Phân tích dữ liệu lớn - Hướng dẫn nhanh
Khối lượng dữ liệu mà người ta phải xử lý đã bùng nổ đến mức không thể tưởng tượng được trong thập kỷ qua, đồng thời giá lưu trữ dữ liệu cũng giảm một cách có hệ thống. Các công ty tư nhân và tổ chức nghiên cứu thu thập hàng terabyte dữ liệu về tương tác của người dùng, hoạt động kinh doanh, mạng xã hội và cả cảm biến từ các thiết bị như điện thoại di động và ô tô. Thách thức của thời đại này là hiểu được biển dữ liệu này. Đây là đâubig data analytics đi vào hình ảnh.
Phân tích dữ liệu lớn chủ yếu liên quan đến việc thu thập dữ liệu từ các nguồn khác nhau, kết hợp dữ liệu theo cách có sẵn để được các nhà phân tích sử dụng và cuối cùng cung cấp các sản phẩm dữ liệu hữu ích cho doanh nghiệp của tổ chức.

Quá trình chuyển đổi một lượng lớn dữ liệu thô không có cấu trúc, được truy xuất từ các nguồn khác nhau thành sản phẩm dữ liệu hữu ích cho các tổ chức là cốt lõi của Phân tích dữ liệu lớn.
Vòng đời khai thác dữ liệu truyền thống
Để cung cấp một khuôn khổ để tổ chức công việc cần thiết của một tổ chức và cung cấp thông tin chi tiết rõ ràng về Dữ liệu lớn, sẽ hữu ích nếu coi nó như một chu trình với các giai đoạn khác nhau. Nó không có nghĩa là tuyến tính, có nghĩa là tất cả các giai đoạn có liên quan với nhau. Chu kỳ này có những điểm tương đồng bề ngoài với chu kỳ khai thác dữ liệu truyền thống hơn như được mô tả trongCRISP methodology.
Phương pháp CRISP-DM
Các CRISP-DM methodologyviết tắt của Cross Industry Standard Process for Data Mining, là một chu trình mô tả các phương pháp tiếp cận thường được sử dụng mà các chuyên gia khai thác dữ liệu sử dụng để giải quyết các vấn đề trong khai thác dữ liệu BI truyền thống. Nó vẫn đang được sử dụng trong các nhóm khai thác dữ liệu BI truyền thống.
Hãy xem hình minh họa sau đây. Nó chỉ ra các giai đoạn chính của chu trình như được mô tả bởi phương pháp CRISP-DM và chúng có mối quan hệ với nhau như thế nào.
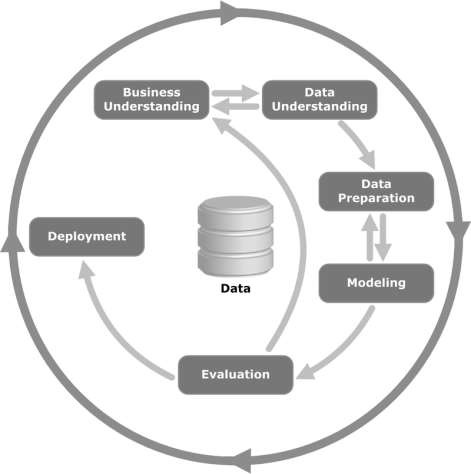
CRISP-DM được hình thành vào năm 1996 và năm tiếp theo, nó được tiến hành như một dự án của Liên minh Châu Âu theo sáng kiến tài trợ của ESPRIT. Dự án được dẫn dắt bởi năm công ty: SPSS, Teradata, Daimler AG, NCR Corporation và OHRA (một công ty bảo hiểm). Dự án cuối cùng đã được kết hợp vào SPSS. Phương pháp này được định hướng cực kỳ chi tiết về cách một dự án khai thác dữ liệu nên được chỉ định.
Bây giờ chúng ta hãy tìm hiểu thêm một chút về từng giai đoạn liên quan đến vòng đời CRISP-DM -
Business Understanding- Giai đoạn ban đầu này tập trung vào việc hiểu các mục tiêu và yêu cầu của dự án từ góc độ kinh doanh, sau đó chuyển kiến thức này thành định nghĩa vấn đề khai thác dữ liệu. Một kế hoạch sơ bộ được thiết kế để đạt được các mục tiêu. Có thể sử dụng mô hình quyết định, đặc biệt là mô hình được xây dựng bằng Mô hình quyết định và tiêu chuẩn Ký hiệu.
Data Understanding - Giai đoạn hiểu dữ liệu bắt đầu với việc thu thập dữ liệu ban đầu và tiến hành các hoạt động để làm quen với dữ liệu, xác định các vấn đề về chất lượng dữ liệu, khám phá những hiểu biết đầu tiên về dữ liệu hoặc phát hiện các tập hợp con thú vị để hình thành giả thuyết cho thông tin ẩn.
Data Preparation- Giai đoạn chuẩn bị dữ liệu bao gồm tất cả các hoạt động để xây dựng tập dữ liệu cuối cùng (dữ liệu sẽ được đưa vào (các) công cụ mô hình hóa) từ dữ liệu thô ban đầu. Các tác vụ chuẩn bị dữ liệu có thể được thực hiện nhiều lần và không theo bất kỳ thứ tự quy định nào. Các nhiệm vụ bao gồm lựa chọn bảng, bản ghi và thuộc tính cũng như chuyển đổi và làm sạch dữ liệu cho các công cụ mô hình hóa.
Modeling- Trong giai đoạn này, các kỹ thuật mô hình hóa khác nhau được lựa chọn và áp dụng và các tham số của chúng được hiệu chỉnh đến các giá trị tối ưu. Thông thường, có một số kỹ thuật cho cùng một loại vấn đề khai thác dữ liệu. Một số kỹ thuật có các yêu cầu cụ thể về dạng dữ liệu. Do đó, thường phải lùi lại giai đoạn chuẩn bị dữ liệu.
Evaluation- Ở giai đoạn này trong dự án, bạn đã xây dựng một mô hình (hoặc các mô hình) có vẻ chất lượng cao, từ góc độ phân tích dữ liệu. Trước khi tiến hành triển khai mô hình cuối cùng, điều quan trọng là phải đánh giá mô hình kỹ lưỡng và xem xét các bước đã thực hiện để xây dựng mô hình, để chắc chắn rằng nó đạt được đúng mục tiêu kinh doanh.
Mục tiêu chính là xác định xem có vấn đề kinh doanh quan trọng nào đó chưa được xem xét đầy đủ hay không. Vào cuối giai đoạn này, cần đưa ra quyết định về việc sử dụng kết quả khai thác dữ liệu.
Deployment- Việc tạo ra mô hình nói chung không phải là kết thúc của dự án. Ngay cả khi mục đích của mô hình là nâng cao kiến thức về dữ liệu, kiến thức thu được sẽ cần được tổ chức và trình bày theo cách hữu ích cho khách hàng.
Tùy thuộc vào các yêu cầu, giai đoạn triển khai có thể đơn giản như tạo một báo cáo hoặc phức tạp như thực hiện tính điểm dữ liệu có thể lặp lại (ví dụ: phân bổ phân đoạn) hoặc quá trình khai thác dữ liệu.
Trong nhiều trường hợp, chính khách hàng chứ không phải nhà phân tích dữ liệu sẽ là người thực hiện các bước triển khai. Ngay cả khi nhà phân tích triển khai mô hình, điều quan trọng là khách hàng phải hiểu trước các hành động sẽ cần được thực hiện để thực sự sử dụng các mô hình đã tạo.
Phương pháp SEMMA
SEMMA là một phương pháp luận khác do SAS phát triển để lập mô hình khai thác dữ liệu. Nó là viết tắt củaSPhong phú, Explore, Modify, Model, và Asses. Dưới đây là mô tả ngắn gọn về các giai đoạn của nó -
Sample- Quá trình bắt đầu với việc lấy mẫu dữ liệu, ví dụ: chọn tập dữ liệu để lập mô hình. Tập dữ liệu phải đủ lớn để chứa đủ thông tin cần truy xuất, nhưng đủ nhỏ để sử dụng hiệu quả. Giai đoạn này cũng xử lý phân vùng dữ liệu.
Explore - Giai đoạn này bao gồm việc hiểu dữ liệu bằng cách khám phá các mối quan hệ dự đoán và không lường trước giữa các biến, và cả những bất thường, với sự trợ giúp của trực quan hóa dữ liệu.
Modify - Pha Modify chứa các phương thức để chọn, tạo và biến đổi các biến để chuẩn bị cho việc mô hình hóa dữ liệu.
Model - Trong giai đoạn Mô hình, trọng tâm là áp dụng các kỹ thuật mô hình hóa (khai thác dữ liệu) khác nhau trên các biến đã chuẩn bị để tạo ra các mô hình có thể cung cấp kết quả mong muốn.
Assess - Việc đánh giá kết quả mô hình hóa cho thấy độ tin cậy và tính hữu dụng của các mô hình được tạo ra.
Sự khác biệt chính giữa CRISM-DM và SEMMA là SEMMA tập trung vào khía cạnh mô hình hóa, trong khi CRISP-DM mang lại tầm quan trọng hơn cho các giai đoạn của chu trình trước khi mô hình hóa như hiểu vấn đề kinh doanh cần giải quyết, hiểu và xử lý trước dữ liệu được được sử dụng làm đầu vào, chẳng hạn như các thuật toán học máy.
Vòng đời dữ liệu lớn
Trong bối cảnh dữ liệu lớn ngày nay, các cách tiếp cận trước đây hoặc là không đầy đủ hoặc không tối ưu. Ví dụ: phương pháp SEMMA hoàn toàn bỏ qua việc thu thập dữ liệu và xử lý trước các nguồn dữ liệu khác nhau. Các giai đoạn này thường cấu thành hầu hết các công việc trong một dự án dữ liệu lớn thành công.
Một chu kỳ phân tích dữ liệu lớn có thể được mô tả theo giai đoạn sau:
- Định nghĩa vấn đề kinh doanh
- Research
- Đánh giá nguồn nhân lực
- Thu thập dữ liệu
- Data Munging
- Lưu trữ dữ liệu
- Phân tích dữ liệu khám phá
- Chuẩn bị dữ liệu để lập mô hình và đánh giá
- Modeling
- Implementation
Trong phần này, chúng tôi sẽ giới thiệu một số thông tin về từng giai đoạn này của vòng đời dữ liệu lớn.
Định nghĩa vấn đề kinh doanh
Đây là điểm chung trong vòng đời phân tích dữ liệu lớn và BI truyền thống. Thông thường, đó là một giai đoạn không quan trọng của một dự án dữ liệu lớn để xác định vấn đề và đánh giá chính xác mức lợi ích tiềm năng mà nó có thể có đối với một tổ chức. Đề cập đến điều này có vẻ hiển nhiên, nhưng cần phải đánh giá lợi nhuận và chi phí dự kiến của dự án là gì.
Nghiên cứu
Phân tích những gì các công ty khác đã làm trong tình huống tương tự. Điều này liên quan đến việc tìm kiếm các giải pháp hợp lý cho công ty của bạn, mặc dù nó liên quan đến việc điều chỉnh các giải pháp khác cho phù hợp với các nguồn lực và yêu cầu mà công ty của bạn có. Trong giai đoạn này, một phương pháp luận cho các giai đoạn tương lai cần được xác định.
Đánh giá nguồn nhân lực
Khi vấn đề đã được xác định, việc tiếp tục phân tích xem nhân viên hiện tại có thể hoàn thành dự án thành công là điều hợp lý. Các nhóm BI truyền thống có thể không đủ khả năng để đưa ra giải pháp tối ưu cho tất cả các giai đoạn, vì vậy cần cân nhắc trước khi bắt đầu dự án nếu có nhu cầu thuê ngoài một phần của dự án hoặc thuê thêm người.
Thu thập dữ liệu
Phần này quan trọng trong vòng đời dữ liệu lớn; nó xác định loại cấu hình nào sẽ cần thiết để cung cấp sản phẩm dữ liệu kết quả. Thu thập dữ liệu là một bước không quan trọng của quy trình; nó thường liên quan đến việc thu thập dữ liệu phi cấu trúc từ các nguồn khác nhau. Để đưa ra một ví dụ, nó có thể liên quan đến việc viết một trình thu thập thông tin để lấy các bài đánh giá từ một trang web. Điều này liên quan đến việc xử lý văn bản, có lẽ bằng các ngôn ngữ khác nhau thường đòi hỏi một lượng thời gian đáng kể để hoàn thành.
Data Munging
Khi dữ liệu được truy xuất, chẳng hạn như từ web, dữ liệu đó cần được lưu trữ ở định dạng dễ sử dụng. Để tiếp tục với các ví dụ đánh giá, hãy giả sử dữ liệu được truy xuất từ các trang web khác nhau, nơi mỗi trang có cách hiển thị dữ liệu khác nhau.
Giả sử một nguồn dữ liệu đưa ra các bài đánh giá về xếp hạng theo sao, do đó, có thể đọc đây là ánh xạ cho biến phản hồi y ∈ {1, 2, 3, 4, 5}. Một nguồn dữ liệu khác đưa ra các đánh giá bằng cách sử dụng hệ thống hai mũi tên, một cho biểu quyết ủng hộ và một cho biểu quyết phản đối. Điều này có nghĩa là một biến phản hồi của biểu mẫuy ∈ {positive, negative}.
Để kết hợp cả hai nguồn dữ liệu, phải đưa ra quyết định để làm cho hai biểu diễn phản hồi này tương đương nhau. Điều này có thể liên quan đến việc chuyển đổi biểu diễn phản hồi nguồn dữ liệu đầu tiên sang dạng thứ hai, coi một sao là tiêu cực và năm sao là tích cực. Quá trình này thường yêu cầu phân bổ thời gian lớn để được giao hàng với chất lượng tốt.
Lưu trữ dữ liệu
Khi dữ liệu được xử lý, đôi khi nó cần được lưu trữ trong cơ sở dữ liệu. Công nghệ dữ liệu lớn cung cấp nhiều lựa chọn thay thế liên quan đến điểm này. Giải pháp thay thế phổ biến nhất là sử dụng Hệ thống tệp Hadoop để lưu trữ, cung cấp cho người dùng phiên bản giới hạn của SQL, được gọi là Ngôn ngữ truy vấn HIVE. Điều này cho phép hầu hết các nhiệm vụ phân tích được thực hiện theo những cách tương tự như sẽ được thực hiện trong các kho dữ liệu BI truyền thống, từ góc độ người dùng. Các tùy chọn lưu trữ khác được xem xét là MongoDB, Redis và SPARK.
Giai đoạn này của chu trình liên quan đến kiến thức nguồn nhân lực về khả năng của họ để thực hiện các kiến trúc khác nhau. Các phiên bản sửa đổi của kho dữ liệu truyền thống vẫn đang được sử dụng trong các ứng dụng quy mô lớn. Ví dụ, teradata và IBM cung cấp cơ sở dữ liệu SQL có thể xử lý hàng terabyte dữ liệu; các giải pháp mã nguồn mở như postgreSQL và MySQL vẫn đang được sử dụng cho các ứng dụng quy mô lớn.
Mặc dù có sự khác biệt về cách các kho lưu trữ khác nhau hoạt động trong nền, từ phía máy khách, hầu hết các giải pháp đều cung cấp API SQL. Do đó, hiểu rõ về SQL vẫn là một kỹ năng quan trọng cần có để phân tích dữ liệu lớn.
Tiên nghiệm giai đoạn này dường như là chủ đề quan trọng nhất, trong thực tế, điều này không đúng. Nó thậm chí không phải là một giai đoạn thiết yếu. Có thể triển khai một giải pháp dữ liệu lớn hoạt động với dữ liệu thời gian thực, vì vậy trong trường hợp này, chúng tôi chỉ cần thu thập dữ liệu để phát triển mô hình và sau đó triển khai nó trong thời gian thực. Vì vậy, sẽ không cần thiết phải lưu trữ dữ liệu một cách chính thức.
Phân tích dữ liệu khám phá
Sau khi dữ liệu đã được làm sạch và lưu trữ theo cách có thể truy xuất thông tin chi tiết từ đó, thì giai đoạn khám phá dữ liệu là bắt buộc. Mục tiêu của giai đoạn này là để hiểu dữ liệu, điều này thường được thực hiện với các kỹ thuật thống kê và cũng vẽ biểu đồ dữ liệu. Đây là một giai đoạn tốt để đánh giá xem định nghĩa vấn đề có hợp lý hay khả thi hay không.
