ngẫu nhiên từ một phân bố đồng đều theo hình dạng mảng đầu vào. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng ta sẽ xáo trộn các phần tử một cách ngẫu nhiên bằng cách sử dụng hàm shuffle (). Nó sẽ xáo trộn mảng dọc theo trục đầu tiên.
data = mx.nd.array([[0, 1, 2], [3, 4, 5], [6, 7, 8],[9,10,11]])
x = mx.sym.Variable('x')
y = mx.sym.random.shuffle(x)
y.eval(x=data)Output
Bạn sẽ thấy kết quả sau:
[
[[ 9. 10. 11.]
[ 0. 1. 2.]
[ 6. 7. 8.]
[ 3. 4. 5.]]
<NDArray 4x3 @cpu(0)>]Example
y.eval(x=data)Output
Khi bạn thực thi đoạn mã trên, bạn sẽ thấy kết quả sau:
[
[[ 6. 7. 8.]
[ 0. 1. 2.]
[ 3. 4. 5.]
[ 9. 10. 11.]]
<NDArray 4x3 @cpu(0)>]Trong ví dụ dưới đây, chúng ta sẽ vẽ các mẫu ngẫu nhiên từ một phân phối nhị thức âm tổng quát. Đối với điều này sẽ được sử dụng chức nănggeneralized_negative_binomial().
mx.sym.random.generalized_negative_binomial(10, 0.1)Output
Đầu ra được đưa ra dưới đây -
<Symbol _random_generalized_negative_binomial0>Symbol.sparse
API biểu tượng thưa thớt được định nghĩa trong gói mxnet.symbol.sparse. Như tên của nó, nó cung cấp đồ thị mạng nơ-ron thưa thớt và tự động phân biệt trên CPU.
Các chức năng và thông số của chúng
Sau đây là một số chức năng quan trọng (bao gồm quy trình tạo biểu tượng, quy trình thao tác ký hiệu, hàm toán học, hàm lượng giác, hàm Hyberbolic, hàm rút gọn, làm tròn, quyền hạn, mạng nơ ron) và các tham số của chúng được bao gồm bởi mxnet.symbol.sparse API -
| Chức năng và các tham số của nó | Định nghĩa |
|---|---|
| ElementWiseSum (* args, ** kwargs) | Hàm này sẽ thêm tất cả các phần tử đối số đầu vào một cách khôn ngoan. Ví dụ: _ (1,2,… = 1 + 2 + ⋯ +). Ở đây, chúng ta có thể thấy rằng add_n có khả năng hiệu quả hơn việc gọi add gấp n lần. |
| Nhúng ([data, weight, input_dim,…]) | Nó sẽ ánh xạ các chỉ số nguyên thành các biểu diễn vectơ tức là các phép nhúng. Nó thực sự ánh xạ các từ sang các vectơ có giá trị thực trong không gian chiều cao được gọi là nhúng từ. |
| LinearRegressionOutput ([dữ liệu, nhãn,…]) | Nó tính toán và tối ưu hóa cho tổn thất bình phương trong quá trình truyền ngược đưa ra dữ liệu đầu ra trong quá trình truyền chuyển tiếp. |
| LogisticRegressionOutput ([dữ liệu, nhãn,…]) | Áp dụng một hàm logistic còn được gọi là hàm sigmoid cho đầu vào. Hàm được tính là 1/1 + exp (−x). |
| MAERegressionOutput ([dữ liệu, nhãn,…]) | Toán tử này tính toán sai số tuyệt đối trung bình của đầu vào. MAE thực chất là một thước đo rủi ro tương ứng với giá trị kỳ vọng của sai số tuyệt đối. |
| abs ([data, name, attr, out]) | Như tên của nó, hàm này sẽ trả về giá trị tuyệt đối theo phần tử của đầu vào. |
| adagrad_update ([trọng lượng, điểm, lịch sử, lr,…]) | Nó là một chức năng cập nhật cho AdaGrad optimizer. |
