Thiết kế trình biên dịch - Hướng dẫn nhanh
Máy tính là sự kết hợp cân bằng giữa phần mềm và phần cứng. Phần cứng chỉ là một phần của thiết bị cơ khí và các chức năng của nó đang được điều khiển bởi một phần mềm tương thích. Phần cứng hiểu các hướng dẫn dưới dạng điện tử, là bản sao của ngôn ngữ nhị phân trong lập trình phần mềm. Ngôn ngữ nhị phân chỉ có hai bảng chữ cái, 0 và 1. Để hướng dẫn, các mã phần cứng phải được viết ở định dạng nhị phân, đơn giản là một dãy số 1 và 0. Sẽ là một nhiệm vụ khó khăn và cồng kềnh đối với các lập trình viên máy tính khi viết những đoạn mã như vậy, đó là lý do tại sao chúng ta có những trình biên dịch để viết những đoạn mã như vậy.
Hệ thống xử lý ngôn ngữ
Chúng tôi đã biết rằng bất kỳ hệ thống máy tính nào cũng được cấu tạo từ phần cứng và phần mềm. Phần cứng hiểu một ngôn ngữ mà con người không thể hiểu được. Vì vậy, chúng tôi viết chương trình bằng ngôn ngữ bậc cao, dễ hiểu và dễ nhớ hơn. Các chương trình này sau đó được đưa vào một loạt công cụ và thành phần hệ điều hành để có được mã mong muốn mà máy có thể sử dụng. Đây được gọi là Hệ thống xử lý ngôn ngữ.
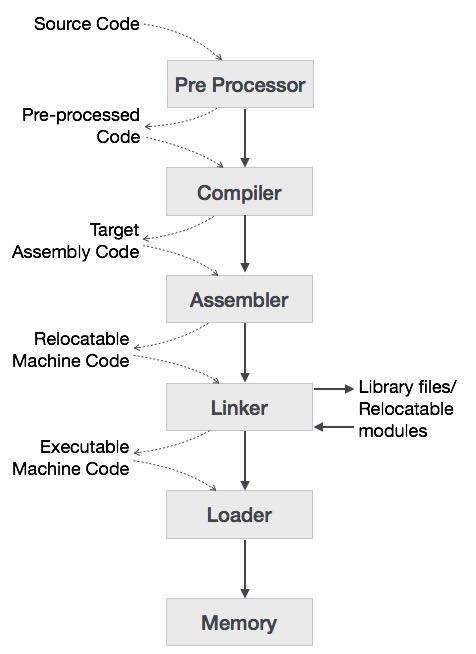
Ngôn ngữ cấp cao được chuyển đổi thành ngôn ngữ nhị phân trong nhiều giai đoạn khác nhau. Acompilerlà chương trình chuyển đổi ngôn ngữ cấp cao sang hợp ngữ. Tương tự, mộtassembler là một chương trình chuyển đổi ngôn ngữ hợp ngữ sang ngôn ngữ cấp máy.
Đầu tiên chúng ta hãy hiểu cách một chương trình, sử dụng trình biên dịch C, được thực thi trên một máy chủ.
Người dùng viết chương trình bằng ngôn ngữ C (ngôn ngữ bậc cao).
Trình biên dịch C, biên dịch chương trình và dịch nó sang chương trình hợp ngữ (ngôn ngữ cấp thấp).
Sau đó, một trình hợp dịch sẽ dịch chương trình hợp ngữ thành mã máy (đối tượng).
Một công cụ trình liên kết được sử dụng để liên kết tất cả các phần của chương trình với nhau để thực thi (mã máy thực thi).
Bộ tải nạp tất cả chúng vào bộ nhớ và sau đó chương trình được thực thi.
Trước khi đi sâu vào các khái niệm về trình biên dịch, chúng ta nên hiểu một vài công cụ khác hoạt động chặt chẽ với trình biên dịch.
Bộ tiền xử lý
Bộ tiền xử lý, thường được coi là một phần của trình biên dịch, là một công cụ tạo ra đầu vào cho trình biên dịch. Nó xử lý macro, tăng cường, bao gồm tệp, mở rộng ngôn ngữ, v.v.
Thông dịch viên
Một trình thông dịch, giống như một trình biên dịch, dịch ngôn ngữ cấp cao sang ngôn ngữ máy cấp thấp. Sự khác biệt nằm ở cách họ đọc mã nguồn hoặc đầu vào. Một trình biên dịch đọc toàn bộ mã nguồn cùng một lúc, tạo mã thông báo, kiểm tra ngữ nghĩa, tạo mã trung gian, thực thi toàn bộ chương trình và có thể liên quan đến nhiều lần chuyển. Ngược lại, một trình thông dịch đọc một câu lệnh từ đầu vào, chuyển nó thành một mã trung gian, thực thi nó, sau đó lấy câu lệnh tiếp theo theo trình tự. Nếu xảy ra lỗi, trình thông dịch sẽ ngừng thực thi và báo cáo lỗi đó. trong khi một trình biên dịch đọc toàn bộ chương trình ngay cả khi nó gặp một số lỗi.
Người lắp ráp
Trình hợp dịch dịch các chương trình hợp ngữ thành mã máy. Đầu ra của trình hợp dịch được gọi là tệp đối tượng, tệp này chứa sự kết hợp của các lệnh máy cũng như dữ liệu cần thiết để đặt các lệnh này trong bộ nhớ.
Người liên kết
Linker là một chương trình máy tính liên kết và kết hợp các tệp đối tượng khác nhau với nhau để tạo thành một tệp thực thi. Tất cả các tệp này có thể đã được biên dịch bởi các trình lắp ráp riêng biệt. Nhiệm vụ chính của trình liên kết là tìm kiếm và định vị mô-đun / quy trình được tham chiếu trong một chương trình và xác định vị trí bộ nhớ nơi các mã này sẽ được tải, làm cho lệnh chương trình có tham chiếu tuyệt đối.
Bộ tải
Loader là một phần của hệ điều hành và chịu trách nhiệm tải các tệp thực thi vào bộ nhớ và thực thi chúng. Nó tính toán kích thước của một chương trình (hướng dẫn và dữ liệu) và tạo không gian bộ nhớ cho nó. Nó khởi tạo các thanh ghi khác nhau để bắt đầu thực thi.
Trình biên dịch chéo
Một trình biên dịch chạy trên nền tảng (A) và có khả năng tạo mã thực thi cho nền tảng (B) được gọi là trình biên dịch chéo.
Trình biên dịch từ nguồn sang nguồn
Một trình biên dịch lấy mã nguồn của một ngôn ngữ lập trình và dịch nó sang mã nguồn của ngôn ngữ lập trình khác được gọi là trình biên dịch mã nguồn.
Kiến trúc trình biên dịch
Nói chung, một trình biên dịch có thể được chia thành hai giai đoạn dựa trên cách chúng biên dịch.
Giai đoạn phân tích
Được gọi là giao diện người dùng của trình biên dịch, analysis giai đoạn của trình biên dịch đọc chương trình nguồn, chia nó thành các phần cốt lõi và sau đó kiểm tra các lỗi từ vựng, ngữ pháp và cú pháp. .
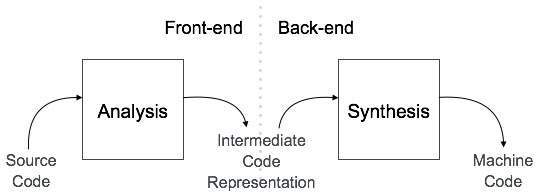
Giai đoạn tổng hợp
Được biết đến như là phần cuối của trình biên dịch, synthesis pha tạo ra chương trình đích với sự trợ giúp của bảng biểu tượng và mã nguồn trung gian.
Một trình biên dịch có thể có nhiều giai đoạn và đường chuyền.
Pass : Một đường chuyền đề cập đến việc truyền qua trình biên dịch qua toàn bộ chương trình.
Phase: Giai đoạn của trình biên dịch là giai đoạn có thể phân biệt được, giai đoạn này lấy đầu vào từ giai đoạn trước, xử lý và tạo ra kết quả đầu ra có thể được sử dụng làm đầu vào cho giai đoạn tiếp theo. Một đường chuyền có thể có nhiều hơn một pha.
Các giai đoạn của trình biên dịch
Quá trình biên dịch là một chuỗi các giai đoạn khác nhau. Mỗi giai đoạn lấy đầu vào từ giai đoạn trước của nó, có đại diện riêng của chương trình nguồn và cung cấp đầu ra của nó cho giai đoạn tiếp theo của trình biên dịch. Hãy để chúng tôi hiểu các giai đoạn của một trình biên dịch.
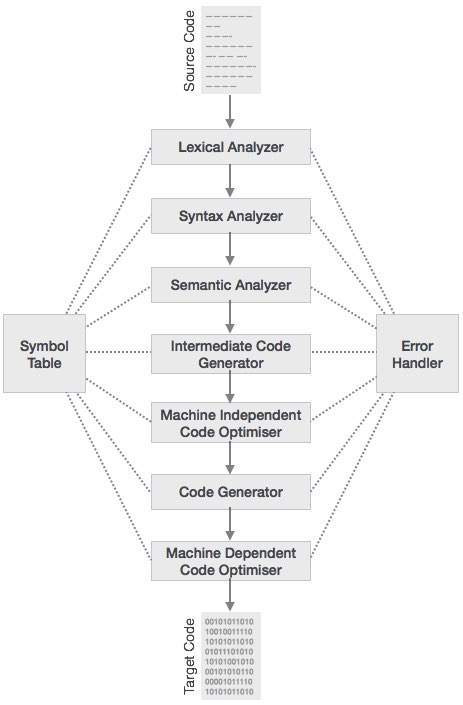
Phân tích từ vựng
Giai đoạn đầu tiên của máy quét hoạt động như một máy quét văn bản. Giai đoạn này quét mã nguồn dưới dạng một luồng ký tự và chuyển đổi nó thành các từ vựng có nghĩa. Trình phân tích từ vựng biểu thị các từ vựng này ở dạng mã thông báo như:
<token-name, attribute-value>Phân tích cú pháp
Giai đoạn tiếp theo được gọi là phân tích cú pháp hoặc parsing. Nó lấy mã thông báo được tạo ra bằng phân tích từ vựng làm đầu vào và tạo cây phân tích cú pháp (hoặc cây cú pháp). Trong giai đoạn này, các sắp xếp mã thông báo được kiểm tra dựa trên ngữ pháp mã nguồn, tức là trình phân tích cú pháp sẽ kiểm tra xem biểu thức tạo bởi các mã thông báo có đúng cú pháp hay không.
Phân tích ngữ nghĩa
Phân tích ngữ nghĩa kiểm tra xem cây phân tích cú pháp được xây dựng có tuân theo các quy tắc của ngôn ngữ hay không. Ví dụ: gán giá trị giữa các kiểu dữ liệu tương thích và thêm chuỗi vào số nguyên. Ngoài ra, trình phân tích ngữ nghĩa theo dõi các định danh, các loại và biểu thức của chúng; liệu các định danh có được khai báo trước khi sử dụng hay không, v.v ... Bộ phân tích ngữ nghĩa tạo ra một cây cú pháp có chú thích như một đầu ra.
Tạo mã trung gian
Sau khi phân tích ngữ nghĩa, trình biên dịch tạo ra một mã trung gian của mã nguồn cho máy đích. Nó đại diện cho một chương trình cho một số máy trừu tượng. Nó nằm giữa ngôn ngữ cấp cao và ngôn ngữ máy. Mã trung gian này nên được tạo theo cách giúp nó dễ dàng được dịch sang mã máy đích hơn.
Tối ưu hóa mã
Giai đoạn tiếp theo thực hiện tối ưu hóa mã của mã trung gian. Tối ưu hóa có thể được coi là việc loại bỏ các dòng mã không cần thiết và sắp xếp chuỗi các câu lệnh để tăng tốc độ thực thi chương trình mà không lãng phí tài nguyên (CPU, bộ nhớ).
Tạo mã
Trong giai đoạn này, trình tạo mã lấy biểu diễn được tối ưu hóa của mã trung gian và ánh xạ nó sang ngôn ngữ máy đích. Bộ tạo mã dịch mã trung gian thành một chuỗi mã máy định vị lại (nói chung). Chuỗi lệnh của mã máy thực hiện tác vụ như mã trung gian sẽ làm.
Bảng ký hiệu
Nó là một cấu trúc dữ liệu được duy trì trong suốt tất cả các giai đoạn của một trình biên dịch. Tất cả tên của mã định danh cùng với loại của chúng được lưu trữ ở đây. Bảng ký hiệu giúp trình biên dịch dễ dàng tìm kiếm nhanh bản ghi định danh và truy xuất nó. Bảng ký hiệu cũng được sử dụng để quản lý phạm vi.
Phân tích từ vựng là giai đoạn đầu tiên của trình biên dịch. Nó lấy mã nguồn đã sửa đổi từ các bộ tiền xử lý ngôn ngữ được viết dưới dạng câu. Trình phân tích từ vựng chia các cú pháp này thành một loạt mã thông báo, bằng cách loại bỏ bất kỳ khoảng trắng hoặc chú thích nào trong mã nguồn.
Nếu trình phân tích từ vựng tìm thấy mã thông báo không hợp lệ, nó sẽ tạo ra lỗi. Bộ phân tích từ vựng hoạt động chặt chẽ với bộ phân tích cú pháp. Nó đọc các luồng ký tự từ mã nguồn, kiểm tra các mã thông báo hợp pháp và chuyển dữ liệu đến trình phân tích cú pháp khi nó yêu cầu.

Token
Lexemes được cho là một chuỗi các ký tự (chữ và số) trong một mã thông báo. Có một số quy tắc được xác định trước để mọi lexeme được xác định là mã thông báo hợp lệ. Các quy tắc này được xác định bởi các quy tắc ngữ pháp, bằng một khuôn mẫu. Một mẫu giải thích những gì có thể là một mã thông báo và những mẫu này được xác định bằng các biểu thức chính quy.
Trong ngôn ngữ lập trình, các từ khóa, hằng số, định danh, chuỗi, số, toán tử và ký hiệu dấu chấm câu có thể được coi là mã thông báo.
Ví dụ, trong ngôn ngữ C, dòng khai báo biến
int value = 100;chứa các mã thông báo:
int (keyword), value (identifier), = (operator), 100 (constant) and ; (symbol).Thông số kỹ thuật của Token
Hãy để chúng tôi hiểu cách lý thuyết ngôn ngữ thực hiện các thuật ngữ sau:
Bảng chữ cái
Bất kỳ bộ ký hiệu hữu hạn nào {0,1} là một bộ bảng chữ cái nhị phân, {0,1,2,3,4,5,6,7,8,9, A, B, C, D, E, F} là một tập hợp các bảng chữ cái Hệ thập lục phân, {az, AZ} là một tập hợp các bảng chữ cái tiếng Anh.
