Apache Storm - Hướng dẫn nhanh
Apache Storm là gì?
Apache Storm là một hệ thống xử lý dữ liệu lớn thời gian thực phân tán. Storm được thiết kế để xử lý lượng lớn dữ liệu theo phương pháp có khả năng chịu lỗi và có thể mở rộng theo chiều ngang. Đây là một khung dữ liệu truyền trực tuyến có khả năng đạt tỷ lệ nhập cao nhất. Mặc dù Storm không có trạng thái, nó quản lý môi trường phân tán và trạng thái cụm thông qua Apache ZooKeeper. Nó đơn giản và bạn có thể thực hiện song song tất cả các loại thao tác trên dữ liệu thời gian thực.
Apache Storm đang tiếp tục dẫn đầu trong lĩnh vực phân tích dữ liệu thời gian thực. Storm dễ cài đặt, vận hành và nó đảm bảo rằng mọi thông báo sẽ được xử lý thông qua cấu trúc liên kết ít nhất một lần.
Apache Storm vs Hadoop
Về cơ bản, các khung công tác Hadoop và Storm được sử dụng để phân tích dữ liệu lớn. Cả hai đều bổ sung cho nhau và khác nhau ở một số khía cạnh. Apache Storm thực hiện tất cả các hoạt động ngoại trừ tính bền bỉ, trong khi Hadoop giỏi mọi thứ nhưng lại chậm trễ trong tính toán thời gian thực. Bảng sau so sánh các thuộc tính của Storm và Hadoop.
| Bão táp | Hadoop |
|---|---|
| Xử lý luồng thời gian thực | Xử lý hàng loạt |
| Không quốc tịch | Trạng thái |
| Kiến trúc Master / Slave với sự phối hợp dựa trên ZooKeeper. Nút chính được gọi lànimbus và nô lệ là supervisors. | Kiến trúc chủ-tớ có / không có phối hợp dựa trên ZooKeeper. Nút chính làjob tracker và nút nô lệ là task tracker. |
| Quá trình phát trực tuyến Storm có thể truy cập hàng chục nghìn tin nhắn mỗi giây trên cụm. | Hệ thống tệp phân tán Hadoop (HDFS) sử dụng khung công tác MapReduce để xử lý lượng lớn dữ liệu mất vài phút hoặc hàng giờ. |
| Cấu trúc liên kết bão chạy cho đến khi người dùng tắt máy hoặc lỗi không thể khôi phục bất ngờ. | Các công việc MapReduce được thực hiện theo thứ tự tuần tự và hoàn thành cuối cùng. |
| Both are distributed and fault-tolerant | |
| Nếu nimbus / người giám sát chết, khởi động lại sẽ làm cho nó tiếp tục từ nơi nó đã dừng, do đó không có gì bị ảnh hưởng. | Nếu JobTracker chết, tất cả các công việc đang chạy sẽ bị mất. |
Các trường hợp sử dụng của Apache Storm
Apache Storm rất nổi tiếng với khả năng xử lý luồng dữ liệu lớn theo thời gian thực. Vì lý do này, hầu hết các công ty đang sử dụng Storm như một phần không thể thiếu trong hệ thống của họ. Một số ví dụ đáng chú ý như sau:
Twitter- Twitter đang sử dụng Apache Storm cho phạm vi “sản phẩm Phân tích nhà xuất bản”. “Sản phẩm phân tích nhà xuất bản” xử lý từng tweet và nhấp chuột trong Nền tảng Twitter. Apache Storm được tích hợp sâu với cơ sở hạ tầng Twitter.
NaviSite- NaviSite đang sử dụng Storm cho hệ thống kiểm tra / giám sát nhật ký sự kiện. Mọi bản ghi được tạo trong hệ thống sẽ đi qua Storm. Storm sẽ kiểm tra thông báo dựa trên tập hợp biểu thức chính quy đã định cấu hình và nếu có sự trùng khớp, thì thông báo cụ thể đó sẽ được lưu vào cơ sở dữ liệu.
Wego- Wego là một công cụ tìm kiếm du lịch đặt tại Singapore. Dữ liệu liên quan đến du lịch đến từ nhiều nguồn trên khắp thế giới với thời gian khác nhau. Storm giúp Wego tìm kiếm dữ liệu theo thời gian thực, giải quyết các vấn đề đồng thời và tìm kết quả phù hợp nhất cho người dùng cuối.
Lợi ích của Apache Storm
Dưới đây là danh sách những lợi ích mà Apache Storm cung cấp:
Storm là mã nguồn mở, mạnh mẽ và thân thiện với người dùng. Nó có thể được sử dụng trong các công ty nhỏ cũng như các tập đoàn lớn.
Storm có khả năng chịu lỗi, linh hoạt, đáng tin cậy và hỗ trợ mọi ngôn ngữ lập trình.
Cho phép xử lý luồng thời gian thực.
Storm nhanh đến khó tin vì nó có sức mạnh xử lý dữ liệu rất lớn.
Storm có thể duy trì hiệu suất ngay cả khi tải ngày càng tăng bằng cách bổ sung tuyến tính tài nguyên. Nó có khả năng mở rộng cao.
Storm thực hiện làm mới dữ liệu và phản hồi phân phối từ đầu đến cuối trong vài giây hoặc vài phút tùy thuộc vào sự cố. Nó có độ trễ rất thấp.
Storm có hoạt động tình báo.
Storm cung cấp khả năng xử lý dữ liệu đảm bảo ngay cả khi bất kỳ nút nào được kết nối trong cụm chết hoặc thông báo bị mất.
Apache Storm đọc luồng dữ liệu thời gian thực thô từ một đầu và chuyển nó qua một chuỗi các đơn vị xử lý nhỏ và xuất ra thông tin hữu ích / đã xử lý ở đầu kia.
Sơ đồ sau đây mô tả khái niệm cốt lõi của Apache Storm.

Bây giờ chúng ta hãy xem xét kỹ hơn các thành phần của Apache Storm -
| Các thành phần | Sự miêu tả |
|---|---|
| Tuple | Tuple là cấu trúc dữ liệu chính trong Storm. Nó là một danh sách các phần tử có thứ tự. Theo mặc định, Tuple hỗ trợ tất cả các kiểu dữ liệu. Nói chung, nó được mô hình hóa như một tập hợp các giá trị được phân tách bằng dấu phẩy và được chuyển đến một cụm Storm. |
| Suối | Luồng là một chuỗi các bộ dữ liệu không có thứ tự. |
| Vòi phun | Nguồn của dòng. Nói chung, Storm chấp nhận dữ liệu đầu vào từ các nguồn dữ liệu thô như Twitter Streaming API, Apache Kafka queue, Kestrel queue, v.v. Nếu không, bạn có thể ghi các vòi để đọc dữ liệu từ các nguồn dữ liệu. “ISpout” là giao diện cốt lõi để triển khai các vòi. Một số giao diện cụ thể là IRichSpout, BaseRichSpout, KafkaSpout, v.v. |
| Bu lông | Bu lông là đơn vị xử lý logic. Các vòi phun truyền dữ liệu đến quá trình xử lý bu lông và bu lông và tạo ra một dòng đầu ra mới. Bu lông có thể thực hiện các thao tác lọc, tổng hợp, nối, tương tác với các nguồn dữ liệu và cơ sở dữ liệu. Bolt nhận dữ liệu và phát ra một hoặc nhiều bu lông. “IBolt” là giao diện cốt lõi để thực hiện các bu lông. Một số giao diện phổ biến là IRichBolt, IBasicBolt, v.v. |
Hãy lấy một ví dụ thời gian thực về “Phân tích Twitter” và xem cách nó có thể được mô hình hóa trong Apache Storm. Sơ đồ sau đây mô tả cấu trúc.

Đầu vào cho “Phân tích Twitter” đến từ API phát trực tuyến của Twitter. Spout sẽ đọc các tweet của người dùng bằng Twitter Streaming API và xuất ra dưới dạng một luồng các bộ giá trị. Một tuple từ vòi sẽ có tên người dùng twitter và một tweet duy nhất dưới dạng các giá trị được phân tách bằng dấu phẩy. Sau đó, bộ giá trị hơi này sẽ được chuyển tiếp đến Bolt và Bolt sẽ chia tweet thành từng từ riêng lẻ, tính toán số lượng từ và lưu giữ thông tin vào một nguồn dữ liệu đã định cấu hình. Bây giờ, chúng ta có thể dễ dàng nhận được kết quả bằng cách truy vấn nguồn dữ liệu.
Tôpô
Các vòi và bu lông được kết nối với nhau và chúng tạo thành một cấu trúc liên kết. Logic ứng dụng thời gian thực được chỉ định bên trong cấu trúc liên kết Storm. Nói một cách đơn giản, cấu trúc liên kết là một đồ thị có hướng trong đó các đỉnh là tính toán và các cạnh là dòng dữ liệu.
Một cấu trúc liên kết đơn giản bắt đầu với các vòi. Spout phát dữ liệu tới một hoặc nhiều bu lông. Bolt đại diện cho một nút trong cấu trúc liên kết có logic xử lý nhỏ nhất và đầu ra của một bu lông có thể được phát ra thành một bu lông khác làm đầu vào.
Storm giữ cho cấu trúc liên kết luôn chạy, cho đến khi bạn giết cấu trúc liên kết. Công việc chính của Apache Storm là chạy cấu trúc liên kết và sẽ chạy bất kỳ số cấu trúc liên kết nào tại một thời điểm nhất định.