Chuẩn bị dữ liệu để lập mô hình và đánh giá
Giai đoạn này liên quan đến việc định hình lại dữ liệu đã làm sạch được truy xuất trước đó và sử dụng xử lý trước thống kê để nhập giá trị bị thiếu, phát hiện ngoại lệ, chuẩn hóa, trích xuất tính năng và lựa chọn tính năng.
Mô hình hóa
Giai đoạn trước nên tạo ra một số bộ dữ liệu để đào tạo và thử nghiệm, ví dụ, một mô hình dự đoán. Giai đoạn này bao gồm việc thử các mô hình khác nhau và mong muốn giải quyết vấn đề kinh doanh trong tầm tay. Trên thực tế, người ta thường mong muốn rằng mô hình sẽ cung cấp một số thông tin chi tiết về doanh nghiệp. Cuối cùng, mô hình tốt nhất hoặc sự kết hợp của các mô hình được chọn đánh giá hiệu suất của nó trên một tập dữ liệu được bỏ qua.
Thực hiện
Trong giai đoạn này, sản phẩm dữ liệu đã phát triển được thực hiện trong đường dẫn dữ liệu của công ty. Điều này liên quan đến việc thiết lập một lược đồ xác thực trong khi sản phẩm dữ liệu đang hoạt động, để theo dõi hiệu suất của nó. Ví dụ, trong trường hợp triển khai mô hình dự đoán, giai đoạn này sẽ liên quan đến việc áp dụng mô hình cho dữ liệu mới và khi có phản hồi, hãy đánh giá mô hình.
Về phương pháp luận, phân tích dữ liệu lớn khác biệt đáng kể so với cách tiếp cận thống kê truyền thống của thiết kế thử nghiệm. Phân tích bắt đầu với dữ liệu. Thông thường, chúng tôi lập mô hình dữ liệu theo cách để giải thích một phản hồi. Mục tiêu của cách tiếp cận này là dự đoán hành vi phản hồi hoặc hiểu cách các biến đầu vào liên quan đến phản hồi. Thông thường trong các thiết kế thử nghiệm thống kê, một thử nghiệm được phát triển và kết quả là dữ liệu được truy xuất. Điều này cho phép tạo dữ liệu theo cách có thể được sử dụng bởi một mô hình thống kê, trong đó các giả định nhất định được giữ nguyên như tính độc lập, tính chuẩn mực và ngẫu nhiên.
Trong phân tích dữ liệu lớn, chúng tôi được trình bày với dữ liệu. Chúng tôi không thể thiết kế một thử nghiệm đáp ứng mô hình thống kê yêu thích của chúng tôi. Trong các ứng dụng phân tích quy mô lớn, cần một lượng lớn công việc (thường là 80% công sức) chỉ để làm sạch dữ liệu, vì vậy nó có thể được sử dụng bởi mô hình học máy.
Chúng tôi không có một phương pháp luận duy nhất để theo dõi trong các ứng dụng quy mô lớn thực sự. Thông thường, một khi vấn đề kinh doanh được xác định, một giai đoạn nghiên cứu là cần thiết để thiết kế phương pháp luận được sử dụng. Tuy nhiên, các hướng dẫn chung có liên quan cần được đề cập và áp dụng cho hầu hết các vấn đề.
Một trong những nhiệm vụ quan trọng nhất trong phân tích dữ liệu lớn là statistical modeling, nghĩa là các vấn đề phân loại hoặc hồi quy có giám sát và không được giám sát. Sau khi dữ liệu được làm sạch và xử lý trước, sẵn sàng cho việc lập mô hình, cần thận trọng khi đánh giá các mô hình khác nhau với các số liệu tổn thất hợp lý và sau đó khi mô hình được triển khai, cần đánh giá thêm và kết quả. Cạm bẫy phổ biến trong mô hình dự đoán là chỉ thực hiện mô hình và không bao giờ đo lường hiệu suất của nó.
Như đã đề cập trong vòng đời dữ liệu lớn, các sản phẩm dữ liệu là kết quả của việc phát triển một sản phẩm dữ liệu lớn trong hầu hết các trường hợp là một số điều sau:
Machine learning implementation - Đây có thể là một thuật toán phân loại, một mô hình hồi quy hoặc một mô hình phân đoạn.
Recommender system - Mục tiêu là phát triển một hệ thống đề xuất các lựa chọn dựa trên hành vi của người dùng. Netflix là ví dụ điển hình của sản phẩm dữ liệu này, trong đó dựa trên xếp hạng của người dùng, các phim khác được đề xuất.
Dashboard- Doanh nghiệp thông thường cần các công cụ để hiển thị dữ liệu tổng hợp. Trang tổng quan là một cơ chế đồ họa để làm cho dữ liệu này có thể truy cập được.
Ad-Hoc analysis - Thông thường các lĩnh vực kinh doanh có các câu hỏi, giả thuyết hoặc huyền thoại có thể được trả lời bằng phân tích đặc biệt với dữ liệu.
Trong các tổ chức lớn, để phát triển thành công một dự án dữ liệu lớn, cần có ban quản lý hỗ trợ dự án. Điều này thường liên quan đến việc tìm cách thể hiện lợi thế kinh doanh của dự án. Chúng tôi không có giải pháp duy nhất cho vấn đề tìm nhà tài trợ cho một dự án, nhưng một số hướng dẫn được đưa ra dưới đây:
Kiểm tra xem ai và ở đâu là nhà tài trợ của các dự án khác tương tự như dự án mà bạn quan tâm.
Việc có liên hệ cá nhân ở các vị trí quản lý quan trọng sẽ giúp ích, vì vậy mọi liên hệ có thể được kích hoạt nếu dự án có triển vọng.
Ai sẽ được lợi từ dự án của bạn? Ai sẽ là khách hàng của bạn khi dự án đang đi đúng hướng?
Phát triển một đề xuất đơn giản, rõ ràng và thoát tục và chia sẻ nó với những người chơi chính trong tổ chức của bạn.
Cách tốt nhất để tìm nhà tài trợ cho một dự án là hiểu vấn đề và sản phẩm dữ liệu kết quả sẽ là gì sau khi nó được triển khai. Sự hiểu biết này sẽ giúp thuyết phục ban lãnh đạo về tầm quan trọng của dự án dữ liệu lớn.
Chuyên viên phân tích dữ liệu có hồ sơ theo định hướng báo cáo, có kinh nghiệm trích xuất và phân tích dữ liệu từ các kho dữ liệu truyền thống sử dụng SQL. Nhiệm vụ của họ thường là lưu trữ dữ liệu hoặc báo cáo kết quả kinh doanh chung. Lưu trữ dữ liệu không có nghĩa là đơn giản, nó chỉ khác với những gì một nhà khoa học dữ liệu làm.
Nhiều tổ chức gặp khó khăn trong việc tìm kiếm các nhà khoa học dữ liệu có năng lực trên thị trường. Tuy nhiên, việc lựa chọn các nhà phân tích dữ liệu tiềm năng và dạy họ các kỹ năng liên quan để trở thành một nhà khoa học dữ liệu là một ý tưởng hay. Đây hoàn toàn không phải là một nhiệm vụ tầm thường và thường liên quan đến người đang có bằng thạc sĩ trong một lĩnh vực định lượng, nhưng nó chắc chắn là một lựa chọn khả thi. Các kỹ năng cơ bản mà một nhà phân tích dữ liệu có năng lực phải có được liệt kê dưới đây:
- Hiểu biết kinh doanh
- Lập trình SQL
- Báo cáo thiết kế và thực hiện
- Phát triển bảng điều khiển
Vai trò của một nhà khoa học dữ liệu thường gắn liền với các nhiệm vụ như mô hình dự đoán, phát triển các thuật toán phân đoạn, hệ thống khuyến nghị, khung thử nghiệm A / B và thường làm việc với dữ liệu thô phi cấu trúc.
Bản chất công việc của họ đòi hỏi sự hiểu biết sâu sắc về toán học, thống kê ứng dụng và lập trình. Có một vài kỹ năng chung giữa một nhà phân tích dữ liệu và một nhà khoa học dữ liệu, ví dụ, khả năng truy vấn cơ sở dữ liệu. Cả hai đều phân tích dữ liệu, nhưng quyết định của một nhà khoa học dữ liệu có thể có tác động lớn hơn trong một tổ chức.
Đây là một tập hợp các kỹ năng mà một nhà khoa học dữ liệu thường cần phải có:
- Lập trình trong một gói thống kê như: R, Python, SAS, SPSS hoặc Julia
- Có thể làm sạch, trích xuất và khám phá dữ liệu từ các nguồn khác nhau
- Nghiên cứu, thiết kế và triển khai các mô hình thống kê
- Kiến thức sâu về thống kê, toán học và khoa học máy tính
Trong phân tích dữ liệu lớn, mọi người thường nhầm lẫn vai trò của một nhà khoa học dữ liệu với vai trò của một kiến trúc sư dữ liệu. Trong thực tế, sự khác biệt là khá đơn giản. Một kiến trúc sư dữ liệu xác định các công cụ và kiến trúc mà dữ liệu sẽ được lưu trữ, trong khi một nhà khoa học dữ liệu sử dụng kiến trúc này. Tất nhiên, một nhà khoa học dữ liệu sẽ có thể thiết lập các công cụ mới nếu cần cho các dự án đặc biệt, nhưng định nghĩa và thiết kế cơ sở hạ tầng không phải là một phần nhiệm vụ của anh ta.
Thông qua hướng dẫn này, chúng tôi sẽ phát triển một dự án. Mỗi chương tiếp theo trong hướng dẫn này đề cập đến một phần của dự án lớn hơn trong phần dự án nhỏ. Đây được cho là một phần hướng dẫn áp dụng sẽ cung cấp khả năng tiếp xúc với một vấn đề trong thế giới thực. Trong trường hợp này, chúng ta sẽ bắt đầu với định nghĩa vấn đề của dự án.
mô tả dự án
Mục tiêu của dự án này là phát triển một mô hình học máy để dự đoán mức lương theo giờ của những người sử dụng văn bản sơ yếu lý lịch (CV) của họ làm đầu vào.
Sử dụng khung được định nghĩa ở trên, việc xác định vấn đề rất đơn giản. Chúng ta có thể định nghĩa X = {x 1 , x 2 ,…, x n } là CV của người dùng, trong đó mỗi đặc điểm có thể, theo cách đơn giản nhất có thể, số lần từ này xuất hiện. Sau đó, phản hồi có giá trị thực, chúng tôi đang cố gắng dự đoán mức lương hàng giờ của các cá nhân bằng đô la.
Hai cân nhắc này đủ để kết luận rằng vấn đề được trình bày có thể được giải quyết bằng thuật toán hồi quy có giám sát.
Định nghĩa vấn đề
Problem Definitioncó lẽ là một trong những giai đoạn phức tạp nhất và bị bỏ quên nhiều nhất trong quy trình phân tích dữ liệu lớn. Để xác định vấn đề mà một sản phẩm dữ liệu sẽ giải quyết, kinh nghiệm là bắt buộc. Hầu hết những người khao khát nhà khoa học dữ liệu đều có ít hoặc không có kinh nghiệm trong giai đoạn này.
Hầu hết các vấn đề về dữ liệu lớn có thể được phân loại theo những cách sau:
- Phân loại có giám sát
- Hồi quy có giám sát
- Học tập không giám sát
- Học cách xếp hạng
Bây giờ chúng ta hãy tìm hiểu thêm về bốn khái niệm này.
Phân loại được giám sát
Cho một ma trận gồm các đặc điểm X = {x 1 , x 2 , ..., x n } chúng ta phát triển một mô hình M để dự đoán các lớp khác nhau được định nghĩa là y = {c 1 , c 2 , ..., c n } . Ví dụ: Với dữ liệu giao dịch của khách hàng trong một công ty bảo hiểm, có thể phát triển một mô hình dự đoán liệu khách hàng có bỏ cuộc hay không. Sau đó là một bài toán phân loại nhị phân, trong đó có hai lớp hoặc biến đích: churn và không churn.
Các vấn đề khác liên quan đến việc dự đoán nhiều hơn một lớp, chúng tôi có thể quan tâm đến việc thực hiện nhận dạng chữ số, do đó vectơ phản hồi sẽ được xác định là: y = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} , một mô hình hiện đại nhất sẽ là mạng nơ-ron tích tụ và ma trận các đặc trưng sẽ được xác định là các pixel của hình ảnh.
Hồi quy được giám sát
Trong trường hợp này, định nghĩa vấn đề khá giống với ví dụ trước; sự khác biệt phụ thuộc vào phản ứng. Trong một bài toán hồi quy, phản hồi y ∈ ℜ, điều này có nghĩa là phản hồi có giá trị thực. Ví dụ: chúng tôi có thể phát triển một mô hình để dự đoán mức lương hàng giờ của các cá nhân được cung cấp trong bản CV của họ.
Học tập không giám sát
Ban quản lý thường khát khao những hiểu biết mới. Mô hình phân khúc có thể cung cấp thông tin chi tiết này để bộ phận tiếp thị phát triển sản phẩm cho các phân khúc khác nhau. Một cách tiếp cận tốt để phát triển mô hình phân đoạn, thay vì nghĩ đến các thuật toán, là chọn các tính năng có liên quan đến phân đoạn mà bạn mong muốn.
Ví dụ, trong một công ty viễn thông, thật thú vị khi phân khúc khách hàng theo mức độ sử dụng điện thoại di động của họ. Điều này sẽ liên quan đến việc bỏ qua các tính năng không liên quan gì đến mục tiêu phân đoạn và chỉ bao gồm những tính năng có liên quan. Trong trường hợp này, đây sẽ là lựa chọn các tính năng như số lượng SMS được sử dụng trong một tháng, số phút đi và đến, v.v.
Học cách xếp hạng
Bài toán này có thể được coi là một bài toán hồi quy, nhưng nó có những đặc điểm riêng và đáng được xử lý riêng. Vấn đề liên quan đến việc đưa ra một bộ sưu tập tài liệu mà chúng tôi tìm cách tìm thứ tự phù hợp nhất cho một truy vấn. Để phát triển một thuật toán học có giám sát, cần phải gắn nhãn mức độ liên quan của một thứ tự, cho một truy vấn.
Cần lưu ý rằng để phát triển một thuật toán học có giám sát, cần phải gắn nhãn dữ liệu đào tạo. Điều này có nghĩa là để đào tạo một mô hình, ví dụ, sẽ nhận ra các chữ số từ một hình ảnh, chúng ta cần phải dán nhãn một lượng đáng kể các ví dụ bằng tay. Có những dịch vụ web có thể tăng tốc quá trình này và thường được sử dụng cho nhiệm vụ này, chẳng hạn như amazon Mechanical turk. Người ta đã chứng minh rằng các thuật toán học tập cải thiện hiệu suất của chúng khi được cung cấp nhiều dữ liệu hơn, vì vậy việc gắn nhãn cho một lượng ví dụ phù hợp là thực tế bắt buộc trong học tập có giám sát.
Thu thập dữ liệu đóng vai trò quan trọng nhất trong chu trình Dữ liệu lớn. Internet cung cấp nguồn dữ liệu gần như không giới hạn cho nhiều chủ đề khác nhau. Tầm quan trọng của lĩnh vực này phụ thuộc vào loại hình kinh doanh, nhưng các ngành công nghiệp truyền thống có thể thu được nguồn dữ liệu bên ngoài đa dạng và kết hợp chúng với dữ liệu giao dịch của họ.
Ví dụ: giả sử chúng tôi muốn xây dựng một hệ thống đề xuất nhà hàng. Bước đầu tiên là thu thập dữ liệu, trong trường hợp này là các đánh giá về nhà hàng từ các trang web khác nhau và lưu trữ chúng trong cơ sở dữ liệu. Vì chúng tôi quan tâm đến văn bản thô và sẽ sử dụng văn bản đó cho phân tích, nên việc lưu trữ dữ liệu để phát triển mô hình sẽ không có liên quan. Điều này nghe có vẻ mâu thuẫn với các công nghệ chính của dữ liệu lớn, nhưng để triển khai một ứng dụng dữ liệu lớn, chúng ta chỉ cần làm cho nó hoạt động trong thời gian thực.
Dự án nhỏ Twitter
Khi vấn đề được xác định, giai đoạn sau là thu thập dữ liệu. Ý tưởng dự án nhỏ sau đây là thu thập dữ liệu từ web và cấu trúc dữ liệu đó để sử dụng trong mô hình học máy. Chúng tôi sẽ thu thập một số tweet từ API phần còn lại của twitter bằng ngôn ngữ lập trình R.
Trước hết, hãy tạo một tài khoản twitter, và sau đó làm theo hướng dẫn trong twitteRgói họa tiết để tạo tài khoản nhà phát triển twitter. Đây là bản tóm tắt các hướng dẫn đó -
Đi đến https://twitter.com/apps/new và đăng nhập.
