Súp đẹp - Hướng dẫn nhanh
Trong thế giới ngày nay, chúng ta có rất nhiều dữ liệu / thông tin phi cấu trúc (chủ yếu là dữ liệu web) có sẵn miễn phí. Đôi khi dữ liệu có sẵn miễn phí rất dễ đọc và đôi khi không. Bất kể dữ liệu của bạn có sẵn như thế nào, tính năng quét web là công cụ rất hữu ích để chuyển đổi dữ liệu phi cấu trúc thành dữ liệu có cấu trúc dễ đọc và phân tích hơn. Nói cách khác, một cách để thu thập, sắp xếp và phân tích lượng dữ liệu khổng lồ này là thông qua việc tìm kiếm trên web. Vì vậy, trước tiên chúng ta hãy hiểu web-nạo là gì.
Tìm kiếm web là gì?
Scraping chỉ đơn giản là một quá trình trích xuất (từ nhiều phương tiện khác nhau), sao chép và sàng lọc dữ liệu.
Khi chúng tôi cạo hoặc trích xuất dữ liệu hoặc nguồn cấp dữ liệu từ web (như từ các trang web hoặc trang web), nó được gọi là quét web.
Vì vậy, nạo web hay còn được gọi là trích xuất dữ liệu web hoặc thu thập web là việc trích xuất dữ liệu từ web. Nói tóm lại, việc tìm kiếm web cung cấp một cách để các nhà phát triển thu thập và phân tích dữ liệu từ internet.
Tại sao lại tìm kiếm trên web?
Web-cạo cung cấp một trong những công cụ tuyệt vời để tự động hóa hầu hết những việc con người làm khi duyệt web. Web-cạo được sử dụng trong một doanh nghiệp theo nhiều cách khác nhau -
Dữ liệu cho nghiên cứu
Nhà phân tích thông minh (như nhà nghiên cứu hoặc nhà báo) sử dụng công cụ quét web thay vì thu thập và làm sạch dữ liệu từ các trang web theo cách thủ công.
Giá sản phẩm và so sánh mức độ phổ biến
Hiện tại, có một số dịch vụ sử dụng trình duyệt web để thu thập dữ liệu từ nhiều trang trực tuyến và sử dụng nó để so sánh mức độ phổ biến và giá cả của sản phẩm.
Giám sát SEO
Có rất nhiều công cụ SEO như Ahrefs, Seobility, SEMrush, v.v., được sử dụng để phân tích cạnh tranh và lấy dữ liệu từ các trang web của khách hàng của bạn.
Công cụ tìm kiếm
Có một số công ty CNTT lớn mà hoạt động kinh doanh của họ chỉ phụ thuộc vào việc quét web.
Bán hàng và marketing
Các nhà tiếp thị có thể sử dụng dữ liệu thu thập thông qua việc tìm kiếm trên web để phân tích các ngách và đối thủ cạnh tranh khác nhau hoặc bởi chuyên gia bán hàng để bán các dịch vụ tiếp thị nội dung hoặc quảng bá trên mạng xã hội.
Tại sao sử dụng Python cho Web Scraping?
Python là một trong những ngôn ngữ phổ biến nhất để quét web vì nó có thể xử lý hầu hết các tác vụ liên quan đến thu thập dữ liệu web một cách rất dễ dàng.
Dưới đây là một số điểm về lý do tại sao nên chọn python để quét web:
Dễ sử dụng
Như hầu hết các nhà phát triển đồng ý rằng python rất dễ viết mã. Chúng ta không phải sử dụng bất kỳ dấu ngoặc nhọn “{}” hoặc dấu chấm phẩy “;” ở bất cứ đâu, điều này làm cho nó dễ đọc và dễ sử dụng hơn trong khi phát triển trình duyệt web.
Hỗ trợ thư viện khổng lồ
Python cung cấp một bộ thư viện khổng lồ cho các yêu cầu khác nhau, vì vậy nó thích hợp cho việc quét web cũng như trực quan hóa dữ liệu, học máy, v.v.
Cú pháp có thể giải thích dễ dàng
Python là một ngôn ngữ lập trình rất dễ đọc vì cú pháp của python rất dễ hiểu. Python rất biểu cảm và việc thụt lề mã giúp người dùng phân biệt các khối hoặc đoạn mã khác nhau trong mã.
Ngôn ngữ được nhập động
Python là một ngôn ngữ được định kiểu động, có nghĩa là dữ liệu được gán cho một biến sẽ cho biết loại biến đó là gì. Nó tiết kiệm rất nhiều thời gian và làm cho công việc nhanh hơn.
Cộng đồng lớn
Cộng đồng Python rất lớn giúp bạn bất cứ nơi nào bạn gặp khó khăn khi viết mã.
Giới thiệu về Beautiful Soup
The Beautiful Soup là một thư viện trăn được đặt tên theo bài thơ cùng tên của Lewis Carroll trong “Cuộc phiêu lưu của Alice ở xứ sở thần tiên”. Beautiful Soup là một gói python và như tên cho thấy, phân tích cú pháp dữ liệu không mong muốn và giúp tổ chức và định dạng dữ liệu web lộn xộn bằng cách sửa lỗi HTML và hiển thị cho chúng ta trong cấu trúc XML dễ duyệt.
Tóm lại, Beautiful Soup là một gói python cho phép chúng tôi lấy dữ liệu ra khỏi các tài liệu HTML và XML.
Vì BeautifulSoup không phải là một thư viện python tiêu chuẩn, chúng tôi cần cài đặt nó trước. Chúng tôi sẽ cài đặt thư viện BeautifulSoup 4 (còn được gọi là BS4), là thư viện mới nhất.
Để cô lập môi trường làm việc của chúng ta để không làm ảnh hưởng đến thiết lập hiện có, trước tiên chúng ta hãy tạo một môi trường ảo.
Tạo môi trường ảo (tùy chọn)
Môi trường ảo cho phép chúng tôi tạo một bản sao làm việc riêng biệt của python cho một dự án cụ thể mà không ảnh hưởng đến thiết lập bên ngoài.
Cách tốt nhất để cài đặt bất kỳ máy gói python nào là sử dụng pip, tuy nhiên, nếu pip chưa được cài đặt (bạn có thể kiểm tra bằng cách sử dụng - “pip –version” trong lệnh hoặc dấu nhắc shell của bạn), bạn có thể cài đặt bằng cách đưa ra lệnh dưới đây -
Môi trường Linux
$sudo apt-get install python-pipMôi trường Windows
Để cài đặt pip trong windows, hãy làm như sau:
Tải xuống get-pip.py từ https://bootstrap.pypa.io/get-pip.py hoặc từ github đến máy tính của bạn.
Mở dấu nhắc lệnh và điều hướng đến thư mục chứa tệp get-pip.py.
Chạy lệnh sau:
>python get-pip.pyVậy là xong, pip hiện đã được cài đặt trong máy tính windows của bạn.
Bạn có thể xác minh pip của mình đã cài đặt bằng cách chạy lệnh dưới đây -
>pip --version
pip 19.2.3 from c:\users\yadur\appdata\local\programs\python\python37\lib\site-packages\pip (python 3.7)Cài đặt môi trường ảo
Chạy lệnh dưới đây trong dấu nhắc lệnh của bạn -
>pip install virtualenvSau khi chạy, bạn sẽ thấy ảnh chụp màn hình bên dưới:

Lệnh dưới đây sẽ tạo một môi trường ảo (“myEnv”) trong thư mục hiện tại của bạn -
>virtualenv myEnvẢnh chụp màn hình

Để kích hoạt môi trường ảo của bạn, hãy chạy lệnh sau:
>myEnv\Scripts\activate
Trong ảnh chụp màn hình ở trên, bạn có thể thấy chúng ta có tiền tố “myEnv” cho chúng ta biết rằng chúng ta đang ở trong môi trường ảo “myEnv”.
Để thoát ra khỏi môi trường ảo, hãy chạy hủy kích hoạt.
(myEnv) C:\Users\yadur>deactivate
C:\Users\yadur>Khi môi trường ảo của chúng ta đã sẵn sàng, bây giờ chúng ta hãy cài đặt beautifulsoup.
Cài đặt BeautifulSoup
Vì BeautifulSoup không phải là một thư viện chuẩn nên chúng ta cần cài đặt nó. Chúng tôi sẽ sử dụng gói BeautifulSoup 4 (được gọi là bs4).
Máy Linux
Để cài đặt bs4 trên Debian hoặc Ubuntu linux bằng trình quản lý gói hệ thống, hãy chạy lệnh dưới đây:
$sudo apt-get install python-bs4 (for python 2.x)
$sudo apt-get install python3-bs4 (for python 3.x)Bạn có thể cài đặt bs4 bằng easy_install hoặc pip (trong trường hợp bạn gặp sự cố khi cài đặt bằng system packager).
$easy_install beautifulsoup4
$pip install beautifulsoup4(Bạn có thể cần sử dụng easy_install3 hoặc pip3 tương ứng nếu bạn đang sử dụng python3)
Máy Windows
Để cài đặt beautifulsoup4 trong windows rất đơn giản, đặc biệt nếu bạn đã cài đặt pip.
>pip install beautifulsoup4
Vì vậy, bây giờ beautifulsoup4 đã được cài đặt trong máy của chúng tôi. Hãy để chúng tôi nói về một số vấn đề gặp phải sau khi cài đặt.
Sự cố sau khi cài đặt
Trên máy windows bạn có thể gặp phải lỗi cài đặt sai phiên bản chủ yếu do -
lỗi: ImportError “No module named HTMLParser”, thì bạn phải đang chạy phiên bản python 2 của mã trong Python 3.
lỗi: ImportError “No module named html.parser” thì bạn phải chạy phiên bản Python 3 của mã trong Python 2.