Dây
Bất kỳ chuỗi hữu hạn của bảng chữ cái được gọi là một chuỗi. Độ dài của chuỗi là tổng số lần xuất hiện của các bảng chữ cái, ví dụ: độ dài của chuỗi hướng dẫn là 14 và được ký hiệu là | tutorialspoint | = 14. Một chuỗi không có bảng chữ cái, tức là một chuỗi có độ dài bằng 0 được gọi là chuỗi rỗng và được ký hiệu là ε (epsilon).
Ký hiệu đặc biệt
Một ngôn ngữ cấp cao điển hình chứa các ký hiệu sau: -
| Biểu tượng số học | Phép cộng (+), Phép trừ (-), Modulo (%), Phép nhân (*), Phép chia (/) |
| Chấm câu | Dấu phẩy (,), Dấu chấm phẩy (;), Dấu chấm (.), Mũi tên (->) |
| Chuyển nhượng | = |
| Nhiệm vụ đặc biệt | + =, / =, * =, - = |
| So sánh | ==,! =, <, <=,>,> = |
| Bộ tiền xử lý | # |
| Công cụ xác định vị trí | & |
| Hợp lý | &, &&, |, ||,! |
| Người điều hành ca | >>, >>>, <<, <<< |
Ngôn ngữ
Một ngôn ngữ được coi là một tập hợp các chuỗi hữu hạn trên một số tập hợp các bảng chữ cái hữu hạn. Các ngôn ngữ máy tính được coi là các tập hợp hữu hạn, và các phép toán tập hợp toán học có thể được thực hiện trên chúng. Các ngôn ngữ hữu hạn có thể được mô tả bằng các biểu thức chính quy.
Biểu thức chính quy
Trình phân tích từ vựng chỉ cần quét và xác định một tập hợp hữu hạn chuỗi / mã thông báo / lexeme hợp lệ thuộc về ngôn ngữ trong tay. Nó tìm kiếm mẫu được xác định bởi các quy tắc ngôn ngữ.
Biểu thức chính quy có khả năng thể hiện các ngôn ngữ hữu hạn bằng cách xác định một mẫu cho các chuỗi ký hiệu hữu hạn. Ngữ pháp được xác định bởi biểu thức chính quy được gọi làregular grammar. Ngôn ngữ được xác định bởi ngữ pháp thông thường được gọi làregular language.
Biểu thức chính quy là một ký hiệu quan trọng để chỉ định các mẫu. Mỗi mẫu khớp với một tập hợp các chuỗi, do đó, các biểu thức chính quy đóng vai trò là tên cho một tập hợp các chuỗi. Mã thông báo ngôn ngữ lập trình có thể được mô tả bằng ngôn ngữ thông thường. Đặc tả của biểu thức chính quy là một ví dụ về định nghĩa đệ quy. Các ngôn ngữ thông thường dễ hiểu và có hiệu quả triển khai.
Có một số luật đại số được tuân theo bởi các biểu thức chính quy, có thể được sử dụng để điều chỉnh các biểu thức chính quy thành các dạng tương đương.
Hoạt động
Các hoạt động khác nhau trên các ngôn ngữ là:
Liên hợp của hai ngôn ngữ L và M được viết là
LUM = {s | s ở L hoặc s ở M}
Phép ghép của hai ngôn ngữ L và M được viết là
LM = {st | s ở L và t ở M}
Câu kết Kleene của một ngôn ngữ L được viết là
L * = Không có hoặc nhiều lần xuất hiện của ngôn ngữ L.
Ký hiệu
Nếu r và s là các biểu thức chính quy biểu thị các ngôn ngữ L (r) và L (s), thì
Union : (r) | (s) là một biểu thức chính quy biểu thị L (r) UL (s)
Concatenation : (r) (s) là một biểu thức chính quy biểu thị L (r) L (s)
Kleene closure : (r) * là một biểu thức chính quy biểu thị (L (r)) *
(r) là một biểu thức chính quy biểu thị L (r)
Tính ưu tiên và tính liên kết
- *, nối (.), và | (dấu ống) được kết hợp trái
- * có mức độ ưu tiên cao nhất
- Liên kết (.) Có mức độ ưu tiên cao thứ hai.
- | (dấu ống) có mức độ ưu tiên thấp nhất trong tất cả.
Biểu diễn mã thông báo hợp lệ của một ngôn ngữ trong biểu thức chính quy
Nếu x là một biểu thức chính quy, thì:
x * có nghĩa là không hoặc nhiều lần xuất hiện x.
tức là, nó có thể tạo ra {e, x, xx, xxx, xxxx,…}
x + có nghĩa là một hoặc nhiều lần xuất hiện của x.
tức là, nó có thể tạo ra {x, xx, xxx, xxxx…} hoặc xx *
x? có nghĩa là nhiều nhất một lần xuất hiện của x
tức là, nó có thể tạo ra {x} hoặc {e}.
[az] là tất cả các bảng chữ cái viết thường của ngôn ngữ tiếng Anh.
[AZ] là tất cả các bảng chữ cái viết hoa của ngôn ngữ tiếng Anh.
[0-9] là tất cả các chữ số tự nhiên được sử dụng trong toán học.
Biểu diễn sự xuất hiện của các ký hiệu bằng cách sử dụng biểu thức chính quy
letter = [a - z] hoặc [A - Z]
chữ số = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 hoặc [0-9]
dấu = [+ | -]
Biểu diễn mã thông báo ngôn ngữ bằng cách sử dụng biểu thức chính quy
Số thập phân = (dấu) ? (chữ số) +
Định danh = (chữ cái) (chữ cái | chữ số) *
Vấn đề duy nhất còn lại với trình phân tích từ vựng là làm thế nào để xác minh tính hợp lệ của một biểu thức chính quy được sử dụng để chỉ định các mẫu từ khóa của một ngôn ngữ. Một giải pháp được chấp nhận tốt là sử dụng dữ liệu tự động hữu hạn để xác minh.
Dữ liệu tự động hữu hạn
Automata hữu hạn là một máy trạng thái lấy một chuỗi ký hiệu làm đầu vào và thay đổi trạng thái của nó tương ứng. Dữ liệu tự động hữu hạn là một trình nhận dạng cho các biểu thức chính quy. Khi một chuỗi biểu thức chính quy được đưa vào ô tự động hữu hạn, nó sẽ thay đổi trạng thái của nó cho mỗi chữ. Nếu chuỗi đầu vào được xử lý thành công và dữ liệu tự động đạt đến trạng thái cuối cùng, nó được chấp nhận, tức là chuỗi vừa được nạp được cho là mã thông báo hợp lệ của ngôn ngữ trong tay.
Mô hình toán học của ô tô hữu hạn bao gồm:
- Tập hợp hữu hạn các trạng thái (Q)
- Tập hợp hữu hạn các ký hiệu đầu vào (Σ)
- Một trạng thái Bắt đầu (q0)
- Tập hợp các trạng thái cuối cùng (qf)
- Hàm chuyển tiếp (δ)
Hàm chuyển tiếp (δ) ánh xạ tập hữu hạn trạng thái (Q) thành một tập hữu hạn các ký hiệu đầu vào (Σ), Q × Σ ➔ Q
Xây dựng dữ liệu tự động hữu hạn
Cho L (r) là một ngôn ngữ thông thường được một số tự động hữu hạn (FA) công nhận.
States: Các quốc gia CHNC được biểu diễn bằng các vòng tròn. Tên tiểu bang được viết bên trong vòng tròn.
Start state: Trạng thái từ nơi bắt đầu tự động, được gọi là trạng thái bắt đầu. Trạng thái bắt đầu có một mũi tên chỉ về phía nó.
Intermediate states: Tất cả các trạng thái trung gian đều có ít nhất hai mũi tên; một trỏ đến và một trỏ ra khỏi chúng.
Final state: Nếu chuỗi đầu vào được phân tích cú pháp thành công, dữ liệu tự động sẽ ở trạng thái này. Trạng thái cuối cùng được biểu diễn bằng các vòng tròn đôi. Nó có thể có bất kỳ số lượng mũi tên lẻ nào trỏ đến nó và số lượng mũi tên chẵn hướng ra từ nó. Số lượng mũi tên lẻ lớn hơn một mũi tên chẵn, tức làodd = even+1.
Transition: Sự chuyển đổi từ trạng thái này sang trạng thái khác xảy ra khi tìm thấy một ký hiệu mong muốn trong đầu vào. Khi chuyển đổi, tự động có thể chuyển sang trạng thái tiếp theo hoặc giữ nguyên trạng thái đó. Chuyển động từ trạng thái này sang trạng thái khác được thể hiện dưới dạng một mũi tên có hướng, trong đó các mũi tên chỉ đến trạng thái đích. Nếu dữ liệu tự động vẫn ở cùng một trạng thái, một mũi tên chỉ từ một trạng thái đến chính nó sẽ được vẽ.
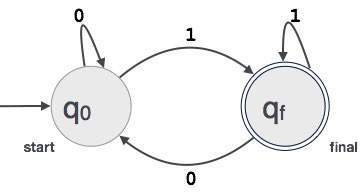
Example: Chúng tôi giả sử FA chấp nhận bất kỳ giá trị nhị phân có ba chữ số nào kết thúc bằng chữ số 1. FA = {Q (q 0 , q f ), Σ (0,1), q 0 , q f , δ}
Quy tắc đối sánh dài nhất
Khi bộ phân tích từ vựng đọc mã nguồn, nó sẽ quét từng ký tự mã; và khi nó gặp phải khoảng trắng, ký hiệu toán tử hoặc các ký hiệu đặc biệt, nó quyết định rằng một từ đã được hoàn thành.
For example:
int intvalue;Trong khi quét cả hai từ vựng cho đến 'int', bộ phân tích từ vựng không thể xác định liệu đó là từ khóa int hay các chữ cái đầu của giá trị int của mã định danh.
Quy tắc đối sánh dài nhất quy định rằng lexeme được quét phải được xác định dựa trên trận đấu dài nhất trong số tất cả các mã thông báo có sẵn.
Máy phân tích từ vựng cũng theo sau rule prioritytrong đó một từ dành riêng, ví dụ, một từ khóa, của một ngôn ngữ được ưu tiên hơn so với đầu vào của người dùng. Nghĩa là, nếu bộ phân tích từ vựng tìm thấy một lexeme khớp với bất kỳ từ dành riêng nào hiện có, nó sẽ tạo ra lỗi.
Phân tích cú pháp hoặc phân tích cú pháp là giai đoạn thứ hai của trình biên dịch. Trong chương này, chúng ta sẽ tìm hiểu các khái niệm cơ bản được sử dụng trong việc xây dựng một trình phân tích cú pháp.
Chúng tôi đã thấy rằng một trình phân tích từ vựng có thể xác định các mã thông báo với sự trợ giúp của các biểu thức chính quy và các quy tắc mẫu. Nhưng một bộ phân tích từ vựng không thể kiểm tra cú pháp của một câu nhất định do những hạn chế của cụm từ thông dụng. Biểu thức chính quy không thể kiểm tra các mã thông báo cân bằng, chẳng hạn như dấu ngoặc đơn. Do đó, giai đoạn này sử dụng ngữ pháp không có ngữ cảnh (CFG), được nhận dạng bởi dữ liệu tự động đẩy xuống.
Mặt khác, CFG là một tập hợp ngữ pháp chính quy, như được mô tả bên dưới:

Nó ngụ ý rằng mọi Ngữ pháp Thông thường cũng không có ngữ cảnh, nhưng tồn tại một số vấn đề, nằm ngoài phạm vi của Ngữ pháp Thông thường. CFG là một công cụ hữu ích trong việc mô tả cú pháp của các ngôn ngữ lập trình.
Ngữ pháp không theo ngữ cảnh
Trong phần này, trước tiên chúng ta sẽ xem định nghĩa của ngữ pháp không theo ngữ cảnh và giới thiệu các thuật ngữ được sử dụng trong công nghệ phân tích cú pháp.
Ngữ pháp không có ngữ cảnh có bốn thành phần:
Một tập hợp các non-terminals(V). Các biến không phải là biến cú pháp biểu thị tập hợp các chuỗi. Các không phải đầu cuối xác định các tập hợp các chuỗi giúp xác định ngôn ngữ được tạo bởi ngữ pháp.
Một tập hợp các mã thông báo, được gọi là terminal symbols(Σ). Thiết bị đầu cuối là các ký hiệu cơ bản mà từ đó các chuỗi được hình thành.
Một tập hợp các productions(P). Các sản phẩm của một ngữ pháp chỉ định cách thức mà các thiết bị đầu cuối và không đầu cuối có thể được kết hợp để tạo thành chuỗi. Mỗi sản xuất bao gồm mộtnon-terminal được gọi là phía bên trái của sản xuất, một mũi tên và một chuỗi các mã thông báo và / hoặc on- terminals, được gọi là mặt phải của sản xuất.
Một trong các đầu cuối không được chỉ định là ký hiệu bắt đầu (S); từ nơi bắt đầu sản xuất.
Các chuỗi có nguồn gốc từ ký hiệu bắt đầu bằng cách thay thế nhiều lần một ký hiệu không phải đầu cuối (ban đầu là biểu tượng bắt đầu) ở phía bên phải của một sản phẩm, cho không phải đầu cuối đó.
Thí dụ
Chúng tôi gặp vấn đề về ngôn ngữ palindrome, ngôn ngữ này không thể được mô tả bằng Biểu thức chính quy. Tức là, L = {w | w = w R } không phải là một ngôn ngữ thông thường. Nhưng nó có thể được mô tả bằng CFG, như minh họa bên dưới:
G = ( V, Σ, P, S )Ở đâu:
V = { Q, Z, N }
Σ = { 0, 1 }
P = { Q → Z | Q → N | Q → ℇ | Z → 0Q0 | N → 1Q1 }
S = { Q }Ngữ pháp này mô tả ngôn ngữ palindrome, chẳng hạn như: 1001, 11100111, 00100, 1010101, 11111, v.v.
Máy phân tích cú pháp
Trình phân tích cú pháp hoặc trình phân tích cú pháp lấy đầu vào từ trình phân tích từ vựng ở dạng các luồng mã thông báo. Trình phân tích cú pháp phân tích mã nguồn (dòng mã thông báo) dựa trên các quy tắc sản xuất để phát hiện bất kỳ lỗi nào trong mã. Đầu ra của giai đoạn này làparse tree.

Bằng cách này, trình phân tích cú pháp hoàn thành hai nhiệm vụ, tức là phân tích cú pháp mã, tìm kiếm lỗi và tạo cây phân tích cú pháp làm đầu ra của pha.
Trình phân tích cú pháp dự kiến sẽ phân tích cú pháp toàn bộ mã ngay cả khi một số lỗi tồn tại trong chương trình. Trình phân tích cú pháp sử dụng các chiến lược khôi phục lỗi mà chúng ta sẽ tìm hiểu ở phần sau của chương này.
