R - Hướng dẫn nhanh
R là một ngôn ngữ lập trình và môi trường phần mềm để phân tích thống kê, biểu diễn đồ họa và báo cáo. R được tạo ra bởi Ross Ihaka và Robert Gentleman tại Đại học Auckland, New Zealand và hiện đang được phát triển bởi R Development Core Team.
Cốt lõi của R là một ngôn ngữ máy tính thông dịch cho phép phân nhánh và lặp lại cũng như lập trình mô-đun sử dụng các hàm. R cho phép tích hợp với các thủ tục được viết bằng ngôn ngữ C, C ++, .Net, Python hoặc FORTRAN để đạt hiệu quả.
R được cung cấp miễn phí theo Giấy phép Công cộng GNU và các phiên bản nhị phân được biên dịch trước được cung cấp cho các hệ điều hành khác nhau như Linux, Windows và Mac.
R là phần mềm miễn phí được phân phối dưới một bản sao kiểu GNU còn lại và là một phần chính thức của dự án GNU được gọi là GNU S.
Sự phát triển của R
R ban đầu được viết bởi Ross Ihaka và Robert Gentlemantại Khoa Thống kê của Đại học Auckland ở Auckland, New Zealand. R xuất hiện lần đầu tiên vào năm 1993.
Một nhóm lớn các cá nhân đã đóng góp cho R bằng cách gửi mã và báo cáo lỗi.
Kể từ giữa năm 1997 đã có một nhóm nòng cốt ("Nhóm lõi R") có thể sửa đổi kho lưu trữ mã nguồn R.
Đặc điểm của R
Như đã nêu trước đó, R là một ngôn ngữ lập trình và môi trường phần mềm để phân tích thống kê, biểu diễn đồ họa và báo cáo. Sau đây là các tính năng quan trọng của R -
R là một ngôn ngữ lập trình được phát triển tốt, đơn giản và hiệu quả bao gồm các điều kiện, vòng lặp, các hàm đệ quy do người dùng định nghĩa và các phương tiện đầu vào và đầu ra.
R có một phương tiện lưu trữ và xử lý dữ liệu hiệu quả,
R cung cấp một bộ toán tử để tính toán trên mảng, danh sách, vectơ và ma trận.
R cung cấp một bộ sưu tập lớn, chặt chẽ và tích hợp các công cụ để phân tích dữ liệu.
R cung cấp các phương tiện đồ họa để phân tích dữ liệu và hiển thị trực tiếp trên máy tính hoặc in ra giấy.
Kết luận, R là ngôn ngữ lập trình thống kê được sử dụng rộng rãi nhất trên thế giới. Đây là sự lựa chọn số 1 của các nhà khoa học dữ liệu và được hỗ trợ bởi một cộng đồng những người đóng góp sôi nổi và tài năng. R được giảng dạy trong các trường đại học và được triển khai trong các ứng dụng kinh doanh quan trọng. Hướng dẫn này sẽ dạy bạn lập trình R cùng với các ví dụ phù hợp theo các bước đơn giản và dễ dàng.
Thiết lập môi trường cục bộ
Nếu bạn vẫn sẵn sàng thiết lập môi trường của mình cho R, bạn có thể làm theo các bước dưới đây.
Cài đặt Windows
Bạn có thể tải xuống phiên bản trình cài đặt Windows của R từ R-3.2.2 dành cho Windows (32/64 bit) và lưu nó trong thư mục cục bộ.
Vì nó là một trình cài đặt Windows (.exe) với tên "R-version-win.exe". Bạn chỉ cần nhấp đúp và chạy trình cài đặt chấp nhận cài đặt mặc định. Nếu Windows của bạn là phiên bản 32 bit, nó sẽ cài đặt phiên bản 32 bit. Nhưng nếu cửa sổ của bạn là 64-bit, thì nó sẽ cài đặt cả phiên bản 32-bit và 64-bit.
Sau khi cài đặt, bạn có thể tìm biểu tượng để chạy Chương trình trong cấu trúc thư mục "R \ R3.2.2 \ bin \ i386 \ Rgui.exe" trong Tệp chương trình Windows. Nhấp vào biểu tượng này sẽ xuất hiện R-GUI, đây là bảng điều khiển R để thực hiện Lập trình R.
Cài đặt Linux
R có sẵn dưới dạng tệp nhị phân cho nhiều phiên bản Linux tại vị trí R Binaries .
Hướng dẫn cài đặt Linux khác nhau tùy theo từng phiên bản. Các bước này được đề cập dưới mỗi loại phiên bản Linux trong liên kết được đề cập. Tuy nhiên, nếu bạn đang vội, thì bạn có thể sử dụngyum lệnh cài đặt R như sau:
$ yum install RLệnh trên sẽ cài đặt chức năng cốt lõi của lập trình R cùng với các gói tiêu chuẩn, bạn vẫn cần gói bổ sung thì có thể khởi chạy dấu nhắc R như sau:
$ R
R version 3.2.0 (2015-04-16) -- "Full of Ingredients"
Copyright (C) 2015 The R Foundation for Statistical Computing
Platform: x86_64-redhat-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under certain conditions.
Type 'license()' or 'licence()' for distribution details.
R is a collaborative project with many contributors.
Type 'contributors()' for more information and
'citation()' on how to cite R or R packages in publications.
Type 'demo()' for some demos, 'help()' for on-line help, or
'help.start()' for an HTML browser interface to help.
Type 'q()' to quit R.
>Bây giờ bạn có thể sử dụng lệnh install tại dấu nhắc R để cài đặt gói cần thiết. Ví dụ: lệnh sau sẽ cài đặtplotrix gói cần thiết cho biểu đồ 3D.
> install.packages("plotrix")Theo quy ước, chúng ta sẽ bắt đầu học lập trình R bằng cách viết câu "Xin chào, Thế giới!" chương trình. Tùy thuộc vào nhu cầu, bạn có thể lập trình tại dấu nhắc lệnh R hoặc bạn có thể sử dụng tệp kịch bản R để viết chương trình của mình. Hãy kiểm tra từng cái một.
R Command Prompt
Khi bạn đã thiết lập môi trường R, thì thật dễ dàng để bắt đầu dấu nhắc lệnh R của bạn bằng cách chỉ cần gõ lệnh sau tại dấu nhắc lệnh của bạn:
$ RThao tác này sẽ khởi chạy trình thông dịch R và bạn sẽ nhận được lời nhắc> nơi bạn có thể bắt đầu nhập chương trình của mình như sau:
> myString <- "Hello, World!"
> print ( myString)
[1] "Hello, World!"Đây là câu lệnh đầu tiên xác định một biến chuỗi myString, nơi chúng tôi gán một chuỗi "Hello, World!" và sau đó câu lệnh tiếp theo print () đang được sử dụng để in giá trị được lưu trữ trong biến myString.
Tập lệnh R
Thông thường, bạn sẽ thực hiện lập trình của mình bằng cách viết chương trình của mình trong các tệp tập lệnh và sau đó bạn thực thi các tập lệnh đó tại dấu nhắc lệnh của mình với sự trợ giúp của trình thông dịch R được gọi là Rscript. Vì vậy, hãy bắt đầu với việc viết mã sau trong một tệp văn bản có tên là test.R như sau:
# My first program in R Programming
myString <- "Hello, World!"
print ( myString)Lưu đoạn mã trên trong tệp test.R và thực thi nó tại dấu nhắc lệnh Linux như được đưa ra bên dưới. Ngay cả khi bạn đang sử dụng Windows hoặc hệ thống khác, cú pháp sẽ vẫn như cũ.
$ Rscript test.RKhi chúng ta chạy chương trình trên, nó tạo ra kết quả như sau.
[1] "Hello, World!"Bình luận
Nhận xét giống như văn bản trợ giúp trong chương trình R của bạn và chúng bị trình thông dịch bỏ qua trong khi thực hiện chương trình thực tế của bạn. Nhận xét đơn được viết bằng # ở đầu câu lệnh như sau:
# My first program in R ProgrammingR không hỗ trợ nhận xét nhiều dòng nhưng bạn có thể thực hiện một thủ thuật như sau:
if(FALSE) {
"This is a demo for multi-line comments and it should be put inside either a
single OR double quote"
}
myString <- "Hello, World!"
print ( myString)[1] "Hello, World!"Mặc dù các nhận xét trên sẽ được thực thi bởi trình thông dịch R, chúng sẽ không can thiệp vào chương trình thực tế của bạn. Bạn nên đặt những bình luận như vậy bên trong, trích dẫn đơn hoặc trích dẫn kép.
Nói chung, trong khi lập trình bằng bất kỳ ngôn ngữ lập trình nào, bạn cần sử dụng các biến khác nhau để lưu trữ các thông tin khác nhau. Các biến không là gì ngoài các vị trí bộ nhớ dành riêng để lưu trữ các giá trị. Điều này có nghĩa là, khi bạn tạo một biến, bạn dự trữ một số không gian trong bộ nhớ.
Bạn có thể muốn lưu trữ thông tin của nhiều kiểu dữ liệu khác nhau như ký tự, ký tự rộng, số nguyên, dấu phẩy động, dấu chấm động kép, Boolean, v.v. Dựa trên kiểu dữ liệu của một biến, hệ điều hành phân bổ bộ nhớ và quyết định những gì có thể được lưu trữ trong bộ nhớ dành riêng.
Ngược lại với các ngôn ngữ lập trình khác như C và java trong R, các biến không được khai báo dưới dạng một số kiểu dữ liệu. Các biến được gán với đối tượng R và kiểu dữ liệu của đối tượng R trở thành kiểu dữ liệu của biến. Có nhiều loại R-object. Những cái thường được sử dụng là -
- Vectors
- Lists
- Matrices
- Arrays
- Factors
- Khung dữ liệu
Đơn giản nhất của những đối tượng này là vector objectvà có sáu kiểu dữ liệu của các vectơ nguyên tử này, còn được gọi là sáu loại vectơ. Các đối tượng R khác được xây dựng dựa trên các vectơ nguyên tử.
| Loại dữ liệu | Thí dụ | Kiểm chứng |
|---|---|---|
| Hợp lý | ĐÚNG SAI |
nó tạo ra kết quả sau: |
| Số | 12,3, 5, 999 |
nó tạo ra kết quả sau: |
| Số nguyên | 2L, 34L, 0L |
nó tạo ra kết quả sau: |
| Phức tạp | 3 + 2i |
nó tạo ra kết quả sau: |
| Tính cách | 'a', "tốt", "TRUE", '23 .4 ' |
nó tạo ra kết quả sau: |
| Nguyên | "Xin chào" được lưu trữ dưới dạng 48 65 6c 6c 6f |
nó tạo ra kết quả sau: |
Trong lập trình R, các kiểu dữ liệu cơ bản là các đối tượng R được gọi là vectorschứa các phần tử của các lớp khác nhau như được hiển thị ở trên. Xin lưu ý trong R, số lượng các lớp không chỉ giới hạn trong sáu loại trên. Ví dụ, chúng ta có thể sử dụng nhiều vectơ nguyên tử và tạo một mảng mà lớp của nó sẽ trở thành mảng.
Vectơ
Khi bạn muốn tạo vectơ có nhiều hơn một phần tử, bạn nên sử dụng c() có nghĩa là kết hợp các phần tử thành một vectơ.
# Create a vector.
apple <- c('red','green',"yellow")
print(apple)
# Get the class of the vector.
print(class(apple))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] "red" "green" "yellow"
[1] "character"Danh sách
Danh sách là một đối tượng R có thể chứa nhiều loại phần tử khác nhau bên trong nó như vectơ, hàm và thậm chí là một danh sách khác bên trong nó.
# Create a list.
list1 <- list(c(2,5,3),21.3,sin)
# Print the list.
print(list1)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[[1]]
[1] 2 5 3
[[2]]
[1] 21.3
[[3]]
function (x) .Primitive("sin")Ma trận
Ma trận là một tập dữ liệu hình chữ nhật hai chiều. Nó có thể được tạo bằng cách sử dụng đầu vào là vector cho hàm ma trận.
# Create a matrix.
M = matrix( c('a','a','b','c','b','a'), nrow = 2, ncol = 3, byrow = TRUE)
print(M)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[,1] [,2] [,3]
[1,] "a" "a" "b"
[2,] "c" "b" "a"Mảng
Trong khi ma trận được giới hạn trong hai chiều, mảng có thể có bất kỳ số thứ nguyên nào. Hàm mảng nhận thuộc tính dim tạo ra số thứ nguyên cần thiết. Trong ví dụ dưới đây, chúng ta tạo một mảng có hai phần tử là ma trận 3x3 mỗi phần tử.
# Create an array.
a <- array(c('green','yellow'),dim = c(3,3,2))
print(a)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
, , 1
[,1] [,2] [,3]
[1,] "green" "yellow" "green"
[2,] "yellow" "green" "yellow"
[3,] "green" "yellow" "green"
, , 2
[,1] [,2] [,3]
[1,] "yellow" "green" "yellow"
[2,] "green" "yellow" "green"
[3,] "yellow" "green" "yellow"Các nhân tố
Yếu tố là các đối tượng r được tạo ra bằng cách sử dụng một vectơ. Nó lưu trữ vector cùng với các giá trị riêng biệt của các phần tử trong vector dưới dạng nhãn. Các nhãn luôn là ký tự bất kể nó là số hay ký tự hoặc Boolean, v.v. trong vectơ đầu vào. Chúng hữu ích trong mô hình thống kê.
Các yếu tố được tạo ra bằng cách sử dụng factor()chức năng. Cácnlevels hàm cung cấp số lượng cấp độ.
# Create a vector.
apple_colors <- c('green','green','yellow','red','red','red','green')
# Create a factor object.
factor_apple <- factor(apple_colors)
# Print the factor.
print(factor_apple)
print(nlevels(factor_apple))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] green green yellow red red red green
Levels: green red yellow
[1] 3Khung dữ liệu
Khung dữ liệu là các đối tượng dữ liệu dạng bảng. Không giống như ma trận trong khung dữ liệu, mỗi cột có thể chứa các chế độ dữ liệu khác nhau. Cột đầu tiên có thể là số trong khi cột thứ hai có thể là ký tự và cột thứ ba có thể là lôgic. Nó là một danh sách các vectơ có độ dài bằng nhau.
Khung dữ liệu được tạo bằng cách sử dụng data.frame() chức năng.
# Create the data frame.
BMI <- data.frame(
gender = c("Male", "Male","Female"),
height = c(152, 171.5, 165),
weight = c(81,93, 78),
Age = c(42,38,26)
)
print(BMI)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
gender height weight Age
1 Male 152.0 81 42
2 Male 171.5 93 38
3 Female 165.0 78 26Một biến cung cấp cho chúng ta bộ nhớ được đặt tên mà chương trình của chúng ta có thể thao tác. Một biến trong R có thể lưu trữ một vectơ nguyên tử, một nhóm vectơ nguyên tử hoặc một tổ hợp của nhiều Robject. Tên biến hợp lệ bao gồm các chữ cái, số và các ký tự dấu chấm hoặc gạch dưới. Tên biến bắt đầu bằng một chữ cái hoặc dấu chấm, không theo sau là số.
| Tên biến | Hiệu lực | Lý do |
|---|---|---|
| var_name2. | có hiệu lực | Có chữ cái, số, dấu chấm và dấu gạch dưới |
| var_name% | không hợp lệ | Có ký tự '%'. Chỉ cho phép dấu chấm (.) Và dấu gạch dưới. |
| 2var_name | không hợp lệ | Bắt đầu bằng một số |
.var_name, var.name |
có hiệu lực | Có thể bắt đầu bằng dấu chấm (.) Nhưng dấu chấm (.) Không được theo sau bằng số. |
| .2var_name | không hợp lệ | Dấu chấm bắt đầu được theo sau bởi một số làm cho nó không hợp lệ. |
| _var_name | không hợp lệ | Bắt đầu bằng _ không hợp lệ |
Chuyển nhượng biến
Các biến có thể được gán giá trị bằng toán tử sang trái, sang phải và bằng. Giá trị của các biến có thể được in bằng cách sử dụngprint() hoặc là cat()chức năng. Cáccat() chức năng kết hợp nhiều mục thành một đầu ra in liên tục.
# Assignment using equal operator.
var.1 = c(0,1,2,3)
# Assignment using leftward operator.
var.2 <- c("learn","R")
# Assignment using rightward operator.
c(TRUE,1) -> var.3
print(var.1)
cat ("var.1 is ", var.1 ,"\n")
cat ("var.2 is ", var.2 ,"\n")
cat ("var.3 is ", var.3 ,"\n")Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 0 1 2 3
var.1 is 0 1 2 3
var.2 is learn R
var.3 is 1 1Note- Vectơ c (TRUE, 1) có hỗn hợp của lớp logic và lớp số. Vì vậy, lớp logic bị ép buộc với lớp số làm TRUE là 1.
