PyTorch - Hướng dẫn nhanh
PyTorch được định nghĩa là một thư viện máy học mã nguồn mở cho Python. Nó được sử dụng cho các ứng dụng như xử lý ngôn ngữ tự nhiên. Ban đầu, nó được phát triển bởi nhóm nghiên cứu trí tuệ nhân tạo của Facebook và phần mềm Pyro của Uber để lập trình xác suất được xây dựng trên nó.
Ban đầu, PyTorch được Hugh Perkins phát triển như một trình bao bọc Python cho LusJIT dựa trên khuôn khổ Torch. Có hai biến thể PyTorch.
PyTorch thiết kế lại và triển khai Torch bằng Python trong khi chia sẻ cùng các thư viện C lõi cho mã phụ trợ. Các nhà phát triển PyTorch đã điều chỉnh mã back-end này để chạy Python một cách hiệu quả. Họ cũng giữ nguyên khả năng tăng tốc phần cứng dựa trên GPU cũng như các tính năng mở rộng đã tạo nên Torch dựa trên Lua.
Đặc trưng
Các tính năng chính của PyTorch được đề cập dưới đây:
Easy Interface- PyTorch cung cấp API dễ sử dụng; do đó nó được coi là rất đơn giản để vận hành và chạy trên Python. Việc thực thi mã trong khuôn khổ này khá dễ dàng.
Python usage- Thư viện này được coi là Pythonic tích hợp trơn tru với ngăn xếp khoa học dữ liệu Python. Do đó, nó có thể tận dụng tất cả các dịch vụ và chức năng được cung cấp bởi môi trường Python.
Computational graphs- PyTorch cung cấp một nền tảng tuyệt vời cung cấp các đồ thị tính toán động. Do đó người dùng có thể thay đổi chúng trong thời gian chạy. Điều này rất hữu ích khi nhà phát triển không biết cần bao nhiêu bộ nhớ để tạo mô hình mạng nơron.
PyTorch được biết đến với ba cấp độ trừu tượng như được đưa ra dưới đây:
Tensor - Mảng n-chiều bắt buộc chạy trên GPU.
Biến - Nút trong đồ thị tính toán. Điều này lưu trữ dữ liệu và gradient.
Mô-đun - Lớp mạng nơ-ron sẽ lưu trữ trạng thái hoặc trọng số có thể học được.
Ưu điểm của PyTorch
Sau đây là những ưu điểm của PyTorch -
Nó rất dễ dàng để gỡ lỗi và hiểu mã.
Nó bao gồm nhiều lớp như Torch.
Nó bao gồm rất nhiều chức năng mất mát.
Có thể coi đây là phần mở rộng NumPy cho GPU.
Nó cho phép xây dựng các mạng có cấu trúc phụ thuộc vào chính tính toán.
TensorFlow so với PyTorch
Chúng ta sẽ xem xét sự khác biệt chính giữa TensorFlow và PyTorch dưới đây:
| PyTorch | TensorFlow |
|---|---|
PyTorch có liên quan chặt chẽ với khung Torch dựa trên lua được sử dụng tích cực trong Facebook. |
TensorFlow được phát triển bởi Google Brain và được sử dụng tích cực tại Google. |
PyTorch tương đối mới so với các công nghệ cạnh tranh khác. |
TensorFlow không phải là mới và được nhiều nhà nghiên cứu và các chuyên gia trong ngành coi là một công cụ cần thiết. |
PyTorch bao gồm mọi thứ theo cách bắt buộc và năng động. |
TensorFlow bao gồm các đồ thị tĩnh và động dưới dạng kết hợp. |
Đồ thị tính toán trong PyTorch được xác định trong thời gian chạy. |
TensorFlow không bao gồm bất kỳ tùy chọn thời gian chạy nào. |
PyTorch bao gồm triển khai đặc trưng cho các khuôn khổ di động và nhúng. |
TensorFlow hoạt động tốt hơn cho các khuôn khổ nhúng. |
PyTorch là một khung học sâu phổ biến. Trong hướng dẫn này, chúng tôi coi “Windows 10” là hệ điều hành của chúng tôi. Các bước để thiết lập môi trường thành công như sau:
Bước 1
Liên kết sau bao gồm danh sách các gói trong đó có các gói phù hợp cho PyTorch.
https://drive.google.com/drive/folders/0B-X0-FlSGfCYdTNldW02UGl4MXMTất cả những gì bạn cần làm là tải xuống các gói tương ứng và cài đặt nó như được hiển thị trong ảnh chụp màn hình sau:


Bước 2
Nó liên quan đến việc xác minh cài đặt khuôn khổ PyTorch bằng Khuôn khổ Anaconda.
Lệnh sau được sử dụng để xác minh cùng một:
conda list
“Danh sách Conda” hiển thị danh sách các khuôn khổ đã được cài đặt.

Phần được đánh dấu cho thấy PyTorch đã được cài đặt thành công trong hệ thống của chúng tôi.
Toán học quan trọng trong bất kỳ thuật toán học máy nào và bao gồm các khái niệm cốt lõi khác nhau của toán học để có được thuật toán phù hợp được thiết kế theo một cách cụ thể.
Tầm quan trọng của các chủ đề toán học đối với học máy và khoa học dữ liệu được đề cập dưới đây:

Bây giờ, chúng ta hãy tập trung vào các khái niệm toán học chính của học máy, điều quan trọng theo quan điểm Xử lý ngôn ngữ tự nhiên -
Vectơ
Vectơ được coi là mảng số liên tục hoặc rời rạc và không gian bao gồm các vectơ được gọi là không gian vectơ. Kích thước không gian của vectơ có thể hữu hạn hoặc vô hạn nhưng người ta đã quan sát thấy rằng các vấn đề về học máy và khoa học dữ liệu giải quyết các vectơ có độ dài cố định.
Biểu diễn vectơ được hiển thị như được đề cập bên dưới:
temp = torch.FloatTensor([23,24,24.5,26,27.2,23.0])
temp.size()
Output - torch.Size([6])Trong học máy, chúng tôi xử lý dữ liệu đa chiều. Vì vậy, vectơ trở nên rất quan trọng và được coi là đặc điểm đầu vào cho bất kỳ câu lệnh bài toán dự đoán nào.
Vô hướng
Vô hướng được gọi là không có thứ nguyên chỉ chứa một giá trị. Khi nói đến PyTorch, nó không bao gồm một tensor đặc biệt với kích thước bằng không; do đó khai báo sẽ được thực hiện như sau:
x = torch.rand(10)
x.size()
Output - torch.Size([10])Ma trận
Hầu hết dữ liệu có cấu trúc thường được biểu diễn dưới dạng bảng hoặc một ma trận cụ thể. Chúng tôi sẽ sử dụng một tập dữ liệu có tên là Giá Nhà ở Boston, có sẵn trong thư viện máy học Python scikit-learning.
boston_tensor = torch.from_numpy(boston.data)
boston_tensor.size()
Output: torch.Size([506, 13])
boston_tensor[:2]
Output:
Columns 0 to 7
0.0063 18.0000 2.3100 0.0000 0.5380 6.5750 65.2000 4.0900
0.0273 0.0000 7.0700 0.0000 0.4690 6.4210 78.9000 4.9671
Columns 8 to 12
1.0000 296.0000 15.3000 396.9000 4.9800
2.0000 242.0000 17.8000 396.9000 9.1400Nguyên tắc chính của mạng nơ-ron bao gồm một tập hợp các phần tử cơ bản, tức là nơ-ron nhân tạo hoặc nơ-ron cảm thụ. Nó bao gồm một số đầu vào cơ bản như x1, x2… .. xn tạo ra đầu ra nhị phân nếu tổng lớn hơn tiềm năng kích hoạt.
Biểu diễn sơ đồ của nơron mẫu được đề cập dưới đây:

Đầu ra được tạo ra có thể được coi là tổng có trọng số với tiềm năng kích hoạt hoặc độ lệch.
$$ Đầu ra = \ sum_jw_jx_j + Bias $$
Kiến trúc mạng nơ-ron điển hình được mô tả dưới đây:

Các lớp giữa đầu vào và đầu ra được gọi là các lớp ẩn, mật độ và kiểu kết nối giữa các lớp là cấu hình. Ví dụ, một cấu hình được kết nối đầy đủ có tất cả các tế bào thần kinh của lớp L được kết nối với các tế bào thần kinh của L + 1. Để bản địa hóa rõ ràng hơn, chúng ta chỉ có thể kết nối một vùng lân cận cục bộ, chẳng hạn như chín tế bào thần kinh, với lớp tiếp theo. Hình 1-9 minh họa hai lớp ẩn với các kết nối dày đặc.
Các loại mạng nơ-ron khác nhau như sau:
Mạng Nơ-ron chuyển tiếp
Mạng nơron truyền thẳng bao gồm các đơn vị cơ bản của họ mạng nơron. Sự di chuyển của dữ liệu trong kiểu mạng nơ-ron này là từ lớp đầu vào đến lớp đầu ra, thông qua các lớp ẩn hiện tại. Đầu ra của một lớp đóng vai trò là lớp đầu vào với các hạn chế đối với bất kỳ loại vòng lặp nào trong kiến trúc mạng.

Mạng thần kinh tái diễn
Mạng thần kinh tái diễn là khi mẫu dữ liệu thay đổi do đó trong một khoảng thời gian. Trong RNN, cùng một lớp được áp dụng để chấp nhận các tham số đầu vào và hiển thị các tham số đầu ra trong mạng nơ-ron được chỉ định.
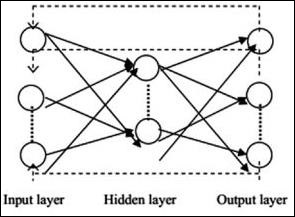
Mạng nơ-ron có thể được xây dựng bằng gói torch.nn.

Nó là một mạng chuyển tiếp đơn giản. Nó lấy đầu vào, nạp lần lượt qua nhiều lớp, rồi cuối cùng đưa ra đầu ra.
Với sự trợ giúp của PyTorch, chúng ta có thể sử dụng các bước sau cho quy trình đào tạo điển hình cho mạng nơron:
- Xác định mạng nơ-ron có một số tham số (hoặc trọng số) có thể học được.
- Lặp lại tập dữ liệu đầu vào.
- Xử lý đầu vào thông qua mạng.
- Tính toán tổn thất (kết quả đầu ra chính xác đến đâu).
- Truyền chuyển màu trở lại các tham số của mạng.
- Cập nhật trọng số của mạng, thường sử dụng một bản cập nhật đơn giản như dưới đây
rule: weight = weight -learning_rate * gradientTrí tuệ nhân tạo đang có xu hướng ngày nay ở mức độ lớn hơn. Học máy và học sâu tạo thành trí tuệ nhân tạo. Biểu đồ Venn được đề cập bên dưới giải thích mối quan hệ của học máy và học sâu.

Học máy
Máy học là nghệ thuật khoa học cho phép máy tính hoạt động theo các thuật toán được thiết kế và lập trình. Nhiều nhà nghiên cứu cho rằng học máy là cách tốt nhất để đạt được tiến bộ đối với AI ở cấp độ con người. Nó bao gồm nhiều loại mẫu khác nhau như -
- Mô hình học tập có giám sát
- Mô hình học tập không giám sát
Học kĩ càng
Học sâu là một lĩnh vực con của học máy trong đó các thuật toán liên quan được lấy cảm hứng từ cấu trúc và chức năng của bộ não được gọi là Mạng thần kinh nhân tạo.
Học sâu đã trở nên quan trọng hơn nhiều thông qua học có giám sát hoặc học từ dữ liệu và thuật toán được gắn nhãn. Mỗi thuật toán trong học sâu trải qua cùng một quy trình. Nó bao gồm hệ thống phân cấp biến đổi phi tuyến của đầu vào và sử dụng để tạo mô hình thống kê như đầu ra.
Quá trình học máy được xác định bằng cách sử dụng các bước sau:
- Xác định các tập dữ liệu có liên quan và chuẩn bị chúng để phân tích.
- Chọn loại thuật toán để sử dụng.
- Xây dựng mô hình phân tích dựa trên thuật toán được sử dụng.
- Đào tạo mô hình trên các tập dữ liệu thử nghiệm, sửa đổi nó khi cần thiết.
- Chạy mô hình để tạo điểm kiểm tra.
Trong chương này, chúng ta sẽ thảo luận về sự khác biệt chính giữa khái niệm Máy học và Học sâu.
Số lượng dữ liệu
Học máy hoạt động với các lượng dữ liệu khác nhau và chủ yếu được sử dụng cho lượng dữ liệu nhỏ. Mặt khác, học sâu hoạt động hiệu quả nếu lượng dữ liệu tăng nhanh. Sơ đồ sau mô tả hoạt động của học máy và học sâu liên quan đến lượng dữ liệu -