Sau khi điền các thông tin cơ bản, hãy chuyển đến tab "Cài đặt" và chọn "Đọc, Viết và Truy cập tin nhắn trực tiếp".
Đảm bảo nhấp vào nút lưu sau khi thực hiện việc này
Trong tab "Chi tiết", hãy ghi lại khóa khách hàng và bí mật người tiêu dùng của bạn
Trong phiên R của bạn, bạn sẽ sử dụng khóa API và các giá trị bí mật của API
Cuối cùng chạy tập lệnh sau. Điều này sẽ cài đặttwitteR gói từ kho của nó trên github.
install.packages(c("devtools", "rjson", "bit64", "httr"))
# Make sure to restart your R session at this point
library(devtools)
install_github("geoffjentry/twitteR")Chúng tôi quan tâm đến việc lấy dữ liệu trong đó chuỗi "big mac" được bao gồm và tìm ra chủ đề nào nổi bật về điều này. Để làm được điều này, bước đầu tiên là thu thập dữ liệu từ twitter. Dưới đây là tập lệnh R của chúng tôi để thu thập dữ liệu cần thiết từ twitter. Mã này cũng có sẵn trong tệp bda / part1 / collect_data / collect_data_twitter.R.
rm(list = ls(all = TRUE)); gc() # Clears the global environment
library(twitteR)
Sys.setlocale(category = "LC_ALL", locale = "C")
### Replace the xxx’s with the values you got from the previous instructions
# consumer_key = "xxxxxxxxxxxxxxxxxxxx"
# consumer_secret = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# access_token = "xxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# access_token_secret= "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
# Connect to twitter rest API
setup_twitter_oauth(consumer_key, consumer_secret, access_token, access_token_secret)
# Get tweets related to big mac
tweets <- searchTwitter(’big mac’, n = 200, lang = ’en’)
df <- twListToDF(tweets)
# Take a look at the data
head(df)
# Check which device is most used
sources <- sapply(tweets, function(x) x$getStatusSource())
sources <- gsub("</a>", "", sources)
sources <- strsplit(sources, ">")
sources <- sapply(sources, function(x) ifelse(length(x) > 1, x[2], x[1]))
source_table = table(sources)
source_table = source_table[source_table > 1]
freq = source_table[order(source_table, decreasing = T)]
as.data.frame(freq)
# Frequency
# Twitter for iPhone 71
# Twitter for Android 29
# Twitter Web Client 25
# recognia 20Khi dữ liệu được thu thập, chúng ta thường có các nguồn dữ liệu đa dạng với các đặc điểm khác nhau. Bước trước mắt nhất là làm cho các nguồn dữ liệu này đồng nhất và tiếp tục phát triển sản phẩm dữ liệu của chúng tôi. Tuy nhiên, nó phụ thuộc vào loại dữ liệu. Chúng ta nên tự hỏi liệu việc đồng nhất dữ liệu có thực tế hay không.
Có thể các nguồn dữ liệu hoàn toàn khác nhau, và sự mất mát thông tin sẽ lớn nếu các nguồn được đồng nhất. Trong trường hợp này, chúng ta có thể nghĩ đến các giải pháp thay thế. Một nguồn dữ liệu có thể giúp tôi xây dựng mô hình hồi quy và nguồn còn lại là mô hình phân loại không? Có thể làm việc với sự không đồng nhất có lợi cho chúng ta hơn là chỉ mất thông tin không? Đưa ra những quyết định này là điều khiến phân tích trở nên thú vị và đầy thách thức.
Trong trường hợp đánh giá, có thể có một ngôn ngữ cho mỗi nguồn dữ liệu. Một lần nữa, chúng tôi có hai lựa chọn -
Homogenization- Nó liên quan đến việc dịch các ngôn ngữ khác nhau sang ngôn ngữ mà chúng ta có nhiều dữ liệu hơn. Chất lượng của dịch vụ dịch có thể chấp nhận được, nhưng nếu chúng tôi muốn dịch một lượng lớn dữ liệu bằng API, chi phí sẽ rất đáng kể. Có các công cụ phần mềm có sẵn cho nhiệm vụ này, nhưng điều đó cũng sẽ tốn kém.
Heterogenization- Có thể phát triển một giải pháp cho mỗi ngôn ngữ không? Vì việc phát hiện ngôn ngữ của một kho ngữ liệu rất đơn giản, chúng tôi có thể phát triển một đề xuất cho mỗi ngôn ngữ. Điều này sẽ đòi hỏi nhiều công việc hơn trong việc điều chỉnh từng giới thiệu theo số lượng ngôn ngữ có sẵn nhưng chắc chắn là một lựa chọn khả thi nếu chúng tôi có sẵn một vài ngôn ngữ.
Dự án nhỏ Twitter
Trong trường hợp hiện tại, trước tiên chúng ta cần làm sạch dữ liệu phi cấu trúc và sau đó chuyển nó thành ma trận dữ liệu để áp dụng mô hình chủ đề trên đó. Nói chung, khi lấy dữ liệu từ twitter, có một số ký tự mà chúng tôi không muốn sử dụng, ít nhất là trong giai đoạn đầu tiên của quá trình làm sạch dữ liệu.
Ví dụ, sau khi nhận được tweet, chúng ta nhận được các ký tự lạ sau: "<ed> <U + 00A0> <U + 00BD> <ed> <U + 00B8> <U + 008B>". Đây có thể là các biểu tượng cảm xúc, vì vậy để xóa dữ liệu, chúng tôi sẽ xóa chúng bằng cách sử dụng tập lệnh sau. Mã này cũng có sẵn trong tệp bda / part1 / collect_data / Cleaning_data.R.
rm(list = ls(all = TRUE)); gc() # Clears the global environment
source('collect_data_twitter.R')
# Some tweets
head(df$text)
[1] "I’m not a big fan of turkey but baked Mac &
cheese <ed><U+00A0><U+00BD><ed><U+00B8><U+008B>"
[2] "@Jayoh30 Like no special sauce on a big mac. HOW"
### We are interested in the text - Let’s clean it!
# We first convert the encoding of the text from latin1 to ASCII
df$text <- sapply(df$text,function(row) iconv(row, "latin1", "ASCII", sub = ""))
# Create a function to clean tweets
clean.text <- function(tx) {
tx <- gsub("htt.{1,20}", " ", tx, ignore.case = TRUE)
tx = gsub("[^#[:^punct:]]|@|RT", " ", tx, perl = TRUE, ignore.case = TRUE)
tx = gsub("[[:digit:]]", " ", tx, ignore.case = TRUE)
tx = gsub(" {1,}", " ", tx, ignore.case = TRUE)
tx = gsub("^\\s+|\\s+$", " ", tx, ignore.case = TRUE) return(tx) } clean_tweets <- lapply(df$text, clean.text)
# Cleaned tweets
head(clean_tweets)
[1] " WeNeedFeminlsm MAC s new make up line features men woc and big girls "
[1] " TravelsPhoto What Happens To Your Body One Hour After A Big Mac "Bước cuối cùng của dự án nhỏ làm sạch dữ liệu là làm sạch văn bản mà chúng ta có thể chuyển đổi thành ma trận và áp dụng một thuật toán. Từ văn bản được lưu trữ trongclean_tweets vectơ chúng ta có thể dễ dàng chuyển đổi nó thành ma trận túi từ và áp dụng một thuật toán học không giám sát.
Báo cáo là rất quan trọng trong phân tích dữ liệu lớn. Mọi tổ chức đều phải cung cấp thông tin thường xuyên để hỗ trợ quá trình ra quyết định của mình. Tác vụ này thường được xử lý bởi các nhà phân tích dữ liệu có kinh nghiệm SQL và ETL (trích xuất, truyền và tải).
Nhóm phụ trách nhiệm vụ này có trách nhiệm truyền bá thông tin được tạo ra trong bộ phận phân tích dữ liệu lớn đến các khu vực khác nhau của tổ chức.
Ví dụ sau minh họa ý nghĩa của việc tóm tắt dữ liệu. Điều hướng đến thư mụcbda/part1/summarize_data và bên trong thư mục, hãy mở summarize_data.Rprojbằng cách nhấp đúp vào nó. Sau đó, mởsummarize_data.R script và xem mã, và làm theo các giải thích được trình bày.
# Install the following packages by running the following code in R.
pkgs = c('data.table', 'ggplot2', 'nycflights13', 'reshape2')
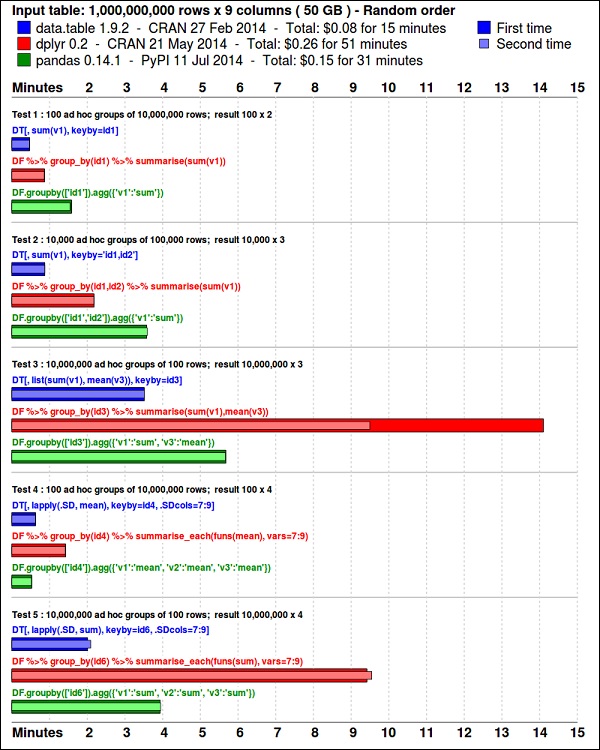
install.packages(pkgs)Các ggplot2gói là tuyệt vời để trực quan hóa dữ liệu. Cácdata.table gói là một lựa chọn tuyệt vời để thực hiện tóm tắt nhanh chóng và hiệu quả về bộ nhớ trong R. Điểm chuẩn gần đây cho thấy nó thậm chí còn nhanh hơnpandas, thư viện python được sử dụng cho các tác vụ tương tự.
Hãy xem dữ liệu bằng đoạn mã sau. Mã này cũng có sẵn trongbda/part1/summarize_data/summarize_data.Rproj tập tin.
library(nycflights13)
library(ggplot2)
library(data.table)
library(reshape2)
# Convert the flights data.frame to a data.table object and call it DT
DT <- as.data.table(flights)
# The data has 336776 rows and 16 columns
dim(DT)
# Take a look at the first rows
head(DT)
# year month day dep_time dep_delay arr_time arr_delay carrier
# 1: 2013 1 1 517 2 830 11 UA
# 2: 2013 1 1 533 4 850 20 UA
# 3: 2013 1 1 542 2 923 33 AA
# 4: 2013 1 1 544 -1 1004 -18 B6
# 5: 2013 1 1 554 -6 812 -25 DL
# 6: 2013 1 1 554 -4 740 12 UA
# tailnum flight origin dest air_time distance hour minute
# 1: N14228 1545 EWR IAH 227 1400 5 17
# 2: N24211 1714 LGA IAH 227 1416 5 33
# 3: N619AA 1141 JFK MIA 160 1089 5 42
# 4: N804JB 725 JFK BQN 183 1576 5 44
# 5: N668DN 461 LGA ATL 116 762 5 54
# 6: N39463 1696 EWR ORD 150 719 5 54Đoạn mã sau đây có một ví dụ về tóm tắt dữ liệu.
### Data Summarization
# Compute the mean arrival delay
DT[, list(mean_arrival_delay = mean(arr_delay, na.rm = TRUE))]
# mean_arrival_delay
# 1: 6.895377
# Now, we compute the same value but for each carrier
mean1 = DT[, list(mean_arrival_delay = mean(arr_delay, na.rm = TRUE)),
by = carrier]
print(mean1)
# carrier mean_arrival_delay
# 1: UA 3.5580111
# 2: AA 0.3642909
# 3: B6 9.4579733
# 4: DL 1.6443409
# 5: EV 15.7964311
# 6: MQ 10.7747334
# 7: US 2.1295951
# 8: WN 9.6491199
# 9: VX 1.7644644
# 10: FL 20.1159055
# 11: AS -9.9308886
# 12: 9E 7.3796692
# 13: F9 21.9207048
# 14: HA -6.9152047
# 15: YV 15.5569853
# 16: OO 11.9310345
# Now let’s compute to means in the same line of code
mean2 = DT[, list(mean_departure_delay = mean(dep_delay, na.rm = TRUE),
mean_arrival_delay = mean(arr_delay, na.rm = TRUE)),
by = carrier]
print(mean2)
# carrier mean_departure_delay mean_arrival_delay
# 1: UA 12.106073 3.5580111
# 2: AA 8.586016 0.3642909
# 3: B6 13.022522 9.4579733
# 4: DL 9.264505 1.6443409
# 5: EV 19.955390 15.7964311
# 6: MQ 10.552041 10.7747334
# 7: US 3.782418 2.1295951
# 8: WN 17.711744 9.6491199
# 9: VX 12.869421 1.7644644
# 10: FL 18.726075 20.1159055
# 11: AS 5.804775 -9.9308886
# 12: 9E 16.725769 7.3796692
# 13: F9 20.215543 21.9207048
# 14: HA 4.900585 -6.9152047
# 15: YV 18.996330 15.5569853
# 16: OO 12.586207 11.9310345
### Create a new variable called gain
# this is the difference between arrival delay and departure delay
DT[, gain:= arr_delay - dep_delay]
# Compute the median gain per carrier
median_gain = DT[, median(gain, na.rm = TRUE), by = carrier]
print(median_gain)Exploratory data analysislà một khái niệm được phát triển bởi John Tuckey (1977) bao gồm một quan điểm mới về thống kê. Ý tưởng của Tuckey là trong thống kê truyền thống, dữ liệu không được khám phá bằng đồ thị, chỉ được sử dụng để kiểm tra các giả thuyết. Nỗ lực đầu tiên để phát triển một công cụ được thực hiện ở Stanford, dự án được gọi là prim9 . Công cụ có thể trực quan hóa dữ liệu theo chín chiều, do đó nó có thể cung cấp góc nhìn đa biến của dữ liệu.
Trong những ngày gần đây, phân tích dữ liệu khám phá là điều bắt buộc và đã được đưa vào vòng đời của phân tích dữ liệu lớn. Khả năng tìm ra cái nhìn sâu sắc và có thể truyền đạt thông tin đó một cách hiệu quả trong một tổ chức được thúc đẩy bằng khả năng EDA mạnh mẽ.
Dựa trên ý tưởng của Tuckey, Bell Labs đã phát triển S programming languageđể cung cấp một giao diện tương tác để thực hiện thống kê. Ý tưởng của S là cung cấp khả năng đồ họa mở rộng với một ngôn ngữ dễ sử dụng. Trong thế giới ngày nay, trong bối cảnh Dữ liệu lớn,R điều đó dựa trên S ngôn ngữ lập trình là phần mềm phổ biến nhất để phân tích.
Chương trình sau đây trình bày việc sử dụng phân tích dữ liệu khám phá.
Sau đây là một ví dụ về phân tích dữ liệu khám phá. Mã này cũng có sẵn trongpart1/eda/exploratory_data_analysis.R tập tin.
library(nycflights13)
library(ggplot2)
library(data.table)
library(reshape2)
# Using the code from the previous section
# This computes the mean arrival and departure delays by carrier.
DT <- as.data.table(flights)
mean2 = DT[, list(mean_departure_delay = mean(dep_delay, na.rm = TRUE),
mean_arrival_delay = mean(arr_delay, na.rm = TRUE)),
by = carrier]
# In order to plot data in R usign ggplot, it is normally needed to reshape the data
# We want to have the data in long format for plotting with ggplot
dt = melt(mean2, id.vars = ’carrier’)
# Take a look at the first rows
print(head(dt))
# Take a look at the help for ?geom_point and geom_line to find similar examples
# Here we take the carrier code as the x axis
# the value from the dt data.table goes in the y axis
# The variable column represents the color
p = ggplot(dt, aes(x = carrier, y = value, color = variable, group = variable)) +
geom_point() + # Plots points
geom_line() + # Plots lines
theme_bw() + # Uses a white background
labs(list(title = 'Mean arrival and departure delay by carrier',
x = 'Carrier', y = 'Mean delay'))
print(p)
# Save the plot to disk
ggsave('mean_delay_by_carrier.png', p,
width = 10.4, height = 5.07)Đoạn mã sẽ tạo ra một hình ảnh như sau:

Để hiểu dữ liệu, thường hữu ích khi hình dung nó. Thông thường trong các ứng dụng Dữ liệu lớn, mối quan tâm phụ thuộc vào việc tìm kiếm thông tin chi tiết hơn là chỉ đưa ra các âm mưu đẹp. Sau đây là các ví dụ về các cách tiếp cận khác nhau để hiểu dữ liệu bằng cách sử dụng các biểu đồ.