| adam_update ([trọng lượng, thang điểm, trung bình, var, lr,…]) | Nó là một chức năng cập nhật cho Adam optimizer. |
| add_n (* args, ** kwargs) | Như tên của nó, nó sẽ thêm tất cả các đối số đầu vào theo phần tử. |
| arccos ([data, name, attr, out]) | Hàm này sẽ trả về cosin nghịch đảo của phần tử của mảng đầu vào. |
| dấu chấm ([lhs, rhs, transpose_a, transpose_b,…]) | Như tên của nó, nó sẽ cung cấp cho sản phẩm dấu chấm của hai mảng. Nó sẽ phụ thuộc vào kích thước mảng đầu vào: 1-D: tích bên trong của vectơ 2-D: phép nhân ma trận ND: Tích tổng trên trục cuối cùng của đầu vào đầu tiên và trục đầu tiên của đầu vào thứ hai. |
| elemwise_add ([lhs, rhs, name, attr, out]) | Như tên của nó, nó sẽ add yếu tố lập luận khôn ngoan. |
| elemwise_div ([lhs, rhs, name, attr, out]) | Như tên của nó, nó sẽ divide yếu tố lập luận khôn ngoan. |
| elemwise_mul ([lhs, rhs, name, attr, out]) | Như tên của nó, nó sẽ Multiply yếu tố lập luận khôn ngoan. |
| elemwise_sub ([lhs, rhs, name, attr, out]) | Như tên của nó, nó sẽ khôn ngoan hơn khi trừ phần tử đối số. |
| exp ([data, name, attr, out]) | Hàm này sẽ trả về giá trị hàm mũ khôn ngoan của phần tử của đầu vào đã cho. |
| sgd_update ([trọng lượng, grad, lr, wd,…]) | Nó hoạt động như một chức năng cập nhật cho trình tối ưu hóa Stochastic Gradient Descent. |
| sigmoid ([data, name, attr, out]) | Như tên của nó, nó sẽ tính toán sigmoid của x phần tử khôn ngoan. |
| dấu ([data, name, attr, out]) | Nó sẽ trả về dấu hiệu khôn ngoan của phần tử của đầu vào đã cho. |
| sin ([data, name, attr, out]) | Như tên của nó, hàm này sẽ tính toán sin của phần tử của mảng đầu vào đã cho. |
Ví dụ triển khai
Trong ví dụ dưới đây, chúng tôi sẽ trộn ngẫu nhiên các phần tử bằng cách sử dụng ElementWiseSum()chức năng. Nó sẽ ánh xạ các chỉ số số nguyên thành các biểu diễn vectơ tức là nhúng từ.
input_dim = 4
output_dim = 5Example
/* Here every row in weight matrix y represents a word. So, y = (w0,w1,w2,w3)
y = [[ 0., 1., 2., 3., 4.],
[ 5., 6., 7., 8., 9.],
[ 10., 11., 12., 13., 14.],
[ 15., 16., 17., 18., 19.]]
/* Here input array x represents n-grams(2-gram). So, x = [(w1,w3), (w0,w2)]
x = [[ 1., 3.],
[ 0., 2.]]
/* Now, Mapped input x to its vector representation y.
Embedding(x, y, 4, 5) = [[[ 5., 6., 7., 8., 9.],
[ 15., 16., 17., 18., 19.]],
[[ 0., 1., 2., 3., 4.],
[ 10., 11., 12., 13., 14.]]]API mô-đun của Apache MXNet giống như một mô hình FeedForward và nó dễ dàng hơn để soạn thảo tương tự như mô-đun Torch. Nó bao gồm các lớp sau:
BaseModule ([logger])
Nó đại diện cho lớp cơ sở của một mô-đun. Một mô-đun có thể được coi là thành phần tính toán hoặc máy tính toán. Công việc của một mô-đun là thực hiện chuyển tiếp và chuyển tiếp. Nó cũng cập nhật các thông số trong một mô hình.