Phụ thuộc phần cứng
Các thuật toán học sâu được thiết kế để phụ thuộc nhiều vào các máy cao cấp, trái ngược với các thuật toán học máy truyền thống. Các thuật toán học sâu thực hiện một lượng lớn các phép toán nhân ma trận đòi hỏi sự hỗ trợ phần cứng rất lớn.
Kỹ thuật tính năng
Kỹ thuật tính năng là quá trình đưa kiến thức miền vào các tính năng cụ thể để giảm độ phức tạp của dữ liệu và tạo các mẫu có thể nhìn thấy được đối với các thuật toán học.
Ví dụ: các mẫu máy học truyền thống tập trung vào pixel và các thuộc tính khác cần thiết cho quy trình kỹ thuật tính năng. Các thuật toán học sâu tập trung vào các tính năng cấp cao từ dữ liệu. Nó làm giảm nhiệm vụ phát triển trình trích xuất tính năng mới cho mọi vấn đề mới.
PyTorch bao gồm một tính năng đặc biệt là tạo và triển khai mạng nơ-ron. Trong chương này, chúng ta sẽ tạo một mạng nơ-ron đơn giản với một lớp ẩn phát triển một đơn vị đầu ra duy nhất.
Chúng tôi sẽ sử dụng các bước sau để triển khai mạng nơ-ron đầu tiên bằng PyTorch:
Bước 1
Đầu tiên, chúng ta cần nhập thư viện PyTorch bằng lệnh dưới đây:
import torch
import torch.nn as nnBước 2
Xác định tất cả các lớp và kích thước lô để bắt đầu thực thi mạng nơ-ron như hình dưới đây:
# Defining input size, hidden layer size, output size and batch size respectively
n_in, n_h, n_out, batch_size = 10, 5, 1, 10Bước 3
Vì mạng nơ-ron bao gồm sự kết hợp của dữ liệu đầu vào để có được dữ liệu đầu ra tương ứng, chúng ta sẽ thực hiện theo cùng một quy trình như dưới đây:
# Create dummy input and target tensors (data)
x = torch.randn(batch_size, n_in)
y = torch.tensor([[1.0], [0.0], [0.0],
[1.0], [1.0], [1.0], [0.0], [0.0], [1.0], [1.0]])Bước 4
Tạo một mô hình tuần tự với sự trợ giúp của các chức năng có sẵn. Sử dụng các dòng mã dưới đây, tạo một mô hình tuần tự -
# Create a model
model = nn.Sequential(nn.Linear(n_in, n_h),
nn.ReLU(),
nn.Linear(n_h, n_out),
nn.Sigmoid())Bước 5
Xây dựng hàm mất mát với sự trợ giúp của trình tối ưu hóa Gradient Descent như hình dưới đây -
Construct the loss function
criterion = torch.nn.MSELoss()
# Construct the optimizer (Stochastic Gradient Descent in this case)
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)Bước 6
Triển khai mô hình dốc xuống với vòng lặp lặp với các dòng mã đã cho -
# Gradient Descent
for epoch in range(50):
# Forward pass: Compute predicted y by passing x to the model
y_pred = model(x)
# Compute and print loss
loss = criterion(y_pred, y)
print('epoch: ', epoch,' loss: ', loss.item())
# Zero gradients, perform a backward pass, and update the weights.
optimizer.zero_grad()
# perform a backward pass (backpropagation)
loss.backward()
# Update the parameters
optimizer.step()Bước 7
Đầu ra được tạo ra như sau:
epoch: 0 loss: 0.2545787990093231
epoch: 1 loss: 0.2545052170753479
epoch: 2 loss: 0.254431813955307
epoch: 3 loss: 0.25435858964920044
epoch: 4 loss: 0.2542854845523834
epoch: 5 loss: 0.25421255826950073
epoch: 6 loss: 0.25413978099823
epoch: 7 loss: 0.25406715273857117
epoch: 8 loss: 0.2539947032928467
epoch: 9 loss: 0.25392240285873413
epoch: 10 loss: 0.25385022163391113
epoch: 11 loss: 0.25377824902534485
epoch: 12 loss: 0.2537063956260681
epoch: 13 loss: 0.2536346912384033
epoch: 14 loss: 0.25356316566467285
epoch: 15 loss: 0.25349172949790955
epoch: 16 loss: 0.25342053174972534
epoch: 17 loss: 0.2533493936061859
epoch: 18 loss: 0.2532784342765808
epoch: 19 loss: 0.25320762395858765
epoch: 20 loss: 0.2531369626522064
epoch: 21 loss: 0.25306645035743713
epoch: 22 loss: 0.252996027469635
epoch: 23 loss: 0.2529257833957672
epoch: 24 loss: 0.25285571813583374
epoch: 25 loss: 0.25278574228286743
epoch: 26 loss: 0.25271597504615784
epoch: 27 loss: 0.25264623761177063
epoch: 28 loss: 0.25257670879364014
epoch: 29 loss: 0.2525072991847992
epoch: 30 loss: 0.2524380087852478
epoch: 31 loss: 0.2523689270019531
epoch: 32 loss: 0.25229987502098083
epoch: 33 loss: 0.25223103165626526
epoch: 34 loss: 0.25216227769851685
epoch: 35 loss: 0.252093642950058
epoch: 36 loss: 0.25202515721321106
epoch: 37 loss: 0.2519568204879761
epoch: 38 loss: 0.251888632774353
epoch: 39 loss: 0.25182053446769714
epoch: 40 loss: 0.2517525553703308
epoch: 41 loss: 0.2516847252845764
epoch: 42 loss: 0.2516169846057892
epoch: 43 loss: 0.2515493929386139
epoch: 44 loss: 0.25148195028305054
epoch: 45 loss: 0.25141456723213196
epoch: 46 loss: 0.2513473629951477
epoch: 47 loss: 0.2512802183628082
epoch: 48 loss: 0.2512132525444031
epoch: 49 loss: 0.2511464059352875Đào tạo một thuật toán học sâu bao gồm các bước sau:
- Xây dựng đường dẫn dữ liệu
- Xây dựng kiến trúc mạng
- Đánh giá kiến trúc bằng hàm mất mát
- Tối ưu hóa trọng số kiến trúc mạng bằng thuật toán tối ưu hóa
Đào tạo một thuật toán học sâu cụ thể là yêu cầu chính xác của việc chuyển đổi mạng nơ-ron thành các khối chức năng như hình dưới đây -