Để bắt đầu phân tích dữ liệu chuyến bay, chúng ta có thể bắt đầu bằng cách kiểm tra xem có mối tương quan giữa các biến số hay không. Mã này cũng có sẵn trongbda/part1/data_visualization/data_visualization.R tập tin.
# Install the package corrplot by running
install.packages('corrplot')
# then load the library
library(corrplot)
# Load the following libraries
library(nycflights13)
library(ggplot2)
library(data.table)
library(reshape2)
# We will continue working with the flights data
DT <- as.data.table(flights)
head(DT) # take a look
# We select the numeric variables after inspecting the first rows.
numeric_variables = c('dep_time', 'dep_delay',
'arr_time', 'arr_delay', 'air_time', 'distance')
# Select numeric variables from the DT data.table
dt_num = DT[, numeric_variables, with = FALSE]
# Compute the correlation matrix of dt_num
cor_mat = cor(dt_num, use = "complete.obs")
print(cor_mat)
### Here is the correlation matrix
# dep_time dep_delay arr_time arr_delay air_time distance
# dep_time 1.00000000 0.25961272 0.66250900 0.23230573 -0.01461948 -0.01413373
# dep_delay 0.25961272 1.00000000 0.02942101 0.91480276 -0.02240508 -0.02168090
# arr_time 0.66250900 0.02942101 1.00000000 0.02448214 0.05429603 0.04718917
# arr_delay 0.23230573 0.91480276 0.02448214 1.00000000 -0.03529709 -0.06186776
# air_time -0.01461948 -0.02240508 0.05429603 -0.03529709 1.00000000 0.99064965
# distance -0.01413373 -0.02168090 0.04718917 -0.06186776 0.99064965 1.00000000
# We can display it visually to get a better understanding of the data
corrplot.mixed(cor_mat, lower = "circle", upper = "ellipse")
# save it to disk
png('corrplot.png')
print(corrplot.mixed(cor_mat, lower = "circle", upper = "ellipse"))
dev.off()Mã này tạo ra hình ảnh hóa ma trận tương quan sau:

Chúng ta có thể thấy trong biểu đồ rằng có mối tương quan chặt chẽ giữa một số biến trong tập dữ liệu. Ví dụ, sự chậm trễ đến và trễ chuyến đi dường như có mối tương quan cao. Chúng ta có thể thấy điều này vì hình elip cho thấy mối quan hệ gần như tuyến tính giữa cả hai biến, tuy nhiên, không đơn giản để tìm ra nhân quả từ kết quả này.
Chúng ta không thể nói rằng vì hai biến có tương quan với nhau, nên biến này có ảnh hưởng đến biến kia. Ngoài ra, chúng tôi thấy trong cốt truyện có mối tương quan chặt chẽ giữa thời gian trên không và khoảng cách, điều này khá hợp lý để mong đợi vì với khoảng cách xa hơn, thời gian bay sẽ tăng lên.
Chúng tôi cũng có thể phân tích dữ liệu đơn biến. Một cách đơn giản và hiệu quả để hình dung các bản phân phối làbox-plots. Đoạn mã sau minh họa cách tạo biểu đồ dạng hộp và dạng lưới bằng thư viện ggplot2. Mã này cũng có sẵn trongbda/part1/data_visualization/boxplots.R tập tin.
source('data_visualization.R')
### Analyzing Distributions using box-plots
# The following shows the distance as a function of the carrier
p = ggplot(DT, aes(x = carrier, y = distance, fill = carrier)) + # Define the carrier
in the x axis and distance in the y axis
geom_box-plot() + # Use the box-plot geom
theme_bw() + # Leave a white background - More in line with tufte's
principles than the default
guides(fill = FALSE) + # Remove legend
labs(list(title = 'Distance as a function of carrier', # Add labels
x = 'Carrier', y = 'Distance'))
p
# Save to disk
png(‘boxplot_carrier.png’)
print(p)
dev.off()
# Let's add now another variable, the month of each flight
# We will be using facet_wrap for this
p = ggplot(DT, aes(carrier, distance, fill = carrier)) +
geom_box-plot() +
theme_bw() +
guides(fill = FALSE) +
facet_wrap(~month) + # This creates the trellis plot with the by month variable
labs(list(title = 'Distance as a function of carrier by month',
x = 'Carrier', y = 'Distance'))
p
# The plot shows there aren't clear differences between distance in different months
# Save to disk
png('boxplot_carrier_by_month.png')
print(p)
dev.off()Phần này dành để giới thiệu cho người dùng về ngôn ngữ lập trình R. R có thể được tải xuống từ trang web cran . Đối với người dùng Windows, việc cài đặt rtools và IDE rstudio sẽ rất hữu ích .
Khái niệm chung đằng sau R là để phục vụ như một giao diện cho phần mềm khác được phát triển bằng các ngôn ngữ biên dịch như C, C ++ và Fortran và cung cấp cho người dùng một công cụ tương tác để phân tích dữ liệu.
Điều hướng đến thư mục của tệp zip sách bda/part2/R_introduction và mở R_introduction.Rprojtập tin. Điều này sẽ mở một phiên RStudio. Sau đó, mở tệp 01_vectors.R. Chạy từng dòng kịch bản và làm theo các nhận xét trong mã. Một tùy chọn hữu ích khác để học là chỉ cần nhập mã, điều này sẽ giúp bạn làm quen với cú pháp R. Trong R chú thích được viết với ký hiệu #.
Để hiển thị kết quả chạy mã R trong sách, sau khi mã được đánh giá, kết quả R trả về được nhận xét. Bằng cách này, bạn có thể sao chép, dán mã vào sách và thử trực tiếp các phần của nó trong R.
# Create a vector of numbers
numbers = c(1, 2, 3, 4, 5)
print(numbers)
# [1] 1 2 3 4 5
# Create a vector of letters
ltrs = c('a', 'b', 'c', 'd', 'e')
# [1] "a" "b" "c" "d" "e"
# Concatenate both
mixed_vec = c(numbers, ltrs)
print(mixed_vec)
# [1] "1" "2" "3" "4" "5" "a" "b" "c" "d" "e"Hãy phân tích những gì đã xảy ra trong đoạn mã trước. Chúng ta có thể thấy rằng có thể tạo các vectơ bằng số và bằng chữ cái. Chúng ta không cần phải cho R biết trước kiểu dữ liệu mà chúng ta muốn. Cuối cùng, chúng ta đã có thể tạo một vector có cả số và chữ. Vector mix_vec đã ép buộc các số thành ký tự, chúng ta có thể thấy điều này bằng cách hình dung cách các giá trị được in bên trong dấu ngoặc kép.
Đoạn mã sau đây hiển thị kiểu dữ liệu của các vectơ khác nhau do lớp hàm trả về. Người ta thường sử dụng hàm lớp để "thẩm vấn" một đối tượng, hỏi anh ta lớp của anh ta là gì.
### Evaluate the data types using class
### One dimensional objects
# Integer vector
num = 1:10
class(num)
# [1] "integer"
# Numeric vector, it has a float, 10.5
num = c(1:10, 10.5)
class(num)
# [1] "numeric"
# Character vector
ltrs = letters[1:10]
class(ltrs)
# [1] "character"
# Factor vector
fac = as.factor(ltrs)
class(fac)
# [1] "factor"R cũng hỗ trợ các đối tượng hai chiều. Trong đoạn mã sau, có các ví dụ về hai cấu trúc dữ liệu phổ biến nhất được sử dụng trong R: ma trận và data.frame.
# Matrix
M = matrix(1:12, ncol = 4)
# [,1] [,2] [,3] [,4]
# [1,] 1 4 7 10
# [2,] 2 5 8 11
# [3,] 3 6 9 12
lM = matrix(letters[1:12], ncol = 4)
# [,1] [,2] [,3] [,4]
# [1,] "a" "d" "g" "j"
# [2,] "b" "e" "h" "k"
# [3,] "c" "f" "i" "l"
# Coerces the numbers to character
# cbind concatenates two matrices (or vectors) in one matrix
cbind(M, lM)
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
# [1,] "1" "4" "7" "10" "a" "d" "g" "j"
# [2,] "2" "5" "8" "11" "b" "e" "h" "k"
# [3,] "3" "6" "9" "12" "c" "f" "i" "l"
class(M)
# [1] "matrix"
class(lM)
# [1] "matrix"
# data.frame
# One of the main objects of R, handles different data types in the same object.
# It is possible to have numeric, character and factor vectors in the same data.frame
df = data.frame(n = 1:5, l = letters[1:5])
df
# n l
# 1 1 a
# 2 2 b
# 3 3 c
# 4 4 d
# 5 5 eNhư đã trình bày trong ví dụ trước, có thể sử dụng các kiểu dữ liệu khác nhau trong cùng một đối tượng. Nói chung, đây là cách dữ liệu được trình bày trong cơ sở dữ liệu, APIs một phần của dữ liệu là văn bản hoặc vectơ ký tự và số khác. Công việc của nhà phân tích là xác định kiểu dữ liệu thống kê nào cần gán và sau đó sử dụng kiểu dữ liệu R chính xác cho nó. Trong thống kê, chúng ta thường coi các biến thuộc các loại sau:
- Numeric
- Danh nghĩa hoặc phân loại
- Ordinal
Trong R, một vectơ có thể thuộc các lớp sau:
- Numeric - Integer
- Factor
- Yếu tố thứ tự
R cung cấp một kiểu dữ liệu cho mỗi kiểu thống kê của biến. Tuy nhiên, yếu tố có thứ tự hiếm khi được sử dụng, nhưng có thể được tạo bởi yếu tố hàm hoặc có thứ tự.
Phần sau đây đề cập đến khái niệm lập chỉ mục. Đây là một hoạt động khá phổ biến và giải quyết vấn đề chọn các phần của một đối tượng và thực hiện các phép biến đổi cho chúng.
# Let's create a data.frame
df = data.frame(numbers = 1:26, letters)
head(df)
# numbers letters
# 1 1 a
# 2 2 b
# 3 3 c
# 4 4 d
# 5 5 e
# 6 6 f
# str gives the structure of a data.frame, it’s a good summary to inspect an object
str(df)
# 'data.frame': 26 obs. of 2 variables:
# $ numbers: int 1 2 3 4 5 6 7 8 9 10 ... # $ letters: Factor w/ 26 levels "a","b","c","d",..: 1 2 3 4 5 6 7 8 9 10 ...
# The latter shows the letters character vector was coerced as a factor.
# This can be explained by the stringsAsFactors = TRUE argumnet in data.frame
# read ?data.frame for more information
class(df)
# [1] "data.frame"
### Indexing
# Get the first row
df[1, ]
# numbers letters
# 1 1 a
# Used for programming normally - returns the output as a list
df[1, , drop = TRUE]
# $numbers # [1] 1 # # $letters
# [1] a
# Levels: a b c d e f g h i j k l m n o p q r s t u v w x y z
# Get several rows of the data.frame
df[5:7, ]
# numbers letters
# 5 5 e
# 6 6 f
# 7 7 g
### Add one column that mixes the numeric column with the factor column
df$mixed = paste(df$numbers, df$letters, sep = ’’) str(df) # 'data.frame': 26 obs. of 3 variables: # $ numbers: int 1 2 3 4 5 6 7 8 9 10 ...
# $ letters: Factor w/ 26 levels "a","b","c","d",..: 1 2 3 4 5 6 7 8 9 10 ... # $ mixed : chr "1a" "2b" "3c" "4d" ...
### Get columns
# Get the first column
df[, 1]
# It returns a one dimensional vector with that column
# Get two columns
df2 = df[, 1:2]
head(df2)
# numbers letters
# 1 1 a
# 2 2 b
# 3 3 c
# 4 4 d
# 5 5 e
# 6 6 f
# Get the first and third columns
df3 = df[, c(1, 3)]
df3[1:3, ]
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
### Index columns from their names
names(df)
# [1] "numbers" "letters" "mixed"
# This is the best practice in programming, as many times indeces change, but
variable names don’t
# We create a variable with the names we want to subset
keep_vars = c("numbers", "mixed")
df4 = df[, keep_vars]
head(df4)
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
# 4 4 4d
# 5 5 5e
# 6 6 6f
### subset rows and columns
# Keep the first five rows
df5 = df[1:5, keep_vars]
df5
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
# 4 4 4d
# 5 5 5e
# subset rows using a logical condition
df6 = df[df$numbers < 10, keep_vars]
df6
# numbers mixed
# 1 1 1a
# 2 2 2b
# 3 3 3c
# 4 4 4d
# 5 5 5e
# 6 6 6f
# 7 7 7g
# 8 8 8h
# 9 9 9iSQL là viết tắt của ngôn ngữ truy vấn có cấu trúc. Nó là một trong những ngôn ngữ được sử dụng rộng rãi nhất để trích xuất dữ liệu từ cơ sở dữ liệu trong kho dữ liệu truyền thống và công nghệ dữ liệu lớn. Để chứng minh những điều cơ bản của SQL, chúng tôi sẽ làm việc với các ví dụ. Để tập trung vào chính ngôn ngữ, chúng ta sẽ sử dụng SQL bên trong R. Về mặt viết mã SQL, điều này chính xác như được thực hiện trong cơ sở dữ liệu.
Cốt lõi của SQL là ba câu lệnh: SELECT, FROM và WHERE. Các ví dụ sau sử dụng các trường hợp sử dụng phổ biến nhất của SQL. Điều hướng đến thư mụcbda/part2/SQL_introduction và mở SQL_introduction.Rprojtập tin. Sau đó, mở tập lệnh 01_select.R. Để viết mã SQL trong R, chúng ta cần cài đặtsqldf gói như được minh họa trong đoạn mã sau.
# Install the sqldf package
install.packages('sqldf')
# load the library
library('sqldf')
library(nycflights13)
# We will be working with the fligths dataset in order to introduce SQL
# Let’s take a look at the table
str(flights)
# Classes 'tbl_d', 'tbl' and 'data.frame': 336776 obs. of 16 variables:
# $ year : int 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 ...
# $ month : int 1 1 1 1 1 1 1 1 1 1 ... # $ day : int 1 1 1 1 1 1 1 1 1 1 ...
# $ dep_time : int 517 533 542 544 554 554 555 557 557 558 ... # $ dep_delay: num 2 4 2 -1 -6 -4 -5 -3 -3 -2 ...
# $ arr_time : int 830 850 923 1004 812 740 913 709 838 753 ... # $ arr_delay: num 11 20 33 -18 -25 12 19 -14 -8 8 ...
# $ carrier : chr "UA" "UA" "AA" "B6" ... # $ tailnum : chr "N14228" "N24211" "N619AA" "N804JB" ...
# $ flight : int 1545 1714 1141 725 461 1696 507 5708 79 301 ... # $ origin : chr "EWR" "LGA" "JFK" "JFK" ...
# $ dest : chr "IAH" "IAH" "MIA" "BQN" ... # $ air_time : num 227 227 160 183 116 150 158 53 140 138 ...
# $ distance : num 1400 1416 1089 1576 762 ... # $ hour : num 5 5 5 5 5 5 5 5 5 5 ...
# $ minute : num 17 33 42 44 54 54 55 57 57 58 ...Câu lệnh select được sử dụng để lấy các cột từ bảng và thực hiện các phép tính trên chúng. Câu lệnh SELECT đơn giản nhất được minh họa trongej1. Chúng tôi cũng có thể tạo các biến mới như được hiển thị trongej2.
### SELECT statement
ej1 = sqldf("
SELECT
dep_time
,dep_delay
,arr_time
,carrier
,tailnum
FROM
flights
")
head(ej1)
# dep_time dep_delay arr_time carrier tailnum
# 1 517 2 830 UA N14228
# 2 533 4 850 UA N24211
# 3 542 2 923 AA N619AA
# 4 544 -1 1004 B6 N804JB
# 5 554 -6 812 DL N668DN
# 6 554 -4 740 UA N39463
# In R we can use SQL with the sqldf function. It works exactly the same as in
a database
# The data.frame (in this case flights) represents the table we are querying
and goes in the FROM statement
# We can also compute new variables in the select statement using the syntax:
# old_variables as new_variable
ej2 = sqldf("
SELECT
arr_delay - dep_delay as gain,
carrier
FROM
flights
")
ej2[1:5, ]
# gain carrier
# 1 9 UA
# 2 16 UA
# 3 31 AA
# 4 -17 B6
# 5 -19 DLMột trong những tính năng được sử dụng phổ biến nhất của SQL là nhóm theo câu lệnh. Điều này cho phép tính toán một giá trị số cho các nhóm khác nhau của một biến khác. Mở tập lệnh 02_group_by.R.
