Thiết kế trình biên dịch - Phân tích cú pháp
Phân tích cú pháp hoặc phân tích cú pháp là giai đoạn thứ hai của trình biên dịch. Trong chương này, chúng ta sẽ tìm hiểu các khái niệm cơ bản được sử dụng trong việc xây dựng một trình phân tích cú pháp.
Chúng tôi đã thấy rằng một trình phân tích từ vựng có thể xác định các mã thông báo với sự trợ giúp của các biểu thức chính quy và các quy tắc mẫu. Nhưng một bộ phân tích từ vựng không thể kiểm tra cú pháp của một câu nhất định do những hạn chế của các biểu thức chính quy. Biểu thức chính quy không thể kiểm tra các mã thông báo cân bằng, chẳng hạn như dấu ngoặc đơn. Do đó, giai đoạn này sử dụng ngữ pháp không có ngữ cảnh (CFG), được nhận dạng bởi dữ liệu tự động đẩy xuống.
Mặt khác, CFG là một tập hợp ngữ pháp chính quy, như được mô tả bên dưới:

Nó ngụ ý rằng mọi Ngữ pháp Thông thường cũng không có ngữ cảnh, nhưng tồn tại một số vấn đề, nằm ngoài phạm vi của Ngữ pháp Thông thường. CFG là một công cụ hữu ích trong việc mô tả cú pháp của các ngôn ngữ lập trình.
Ngữ pháp không theo ngữ cảnh
Trong phần này, trước tiên chúng ta sẽ xem định nghĩa của ngữ pháp không theo ngữ cảnh và giới thiệu các thuật ngữ được sử dụng trong công nghệ phân tích cú pháp.
Ngữ pháp không có ngữ cảnh có bốn thành phần:
Một tập hợp các non-terminals(V). Các biến không phải là biến cú pháp biểu thị các tập hợp các chuỗi. Các không phải đầu cuối xác định các tập hợp các chuỗi giúp xác định ngôn ngữ do ngữ pháp tạo ra.
Một tập hợp các mã thông báo, được gọi là terminal symbols(Σ). Thiết bị đầu cuối là các ký hiệu cơ bản mà từ đó các chuỗi được hình thành.
Một tập hợp các productions(P). Các sản phẩm của một ngữ pháp xác định cách thức mà các thiết bị đầu cuối và không đầu cuối có thể được kết hợp để tạo thành chuỗi. Mỗi sản xuất bao gồm mộtnon-terminal được gọi là bên trái của quá trình sản xuất, một mũi tên và một chuỗi các mã thông báo và / hoặc on- terminals, được gọi là mặt phải của sản xuất.
Một trong các thiết bị đầu cuối không được chỉ định là ký hiệu bắt đầu (S); từ nơi bắt đầu sản xuất.
Các chuỗi có nguồn gốc từ biểu tượng bắt đầu bằng cách thay thế liên tục một ký hiệu không phải đầu cuối (ban đầu là biểu tượng bắt đầu) ở phía bên phải của một sản phẩm, cho không phải đầu cuối đó.
Thí dụ
Chúng tôi gặp vấn đề về ngôn ngữ palindrome, ngôn ngữ này không thể được mô tả bằng Biểu thức chính quy. Tức là, L = {w | w = w R } không phải là một ngôn ngữ thông thường. Nhưng nó có thể được mô tả bằng CFG, như minh họa bên dưới:
G = ( V, Σ, P, S )Ở đâu:
V = { Q, Z, N }
Σ = { 0, 1 }
P = { Q → Z | Q → N | Q → ℇ | Z → 0Q0 | N → 1Q1 }
S = { Q }Ngữ pháp này mô tả ngôn ngữ palindrome, chẳng hạn như: 1001, 11100111, 00100, 1010101, 11111, v.v.
Máy phân tích cú pháp
Trình phân tích cú pháp hoặc trình phân tích cú pháp lấy đầu vào từ trình phân tích từ vựng dưới dạng các luồng mã thông báo. Trình phân tích cú pháp phân tích mã nguồn (dòng mã thông báo) dựa trên các quy tắc sản xuất để phát hiện bất kỳ lỗi nào trong mã. Đầu ra của giai đoạn này làparse tree.

Bằng cách này, trình phân tích cú pháp hoàn thành hai nhiệm vụ, tức là phân tích cú pháp mã, tìm kiếm lỗi và tạo cây phân tích cú pháp như là đầu ra của pha.
Trình phân tích cú pháp dự kiến sẽ phân tích cú pháp toàn bộ mã ngay cả khi một số lỗi tồn tại trong chương trình. Trình phân tích cú pháp sử dụng các chiến lược khôi phục lỗi mà chúng ta sẽ tìm hiểu ở phần sau của chương này.