Nhiệm vụ
Bây giờ bạn có một ý tưởng cơ bản về vòi và bu lông. Chúng là đơn vị logic nhỏ nhất của cấu trúc liên kết và cấu trúc liên kết được xây dựng bằng cách sử dụng một vòi và một mảng bu lông. Chúng phải được thực thi đúng theo một thứ tự cụ thể để cấu trúc liên kết chạy thành công. Việc thực hiện từng vòi và tia của Storm được gọi là "Nhiệm vụ". Nói một cách đơn giản, một nhiệm vụ là việc thực hiện một cái vòi hoặc một cái bu lông. Tại một thời điểm nhất định, mỗi vòi và bu lông có thể có nhiều trường hợp chạy trong nhiều luồng riêng biệt.
Công nhân
Cấu trúc liên kết chạy theo cách phân tán, trên nhiều nút công nhân. Storm rải đều các nhiệm vụ trên tất cả các nút công nhân. Vai trò của nút công nhân là lắng nghe các công việc và bắt đầu hoặc dừng các quy trình bất cứ khi nào có công việc mới.
Nhóm luồng
Luồng dữ liệu chảy từ vòi đến bu lông hoặc từ bu lông này sang bu lông khác. Nhóm luồng kiểm soát cách các bộ dữ liệu được định tuyến trong cấu trúc liên kết và giúp chúng tôi hiểu dòng bộ dữ liệu trong cấu trúc liên kết. Có bốn nhóm được tạo sẵn như được giải thích bên dưới.
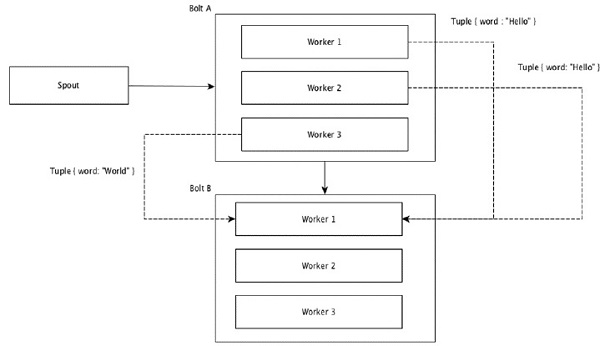
Trộn nhóm
Trong nhóm xáo trộn, một số lượng bằng nhau các bộ được phân phối ngẫu nhiên trên tất cả các công nhân thực hiện các bu lông. Sơ đồ sau đây mô tả cấu trúc.

Nhóm trường
Các trường có cùng giá trị trong các bộ giá trị được nhóm lại với nhau và các bộ giá trị còn lại được giữ bên ngoài. Sau đó, các bộ giá trị có cùng giá trị trường được gửi tới cùng một công nhân thực hiện các bu lông. Ví dụ: nếu luồng được nhóm theo trường “từ”, thì các bộ giá trị có cùng chuỗi, “Xin chào” sẽ chuyển đến cùng một trình xử lý. Sơ đồ sau đây cho thấy cách hoạt động của Nhóm trường.

Nhóm toàn cầu
Tất cả các luồng có thể được nhóm lại và chuyển tiếp đến một chốt. Việc nhóm này gửi các bộ giá trị được tạo bởi tất cả các bản sao của nguồn đến một bản sao đích duy nhất (cụ thể là chọn công nhân có ID thấp nhất).
Tất cả các nhóm
All Grouping sẽ gửi một bản sao duy nhất của mỗi bộ tới tất cả các trường hợp của bu lông nhận. Loại nhóm này được sử dụng để gửi tín hiệu đến bu lông. Tất cả các nhóm đều hữu ích cho các hoạt động nối.

Một trong những điểm nổi bật chính của Apache Storm là nó có khả năng chịu lỗi, nhanh chóng mà không có ứng dụng phân tán “Điểm lỗi duy nhất” (SPOF). Chúng ta có thể cài đặt Apache Storm trong nhiều hệ thống nếu cần để tăng dung lượng của ứng dụng.
Chúng ta hãy xem cách cụm Apache Storm được thiết kế và kiến trúc bên trong của nó. Sơ đồ sau đây mô tả thiết kế cụm.

Apache Storm có hai loại nút, Nimbus (nút chính) và Supervisor(nút công nhân). Nimbus là thành phần trung tâm của Apache Storm. Công việc chính của Nimbus là chạy cấu trúc liên kết Storm. Nimbus phân tích cấu trúc liên kết và tập hợp nhiệm vụ được thực thi. Sau đó, nó sẽ phân phối nhiệm vụ cho một người giám sát có sẵn.
Một người giám sát sẽ có một hoặc nhiều quy trình của công nhân. Người giám sát sẽ ủy thác các nhiệm vụ cho các quy trình của công nhân. Quy trình công nhân sẽ sinh ra bao nhiêu người thực thi khi cần thiết và chạy tác vụ. Apache Storm sử dụng một hệ thống nhắn tin phân tán nội bộ để liên lạc giữa nimbus và người giám sát.
| Các thành phần | Sự miêu tả |
|---|---|
| Nimbus | Nimbus là một nút chính của Storm cluster. Tất cả các nút khác trong cụm được gọi làworker nodes. Nút chính chịu trách nhiệm phân phối dữ liệu giữa tất cả các nút công nhân, giao nhiệm vụ cho các nút công nhân và giám sát các lỗi. |
| Người giám sát | Các nút tuân theo hướng dẫn do nimbus đưa ra được gọi là Người giám sát. Asupervisor có nhiều quy trình của nhân viên và nó điều chỉnh các quy trình của nhân viên để hoàn thành các nhiệm vụ được giao bởi nimbus. |
| Quy trình công nhân | Một quy trình công nhân sẽ thực thi các tác vụ liên quan đến một cấu trúc liên kết cụ thể. Quá trình worker sẽ không tự chạy một tác vụ, thay vào đó nó tạo raexecutorsvà yêu cầu họ thực hiện một nhiệm vụ cụ thể. Một quy trình công nhân sẽ có nhiều người thực thi. |
| Người thừa hành | Một trình thực thi không là gì khác ngoài một luồng duy nhất được sinh ra bởi một quy trình công nhân. Người thực thi chạy một hoặc nhiều nhiệm vụ nhưng chỉ cho một vòi hoặc chốt cụ thể. |
| Bài tập | Một nhiệm vụ thực hiện xử lý dữ liệu thực tế. Vì vậy, nó có thể là một vòi hoặc một bu lông. |
| Khung ZooKeeper | Apache ZooKeeper là một dịch vụ được sử dụng bởi một cụm (nhóm các nút) để phối hợp giữa chúng và duy trì dữ liệu được chia sẻ với các kỹ thuật đồng bộ hóa mạnh mẽ. Nimbus là không trạng thái, vì vậy nó phụ thuộc vào ZooKeeper để giám sát trạng thái nút làm việc. ZooKeeper giúp người giám sát tương tác với nimbus. Có trách nhiệm duy trì trạng thái nimbus và giám sát. |
Storm là không quốc tịch trong tự nhiên. Mặc dù bản chất không trạng thái có những nhược điểm riêng nhưng nó thực sự giúp Storm xử lý dữ liệu thời gian thực theo cách tốt nhất và nhanh nhất có thể.
Tuy nhiên, Storm không hoàn toàn không có trạng thái. Nó lưu trữ trạng thái của nó trong Apache ZooKeeper. Vì trạng thái có sẵn trong Apache ZooKeeper, một nimbus bị lỗi có thể được khởi động lại và hoạt động từ nơi nó rời đi. Thông thường, các công cụ giám sát dịch vụ nhưmonit sẽ giám sát Nimbus và khởi động lại nó nếu có bất kỳ lỗi nào.
Apache Storm cũng có một cấu trúc liên kết nâng cao được gọi là Trident Topologyvới bảo trì trạng thái và nó cũng cung cấp API cấp cao như Pig. Chúng ta sẽ thảo luận về tất cả các tính năng này trong các chương tới.
Một cụm Storm đang hoạt động nên có một nimbus và một hoặc nhiều giám sát viên. Một nút quan trọng khác là Apache ZooKeeper, sẽ được sử dụng để điều phối giữa nimbus và các giám sát viên.
Bây giờ chúng ta hãy xem xét kỹ quy trình làm việc của Apache Storm -
Ban đầu, nimbus sẽ đợi "Cấu trúc liên kết bão" được gửi cho nó.
Khi một cấu trúc liên kết được gửi, nó sẽ xử lý cấu trúc liên kết và tập hợp tất cả các tác vụ sẽ được thực hiện và thứ tự thực hiện tác vụ đó.
Sau đó, nimbus sẽ phân bổ đồng đều các nhiệm vụ cho tất cả các giám sát viên hiện có.
Vào một khoảng thời gian cụ thể, tất cả các giám sát viên sẽ gửi nhịp tim đến nimbus để thông báo rằng họ vẫn còn sống.
Khi một giám sát viên qua đời và không gửi nhịp tim đến nimbus, nimbus sẽ giao nhiệm vụ cho một giám sát viên khác.
Khi nimbus tự chết, người giám sát sẽ làm việc với nhiệm vụ đã được giao mà không gặp bất kỳ vấn đề gì.
Sau khi hoàn thành tất cả các nhiệm vụ, người giám sát sẽ chờ một nhiệm vụ mới đến.
Trong thời gian chờ đợi, nimbus đã chết sẽ được khởi động lại tự động bằng các công cụ giám sát dịch vụ.
Nimmbus được khởi động lại sẽ tiếp tục từ nơi nó dừng lại. Tương tự, người giám sát đã chết cũng có thể được khởi động lại tự động. Vì cả nimbus và trình giám sát đều có thể được khởi động lại tự động và cả hai sẽ tiếp tục như trước, Storm được đảm bảo sẽ xử lý tất cả nhiệm vụ ít nhất một lần.
Khi tất cả các cấu trúc liên kết được xử lý, nimbus sẽ đợi một cấu trúc liên kết mới đến và tương tự như vậy, người giám sát đợi các nhiệm vụ mới.