Phương pháp
Bảng sau cho thấy các phương pháp bao gồm BaseModule class-
Phương thức này sẽ nhận trạng thái từ tất cả các thiết bị| Phương pháp | Định nghĩa |
|---|---|
| lùi lại ([out_grads]) | Như tên của nó, phương thức này thực hiện backward tính toán. |
| ràng buộc (data_shapes [, label_shapes,…]) | Nó liên kết các ký hiệu để xây dựng các trình thực thi và nó là cần thiết trước khi người ta có thể thực hiện tính toán với mô-đun. |
| phù hợp (train_data [, eval_data, eval_metric,…]) | Phương thức này huấn luyện các tham số mô-đun. |
| chuyển tiếp (data_batch [, is_train]) | Như tên của nó, phương pháp này thực hiện tính toán Chuyển tiếp. Phương pháp này hỗ trợ các lô dữ liệu với nhiều hình dạng khác nhau như kích thước lô khác nhau hoặc kích thước hình ảnh khác nhau. |
| forward_backward (data_batch) | Nó là một chức năng thuận tiện, như tên của nó, gọi cả tiến và lùi. |
| get_input_grads ([merge_multi_context]) | Phương pháp này sẽ lấy các gradient cho các đầu vào được tính toán trong phép tính ngược trước đó. |
| get_outputs ([merge_multi_context]) | Như tên của nó, phương thức này sẽ nhận kết quả đầu ra của phép tính chuyển tiếp trước đó. |
| get_params () | Nó nhận các tham số, đặc biệt là những tham số có khả năng là bản sao của các tham số thực được sử dụng để tính toán trên thiết bị. |
| get_states ([merge_multi_context]) | |
| init_optimizer ([kvstore, trình tối ưu hóa,…]) | Phương pháp này cài đặt và khởi tạo trình tối ưu hóa. Nó cũng khởi tạokvstore để phân phối đào tạo. |
| init_params ([khởi tạo, arg_params,…]) | Như tên của nó, phương thức này sẽ khởi tạo các tham số và trạng thái bổ trợ. |
| install_monitor (mon) | Phương pháp này sẽ cài đặt màn hình trên tất cả các trình thực thi. |
| iter_p Dự đoán (eval_data [, num_batch, đặt lại,…]) | Phương thức này sẽ lặp lại các dự đoán. |
| load_params (fname) | Như tên chỉ định, nó sẽ tải các thông số mô hình từ tệp. |
| dự đoán (eval_data [, num_batch,…]) | Nó sẽ chạy dự đoán và thu thập kết quả đầu ra. |
| chuẩn bị (data_batch [, precision_row_id_fn]) | Người vận hành chuẩn bị mô-đun để xử lý một lô dữ liệu nhất định. |
| save_params (fname) | Như tên đã chỉ định, hàm này sẽ lưu các tham số của mô hình vào tệp. |
| điểm (eval_data, eval_metric [, num_batch,…]) | Nó chạy dự đoán trên eval_data và cũng đánh giá hiệu suất theo eval_metric. |
| set_params (arg_params, aux_params [,…]) | Phương thức này sẽ gán các giá trị tham số và trạng thái aux. |
| set_states ([trạng thái, giá trị]) | Phương thức này, như tên của nó, đặt giá trị cho các trạng thái. |
| cập nhật () | Phương pháp này cập nhật các tham số đã cho theo trình tối ưu hóa đã cài đặt. Nó cũng cập nhật các độ dốc được tính trong lô chuyển tiếp trước đó. |
| update_metric (eval_metric, label [, pre_sliced]) | Phương pháp này, như tên của nó, đánh giá và tích lũy số liệu đánh giá trên các đầu ra của phép tính chuyển tiếp cuối cùng. |
| lùi lại ([out_grads]) | Như tên của nó, phương thức này thực hiện backward tính toán. |
| ràng buộc (data_shapes [, label_shapes,…]) | Nó thiết lập các nhóm và liên kết trình thực thi cho khóa nhóm mặc định. Phương thức này thể hiện sự ràng buộc đối với mộtBucketingModule. |
| chuyển tiếp (data_batch [, is_train]) | Như tên của nó, phương pháp này thực hiện tính toán Chuyển tiếp. Phương pháp này hỗ trợ các lô dữ liệu với nhiều hình dạng khác nhau như kích thước lô khác nhau hoặc kích thước hình ảnh khác nhau. |
