Phân tích dữ liệu lớn - Vòng đời dữ liệu
Vòng đời khai thác dữ liệu truyền thống
Để cung cấp một khuôn khổ để tổ chức công việc cần thiết của một tổ chức và cung cấp thông tin chi tiết rõ ràng về Dữ liệu lớn, sẽ hữu ích nếu coi nó như một chu trình với các giai đoạn khác nhau. Nó không có nghĩa là tuyến tính, có nghĩa là tất cả các giai đoạn có liên quan với nhau. Chu kỳ này có những điểm tương đồng bề ngoài với chu kỳ khai thác dữ liệu truyền thống hơn như được mô tả trongCRISP methodology.
Phương pháp CRISP-DM
Các CRISP-DM methodologyviết tắt của Cross Industry Standard Process for Data Mining, là một chu trình mô tả các phương pháp tiếp cận thường được sử dụng mà các chuyên gia khai thác dữ liệu sử dụng để giải quyết các vấn đề trong khai thác dữ liệu BI truyền thống. Nó vẫn đang được sử dụng trong các nhóm khai thác dữ liệu BI truyền thống.
Hãy xem hình minh họa sau đây. Nó chỉ ra các giai đoạn chính của chu trình như được mô tả bằng phương pháp CRISP-DM và chúng có mối quan hệ với nhau như thế nào.
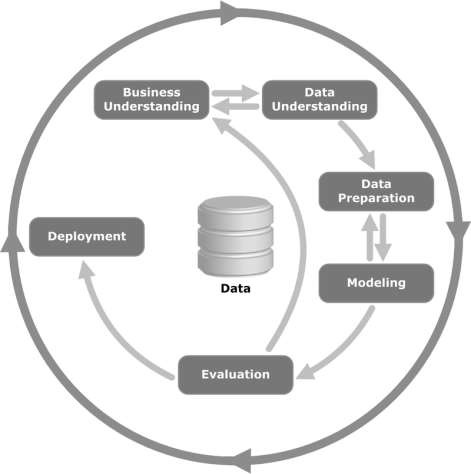
CRISP-DM được hình thành vào năm 1996 và năm tiếp theo, nó được tiến hành như một dự án của Liên minh Châu Âu theo sáng kiến tài trợ của ESPRIT. Dự án được dẫn đầu bởi năm công ty: SPSS, Teradata, Daimler AG, NCR Corporation và OHRA (một công ty bảo hiểm). Dự án cuối cùng đã được kết hợp vào SPSS. Phương pháp này được định hướng cực kỳ chi tiết về cách một dự án khai thác dữ liệu nên được chỉ định.
Bây giờ chúng ta hãy tìm hiểu thêm một chút về từng giai đoạn liên quan đến vòng đời CRISP-DM -
Business Understanding- Giai đoạn ban đầu này tập trung vào việc hiểu các mục tiêu và yêu cầu của dự án từ góc độ kinh doanh, sau đó chuyển đổi kiến thức này thành định nghĩa vấn đề khai thác dữ liệu. Một kế hoạch sơ bộ được thiết kế để đạt được các mục tiêu. Có thể sử dụng mô hình quyết định, đặc biệt là mô hình được xây dựng bằng cách sử dụng tiêu chuẩn Mô hình quyết định và ký hiệu.
Data Understanding - Giai đoạn hiểu dữ liệu bắt đầu với việc thu thập dữ liệu ban đầu và tiến hành các hoạt động để làm quen với dữ liệu, xác định các vấn đề về chất lượng dữ liệu, khám phá những hiểu biết đầu tiên về dữ liệu hoặc phát hiện các tập hợp con thú vị để hình thành giả thuyết cho thông tin ẩn.
Data Preparation- Giai đoạn chuẩn bị dữ liệu bao gồm tất cả các hoạt động để xây dựng tập dữ liệu cuối cùng (dữ liệu sẽ được đưa vào (các) công cụ mô hình hóa) từ dữ liệu thô ban đầu. Các tác vụ chuẩn bị dữ liệu có thể được thực hiện nhiều lần và không theo bất kỳ thứ tự quy định nào. Các nhiệm vụ bao gồm lựa chọn bảng, bản ghi và thuộc tính cũng như chuyển đổi và làm sạch dữ liệu cho các công cụ mô hình hóa.