Theo mặc định, có hai chế độ trong một cụm Storm -
Local mode- Chế độ này được sử dụng để phát triển, thử nghiệm và gỡ lỗi vì nó là cách dễ nhất để xem tất cả các thành phần cấu trúc liên kết hoạt động cùng nhau. Trong chế độ này, chúng tôi có thể điều chỉnh các thông số cho phép chúng tôi xem cấu trúc liên kết của chúng tôi chạy như thế nào trong các môi trường cấu hình Storm khác nhau. Ở chế độ Cục bộ, cấu trúc liên kết bão chạy trên máy cục bộ trong một JVM.
Production mode- Trong chế độ này, chúng tôi gửi cấu trúc liên kết của chúng tôi đến cụm bão đang làm việc, bao gồm nhiều quy trình, thường chạy trên các máy khác nhau. Như đã thảo luận trong quy trình làm việc của cơn bão, một cụm làm việc sẽ chạy vô thời hạn cho đến khi nó ngừng hoạt động.
Apache Storm xử lý dữ liệu thời gian thực và thông thường đầu vào đến từ hệ thống xếp hàng tin nhắn. Một hệ thống nhắn tin phân tán bên ngoài sẽ cung cấp đầu vào cần thiết cho việc tính toán thời gian thực. Spout sẽ đọc dữ liệu từ hệ thống nhắn tin và chuyển nó thành các bộ dữ liệu và nhập vào Apache Storm. Thực tế thú vị là Apache Storm sử dụng hệ thống nhắn tin phân tán của riêng nó trong nội bộ để liên lạc giữa nimbus và người giám sát của nó.
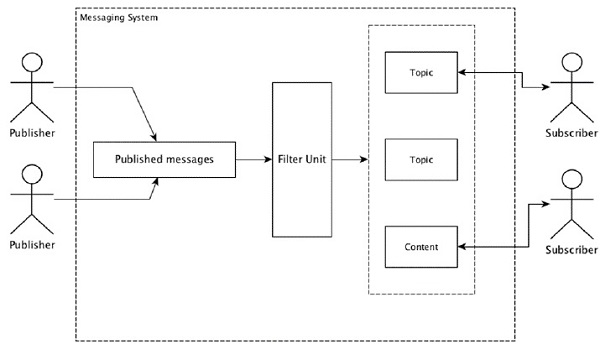
Hệ thống nhắn tin phân tán là gì?
Nhắn tin phân tán dựa trên khái niệm xếp hàng tin nhắn đáng tin cậy. Tin nhắn được xếp hàng đợi không đồng bộ giữa các ứng dụng khách và hệ thống nhắn tin. Hệ thống nhắn tin phân tán cung cấp các lợi ích về độ tin cậy, khả năng mở rộng và tính bền bỉ.
Hầu hết các kiểu nhắn tin tuân theo publish-subscribe mô hình (đơn giản là Pub-Sub) nơi mà người gửi tin nhắn được gọi publishers và những người muốn nhận tin nhắn được gọi là subscribers.
Khi tin nhắn đã được người gửi xuất bản, người đăng ký có thể nhận được tin nhắn đã chọn với sự trợ giúp của tùy chọn lọc. Thông thường chúng ta có hai loại lọc, một làtopic-based filtering và một cái khác là content-based filtering.
Lưu ý rằng mô hình pub-sub chỉ có thể giao tiếp qua tin nhắn. Nó là một kiến trúc được kết hợp rất lỏng lẻo; ngay cả người gửi cũng không biết người đăng ký của họ là ai. Nhiều mẫu tin nhắn cho phép người môi giới tin nhắn trao đổi các tin nhắn đã xuất bản để nhiều người đăng ký truy cập kịp thời. Một ví dụ thực tế là Dish TV, nơi xuất bản các kênh khác nhau như thể thao, phim, âm nhạc, v.v. và bất kỳ ai cũng có thể đăng ký tập hợp kênh của riêng mình và tải chúng bất cứ khi nào có kênh đã đăng ký của họ.
Bảng sau đây mô tả một số hệ thống nhắn tin thông lượng cao phổ biến:
| Hệ thống nhắn tin phân tán | Sự miêu tả |
|---|---|
| Apache Kafka | Kafka được phát triển tại tập đoàn LinkedIn và sau đó nó trở thành một dự án con của Apache. Apache Kafka dựa trên mô hình đăng ký xuất bản phân tán, liên tục, được phân phối đã bẻ khóa. Kafka nhanh, có thể mở rộng và hiệu quả cao. |
| RabbitMQ | RabbitMQ là một ứng dụng nhắn tin mạnh mẽ phân tán mã nguồn mở. Nó rất dễ sử dụng và chạy trên tất cả các nền tảng. |
| JMS (Dịch vụ tin nhắn Java) | JMS là một API mã nguồn mở hỗ trợ tạo, đọc và gửi tin nhắn từ ứng dụng này sang ứng dụng khác. Nó cung cấp thông điệp được đảm bảo và theo mô hình đăng ký xuất bản. |
| ActiveMQ | Hệ thống nhắn tin ActiveMQ là một API mã nguồn mở của JMS. |
| ZeroMQ | ZeroMQ là xử lý tin nhắn ngang hàng không có người môi giới. Nó cung cấp các mẫu tin nhắn push-pull, router-agent. |
| Kestrel | Kestrel là một hàng đợi tin nhắn phân tán nhanh, đáng tin cậy và đơn giản. |
Giao thức tiết kiệm
Thrift được xây dựng tại Facebook để phát triển các dịch vụ đa ngôn ngữ và gọi thủ tục từ xa (RPC). Sau đó, nó trở thành một dự án Apache mã nguồn mở. Apache Thrift là mộtInterface Definition Language và cho phép xác định các kiểu dữ liệu mới và triển khai dịch vụ trên các kiểu dữ liệu đã xác định một cách dễ dàng.
Apache Thrift cũng là một khung giao tiếp hỗ trợ các hệ thống nhúng, ứng dụng di động, ứng dụng web và nhiều ngôn ngữ lập trình khác. Một số tính năng chính liên quan đến Apache Thrift là tính mô-đun, tính linh hoạt và hiệu suất cao. Ngoài ra, nó có thể thực hiện truyền trực tuyến, nhắn tin và RPC trong các ứng dụng phân tán.
Storm sử dụng rộng rãi Giao thức Thrift cho giao tiếp nội bộ và định nghĩa dữ liệu. Cấu trúc liên kết bão chỉ đơn giản làThrift Structs. Storm Nimbus chạy cấu trúc liên kết trong Apache Storm là mộtThrift service.
Bây giờ chúng ta hãy xem cách cài đặt Apache Storm framework trên máy tính của bạn. Có ba bước chính ở đây -
- Cài đặt Java trên hệ thống của bạn, nếu bạn chưa có.
- Cài đặt khung công tác ZooKeeper.
- Cài đặt khung Apache Storm.
Bước 1 - Xác minh cài đặt Java
Sử dụng lệnh sau để kiểm tra xem bạn đã cài đặt Java trên hệ thống của mình chưa.
$ java -versionNếu Java đã có, thì bạn sẽ thấy số phiên bản của nó. Nếu không, hãy tải xuống phiên bản mới nhất của JDK.
Bước 1.1 - Tải xuống JDK
Tải xuống phiên bản JDK mới nhất bằng cách sử dụng liên kết sau - www.oracle.com
Phiên bản mới nhất là JDK 8u 60 và tệp là “jdk-8u60-linux-x64.tar.gz”. Tải xuống tệp trên máy của bạn.
Bước 1.2 - Giải nén tệp
Nói chung các tệp đang được tải xuống downloadsthư mục. Giải nén thiết lập tar bằng các lệnh sau.
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzBước 1.3 - Di chuyển đến thư mục opt
Để cung cấp Java cho tất cả người dùng, hãy di chuyển nội dung java đã giải nén vào thư mục “/ usr / local / java”.
$ su
password: (type password of root user)
$ mkdir /opt/jdk
$ mv jdk-1.8.0_60 /opt/jdk/Bước 1.4 - Đặt đường dẫn
Để đặt đường dẫn và các biến JAVA_HOME, hãy thêm các lệnh sau vào tệp ~ / .bashrc.
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/binBây giờ áp dụng tất cả các thay đổi cho hệ thống đang chạy hiện tại.
$ source ~/.bashrcBước 1.5 - Các lựa chọn thay thế Java
Sử dụng lệnh sau để thay đổi các lựa chọn thay thế Java.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100Bước 1.6
Bây giờ hãy xác minh cài đặt Java bằng lệnh xác minh (java -version) được giải thích trong Bước 1.
Bước 2 - Cài đặt ZooKeeper Framework
Bước 2.1 - Tải xuống ZooKeeper
Để cài đặt ZooKeeper framework trên máy của bạn, hãy truy cập liên kết sau và tải xuống phiên bản ZooKeeper mới nhất http://zookeeper.apache.org/releases.html
Hiện tại, phiên bản mới nhất của ZooKeeper là 3.4.6 (ZooKeeper-3.4.6.tar.gz).
Bước 2.2 - Giải nén tệp tar
Giải nén tệp tar bằng các lệnh sau:
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz
$ cd zookeeper-3.4.6
$ mkdir dataBước 2.3 - Tạo tệp cấu hình
Mở tệp cấu hình có tên “conf / zoo.cfg” bằng lệnh “vi conf / zoo.cfg” và đặt tất cả các tham số sau làm điểm bắt đầu.
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2Khi tệp cấu hình đã được lưu thành công, bạn có thể khởi động máy chủ ZooKeeper.
Bước 2.4 - Khởi động Máy chủ ZooKeeper
Sử dụng lệnh sau để khởi động máy chủ ZooKeeper.
$ bin/zkServer.sh startSau khi thực hiện lệnh này, bạn sẽ nhận được phản hồi như sau:
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg
$ Starting zookeeper ... STARTEDBước 2.5 - Khởi động CLI
Sử dụng lệnh sau để khởi động CLI.