| get_input_grads ([merge_multi_context]) | Phương pháp này sẽ lấy các gradient cho các đầu vào được tính toán trong phép tính ngược trước đó. |
| get_outputs ([merge_multi_context]) | Như tên của nó, phương thức này sẽ nhận được kết quả từ tính toán chuyển tiếp trước đó. |
| get_params () | Nó nhận các thông số hiện tại, đặc biệt là những thông số có khả năng là bản sao của các thông số thực được sử dụng để tính toán trên thiết bị. |
| get_states ([merge_multi_context]) | Phương thức này sẽ nhận trạng thái từ tất cả các thiết bị. |
| init_optimizer ([kvstore, trình tối ưu hóa,…]) | Phương pháp này cài đặt và khởi tạo trình tối ưu hóa. Nó cũng khởi tạokvstore để phân phối đào tạo. |
| init_params ([khởi tạo, arg_params,…]) | Như tên của nó, phương thức này sẽ khởi tạo các tham số và trạng thái bổ trợ. |
| install_monitor (mon) | Phương pháp này sẽ cài đặt màn hình trên tất cả các trình thực thi. |
| tải (tiền tố, epoch [, sym_gen,…]) | Phương pháp này sẽ tạo một mô hình từ trạm kiểm soát đã lưu trước đó. |
| load_dict ([sym_dict, sym_gen,…]) | Phương pháp này sẽ tạo một mô hình từ ánh xạ từ điển (dict) bucket_keyđến các ký hiệu. Nó cũng chia sẻarg_params và aux_params. |
| chuẩn bị (data_batch [, precision_row_id_fn]) | Người vận hành chuẩn bị mô-đun để xử lý một lô dữ liệu nhất định. |
| save_checkpoint (tiền tố, epoch [, remove_amp_cast]) | Phương pháp này, như tên của nó, lưu tiến trình hiện tại đến điểm kiểm tra cho tất cả các nhóm trong BucketingModule. Bạn nên sử dụng mx.callback.module_checkpoint dưới dạng epoch_end_callback để lưu trong quá trình đào tạo. |
| set_params (arg_params, aux_params [,…]) | Như tên chỉ định, hàm này sẽ gán các tham số và giá trị trạng thái aux. |
| set_states ([trạng thái, giá trị]) | Phương thức này, như tên của nó, đặt giá trị cho các trạng thái. |
| switch_bucket (bucket_key, data_shapes [,…]) | Nó sẽ chuyển sang một nhóm khác. |
| cập nhật () | Phương pháp này cập nhật các tham số đã cho theo trình tối ưu hóa đã cài đặt. Nó cũng cập nhật các độ dốc được tính trong lô chuyển tiếp trước đó. |
| update_metric (eval_metric, label [, pre_sliced]) | Phương pháp này, như tên của nó, đánh giá và tích lũy số liệu đánh giá trên các đầu ra của phép tính chuyển tiếp cuối cùng. |
Thuộc tính
Bảng sau cho thấy các thuộc tính bao gồm trong các phương thức của BaseModule lớp học -
| Thuộc tính | Định nghĩa |
|---|---|
| data_names | Nó bao gồm danh sách các tên cho dữ liệu theo yêu cầu của mô-đun này. |
| data_shapes | Nó bao gồm danh sách các cặp (tên, hình dạng) chỉ định các đầu vào dữ liệu cho mô-đun này. |
| label_shapes | Nó hiển thị danh sách các cặp (tên, hình dạng) chỉ định các đầu vào nhãn cho mô-đun này. |
| output_names | Nó bao gồm danh sách tên cho các đầu ra của mô-đun này. |
| output_shapes | Nó bao gồm danh sách các cặp (tên, hình dạng) xác định đầu ra của mô-đun này. |
| Biểu tượng | Như tên đã chỉ định, thuộc tính này có ký hiệu được liên kết với mô-đun này. |
data_shapes: Bạn có thể tham khảo liên kết có sẵn tại https://mxnet.apache.orgđể biết chi tiết. output_shapes: Thêm
output_shapes: Có thêm thông tin tại https://mxnet.apache.org/api/python
BucketingModule (sym_gen […])
Nó đại diện cho Bucketingmodule lớp của một Mô-đun giúp xử lý hiệu quả với các đầu vào có độ dài khác nhau.