Modeling- Trong giai đoạn này, các kỹ thuật mô hình hóa khác nhau được lựa chọn và áp dụng và các thông số của chúng được hiệu chỉnh đến các giá trị tối ưu. Thông thường, có một số kỹ thuật cho cùng một loại vấn đề khai thác dữ liệu. Một số kỹ thuật có các yêu cầu cụ thể về dạng dữ liệu. Do đó, thường phải lùi lại giai đoạn chuẩn bị dữ liệu.
Evaluation- Ở giai đoạn này trong dự án, bạn đã xây dựng một mô hình (hoặc các mô hình) có vẻ có chất lượng cao, từ góc độ phân tích dữ liệu. Trước khi tiến hành triển khai mô hình cuối cùng, điều quan trọng là phải đánh giá mô hình kỹ lưỡng và xem xét các bước đã thực hiện để xây dựng mô hình, để chắc chắn rằng nó đạt được các mục tiêu kinh doanh một cách phù hợp.
Mục tiêu chính là xác định xem có vấn đề kinh doanh quan trọng nào đó chưa được xem xét đầy đủ hay không. Vào cuối giai đoạn này, cần đưa ra quyết định về việc sử dụng các kết quả khai thác dữ liệu.
Deployment- Việc tạo ra mô hình nói chung không phải là kết thúc của dự án. Ngay cả khi mục đích của mô hình là tăng cường kiến thức về dữ liệu, kiến thức thu được sẽ cần được tổ chức và trình bày theo cách hữu ích cho khách hàng.
Tùy thuộc vào các yêu cầu, giai đoạn triển khai có thể đơn giản như tạo một báo cáo hoặc phức tạp như thực hiện tính điểm dữ liệu có thể lặp lại (ví dụ: phân bổ phân đoạn) hoặc quá trình khai thác dữ liệu.
Trong nhiều trường hợp, chính khách hàng chứ không phải nhà phân tích dữ liệu sẽ là người thực hiện các bước triển khai. Ngay cả khi nhà phân tích triển khai mô hình, điều quan trọng là khách hàng phải hiểu trước các hành động sẽ cần được thực hiện để thực sự sử dụng các mô hình đã tạo.
Phương pháp SEMMA
SEMMA là một phương pháp khác do SAS phát triển để lập mô hình khai thác dữ liệu. Nó là viết tắt củaSPhong phú, Explore, Modify, Model, và Asses. Dưới đây là mô tả ngắn gọn về các giai đoạn của nó -
Sample- Quá trình bắt đầu với việc lấy mẫu dữ liệu, ví dụ: chọn tập dữ liệu để lập mô hình. Tập dữ liệu phải đủ lớn để chứa đủ thông tin cần truy xuất, nhưng đủ nhỏ để sử dụng hiệu quả. Giai đoạn này cũng xử lý phân vùng dữ liệu.
Explore - Giai đoạn này bao gồm sự hiểu biết về dữ liệu bằng cách khám phá các mối quan hệ được dự đoán và không lường trước giữa các biến, và cả những bất thường, với sự trợ giúp của trực quan hóa dữ liệu.
Modify - Pha Modify chứa các phương thức để chọn, tạo và biến đổi các biến để chuẩn bị cho việc mô hình hóa dữ liệu.
Model - Trong giai đoạn Mô hình, trọng tâm là áp dụng các kỹ thuật mô hình hóa (khai thác dữ liệu) khác nhau trên các biến đã chuẩn bị để tạo ra các mô hình có thể cung cấp kết quả mong muốn.
Assess - Việc đánh giá kết quả mô hình cho thấy độ tin cậy và tính hữu dụng của các mô hình được tạo ra.
Sự khác biệt chính giữa CRISM – DM và SEMMA là SEMMA tập trung vào khía cạnh mô hình hóa, trong khi CRISP-DM mang lại tầm quan trọng hơn cho các giai đoạn của chu trình trước khi mô hình hóa, chẳng hạn như hiểu vấn đề kinh doanh cần giải quyết, hiểu và xử lý trước dữ liệu. được sử dụng làm đầu vào, chẳng hạn như các thuật toán học máy.
Vòng đời dữ liệu lớn
Trong bối cảnh dữ liệu lớn ngày nay, các cách tiếp cận trước đây hoặc là không đầy đủ hoặc không tối ưu. Ví dụ: phương pháp SEMMA hoàn toàn không quan tâm đến việc thu thập dữ liệu và xử lý trước các nguồn dữ liệu khác nhau. Các giai đoạn này thường cấu thành hầu hết các công việc trong một dự án dữ liệu lớn thành công.