$ bin/zkCli.shSau khi thực hiện lệnh trên, bạn sẽ được kết nối với máy chủ ZooKeeper và nhận được phản hồi sau.
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]Bước 2.6 - Dừng máy chủ ZooKeeper
Sau khi kết nối máy chủ và thực hiện tất cả các thao tác, bạn có thể dừng máy chủ ZooKeeper bằng cách sử dụng lệnh sau.
bin/zkServer.sh stopBạn đã cài đặt thành công Java và ZooKeeper trên máy của mình. Bây giờ chúng ta hãy xem các bước để cài đặt Apache Storm framework.
Bước 3 - Cài đặt Apache Storm Framework
Bước 3.1 Tải xuống Storm
Để cài đặt Storm framework trên máy của bạn, hãy truy cập vào liên kết sau và tải xuống phiên bản Storm mới nhất http://storm.apache.org/downloads.html
Hiện tại, phiên bản mới nhất của Storm là “apache-Storm-0.9.5.tar.gz”.
Bước 3.2 - Giải nén tệp tar
Giải nén tệp tar bằng các lệnh sau:
$ cd opt/
$ tar -zxf apache-storm-0.9.5.tar.gz
$ cd apache-storm-0.9.5
$ mkdir dataBước 3.3 - Mở tệp cấu hình
Bản phát hành hiện tại của Storm chứa một tệp tại “conf / Storm.yaml” định cấu hình các daemon Storm. Thêm thông tin sau vào tệp đó.
$ vi conf/storm.yaml
storm.zookeeper.servers:
- "localhost"
storm.local.dir: “/path/to/storm/data(any path)”
nimbus.host: "localhost"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703Sau khi áp dụng tất cả các thay đổi, hãy lưu và quay lại thiết bị đầu cuối.
Bước 3.4 - Khởi động Nimbus
$ bin/storm nimbusBước 3.5 - Khởi động Trình giám sát
$ bin/storm supervisorBước 3.6 Khởi động giao diện người dùng
$ bin/storm uiSau khi khởi động ứng dụng giao diện người dùng Storm, hãy nhập URL http://localhost:8080trong trình duyệt yêu thích của bạn và bạn có thể thấy thông tin cụm Storm và cấu trúc liên kết đang chạy của nó. Trang sẽ trông giống như ảnh chụp màn hình sau đây.

Chúng ta đã xem qua các chi tiết kỹ thuật cốt lõi của Apache Storm và bây giờ đã đến lúc viết mã một số kịch bản đơn giản.
Kịch bản - Trình phân tích nhật ký cuộc gọi di động
Cuộc gọi di động và thời lượng của nó sẽ được cung cấp làm đầu vào cho Apache Storm và Storm sẽ xử lý và nhóm cuộc gọi giữa người gọi và người nhận giống nhau và tổng số cuộc gọi của họ.
Tạo vòi
Spout là một thành phần được sử dụng để tạo dữ liệu. Về cơ bản, một vòi sẽ triển khai giao diện IRichSpout. Giao diện “IRichSpout” có các phương thức quan trọng sau:
open- Cung cấp cho vòi có môi trường để thực thi. Những người thực thi sẽ chạy phương thức này để khởi tạo vòi.
nextTuple - Truyền dữ liệu đã tạo thông qua bộ thu thập.
close - Phương thức này được gọi khi vòi sắp tắt.
declareOutputFields - Khai báo lược đồ đầu ra của bộ tuple.
ack - Xác nhận rằng một tuple cụ thể được xử lý
fail - Chỉ định rằng một tuple cụ thể không được xử lý và không được xử lý lại.
Mở
Chữ ký của open phương pháp như sau:
open(Map conf, TopologyContext context, SpoutOutputCollector collector)conf - Cung cấp cấu hình bão cho vòi này.
context - Cung cấp thông tin đầy đủ về vị trí vòi trong cấu trúc liên kết, id nhiệm vụ, thông tin đầu vào và đầu ra của nó.
collector - Cho phép chúng tôi phát ra tuple sẽ được xử lý bởi các bu lông.
nextTuple
Chữ ký của nextTuple phương pháp như sau:
nextTuple()nextTuple () được gọi định kỳ từ cùng một vòng lặp với các phương thức ack () và fail (). Nó phải giải phóng quyền kiểm soát luồng khi không có việc gì phải làm, để các phương thức khác có cơ hội được gọi. Vì vậy, dòng đầu tiên của nextTuple kiểm tra xem quá trình xử lý đã hoàn tất chưa. Nếu vậy, nó nên ngủ ít nhất một phần nghìn giây để giảm tải cho bộ xử lý trước khi quay trở lại.
đóng
Chữ ký của close phương pháp như sau:
close()statementOutputFields
Chữ ký của declareOutputFields phương pháp như sau:
declareOutputFields(OutputFieldsDeclarer declarer)declarer - Nó được sử dụng để khai báo id luồng đầu ra, trường đầu ra, v.v.
Phương thức này được sử dụng để chỉ định lược đồ đầu ra của bộ tuple.
ack
Chữ ký của ack phương pháp như sau:
ack(Object msgId)Phương thức này xác nhận rằng một tuple cụ thể đã được xử lý.
Thất bại
Chữ ký của nextTuple phương pháp như sau:
ack(Object msgId)Phương thức này thông báo rằng một tuple cụ thể chưa được xử lý hoàn toàn. Storm sẽ xử lý lại bộ tuple cụ thể.
FakeCallLogReaderSpout
Trong kịch bản của chúng tôi, chúng tôi cần thu thập chi tiết nhật ký cuộc gọi. Thông tin của nhật ký cuộc gọi chứa.
- số người gọi
- số người nhận
- duration
Vì chúng tôi không có thông tin thời gian thực của nhật ký cuộc gọi, chúng tôi sẽ tạo nhật ký cuộc gọi giả. Thông tin giả sẽ được tạo bằng lớp Random. Mã chương trình hoàn chỉnh được cung cấp bên dưới.
Mã hóa - FakeCallLogReaderSpout.java
import java.util.*;
//import storm tuple packages
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import Spout interface packages
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
//Create a class FakeLogReaderSpout which implement IRichSpout interface
to access functionalities
public class FakeCallLogReaderSpout implements IRichSpout {
//Create instance for SpoutOutputCollector which passes tuples to bolt.
private SpoutOutputCollector collector;
private boolean completed = false;
//Create instance for TopologyContext which contains topology data.
private TopologyContext context;
//Create instance for Random class.
private Random randomGenerator = new Random();
private Integer idx = 0;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
if(this.idx <= 1000) {
List<String> mobileNumbers = new ArrayList<String>();
mobileNumbers.add("1234123401");
mobileNumbers.add("1234123402");
mobileNumbers.add("1234123403");
mobileNumbers.add("1234123404");
Integer localIdx = 0;
while(localIdx++ < 100 && this.idx++ < 1000) {
String fromMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
String toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
while(fromMobileNumber == toMobileNumber) {
toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
}
Integer duration = randomGenerator.nextInt(60);
this.collector.emit(new Values(fromMobileNumber, toMobileNumber, duration));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("from", "to", "duration"));
}
//Override all the interface methods
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Tạo bu lông
Bolt là một thành phần lấy các bộ giá trị làm đầu vào, xử lý bộ giá trị và tạo ra các bộ giá trị mới làm đầu ra. Bu lông sẽ thực hiệnIRichBoltgiao diện. Trong chương trình này, hai lớp bu lôngCallLogCreatorBolt và CallLogCounterBolt được sử dụng để thực hiện các hoạt động.
Giao diện IRichBolt có các phương thức sau:
prepare- Cung cấp cho bu lông một môi trường để thực thi. Những người thực thi sẽ chạy phương thức này để khởi tạo vòi.
execute - Xử lý một bộ dữ liệu đầu vào.
cleanup - Được gọi khi một bu lông sắp tắt.
declareOutputFields - Khai báo lược đồ đầu ra của bộ tuple.
Chuẩn bị
Chữ ký của prepare phương pháp như sau:
prepare(Map conf, TopologyContext context, OutputCollector collector)conf - Cung cấp cấu hình Storm cho bu lông này.
context - Cung cấp thông tin đầy đủ về vị trí bu lông trong cấu trúc liên kết, id nhiệm vụ của nó, thông tin đầu vào và đầu ra, v.v.
collector - Cho phép chúng tôi phát ra bộ tuple đã xử lý.
hành hình
Chữ ký của execute phương pháp như sau:
execute(Tuple tuple)Đây tuple là bộ dữ liệu đầu vào được xử lý.
Các executephương thức xử lý một bộ dữ liệu tại một thời điểm. Dữ liệu tuple có thể được truy cập bằng phương thức getValue của lớp Tuple. Không cần thiết phải xử lý bộ đầu vào ngay lập tức. Nhiều bộ có thể được xử lý và xuất ra như một bộ đầu ra duy nhất. Tuple đã xử lý có thể được phát ra bằng cách sử dụng lớp OutputCollector.
dọn dẹp
Chữ ký của cleanup phương pháp như sau:
cleanup()statementOutputFields
Chữ ký của declareOutputFields phương pháp như sau:
declareOutputFields(OutputFieldsDeclarer declarer)Đây là thông số declarer được sử dụng để khai báo id luồng đầu ra, trường đầu ra, v.v.
Phương thức này được sử dụng để chỉ định lược đồ đầu ra của bộ tuple
Nhật ký cuộc gọi Bolt Creator
Chốt tạo nhật ký cuộc gọi nhận bộ ghi nhật ký cuộc gọi. Bộ ghi nhật ký cuộc gọi có số người gọi, số người nhận và thời lượng cuộc gọi. Chốt này chỉ đơn giản là tạo ra một giá trị mới bằng cách kết hợp số người gọi và số người nhận. Định dạng của giá trị mới là "Số người gọi - Số người nhận" và nó được đặt tên là trường mới, "cuộc gọi". Mã hoàn chỉnh được đưa ra bên dưới.