Nguồn gốc
Một dẫn xuất về cơ bản là một chuỗi các quy tắc sản xuất, để lấy chuỗi đầu vào. Trong quá trình phân tích cú pháp, chúng tôi đưa ra hai quyết định đối với một số hình thức nhập liệu ủy thác:
- Quyết định thiết bị đầu cuối sẽ được thay thế.
- Quyết định quy tắc sản xuất, theo đó, thiết bị đầu cuối sẽ được thay thế.
Để quyết định không phải đầu cuối nào sẽ được thay thế bằng quy tắc sản xuất, chúng ta có thể có hai lựa chọn.
Xuất phát ngoài cùng bên trái
Nếu dạng ủy thác của một đầu vào được quét và thay thế từ trái sang phải, nó được gọi là dẫn xuất ngoài cùng bên trái. Biểu mẫu thông tin gửi được tạo ra bởi phái sinh bên trái nhất được gọi là biểu mẫu thông tin gửi bên trái.
Nguồn gốc bên phải nhất
Nếu chúng ta quét và thay thế dữ liệu đầu vào bằng các quy tắc sản xuất, từ phải sang trái, thì nó được gọi là phần dẫn xuất bên phải. Biểu mẫu thông tin gửi từ phái sinh bên phải nhất được gọi là biểu mẫu thông tin gửi bên phải.
Example
Quy tắc sản xuất:
E → E + E
E → E * E
E → idChuỗi đầu vào: id + id * id
Từ ngoài cùng bên trái là:
E → E * E
E → E + E * E
E → id + E * E
E → id + id * E
E → id + id * idLưu ý rằng không phải đầu cuối bên trái luôn được xử lý trước.
Phái sinh bên phải nhất là:
E → E + E
E → E + E * E
E → E + E * id
E → E + id * id
E → id + id * idCây phân tích cú pháp
Cây phân tích cú pháp là một mô tả đồ họa của một dẫn xuất. Thật thuận tiện để xem các chuỗi được lấy từ biểu tượng bắt đầu như thế nào. Biểu tượng bắt đầu của dẫn xuất trở thành gốc của cây phân tích cú pháp. Hãy để chúng tôi thấy điều này bằng một ví dụ từ chủ đề trước.
Chúng tôi lấy đạo hàm ngoài cùng bên trái của a + b * c
Từ ngoài cùng bên trái là:
E → E * E
E → E + E * E
E → id + E * E
E → id + id * E
E → id + id * idBước 1:
| E → E * E |
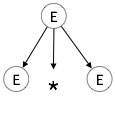
|
Bước 2:
| E → E + E * E |
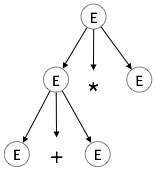
|
Bước 3:
| E → id + E * E |
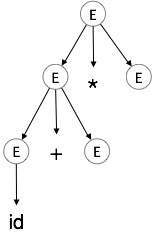
|
Bước 4:
| E → id + id * E |
|
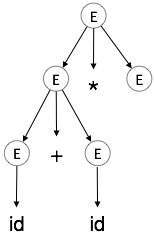
Bước 5:
| E → id + id * id |
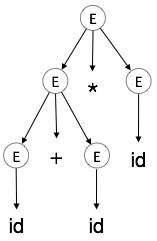
|
Trong một cây phân tích cú pháp:
- Tất cả các nút lá đều là thiết bị đầu cuối.
- Tất cả các nút bên trong đều không phải là thiết bị đầu cuối.
- Truyền theo thứ tự cung cấp chuỗi đầu vào ban đầu.
Cây phân tích cú pháp mô tả tính liên kết và mức độ ưu tiên của các toán tử. Cây con sâu nhất được duyệt trước, do đó toán tử trong cây con đó được ưu tiên hơn toán tử trong các nút cha.
Các loại phân tích cú pháp
Trình phân tích cú pháp tuân theo các quy tắc sản xuất được xác định bằng ngữ pháp không có ngữ cảnh. Cách thực hiện các quy tắc sản xuất (dẫn xuất) chia phân tích cú pháp thành hai loại: phân tích cú pháp từ trên xuống và phân tích cú pháp từ dưới lên.
Phân tích cú pháp từ trên xuống
Khi trình phân tích cú pháp bắt đầu xây dựng cây phân tích cú pháp từ biểu tượng bắt đầu và sau đó cố gắng chuyển đổi biểu tượng bắt đầu thành đầu vào, nó được gọi là phân tích cú pháp từ trên xuống.
Recursive descent parsing: Đây là một dạng phân tích cú pháp từ trên xuống phổ biến. Nó được gọi là đệ quy vì nó sử dụng các thủ tục đệ quy để xử lý đầu vào. Phân tích cú pháp gốc đệ quy gặp phải tình trạng bẻ khóa ngược.
Backtracking: Có nghĩa là, nếu một bản dẫn xuất của một sản xuất không thành công, trình phân tích cú pháp sẽ khởi động lại quy trình bằng cách sử dụng các quy tắc khác nhau của cùng một sản xuất. Kỹ thuật này có thể xử lý chuỗi đầu vào nhiều lần để xác định sản xuất phù hợp.
Phân tích cú pháp từ dưới lên
Như tên cho thấy, phân tích cú pháp từ dưới lên bắt đầu với các ký hiệu đầu vào và cố gắng xây dựng cây phân tích cú pháp lên đến ký hiệu bắt đầu.
Example:
Chuỗi đầu vào: a + b * c
Quy tắc sản xuất:
S → E
E → E + T
E → E * T
E → T
T → idHãy để chúng tôi bắt đầu phân tích cú pháp từ dưới lên
a + b * cĐọc đầu vào và kiểm tra xem có sản phẩm nào khớp với đầu vào không:
a + b * c
T + b * c
E + b * c
E + T * c
E * c
E * T
E
SMơ hồ
Ngữ pháp G được cho là không rõ ràng nếu nó có nhiều hơn một cây phân tích cú pháp (dẫn xuất trái hoặc phải) cho ít nhất một chuỗi.
Example
E → E + E
E → E – E
E → idĐối với chuỗi id + id - id, ngữ pháp trên tạo ra hai cây phân tích cú pháp:

Ngôn ngữ được tạo ra bởi một ngữ pháp không rõ ràng được cho là inherently ambiguous. Sự mơ hồ về ngữ pháp không tốt cho việc xây dựng trình biên dịch. Không có phương pháp nào có thể tự động phát hiện và loại bỏ sự mơ hồ, nhưng nó có thể được loại bỏ bằng cách viết lại toàn bộ ngữ pháp mà không có sự mơ hồ, hoặc bằng cách thiết lập và tuân theo các ràng buộc liên kết và ưu tiên.
Sự liên kết
Nếu một toán hạng có các toán tử ở cả hai phía, thì phía mà toán tử lấy toán hạng này được quyết định bởi tính liên kết của các toán tử đó. Nếu phép toán là liên kết trái, thì toán hạng sẽ được thực hiện bởi toán tử bên trái hoặc nếu hoạt động là liên kết phải, thì toán tử bên phải sẽ lấy toán hạng.
Example
Các phép toán như Phép cộng, Phép nhân, Phép trừ và Phép chia được kết hợp trái. Nếu biểu thức chứa:
id op id op idnó sẽ được đánh giá là:
(id op id) op idVí dụ: (id + id) + id
Các phép toán như Phép toán lũy thừa là phép kết hợp đúng, tức là, thứ tự đánh giá trong cùng một biểu thức sẽ là:
id op (id op id)Ví dụ: id ^ (id ^ id)
Quyền ưu tiên
Nếu hai toán tử khác nhau chia sẻ một toán hạng chung, thứ tự ưu tiên của các toán tử sẽ quyết định toán hạng nào sẽ lấy toán hạng. Nghĩa là, 2 + 3 * 4 có thể có hai cây phân tích cú pháp khác nhau, một cây tương ứng với (2 + 3) * 4 và cây khác tương ứng với 2+ (3 * 4). Bằng cách đặt mức độ ưu tiên giữa các toán tử, vấn đề này có thể dễ dàng được loại bỏ. Như trong ví dụ trước, về mặt toán học * (phép nhân) được ưu tiên hơn + (phép cộng), do đó biểu thức 2 + 3 * 4 sẽ luôn được hiểu là:
2 + (3 * 4)Những phương pháp này làm giảm nguy cơ mơ hồ trong một ngôn ngữ hoặc ngữ pháp của nó.
Đệ quy trái
Một ngữ pháp sẽ trở thành đệ quy trái nếu nó có bất kỳ ký hiệu nào không phải là đầu cuối 'A' có dẫn xuất chứa chính 'A' là ký hiệu ngoài cùng bên trái. Ngữ pháp đệ quy trái được coi là một tình huống có vấn đề đối với trình phân tích cú pháp từ trên xuống. Bộ phân tích cú pháp từ trên xuống bắt đầu phân tích cú pháp từ biểu tượng Bắt đầu, bản thân nó không phải là ký hiệu đầu cuối. Vì vậy, khi trình phân tích cú pháp gặp cùng một ký tự không đầu cuối trong dẫn xuất của nó, nó sẽ trở nên khó phán đoán khi nào nên dừng phân tích cú pháp không phải đầu cuối bên trái và nó đi vào một vòng lặp vô hạn.
Example:
(1) A => Aα | β
(2) S => Aα | β
A => Sd(1) là một ví dụ về đệ quy bên trái ngay lập tức, trong đó A là bất kỳ ký hiệu không phải đầu cuối nào và α đại diện cho một chuỗi không phải đầu cuối.
(2) là một ví dụ về đệ quy gián tiếp-trái.
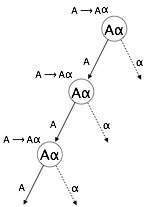
Một trình phân tích cú pháp từ trên xuống trước tiên sẽ phân tích cú pháp A, đến lượt nó sẽ mang lại một chuỗi bao gồm chính A và trình phân tích cú pháp có thể lặp lại mãi mãi.
Loại bỏ đệ quy trái
Một cách để loại bỏ đệ quy trái là sử dụng kỹ thuật sau:
Sản phẩm
A => Aα | βđược chuyển đổi thành các sản phẩm sau
A => βA’
A => αA’ | εĐiều này không ảnh hưởng đến các chuỗi bắt nguồn từ ngữ pháp, nhưng nó loại bỏ đệ quy bên trái ngay lập tức.
Phương pháp thứ hai là sử dụng thuật toán sau, thuật toán này sẽ loại bỏ tất cả các đệ quy trái trực tiếp và gián tiếp.
Algorithm
START
Arrange non-terminals in some order like A1, A2, A3,…, An
for each i from 1 to n
{
for each j from 1 to i-1
{
replace each production of form Ai⟹Aj
with Ai ⟹ δ1 | δ2 | δ3 |…|
where Aj ⟹ δ1 | δ2|…| δn are current Aj productions
}
}
eliminate immediate left-recursion
ENDExample
Bộ sản xuất
S => Aα | β
A => Sdsau khi áp dụng thuật toán trên, sẽ trở thành
S => Aα | β
A => Aαd | βdvà sau đó, loại bỏ đệ quy bên trái ngay lập tức bằng cách sử dụng kỹ thuật đầu tiên.
A => βdA’
A => αdA’ | εBây giờ không có sản xuất nào có đệ quy trái trực tiếp hoặc gián tiếp.
Bao thanh toán bên trái
Nếu nhiều quy tắc sản xuất ngữ pháp có một chuỗi tiền tố chung, thì trình phân tích cú pháp từ trên xuống không thể đưa ra lựa chọn sản xuất nào mà nó sẽ thực hiện để phân tích chuỗi trong tay.
Example
Nếu trình phân tích cú pháp từ trên xuống gặp phải sản xuất như
A ⟹ αβ | α | …Sau đó, nó không thể xác định sản xuất nào cần tuân theo để phân tích chuỗi vì cả hai sản phẩm đều bắt đầu từ cùng một đầu cuối (hoặc không phải thiết bị đầu cuối). Để loại bỏ sự nhầm lẫn này, chúng tôi sử dụng một kỹ thuật được gọi là bao thanh toán trái.
Bao thanh toán bên trái biến đổi ngữ pháp để làm cho nó hữu ích cho trình phân tích cú pháp từ trên xuống. Trong kỹ thuật này, chúng tôi tạo một sản phẩm cho mỗi tiền tố chung và phần còn lại của phần dẫn xuất được thêm vào bởi các sản phẩm mới.
Example
Các sản phẩm trên có thể được viết là
A => αA’
A’=> β | | …Giờ đây, trình phân tích cú pháp chỉ có một sản xuất cho mỗi tiền tố, giúp bạn dễ dàng đưa ra quyết định hơn.
Bộ đầu tiên và theo dõi
Một phần quan trọng của việc xây dựng bảng phân tích cú pháp là tạo các tập hợp đầu tiên và theo sau. Các bộ này có thể cung cấp vị trí thực của bất kỳ thiết bị đầu cuối nào trong dẫn xuất. Điều này được thực hiện để tạo bảng phân tích cú pháp trong đó quyết định thay thế T [A, t] = α bằng một số quy tắc sản xuất.
Tập đầu tiên
Tập hợp này được tạo ra để biết ký hiệu đầu cuối nào được lấy ở vị trí đầu tiên bởi một ký hiệu không phải đầu cuối. Ví dụ,
α → t βNghĩa là α suy ra t (thiết bị đầu cuối) ở vị trí đầu tiên. Vì vậy, t ∈ FIRST (α).
Thuật toán tính toán Tập hợp đầu tiên
Nhìn vào định nghĩa của tập FIRST (α):
- nếu α là một đầu cuối, thì FIRST (α) = {α}.
- nếu α là một đầu cuối và α → ℇ là một sản phẩm, thì FIRST (α) = {ℇ}.
- nếu α không phải là đầu cuối và α → 1 2 3… n và bất kỳ FIRST () chứa t thì t nằm trong FIRST (α).
Tập đầu tiên có thể được xem là: FIRST (α) = {t | α → * t β} ∪ {ℇ | α → * ε}
Theo bộ
Tương tự như vậy, chúng tôi tính toán ký hiệu đầu cuối nào ngay sau ký hiệu đầu cuối α không phải đầu cuối trong quy tắc sản xuất. Chúng tôi không xem xét những gì mà không phải thiết bị đầu cuối có thể tạo ra nhưng thay vào đó, chúng tôi xem những gì sẽ là biểu tượng thiết bị đầu cuối tiếp theo sau quá trình sản xuất của một thiết bị không đầu cuối.
Thuật toán tính toán Theo tập hợp:
nếu α là ký hiệu bắt đầu, thì FOLLOW () = $
nếu α không phải là đầu cuối và có sản lượng α → AB, thì FIRST (B) nằm trong FOLLOW (A) ngoại trừ ℇ.
nếu α là một đầu cuối không và có sản lượng α → AB, trong đó B ℇ, thì FOLLOW (A) là FOLLOW (α).