Cách tốt nhất để thoát khỏi hai trường hợp trên là cài đặt lại BeautifulSoup một lần nữa, xóa hoàn toàn cài đặt hiện có.
Nếu bạn nhận được SyntaxError “Invalid syntax” trên dòng ROOT_TAG_NAME = u '[document]', thì bạn cần chuyển đổi mã python 2 thành python 3, chỉ bằng cách cài đặt gói -
$ python3 setup.py installhoặc bằng cách chạy thủ công tập lệnh chuyển đổi 2 đến 3 của python trên thư mục bs4 -
$ 2to3-3.2 -w bs4Cài đặt trình phân tích cú pháp
Theo mặc định, Beautiful Soup hỗ trợ trình phân tích cú pháp HTML có trong thư viện chuẩn của Python, tuy nhiên, nó cũng hỗ trợ nhiều trình phân tích cú pháp python bên thứ ba bên ngoài như trình phân tích cú pháp lxml hoặc html5lib.
Để cài đặt trình phân tích cú pháp lxml hoặc html5lib, hãy sử dụng lệnh -
Máy Linux
$apt-get install python-lxml
$apt-get insall python-html5libMáy Windows
$pip install lxml
$pip install html5lib
Nói chung, người dùng sử dụng lxml để tăng tốc độ và nên sử dụng trình phân tích cú pháp lxml hoặc html5lib nếu bạn đang sử dụng phiên bản cũ hơn của python 2 (trước phiên bản 2.7.3) hoặc python 3 (trước 3.2.2) vì trình phân tích cú pháp HTML tích hợp của python là không tốt lắm trong việc xử lý phiên bản cũ.
Running Beautiful Soup
Đã đến lúc thử nghiệm gói Beautiful Soup của chúng tôi trên một trong các trang html (lấy trang web - https://www.tutorialspoint.com/index.htm, bạn có thể chọn bất kỳ trang web nào khác mà bạn muốn) và trích xuất một số thông tin từ đó.
Trong đoạn mã dưới đây, chúng tôi đang cố gắng trích xuất tiêu đề từ trang web -
from bs4 import BeautifulSoup
import requests
url = "https://www.tutorialspoint.com/index.htm"
req = requests.get(url)
soup = BeautifulSoup(req.text, "html.parser")
print(soup.title)Đầu ra
<title>H2O, Colab, Theano, Flutter, KNime, Mean.js, Weka, Solidity, Org.Json, AWS QuickSight, JSON.Simple, Jackson Annotations, Passay, Boon, MuleSoft, Nagios, Matplotlib, Java NIO, PyTorch, SLF4J, Parallax Scrolling, Java Cryptography</title>Một nhiệm vụ phổ biến là trích xuất tất cả các URL trong một trang web. Để làm được điều đó, chúng ta chỉ cần thêm dòng mã bên dưới -
for link in soup.find_all('a'):
print(link.get('href'))Đầu ra
https://www.tutorialspoint.com/index.htm
https://www.tutorialspoint.com/about/about_careers.htm
https://www.tutorialspoint.com/questions/index.php
https://www.tutorialspoint.com/online_dev_tools.htm
https://www.tutorialspoint.com/codingground.htm
https://www.tutorialspoint.com/current_affairs.htm
https://www.tutorialspoint.com/upsc_ias_exams.htm
https://www.tutorialspoint.com/tutor_connect/index.php
https://www.tutorialspoint.com/whiteboard.htm
https://www.tutorialspoint.com/netmeeting.php
https://www.tutorialspoint.com/index.htm
https://www.tutorialspoint.com/tutorialslibrary.htm
https://www.tutorialspoint.com/videotutorials/index.php
https://store.tutorialspoint.com
https://www.tutorialspoint.com/gate_exams_tutorials.htm
https://www.tutorialspoint.com/html_online_training/index.asp
https://www.tutorialspoint.com/css_online_training/index.asp
https://www.tutorialspoint.com/3d_animation_online_training/index.asp
https://www.tutorialspoint.com/swift_4_online_training/index.asp
https://www.tutorialspoint.com/blockchain_online_training/index.asp
https://www.tutorialspoint.com/reactjs_online_training/index.asp
https://www.tutorix.com
https://www.tutorialspoint.com/videotutorials/top-courses.php
https://www.tutorialspoint.com/the_full_stack_web_development/index.asp
….
….
https://www.tutorialspoint.com/online_dev_tools.htm
https://www.tutorialspoint.com/free_web_graphics.htm
https://www.tutorialspoint.com/online_file_conversion.htm
https://www.tutorialspoint.com/netmeeting.php
https://www.tutorialspoint.com/free_online_whiteboard.htm
http://www.tutorialspoint.com
https://www.facebook.com/tutorialspointindia
https://plus.google.com/u/0/+tutorialspoint
http://www.twitter.com/tutorialspoint
http://www.linkedin.com/company/tutorialspoint
https://www.youtube.com/channel/UCVLbzhxVTiTLiVKeGV7WEBg
https://www.tutorialspoint.com/index.htm
/about/about_privacy.htm#cookies
/about/faq.htm
/about/about_helping.htm
/about/contact_us.htmTương tự, chúng ta có thể trích xuất thông tin hữu ích bằng cách sử dụng beautifulsoup4.
Bây giờ chúng ta hãy hiểu thêm về "súp" trong ví dụ trên.
Trong ví dụ mã trước, chúng ta phân tích cú pháp tài liệu thông qua hàm tạo đẹp bằng phương thức chuỗi. Một cách khác là chuyển tài liệu qua bộ xử lý tệp đang mở.
from bs4 import BeautifulSoup
with open("example.html") as fp:
soup = BeautifulSoup(fp)
soup = BeautifulSoup("<html>data</html>")Đầu tiên, tài liệu được chuyển đổi sang Unicode và các thực thể HTML được chuyển đổi thành các ký tự Unicode: </p>
import bs4
html = '''<b>tutorialspoint</b>, <i>&web scraping &data science;</i>'''
soup = bs4.BeautifulSoup(html, 'lxml')
print(soup)Đầu ra
<html><body><b>tutorialspoint</b>, <i>&web scraping &data science;</i></body></html>BeautifulSoup sau đó phân tích cú pháp dữ liệu bằng trình phân tích cú pháp HTML hoặc bạn yêu cầu rõ ràng nó phân tích cú pháp bằng trình phân tích cú pháp XML.
Cấu trúc cây HTML
Trước khi chúng ta xem xét các thành phần khác nhau của một trang HTML, trước tiên chúng ta hãy hiểu cấu trúc cây HTML.
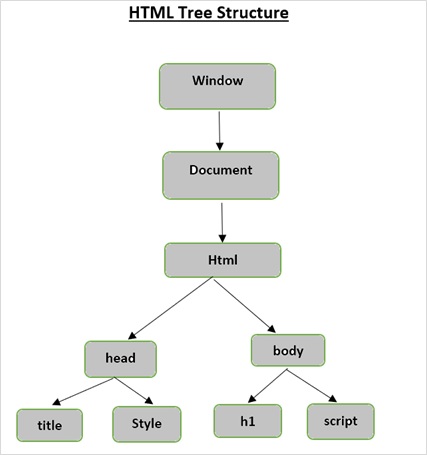
Phần tử gốc trong cây tài liệu là html, có thể có cha mẹ, con cái và anh chị em và điều này xác định bởi vị trí của nó trong cấu trúc cây. Để di chuyển giữa các phần tử, thuộc tính và văn bản HTML, bạn phải di chuyển giữa các nút trong cấu trúc cây của mình.
Giả sử trang web như hình dưới đây -
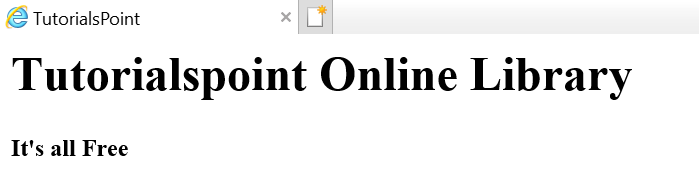
Dịch sang tài liệu html như sau:
<html><head><title>TutorialsPoint</title></head><h1>Tutorialspoint Online Library</h1><p<<b>It's all Free</b></p></body></html>Điều đơn giản có nghĩa là, đối với tài liệu html ở trên, chúng ta có cấu trúc cây html như sau:
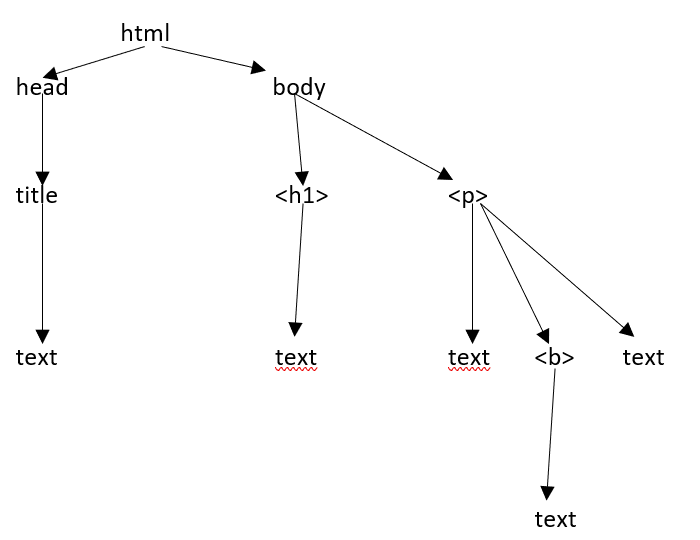
Khi chúng tôi chuyển một tài liệu hoặc chuỗi html đến một phương thức khởi tạo beautifulsoup, về cơ bản, beautifulsoup sẽ chuyển đổi một trang html phức tạp thành các đối tượng python khác nhau. Dưới đây chúng ta sẽ thảo luận về bốn loại đối tượng chính:
Tag
NavigableString
BeautifulSoup
Comments
Đối tượng thẻ
Thẻ HTML được sử dụng để xác định nhiều loại nội dung khác nhau. Đối tượng thẻ trong BeautifulSoup tương ứng với thẻ HTML hoặc XML trong trang hoặc tài liệu thực tế.