Phương pháp
Bảng sau cho thấy các phương pháp bao gồm BucketingModule class -
Thuộc tính
Bảng sau cho thấy các thuộc tính bao gồm trong các phương thức của BaseModule class -
| Thuộc tính | Định nghĩa |
|---|---|
| data_names | Nó bao gồm danh sách các tên cho dữ liệu theo yêu cầu của mô-đun này. |
| data_shapes | Nó bao gồm danh sách các cặp (tên, hình dạng) chỉ định các đầu vào dữ liệu cho mô-đun này. |
| label_shapes | Nó hiển thị danh sách các cặp (tên, hình dạng) chỉ định các đầu vào nhãn cho mô-đun này. |
| output_names | Nó bao gồm danh sách tên cho các đầu ra của mô-đun này. |
| output_shapes | Nó bao gồm danh sách các cặp (tên, hình dạng) xác định đầu ra của mô-đun này. |
| Biểu tượng | Như tên đã chỉ định, thuộc tính này có ký hiệu được liên kết với mô-đun này. |
data_shapes - Bạn có thể tham khảo liên kết tại https://mxnet.apache.org/api/python/docs để biết thêm thông tin.
output_shapes− Bạn có thể tham khảo liên kết tại https://mxnet.apache.org/api/python/docs để biết thêm thông tin.
Mô-đun (ký hiệu [, data_names, label_names,…])
Nó đại diện cho một mô-đun cơ bản bao bọc một symbol.
Phương pháp
Bảng sau cho thấy các phương pháp bao gồm Module class -
| Phương pháp | Định nghĩa |
|---|---|
| lùi lại ([out_grads]) | Như tên của nó, phương thức này thực hiện backward tính toán. |
| ràng buộc (data_shapes [, label_shapes,…]) | Nó liên kết các ký hiệu để xây dựng các trình thực thi và nó là cần thiết trước khi người ta có thể thực hiện tính toán với mô-đun. |
| loan_optimizer (shared_module) | Như tên của nó, phương pháp này sẽ mượn trình tối ưu hóa từ một mô-đun được chia sẻ. |
| chuyển tiếp (data_batch [, is_train]) | Như tên của nó, phương thức này thực hiện Forwardtính toán. Phương pháp này hỗ trợ các lô dữ liệu với nhiều hình dạng khác nhau như kích thước lô khác nhau hoặc kích thước hình ảnh khác nhau. |
| get_input_grads ([merge_multi_context]) | Phương pháp này sẽ lấy các gradient cho các đầu vào được tính toán trong phép tính ngược trước đó. |
| get_outputs ([merge_multi_context]) | Như tên của nó, phương thức này sẽ nhận kết quả đầu ra của phép tính chuyển tiếp trước đó. |
| get_params () | Nó nhận các tham số, đặc biệt là những tham số có khả năng là bản sao của các tham số thực được sử dụng để tính toán trên thiết bị. |
| get_states ([merge_multi_context]) | Phương thức này sẽ nhận trạng thái từ tất cả các thiết bị |
| init_optimizer ([kvstore, trình tối ưu hóa,…]) | Phương pháp này cài đặt và khởi tạo trình tối ưu hóa. Nó cũng khởi tạokvstore để phân phối đào tạo. |
| init_params ([khởi tạo, arg_params,…]) | Như tên của nó, phương thức này sẽ khởi tạo các tham số và trạng thái bổ trợ. |
| install_monitor (mon) | Phương pháp này sẽ cài đặt màn hình trên tất cả các trình thực thi. |
| tải (tiền tố, epoch [, sym_gen,…]) | Phương pháp này sẽ tạo một mô hình từ trạm kiểm soát đã lưu trước đó. |
| load_optimizer_states (fname) | Phương thức này sẽ tải một trình tối ưu hóa tức là trạng thái của trình cập nhật từ một tệp. |
| chuẩn bị (data_batch [, precision_row_id_fn]) | Người vận hành chuẩn bị mô-đun để xử lý một lô dữ liệu nhất định. |
