Impala - Hướng dẫn nhanh
Impala là gì?
Impala là công cụ truy vấn SQL MPP (Xử lý song song khối lượng lớn) để xử lý khối lượng dữ liệu khổng lồ được lưu trữ trong cụm Hadoop. Nó là một phần mềm mã nguồn mở được viết bằng C ++ và Java. Nó cung cấp hiệu suất cao và độ trễ thấp so với các công cụ SQL khác cho Hadoop.
Nói cách khác, Impala là công cụ SQL có hiệu suất cao nhất (mang lại trải nghiệm giống RDBMS), cung cấp cách nhanh nhất để truy cập dữ liệu được lưu trữ trong Hệ thống tệp phân tán Hadoop.
Tại sao Impala?
Impala kết hợp hỗ trợ SQL và hiệu suất đa người dùng của cơ sở dữ liệu phân tích truyền thống với khả năng mở rộng và tính linh hoạt của Apache Hadoop, bằng cách sử dụng các thành phần tiêu chuẩn như HDFS, HBase, Metastore, YARN và Sentry.
Với Impala, người dùng có thể giao tiếp với HDFS hoặc HBase bằng cách sử dụng các truy vấn SQL theo cách nhanh hơn so với các công cụ SQL khác như Hive.
Impala có thể đọc hầu hết các định dạng tệp như Parquet, Avro, RCFile mà Hadoop sử dụng.
Impala sử dụng cùng siêu dữ liệu, cú pháp SQL (Hive SQL), trình điều khiển ODBC và giao diện người dùng (Hue Beeswax) như Apache Hive, cung cấp một nền tảng quen thuộc và thống nhất cho các truy vấn theo hướng hàng loạt hoặc thời gian thực.
Không giống như Apache Hive, Impala is not based on MapReduce algorithms. Nó thực hiện một kiến trúc phân tán dựa trêndaemon processes chịu trách nhiệm về tất cả các khía cạnh của việc thực thi truy vấn chạy trên cùng một máy.
Do đó, nó làm giảm độ trễ của việc sử dụng MapReduce và điều này làm cho Impala nhanh hơn Apache Hive.
Ưu điểm của Impala
Dưới đây là danh sách một số lợi thế đáng chú ý của Cloudera Impala.
Sử dụng impala, bạn có thể xử lý dữ liệu được lưu trữ trong HDFS với tốc độ cực nhanh với kiến thức SQL truyền thống.
Vì quá trình xử lý dữ liệu được thực hiện tại nơi dữ liệu cư trú (trên cụm Hadoop), nên không cần chuyển đổi dữ liệu và di chuyển dữ liệu đối với dữ liệu được lưu trữ trên Hadoop khi làm việc với Impala.
Sử dụng Impala, bạn có thể truy cập dữ liệu được lưu trữ trong HDFS, HBase và Amazon s3 mà không cần biết về Java (công việc MapReduce). Bạn có thể truy cập chúng với ý tưởng cơ bản về các truy vấn SQL.
Để viết các truy vấn trong các công cụ nghiệp vụ, dữ liệu phải trải qua một chu trình trích xuất-biến đổi-tải (ETL) phức tạp. Nhưng, với Impala, thủ tục này được rút ngắn. Các giai đoạn tốn thời gian tải và sắp xếp lại được khắc phục bằng các kỹ thuật mới nhưexploratory data analysis & data discovery làm cho quá trình nhanh hơn.
Impala đang đi tiên phong trong việc sử dụng định dạng tệp Parquet, một bố cục lưu trữ dạng cột được tối ưu hóa cho các truy vấn quy mô lớn điển hình trong các kịch bản kho dữ liệu.
Đặc điểm của Impala
Dưới đây là các tính năng của cloudera Impala -
Impala có sẵn miễn phí dưới dạng mã nguồn mở theo giấy phép Apache.
Impala hỗ trợ xử lý dữ liệu trong bộ nhớ, tức là nó truy cập / phân tích dữ liệu được lưu trữ trên các nút dữ liệu Hadoop mà không cần di chuyển dữ liệu.
Bạn có thể truy cập dữ liệu bằng Impala bằng các truy vấn giống SQL.
Impala cung cấp khả năng truy cập dữ liệu trong HDFS nhanh hơn khi so sánh với các công cụ SQL khác.
Sử dụng Impala, bạn có thể lưu trữ dữ liệu trong các hệ thống lưu trữ như HDFS, Apache HBase và Amazon s3.
Bạn có thể tích hợp Impala với các công cụ thông minh kinh doanh như Tableau, Pentaho, chiến lược vi mô và dữ liệu thu phóng.
Impala hỗ trợ nhiều định dạng tệp khác nhau như LZO, Tệp trình tự, Avro, RCFile và Parquet.
Impala sử dụng siêu dữ liệu, trình điều khiển ODBC và cú pháp SQL từ Apache Hive.
Cơ sở dữ liệu quan hệ và Impala
Impala sử dụng ngôn ngữ Truy vấn tương tự như SQL và HiveQL. Bảng sau đây mô tả một số điểm khác biệt chính giữa ngôn ngữ truy vấn SQL và Impala.
| Impala | Cơ sở dữ liệu quan hệ |
|---|---|
| Impala sử dụng ngôn ngữ truy vấn giống SQL tương tự như HiveQL. | Cơ sở dữ liệu quan hệ sử dụng ngôn ngữ SQL. |
| Trong Impala, bạn không thể cập nhật hoặc xóa các bản ghi riêng lẻ. | Trong cơ sở dữ liệu quan hệ, có thể cập nhật hoặc xóa các bản ghi riêng lẻ. |
| Impala không hỗ trợ giao dịch. | Cơ sở dữ liệu quan hệ hỗ trợ các giao dịch. |
| Impala không hỗ trợ lập chỉ mục. | Cơ sở dữ liệu quan hệ hỗ trợ lập chỉ mục. |
| Impala lưu trữ và quản lý một lượng lớn dữ liệu (petabyte). | Cơ sở dữ liệu quan hệ xử lý lượng dữ liệu nhỏ hơn (terabyte) khi so sánh với Impala. |
Hive, Hbase và Impala
Mặc dù Cloudera Impala sử dụng cùng một ngôn ngữ truy vấn, phổ biến và giao diện người dùng như Hive, nó khác với Hive và HBase ở một số khía cạnh nhất định. Bảng sau đây trình bày một phân tích so sánh giữa HBase, Hive và Impala.
| HBase | Hive | Impala |
|---|---|---|
| HBase là cơ sở dữ liệu cửa hàng cột rộng dựa trên Apache Hadoop. Nó sử dụng các khái niệm của BigTable. | Hive là một phần mềm kho dữ liệu. Sử dụng điều này, chúng tôi có thể truy cập và quản lý các tập dữ liệu phân tán lớn, được xây dựng trên Hadoop. | Impala là công cụ quản lý, phân tích dữ liệu được lưu trữ trên Hadoop. |
| Mô hình dữ liệu của HBase là kho lưu trữ cột rộng. | Hive theo mô hình Quan hệ. | Impala tuân theo mô hình quan hệ. |
| HBase được phát triển bằng ngôn ngữ Java. | Hive được phát triển bằng ngôn ngữ Java. | Impala được phát triển bằng C ++. |
| Mô hình dữ liệu của HBase là không có giản đồ. | Mô hình dữ liệu của Hive dựa trên lược đồ. | Mô hình dữ liệu của Impala dựa trên lược đồ. |
| HBase cung cấp API của Java, RESTful và Thrift. | Hive cung cấp JDBC, ODBC, Thrift API's. | Impala cung cấp API JDBC và ODBC. |
| Hỗ trợ các ngôn ngữ lập trình như C, C #, C ++, Groovy, Java PHP, Python và Scala. | Hỗ trợ các ngôn ngữ lập trình như C ++, Java, PHP và Python. | Impala hỗ trợ tất cả các ngôn ngữ hỗ trợ JDBC / ODBC. |
| HBase cung cấp hỗ trợ cho các trình kích hoạt. | Hive không cung cấp bất kỳ hỗ trợ nào cho các trình kích hoạt. | Impala không cung cấp bất kỳ hỗ trợ nào cho các trình kích hoạt. |
Tất cả ba cơ sở dữ liệu này -
Là cơ sở dữ liệu NOSQL.
Có sẵn dưới dạng mã nguồn mở.
Hỗ trợ tập lệnh phía máy chủ.
Theo dõi các thuộc tính ACID như Độ bền và Đồng tiền.
Sử dụng sharding cho partitioning.
Hạn chế của Impala
Một số hạn chế của việc sử dụng Impala như sau:
- Impala không cung cấp bất kỳ hỗ trợ nào cho Serialization và Deserialization.
- Impala chỉ có thể đọc các tệp văn bản, không phải tệp nhị phân tùy chỉnh.
- Bất cứ khi nào bản ghi / tệp mới được thêm vào thư mục dữ liệu trong HDFS, bảng cần được làm mới.
Chương này giải thích các điều kiện tiên quyết để cài đặt Impala, cách tải xuống, cài đặt và thiết lập Impala trong hệ thống của bạn.
Tương tự như Hadoop và phần mềm hệ sinh thái của nó, chúng ta cần cài đặt Impala trên hệ điều hành Linux. Kể từ khi cloudera vận chuyển Impala, nó có sẵn vớiCloudera Quick Start VM.
Chương này mô tả cách tải xuống Cloudera Quick Start VM và khởi động Impala.
Tải xuống Cloudera Quick Start VM
Làm theo các bước dưới đây để tải xuống phiên bản mới nhất của Cloudera QuickStartVM.
Bước 1
Mở trang chủ của trang web cloudera http://www.cloudera.com/. Bạn sẽ nhận được trang như hình dưới đây.

Bước 2
Nhấn vào Sign in liên kết trên trang chủ cloudera, sẽ chuyển hướng bạn đến trang Đăng nhập như hình dưới đây.

Nếu bạn chưa đăng ký, hãy nhấp vào Register Now liên kết sẽ cung cấp cho bạn Account Registrationhình thức. Đăng ký ở đó và đăng nhập vào tài khoản cloudera.
Bước 3
Sau khi đăng nhập, hãy mở trang tải xuống của trang web cloudera bằng cách nhấp vào Downloads liên kết được đánh dấu trong ảnh chụp nhanh sau đây.
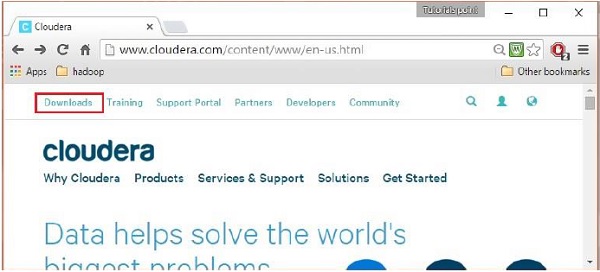
Bước 4 - Tải xuống QuickStartVM
Tải xuống cloudera QuickStartVM bằng cách nhấp vào Download Now , như được đánh dấu trong ảnh chụp nhanh sau
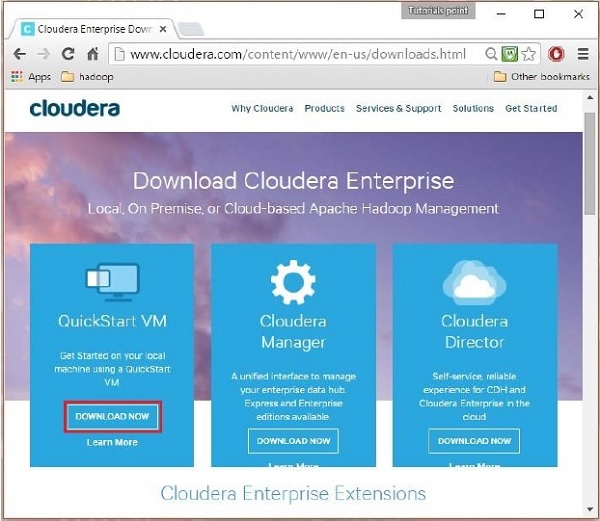
Thao tác này sẽ chuyển hướng bạn đến trang tải xuống của QuickStart VM.
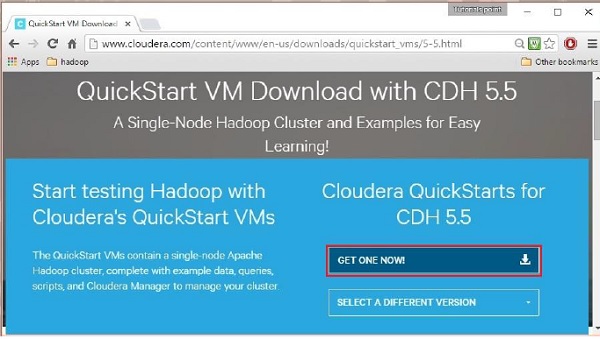
Nhấn vào Get ONE NOW , chấp nhận thỏa thuận cấp phép và nhấp vào nút gửi như hình dưới đây.
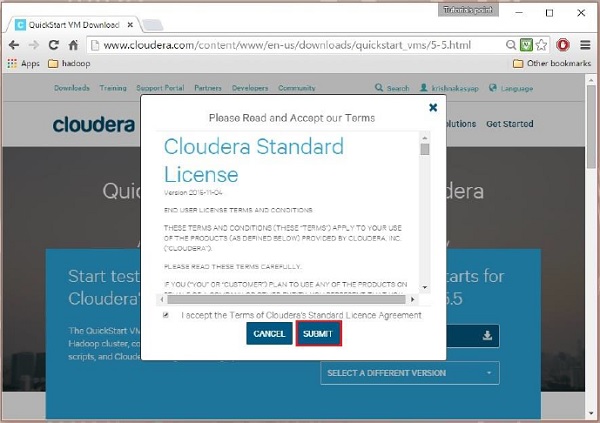
Cloudera cung cấp VMware, KVM và VIRTUALBOX tương thích với máy ảo. Chọn phiên bản cần thiết. Ở đây trong hướng dẫn của chúng tôi, chúng tôi đang chứng minhCloudera QuickStartVM thiết lập bằng hộp ảo, do đó hãy nhấp vào VIRTUALBOX DOWNLOAD , như được hiển thị trong ảnh chụp nhanh bên dưới.
Thao tác này sẽ bắt đầu tải xuống tệp có tên cloudera-quickstart-vm-5.5.0-0-virtualbox.ovf là một tệp hình ảnh hộp ảo.
Nhập Cloudera QuickStartVM
Sau khi tải xuống cloudera-quickstart-vm-5.5.0-0-virtualbox.ovf, chúng ta cần nhập nó bằng hộp ảo. Để làm được điều đó, trước hết, bạn cần cài đặt hộp ảo trong hệ thống của mình. Làm theo các bước dưới đây để nhập tệp hình ảnh đã tải xuống.