Đối với sơ đồ trên, bất kỳ thuật toán học sâu nào đều liên quan đến việc lấy dữ liệu đầu vào, xây dựng kiến trúc tương ứng bao gồm một loạt các lớp được nhúng trong chúng.
Nếu bạn quan sát sơ đồ trên, độ chính xác được đánh giá bằng cách sử dụng một hàm mất mát liên quan đến việc tối ưu hóa trọng số của mạng nơ-ron.
Trong chương này, chúng ta sẽ thảo luận về một số thuật ngữ được sử dụng phổ biến nhất trong PyTorch.
PyTorch NumPy
Một tenxơ PyTorch giống hệt một mảng NumPy. Tensor là một mảng n chiều và đối với PyTorch, nó cung cấp nhiều chức năng để hoạt động trên các tensor này.
Bộ căng PyTorch thường sử dụng GPU để tăng tốc các phép tính số của chúng. Những tensors này được tạo ra trong PyTorch có thể được sử dụng để điều chỉnh một mạng hai lớp với dữ liệu ngẫu nhiên. Người dùng có thể thực hiện thủ công chuyển tiếp và chuyển tiếp qua mạng.
Biến và Autograd
Khi sử dụng autograd, chuyển tiếp mạng của bạn sẽ xác định computational graph - các nút trong biểu đồ sẽ là các Tensors, và các cạnh sẽ là các hàm tạo ra Tensors đầu ra từ Tensors đầu vào.
PyTorch Tensors có thể được tạo dưới dạng các đối tượng biến trong đó một biến đại diện cho một nút trong đồ thị tính toán.
Đồ thị động
Đồ thị tĩnh rất đẹp vì người dùng có thể tối ưu hóa đồ thị trước. Nếu các lập trình viên đang sử dụng lặp đi lặp lại cùng một biểu đồ, thì việc tối ưu hóa trước có thể tốn kém này có thể được duy trì khi cùng một biểu đồ được chạy đi chạy lại nhiều lần.
Sự khác biệt chính giữa chúng là đồ thị tính toán của Tensor Flow là tĩnh và PyTorch sử dụng đồ thị tính toán động.
Gói tối ưu
Gói tối ưu trong PyTorch tóm tắt ý tưởng về một thuật toán tối ưu hóa được thực hiện theo nhiều cách và cung cấp các hình ảnh minh họa về các thuật toán tối ưu hóa thường được sử dụng. Điều này có thể được gọi trong câu lệnh nhập.
Đa xử lý
Đa xử lý hỗ trợ các hoạt động giống nhau, do đó tất cả các bộ căng hoạt động trên nhiều bộ xử lý. Hàng đợi sẽ chuyển dữ liệu của chúng vào bộ nhớ dùng chung và sẽ chỉ gửi một xử lý đến một tiến trình khác.
PyTorch bao gồm một gói có tên là torchvision được sử dụng để tải và chuẩn bị tập dữ liệu. Nó bao gồm hai chức năng cơ bản là Dataset và DataLoader, giúp chuyển đổi và tải tập dữ liệu.
Dataset
Tập dữ liệu được sử dụng để đọc và chuyển đổi một điểm dữ liệu từ tập dữ liệu đã cho. Cú pháp cơ bản để triển khai được đề cập bên dưới:
trainset = torchvision.datasets.CIFAR10(root = './data', train = True,
download = True, transform = transform)DataLoader được sử dụng để trộn và trộn dữ liệu hàng loạt. Nó có thể được sử dụng để tải dữ liệu song song với các công nhân đa xử lý.
trainloader = torch.utils.data.DataLoader(trainset, batch_size = 4,
shuffle = True, num_workers = 2)Ví dụ: Đang tải tệp CSV
Chúng tôi sử dụng gói Python Panda để tải tệp csv. File gốc có định dạng như sau: (tên ảnh, 68 mốc - mỗi mốc có tọa độ ax, y).
landmarks_frame = pd.read_csv('faces/face_landmarks.csv')
n = 65
img_name = landmarks_frame.iloc[n, 0]
landmarks = landmarks_frame.iloc[n, 1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1, 2)Trong chương này, chúng ta sẽ tập trung vào ví dụ cơ bản về triển khai hồi quy tuyến tính bằng cách sử dụng TensorFlow. Hồi quy logistic hoặc hồi quy tuyến tính là một cách tiếp cận máy học có giám sát để phân loại các danh mục rời rạc theo thứ tự. Mục tiêu của chúng tôi trong chương này là xây dựng một mô hình mà qua đó người dùng có thể dự đoán mối quan hệ giữa các biến dự báo và một hoặc nhiều biến độc lập.
Mối quan hệ giữa hai biến này được coi là tuyến tính, nghĩa là, nếu y là biến phụ thuộc và x được coi là biến độc lập, thì mối quan hệ hồi quy tuyến tính của hai biến sẽ giống như phương trình được đề cập dưới đây:
Y = Ax+bTiếp theo, chúng tôi sẽ thiết kế một thuật toán cho hồi quy tuyến tính cho phép chúng tôi hiểu hai khái niệm quan trọng được đưa ra dưới đây:
- Chức năng ước lượng
- Thuật toán Gradient Descent
Biểu diễn giản đồ của hồi quy tuyến tính được đề cập dưới đây
Diễn giải kết quả
$$ Y = ax + b $$
Giá trị của a là độ dốc.
Giá trị của b là y − intercept.
r là correlation coefficient.
r2 là correlation coefficient.
Hình ảnh đồ thị của phương trình hồi quy tuyến tính được đề cập dưới đây:

Các bước sau được sử dụng để thực hiện hồi quy tuyến tính bằng PyTorch:
Bước 1
Nhập các gói cần thiết để tạo hồi quy tuyến tính trong PyTorch bằng cách sử dụng mã dưới đây:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
import seaborn as sns
import pandas as pd
%matplotlib inline
sns.set_style(style = 'whitegrid')
plt.rcParams["patch.force_edgecolor"] = TrueBước 2
Tạo một tập huấn luyện duy nhất với tập dữ liệu có sẵn như hình dưới đây -
m = 2 # slope
c = 3 # interceptm = 2 # slope
c = 3 # intercept
x = np.random.rand(256)
noise = np.random.randn(256) / 4
y = x * m + c + noise
df = pd.DataFrame()
df['x'] = x
df['y'] = y
sns.lmplot(x ='x', y ='y', data = df)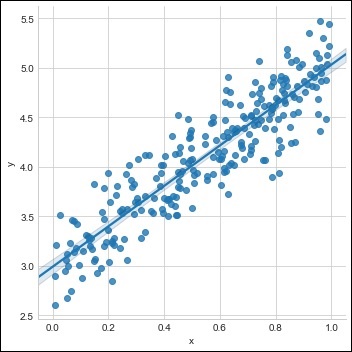
Bước 3
Thực hiện hồi quy tuyến tính với các thư viện PyTorch như được đề cập bên dưới -
import torch
import torch.nn as nn
from torch.autograd import Variable
x_train = x.reshape(-1, 1).astype('float32')
y_train = y.reshape(-1, 1).astype('float32')
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
input_dim = x_train.shape[1]
output_dim = y_train.shape[1]
input_dim, output_dim(1, 1)
model = LinearRegressionModel(input_dim, output_dim)
criterion = nn.MSELoss()
[w, b] = model.parameters()
def get_param_values():
return w.data[0][0], b.data[0]
def plot_current_fit(title = ""):
plt.figure(figsize = (12,4))
plt.title(title)
plt.scatter(x, y, s = 8)
w1 = w.data[0][0]
b1 = b.data[0]
x1 = np.array([0., 1.])
y1 = x1 * w1 + b1
plt.plot(x1, y1, 'r', label = 'Current Fit ({:.3f}, {:.3f})'.format(w1, b1))
plt.xlabel('x (input)')
plt.ylabel('y (target)')
plt.legend()
plt.show()
plot_current_fit('Before training')Cốt truyện được tạo ra như sau:

Học sâu là một bộ phận của học máy và được các nhà nghiên cứu coi là một bước quan trọng trong những thập kỷ gần đây. Các ví dụ về triển khai học sâu bao gồm các ứng dụng như nhận dạng hình ảnh và nhận dạng giọng nói.
Hai loại mạng nơ ron sâu quan trọng được đưa ra dưới đây:
- Mạng thần kinh chuyển đổi
- Mạng thần kinh định kỳ.
Trong chương này, chúng ta sẽ tập trung vào loại đầu tiên, tức là Mạng thần kinh chuyển đổi (CNN).
Mạng thần kinh chuyển đổi
Mạng Neural Convolutions được thiết kế để xử lý dữ liệu thông qua nhiều lớp mảng. Loại mạng thần kinh này được sử dụng trong các ứng dụng như nhận dạng hình ảnh hoặc nhận dạng khuôn mặt.
Sự khác biệt cơ bản giữa CNN và bất kỳ mạng nơron thông thường nào khác là CNN nhận đầu vào là một mảng hai chiều và hoạt động trực tiếp trên hình ảnh thay vì tập trung vào việc trích xuất tính năng mà các mạng nơron khác tập trung vào.
Cách tiếp cận chủ đạo của CNN bao gồm giải pháp cho các vấn đề về nhận dạng. Các công ty hàng đầu như Google và Facebook đã đầu tư vào các dự án nghiên cứu và phát triển các dự án công nhận để hoàn thành các hoạt động với tốc độ nhanh hơn.
Mỗi mạng nơ-ron tích tụ bao gồm ba ý tưởng cơ bản:
- Các trường tương ứng địa phương
- Convolution
- Pooling
Hãy để chúng tôi hiểu chi tiết từng thuật ngữ này.
Các trường phản hồi cục bộ
CNN sử dụng các mối tương quan không gian tồn tại trong dữ liệu đầu vào. Mỗi trong các lớp đồng thời của mạng nơ-ron kết nối với một số nơ-ron đầu vào. Vùng cụ thể này được gọi là Trường tiếp nhận cục bộ. Nó chỉ tập trung vào các tế bào thần kinh ẩn. Nơron ẩn sẽ xử lý dữ liệu đầu vào bên trong trường được đề cập mà không nhận ra những thay đổi bên ngoài ranh giới cụ thể.
Biểu đồ biểu diễn tạo các trường tương ứng cục bộ được đề cập dưới đây:

Convolution
Trong hình trên, chúng ta quan sát thấy rằng mỗi kết nối học một trọng số của nơ-ron ẩn với mối liên hệ liên kết với sự chuyển động từ lớp này sang lớp khác. Tại đây, các tế bào thần kinh riêng lẻ thực hiện sự thay đổi theo thời gian. Quá trình này được gọi là "tích chập".
Ánh xạ các kết nối từ lớp đầu vào đến bản đồ đối tượng ẩn được định nghĩa là "trọng số được chia sẻ" và thiên vị bao gồm được gọi là "thiên vị được chia sẻ".
Tổng hợp
Mạng nơron hợp pháp sử dụng các lớp tổng hợp được định vị ngay sau khi CNN khai báo. Nó lấy thông tin đầu vào từ người dùng dưới dạng bản đồ tính năng tạo ra các mạng phức hợp và chuẩn bị một bản đồ tính năng cô đọng. Việc gộp các lớp giúp tạo các lớp với các tế bào thần kinh của các lớp trước.
Triển khai PyTorch
Các bước sau được sử dụng để tạo Mạng nơ-ron liên kết bằng PyTorch.
Bước 1
Nhập các gói cần thiết để tạo một mạng nơ-ron đơn giản.
from torch.autograd import Variable
import torch.nn.functional as FBước 2
Tạo một lớp với đại diện hàng loạt của mạng nơ-ron tích tụ. Hình dạng lô của chúng tôi cho đầu vào x có kích thước là (3, 32, 32).
class SimpleCNN(torch.nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
#Input channels = 3, output channels = 18
self.conv1 = torch.nn.Conv2d(3, 18, kernel_size = 3, stride = 1, padding = 1)
self.pool = torch.nn.MaxPool2d(kernel_size = 2, stride = 2, padding = 0)
#4608 input features, 64 output features (see sizing flow below)
self.fc1 = torch.nn.Linear(18 * 16 * 16, 64)
#64 input features, 10 output features for our 10 defined classes
self.fc2 = torch.nn.Linear(64, 10)Bước 3
Tính toán kích hoạt thay đổi kích thước tích chập đầu tiên từ (3, 32, 32) thành (18, 32, 32).
Kích thước của thứ nguyên thay đổi từ (18, 32, 32) thành (18, 16, 16). Định hình lại kích thước dữ liệu của lớp đầu vào của mạng thần kinh do kích thước thay đổi từ (18, 16, 16) thành (1, 4608).
Nhớ lại rằng -1 suy ra thứ nguyên này từ thứ nguyên khác đã cho.
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(x)
x = x.view(-1, 18 * 16 *16)
x = F.relu(self.fc1(x))
#Computes the second fully connected layer (activation applied later)
#Size changes from (1, 64) to (1, 10)
x = self.fc2(x)
return(x)Mạng nơ-ron tuần hoàn là một loại thuật toán định hướng học sâu theo cách tiếp cận tuần tự. Trong mạng nơ-ron, chúng ta luôn giả định rằng mỗi đầu vào và đầu ra là độc lập với tất cả các lớp khác. Loại mạng nơ-ron này được gọi là mạng tuần hoàn vì chúng thực hiện các phép tính toán học theo cách tuần tự hoàn thành nhiệm vụ này đến nhiệm vụ khác.
Sơ đồ dưới đây chỉ rõ cách tiếp cận hoàn chỉnh và hoạt động của mạng nơ-ron tuần hoàn -

