Kibana - Giới thiệu về Elk Stack
Kibana là một công cụ trực quan mã nguồn mở chủ yếu được sử dụng để phân tích một lượng lớn nhật ký dưới dạng biểu đồ đường, biểu đồ thanh, biểu đồ hình tròn, bản đồ nhiệt, v.v. Kibana hoạt động đồng bộ với Elasticsearch và Logstash, cùng nhau tạo thành cái gọi là ELK cây rơm.
ELK là viết tắt của Elasticsearch, Logstash và Kibana. ELK là một trong những nền tảng quản lý nhật ký phổ biến được sử dụng trên toàn thế giới để phân tích nhật ký.
Trong ngăn xếp ELK -
Logstashtrích xuất dữ liệu ghi nhật ký hoặc các sự kiện khác từ các nguồn đầu vào khác nhau. Nó xử lý các sự kiện và sau đó lưu trữ nó trong Elasticsearch.
Kibana là một công cụ trực quan hóa, truy cập nhật ký từ Elasticsearch và có thể hiển thị cho người dùng dưới dạng biểu đồ đường, biểu đồ thanh, biểu đồ hình tròn, v.v.
Trong hướng dẫn này, chúng tôi sẽ làm việc chặt chẽ với Kibana và Elasticsearch và trực quan hóa dữ liệu ở các dạng khác nhau.
Trong chương này, chúng ta hãy hiểu cách làm việc với ngăn xếp ELK cùng nhau. Bên cạnh đó, bạn cũng sẽ thấy cách -
- Tải dữ liệu CSV từ Logstash sang Elasticsearch.
- Sử dụng các chỉ số từ Elasticsearch trong Kibana.
Tải dữ liệu CSV từ Logstash sang Elasticsearch
Chúng tôi sẽ sử dụng dữ liệu CSV để tải dữ liệu bằng Logstash lên Elasticsearch. Để phân tích dữ liệu, chúng tôi có thể lấy dữ liệu từ trang web kaggle.com. Trang Kaggle.com có tất cả các loại dữ liệu được tải lên và người dùng có thể sử dụng nó để phân tích dữ liệu.
Chúng tôi đã lấy dữ liệu country.csv từ đây: https://www.kaggle.com/fernandol/countries-of-the-world. Bạn có thể tải xuống tệp csv và sử dụng nó.
Tệp csv mà chúng tôi sẽ sử dụng có các chi tiết sau.
Tên tệp - countrydata.csv
Cột - "Quốc gia", "Khu vực", "Dân số", "Khu vực"
Bạn cũng có thể tạo một tệp csv giả và sử dụng nó. Chúng tôi sẽ sử dụng logstash để đổ dữ liệu này từ countriesdata.csv để elasticsearch.
Khởi động tìm kiếm đàn hồi và Kibana trong thiết bị đầu cuối của bạn và tiếp tục chạy. Chúng tôi phải tạo tệp cấu hình cho logstash sẽ có thông tin chi tiết về các cột của tệp CSV và các chi tiết khác như được hiển thị trong tệp logstash-config được cung cấp bên dưới:
input {
file {
path => "C:/kibanaproject/countriesdata.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns => ["Country","Region","Population","Area"]
}
mutate {convert => ["Population", "integer"]}
mutate {convert => ["Area", "integer"]}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
=> "countriesdata-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}Trong tệp cấu hình, chúng tôi đã tạo 3 thành phần:
Đầu vào
Chúng tôi cần chỉ định đường dẫn của tệp đầu vào mà trong trường hợp của chúng tôi là tệp csv. Đường dẫn nơi tệp csv được lưu trữ được cấp cho trường đường dẫn.
Bộ lọc
Sẽ có thành phần csv với dấu phân tách được sử dụng trong trường hợp của chúng tôi là dấu phẩy và cũng có các cột có sẵn cho tệp csv của chúng tôi. Vì logstash coi tất cả dữ liệu đến dưới dạng chuỗi, nên trong trường hợp chúng ta muốn bất kỳ cột nào được sử dụng dưới dạng số nguyên, thì float phải được chỉ định bằng cách sử dụng mutate như được hiển thị ở trên.
Đầu ra
Đối với đầu ra, chúng ta cần xác định nơi chúng ta cần đặt dữ liệu. Ở đây, trong trường hợp của chúng tôi, chúng tôi đang sử dụngasticsearch. Dữ liệu cần thiết để cung cấp cho đàn hồi tìm kiếm là các máy chủ nơi nó đang chạy, chúng tôi đã đề cập đến nó là localhost. Các lĩnh vực tiếp theo trong là chỉ số mà chúng tôi đã được đặt tên như nước -currentdate. Chúng tôi phải sử dụng cùng một chỉ mục trong Kibana khi dữ liệu được cập nhật trong Elasticsearch.
Lưu tệp cấu hình ở trên dưới dạng logstash_countries.config . Lưu ý rằng chúng ta cần cung cấp đường dẫn của cấu hình này cho lệnh logstash trong bước tiếp theo.
Để tải dữ liệu từ tệp csv vàoasticsearch, chúng tôi cần khởi động máy chủasticsearch -
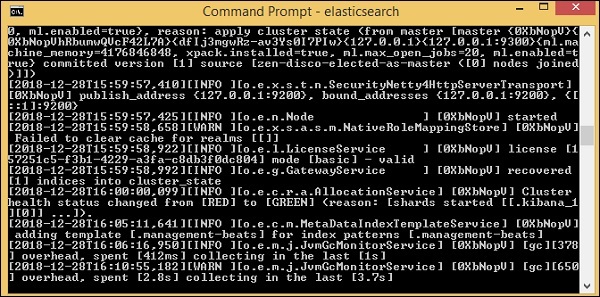
Bây giờ, chạy http://localhost:9200 trong trình duyệt để xác nhận xem liệu đàn hồi tìm kiếm có đang chạy thành công hay không.