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup('<b class="boldest">TutorialsPoint</b>')
>>> tag = soup.html
>>> type(tag)
<class 'bs4.element.Tag'>Thẻ chứa rất nhiều thuộc tính và phương thức và hai tính năng quan trọng của thẻ là tên và thuộc tính của nó.
Tên (tag.name)
Mỗi thẻ chứa một tên và có thể được truy cập thông qua '.name' làm hậu tố. tag.name sẽ trả về loại thẻ.
>>> tag.name
'html'Tuy nhiên, nếu chúng tôi thay đổi tên thẻ, điều tương tự sẽ được phản ánh trong đánh dấu HTML được tạo bởi BeautifulSoup.
>>> tag.name = "Strong"
>>> tag
<Strong><body><b class="boldest">TutorialsPoint</b></body></Strong>
>>> tag.name
'Strong'Các thuộc tính (tag.attrs)
Một đối tượng thẻ có thể có bất kỳ số lượng thuộc tính nào. Thẻ <b class = ”boldest”> có thuộc tính 'class' có giá trị là "boldest". Bất kỳ thứ gì không phải là thẻ NOT, về cơ bản là một thuộc tính và phải chứa một giá trị. Bạn có thể truy cập các thuộc tính thông qua truy cập các khóa (như truy cập “lớp” trong ví dụ trên) hoặc truy cập trực tiếp thông qua “.attrs”
>>> tutorialsP = BeautifulSoup("<div class='tutorialsP'></div>",'lxml')
>>> tag2 = tutorialsP.div
>>> tag2['class']
['tutorialsP']Chúng tôi có thể thực hiện tất cả các loại sửa đổi đối với các thuộc tính của thẻ (thêm / xóa / sửa đổi).
>>> tag2['class'] = 'Online-Learning'
>>> tag2['style'] = '2007'
>>>
>>> tag2
<div class="Online-Learning" style="2007"></div>
>>> del tag2['style']
>>> tag2
<div class="Online-Learning"></div>
>>> del tag['class']
>>> tag
<b SecondAttribute="2">TutorialsPoint</b>
>>>
>>> del tag['SecondAttribute']
>>> tag
</b>
>>> tag2['class']
'Online-Learning'
>>> tag2['style']
KeyError: 'style'Thuộc tính đa giá trị
Một số thuộc tính HTML5 có thể có nhiều giá trị. Thường được sử dụng nhất là thuộc tính lớp có thể có nhiều giá trị CSS. Những thứ khác bao gồm 'rel', 'rev', 'headers', 'accesskey' và 'accept-charset'. Các thuộc tính đa giá trị trong món súp đẹp được hiển thị dưới dạng danh sách.
>>> from bs4 import BeautifulSoup
>>>
>>> css_soup = BeautifulSoup('<p class="body"></p>')
>>> css_soup.p['class']
['body']
>>>
>>> css_soup = BeautifulSoup('<p class="body bold"></p>')
>>> css_soup.p['class']
['body', 'bold']Tuy nhiên, nếu bất kỳ thuộc tính nào chứa nhiều hơn một giá trị nhưng nó không phải là thuộc tính đa giá trị theo bất kỳ phiên bản nào của tiêu chuẩn HTML, thì món canh đẹp sẽ để riêng thuộc tính -
>>> id_soup = BeautifulSoup('<p id="body bold"></p>')
>>> id_soup.p['id']
'body bold'
>>> type(id_soup.p['id'])
<class 'str'>Bạn có thể hợp nhất nhiều giá trị thuộc tính nếu bạn chuyển thẻ thành một chuỗi.
>>> rel_soup = BeautifulSoup("<p> tutorialspoint Main <a rel='Index'> Page</a></p>")
>>> rel_soup.a['rel']
['Index']
>>> rel_soup.a['rel'] = ['Index', ' Online Library, Its all Free']
>>> print(rel_soup.p)
<p> tutorialspoint Main <a rel="Index Online Library, Its all Free"> Page</a></p>Bằng cách sử dụng 'get_attribute_list', bạn nhận được một giá trị luôn là một danh sách, chuỗi, bất kể nó có phải là nhiều giá trị hay không.
id_soup.p.get_attribute_list(‘id’)Tuy nhiên, nếu bạn phân tích cú pháp tài liệu là 'xml', sẽ không có thuộc tính đa giá trị nào -
>>> xml_soup = BeautifulSoup('<p class="body bold"></p>', 'xml')
>>> xml_soup.p['class']
'body bold'NavigableString
Đối tượng điều hướng được sử dụng để đại diện cho nội dung của thẻ. Để truy cập nội dung, hãy sử dụng thẻ “.string”.
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>")
>>>
>>> soup.string
'Hello, Tutorialspoint!'
>>> type(soup.string)
>Bạn có thể thay thế chuỗi bằng một chuỗi khác nhưng bạn không thể chỉnh sửa chuỗi hiện có.
>>> soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>")
>>> soup.string.replace_with("Online Learning!")
'Hello, Tutorialspoint!'
>>> soup.string
'Online Learning!'
>>> soup
<html><body><h2 id="message">Online Learning!</h2></body></html>BeautifulSoup
BeautifulSoup là đối tượng được tạo ra khi chúng ta cố gắng thu thập tài nguyên web. Vì vậy, nó là tài liệu hoàn chỉnh mà chúng tôi đang cố gắng thu thập. Hầu hết thời gian, nó là đối tượng thẻ được xử lý.
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup("<h2 id='message'>Hello, Tutorialspoint!</h2>")
>>> type(soup)
<class 'bs4.BeautifulSoup'>
>>> soup.name
'[document]'Bình luận
Đối tượng bình luận minh họa phần bình luận của tài liệu web. Nó chỉ là một loại NavigableString đặc biệt.
>>> soup = BeautifulSoup('<p><!-- Everything inside it is COMMENTS --></p>')
>>> comment = soup.p.string
>>> type(comment)
<class 'bs4.element.Comment'>
>>> type(comment)
<class 'bs4.element.Comment'>
>>> print(soup.p.prettify())
<p>
<!-- Everything inside it is COMMENTS -->
</p>Đối tượng NavigableString
Các đối tượng điều hướng được sử dụng để đại diện cho văn bản trong các thẻ, thay vì chính các thẻ.
Trong chương này, chúng ta sẽ thảo luận về Điều hướng bằng thẻ.
Dưới đây là tài liệu html của chúng tôi -
>>> html_doc = """
<html><head><title>Tutorials Point</title></head>
<body>
<p class="title"><b>The Biggest Online Tutorials Library, It's all Free</b></p>
<p class="prog">Top 5 most used Programming Languages are:
<a href="https://www.tutorialspoint.com/java/java_overview.htm" class="prog" id="link1">Java</a>,
<a href="https://www.tutorialspoint.com/cprogramming/index.htm" class="prog" id="link2">C</a>,
<a href="https://www.tutorialspoint.com/python/index.htm" class="prog" id="link3">Python</a>,
<a href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" class="prog" id="link4">JavaScript</a> and
<a href="https://www.tutorialspoint.com/ruby/index.htm" class="prog" id="link5">C</a>;
as per online survey.</p>
<p class="prog">Programming Languages</p>
"""
>>>
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html_doc, 'html.parser')
>>>Dựa trên tài liệu trên, chúng tôi sẽ cố gắng chuyển từ phần này sang phần khác.
Đi xuống
Một trong những thành phần quan trọng trong bất kỳ phần nào của tài liệu HTML là các thẻ, có thể chứa các thẻ / chuỗi khác (con của thẻ). Beautiful Soup cung cấp các cách khác nhau để điều hướng và lặp lại các thẻ con của thẻ.
Điều hướng bằng tên thẻ
Cách dễ nhất để tìm kiếm cây phân tích cú pháp là tìm kiếm thẻ theo tên của nó. Nếu bạn muốn có thẻ <head>, hãy sử dụng soup.head -
>>> soup.head
<head>&t;title>Tutorials Point</title></head>
>>> soup.title
<title>Tutorials Point</title>Để nhận thẻ cụ thể (như thẻ <b> đầu tiên) trong thẻ <body>.