Trong hình trên, c1, c2, c3 và x1 được coi là đầu vào bao gồm một số giá trị đầu vào ẩn cụ thể là h1, h2 và h3 cung cấp đầu ra tương ứng là o1. Bây giờ chúng tôi sẽ tập trung vào việc triển khai PyTorch để tạo ra một làn sóng sin với sự trợ giúp của các mạng thần kinh tái phát.
Trong quá trình đào tạo, chúng tôi sẽ thực hiện theo cách tiếp cận đào tạo đối với mô hình của chúng tôi với một điểm dữ liệu tại một thời điểm. Chuỗi đầu vào x bao gồm 20 điểm dữ liệu và chuỗi đích được coi là giống với chuỗi đầu vào.
Bước 1
Nhập các gói cần thiết để triển khai mạng nơ-ron lặp lại bằng cách sử dụng mã dưới đây:
import torch
from torch.autograd import Variable
import numpy as np
import pylab as pl
import torch.nn.init as initBước 2
Chúng ta sẽ thiết lập các tham số siêu mô hình với kích thước của lớp đầu vào được đặt là 7. Sẽ có 6 neuron ngữ cảnh và 1 neuron đầu vào để tạo chuỗi đích.
dtype = torch.FloatTensor
input_size, hidden_size, output_size = 7, 6, 1
epochs = 300
seq_length = 20
lr = 0.1
data_time_steps = np.linspace(2, 10, seq_length + 1)
data = np.sin(data_time_steps)
data.resize((seq_length + 1, 1))
x = Variable(torch.Tensor(data[:-1]).type(dtype), requires_grad=False)
y = Variable(torch.Tensor(data[1:]).type(dtype), requires_grad=False)Chúng tôi sẽ tạo dữ liệu đào tạo, trong đó x là chuỗi dữ liệu đầu vào và y là chuỗi đích bắt buộc.
Bước 3
Trọng số được khởi tạo trong mạng nơ-ron tuần hoàn bằng cách sử dụng phân phối chuẩn với giá trị trung bình bằng không. W1 sẽ đại diện cho việc chấp nhận các biến đầu vào và w2 sẽ đại diện cho đầu ra được tạo như hình dưới đây:
w1 = torch.FloatTensor(input_size,
hidden_size).type(dtype)
init.normal(w1, 0.0, 0.4)
w1 = Variable(w1, requires_grad = True)
w2 = torch.FloatTensor(hidden_size, output_size).type(dtype)
init.normal(w2, 0.0, 0.3)
w2 = Variable(w2, requires_grad = True)Bước 4
Bây giờ, điều quan trọng là tạo một hàm cho nguồn cấp dữ liệu chuyển tiếp để xác định duy nhất mạng nơ-ron.
def forward(input, context_state, w1, w2):
xh = torch.cat((input, context_state), 1)
context_state = torch.tanh(xh.mm(w1))
out = context_state.mm(w2)
return (out, context_state)Bước 5
Bước tiếp theo là bắt đầu đào tạo quy trình triển khai sóng sin của mạng nơron tái phát. Vòng lặp bên ngoài lặp qua mỗi vòng lặp và vòng lặp bên trong lặp lại qua phần tử của trình tự. Ở đây, chúng tôi cũng sẽ tính toán Lỗi bình phương trung bình (MSE) giúp dự đoán các biến liên tục.
for i in range(epochs):
total_loss = 0
context_state = Variable(torch.zeros((1, hidden_size)).type(dtype), requires_grad = True)
for j in range(x.size(0)):
input = x[j:(j+1)]
target = y[j:(j+1)]
(pred, context_state) = forward(input, context_state, w1, w2)
loss = (pred - target).pow(2).sum()/2
total_loss += loss
loss.backward()
w1.data -= lr * w1.grad.data
w2.data -= lr * w2.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
context_state = Variable(context_state.data)
if i % 10 == 0:
print("Epoch: {} loss {}".format(i, total_loss.data[0]))
context_state = Variable(torch.zeros((1, hidden_size)).type(dtype), requires_grad = False)
predictions = []
for i in range(x.size(0)):
input = x[i:i+1]
(pred, context_state) = forward(input, context_state, w1, w2)
context_state = context_state
predictions.append(pred.data.numpy().ravel()[0])Bước 6
Bây giờ, đã đến lúc vẽ biểu đồ sóng sin theo cách cần thiết.
pl.scatter(data_time_steps[:-1], x.data.numpy(), s = 90, label = "Actual")
pl.scatter(data_time_steps[1:], predictions, label = "Predicted")
pl.legend()
pl.show()Đầu ra
Đầu ra cho quá trình trên như sau:

Trong chương này, chúng tôi sẽ tập trung nhiều hơn vào torchvision.datasetsvà các loại khác nhau của nó. PyTorch bao gồm các bộ tải tập dữ liệu sau:
- MNIST
- COCO (Chú thích và phát hiện)
Tập dữ liệu bao gồm phần lớn hai loại chức năng được đưa ra dưới đây:
Transform- một chức năng nhận hình ảnh và trả về phiên bản đã sửa đổi của nội dung tiêu chuẩn. Chúng có thể được tạo cùng với các phép biến đổi.
Target_transform- một hàm lấy mục tiêu và biến đổi nó. Ví dụ: lấy chuỗi phụ đề và trả về hàng chục chỉ số thế giới.
MNIST
Sau đây là mã mẫu cho tập dữ liệu MNIST -
dset.MNIST(root, train = TRUE, transform = NONE,
target_transform = None, download = FALSE)Các thông số như sau:
root - thư mục gốc của tập dữ liệu nơi dữ liệu đã xử lý tồn tại.
train - Đúng = Tập huấn luyện, Sai = Tập kiểm tra
download - True = tải xuống tập dữ liệu từ internet và đặt nó vào thư mục gốc.
COCO
Điều này yêu cầu API COCO phải được cài đặt. Ví dụ sau được sử dụng để chứng minh việc triển khai COCO của tập dữ liệu bằng PyTorch:
import torchvision.dataset as dset
import torchvision.transforms as transforms
cap = dset.CocoCaptions(root = ‘ dir where images are’,
annFile = ’json annotation file’,
transform = transforms.ToTensor())
print(‘Number of samples: ‘, len(cap))
print(target)Kết quả đạt được như sau:
Number of samples: 82783
Image Size: (3L, 427L, 640L)Convents là tất cả về việc xây dựng mô hình CNN từ đầu. Kiến trúc mạng sẽ bao gồm sự kết hợp của các bước sau:
- Conv2d
- MaxPool2d
- Đơn vị tuyến tính chỉnh lưu
- View
- Lớp tuyến tính
Đào tạo người mẫu
Đào tạo mô hình là một quá trình giống như các bài toán phân loại ảnh. Đoạn mã sau hoàn thành quy trình của mô hình đào tạo trên tập dữ liệu được cung cấp -
def fit(epoch,model,data_loader,phase
= 'training',volatile = False):
if phase == 'training':
model.train()
if phase == 'training':
model.train()
if phase == 'validation':
model.eval()
volatile=True
running_loss = 0.0
running_correct = 0
for batch_idx , (data,target) in enumerate(data_loader):
if is_cuda:
data,target = data.cuda(),target.cuda()
data , target = Variable(data,volatile),Variable(target)
if phase == 'training':
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output,target)
running_loss + =
F.nll_loss(output,target,size_average =
False).data[0]
preds = output.data.max(dim = 1,keepdim = True)[1]
running_correct + =
preds.eq(target.data.view_as(preds)).cpu().sum()
if phase == 'training':
loss.backward()
optimizer.step()
loss = running_loss/len(data_loader.dataset)
accuracy = 100. * running_correct/len(data_loader.dataset)
print(f'{phase} loss is {loss:{5}.{2}} and {phase} accuracy is {running_correct}/{len(data_loader.dataset)}{accuracy:{return loss,accuracy}})Phương pháp này bao gồm các logic khác nhau để đào tạo và xác nhận. Có hai lý do chính để sử dụng các chế độ khác nhau -
Trong chế độ tàu, việc bỏ học sẽ loại bỏ một phần trăm giá trị, điều này sẽ không xảy ra trong giai đoạn xác nhận hoặc thử nghiệm.
Đối với chế độ đào tạo, chúng tôi tính toán độ dốc và thay đổi giá trị tham số của mô hình, nhưng không cần truyền ngược trong giai đoạn thử nghiệm hoặc xác nhận.
Trong chương này, chúng ta sẽ tập trung vào việc tạo một tu viện từ đầu. Điều này thể hiện trong việc tạo mạng nơ-ron mẫu hoặc quy ước tương ứng với đèn pin.
Bước 1
Tạo một lớp cần thiết với các tham số tương ứng. Các tham số bao gồm trọng số với giá trị ngẫu nhiên.
class Neural_Network(nn.Module):
def __init__(self, ):
super(Neural_Network, self).__init__()
self.inputSize = 2
self.outputSize = 1
self.hiddenSize = 3
# weights
self.W1 = torch.randn(self.inputSize,
self.hiddenSize) # 3 X 2 tensor
self.W2 = torch.randn(self.hiddenSize, self.outputSize) # 3 X 1 tensorBước 2
Tạo một mẫu chức năng chuyển tiếp nguồn cấp dữ liệu với các chức năng sigmoid.
def forward(self, X):
self.z = torch.matmul(X, self.W1) # 3 X 3 ".dot"
does not broadcast in PyTorch
self.z2 = self.sigmoid(self.z) # activation function
self.z3 = torch.matmul(self.z2, self.W2)
o = self.sigmoid(self.z3) # final activation
function
return o
def sigmoid(self, s):
return 1 / (1 + torch.exp(-s))
def sigmoidPrime(self, s):
# derivative of sigmoid
return s * (1 - s)
def backward(self, X, y, o):
self.o_error = y - o # error in output
self.o_delta = self.o_error * self.sigmoidPrime(o) # derivative of sig to error
self.z2_error = torch.matmul(self.o_delta, torch.t(self.W2))
self.z2_delta = self.z2_error * self.sigmoidPrime(self.z2)
self.W1 + = torch.matmul(torch.t(X), self.z2_delta)
self.W2 + = torch.matmul(torch.t(self.z2), self.o_delta)Bước 3
Tạo mô hình đào tạo và dự đoán như được đề cập bên dưới -
def train(self, X, y):
# forward + backward pass for training
o = self.forward(X)
self.backward(X, y, o)
def saveWeights(self, model):
# Implement PyTorch internal storage functions
torch.save(model, "NN")
# you can reload model with all the weights and so forth with:
# torch.load("NN")
def predict(self):
print ("Predicted data based on trained weights: ")
print ("Input (scaled): \n" + str(xPredicted))
print ("Output: \n" + str(self.forward(xPredicted)))Mạng nơ-ron hợp hiến bao gồm một tính năng chính, extraction. Các bước sau được sử dụng để thực hiện việc trích xuất tính năng của mạng nơ-ron tích tụ.
Bước 1
Nhập các mô hình tương ứng để tạo mô hình trích xuất đối tượng địa lý với “PyTorch”.
import torch
import torch.nn as nn
from torchvision import modelsBước 2
Tạo một lớp trích xuất tính năng có thể được gọi khi cần thiết.
class Feature_extractor(nn.module):
def forward(self, input):
self.feature = input.clone()
return input
new_net = nn.Sequential().cuda() # the new network
target_layers = [conv_1, conv_2, conv_4] # layers you want to extract`
i = 1
for layer in list(cnn):
if isinstance(layer,nn.Conv2d):
name = "conv_"+str(i)
art_net.add_module(name,layer)
if name in target_layers:
new_net.add_module("extractor_"+str(i),Feature_extractor())
i+=1
if isinstance(layer,nn.ReLU):
name = "relu_"+str(i)
new_net.add_module(name,layer)
if isinstance(layer,nn.MaxPool2d):
name = "pool_"+str(i)
new_net.add_module(name,layer)
new_net.forward(your_image)
print (new_net.extractor_3.feature)Trong chương này, chúng ta sẽ tập trung vào mô hình trực quan hóa dữ liệu với sự trợ giúp của các đối chiếu. Cần thực hiện các bước sau để có được một bức tranh trực quan hoàn hảo với mạng nơ-ron thông thường.
Bước 1
Nhập các mô-đun cần thiết quan trọng cho việc hiển thị các mạng nơ-ron thông thường.
import os
import numpy as np
import pandas as pd
from scipy.misc import imread
from sklearn.metrics import accuracy_score
import keras
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Flatten, Activation, Input
from keras.layers import Conv2D, MaxPooling2D
import torchBước 2
Để ngăn chặn sự ngẫu nhiên tiềm ẩn với dữ liệu đào tạo và thử nghiệm, hãy gọi tập dữ liệu tương ứng như được cung cấp trong đoạn mã bên dưới -
seed = 128
rng = np.random.RandomState(seed)
data_dir = "../../datasets/MNIST"
train = pd.read_csv('../../datasets/MNIST/train.csv')
test = pd.read_csv('../../datasets/MNIST/Test_fCbTej3.csv')
img_name = rng.choice(train.filename)
filepath = os.path.join(data_dir, 'train', img_name)
img = imread(filepath, flatten=True)Bước 3
Vẽ các hình ảnh cần thiết để có được dữ liệu đào tạo và kiểm tra được xác định một cách hoàn hảo bằng cách sử dụng đoạn mã dưới đây:
pylab.imshow(img, cmap ='gray')
pylab.axis('off')
pylab.show()Đầu ra được hiển thị như bên dưới -