### GROUP BY
# Computing the average
ej3 = sqldf("
SELECT
avg(arr_delay) as mean_arr_delay,
avg(dep_delay) as mean_dep_delay,
carrier
FROM
flights
GROUP BY
carrier
")
# mean_arr_delay mean_dep_delay carrier
# 1 7.3796692 16.725769 9E
# 2 0.3642909 8.586016 AA
# 3 -9.9308886 5.804775 AS
# 4 9.4579733 13.022522 B6
# 5 1.6443409 9.264505 DL
# 6 15.7964311 19.955390 EV
# 7 21.9207048 20.215543 F9
# 8 20.1159055 18.726075 FL
# 9 -6.9152047 4.900585 HA
# 10 10.7747334 10.552041 MQ
# 11 11.9310345 12.586207 OO
# 12 3.5580111 12.106073 UA
# 13 2.1295951 3.782418 US
# 14 1.7644644 12.869421 VX
# 15 9.6491199 17.711744 WN
# 16 15.5569853 18.996330 YV
# Other aggregations
ej4 = sqldf("
SELECT
avg(arr_delay) as mean_arr_delay,
min(dep_delay) as min_dep_delay,
max(dep_delay) as max_dep_delay,
carrier
FROM
flights
GROUP BY
carrier
")
# We can compute the minimun, mean, and maximum values of a numeric value
ej4
# mean_arr_delay min_dep_delay max_dep_delay carrier
# 1 7.3796692 -24 747 9E
# 2 0.3642909 -24 1014 AA
# 3 -9.9308886 -21 225 AS
# 4 9.4579733 -43 502 B6
# 5 1.6443409 -33 960 DL
# 6 15.7964311 -32 548 EV
# 7 21.9207048 -27 853 F9
# 8 20.1159055 -22 602 FL
# 9 -6.9152047 -16 1301 HA
# 10 10.7747334 -26 1137 MQ
# 11 11.9310345 -14 154 OO
# 12 3.5580111 -20 483 UA
# 13 2.1295951 -19 500 US
# 14 1.7644644 -20 653 VX
# 15 9.6491199 -13 471 WN
# 16 15.5569853 -16 387 YV
### We could be also interested in knowing how many observations each carrier has
ej5 = sqldf("
SELECT
carrier, count(*) as count
FROM
flights
GROUP BY
carrier
")
ej5
# carrier count
# 1 9E 18460
# 2 AA 32729
# 3 AS 714
# 4 B6 54635
# 5 DL 48110
# 6 EV 54173
# 7 F9 685
# 8 FL 3260
# 9 HA 342
# 10 MQ 26397
# 11 OO 32
# 12 UA 58665
# 13 US 20536
# 14 VX 5162
# 15 WN 12275
# 16 YV 601Tính năng hữu ích nhất của SQL là các phép nối. Phép nối có nghĩa là chúng ta muốn kết hợp bảng A và bảng B trong một bảng bằng cách sử dụng một cột để khớp các giá trị của cả hai bảng. Có nhiều loại liên kết khác nhau, về mặt thực tế, để bắt đầu, chúng sẽ là những loại hữu ích nhất: liên kết bên trong và liên kết bên ngoài bên trái.
# Let’s create two tables: A and B to demonstrate joins.
A = data.frame(c1 = 1:4, c2 = letters[1:4])
B = data.frame(c1 = c(2,4,5,6), c2 = letters[c(2:5)])
A
# c1 c2
# 1 a
# 2 b
# 3 c
# 4 d
B
# c1 c2
# 2 b
# 4 c
# 5 d
# 6 e
### INNER JOIN
# This means to match the observations of the column we would join the tables by.
inner = sqldf("
SELECT
A.c1, B.c2
FROM
A INNER JOIN B
ON A.c1 = B.c1
")
# Only the rows that match c1 in both A and B are returned
inner
# c1 c2
# 2 b
# 4 c
### LEFT OUTER JOIN
# the left outer join, sometimes just called left join will return the
# first all the values of the column used from the A table
left = sqldf("
SELECT
A.c1, B.c2
FROM
A LEFT OUTER JOIN B
ON A.c1 = B.c1
")
# Only the rows that match c1 in both A and B are returned
left
# c1 c2
# 1 <NA>
# 2 b
# 3 <NA>
# 4 cCách tiếp cận đầu tiên để phân tích dữ liệu là phân tích nó một cách trực quan. Mục tiêu khi thực hiện việc này thường là tìm kiếm các mối quan hệ giữa các biến và mô tả đơn biến của các biến. Chúng ta có thể chia các chiến lược này thành -
- Phân tích đơn biến
- Phân tích đa biến
Phương pháp đồ thị đơn biến
Univariatelà một thuật ngữ thống kê. Trong thực tế, điều đó có nghĩa là chúng ta muốn phân tích một biến độc lập với phần còn lại của dữ liệu. Các âm mưu cho phép thực hiện điều này một cách hiệu quả là -
Box-Plots
Box-Plots thường được sử dụng để so sánh các bản phân phối. Đó là một cách tuyệt vời để kiểm tra trực quan nếu có sự khác biệt giữa các bản phân phối. Chúng ta có thể thấy nếu có sự khác biệt giữa giá kim cương cho các lần cắt khác nhau.
# We will be using the ggplot2 library for plotting
library(ggplot2)
data("diamonds")
# We will be using the diamonds dataset to analyze distributions of numeric variables
head(diamonds)
# carat cut color clarity depth table price x y z
# 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
# 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
# 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
# 4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
# 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
# 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
### Box-Plots
p = ggplot(diamonds, aes(x = cut, y = price, fill = cut)) +
geom_box-plot() +
theme_bw()
print(p)Chúng ta có thể thấy trong biểu đồ có sự khác biệt trong việc phân bổ giá kim cương ở các dạng cắt khác nhau.

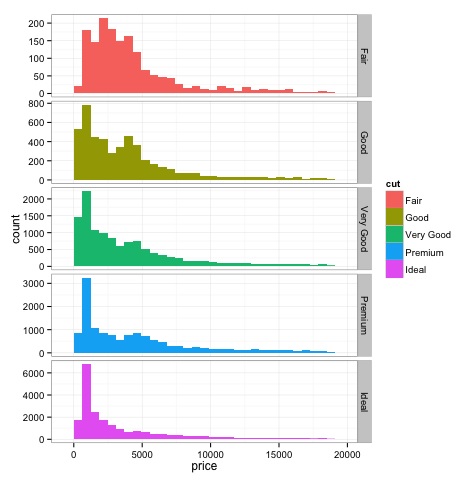
Biểu đồ
source('01_box_plots.R')
# We can plot histograms for each level of the cut factor variable using
facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~ .) +
theme_bw()
p
# the previous plot doesn’t allow to visuallize correctly the data because of
the differences in scale
# we can turn this off using the scales argument of facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~ ., scales = 'free') +
theme_bw()
p
png('02_histogram_diamonds_cut.png')
print(p)
dev.off()Đầu ra của đoạn mã trên sẽ như sau:
Phương pháp đồ họa đa biến
Phương pháp đồ họa đa biến trong phân tích dữ liệu khám phá có mục tiêu tìm kiếm mối quan hệ giữa các biến khác nhau. Có hai cách để thực hiện điều này thường được sử dụng: vẽ biểu đồ ma trận tương quan của các biến số hoặc đơn giản là vẽ dữ liệu thô dưới dạng ma trận các biểu đồ phân tán.
Để chứng minh điều này, chúng tôi sẽ sử dụng tập dữ liệu kim cương. Để làm theo mã, hãy mở tập lệnhbda/part2/charts/03_multivariate_analysis.R.
library(ggplot2)
data(diamonds)
# Correlation matrix plots
keep_vars = c('carat', 'depth', 'price', 'table')
df = diamonds[, keep_vars]
# compute the correlation matrix
M_cor = cor(df)
# carat depth price table
# carat 1.00000000 0.02822431 0.9215913 0.1816175
# depth 0.02822431 1.00000000 -0.0106474 -0.2957785
# price 0.92159130 -0.01064740 1.0000000 0.1271339
# table 0.18161755 -0.29577852 0.1271339 1.0000000
# plots
heat-map(M_cor)Mã sẽ tạo ra kết quả sau:

Đây là một bản tóm tắt, nó cho chúng ta biết rằng có mối tương quan chặt chẽ giữa giá và dấu mũ, và không nhiều giữa các biến khác.
Ma trận tương quan có thể hữu ích khi chúng ta có một số lượng lớn các biến, trong trường hợp đó, việc vẽ dữ liệu thô sẽ không thực tế. Như đã đề cập, cũng có thể hiển thị dữ liệu thô -
library(GGally)
ggpairs(df)Chúng ta có thể thấy trong biểu đồ mà kết quả hiển thị trong bản đồ nhiệt được xác nhận, có mối tương quan 0,922 giữa các biến giá và carat.
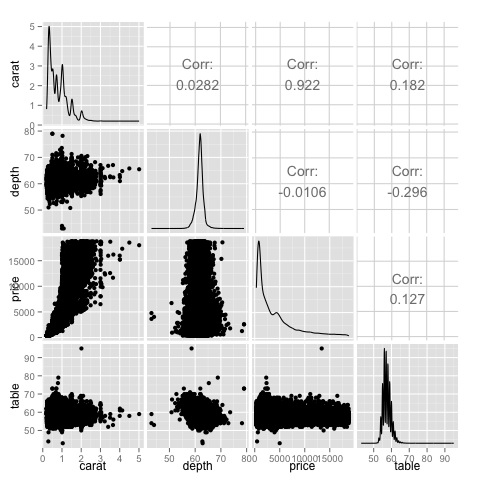
Có thể hình dung mối quan hệ này trong biểu đồ phân tán giá carat nằm trong chỉ số (3, 1) của ma trận biểu đồ phân tán.
Có nhiều công cụ cho phép nhà khoa học dữ liệu phân tích dữ liệu một cách hiệu quả. Thông thường khía cạnh kỹ thuật của phân tích dữ liệu tập trung vào cơ sở dữ liệu, nhà khoa học dữ liệu tập trung vào các công cụ có thể triển khai các sản phẩm dữ liệu. Phần dưới đây thảo luận về những ưu điểm của các công cụ khác nhau, tập trung vào các gói thống kê mà nhà khoa học dữ liệu sử dụng trong thực tế thường xuyên nhất.
Ngôn ngữ lập trình R
R là một ngôn ngữ lập trình mã nguồn mở tập trung vào phân tích thống kê. Nó có khả năng cạnh tranh với các công cụ thương mại như SAS, SPSS về khả năng thống kê. Nó được cho là một giao diện cho các ngôn ngữ lập trình khác như C, C ++ hoặc Fortran.
Một ưu điểm khác của R là số lượng lớn các thư viện mã nguồn mở có sẵn. Trong CRAN, có hơn 6000 gói có thể được tải xuống miễn phí vàGithub có rất nhiều gói R khác nhau.
Về mặt hiệu suất, R chậm đối với các hoạt động chuyên sâu, do số lượng lớn các thư viện có sẵn, các phần chậm của mã được viết bằng ngôn ngữ biên dịch. Nhưng nếu bạn đang có ý định thực hiện các thao tác yêu cầu viết sâu cho các vòng lặp, thì R không phải là sự thay thế tốt nhất cho bạn. Đối với mục đích phân tích dữ liệu, có các thư viện tốt đẹp nhưdata.table, glmnet, ranger, xgboost, ggplot2, caret cho phép sử dụng R làm giao diện cho các ngôn ngữ lập trình nhanh hơn.
Python để phân tích dữ liệu
Python là một ngôn ngữ lập trình có mục đích chung và nó chứa một số lượng đáng kể các thư viện dành cho việc phân tích dữ liệu như pandas, scikit-learn, theano, numpy và scipy.
Hầu hết những gì có sẵn trong R cũng có thể được thực hiện bằng Python nhưng chúng tôi nhận thấy rằng R dễ sử dụng hơn. Trong trường hợp bạn đang làm việc với các bộ dữ liệu lớn, thông thường Python là lựa chọn tốt hơn R. Python có thể được sử dụng khá hiệu quả để làm sạch và xử lý từng dòng dữ liệu. Điều này có thể thực hiện được từ R nhưng nó không hiệu quả bằng Python cho các tác vụ kịch bản.
Đối với học máy, scikit-learnlà một môi trường tốt có sẵn một lượng lớn các thuật toán có thể xử lý các tập dữ liệu có kích thước trung bình mà không gặp vấn đề gì. So với thư viện tương đương của R (dấu mũ),scikit-learn có API sạch hơn và nhất quán hơn.
Julia
Julia là một ngôn ngữ lập trình động hiệu suất cao cấp cao dành cho máy tính kỹ thuật. Cú pháp của nó khá giống với R hoặc Python, vì vậy nếu bạn đã làm việc với R hoặc Python thì việc viết cùng một đoạn mã trong Julia sẽ khá đơn giản. Ngôn ngữ này khá mới và đã phát triển đáng kể trong những năm gần đây, vì vậy nó chắc chắn là một lựa chọn vào lúc này.
Chúng tôi muốn giới thiệu Julia cho các thuật toán tạo mẫu chuyên sâu về tính toán, chẳng hạn như mạng nơ-ron. Nó là một công cụ tuyệt vời để nghiên cứu. Về mặt triển khai một mô hình trong sản xuất, có lẽ Python có các lựa chọn thay thế tốt hơn. Tuy nhiên, điều này ngày càng trở nên ít vấn đề hơn vì có những dịch vụ web thực hiện kỹ thuật triển khai các mô hình bằng R, Python và Julia.
SAS
SAS là một ngôn ngữ thương mại vẫn đang được sử dụng cho kinh doanh thông minh. Nó có một ngôn ngữ cơ sở cho phép người dùng lập trình nhiều loại ứng dụng. Nó chứa khá nhiều sản phẩm thương mại cung cấp cho người dùng không phải chuyên gia khả năng sử dụng các công cụ phức tạp như thư viện mạng thần kinh mà không cần lập trình.
Ngoài nhược điểm rõ ràng của các công cụ thương mại, SAS không mở rộng quy mô tốt cho các bộ dữ liệu lớn. Ngay cả tập dữ liệu có kích thước trung bình cũng sẽ gặp sự cố với SAS và làm cho máy chủ bị sập. Chỉ khi bạn đang làm việc với các bộ dữ liệu nhỏ và người dùng không phải là nhà khoa học dữ liệu chuyên nghiệp, thì SAS mới được khuyến nghị. Đối với người dùng nâng cao, R và Python cung cấp một môi trường hiệu quả hơn.
SPSS
SPSS, hiện là một sản phẩm của IBM để phân tích thống kê. Nó chủ yếu được sử dụng để phân tích dữ liệu khảo sát và đối với những người dùng không có khả năng lập trình, nó là một lựa chọn thay thế phù hợp. Nó có thể đơn giản để sử dụng như SAS, nhưng về mặt triển khai một mô hình, nó đơn giản hơn vì nó cung cấp một mã SQL để tính điểm cho một mô hình. Mã này thường không hiệu quả, nhưng đó là một bước khởi đầu trong khi SAS bán sản phẩm cho điểm các mô hình cho từng cơ sở dữ liệu riêng biệt. Đối với dữ liệu nhỏ và nhóm chưa có kinh nghiệm, SPSS là một lựa chọn tốt như SAS.
Tuy nhiên, phần mềm này khá hạn chế và những người dùng có kinh nghiệm sẽ sử dụng R hoặc Python có năng suất cao hơn.
Matlab, Octave
Có các công cụ khác có sẵn như Matlab hoặc phiên bản nguồn mở của nó (Octave). Những công cụ này hầu hết được sử dụng để nghiên cứu. Về khả năng R hoặc Python có thể làm tất cả những gì có trong Matlab hoặc Octave. Chỉ có ý nghĩa khi mua giấy phép của sản phẩm nếu bạn quan tâm đến sự hỗ trợ mà họ cung cấp.
Khi phân tích dữ liệu, có thể có một phương pháp thống kê. Các công cụ cơ bản cần thiết để thực hiện phân tích cơ bản là:
- Phân tích tương quan
- Phân tích phương sai
- Kiểm tra giả thuyết
Khi làm việc với các tập dữ liệu lớn, nó không liên quan đến vấn đề vì các phương pháp này không chuyên sâu về mặt tính toán, ngoại trừ Phân tích tương quan. Trong trường hợp này, luôn có thể lấy mẫu và kết quả phải chắc chắn.