Loại dữ liệu của một biến
Trong R, bản thân một biến không được khai báo kiểu dữ liệu nào, thay vào đó, nó nhận kiểu dữ liệu của đối tượng R được gán cho nó. Vì vậy R được gọi là ngôn ngữ kiểu động, có nghĩa là chúng ta có thể thay đổi kiểu dữ liệu của một biến của cùng một biến khi sử dụng nó trong một chương trình.
var_x <- "Hello"
cat("The class of var_x is ",class(var_x),"\n")
var_x <- 34.5
cat(" Now the class of var_x is ",class(var_x),"\n")
var_x <- 27L
cat(" Next the class of var_x becomes ",class(var_x),"\n")Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
The class of var_x is character
Now the class of var_x is numeric
Next the class of var_x becomes integerTìm biến
Để biết tất cả các biến hiện có trong không gian làm việc, chúng tôi sử dụng ls()chức năng. Ngoài ra, hàm ls () có thể sử dụng các mẫu để khớp với tên biến.
print(ls())Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] "my var" "my_new_var" "my_var" "var.1"
[5] "var.2" "var.3" "var.name" "var_name2."
[9] "var_x" "varname"Note - Đây là đầu ra mẫu tùy thuộc vào những biến nào được khai báo trong môi trường của bạn.
Hàm ls () có thể sử dụng các mẫu để khớp với tên biến.
# List the variables starting with the pattern "var".
print(ls(pattern = "var"))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] "my var" "my_new_var" "my_var" "var.1"
[5] "var.2" "var.3" "var.name" "var_name2."
[9] "var_x" "varname"Các biến bắt đầu bằng dot(.) bị ẩn, chúng có thể được liệt kê bằng cách sử dụng đối số "all.names = TRUE" cho hàm ls ().
print(ls(all.name = TRUE))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] ".cars" ".Random.seed" ".var_name" ".varname" ".varname2"
[6] "my var" "my_new_var" "my_var" "var.1" "var.2"
[11]"var.3" "var.name" "var_name2." "var_x"Xóa các biến
Có thể xóa các biến bằng cách sử dụng rm()chức năng. Dưới đây chúng tôi xóa biến var.3. Khi in giá trị của lỗi biến được ném ra.
rm(var.3)
print(var.3)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] "var.3"
Error in print(var.3) : object 'var.3' not foundTất cả các biến có thể bị xóa bằng cách sử dụng rm() và ls() cùng chức năng.
rm(list = ls())
print(ls())Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
character(0)Một toán tử là một ký hiệu yêu cầu trình biên dịch thực hiện các thao tác toán học hoặc logic cụ thể. Ngôn ngữ R có nhiều toán tử cài sẵn và cung cấp các loại toán tử sau.
Các loại nhà điều hành
Chúng ta có các loại toán tử sau trong lập trình R:
- Toán tử số học
- Toán tử quan hệ
- Toán tử logic
- Người điều hành nhiệm vụ
- Các nhà khai thác khác
Toán tử số học
Bảng sau đây cho thấy các toán tử số học được ngôn ngữ R hỗ trợ. Các toán tử tác động lên từng phần tử của vectơ.
| Nhà điều hành | Sự miêu tả | Thí dụ |
|---|---|---|
| + | Thêm hai vectơ |
nó tạo ra kết quả sau: |
| - | Trừ vectơ thứ hai khỏi vectơ thứ nhất |
nó tạo ra kết quả sau: |
| * | Nhân cả hai vectơ |
nó tạo ra kết quả sau: |
| / | Chia vectơ đầu tiên với vectơ thứ hai |
Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau: |
| %% | Cho phần còn lại của vectơ thứ nhất với vectơ thứ hai |
nó tạo ra kết quả sau: |
| % /% | Kết quả của phép chia vector thứ nhất với thứ hai (thương số) |
nó tạo ra kết quả sau: |
| ^ | Vectơ đầu tiên được nâng lên thành số mũ của vectơ thứ hai |
nó tạo ra kết quả sau: |
Toán tử quan hệ
Bảng sau đây cho thấy các toán tử quan hệ được hỗ trợ bởi ngôn ngữ R. Mỗi phần tử của vectơ đầu tiên được so sánh với phần tử tương ứng của vectơ thứ hai. Kết quả của phép so sánh là một giá trị Boolean.
| Nhà điều hành | Sự miêu tả | Thí dụ |
|---|---|---|
| > | Kiểm tra xem mỗi phần tử của vectơ đầu tiên có lớn hơn phần tử tương ứng của vectơ thứ hai hay không. |
nó tạo ra kết quả sau: |
| < | Kiểm tra xem mỗi phần tử của vectơ đầu tiên có nhỏ hơn phần tử tương ứng của vectơ thứ hai hay không. |
nó tạo ra kết quả sau: |
| == | Kiểm tra xem mỗi phần tử của vectơ đầu tiên có bằng với phần tử tương ứng của vectơ thứ hai hay không. |
nó tạo ra kết quả sau: |
| <= | Kiểm tra xem mỗi phần tử của vectơ đầu tiên nhỏ hơn hoặc bằng phần tử tương ứng của vectơ thứ hai. |
nó tạo ra kết quả sau: |
| > = | Kiểm tra xem mỗi phần tử của vectơ đầu tiên có lớn hơn hoặc bằng phần tử tương ứng của vectơ thứ hai hay không. |
nó tạo ra kết quả sau: |
| ! = | Kiểm tra xem mỗi phần tử của vectơ đầu tiên có bằng với phần tử tương ứng của vectơ thứ hai hay không. |
nó tạo ra kết quả sau: |
Toán tử logic
Bảng sau đây cho thấy các toán tử logic được hỗ trợ bởi ngôn ngữ R. Nó chỉ áp dụng cho các vectơ kiểu lôgic, số hoặc phức. Tất cả các số lớn hơn 1 được coi là giá trị logic ĐÚNG.
Mỗi phần tử của vectơ đầu tiên được so sánh với phần tử tương ứng của vectơ thứ hai. Kết quả của phép so sánh là một giá trị Boolean.
| Nhà điều hành | Sự miêu tả | Thí dụ |
|---|---|---|
| & | Nó được gọi là toán tử logic AND nguyên tố. Nó kết hợp từng phần tử của vectơ đầu tiên với phần tử tương ứng của vectơ thứ hai và cho kết quả là TRUE nếu cả hai phần tử đều ĐÚNG. |
nó tạo ra kết quả sau: |
| | | Nó được gọi là toán tử logic HOẶC yếu tố khôn ngoan. Nó kết hợp từng phần tử của vectơ đầu tiên với phần tử tương ứng của vectơ thứ hai và cho ra kết quả TRUE nếu một trong các phần tử là ĐÚNG. |
nó tạo ra kết quả sau: |
| ! | Nó được gọi là toán tử logic NOT. Lấy từng phần tử của vectơ và cho giá trị lôgic ngược lại. |
nó tạo ra kết quả sau: |
Toán tử logic && và || chỉ xem xét phần tử đầu tiên của các vectơ và cho một vectơ gồm một phần tử duy nhất làm đầu ra.
| Nhà điều hành | Sự miêu tả | Thí dụ |
|---|---|---|
| && | Được gọi là toán tử logic AND. Lấy phần tử đầu tiên của cả hai vectơ và chỉ đưa ra giá trị TRUE nếu cả hai đều là ĐÚNG. |
nó tạo ra kết quả sau: |
| || | Được gọi là toán tử logic HOẶC. Lấy phần tử đầu tiên của cả hai vectơ và cho giá trị TRUE nếu một trong số chúng là TRUE. |
nó tạo ra kết quả sau: |
Người điều hành nhiệm vụ
Các toán tử này được sử dụng để gán giá trị cho vectơ.
| Nhà điều hành | Sự miêu tả | Thí dụ |
|---|---|---|
| <- hoặc là = hoặc là << - |
Được gọi là nhiệm vụ trái |
nó tạo ra kết quả sau: |
| -> hoặc là - >> |
Được gọi là Chuyển nhượng Đúng |
nó tạo ra kết quả sau: |
Các nhà khai thác khác
Các toán tử này được sử dụng cho mục đích cụ thể chứ không phải tính toán toán học hoặc logic chung chung.
| Nhà điều hành | Sự miêu tả | Thí dụ |
|---|---|---|
| : | Toán tử đại tràng. Nó tạo ra chuỗi số theo thứ tự cho một vectơ. |
nó tạo ra kết quả sau: |
| %trong% | Toán tử này được sử dụng để xác định xem một phần tử có thuộc vectơ hay không. |
nó tạo ra kết quả sau: |
| % *% | Toán tử này được sử dụng để nhân một ma trận với chuyển vị của nó. |
nó tạo ra kết quả sau: |
Cấu trúc ra quyết định yêu cầu người lập trình chỉ định một hoặc nhiều điều kiện để được đánh giá hoặc kiểm tra bởi chương trình, cùng với một câu lệnh hoặc các câu lệnh sẽ được thực thi nếu điều kiện đó được xác định là truevà tùy chọn, các câu lệnh khác sẽ được thực thi nếu điều kiện được xác định là false.
Sau đây là dạng chung của cấu trúc ra quyết định điển hình được tìm thấy trong hầu hết các ngôn ngữ lập trình:
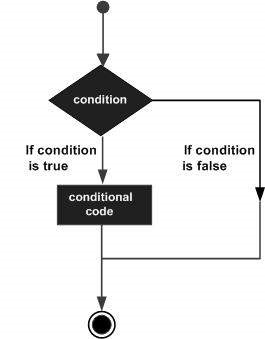
R cung cấp các loại câu lệnh ra quyết định sau đây. Nhấp vào các liên kết sau để kiểm tra chi tiết của chúng.
| Sr.No. | Tuyên bố & Mô tả |
|---|---|
| 1 | câu lệnh if An if câu lệnh bao gồm một biểu thức Boolean theo sau là một hoặc nhiều câu lệnh. |
| 2 | câu lệnh if ... else An if câu lệnh có thể được theo sau bởi một tùy chọn else câu lệnh này thực thi khi biểu thức Boolean sai. |
| 3 | chuyển đổi tuyên bố A switch câu lệnh cho phép một biến được kiểm tra tính bình đẳng với một danh sách các giá trị. |
Có thể có một tình huống khi bạn cần thực thi một khối mã nhiều lần. Nói chung, các câu lệnh được thực hiện tuần tự. Câu lệnh đầu tiên trong một hàm được thực thi đầu tiên, tiếp theo là câu lệnh thứ hai, v.v.
Các ngôn ngữ lập trình cung cấp các cấu trúc điều khiển khác nhau cho phép các đường dẫn thực thi phức tạp hơn.
Câu lệnh lặp cho phép chúng ta thực hiện một câu lệnh hoặc một nhóm câu lệnh nhiều lần và sau đây là dạng chung của câu lệnh lặp trong hầu hết các ngôn ngữ lập trình:
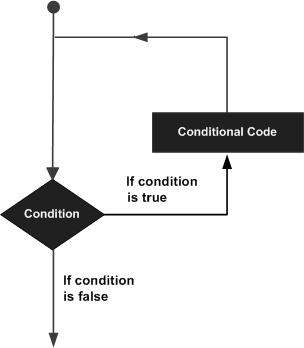
Ngôn ngữ lập trình R cung cấp các loại vòng lặp sau để xử lý các yêu cầu lặp. Nhấp vào các liên kết sau để kiểm tra chi tiết của chúng.
| Sr.No. | Loại vòng lặp & Mô tả |
|---|---|
| 1 | lặp lại vòng lặp Thực thi một chuỗi các câu lệnh nhiều lần và viết tắt mã quản lý biến vòng lặp. |
| 2 | trong khi lặp lại Lặp lại một câu lệnh hoặc một nhóm câu lệnh trong khi một điều kiện đã cho là đúng. Nó kiểm tra điều kiện trước khi thực thi phần thân của vòng lặp. |
| 3 | vòng lặp for Giống như một câu lệnh while, ngoại trừ việc nó kiểm tra điều kiện ở cuối thân vòng lặp. |
Tuyên bố kiểm soát vòng lặp
Các câu lệnh điều khiển vòng lặp thay đổi việc thực thi từ trình tự bình thường của nó. Khi việc thực thi rời khỏi một phạm vi, tất cả các đối tượng tự động được tạo trong phạm vi đó sẽ bị phá hủy.
R hỗ trợ các câu lệnh điều khiển sau. Nhấp vào các liên kết sau để kiểm tra chi tiết của chúng.
| Sr.No. | Tuyên bố & Mô tả Kiểm soát |
|---|---|
| 1 | tuyên bố ngắt Chấm dứt loop câu lệnh và chuyển việc thực thi câu lệnh ngay sau vòng lặp. |
| 2 | Tuyên bố tiếp theo Các next câu lệnh mô phỏng hành vi của công tắc R. |
Hàm là một tập hợp các câu lệnh được tổ chức lại với nhau để thực hiện một nhiệm vụ cụ thể. R có một số lượng lớn các chức năng được tích hợp sẵn và người dùng có thể tạo các chức năng của riêng họ.
Trong R, một hàm là một đối tượng nên trình thông dịch R có thể chuyển quyền điều khiển cho hàm, cùng với các đối số có thể cần thiết để hàm thực hiện các hành động.
Đến lượt nó, hàm thực hiện nhiệm vụ của nó và trả lại quyền điều khiển cho trình thông dịch cũng như bất kỳ kết quả nào có thể được lưu trữ trong các đối tượng khác.
Định nghĩa hàm
Một hàm R được tạo bằng cách sử dụng từ khóa function. Cú pháp cơ bản của định nghĩa hàm R như sau:
function_name <- function(arg_1, arg_2, ...) {
Function body
}Các thành phần chức năng
Các phần khác nhau của một hàm là -
Function Name- Đây là tên thực của hàm. Nó được lưu trữ trong môi trường R như một đối tượng với tên này.
Arguments- Một đối số là một trình giữ chỗ. Khi một hàm được gọi, bạn truyền một giá trị cho đối số. Đối số là tùy chọn; nghĩa là, một hàm có thể không chứa đối số. Ngoài ra, các đối số có thể có giá trị mặc định.
Function Body - Phần thân của hàm chứa một tập hợp các câu lệnh xác định những gì hàm thực hiện.
Return Value - Giá trị trả về của một hàm là biểu thức cuối cùng trong thân hàm được đánh giá.
R có nhiều in-builtcác hàm có thể được gọi trực tiếp trong chương trình mà không cần xác định chúng trước. Chúng tôi cũng có thể tạo và sử dụng các chức năng của riêng mình, được gọi làuser defined chức năng.
Chức năng tích hợp
Ví dụ đơn giản về các hàm tích hợp là seq(), mean(), max(), sum(x) và paste(...)vv Chúng được gọi trực tiếp bởi các chương trình do người dùng viết. Bạn có thể tham khảo các hàm R được sử dụng rộng rãi nhất.
# Create a sequence of numbers from 32 to 44.
print(seq(32,44))
# Find mean of numbers from 25 to 82.
print(mean(25:82))
# Find sum of numbers frm 41 to 68.
print(sum(41:68))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 32 33 34 35 36 37 38 39 40 41 42 43 44
[1] 53.5
[1] 1526Chức năng do người dùng xác định
Chúng ta có thể tạo các hàm do người dùng định nghĩa trong R. Chúng cụ thể cho những gì người dùng muốn và sau khi được tạo, chúng có thể được sử dụng giống như các hàm tích hợp sẵn. Dưới đây là một ví dụ về cách một hàm được tạo và sử dụng.
# Create a function to print squares of numbers in sequence.
new.function <- function(a) {
for(i in 1:a) {
b <- i^2
print(b)
}
}Gọi một hàm
# Create a function to print squares of numbers in sequence.
new.function <- function(a) {
for(i in 1:a) {
b <- i^2
print(b)
}
}
# Call the function new.function supplying 6 as an argument.
new.function(6)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 1
[1] 4
[1] 9
[1] 16
[1] 25
[1] 36Gọi một hàm mà không cần đối số
# Create a function without an argument.
new.function <- function() {
for(i in 1:5) {
print(i^2)
}
}
# Call the function without supplying an argument.
new.function()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 1
[1] 4
[1] 9
[1] 16
[1] 25Gọi một hàm với các giá trị đối số (theo vị trí và theo tên)
Các đối số cho một lệnh gọi hàm có thể được cung cấp theo cùng một trình tự như được định nghĩa trong hàm hoặc chúng có thể được cung cấp theo một trình tự khác nhưng được gán cho tên của các đối số.