Bước 1
Tải xuống hộp ảo từ liên kết sau và cài đặt nó https://www.virtualbox.org/
Bước 2
Mở phần mềm hộp ảo. Nhấp chuộtFile và lựa chọn Import Appliance, như hình dưới đây.
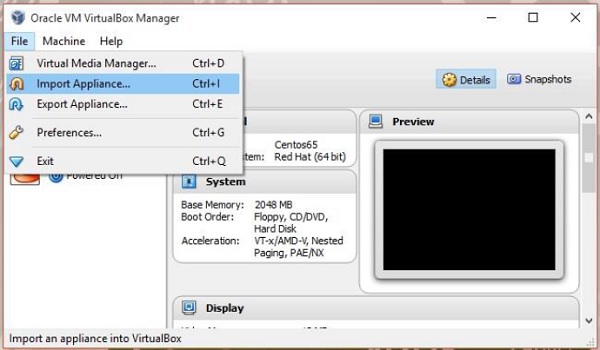
Bước 3
Khi nhấp vào Import Appliance, bạn sẽ nhận được cửa sổ Import Virtual Appliance. Chọn vị trí của tệp hình ảnh tải xuống như hình dưới đây.
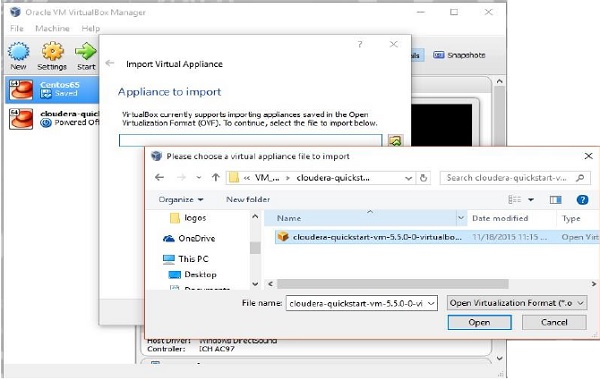
Sau khi nhập khẩu Cloudera QuickStartVMhình ảnh, khởi động máy ảo. Máy ảo này đã cài đặt Hadoop, cloudera Impala và tất cả các phần mềm cần thiết. Ảnh chụp nhanh của VM được hiển thị bên dưới.

Khởi động Impala Shell
Để khởi động Impala, hãy mở terminal và thực hiện lệnh sau.
[cloudera@quickstart ~] $ impala-shellThao tác này sẽ khởi động Impala Shell, hiển thị thông báo sau.
Starting Impala Shell without Kerberos authentication
Connected to quickstart.cloudera:21000
Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
********************************************************************************
Welcome to the Impala shell. Copyright (c) 2015 Cloudera, Inc. All rights reserved.
(Impala Shell v2.3.0-cdh5.5.0 (0c891d7) built on Mon Nov 9 12:18:12 PST 2015)
Press TAB twice to see a list of available commands.
********************************************************************************
[quickstart.cloudera:21000] >Note - Chúng ta sẽ thảo luận về tất cả các lệnh impala-shell trong các chương sau.
Trình chỉnh sửa truy vấn Impala
Ngoài Impala shell, bạn có thể giao tiếp với Impala bằng trình duyệt Hue. Sau khi cài đặt CDH5 và khởi động Impala, bạn mở trình duyệt lên sẽ nhận được trang chủ cloudera như hình bên dưới.
Bây giờ, hãy nhấp vào dấu trang Hueđể mở trình duyệt Hue. Khi nhấp vào, bạn có thể thấy trang đăng nhập của Hue Browser, đăng nhập bằng thông tin đăng nhập cloudera và cloudera.
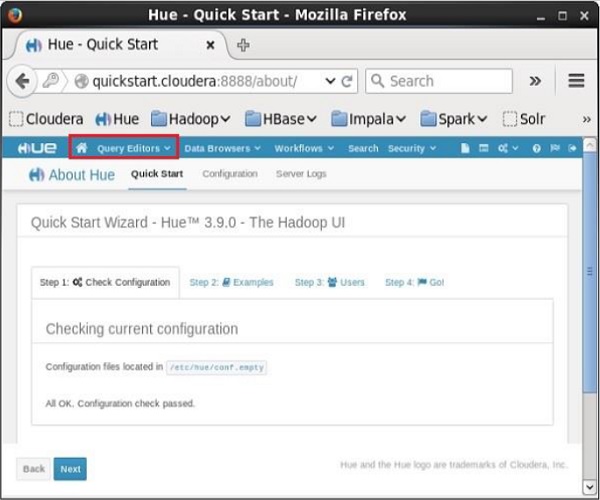
Ngay sau khi bạn đăng nhập vào trình duyệt Hue, bạn có thể thấy Quick Start Wizard của trình duyệt Hue như hình dưới đây.
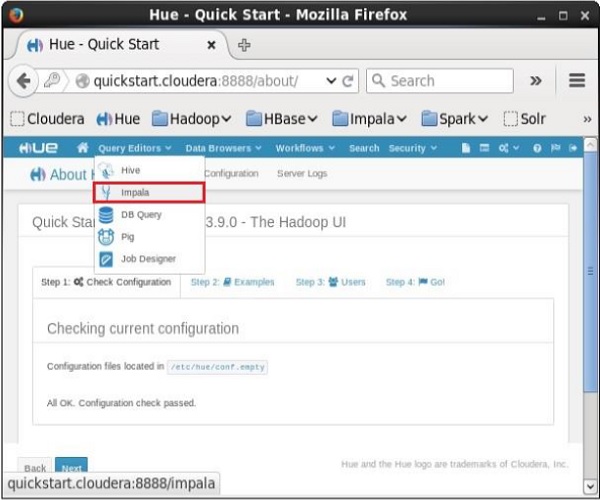
Khi nhấp vào Query Editors trình đơn thả xuống, bạn sẽ nhận được danh sách các trình chỉnh sửa mà Impala hỗ trợ như thể hiện trong ảnh chụp màn hình sau.
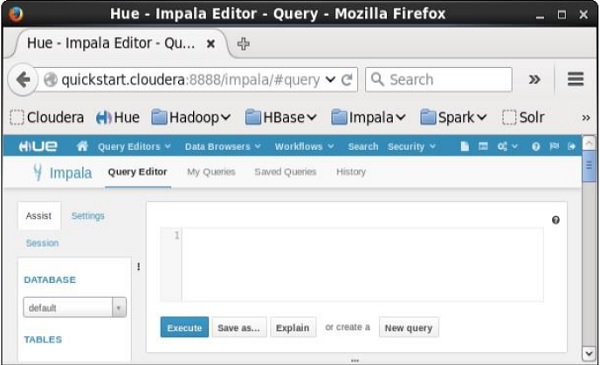
Khi nhấp vào Impala trong menu thả xuống, bạn sẽ nhận được trình chỉnh sửa truy vấn Impala như hình dưới đây.
Impala là một công cụ thực thi truy vấn MPP (Xử lý song song khối lượng lớn) chạy trên một số hệ thống trong cụm Hadoop. Không giống như các hệ thống lưu trữ truyền thống, impala được tách ra khỏi công cụ lưu trữ của nó. Nó có ba thành phần chính là Impala daemon (Impalad) , Impala Statestore, và siêu dữ liệu Impala hoặc di căn.
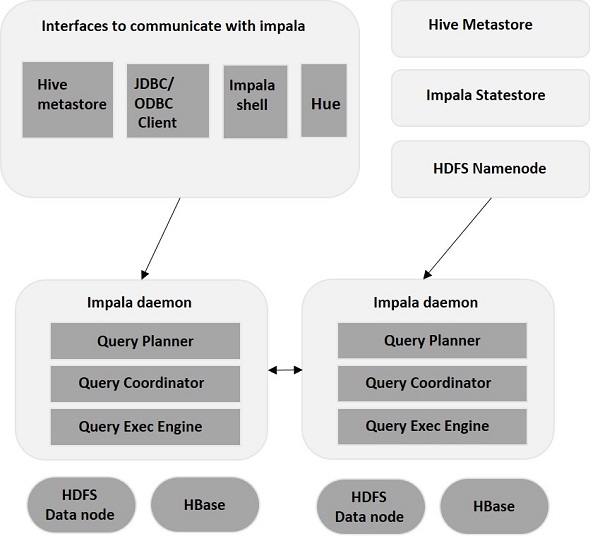
Impala daemon ( Impalad )
Impala daemon (còn được gọi là impalad) chạy trên mỗi nút nơi Impala được cài đặt. Nó chấp nhận các truy vấn từ các giao diện khác nhau như impala shell, hue browser, v.v.… và xử lý chúng.
Bất cứ khi nào một truy vấn được gửi đến một bộ phận trên một nút cụ thể, nút đó sẽ đóng vai trò là “coordinator node”Cho truy vấn đó. Nhiều truy vấn cũng được cung cấp bởi Impalad chạy trên các nút khác. Sau khi chấp nhận truy vấn, Impalad đọc và ghi vào các tệp dữ liệu và song song hóa các truy vấn bằng cách phân phối công việc cho các nút Impala khác trong cụm Impala. Khi các truy vấn đang xử lý trên các phiên bản Impalad khác nhau , tất cả chúng đều trả về kết quả cho nút điều phối trung tâm.
Tùy thuộc vào yêu cầu, các truy vấn có thể được gửi đến một Impalad chuyên dụng hoặc theo cách cân bằng tải tới một Impalad khác trong cụm của bạn.
Cửa hàng tiểu bang Impala
Impala có một thành phần quan trọng khác được gọi là Impala State store, có nhiệm vụ kiểm tra sức khỏe của từng Impalad và sau đó thường xuyên chuyển tiếp sức khỏe của từng daemon Impala cho các daemon khác. Điều này có thể chạy trên cùng một nút nơi máy chủ Impala hoặc nút khác trong cụm đang chạy.
Tên của tiến trình daemon Impala State store là State được lưu trữ . Impalad báo cáo tình trạng sức khỏe của nó cho daemon Impala State store, tức là State được lưu trữ .
Trong trường hợp một nút bị lỗi do bất kỳ lý do nào, Statestore sẽ cập nhật tất cả các nút khác về lỗi này và một khi có thông báo như vậy cho bộ phận xung kích khác , không có trình nền Impala nào khác gán thêm bất kỳ truy vấn nào cho nút bị ảnh hưởng.
Cửa hàng siêu dữ liệu & siêu dữ liệu Impala
Siêu dữ liệu và cửa hàng meta Impala là một thành phần quan trọng khác. Impala sử dụng cơ sở dữ liệu MySQL hoặc PostgreSQL truyền thống để lưu trữ các định nghĩa bảng. Các chi tiết quan trọng như thông tin bảng & cột & định nghĩa bảng được lưu trữ trong cơ sở dữ liệu tập trung được gọi là siêu lưu trữ.
Mỗi nút Impala lưu trữ cục bộ tất cả siêu dữ liệu. Khi xử lý một lượng dữ liệu cực lớn và / hoặc nhiều phân vùng, việc lấy siêu dữ liệu cụ thể của bảng có thể mất một lượng thời gian đáng kể. Vì vậy, bộ nhớ cache siêu dữ liệu được lưu trữ cục bộ giúp cung cấp thông tin đó ngay lập tức.
Khi định nghĩa bảng hoặc dữ liệu bảng được cập nhật, các daemon Impala khác phải cập nhật bộ đệm siêu dữ liệu của họ bằng cách truy xuất siêu dữ liệu mới nhất trước khi đưa ra truy vấn mới đối với bảng được đề cập.
Giao diện xử lý truy vấn
Để xử lý các truy vấn, Impala cung cấp ba giao diện như được liệt kê bên dưới.
Impala-shell - Sau khi thiết lập Impala bằng máy ảo Cloudera, bạn có thể khởi động trình bao Impala bằng cách gõ lệnh impala-shelltrong trình soạn thảo. Chúng ta sẽ thảo luận nhiều hơn về Impala shell trong các chương tới.
Hue interface- Bạn có thể xử lý các truy vấn Impala bằng trình duyệt Hue. Trong trình duyệt Hue, bạn có trình soạn thảo truy vấn Impala, nơi bạn có thể nhập và thực thi các truy vấn impala. Để truy cập trình soạn thảo này, trước hết, bạn cần đăng nhập vào trình duyệt Hue.
ODBC/JDBC drivers- Cũng giống như các cơ sở dữ liệu khác, Impala cung cấp trình điều khiển ODBC / JDBC. Sử dụng các trình điều khiển này, bạn có thể kết nối với impala thông qua các ngôn ngữ lập trình hỗ trợ các trình điều khiển này và xây dựng các ứng dụng xử lý các truy vấn trong impala bằng các ngôn ngữ lập trình đó.
Thủ tục thực thi truy vấn
Bất cứ khi nào người dùng chuyển một truy vấn bằng bất kỳ giao diện nào được cung cấp, điều này được chấp nhận bởi một trong những Impalads trong cụm. Impalad này được coi như một bộ điều phối cho truy vấn cụ thể đó.
Sau khi nhận được truy vấn, điều phối viên truy vấn xác minh xem truy vấn có phù hợp hay không, sử dụng Table Schematừ cửa hàng meta Hive. Sau đó, nó thu thập thông tin về vị trí của dữ liệu được yêu cầu để thực hiện truy vấn, từ nút tên HDFS và gửi thông tin này đến các bộ đệm khác để thực hiện truy vấn.
Tất cả các daemon Impala khác đọc khối dữ liệu được chỉ định và xử lý truy vấn. Ngay sau khi tất cả các daemon hoàn thành nhiệm vụ của chúng, điều phối viên truy vấn sẽ thu thập kết quả trở lại và gửi nó cho người dùng.
Trong các chương trước, chúng ta đã thấy việc cài đặt Impala bằng cách sử dụng cloudera và kiến trúc của nó.
- Impala shell (dấu nhắc lệnh)
- Hue (Giao diện người dùng)
- ODBC và JDBC (Thư viện bên thứ ba)
Chương này giải thích cách khởi động Impala Shell và các tùy chọn khác nhau của trình bao.
Tham chiếu lệnh Impala Shell
Các lệnh của Impala shell được phân loại là general commands, query specific optionsvà table and database specific options, như giải thích bên dưới.
Các lệnh chung
- help
- version
- history
- shell (hoặc)!
- connect
- lối ra | bỏ cuộc
Truy vấn các tùy chọn cụ thể
- Set/unset
- Profile
- Explain
Các tùy chọn cụ thể về Bảng và Cơ sở dữ liệu
- Alter
- describe
- drop
- insert
- select
- show
- use
Khởi động Impala Shell
Mở thiết bị đầu cuối cloudera, đăng nhập với tư cách siêu người dùng và nhập cloudera như mật khẩu như hình dưới đây.