Phân tích tương quan
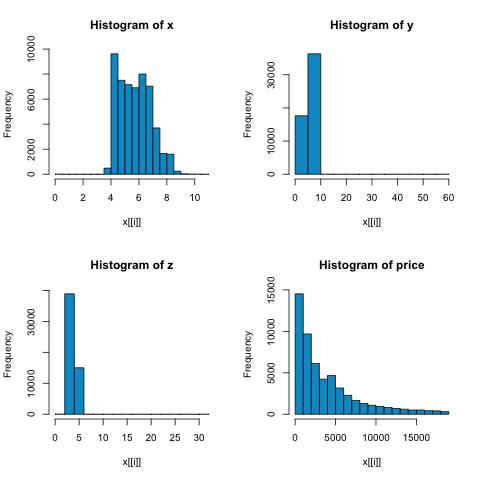
Phân tích tương quan tìm kiếm mối quan hệ tuyến tính giữa các biến số. Điều này có thể được sử dụng trong các trường hợp khác nhau. Một cách sử dụng phổ biến là phân tích dữ liệu khám phá, trong phần 16.0.2 của cuốn sách có một ví dụ cơ bản về cách tiếp cận này. Trước hết, số liệu tương quan được sử dụng trong ví dụ được đề cập dựa trênPearson coefficient. Tuy nhiên, có một thước đo tương quan thú vị khác không bị ảnh hưởng bởi các yếu tố ngoại lai. Số liệu này được gọi là mối tương quan giữa các mũi nhọn.
Các spearman correlation metric mạnh mẽ hơn đối với sự hiện diện của các giá trị ngoại lệ so với phương pháp Pearson và đưa ra các ước tính tốt hơn về quan hệ tuyến tính giữa biến số khi dữ liệu không được phân phối bình thường.
library(ggplot2)
# Select variables that are interesting to compare pearson and spearman
correlation methods.
x = diamonds[, c('x', 'y', 'z', 'price')]
# From the histograms we can expect differences in the correlations of both
metrics.
# In this case as the variables are clearly not normally distributed, the
spearman correlation
# is a better estimate of the linear relation among numeric variables.
par(mfrow = c(2,2))
colnm = names(x)
for(i in 1:4) {
hist(x[[i]], col = 'deepskyblue3', main = sprintf('Histogram of %s', colnm[i]))
}
par(mfrow = c(1,1))Từ các biểu đồ trong hình sau, chúng ta có thể mong đợi sự khác biệt trong mối tương quan của cả hai chỉ số. Trong trường hợp này, vì các biến rõ ràng không được phân phối chuẩn, nên tương quan cạnh là một ước lượng tốt hơn về mối quan hệ tuyến tính giữa các biến số.
Để tính toán mối tương quan trong R, hãy mở tệp bda/part2/statistical_methods/correlation/correlation.R có phần mã này.
## Correlation Matrix - Pearson and spearman
cor_pearson <- cor(x, method = 'pearson')
cor_spearman <- cor(x, method = 'spearman')
### Pearson Correlation
print(cor_pearson)
# x y z price
# x 1.0000000 0.9747015 0.9707718 0.8844352
# y 0.9747015 1.0000000 0.9520057 0.8654209
# z 0.9707718 0.9520057 1.0000000 0.8612494
# price 0.8844352 0.8654209 0.8612494 1.0000000
### Spearman Correlation
print(cor_spearman)
# x y z price
# x 1.0000000 0.9978949 0.9873553 0.9631961
# y 0.9978949 1.0000000 0.9870675 0.9627188
# z 0.9873553 0.9870675 1.0000000 0.9572323
# price 0.9631961 0.9627188 0.9572323 1.0000000Kiểm tra chi bình phương
Kiểm định chi bình phương cho phép chúng ta kiểm tra xem hai biến ngẫu nhiên có độc lập hay không. Điều này có nghĩa là phân phối xác suất của mỗi biến không ảnh hưởng đến biến khác. Để đánh giá thử nghiệm trong R, trước tiên, chúng ta cần tạo một bảng dự phòng, và sau đó chuyển bảng chochisq.test R chức năng.
Ví dụ, hãy kiểm tra xem có sự liên quan giữa các biến: cắt và màu từ tập dữ liệu kim cương hay không. Bài kiểm tra được định nghĩa chính thức là -
- H0: Biến cắt và hình thoi là độc lập
- H1: Biến cắt và hình thoi không độc lập
Chúng tôi giả định rằng có mối quan hệ giữa hai biến này theo tên của chúng, nhưng thử nghiệm có thể đưa ra một "quy tắc" khách quan cho biết kết quả này có ý nghĩa như thế nào hay không.
Trong đoạn mã sau, chúng tôi thấy rằng giá trị p của bài kiểm tra là 2,2e-16, điều này gần như bằng không trong điều kiện thực tế. Sau đó, sau khi chạy thử nghiệm,Monte Carlo simulation, chúng tôi nhận thấy rằng giá trị p là 0,0004998, vẫn còn khá thấp hơn ngưỡng 0,05. Kết quả này có nghĩa là chúng tôi bác bỏ giả thuyết vô hiệu (H0), vì vậy chúng tôi tin rằng các biếncut và color không độc lập.
library(ggplot2)
# Use the table function to compute the contingency table
tbl = table(diamonds$cut, diamonds$color)
tbl
# D E F G H I J
# Fair 163 224 312 314 303 175 119
# Good 662 933 909 871 702 522 307
# Very Good 1513 2400 2164 2299 1824 1204 678
# Premium 1603 2337 2331 2924 2360 1428 808
# Ideal 2834 3903 3826 4884 3115 2093 896
# In order to run the test we just use the chisq.test function.
chisq.test(tbl)
# Pearson’s Chi-squared test
# data: tbl
# X-squared = 310.32, df = 24, p-value < 2.2e-16
# It is also possible to compute the p-values using a monte-carlo simulation
# It's needed to add the simulate.p.value = TRUE flag and the amount of
simulations
chisq.test(tbl, simulate.p.value = TRUE, B = 2000)
# Pearson’s Chi-squared test with simulated p-value (based on 2000 replicates)
# data: tbl
# X-squared = 310.32, df = NA, p-value = 0.0004998T-test
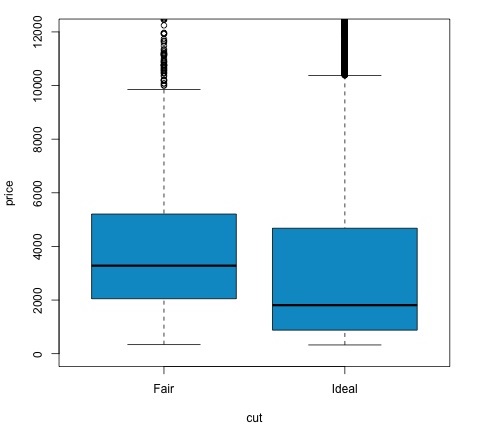
Ý tưởng về t-testlà để đánh giá xem có sự khác biệt trong phân phối # biến số giữa các nhóm khác nhau của biến danh nghĩa hay không. Để chứng minh điều này, tôi sẽ chọn các mức của mức Khá và Mức lý tưởng của phần cắt biến nhân tố, sau đó chúng tôi sẽ so sánh các giá trị của một biến số giữa hai nhóm đó.
data = diamonds[diamonds$cut %in% c('Fair', 'Ideal'), ]
data$cut = droplevels.factor(data$cut) # Drop levels that aren’t used from the
cut variable
df1 = data[, c('cut', 'price')]
# We can see the price means are different for each group
tapply(df1$price, df1$cut, mean)
# Fair Ideal
# 4358.758 3457.542Kiểm tra t được thực hiện trong R với t.testchức năng. Giao diện công thức cho t.test là cách đơn giản nhất để sử dụng, ý tưởng là một biến số được giải thích bởi một biến nhóm.
Ví dụ: t.test(numeric_variable ~ group_variable, data = data). Trong ví dụ trước,numeric_variable Là price và group_variable Là cut.
Từ góc độ thống kê, chúng tôi đang kiểm tra xem có sự khác biệt trong phân phối của biến số giữa hai nhóm hay không. Về mặt hình thức, kiểm định giả thuyết được mô tả với giả thuyết không (H0) và giả thuyết thay thế (H1).
H0: Không có sự khác biệt trong phân phối biến giá giữa các nhóm Trung bình và Lý tưởng
H1 Có sự khác biệt trong sự phân bổ của biến giá giữa các nhóm Khá và Lý tưởng
Điều sau có thể được thực hiện trong R với mã sau:
t.test(price ~ cut, data = data)
# Welch Two Sample t-test
#
# data: price by cut
# t = 9.7484, df = 1894.8, p-value < 2.2e-16
# alternative hypothesis: true difference in means is not equal to 0
# 95 percent confidence interval:
# 719.9065 1082.5251
# sample estimates:
# mean in group Fair mean in group Ideal
# 4358.758 3457.542
# Another way to validate the previous results is to just plot the
distributions using a box-plot
plot(price ~ cut, data = data, ylim = c(0,12000),
col = 'deepskyblue3')Chúng ta có thể phân tích kết quả thử nghiệm bằng cách kiểm tra xem giá trị p có thấp hơn 0,05 hay không. Nếu đúng như vậy, chúng tôi giữ nguyên giả thuyết thay thế. Điều này có nghĩa là chúng tôi đã tìm thấy sự khác biệt về giá giữa hai mức của yếu tố cắt giảm. Theo tên của các cấp độ, chúng tôi đã mong đợi kết quả này, nhưng chúng tôi không mong đợi rằng giá trung bình trong nhóm Không đạt sẽ cao hơn trong nhóm Lý tưởng. Chúng ta có thể thấy điều này bằng cách so sánh phương tiện của từng yếu tố.
Các plotlệnh tạo ra một đồ thị cho thấy mối quan hệ giữa giá và biến cắt giảm. Đó là một âm mưu hộp; chúng tôi đã đề cập đến biểu đồ này trong phần 16.0.1 nhưng về cơ bản nó cho thấy sự phân phối của biến giá đối với hai mức cắt giảm mà chúng tôi đang phân tích.
Phân tích phương sai
Phân tích phương sai (ANOVA) là một mô hình thống kê được sử dụng để phân tích sự khác biệt giữa các nhóm phân phối bằng cách so sánh giá trị trung bình và phương sai của mỗi nhóm, mô hình được phát triển bởi Ronald Fisher. ANOVA cung cấp một bài kiểm tra thống kê về việc liệu phương tiện của một số nhóm có bằng nhau hay không, và do đó tổng quát hóa phép kiểm tra t cho nhiều hơn hai nhóm.
ANOVA hữu ích để so sánh ba nhóm trở lên để có ý nghĩa thống kê vì thực hiện nhiều thử nghiệm t hai mẫu sẽ dẫn đến tăng khả năng mắc lỗi thống kê loại I.
Về mặt cung cấp một lời giải thích toán học, những điều sau đây là cần thiết để hiểu bài kiểm tra.
x ij = x + (x i - x) + (x ij - x)
Điều này dẫn đến mô hình sau:
x ij = μ + α i + ∈ ij
trong đó μ là trung bình lớn và α i là trung bình nhóm thứ i. Thuật ngữ lỗi ∈ ij được giả định là iid từ phân phối chuẩn. Giả thuyết vô hiệu của bài kiểm tra là -
α 1 = α 2 =… = α k
Về mặt tính toán thống kê thử nghiệm, chúng ta cần tính hai giá trị:
- Tổng bình phương cho giữa hiệu số nhóm -
$$SSD_B = \sum_{i}^{k} \sum_{j}^{n}(\bar{x_{\bar{i}}} - \bar{x})^2$$
- Tổng số ô vuông trong nhóm
$$SSD_W = \sum_{i}^{k} \sum_{j}^{n}(\bar{x_{\bar{ij}}} - \bar{x_{\bar{i}}})^2$$
trong đó SSD B có bậc tự do k − 1 và SSD W có bậc tự do N − k. Sau đó, chúng tôi có thể xác định sự khác biệt bình phương trung bình cho mỗi số liệu.
MS B = SSD B / (k - 1)
MS w = SSD w / (N - k)
Cuối cùng, thống kê kiểm định trong ANOVA được định nghĩa là tỷ số của hai đại lượng trên
F = MS B / MS w
tuân theo phân phối F với k − 1 và N − k bậc tự do. Nếu giả thuyết vô hiệu là đúng, F có thể gần bằng 1. Nếu không, MSB bình phương trung bình giữa nhóm có thể lớn, dẫn đến giá trị F lớn.
Về cơ bản, ANOVA kiểm tra hai nguồn của tổng phương sai và xem phần nào đóng góp nhiều hơn. Đây là lý do tại sao nó được gọi là phân tích phương sai mặc dù mục đích là để so sánh các phương tiện của nhóm.
Về mặt tính toán thống kê, nó thực sự khá đơn giản để thực hiện trong R. Ví dụ sau đây sẽ chứng minh cách nó được thực hiện và vẽ biểu đồ kết quả.
library(ggplot2)
# We will be using the mtcars dataset
head(mtcars)
# mpg cyl disp hp drat wt qsec vs am gear carb
# Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
# Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
# Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
# Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
# Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
# Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
# Let's see if there are differences between the groups of cyl in the mpg variable.
data = mtcars[, c('mpg', 'cyl')]
fit = lm(mpg ~ cyl, data = mtcars)
anova(fit)
# Analysis of Variance Table
# Response: mpg
# Df Sum Sq Mean Sq F value Pr(>F)
# cyl 1 817.71 817.71 79.561 6.113e-10 ***
# Residuals 30 308.33 10.28
# Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 .
# Plot the distribution
plot(mpg ~ as.factor(cyl), data = mtcars, col = 'deepskyblue3')Mã sẽ tạo ra kết quả sau:

Giá trị p mà chúng ta nhận được trong ví dụ này nhỏ hơn đáng kể so với 0,05, vì vậy R trả về ký hiệu '***' để biểu thị điều này. Nó có nghĩa là chúng tôi bác bỏ giả thuyết vô hiệu và chúng tôi tìm thấy sự khác biệt giữa giá trị mpg giữa các nhóm khác nhau củacyl Biến đổi.
Học máy là một lĩnh vực con của khoa học máy tính giải quyết các tác vụ như nhận dạng mẫu, thị giác máy tính, nhận dạng giọng nói, phân tích văn bản và có mối liên hệ chặt chẽ với thống kê và tối ưu hóa toán học. Các ứng dụng bao gồm phát triển công cụ tìm kiếm, lọc thư rác, Nhận dạng ký tự quang học (OCR) trong số những ứng dụng khác. Ranh giới giữa khai thác dữ liệu, nhận dạng mẫu và lĩnh vực thống kê học là không rõ ràng và về cơ bản tất cả đều đề cập đến các vấn đề tương tự.
Học máy có thể được chia thành hai loại nhiệm vụ:
- Học tập có giám sát
- Học tập không giám sát
Học tập có giám sát
Học có giám sát đề cập đến một dạng vấn đề trong đó có dữ liệu đầu vào được xác định là ma trận X và chúng tôi quan tâm đến việc dự đoán một phản hồi y . Trong đó X = {x 1 , x 2 ,…, x n } có n dự đoán và có hai giá trị y = {c 1 , c 2 } .
Một ứng dụng ví dụ sẽ là dự đoán xác suất người dùng web nhấp vào quảng cáo bằng cách sử dụng các tính năng nhân khẩu học làm yếu tố dự đoán. Điều này thường được gọi để dự đoán tỷ lệ nhấp chuột (CTR). Sau đó, y = {click, not - click} và các yếu tố dự đoán có thể là địa chỉ IP được sử dụng, ngày anh ta vào trang web, thành phố, quốc gia của người dùng trong số các tính năng khác có thể có.
Học tập không giám sát
Học không giám sát giải quyết vấn đề tìm kiếm các nhóm tương tự nhau mà không cần có lớp học để học hỏi. Có một số cách tiếp cận đối với nhiệm vụ học cách lập bản đồ từ các yếu tố dự báo để tìm ra các nhóm chia sẻ các trường hợp tương tự trong mỗi nhóm và khác biệt với nhau.
Một ví dụ về ứng dụng học tập không giám sát là phân khúc khách hàng. Ví dụ, trong ngành viễn thông, một nhiệm vụ phổ biến là phân khúc người dùng theo mức độ sử dụng mà họ dành cho điện thoại. Điều này sẽ cho phép bộ phận tiếp thị nhắm mục tiêu mỗi nhóm với một sản phẩm khác nhau.