Tập theo có thể được xem là: FOLLOW (α) = {t | S * αt *}
Chiến lược khôi phục lỗi
Trình phân tích cú pháp sẽ có thể phát hiện và báo cáo bất kỳ lỗi nào trong chương trình. Dự kiến rằng khi gặp lỗi, trình phân tích cú pháp sẽ có thể xử lý nó và tiếp tục phân tích cú pháp phần còn lại của đầu vào. Hầu hết nó được mong đợi từ trình phân tích cú pháp để kiểm tra lỗi nhưng lỗi có thể gặp phải ở các giai đoạn khác nhau của quá trình biên dịch. Một chương trình có thể có các loại lỗi sau ở các giai đoạn khác nhau:
Lexical : tên của một số định danh được nhập sai
Syntactical : thiếu dấu chấm phẩy hoặc dấu ngoặc đơn không cân đối
Semantical : gán giá trị không tương thích
Logical : không thể truy cập mã, vòng lặp vô hạn
Có bốn chiến lược khôi phục lỗi phổ biến có thể được thực hiện trong trình phân tích cú pháp để xử lý các lỗi trong mã.
Chế độ hoảng sợ
Khi trình phân tích cú pháp gặp lỗi ở bất kỳ đâu trong câu lệnh, nó sẽ bỏ qua phần còn lại của câu lệnh bằng cách không xử lý đầu vào từ đầu vào sai đến dấu phân cách, chẳng hạn như dấu chấm phẩy. Đây là cách dễ nhất để khôi phục lỗi và nó cũng ngăn trình phân tích cú pháp phát triển các vòng lặp vô hạn.
Chế độ tuyên bố
Khi một trình phân tích cú pháp gặp lỗi, nó sẽ cố gắng thực hiện các biện pháp sửa chữa để phần còn lại của các đầu vào của câu lệnh cho phép trình phân tích cú pháp phân tích cú pháp trước. Ví dụ, chèn một dấu chấm phẩy bị thiếu, thay thế dấu phẩy bằng dấu chấm phẩy, v.v. Các nhà thiết kế phân tích cú pháp phải cẩn thận ở đây vì một lần sửa sai có thể dẫn đến một vòng lặp vô hạn.
Lỗi sản xuất
Các nhà thiết kế trình biên dịch đã biết một số lỗi phổ biến có thể xảy ra trong mã. Ngoài ra, các nhà thiết kế có thể tạo ngữ pháp tăng cường để sử dụng, như các sản phẩm tạo ra cấu trúc sai khi gặp những lỗi này.
Hiệu chỉnh toàn cầu
Trình phân tích cú pháp xem xét toàn bộ chương trình trong tay và cố gắng tìm ra chương trình dự định làm gì và cố gắng tìm ra kết quả phù hợp nhất cho chương trình mà không có lỗi. Khi một đầu vào (câu lệnh) X có lỗi được cung cấp, nó sẽ tạo ra một cây phân tích cú pháp cho một số câu lệnh không có lỗi gần nhất Y. Điều này có thể cho phép trình phân tích cú pháp thực hiện các thay đổi tối thiểu trong mã nguồn, nhưng do độ phức tạp (thời gian và không gian) của chiến lược này vẫn chưa được thực hiện trong thực tế.
Cây cú pháp trừu tượng
Các biểu diễn cây phân tích cú pháp không dễ dàng được trình biên dịch phân tích cú pháp, vì chúng chứa nhiều chi tiết hơn thực tế cần thiết. Lấy cây phân tích cú pháp sau làm ví dụ:
Nếu quan sát kỹ, chúng tôi thấy hầu hết các nút lá là con đơn lẻ đối với các nút cha của chúng. Thông tin này có thể được loại bỏ trước khi cấp cho giai đoạn tiếp theo. Bằng cách ẩn thông tin bổ sung, chúng ta có thể có được một cây như hình dưới đây:
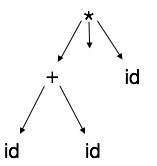
Cây trừu tượng có thể được biểu diễn dưới dạng:
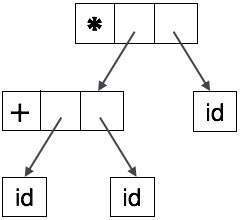
AST là cấu trúc dữ liệu quan trọng trong trình biên dịch với ít thông tin không cần thiết nhất. AST nhỏ gọn hơn một cây phân tích cú pháp và có thể dễ dàng sử dụng bởi trình biên dịch.
Hạn chế của trình phân tích cú pháp
Các bộ phân tích cú pháp nhận đầu vào của chúng, dưới dạng mã thông báo, từ các bộ phân tích từ vựng. Máy phân tích cú pháp chịu trách nhiệm về tính hợp lệ của mã thông báo do trình phân tích cú pháp cung cấp. Máy phân tích cú pháp có những nhược điểm sau:
- nó không thể xác định xem mã thông báo có hợp lệ hay không,
- nó không thể xác định xem một mã thông báo có được khai báo trước khi nó được sử dụng hay không,
- nó không thể xác định xem một mã thông báo có được khởi tạo trước khi nó được sử dụng hay không,
- nó không thể xác định xem một hoạt động được thực hiện trên một loại mã thông báo có hợp lệ hay không.
Những nhiệm vụ này được thực hiện bởi trình phân tích ngữ nghĩa, mà chúng ta sẽ nghiên cứu trong Phân tích ngữ nghĩa.
Chúng ta đã học cách trình phân tích cú pháp xây dựng cây phân tích cú pháp trong giai đoạn phân tích cú pháp. Cây phân tích cú pháp đơn giản được xây dựng trong giai đoạn đó thường không sử dụng cho trình biên dịch, vì nó không mang bất kỳ thông tin nào về cách đánh giá cây. Việc tạo ra ngữ pháp không có ngữ cảnh, tạo ra các quy tắc của ngôn ngữ, không phù hợp với cách diễn giải chúng.
Ví dụ
E → E + TQuá trình sản xuất CFG ở trên không có quy tắc ngữ nghĩa nào đi kèm với nó và nó không thể giúp ích cho việc tạo ra bất kỳ ý nghĩa nào cho quá trình sản xuất.
Ngữ nghĩa
Ngữ nghĩa của một ngôn ngữ cung cấp ý nghĩa cho các cấu trúc của nó, như mã thông báo và cấu trúc cú pháp. Ngữ nghĩa học giúp giải thích các ký hiệu, loại của chúng và mối quan hệ của chúng với nhau. Phân tích ngữ nghĩa đánh giá liệu cấu trúc cú pháp được xây dựng trong chương trình nguồn có phát sinh bất kỳ ý nghĩa nào hay không.
CFG + semantic rules = Syntax Directed DefinitionsVí dụ:
int a = “value”;không nên đưa ra lỗi trong giai đoạn phân tích từ vựng và cú pháp, vì nó đúng về mặt từ vựng và cấu trúc, nhưng nó sẽ tạo ra lỗi ngữ nghĩa vì kiểu của bài tập khác nhau. Các quy tắc này được đặt ra bởi ngữ pháp của ngôn ngữ và được đánh giá trong phân tích ngữ nghĩa. Các tác vụ sau cần được thực hiện trong phân tích ngữ nghĩa:
- Độ phân giải phạm vi
- Loại kiểm tra
- Kiểm tra giới hạn mảng
Lỗi ngữ nghĩa
Chúng tôi đã đề cập đến một số lỗi ngữ nghĩa mà trình phân tích ngữ nghĩa sẽ nhận ra:
- Loại không phù hợp
- Biến không được khai báo
- Sử dụng sai mã định danh dành riêng.
- Khai báo nhiều biến trong một phạm vi.
- Truy cập một biến ngoài phạm vi.
- Thực tế và thông số chính thức không khớp.
Ngữ pháp thuộc tính
Ngữ pháp thuộc tính là một dạng ngữ pháp không có ngữ cảnh đặc biệt, trong đó một số thông tin bổ sung (thuộc tính) được nối vào một hoặc nhiều đầu cuối không phải của nó để cung cấp thông tin nhạy cảm theo ngữ cảnh. Mỗi thuộc tính có miền giá trị được xác định rõ ràng, chẳng hạn như số nguyên, số float, ký tự, chuỗi và biểu thức.
Ngữ pháp thuộc tính là một phương tiện để cung cấp ngữ nghĩa cho ngữ pháp không có ngữ cảnh và nó có thể giúp xác định cú pháp và ngữ nghĩa của một ngôn ngữ lập trình. Ngữ pháp thuộc tính (khi được xem như một cây phân tích cú pháp) có thể chuyển các giá trị hoặc thông tin giữa các nút của cây.
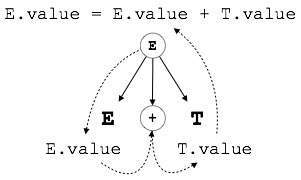
Example:
E → E + T { E.value = E.value + T.value }Phần bên phải của CFG chứa các quy tắc ngữ nghĩa chỉ định cách diễn giải ngữ pháp. Ở đây, các giá trị của không phải đầu cuối E và T được cộng lại với nhau và kết quả được sao chép vào đầu cuối E.
Các thuộc tính ngữ nghĩa có thể được gán cho các giá trị của chúng từ miền của chúng tại thời điểm phân tích cú pháp và đánh giá tại thời điểm gán hoặc điều kiện. Dựa trên cách các thuộc tính nhận được giá trị của chúng, chúng có thể được chia thành hai loại: thuộc tính tổng hợp và thuộc tính kế thừa.
Thuộc tính tổng hợp
Các thuộc tính này nhận giá trị từ các giá trị thuộc tính của các nút con của chúng. Để minh họa, giả sử sản xuất sau:
S → ABCNếu S đang nhận các giá trị từ các nút con của nó (A, B, C), thì nó được cho là một thuộc tính tổng hợp, vì các giá trị của ABC được tổng hợp thành S.
Như trong ví dụ trước của chúng ta (E → E + T), nút cha E nhận giá trị từ nút con của nó. Các thuộc tính tổng hợp không bao giờ lấy giá trị từ các nút cha của chúng hoặc bất kỳ nút anh em nào.
Thuộc tính kế thừa
Ngược lại với các thuộc tính tổng hợp, các thuộc tính kế thừa có thể lấy giá trị từ cha mẹ và / hoặc anh chị em. Như trong sản xuất sau,
S → ABCA có thể nhận giá trị từ S, B và C. B có thể nhận giá trị từ S, A và C. Tương tự như vậy, C có thể nhận giá trị từ S, A và B.
Expansion : Khi một không phải đầu cuối được mở rộng thành các đầu cuối theo quy tắc ngữ pháp
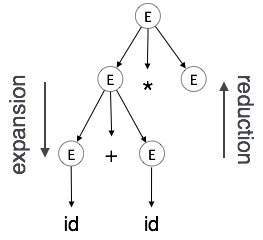
Reduction: Khi một đầu cuối được giảm xuống không phải đầu cuối tương ứng của nó theo quy tắc ngữ pháp. Cây cú pháp được phân tích cú pháp từ trên xuống và từ trái sang phải. Bất cứ khi nào việc giảm xảy ra, chúng tôi áp dụng các quy tắc ngữ nghĩa tương ứng (hành động) của nó.
Phân tích ngữ nghĩa sử dụng Bản dịch theo hướng cú pháp để thực hiện các nhiệm vụ trên.
Bộ phân tích ngữ nghĩa nhận AST (Cây cú pháp trừu tượng) từ giai đoạn trước của nó (phân tích cú pháp).
Bộ phân tích ngữ nghĩa đính kèm thông tin thuộc tính với AST, được gọi là AST thuộc tính.
Các thuộc tính là hai bộ giá trị, <tên thuộc tính, giá trị thuộc tính>
Ví dụ:
int value = 5;
<type, “integer”>
<presentvalue, “5”>Đối với mỗi sản phẩm, chúng tôi đính kèm một quy tắc ngữ nghĩa.
SDT được phân bổ cho S
Nếu một SDT chỉ sử dụng các thuộc tính tổng hợp, nó được gọi là SDT phân bổ S. Các thuộc tính này được đánh giá bằng cách sử dụng các SDT được phân bổ S có các hành động ngữ nghĩa của chúng được viết sau khi sản xuất (phía bên phải).
Như được mô tả ở trên, các thuộc tính trong SDT do S phân bổ được đánh giá trong phân tích cú pháp từ dưới lên, vì giá trị của các nút cha phụ thuộc vào giá trị của các nút con.
SDT được phân bổ L
Dạng SDT này sử dụng cả thuộc tính tổng hợp và thuộc tính kế thừa với hạn chế là không lấy giá trị từ anh chị em phải.
Trong SDT được phân bổ theo L, một thiết bị đầu cuối không phải là thiết bị đầu cuối có thể nhận các giá trị từ các nút cha, con và anh chị em của nó. Như trong sản xuất sau
S → ABCS có thể nhận giá trị từ A, B và C (tổng hợp). A chỉ có thể nhận các giá trị từ S. B có thể nhận các giá trị từ S và A. C có thể nhận các giá trị từ S, A và B. Không có đầu cuối nào có thể nhận các giá trị từ phần tử anh em bên phải của nó.
Các thuộc tính trong SDT do L phân bổ được đánh giá theo cách phân tích cú pháp theo chiều sâu từ trái sang phải.
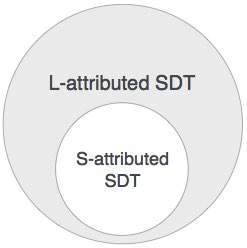
Chúng ta có thể kết luận rằng nếu một định nghĩa được quy cho S, thì nó cũng được quy cho L vì định nghĩa được quy cho L bao gồm các định nghĩa được quy cho S.
Trong chương trước, chúng ta đã hiểu các khái niệm cơ bản liên quan đến phân tích cú pháp. Trong chương này, chúng ta sẽ tìm hiểu các loại phương pháp xây dựng trình phân tích cú pháp có sẵn.
Phân tích cú pháp có thể được định nghĩa là từ trên xuống hoặc từ dưới lên dựa trên cách cấu trúc cây phân tích cú pháp.

Phân tích cú pháp từ trên xuống
Chúng ta đã học trong chương trước rằng kỹ thuật phân tích cú pháp từ trên xuống sẽ phân tích dữ liệu đầu vào và bắt đầu xây dựng cây phân tích cú pháp từ nút gốc dần dần di chuyển xuống các nút lá. Các loại phân tích cú pháp từ trên xuống được mô tả bên dưới:
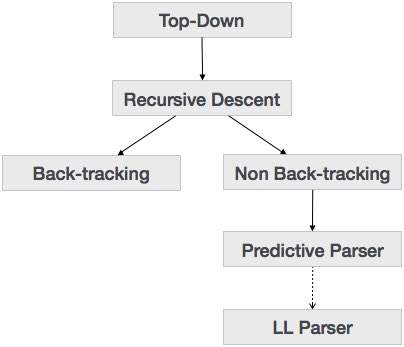
Phân tích cú pháp đi xuống đệ quy
Đường xuống đệ quy là một kỹ thuật phân tích cú pháp từ trên xuống để xây dựng cây phân tích cú pháp từ trên xuống và đầu vào được đọc từ trái sang phải. Nó sử dụng các thủ tục cho mọi thực thể đầu cuối và không đầu cuối. Kỹ thuật phân tích cú pháp này phân tích cú pháp đệ quy đầu vào để tạo một cây phân tích cú pháp, có thể có hoặc không yêu cầu theo dõi ngược. Nhưng ngữ pháp liên quan đến nó (nếu không được tính đến) không thể tránh được việc theo dõi ngược. Một hình thức phân tích cú pháp gốc đệ quy không yêu cầu bất kỳ theo dõi ngược nào được gọi làpredictive parsing.