[cloudera@quickstart ~]$ su
Password: cloudera
[root@quickstart cloudera]#Khởi động trình bao Impala bằng cách gõ lệnh sau:
[root@quickstart cloudera] # impala-shell
Starting Impala Shell without Kerberos authentication
Connected to quickstart.cloudera:21000
Server version: impalad version 2.3.0-cdh5.5.0 RELEASE
(build 0c891d79aa38f297d244855a32f1e17280e2129b)
*********************************************************************
Welcome to the Impala shell. Copyright (c) 2015 Cloudera, Inc. All rights reserved.
(Impala Shell v2.3.0-cdh5.5.0 (0c891d7) built on Mon Nov 9 12:18:12 PST 2015)
Want to know what version of Impala you're connected to? Run the VERSION command to
find out!
*********************************************************************
[quickstart.cloudera:21000] >Impala - Lệnh mục đích chung
Các lệnh mục đích chung của Impala được giải thích dưới đây:
lệnh trợ giúp
Các help lệnh của Impala shell cung cấp cho bạn danh sách các lệnh có sẵn trong Impala -
[quickstart.cloudera:21000] > help;
Documented commands (type help <topic>):
========================================================
compute describe insert set unset with version
connect explain quit show values use
exit history profile select shell tip
Undocumented commands:
=========================================
alter create desc drop help load summarylệnh phiên bản
Các version lệnh cung cấp cho bạn phiên bản hiện tại của Impala, như được hiển thị bên dưới.
[quickstart.cloudera:21000] > version;
Shell version: Impala Shell v2.3.0-cdh5.5.0 (0c891d7) built on Mon Nov 9
12:18:12 PST 2015
Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)lệnh lịch sử
Các historylệnh của Impala hiển thị 10 lệnh cuối cùng được thực thi trong trình bao. Sau đây là ví dụ vềhistorychỉ huy. Ở đây chúng tôi đã thực hiện 5 lệnh, đó là phiên bản, trợ giúp, hiển thị, sử dụng và lịch sử.
[quickstart.cloudera:21000] > history;
[1]:version;
[2]:help;
[3]:show databases;
[4]:use my_db;
[5]:history;lệnh thoát / thoát
Bạn có thể thoát ra khỏi vỏ Impala bằng cách sử dụng quit hoặc là exit như hình bên dưới.
[quickstart.cloudera:21000] > exit;
Goodbye clouderakết nối lệnh
Các connectlệnh được sử dụng để kết nối với một phiên bản Impala nhất định. Trong trường hợp bạn không chỉ định bất kỳ phiên bản nào, thì nó sẽ kết nối với cổng mặc định21000 như hình bên dưới.
[quickstart.cloudera:21000] > connect;
Connected to quickstart.cloudera:21000
Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)Các tùy chọn cụ thể cho truy vấn Impala
Các lệnh truy vấn cụ thể của Impala chấp nhận một truy vấn. Chúng được giải thích bên dưới -
Giải thích
Các explain lệnh trả về kế hoạch thực thi cho truy vấn đã cho.
[quickstart.cloudera:21000] > explain select * from sample;
Query: explain select * from sample
+------------------------------------------------------------------------------------+
| Explain String |
+------------------------------------------------------------------------------------+
| Estimated Per-Host Requirements: Memory = 48.00MB VCores = 1 |
| WARNING: The following tables are missing relevant table and/or column statistics. |
| my_db.customers |
| 01:EXCHANGE [UNPARTITIONED] |
| 00:SCAN HDFS [my_db.customers] |
| partitions = 1/1 files = 6 size = 148B |
+------------------------------------------------------------------------------------+
Fetched 7 row(s) in 0.17sHồ sơ
Các profilelệnh hiển thị thông tin cấp thấp về truy vấn gần đây. Lệnh này được sử dụng để chẩn đoán và điều chỉnh hiệu suất của một truy vấn. Sau đây là ví dụ về mộtprofilechỉ huy. Trong trường hợp này,profile lệnh trả về thông tin cấp thấp của explain truy vấn.
[quickstart.cloudera:21000] > profile;
Query Runtime Profile:
Query (id=164b1294a1049189:a67598a6699e3ab6):
Summary:
Session ID: e74927207cd752b5:65ca61e630ad3ad
Session Type: BEESWAX
Start Time: 2016-04-17 23:49:26.08148000 End Time: 2016-04-17 23:49:26.2404000
Query Type: EXPLAIN
Query State: FINISHED
Query Status: OK
Impala Version: impalad version 2.3.0-cdh5.5.0 RELEASE (build 0c891d77280e2129b)
User: cloudera
Connected User: cloudera
Delegated User:
Network Address:10.0.2.15:43870
Default Db: my_db
Sql Statement: explain select * from sample
Coordinator: quickstart.cloudera:22000
: 0ns
Query Timeline: 167.304ms
- Start execution: 41.292us (41.292us) - Planning finished: 56.42ms (56.386ms)
- Rows available: 58.247ms (1.819ms)
- First row fetched: 160.72ms (101.824ms)
- Unregister query: 166.325ms (6.253ms)
ImpalaServer:
- ClientFetchWaitTimer: 107.969ms
- RowMaterializationTimer: 0nsCác tùy chọn cụ thể cho bảng và cơ sở dữ liệu
Bảng sau liệt kê bảng và các tùy chọn dữ liệu cụ thể trong Impala.
| Sr.No | Lệnh & Giải thích |
|---|---|
| 1 | Alter Các alter lệnh được sử dụng để thay đổi cấu trúc và tên của một bảng trong Impala. |
| 2 | Describe Các describelệnh của Impala cung cấp siêu dữ liệu của một bảng. Nó chứa thông tin như cột và kiểu dữ liệu của chúng. Cácdescribe lệnh có desc như một đường tắt. |
| 3 | Drop Các drop lệnh được sử dụng để xóa một cấu trúc khỏi Impala, trong đó một cấu trúc có thể là một bảng, một dạng xem hoặc một hàm cơ sở dữ liệu. |
| 4 | insert Các insert lệnh của Impala được sử dụng để,
|
| 5 | select Các selectcâu lệnh được sử dụng để thực hiện một hoạt động mong muốn trên một tập dữ liệu cụ thể. Nó chỉ định tập dữ liệu để hoàn thành một số hành động. Bạn có thể in hoặc lưu trữ (trong một tệp) kết quả của câu lệnh select. |
| 6 | show Các show tuyên bố của Impala được sử dụng để hiển thị phần lớn của các cấu trúc khác nhau như bảng, cơ sở dữ liệu và bảng. |
| 7 | use Các use câu lệnh của Impala được sử dụng để thay đổi ngữ cảnh hiện tại thành cơ sở dữ liệu mong muốn. |
Các loại dữ liệu Impala
Bảng sau đây mô tả các kiểu dữ liệu Impala.
| Sr.No | Loại dữ liệu & Mô tả |
|---|---|
| 1 | BIGINT Kiểu dữ liệu này lưu trữ các giá trị số và phạm vi của kiểu dữ liệu này là -9223372036854775808 đến 9223372036854775807. Kiểu dữ liệu này được sử dụng trong tạo bảng và thay đổi câu lệnh bảng. |
| 2 | BOOLEAN Loại dữ liệu này chỉ lưu trữ true hoặc là false và nó được sử dụng trong định nghĩa cột của câu lệnh tạo bảng. |
| 3 | CHAR Kiểu dữ liệu này là nơi lưu trữ có độ dài cố định, nó được đệm bằng khoảng trắng, bạn có thể lưu trữ với độ dài tối đa là 255. |
| 4 | DECIMAL Kiểu dữ liệu này được sử dụng để lưu trữ các giá trị thập phân và nó được sử dụng để tạo bảng và thay đổi các câu lệnh bảng. |
| 5 | DOUBLE Kiểu dữ liệu này được sử dụng để lưu trữ các giá trị dấu phẩy động trong phạm vi 4,94065645841246544e-324d -1,79769313486231570e + 308. |
| 6 | FLOAT Kiểu dữ liệu này được sử dụng để lưu trữ các kiểu dữ liệu giá trị động chính xác duy nhất trong phạm vi dương hoặc âm 1.40129846432481707e-45 .. 3.40282346638528860e + 38. |
| 7 | INT Kiểu dữ liệu này được sử dụng để lưu trữ số nguyên 4 byte trong phạm vi từ -2147483648 đến 2147483647. |
| số 8 | SMALLINT Kiểu dữ liệu này được sử dụng để lưu trữ số nguyên 2 byte trong phạm vi từ -32768 đến 32767. |
| 9 | STRING Điều này được sử dụng để lưu trữ các giá trị chuỗi. |
| 10 | TIMESTAMP Kiểu dữ liệu này được sử dụng để biểu diễn một điểm trong một thời gian. |
| 11 | TINYINT Kiểu dữ liệu này được sử dụng để lưu trữ giá trị số nguyên 1 byte trong phạm vi từ -128 đến 127. |
| 12 | VARCHAR Kiểu dữ liệu này được sử dụng để lưu trữ ký tự có độ dài thay đổi lên đến độ dài tối đa 65,535. |
| 13 | ARRAY Đây là một kiểu dữ liệu phức tạp và nó được sử dụng để lưu trữ số lượng phần tử có thứ tự thay đổi. |
| 14 | Map Đây là một kiểu dữ liệu phức tạp và nó được sử dụng để lưu trữ số lượng các cặp khóa-giá trị thay đổi. |
| 15 | Struct Đây là một kiểu dữ liệu phức tạp và được sử dụng để đại diện cho nhiều trường của một mục. |
Nhận xét trong Impala
Các chú thích trong Impala tương tự như chú thích trong SQL, nói chung chúng ta có hai loại chú thích trong ngôn ngữ lập trình là chú thích một dòng và chú thích nhiều dòng.
Single-line comments- Mỗi dòng được theo sau bởi "-" được coi là một nhận xét trong Impala. Sau đây là một ví dụ về nhận xét một dòng trong Impala.
-- Hello welcome to tutorials point.Multiline comments - Tất cả các đường giữa /* và */được coi là bình luận nhiều dòng trong Impala. Sau đây là một ví dụ về nhận xét nhiều dòng trong Impala.
/*
Hi this is an example
Of multiline comments in Impala
*/Các toán tử trong Impala tương tự như trong SQL. Tham khảo hướng dẫn SQL của chúng tôi bằng cách nhấp vào liên kết sautoán tử sql.
Impala - Tạo cơ sở dữ liệu
Trong Impala, cơ sở dữ liệu là một cấu trúc chứa các bảng, dạng xem và chức năng liên quan trong không gian tên của chúng. Nó được biểu diễn dưới dạng cây thư mục trong HDFS; nó chứa các phân vùng bảng và tệp dữ liệu. Chương này giải thích cách tạo cơ sở dữ liệu trong Impala.
TẠO Tuyên bố CƠ SỞ DỮ LIỆU
Các CREATE DATABASE Statement được sử dụng để tạo cơ sở dữ liệu mới trong Impala.
Cú pháp
Sau đây là cú pháp của CREATE DATABASE Tuyên bố.
CREATE DATABASE IF NOT EXISTS database_name;Đây, IF NOT EXISTSlà một mệnh đề không bắt buộc. Nếu chúng ta sử dụng mệnh đề này, một cơ sở dữ liệu với tên đã cho sẽ được tạo ra, chỉ khi không có cơ sở dữ liệu nào có cùng tên hiện có.
Thí dụ
Sau đây là một ví dụ về create database statement. Trong ví dụ này, chúng tôi đã tạo một cơ sở dữ liệu với tênmy_database.
[quickstart.cloudera:21000] > CREATE DATABASE IF NOT EXISTS my_database;Khi thực hiện truy vấn trên trong cloudera impala-shell, bạn sẽ nhận được kết quả sau.
Query: create DATABASE my_database
Fetched 0 row(s) in 0.21sxác minh
Các SHOW DATABASES truy vấn cung cấp danh sách cơ sở dữ liệu trong Impala, do đó bạn có thể xác minh xem cơ sở dữ liệu có được tạo hay không, bằng cách sử dụng SHOWCâu lệnh DATABASES. Tại đây bạn có thể quan sát cơ sở dữ liệu mới được tạomy_db trong danh sách.
[quickstart.cloudera:21000] > show databases;
Query: show databases
+-----------------------------------------------+
| name |
+-----------------------------------------------+
| _impala_builtins |
| default |
| my_db |
+-----------------------------------------------+
Fetched 3 row(s) in 0.20s
[quickstart.cloudera:21000] >Đường dẫn Hdfs
Để tạo cơ sở dữ liệu trong hệ thống tệp HDFS, bạn cần chỉ định vị trí nơi cơ sở dữ liệu sẽ được tạo.
CREATE DATABASE IF NOT EXISTS database_name LOCATION hdfs_path;Tạo cơ sở dữ liệu bằng trình duyệt Huế
Mở trình chỉnh sửa Truy vấn Impala và nhập CREATE DATABASEtuyên bố trong đó. Sau đó, nhấp vào nút thực thi như được hiển thị trong ảnh chụp màn hình sau.
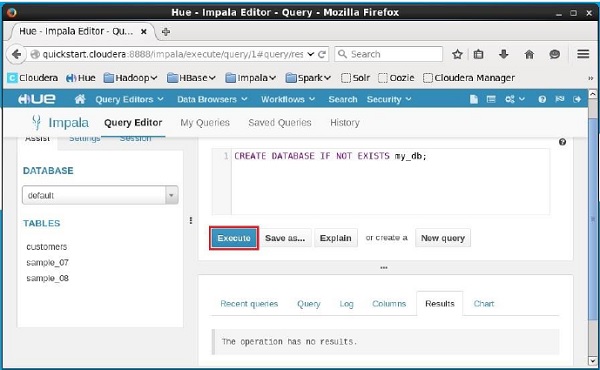
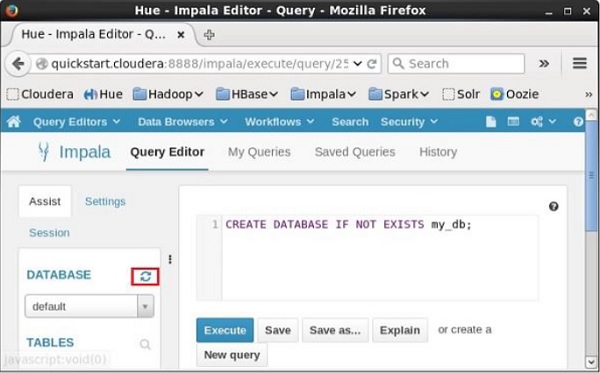
Sau khi thực hiện truy vấn, nhẹ nhàng di chuyển con trỏ lên đầu trình đơn thả xuống và bạn sẽ tìm thấy biểu tượng làm mới. Nếu bạn nhấp vào biểu tượng làm mới, danh sách cơ sở dữ liệu sẽ được làm mới và các thay đổi gần đây được áp dụng cho nó.
xác minh
Nhấn vào drop-down box dưới tiêu đề DATABASEở phía bên trái của trình chỉnh sửa. Ở đó bạn có thể thấy danh sách các cơ sở dữ liệu trong hệ thống. Tại đây bạn có thể quan sát cơ sở dữ liệu mới được tạomy_db như hình bên dưới.