Mã hóa - CallLogCreatorBolt.java
//import util packages
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
//import Storm IRichBolt package
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
//Create a class CallLogCreatorBolt which implement IRichBolt interface
public class CallLogCreatorBolt implements IRichBolt {
//Create instance for OutputCollector which collects and emits tuples to produce output
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String from = tuple.getString(0);
String to = tuple.getString(1);
Integer duration = tuple.getInteger(2);
collector.emit(new Values(from + " - " + to, duration));
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call", "duration"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Nhật ký cuộc gọi Chốt bộ đếm
Chốt bộ đếm nhật ký cuộc gọi nhận cuộc gọi và thời lượng của nó dưới dạng một bộ. Bu lông này khởi tạo một đối tượng từ điển (Bản đồ) trong phương thức chuẩn bị. Trongexecute, nó sẽ kiểm tra tuple và tạo một mục nhập mới trong đối tượng từ điển cho mọi giá trị "gọi" mới trong bộ tuple và đặt giá trị 1 trong đối tượng từ điển. Đối với mục nhập đã có sẵn trong từ điển, nó chỉ tăng giá trị của nó. Nói một cách dễ hiểu, bu lông này lưu cuộc gọi và số lượng của nó trong đối tượng từ điển. Thay vì lưu cuộc gọi và số lượng của nó trong từ điển, chúng tôi cũng có thể lưu nó vào một nguồn dữ liệu. Mã chương trình hoàn chỉnh như sau:
Mã hóa - CallLogCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class CallLogCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String call = tuple.getString(0);
Integer duration = tuple.getInteger(1);
if(!counterMap.containsKey(call)){
counterMap.put(call, 1);
}else{
Integer c = counterMap.get(call) + 1;
counterMap.put(call, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Tạo cấu trúc liên kết
Cấu trúc liên kết Storm về cơ bản là một cấu trúc Tiết kiệm. Lớp TopologyBuilder cung cấp các phương thức đơn giản và dễ dàng để tạo các cấu trúc liên kết phức tạp. Lớp TopologyBuilder có các phương thức để thiết lập vòi(setSpout) và để đặt bu lông (setBolt). Cuối cùng, TopologyBuilder có createTopology để tạo cấu trúc liên kết. Sử dụng đoạn mã sau để tạo cấu trúc liên kết -
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));shuffleGrouping và fieldsGrouping các phương pháp giúp thiết lập nhóm dòng cho vòi và bu lông.
Cụm cục bộ
Đối với mục đích phát triển, chúng ta có thể tạo một cụm cục bộ bằng cách sử dụng đối tượng "LocalCluster" và sau đó gửi cấu trúc liên kết bằng cách sử dụng phương pháp "submitTopology" của lớp "LocalCluster". Một trong những đối số cho "submitTopology" là một thể hiện của lớp "Config". Lớp "Cấu hình" được sử dụng để đặt các tùy chọn cấu hình trước khi gửi cấu trúc liên kết. Tùy chọn cấu hình này sẽ được hợp nhất với cấu hình cụm tại thời điểm chạy và được gửi đến tất cả tác vụ (vòi và chốt) bằng phương thức chuẩn bị. Khi cấu trúc liên kết được gửi đến cụm, chúng tôi sẽ đợi 10 giây để cụm tính toán cấu trúc liên kết đã gửi và sau đó tắt cụm bằng cách sử dụng phương pháp "tắt máy" của "LocalCluster". Mã chương trình hoàn chỉnh như sau:
Mã hóa - LogAnalyserStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import storm configuration packages
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
//Create main class LogAnalyserStorm submit topology.
public class LogAnalyserStorm {
public static void main(String[] args) throws Exception{
//Create Config instance for cluster configuration
Config config = new Config();
config.setDebug(true);
//
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LogAnalyserStorm", config, builder.createTopology());
Thread.sleep(10000);
//Stop the topology
cluster.shutdown();
}
}Xây dựng và chạy ứng dụng
Ứng dụng hoàn chỉnh có bốn mã Java. Họ là -
- FakeCallLogReaderSpout.java
- CallLogCreaterBolt.java
- CallLogCounterBolt.java
- LogAnalyerStorm.java
Ứng dụng có thể được tạo bằng lệnh sau:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaỨng dụng có thể được chạy bằng lệnh sau:
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserStormĐầu ra
Khi ứng dụng được khởi động, nó sẽ xuất ra thông tin chi tiết đầy đủ về quy trình khởi động cụm, xử lý vòi và chốt, và cuối cùng là quy trình tắt cụm. Trong "CallLogCounterBolt", chúng tôi đã in chi tiết cuộc gọi và số lượng của nó. Thông tin này sẽ được hiển thị trên bảng điều khiển như sau:
1234123402 - 1234123401 : 78
1234123402 - 1234123404 : 88
1234123402 - 1234123403 : 105
1234123401 - 1234123404 : 74
1234123401 - 1234123403 : 81
1234123401 - 1234123402 : 81
1234123403 - 1234123404 : 86
1234123404 - 1234123401 : 63
1234123404 - 1234123402 : 82
1234123403 - 1234123402 : 83
1234123404 - 1234123403 : 86
1234123403 - 1234123401 : 93Ngôn ngữ không phải JVM
Các cấu trúc liên kết Storm được triển khai bởi các giao diện Thrift, giúp dễ dàng gửi cấu trúc liên kết bằng bất kỳ ngôn ngữ nào. Storm hỗ trợ Ruby, Python và nhiều ngôn ngữ khác. Chúng ta hãy xem liên kết python.
Python Binding
Python là một ngôn ngữ lập trình thông dịch, tương tác, hướng đối tượng và cấp cao có mục đích chung. Storm hỗ trợ Python để triển khai cấu trúc liên kết của nó. Python hỗ trợ các hoạt động phát ra, neo, đánh dấu và ghi nhật ký.
Như bạn đã biết, bu lông có thể được định nghĩa bằng bất kỳ ngôn ngữ nào. Các bu lông được viết bằng ngôn ngữ khác được thực thi dưới dạng các quy trình con và Storm giao tiếp với các quy trình con đó bằng các thông báo JSON qua stdin / stdout. Trước tiên, hãy lấy một chốt mẫu WordCount hỗ trợ liên kết python.
public static class WordCount implements IRichBolt {
public WordSplit() {
super("python", "splitword.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}Đây lớp WordCount thực hiện IRichBoltgiao diện và chạy với việc triển khai python đã chỉ định đối số siêu phương thức "splitword.py". Bây giờ, hãy tạo một triển khai python có tên "splitword.py".
import storm
class WordCountBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
WordCountBolt().run()Đây là cách triển khai mẫu cho Python để đếm các từ trong một câu nhất định. Tương tự, bạn cũng có thể liên kết với các ngôn ngữ hỗ trợ khác.
Trident là một phần mở rộng của Storm. Giống như Storm, Trident cũng được phát triển bởi Twitter. Lý do chính đằng sau việc phát triển Trident là cung cấp sự trừu tượng cấp cao trên Storm cùng với xử lý luồng trạng thái và truy vấn phân tán độ trễ thấp.
Trident sử dụng vòi và bu lông, nhưng các thành phần cấp thấp này được Trident tạo tự động trước khi thực thi. Trident có các chức năng, bộ lọc, nối, nhóm và tổng hợp.
Trident xử lý các luồng dưới dạng một loạt các lô được gọi là giao dịch. Nói chung kích thước của các lô nhỏ đó sẽ theo thứ tự hàng nghìn hoặc hàng triệu bộ, tùy thuộc vào luồng đầu vào. Bằng cách này, Trident khác với Storm, nó thực hiện xử lý từng tuple.
Batch processing concept is very similar to database transactions. Every transaction is assigned a transaction ID. The transaction is considered successful, once all its processing complete. However, a failure in processing one of the transaction's tuples will cause the entire transaction to be retransmitted. For each batch, Trident will call beginCommit at the beginning of the transaction, and commit at the end of it.
Cấu trúc liên kết Trident
Trident API cho thấy một tùy chọn dễ dàng để tạo cấu trúc liên kết Trident bằng cách sử dụng lớp “TridentTopology”. Về cơ bản, cấu trúc liên kết Trident nhận luồng đầu vào từ vòi và thực hiện chuỗi hoạt động theo thứ tự (lọc, tổng hợp, nhóm, v.v.) trên luồng. Storm Tuple được thay thế bằng Trident Tuple và Bolts được thay thế bằng hoạt động. Một cấu trúc liên kết Trident đơn giản có thể được tạo như sau:
TridentTopology topology = new TridentTopology();Trident Tuples
Trident tuple là một danh sách các giá trị được đặt tên. Giao diện TridentTuple là mô hình dữ liệu của cấu trúc liên kết Trident. Giao diện TridentTuple là đơn vị dữ liệu cơ bản có thể được xử lý bởi cấu trúc liên kết Trident.
Vòi đinh ba
Vòi Trident tương tự như vòi Storm, với các tùy chọn bổ sung để sử dụng các tính năng của Trident. Trên thực tế, chúng tôi vẫn có thể sử dụng IRichSpout, mà chúng tôi đã sử dụng trong cấu trúc liên kết Storm, nhưng nó sẽ không mang tính giao dịch về bản chất và chúng tôi sẽ không thể sử dụng các lợi thế do Trident cung cấp.
Vòi cơ bản có tất cả các chức năng để sử dụng các tính năng của Trident là "ITridentSpout". Nó hỗ trợ cả ngữ nghĩa giao dịch và không rõ ràng. Các vòi khác là IBatchSpout, IPartitionedTridentSpout và IOpaquePartitionedTridentSpout.