Kỹ thuật phân tích cú pháp này được coi là đệ quy vì nó sử dụng ngữ pháp không có ngữ cảnh mà bản chất là đệ quy.
Theo dõi lại
Bộ phân tích cú pháp từ trên xuống bắt đầu từ nút gốc (ký hiệu bắt đầu) và khớp chuỗi đầu vào theo quy tắc sản xuất để thay thế chúng (nếu khớp). Để hiểu điều này, hãy lấy ví dụ sau về CFG:
S → rXd | rZd
X → oa | ea
Z → aiĐối với một chuỗi đầu vào: read, một trình phân tích cú pháp từ trên xuống, sẽ hoạt động như sau:
Nó sẽ bắt đầu bằng S từ các quy tắc sản xuất và sẽ khớp sản lượng của nó với chữ cái ngoài cùng bên trái của đầu vào, tức là 'r'. Việc sản xuất S (S → rXd) phù hợp với nó. Vì vậy, trình phân tích cú pháp từ trên xuống tiến tới ký tự đầu vào tiếp theo (tức là 'e'). Trình phân tích cú pháp cố gắng mở rộng 'X' không phải đầu cuối và kiểm tra sản xuất của nó từ bên trái (X → oa). Nó không khớp với ký hiệu đầu vào tiếp theo. Vì vậy, trình phân tích cú pháp từ trên xuống sẽ lùi lại để thu được quy tắc sản xuất tiếp theo của X, (X → ea).
Bây giờ trình phân tích cú pháp khớp với tất cả các chữ cái đầu vào theo cách có thứ tự. Chuỗi được chấp nhận.
|
|
|
|
|
Trình phân tích cú pháp dự đoán
Bộ phân tích cú pháp dự đoán là bộ phân tích cú pháp gốc đệ quy, có khả năng dự đoán sản xuất nào sẽ được sử dụng để thay thế chuỗi đầu vào. Trình phân tích cú pháp dự đoán không bị backtracking.
Để hoàn thành nhiệm vụ của mình, trình phân tích cú pháp tiên đoán sử dụng một con trỏ nhìn trước, trỏ đến các ký hiệu đầu vào tiếp theo. Để làm cho trình phân tích cú pháp trở lại theo dõi miễn phí, trình phân tích cú pháp tiên đoán đặt một số ràng buộc đối với ngữ pháp và chỉ chấp nhận một lớp ngữ pháp được gọi là ngữ pháp LL (k).
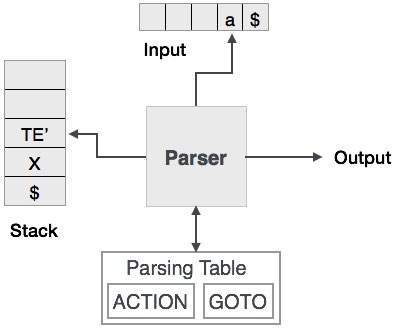
Phân tích cú pháp dự đoán sử dụng ngăn xếp và bảng phân tích cú pháp để phân tích cú pháp đầu vào và tạo cây phân tích cú pháp. Cả ngăn xếp và đầu vào đều chứa ký hiệu kết thúc$để biểu thị rằng ngăn xếp trống và đầu vào đã được tiêu thụ. Trình phân tích cú pháp đề cập đến bảng phân tích cú pháp để đưa ra bất kỳ quyết định nào về kết hợp phần tử đầu vào và ngăn xếp.
Trong phân tích cú pháp gốc đệ quy, trình phân tích cú pháp có thể có nhiều hơn một sản xuất để lựa chọn cho một phiên bản đầu vào, trong khi trong phân tích cú pháp tiên đoán, mỗi bước có nhiều nhất một sản xuất để lựa chọn. Có thể có những trường hợp không có sản phẩm khớp với chuỗi đầu vào, làm cho quy trình phân tích cú pháp không thành công.
LL Parser
Trình phân tích cú pháp LL chấp nhận ngữ pháp LL. Ngữ pháp LL là một tập hợp con của ngữ pháp không có ngữ cảnh nhưng có một số hạn chế để có được phiên bản đơn giản hóa, nhằm dễ dàng triển khai. Ngữ pháp LL có thể được thực hiện bằng cả hai thuật toán cụ thể là, hướng xuống đệ quy hoặc hướng bảng.
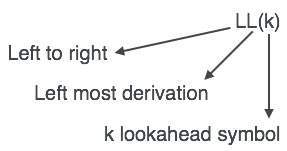
Bộ phân tích cú pháp LL được ký hiệu là LL (k). Chữ L đầu tiên trong LL (k) đang phân tích dữ liệu đầu vào từ trái sang phải, chữ L thứ hai trong LL (k) là viết tắt của phái sinh ngoài cùng bên trái và bản thân k thể hiện số lần nhìn về phía trước. Nói chung k = 1, vì vậy LL (k) cũng có thể được viết là LL (1).
Thuật toán phân tích cú pháp LL
Chúng tôi có thể bám vào LL xác định (1) để giải thích phân tích cú pháp, vì kích thước của bảng tăng lên theo cấp số nhân với giá trị của k. Thứ hai, nếu một văn phạm nhất định không phải là LL (1), thì thông thường, nó không phải là LL (k), với bất kỳ k đã cho.
Dưới đây là một thuật toán cho LL (1) Phân tích cú pháp:
Input:
string ω
parsing table M for grammar G
Output:
If ω is in L(G) then left-most derivation of ω,
error otherwise.
Initial State : $S on stack (with S being start symbol) ω$ in the input buffer
SET ip to point the first symbol of ω$.
repeat
let X be the top stack symbol and a the symbol pointed by ip.
if X∈ Vt or $
if X = a
POP X and advance ip.
else
error()
endif
else /* X is non-terminal */
if M[X,a] = X → Y1, Y2,... Yk
POP X
PUSH Yk, Yk-1,... Y1 /* Y1 on top */
Output the production X → Y1, Y2,... Yk
else
error()
endif
endif
until X = $ /* empty stack */Ngữ pháp G là LL (1) nếu A-> alpha | b là hai sản phẩm khác biệt của G:
đối với không có thiết bị đầu cuối, cả alpha và beta đều lấy chuỗi bắt đầu bằng a.
nhiều nhất một trong số alpha và beta có thể lấy được chuỗi trống.
nếu beta => t, thì alpha không dẫn xuất bất kỳ chuỗi nào bắt đầu bằng đầu cuối trong FOLLOW (A).
Phân tích cú pháp từ dưới lên
Phân tích cú pháp từ dưới lên bắt đầu từ các nút lá của cây và hoạt động theo hướng đi lên cho đến khi nó đến nút gốc. Ở đây, chúng tôi bắt đầu từ một câu và sau đó áp dụng các quy tắc sản xuất theo cách ngược lại để đạt được biểu tượng bắt đầu. Hình ảnh dưới đây mô tả các trình phân tích cú pháp từ dưới lên có sẵn.

Shift-Reduce Parsing
Phân tích cú pháp Shift-Reduce sử dụng hai bước duy nhất để phân tích cú pháp từ dưới lên. Các bước này được gọi là bước chuyển và bước giảm.
Shift step: Bước dịch chuyển đề cập đến sự tiến của con trỏ đầu vào tới ký hiệu đầu vào tiếp theo, được gọi là ký hiệu đã dịch chuyển. Biểu tượng này được đẩy lên ngăn xếp. Biểu tượng được dịch chuyển được coi như một nút duy nhất của cây phân tích cú pháp.
Reduce step: Khi trình phân tích cú pháp tìm thấy một quy tắc ngữ pháp hoàn chỉnh (RHS) và thay thế nó thành (LHS), nó được gọi là bước rút gọn. Điều này xảy ra khi trên cùng của ngăn xếp có một chốt. Để giảm bớt, một hàm POP được thực hiện trên ngăn xếp bật ra khỏi tay cầm và thay thế nó bằng biểu tượng không đầu cuối LHS.
Trình phân tích cú pháp LR
Trình phân tích cú pháp LR là trình phân tích cú pháp không đệ quy, shift-giảm, từ dưới lên. Nó sử dụng nhiều loại ngữ pháp không có ngữ cảnh, điều này làm cho nó trở thành kỹ thuật phân tích cú pháp hiệu quả nhất. Bộ phân tích cú pháp LR còn được gọi là bộ phân tích cú pháp LR (k), trong đó L là viết tắt của việc quét từ trái sang phải của luồng đầu vào; R là viết tắt của việc xây dựng đạo hàm bên phải ngược lại và k biểu thị số lượng ký hiệu nhìn trước để đưa ra quyết định.
Có ba thuật toán được sử dụng rộng rãi có sẵn để xây dựng trình phân tích cú pháp LR:
- SLR (1) - Trình phân tích cú pháp LR đơn giản:
- Hoạt động trên lớp ngữ pháp nhỏ nhất
- Rất ít trạng thái, do đó bảng rất nhỏ
- Thi công đơn giản và nhanh chóng
- LR (1) - Bộ phân tích cú pháp LR:
- Hoạt động trên bộ hoàn chỉnh LR (1) Ngữ pháp
- Tạo bảng lớn và số lượng lớn các trạng thái
- Thi công chậm
- LALR (1) - Trình phân tích cú pháp LR Nhìn trước:
- Hoạt động trên kích thước trung bình của ngữ pháp
- Số trạng thái giống như trong SLR (1)
Thuật toán phân tích cú pháp LR
Ở đây chúng tôi mô tả thuật toán khung của trình phân tích cú pháp LR:
token = next_token()
repeat forever
s = top of stack
if action[s, token] = “shift si” then
PUSH token
PUSH si
token = next_token()
else if action[s, tpken] = “reduce A::= β“ then
POP 2 * |β| symbols
s = top of stack
PUSH A
PUSH goto[s,A]
else if action[s, token] = “accept” then
return
else
error()LL so với LR
| LL | LR |
|---|---|
| Có một dẫn xuất ngoài cùng bên trái. | Có một dẫn xuất ngoài cùng bên phải ngược lại. |
| Bắt đầu với danh nghĩa gốc trên ngăn xếp. | Kết thúc với danh nghĩa gốc trên ngăn xếp. |
| Kết thúc khi ngăn xếp trống. | Bắt đầu với một ngăn xếp trống. |
| Sử dụng ngăn xếp để chỉ định những gì vẫn được mong đợi. | Sử dụng ngăn xếp để chỉ định những gì đã thấy. |
| Tạo cây phân tích cú pháp từ trên xuống. | Xây dựng cây phân tích cú pháp từ dưới lên. |
| Liên tục bật một danh nghĩa ra khỏi ngăn xếp và đẩy phía bên tay phải tương ứng. | Cố gắng nhận ra một mặt bên phải trên ngăn xếp, bật nó ra và đẩy danh nghĩa tương ứng. |
| Mở rộng các thiết bị đầu cuối. | Giảm các thiết bị không đầu cuối. |
| Đọc các thiết bị đầu cuối khi nó bật một đầu ra khỏi ngăn xếp. | Đọc các thiết bị đầu cuối trong khi nó đẩy chúng vào ngăn xếp. |
| Đặt trước trình duyệt của cây phân tích cú pháp. | Duyệt theo thứ tự của cây phân tích cú pháp. |
Một chương trình như một mã nguồn chỉ đơn thuần là một tập hợp các văn bản (mã, câu lệnh, v.v.) và để làm cho nó tồn tại, nó yêu cầu các hành động được thực hiện trên máy đích. Một chương trình cần tài nguyên bộ nhớ để thực hiện các lệnh. Một chương trình chứa tên cho các thủ tục, số nhận dạng, v.v., yêu cầu ánh xạ với vị trí bộ nhớ thực trong thời gian chạy.
Theo thời gian chạy, chúng tôi có nghĩa là một chương trình đang được thực thi. Môi trường thời gian chạy là một trạng thái của máy đích, có thể bao gồm các thư viện phần mềm, các biến môi trường, v.v., để cung cấp dịch vụ cho các tiến trình đang chạy trong hệ thống.
Hệ thống hỗ trợ thời gian chạy là một gói, hầu hết được tạo bằng chính chương trình thực thi và tạo điều kiện cho quá trình giao tiếp giữa quá trình và môi trường thời gian chạy. Nó đảm nhiệm việc cấp phát bộ nhớ và khử cấp phát trong khi chương trình đang được thực thi.
Cây kích hoạt
Chương trình là một chuỗi các lệnh được kết hợp thành một số thủ tục. Các hướng dẫn trong một thủ tục được thực hiện tuần tự. Một thủ tục có một dấu phân cách bắt đầu và kết thúc và mọi thứ bên trong nó được gọi là phần thân của thủ tục. Định danh thủ tục và chuỗi các lệnh hữu hạn bên trong nó tạo nên phần thân của thủ tục.
Việc thực hiện một thủ tục được gọi là sự kích hoạt của nó. Một bản ghi kích hoạt chứa tất cả các thông tin cần thiết cần thiết để gọi một thủ tục. Một bản ghi kích hoạt có thể chứa các đơn vị sau (tùy thuộc vào ngôn ngữ nguồn được sử dụng).
| Tạm thời | Lưu trữ các giá trị tạm thời và trung gian của một biểu thức. |
| Dữ liệu cục bộ | Lưu trữ dữ liệu cục bộ của thủ tục được gọi. |
| Tình trạng máy | Lưu trữ trạng thái máy như Sổ đăng ký, Bộ đếm chương trình, v.v., trước khi quy trình được gọi. |
| Liên kết kiểm soát | Lưu trữ địa chỉ của hồ sơ kích hoạt của thủ tục người gọi. |
| Truy cập liên kết | Lưu trữ thông tin dữ liệu nằm ngoài phạm vi cục bộ. |
| Các thông số thực tế | Lưu trữ các tham số thực, tức là các tham số được sử dụng để gửi đầu vào cho thủ tục được gọi. |
| Giá trị trả lại | Cửa hàng trả về giá trị. |
Bất cứ khi nào một thủ tục được thực thi, bản ghi kích hoạt của nó được lưu trữ trên ngăn xếp, còn được gọi là ngăn xếp điều khiển. Khi một thủ tục gọi một thủ tục khác, quá trình thực thi của trình gọi sẽ bị tạm dừng cho đến khi thủ tục được gọi kết thúc thực thi. Tại thời điểm này, bản ghi kích hoạt của thủ tục được gọi được lưu trữ trên ngăn xếp.
