Phân tích dữ liệu lớn - Biểu đồ & đồ thị
Cách tiếp cận đầu tiên để phân tích dữ liệu là phân tích nó một cách trực quan. Các mục tiêu khi thực hiện điều này thường là tìm kiếm mối quan hệ giữa các biến và mô tả đơn biến của các biến. Chúng ta có thể chia các chiến lược này thành -
- Phân tích đơn biến
- Phân tích đa biến
Phương pháp đồ thị đơn biến
Univariatelà một thuật ngữ thống kê. Trong thực tế, điều đó có nghĩa là chúng ta muốn phân tích một biến độc lập với phần còn lại của dữ liệu. Các âm mưu cho phép thực hiện điều này một cách hiệu quả là -
Box-Plots
Box-Plots thường được sử dụng để so sánh các bản phân phối. Đó là một cách tuyệt vời để kiểm tra trực quan nếu có sự khác biệt giữa các bản phân phối. Chúng ta có thể thấy nếu có sự khác biệt giữa giá kim cương cho các lần cắt khác nhau.
# We will be using the ggplot2 library for plotting
library(ggplot2)
data("diamonds")
# We will be using the diamonds dataset to analyze distributions of numeric variables
head(diamonds)
# carat cut color clarity depth table price x y z
# 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
# 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
# 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
# 4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
# 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
# 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
### Box-Plots
p = ggplot(diamonds, aes(x = cut, y = price, fill = cut)) +
geom_box-plot() +
theme_bw()
print(p)Chúng ta có thể thấy trong biểu đồ có sự khác biệt trong việc phân bổ giá kim cương ở các dạng cắt khác nhau.

Biểu đồ
source('01_box_plots.R')
# We can plot histograms for each level of the cut factor variable using
facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~ .) +
theme_bw()
p
# the previous plot doesn’t allow to visuallize correctly the data because of
the differences in scale
# we can turn this off using the scales argument of facet_grid
p = ggplot(diamonds, aes(x = price, fill = cut)) +
geom_histogram() +
facet_grid(cut ~ ., scales = 'free') +
theme_bw()
p
png('02_histogram_diamonds_cut.png')
print(p)
dev.off()Đầu ra của đoạn mã trên sẽ như sau:
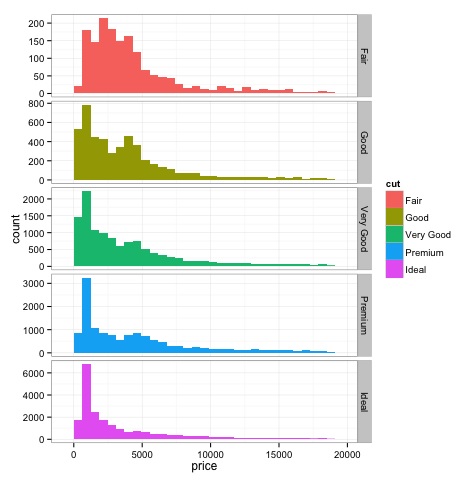
Phương pháp đồ họa đa biến
Phương pháp đồ họa đa biến trong phân tích dữ liệu khám phá có mục tiêu tìm kiếm mối quan hệ giữa các biến khác nhau. Có hai cách để thực hiện điều này thường được sử dụng: vẽ biểu đồ ma trận tương quan của các biến số hoặc đơn giản là vẽ dữ liệu thô dưới dạng ma trận các biểu đồ phân tán.
Để chứng minh điều này, chúng tôi sẽ sử dụng tập dữ liệu kim cương. Để làm theo mã, hãy mở tập lệnhbda/part2/charts/03_multivariate_analysis.R.
library(ggplot2)
data(diamonds)
# Correlation matrix plots
keep_vars = c('carat', 'depth', 'price', 'table')
df = diamonds[, keep_vars]
# compute the correlation matrix
M_cor = cor(df)
# carat depth price table
# carat 1.00000000 0.02822431 0.9215913 0.1816175
# depth 0.02822431 1.00000000 -0.0106474 -0.2957785
# price 0.92159130 -0.01064740 1.0000000 0.1271339
# table 0.18161755 -0.29577852 0.1271339 1.0000000
# plots
heat-map(M_cor)Mã sẽ tạo ra kết quả sau:

Đây là một bản tóm tắt, nó cho chúng ta biết rằng có mối tương quan chặt chẽ giữa giá và dấu mũ, và không nhiều giữa các biến khác.
Ma trận tương quan có thể hữu ích khi chúng ta có một số lượng lớn các biến, trong trường hợp đó, việc vẽ dữ liệu thô sẽ không thực tế. Như đã đề cập, cũng có thể hiển thị dữ liệu thô -
library(GGally)
ggpairs(df)Chúng ta có thể thấy trong biểu đồ mà kết quả hiển thị trong bản đồ nhiệt được xác nhận, có mối tương quan 0,922 giữa các biến giá và carat.
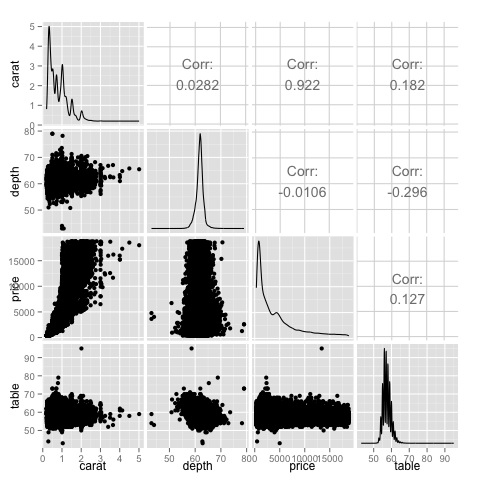
Có thể hình dung mối quan hệ này trong biểu đồ phân tán giá carat nằm trong chỉ số (3, 1) của ma trận biểu đồ phân tán.