Ngoài những vòi chung này, Trident có nhiều mẫu thực hiện vòi đinh ba. Một trong số đó là vòi FeederBatchSpout, chúng ta có thể sử dụng để gửi danh sách các bộ đinh ba được đặt tên một cách dễ dàng mà không cần lo lắng về việc xử lý hàng loạt, song song, v.v.
Việc tạo FeederBatchSpout và cung cấp dữ liệu có thể được thực hiện như hình dưới đây -
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(
ImmutableList.of("fromMobileNumber", "toMobileNumber", “duration”));
topology.newStream("fixed-batch-spout", testSpout)
testSpout.feed(ImmutableList.of(new Values("1234123401", "1234123402", 20)));Hoạt động Trident
Trident dựa vào “Hoạt động của đinh ba” để xử lý dòng đầu vào của bộ đinh ba. Trident API có một số hoạt động được tích hợp sẵn để xử lý quá trình xử lý luồng từ đơn giản đến phức tạp. Các hoạt động này bao gồm từ xác nhận đơn giản đến phức tạp nhóm và tổng hợp các bộ giá trị đinh ba. Hãy cùng chúng tôi điểm qua các thao tác quan trọng nhất và được sử dụng thường xuyên.
Bộ lọc
Bộ lọc là một đối tượng được sử dụng để thực hiện nhiệm vụ xác nhận đầu vào. Bộ lọc Trident lấy một tập con gồm các trường đinh ba làm đầu vào và trả về true hoặc false tùy thuộc vào việc một số điều kiện nhất định có được thỏa mãn hay không. Nếu trả về true, thì tuple được giữ trong luồng đầu ra; nếu không, tuple sẽ bị xóa khỏi luồng. Bộ lọc về cơ bản sẽ kế thừa từBaseFilter lớp và thực hiện isKeepphương pháp. Đây là một triển khai mẫu của hoạt động bộ lọc -
public class MyFilter extends BaseFilter {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(1) % 2 == 0;
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2]
[1, 4]Chức năng bộ lọc có thể được gọi trong cấu trúc liên kết bằng cách sử dụng phương thức "mỗi". Lớp “Fields” có thể được sử dụng để chỉ định đầu vào (tập con của bộ trident). Mã mẫu như sau:
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields("a", "b"), new MyFilter())Chức năng
Functionlà một đối tượng được sử dụng để thực hiện một hoạt động đơn giản trên một bộ đinh ba duy nhất. Nó nhận một tập hợp con của các trường tuple đinh ba và phát ra không hoặc nhiều trường tuple mới.
Function về cơ bản kế thừa từ BaseFunction lớp học và thực hiện executephương pháp. Một triển khai mẫu được đưa ra dưới đây:
public class MyFunction extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
int a = tuple.getInteger(0);
int b = tuple.getInteger(1);
collector.emit(new Values(a + b));
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2, 3]
[1, 3, 4]
[1, 4, 5]Cũng giống như hoạt động Bộ lọc, hoạt động Hàm có thể được gọi trong cấu trúc liên kết bằng cách sử dụng eachphương pháp. Mã mẫu như sau:
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d")));Tổng hợp
Tổng hợp là một đối tượng được sử dụng để thực hiện các hoạt động tổng hợp trên một lô hoặc phân vùng hoặc luồng đầu vào. Trident có ba kiểu tập hợp. Chúng như sau:
aggregate- Tổng hợp từng lô củ đinh ba một cách riêng biệt. Trong quá trình tổng hợp, các bộ giá trị ban đầu được phân vùng lại bằng cách sử dụng nhóm toàn cục để kết hợp tất cả các phân vùng của cùng một lô thành một phân vùng duy nhất.
partitionAggregate- Tổng hợp từng phân vùng thay vì toàn bộ loạt tuple trident. Đầu ra của tập hợp phân vùng thay thế hoàn toàn bộ dữ liệu đầu vào. Đầu ra của tập hợp phân vùng chứa một bộ trường duy nhất.
persistentaggregate - Tổng hợp trên tất cả bộ đinh ba trên tất cả các lô và lưu trữ kết quả trong bộ nhớ hoặc cơ sở dữ liệu.
TridentTopology topology = new TridentTopology();
// aggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.aggregate(new Count(), new Fields(“count”))
// partitionAggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.partitionAggregate(new Count(), new Fields(“count"))
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));Hoạt động tổng hợp có thể được tạo bằng cách sử dụng giao diện CombinerAggregator, ReducerAggregator hoặc Aggregator chung. Bộ tổng hợp "đếm" được sử dụng trong ví dụ trên là một trong những bộ tổng hợp tích hợp. Nó được triển khai bằng cách sử dụng "CombinerAggregator". Cách triển khai như sau:
public class Count implements CombinerAggregator<Long> {
@Override
public Long init(TridentTuple tuple) {
return 1L;
}
@Override
public Long combine(Long val1, Long val2) {
return val1 + val2;
}
@Override
public Long zero() {
return 0L;
}
}Phân nhóm
Hoạt động nhóm là một hoạt động có sẵn và có thể được gọi bởi groupByphương pháp. Phương thức groupBy định hướng lại luồng bằng cách thực hiện phân vùng Bằng các trường được chỉ định và sau đó trong mỗi phân vùng, nó nhóm các bộ dữ liệu lại với nhau có các trường nhóm bằng nhau. Thông thường, chúng tôi sử dụng “groupBy” cùng với “dai dẳngAggregate” để lấy tổng hợp được nhóm lại. Mã mẫu như sau:
TridentTopology topology = new TridentTopology();
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.groupBy(new Fields(“d”)
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));Hợp nhất và Gia nhập
Việc hợp nhất và kết hợp có thể được thực hiện bằng cách sử dụng phương pháp “hợp nhất” và “nối” tương ứng. Hợp nhất kết hợp một hoặc nhiều luồng. Tham gia tương tự như hợp nhất, ngoại trừ thực tế là việc tham gia sử dụng trường đinh ba từ cả hai phía để kiểm tra và tham gia hai luồng. Hơn nữa, việc tham gia sẽ chỉ hoạt động ở cấp độ hàng loạt. Mã mẫu như sau:
TridentTopology topology = new TridentTopology();
topology.merge(stream1, stream2, stream3);
topology.join(stream1, new Fields("key"), stream2, new Fields("x"),
new Fields("key", "a", "b", "c"));Bảo trì trạng thái
Trident cung cấp một cơ chế để duy trì trạng thái. Thông tin trạng thái có thể được lưu trữ trong chính cấu trúc liên kết, nếu không bạn cũng có thể lưu trữ nó trong một cơ sở dữ liệu riêng biệt. Lý do là để duy trì trạng thái rằng nếu bất kỳ bộ dữ liệu nào bị lỗi trong quá trình xử lý, thì bộ dữ liệu bị lỗi sẽ được thử lại. Điều này tạo ra sự cố trong khi cập nhật trạng thái vì bạn không chắc liệu trạng thái của tuple này đã được cập nhật trước đó hay chưa. Nếu tuple bị lỗi trước khi cập nhật trạng thái, thì việc thử lại tuple sẽ làm cho trạng thái ổn định. Tuy nhiên, nếu tuple bị lỗi sau khi cập nhật trạng thái, thì việc thử lại cùng một tuple sẽ lại làm tăng số lượng trong cơ sở dữ liệu và làm cho trạng thái không ổn định. Người ta cần thực hiện các bước sau để đảm bảo thư chỉ được xử lý một lần -
Xử lý các bộ giá trị thành từng đợt nhỏ.
Chỉ định một ID duy nhất cho mỗi lô. Nếu lô được thử lại, lô sẽ được cung cấp cùng một ID duy nhất.
Các bản cập nhật trạng thái được sắp xếp giữa các đợt. Ví dụ: cập nhật trạng thái của lô thứ hai sẽ không thể thực hiện được cho đến khi hoàn thành cập nhật trạng thái cho lô đầu tiên.
RPC phân tán
RPC phân tán được sử dụng để truy vấn và lấy kết quả từ cấu trúc liên kết Trident. Storm có một máy chủ RPC phân tán sẵn có. Máy chủ RPC phân tán nhận yêu cầu RPC từ máy khách và chuyển nó đến cấu trúc liên kết. Cấu trúc liên kết xử lý yêu cầu và gửi kết quả đến máy chủ RPC phân tán, được máy chủ RPC phân phối chuyển hướng đến máy khách. Truy vấn RPC phân tán của Trident thực thi giống như một truy vấn RPC thông thường, ngoại trừ thực tế là các truy vấn này được chạy song song.
Khi nào sử dụng Trident?
Như trong nhiều trường hợp sử dụng, nếu yêu cầu là xử lý truy vấn chỉ một lần, chúng ta có thể đạt được nó bằng cách viết cấu trúc liên kết trong Trident. Mặt khác, sẽ rất khó để đạt được chính xác một lần xử lý trong trường hợp Storm. Do đó, Trident sẽ hữu ích cho những trường hợp sử dụng mà bạn yêu cầu xử lý chính xác một lần. Trident không dành cho tất cả các trường hợp sử dụng, đặc biệt là các trường hợp sử dụng hiệu suất cao vì nó tăng thêm độ phức tạp cho Storm và quản lý trạng thái.
Ví dụ làm việc của Trident
Chúng tôi sẽ chuyển đổi ứng dụng phân tích nhật ký cuộc gọi của chúng tôi đã được thực hiện trong phần trước sang khuôn khổ Trident. Ứng dụng Trident sẽ tương đối dễ dàng so với bão thông thường, nhờ API cấp cao của nó. Về cơ bản, Storm sẽ được yêu cầu thực hiện bất kỳ một trong các hoạt động Chức năng, Lọc, Tổng hợp, NhómBy, Tham gia và Hợp nhất trong Trident. Cuối cùng, chúng tôi sẽ khởi động Máy chủ DRPC bằng cách sử dụngLocalDRPC lớp và tìm kiếm một số từ khóa bằng cách sử dụng execute phương thức của lớp LocalDRPC.