Chúng ta giả sử rằng điều khiển chương trình chạy theo cách tuần tự và khi một thủ tục được gọi, điều khiển của nó được chuyển sang thủ tục được gọi. Khi một thủ tục được gọi được thực thi, nó sẽ trả lại quyền điều khiển cho người gọi. Loại luồng điều khiển này giúp dễ dàng biểu diễn một loạt các kích hoạt dưới dạng cây, được gọi làactivation tree.
Để hiểu khái niệm này, chúng tôi lấy một đoạn mã làm ví dụ:
. . .
printf(“Enter Your Name: “);
scanf(“%s”, username);
show_data(username);
printf(“Press any key to continue…”);
. . .
int show_data(char *user)
{
printf(“Your name is %s”, username);
return 0;
}
. . .Dưới đây là cây kích hoạt của mã được đưa ra.

Bây giờ chúng ta hiểu rằng các thủ tục được thực thi theo cách thức chuyên sâu, do đó phân bổ ngăn xếp là hình thức lưu trữ phù hợp nhất để kích hoạt thủ tục.
Phân bổ lưu trữ
Môi trường thời gian chạy quản lý các yêu cầu bộ nhớ thời gian chạy cho các thực thể sau:
Code: Nó được gọi là phần văn bản của chương trình không thay đổi trong thời gian chạy. Yêu cầu bộ nhớ của nó đã được biết tại thời điểm biên dịch.
Procedures: Phần văn bản của chúng là tĩnh nhưng chúng được gọi theo cách ngẫu nhiên. Đó là lý do tại sao, lưu trữ ngăn xếp được sử dụng để quản lý các lệnh gọi và kích hoạt thủ tục.
Variables: Các biến chỉ được biết trong thời gian chạy, trừ khi chúng là toàn cục hoặc hằng số. Lược đồ cấp phát bộ nhớ Heap được sử dụng để quản lý cấp phát và cấp phát bộ nhớ cho các biến trong thời gian chạy.
Phân bổ tĩnh
Trong lược đồ cấp phát này, dữ liệu biên dịch được gắn vào một vị trí cố định trong bộ nhớ và nó không thay đổi khi chương trình thực thi. Vì yêu cầu bộ nhớ và vị trí lưu trữ đã được biết trước, nên không cần gói hỗ trợ thời gian chạy để cấp phát và hủy cấp phát bộ nhớ.
Phân bổ ngăn xếp
Các cuộc gọi thủ tục và kích hoạt của chúng được quản lý bằng cách cấp phát bộ nhớ ngăn xếp. Nó hoạt động theo phương pháp last-in-first-out (LIFO) và chiến lược phân bổ này rất hữu ích cho các cuộc gọi thủ tục đệ quy.
Phân bổ đống
Các biến cục bộ của một thủ tục chỉ được cấp phát và hủy cấp phát trong thời gian chạy. Cấp phát đống được sử dụng để cấp phát động bộ nhớ cho các biến và yêu cầu nó trở lại khi các biến không còn yêu cầu nữa.
Ngoại trừ vùng bộ nhớ được cấp phát tĩnh, cả bộ nhớ ngăn xếp và bộ nhớ heap đều có thể phát triển và thu nhỏ một cách động và bất ngờ. Do đó, chúng không thể được cung cấp một lượng bộ nhớ cố định trong hệ thống.
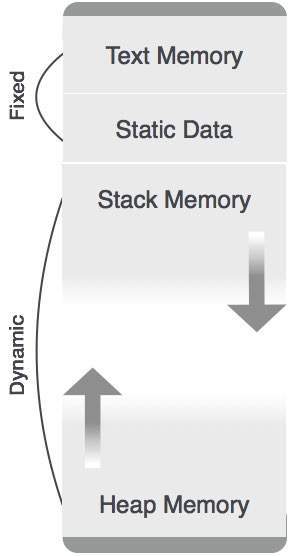
Như trong hình trên, phần văn bản của mã được cấp một lượng bộ nhớ cố định. Bộ nhớ ngăn xếp và bộ nhớ heap được sắp xếp ở các cực của tổng bộ nhớ được cấp cho chương trình. Cả hai đều co lại và phát triển chống lại nhau.
Truyền tham số
Phương tiện giao tiếp giữa các thủ tục được gọi là truyền tham số. Giá trị của các biến từ một thủ tục gọi được chuyển sang thủ tục được gọi bởi một số cơ chế. Trước khi tiếp tục, trước tiên hãy xem qua một số thuật ngữ cơ bản liên quan đến các giá trị trong một chương trình.
giá trị r
Giá trị của một biểu thức được gọi là giá trị r của nó. Giá trị chứa trong một biến đơn lẻ cũng trở thành giá trị r nếu nó xuất hiện ở phía bên phải của toán tử gán. Giá trị r luôn có thể được gán cho một số biến khác.
giá trị l
Vị trí của bộ nhớ (địa chỉ) nơi một biểu thức được lưu trữ được gọi là giá trị l của biểu thức đó. Nó luôn xuất hiện ở bên trái của toán tử gán.
Ví dụ:
day = 1;
week = day * 7;
month = 1;
year = month * 12;Từ ví dụ này, chúng ta hiểu rằng các giá trị không đổi như 1, 7, 12 và các biến như ngày, tuần, tháng và năm, tất cả đều có giá trị r. Chỉ các biến có giá trị l vì chúng cũng đại diện cho vị trí bộ nhớ được gán cho chúng.
Ví dụ:
7 = x + y;là lỗi giá trị l, vì hằng số 7 không đại diện cho bất kỳ vị trí bộ nhớ nào.
Thông số chính thức
Các biến lấy thông tin được truyền bởi thủ tục người gọi được gọi là tham số chính thức. Các biến này được khai báo trong định nghĩa của hàm được gọi.
Các thông số thực tế
Các biến có giá trị hoặc địa chỉ đang được chuyển đến thủ tục được gọi được gọi là tham số thực tế. Các biến này được chỉ định trong lệnh gọi hàm dưới dạng đối số.
Example:
fun_one()
{
int actual_parameter = 10;
call fun_two(int actual_parameter);
}
fun_two(int formal_parameter)
{
print formal_parameter;
}Các tham số chính thức giữ thông tin của tham số thực, tùy thuộc vào kỹ thuật truyền tham số được sử dụng. Nó có thể là một giá trị hoặc một địa chỉ.
Vượt qua giá trị
Trong cơ chế truyền theo giá trị, thủ tục gọi chuyển giá trị r của các tham số thực tế và trình biên dịch đưa giá trị đó vào bản ghi kích hoạt của thủ tục được gọi. Các tham số chính thức sau đó giữ các giá trị được truyền bởi thủ tục gọi. Nếu các giá trị được giữ bởi các tham số chính thức được thay đổi, nó sẽ không ảnh hưởng đến các tham số thực tế.
Chuyển qua tài liệu tham khảo
Trong cơ chế tham chiếu truyền, giá trị l của tham số thực được sao chép vào bản ghi kích hoạt của thủ tục được gọi. Bằng cách này, thủ tục được gọi bây giờ có địa chỉ (vị trí bộ nhớ) của tham số thực và tham số chính thức đề cập đến cùng một vị trí bộ nhớ. Do đó, nếu giá trị được trỏ bởi tham số chính thức bị thay đổi, tác động sẽ được nhìn thấy trên tham số thực vì chúng cũng phải trỏ đến cùng một giá trị.
Vượt qua sao chép-khôi phục
Cơ chế truyền tham số này hoạt động tương tự như 'truyền tham chiếu' ngoại trừ việc các thay đổi đối với tham số thực được thực hiện khi thủ tục được gọi kết thúc. Khi gọi hàm, giá trị của các tham số thực được sao chép trong bản ghi kích hoạt của thủ tục được gọi. Các tham số chính thức nếu được thao tác sẽ không có tác dụng theo thời gian thực đối với các tham số thực tế (khi các giá trị l được truyền), nhưng khi thủ tục được gọi kết thúc, các giá trị l của các tham số chính thức được sao chép sang các giá trị l của các tham số thực tế.
Example:
int y;
calling_procedure()
{
y = 10;
copy_restore(y); //l-value of y is passed
printf y; //prints 99
}
copy_restore(int x)
{
x = 99; // y still has value 10 (unaffected)
y = 0; // y is now 0
}Khi hàm này kết thúc, giá trị l của tham số chính thức x được sao chép vào tham số thực tế y. Ngay cả khi giá trị của y được thay đổi trước khi thủ tục kết thúc, giá trị l của x được sao chép sang giá trị l của y khiến nó hoạt động giống như lệnh gọi bằng tham chiếu.
Vượt qua tên
Các ngôn ngữ như Algol cung cấp một loại cơ chế truyền tham số mới hoạt động giống như bộ tiền xử lý trong ngôn ngữ C. Trong cơ chế pass by name, tên của thủ tục được gọi được thay thế bằng phần thân thực của nó. Pass-by-name thay thế bằng văn bản các biểu thức đối số trong một lệnh gọi thủ tục cho các tham số tương ứng trong phần thân của thủ tục để bây giờ nó có thể hoạt động trên các tham số thực tế, giống như kiểu truyền qua tham chiếu.
Bảng ký hiệu là một cấu trúc dữ liệu quan trọng được tạo và duy trì bởi trình biên dịch để lưu trữ thông tin về sự xuất hiện của các thực thể khác nhau như tên biến, tên hàm, đối tượng, lớp, giao diện, v.v. Bảng ký hiệu được sử dụng cho cả phân tích và tổng hợp các bộ phận của trình biên dịch.
Một bảng ký hiệu có thể phục vụ các mục đích sau tùy thuộc vào ngôn ngữ có trong tay:
Để lưu trữ tên của tất cả các thực thể trong một biểu mẫu có cấu trúc tại một nơi.
Để xác minh xem một biến đã được khai báo hay chưa.
Để thực hiện kiểm tra kiểu, bằng cách xác minh các phép gán và biểu thức trong mã nguồn là đúng về mặt ngữ nghĩa.
Để xác định phạm vi của một tên (độ phân giải phạm vi).
Bảng ký hiệu đơn giản là một bảng có thể là bảng tuyến tính hoặc bảng băm. Nó duy trì một mục nhập cho mỗi tên ở định dạng sau:
<symbol name, type, attribute>Ví dụ, nếu một bảng ký hiệu phải lưu trữ thông tin về khai báo biến sau:
static int interest;thì nó sẽ lưu trữ mục nhập như:
<interest, int, static>Mệnh đề thuộc tính chứa các mục liên quan đến tên.
Thực hiện
Nếu một trình biên dịch phải xử lý một lượng nhỏ dữ liệu, thì bảng ký hiệu có thể được triển khai dưới dạng danh sách không có thứ tự, dễ viết mã, nhưng nó chỉ phù hợp với các bảng nhỏ. Một bảng ký hiệu có thể được triển khai theo một trong những cách sau:
- Danh sách tuyến tính (được sắp xếp hoặc không được sắp xếp)
- Cây tìm kiếm nhị phân
- Bảng băm
Trong số tất cả, các bảng biểu tượng chủ yếu được triển khai dưới dạng bảng băm, trong đó bản thân biểu tượng mã nguồn được coi như một khóa cho hàm băm và giá trị trả về là thông tin về biểu tượng.
Hoạt động
Một bảng ký hiệu, tuyến tính hoặc băm, phải cung cấp các phép toán sau.
chèn()
Thao tác này được sử dụng thường xuyên hơn trong giai đoạn phân tích, tức là nửa đầu của trình biên dịch nơi mã thông báo được xác định và tên được lưu trữ trong bảng. Thao tác này được sử dụng để thêm thông tin trong bảng ký hiệu về các tên duy nhất xuất hiện trong mã nguồn. Định dạng hoặc cấu trúc mà các tên được lưu trữ phụ thuộc vào trình biên dịch trong tay.
Thuộc tính cho một ký hiệu trong mã nguồn là thông tin được liên kết với ký hiệu đó. Thông tin này chứa giá trị, trạng thái, phạm vi và loại về biểu tượng. Hàm insert () lấy biểu tượng và các thuộc tính của nó làm đối số và lưu trữ thông tin trong bảng biểu tượng.
Ví dụ:
int a;nên được xử lý bởi trình biên dịch như:
insert(a, int);tra cứu()
Thao tác lookup () được sử dụng để tìm kiếm tên trong bảng ký hiệu nhằm xác định:
- nếu ký hiệu tồn tại trong bảng.
- nếu nó được khai báo trước khi nó được sử dụng.
- nếu tên được sử dụng trong phạm vi.
- nếu ký hiệu được khởi tạo.
- nếu ký hiệu được khai báo nhiều lần.
Định dạng của hàm lookup () thay đổi tùy theo ngôn ngữ lập trình. Định dạng cơ bản phải phù hợp với những điều sau:
lookup(symbol)Phương thức này trả về 0 (không) nếu ký hiệu không tồn tại trong bảng ký hiệu. Nếu biểu tượng tồn tại trong bảng biểu tượng, nó sẽ trả về các thuộc tính của nó được lưu trữ trong bảng.
Phạm vi quản lí
Một trình biên dịch duy trì hai loại bảng ký hiệu: a global symbol table có thể được truy cập bằng tất cả các thủ tục và scope symbol tables được tạo cho từng phạm vi trong chương trình.
Để xác định phạm vi của tên, các bảng ký hiệu được sắp xếp theo cấu trúc phân cấp như thể hiện trong ví dụ dưới đây:
. . .
int value=10;
void pro_one()
{
int one_1;
int one_2;
{ \
int one_3; |_ inner scope 1
int one_4; |
} /
int one_5;
{ \
int one_6; |_ inner scope 2
int one_7; |
} /
}
void pro_two()
{
int two_1;
int two_2;
{ \
int two_3; |_ inner scope 3
int two_4; |
} /
int two_5;
}
. . .Chương trình trên có thể được biểu diễn theo cấu trúc phân cấp của các bảng ký hiệu:

Bảng ký hiệu toàn cục chứa tên cho một biến toàn cục (giá trị int) và hai tên thủ tục, những tên này sẽ có sẵn cho tất cả các nút con được hiển thị ở trên. Các tên được đề cập trong bảng biểu tượng pro_one (và tất cả các bảng con của nó) không có sẵn cho biểu tượng pro_two và các bảng con của nó.