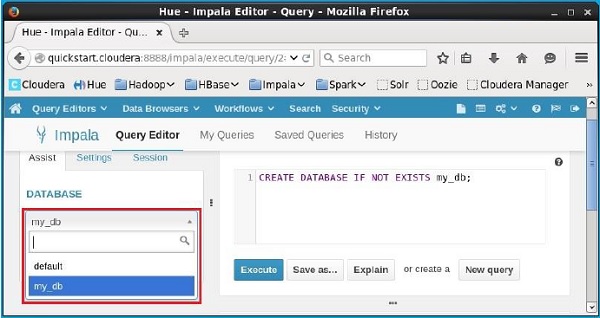
Nếu quan sát kỹ, bạn chỉ có thể thấy một cơ sở dữ liệu, tức là my_db trong danh sách cùng với cơ sở dữ liệu mặc định.
Các DROP DATABASE Statementof Impala được sử dụng để xóa một cơ sở dữ liệu khỏi Impala. Trước khi xóa cơ sở dữ liệu, bạn nên xóa tất cả các bảng khỏi nó.
Cú pháp
Sau đây là cú pháp của DROP DATABASE Tuyên bố.
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT |
CASCADE] [LOCATION hdfs_path];Đây, IF EXISTSlà một mệnh đề không bắt buộc. Nếu chúng ta sử dụng mệnh đề này khi một cơ sở dữ liệu với tên đã cho tồn tại, thì nó sẽ bị xóa. Và nếu không có cơ sở dữ liệu hiện có với tên đã cho, thì không có thao tác nào được thực hiện.
Thí dụ
Sau đây là một ví dụ về DROP DATABASEtuyên bố. Giả sử bạn có một cơ sở dữ liệu trong Impala với tênsample_database.
Và, nếu bạn xác minh danh sách cơ sở dữ liệu bằng cách sử dụng SHOW DATABASES bạn sẽ thấy tên trong đó.
[quickstart.cloudera:21000] > SHOW DATABASES;
Query: show DATABASES
+-----------------------+
| name |
+-----------------------+
| _impala_builtins |
| default |
| my_db |
| sample_database |
+-----------------------+
Fetched 4 row(s) in 0.11sBây giờ, bạn có thể xóa cơ sở dữ liệu này bằng cách sử dụng DROP DATABASE Statement như hình bên dưới.
< DROP DATABASE IF EXISTS sample_database;Thao tác này sẽ xóa cơ sở dữ liệu được chỉ định và cung cấp cho bạn kết quả sau.
Query: drop DATABASE IF EXISTS sample_database;xác minh
Bạn có thể xác minh xem cơ sở dữ liệu đã cho có bị xóa hay không, bằng cách sử dụng SHOW DATABASEStuyên bố. Ở đây bạn có thể thấy rằng cơ sở dữ liệu có tênsample_database bị xóa khỏi danh sách cơ sở dữ liệu.
[quickstart.cloudera:21000] > SHOW DATABASES;
Query: show DATABASES
+----------------------+
| name |
+----------------------+
| _impala_builtins |
| default |
| my_db |
+----------------------+
Fetched 3 row(s) in 0.10s
[quickstart.cloudera:21000] >Cascade
Nói chung, để xóa cơ sở dữ liệu, bạn cần xóa tất cả các bảng trong đó theo cách thủ công. Nếu bạn sử dụng cascade, Impala sẽ xóa các bảng trong cơ sở dữ liệu được chỉ định trước khi xóa nó.
Thí dụ
Giả sử có một cơ sở dữ liệu trong Impala có tên samplevà nó chứa hai bảng, cụ thể là student và test. Nếu bạn cố gắng loại bỏ cơ sở dữ liệu này trực tiếp, bạn sẽ gặp lỗi như hình dưới đây.
[quickstart.cloudera:21000] > DROP database sample;
Query: drop database sample
ERROR:
ImpalaRuntimeException: Error making 'dropDatabase' RPC to Hive Metastore:
CAUSED BY: InvalidOperationException: Database sample is not empty. One or more
tables exist.Sử dụng cascade, bạn có thể xóa cơ sở dữ liệu này trực tiếp (mà không cần xóa nội dung của nó theo cách thủ công) như hình dưới đây.
[quickstart.cloudera:21000] > DROP database sample cascade;
Query: drop database sample cascadeNote - Bạn không thể xóa “current database”Ở Impala. Do đó, trước khi xóa cơ sở dữ liệu, bạn cần đảm bảo rằng ngữ cảnh hiện tại được đặt thành cơ sở dữ liệu khác với ngữ cảnh bạn định xóa.
Xóa Cơ sở dữ liệu bằng Trình duyệt Huế
Mở trình chỉnh sửa Truy vấn Impala và nhập DELETE DATABASEtrong đó và nhấp vào nút thực thi như hình dưới đây. Giả sử có ba cơ sở dữ liệu, cụ thể làmy_db, my_databasevà sample_databasecùng với cơ sở dữ liệu mặc định. Ở đây chúng tôi đang xóa cơ sở dữ liệu có tên my_database.

Sau khi thực hiện truy vấn, nhẹ nhàng di chuyển con trỏ lên đầu trình đơn thả xuống. Sau đó, bạn sẽ tìm thấy một biểu tượng làm mới như được hiển thị trong ảnh chụp màn hình bên dưới. Nếu bạn nhấp vào biểu tượng làm mới, danh sách cơ sở dữ liệu sẽ được làm mới và những thay đổi gần đây được thực hiện sẽ được áp dụng cho nó.
xác minh
Bấm vào drop down dưới tiêu đề DATABASEở phía bên trái của trình chỉnh sửa. Tại đó, bạn có thể xem danh sách các cơ sở dữ liệu trong hệ thống. Tại đây bạn có thể quan sát cơ sở dữ liệu mới được tạomy_db như hình bên dưới.
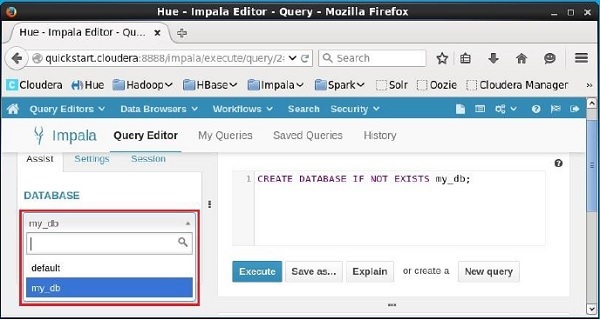
Nếu quan sát kỹ, bạn chỉ có thể thấy một cơ sở dữ liệu, tức là my_db trong danh sách cùng với cơ sở dữ liệu mặc định.
Khi bạn đã kết nối với Impala, bạn phải chọn một trong số các cơ sở dữ liệu có sẵn. CácUSE DATABASE Statement của Impala được sử dụng để chuyển phiên hiện tại sang cơ sở dữ liệu khác.
Cú pháp
Sau đây là cú pháp của USE Tuyên bố.
USE db_name;Thí dụ
Sau đây là một ví dụ về USE statement. Trước hết, chúng ta hãy tạo một cơ sở dữ liệu với tênsample_database như hình bên dưới.
> CREATE DATABASE IF NOT EXISTS sample_database;Thao tác này sẽ tạo một cơ sở dữ liệu mới và cung cấp cho bạn kết quả sau.
Query: create DATABASE IF NOT EXISTS my_db2
Fetched 0 row(s) in 2.73sNếu bạn xác minh danh sách cơ sở dữ liệu bằng cách sử dụng SHOW DATABASES , bạn có thể quan sát tên của cơ sở dữ liệu mới được tạo trong đó.
> SHOW DATABASES;
Query: show DATABASES
+-----------------------+
| name |
+-----------------------+
| _impala_builtins |
| default |
| my_db |
| sample_database |
+-----------------------+
Fetched 4 row(s) in 0.11sBây giờ, hãy chuyển phiên sang cơ sở dữ liệu mới được tạo (sample_database) bằng cách sử dụng USE Câu lệnh như hình bên dưới.
> USE sample_database;Thao tác này sẽ thay đổi ngữ cảnh hiện tại thành sample_database và hiển thị thông báo như hình dưới đây.
Query: use sample_databaseChọn Cơ sở dữ liệu bằng Trình duyệt Huế
Ở phía bên trái của Query Editor của Impala, bạn sẽ tìm thấy một menu thả xuống như trong ảnh chụp màn hình sau.
Nếu bạn nhấp vào menu thả xuống, bạn sẽ tìm thấy danh sách tất cả các cơ sở dữ liệu trong Impala như hình bên dưới.
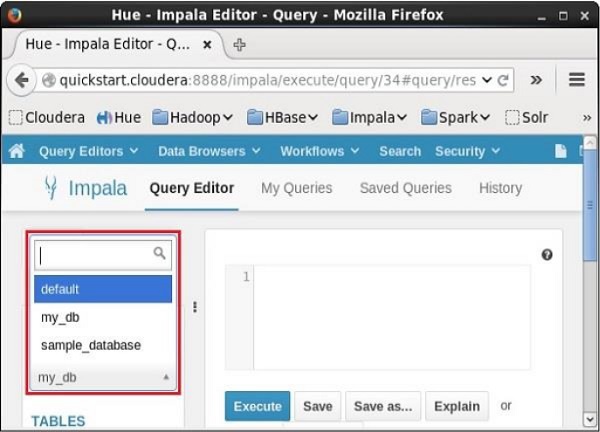
Chỉ cần chọn cơ sở dữ liệu mà bạn cần để thay đổi ngữ cảnh hiện tại.
Các CREATE TABLECâu lệnh được sử dụng để tạo một bảng mới trong cơ sở dữ liệu được yêu cầu trong Impala. Tạo một bảng cơ bản bao gồm việc đặt tên cho bảng và xác định các cột của nó và kiểu dữ liệu của mỗi cột.
Cú pháp
Sau đây là cú pháp của CREATE TABLETuyên bố. Đây,IF NOT EXISTSlà một mệnh đề không bắt buộc. Nếu chúng ta sử dụng mệnh đề này, một bảng có tên đã cho sẽ được tạo, chỉ khi không có bảng hiện có trong cơ sở dữ liệu được chỉ định có cùng tên.
create table IF NOT EXISTS database_name.table_name (
column1 data_type,
column2 data_type,
column3 data_type,
………
columnN data_type
);CREATE TABLE là từ khóa hướng dẫn hệ thống cơ sở dữ liệu tạo một bảng mới. Tên hoặc mã định danh duy nhất cho bảng tuân theo câu lệnh CREATE TABLE. Tùy ý bạn có thể chỉ địnhdatabase_name cùng với table_name.
Thí dụ
Sau đây là một ví dụ về câu lệnh tạo bảng. Trong ví dụ này, chúng tôi đã tạo một bảng có tênstudent trong cơ sở dữ liệu my_db.
[quickstart.cloudera:21000] > CREATE TABLE IF NOT EXISTS my_db.student
(name STRING, age INT, contact INT );Khi thực hiện câu lệnh trên, một bảng với tên được chỉ định sẽ được tạo, hiển thị kết quả sau.
Query: create table student (name STRING, age INT, phone INT)
Fetched 0 row(s) in 0.48sxác minh
Các show Tablestruy vấn đưa ra danh sách các bảng trong cơ sở dữ liệu hiện tại trong Impala. Do đó, bạn có thể xác minh xem bảng có được tạo hay không bằng cách sử dụngShow Tables tuyên bố.
Trước hết, bạn cần chuyển ngữ cảnh sang cơ sở dữ liệu mà bảng yêu cầu tồn tại, như hình dưới đây.
[quickstart.cloudera:21000] > use my_db;
Query: use my_dbSau đó, nếu bạn nhận được danh sách các bảng bằng cách sử dụng show tables truy vấn, bạn có thể quan sát bảng có tên student trong đó như hình bên dưới.
[quickstart.cloudera:21000] > show tables;
Query: show tables
+-----------+
| name |
+-----------+
| student |
+-----------+
Fetched 1 row(s) in 0.10sĐường dẫn HDFS
Để tạo cơ sở dữ liệu trong hệ thống tệp HDFS, bạn cần xác định vị trí nơi cơ sở dữ liệu sẽ được tạo như hình dưới đây.
CREATE DATABASE IF NOT EXISTS database_name LOCATION hdfs_path;Tạo cơ sở dữ liệu bằng trình duyệt Huế
Mở trình chỉnh sửa Truy vấn impala và nhập CREATE TableTuyên bố trong đó. Và nhấp vào nút thực thi như được hiển thị trong ảnh chụp màn hình sau.
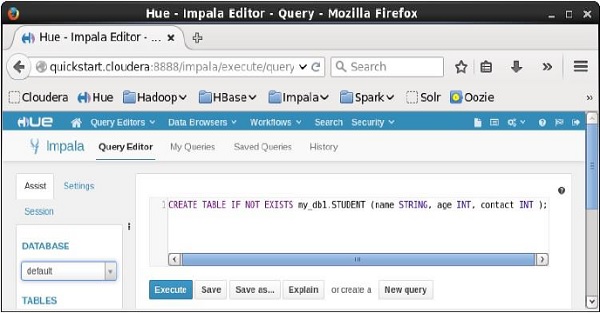
Sau khi thực hiện truy vấn, nhẹ nhàng di chuyển con trỏ lên đầu trình đơn thả xuống và bạn sẽ tìm thấy biểu tượng làm mới. Nếu bạn nhấp vào biểu tượng làm mới, danh sách cơ sở dữ liệu sẽ được làm mới và những thay đổi gần đây được thực hiện sẽ được áp dụng cho nó.
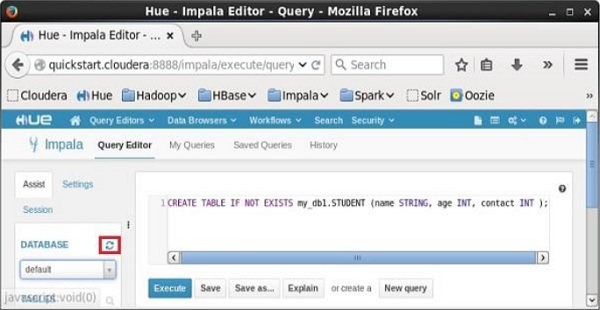
xác minh
Bấm vào drop down dưới tiêu đề DATABASEở phía bên trái của trình chỉnh sửa. Ở đó bạn có thể thấy danh sách các cơ sở dữ liệu. Chọn cơ sở dữ liệumy_db như hình bên dưới.