Định dạng thông tin cuộc gọi
Mục đích của lớp FormatCall là định dạng thông tin cuộc gọi bao gồm "Số người gọi" và "Số người nhận". Mã chương trình hoàn chỉnh như sau:
Mã hóa: FormatCall.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class FormatCall extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String fromMobileNumber = tuple.getString(0);
String toMobileNumber = tuple.getString(1);
collector.emit(new Values(fromMobileNumber + " - " + toMobileNumber));
}
}CSVSplit
Mục đích của lớp CSVSplit là tách chuỗi đầu vào dựa trên “dấu phẩy (,)” và phát ra mọi từ trong chuỗi. Hàm này được sử dụng để phân tích cú pháp đối số đầu vào của truy vấn phân tán. Mã hoàn chỉnh như sau:
Mã hóa: CSVSplit.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class CSVSplit extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
for(String word: tuple.getString(0).split(",")) {
if(word.length() > 0) {
collector.emit(new Values(word));
}
}
}
}Trình phân tích nhật ký
Đây là ứng dụng chính. Ban đầu, ứng dụng sẽ khởi tạo TridentTopology và thông tin người gọi nguồn cấp dữ liệu bằng cách sử dụngFeederBatchSpout. Luồng cấu trúc liên kết Trident có thể được tạo bằng cách sử dụngnewStreamphương pháp của lớp TridentTopology. Tương tự, luồng DRPC cấu trúc liên kết Trident có thể được tạo bằng cách sử dụngnewDRCPStreamphương pháp của lớp TridentTopology. Một máy chủ DRCP đơn giản có thể được tạo bằng cách sử dụng lớp LocalDRPC.LocalDRPCcó phương thức thực thi để tìm kiếm một số từ khóa. Mã hoàn chỉnh được đưa ra bên dưới.
Mã hóa: LogAnalyserTrident.java
import java.util.*;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.utils.DRPCClient;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import storm.trident.TridentState;
import storm.trident.TridentTopology;
import storm.trident.tuple.TridentTuple;
import storm.trident.operation.builtin.FilterNull;
import storm.trident.operation.builtin.Count;
import storm.trident.operation.builtin.Sum;
import storm.trident.operation.builtin.MapGet;
import storm.trident.operation.builtin.Debug;
import storm.trident.operation.BaseFilter;
import storm.trident.testing.FixedBatchSpout;
import storm.trident.testing.FeederBatchSpout;
import storm.trident.testing.Split;
import storm.trident.testing.MemoryMapState;
import com.google.common.collect.ImmutableList;
public class LogAnalyserTrident {
public static void main(String[] args) throws Exception {
System.out.println("Log Analyser Trident");
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(ImmutableList.of("fromMobileNumber",
"toMobileNumber", "duration"));
TridentState callCounts = topology
.newStream("fixed-batch-spout", testSpout)
.each(new Fields("fromMobileNumber", "toMobileNumber"),
new FormatCall(), new Fields("call"))
.groupBy(new Fields("call"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(),
new Fields("count"));
LocalDRPC drpc = new LocalDRPC();
topology.newDRPCStream("call_count", drpc)
.stateQuery(callCounts, new Fields("args"), new MapGet(), new Fields("count"));
topology.newDRPCStream("multiple_call_count", drpc)
.each(new Fields("args"), new CSVSplit(), new Fields("call"))
.groupBy(new Fields("call"))
.stateQuery(callCounts, new Fields("call"), new MapGet(),
new Fields("count"))
.each(new Fields("call", "count"), new Debug())
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
Config conf = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("trident", conf, topology.build());
Random randomGenerator = new Random();
int idx = 0;
while(idx < 10) {
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123402", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123403", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123404", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123402",
"1234123403", randomGenerator.nextInt(60))));
idx = idx + 1;
}
System.out.println("DRPC : Query starts");
System.out.println(drpc.execute("call_count","1234123401 - 1234123402"));
System.out.println(drpc.execute("multiple_call_count", "1234123401 -
1234123402,1234123401 - 1234123403"));
System.out.println("DRPC : Query ends");
cluster.shutdown();
drpc.shutdown();
// DRPCClient client = new DRPCClient("drpc.server.location", 3772);
}
}Xây dựng và chạy ứng dụng
Ứng dụng hoàn chỉnh có ba mã Java. Chúng như sau:
- FormatCall.java
- CSVSplit.java
- LogAnalyerTrident.java
Ứng dụng có thể được tạo bằng cách sử dụng lệnh sau:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaỨng dụng có thể được chạy bằng cách sử dụng lệnh sau:
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserTridentĐầu ra
Khi ứng dụng được khởi động, ứng dụng sẽ xuất ra chi tiết đầy đủ về quá trình khởi động cụm, xử lý hoạt động, Máy chủ DRPC và thông tin máy khách, và cuối cùng là quá trình tắt cụm. Đầu ra này sẽ được hiển thị trên bảng điều khiển như hình dưới đây.
DRPC : Query starts
[["1234123401 - 1234123402",10]]
DEBUG: [1234123401 - 1234123402, 10]
DEBUG: [1234123401 - 1234123403, 10]
[[20]]
DRPC : Query endsỞ đây trong chương này, chúng ta sẽ thảo luận về ứng dụng thời gian thực của Apache Storm. Chúng ta sẽ xem Storm được sử dụng như thế nào trên Twitter.
Twitter là một dịch vụ mạng xã hội trực tuyến cung cấp nền tảng để gửi và nhận các tweet của người dùng. Người dùng đã đăng ký có thể đọc và đăng tweet, nhưng người dùng chưa đăng ký chỉ có thể đọc tweet. Hashtag được sử dụng để phân loại các tweet theo từ khóa bằng cách thêm # trước từ khóa có liên quan. Bây giờ chúng ta hãy thực hiện một kịch bản thời gian thực để tìm thẻ bắt đầu bằng # được sử dụng nhiều nhất cho mỗi chủ đề.
Tạo vòi
Mục đích của spout là để mọi người gửi tweet càng sớm càng tốt. Twitter cung cấp “Twitter Streaming API”, một công cụ dựa trên dịch vụ web để truy xuất các tweet do mọi người gửi trong thời gian thực. Twitter Streaming API có thể được truy cập bằng bất kỳ ngôn ngữ lập trình nào.
twitter4j là một thư viện Java không chính thức, mã nguồn mở, cung cấp một mô-đun dựa trên Java để dễ dàng truy cập vào Twitter Streaming API. twitter4jcung cấp một khuôn khổ dựa trên người nghe để truy cập các tweet. Để truy cập API truyền trực tuyến của Twitter, chúng tôi cần đăng nhập vào tài khoản nhà phát triển Twitter và sẽ nhận được các chi tiết xác thực OAuth sau đây.
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
Storm cung cấp một kênh twitter, TwitterSampleSpout,trong bộ khởi động của nó. Chúng tôi sẽ sử dụng nó để lấy các tweet. Vòi cần chi tiết xác thực OAuth và ít nhất một từ khóa. Vòi sẽ phát ra các tweet theo thời gian thực dựa trên các từ khóa. Mã chương trình hoàn chỉnh được cung cấp bên dưới.
Mã hóa: TwitterSampleSpout.java
import java.util.Map;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.FilterQuery;
import twitter4j.StallWarning;
import twitter4j.Status;
import twitter4j.StatusDeletionNotice;
import twitter4j.StatusListener;
import twitter4j.TwitterStream;
import twitter4j.TwitterStreamFactory;
import twitter4j.auth.AccessToken;
import twitter4j.conf.ConfigurationBuilder;
import backtype.storm.Config;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
@SuppressWarnings("serial")
public class TwitterSampleSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
LinkedBlockingQueue<Status> queue = null;
TwitterStream _twitterStream;
String consumerKey;
String consumerSecret;
String accessToken;
String accessTokenSecret;
String[] keyWords;
public TwitterSampleSpout(String consumerKey, String consumerSecret,
String accessToken, String accessTokenSecret, String[] keyWords) {
this.consumerKey = consumerKey;
this.consumerSecret = consumerSecret;
this.accessToken = accessToken;
this.accessTokenSecret = accessTokenSecret;
this.keyWords = keyWords;
}
public TwitterSampleSpout() {
// TODO Auto-generated constructor stub
}
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
queue = new LinkedBlockingQueue<Status>(1000);
_collector = collector;
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
}
@Override
public void onDeletionNotice(StatusDeletionNotice sdn) {}
@Override
public void onTrackLimitationNotice(int i) {}
@Override
public void onScrubGeo(long l, long l1) {}
@Override
public void onException(Exception ex) {}
@Override
public void onStallWarning(StallWarning arg0) {
// TODO Auto-generated method stub
}
};
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
_twitterStream = new TwitterStreamFactory(cb.build()).getInstance();
_twitterStream.addListener(listener);
if (keyWords.length == 0) {
_twitterStream.sample();
}else {
FilterQuery query = new FilterQuery().track(keyWords);
_twitterStream.filter(query);
}
}
@Override
public void nextTuple() {
Status ret = queue.poll();
if (ret == null) {
Utils.sleep(50);
} else {
_collector.emit(new Values(ret));
}
}
@Override
public void close() {
_twitterStream.shutdown();
}
@Override
public Map<String, Object> getComponentConfiguration() {
Config ret = new Config();
ret.setMaxTaskParallelism(1);
return ret;
}
@Override
public void ack(Object id) {}
@Override
public void fail(Object id) {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("tweet"));
}
}Trình đọc Hashtag Bolt
Tweet phát ra bởi vòi sẽ được chuyển tiếp đến HashtagReaderBolt, sẽ xử lý tweet và phát ra tất cả các thẻ bắt đầu bằng # có sẵn. HashtagReaderBolt sử dụnggetHashTagEntitiesphương pháp được cung cấp bởi twitter4j. getHashTagEntities đọc tweet và trả về danh sách các hashtag. Mã chương trình hoàn chỉnh như sau:
Mã hóa: HashtagReaderBolt.java
import java.util.HashMap;
import java.util.Map;
import twitter4j.*;
import twitter4j.conf.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagReaderBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
Status tweet = (Status) tuple.getValueByField("tweet");
for(HashtagEntity hashtage : tweet.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
this.collector.emit(new Values(hashtage.getText()));
}
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Hashtag Counter Bolt
Thẻ bắt đầu bằng # được phát ra sẽ được chuyển tiếp đến HashtagCounterBolt. Chốt này sẽ xử lý tất cả các thẻ bắt đầu bằng # và lưu từng thẻ bắt đầu bằng # và số lượng của nó trong bộ nhớ bằng cách sử dụng đối tượng Java Map. Mã chương trình hoàn chỉnh được cung cấp bên dưới.
