Impala - Kiến trúc
Impala là một công cụ thực thi truy vấn MPP (Xử lý song song khối lượng lớn) chạy trên một số hệ thống trong cụm Hadoop. Không giống như các hệ thống lưu trữ truyền thống, impala được tách ra khỏi công cụ lưu trữ của nó. Nó có ba thành phần chính là Impala daemon (Impalad) , Impala Statestore, và siêu dữ liệu Impala hoặc di căn.
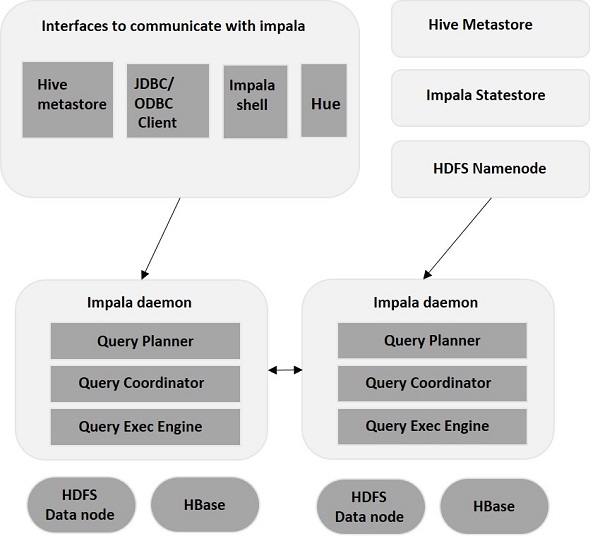
Impala daemon ( Impalad )
Impala daemon (còn được gọi là impalad) chạy trên mỗi nút nơi Impala được cài đặt. Nó chấp nhận các truy vấn từ các giao diện khác nhau như impala shell, hue browser, v.v.… và xử lý chúng.
Bất cứ khi nào một truy vấn được gửi đến một bộ phận trên một nút cụ thể, nút đó sẽ đóng vai trò là “coordinator node”Cho truy vấn đó. Nhiều truy vấn cũng được cung cấp bởi Impalad chạy trên các nút khác. Sau khi chấp nhận truy vấn, Impalad đọc và ghi vào các tệp dữ liệu và song song hóa các truy vấn bằng cách phân phối công việc cho các nút Impala khác trong cụm Impala. Khi các truy vấn đang xử lý trên các phiên bản Impalad khác nhau , tất cả chúng đều trả về kết quả cho nút điều phối trung tâm.
Tùy thuộc vào yêu cầu, các truy vấn có thể được gửi đến một Impalad chuyên dụng hoặc theo cách cân bằng tải tới một Impalad khác trong cụm của bạn.
Cửa hàng tiểu bang Impala
Impala có một thành phần quan trọng khác được gọi là Impala State store, có nhiệm vụ kiểm tra sức khỏe của từng Impalad và sau đó chuyển tiếp sức khỏe của từng daemon Impala cho các daemon khác thường xuyên. Điều này có thể chạy trên cùng một nút nơi máy chủ Impala hoặc nút khác trong cụm đang chạy.
Tên của tiến trình daemon Impala State store là State được lưu trữ . Impalad báo cáo tình trạng sức khỏe của nó cho daemon Impala State store, tức là State được lưu trữ .
Trong trường hợp một nút bị lỗi do bất kỳ lý do nào, Statestore sẽ cập nhật tất cả các nút khác về lỗi này và một khi có thông báo như vậy cho bộ phận xung kích khác , không có trình nền Impala nào khác gán thêm bất kỳ truy vấn nào cho nút bị ảnh hưởng.
Cửa hàng siêu dữ liệu & siêu dữ liệu Impala
Siêu dữ liệu và cửa hàng meta Impala là một thành phần quan trọng khác. Impala sử dụng cơ sở dữ liệu MySQL hoặc PostgreSQL truyền thống để lưu trữ các định nghĩa bảng. Các chi tiết quan trọng như thông tin bảng & cột & định nghĩa bảng được lưu trữ trong cơ sở dữ liệu tập trung được gọi là siêu lưu trữ.
Mỗi nút Impala lưu trữ cục bộ tất cả siêu dữ liệu. Khi xử lý một lượng dữ liệu cực lớn và / hoặc nhiều phân vùng, việc lấy siêu dữ liệu cụ thể của bảng có thể mất một lượng thời gian đáng kể. Vì vậy, bộ nhớ cache siêu dữ liệu được lưu trữ cục bộ giúp cung cấp thông tin đó ngay lập tức.
Khi định nghĩa bảng hoặc dữ liệu bảng được cập nhật, các daemon Impala khác phải cập nhật bộ đệm siêu dữ liệu của họ bằng cách truy xuất siêu dữ liệu mới nhất trước khi đưa ra truy vấn mới đối với bảng được đề cập.
Giao diện xử lý truy vấn
Để xử lý các truy vấn, Impala cung cấp ba giao diện như được liệt kê bên dưới.
Impala-shell - Sau khi thiết lập Impala bằng máy ảo Cloudera, bạn có thể khởi động trình bao Impala bằng cách gõ lệnh impala-shelltrong trình soạn thảo. Chúng ta sẽ thảo luận nhiều hơn về Impala shell trong các chương tới.
Hue interface- Bạn có thể xử lý các truy vấn Impala bằng trình duyệt Hue. Trong trình duyệt Hue, bạn có trình soạn thảo truy vấn Impala, nơi bạn có thể nhập và thực thi các truy vấn impala. Để truy cập trình soạn thảo này, trước hết, bạn cần đăng nhập vào trình duyệt Hue.
ODBC/JDBC drivers- Cũng giống như các cơ sở dữ liệu khác, Impala cung cấp trình điều khiển ODBC / JDBC. Sử dụng các trình điều khiển này, bạn có thể kết nối với impala thông qua các ngôn ngữ lập trình hỗ trợ các trình điều khiển này và xây dựng các ứng dụng xử lý các truy vấn trong impala bằng các ngôn ngữ lập trình đó.
Thủ tục thực thi truy vấn
Bất cứ khi nào người dùng chuyển một truy vấn bằng bất kỳ giao diện nào được cung cấp, điều này được chấp nhận bởi một trong những Impalads trong cụm. Impalad này được coi như một bộ điều phối cho truy vấn cụ thể đó.
Sau khi nhận được truy vấn, điều phối viên truy vấn xác minh xem truy vấn có phù hợp hay không, sử dụng Table Schematừ cửa hàng meta Hive. Sau đó, nó thu thập thông tin về vị trí của dữ liệu được yêu cầu để thực hiện truy vấn, từ nút tên HDFS và gửi thông tin này đến các bộ đệm khác để thực hiện truy vấn.
Tất cả các daemon Impala khác đọc khối dữ liệu được chỉ định và xử lý truy vấn. Ngay sau khi tất cả các daemon hoàn thành nhiệm vụ của chúng, điều phối viên truy vấn sẽ thu thập kết quả trở lại và gửi nó cho người dùng.