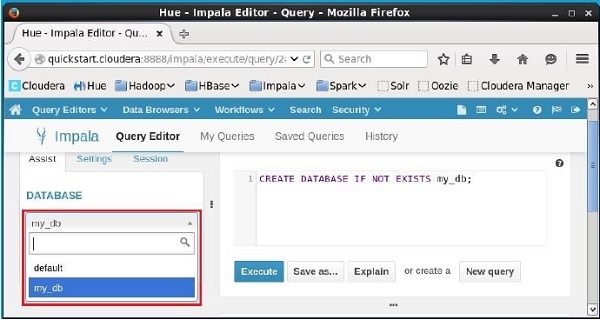
Khi chọn cơ sở dữ liệu my_dbbạn có thể thấy danh sách các bảng trong đó như hình dưới đây. Tại đây bạn có thể tìm thấy bảng mới được tạostudent như hình bên dưới.

Các INSERT Tuyên bố của Impala có hai mệnh đề - into và overwrite. Chèn câu lệnh vớiinto mệnh đề được sử dụng để thêm bản ghi mới vào bảng hiện có trong cơ sở dữ liệu.
Cú pháp
Có hai cú pháp cơ bản của INSERT tuyên bố như sau -
insert into table_name (column1, column2, column3,...columnN)
values (value1, value2, value3,...valueN);Ở đây, column1, column2, ... columnN là tên của các cột trong bảng mà bạn muốn chèn dữ liệu vào.
Bạn cũng có thể thêm các giá trị mà không cần chỉ định tên cột, nhưng bạn cần đảm bảo thứ tự của các giá trị theo thứ tự như các cột trong bảng như hình dưới đây.
Insert into table_name values (value1, value2, value2);CREATE TABLE là từ khóa yêu cầu hệ thống cơ sở dữ liệu tạo một bảng mới. Tên hoặc mã định danh duy nhất cho bảng tuân theo câu lệnh CREATE TABLE. Tùy ý bạn có thể chỉ địnhdatabase_name cùng với table_name.
Thí dụ
Giả sử chúng ta đã tạo một bảng có tên student trong Impala như hình dưới đây.
create table employee (Id INT, name STRING, age INT,address STRING, salary BIGINT);Sau đây là một ví dụ về việc tạo một bản ghi trong bảng có tên employee.
[quickstart.cloudera:21000] > insert into employee
(ID,NAME,AGE,ADDRESS,SALARY)VALUES (1, 'Ramesh', 32, 'Ahmedabad', 20000 );Khi thực hiện câu lệnh trên, một bản ghi được chèn vào bảng có tên employee hiển thị thông báo sau.
Query: insert into employee (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Ramesh',
32, 'Ahmedabad', 20000 )
Inserted 1 row(s) in 1.32sBạn có thể chèn một bản ghi khác mà không cần chỉ định tên cột như hình dưới đây.
[quickstart.cloudera:21000] > insert into employee values (2, 'Khilan', 25,
'Delhi', 15000 );Khi thực hiện câu lệnh trên, một bản ghi được chèn vào bảng có tên employee hiển thị thông báo sau.
Query: insert into employee values (2, 'Khilan', 25, 'Delhi', 15000 )
Inserted 1 row(s) in 0.31sBạn có thể chèn thêm một vài bản ghi trong bảng nhân viên như hình bên dưới.
Insert into employee values (3, 'kaushik', 23, 'Kota', 30000 );
Insert into employee values (4, 'Chaitali', 25, 'Mumbai', 35000 );
Insert into employee values (5, 'Hardik', 27, 'Bhopal', 40000 );
Insert into employee values (6, 'Komal', 22, 'MP', 32000 );Sau khi chèn các giá trị, employee bảng trong Impala sẽ như hình dưới đây.
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 6 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+Ghi đè dữ liệu trong bảng
Chúng ta có thể ghi đè các bản ghi của một bảng bằng mệnh đề ghi đè. Các bản ghi ghi đè sẽ bị xóa vĩnh viễn khỏi bảng. Sau đây là cú pháp của việc sử dụng mệnh đề ghi đè.
Insert overwrite table_name values (value1, value2, value2);Thí dụ
Sau đây là một ví dụ về việc sử dụng mệnh đề overwrite.
[quickstart.cloudera:21000] > Insert overwrite employee values (1, 'Ram', 26,
'Vishakhapatnam', 37000 );Khi thực hiện truy vấn trên, điều này sẽ ghi đè dữ liệu bảng với bản ghi được chỉ định hiển thị thông báo sau.
Query: insert overwrite employee values (1, 'Ram', 26, 'Vishakhapatnam', 37000 )
Inserted 1 row(s) in 0.31sKhi xác minh bảng, bạn có thể thấy rằng tất cả các bản ghi của bảng employee được ghi đè bởi các bản ghi mới như được hiển thị bên dưới.
+----+------+-----+---------------+--------+
| id | name | age | address | salary |
+----+------+-----+---------------+--------+
| 1 | Ram | 26 | Vishakhapatnam| 37000 |
+----+------+-----+---------------+--------+Chèn dữ liệu bằng Trình duyệt Huế
Mở trình chỉnh sửa Truy vấn Impala và nhập insertTuyên bố trong đó. Và nhấp vào nút thực thi như được hiển thị trong ảnh chụp màn hình sau.

Sau khi thực hiện truy vấn / câu lệnh, bản ghi này được thêm vào bảng.
Impala SELECTcâu lệnh được sử dụng để tìm nạp dữ liệu từ một hoặc nhiều bảng trong cơ sở dữ liệu. Truy vấn này trả về dữ liệu dưới dạng bảng.
Cú pháp
Sau đây là cú pháp của Impala select tuyên bố.
SELECT column1, column2, columnN from table_name;Ở đây, column1, column2 ... là các trường của bảng có các giá trị mà bạn muốn tìm nạp. Nếu bạn muốn tìm nạp tất cả các trường có sẵn trong trường, thì bạn có thể sử dụng cú pháp sau:
SELECT * FROM table_name;Thí dụ
Giả sử chúng ta có một bảng tên customers ở Impala, với dữ liệu sau:
ID NAME AGE ADDRESS SALARY
--- ------- --- ---------- -------
1 Ramesh 32 Ahmedabad 20000
2 Khilan 25 Delhi 15000
3 Hardik 27 Bhopal 40000
4 Chaitali 25 Mumbai 35000
5 kaushik 23 Kota 30000
6 Komal 22 Mp 32000Bạn có thể lấy id, namevà age của tất cả các bản ghi của customers bàn sử dụng select câu lệnh như hình dưới đây -
[quickstart.cloudera:21000] > select id, name, age from customers;Khi thực hiện truy vấn trên, Impala tìm nạp id, tên, tuổi của tất cả các bản ghi từ bảng được chỉ định và hiển thị chúng như hình dưới đây.
Query: select id,name,age from customers
+----+----------+-----+
| id | name | age |
| 1 | Ramesh | 32 |
| 2 | Khilan | 25 |
| 3 | Hardik | 27 |
| 4 | Chaitali | 25 |
| 5 | kaushik | 23 |
| 6 | Komal | 22 |
+----+----------+-----+
Fetched 6 row(s) in 0.66sBạn cũng có thể tìm nạp all hồ sơ từ customers bảng sử dụng select truy vấn như hình dưới đây.
[quickstart.cloudera:21000] > select name, age from customers;
Query: select * from customersKhi thực hiện truy vấn trên, Impala tìm nạp và hiển thị tất cả các bản ghi từ bảng được chỉ định như được hiển thị bên dưới.
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | Hardik | 27 | Bhopal | 40000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | kaushik | 23 | Kota | 30000 |
| 6 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.66sTìm nạp các bản ghi bằng Hue
Mở trình chỉnh sửa Truy vấn Impala và nhập selectTuyên bố trong đó. Và nhấp vào nút thực thi như được hiển thị trong ảnh chụp màn hình sau.
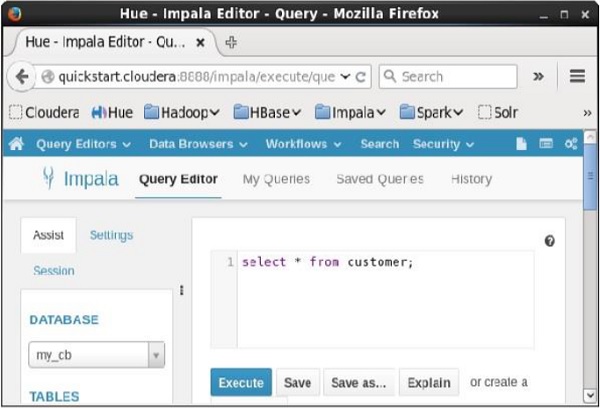
Sau khi thực hiện truy vấn, nếu bạn cuộn xuống và chọn Results , bạn có thể xem danh sách các bản ghi của bảng được chỉ định như hình dưới đây.
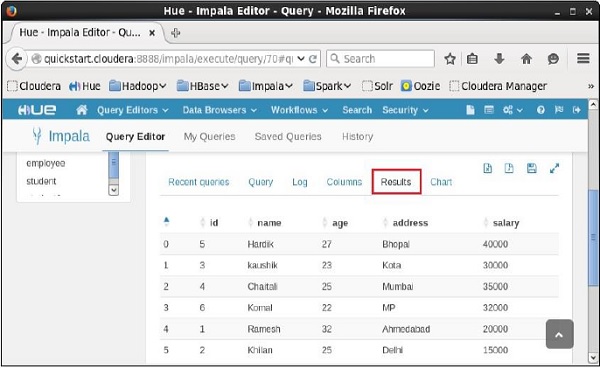
Các describecâu lệnh trong Impala được sử dụng để đưa ra mô tả của bảng. Kết quả của câu lệnh này chứa thông tin về bảng như tên cột và kiểu dữ liệu của chúng.
Cú pháp
Sau đây là cú pháp của Impala describe tuyên bố.
Describe table_name;Thí dụ
Ví dụ: giả sử chúng ta có một bảng tên customer ở Impala, với dữ liệu sau:
ID NAME AGE ADDRESS SALARY
--- --------- ----- ----------- -----------
1 Ramesh 32 Ahmedabad 20000
2 Khilan 25 Delhi 15000
3 Hardik 27 Bhopal 40000
4 Chaitali 25 Mumbai 35000
5 kaushik 23 Kota 30000
6 Komal 22 Mp 32000Bạn có thể nhận được mô tả của customer bảng sử dụng describe câu lệnh như hình dưới đây -
[quickstart.cloudera:21000] > describe customer;Khi thực hiện truy vấn trên, Impala tìm nạp metadata của bảng được chỉ định và hiển thị nó như hình dưới đây.
Query: describe customer
+---------+--------+---------+
| name | type | comment |
+---------+--------+---------+
| id | int | |
| name | string | |
| age | int | |
| address | string | |
| salary | bigint | |
+---------+--------+---------+
Fetched 5 row(s) in 0.51sMô tả các bản ghi bằng Hue
Mở trình chỉnh sửa Truy vấn Impala và nhập describe trong đó và nhấp vào nút thực thi như thể hiện trong ảnh chụp màn hình sau.
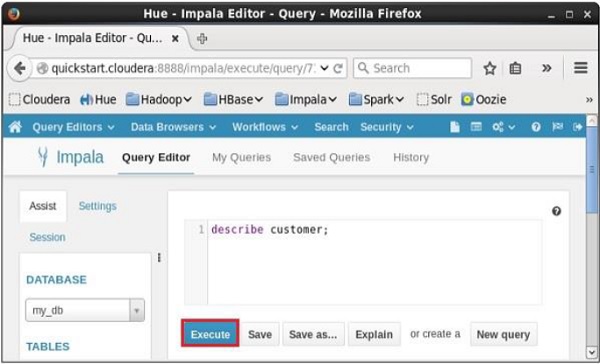
Sau khi thực hiện truy vấn, nếu bạn cuộn xuống và chọn Results , bạn có thể xem siêu dữ liệu của bảng như hình dưới đây.

Câu lệnh bảng Alter trong Impala được sử dụng để thực hiện các thay đổi trên một bảng nhất định. Sử dụng câu lệnh này, chúng tôi có thể thêm, xóa hoặc sửa đổi các cột trong bảng hiện có và chúng tôi cũng có thể đổi tên nó.
Chương này giải thích các loại câu lệnh thay đổi khác nhau với cú pháp và ví dụ. Trước hết, giả sử rằng chúng ta có một bảng có têncustomers bên trong my_db cơ sở dữ liệu trong Impala, với dữ liệu sau
ID NAME AGE ADDRESS SALARY
--- --------- ----- ----------- --------
1 Ramesh 32 Ahmedabad 20000
2 Khilan 25 Delhi 15000
3 Hardik 27 Bhopal 40000
4 Chaitali 25 Mumbai 35000
5 kaushik 23 Kota 30000
6 Komal 22 Mp 32000Và, nếu bạn nhận được danh sách các bảng trong cơ sở dữ liệu my_db, bạn có thể tìm thấy customers bảng trong đó như hình dưới đây.
[quickstart.cloudera:21000] > show tables;
Query: show tables
+-----------+
| name |
+-----------+
| customers |
| employee |
| student |
| student1 |
+-----------+Thay đổi tên của một bảng
Cú pháp
Cú pháp cơ bản của ALTER TABLE để đổi tên một bảng hiện có như sau:
ALTER TABLE [old_db_name.]old_table_name RENAME TO [new_db_name.]new_table_nameThí dụ
Sau đây là một ví dụ về việc thay đổi tên của bảng bằng cách sử dụng altertuyên bố. Ở đây chúng tôi đang thay đổi tên của bảngcustomers cho người dùng.
[quickstart.cloudera:21000] > ALTER TABLE my_db.customers RENAME TO my_db.users;Sau khi thực hiện truy vấn trên, Impala thay đổi tên của bảng theo yêu cầu, hiển thị thông báo sau.
Query: alter TABLE my_db.customers RENAME TO my_db.usersBạn có thể xác minh danh sách các bảng trong cơ sở dữ liệu hiện tại bằng cách sử dụng show tablestuyên bố. Bạn có thể tìm thấy bảng có tênusers thay vì customers.