>>> soup.body.b
<b>The Biggest Online Tutorials Library, It's all Free</b>Sử dụng tên thẻ làm thuộc tính sẽ chỉ cung cấp cho bạn thẻ đầu tiên có tên đó -
>>> soup.a
<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>Để lấy tất cả thuộc tính của thẻ, bạn có thể sử dụng phương thức find_all () -
>>> soup.find_all("a")
[<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>, <a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>, <a class="prog" href="https://www.tutorialspoint.com/python/index.htm" id="link3">Python</a>, <a class="prog" href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>, <a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>]>>> soup.find_all("a")
[<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>, <a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>, <a class="prog" href="https://www.tutorialspoint.com/python/index.htm" id="link3">Python</a>, <a class="prog" href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>, <a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>].contents và .children
Chúng tôi có thể tìm kiếm thẻ con của thẻ trong danh sách theo .contents -
>>> head_tag = soup.head
>>> head_tag
<head><title>Tutorials Point</title></head>
>>> Htag = soup.head
>>> Htag
<head><title>Tutorials Point</title></head>
>>>
>>> Htag.contents
[<title>Tutorials Point</title>
>>>
>>> Ttag = head_tag.contents[0]
>>> Ttag
<title>Tutorials Point</title>
>>> Ttag.contents
['Tutorials Point']Bản thân đối tượng BeautifulSoup có con. Trong trường hợp này, thẻ <html> là con của đối tượng BeautifulSoup -
>>> len(soup.contents)
2
>>> soup.contents[1].name
'html'Một chuỗi không có .contents, vì nó không thể chứa bất cứ thứ gì -
>>> text = Ttag.contents[0]
>>> text.contents
self.__class__.__name__, attr))
AttributeError: 'NavigableString' object has no attribute 'contents'Thay vì lấy chúng dưới dạng danh sách, hãy sử dụng trình tạo .children để truy cập vào thẻ con của thẻ -
>>> for child in Ttag.children:
print(child)
Tutorials Point.hậu duệ
Thuộc tính .descendants cho phép bạn lặp lại trên tất cả các thẻ con của thẻ, một cách đệ quy -
con trực hệ của nó và con của những đứa con trực hệ của nó, v.v. -
>>> for child in Htag.descendants:
print(child)
<title>Tutorials Point</title>
Tutorials PointThẻ <head> chỉ có một thẻ con, nhưng nó có hai thẻ con: thẻ <title> và thẻ con <title>. Đối tượng beautifulsoup chỉ có một con trực tiếp (thẻ <html>), nhưng nó có rất nhiều con -
>>> len(list(soup.children))
2
>>> len(list(soup.descendants))
33.chuỗi
Nếu thẻ chỉ có một con và con đó là NavigableString, con đó sẽ có sẵn dưới dạng .string -
>>> Ttag.string
'Tutorials Point'Nếu thẻ con duy nhất của thẻ là một thẻ khác và thẻ đó có .string, thì thẻ mẹ được coi là có cùng .string với thẻ con của nó -
>>> Htag.contents
[<title>Tutorials Point</title>]
>>>
>>> Htag.string
'Tutorials Point'Tuy nhiên, nếu thẻ chứa nhiều hơn một thứ, thì không rõ .string nên tham chiếu đến cái gì, vì vậy .string được định nghĩa là Không có -
>>> print(soup.html.string)
None.strings và stripe_strings
Nếu có nhiều thứ bên trong thẻ, bạn vẫn có thể chỉ xem các chuỗi. Sử dụng trình tạo .strings -
>>> for string in soup.strings:
print(repr(string))
'\n'
'Tutorials Point'
'\n'
'\n'
"The Biggest Online Tutorials Library, It's all Free"
'\n'
'Top 5 most used Programming Languages are: \n'
'Java'
',\n'
'C'
',\n'
'Python'
',\n'
'JavaScript'
' and\n'
'C'
';\n \nas per online survey.'
'\n'
'Programming Languages'
'\n'Để loại bỏ khoảng trắng thừa, hãy sử dụng trình tạo .stripped_strings -
>>> for string in soup.stripped_strings:
print(repr(string))
'Tutorials Point'
"The Biggest Online Tutorials Library, It's all Free"
'Top 5 most used Programming Languages are:'
'Java'
','
'C'
','
'Python'
','
'JavaScript'
'and'
'C'
';\n \nas per online survey.'
'Programming Languages'Đi lên
Trong kiểu tương tự "cây gia đình", mọi thẻ và mọi chuỗi đều có cha mẹ: thẻ chứa nó:
.cha mẹ
Để truy cập phần tử mẹ của phần tử, hãy sử dụng thuộc tính .parent.
>>> Ttag = soup.title
>>> Ttag
<title>Tutorials Point</title>
>>> Ttag.parent
<head>title>Tutorials Point</title></head>Trong html_doc của chúng tôi, bản thân chuỗi tiêu đề có một phụ huynh: thẻ <title> chứa nó−
>>> Ttag.string.parent
<title>Tutorials Point</title>Cấp độ gốc của thẻ cấp cao nhất như <html> chính là đối tượng Beautifulsoup -
>>> htmltag = soup.html
>>> type(htmltag.parent)
<class 'bs4.BeautifulSoup'>.Parent của một đối tượng Beautifulsoup được định nghĩa là Không có -
>>> print(soup.parent)
None.cha mẹ
Để lặp lại trên tất cả các phần tử cha mẹ, hãy sử dụng thuộc tính. Parent.
>>> link = soup.a
>>> link
<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>
>>>
>>> for parent in link.parents:
if parent is None:
print(parent)
else:
print(parent.name)
p
body
html
[document]Đi ngang
Dưới đây là một tài liệu đơn giản -
>>> sibling_soup = BeautifulSoup("<a><b>TutorialsPoint</b><c><strong>The Biggest Online Tutorials Library, It's all Free</strong></b></a>")
>>> print(sibling_soup.prettify())
<html>
<body>
<a>
<b>
TutorialsPoint
</b>
<c>
<strong>
The Biggest Online Tutorials Library, It's all Free
</strong>
</c>
</a>
</body>
</html>Trong tài liệu trên, thẻ <b> và <c> ở cùng cấp và cả hai đều là con của cùng một thẻ. Cả thẻ <b> và <c> đều là anh em ruột.
.next_sibling và .previous_sibling
Sử dụng .next_sibling và .previous_sibling để điều hướng giữa các phần tử trang ở cùng cấp của cây phân tích cú pháp:
>>> sibling_soup.b.next_sibling
<c><strong>The Biggest Online Tutorials Library, It's all Free</strong></c>
>>>
>>> sibling_soup.c.previous_sibling
<b>TutorialsPoint</b>Thẻ <b> có .next_sibling nhưng không có .previous_sibling, vì không có gì trước thẻ <b> ở cùng cấp của cây, trường hợp tương tự với thẻ <c>.
>>> print(sibling_soup.b.previous_sibling)
None
>>> print(sibling_soup.c.next_sibling)
NoneHai chuỗi không phải là anh em ruột, vì chúng không có cùng cha mẹ.
>>> sibling_soup.b.string
'TutorialsPoint'
>>>
>>> print(sibling_soup.b.string.next_sibling)
None.next_siblings và .previous_siblings
Để lặp lại các thẻ anh chị em của thẻ, hãy sử dụng .next_siblings và .previous_siblings.
>>> for sibling in soup.a.next_siblings:
print(repr(sibling))
',\n'
<a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>
',\n'
>a class="prog" href="https://www.tutorialspoint.com/python/index.htm" id="link3">Python</a>
',\n'
<a class="prog" href="https://www.tutorialspoint.com/javascript/javascript_overview.htm" id="link4">JavaScript</a>
' and\n'
<a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm"
id="link5">C</a>
';\n \nas per online survey.'
>>> for sibling in soup.find(id="link3").previous_siblings:
print(repr(sibling))
',\n'
<a class="prog" href="https://www.tutorialspoint.com/cprogramming/index.htm" id="link2">C</a>
',\n'
<a class="prog" href="https://www.tutorialspoint.com/java/java_overview.htm" id="link1">Java</a>
'Top 5 most used Programming Languages are: \n'Quay đi quay lại
Bây giờ chúng ta hãy quay lại hai dòng đầu tiên trong ví dụ “html_doc” trước đây của chúng tôi -
&t;html><head><title>Tutorials Point</title></head>
<body>
<h4 class="tagLine"><b>The Biggest Online Tutorials Library, It's all Free</b></h4>Trình phân tích cú pháp HTML lấy chuỗi ký tự phía trên và biến nó thành một chuỗi sự kiện như “mở thẻ <html>”, “mở thẻ <head>”, “mở thẻ <title>”, “thêm chuỗi”, “Đóng thẻ </title>”, “đóng thẻ </head>”, “mở thẻ <h4>”, v.v. BeautifulSoup cung cấp các phương pháp khác nhau để tạo lại phân tích cú pháp ban đầu của tài liệu.
.next_element và .previous_element
Thuộc tính .next_element của thẻ hoặc chuỗi trỏ đến bất kỳ thứ gì được phân tích cú pháp ngay sau đó. Đôi khi nó trông giống với .next_sibling, tuy nhiên nó không giống hoàn toàn. Dưới đây là thẻ <a> cuối cùng trong tài liệu mẫu “html_doc” của chúng tôi.
>>> last_a_tag = soup.find("a", id="link5")
>>> last_a_tag
<a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>
>>> last_a_tag.next_sibling
';\n \nas per online survey.'Tuy nhiên, .next_element của thẻ <a> đó, thứ được phân tích cú pháp ngay sau thẻ <a>, không phải là phần còn lại của câu đó: đó là từ “C”:
>>> last_a_tag.next_element
'C'Hành vi trên là do trong đánh dấu ban đầu, chữ “C” đã xuất hiện trước dấu chấm phẩy đó. Trình phân tích cú pháp gặp thẻ <a>, sau đó đến chữ cái “C”, sau đó là thẻ đóng </a>, sau đó là dấu chấm phẩy và phần còn lại của câu. Dấu chấm phẩy ở cùng cấp với thẻ <a>, nhưng chữ “C” đã xuất hiện đầu tiên.
Thuộc tính .previous_element hoàn toàn ngược lại với .next_element. Nó trỏ đến bất kỳ phần tử nào đã được phân tích cú pháp ngay trước phần tử này.
>>> last_a_tag.previous_element
' and\n'
>>>
>>> last_a_tag.previous_element.next_element
<a class="prog" href="https://www.tutorialspoint.com/ruby/index.htm" id="link5">C</a>.next_elements và .previous_elements
Chúng tôi sử dụng các trình vòng lặp này để chuyển tới và lùi tới một phần tử.
>>> for element in last_a_tag.next_e lements:
print(repr(element))
'C'
';\n \nas per online survey.'