Trong chương này, chúng tôi đề xuất một cách tiếp cận thay thế dựa trên một mạng nơ ron tích tụ 2D duy nhất trên cả hai chuỗi. Mỗi lớp trong mạng của chúng tôi mã lại mã nguồn trên cơ sở chuỗi đầu ra được tạo cho đến nay. Do đó, các thuộc tính giống như sự chú ý được phổ biến trên toàn mạng.
Ở đây, chúng tôi sẽ tập trung vào creating the sequential network with specific pooling from the values included in dataset. Quá trình này cũng được áp dụng tốt nhất trong “Mô-đun nhận dạng hình ảnh”.

Các bước sau được sử dụng để tạo mô hình xử lý trình tự với các chuyển đổi bằng PyTorch:
Bước 1
Nhập các mô-đun cần thiết để thực hiện xử lý trình tự bằng cách sử dụng chuyển đổi.
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
import numpy as npBước 2
Thực hiện các thao tác cần thiết để tạo một mẫu theo trình tự tương ứng bằng cách sử dụng đoạn mã dưới đây:
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000,28,28,1)
x_test = x_test.reshape(10000,28,28,1)
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)Bước 3
Biên dịch mô hình và phù hợp với mô hình trong mô hình mạng nơ-ron thông thường được đề cập như hình dưới đây:
model.compile(loss =
keras.losses.categorical_crossentropy,
optimizer = keras.optimizers.Adadelta(), metrics =
['accuracy'])
model.fit(x_train, y_train,
batch_size = batch_size, epochs = epochs,
verbose = 1, validation_data = (x_test, y_test))
score = model.evaluate(x_test, y_test, verbose = 0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])Đầu ra được tạo ra như sau:

Trong chương này, chúng ta sẽ hiểu về mô hình nhúng từ nổi tiếng - word2vec. Mô hình Word2vec được sử dụng để tạo nhúng từ với sự trợ giúp của nhóm các mô hình liên quan. Mô hình Word2vec được triển khai bằng mã C thuần túy và gradient được tính toán thủ công.
Việc triển khai mô hình word2vec trong PyTorch được giải thích trong các bước dưới đây:
Bước 1
Triển khai các thư viện trong nhúng từ như được đề cập bên dưới -
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as FBước 2
Triển khai Mô hình nhúng từ vựng Skip Gram với lớp có tên là word2vec. Nó bao gồmemb_size, emb_dimension, u_embedding, v_embedding loại thuộc tính.
class SkipGramModel(nn.Module):
def __init__(self, emb_size, emb_dimension):
super(SkipGramModel, self).__init__()
self.emb_size = emb_size
self.emb_dimension = emb_dimension
self.u_embeddings = nn.Embedding(emb_size, emb_dimension, sparse=True)
self.v_embeddings = nn.Embedding(emb_size, emb_dimension, sparse = True)
self.init_emb()
def init_emb(self):
initrange = 0.5 / self.emb_dimension
self.u_embeddings.weight.data.uniform_(-initrange, initrange)
self.v_embeddings.weight.data.uniform_(-0, 0)
def forward(self, pos_u, pos_v, neg_v):
emb_u = self.u_embeddings(pos_u)
emb_v = self.v_embeddings(pos_v)
score = torch.mul(emb_u, emb_v).squeeze()
score = torch.sum(score, dim = 1)
score = F.logsigmoid(score)
neg_emb_v = self.v_embeddings(neg_v)
neg_score = torch.bmm(neg_emb_v, emb_u.unsqueeze(2)).squeeze()
neg_score = F.logsigmoid(-1 * neg_score)
return -1 * (torch.sum(score)+torch.sum(neg_score))
def save_embedding(self, id2word, file_name, use_cuda):
if use_cuda:
embedding = self.u_embeddings.weight.cpu().data.numpy()
else:
embedding = self.u_embeddings.weight.data.numpy()
fout = open(file_name, 'w')
fout.write('%d %d\n' % (len(id2word), self.emb_dimension))
for wid, w in id2word.items():
e = embedding[wid]
e = ' '.join(map(lambda x: str(x), e))
fout.write('%s %s\n' % (w, e))
def test():
model = SkipGramModel(100, 100)
id2word = dict()
for i in range(100):
id2word[i] = str(i)
model.save_embedding(id2word)Bước 3
Triển khai phương thức chính để mô hình nhúng từ được hiển thị theo cách thích hợp.
if __name__ == '__main__':
test()Mạng nơ-ron sâu có một tính năng độc quyền cho phép tạo ra những đột phá trong việc học máy hiểu quá trình ngôn ngữ tự nhiên. Có thể quan sát thấy rằng hầu hết các mô hình này coi ngôn ngữ như một chuỗi các từ hoặc ký tự phẳng và sử dụng một loại mô hình được gọi là mạng nơ-ron lặp lại hoặc RNN.
Nhiều nhà nghiên cứu đi đến kết luận rằng ngôn ngữ được hiểu tốt nhất đối với cây phân cấp các cụm từ. Loại này được bao gồm trong mạng nơ-ron đệ quy có tính đến cấu trúc cụ thể.
PyTorch có một tính năng cụ thể giúp làm cho các mô hình xử lý ngôn ngữ tự nhiên phức tạp này dễ dàng hơn rất nhiều. Nó là một khuôn khổ đầy đủ tính năng cho tất cả các loại học sâu với sự hỗ trợ mạnh mẽ cho thị giác máy tính.
Các tính năng của mạng nơron đệ quy
Một mạng nơron đệ quy được tạo ra theo cách nó bao gồm việc áp dụng cùng một tập trọng số với các cấu trúc giống như đồ thị khác nhau.
Các nút được duyệt theo thứ tự tôpô.
Loại mạng này được đào tạo theo phương thức phân biệt tự động ngược lại.
Xử lý ngôn ngữ tự nhiên bao gồm một trường hợp đặc biệt của mạng nơron đệ quy.
Mạng tensor nơ ron đệ quy này bao gồm các nút chức năng thành phần khác nhau trong cây.
Ví dụ về mạng nơron đệ quy được trình bày dưới đây:
