Apache Storm - Khái niệm cốt lõi
Apache Storm đọc luồng dữ liệu thời gian thực thô từ một đầu và chuyển nó qua một chuỗi các đơn vị xử lý nhỏ và xuất ra thông tin đã xử lý / hữu ích ở đầu kia.
Sơ đồ sau đây mô tả khái niệm cốt lõi của Apache Storm.

Bây giờ chúng ta hãy xem xét kỹ hơn các thành phần của Apache Storm -
| Các thành phần | Sự miêu tả |
|---|---|
| Tuple | Tuple là cấu trúc dữ liệu chính trong Storm. Nó là một danh sách các phần tử có thứ tự. Theo mặc định, Tuple hỗ trợ tất cả các kiểu dữ liệu. Nói chung, nó được mô hình hóa như một tập hợp các giá trị được phân tách bằng dấu phẩy và được chuyển đến một cụm Storm. |
| Suối | Luồng là một chuỗi các bộ dữ liệu không có thứ tự. |
| Vòi phun | Nguồn của dòng. Nói chung, Storm chấp nhận dữ liệu đầu vào từ các nguồn dữ liệu thô như Twitter Streaming API, Apache Kafka queue, Kestrel queue, v.v. Nếu không, bạn có thể ghi các vòi để đọc dữ liệu từ các nguồn dữ liệu. “ISpout” là giao diện cốt lõi để triển khai các vòi. Một số giao diện cụ thể là IRichSpout, BaseRichSpout, KafkaSpout, v.v. |
| Bu lông | Bu lông là đơn vị xử lý logic. Các vòi phun truyền dữ liệu đến quá trình xử lý bu lông và bu lông và tạo ra một dòng đầu ra mới. Bu lông có thể thực hiện các thao tác lọc, tổng hợp, nối, tương tác với các nguồn dữ liệu và cơ sở dữ liệu. Bolt nhận dữ liệu và phát ra một hoặc nhiều bu lông. “IBolt” là giao diện cốt lõi để thực hiện các bu lông. Một số giao diện phổ biến là IRichBolt, IBasicBolt, v.v. |
Hãy lấy một ví dụ thời gian thực về “Phân tích Twitter” và xem cách nó có thể được mô hình hóa trong Apache Storm. Sơ đồ sau đây mô tả cấu trúc.