| định hình lại (data_shapes [, label_shapes]) | Phương thức này, như tên của nó, định hình lại mô-đun cho các hình dạng đầu vào mới. |
| save_checkpoint (tiền tố, kỷ nguyên [,…]) | Nó lưu tiến trình hiện tại vào trạm kiểm soát. |
| save_optimizer_states (fname) | Phương pháp này lưu trình tối ưu hóa hoặc trạng thái trình cập nhật vào một tệp. |
| set_params (arg_params, aux_params [,…]) | Như tên chỉ định, hàm này sẽ gán các tham số và giá trị trạng thái aux. |
| set_states ([trạng thái, giá trị]) | Phương thức này, như tên của nó, đặt giá trị cho các trạng thái. |
| cập nhật () | Phương pháp này cập nhật các tham số đã cho theo trình tối ưu hóa đã cài đặt. Nó cũng cập nhật các độ dốc được tính trong lô chuyển tiếp trước đó. |
| update_metric (eval_metric, label [, pre_sliced]) | Phương pháp này, như tên của nó, đánh giá và tích lũy số liệu đánh giá trên các đầu ra của phép tính chuyển tiếp cuối cùng. |
Thuộc tính
Bảng sau cho thấy các thuộc tính bao gồm trong các phương thức của Module class -
| Thuộc tính | Định nghĩa |
|---|---|
| data_names | Nó bao gồm danh sách các tên cho dữ liệu theo yêu cầu của mô-đun này. |
| data_shapes | Nó bao gồm danh sách các cặp (tên, hình dạng) chỉ định các đầu vào dữ liệu cho mô-đun này. |
| label_shapes | Nó hiển thị danh sách các cặp (tên, hình dạng) chỉ định các đầu vào nhãn cho mô-đun này. |
| output_names | Nó bao gồm danh sách tên cho các đầu ra của mô-đun này. |
| output_shapes | Nó bao gồm danh sách các cặp (tên, hình dạng) xác định đầu ra của mô-đun này. |
| label_names | Nó bao gồm danh sách tên cho các nhãn mà mô-đun này yêu cầu. |
data_shapes: Truy cập liên kết https://mxnet.apache.org/api/python/docs/api/module để biết thêm chi tiết.
output_shapes: Liên kết được cung cấp kèm theo đây https://mxnet.apache.org/api/python/docs/api/module/index.html sẽ cung cấp thông tin quan trọng khác.
PythonLossModule ([tên, data_names,…])
Cơ sở của lớp này là mxnet.module.python_module.PythonModule. Lớp PythonLossModule là một lớp mô-đun tiện lợi, thực hiện tất cả hoặc nhiều API mô-đun dưới dạng các hàm trống.
Phương pháp
Bảng sau cho thấy các phương pháp bao gồm PythonLossModule lớp học:
| Phương pháp | Định nghĩa |
|---|---|
| lùi lại ([out_grads]) | Như tên của nó, phương thức này thực hiện backward tính toán. |
| chuyển tiếp (data_batch [, is_train]) | Như tên của nó, phương thức này thực hiện Forwardtính toán. Phương pháp này hỗ trợ các lô dữ liệu với nhiều hình dạng khác nhau như kích thước lô khác nhau hoặc kích thước hình ảnh khác nhau. |
| get_input_grads ([merge_multi_context]) | Phương pháp này sẽ lấy các gradient cho các đầu vào được tính toán trong phép tính ngược trước đó. |
| get_outputs ([merge_multi_context]) | Như tên của nó, phương thức này sẽ nhận kết quả đầu ra của phép tính chuyển tiếp trước đó. |
| install_monitor (mon) | Phương pháp này sẽ cài đặt màn hình trên tất cả các trình thực thi. |
PythonModule ([data_names, label_names…])
Cơ sở của lớp này là mxnet.module.base_module.BaseModule. Lớp PythonModule cũng là một lớp mô-đun thuận tiện, thực hiện tất cả hoặc nhiều API mô-đun dưới dạng các hàm trống.