Naive Bayes là một kỹ thuật xác suất để xây dựng bộ phân loại. Giả định đặc trưng của bộ phân loại Bayes ngây thơ là xem xét rằng giá trị của một đối tượng cụ thể là độc lập với giá trị của bất kỳ đối tượng địa lý nào khác, cho trước biến lớp.
Bất chấp các giả định đơn giản hóa quá mức đã đề cập trước đây, các bộ phân loại Bayes ngây thơ có kết quả tốt trong các tình huống thực tế phức tạp. Một ưu điểm của Bayes ngây thơ là nó chỉ yêu cầu một lượng nhỏ dữ liệu huấn luyện để ước tính các tham số cần thiết cho việc phân loại và bộ phân loại có thể được huấn luyện tăng dần.
Naive Bayes là một mô hình xác suất có điều kiện: đưa ra một trường hợp vấn đề được phân loại, được biểu diễn bằng một vectơ x= (x 1 ,…, x n ) đại diện cho một số đặc điểm n (biến độc lập), nó gán cho xác suất trường hợp này cho mỗi K kết quả hoặc lớp có thể có.
$$p(C_k|x_1,....., x_n)$$
Vấn đề với công thức trên là nếu số lượng đặc trưng n lớn hoặc nếu một đối tượng có thể nhận một số lượng lớn giá trị, thì việc đặt mô hình như vậy trên các bảng xác suất là không khả thi. Do đó, chúng tôi định dạng lại mô hình để làm cho nó đơn giản hơn. Sử dụng định lý Bayes, xác suất có điều kiện có thể được phân tách thành:
$$p(C_k|x) = \frac{p(C_k)p(x|C_k)}{p(x)}$$
Điều này có nghĩa là theo các giả định về tính độc lập ở trên, phân phối có điều kiện trên biến lớp C là:
$$p(C_k|x_1,....., x_n)\: = \: \frac{1}{Z}p(C_k)\prod_{i = 1}^{n}p(x_i|C_k)$$
trong đó bằng chứng Z = p (x) là hệ số tỷ lệ chỉ phụ thuộc vào x 1 ,…, x n , đó là một hằng số nếu giá trị của các biến đặc trưng được biết. Một nguyên tắc phổ biến là chọn giả thuyết có khả năng xảy ra nhất; đây được gọi là quy tắc quyết định posteriori hoặc MAP tối đa. Bộ phân loại tương ứng, bộ phân loại Bayes, là hàm gán nhãn lớp$\hat{y} = C_k$ cho một số k như sau -
$$\hat{y} = argmax\: p(C_k)\prod_{i = 1}^{n}p(x_i|C_k)$$
Thực hiện thuật toán trong R là một quá trình đơn giản. Ví dụ sau minh họa cách huấn luyện bộ phân loại Naive Bayes và sử dụng nó để dự đoán trong vấn đề lọc thư rác.
Tập lệnh sau có sẵn trong bda/part3/naive_bayes/naive_bayes.R tập tin.
# Install these packages
pkgs = c("klaR", "caret", "ElemStatLearn")
install.packages(pkgs)
library('ElemStatLearn')
library("klaR")
library("caret")
# Split the data in training and testing
inx = sample(nrow(spam), round(nrow(spam) * 0.9))
train = spam[inx,]
test = spam[-inx,]
# Define a matrix with features, X_train
# And a vector with class labels, y_train
X_train = train[,-58]
y_train = train$spam X_test = test[,-58] y_test = test$spam
# Train the model
nb_model = train(X_train, y_train, method = 'nb',
trControl = trainControl(method = 'cv', number = 3))
# Compute
preds = predict(nb_model$finalModel, X_test)$class
tbl = table(y_test, yhat = preds)
sum(diag(tbl)) / sum(tbl)
# 0.7217391Như chúng ta có thể thấy từ kết quả, độ chính xác của mô hình Naive Bayes là 72%. Điều này có nghĩa là mô hình phân loại chính xác 72% các trường hợp.
Phân cụm k-mean nhằm mục đích phân vùng n quan sát thành k cụm trong đó mỗi quan sát thuộc về cụm có giá trị trung bình gần nhất, đóng vai trò như một nguyên mẫu của cụm. Điều này dẫn đến việc phân vùng không gian dữ liệu thành các ô Voronoi.
Cho một tập hợp các quan sát (x 1 , x 2 ,…, x n ) , trong đó mỗi quan sát là một vectơ thực d chiều, phân cụm k-mean nhằm phân chia n quan sát thành k nhóm G = {G 1 , G 2 ,…, G k } để giảm thiểu tổng bình phương trong cụm (WCSS) được xác định như sau:
$$argmin \: \sum_{i = 1}^{k} \sum_{x \in S_{i}}\parallel x - \mu_{i}\parallel ^2$$
Công thức sau cho thấy hàm mục tiêu được tối thiểu hóa để tìm các nguyên mẫu tối ưu trong phân cụm k-mean. Trực giác của công thức là chúng ta muốn tìm các nhóm khác biệt với nhau và mỗi thành viên của mỗi nhóm phải tương tự với các thành viên khác của mỗi nhóm.
Ví dụ sau minh họa cách chạy thuật toán phân cụm k-mean trong R.
library(ggplot2)
# Prepare Data
data = mtcars
# We need to scale the data to have zero mean and unit variance
data <- scale(data)
# Determine number of clusters
wss <- (nrow(data)-1)*sum(apply(data,2,var))
for (i in 2:dim(data)[2]) {
wss[i] <- sum(kmeans(data, centers = i)$withinss)
}
# Plot the clusters
plot(1:dim(data)[2], wss, type = "b", xlab = "Number of Clusters",
ylab = "Within groups sum of squares")Để tìm một giá trị tốt cho K, chúng ta có thể vẽ biểu đồ tổng bình phương bên trong các nhóm cho các giá trị khác nhau của K. Chỉ số này thường giảm khi có nhiều nhóm được thêm vào, chúng tôi muốn tìm một điểm mà sự giảm đi trong tổng các nhóm số hình vuông bắt đầu giảm dần. Trong biểu đồ, giá trị này được thể hiện tốt nhất bằng K = 6.

Bây giờ giá trị của K đã được xác định, cần phải chạy thuật toán với giá trị đó.
# K-Means Cluster Analysis
fit <- kmeans(data, 5) # 5 cluster solution
# get cluster means
aggregate(data,by = list(fit$cluster),FUN = mean)
# append cluster assignment
data <- data.frame(data, fit$cluster)Gọi I = i 1 , i 2 , ..., i n là tập n thuộc tính nhị phân được gọi là mục. Gọi D = t 1 , t 2 , ..., t m là tập các giao dịch được gọi là cơ sở dữ liệu. Mỗi giao dịch trong D có một ID giao dịch duy nhất và chứa một tập hợp con của các mục trong I. Một quy tắc được định nghĩa là hàm ý của dạng X ⇒ Y trong đó X, Y ⊆ I và X ∩ Y = ∅.
Tập hợp các mục (đối với các tập hợp mục ngắn) X và Y được gọi là tiền đề (bên trái hoặc LHS) và là hệ quả (bên phải hoặc RHS) của quy tắc.
Để minh họa các khái niệm, chúng tôi sử dụng một ví dụ nhỏ từ miền siêu thị. Tập hợp các mục là I = {sữa, bánh mì, bơ, bia} và một cơ sở dữ liệu nhỏ chứa các mục được hiển thị trong bảng sau.
| ID giao dịch | Mặt hàng |
|---|---|
| 1 | bánh mì sữa |
| 2 | bơ bánh mì |
| 3 | bia |
| 4 | sữa, bánh mì, bơ |
| 5 | bơ bánh mì |
Một quy tắc ví dụ cho siêu thị có thể là {milk, bread} ⇒ {butter} có nghĩa là nếu mua sữa và bánh mì thì khách hàng cũng mua bơ. Để chọn các quy tắc thú vị từ tập hợp tất cả các quy tắc có thể có, có thể sử dụng các ràng buộc về các thước đo ý nghĩa và mức độ quan tâm khác nhau. Các hạn chế được biết đến nhiều nhất là ngưỡng tối thiểu về sự hỗ trợ và sự tự tin.
Hỗ trợ supp (X) của tập hợp mục X được định nghĩa là tỷ lệ các giao dịch trong tập dữ liệu chứa tập hợp mục. Trong cơ sở dữ liệu ví dụ ở Bảng 1, bộ mục {sữa, bánh mì} có hỗ trợ là 2/5 = 0,4 vì nó xảy ra trong 40% tất cả các giao dịch (2 trong số 5 giao dịch). Việc tìm kiếm các tập hợp mục thường xuyên có thể được coi là đơn giản hóa vấn đề học tập không có giám sát.
Độ tin cậy của một quy tắc được xác định conf (X ⇒ Y) = supp (X ∪ Y) / supp (X). Ví dụ: quy tắc {sữa, bánh mì} ⇒ {butter} có độ tin cậy là 0,2 / 0,4 = 0,5 trong cơ sở dữ liệu trong Bảng 1, có nghĩa là đối với 50% các giao dịch có chứa sữa và bánh mì, quy tắc là đúng. Độ tin cậy có thể được hiểu là ước tính xác suất P (Y | X), xác suất tìm thấy RHS của quy tắc trong các giao dịch với điều kiện các giao dịch này cũng chứa LHS.
Trong tập lệnh nằm ở bda/part3/apriori.R mã để triển khai apriori algorithm có thể được tìm thấy.
# Load the library for doing association rules
# install.packages(’arules’)
library(arules)
# Data preprocessing
data("AdultUCI")
AdultUCI[1:2,]
AdultUCI[["fnlwgt"]] <- NULL
AdultUCI[["education-num"]] <- NULL
AdultUCI[[ "age"]] <- ordered(cut(AdultUCI[[ "age"]], c(15,25,45,65,100)),
labels = c("Young", "Middle-aged", "Senior", "Old"))
AdultUCI[[ "hours-per-week"]] <- ordered(cut(AdultUCI[[ "hours-per-week"]],
c(0,25,40,60,168)), labels = c("Part-time", "Full-time", "Over-time", "Workaholic"))
AdultUCI[[ "capital-gain"]] <- ordered(cut(AdultUCI[[ "capital-gain"]],
c(-Inf,0,median(AdultUCI[[ "capital-gain"]][AdultUCI[[ "capitalgain"]]>0]),Inf)),
labels = c("None", "Low", "High"))
AdultUCI[[ "capital-loss"]] <- ordered(cut(AdultUCI[[ "capital-loss"]],
c(-Inf,0, median(AdultUCI[[ "capital-loss"]][AdultUCI[[ "capitalloss"]]>0]),Inf)),
labels = c("none", "low", "high"))Để tạo các quy tắc sử dụng thuật toán apriori, chúng ta cần tạo một ma trận giao dịch. Đoạn mã sau đây cho thấy cách thực hiện việc này trong R.
# Convert the data into a transactions format
Adult <- as(AdultUCI, "transactions")
Adult
# transactions in sparse format with
# 48842 transactions (rows) and
# 115 items (columns)
summary(Adult)
# Plot frequent item-sets
itemFrequencyPlot(Adult, support = 0.1, cex.names = 0.8)
# generate rules
min_support = 0.01
confidence = 0.6
rules <- apriori(Adult, parameter = list(support = min_support, confidence = confidence))
rules
inspect(rules[100:110, ])
# lhs rhs support confidence lift
# {occupation = Farming-fishing} => {sex = Male} 0.02856148 0.9362416 1.4005486
# {occupation = Farming-fishing} => {race = White} 0.02831579 0.9281879 1.0855456
# {occupation = Farming-fishing} => {native-country 0.02671881 0.8758389 0.9759474
= United-States}Cây quyết định là một thuật toán được sử dụng cho các vấn đề học tập có giám sát như phân loại hoặc hồi quy. Cây quyết định hoặc cây phân loại là một cây trong đó mỗi nút bên trong (không phải nút) được gắn nhãn với một tính năng đầu vào. Các cung đến từ một nút được gắn nhãn đối tượng được gắn nhãn với từng giá trị có thể có của đối tượng. Mỗi lá của cây được dán nhãn với một lớp hoặc một phân bố xác suất trên các lớp.
Một cây có thể được "học" bằng cách tách tập nguồn thành các tập con dựa trên kiểm tra giá trị thuộc tính. Quá trình này được lặp lại trên mỗi tập con dẫn xuất theo cách đệ quy được gọi làrecursive partitioning. Quá trình đệ quy được hoàn thành khi tập hợp con tại một nút có tất cả cùng giá trị của biến mục tiêu hoặc khi việc tách không còn thêm giá trị vào các dự đoán. Quá trình quy nạp cây quyết định từ trên xuống này là một ví dụ của thuật toán tham lam và nó là chiến lược phổ biến nhất để học cây quyết định.
Cây quyết định được sử dụng trong khai thác dữ liệu có hai loại chính:
Classification tree - khi phản hồi là một biến danh nghĩa, chẳng hạn như email có phải là thư rác hay không.
Regression tree - khi kết quả dự đoán có thể được coi là một số thực (ví dụ tiền lương của một công nhân).
Cây quyết định là một phương pháp đơn giản và như vậy có một số vấn đề. Một trong những vấn đề này là phương sai cao trong các mô hình kết quả mà cây quyết định tạo ra. Để giảm bớt vấn đề này, các phương pháp tổng hợp về cây quyết định đã được phát triển. Có hai nhóm phương pháp tổng hợp hiện đang được sử dụng rộng rãi -
Bagging decision trees- Những cây này được sử dụng để xây dựng nhiều cây quyết định bằng cách lấy mẫu lại nhiều lần dữ liệu đào tạo với sự thay thế và bỏ phiếu các cây để đưa ra dự đoán đồng thuận. Thuật toán này đã được gọi là rừng ngẫu nhiên.
Boosting decision trees- Tăng độ dốc kết hợp người học yếu; trong trường hợp này, cây quyết định thành một người học giỏi duy nhất, theo kiểu lặp đi lặp lại. Nó phù hợp với một cây yếu với dữ liệu và lặp đi lặp lại tiếp tục phù hợp với những người học yếu để sửa lỗi của mô hình trước đó.
# Install the party package
# install.packages('party')
library(party)
library(ggplot2)
head(diamonds)
# We will predict the cut of diamonds using the features available in the
diamonds dataset.
ct = ctree(cut ~ ., data = diamonds)
# plot(ct, main="Conditional Inference Tree")
# Example output
# Response: cut
# Inputs: carat, color, clarity, depth, table, price, x, y, z
# Number of observations: 53940
#
# 1) table <= 57; criterion = 1, statistic = 10131.878
# 2) depth <= 63; criterion = 1, statistic = 8377.279
# 3) table <= 56.4; criterion = 1, statistic = 226.423
# 4) z <= 2.64; criterion = 1, statistic = 70.393
# 5) clarity <= VS1; criterion = 0.989, statistic = 10.48
# 6) color <= E; criterion = 0.997, statistic = 12.829
# 7)* weights = 82
# 6) color > E
#Table of prediction errors
table(predict(ct), diamonds$cut)
# Fair Good Very Good Premium Ideal
# Fair 1388 171 17 0 14
# Good 102 2912 499 26 27
# Very Good 54 998 3334 249 355
# Premium 44 711 5054 11915 1167
# Ideal 22 114 3178 1601 19988
# Estimated class probabilities
probs = predict(ct, newdata = diamonds, type = "prob")
probs = do.call(rbind, probs)
head(probs)Hồi quy logistic là một mô hình phân loại trong đó biến phản hồi là phân loại. Nó là một thuật toán xuất phát từ thống kê và được sử dụng cho các bài toán phân loại có giám sát. Trong hồi quy logistic, chúng ta tìm kiếm vectơ β của các tham số trong phương trình sau đây mà hàm chi phí tối thiểu hóa.
$$logit(p_i) = ln \left ( \frac{p_i}{1 - p_i} \right ) = \beta_0 + \beta_1x_{1,i} + ... + \beta_kx_{k,i}$$
Đoạn mã sau đây trình bày cách phù hợp với mô hình hồi quy logistic trong R. Chúng tôi sẽ sử dụng ở đây tập dữ liệu spam để chứng minh hồi quy logistic, giống như được sử dụng cho Naive Bayes.