'\n'
<p class="prog">Programming Languages</p>
'Programming Languages'
'\n'Có nhiều phương thức Beautifulsoup, cho phép chúng ta tìm kiếm một cây phân tích cú pháp. Hai phương thức phổ biến nhất và được sử dụng là find () và find_all ().
Trước khi nói về find () và find_all (), chúng ta hãy xem một số ví dụ về các bộ lọc khác nhau mà bạn có thể chuyển vào các phương thức này.
Các loại bộ lọc
Chúng tôi có các bộ lọc khác nhau mà chúng tôi có thể chuyển vào các phương pháp này và hiểu biết về các bộ lọc này là rất quan trọng vì các bộ lọc này được sử dụng lặp đi lặp lại trong toàn bộ API tìm kiếm. Chúng tôi có thể sử dụng các bộ lọc này dựa trên tên thẻ, thuộc tính của thẻ, trên văn bản của một chuỗi hoặc kết hợp các bộ lọc này.
Một chuỗi
Một trong những loại bộ lọc đơn giản nhất là một chuỗi. Chuyển một chuỗi đến phương thức tìm kiếm và Beautifulsoup sẽ thực hiện đối sánh với chuỗi chính xác đó.
Đoạn mã dưới đây sẽ tìm thấy tất cả các thẻ <p> trong tài liệu -
>>> markup = BeautifulSoup('<p>Top Three</p><p><pre>Programming Languages are:</pre></p><p><b>Java, Python, Cplusplus</b></p>')
>>> markup.find_all('p')
[<p>Top Three</p>, <p></p>, <p><b>Java, Python, Cplusplus</b></p>]Biểu hiện thông thường
Bạn có thể tìm thấy tất cả các thẻ bắt đầu bằng một chuỗi / thẻ nhất định. Trước đó, chúng ta cần nhập mô-đun re để sử dụng biểu thức chính quy.
>>> import re
>>> markup = BeautifulSoup('<p>Top Three</p><p><pre>Programming Languages are:</pre></p><p><b>Java, Python, Cplusplus</b></p>')
>>>
>>> markup.find_all(re.compile('^p'))
[<p>Top Three</p>, <p></p>, <pre>Programming Languages are:</pre>, <p><b>Java, Python, Cplusplus</b></p>]Danh sách
Bạn có thể chuyển nhiều thẻ để tìm bằng cách cung cấp danh sách. Đoạn mã dưới đây tìm thấy tất cả các thẻ <b> và <pre> -
>>> markup.find_all(['pre', 'b'])
[<pre>Programming Languages are:</pre>, <b>Java, Python, Cplusplus</b>]Thật
True sẽ trả về tất cả các thẻ mà nó có thể tìm thấy, nhưng không có chuỗi của riêng chúng -
>>> markup.find_all(True)
[<html><body><p>Top Three</p><p></p><pre>Programming Languages are:</pre>
<p><b>Java, Python, Cplusplus</b> </p> </body></html>,
<body><p>Top Three</p><p></p><pre> Programming Languages are:</pre><p><b>Java, Python, Cplusplus</b></p>
</body>,
<p>Top Three</p>, <p></p>, <pre>Programming Languages are:</pre>, <p><b>Java, Python, Cplusplus</b></p>, <b>Java, Python, Cplusplus</b>]Để chỉ trả lại các thẻ từ súp trên -
>>> for tag in markup.find_all(True):
(tag.name)
'html'
'body'
'p'
'p'
'pre'
'p'
'b'find_all ()
Bạn có thể sử dụng find_all để trích xuất tất cả các lần xuất hiện của một thẻ cụ thể từ phản hồi trang dưới dạng:
Cú pháp
find_all(name, attrs, recursive, string, limit, **kwargs)Hãy để chúng tôi trích xuất một số dữ liệu thú vị từ IMDB- “Phim được xếp hạng cao nhất” mọi thời đại.
>>> url="https://www.imdb.com/chart/top/?ref_=nv_mv_250"
>>> content = requests.get(url)
>>> soup = BeautifulSoup(content.text, 'html.parser')
#Extract title Page
>>> print(soup.find('title'))
<title>IMDb Top 250 - IMDb</title>
#Extracting main heading
>>> for heading in soup.find_all('h1'):
print(heading.text)
Top Rated Movies
#Extracting sub-heading
>>> for heading in soup.find_all('h3'):
print(heading.text)
IMDb Charts
You Have Seen
IMDb Charts
Top India Charts
Top Rated Movies by Genre
Recently ViewedTừ phía trên, chúng ta có thể thấy find_all sẽ cung cấp cho chúng ta tất cả các mục phù hợp với tiêu chí tìm kiếm mà chúng ta xác định. Tất cả các bộ lọc chúng ta có thể sử dụng với find_all () đều có thể được sử dụng với find () và các phương pháp tìm kiếm khác như find_arent () hoặc find_siblings ().
tìm thấy()
Chúng ta đã thấy ở trên, find_all () dùng để quét toàn bộ tài liệu để tìm tất cả nội dung nhưng có điều, yêu cầu là chỉ tìm được một kết quả. Nếu bạn biết rằng tài liệu chỉ chứa một thẻ <body>, thì sẽ lãng phí thời gian để tìm kiếm toàn bộ tài liệu. Một cách là gọi find_all () với limit = 1 mọi lúc, nếu không chúng ta có thể sử dụng phương thức find () để thực hiện tương tự -
Cú pháp
find(name, attrs, recursive, string, **kwargs)Vì vậy, dưới đây hai phương pháp khác nhau cho cùng một đầu ra -
>>> soup.find_all('title',limit=1)
[<title>IMDb Top 250 - IMDb</title>]
>>>
>>> soup.find('title')
<title>IMDb Top 250 - IMDb</title>Trong các kết quả đầu ra ở trên, chúng ta có thể thấy phương thức find_all () trả về một danh sách chứa một mục trong khi phương thức find () trả về một kết quả.
Một sự khác biệt khác giữa phương thức find () và find_all () là -
>>> soup.find_all('h2')
[]
>>>
>>> soup.find('h2')Nếu phương thức soup.find_all () không tìm thấy gì, nó trả về danh sách trống trong khi find () trả về None.
find_arent () và find_parent ()
Không giống như các phương thức find_all () và find () đi qua cây, nhìn vào con của thẻ, các phương thức find_arent () và find_arent () làm ngược lại, chúng đi ngang cây lên trên và xem xét cha mẹ của một thẻ (hoặc một chuỗi).
Cú pháp
find_parents(name, attrs, string, limit, **kwargs)
find_parent(name, attrs, string, **kwargs)
>>> a_string = soup.find(string="The Godfather")
>>> a_string
'The Godfather'
>>> a_string.find_parents('a')
[<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>]
>>> a_string.find_parent('a')
<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>
>>> a_string.find_parent('tr')
<tr>
<td class="posterColumn">
<span data-value="2" name="rk"></span>
<span data-value="9.149038526210072" name="ir"></span>
<span data-value="6.93792E10" name="us"></span>
<span data-value="1485540" name="nv"></span>
<span data-value="-1.850961473789928" name="ur"></span>
<a href="/title/tt0068646/"> <img alt="The Godfather" height="67" src="https://m.media-amazon.com/images/M/MV5BM2MyNjYxNmUtYTAwNi00MTYxLWJmNWYtYzZlODY3ZTk3OTFlXkEyXkFqcGdeQXVyNzkwMjQ5NzM@._V1_UY67_CR1,0,45,67_AL_.jpg" width="45"/>
</a> </td>
<td class="titleColumn">
2.
<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>
<span class="secondaryInfo">(1972)</span>
</td>
<td class="ratingColumn imdbRating">
<strong title="9.1 based on 1,485,540 user ratings">9.1</strong>
</td>
<td class="ratingColumn">
<div class="seen-widget seen-widget-tt0068646 pending" data-titleid="tt0068646">
<div class="boundary">
<div class="popover">
<span class="delete"> </span><ol><li>1<li>2<li>3<li>4<li>5<li>6<li>7<li>8<li>9<li>10</li>0</li></li></li></li&td;</li></li></li></li></li></ol> </div>
</div>
<div class="inline">
<div class="pending"></div>
<div class="unseeable">NOT YET RELEASED</div>
<div class="unseen"> </div>
<div class="rating"></div>
<div class="seen">Seen</div>
</div>
</div>
</td>
<td class="watchlistColumn">
<div class="wlb_ribbon" data-recordmetrics="true" data-tconst="tt0068646"></div>
</td>
</tr>
>>>
>>> a_string.find_parents('td')
[<td class="titleColumn">
2.
<a href="/title/tt0068646/" title="Francis Ford Coppola (dir.), Marlon Brando, Al Pacino">The Godfather</a>
<span class="secondaryInfo">(1972)</span>
</td>]Có tám phương pháp tương tự khác -
find_next_siblings(name, attrs, string, limit, **kwargs)
find_next_sibling(name, attrs, string, **kwargs)
find_previous_siblings(name, attrs, string, limit, **kwargs)
find_previous_sibling(name, attrs, string, **kwargs)
find_all_next(name, attrs, string, limit, **kwargs)
find_next(name, attrs, string, **kwargs)
find_all_previous(name, attrs, string, limit, **kwargs)
find_previous(name, attrs, string, **kwargs)Ở đâu,
find_next_siblings() và find_next_sibling() các phương thức sẽ lặp lại trên tất cả các anh chị em của phần tử đứng sau phần tử hiện tại.
find_previous_siblings() và find_previous_sibling() các phương thức sẽ lặp qua tất cả các anh chị em đứng trước phần tử hiện tại.
find_all_next() và find_next() phương thức sẽ lặp qua tất cả các thẻ và chuỗi đứng sau phần tử hiện tại.
find_all_previous và find_previous() các phương thức sẽ lặp lại trên tất cả các thẻ và chuỗi đứng trước phần tử hiện tại.