Đầu vào cho “Phân tích Twitter” đến từ API phát trực tuyến của Twitter. Spout sẽ đọc các tweet của người dùng bằng Twitter Streaming API và xuất ra dưới dạng một luồng các bộ giá trị. Một tuple từ vòi sẽ có tên người dùng twitter và một tweet duy nhất dưới dạng các giá trị được phân tách bằng dấu phẩy. Sau đó, bộ giá trị hơi này sẽ được chuyển tiếp đến Bolt và Bolt sẽ chia tweet thành từng từ riêng lẻ, tính toán số lượng từ và lưu giữ thông tin vào một nguồn dữ liệu đã định cấu hình. Bây giờ, chúng ta có thể dễ dàng nhận được kết quả bằng cách truy vấn nguồn dữ liệu.
Tôpô
Các vòi và bu lông được kết nối với nhau và chúng tạo thành một cấu trúc liên kết. Logic ứng dụng thời gian thực được chỉ định bên trong cấu trúc liên kết Storm. Nói một cách đơn giản, cấu trúc liên kết là một đồ thị có hướng trong đó các đỉnh là tính toán và các cạnh là dòng dữ liệu.
Một cấu trúc liên kết đơn giản bắt đầu với các vòi. Spout phát dữ liệu tới một hoặc nhiều bu lông. Bolt đại diện cho một nút trong cấu trúc liên kết có logic xử lý nhỏ nhất và đầu ra của một bu lông có thể được phát ra thành một bu lông khác làm đầu vào.
Storm giữ cho cấu trúc liên kết luôn chạy, cho đến khi bạn giết cấu trúc liên kết. Công việc chính của Apache Storm là chạy cấu trúc liên kết và sẽ chạy bất kỳ số cấu trúc liên kết nào tại một thời điểm nhất định.
Nhiệm vụ
Bây giờ bạn có một ý tưởng cơ bản về vòi và bu lông. Chúng là đơn vị logic nhỏ nhất của cấu trúc liên kết và cấu trúc liên kết được xây dựng bằng cách sử dụng một vòi và một mảng bu lông. Chúng phải được thực thi đúng theo một thứ tự cụ thể để cấu trúc liên kết chạy thành công. Việc thực hiện từng vòi và tia của Storm được gọi là "Nhiệm vụ". Nói một cách đơn giản, một nhiệm vụ là việc thực hiện một cái vòi hoặc một cái bu lông. Tại một thời điểm nhất định, mỗi vòi và bu lông có thể có nhiều trường hợp chạy trong nhiều luồng riêng biệt.
Công nhân
Cấu trúc liên kết chạy theo cách phân tán, trên nhiều nút công nhân. Storm rải đều các nhiệm vụ trên tất cả các nút công nhân. Vai trò của nút công nhân là lắng nghe các công việc và bắt đầu hoặc dừng các quy trình bất cứ khi nào có công việc mới.
Nhóm luồng
Luồng dữ liệu chảy từ vòi đến bu lông hoặc từ bu lông này sang bu lông khác. Nhóm luồng kiểm soát cách các bộ dữ liệu được định tuyến trong cấu trúc liên kết và giúp chúng tôi hiểu dòng bộ dữ liệu trong cấu trúc liên kết. Có bốn nhóm được tạo sẵn như được giải thích bên dưới.
Trộn nhóm
Trong nhóm xáo trộn, một số lượng bằng nhau các bộ được phân phối ngẫu nhiên trên tất cả các công nhân thực hiện các bu lông. Sơ đồ sau đây mô tả cấu trúc.

Nhóm trường
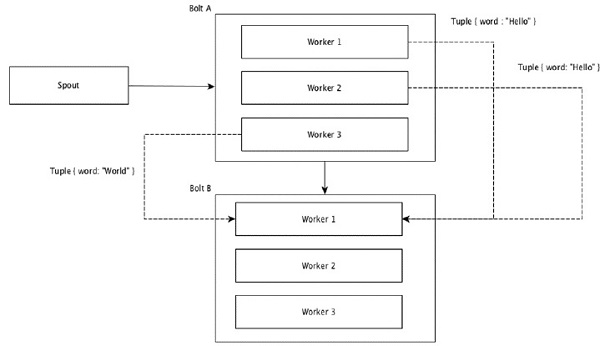
Các trường có cùng giá trị trong các bộ giá trị được nhóm lại với nhau và các bộ giá trị còn lại được giữ bên ngoài. Sau đó, các bộ giá trị có cùng giá trị trường được gửi tới cùng một công nhân thực hiện các bu lông. Ví dụ: nếu luồng được nhóm theo trường “từ”, thì các bộ giá trị có cùng chuỗi, “Xin chào” sẽ chuyển đến cùng một trình xử lý. Sơ đồ sau đây cho thấy cách hoạt động của Nhóm trường.

Nhóm toàn cầu
Tất cả các luồng có thể được nhóm lại và chuyển tiếp đến một chốt. Việc nhóm này gửi các bộ giá trị được tạo bởi tất cả các bản sao của nguồn đến một bản sao đích duy nhất (cụ thể là chọn công nhân có ID thấp nhất).
Tất cả các nhóm
All Grouping sẽ gửi một bản sao duy nhất của từng bộ tới tất cả các trường hợp của bu lông nhận. Loại nhóm này được sử dụng để gửi tín hiệu đến bu lông. Tất cả các nhóm đều hữu ích cho các hoạt động nối.