# Create a function with arguments.
new.function <- function(a,b,c) {
result <- a * b + c
print(result)
}
# Call the function by position of arguments.
new.function(5,3,11)
# Call the function by names of the arguments.
new.function(a = 11, b = 5, c = 3)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 26
[1] 58Gọi một hàm với đối số mặc định
Chúng ta có thể xác định giá trị của các đối số trong định nghĩa hàm và gọi hàm mà không cần cung cấp bất kỳ đối số nào để lấy kết quả mặc định. Nhưng chúng ta cũng có thể gọi các hàm như vậy bằng cách cung cấp các giá trị mới của đối số và nhận kết quả không mặc định.
# Create a function with arguments.
new.function <- function(a = 3, b = 6) {
result <- a * b
print(result)
}
# Call the function without giving any argument.
new.function()
# Call the function with giving new values of the argument.
new.function(9,5)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 18
[1] 45Đánh giá chức năng lười biếng
Các đối số cho các hàm được đánh giá một cách lười biếng, có nghĩa là chúng chỉ được đánh giá khi cần thiết bởi thân hàm.
# Create a function with arguments.
new.function <- function(a, b) {
print(a^2)
print(a)
print(b)
}
# Evaluate the function without supplying one of the arguments.
new.function(6)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 36
[1] 6
Error in print(b) : argument "b" is missing, with no defaultBất kỳ giá trị nào được viết trong một cặp dấu nháy đơn hoặc dấu nháy kép trong R đều được coi là một chuỗi. Bên trong R lưu trữ mọi chuỗi trong dấu ngoặc kép, ngay cả khi bạn tạo chúng bằng dấu nháy đơn.
Các quy tắc được áp dụng trong xây dựng chuỗi
Các dấu ngoặc kép ở đầu và cuối chuỗi phải là cả hai dấu ngoặc kép hoặc cả hai dấu ngoặc kép. Chúng không thể được trộn lẫn.
Dấu ngoặc kép có thể được chèn vào một chuỗi bắt đầu và kết thúc bằng dấu ngoặc kép.
Dấu ngoặc kép có thể được chèn vào một chuỗi bắt đầu và kết thúc bằng dấu ngoặc kép.
Không thể chèn dấu ngoặc kép vào một chuỗi bắt đầu và kết thúc bằng dấu ngoặc kép.
Không thể chèn một dấu ngoặc kép vào một chuỗi bắt đầu và kết thúc bằng một dấu ngoặc kép.
Ví dụ về chuỗi hợp lệ
Các ví dụ sau làm rõ các quy tắc về cách tạo một chuỗi trong R.
a <- 'Start and end with single quote'
print(a)
b <- "Start and end with double quotes"
print(b)
c <- "single quote ' in between double quotes"
print(c)
d <- 'Double quotes " in between single quote'
print(d)Khi đoạn mã trên được chạy, chúng tôi nhận được kết quả sau:
[1] "Start and end with single quote"
[1] "Start and end with double quotes"
[1] "single quote ' in between double quote"
[1] "Double quote \" in between single quote"Ví dụ về chuỗi không hợp lệ
e <- 'Mixed quotes"
print(e)
f <- 'Single quote ' inside single quote'
print(f)
g <- "Double quotes " inside double quotes"
print(g)Khi chúng tôi chạy tập lệnh, nó không cho kết quả bên dưới.
Error: unexpected symbol in:
"print(e)
f <- 'Single"
Execution haltedThao tác chuỗi
Nối chuỗi - hàm paste ()
Nhiều chuỗi trong R được kết hợp bằng cách sử dụng paste()chức năng. Có thể lấy bất kỳ số lượng đối số nào để được kết hợp với nhau.
Cú pháp
Cú pháp cơ bản cho hàm dán là:
paste(..., sep = " ", collapse = NULL)Sau đây là mô tả về các tham số được sử dụng:
... đại diện cho bất kỳ số lượng đối số được kết hợp.
sepđại diện cho bất kỳ dấu phân cách nào giữa các đối số. Nó là tùy chọn.
collapseđược sử dụng để loại bỏ khoảng cách giữa hai chuỗi. Nhưng không phải là khoảng trắng trong hai từ của một chuỗi.
Thí dụ
a <- "Hello"
b <- 'How'
c <- "are you? "
print(paste(a,b,c))
print(paste(a,b,c, sep = "-"))
print(paste(a,b,c, sep = "", collapse = ""))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] "Hello How are you? "
[1] "Hello-How-are you? "
[1] "HelloHoware you? "Định dạng số & chuỗi - hàm format ()
Các số và chuỗi có thể được định dạng theo một kiểu cụ thể bằng cách sử dụng format() chức năng.
Cú pháp
Cú pháp cơ bản cho hàm định dạng là -
format(x, digits, nsmall, scientific, width, justify = c("left", "right", "centre", "none"))Sau đây là mô tả về các tham số được sử dụng:
x là đầu vào vectơ.
digits là tổng số chữ số được hiển thị.
nsmall là số chữ số tối thiểu ở bên phải dấu thập phân.
scientific được đặt thành TRUE để hiển thị ký hiệu khoa học.
width cho biết chiều rộng tối thiểu được hiển thị bằng khoảng trống đệm ở phần đầu.
justify là sự hiển thị của chuỗi sang trái, phải hoặc trung tâm.
Thí dụ
# Total number of digits displayed. Last digit rounded off.
result <- format(23.123456789, digits = 9)
print(result)
# Display numbers in scientific notation.
result <- format(c(6, 13.14521), scientific = TRUE)
print(result)
# The minimum number of digits to the right of the decimal point.
result <- format(23.47, nsmall = 5)
print(result)
# Format treats everything as a string.
result <- format(6)
print(result)
# Numbers are padded with blank in the beginning for width.
result <- format(13.7, width = 6)
print(result)
# Left justify strings.
result <- format("Hello", width = 8, justify = "l")
print(result)
# Justfy string with center.
result <- format("Hello", width = 8, justify = "c")
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] "23.1234568"
[1] "6.000000e+00" "1.314521e+01"
[1] "23.47000"
[1] "6"
[1] " 13.7"
[1] "Hello "
[1] " Hello "Đếm số ký tự trong một chuỗi - hàm nchar ()
Hàm này đếm số ký tự bao gồm cả khoảng trắng trong một chuỗi.
Cú pháp
Cú pháp cơ bản cho hàm nchar () là -
nchar(x)Sau đây là mô tả về các tham số được sử dụng:
x là đầu vào vectơ.
Thí dụ
result <- nchar("Count the number of characters")
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 30Thay đổi trường hợp - hàm toupper () & tolower ()
Các hàm này thay đổi trường hợp ký tự của một chuỗi.
Cú pháp
Cú pháp cơ bản cho hàm toupper () & tolower () là -
toupper(x)
tolower(x)Sau đây là mô tả về các tham số được sử dụng:
x là đầu vào vectơ.
Thí dụ
# Changing to Upper case.
result <- toupper("Changing To Upper")
print(result)
# Changing to lower case.
result <- tolower("Changing To Lower")
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] "CHANGING TO UPPER"
[1] "changing to lower"Trích xuất các phần của một chuỗi - hàm substring ()
Hàm này trích xuất các phần của một Chuỗi.
Cú pháp
Cú pháp cơ bản cho hàm substring () là -
substring(x,first,last)Sau đây là mô tả về các tham số được sử dụng:
x là đầu vào vector ký tự.
first là vị trí của ký tự đầu tiên được trích xuất.
last là vị trí của ký tự cuối cùng được trích xuất.
Thí dụ
# Extract characters from 5th to 7th position.
result <- substring("Extract", 5, 7)
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] "act"Vectơ là đối tượng dữ liệu R cơ bản nhất và có sáu loại vectơ nguyên tử. Chúng là logic, số nguyên, kép, phức tạp, ký tự và thô.
Tạo vectơ
Véc tơ nguyên tố đơn
Ngay cả khi bạn chỉ viết một giá trị vào R, nó sẽ trở thành một vectơ có độ dài 1 và thuộc một trong các loại vectơ trên.
# Atomic vector of type character.
print("abc");
# Atomic vector of type double.
print(12.5)
# Atomic vector of type integer.
print(63L)
# Atomic vector of type logical.
print(TRUE)
# Atomic vector of type complex.
print(2+3i)
# Atomic vector of type raw.
print(charToRaw('hello'))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] "abc"
[1] 12.5
[1] 63
[1] TRUE
[1] 2+3i
[1] 68 65 6c 6c 6fNhiều yếu tố Vector
Using colon operator with numeric data
# Creating a sequence from 5 to 13.
v <- 5:13
print(v)
# Creating a sequence from 6.6 to 12.6.
v <- 6.6:12.6
print(v)
# If the final element specified does not belong to the sequence then it is discarded.
v <- 3.8:11.4
print(v)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 5 6 7 8 9 10 11 12 13
[1] 6.6 7.6 8.6 9.6 10.6 11.6 12.6
[1] 3.8 4.8 5.8 6.8 7.8 8.8 9.8 10.8Using sequence (Seq.) operator
# Create vector with elements from 5 to 9 incrementing by 0.4.
print(seq(5, 9, by = 0.4))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 5.0 5.4 5.8 6.2 6.6 7.0 7.4 7.8 8.2 8.6 9.0Using the c() function
Các giá trị không phải ký tự được ép buộc thành kiểu ký tự nếu một trong các phần tử là ký tự.
# The logical and numeric values are converted to characters.
s <- c('apple','red',5,TRUE)
print(s)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] "apple" "red" "5" "TRUE"Truy cập các yếu tố vectơ
Các phần tử của một Vectơ được truy cập bằng cách sử dụng lập chỉ mục. Các[ ] bracketsđược sử dụng để lập chỉ mục. Lập chỉ mục bắt đầu với vị trí 1. Việc đưa ra giá trị âm trong chỉ mục sẽ loại bỏ phần tử đó khỏi kết quả.TRUE, FALSE hoặc là 0 và 1 cũng có thể được sử dụng để lập chỉ mục.
# Accessing vector elements using position.
t <- c("Sun","Mon","Tue","Wed","Thurs","Fri","Sat")
u <- t[c(2,3,6)]
print(u)
# Accessing vector elements using logical indexing.
v <- t[c(TRUE,FALSE,FALSE,FALSE,FALSE,TRUE,FALSE)]
print(v)
# Accessing vector elements using negative indexing.
x <- t[c(-2,-5)]
print(x)
# Accessing vector elements using 0/1 indexing.
y <- t[c(0,0,0,0,0,0,1)]
print(y)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] "Mon" "Tue" "Fri"
[1] "Sun" "Fri"
[1] "Sun" "Tue" "Wed" "Fri" "Sat"
[1] "Sun"Thao tác vector
Véc tơ số học
Hai vectơ có cùng độ dài có thể được cộng, trừ, nhân hoặc chia cho kết quả là đầu ra vectơ.
# Create two vectors.
v1 <- c(3,8,4,5,0,11)
v2 <- c(4,11,0,8,1,2)
# Vector addition.
add.result <- v1+v2
print(add.result)
# Vector subtraction.
sub.result <- v1-v2
print(sub.result)
# Vector multiplication.
multi.result <- v1*v2
print(multi.result)
# Vector division.
divi.result <- v1/v2
print(divi.result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 7 19 4 13 1 13
[1] -1 -3 4 -3 -1 9
[1] 12 88 0 40 0 22
[1] 0.7500000 0.7272727 Inf 0.6250000 0.0000000 5.5000000Tái chế nguyên tố vector
Nếu chúng ta áp dụng các phép toán số học cho hai vectơ có độ dài không bằng nhau, thì các phần tử của vectơ ngắn hơn sẽ được tái chế để hoàn thành các phép toán.
v1 <- c(3,8,4,5,0,11)
v2 <- c(4,11)
# V2 becomes c(4,11,4,11,4,11)
add.result <- v1+v2
print(add.result)
sub.result <- v1-v2
print(sub.result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 7 19 8 16 4 22
[1] -1 -3 0 -6 -4 0Sắp xếp thành phần vector
Các phần tử trong một vectơ có thể được sắp xếp bằng cách sử dụng sort() chức năng.
v <- c(3,8,4,5,0,11, -9, 304)
# Sort the elements of the vector.
sort.result <- sort(v)
print(sort.result)
# Sort the elements in the reverse order.
revsort.result <- sort(v, decreasing = TRUE)
print(revsort.result)
# Sorting character vectors.
v <- c("Red","Blue","yellow","violet")
sort.result <- sort(v)
print(sort.result)
# Sorting character vectors in reverse order.
revsort.result <- sort(v, decreasing = TRUE)
print(revsort.result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] -9 0 3 4 5 8 11 304
[1] 304 11 8 5 4 3 0 -9
[1] "Blue" "Red" "violet" "yellow"
[1] "yellow" "violet" "Red" "Blue"Danh sách là các đối tượng R chứa các phần tử thuộc các kiểu khác nhau như - số, chuỗi, vectơ và một danh sách khác bên trong nó. Một danh sách cũng có thể chứa một ma trận hoặc một hàm dưới dạng các phần tử của nó. Danh sách được tạo bằnglist() chức năng.
Tạo danh sách
Sau đây là một ví dụ để tạo một danh sách chứa chuỗi, số, vectơ và một giá trị logic.
# Create a list containing strings, numbers, vectors and a logical
# values.
list_data <- list("Red", "Green", c(21,32,11), TRUE, 51.23, 119.1)
print(list_data)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[[1]]
[1] "Red"
[[2]]
[1] "Green"
[[3]]
[1] 21 32 11
[[4]]
[1] TRUE
[[5]]
[1] 51.23
[[6]]
[1] 119.1Đặt tên phần tử danh sách
Các phần tử danh sách có thể được đặt tên và chúng có thể được truy cập bằng các tên này.
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Show the list.
print(list_data)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
$`1st_Quarter` [1] "Jan" "Feb" "Mar" $A_Matrix
[,1] [,2] [,3]
[1,] 3 5 -2
[2,] 9 1 8
$A_Inner_list $A_Inner_list[[1]]
[1] "green"
$A_Inner_list[[2]]
[1] 12.3Truy cập các phần tử danh sách
Các phần tử của danh sách có thể được truy cập bằng chỉ mục của phần tử trong danh sách. Trong trường hợp danh sách được đặt tên, nó cũng có thể được truy cập bằng cách sử dụng tên.
Chúng tôi tiếp tục sử dụng danh sách trong ví dụ trên -
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Access the first element of the list.
print(list_data[1])
# Access the thrid element. As it is also a list, all its elements will be printed.
print(list_data[3])
# Access the list element using the name of the element.
print(list_data$A_Matrix)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
$`1st_Quarter` [1] "Jan" "Feb" "Mar" $A_Inner_list
$A_Inner_list[[1]] [1] "green" $A_Inner_list[[2]]
[1] 12.3
[,1] [,2] [,3]
[1,] 3 5 -2
[2,] 9 1 8Thao tác các phần tử danh sách
Chúng ta có thể thêm, xóa và cập nhật các phần tử danh sách như hình dưới đây. Chúng tôi chỉ có thể thêm và xóa các phần tử ở cuối danh sách. Nhưng chúng tôi có thể cập nhật bất kỳ phần tử nào.
# Create a list containing a vector, a matrix and a list.
list_data <- list(c("Jan","Feb","Mar"), matrix(c(3,9,5,1,-2,8), nrow = 2),
list("green",12.3))
# Give names to the elements in the list.
names(list_data) <- c("1st Quarter", "A_Matrix", "A Inner list")
# Add element at the end of the list.
list_data[4] <- "New element"
print(list_data[4])
# Remove the last element.
list_data[4] <- NULL
# Print the 4th Element.
print(list_data[4])
# Update the 3rd Element.
list_data[3] <- "updated element"
print(list_data[3])Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[[1]]
[1] "New element"
$<NA> NULL $`A Inner list`
[1] "updated element"Hợp nhất danh sách
Bạn có thể hợp nhất nhiều danh sách thành một danh sách bằng cách đặt tất cả các danh sách bên trong một hàm list ().
# Create two lists.
list1 <- list(1,2,3)
list2 <- list("Sun","Mon","Tue")
# Merge the two lists.
merged.list <- c(list1,list2)
# Print the merged list.
print(merged.list)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
[[4]]
[1] "Sun"
[[5]]
[1] "Mon"
[[6]]
[1] "Tue"Chuyển đổi danh sách thành vectơ
Một danh sách có thể được chuyển đổi thành một vectơ để các phần tử của vectơ có thể được sử dụng để thao tác thêm. Tất cả các phép toán số học trên vectơ có thể được áp dụng sau khi danh sách được chuyển thành vectơ. Để thực hiện chuyển đổi này, chúng tôi sử dụngunlist()chức năng. Nó lấy danh sách làm đầu vào và tạo ra một vector.