Bộ chọn CSS
Thư viện BeautifulSoup để hỗ trợ các bộ chọn CSS thông dụng nhất. Bạn có thể tìm kiếm các phần tử bằng bộ chọn CSS với sự trợ giúp của phương thức select ().
Đây là một số ví dụ -
>>> soup.select('title')
[<title>IMDb Top 250 - IMDb</title>, <title>IMDb Top Rated Movies</title>]
>>>
>>> soup.select("p:nth-of-type(1)")
[<p>The Top Rated Movie list only includes theatrical features.</p>, <p> class="imdb-footer__copyright _2-iNNCFskmr4l2OFN2DRsf">© 1990- by IMDb.com, Inc.</p>]
>>> len(soup.select("p:nth-of-type(1)"))
2
>>> len(soup.select("a"))
609
>>> len(soup.select("p"))
2
>>> soup.select("html head title")
[<title>IMDb Top 250 - IMDb</title>, <title>IMDb Top Rated Movies</title>]
>>> soup.select("head > title")
[<title>IMDb Top 250 - IMDb</title>]
#print HTML code of the tenth li elemnet
>>> soup.select("li:nth-of-type(10)")
[<li class="subnav_item_main">
<a href="/search/title?genres=film_noir&sort=user_rating,desc&title_type=feature&num_votes=25000,">Film-Noir
</a> </li>]Một trong những khía cạnh quan trọng của BeautifulSoup là tìm kiếm cây phân tích cú pháp và nó cho phép bạn thực hiện các thay đổi đối với tài liệu web theo yêu cầu của bạn. Chúng tôi có thể thực hiện các thay đổi đối với các thuộc tính của thẻ bằng cách sử dụng các thuộc tính của nó, chẳng hạn như phương thức .name, .string hoặc .append (). Nó cho phép bạn thêm các thẻ và chuỗi mới vào thẻ hiện có với sự trợ giúp của các phương thức .new_string () và .new_tag (). Cũng có các phương thức khác, chẳng hạn như .insert (), .insert_before () hoặc .insert_osystem () để thực hiện các sửa đổi khác nhau đối với tài liệu HTML hoặc XML của bạn.
Thay đổi tên thẻ và thuộc tính
Khi bạn đã tạo súp, bạn có thể dễ dàng thực hiện sửa đổi như đổi tên thẻ, sửa đổi các thuộc tính của nó, thêm thuộc tính mới và xóa thuộc tính.
>>> soup = BeautifulSoup('<b class="bolder">Very Bold</b>')
>>> tag = soup.bSửa đổi và thêm các thuộc tính mới như sau:
>>> tag.name = 'Blockquote'
>>> tag['class'] = 'Bolder'
>>> tag['id'] = 1.1
>>> tag
<Blockquote class="Bolder" id="1.1">Very Bold</Blockquote>Việc xóa các thuộc tính như sau:
>>> del tag['class']
>>> tag
<Blockquote id="1.1">Very Bold</Blockquote>
>>> del tag['id']
>>> tag
<Blockquote>Very Bold</Blockquote>Đang sửa đổi .string
Bạn có thể dễ dàng sửa đổi thuộc tính .string của thẻ -
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">Must for every <i>Learner>/i<</a>'
>>> Bsoup = BeautifulSoup(markup)
>>> tag = Bsoup.a
>>> tag.string = "My Favourite spot."
>>> tag
<a href="https://www.tutorialspoint.com/index.htm">My Favourite spot.</a>Từ phía trên, chúng ta có thể thấy nếu thẻ chứa bất kỳ thẻ nào khác, chúng và tất cả nội dung của chúng sẽ được thay thế bằng dữ liệu mới.
chắp thêm ()
Thêm dữ liệu / nội dung mới vào thẻ hiện có bằng cách sử dụng phương thức tag.append (). Nó rất giống với phương thức append () trong danh sách Python.
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">Must for every <i>Learner</i></a>'
>>> Bsoup = BeautifulSoup(markup)
>>> Bsoup.a.append(" Really Liked it")
>>> Bsoup
<html><body><a href="https://www.tutorialspoint.com/index.htm">Must for every <i>Learner</i> Really Liked it</a></body></html>
>>> Bsoup.a.contents
['Must for every ', <i>Learner</i>, ' Really Liked it']NavigableString () và .new_tag ()
Trong trường hợp bạn muốn thêm một chuỗi vào tài liệu, điều này có thể được thực hiện dễ dàng bằng cách sử dụng append () hoặc bằng hàm tạo NavigableString () -
>>> soup = BeautifulSoup("<b></b>")
>>> tag = soup.b
>>> tag.append("Start")
>>>
>>> new_string = NavigableString(" Your")
>>> tag.append(new_string)
>>> tag
<b>Start Your</b>
>>> tag.contents
['Start', ' Your']Note: Nếu bạn tìm thấy bất kỳ tên nào Lỗi khi truy cập hàm NavigableString (), như sau:
NameError: tên 'NavigableString' không được xác định
Chỉ cần nhập thư mục NavigableString từ gói bs4 -
>>> from bs4 import NavigableStringChúng tôi có thể giải quyết lỗi trên.
Bạn có thể thêm nhận xét vào thẻ hiện tại của mình hoặc có thể thêm một số lớp con khác của NavigableString, chỉ cần gọi hàm tạo.
>>> from bs4 import Comment
>>> adding_comment = Comment("Always Learn something Good!")
>>> tag.append(adding_comment)
>>> tag
<b>Start Your<!--Always Learn something Good!--></b>
>>> tag.contents
['Start', ' Your', 'Always Learn something Good!']Có thể thực hiện thêm một thẻ hoàn toàn mới (không nối vào thẻ hiện có) bằng cách sử dụng phương pháp có sẵn Beautifulsoup, BeautifulSoup.new_tag () -
>>> soup = BeautifulSoup("<b></b>")
>>> Otag = soup.b
>>>
>>> Newtag = soup.new_tag("a", href="https://www.tutorialspoint.com")
>>> Otag.append(Newtag)
>>> Otag
<b><a href="https://www.tutorialspoint.com"></a></b>Chỉ đối số đầu tiên, tên thẻ, là bắt buộc.
chèn()
Tương tự như phương thức .insert () trên danh sách python, tag.insert () sẽ chèn phần tử mới, tuy nhiên, không giống như tag.append (), phần tử mới không nhất thiết phải đi ở cuối nội dung gốc của nó. Phần tử mới có thể được thêm vào bất kỳ vị trí nào.
>>> markup = '<a href="https://www.djangoproject.com/community/">Django Official website <i>Huge Community base</i></a>'
>>> soup = BeautifulSoup(markup)
>>> tag = soup.a
>>>
>>> tag.insert(1, "Love this framework ")
>>> tag
<a href="https://www.djangoproject.com/community/">Django Official website Love this framework <i>Huge Community base</i></a>
>>> tag.contents
['Django Official website ', 'Love this framework ', <i>Huge Community base</i
>]
>>>insert_before () và insert_ after ()
Để chèn một số thẻ hoặc chuỗi ngay trước một cái gì đó trong cây phân tích cú pháp, chúng tôi sử dụng insert_before () -
>>> soup = BeautifulSoup("Brave")
>>> tag = soup.new_tag("i")
>>> tag.string = "Be"
>>>
>>> soup.b.string.insert_before(tag)
>>> soup.b
<b><i>Be</i>Brave</b>Tương tự như vậy để chèn một số thẻ hoặc chuỗi ngay sau một cái gì đó trong cây phân tích cú pháp, hãy sử dụng insert_ after ().
>>> soup.b.i.insert_after(soup.new_string(" Always "))
>>> soup.b
<b><i>Be</i> Always Brave</b>
>>> soup.b.contents
[<i>Be</i>, ' Always ', 'Brave']thông thoáng()
Để xóa nội dung của thẻ, hãy sử dụng tag.clear () -
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical&lr;/i> Contents</a>'
>>> soup = BeautifulSoup(markup)
>>> tag = soup.a
>>> tag
<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical</i> Contents</a>
>>>
>>> tag.clear()
>>> tag
<a href="https://www.tutorialspoint.com/index.htm"></a>trích xuất()
Để xóa thẻ hoặc chuỗi khỏi cây, hãy sử dụng PageElement.extract ().
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">For <i&gr;technical & Non-technical</i> Contents</a>'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>>
>>> i_tag = soup.i.extract()
>>>
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">For Contents</a>
>>>
>>> i_tag
<i>technical & Non-technical</i>
>>>
>>> print(i_tag.parent)
Nonephân hủy ()
Thẻ.decompose () xóa một thẻ khỏi cây và xóa tất cả nội dung của nó.
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical</i> Contents</a>'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">For <i>technical & Non-technical</i> Contents</a>
>>>
>>> soup.i.decompose()
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">For Contents</a>
>>>Thay thế bằng()
Như tên cho thấy, hàm pageElement.replace_with () sẽ thay thế thẻ hoặc chuỗi cũ bằng thẻ hoặc chuỗi mới trong cây -
>>> markup = '<a href="https://www.tutorialspoint.com/index.htm">Complete Python <i>Material</i></a>'
>>> soup = BeautifulSoup(markup)
>>> a_tag = soup.a
>>>
>>> new_tag = soup.new_tag("Official_site")
>>> new_tag.string = "https://www.python.org/"
>>> a_tag.i.replace_with(new_tag)
<i>Material</i>
>>>
>>> a_tag
<a href="https://www.tutorialspoint.com/index.htm">Complete Python <Official_site>https://www.python.org/</Official_site></a>Trong kết quả đầu ra ở trên, bạn đã nhận thấy rằng Replace_with () trả về thẻ hoặc chuỗi đã được thay thế (như “Material” trong trường hợp của chúng tôi), vì vậy bạn có thể kiểm tra hoặc thêm lại nó vào một phần khác của cây.
bọc ()
TrangElement.wrap () bao gồm một phần tử trong thẻ bạn chỉ định và trả về một trình bao bọc mới -
>>> soup = BeautifulSoup("<p>tutorialspoint.com</p>")
>>> soup.p.string.wrap(soup.new_tag("b"))
<b>tutorialspoint.com</b>
>>>
>>> soup.p.wrap(soup.new_tag("Div"))
<Div><p><b>tutorialspoint.com</b></p></Div>mở ra ()
Thẻ.unwrap () đối lập với wrap () và thay thế một thẻ bằng bất cứ thứ gì bên trong thẻ đó.