Query: show tables
+----------+
| name |
+----------+
| employee |
| student |
| student1 |
| users |
+----------+
Fetched 4 row(s) in 0.10sThêm cột vào bảng
Cú pháp
Cú pháp cơ bản của ALTER TABLE để thêm cột vào bảng hiện có như sau:
ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...])Thí dụ
Truy vấn sau đây là một ví dụ minh họa cách thêm cột vào bảng hiện có. Ở đây chúng tôi đang thêm hai cột account_no và phone_number (cả hai đều thuộc loại dữ liệu bigint) vàousers bàn.
[quickstart.cloudera:21000] > ALTER TABLE users ADD COLUMNS (account_no BIGINT,
phone_no BIGINT);Khi thực hiện truy vấn trên, nó sẽ thêm các cột được chỉ định vào bảng có tên student, hiển thị thông báo sau.
Query: alter TABLE users ADD COLUMNS (account_no BIGINT, phone_no BIGINT)Nếu bạn xác minh lược đồ của bảng users, bạn có thể tìm thấy các cột mới được thêm vào trong đó như hình dưới đây.
quickstart.cloudera:21000] > describe users;
Query: describe users
+------------+--------+---------+
| name | type | comment |
+------------+--------+---------+
| id | int | |
| name | string | |
| age | int | |
| address | string | |
| salary | bigint | |
| account_no | bigint | |
| phone_no | bigint | |
+------------+--------+---------+
Fetched 7 row(s) in 0.20sBỏ cột khỏi bảng
Cú pháp
Cú pháp cơ bản của ALTER TABLE thành DROP COLUMN trong một bảng hiện có như sau:
ALTER TABLE name DROP [COLUMN] column_nameThí dụ
Truy vấn sau đây là một ví dụ về việc xóa các cột khỏi một bảng hiện có. Ở đây chúng tôi đang xóa cột có tênaccount_no.
[quickstart.cloudera:21000] > ALTER TABLE users DROP account_no;Khi thực hiện truy vấn trên, Impala xóa cột có tên account_no hiển thị thông báo sau.
Query: alter TABLE users DROP account_noNếu bạn xác minh lược đồ của bảng users, bạn không thể tìm thấy cột có tên account_no vì nó đã bị xóa.
[quickstart.cloudera:21000] > describe users;
Query: describe users
+----------+--------+---------+
| name | type | comment |
+----------+--------+---------+
| id | int | |
| name | string | |
| age | int | |
| address | string | |
| salary | bigint | |
| phone_no | bigint | |
+----------+--------+---------+
Fetched 6 row(s) in 0.11sThay đổi tên và loại cột
Cú pháp
Cú pháp cơ bản của ALTER TABLE thành change the name and datatype của một cột trong bảng hiện có như sau:
ALTER TABLE name CHANGE column_name new_name new_typeThí dụ
Sau đây là một ví dụ về việc thay đổi tên và kiểu dữ liệu của một cột bằng cách sử dụng câu lệnh thay đổi. Ở đây chúng tôi đang thay đổi tên của cộtphone_no to email và kiểu dữ liệu của nó để string.
[quickstart.cloudera:21000] > ALTER TABLE users CHANGE phone_no e_mail string;Khi thực hiện truy vấn trên, Impala thực hiện các thay đổi được chỉ định, hiển thị thông báo sau.
Query: alter TABLE users CHANGE phone_no e_mail stringBạn có thể xác minh siêu dữ liệu của những người dùng bảng bằng cách sử dụng describetuyên bố. Bạn có thể thấy rằng Impala đã thực hiện các thay đổi cần thiết cho cột được chỉ định.
[quickstart.cloudera:21000] > describe users;
Query: describe users
+----------+--------+---------+
| name | type | comment |
+----------+--------+---------+
| id | int | |
| name | string | |
| age | int | |
| address | string | |
| salary | bigint | |
| phone_no | bigint | |
+----------+--------+---------+
Fetched 6 row(s) in 0.11sThay đổi bảng bằng cách sử dụng Hue
Mở trình chỉnh sửa Truy vấn Impala và nhập alter trong đó và nhấp vào nút thực thi như thể hiện trong ảnh chụp màn hình sau.
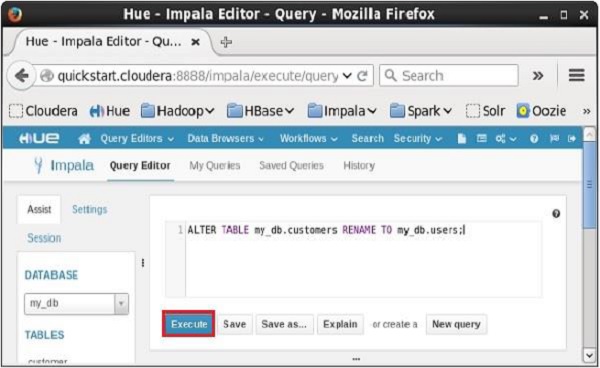
Khi thực hiện truy vấn trên, nó sẽ thay đổi tên của bảng customers đến users. Theo cách tương tự, chúng tôi có thể thực hiện tất cảalter truy vấn.
Impala drop tablecâu lệnh được sử dụng để xóa một bảng hiện có trong Impala. Câu lệnh này cũng xóa các tệp HDFS cơ bản cho các bảng nội bộ
NOTE - Bạn phải cẩn thận khi sử dụng lệnh này vì một khi một bảng bị xóa, thì tất cả thông tin có sẵn trong bảng cũng sẽ bị mất vĩnh viễn.
Cú pháp
Sau đây là cú pháp của DROP TABLETuyên bố. Đây,IF EXISTSlà một mệnh đề không bắt buộc. Nếu chúng ta sử dụng mệnh đề này, một bảng có tên đã cho sẽ bị xóa, chỉ khi nó tồn tại. Nếu không, sẽ không có hoạt động nào được thực hiện.
DROP table database_name.table_name;Nếu bạn cố gắng xóa một bảng không tồn tại mà không có mệnh đề IF EXISTS, một lỗi sẽ được tạo ra. Tùy ý bạn có thể chỉ địnhdatabase_name cùng với table_name.
Thí dụ
Trước tiên hãy để chúng tôi xác minh danh sách các bảng trong cơ sở dữ liệu my_db như hình bên dưới.
[quickstart.cloudera:21000] > show tables;
Query: show tables
+------------+
| name |
+------------+
| customers |
| employee |
| student |
+------------+
Fetched 3 row(s) in 0.11sTừ kết quả trên, bạn có thể thấy rằng cơ sở dữ liệu my_db chứa 3 bảng
Sau đây là một ví dụ về drop table statement. Trong ví dụ này, chúng tôi đang xóa bảng có tênstudent từ cơ sở dữ liệu my_db.
[quickstart.cloudera:21000] > drop table if exists my_db.student;Khi thực hiện truy vấn trên, một bảng có tên được chỉ định sẽ bị xóa, hiển thị kết quả sau.
Query: drop table if exists studentxác minh
Các show Tablestruy vấn đưa ra danh sách các bảng trong cơ sở dữ liệu hiện tại trong Impala. Do đó, bạn có thể xác minh xem một bảng có bị xóa hay không bằng cách sử dụngShow Tables tuyên bố.
Trước hết, bạn cần chuyển ngữ cảnh sang cơ sở dữ liệu mà bảng yêu cầu tồn tại, như hình dưới đây.
[quickstart.cloudera:21000] > use my_db;
Query: use my_dbSau đó, nếu bạn nhận được danh sách các bảng bằng cách sử dụng show tables truy vấn, bạn có thể quan sát bảng có tên student không có trong danh sách.
[quickstart.cloudera:21000] > show tables;
Query: show tables
+-----------+
| name |
+-----------+
| customers |
| employee |
| student |
+-----------+
Fetched 3 row(s) in 0.11sTạo cơ sở dữ liệu bằng trình duyệt Huế
Mở trình chỉnh sửa Truy vấn Impala và nhập drop TableTuyên bố trong đó. Và nhấp vào nút thực thi như được hiển thị trong ảnh chụp màn hình sau.
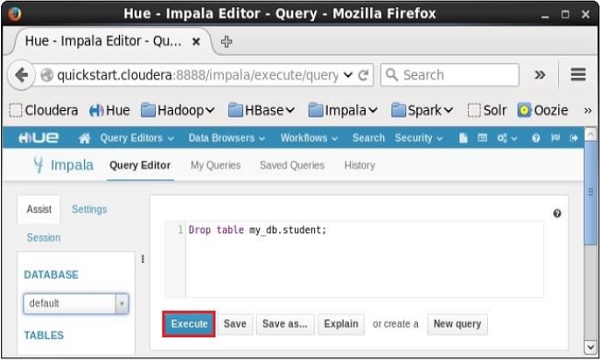
Sau khi thực hiện truy vấn, nhẹ nhàng di chuyển con trỏ lên đầu trình đơn thả xuống và bạn sẽ tìm thấy biểu tượng làm mới. Nếu bạn nhấp vào biểu tượng làm mới, danh sách cơ sở dữ liệu sẽ được làm mới và những thay đổi gần đây được thực hiện sẽ được áp dụng cho nó.
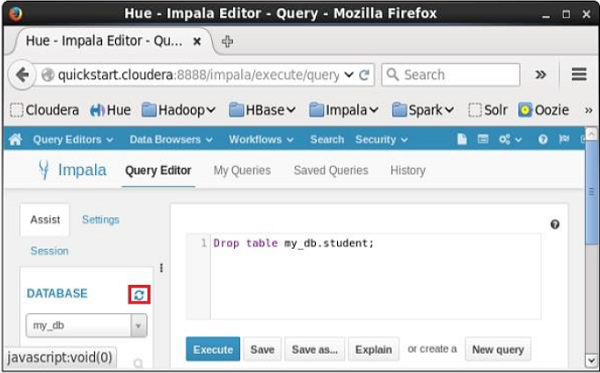
xác minh
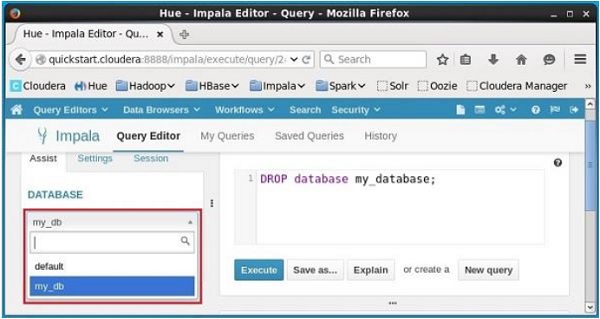
Bấm vào drop down dưới tiêu đề DATABASEở phía bên trái của trình chỉnh sửa. Ở đó bạn có thể thấy danh sách các cơ sở dữ liệu; chọn cơ sở dữ liệumy_db như hình bên dưới.
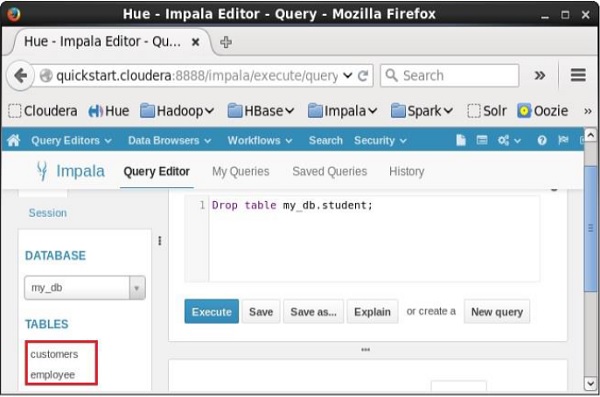
Khi chọn cơ sở dữ liệu my_db, bạn có thể xem danh sách các bảng trong đó như hình bên dưới. Ở đây bạn không thể tìm thấy bảng đã xóastudent trong danh sách như hình dưới đây.
Các Truncate Table Câu lệnh Impala được sử dụng để xóa tất cả các bản ghi khỏi một bảng hiện có.
Bạn cũng có thể sử dụng lệnh DROP TABLE để xóa một bảng hoàn chỉnh, nhưng nó sẽ xóa cấu trúc bảng hoàn chỉnh khỏi cơ sở dữ liệu và bạn sẽ cần phải tạo lại bảng này một lần nữa nếu muốn lưu trữ một số dữ liệu.
Cú pháp
Sau đây là cú pháp của câu lệnh bảng cắt ngắn.
truncate table_name;Thí dụ
Giả sử, chúng ta có một bảng tên là customerstrong Impala, và nếu bạn xác minh nội dung của nó, bạn sẽ nhận được kết quả sau. Điều này có nghĩa là bảng khách hàng chứa 6 bản ghi.
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+--------+
| id | name | age | address | salary | e_mail |
+----+----------+-----+-----------+--------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 | NULL |
| 2 | Khilan | 25 | Delhi | 15000 | NULL |
| 3 | kaushik | 23 | Kota | 30000 | NULL |
| 4 | Chaitali | 25 | Mumbai | 35000 | NULL |
| 5 | Hardik | 27 | Bhopal | 40000 | NULL |
| 6 | Komal | 22 | MP | 32000 | NULL |
+----+----------+-----+-----------+--------+--------+Sau đây là một ví dụ về việc cắt bớt một bảng trong Impala bằng cách sử dụng truncate statement. Ở đây chúng tôi đang xóa tất cả các bản ghi của bảng có têncustomers.
[quickstart.cloudera:21000] > truncate customers;Khi thực hiện câu lệnh trên, Impala xóa tất cả các bản ghi của bảng được chỉ định, hiển thị thông báo sau.
Query: truncate customers
Fetched 0 row(s) in 0.37sxác minh
Nếu bạn xác minh nội dung của bảng khách hàng, sau thao tác xóa, sử dụng select câu lệnh, bạn sẽ nhận được một hàng trống như hình dưới đây.
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
Fetched 0 row(s) in 0.12sCắt bớt một bảng bằng trình duyệt Huế
Mở trình chỉnh sửa Truy vấn Impala và nhập truncateTuyên bố trong đó. Và nhấp vào nút thực thi như được hiển thị trong ảnh chụp màn hình sau.
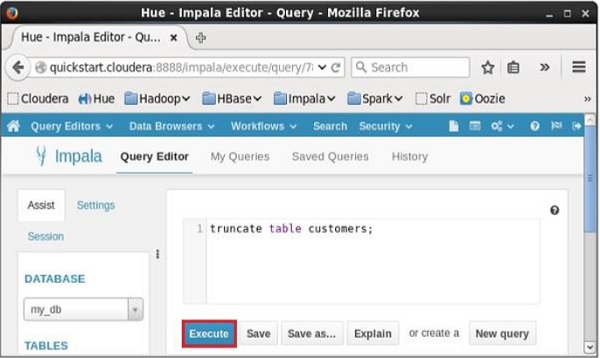
Sau khi thực hiện truy vấn / câu lệnh, tất cả các bản ghi từ bảng sẽ bị xóa.
Các show tables câu lệnh trong Impala được sử dụng để lấy danh sách tất cả các bảng hiện có trong cơ sở dữ liệu hiện tại.
Thí dụ
Sau đây là một ví dụ về show tablestuyên bố. Nếu bạn muốn lấy danh sách các bảng trong một cơ sở dữ liệu cụ thể, trước hết, hãy thay đổi ngữ cảnh thành cơ sở dữ liệu bắt buộc và lấy danh sách các bảng trong đó bằng cách sử dụngshow tables như hình dưới đây.
[quickstart.cloudera:21000] > use my_db;
Query: use my_db
[quickstart.cloudera:21000] > show tables;Khi thực hiện truy vấn trên, Impala tìm nạp danh sách tất cả các bảng trong cơ sở dữ liệu được chỉ định và hiển thị nó như hình dưới đây.
Query: show tables
+-----------+
| name |
+-----------+
| customers |
| employee |
+-----------+
Fetched 2 row(s) in 0.10sLiệt kê các bảng bằng Hue
Mở trình chỉnh sửa Truy vấn impala, chọn ngữ cảnh là my_db và gõ show tables trong đó và nhấp vào nút thực thi như thể hiện trong ảnh chụp màn hình sau.
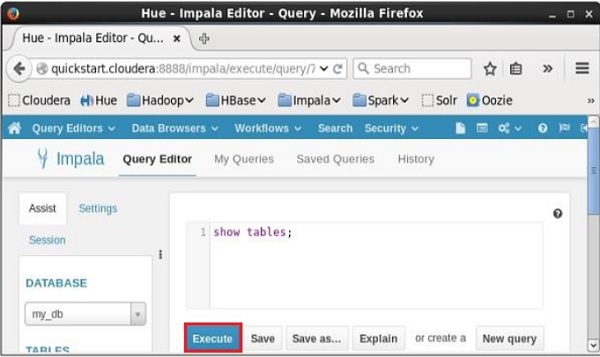
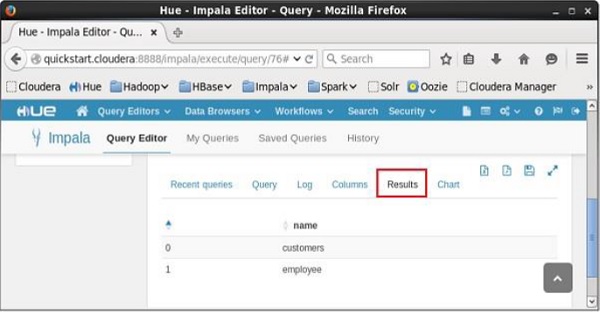
Sau khi thực hiện truy vấn, nếu bạn cuộn xuống và chọn Results , bạn có thể xem danh sách các bảng như hình dưới đây.
Một khung nhìn chỉ là một câu lệnh của ngôn ngữ truy vấn Impala được lưu trữ trong cơ sở dữ liệu với một tên liên quan. Nó là một thành phần của một bảng dưới dạng một truy vấn SQL được xác định trước.
Một dạng xem có thể chứa tất cả các hàng của bảng hoặc các hàng đã chọn. Một khung nhìn có thể được tạo từ một hoặc nhiều bảng. Chế độ xem cho phép người dùng -
Cấu trúc dữ liệu theo cách mà người dùng hoặc lớp người dùng thấy tự nhiên hoặc trực quan.
Hạn chế quyền truy cập vào dữ liệu để người dùng có thể xem và (đôi khi) sửa đổi chính xác những gì họ cần và không cần nữa.
Tổng hợp dữ liệu từ các bảng khác nhau có thể được sử dụng để tạo báo cáo.
Bạn có thể tạo chế độ xem bằng cách sử dụng Create View tuyên bố của Impala.
Cú pháp
Sau đây là cú pháp của câu lệnh create view. IF NOT EXISTSlà một mệnh đề không bắt buộc. Nếu chúng ta sử dụng mệnh đề này, một bảng có tên đã cho sẽ được tạo, chỉ khi không có bảng hiện có trong cơ sở dữ liệu được chỉ định có cùng tên.
Create View IF NOT EXISTS view_name as Select statementThí dụ
Ví dụ: giả sử chúng ta có một bảng tên customers bên trong my_db cơ sở dữ liệu trong Impala, với dữ liệu sau.
ID NAME AGE ADDRESS SALARY
--- --------- ----- ----------- --------
1 Ramesh 32 Ahmedabad 20000
2 Khilan 25 Delhi 15000
3 Hardik 27 Bhopal 40000
4 Chaitali 25 Mumbai 35000
5 kaushik 23 Kota 30000
6 Komal 22 MP 32000Sau đây là một ví dụ về Create View Statement. Trong ví dụ này, chúng tôi đang tạo một chế độ xem nhưcustomers bảng chứa các cột, tên và tuổi.
[quickstart.cloudera:21000] > CREATE VIEW IF NOT EXISTS customers_view AS
select name, age from customers;Khi thực hiện truy vấn trên, một dạng xem với các cột mong muốn được tạo, hiển thị thông báo sau.
Query: create VIEW IF NOT EXISTS sample AS select * from customers
Fetched 0 row(s) in 0.33sxác minh
Bạn có thể xác minh nội dung của dạng xem vừa được tạo bằng cách sử dụng select như hình dưới đây.
[quickstart.cloudera:21000] > select * from customers_view;Điều này sẽ tạo ra kết quả sau.
Query: select * from customers_view
+----------+-----+
| name | age |
+----------+-----+
| Komal | 22 |
| Khilan | 25 |
| Ramesh | 32 |
| Hardik | 27 |
| Chaitali | 25 |
| kaushik | 23 |
+----------+-----+
Fetched 6 row(s) in 4.80sTạo Chế độ xem bằng Hue
Mở trình chỉnh sửa Truy vấn Impala, chọn bối cảnh là my_dbvà nhập Create View trong đó và nhấp vào nút thực thi như thể hiện trong ảnh chụp màn hình sau.
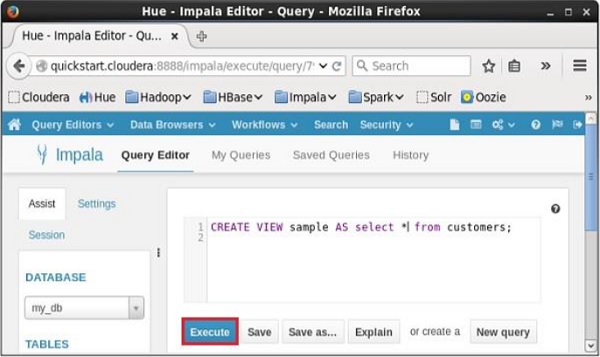
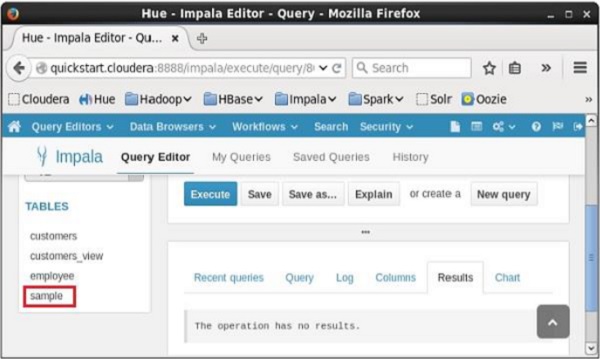
Sau khi thực hiện truy vấn, nếu bạn cuộn xuống, bạn có thể thấy view được đặt tên sample được tạo trong danh sách các bảng như hình dưới đây.
Các Alter Viewtuyên bố của Impala được sử dụng để thay đổi chế độ xem. Sử dụng câu lệnh này, bạn có thể thay đổi tên của một dạng xem, thay đổi cơ sở dữ liệu và truy vấn được liên kết với nó.
Từ một view là một cấu trúc logic, không có dữ liệu vật lý nào sẽ bị ảnh hưởng bởi alter view truy vấn.
Cú pháp
Sau đây là cú pháp của Alter View tuyên bố
ALTER VIEW database_name.view_name as Select statementThí dụ
Ví dụ: giả sử chúng ta có một chế độ xem có tên customers_view bên trong my_db cơ sở dữ liệu trong Impala với các nội dung sau.
+----------+-----+
| name | age |
+----------+-----+
| Komal | 22 |
| Khilan | 25 |
| Ramesh | 32 |
| Hardik | 27 |
| Chaitali | 25 |
| kaushik | 23 |
+----------+-----+Sau đây là một ví dụ về Alter View Statement. Trong ví dụ này, chúng tôi bao gồm các cột id, tên và lương thay vì tên và tuổi vàocustomers_view.
[quickstart.cloudera:21000] > Alter view customers_view as select id, name,
salary from customers;Khi thực hiện truy vấn trên, Impala thực hiện các thay đổi được chỉ định đối với customers_view, hiển thị thông báo sau.
Query: alter view customers_view as select id, name, salary from customersxác minh
Bạn có thể xác minh nội dung của view được đặt tên customers_view, sử dụng select như hình dưới đây.
[quickstart.cloudera:21000] > select * from customers_view;
Query: select * from customers_viewĐiều này sẽ tạo ra kết quả sau.
+----+----------+--------+
| id | name | salary |
+----+----------+--------+
| 3 | kaushik | 30000 |
| 2 | Khilan | 15000 |
| 5 | Hardik | 40000 |
| 6 | Komal | 32000 |
| 1 | Ramesh | 20000 |
| 4 | Chaitali | 35000 |
+----+----------+--------+
Fetched 6 row(s) in 0.69sThay đổi chế độ xem bằng cách sử dụng Hue
Mở trình chỉnh sửa Truy vấn Impala, chọn bối cảnh là my_dbvà nhập Alter View trong đó và nhấp vào nút thực thi như thể hiện trong ảnh chụp màn hình sau.
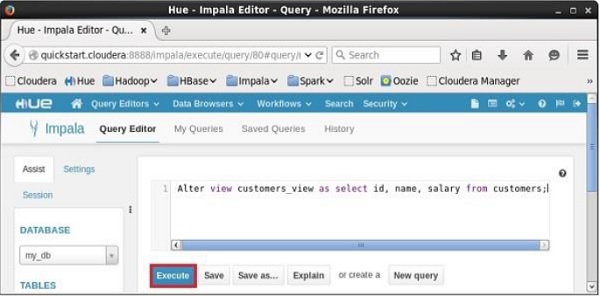
Sau khi thực hiện truy vấn, view được đặt tên sample sẽ được thay đổi cho phù hợp.
Các Drop Viewtruy vấn của Impala được sử dụng để xóa một dạng xem hiện có. Từ mộtview là một cấu trúc logic, không có dữ liệu vật lý nào sẽ bị ảnh hưởng bởi drop view truy vấn.
Cú pháp
Sau đây là cú pháp của câu lệnh drop view.
DROP VIEW database_name.view_name;Thí dụ
Ví dụ: giả sử chúng ta có một chế độ xem có tên customers_view bên trong my_db cơ sở dữ liệu trong Impala với các nội dung sau.
+----------+-----+
| name | age |
+----------+-----+
| Komal | 22 |
| Khilan | 25 |
| Ramesh | 32 |
| Hardik | 27 |
| Chaitali | 25 |
| kaushik | 23 |
+----------+-----+Sau đây là một ví dụ về Drop View Statement. Trong ví dụ này, chúng tôi đang cố gắng xóaview được đặt tên customers_view sử dụng drop view truy vấn.
[quickstart.cloudera:21000] > Drop view customers_view;Khi thực hiện truy vấn trên, Impala xóa chế độ xem được chỉ định, hiển thị thông báo sau.
Query: drop view customers_viewxác minh
Nếu bạn xác minh danh sách các bảng bằng cách sử dụng show tables tuyên bố, bạn có thể quan sát rằng view được đặt tên customers_view bị xóa.
[quickstart.cloudera:21000] > show tables;Điều này sẽ tạo ra kết quả sau.
Query: show tables
+-----------+
| name |
+-----------+
| customers |
| employee |
| sample |
+-----------+
Fetched 3 row(s) in 0.10sThả chế độ xem bằng Hue
Mở trình chỉnh sửa Truy vấn Impala, chọn bối cảnh là my_dbvà nhập Drop view trong đó và nhấp vào nút thực thi như thể hiện trong ảnh chụp màn hình sau.
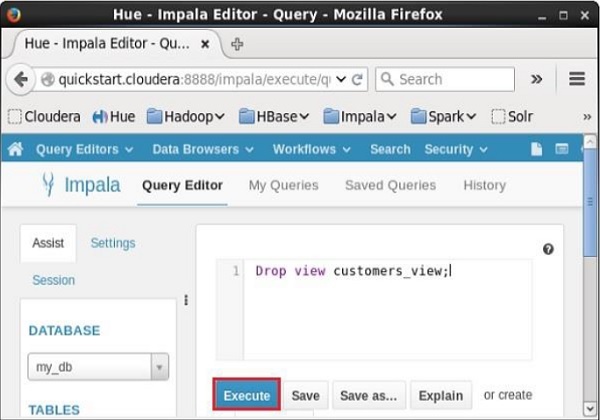
Sau khi thực hiện truy vấn, nếu bạn cuộn xuống, bạn có thể thấy một danh sách có tên TABLES. Danh sách này chứa tất cảtables và viewstrong cơ sở dữ liệu hiện tại. Từ danh sách này, bạn có thể thấy rằngview đã bị xóa.
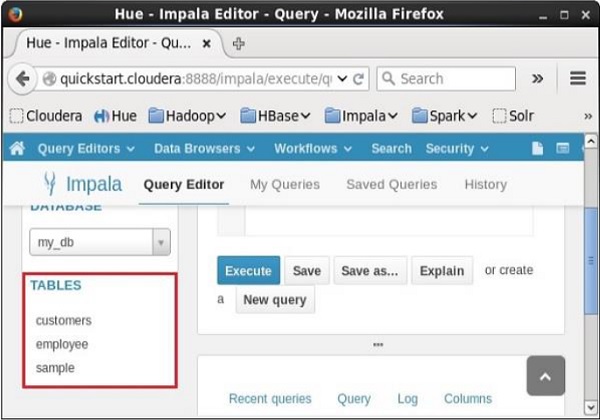
Impala ORDER BYmệnh đề được sử dụng để sắp xếp dữ liệu theo thứ tự tăng dần hoặc giảm dần, dựa trên một hoặc nhiều cột. Một số cơ sở dữ liệu sắp xếp các kết quả truy vấn theo thứ tự tăng dần theo mặc định.
Cú pháp
Sau đây là cú pháp của mệnh đề ORDER BY.
select * from table_name ORDER BY col_name [ASC|DESC] [NULLS FIRST|NULLS LAST]Bạn có thể sắp xếp dữ liệu trong bảng theo thứ tự tăng dần hoặc giảm dần bằng cách sử dụng các từ khóa ASC hoặc là DESC tương ứng.