# Create lists.
list1 <- list(1:5)
print(list1)
list2 <-list(10:14)
print(list2)
# Convert the lists to vectors.
v1 <- unlist(list1)
v2 <- unlist(list2)
print(v1)
print(v2)
# Now add the vectors
result <- v1+v2
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[[1]]
[1] 1 2 3 4 5
[[1]]
[1] 10 11 12 13 14
[1] 1 2 3 4 5
[1] 10 11 12 13 14
[1] 11 13 15 17 19Ma trận là đối tượng R trong đó các phần tử được sắp xếp theo bố cục hình chữ nhật hai chiều. Chúng chứa các nguyên tố cùng loại nguyên tử. Mặc dù chúng ta có thể tạo một ma trận chỉ chứa các ký tự hoặc chỉ các giá trị logic, chúng không được sử dụng nhiều. Chúng tôi sử dụng ma trận chứa các phần tử số để dùng trong tính toán toán học.
Ma trận được tạo bằng cách sử dụng matrix() chức năng.
Cú pháp
Cú pháp cơ bản để tạo ma trận trong R là:
matrix(data, nrow, ncol, byrow, dimnames)Sau đây là mô tả về các tham số được sử dụng:
data là vectơ đầu vào trở thành phần tử dữ liệu của ma trận.
nrow là số hàng sẽ được tạo.
ncol là số cột sẽ được tạo.
byrowlà một manh mối hợp lý. Nếu TRUE thì các phần tử vector đầu vào được sắp xếp theo hàng.
dimname là tên được gán cho các hàng và cột.
Thí dụ
Tạo một ma trận lấy một vectơ số làm đầu vào.
# Elements are arranged sequentially by row.
M <- matrix(c(3:14), nrow = 4, byrow = TRUE)
print(M)
# Elements are arranged sequentially by column.
N <- matrix(c(3:14), nrow = 4, byrow = FALSE)
print(N)
# Define the column and row names.
rownames = c("row1", "row2", "row3", "row4")
colnames = c("col1", "col2", "col3")
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
print(P)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[,1] [,2] [,3]
[1,] 3 4 5
[2,] 6 7 8
[3,] 9 10 11
[4,] 12 13 14
[,1] [,2] [,3]
[1,] 3 7 11
[2,] 4 8 12
[3,] 5 9 13
[4,] 6 10 14
col1 col2 col3
row1 3 4 5
row2 6 7 8
row3 9 10 11
row4 12 13 14Truy cập các phần tử của ma trận
Các phần tử của ma trận có thể được truy cập bằng cách sử dụng chỉ số cột và hàng của phần tử. Ta xét ma trận P ở trên để tìm các phần tử cụ thể bên dưới.
# Define the column and row names.
rownames = c("row1", "row2", "row3", "row4")
colnames = c("col1", "col2", "col3")
# Create the matrix.
P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
# Access the element at 3rd column and 1st row.
print(P[1,3])
# Access the element at 2nd column and 4th row.
print(P[4,2])
# Access only the 2nd row.
print(P[2,])
# Access only the 3rd column.
print(P[,3])Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 5
[1] 13
col1 col2 col3
6 7 8
row1 row2 row3 row4
5 8 11 14Tính toán ma trận
Các phép toán khác nhau được thực hiện trên ma trận bằng cách sử dụng các toán tử R. Kết quả của phép toán cũng là một ma trận.
Kích thước (số hàng và cột) phải giống nhau cho các ma trận tham gia vào hoạt động.
Phép cộng và phép trừ ma trận
# Create two 2x3 matrices.
matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2)
print(matrix1)
matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2)
print(matrix2)
# Add the matrices.
result <- matrix1 + matrix2
cat("Result of addition","\n")
print(result)
# Subtract the matrices
result <- matrix1 - matrix2
cat("Result of subtraction","\n")
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[,1] [,2] [,3]
[1,] 3 -1 2
[2,] 9 4 6
[,1] [,2] [,3]
[1,] 5 0 3
[2,] 2 9 4
Result of addition
[,1] [,2] [,3]
[1,] 8 -1 5
[2,] 11 13 10
Result of subtraction
[,1] [,2] [,3]
[1,] -2 -1 -1
[2,] 7 -5 2Phép nhân & phép chia ma trận
# Create two 2x3 matrices.
matrix1 <- matrix(c(3, 9, -1, 4, 2, 6), nrow = 2)
print(matrix1)
matrix2 <- matrix(c(5, 2, 0, 9, 3, 4), nrow = 2)
print(matrix2)
# Multiply the matrices.
result <- matrix1 * matrix2
cat("Result of multiplication","\n")
print(result)
# Divide the matrices
result <- matrix1 / matrix2
cat("Result of division","\n")
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[,1] [,2] [,3]
[1,] 3 -1 2
[2,] 9 4 6
[,1] [,2] [,3]
[1,] 5 0 3
[2,] 2 9 4
Result of multiplication
[,1] [,2] [,3]
[1,] 15 0 6
[2,] 18 36 24
Result of division
[,1] [,2] [,3]
[1,] 0.6 -Inf 0.6666667
[2,] 4.5 0.4444444 1.5000000Mảng là đối tượng dữ liệu R có thể lưu trữ dữ liệu trong nhiều hơn hai chiều. Ví dụ - Nếu chúng ta tạo một mảng có kích thước (2, 3, 4) thì nó sẽ tạo ra 4 ma trận hình chữ nhật, mỗi ma trận có 2 hàng và 3 cột. Mảng chỉ có thể lưu trữ kiểu dữ liệu.
Một mảng được tạo bằng cách sử dụng array()chức năng. Nó nhận vectơ làm đầu vào và sử dụng các giá trị trongdim tham số để tạo một mảng.
Thí dụ
Ví dụ sau tạo một mảng gồm hai ma trận 3x3, mỗi ma trận có 3 hàng và 3 cột.
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2))
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
, , 1
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
, , 2
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15Đặt tên cho các cột và hàng
Chúng ta có thể đặt tên cho các hàng, cột và ma trận trong mảng bằng cách sử dụng dimnames tham số.
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
column.names <- c("COL1","COL2","COL3")
row.names <- c("ROW1","ROW2","ROW3")
matrix.names <- c("Matrix1","Matrix2")
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,column.names,
matrix.names))
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
, , Matrix1
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15
, , Matrix2
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15Truy cập các phần tử mảng
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
column.names <- c("COL1","COL2","COL3")
row.names <- c("ROW1","ROW2","ROW3")
matrix.names <- c("Matrix1","Matrix2")
# Take these vectors as input to the array.
result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,
column.names, matrix.names))
# Print the third row of the second matrix of the array.
print(result[3,,2])
# Print the element in the 1st row and 3rd column of the 1st matrix.
print(result[1,3,1])
# Print the 2nd Matrix.
print(result[,,2])Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
COL1 COL2 COL3
3 12 15
[1] 13
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15Thao tác với các phần tử mảng
Vì mảng được tạo thành các ma trận theo nhiều chiều, các phép toán trên các phần tử của mảng được thực hiện bằng cách truy cập các phần tử của ma trận.
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
array1 <- array(c(vector1,vector2),dim = c(3,3,2))
# Create two vectors of different lengths.
vector3 <- c(9,1,0)
vector4 <- c(6,0,11,3,14,1,2,6,9)
array2 <- array(c(vector1,vector2),dim = c(3,3,2))
# create matrices from these arrays.
matrix1 <- array1[,,2]
matrix2 <- array2[,,2]
# Add the matrices.
result <- matrix1+matrix2
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[,1] [,2] [,3]
[1,] 10 20 26
[2,] 18 22 28
[3,] 6 24 30Tính toán trên các phần tử mảng
Chúng ta có thể thực hiện các phép tính trên các phần tử trong một mảng bằng cách sử dụng apply() chức năng.
Cú pháp
apply(x, margin, fun)Sau đây là mô tả về các tham số được sử dụng:
x là một mảng.
margin là tên của tập dữ liệu được sử dụng.
fun là hàm được áp dụng trên các phần tử của mảng.
Thí dụ
Chúng tôi sử dụng hàm apply () bên dưới để tính tổng các phần tử trong các hàng của một mảng trên tất cả các ma trận.
# Create two vectors of different lengths.
vector1 <- c(5,9,3)
vector2 <- c(10,11,12,13,14,15)
# Take these vectors as input to the array.
new.array <- array(c(vector1,vector2),dim = c(3,3,2))
print(new.array)
# Use apply to calculate the sum of the rows across all the matrices.
result <- apply(new.array, c(1), sum)
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
, , 1
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
, , 2
[,1] [,2] [,3]
[1,] 5 10 13
[2,] 9 11 14
[3,] 3 12 15
[1] 56 68 60Factors là các đối tượng dữ liệu được sử dụng để phân loại dữ liệu và lưu trữ nó dưới dạng các cấp. Chúng có thể lưu trữ cả chuỗi và số nguyên. Chúng hữu ích trong các cột có một số giá trị duy nhất hạn chế. Như "Nam," Nữ "và Đúng, Sai, v.v. Chúng rất hữu ích trong việc phân tích dữ liệu để lập mô hình thống kê.
Các yếu tố được tạo ra bằng cách sử dụng factor () chức năng bằng cách lấy một vectơ làm đầu vào.
Thí dụ
# Create a vector as input.
data <- c("East","West","East","North","North","East","West","West","West","East","North")
print(data)
print(is.factor(data))
# Apply the factor function.
factor_data <- factor(data)
print(factor_data)
print(is.factor(factor_data))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] "East" "West" "East" "North" "North" "East" "West" "West" "West" "East" "North"
[1] FALSE
[1] East West East North North East West West West East North
Levels: East North West
[1] TRUECác yếu tố trong khung dữ liệu
Khi tạo bất kỳ khung dữ liệu nào có một cột dữ liệu văn bản, R coi cột văn bản là dữ liệu phân loại và tạo các yếu tố trên đó.
# Create the vectors for data frame.
height <- c(132,151,162,139,166,147,122)
weight <- c(48,49,66,53,67,52,40)
gender <- c("male","male","female","female","male","female","male")
# Create the data frame.
input_data <- data.frame(height,weight,gender)
print(input_data)
# Test if the gender column is a factor.
print(is.factor(input_data$gender)) # Print the gender column so see the levels. print(input_data$gender)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
height weight gender
1 132 48 male
2 151 49 male
3 162 66 female
4 139 53 female
5 166 67 male
6 147 52 female
7 122 40 male
[1] TRUE
[1] male male female female male female male
Levels: female maleThay đổi thứ tự các cấp
Thứ tự của các mức trong một yếu tố có thể được thay đổi bằng cách áp dụng lại hàm nhân tố với thứ tự mới của các mức.
data <- c("East","West","East","North","North","East","West",
"West","West","East","North")
# Create the factors
factor_data <- factor(data)
print(factor_data)
# Apply the factor function with required order of the level.
new_order_data <- factor(factor_data,levels = c("East","West","North"))
print(new_order_data)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] East West East North North East West West West East North
Levels: East North West
[1] East West East North North East West West West East North
Levels: East West NorthCác mức nhân tố tạo ra
Chúng tôi có thể tạo các mức yếu tố bằng cách sử dụng gl()chức năng. Nó nhận hai số nguyên làm đầu vào cho biết có bao nhiêu cấp độ và bao nhiêu lần mỗi cấp độ.
Cú pháp
gl(n, k, labels)Sau đây là mô tả về các tham số được sử dụng:
n là một số nguyên cho số cấp độ.
k là một số nguyên cho số lần lặp lại.
labels là một vectơ nhãn cho các mức yếu tố kết quả.
Thí dụ
v <- gl(3, 4, labels = c("Tampa", "Seattle","Boston"))
print(v)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Tampa Tampa Tampa Tampa Seattle Seattle Seattle Seattle Boston
[10] Boston Boston Boston
Levels: Tampa Seattle BostonKhung dữ liệu là một bảng hoặc một cấu trúc giống như mảng hai chiều, trong đó mỗi cột chứa các giá trị của một biến và mỗi hàng chứa một bộ giá trị từ mỗi cột.
Sau đây là các đặc điểm của khung dữ liệu.
- Tên cột không được để trống.
- Tên hàng phải là duy nhất.
- Dữ liệu được lưu trữ trong một khung dữ liệu có thể là kiểu số, hệ số hoặc ký tự.
- Mỗi cột phải chứa cùng một số mục dữ liệu.
Create Data Frame
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Print the data frame.
print(emp.data)When we execute the above code, it produces the following result −
emp_id emp_name salary start_date
1 1 Rick 623.30 2012-01-01
2 2 Dan 515.20 2013-09-23
3 3 Michelle 611.00 2014-11-15
4 4 Ryan 729.00 2014-05-11
5 5 Gary 843.25 2015-03-27Get the Structure of the Data Frame
The structure of the data frame can be seen by using str() function.
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Get the structure of the data frame.
str(emp.data)When we execute the above code, it produces the following result −
'data.frame': 5 obs. of 4 variables:
$ emp_id : int 1 2 3 4 5 $ emp_name : chr "Rick" "Dan" "Michelle" "Ryan" ...
$ salary : num 623 515 611 729 843 $ start_date: Date, format: "2012-01-01" "2013-09-23" "2014-11-15" "2014-05-11" ...Summary of Data in Data Frame
The statistical summary and nature of the data can be obtained by applying summary() function.
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Print the summary.
print(summary(emp.data))When we execute the above code, it produces the following result −
emp_id emp_name salary start_date
Min. :1 Length:5 Min. :515.2 Min. :2012-01-01
1st Qu.:2 Class :character 1st Qu.:611.0 1st Qu.:2013-09-23
Median :3 Mode :character Median :623.3 Median :2014-05-11
Mean :3 Mean :664.4 Mean :2014-01-14
3rd Qu.:4 3rd Qu.:729.0 3rd Qu.:2014-11-15
Max. :5 Max. :843.2 Max. :2015-03-27Extract Data from Data Frame
Extract specific column from a data frame using column name.
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01","2013-09-23","2014-11-15","2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract Specific columns.
result <- data.frame(emp.data$emp_name,emp.data$salary)
print(result)When we execute the above code, it produces the following result −
emp.data.emp_name emp.data.salary
1 Rick 623.30
2 Dan 515.20
3 Michelle 611.00
4 Ryan 729.00
5 Gary 843.25Extract the first two rows and then all columns
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract first two rows.
result <- emp.data[1:2,]
print(result)When we execute the above code, it produces the following result −
emp_id emp_name salary start_date
1 1 Rick 623.3 2012-01-01
2 2 Dan 515.2 2013-09-23Extract 3rd and 5th row with 2nd and 4th column
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Extract 3rd and 5th row with 2nd and 4th column.
result <- emp.data[c(3,5),c(2,4)]
print(result)When we execute the above code, it produces the following result −
emp_name start_date
3 Michelle 2014-11-15
5 Gary 2015-03-27Expand Data Frame
A data frame can be expanded by adding columns and rows.
Add Column
Just add the column vector using a new column name.
# Create the data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
stringsAsFactors = FALSE
)
# Add the "dept" coulmn.
emp.data$dept <- c("IT","Operations","IT","HR","Finance")
v <- emp.data
print(v)When we execute the above code, it produces the following result −
emp_id emp_name salary start_date dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 5 Gary 843.25 2015-03-27 FinanceAdd Row
To add more rows permanently to an existing data frame, we need to bring in the new rows in the same structure as the existing data frame and use the rbind() function.
In the example below we create a data frame with new rows and merge it with the existing data frame to create the final data frame.
# Create the first data frame.
emp.data <- data.frame(
emp_id = c (1:5),
emp_name = c("Rick","Dan","Michelle","Ryan","Gary"),
salary = c(623.3,515.2,611.0,729.0,843.25),
start_date = as.Date(c("2012-01-01", "2013-09-23", "2014-11-15", "2014-05-11",
"2015-03-27")),
dept = c("IT","Operations","IT","HR","Finance"),
stringsAsFactors = FALSE
)
# Create the second data frame
emp.newdata <- data.frame(
emp_id = c (6:8),
emp_name = c("Rasmi","Pranab","Tusar"),
salary = c(578.0,722.5,632.8),
start_date = as.Date(c("2013-05-21","2013-07-30","2014-06-17")),
dept = c("IT","Operations","Fianance"),
stringsAsFactors = FALSE
)
# Bind the two data frames.
emp.finaldata <- rbind(emp.data,emp.newdata)
print(emp.finaldata)When we execute the above code, it produces the following result −
emp_id emp_name salary start_date dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 5 Gary 843.25 2015-03-27 Finance
6 6 Rasmi 578.00 2013-05-21 IT
7 7 Pranab 722.50 2013-07-30 Operations
8 8 Tusar 632.80 2014-06-17 FiananceR packages are a collection of R functions, complied code and sample data. They are stored under a directory called "library" in the R environment. By default, R installs a set of packages during installation. More packages are added later, when they are needed for some specific purpose. When we start the R console, only the default packages are available by default. Other packages which are already installed have to be loaded explicitly to be used by the R program that is going to use them.