Từ các kết quả dự đoán về độ chính xác, chúng tôi thấy rằng mô hình hồi quy đạt độ chính xác 92,5% trong tập thử nghiệm, so với 72% đạt được bởi bộ phân loại Naive Bayes.
library(ElemStatLearn)
head(spam)
# Split dataset in training and testing
inx = sample(nrow(spam), round(nrow(spam) * 0.8))
train = spam[inx,]
test = spam[-inx,]
# Fit regression model
fit = glm(spam ~ ., data = train, family = binomial())
summary(fit)
# Call:
# glm(formula = spam ~ ., family = binomial(), data = train)
#
# Deviance Residuals:
# Min 1Q Median 3Q Max
# -4.5172 -0.2039 0.0000 0.1111 5.4944
# Coefficients:
# Estimate Std. Error z value Pr(>|z|)
# (Intercept) -1.511e+00 1.546e-01 -9.772 < 2e-16 ***
# A.1 -4.546e-01 2.560e-01 -1.776 0.075720 .
# A.2 -1.630e-01 7.731e-02 -2.108 0.035043 *
# A.3 1.487e-01 1.261e-01 1.179 0.238591
# A.4 2.055e+00 1.467e+00 1.401 0.161153
# A.5 6.165e-01 1.191e-01 5.177 2.25e-07 ***
# A.6 7.156e-01 2.768e-01 2.585 0.009747 **
# A.7 2.606e+00 3.917e-01 6.652 2.88e-11 ***
# A.8 6.750e-01 2.284e-01 2.955 0.003127 **
# A.9 1.197e+00 3.362e-01 3.559 0.000373 ***
# Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
### Make predictions
preds = predict(fit, test, type = ’response’)
preds = ifelse(preds > 0.5, 1, 0)
tbl = table(target = test$spam, preds)
tbl
# preds
# target 0 1
# email 535 23
# spam 46 316
sum(diag(tbl)) / sum(tbl)
# 0.925Chuỗi thời gian là một chuỗi các quan sát của các biến phân loại hoặc số được lập chỉ mục theo ngày hoặc dấu thời gian. Một ví dụ rõ ràng về dữ liệu chuỗi thời gian là chuỗi thời gian của giá cổ phiếu. Trong bảng sau, chúng ta có thể thấy cấu trúc cơ bản của dữ liệu chuỗi thời gian. Trong trường hợp này, các quan sát được ghi lại mỗi giờ.
| Dấu thời gian | Giá cổ phiếu |
|---|---|
| 2015-10-11 09:00:00 | 100 |
| 2015-10-11 10:00:00 | 110 |
| 2015-10-11 11:00:00 | 105 |
| 2015-10-11 12:00:00 | 90 |
| 2015-10-11 13:00:00 | 120 |
Thông thường, bước đầu tiên trong phân tích chuỗi thời gian là vẽ biểu đồ của chuỗi, điều này thường được thực hiện với biểu đồ đường.
Ứng dụng phổ biến nhất của phân tích chuỗi thời gian là dự báo giá trị tương lai của một giá trị số bằng cách sử dụng cấu trúc thời gian của dữ liệu. Điều này có nghĩa là, các quan sát có sẵn được sử dụng để dự đoán các giá trị từ tương lai.
Thứ tự thời gian của dữ liệu, ngụ ý rằng các phương pháp hồi quy truyền thống không hữu ích. Để xây dựng dự báo mạnh mẽ, chúng tôi cần các mô hình có tính đến thứ tự thời gian của dữ liệu.
Mô hình được sử dụng rộng rãi nhất để phân tích chuỗi thời gian được gọi là Autoregressive Moving Average(ARMA). Mô hình bao gồm hai phần,autoregressive (AR) một phần và một moving average(MA) một phần. Sau đó, mô hình này thường được gọi là mô hình ARMA (p, q) trong đó p là bậc của phần tự hồi quy và q là bậc của phần trung bình động.
Mô hình tự động hồi phục
Các AR (p) được đọc như một mô hình tự hồi trật tự p. Về mặt toán học, nó được viết là -
$$ X_t = c + \ sum_ {i = 1} ^ {P} \ phi_i X_ {t - i} + \ varepsilon_ {t} $$
trong đó {φ 1 ,…, φ p } là các tham số được ước lượng, c là hằng số và biến ngẫu nhiên ε t đại diện cho nhiễu trắng. Một số ràng buộc là cần thiết đối với các giá trị của các tham số để mô hình vẫn đứng yên.
Trung bình động
Ký hiệu MA (q) đề cập đến mô hình trung bình động của bậc q -
$$ X_t = \ mu + \ varepsilon_t + \ sum_ {i = 1} ^ {q} \ theta_i \ varepsilon_ {t - i} $$
trong đó θ 1 , ..., θ q là các tham số của mô hình, μ là kỳ vọng của X t và ε t , ε t - 1 , ... là các thuật ngữ lỗi nhiễu trắng.
Đường trung bình động tự động hồi phục
Mô hình ARMA (p, q) kết hợp p số hạng tự hồi quy và q số hạng trung bình động. Về mặt toán học, mô hình được biểu diễn theo công thức sau:
$$ X_t = c + \ varepsilon_t + \ sum_ {i = 1} ^ {P} \ phi_iX_ {t - 1} + \ sum_ {i = 1} ^ {q} \ theta_i \ varepsilon_ {ti} $$
Chúng ta có thể thấy rằng mô hình ARMA (p, q) là sự kết hợp của mô hình AR (p) và MA (q) .
Để cung cấp một số trực giác của mô hình, hãy xem xét rằng phần AR của phương trình tìm cách ước lượng các tham số cho X t - i quan sát để dự đoán giá trị của biến trong X t . Cuối cùng, nó là giá trị trung bình có trọng số của các giá trị trong quá khứ. Phần MA sử dụng cách tiếp cận tương tự nhưng với sai số của các quan sát trước đó, ε t - i . Vì vậy, cuối cùng, kết quả của mô hình là một trung bình có trọng số.
Đoạn mã dưới đây trình bày cách thực hiện một ARMA (p, q) trong R .
# install.packages("forecast")
library("forecast")
# Read the data
data = scan('fancy.dat')
ts_data <- ts(data, frequency = 12, start = c(1987,1))
ts_data
plot.ts(ts_data)Vẽ sơ đồ dữ liệu thường là bước đầu tiên để tìm xem có cấu trúc thời gian trong dữ liệu hay không. Chúng ta có thể thấy từ cốt truyện rằng có những đột biến mạnh mẽ vào mỗi cuối năm.
Đoạn mã sau phù hợp với mô hình ARMA với dữ liệu. Nó chạy một số mô hình kết hợp và chọn một mô hình có ít lỗi hơn.
# Fit the ARMA model
fit = auto.arima(ts_data)
summary(fit)
# Series: ts_data
# ARIMA(1,1,1)(0,1,1)[12]
# Coefficients:
# ar1 ma1 sma1
# 0.2401 -0.9013 0.7499
# s.e. 0.1427 0.0709 0.1790
#
# sigma^2 estimated as 15464184: log likelihood = -693.69
# AIC = 1395.38 AICc = 1395.98 BIC = 1404.43
# Training set error measures:
# ME RMSE MAE MPE MAPE MASE ACF1
# Training set 328.301 3615.374 2171.002 -2.481166 15.97302 0.4905797 -0.02521172Trong chương này, chúng ta sẽ sử dụng dữ liệu được thu thập trong phần 1 của cuốn sách. Dữ liệu có văn bản mô tả hồ sơ của các dịch giả tự do và mức phí hàng giờ mà họ đang tính bằng USD. Ý tưởng của phần sau là để phù hợp với một mô hình có các kỹ năng của một freelancer, chúng tôi có thể dự đoán mức lương theo giờ của người đó.
Đoạn mã sau đây chỉ ra cách chuyển đổi văn bản thô mà trong trường hợp này là các kỹ năng của người dùng trong một ma trận nhiều từ. Đối với điều này, chúng tôi sử dụng một thư viện R được gọi là tm. Điều này có nghĩa là đối với mỗi từ trong kho ngữ liệu, chúng tôi tạo biến với số lần xuất hiện của mỗi biến.
library(tm)
library(data.table)
source('text_analytics/text_analytics_functions.R')
data = fread('text_analytics/data/profiles.txt')
rate = as.numeric(data$rate)
keep = !is.na(rate)
rate = rate[keep]
### Make bag of words of title and body
X_all = bag_words(data$user_skills[keep])
X_all = removeSparseTerms(X_all, 0.999)
X_all
# <<DocumentTermMatrix (documents: 389, terms: 1422)>>
# Non-/sparse entries: 4057/549101
# Sparsity : 99%
# Maximal term length: 80
# Weighting : term frequency - inverse document frequency (normalized) (tf-idf)
### Make a sparse matrix with all the data
X_all <- as_sparseMatrix(X_all)Bây giờ chúng ta có văn bản được biểu diễn dưới dạng ma trận thưa thớt, chúng ta có thể phù hợp với một mô hình sẽ cho một giải pháp thưa thớt. Một thay thế tốt cho trường hợp này là sử dụng LASSO (toán tử lựa chọn và co ngót ít nhất tuyệt đối). Đây là một mô hình hồi quy có thể chọn các tính năng phù hợp nhất để dự đoán mục tiêu.
train_inx = 1:200
X_train = X_all[train_inx, ]
y_train = rate[train_inx]
X_test = X_all[-train_inx, ]
y_test = rate[-train_inx]
# Train a regression model
library(glmnet)
fit <- cv.glmnet(x = X_train, y = y_train,
family = 'gaussian', alpha = 1,
nfolds = 3, type.measure = 'mae')
plot(fit)
# Make predictions
predictions = predict(fit, newx = X_test)
predictions = as.vector(predictions[,1])
head(predictions)
# 36.23598 36.43046 51.69786 26.06811 35.13185 37.66367
# We can compute the mean absolute error for the test data
mean(abs(y_test - predictions))
# 15.02175Bây giờ chúng tôi có một mô hình đưa ra một bộ kỹ năng có thể dự đoán mức lương hàng giờ của một freelancer. Nếu nhiều dữ liệu hơn được thu thập, hiệu suất của mô hình sẽ cải thiện, nhưng mã để triển khai đường dẫn này sẽ giống nhau.
Học trực tuyến là một lĩnh vực con của học máy cho phép mở rộng mô hình học có giám sát thành tập dữ liệu lớn. Ý tưởng cơ bản là chúng ta không cần phải đọc tất cả dữ liệu trong bộ nhớ để phù hợp với một mô hình, chúng ta chỉ cần đọc từng thể hiện tại một thời điểm.
Trong trường hợp này, chúng tôi sẽ trình bày cách triển khai thuật toán học trực tuyến bằng cách sử dụng hồi quy logistic. Như trong hầu hết các thuật toán học có giám sát, có một hàm chi phí được giảm thiểu. Trong hồi quy logistic, hàm chi phí được định nghĩa là:
$$ J (\ theta) \: = \: \ frac {-1} {m} \ left [\ sum_ {i = 1} ^ {m} y ^ {(i)} log (h _ {\ theta} ( x ^ {(i)})) + (1 - y ^ {(i)}) log (1 - h _ {\ theta} (x ^ {(i)})) \ right] $$
trong đó J (θ) đại diện cho hàm chi phí và h θ (x) đại diện cho giả thuyết. Trong trường hợp hồi quy logistic, nó được định nghĩa theo công thức sau:
$$ h_ \ theta (x) = \ frac {1} {1 + e ^ {\ theta ^ T x}} $$
Bây giờ chúng ta đã xác định hàm chi phí, chúng ta cần tìm một thuật toán để giảm thiểu nó. Thuật toán đơn giản nhất để đạt được điều này được gọi là descent gradient ngẫu nhiên. Quy tắc cập nhật của thuật toán cho các trọng số của mô hình hồi quy logistic được định nghĩa là:
$$ \ theta_j: = \ theta_j - \ alpha (h_ \ theta (x) - y) x $$
Có một số cách triển khai của thuật toán sau đây, nhưng thuật toán được triển khai trong thư viện wabbit thềpal cho đến nay là cách được phát triển nhất. Thư viện cho phép đào tạo các mô hình hồi quy quy mô lớn và sử dụng lượng RAM nhỏ. Theo lời của chính những người sáng tạo, nó được mô tả là: "Dự án Vowpal Wabbit (VW) là một hệ thống học tập nhanh ngoài lõi được tài trợ bởi Microsoft Research và (trước đây) là Yahoo! Research".
Chúng tôi sẽ làm việc với bộ dữ liệu titanic từ một kagglecuộc thi. Dữ liệu gốc có thể được tìm thấy trongbda/part3/vwthư mục. Ở đây, chúng tôi có hai tệp -
- Chúng tôi có dữ liệu đào tạo (train_titanic.csv) và
- dữ liệu chưa được gắn nhãn để đưa ra các dự đoán mới (test_titanic.csv).
Để chuyển đổi định dạng csv sang vowpal wabbit định dạng đầu vào sử dụng csv_to_vowpal_wabbit.pytập lệnh python. Rõ ràng bạn sẽ cần phải cài đặt python cho việc này. Điều hướng đếnbda/part3/vw thư mục, mở terminal và thực hiện lệnh sau:
python csv_to_vowpal_wabbit.pyLưu ý rằng đối với phần này, nếu bạn đang sử dụng windows, bạn sẽ cần cài đặt một dòng lệnh Unix, hãy nhập trang web cygwin cho điều đó.
Mở thiết bị đầu cuối và cả trong thư mục bda/part3/vw và thực hiện lệnh sau:
vw train_titanic.vw -f model.vw --binary --passes 20 -c -q ff --sgd --l1
0.00000001 --l2 0.0000001 --learning_rate 0.5 --loss_function logisticHãy để chúng tôi phân tích từng đối số của vw call có nghĩa.
-f model.vw - có nghĩa là chúng tôi đang lưu mô hình trong tệp model.vw để đưa ra dự đoán sau này
--binary - Báo cáo tổn thất dưới dạng phân loại nhị phân với -1,1 nhãn
--passes 20 - Dữ liệu được sử dụng 20 lần để tìm hiểu trọng số
-c - tạo một tệp bộ nhớ cache
-q ff - Sử dụng các tính năng bậc hai trong không gian tên f
--sgd - sử dụng cập nhật dốc nghiêng ngẫu nhiên thường xuyên / cổ điển / đơn giản, tức là, không có bản gốc, không chuẩn hóa và không bất biến.
--l1 --l2 - Chính quy định mức L1 và L2
--learning_rate 0.5 - Tốc độ học tập αas được xác định trong công thức quy tắc cập nhật
Đoạn mã sau đây cho thấy kết quả của việc chạy mô hình hồi quy trong dòng lệnh. Trong kết quả, chúng tôi nhận được tổn thất log trung bình và một báo cáo nhỏ về hiệu suất thuật toán.
-loss_function logistic
creating quadratic features for pairs: ff
using l1 regularization = 1e-08
using l2 regularization = 1e-07
final_regressor = model.vw
Num weight bits = 18
learning rate = 0.5
initial_t = 1
power_t = 0.5
decay_learning_rate = 1
using cache_file = train_titanic.vw.cache
ignoring text input in favor of cache input
num sources = 1
average since example example current current current
loss last counter weight label predict features
0.000000 0.000000 1 1.0 -1.0000 -1.0000 57
0.500000 1.000000 2 2.0 1.0000 -1.0000 57
0.250000 0.000000 4 4.0 1.0000 1.0000 57
0.375000 0.500000 8 8.0 -1.0000 -1.0000 73
0.625000 0.875000 16 16.0 -1.0000 1.0000 73
0.468750 0.312500 32 32.0 -1.0000 -1.0000 57
0.468750 0.468750 64 64.0 -1.0000 1.0000 43
0.375000 0.281250 128 128.0 1.0000 -1.0000 43
0.351562 0.328125 256 256.0 1.0000 -1.0000 43
0.359375 0.367188 512 512.0 -1.0000 1.0000 57
0.274336 0.274336 1024 1024.0 -1.0000 -1.0000 57 h
0.281938 0.289474 2048 2048.0 -1.0000 -1.0000 43 h
0.246696 0.211454 4096 4096.0 -1.0000 -1.0000 43 h
0.218922 0.191209 8192 8192.0 1.0000 1.0000 43 h
finished run
number of examples per pass = 802
passes used = 11
weighted example sum = 8822
weighted label sum = -2288
average loss = 0.179775 h
best constant = -0.530826
best constant’s loss = 0.659128
total feature number = 427878Bây giờ chúng ta có thể sử dụng model.vw chúng tôi đã đào tạo để tạo dự đoán với dữ liệu mới.
vw -d test_titanic.vw -t -i model.vw -p predictions.txtCác dự đoán được tạo trong lệnh trước không được chuẩn hóa để phù hợp với phạm vi [0, 1]. Để làm điều này, chúng tôi sử dụng một phép biến đổi sigmoid.
# Read the predictions
preds = fread('vw/predictions.txt')
# Define the sigmoid function
sigmoid = function(x) {
1 / (1 + exp(-x))
}
probs = sigmoid(preds[[1]])
# Generate class labels
preds = ifelse(probs > 0.5, 1, 0)
head(preds)
# [1] 0 1 0 0 1 0