>>> soup = BeautifulSoup('<a href="https://www.tutorialspoint.com/">I liked <i>tutorialspoint</i></a>')
>>> a_tag = soup.a
>>>
>>> a_tag.i.unwrap()
<i></i>
>>> a_tag
<a href="https://www.tutorialspoint.com/">I liked tutorialspoint</a>Từ trên, bạn đã nhận thấy rằng như Replace_with (), Unrap () trả về thẻ đã được thay thế.
Dưới đây là một ví dụ khác về unsrap () để hiểu rõ hơn:
>>> soup = BeautifulSoup("<p>I <strong>AM</strong> a <i>text</i>.</p>")
>>> soup.i.unwrap()
<i></i>
>>> soup
<html><body><p>I <strong>AM</strong> a text.</p></body></html>Unrap () rất tốt để loại bỏ đánh dấu.
Tất cả các tài liệu HTML hoặc XML được viết bằng một số mã hóa cụ thể như ASCII hoặc UTF-8. Tuy nhiên, khi bạn tải tài liệu HTML / XML đó vào BeautifulSoup, nó đã được chuyển đổi sang Unicode.
>>> markup = "<p>I will display £</p>"
>>> Bsoup = BeautifulSoup(markup)
>>> Bsoup.p
<p>I will display £</p>
>>> Bsoup.p.string
'I will display £'Hành vi trên là do BeautifulSoup sử dụng nội bộ thư viện con được gọi là Unicode, Dammit để phát hiện bảng mã của tài liệu và sau đó chuyển đổi nó thành Unicode.
Tuy nhiên, không phải lúc nào Unicode, Dammit cũng đoán đúng. Vì tài liệu được tìm kiếm từng byte để đoán mã hóa nên mất rất nhiều thời gian. Bạn có thể tiết kiệm một chút thời gian và tránh sai lầm, nếu bạn đã biết mã hóa bằng cách chuyển nó đến phương thức khởi tạo BeautifulSoup dưới dạng from_encoding.
Dưới đây là một ví dụ mà BeautifulSoup xác định sai, tài liệu ISO-8859-8 là ISO-8859-7 -
>>> markup = b"<h1>\xed\xe5\xec\xf9</h1>"
>>> soup = BeautifulSoup(markup)
>>> soup.h1
<h1>νεμω</h1>
>>> soup.original_encoding
'ISO-8859-7'
>>>Để giải quyết vấn đề trên, hãy chuyển nó cho BeautifulSoup bằng from_encoding -
>>> soup = BeautifulSoup(markup, from_encoding="iso-8859-8")
>>> soup.h1
<h1>ולש </h1>
>>> soup.original_encoding
'iso-8859-8'
>>>Một tính năng mới khác được bổ sung từ BeautifulSoup 4.4.0 là, mã hóa loại trừ. Nó có thể được sử dụng, khi bạn không biết mã hóa chính xác nhưng chắc chắn rằng Unicode, Dammit đang hiển thị kết quả sai.
>>> soup = BeautifulSoup(markup, exclude_encodings=["ISO-8859-7"])Mã hóa đầu ra
Đầu ra từ BeautifulSoup là tài liệu UTF-8, bất kể tài liệu đã nhập vào BeautifulSoup. Bên dưới tài liệu, nơi các ký tự đánh bóng ở định dạng ISO-8859-2.
html_markup = """
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<HTML>
<HEAD>
<META HTTP-EQUIV="content-type" CONTENT="text/html; charset=iso-8859-2">
</HEAD>
<BODY>
ą ć ę ł ń ó ś ź ż Ą Ć Ę Ł Ń Ó Ś Ź Ż
</BODY>
</HTML>
"""
>>> soup = BeautifulSoup(html_markup)
>>> print(soup.prettify())
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<meta content="text/html; charset=utf-8" http-equiv="content-type"/>
</head>
<body>
ą ć ę ł ń ó ś ź ż Ą Ć Ę Ł Ń Ó Ś Ź Ż
</body>
</html>Trong ví dụ trên, nếu bạn nhận thấy, thẻ <meta> đã được viết lại để phản ánh tài liệu được tạo từ BeautifulSoup hiện ở định dạng UTF-8.
Nếu bạn không muốn đầu ra được tạo trong UTF-8, bạn có thể chỉ định mã hóa mong muốn trong pretify ().
>>> print(soup.prettify("latin-1"))
b'<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">\n<html>\n <head>\n <meta content="text/html; charset=latin-1" http-equiv="content-type"/>\n </head>\n <body>\n ą ć ę ł ń \xf3 ś ź ż Ą Ć Ę Ł Ń \xd3 Ś Ź Ż\n </body>\n</html>\n'Trong ví dụ trên, chúng tôi đã mã hóa tài liệu hoàn chỉnh, tuy nhiên bạn có thể mã hóa, bất kỳ phần tử cụ thể nào trong súp như thể chúng là một chuỗi python -
>>> soup.p.encode("latin-1")
b'<p>0My first paragraph.</p>'
>>> soup.h1.encode("latin-1")
b'<h1>My First Heading</h1>'Bất kỳ ký tự nào không thể được biểu diễn trong bảng mã đã chọn của bạn sẽ được chuyển đổi thành các tham chiếu thực thể XML số. Dưới đây là một ví dụ như vậy -
>>> markup = u"<b>\N{SNOWMAN}</b>"
>>> snowman_soup = BeautifulSoup(markup)
>>> tag = snowman_soup.b
>>> print(tag.encode("utf-8"))
b'<b>\xe2\x98\x83</b>'Nếu bạn cố gắng mã hóa phần trên bằng “latin-1” hoặc “ascii”, nó sẽ tạo ra “☃”, cho biết không có đại diện nào cho điều đó.
>>> print (tag.encode("latin-1"))
b'<b>☃</b>'
>>> print (tag.encode("ascii"))
b'<b>☃</b>'Unicode, chết tiệt
Unicode, Dammit được sử dụng chủ yếu khi tài liệu đến có định dạng không xác định (chủ yếu là tiếng nước ngoài) và chúng tôi muốn mã hóa ở một số định dạng đã biết (Unicode) và chúng tôi cũng không cần Beautifulsoup để làm tất cả điều này.
Điểm bắt đầu của bất kỳ dự án BeautifulSoup nào, là đối tượng BeautifulSoup. Đối tượng BeautifulSoup đại diện cho tài liệu HTML / XML đầu vào được sử dụng để tạo nó.
Chúng tôi có thể chuyển một chuỗi hoặc một đối tượng giống tệp cho Beautiful Soup, nơi các tệp (đối tượng) được lưu trữ cục bộ trong máy của chúng tôi hoặc một trang web.
Đối tượng BeautifulSoup phổ biến nhất là -
- Tag
- NavigableString
- BeautifulSoup
- Comment
So sánh các đối tượng để bình đẳng
Theo cách nói đẹp, hai đối tượng chuỗi hoặc thẻ có thể điều hướng bằng nhau nếu chúng đại diện cho cùng một đánh dấu HTML / XML.
Bây giờ chúng ta hãy xem ví dụ dưới đây, trong đó hai thẻ <b> được coi là bằng nhau, mặc dù chúng nằm ở các phần khác nhau của cây đối tượng, vì cả hai đều giống “<b> Java </b>”.
>>> markup = "<p>Learn Python and <b>Java</b> and advanced <b>Java</b>! from Tutorialspoint</p>"
>>> soup = BeautifulSoup(markup, "html.parser")
>>> first_b, second_b = soup.find_all('b')
>>> print(first_b == second_b)
True
>>> print(first_b.previous_element == second_b.previous_element)
FalseTuy nhiên, để kiểm tra xem hai biến có tham chiếu đến cùng các đối tượng hay không, bạn có thể sử dụng như sau:
>>> print(first_b is second_b)
FalseSao chép các đối tượng Soup đẹp
Để tạo bản sao của bất kỳ thẻ nào hoặc NavigableString, hãy sử dụng hàm copy.copy (), giống như bên dưới:
>>> import copy
>>> p_copy = copy.copy(soup.p)
>>> print(p_copy)
<p>Learn Python and <b>Java</b> and advanced <b>Java</b>! from Tutorialspoint</p>
>>>Mặc dù hai bản sao (bản gốc và bản đã sao chép) chứa cùng một đánh dấu, tuy nhiên, hai bản không đại diện cho cùng một đối tượng -
>>> print(soup.p == p_copy)
True
>>>
>>> print(soup.p is p_copy)
False
>>>Sự khác biệt thực sự duy nhất là bản sao hoàn toàn tách rời khỏi cây đối tượng Beautiful Soup ban đầu, giống như thể trích xuất () đã được gọi trên nó.
>>> print(p_copy.parent)
NoneHành vi trên là do hai đối tượng thẻ khác nhau không thể chiếm cùng một không gian cùng một lúc.