All the packages available in R language are listed at R Packages.
Below is a list of commands to be used to check, verify and use the R packages.
Check Available R Packages
Get library locations containing R packages
.libPaths()When we execute the above code, it produces the following result. It may vary depending on the local settings of your pc.
[2] "C:/Program Files/R/R-3.2.2/library"Get the list of all the packages installed
library()When we execute the above code, it produces the following result. It may vary depending on the local settings of your pc.
Packages in library ‘C:/Program Files/R/R-3.2.2/library’:
base The R Base Package
boot Bootstrap Functions (Originally by Angelo Canty
for S)
class Functions for Classification
cluster "Finding Groups in Data": Cluster Analysis
Extended Rousseeuw et al.
codetools Code Analysis Tools for R
compiler The R Compiler Package
datasets The R Datasets Package
foreign Read Data Stored by 'Minitab', 'S', 'SAS',
'SPSS', 'Stata', 'Systat', 'Weka', 'dBase', ...
graphics The R Graphics Package
grDevices The R Graphics Devices and Support for Colours
and Fonts
grid The Grid Graphics Package
KernSmooth Functions for Kernel Smoothing Supporting Wand
& Jones (1995)
lattice Trellis Graphics for R
MASS Support Functions and Datasets for Venables and
Ripley's MASS
Matrix Sparse and Dense Matrix Classes and Methods
methods Formal Methods and Classes
mgcv Mixed GAM Computation Vehicle with GCV/AIC/REML
Smoothness Estimation
nlme Linear and Nonlinear Mixed Effects Models
nnet Feed-Forward Neural Networks and Multinomial
Log-Linear Models
parallel Support for Parallel computation in R
rpart Recursive Partitioning and Regression Trees
spatial Functions for Kriging and Point Pattern
Analysis
splines Regression Spline Functions and Classes
stats The R Stats Package
stats4 Statistical Functions using S4 Classes
survival Survival Analysis
tcltk Tcl/Tk Interface
tools Tools for Package Development
utils The R Utils PackageGet all packages currently loaded in the R environment
search()When we execute the above code, it produces the following result. It may vary depending on the local settings of your pc.
[1] ".GlobalEnv" "package:stats" "package:graphics"
[4] "package:grDevices" "package:utils" "package:datasets"
[7] "package:methods" "Autoloads" "package:base"Install a New Package
There are two ways to add new R packages. One is installing directly from the CRAN directory and another is downloading the package to your local system and installing it manually.
Install directly from CRAN
The following command gets the packages directly from CRAN webpage and installs the package in the R environment. You may be prompted to choose a nearest mirror. Choose the one appropriate to your location.
install.packages("Package Name")
# Install the package named "XML".
install.packages("XML")Install package manually
Go to the link R Packages to download the package needed. Save the package as a .zip file in a suitable location in the local system.
Now you can run the following command to install this package in the R environment.
install.packages(file_name_with_path, repos = NULL, type = "source")
# Install the package named "XML"
install.packages("E:/XML_3.98-1.3.zip", repos = NULL, type = "source")Load Package to Library
Before a package can be used in the code, it must be loaded to the current R environment. You also need to load a package that is already installed previously but not available in the current environment.
A package is loaded using the following command −
library("package Name", lib.loc = "path to library")
# Load the package named "XML"
install.packages("E:/XML_3.98-1.3.zip", repos = NULL, type = "source")Data Reshaping in R is about changing the way data is organized into rows and columns. Most of the time data processing in R is done by taking the input data as a data frame. It is easy to extract data from the rows and columns of a data frame but there are situations when we need the data frame in a format that is different from format in which we received it. R has many functions to split, merge and change the rows to columns and vice-versa in a data frame.
Joining Columns and Rows in a Data Frame
We can join multiple vectors to create a data frame using the cbind()function. Also we can merge two data frames using rbind() function.
# Create vector objects.
city <- c("Tampa","Seattle","Hartford","Denver")
state <- c("FL","WA","CT","CO")
zipcode <- c(33602,98104,06161,80294)
# Combine above three vectors into one data frame.
addresses <- cbind(city,state,zipcode)
# Print a header.
cat("# # # # The First data frame\n")
# Print the data frame.
print(addresses)
# Create another data frame with similar columns
new.address <- data.frame(
city = c("Lowry","Charlotte"),
state = c("CO","FL"),
zipcode = c("80230","33949"),
stringsAsFactors = FALSE
)
# Print a header.
cat("# # # The Second data frame\n")
# Print the data frame.
print(new.address)
# Combine rows form both the data frames.
all.addresses <- rbind(addresses,new.address)
# Print a header.
cat("# # # The combined data frame\n")
# Print the result.
print(all.addresses)When we execute the above code, it produces the following result −
# # # # The First data frame
city state zipcode
[1,] "Tampa" "FL" "33602"
[2,] "Seattle" "WA" "98104"
[3,] "Hartford" "CT" "6161"
[4,] "Denver" "CO" "80294"
# # # The Second data frame
city state zipcode
1 Lowry CO 80230
2 Charlotte FL 33949
# # # The combined data frame
city state zipcode
1 Tampa FL 33602
2 Seattle WA 98104
3 Hartford CT 6161
4 Denver CO 80294
5 Lowry CO 80230
6 Charlotte FL 33949Merging Data Frames
We can merge two data frames by using the merge() function. The data frames must have same column names on which the merging happens.
In the example below, we consider the data sets about Diabetes in Pima Indian Women available in the library names "MASS". we merge the two data sets based on the values of blood pressure("bp") and body mass index("bmi"). On choosing these two columns for merging, the records where values of these two variables match in both data sets are combined together to form a single data frame.
library(MASS)
merged.Pima <- merge(x = Pima.te, y = Pima.tr,
by.x = c("bp", "bmi"),
by.y = c("bp", "bmi")
)
print(merged.Pima)
nrow(merged.Pima)When we execute the above code, it produces the following result −
bp bmi npreg.x glu.x skin.x ped.x age.x type.x npreg.y glu.y skin.y ped.y
1 60 33.8 1 117 23 0.466 27 No 2 125 20 0.088
2 64 29.7 2 75 24 0.370 33 No 2 100 23 0.368
3 64 31.2 5 189 33 0.583 29 Yes 3 158 13 0.295
4 64 33.2 4 117 27 0.230 24 No 1 96 27 0.289
5 66 38.1 3 115 39 0.150 28 No 1 114 36 0.289
6 68 38.5 2 100 25 0.324 26 No 7 129 49 0.439
7 70 27.4 1 116 28 0.204 21 No 0 124 20 0.254
8 70 33.1 4 91 32 0.446 22 No 9 123 44 0.374
9 70 35.4 9 124 33 0.282 34 No 6 134 23 0.542
10 72 25.6 1 157 21 0.123 24 No 4 99 17 0.294
11 72 37.7 5 95 33 0.370 27 No 6 103 32 0.324
12 74 25.9 9 134 33 0.460 81 No 8 126 38 0.162
13 74 25.9 1 95 21 0.673 36 No 8 126 38 0.162
14 78 27.6 5 88 30 0.258 37 No 6 125 31 0.565
15 78 27.6 10 122 31 0.512 45 No 6 125 31 0.565
16 78 39.4 2 112 50 0.175 24 No 4 112 40 0.236
17 88 34.5 1 117 24 0.403 40 Yes 4 127 11 0.598
age.y type.y
1 31 No
2 21 No
3 24 No
4 21 No
5 21 No
6 43 Yes
7 36 Yes
8 40 No
9 29 Yes
10 28 No
11 55 No
12 39 No
13 39 No
14 49 Yes
15 49 Yes
16 38 No
17 28 No
[1] 17Melting and Casting
One of the most interesting aspects of R programming is about changing the shape of the data in multiple steps to get a desired shape. The functions used to do this are called melt() and cast().
We consider the dataset called ships present in the library called "MASS".
library(MASS)
print(ships)When we execute the above code, it produces the following result −
type year period service incidents
1 A 60 60 127 0
2 A 60 75 63 0
3 A 65 60 1095 3
4 A 65 75 1095 4
5 A 70 60 1512 6
.............
.............
8 A 75 75 2244 11
9 B 60 60 44882 39
10 B 60 75 17176 29
11 B 65 60 28609 58
............
............
17 C 60 60 1179 1
18 C 60 75 552 1
19 C 65 60 781 0
............
............Melt the Data
Now we melt the data to organize it, converting all columns other than type and year into multiple rows.
molten.ships <- melt(ships, id = c("type","year"))
print(molten.ships)When we execute the above code, it produces the following result −
type year variable value
1 A 60 period 60
2 A 60 period 75
3 A 65 period 60
4 A 65 period 75
............
............
9 B 60 period 60
10 B 60 period 75
11 B 65 period 60
12 B 65 period 75
13 B 70 period 60
...........
...........
41 A 60 service 127
42 A 60 service 63
43 A 65 service 1095
...........
...........
70 D 70 service 1208
71 D 75 service 0
72 D 75 service 2051
73 E 60 service 45
74 E 60 service 0
75 E 65 service 789
...........
...........
101 C 70 incidents 6
102 C 70 incidents 2
103 C 75 incidents 0
104 C 75 incidents 1
105 D 60 incidents 0
106 D 60 incidents 0
...........
...........Cast the Molten Data
We can cast the molten data into a new form where the aggregate of each type of ship for each year is created. It is done using the cast() function.
recasted.ship <- cast(molten.ships, type+year~variable,sum)
print(recasted.ship)When we execute the above code, it produces the following result −
type year period service incidents
1 A 60 135 190 0
2 A 65 135 2190 7
3 A 70 135 4865 24
4 A 75 135 2244 11
5 B 60 135 62058 68
6 B 65 135 48979 111
7 B 70 135 20163 56
8 B 75 135 7117 18
9 C 60 135 1731 2
10 C 65 135 1457 1
11 C 70 135 2731 8
12 C 75 135 274 1
13 D 60 135 356 0
14 D 65 135 480 0
15 D 70 135 1557 13
16 D 75 135 2051 4
17 E 60 135 45 0
18 E 65 135 1226 14
19 E 70 135 3318 17
20 E 75 135 542 1In R, we can read data from files stored outside the R environment. We can also write data into files which will be stored and accessed by the operating system. R can read and write into various file formats like csv, excel, xml etc.
In this chapter we will learn to read data from a csv file and then write data into a csv file. The file should be present in current working directory so that R can read it. Of course we can also set our own directory and read files from there.
Getting and Setting the Working Directory
You can check which directory the R workspace is pointing to using the getwd() function. You can also set a new working directory using setwd()function.
# Get and print current working directory.
print(getwd())
# Set current working directory.
setwd("/web/com")
# Get and print current working directory.
print(getwd())When we execute the above code, it produces the following result −
[1] "/web/com/1441086124_2016"
[1] "/web/com"This result depends on your OS and your current directory where you are working.
Input as CSV File
The csv file is a text file in which the values in the columns are separated by a comma. Let's consider the following data present in the file named input.csv.
You can create this file using windows notepad by copying and pasting this data. Save the file as input.csv using the save As All files(*.*) option in notepad.
id,name,salary,start_date,dept
1,Rick,623.3,2012-01-01,IT
2,Dan,515.2,2013-09-23,Operations
3,Michelle,611,2014-11-15,IT
4,Ryan,729,2014-05-11,HR
5,Gary,843.25,2015-03-27,Finance
6,Nina,578,2013-05-21,IT
7,Simon,632.8,2013-07-30,Operations
8,Guru,722.5,2014-06-17,FinanceReading a CSV File
Following is a simple example of read.csv() function to read a CSV file available in your current working directory −
data <- read.csv("input.csv")
print(data)When we execute the above code, it produces the following result −
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 FinancePhân tích tệp CSV
Theo mặc định, read.csv()hàm cung cấp đầu ra dưới dạng khung dữ liệu. Có thể dễ dàng kiểm tra điều này như sau. Ngoài ra, chúng ta có thể kiểm tra số cột và số hàng.
data <- read.csv("input.csv")
print(is.data.frame(data))
print(ncol(data))
print(nrow(data))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] TRUE
[1] 5
[1] 8Khi chúng ta đọc dữ liệu trong khung dữ liệu, chúng ta có thể áp dụng tất cả các chức năng áp dụng cho khung dữ liệu như được giải thích trong phần tiếp theo.
Nhận mức lương tối đa
# Create a data frame.
data <- read.csv("input.csv")
# Get the max salary from data frame.
sal <- max(data$salary)
print(sal)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 843.25Nhận thông tin chi tiết về người có mức lương tối đa
Chúng ta có thể tìm nạp các hàng đáp ứng các tiêu chí bộ lọc cụ thể tương tự như mệnh đề where trong SQL.
# Create a data frame.
data <- read.csv("input.csv")
# Get the max salary from data frame.
sal <- max(data$salary)
# Get the person detail having max salary.
retval <- subset(data, salary == max(salary))
print(retval)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
id name salary start_date dept
5 NA Gary 843.25 2015-03-27 FinanceNhận tất cả những người làm việc trong bộ phận CNTT
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset( data, dept == "IT")
print(retval)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
id name salary start_date dept
1 1 Rick 623.3 2012-01-01 IT
3 3 Michelle 611.0 2014-11-15 IT
6 6 Nina 578.0 2013-05-21 ITNhận những người trong bộ phận CNTT có mức lương lớn hơn 600
# Create a data frame.
data <- read.csv("input.csv")
info <- subset(data, salary > 600 & dept == "IT")
print(info)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
id name salary start_date dept
1 1 Rick 623.3 2012-01-01 IT
3 3 Michelle 611.0 2014-11-15 ITThu hút những người đã tham gia vào hoặc sau năm 2014
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
print(retval)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
id name salary start_date dept
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
8 8 Guru 722.50 2014-06-17 FinanceGhi vào tệp CSV
R có thể tạo tệp csv dạng khung dữ liệu hiện có. Cácwrite.csv()được sử dụng để tạo tệp csv. Tệp này được tạo trong thư mục làm việc.
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
# Write filtered data into a new file.
write.csv(retval,"output.csv")
newdata <- read.csv("output.csv")
print(newdata)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
X id name salary start_date dept
1 3 3 Michelle 611.00 2014-11-15 IT
2 4 4 Ryan 729.00 2014-05-11 HR
3 5 NA Gary 843.25 2015-03-27 Finance
4 8 8 Guru 722.50 2014-06-17 FinanceỞ đây, cột X đến từ tập dữ liệu mới hơn. Điều này có thể được loại bỏ bằng cách sử dụng các tham số bổ sung trong khi ghi tệp.
# Create a data frame.
data <- read.csv("input.csv")
retval <- subset(data, as.Date(start_date) > as.Date("2014-01-01"))
# Write filtered data into a new file.
write.csv(retval,"output.csv", row.names = FALSE)
newdata <- read.csv("output.csv")
print(newdata)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
id name salary start_date dept
1 3 Michelle 611.00 2014-11-15 IT
2 4 Ryan 729.00 2014-05-11 HR
3 NA Gary 843.25 2015-03-27 Finance
4 8 Guru 722.50 2014-06-17 FinanceMicrosoft Excel là chương trình bảng tính được sử dụng rộng rãi nhất để lưu trữ dữ liệu ở định dạng .xls hoặc .xlsx. R có thể đọc trực tiếp từ các tệp này bằng một số gói cụ thể của excel. Rất ít gói như vậy - XLConnect, xlsx, gdata, v.v. Chúng tôi sẽ sử dụng gói xlsx. R cũng có thể ghi vào tệp excel bằng gói này.
Cài đặt gói xlsx
Bạn có thể sử dụng lệnh sau trong bảng điều khiển R để cài đặt gói "xlsx". Nó có thể yêu cầu cài đặt một số gói bổ sung mà gói này phụ thuộc vào. Làm theo lệnh tương tự với tên gói bắt buộc để cài đặt các gói bổ sung.
install.packages("xlsx")Xác minh và tải gói "xlsx"
Sử dụng lệnh sau để xác minh và tải gói "xlsx".
# Verify the package is installed.
any(grepl("xlsx",installed.packages()))
# Load the library into R workspace.
library("xlsx")Khi tập lệnh được chạy, chúng tôi nhận được kết quả sau.