Phương pháp
Bảng sau cho thấy các phương pháp bao gồm PythonModule lớp học -
| Phương pháp | Định nghĩa |
|---|---|
| ràng buộc (data_shapes [, label_shapes,…]) | Nó liên kết các ký hiệu để xây dựng các trình thực thi và nó là cần thiết trước khi người ta có thể thực hiện tính toán với mô-đun. |
| get_params () | Nó nhận các tham số, đặc biệt là những tham số có khả năng là bản sao của các tham số thực được sử dụng để tính toán trên thiết bị. |
| init_optimizer ([kvstore, trình tối ưu hóa,…]) | Phương pháp này cài đặt và khởi tạo trình tối ưu hóa. Nó cũng khởi tạokvstore để phân phối đào tạo. |
| init_params ([khởi tạo, arg_params,…]) | Như tên của nó, phương thức này sẽ khởi tạo các tham số và trạng thái bổ trợ. |
| cập nhật () | Phương pháp này cập nhật các tham số đã cho theo trình tối ưu hóa đã cài đặt. Nó cũng cập nhật các độ dốc được tính trong lô chuyển tiếp trước đó. |
| update_metric (eval_metric, label [, pre_sliced]) | Phương pháp này, như tên của nó, đánh giá và tích lũy số liệu đánh giá trên các đầu ra của phép tính chuyển tiếp cuối cùng. |
Thuộc tính
Bảng sau cho thấy các thuộc tính bao gồm trong các phương thức của PythonModule lớp học -
| Thuộc tính | Định nghĩa |
|---|---|
| data_names | Nó bao gồm danh sách các tên cho dữ liệu theo yêu cầu của mô-đun này. |
| data_shapes | Nó bao gồm danh sách các cặp (tên, hình dạng) chỉ định các đầu vào dữ liệu cho mô-đun này. |
| label_shapes | Nó hiển thị danh sách các cặp (tên, hình dạng) chỉ định các đầu vào nhãn cho mô-đun này. |
| output_names | Nó bao gồm danh sách tên cho các đầu ra của mô-đun này. |
| output_shapes | Nó bao gồm danh sách các cặp (tên, hình dạng) xác định đầu ra của mô-đun này. |
data_shapes - Theo liên kết https://mxnet.apache.org để biết chi tiết.
output_shapes - Để biết thêm chi tiết, hãy truy cập liên kết có sẵn tại https://mxnet.apache.org
SequentialModule ([logger])
Cơ sở của lớp này là mxnet.module.base_module.BaseModule. Lớp SequentialModule cũng là một mô-đun vùng chứa có thể kết nối nhiều hơn hai (nhiều) mô-đun với nhau.
Phương pháp
Bảng sau cho thấy các phương pháp bao gồm SequentialModule lớp học
| Phương pháp | Định nghĩa |
|---|---|
| thêm (mô-đun, ** kwargs) | Đây là chức năng quan trọng nhất của lớp này. Nó thêm một mô-đun vào chuỗi. |
| lùi lại ([out_grads]) | Như tên của nó, phương thức này thực hiện tính toán ngược. |
| ràng buộc (data_shapes [, label_shapes,…]) | Nó liên kết các ký hiệu để xây dựng các trình thực thi và nó là cần thiết trước khi người ta có thể thực hiện tính toán với mô-đun. |
| chuyển tiếp (data_batch [, is_train]) | Như tên của nó, phương pháp này thực hiện tính toán Chuyển tiếp. Phương pháp này hỗ trợ các lô dữ liệu với nhiều hình dạng khác nhau như kích thước lô khác nhau hoặc kích thước hình ảnh khác nhau. |
| get_input_grads ([merge_multi_context]) | Phương pháp này sẽ lấy các gradient cho các đầu vào được tính toán trong phép tính ngược trước đó. |
| get_outputs ([merge_multi_context]) | Như tên của nó, phương thức này sẽ nhận kết quả đầu ra của phép tính chuyển tiếp trước đó. |
| get_params () | Nó nhận các tham số, đặc biệt là những tham số có khả năng là bản sao của các tham số thực được sử dụng để tính toán trên thiết bị. |