Một chu kỳ phân tích dữ liệu lớn có thể được mô tả theo giai đoạn sau:
- Định nghĩa vấn đề kinh doanh
- Research
- Đánh giá nguồn nhân lực
- Thu thập dữ liệu
- Data Munging
- Lưu trữ dữ liệu
- Phân tích dữ liệu khám phá
- Chuẩn bị dữ liệu để lập mô hình và đánh giá
- Modeling
- Implementation
Trong phần này, chúng tôi sẽ giới thiệu một số thông tin về từng giai đoạn này của vòng đời dữ liệu lớn.
Định nghĩa vấn đề kinh doanh
Đây là điểm phổ biến trong vòng đời phân tích dữ liệu lớn và BI truyền thống. Thông thường, đó là một giai đoạn không quan trọng của một dự án dữ liệu lớn để xác định vấn đề và đánh giá một cách chính xác mức lợi ích tiềm năng mà nó có thể có đối với một tổ chức. Đề cập đến vấn đề này có vẻ hiển nhiên, nhưng cần phải đánh giá lợi nhuận và chi phí dự kiến của dự án là gì.
Nghiên cứu
Phân tích những gì các công ty khác đã làm trong tình huống tương tự. Điều này liên quan đến việc tìm kiếm các giải pháp hợp lý cho công ty của bạn, mặc dù nó liên quan đến việc điều chỉnh các giải pháp khác cho phù hợp với các nguồn lực và yêu cầu mà công ty của bạn có. Trong giai đoạn này, một phương pháp luận cho các giai đoạn tương lai cần được xác định.
Đánh giá nguồn nhân lực
Khi vấn đề đã được xác định, việc tiếp tục phân tích xem nhân viên hiện tại có thể hoàn thành dự án thành công là điều hợp lý. Các nhóm BI truyền thống có thể không có khả năng cung cấp giải pháp tối ưu cho tất cả các giai đoạn, vì vậy cần cân nhắc trước khi bắt đầu dự án nếu có nhu cầu thuê ngoài một phần của dự án hoặc thuê thêm người.
Thu thập dữ liệu
Phần này quan trọng trong vòng đời dữ liệu lớn; nó xác định loại cấu hình nào sẽ cần thiết để cung cấp sản phẩm dữ liệu kết quả. Thu thập dữ liệu là một bước không quan trọng của quy trình; nó thường liên quan đến việc thu thập dữ liệu phi cấu trúc từ các nguồn khác nhau. Để đưa ra một ví dụ, nó có thể liên quan đến việc viết một trình thu thập thông tin để lấy các bài đánh giá từ một trang web. Điều này liên quan đến việc xử lý văn bản, có lẽ bằng các ngôn ngữ khác nhau thường đòi hỏi một lượng thời gian đáng kể để hoàn thành.
Data Munging
Khi dữ liệu được truy xuất, ví dụ, từ web, dữ liệu đó cần được lưu trữ ở định dạng dễ sử dụng. Để tiếp tục với các ví dụ đánh giá, hãy giả sử dữ liệu được truy xuất từ các trang web khác nhau, nơi mỗi trang có cách hiển thị dữ liệu khác nhau.
Giả sử một nguồn dữ liệu đưa ra các đánh giá về xếp hạng theo sao, do đó, có thể đọc đây là ánh xạ cho biến phản hồi y ∈ {1, 2, 3, 4, 5}. Một nguồn dữ liệu khác đưa ra các đánh giá bằng cách sử dụng hệ thống hai mũi tên, một cho biểu quyết ủng hộ và một cho biểu quyết phản đối. Điều này có nghĩa là một biến phản hồi của biểu mẫuy ∈ {positive, negative}.
Để kết hợp cả hai nguồn dữ liệu, phải đưa ra quyết định để làm cho hai biểu diễn phản hồi này tương đương nhau. Điều này có thể liên quan đến việc chuyển đổi biểu diễn phản hồi nguồn dữ liệu đầu tiên sang dạng thứ hai, coi một sao là tiêu cực và năm sao là tích cực. Quá trình này thường yêu cầu phân bổ thời gian lớn để được giao hàng với chất lượng tốt.
Lưu trữ dữ liệu
Khi dữ liệu được xử lý, đôi khi nó cần được lưu trữ trong cơ sở dữ liệu. Công nghệ dữ liệu lớn cung cấp nhiều lựa chọn thay thế liên quan đến điểm này. Giải pháp thay thế phổ biến nhất là sử dụng Hệ thống tệp Hadoop để lưu trữ, cung cấp cho người dùng phiên bản SQL giới hạn, được gọi là Ngôn ngữ truy vấn HIVE. Điều này cho phép hầu hết các nhiệm vụ phân tích được thực hiện theo những cách tương tự như sẽ được thực hiện trong các kho dữ liệu BI truyền thống, từ góc độ người dùng. Các tùy chọn lưu trữ khác được xem xét là MongoDB, Redis và SPARK.
Giai đoạn này của chu trình liên quan đến kiến thức nguồn nhân lực về khả năng của họ để thực hiện các kiến trúc khác nhau. Các phiên bản sửa đổi của kho dữ liệu truyền thống vẫn đang được sử dụng trong các ứng dụng quy mô lớn. Ví dụ, teradata và IBM cung cấp cơ sở dữ liệu SQL có thể xử lý hàng terabyte dữ liệu; các giải pháp mã nguồn mở như postgreSQL và MySQL vẫn đang được sử dụng cho các ứng dụng quy mô lớn.
Mặc dù có sự khác biệt về cách các kho lưu trữ khác nhau hoạt động trong nền, từ phía máy khách, hầu hết các giải pháp đều cung cấp API SQL. Do đó, hiểu rõ về SQL vẫn là một kỹ năng quan trọng cần có để phân tích dữ liệu lớn.
Tiên nghiệm giai đoạn này dường như là chủ đề quan trọng nhất, trong thực tế, điều này không đúng. Nó thậm chí không phải là một giai đoạn thiết yếu. Có thể triển khai một giải pháp dữ liệu lớn hoạt động với dữ liệu thời gian thực, vì vậy trong trường hợp này, chúng tôi chỉ cần thu thập dữ liệu để phát triển mô hình và sau đó triển khai nó trong thời gian thực. Vì vậy, sẽ không cần thiết phải lưu trữ dữ liệu một cách chính thức.
Phân tích dữ liệu khám phá
Sau khi dữ liệu đã được làm sạch và lưu trữ theo cách có thể truy xuất thông tin chi tiết từ đó, thì giai đoạn khám phá dữ liệu là bắt buộc. Mục tiêu của giai đoạn này là để hiểu dữ liệu, điều này thường được thực hiện với các kỹ thuật thống kê và cũng là biểu đồ của dữ liệu. Đây là một giai đoạn tốt để đánh giá xem định nghĩa vấn đề có hợp lý hay khả thi hay không.
Chuẩn bị dữ liệu để lập mô hình và đánh giá
Giai đoạn này liên quan đến việc định hình lại dữ liệu đã làm sạch được truy xuất trước đó và sử dụng tiền xử lý thống kê để nhập giá trị bị thiếu, phát hiện ngoại lệ, chuẩn hóa, trích xuất tính năng và lựa chọn tính năng.
Mô hình hóa
Giai đoạn trước nên tạo ra một số bộ dữ liệu để đào tạo và thử nghiệm, ví dụ, một mô hình dự đoán. Giai đoạn này bao gồm việc thử các mô hình khác nhau và mong muốn giải quyết vấn đề kinh doanh trong tầm tay. Trên thực tế, người ta thường mong muốn rằng mô hình sẽ cung cấp một số thông tin chi tiết về doanh nghiệp. Cuối cùng, mô hình tốt nhất hoặc sự kết hợp của các mô hình được chọn đánh giá hiệu suất của nó trên một tập dữ liệu được bỏ qua.
Thực hiện
Trong giai đoạn này, sản phẩm dữ liệu đã phát triển được thực hiện trong đường ống dữ liệu của công ty. Điều này liên quan đến việc thiết lập một lược đồ xác thực trong khi sản phẩm dữ liệu đang hoạt động, để theo dõi hiệu suất của nó. Ví dụ, trong trường hợp triển khai mô hình dự đoán, giai đoạn này sẽ liên quan đến việc áp dụng mô hình vào dữ liệu mới và khi có phản hồi, hãy đánh giá mô hình.