[1] TRUE
Loading required package: rJava
Loading required package: methods
Loading required package: xlsxjarsNhập dưới dạng tệp xlsx
Mở Microsoft excel. Sao chép và dán dữ liệu sau vào trang tính có tên là sheet1.
id name salary start_date dept
1 Rick 623.3 1/1/2012 IT
2 Dan 515.2 9/23/2013 Operations
3 Michelle 611 11/15/2014 IT
4 Ryan 729 5/11/2014 HR
5 Gary 43.25 3/27/2015 Finance
6 Nina 578 5/21/2013 IT
7 Simon 632.8 7/30/2013 Operations
8 Guru 722.5 6/17/2014 FinanceĐồng thời sao chép và dán dữ liệu sau vào một trang tính khác và đổi tên trang tính này thành "thành phố".
name city
Rick Seattle
Dan Tampa
Michelle Chicago
Ryan Seattle
Gary Houston
Nina Boston
Simon Mumbai
Guru DallasLưu tệp Excel dưới dạng "input.xlsx". Bạn nên lưu nó trong thư mục làm việc hiện tại của không gian làm việc R.
Đọc tệp Excel
Input.xlsx được đọc bằng cách sử dụng read.xlsx()chức năng như hình dưới đây. Kết quả được lưu trữ dưới dạng khung dữ liệu trong môi trường R.
# Read the first worksheet in the file input.xlsx.
data <- read.xlsx("input.xlsx", sheetIndex = 1)
print(data)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 FinanceTệp nhị phân là tệp chứa thông tin chỉ được lưu trữ dưới dạng bit và byte. (0 và 1). Chúng không thể đọc được bởi con người vì các byte trong đó chuyển thành các ký tự và ký hiệu chứa nhiều ký tự không thể in khác. Cố gắng đọc tệp nhị phân bằng bất kỳ trình soạn thảo văn bản nào sẽ hiển thị các ký tự như Ø và ð.
Tệp nhị phân phải được đọc bởi các chương trình cụ thể để có thể sử dụng được. Ví dụ: tệp nhị phân của chương trình Microsoft Word chỉ có thể đọc được ở dạng con người có thể đọc được bằng chương trình Word. Điều đó chỉ ra rằng, bên cạnh văn bản con người có thể đọc được, còn có rất nhiều thông tin khác như định dạng các ký tự và số trang, v.v., cũng được lưu trữ cùng với các ký tự chữ và số. Và cuối cùng một tệp nhị phân là một chuỗi byte liên tục. Dấu ngắt dòng chúng ta thấy trong tệp văn bản là một ký tự nối dòng đầu tiên với dòng tiếp theo.
Đôi khi, dữ liệu do các chương trình khác tạo ra được yêu cầu R xử lý dưới dạng tệp nhị phân. Ngoài ra R là cần thiết để tạo các tệp nhị phân có thể được chia sẻ với các chương trình khác.
R có hai chức năng WriteBin() và readBin() để tạo và đọc các tệp nhị phân.
Cú pháp
writeBin(object, con)
readBin(con, what, n )Sau đây là mô tả về các tham số được sử dụng:
con là đối tượng kết nối để đọc hoặc ghi tệp nhị phân.
object là tệp nhị phân được ghi.
what là chế độ như ký tự, số nguyên, v.v. đại diện cho các byte được đọc.
n là số byte để đọc từ tệp nhị phân.
Thí dụ
Chúng tôi coi dữ liệu sẵn có R là "mtcars". Đầu tiên, chúng tôi tạo một tệp csv từ nó và chuyển đổi nó thành tệp nhị phân và lưu trữ dưới dạng tệp hệ điều hành. Tiếp theo chúng ta đọc tệp nhị phân này được tạo thành R.
Viết tệp nhị phân
Chúng tôi đọc khung dữ liệu "mtcars" dưới dạng tệp csv và sau đó ghi nó dưới dạng tệp nhị phân vào hệ điều hành.
# Read the "mtcars" data frame as a csv file and store only the columns
"cyl", "am" and "gear".
write.table(mtcars, file = "mtcars.csv",row.names = FALSE, na = "",
col.names = TRUE, sep = ",")
# Store 5 records from the csv file as a new data frame.
new.mtcars <- read.table("mtcars.csv",sep = ",",header = TRUE,nrows = 5)
# Create a connection object to write the binary file using mode "wb".
write.filename = file("/web/com/binmtcars.dat", "wb")
# Write the column names of the data frame to the connection object.
writeBin(colnames(new.mtcars), write.filename)
# Write the records in each of the column to the file.
writeBin(c(new.mtcars$cyl,new.mtcars$am,new.mtcars$gear), write.filename)
# Close the file for writing so that it can be read by other program.
close(write.filename)Đọc tệp nhị phân
Tệp nhị phân được tạo ở trên lưu trữ tất cả dữ liệu dưới dạng các byte liên tục. Vì vậy, chúng tôi sẽ đọc nó bằng cách chọn các giá trị thích hợp của tên cột cũng như giá trị của cột.
# Create a connection object to read the file in binary mode using "rb".
read.filename <- file("/web/com/binmtcars.dat", "rb")
# First read the column names. n = 3 as we have 3 columns.
column.names <- readBin(read.filename, character(), n = 3)
# Next read the column values. n = 18 as we have 3 column names and 15 values.
read.filename <- file("/web/com/binmtcars.dat", "rb")
bindata <- readBin(read.filename, integer(), n = 18)
# Print the data.
print(bindata)
# Read the values from 4th byte to 8th byte which represents "cyl".
cyldata = bindata[4:8]
print(cyldata)
# Read the values form 9th byte to 13th byte which represents "am".
amdata = bindata[9:13]
print(amdata)
# Read the values form 9th byte to 13th byte which represents "gear".
geardata = bindata[14:18]
print(geardata)
# Combine all the read values to a dat frame.
finaldata = cbind(cyldata, amdata, geardata)
colnames(finaldata) = column.names
print(finaldata)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả và biểu đồ sau:
[1] 7108963 1728081249 7496037 6 6 4
[7] 6 8 1 1 1 0
[13] 0 4 4 4 3 3
[1] 6 6 4 6 8
[1] 1 1 1 0 0
[1] 4 4 4 3 3
cyl am gear
[1,] 6 1 4
[2,] 6 1 4
[3,] 4 1 4
[4,] 6 0 3
[5,] 8 0 3Như chúng ta thấy, chúng ta đã lấy lại dữ liệu ban đầu bằng cách đọc tệp nhị phân trong R.
XML là một định dạng tệp chia sẻ cả định dạng tệp và dữ liệu trên World Wide Web, mạng nội bộ và các nơi khác bằng cách sử dụng văn bản ASCII chuẩn. Nó là viết tắt của Ngôn ngữ đánh dấu mở rộng (XML). Tương tự như HTML, nó chứa các thẻ đánh dấu. Nhưng không giống như HTML trong đó thẻ đánh dấu mô tả cấu trúc của trang, trong xml, các thẻ đánh dấu mô tả ý nghĩa của dữ liệu chứa trong tệp anh ấy.
Bạn có thể đọc tệp xml trong R bằng cách sử dụng gói "XML". Gói này có thể được cài đặt bằng lệnh sau.
install.packages("XML")Dữ liệu đầu vào
Tạo tệp XMl bằng cách sao chép dữ liệu bên dưới vào trình soạn thảo văn bản như notepad. Lưu tệp với một.xml phần mở rộng và chọn loại tệp là all files(*.*).
<RECORDS>
<EMPLOYEE>
<ID>1</ID>
<NAME>Rick</NAME>
<SALARY>623.3</SALARY>
<STARTDATE>1/1/2012</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>2</ID>
<NAME>Dan</NAME>
<SALARY>515.2</SALARY>
<STARTDATE>9/23/2013</STARTDATE>
<DEPT>Operations</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>3</ID>
<NAME>Michelle</NAME>
<SALARY>611</SALARY>
<STARTDATE>11/15/2014</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>4</ID>
<NAME>Ryan</NAME>
<SALARY>729</SALARY>
<STARTDATE>5/11/2014</STARTDATE>
<DEPT>HR</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>5</ID>
<NAME>Gary</NAME>
<SALARY>843.25</SALARY>
<STARTDATE>3/27/2015</STARTDATE>
<DEPT>Finance</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>6</ID>
<NAME>Nina</NAME>
<SALARY>578</SALARY>
<STARTDATE>5/21/2013</STARTDATE>
<DEPT>IT</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>7</ID>
<NAME>Simon</NAME>
<SALARY>632.8</SALARY>
<STARTDATE>7/30/2013</STARTDATE>
<DEPT>Operations</DEPT>
</EMPLOYEE>
<EMPLOYEE>
<ID>8</ID>
<NAME>Guru</NAME>
<SALARY>722.5</SALARY>
<STARTDATE>6/17/2014</STARTDATE>
<DEPT>Finance</DEPT>
</EMPLOYEE>
</RECORDS>Đọc tệp XML
Tệp xml được đọc bởi R bằng hàm xmlParse(). Nó được lưu trữ dưới dạng danh sách trong R.
# Load the package required to read XML files.
library("XML")
# Also load the other required package.
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Print the result.
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
1
Rick
623.3
1/1/2012
IT
2
Dan
515.2
9/23/2013
Operations
3
Michelle
611
11/15/2014
IT
4
Ryan
729
5/11/2014
HR
5
Gary
843.25
3/27/2015
Finance
6
Nina
578
5/21/2013
IT
7
Simon
632.8
7/30/2013
Operations
8
Guru
722.5
6/17/2014
FinanceNhận số lượng nút có trong tệp XML
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Find number of nodes in the root.
rootsize <- xmlSize(rootnode)
# Print the result.
print(rootsize)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
output
[1] 8Chi tiết về nút đầu tiên
Hãy xem bản ghi đầu tiên của tệp đã phân tích cú pháp. Nó sẽ cung cấp cho chúng ta ý tưởng về các phần tử khác nhau có trong nút cấp cao nhất.
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Print the result.
print(rootnode[1])Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
$EMPLOYEE
1
Rick
623.3
1/1/2012
IT
attr(,"class")
[1] "XMLInternalNodeList" "XMLNodeList"Nhận các phần tử khác nhau của một nút
# Load the packages required to read XML files.
library("XML")
library("methods")
# Give the input file name to the function.
result <- xmlParse(file = "input.xml")
# Exract the root node form the xml file.
rootnode <- xmlRoot(result)
# Get the first element of the first node.
print(rootnode[[1]][[1]])
# Get the fifth element of the first node.
print(rootnode[[1]][[5]])
# Get the second element of the third node.
print(rootnode[[3]][[2]])Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
1
IT
MichelleXML thành khung dữ liệu
Để xử lý dữ liệu hiệu quả trong các tệp lớn, chúng tôi đọc dữ liệu trong tệp xml dưới dạng khung dữ liệu. Sau đó xử lý khung dữ liệu để phân tích dữ liệu.
# Load the packages required to read XML files.
library("XML")
library("methods")
# Convert the input xml file to a data frame.
xmldataframe <- xmlToDataFrame("input.xml")
print(xmldataframe)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
ID NAME SALARY STARTDATE DEPT
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 FinanceVì dữ liệu hiện đã có sẵn dưới dạng khung dữ liệu, chúng ta có thể sử dụng chức năng liên quan đến khung dữ liệu để đọc và thao tác tệp.
Tệp JSON lưu trữ dữ liệu dưới dạng văn bản ở định dạng con người có thể đọc được. Json là viết tắt của JavaScript Object Notation. R có thể đọc các tệp JSON bằng cách sử dụng gói rjson.
Cài đặt gói rjson
Trong bảng điều khiển R, bạn có thể sử dụng lệnh sau để cài đặt gói rjson.
install.packages("rjson")Dữ liệu đầu vào
Tạo tệp JSON bằng cách sao chép dữ liệu bên dưới vào trình soạn thảo văn bản như notepad. Lưu tệp với một.json phần mở rộng và chọn loại tệp là all files(*.*).
{
"ID":["1","2","3","4","5","6","7","8" ],
"Name":["Rick","Dan","Michelle","Ryan","Gary","Nina","Simon","Guru" ],
"Salary":["623.3","515.2","611","729","843.25","578","632.8","722.5" ],
"StartDate":[ "1/1/2012","9/23/2013","11/15/2014","5/11/2014","3/27/2015","5/21/2013",
"7/30/2013","6/17/2014"],
"Dept":[ "IT","Operations","IT","HR","Finance","IT","Operations","Finance"]
}Đọc tệp JSON
Tệp JSON được đọc bởi R bằng cách sử dụng hàm từ JSON(). Nó được lưu trữ dưới dạng danh sách trong R.
# Load the package required to read JSON files.
library("rjson")
# Give the input file name to the function.
result <- fromJSON(file = "input.json")
# Print the result.
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
$ID
[1] "1" "2" "3" "4" "5" "6" "7" "8"
$Name [1] "Rick" "Dan" "Michelle" "Ryan" "Gary" "Nina" "Simon" "Guru" $Salary
[1] "623.3" "515.2" "611" "729" "843.25" "578" "632.8" "722.5"
$StartDate [1] "1/1/2012" "9/23/2013" "11/15/2014" "5/11/2014" "3/27/2015" "5/21/2013" "7/30/2013" "6/17/2014" $Dept
[1] "IT" "Operations" "IT" "HR" "Finance" "IT"
"Operations" "Finance"Chuyển đổi JSON thành Khung dữ liệu
Chúng tôi có thể chuyển đổi dữ liệu được trích xuất ở trên thành khung dữ liệu R để phân tích thêm bằng cách sử dụng as.data.frame() chức năng.
# Load the package required to read JSON files.
library("rjson")
# Give the input file name to the function.
result <- fromJSON(file = "input.json")
# Convert JSON file to a data frame.
json_data_frame <- as.data.frame(result)
print(json_data_frame)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
id, name, salary, start_date, dept
1 1 Rick 623.30 2012-01-01 IT
2 2 Dan 515.20 2013-09-23 Operations
3 3 Michelle 611.00 2014-11-15 IT
4 4 Ryan 729.00 2014-05-11 HR
5 NA Gary 843.25 2015-03-27 Finance
6 6 Nina 578.00 2013-05-21 IT
7 7 Simon 632.80 2013-07-30 Operations
8 8 Guru 722.50 2014-06-17 FinanceNhiều trang web cung cấp dữ liệu cho người dùng của nó. Ví dụ: Tổ chức Y tế Thế giới (WHO) cung cấp các báo cáo về sức khỏe và thông tin y tế dưới dạng tệp CSV, txt và XML. Sử dụng các chương trình R, chúng tôi có thể trích xuất dữ liệu cụ thể từ các trang web như vậy theo chương trình. Một số gói trong R được sử dụng để thu thập dữ liệu hình thành web là - "RCurl", XML "và" stringr ". Chúng được sử dụng để kết nối với URL, xác định các liên kết bắt buộc cho tệp và tải chúng xuống môi trường cục bộ.
Cài đặt gói R
Các gói sau là bắt buộc để xử lý URL và liên kết đến tệp. Nếu chúng không có sẵn trong Môi trường R của bạn, bạn có thể cài đặt chúng bằng các lệnh sau.
install.packages("RCurl")
install.packages("XML")
install.packages("stringr")
install.packages("plyr")Dữ liệu đầu vào
Chúng tôi sẽ truy cập dữ liệu thời tiết URL và tải xuống tệp CSV sử dụng R cho năm 2015.
Thí dụ
Chúng tôi sẽ sử dụng hàm getHTMLLinks()để thu thập URL của các tệp. Sau đó, chúng ta sẽ sử dụng hàmdownload.file()để lưu các tệp vào hệ thống cục bộ. Vì chúng ta sẽ áp dụng lặp lại cùng một mã cho nhiều tệp, chúng ta sẽ tạo một hàm để được gọi nhiều lần. Tên tệp được chuyển dưới dạng tham số dưới dạng đối tượng danh sách R cho hàm này.
# Read the URL.
url <- "http://www.geos.ed.ac.uk/~weather/jcmb_ws/"
# Gather the html links present in the webpage.
links <- getHTMLLinks(url)
# Identify only the links which point to the JCMB 2015 files.
filenames <- links[str_detect(links, "JCMB_2015")]
# Store the file names as a list.
filenames_list <- as.list(filenames)
# Create a function to download the files by passing the URL and filename list.
downloadcsv <- function (mainurl,filename) {
filedetails <- str_c(mainurl,filename)
download.file(filedetails,filename)
}
# Now apply the l_ply function and save the files into the current R working directory.
l_ply(filenames,downloadcsv,mainurl = "http://www.geos.ed.ac.uk/~weather/jcmb_ws/")Xác minh việc tải xuống tệp
Sau khi chạy đoạn mã trên, bạn có thể định vị các tệp sau trong thư mục làm việc R hiện tại.