Hệ thống phân cấp cấu trúc dữ liệu bảng ký hiệu này được lưu trữ trong trình phân tích ngữ nghĩa và bất cứ khi nào một tên cần được tìm kiếm trong bảng ký hiệu, nó sẽ được tìm kiếm bằng thuật toán sau:
đầu tiên một biểu tượng sẽ được tìm kiếm trong phạm vi hiện tại, tức là bảng biểu tượng hiện tại.
nếu một tên được tìm thấy, thì quá trình tìm kiếm sẽ hoàn tất, nếu không nó sẽ được tìm kiếm trong bảng ký hiệu mẹ cho đến khi,
tên được tìm thấy hoặc bảng ký hiệu chung đã được tìm kiếm tên.
Một mã nguồn có thể được dịch trực tiếp thành mã máy đích của nó, vậy tại sao chúng ta lại cần dịch mã nguồn thành một mã trung gian và sau đó được dịch sang mã đích của nó? Hãy để chúng tôi xem lý do tại sao chúng tôi cần một mã trung gian.
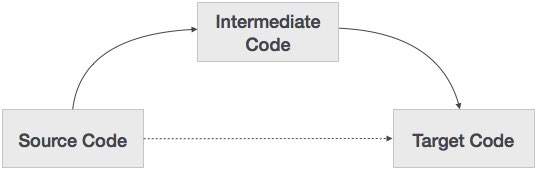
Nếu một trình biên dịch dịch ngôn ngữ nguồn sang ngôn ngữ máy đích của nó mà không có tùy chọn tạo mã trung gian, thì đối với mỗi máy mới, cần có một trình biên dịch gốc đầy đủ.
Mã trung gian loại bỏ sự cần thiết của một trình biên dịch đầy đủ mới cho mọi máy duy nhất bằng cách giữ nguyên phần phân tích cho tất cả các trình biên dịch.
Phần thứ hai của trình biên dịch, tổng hợp, được thay đổi theo máy đích.
Việc áp dụng các sửa đổi mã nguồn để cải thiện hiệu suất mã trở nên dễ dàng hơn bằng cách áp dụng các kỹ thuật tối ưu hóa mã trên mã trung gian.
Đại diện trung gian
Mã trung gian có thể được biểu diễn theo nhiều cách khác nhau và chúng có những lợi ích riêng.
High Level IR- Biểu diễn mã trung gian bậc cao rất gần với chính ngôn ngữ nguồn. Chúng có thể dễ dàng được tạo ra từ mã nguồn và chúng ta có thể dễ dàng áp dụng các sửa đổi mã để nâng cao hiệu suất. Nhưng để tối ưu hóa máy mục tiêu, nó ít được ưu tiên hơn.
Low Level IR - Cái này gần với máy đích, phù hợp cho việc cấp phát thanh ghi và bộ nhớ, lựa chọn tập lệnh, v.v. Nó rất tốt cho việc tối ưu hóa phụ thuộc vào máy.
Mã trung gian có thể là ngôn ngữ cụ thể (ví dụ: Mã Byte cho Java) hoặc ngôn ngữ độc lập (mã ba địa chỉ).
Mã ba địa chỉ
Trình tạo mã trung gian nhận đầu vào từ giai đoạn tiền nhiệm của nó, trình phân tích ngữ nghĩa, dưới dạng cây cú pháp có chú thích. Sau đó, cây cú pháp đó có thể được chuyển đổi thành một biểu diễn tuyến tính, ví dụ: ký hiệu hậu tố. Mã trung gian có xu hướng là mã độc lập với máy. Do đó, bộ tạo mã giả định có số lượng bộ nhớ lưu trữ (thanh ghi) không giới hạn để tạo mã.
Ví dụ:
a = b + c * d;Bộ tạo mã trung gian sẽ cố gắng chia biểu thức này thành các biểu thức con và sau đó tạo mã tương ứng.
r1 = c * d;
r2 = b + r1;
a = r2r được sử dụng như các thanh ghi trong chương trình đích.
Mã ba địa chỉ có nhiều nhất ba vị trí địa chỉ để tính toán biểu thức. Mã ba địa chỉ có thể được biểu diễn dưới hai dạng: bộ bốn và bộ ba.
Tứ giác
Mỗi lệnh trong bản trình bày tứ phân được chia thành bốn trường: toán tử, arg1, arg2 và kết quả. Ví dụ trên được trình bày dưới đây ở định dạng tứ phân:
| Op | tranh luận 1 | tranh luận 2 | kết quả |
| * | c | d | r1 |
| + | b | r1 | r2 |
| + | r2 | r1 | r3 |
| = | r3 | a |
Bộ ba
Mỗi lệnh trong phần trình bày bộ ba có ba trường: op, arg1 và arg2. Kết quả của các biểu thức con tương ứng được biểu thị bằng vị trí của biểu thức. Các bộ ba thể hiện sự tương tự với DAG và cây cú pháp. Chúng tương đương với DAG trong khi biểu diễn các biểu thức.
| Op | tranh luận 1 | tranh luận 2 |
| * | c | d |
| + | b | (0) |
| + | (1) | (0) |
| = | (2) |
Bộ ba phải đối mặt với vấn đề về tính bất động của mã trong khi tối ưu hóa, vì kết quả có vị trí và việc thay đổi thứ tự hoặc vị trí của một biểu thức có thể gây ra vấn đề.
Bộ ba gián tiếp
Biểu diễn này là một sự cải tiến so với biểu diễn ba lần. Nó sử dụng con trỏ thay vì vị trí để lưu trữ kết quả. Điều này cho phép các trình tối ưu hóa tự do định vị lại biểu thức con để tạo ra mã được tối ưu hóa.
Tuyên bố
Một biến hoặc thủ tục phải được khai báo trước khi nó có thể được sử dụng. Khai báo liên quan đến việc phân bổ không gian trong bộ nhớ và nhập kiểu và tên trong bảng ký hiệu. Một chương trình có thể được mã hóa và thiết kế để lưu ý đến cấu trúc máy đích, nhưng không phải lúc nào cũng có thể chuyển đổi chính xác mã nguồn sang ngôn ngữ đích của nó.
Lấy toàn bộ chương trình làm tập hợp các thủ tục và thủ tục con, có thể khai báo tất cả các tên cục bộ cho thủ tục. Việc cấp phát bộ nhớ được thực hiện liên tiếp và các tên được cấp phát cho bộ nhớ theo trình tự mà chúng được khai báo trong chương trình. Chúng tôi sử dụng biến offset và đặt nó thành 0 {offset = 0} biểu thị địa chỉ cơ sở.
Ngôn ngữ lập trình nguồn và kiến trúc máy đích có thể khác nhau trong cách lưu trữ tên, do đó, việc sử dụng địa chỉ tương đối. Trong khi tên đầu tiên được cấp phát bộ nhớ bắt đầu từ vị trí bộ nhớ 0 {offset = 0}, tên tiếp theo được khai báo sau, sẽ được cấp phát bộ nhớ bên cạnh tên đầu tiên.
Example:
Chúng ta lấy ví dụ về ngôn ngữ lập trình C trong đó một biến số nguyên được gán 2 byte bộ nhớ và một biến float được gán 4 byte bộ nhớ.
int a;
float b;
Allocation process:
{offset = 0}
int a;
id.type = int
id.width = 2
offset = offset + id.width
{offset = 2}
float b;
id.type = float
id.width = 4
offset = offset + id.width
{offset = 6}Để nhập chi tiết này vào bảng ký hiệu, có thể sử dụng một thủ tục nhập . Phương thức này có thể có cấu trúc sau:
enter(name, type, offset)Thủ tục này sẽ tạo một mục nhập trong bảng ký hiệu, cho tên biến , có kiểu của nó được đặt thành kiểu và độ lệch địa chỉ tương đối trong vùng dữ liệu của nó.
Tạo mã có thể được coi là giai đoạn cuối cùng của quá trình biên dịch. Thông qua quá trình tạo mã bài, quá trình tối ưu hóa có thể được áp dụng trên mã, nhưng đó có thể được coi là một phần của giai đoạn tạo mã. Mã do trình biên dịch tạo ra là mã đối tượng của một số ngôn ngữ lập trình cấp thấp hơn, ví dụ, hợp ngữ. Chúng tôi đã thấy rằng mã nguồn được viết bằng ngôn ngữ cấp cao hơn được chuyển đổi thành ngôn ngữ cấp thấp hơn dẫn đến mã đối tượng cấp thấp hơn, mã này phải có các thuộc tính tối thiểu sau:
- Nó phải mang ý nghĩa chính xác của mã nguồn.
- Nó phải hiệu quả về mặt sử dụng CPU và quản lý bộ nhớ.
Bây giờ chúng ta sẽ xem cách mã trung gian được chuyển đổi thành mã đối tượng đích (mã hợp ngữ, trong trường hợp này).
Đồ thị Acyclic có hướng
Directed Acyclic Graph (DAG) là một công cụ mô tả cấu trúc của các khối cơ bản, giúp xem luồng giá trị luân chuyển giữa các khối cơ bản và cũng cung cấp tối ưu hóa. DAG cung cấp chuyển đổi dễ dàng trên các khối cơ bản. DAG có thể được hiểu ở đây:
Các nút lá thể hiện định danh, tên hoặc hằng số.
Các nút bên trong đại diện cho các toán tử.
Các nút bên trong cũng đại diện cho kết quả của các biểu thức hoặc số nhận dạng / tên nơi các giá trị sẽ được lưu trữ hoặc gán.
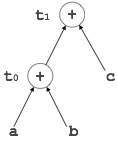
Example:
t0 = a + b
t1 = t0 + c
d = t0 + t1

[t 0 = a + b] |
[t 1 = t 0 + c] |
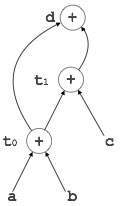
[d = t 0 + t 1 ] |
Tối ưu hóa lỗ nhìn trộm
Kỹ thuật tối ưu hóa này hoạt động cục bộ trên mã nguồn để chuyển nó thành mã tối ưu hóa. Theo cục bộ, chúng tôi muốn nói đến một phần nhỏ của khối mã trong tầm tay. Các phương pháp này có thể được áp dụng trên mã trung gian cũng như trên mã đích. Một loạt các câu lệnh được phân tích và được kiểm tra để có thể tối ưu hóa sau:
Loại bỏ lệnh dư thừa
Ở cấp độ mã nguồn, người dùng có thể thực hiện những điều sau:
|
|
|
|
Ở cấp độ biên dịch, trình biên dịch tìm kiếm các hướng dẫn thừa trong tự nhiên. Việc tải và lưu trữ nhiều hướng dẫn có thể mang cùng một ý nghĩa ngay cả khi một số trong số chúng bị xóa. Ví dụ:
- MOV x, R0
- MOV R0, R1
Chúng ta có thể xóa lệnh đầu tiên và viết lại câu dưới dạng:
MOV x, R1Mã không thể truy cập
Mã không thể truy cập là một phần của mã chương trình không bao giờ được truy cập do cấu trúc lập trình. Các lập trình viên có thể đã vô tình viết một đoạn mã mà không bao giờ có thể tiếp cận được.
Example:
void add_ten(int x)
{
return x + 10;
printf(“value of x is %d”, x);
}Trong đoạn mã này, printf câu lệnh sẽ không bao giờ được thực thi vì điều khiển chương trình trả về trước khi nó có thể thực thi, do đó printf có thể gỡ bỏ.
Luồng tối ưu hóa kiểm soát
Có những trường hợp trong mã mà điều khiển chương trình nhảy qua lại mà không thực hiện bất kỳ tác vụ quan trọng nào. Các bước nhảy này có thể được loại bỏ. Hãy xem xét đoạn mã sau:
...
MOV R1, R2
GOTO L1
...
L1 : GOTO L2
L2 : INC R1Trong mã này, nhãn L1 có thể bị loại bỏ khi nó chuyển quyền điều khiển đến L2. Vì vậy, thay vì nhảy đến L1 và sau đó đến L2, điều khiển có thể trực tiếp đến L2, như hình dưới đây:
...
MOV R1, R2
GOTO L2
...
L2 : INC R1Đơn giản hóa biểu thức đại số
Có những trường hợp mà các biểu thức đại số có thể trở nên đơn giản. Ví dụ, biểu thứca = a + 0 có thể được thay thế bởi a chính nó và biểu thức a = a + 1 có thể đơn giản được thay thế bằng INC a.
Giảm sức mạnh
Có những thao tác tiêu tốn nhiều thời gian và không gian hơn. 'Sức mạnh' của chúng có thể được giảm bớt bằng cách thay thế chúng bằng các hoạt động khác tiêu tốn ít thời gian và không gian hơn, nhưng tạo ra cùng một kết quả.
Ví dụ, x * 2 có thể được thay thế bởi x << 1, chỉ liên quan đến một ca sang trái. Mặc dù đầu ra của a * a và a 2 là như nhau, nhưng a 2 sẽ hiệu quả hơn nhiều để triển khai.
Truy cập hướng dẫn máy
Máy mục tiêu có thể triển khai các lệnh phức tạp hơn, có thể có khả năng thực hiện các hoạt động cụ thể một cách hiệu quả hơn nhiều. Nếu mã đích có thể đáp ứng các hướng dẫn đó một cách trực tiếp, điều đó sẽ không chỉ cải thiện chất lượng của mã mà còn mang lại kết quả hiệu quả hơn.
Trình tạo mã
Một trình tạo mã được mong đợi có hiểu biết về môi trường thời gian chạy của máy mục tiêu và tập lệnh của nó. Trình tạo mã nên xem xét những điều sau để tạo mã:
Target language: Trình tạo mã phải nhận thức được bản chất của ngôn ngữ đích mà mã sẽ được chuyển đổi. Ngôn ngữ đó có thể hỗ trợ một số hướng dẫn dành riêng cho máy để giúp trình biên dịch tạo mã theo cách thuận tiện hơn. Máy đích có thể có kiến trúc bộ xử lý CISC hoặc RISC.
IR Type: Biểu diễn trung gian có nhiều dạng khác nhau. Nó có thể nằm trong cấu trúc Cây cú pháp trừu tượng (AST), Ký hiệu đánh bóng ngược hoặc mã 3 địa chỉ.
Selection of instruction: Bộ tạo mã lấy Biểu diễn trung gian làm đầu vào và chuyển đổi (ánh xạ) nó thành tập lệnh của máy đích. Một biểu diễn có thể có nhiều cách (hướng dẫn) để chuyển đổi nó, vì vậy trách nhiệm của người tạo mã là lựa chọn các hướng dẫn thích hợp một cách khôn ngoan.
Register allocation: Một chương trình có một số giá trị được duy trì trong quá trình thực thi. Kiến trúc của máy đích có thể không cho phép tất cả các giá trị được lưu trong bộ nhớ hoặc thanh ghi CPU. Trình tạo mã quyết định những giá trị nào cần giữ trong thanh ghi. Ngoài ra, nó quyết định các thanh ghi được sử dụng để giữ các giá trị này.
Ordering of instructions: Cuối cùng, trình tạo mã quyết định thứ tự thực hiện lệnh. Nó tạo lịch trình cho các hướng dẫn để thực hiện chúng.