Mã hóa: HashtagCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String key = tuple.getString(0);
if(!counterMap.containsKey(key)){
counterMap.put(key, 1);
}else{
Integer c = counterMap.get(key) + 1;
counterMap.put(key, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println("Result: " + entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Gửi một cấu trúc liên kết
Gửi một cấu trúc liên kết là ứng dụng chính. Cấu trúc liên kết Twitter bao gồmTwitterSampleSpout, HashtagReaderBoltvà HashtagCounterBolt. Mã chương trình sau đây cho thấy cách gửi một cấu trúc liên kết.
Mã hóa: TwitterHashtagStorm.java
import java.util.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class TwitterHashtagStorm {
public static void main(String[] args) throws Exception{
String consumerKey = args[0];
String consumerSecret = args[1];
String accessToken = args[2];
String accessTokenSecret = args[3];
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 4, arguments.length);
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("twitter-spout", new TwitterSampleSpout(consumerKey,
consumerSecret, accessToken, accessTokenSecret, keyWords));
builder.setBolt("twitter-hashtag-reader-bolt", new HashtagReaderBolt())
.shuffleGrouping("twitter-spout");
builder.setBolt("twitter-hashtag-counter-bolt", new HashtagCounterBolt())
.fieldsGrouping("twitter-hashtag-reader-bolt", new Fields("hashtag"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("TwitterHashtagStorm", config,
builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}Xây dựng và chạy ứng dụng
Ứng dụng hoàn chỉnh có bốn mã Java. Chúng như sau:
- TwitterSampleSpout.java
- HashtagReaderBolt.java
- HashtagCounterBolt.java
- TwitterHashtagStorm.java
Bạn có thể biên dịch ứng dụng bằng lệnh sau:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*” *.javaThực thi ứng dụng bằng các lệnh sau:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*”:.
TwitterHashtagStorm <customerkey> <customersecret> <accesstoken> <accesstokensecret>
<keyword1> <keyword2> … <keywordN>Đầu ra
Ứng dụng sẽ in hashtag hiện có sẵn và số lượng của nó. Đầu ra phải tương tự như sau:
Result: jazztastic : 1
Result: foodie : 1
Result: Redskins : 1
Result: Recipe : 1
Result: cook : 1
Result: android : 1
Result: food : 2
Result: NoToxicHorseMeat : 1
Result: Purrs4Peace : 1
Result: livemusic : 1
Result: VIPremium : 1
Result: Frome : 1
Result: SundayRoast : 1
Result: Millennials : 1
Result: HealthWithKier : 1
Result: LPs30DaysofGratitude : 1
Result: cooking : 1
Result: gameinsight : 1
Result: Countryfile : 1
Result: androidgames : 1Yahoo! Finance là trang web dữ liệu tài chính và tin tức kinh doanh hàng đầu trên Internet. Nó là một phần của Yahoo! và cung cấp thông tin về tin tức tài chính, thống kê thị trường, dữ liệu thị trường quốc tế và các thông tin khác về nguồn tài chính mà bất kỳ ai cũng có thể truy cập.
Nếu bạn là người đăng ký Yahoo! người dùng, sau đó bạn có thể tùy chỉnh Yahoo! Tài chính để tận dụng các dịch vụ nhất định của nó. Yahoo! API tài chính được sử dụng để truy vấn dữ liệu tài chính từ Yahoo!
API này hiển thị dữ liệu bị trễ 15 phút so với thời gian thực và cập nhật cơ sở dữ liệu của nó sau mỗi 1 phút, để truy cập thông tin liên quan đến chứng khoán hiện tại. Bây giờ chúng ta hãy xem một kịch bản thời gian thực của một công ty và xem cách tăng cảnh báo khi giá trị cổ phiếu của công ty đó xuống dưới 100.
Tạo vòi
Mục đích của vòi là để lấy các chi tiết của ty và phát ra các giá vào bu lông. Bạn có thể sử dụng mã chương trình sau để tạo vòi.
Mã hóa: YahooFinanceSpout.java
import java.util.*;
import java.io.*;
import java.math.BigDecimal;
//import yahoofinace packages
import yahoofinance.YahooFinance;
import yahoofinance.Stock;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
public class YahooFinanceSpout implements IRichSpout {
private SpoutOutputCollector collector;
private boolean completed = false;
private TopologyContext context;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector){
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
try {
Stock stock = YahooFinance.get("INTC");
BigDecimal price = stock.getQuote().getPrice();
this.collector.emit(new Values("INTC", price.doubleValue()));
stock = YahooFinance.get("GOOGL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("GOOGL", price.doubleValue()));
stock = YahooFinance.get("AAPL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("AAPL", price.doubleValue()));
} catch(Exception e) {}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("company", "price"));
}
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Tạo bu lông
Ở đây, mục đích của bolt là xử lý giá của công ty nhất định khi giá giảm xuống dưới 100. Nó sử dụng đối tượng Bản đồ Java để đặt cảnh báo giới hạn giá cắt như truekhi giá cổ phiếu giảm xuống dưới 100; nếu không thì sai. Mã chương trình hoàn chỉnh như sau:
Mã hóa: PriceCutOffBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class PriceCutOffBolt implements IRichBolt {
Map<String, Integer> cutOffMap;
Map<String, Boolean> resultMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.cutOffMap = new HashMap <String, Integer>();
this.cutOffMap.put("INTC", 100);
this.cutOffMap.put("AAPL", 100);
this.cutOffMap.put("GOOGL", 100);
this.resultMap = new HashMap<String, Boolean>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String company = tuple.getString(0);
Double price = tuple.getDouble(1);
if(this.cutOffMap.containsKey(company)){
Integer cutOffPrice = this.cutOffMap.get(company);
if(price < cutOffPrice) {
this.resultMap.put(company, true);
} else {
this.resultMap.put(company, false);
}
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Boolean> entry:resultMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("cut_off_price"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Gửi một cấu trúc liên kết
Đây là ứng dụng chính nơi YahooFinanceSpout.java và PriceCutOffBolt.java được kết nối với nhau và tạo ra cấu trúc liên kết. Mã chương trình sau đây cho thấy cách bạn có thể gửi một cấu trúc liên kết.
Mã hóa: YahooFinanceStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class YahooFinanceStorm {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("yahoo-finance-spout", new YahooFinanceSpout());
builder.setBolt("price-cutoff-bolt", new PriceCutOffBolt())
.fieldsGrouping("yahoo-finance-spout", new Fields("company"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("YahooFinanceStorm", config, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}Xây dựng và chạy ứng dụng
Ứng dụng hoàn chỉnh có ba mã Java. Chúng như sau:
- YahooFinanceSpout.java
- PriceCutOffBolt.java
- YahooFinanceStorm.java
Ứng dụng có thể được tạo bằng lệnh sau:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*” *.javaỨng dụng có thể được chạy bằng lệnh sau:
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*”:.
YahooFinanceStormĐầu ra
Đầu ra sẽ tương tự như sau:
GOOGL : false
AAPL : false
INTC : trueApache Storm framework hỗ trợ nhiều ứng dụng công nghiệp tốt nhất hiện nay. Chúng tôi sẽ cung cấp một cái nhìn tổng quan rất ngắn gọn về một số ứng dụng đáng chú ý nhất của Storm trong chương này.
Klout
Klout là một ứng dụng sử dụng phân tích phương tiện truyền thông xã hội để xếp hạng người dùng dựa trên ảnh hưởng xã hội trực tuyến thông qua Klout Score, là một giá trị số từ 1 đến 100. Klout sử dụng phép trừu tượng Trident có sẵn của Apache Storm để tạo các cấu trúc liên kết phức tạp truyền dữ liệu.
Kênh thời tiết
Kênh thời tiết sử dụng cấu trúc liên kết Storm để nhập dữ liệu thời tiết. Nó đã liên kết với Twitter để cho phép quảng cáo thông báo thời tiết trên Twitter và các ứng dụng di động.OpenSignal là một công ty chuyên về lập bản đồ vùng phủ sóng không dây. StormTag và WeatherSignallà các dự án dựa trên thời tiết được tạo bởi OpenSignal. StormTag là một trạm thời tiết Bluetooth gắn vào một chuỗi khóa. Dữ liệu thời tiết do thiết bị thu thập được gửi đến ứng dụng WeatherSignal và máy chủ OpenSignal.
Ngành viễn thông
Các nhà cung cấp dịch vụ viễn thông xử lý hàng triệu cuộc gọi điện thoại mỗi giây. Họ thực hiện pháp y đối với các cuộc gọi bị rớt và chất lượng âm thanh kém. Các bản ghi chi tiết cuộc gọi lưu chuyển với tốc độ hàng triệu mỗi giây và Apache Storm xử lý các bản ghi đó trong thời gian thực và xác định bất kỳ mẫu rắc rối nào. Phân tích bão có thể được sử dụng để liên tục cải thiện chất lượng cuộc gọi.