| init_optimizer ([kvstore, trình tối ưu hóa,…]) | Phương pháp này cài đặt và khởi tạo trình tối ưu hóa. Nó cũng khởi tạokvstore để phân phối đào tạo. |
| init_params ([khởi tạo, arg_params,…]) | Như tên của nó, phương thức này sẽ khởi tạo các tham số và trạng thái bổ trợ. |
| install_monitor (mon) | Phương pháp này sẽ cài đặt màn hình trên tất cả các trình thực thi. |
| cập nhật () | Phương pháp này cập nhật các tham số đã cho theo trình tối ưu hóa đã cài đặt. Nó cũng cập nhật các độ dốc được tính trong lô chuyển tiếp trước đó. |
| update_metric (eval_metric, label [, pre_sliced]) | Phương pháp này, như tên của nó, đánh giá và tích lũy số liệu đánh giá trên các đầu ra của phép tính chuyển tiếp cuối cùng. |
Thuộc tính
Bảng sau đây cho thấy các thuộc tính bao gồm trong các phương thức của lớp BaseModule:
| Thuộc tính | Định nghĩa |
|---|---|
| data_names | Nó bao gồm danh sách các tên cho dữ liệu theo yêu cầu của mô-đun này. |
| data_shapes | Nó bao gồm danh sách các cặp (tên, hình dạng) chỉ định các đầu vào dữ liệu cho mô-đun này. |
| label_shapes | Nó hiển thị danh sách các cặp (tên, hình dạng) chỉ định các đầu vào nhãn cho mô-đun này. |
| output_names | Nó bao gồm danh sách tên cho các đầu ra của mô-đun này. |
| output_shapes | Nó bao gồm danh sách các cặp (tên, hình dạng) xác định đầu ra của mô-đun này. |
| output_shapes | Nó bao gồm danh sách các cặp (tên, hình dạng) xác định đầu ra của mô-đun này. |
data_shapes - Liên kết được cung cấp kèm theo đây https://mxnet.apache.org sẽ giúp bạn hiểu thuộc tính một cách chi tiết.
output_shapes - Theo đường dẫn có sẵn tại https://mxnet.apache.org/api để biết chi tiết.
Ví dụ triển khai
Trong ví dụ dưới đây, chúng tôi sẽ tạo mxnet mô-đun.
import mxnet as mx
input_data = mx.symbol.Variable('input_data')
f_connected1 = mx.symbol.FullyConnected(data, name='f_connected1', num_hidden=128)
activation_1 = mx.symbol.Activation(f_connected1, name='relu1', act_type="relu")
f_connected2 = mx.symbol.FullyConnected(activation_1, name = 'f_connected2', num_hidden = 64)
activation_2 = mx.symbol.Activation(f_connected2, name='relu2',
act_type="relu")
f_connected3 = mx.symbol.FullyConnected(activation_2, name='fc3', num_hidden=10)
out = mx.symbol.SoftmaxOutput(f_connected3, name = 'softmax')
mod = mx.mod.Module(out)
print(out)Output
Đầu ra được đề cập bên dưới -
<Symbol softmax>Example
print(mod)Output
Đầu ra được hiển thị bên dưới -
<mxnet.module.module.Module object at 0x00000123A9892F28>Trong ví dụ dưới đây, chúng tôi sẽ triển khai tính toán chuyển tiếp
import mxnet as mx
from collections import namedtuple
Batch = namedtuple('Batch', ['data'])
data = mx.sym.Variable('data')
out = data * 2
mod = mx.mod.Module(symbol=out, label_names=None)
mod.bind(data_shapes=[('data', (1, 10))])
mod.init_params()
data1 = [mx.nd.ones((1, 10))]
mod.forward(Batch(data1))
print (mod.get_outputs()[0].asnumpy())Output
Khi bạn thực thi đoạn mã trên, bạn sẽ thấy kết quả sau:
[[2. 2. 2. 2. 2. 2. 2. 2. 2. 2.]]Example
data2 = [mx.nd.ones((3, 5))]
mod.forward(Batch(data2))
print (mod.get_outputs()[0].asnumpy())Output
Dưới đây là đầu ra của mã:
[[2. 2. 2. 2. 2.]
[2. 2. 2. 2. 2.]
[2. 2. 2. 2. 2.]]