Theo cách tương tự, nếu chúng ta sử dụng NULLS FIRST, tất cả các giá trị null trong bảng được sắp xếp ở các hàng trên cùng; và nếu chúng ta sử dụng NULLS LAST, các hàng chứa giá trị null sẽ được sắp xếp sau cùng.
Thí dụ
Giả sử chúng ta có một bảng tên customers trong cơ sở dữ liệu my_db và nội dung của nó như sau:
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 3 | kaushik | 23 | Kota | 30000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 6 | Komal | 22 | MP | 32000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.51sSau đây là một ví dụ về việc sắp xếp dữ liệu trong customers bảng, theo thứ tự tăng dần của id’s sử dụng order by mệnh đề.
[quickstart.cloudera:21000] > Select * from customers ORDER BY id asc;Khi thực thi, truy vấn trên tạo ra kết quả sau.
Query: select * from customers ORDER BY id asc
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 6 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.56sTheo cách tương tự, bạn có thể sắp xếp dữ liệu của customers bảng theo thứ tự giảm dần bằng cách sử dụng order by như hình bên dưới.
[quickstart.cloudera:21000] > Select * from customers ORDER BY id desc;Khi thực thi, truy vấn trên tạo ra kết quả sau.
Query: select * from customers ORDER BY id desc
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 6 | Komal | 22 | MP | 32000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.54sImpala GROUP BY mệnh đề được sử dụng phối hợp với câu lệnh SELECT để sắp xếp dữ liệu giống nhau thành các nhóm.
Cú pháp
Sau đây là cú pháp của mệnh đề GROUP BY.
select data from table_name Group BY col_name;Thí dụ
Giả sử chúng ta có một bảng tên customers trong cơ sở dữ liệu my_db và nội dung của nó như sau:
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 6 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.51sBạn có thể nhận được tổng số tiền lương của từng khách hàng bằng cách sử dụng truy vấn GROUP BY như hình dưới đây.
[quickstart.cloudera:21000] > Select name, sum(salary) from customers Group BY name;Khi thực thi, truy vấn trên cho kết quả sau.
Query: select name, sum(salary) from customers Group BY name
+----------+-------------+
| name | sum(salary) |
+----------+-------------+
| Ramesh | 20000 |
| Komal | 32000 |
| Hardik | 40000 |
| Khilan | 15000 |
| Chaitali | 35000 |
| kaushik | 30000 |
+----------+-------------+
Fetched 6 row(s) in 1.75sGiả sử rằng bảng này có nhiều bản ghi như hình dưới đây.
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Ramesh | 32 | Ahmedabad | 1000| |
| 3 | Khilan | 25 | Delhi | 15000 |
| 4 | kaushik | 23 | Kota | 30000 |
| 5 | Chaitali | 25 | Mumbai | 35000 |
| 6 | Chaitali | 25 | Mumbai | 2000 |
| 7 | Hardik | 27 | Bhopal | 40000 |
| 8 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+Bây giờ một lần nữa, bạn có thể nhận được tổng số tiền lương của nhân viên, xem xét các mục nhập lặp lại của hồ sơ, sử dụng Group By như hình bên dưới.
Select name, sum(salary) from customers Group BY name;Khi thực thi, truy vấn trên cho kết quả sau.
Query: select name, sum(salary) from customers Group BY name
+----------+-------------+
| name | sum(salary) |
+----------+-------------+
| Ramesh | 21000 |
| Komal | 32000 |
| Hardik | 40000 |
| Khilan | 15000 |
| Chaitali | 37000 |
| kaushik | 30000 |
+----------+-------------+
Fetched 6 row(s) in 1.75sCác Having mệnh đề trong Impala cho phép bạn chỉ định các điều kiện lọc kết quả nhóm nào xuất hiện trong kết quả cuối cùng.
Nói chung, Having mệnh đề được sử dụng cùng với group bymệnh đề; nó đặt điều kiện cho các nhóm được tạo bởi mệnh đề GROUP BY.
Cú pháp
Sau đây là cú pháp của Havingmệnh đề.
select * from table_name ORDER BY col_name [ASC|DESC] [NULLS FIRST|NULLS LAST]Thí dụ
Giả sử chúng ta có một bảng tên customers trong cơ sở dữ liệu my_db và nội dung của nó như sau:
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-------------+--------+
| id | name | age | address | salary |
+----+----------+-----+-------------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 6 | Komal | 22 | MP | 32000 |
| 7 | ram | 25 | chennai | 23000 |
| 8 | rahim | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.51sSau đây là một ví dụ về việc sử dụng Having mệnh đề trong Impala -
[quickstart.cloudera:21000] > select max(salary) from customers group by age having max(salary) > 20000;Truy vấn này ban đầu nhóm bảng theo độ tuổi và chọn mức lương tối đa của mỗi nhóm và hiển thị các mức lương lớn hơn 20000 như hình dưới đây.
20000
+-------------+
| max(salary) |
+-------------+
| 30000 |
| 35000 |
| 40000 |
| 32000 |
+-------------+
Fetched 4 row(s) in 1.30sCác limit mệnh đề trong Impala được sử dụng để hạn chế số hàng của tập kết quả ở một số mong muốn, tức là tập kết quả của truy vấn không giữ các bản ghi vượt quá giới hạn đã chỉ định.
Cú pháp
Sau đây là cú pháp của Limit mệnh đề trong Impala.
select * from table_name order by id limit numerical_expression;Thí dụ
Giả sử chúng ta có một bảng tên customers trong cơ sở dữ liệu my_db và nội dung của nó như sau:
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 3 | kaushik | 23 | Kota | 30000 |
| 6 | Komal | 22 | MP | 32000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 8 | ram | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
| 7 | ram | 25 | chennai | 23000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.51sBạn có thể sắp xếp các bản ghi trong bảng theo thứ tự tăng dần của id của chúng bằng cách sử dụng order by như hình bên dưới.
[quickstart.cloudera:21000] > select * from customers order by id;
Query: select * from customers order by id
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 6 | Komal | 22 | MP | 32000 |
| 7 | ram | 25 | chennai | 23000 |
| 8 | ram | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.54sBây giờ, bằng cách sử dụng limit , bạn có thể hạn chế số lượng bản ghi của đầu ra là 4, bằng cách sử dụng limit như hình bên dưới.
[quickstart.cloudera:21000] > select * from customers order by id limit 4;Khi thực thi, truy vấn trên cho kết quả sau.
Query: select * from customers order by id limit 4
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 4 row(s) in 0.64sNói chung, các hàng trong tập kết quả của một select truy vấn bắt đầu từ 0. Sử dụng offset, chúng ta có thể quyết định xem kết quả đầu ra từ đâu. Ví dụ, nếu chúng ta chọn độ lệch là 0, kết quả sẽ như bình thường và nếu chúng ta chọn độ lệch là 5, kết quả bắt đầu từ hàng thứ năm.
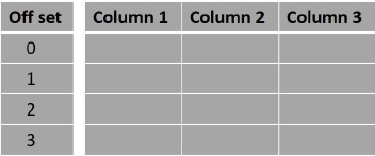
Cú pháp
Sau đây là cú pháp của offsetmệnh đề trong Impala.
select data from table_name Group BY col_name;Thí dụ
Giả sử chúng ta có một bảng tên customers trong cơ sở dữ liệu my_db và nội dung của nó như sau:
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 3 | kaushik | 23 | Kota | 30000 |
| 6 | Komal | 22 | MP | 32000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 8 | ram | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
| 7 | ram | 25 | chennai | 23000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.51sBạn có thể sắp xếp các bản ghi trong bảng theo thứ tự tăng dần của id của chúng và giới hạn số lượng bản ghi là 4, sử dụng limit và order by mệnh đề như hình dưới đây.
Query: select * from customers order by id limit 4
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 4 row(s) in 0.64sSau đây là một ví dụ về offsetmệnh đề. Ở đây, chúng tôi đang nhận được các bản ghi trongcustomersbảng theo thứ tự id của chúng và in bốn hàng đầu tiên bắt đầu từ hàng thứ 0 .
[quickstart.cloudera:21000] > select * from customers order by id limit 4 offset 0;Khi thực thi, truy vấn trên cho kết quả sau.
Query: select * from customers order by id limit 4 offset 0
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 4 row(s) in 0.62sTheo cách tương tự, bạn có thể lấy bốn bản ghi từ customers bảng bắt đầu từ hàng có độ lệch 5 như hình dưới đây.
[quickstart.cloudera:21000] > select * from customers order by id limit 4 offset 5;
Query: select * from customers order by id limit 4 offset 5
+----+--------+-----+----------+--------+
| id | name | age | address | salary |
+----+--------+-----+----------+--------+
| 6 | Komal | 22 | MP | 32000 |
| 7 | ram | 25 | chennai | 23000 |
| 8 | ram | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
+----+--------+-----+----------+--------+
Fetched 4 row(s) in 0.52sBạn có thể kết hợp kết quả của hai truy vấn bằng cách sử dụng Union mệnh đề của Impala.
Cú pháp
Sau đây là cú pháp của Union mệnh đề trong Impala.
query1 union query2;Thí dụ
Giả sử chúng ta có một bảng tên customers trong cơ sở dữ liệu my_db và nội dung của nó như sau:
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 9 | robert | 23 | banglore | 28000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 7 | ram | 25 | chennai | 23000 |
| 6 | Komal | 22 | MP | 32000 |
| 8 | ram | 22 | vizag | 31000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 3 | kaushik | 23 | Kota | 30000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.59sTheo cách tương tự, giả sử chúng ta có một bảng khác có tên employee và nội dung của nó như sau:
[quickstart.cloudera:21000] > select * from employee;
Query: select * from employee
+----+---------+-----+---------+--------+
| id | name | age | address | salary |
+----+---------+-----+---------+--------+
| 3 | mahesh | 54 | Chennai | 55000 |
| 2 | ramesh | 44 | Chennai | 50000 |
| 4 | Rupesh | 64 | Delhi | 60000 |
| 1 | subhash | 34 | Delhi | 40000 |
+----+---------+-----+---------+--------+
Fetched 4 row(s) in 0.59sSau đây là một ví dụ về unionmệnh đề trong Impala. Trong ví dụ này, chúng tôi sắp xếp các bản ghi trong cả hai bảng theo thứ tự id của chúng và giới hạn số lượng của chúng là 3 bằng cách sử dụng hai truy vấn riêng biệt và kết hợp các truy vấn này bằng cách sử dụngUNION mệnh đề.
[quickstart.cloudera:21000] > select * from customers order by id limit 3
union select * from employee order by id limit 3;Khi thực thi, truy vấn trên cho kết quả sau.
Query: select * from customers order by id limit 3 union select
* from employee order by id limit 3
+----+---------+-----+-----------+--------+
| id | name | age | address | salary |
+----+---------+-----+-----------+--------+
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | mahesh | 54 | Chennai | 55000 |
| 1 | subhash | 34 | Delhi | 40000 |
| 2 | ramesh | 44 | Chennai | 50000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
+----+---------+-----+-----------+--------+
Fetched 6 row(s) in 3.11sTrong trường hợp một truy vấn quá phức tạp, chúng tôi có thể xác định aliases đến các phần phức tạp và đưa chúng vào truy vấn bằng cách sử dụng with mệnh đề của Impala.
Cú pháp
Sau đây là cú pháp của with mệnh đề trong Impala.
with x as (select 1), y as (select 2) (select * from x union y);Thí dụ
Giả sử chúng ta có một bảng tên customers trong cơ sở dữ liệu my_db và nội dung của nó như sau:
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 9 | robert | 23 | banglore | 28000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 7 | ram | 25 | chennai | 23000 |
| 6 | Komal | 22 | MP | 32000 |
| 8 | ram | 22 | vizag | 31000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 3 | kaushik | 23 | Kota | 30000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.59sTheo cách tương tự, giả sử chúng ta có một bảng khác có tên employee và nội dung của nó như sau:
[quickstart.cloudera:21000] > select * from employee;
Query: select * from employee
+----+---------+-----+---------+--------+
| id | name | age | address | salary |
+----+---------+-----+---------+--------+
| 3 | mahesh | 54 | Chennai | 55000 |
| 2 | ramesh | 44 | Chennai | 50000 |
| 4 | Rupesh | 64 | Delhi | 60000 |
| 1 | subhash | 34 | Delhi | 40000 |
+----+---------+-----+---------+--------+
Fetched 4 row(s) in 0.59sSau đây là một ví dụ về withmệnh đề trong Impala. Trong ví dụ này, chúng tôi đang hiển thị các bản ghi từ cả haiemployee và customers có độ tuổi lớn hơn 25 sử dụng with mệnh đề.
[quickstart.cloudera:21000] >
with t1 as (select * from customers where age>25),
t2 as (select * from employee where age>25)
(select * from t1 union select * from t2);Khi thực thi, truy vấn trên cho kết quả sau.
Query: with t1 as (select * from customers where age>25), t2 as (select * from employee where age>25)
(select * from t1 union select * from t2)
+----+---------+-----+-----------+--------+
| id | name | age | address | salary |
+----+---------+-----+-----------+--------+
| 3 | mahesh | 54 | Chennai | 55000 |
| 1 | subhash | 34 | Delhi | 40000 |
| 2 | ramesh | 44 | Chennai | 50000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 4 | Rupesh | 64 | Delhi | 60000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
+----+---------+-----+-----------+--------+
Fetched 6 row(s) in 1.73sCác distinct toán tử trong Impala được sử dụng để nhận các giá trị duy nhất bằng cách loại bỏ các bản sao.
Cú pháp
Sau đây là cú pháp của distinct nhà điều hành.
select distinct columns… from table_name;Thí dụ
Giả sử rằng chúng ta có một bảng có tên customers trong Impala và nội dung của nó như sau:
[quickstart.cloudera:21000] > select distinct id, name, age, salary from customers;
Query: select distinct id, name, age, salary from customersTại đây, bạn có thể quan sát mức lương của những khách hàng mà Ramesh và Chaitali đã nhập hai lần và sử dụng distinct , chúng ta có thể chọn các giá trị duy nhất như hình dưới đây.
[quickstart.cloudera:21000] > select distinct name, age, address from customers;Khi thực thi, truy vấn trên cho kết quả sau.
Query: select distinct id, name from customers
+----------+-----+-----------+
| name | age | address |
+----------+-----+-----------+
| Ramesh | 32 | Ahmedabad |
| Khilan | 25 | Delhi |
| kaushik | 23 | Kota |
| Chaitali | 25 | Mumbai |
| Hardik | 27 | Bhopal |
| Komal | 22 | MP |
+----------+-----+-----------+
Fetched 9 row(s) in 1.46s