"JCMB_2015.csv" "JCMB_2015_Apr.csv" "JCMB_2015_Feb.csv" "JCMB_2015_Jan.csv"
"JCMB_2015_Mar.csv"Dữ liệu là Hệ thống cơ sở dữ liệu quan hệ được lưu trữ ở định dạng chuẩn hóa. Vì vậy, để thực hiện tính toán thống kê, chúng ta sẽ cần các truy vấn Sql rất nâng cao và phức tạp. Nhưng R có thể kết nối dễ dàng với nhiều cơ sở dữ liệu quan hệ như MySql, Oracle, máy chủ Sql, v.v. và lấy các bản ghi từ chúng dưới dạng khung dữ liệu. Khi dữ liệu có sẵn trong môi trường R, nó sẽ trở thành tập dữ liệu R bình thường và có thể được thao tác hoặc phân tích bằng cách sử dụng tất cả các gói và chức năng mạnh mẽ.
Trong hướng dẫn này, chúng tôi sẽ sử dụng MySql làm cơ sở dữ liệu tham chiếu để kết nối với R.
Gói RMySQL
R có một gói tích hợp có tên "RMySQL" cung cấp kết nối gốc giữa với cơ sở dữ liệu MySql. Bạn có thể cài đặt gói này trong môi trường R bằng lệnh sau.
install.packages("RMySQL")Kết nối R với MySql
Khi gói được cài đặt, chúng tôi tạo một đối tượng kết nối trong R để kết nối với cơ sở dữ liệu. Nó lấy tên người dùng, mật khẩu, tên cơ sở dữ liệu và tên máy chủ làm đầu vào.
# Create a connection Object to MySQL database.
# We will connect to the sampel database named "sakila" that comes with MySql installation.
mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'sakila',
host = 'localhost')
# List the tables available in this database.
dbListTables(mysqlconnection)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] "actor" "actor_info"
[3] "address" "category"
[5] "city" "country"
[7] "customer" "customer_list"
[9] "film" "film_actor"
[11] "film_category" "film_list"
[13] "film_text" "inventory"
[15] "language" "nicer_but_slower_film_list"
[17] "payment" "rental"
[19] "sales_by_film_category" "sales_by_store"
[21] "staff" "staff_list"
[23] "store"Truy vấn các bảng
Chúng ta có thể truy vấn các bảng cơ sở dữ liệu trong MySql bằng cách sử dụng hàm dbSendQuery(). Truy vấn được thực thi trong MySql và tập kết quả được trả về bằng cách sử dụng Rfetch()chức năng. Cuối cùng nó được lưu trữ dưới dạng khung dữ liệu trong R.
# Query the "actor" tables to get all the rows.
result = dbSendQuery(mysqlconnection, "select * from actor")
# Store the result in a R data frame object. n = 5 is used to fetch first 5 rows.
data.frame = fetch(result, n = 5)
print(data.fame)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
actor_id first_name last_name last_update
1 1 PENELOPE GUINESS 2006-02-15 04:34:33
2 2 NICK WAHLBERG 2006-02-15 04:34:33
3 3 ED CHASE 2006-02-15 04:34:33
4 4 JENNIFER DAVIS 2006-02-15 04:34:33
5 5 JOHNNY LOLLOBRIGIDA 2006-02-15 04:34:33Truy vấn với mệnh đề bộ lọc
Chúng tôi có thể chuyển bất kỳ truy vấn chọn hợp lệ nào để lấy kết quả.
result = dbSendQuery(mysqlconnection, "select * from actor where last_name = 'TORN'")
# Fetch all the records(with n = -1) and store it as a data frame.
data.frame = fetch(result, n = -1)
print(data)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
actor_id first_name last_name last_update
1 18 DAN TORN 2006-02-15 04:34:33
2 94 KENNETH TORN 2006-02-15 04:34:33
3 102 WALTER TORN 2006-02-15 04:34:33Cập nhật hàng trong bảng
Chúng ta có thể cập nhật các hàng trong bảng Mysql bằng cách chuyển truy vấn cập nhật tới hàm dbSendQuery ().
dbSendQuery(mysqlconnection, "update mtcars set disp = 168.5 where hp = 110")Sau khi thực hiện đoạn mã trên, chúng ta có thể thấy bảng được cập nhật trong MySql Environment.
Chèn dữ liệu vào bảng
dbSendQuery(mysqlconnection,
"insert into mtcars(row_names, mpg, cyl, disp, hp, drat, wt, qsec, vs, am, gear, carb)
values('New Mazda RX4 Wag', 21, 6, 168.5, 110, 3.9, 2.875, 17.02, 0, 1, 4, 4)"
)Sau khi thực hiện đoạn mã trên, chúng ta có thể thấy hàng được chèn vào bảng trong Môi trường MySql.
Tạo bảng trong MySql
Chúng ta có thể tạo bảng trong MySql bằng cách sử dụng hàm dbWriteTable(). Nó ghi đè bảng nếu nó đã tồn tại và lấy khung dữ liệu làm đầu vào.
# Create the connection object to the database where we want to create the table.
mysqlconnection = dbConnect(MySQL(), user = 'root', password = '', dbname = 'sakila',
host = 'localhost')
# Use the R data frame "mtcars" to create the table in MySql.
# All the rows of mtcars are taken inot MySql.
dbWriteTable(mysqlconnection, "mtcars", mtcars[, ], overwrite = TRUE)Sau khi thực hiện đoạn mã trên, chúng ta có thể thấy bảng được tạo trong Môi trường MySql.
Bỏ bảng trong MySql
Chúng ta có thể thả các bảng trong cơ sở dữ liệu MySql truyền câu lệnh drop table vào dbSendQuery () giống như cách chúng ta sử dụng nó để truy vấn dữ liệu từ các bảng.
dbSendQuery(mysqlconnection, 'drop table if exists mtcars')Sau khi thực hiện đoạn mã trên, chúng ta có thể thấy bảng bị xóa trong Môi trường MySql.
R Ngôn ngữ lập trình có nhiều thư viện để tạo biểu đồ và đồ thị. Biểu đồ hình tròn là biểu diễn các giá trị dưới dạng các lát của hình tròn với các màu khác nhau. Các lát được dán nhãn và các số tương ứng với mỗi lát cũng được thể hiện trong biểu đồ.
Trong R, biểu đồ hình tròn được tạo bằng cách sử dụng pie()hàm nhận các số dương làm đầu vào vectơ. Các tham số bổ sung được sử dụng để kiểm soát nhãn, màu sắc, tiêu đề, v.v.
Cú pháp
Cú pháp cơ bản để tạo biểu đồ hình tròn sử dụng R là:
pie(x, labels, radius, main, col, clockwise)Sau đây là mô tả về các tham số được sử dụng:
x là một vectơ chứa các giá trị số được sử dụng trong biểu đồ hình tròn.
labels được sử dụng để mô tả cho các lát.
radius cho biết bán kính của hình tròn của biểu đồ tròn. (giá trị từ −1 đến +1).
main cho biết tiêu đề của biểu đồ.
col cho biết bảng màu.
clockwise là một giá trị logic cho biết nếu các lát cắt được vẽ theo chiều kim đồng hồ hay ngược chiều kim đồng hồ.
Thí dụ
Một biểu đồ hình tròn rất đơn giản được tạo chỉ bằng cách sử dụng vectơ đầu vào và các nhãn. Tập lệnh dưới đây sẽ tạo và lưu biểu đồ hình tròn trong thư mục làm việc R hiện tại.
# Create data for the graph.
x <- c(21, 62, 10, 53)
labels <- c("London", "New York", "Singapore", "Mumbai")
# Give the chart file a name.
png(file = "city.png")
# Plot the chart.
pie(x,labels)
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Tiêu đề và màu sắc biểu đồ hình tròn
Chúng ta có thể mở rộng các tính năng của biểu đồ bằng cách thêm nhiều tham số vào hàm. Chúng tôi sẽ sử dụng tham sốmain để thêm tiêu đề vào biểu đồ và một tham số khác là colsẽ sử dụng pallet màu cầu vồng trong khi vẽ biểu đồ. Chiều dài của pallet phải giống với số lượng giá trị mà chúng ta có cho biểu đồ. Do đó chúng tôi sử dụng length (x).
Thí dụ
Tập lệnh dưới đây sẽ tạo và lưu biểu đồ hình tròn trong thư mục làm việc R hiện tại.
# Create data for the graph.
x <- c(21, 62, 10, 53)
labels <- c("London", "New York", "Singapore", "Mumbai")
# Give the chart file a name.
png(file = "city_title_colours.jpg")
# Plot the chart with title and rainbow color pallet.
pie(x, labels, main = "City pie chart", col = rainbow(length(x)))
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Phần trăm lát cắt và chú giải biểu đồ
Chúng tôi có thể thêm tỷ lệ phần trăm lát và chú giải biểu đồ bằng cách tạo các biến biểu đồ bổ sung.
# Create data for the graph.
x <- c(21, 62, 10,53)
labels <- c("London","New York","Singapore","Mumbai")
piepercent<- round(100*x/sum(x), 1)
# Give the chart file a name.
png(file = "city_percentage_legends.jpg")
# Plot the chart.
pie(x, labels = piepercent, main = "City pie chart",col = rainbow(length(x)))
legend("topright", c("London","New York","Singapore","Mumbai"), cex = 0.8,
fill = rainbow(length(x)))
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
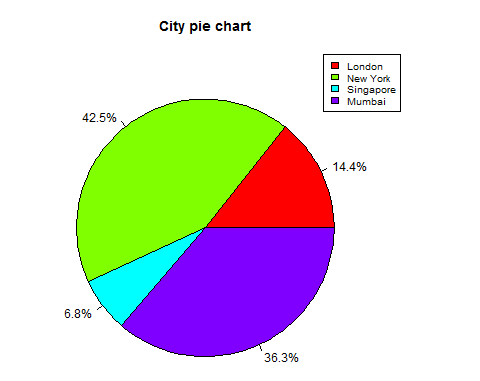
Biểu đồ hình tròn 3D
Biểu đồ hình tròn có 3 kích thước có thể được vẽ bằng các gói bổ sung. Góiplotrix có một chức năng được gọi là pie3D() được sử dụng cho việc này.
# Get the library.
library(plotrix)
# Create data for the graph.
x <- c(21, 62, 10,53)
lbl <- c("London","New York","Singapore","Mumbai")
# Give the chart file a name.
png(file = "3d_pie_chart.jpg")
# Plot the chart.
pie3D(x,labels = lbl,explode = 0.1, main = "Pie Chart of Countries ")
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Biểu đồ thanh biểu thị dữ liệu trong các thanh hình chữ nhật với chiều dài của thanh tỷ lệ với giá trị của biến. R sử dụng hàmbarplot()để tạo biểu đồ thanh. R có thể vẽ cả thanh dọc và thanh ngang trong biểu đồ thanh. Trong biểu đồ thanh, mỗi thanh có thể có các màu khác nhau.
Cú pháp
Cú pháp cơ bản để tạo biểu đồ thanh trong R là:
barplot(H,xlab,ylab,main, names.arg,col)Sau đây là mô tả về các tham số được sử dụng:
- H là một vectơ hoặc ma trận chứa các giá trị số được sử dụng trong biểu đồ thanh.
- xlab là nhãn cho trục x.
- ylab là nhãn cho trục y.
- main là tiêu đề của biểu đồ thanh.
- names.arg là một vectơ tên xuất hiện dưới mỗi thanh.
- col được sử dụng để cung cấp màu sắc cho các thanh trong biểu đồ.
Thí dụ
Một biểu đồ thanh đơn giản được tạo chỉ bằng cách sử dụng vectơ đầu vào và tên của mỗi thanh.
Tập lệnh dưới đây sẽ tạo và lưu biểu đồ thanh trong thư mục làm việc R hiện tại.
# Create the data for the chart
H <- c(7,12,28,3,41)
# Give the chart file a name
png(file = "barchart.png")
# Plot the bar chart
barplot(H)
# Save the file
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Nhãn biểu đồ thanh, tiêu đề và màu sắc
Các tính năng của biểu đồ thanh có thể được mở rộng bằng cách thêm nhiều tham số. Cácmain tham số được sử dụng để thêm title. Cáccoltham số được sử dụng để thêm màu vào các thanh. Cácargs.name là một vectơ có cùng số giá trị với vectơ đầu vào để mô tả ý nghĩa của mỗi thanh.
Thí dụ
Tập lệnh dưới đây sẽ tạo và lưu biểu đồ thanh trong thư mục làm việc R hiện tại.
# Create the data for the chart
H <- c(7,12,28,3,41)
M <- c("Mar","Apr","May","Jun","Jul")
# Give the chart file a name
png(file = "barchart_months_revenue.png")
# Plot the bar chart
barplot(H,names.arg=M,xlab="Month",ylab="Revenue",col="blue",
main="Revenue chart",border="red")
# Save the file
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
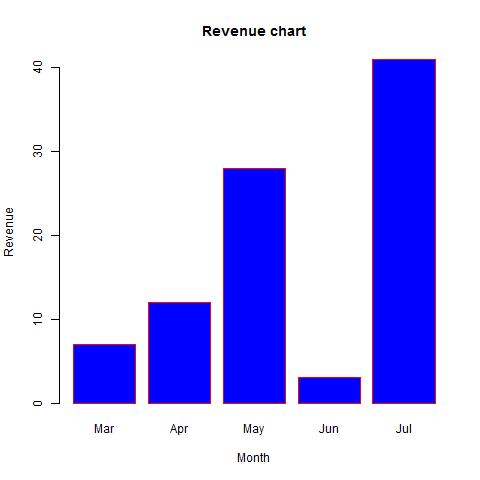
Biểu đồ thanh nhóm và biểu đồ thanh xếp chồng
Chúng ta có thể tạo biểu đồ thanh với các nhóm thanh và ngăn xếp trong mỗi thanh bằng cách sử dụng ma trận làm giá trị đầu vào.
Nhiều hơn hai biến được biểu diễn dưới dạng ma trận được sử dụng để tạo biểu đồ thanh nhóm và biểu đồ thanh xếp chồng.
# Create the input vectors.
colors = c("green","orange","brown")
months <- c("Mar","Apr","May","Jun","Jul")
regions <- c("East","West","North")
# Create the matrix of the values.
Values <- matrix(c(2,9,3,11,9,4,8,7,3,12,5,2,8,10,11), nrow = 3, ncol = 5, byrow = TRUE)
# Give the chart file a name
png(file = "barchart_stacked.png")
# Create the bar chart
barplot(Values, main = "total revenue", names.arg = months, xlab = "month", ylab = "revenue", col = colors)
# Add the legend to the chart
legend("topleft", regions, cex = 1.3, fill = colors)
# Save the file
dev.off()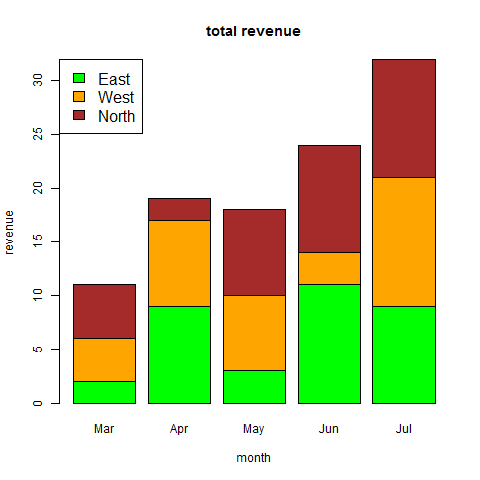
Boxplots là một thước đo về mức độ phân phối dữ liệu trong một tập dữ liệu. Nó chia tập dữ liệu thành ba phần tư. Biểu đồ này đại diện cho phần tư tối thiểu, tối đa, trung vị, phần tư thứ nhất và phần tư thứ ba trong tập dữ liệu. Nó cũng hữu ích trong việc so sánh sự phân bố dữ liệu giữa các tập dữ liệu bằng cách vẽ các ô vuông cho mỗi tập dữ liệu.
Boxplots được tạo trong R bằng cách sử dụng boxplot() chức năng.
Cú pháp
Cú pháp cơ bản để tạo boxplot trong R là:
boxplot(x, data, notch, varwidth, names, main)Sau đây là mô tả về các tham số được sử dụng:
x là một vectơ hoặc một công thức.
data là khung dữ liệu.
notchlà một giá trị logic. Đặt là TRUE để vẽ một khía.
varwidthlà một giá trị logic. Đặt là true để vẽ chiều rộng của hộp tương ứng với kích thước mẫu.
names là các nhãn nhóm sẽ được in dưới mỗi ô.
main được sử dụng để đặt tiêu đề cho biểu đồ.