Nguồn gốc
Một dẫn xuất về cơ bản là một chuỗi các quy tắc sản xuất, để lấy chuỗi đầu vào. Trong quá trình phân tích cú pháp, chúng tôi đưa ra hai quyết định đối với một số hình thức đầu vào ủy nhiệm:
- Quyết định thiết bị đầu cuối sẽ được thay thế.
- Quyết định quy tắc sản xuất, theo đó, thiết bị đầu cuối sẽ được thay thế.
Để quyết định không phải đầu cuối nào sẽ được thay thế bằng quy tắc sản xuất, chúng ta có thể có hai lựa chọn.
Xuất phát ngoài cùng bên trái
Nếu dạng ủy thác của một đầu vào được quét và thay thế từ trái sang phải, nó được gọi là dẫn xuất ngoài cùng bên trái. Biểu mẫu thông tin gửi được tạo ra bởi phái sinh bên trái nhất được gọi là biểu mẫu thông tin gửi bên trái.
Nguồn gốc ngoài cùng bên phải
Nếu chúng ta quét và thay thế dữ liệu đầu vào bằng các quy tắc sản xuất, từ phải sang trái, thì nó được gọi là phương pháp lấy gốc từ bên phải. Biểu mẫu thông tin gửi từ phái sinh bên phải nhất được gọi là biểu mẫu thông tin gửi bên phải.
Example
Quy tắc sản xuất:
E → E + E
E → E * E
E → idChuỗi đầu vào: id + id * id
Từ ngoài cùng bên trái là:
E → E * E
E → E + E * E
E → id + E * E
E → id + id * E
E → id + id * idLưu ý rằng không phải đầu cuối bên trái luôn được xử lý trước.
Phái sinh bên phải nhất là:
E → E + E
E → E + E * E
E → E + E * id
E → E + id * id
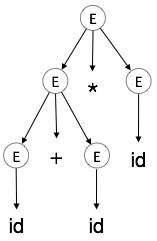
E → id + id * idCây phân tích cú pháp
Cây phân tích cú pháp là một mô tả đồ họa của một dẫn xuất. Thật thuận tiện để xem các chuỗi được lấy từ biểu tượng bắt đầu như thế nào. Biểu tượng bắt đầu của dẫn xuất trở thành gốc của cây phân tích cú pháp. Hãy để chúng tôi thấy điều này bằng một ví dụ từ chủ đề trước.
Chúng tôi lấy đạo hàm ngoài cùng bên trái của a + b * c
Từ ngoài cùng bên trái là:
E → E * E
E → E + E * E
E → id + E * E
E → id + id * E
E → id + id * idBước 1:
| E → E * E |
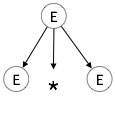
|
Bước 2:
| E → E + E * E |
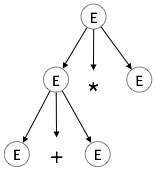
|
Bước 3:
| E → id + E * E |
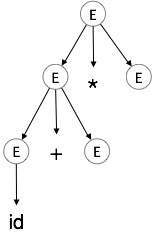
|
Bước 4:
| E → id + id * E |
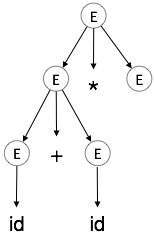
|
Bước 5:
| E → id + id * id |
|
Trong một cây phân tích cú pháp:
- Tất cả các nút lá đều là thiết bị đầu cuối.
- Tất cả các nút bên trong đều không phải là thiết bị đầu cuối.
- Truyền theo thứ tự cung cấp chuỗi đầu vào ban đầu.
Cây phân tích cú pháp mô tả tính liên kết và mức độ ưu tiên của các toán tử. Cây con sâu nhất được duyệt trước, do đó toán tử trong cây con đó được ưu tiên hơn toán tử trong các nút cha.
Mơ hồ
Ngữ pháp G được cho là không rõ ràng nếu nó có nhiều hơn một cây phân tích cú pháp (dẫn xuất trái hoặc phải) cho ít nhất một chuỗi.
Example
E → E + E
E → E – E
E → idĐối với chuỗi id + id - id, ngữ pháp trên tạo ra hai cây phân tích cú pháp:

Ngôn ngữ được tạo ra bởi một ngữ pháp không rõ ràng được cho là inherently ambiguous. Sự mơ hồ về ngữ pháp không tốt cho việc xây dựng trình biên dịch. Không có phương pháp nào có thể tự động phát hiện và loại bỏ sự không rõ ràng, nhưng nó có thể được loại bỏ bằng cách viết lại toàn bộ ngữ pháp mà không có sự mơ hồ, hoặc bằng cách đặt và tuân theo các ràng buộc liên kết và ưu tiên.
Sự liên kết
Nếu một toán hạng có các toán tử ở cả hai phía, phía mà toán tử nhận toán hạng này được quyết định bởi tính liên kết của các toán tử đó. Nếu phép toán là liên kết trái, thì toán hạng sẽ được thực hiện bởi toán tử bên trái hoặc nếu hoạt động là liên kết phải, thì toán tử bên phải sẽ lấy toán hạng.
Example
Các phép toán như Phép cộng, Phép nhân, Phép trừ và Phép chia được kết hợp trái. Nếu biểu thức chứa:
id op id op idnó sẽ được đánh giá là:
(id op id) op idVí dụ: (id + id) + id
Các phép toán như Phép toán lũy thừa là phép kết hợp đúng, tức là, thứ tự đánh giá trong cùng một biểu thức sẽ là:
id op (id op id)Ví dụ: id ^ (id ^ id)
Quyền ưu tiên
Nếu hai toán tử khác nhau chia sẻ một toán hạng chung, thứ tự ưu tiên của toán tử sẽ quyết định toán hạng nào sẽ lấy toán hạng. Nghĩa là, 2 + 3 * 4 có thể có hai cây phân tích cú pháp khác nhau, một cây tương ứng với (2 + 3) * 4 và cây khác tương ứng với 2+ (3 * 4). Bằng cách đặt mức độ ưu tiên giữa các toán tử, vấn đề này có thể dễ dàng được loại bỏ. Như trong ví dụ trước, về mặt toán học * (phép nhân) được ưu tiên hơn + (phép cộng), vì vậy biểu thức 2 + 3 * 4 sẽ luôn được hiểu là:
2 + (3 * 4)Những phương pháp này làm giảm nguy cơ mơ hồ trong một ngôn ngữ hoặc ngữ pháp của nó.
Đệ quy trái
Một ngữ pháp trở thành đệ quy bên trái nếu nó có bất kỳ ký hiệu nào không phải là đầu cuối 'A' có dẫn xuất chứa chính 'A' là ký hiệu ngoài cùng bên trái. Ngữ pháp đệ quy trái được coi là một tình huống có vấn đề đối với trình phân tích cú pháp từ trên xuống. Trình phân tích cú pháp từ trên xuống bắt đầu phân tích cú pháp từ biểu tượng Bắt đầu, bản thân nó không phải là ký hiệu đầu cuối. Vì vậy, khi trình phân tích cú pháp gặp cùng một ký tự không đầu cuối trong dẫn xuất của nó, nó sẽ trở nên khó đoán khi nào dừng phân tích cú pháp không phải đầu cuối bên trái và nó đi vào một vòng lặp vô hạn.
Example:
(1) A => Aα | β
(2) S => Aα | β
A => Sd(1) là một ví dụ về đệ quy bên trái tức thì, trong đó A là bất kỳ ký hiệu không phải đầu cuối nào và α đại diện cho một chuỗi không phải đầu cuối.
(2) là một ví dụ về đệ quy gián tiếp-trái.
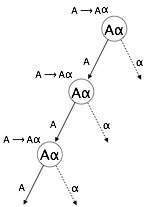
Một trình phân tích cú pháp từ trên xuống trước tiên sẽ phân tích cú pháp A, đến lượt nó sẽ tạo ra một chuỗi bao gồm chính A và trình phân tích cú pháp có thể lặp lại mãi mãi.
Loại bỏ đệ quy trái
Một cách để loại bỏ đệ quy trái là sử dụng kỹ thuật sau:
Sản phẩm
A => Aα | βđược chuyển đổi thành các sản phẩm sau
A => βA'
A'=> αA' | εĐiều này không ảnh hưởng đến các chuỗi bắt nguồn từ ngữ pháp, nhưng nó loại bỏ đệ quy bên trái ngay lập tức.
Phương pháp thứ hai là sử dụng thuật toán sau, thuật toán này sẽ loại bỏ tất cả các đệ quy trái trực tiếp và gián tiếp.
START
Arrange non-terminals in some order like A1, A2, A3,…, An
for each i from 1 to n
{
for each j from 1 to i-1
{
replace each production of form Ai ⟹Aj
with Ai ⟹ δ1 | δ2 | δ3 |…|
where Aj ⟹ δ1 | δ2|…| δn are current Aj productions
}
}
eliminate immediate left-recursion
ENDExample
Bộ sản xuất
S => Aα | β
A => Sdsau khi áp dụng thuật toán trên, sẽ trở thành
S => Aα | β
A => Aαd | βdvà sau đó, loại bỏ đệ quy bên trái ngay lập tức bằng cách sử dụng kỹ thuật đầu tiên.
A => βdA'
A' => αdA' | εBây giờ không có sản xuất nào có đệ quy trái trực tiếp hoặc gián tiếp.
Bao thanh toán bên trái
Nếu nhiều quy tắc sản xuất ngữ pháp có một chuỗi tiền tố chung, thì trình phân tích cú pháp từ trên xuống không thể đưa ra lựa chọn sản xuất nào mà nó sẽ thực hiện để phân tích chuỗi trong tay.
Example
Nếu trình phân tích cú pháp từ trên xuống gặp phải sản xuất như
A ⟹ αβ | α | …Sau đó, nó không thể xác định sản xuất nào cần tuân theo để phân tích chuỗi vì cả hai quá trình sản xuất đều bắt đầu từ cùng một thiết bị đầu cuối (hoặc không phải thiết bị đầu cuối). Để loại bỏ sự nhầm lẫn này, chúng tôi sử dụng một kỹ thuật gọi là bao thanh toán trái.
Bao thanh toán trái biến đổi ngữ pháp để làm cho nó hữu ích cho các trình phân tích cú pháp từ trên xuống. Trong kỹ thuật này, chúng tôi tạo một sản phẩm cho mỗi tiền tố chung và phần còn lại của dẫn xuất được thêm vào bởi các sản phẩm mới.
Example
Các sản phẩm trên có thể được viết là
A => αA'
A'=> β | | …Giờ đây, trình phân tích cú pháp chỉ có một sản xuất cho mỗi tiền tố, giúp dễ dàng đưa ra quyết định hơn.
Bộ đầu tiên và theo dõi
Một phần quan trọng của việc xây dựng bảng phân tích cú pháp là tạo các tập hợp đầu tiên và theo sau. Các tập hợp này có thể cung cấp vị trí thực tế của bất kỳ thiết bị đầu cuối nào trong dẫn xuất. Điều này được thực hiện để tạo bảng phân tích cú pháp trong đó quyết định thay thế T [A, t] = α bằng một số quy tắc sản xuất.
Tập đầu tiên
Tập hợp này được tạo ra để biết ký hiệu đầu cuối nào được lấy ở vị trí đầu tiên bởi một ký hiệu không phải đầu cuối. Ví dụ,
α → t βNghĩa là α suy ra t (thiết bị đầu cuối) ở vị trí đầu tiên. Vì vậy, t ∈ FIRST (α).
Thuật toán tính toán Tập hợp đầu tiên
Nhìn vào định nghĩa của tập FIRST (α):
- nếu α là một đầu cuối, thì FIRST (α) = {α}.
- nếu α là một phi đầu cuối và α → ℇ là một sản phẩm, thì FIRST (α) = {ℇ}.
- nếu α không phải là đầu cuối và α → 1 2 3… n và bất kỳ FIRST () chứa t thì t nằm trong FIRST (α).
Bộ đầu tiên có thể được xem là:
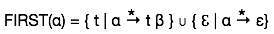
Theo bộ
Tương tự như vậy, chúng tôi tính toán ký hiệu đầu cuối nào ngay sau ký hiệu không phải đầu cuối α trong quy tắc sản xuất. Chúng tôi không xem xét những gì không phải thiết bị đầu cuối có thể tạo ra nhưng thay vào đó, chúng tôi xem biểu tượng thiết bị đầu cuối tiếp theo sẽ là gì sau quá trình sản xuất của một thiết bị không đầu cuối.
Thuật toán tính toán Theo tập hợp:
nếu α là ký hiệu bắt đầu, thì FOLLOW () = $
nếu α không phải là đầu cuối và có sản lượng α → AB, thì FIRST (B) nằm trong FOLLOW (A) ngoại trừ ℇ.
nếu α là một đầu cuối không và có sản lượng α → AB, trong đó B ℇ, thì FOLLOW (A) nằm trong FOLLOW (α).
Tập theo có thể được xem là: FOLLOW (α) = {t | S * αt *}
Hạn chế của Trình phân tích cú pháp
Các bộ phân tích cú pháp nhận đầu vào của chúng, dưới dạng mã thông báo, từ các bộ phân tích từ vựng. Máy phân tích cú pháp chịu trách nhiệm về tính hợp lệ của mã thông báo do trình phân tích cú pháp cung cấp. Máy phân tích cú pháp có những nhược điểm sau:
- nó không thể xác định xem một mã thông báo có hợp lệ hay không,
- nó không thể xác định xem một mã thông báo có được khai báo trước khi nó được sử dụng hay không,
- nó không thể xác định xem một mã thông báo có được khởi tạo trước khi nó được sử dụng hay không,
- nó không thể xác định xem một hoạt động được thực hiện trên một loại mã thông báo có hợp lệ hay không.
Những nhiệm vụ này được thực hiện bởi trình phân tích ngữ nghĩa, mà chúng ta sẽ nghiên cứu trong Phân tích ngữ nghĩa.