Có nhiều trường hợp bạn muốn trích xuất các loại thông tin cụ thể (chỉ các thẻ <a>) bằng Beautifulsoup4. Lớp SoupStrainer trong Beautifulsoup cho phép bạn phân tích cú pháp chỉ một phần cụ thể của tài liệu đến.
Một cách là tạo SoupStrainer và chuyển nó tới hàm tạo Beautifulsoup4 làm đối số parse_only.
SoupStrainer
Một SoupStrainer cho BeautifulSoup biết những phần trích xuất và cây phân tích cú pháp chỉ bao gồm những phần tử này. Nếu bạn thu hẹp thông tin cần thiết của mình vào một phần cụ thể của HTML, điều này sẽ tăng tốc kết quả tìm kiếm của bạn.
product = SoupStrainer('div',{'id': 'products_list'})
soup = BeautifulSoup(html,parse_only=product)Các dòng mã trên sẽ chỉ phân tích cú pháp các tiêu đề từ trang web sản phẩm, có thể nằm bên trong trường thẻ.
Tương tự như trên, chúng ta có thể sử dụng các đối tượng soupStrainer khác để phân tích cú pháp thông tin cụ thể từ thẻ HTML. Dưới đây là một số ví dụ -
from bs4 import BeautifulSoup, SoupStrainer
#Only "a" tags
only_a_tags = SoupStrainer("a")
#Will parse only the below mentioned "ids".
parse_only = SoupStrainer(id=["first", "third", "my_unique_id"])
soup = BeautifulSoup(my_document, "html.parser", parse_only=parse_only)
#parse only where string length is less than 10
def is_short_string(string):
return len(string) < 10
only_short_strings =SoupStrainer(string=is_short_string)Xử lý lỗi
Có hai loại lỗi chính cần được xử lý trong BeautifulSoup. Hai lỗi này không phải từ tập lệnh của bạn mà từ cấu trúc của đoạn mã vì API BeautifulSoup tạo ra một lỗi.
Hai lỗi chính như sau:
AttributeError
Nó được gây ra khi ký hiệu dấu chấm không tìm thấy thẻ anh em với thẻ HTML hiện tại. Ví dụ: bạn có thể đã gặp phải lỗi này, do thiếu "thẻ liên kết", khóa chi phí sẽ tạo ra lỗi khi nó đi ngang qua và yêu cầu thẻ liên kết.
KeyError
Lỗi này xảy ra nếu thiếu thuộc tính thẻ HTML bắt buộc. Ví dụ: nếu chúng ta không có thuộc tính data-pid trong một đoạn mã, thì khóa pid sẽ tạo ra lỗi khóa.
Để tránh hai lỗi được liệt kê ở trên khi phân tích cú pháp một kết quả, kết quả đó sẽ được bỏ qua để đảm bảo rằng đoạn mã không đúng định dạng không được chèn vào cơ sở dữ liệu -
except(AttributeError, KeyError) as er:
passchẩn đoán ()
Bất cứ khi nào chúng tôi gặp bất kỳ khó khăn nào trong việc hiểu BeautifulSoup làm gì với tài liệu hoặc HTML của mình, chỉ cần chuyển nó vào hàm chẩn đoán (). Khi chuyển tệp tài liệu đến hàm chẩn đoán (), chúng tôi có thể hiển thị cách danh sách trình phân tích cú pháp khác nhau xử lý tài liệu.
Dưới đây là một ví dụ để chứng minh việc sử dụng hàm chẩn đoán () -
from bs4.diagnose import diagnose
with open("20 Books.html",encoding="utf8") as fp:
data = fp.read()
diagnose(data)Đầu ra
Lỗi phân tích cú pháp
Có hai loại lỗi phân tích cú pháp chính. Bạn có thể gặp một ngoại lệ như HTMLParseError, khi bạn cấp tài liệu của mình cho BeautifulSoup. Bạn cũng có thể nhận được một kết quả không mong muốn, trong đó cây phân tích cú pháp BeautifulSoup trông rất khác so với kết quả mong đợi từ tài liệu phân tích cú pháp.
Không có lỗi phân tích cú pháp nào là do BeautifulSoup. Đó là do trình phân tích cú pháp bên ngoài mà chúng tôi sử dụng (html5lib, lxml) vì BeautifulSoup không chứa bất kỳ mã phân tích cú pháp nào. Một cách để giải quyết lỗi phân tích cú pháp ở trên là sử dụng một trình phân tích cú pháp khác.
from HTMLParser import HTMLParser
try:
from HTMLParser import HTMLParseError
except ImportError, e:
# From python 3.5, HTMLParseError is removed. Since it can never be
# thrown in 3.5, we can just define our own class as a placeholder.
class HTMLParseError(Exception):
passTrình phân tích cú pháp HTML tích hợp trong Python gây ra hai lỗi phân tích cú pháp phổ biến nhất, HTMLParser.HTMLParserError: thẻ bắt đầu không đúng định dạng và HTMLParser.HTMLParserError: thẻ kết thúc không hợp lệ và để giải quyết điều này, chủ yếu là sử dụng một trình phân tích cú pháp khác: lxml hoặc html5lib.
Một loại hành vi không mong muốn phổ biến khác là bạn không thể tìm thấy thẻ mà bạn biết là có trong tài liệu. Tuy nhiên, khi bạn chạy find_all () trả về [] hoặc find () trả về None.
Điều này có thể do trình phân tích cú pháp HTML tích hợp trong python đôi khi bỏ qua các thẻ mà nó không hiểu.
Lỗi phân tích cú pháp XML
Theo mặc định, gói BeautifulSoup phân tích cú pháp các tài liệu dưới dạng HTML, tuy nhiên, nó rất dễ sử dụng và xử lý XML không đúng định dạng một cách rất thanh lịch bằng cách sử dụng beautifulsoup4.
Để phân tích cú pháp tài liệu dưới dạng XML, bạn cần có trình phân tích cú pháp lxml và bạn chỉ cần chuyển “xml” làm đối số thứ hai cho hàm tạo Beautifulsoup -
soup = BeautifulSoup(markup, "lxml-xml")hoặc là
soup = BeautifulSoup(markup, "xml")Một lỗi phân tích cú pháp XML phổ biến là:
AttributeError: 'NoneType' object has no attribute 'attrib'Điều này có thể xảy ra trong trường hợp, một số phần tử bị thiếu hoặc không được xác định khi sử dụng hàm find () hoặc findall ().
Các lỗi phân tích cú pháp khác
Dưới đây là một số lỗi phân tích cú pháp khác mà chúng ta sẽ thảo luận trong phần này -
Vấn đề môi trường
Ngoài các lỗi phân tích cú pháp được đề cập ở trên, bạn có thể gặp phải các vấn đề phân tích cú pháp khác, chẳng hạn như các vấn đề môi trường trong đó tập lệnh của bạn có thể hoạt động trong một hệ điều hành nhưng không hoạt động trong một hệ điều hành khác hoặc có thể hoạt động trong một môi trường ảo nhưng không hoạt động trong môi trường ảo khác hoặc có thể không hoạt động ngoài môi trường ảo. Tất cả những vấn đề này có thể là do hai môi trường có sẵn các thư viện phân tích cú pháp khác nhau.
Bạn nên biết hoặc kiểm tra trình phân tích cú pháp mặc định của mình trong môi trường làm việc hiện tại của bạn. Bạn có thể kiểm tra trình phân tích cú pháp mặc định hiện tại có sẵn cho môi trường làm việc hiện tại hoặc nếu không thì chuyển rõ ràng thư viện trình phân tích cú pháp được yêu cầu làm đối số thứ hai cho hàm tạo BeautifulSoup.
Trường hợp không nhạy cảm
Vì các thẻ và thuộc tính HTML không phân biệt chữ hoa chữ thường, nên cả ba trình phân tích cú pháp HTML đều chuyển đổi tên thẻ và thuộc tính thành chữ thường. Tuy nhiên, nếu bạn muốn duy trì các thẻ và thuộc tính dạng hỗn hợp hoặc chữ hoa, thì tốt hơn nên phân tích cú pháp tài liệu dưới dạng XML.
UnicodeEncodeError
Hãy để chúng tôi xem xét phân đoạn mã bên dưới -
soup = BeautifulSoup(response, "html.parser")
print (soup)Đầu ra
UnicodeEncodeError: 'charmap' codec can't encode character '\u011f'Vấn đề trên có thể là do hai tình huống chính. Bạn có thể đang cố in ra một ký tự unicode mà bảng điều khiển của bạn không biết cách hiển thị. Thứ hai, bạn đang cố gắng ghi vào một tệp và bạn chuyển vào một ký tự Unicode không được mã hóa mặc định của bạn hỗ trợ.
Một cách để giải quyết vấn đề trên là mã hóa văn bản / ký tự phản hồi trước khi thực hiện món súp để có được kết quả mong muốn, như sau:
responseTxt = response.text.encode('UTF-8')KeyError: [attr]
Nguyên nhân là do truy cập thẻ ['attr'] khi thẻ được đề cập không xác định thuộc tính attr. Các lỗi phổ biến nhất là: “KeyError: 'href'” và “KeyError: 'class'”. Sử dụng tag.get ('attr') nếu bạn không chắc chắn rằng attr được xác định.
for item in soup.fetch('a'):
try:
if (item['href'].startswith('/') or "tutorialspoint" in item['href']):
(...)
except KeyError:
pass # or some other fallback actionAttributeError
Bạn có thể gặp lỗi AttributeError như sau:
AttributeError: 'list' object has no attribute 'find_all'Lỗi trên chủ yếu xảy ra vì bạn mong đợi find_all () trả về một thẻ hoặc chuỗi. Tuy nhiên, soup.find_all trả về một danh sách các phần tử trong python.
Tất cả những gì bạn cần làm là lặp lại danh sách và bắt dữ liệu từ các phần tử đó.