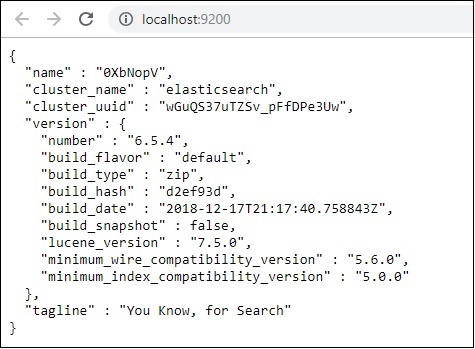
Chúng tôi đang chạy tìm kiếm đàn hồi. Bây giờ đi đến đường dẫn nơi logstash được cài đặt và chạy lệnh sau để tải dữ liệu lênasticsearch.
> logstash -f logstash_countries.conf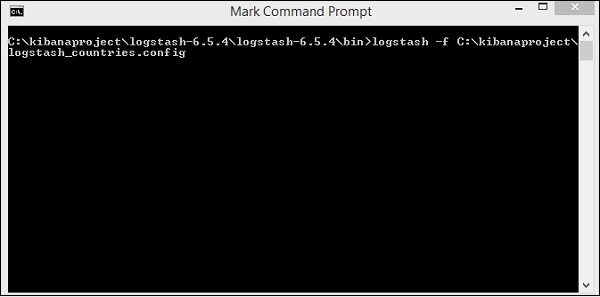
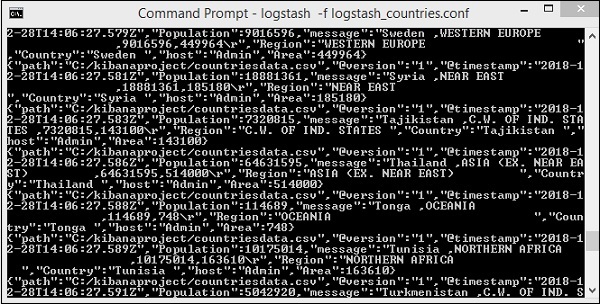
Màn hình trên hiển thị tải dữ liệu từ tệp CSV đến Elasticsearch. Để biết liệu chúng ta có chỉ mục được tạo trong Elasticsearch hay không, chúng ta có thể kiểm tra như sau:
Chúng ta có thể thấy chỉ mục countrydata-28.12.2018 được tạo như hình trên.

Chi tiết của chỉ số - quốc gia-28.12.2018 như sau -
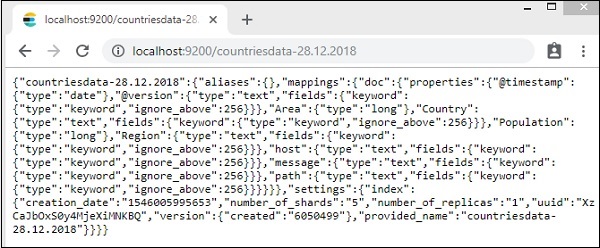
Lưu ý rằng các chi tiết ánh xạ với các thuộc tính được tạo khi dữ liệu được tải lên từ logstash đếnasticsearch.
Sử dụng dữ liệu từ Elasticsearch trong Kibana
Hiện tại, chúng tôi có Kibana đang chạy trên localhost, cổng 5601 - http://localhost:5601. Giao diện người dùng của Kibana được hiển thị ở đây -
Lưu ý rằng chúng tôi đã có Kibana kết nối với Elasticsearch và chúng tôi có thể thấy index :countries-28.12.2018 bên trong Kibana.
Trong giao diện người dùng Kibana, nhấp vào tùy chọn Menu Quản lý ở bên trái -
Bây giờ, hãy nhấp vào Quản lý chỉ mục -
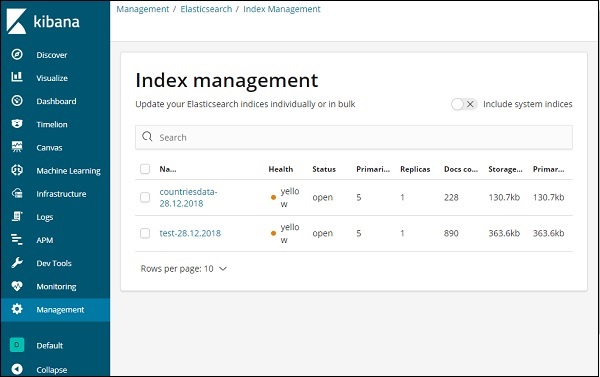
Các chỉ số có trong Elasticsearch được hiển thị trong quản lý chỉ mục. Chỉ mục chúng tôi sẽ sử dụng trong Kibana là countrydata-28.12.2018.
Vì vậy, vì chúng ta đã có chỉ mục tìm kiếm đàn hồi trong Kibana, tiếp theo sẽ hiểu cách sử dụng chỉ mục trong Kibana để trực quan hóa dữ liệu dưới dạng biểu đồ tròn, biểu đồ thanh, biểu đồ đường, v.v.