Người mô tả
Trình tạo mã phải theo dõi cả thanh ghi (tính khả dụng) và địa chỉ (vị trí của các giá trị) trong khi tạo mã. Đối với cả hai, hai bộ mô tả sau được sử dụng:
Register descriptor: Bộ mô tả thanh ghi được sử dụng để thông báo cho bộ tạo mã về tính khả dụng của các thanh ghi. Bộ mô tả thanh ghi theo dõi các giá trị được lưu trữ trong mỗi thanh ghi. Bất cứ khi nào một thanh ghi mới được yêu cầu trong quá trình tạo mã, bộ mô tả này sẽ được tham khảo để biết tính khả dụng của thanh ghi.
Address descriptor: Giá trị của các tên (mã định danh) được sử dụng trong chương trình có thể được lưu trữ tại các vị trí khác nhau trong khi thực thi. Bộ mô tả địa chỉ được sử dụng để theo dõi các vị trí bộ nhớ nơi các giá trị của mã định danh được lưu trữ. Các vị trí này có thể bao gồm thanh ghi CPU, đống, ngăn xếp, bộ nhớ hoặc kết hợp các vị trí được đề cập.
Trình tạo mã giữ cho cả bộ mô tả được cập nhật trong thời gian thực. Đối với câu lệnh tải, LD R1, x, trình tạo mã:
- cập nhật Bộ mô tả thanh ghi R1 có giá trị là x và
- cập nhật Bộ mô tả địa chỉ (x) để hiển thị rằng một phiên bản của x nằm trong R1.
Tạo mã
Các khối cơ bản bao gồm một chuỗi các lệnh ba địa chỉ. Trình tạo mã lấy chuỗi các lệnh này làm đầu vào.
Note: Nếu giá trị của tên được tìm thấy ở nhiều nơi (thanh ghi, bộ đệm hoặc bộ nhớ), giá trị của thanh ghi sẽ được ưu tiên hơn bộ nhớ đệm và bộ nhớ chính. Tương tự như vậy, giá trị của bộ nhớ cache sẽ được ưu tiên hơn bộ nhớ chính. Bộ nhớ chính hầu như không được ưu tiên.
getReg: Trình tạo mã sử dụng hàm getReg để xác định trạng thái của các thanh ghi có sẵn và vị trí của các giá trị tên. getReg hoạt động như sau:
Nếu biến Y đã có trong thanh ghi R, nó sẽ sử dụng thanh ghi đó.
Nếu không có thanh ghi R nào đó, nó sẽ sử dụng thanh ghi đó.
Ngược lại, nếu cả hai tùy chọn trên đều không thể thực hiện được, nó sẽ chọn một thanh ghi yêu cầu số lần tải và lưu trữ tối thiểu.
Đối với lệnh x = y OP z, trình tạo mã có thể thực hiện các hành động sau. Giả sử rằng L là vị trí (tốt nhất là thanh ghi) nơi lưu đầu ra của y OP z:
Gọi hàm getReg, để quyết định vị trí của L.
Xác định vị trí hiện tại (thanh ghi hoặc bộ nhớ) của y bằng cách tham khảo Người mô tả địa chỉ của y. Nếuy hiện không có trong sổ đăng ký L, sau đó tạo lệnh sau để sao chép giá trị của y đến L:
MOV y ', L
Ở đâu y’ đại diện cho giá trị được sao chép của y.
Xác định vị trí hiện tại của z sử dụng cùng một phương pháp được sử dụng trong bước 2 cho y và tạo ra lệnh sau:
OP z ', L
Ở đâu z’ đại diện cho giá trị được sao chép của z.
Bây giờ L chứa giá trị của y OP z, giá trị này được dùng để gán cho x. Vì vậy, nếu L là một thanh ghi, hãy cập nhật bộ mô tả của nó để chỉ ra rằng nó chứa giá trị củax. Cập nhật bộ mô tả củax để chỉ ra rằng nó được lưu trữ tại vị trí L.
Nếu y và z không còn sử dụng nữa, chúng có thể được trả lại cho hệ thống.
Các cấu trúc mã khác như vòng lặp và câu lệnh điều kiện được chuyển đổi thành hợp ngữ theo cách hợp ngữ chung.
Tối ưu hóa là một kỹ thuật chuyển đổi chương trình, cố gắng cải thiện mã bằng cách làm cho nó tiêu thụ ít tài nguyên hơn (tức là CPU, Bộ nhớ) và cung cấp tốc độ cao.
Trong tối ưu hóa, các cấu trúc lập trình chung cấp cao được thay thế bằng các mã lập trình cấp thấp rất hiệu quả. Quy trình tối ưu hóa mã phải tuân theo ba quy tắc được đưa ra dưới đây:
Mã đầu ra, theo bất kỳ cách nào, không được thay đổi ý nghĩa của chương trình.
Việc tối ưu hóa sẽ tăng tốc độ của chương trình và nếu có thể, chương trình sẽ yêu cầu ít tài nguyên hơn.
Bản thân việc tối ưu hóa phải nhanh chóng và không được làm chậm quá trình biên dịch tổng thể.
Các nỗ lực cho một mã tối ưu hóa có thể được thực hiện ở nhiều cấp độ biên dịch quy trình.
Khi bắt đầu, người dùng có thể thay đổi / sắp xếp lại mã hoặc sử dụng các thuật toán tốt hơn để viết mã.
Sau khi tạo mã trung gian, trình biên dịch có thể sửa đổi mã trung gian bằng cách tính toán địa chỉ và cải thiện các vòng lặp.
Trong khi tạo mã máy đích, trình biên dịch có thể sử dụng phân cấp bộ nhớ và thanh ghi CPU.
Tối ưu hóa có thể được phân loại rộng rãi thành hai loại: độc lập với máy và phụ thuộc vào máy.
Tối ưu hóa độc lập với máy móc
Trong tối ưu hóa này, trình biên dịch lấy mã trung gian và biến đổi một phần của mã không liên quan đến bất kỳ thanh ghi CPU và / hoặc vị trí bộ nhớ tuyệt đối nào. Ví dụ:
do
{
item = 10;
value = value + item;
}while(value<100);Mã này liên quan đến việc chỉ định lặp đi lặp lại mục định danh, nếu chúng ta đặt theo cách này:
Item = 10;
do
{
value = value + item;
} while(value<100);không chỉ lưu các chu kỳ CPU mà có thể được sử dụng trên bất kỳ bộ xử lý nào.
Tối ưu hóa phụ thuộc vào máy móc
Tối ưu hóa phụ thuộc vào máy được thực hiện sau khi mã đích đã được tạo và khi mã được chuyển đổi theo kiến trúc máy đích. Nó liên quan đến các thanh ghi CPU và có thể có tham chiếu bộ nhớ tuyệt đối hơn là tham chiếu tương đối. Các trình tối ưu hóa phụ thuộc vào máy móc nỗ lực để tận dụng tối đa hệ thống phân cấp bộ nhớ.
Khối cơ bản
Mã nguồn thường có một số lệnh, các lệnh này luôn được thực thi theo trình tự và được coi là các khối cơ bản của mã. Các khối cơ bản này không có bất kỳ lệnh nhảy nào trong số chúng, tức là khi lệnh đầu tiên được thực hiện, tất cả các lệnh trong cùng khối cơ bản sẽ được thực hiện theo trình tự xuất hiện của chúng mà không làm mất quyền kiểm soát luồng của chương trình.
Một chương trình có thể có nhiều cấu trúc khác nhau dưới dạng các khối cơ bản, như IF-THEN-ELSE, câu lệnh điều kiện SWITCH-CASE và các vòng lặp như DO-WHILE, FOR và REPEAT-UNTIL, v.v.
Nhận dạng khối cơ bản
Chúng tôi có thể sử dụng thuật toán sau để tìm các khối cơ bản trong một chương trình:
Câu lệnh tiêu đề tìm kiếm của tất cả các khối cơ bản từ nơi bắt đầu khối cơ bản:
- Câu lệnh đầu tiên của một chương trình.
- Các câu lệnh là đích của bất kỳ nhánh nào (có điều kiện / không điều kiện).
- Các câu lệnh theo sau bất kỳ câu lệnh nhánh nào.
Các câu lệnh tiêu đề và các câu lệnh theo sau chúng tạo thành một khối cơ bản.
Một khối cơ bản không bao gồm bất kỳ câu lệnh tiêu đề nào của bất kỳ khối cơ bản nào khác.
Khối cơ bản là những khái niệm quan trọng theo cả quan điểm tạo mã và tối ưu hóa.
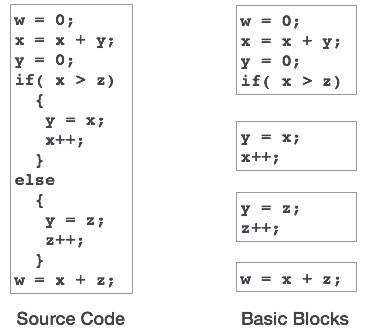
Các khối cơ bản đóng một vai trò quan trọng trong việc xác định các biến, đang được sử dụng nhiều lần trong một khối cơ bản duy nhất. Nếu bất kỳ biến nào đang được sử dụng nhiều hơn một lần, bộ nhớ thanh ghi được cấp cho biến đó không cần được làm trống trừ khi khối kết thúc thực thi.
Đồ thị luồng điều khiển
Các khối cơ bản trong một chương trình có thể được biểu diễn bằng biểu đồ luồng điều khiển. Biểu đồ luồng điều khiển mô tả cách điều khiển chương trình đang được chuyển giữa các khối. Nó là một công cụ hữu ích giúp tối ưu hóa bằng cách giúp định vị bất kỳ vòng lặp không mong muốn nào trong chương trình.
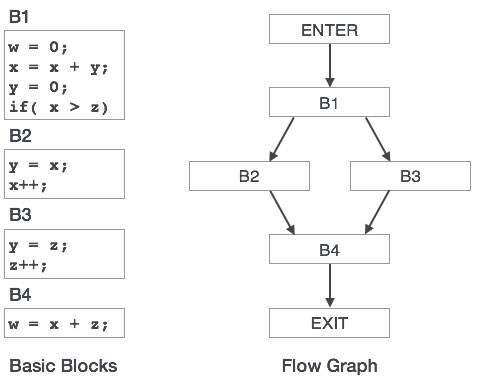
Tối ưu hóa vòng lặp
Hầu hết các chương trình chạy như một vòng lặp trong hệ thống. Nó trở nên cần thiết để tối ưu hóa các vòng lặp để tiết kiệm chu kỳ CPU và bộ nhớ. Các vòng lặp có thể được tối ưu hóa bằng các kỹ thuật sau:
Invariant code: Một đoạn mã nằm trong vòng lặp và tính giá trị giống nhau tại mỗi lần lặp được gọi là mã bất biến của vòng lặp. Mã này có thể được di chuyển ra khỏi vòng lặp bằng cách lưu nó để được tính toán chỉ một lần, thay vì mỗi lần lặp lại.
Induction analysis : Một biến được gọi là biến cảm ứng nếu giá trị của nó bị thay đổi trong vòng lặp bởi một giá trị bất biến của vòng lặp.
Strength reduction: Có những biểu thức tiêu tốn nhiều chu kỳ, thời gian và bộ nhớ CPU hơn. Các biểu thức này nên được thay thế bằng các biểu thức rẻ hơn mà không ảnh hưởng đến kết quả đầu ra của biểu thức. Ví dụ, phép nhân (x * 2) tốn kém về chu kỳ CPU hơn (x << 1) và cho kết quả tương tự.
Loại bỏ mã chết
Mã chết là một hoặc nhiều câu lệnh mã, đó là:
- Không bao giờ được thực thi hoặc không thể truy cập,
- Hoặc nếu được thực thi, đầu ra của chúng sẽ không bao giờ được sử dụng.
Vì vậy, mã chết không đóng vai trò gì trong bất kỳ hoạt động chương trình nào và do đó nó có thể bị loại bỏ một cách đơn giản.
Mã chết một phần
Có một số câu lệnh mã mà các giá trị được tính toán chỉ được sử dụng trong một số trường hợp nhất định, tức là, đôi khi các giá trị được sử dụng và đôi khi chúng không được sử dụng. Những mã như vậy được gọi là mã chết một phần.
Biểu đồ luồng điều khiển ở trên mô tả một đoạn chương trình trong đó biến 'a' được sử dụng để gán đầu ra của biểu thức 'x * y'. Giả sử rằng giá trị được gán cho 'a' không bao giờ được sử dụng trong vòng lặp. Ngay sau khi điều khiển rời khỏi vòng lặp, 'a' được gán giá trị của biến 'z', sẽ được sử dụng sau này trong chương trình. Chúng tôi kết luận ở đây rằng mã gán của 'a' không bao giờ được sử dụng ở bất kỳ đâu, do đó nó đủ điều kiện để loại bỏ.
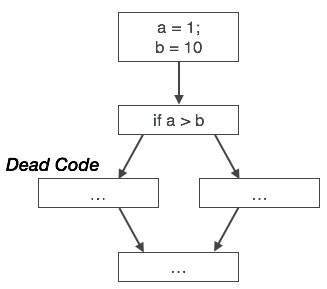
Tương tự như vậy, hình trên mô tả rằng câu lệnh điều kiện luôn sai, ngụ ý rằng mã, được viết trong trường hợp đúng, sẽ không bao giờ được thực thi, do đó nó có thể bị xóa.
Dự phòng một phần
Các biểu thức dư thừa được tính toán nhiều lần trong một đường dẫn song song mà không có bất kỳ thay đổi nào trong toán hạng. Trong khi các biểu thức dư thừa một phần được tính toán nhiều lần trong một đường dẫn mà không có bất kỳ thay đổi nào trong các toán hạng. Ví dụ,
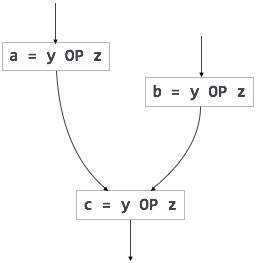
[biểu thức thừa] |
[biểu thức dư thừa một phần] |
Mã bất biến vòng lặp là một phần dư thừa và có thể được loại bỏ bằng cách sử dụng kỹ thuật chuyển động mã.
Một ví dụ khác về mã dự phòng một phần có thể là:
If (condition)
{
a = y OP z;
}
else
{
...
}
c = y OP z;Chúng tôi giả định rằng các giá trị của toán hạng (y và z) không bị thay đổi từ việc gán biến a biến c. Ở đây, nếu câu lệnh điều kiện là đúng, thì y OP z được tính hai lần, nếu không thì một lần. Chuyển động mã có thể được sử dụng để loại bỏ sự dư thừa này, như được hiển thị bên dưới:
If (condition)
{
...
tmp = y OP z;
a = tmp;
...
}
else
{
...
tmp = y OP z;
}
c = tmp;Ở đây, cho dù điều kiện là đúng hay sai; y OP z chỉ nên được tính một lần.