Thí dụ
Chúng tôi sử dụng tập dữ liệu "mtcars" có sẵn trong môi trường R để tạo một boxplot cơ bản. Hãy xem các cột "mpg" và "cyl" trong mtcars.
input <- mtcars[,c('mpg','cyl')]
print(head(input))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
mpg cyl
Mazda RX4 21.0 6
Mazda RX4 Wag 21.0 6
Datsun 710 22.8 4
Hornet 4 Drive 21.4 6
Hornet Sportabout 18.7 8
Valiant 18.1 6Tạo Boxplot
Kịch bản dưới đây sẽ tạo ra một biểu đồ boxplot cho mối quan hệ giữa mpg (dặm mỗi gallon) và cyl (số xi-lanh).
# Give the chart file a name.
png(file = "boxplot.png")
# Plot the chart.
boxplot(mpg ~ cyl, data = mtcars, xlab = "Number of Cylinders",
ylab = "Miles Per Gallon", main = "Mileage Data")
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
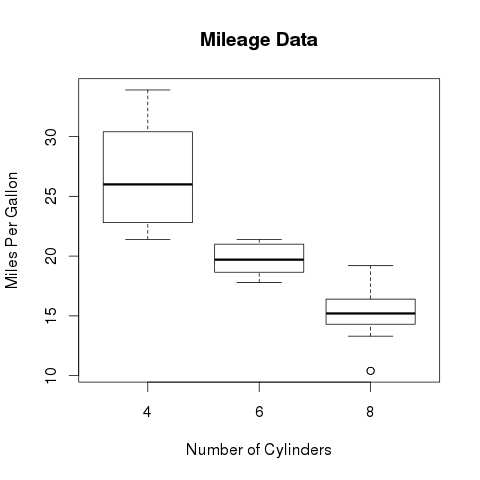
Boxplot với Notch
Chúng ta có thể vẽ boxplot với notch để tìm hiểu cách các đường trung bình của các nhóm dữ liệu khác nhau khớp với nhau.
Tập lệnh dưới đây sẽ tạo một biểu đồ hình hộp có khía cho mỗi nhóm dữ liệu.
# Give the chart file a name.
png(file = "boxplot_with_notch.png")
# Plot the chart.
boxplot(mpg ~ cyl, data = mtcars,
xlab = "Number of Cylinders",
ylab = "Miles Per Gallon",
main = "Mileage Data",
notch = TRUE,
varwidth = TRUE,
col = c("green","yellow","purple"),
names = c("High","Medium","Low")
)
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
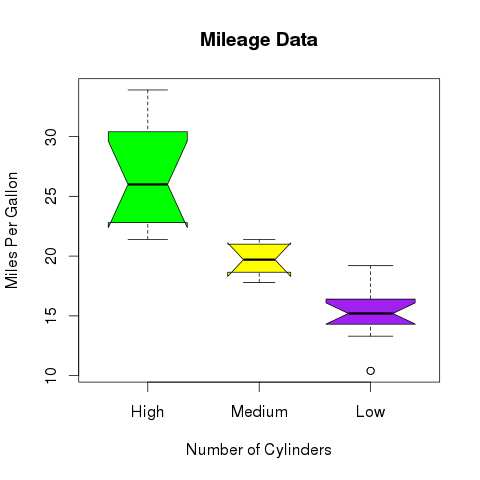
Biểu đồ biểu thị tần số của các giá trị của một biến được phân loại thành các phạm vi. Biểu đồ tương tự như trò chuyện thanh nhưng sự khác biệt là nó nhóm các giá trị thành các phạm vi liên tục. Mỗi thanh trong biểu đồ biểu thị chiều cao của số lượng giá trị có trong phạm vi đó.
R tạo biểu đồ bằng cách sử dụng hist()chức năng. Hàm này lấy một vectơ làm đầu vào và sử dụng thêm một số tham số để vẽ biểu đồ.
Cú pháp
Cú pháp cơ bản để tạo biểu đồ bằng R là:
hist(v,main,xlab,xlim,ylim,breaks,col,border)Sau đây là mô tả về các tham số được sử dụng:
v là một vectơ chứa các giá trị số được sử dụng trong biểu đồ.
main cho biết tiêu đề của biểu đồ.
col được sử dụng để thiết lập màu sắc của các thanh.
border được sử dụng để thiết lập màu đường viền của mỗi thanh.
xlab được sử dụng để đưa ra mô tả về trục x.
xlim được sử dụng để chỉ định phạm vi giá trị trên trục x.
ylim được sử dụng để chỉ định phạm vi giá trị trên trục y.
breaks được sử dụng để đề cập đến chiều rộng của mỗi thanh.
Thí dụ
Một biểu đồ đơn giản được tạo bằng cách sử dụng các tham số vector, nhãn, col và đường viền đầu vào.
Tập lệnh dưới đây sẽ tạo và lưu biểu đồ trong thư mục làm việc R hiện tại.
# Create data for the graph.
v <- c(9,13,21,8,36,22,12,41,31,33,19)
# Give the chart file a name.
png(file = "histogram.png")
# Create the histogram.
hist(v,xlab = "Weight",col = "yellow",border = "blue")
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
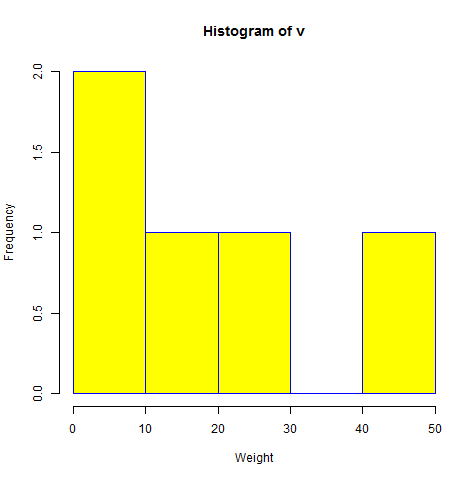
Phạm vi giá trị X và Y
Để chỉ định phạm vi giá trị được phép trong trục X và trục Y, chúng ta có thể sử dụng các tham số xlim và ylim.
Chiều rộng của mỗi thanh có thể được quyết định bằng cách sử dụng các dấu ngắt.
# Create data for the graph.
v <- c(9,13,21,8,36,22,12,41,31,33,19)
# Give the chart file a name.
png(file = "histogram_lim_breaks.png")
# Create the histogram.
hist(v,xlab = "Weight",col = "green",border = "red", xlim = c(0,40), ylim = c(0,5),
breaks = 5)
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Biểu đồ đường là một đồ thị nối một loạt các điểm bằng cách vẽ các đoạn thẳng giữa chúng. Các điểm này được sắp xếp theo một trong các giá trị tọa độ của chúng (thường là tọa độ x). Biểu đồ đường thường được sử dụng để xác định xu hướng trong dữ liệu.
Các plot() hàm trong R được sử dụng để tạo đồ thị đường.
Cú pháp
Cú pháp cơ bản để tạo biểu đồ đường trong R là:
plot(v,type,col,xlab,ylab)Sau đây là mô tả về các tham số được sử dụng:
v là một vectơ chứa các giá trị số.
type lấy giá trị "p" để chỉ các điểm, "l" để vẽ các đường thẳng và "o" để vẽ cả các điểm và đường thẳng.
xlab là nhãn cho trục x.
ylab là nhãn cho trục y.
main là Tiêu đề của biểu đồ.
col được sử dụng để cung cấp màu sắc cho cả điểm và đường.
Thí dụ
Một biểu đồ đường đơn giản được tạo bằng cách sử dụng vectơ đầu vào và tham số kiểu là "O". Tập lệnh dưới đây sẽ tạo và lưu một biểu đồ đường trong thư mục làm việc R hiện tại.
# Create the data for the chart.
v <- c(7,12,28,3,41)
# Give the chart file a name.
png(file = "line_chart.jpg")
# Plot the bar chart.
plot(v,type = "o")
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Tiêu đề, Màu và Nhãn của Biểu đồ Đường
Các tính năng của biểu đồ đường có thể được mở rộng bằng cách sử dụng các tham số bổ sung. Chúng tôi thêm màu cho các điểm và đường, đặt tiêu đề cho biểu đồ và thêm nhãn cho các trục.
Thí dụ
# Create the data for the chart.
v <- c(7,12,28,3,41)
# Give the chart file a name.
png(file = "line_chart_label_colored.jpg")
# Plot the bar chart.
plot(v,type = "o", col = "red", xlab = "Month", ylab = "Rain fall",
main = "Rain fall chart")
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Nhiều dòng trong một biểu đồ đường
Có thể vẽ nhiều hơn một đường trên cùng một biểu đồ bằng cách sử dụng lines()chức năng.
Sau khi dòng đầu tiên được vẽ, hàm lines () có thể sử dụng một vectơ bổ sung làm đầu vào để vẽ dòng thứ hai trong biểu đồ,
# Create the data for the chart.
v <- c(7,12,28,3,41)
t <- c(14,7,6,19,3)
# Give the chart file a name.
png(file = "line_chart_2_lines.jpg")
# Plot the bar chart.
plot(v,type = "o",col = "red", xlab = "Month", ylab = "Rain fall",
main = "Rain fall chart")
lines(t, type = "o", col = "blue")
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Biểu đồ phân tán cho thấy nhiều điểm được vẽ trong mặt phẳng Descartes. Mỗi điểm đại diện cho các giá trị của hai biến. Một biến được chọn trong trục hoành và một biến khác trong trục tung.
Biểu đồ phân tán đơn giản được tạo bằng cách sử dụng plot() chức năng.
Cú pháp
Cú pháp cơ bản để tạo scatterplot trong R là:
plot(x, y, main, xlab, ylab, xlim, ylim, axes)Sau đây là mô tả về các tham số được sử dụng:
x là tập dữ liệu có giá trị là tọa độ ngang.
y là tập dữ liệu có giá trị là tọa độ dọc.
main là ô của biểu đồ.
xlab là nhãn trong trục hoành.
ylab là nhãn trong trục tung.
xlim là giới hạn của các giá trị của x được sử dụng để vẽ biểu đồ.
ylim là giới hạn của các giá trị của y được sử dụng để vẽ biểu đồ.
axes cho biết liệu cả hai trục có nên được vẽ trên biểu đồ hay không.
Thí dụ
Chúng tôi sử dụng tập dữ liệu "mtcars"có sẵn trong môi trường R để tạo biểu đồ phân tán cơ bản. Hãy sử dụng các cột "wt" và "mpg" trong mtcars.
input <- mtcars[,c('wt','mpg')]
print(head(input))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
wt mpg
Mazda RX4 2.620 21.0
Mazda RX4 Wag 2.875 21.0
Datsun 710 2.320 22.8
Hornet 4 Drive 3.215 21.4
Hornet Sportabout 3.440 18.7
Valiant 3.460 18.1Tạo Scatterplot
Kịch bản dưới đây sẽ tạo ra một biểu đồ phân tán cho mối quan hệ giữa trọng lượng (trọng lượng) và mpg (dặm mỗi gallon).
# Get the input values.
input <- mtcars[,c('wt','mpg')]
# Give the chart file a name.
png(file = "scatterplot.png")
# Plot the chart for cars with weight between 2.5 to 5 and mileage between 15 and 30.
plot(x = input$wt,y = input$mpg,
xlab = "Weight",
ylab = "Milage",
xlim = c(2.5,5),
ylim = c(15,30),
main = "Weight vs Milage"
)
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
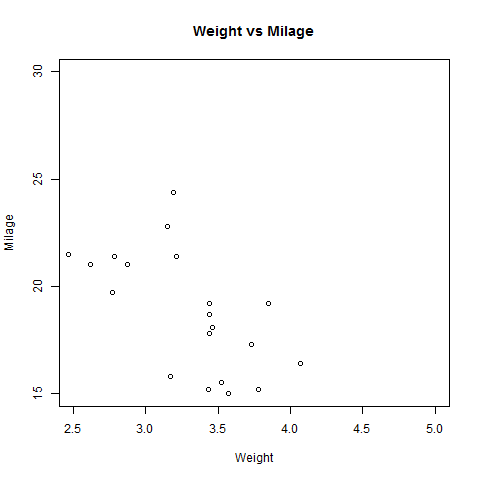
Ma trận Scatterplot
Khi chúng ta có nhiều hơn hai biến và chúng ta muốn tìm mối tương quan giữa một biến so với những biến còn lại, chúng ta sử dụng ma trận scatterplot. Chúng tôi sử dụngpairs() chức năng tạo ma trận phân tán.
Cú pháp
Cú pháp cơ bản để tạo ma trận scatterplot trong R là:
pairs(formula, data)Sau đây là mô tả về các tham số được sử dụng:
formula đại diện cho chuỗi các biến được sử dụng theo cặp.
data đại diện cho tập dữ liệu mà từ đó các biến sẽ được lấy.
Thí dụ
Mỗi biến được ghép nối với mỗi biến còn lại. Biểu đồ phân tán được vẽ cho mỗi cặp.
# Give the chart file a name.
png(file = "scatterplot_matrices.png")
# Plot the matrices between 4 variables giving 12 plots.
# One variable with 3 others and total 4 variables.
pairs(~wt+mpg+disp+cyl,data = mtcars,
main = "Scatterplot Matrix")
# Save the file.
dev.off()Khi đoạn mã trên được thực thi, chúng ta nhận được kết quả sau.
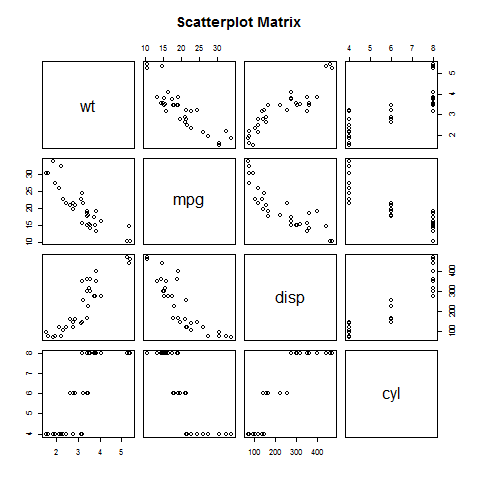
Phân tích thống kê trong R được thực hiện bằng cách sử dụng nhiều hàm tích hợp sẵn. Hầu hết các chức năng này là một phần của gói cơ sở R. Các hàm này lấy vector R làm đầu vào cùng với các đối số và đưa ra kết quả.
Các chức năng chúng ta đang thảo luận trong chương này là trung bình, trung vị và chế độ.
Nghĩa là
Nó được tính bằng cách lấy tổng các giá trị và chia cho số giá trị trong một chuỗi dữ liệu.
Chức năng mean() được sử dụng để tính toán điều này trong R.
Cú pháp
Cú pháp cơ bản để tính giá trị trung bình trong R là:
mean(x, trim = 0, na.rm = FALSE, ...)Sau đây là mô tả về các tham số được sử dụng:
x là vector đầu vào.
trim được sử dụng để loại bỏ một số quan sát từ cả hai đầu của vectơ đã sắp xếp.
na.rm được sử dụng để loại bỏ các giá trị bị thiếu khỏi vectơ đầu vào.
Thí dụ
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find Mean.
result.mean <- mean(x)
print(result.mean)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 8.22Áp dụng tùy chọn Trim
Khi tham số trim được cung cấp, các giá trị trong vectơ sẽ được sắp xếp và sau đó số lượng quan sát cần thiết bị loại bỏ khỏi việc tính giá trị trung bình.
Khi trim = 0,3, 3 giá trị từ mỗi đầu sẽ bị loại bỏ khỏi các phép tính để tìm giá trị trung bình.
Trong trường hợp này, vectơ được sắp xếp là (−21, −5, 2, 3, 4.2, 7, 8, 12, 18, 54) và các giá trị bị loại bỏ khỏi vectơ để tính giá trị trung bình là (−21, −5,2) từ trái và (12,18,54) từ phải.
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find Mean.
result.mean <- mean(x,trim = 0.3)
print(result.mean)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 5.55Áp dụng tùy chọn NA
Nếu thiếu giá trị, thì hàm trung bình trả về NA.
Để loại bỏ các giá trị bị thiếu khỏi phép tính, hãy sử dụng na.rm = TRUE. có nghĩa là loại bỏ các giá trị NA.
# Create a vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5,NA)
# Find mean.
result.mean <- mean(x)
print(result.mean)
# Find mean dropping NA values.
result.mean <- mean(x,na.rm = TRUE)
print(result.mean)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] NA
[1] 8.22Trung bình
Giá trị lớn nhất ở giữa trong chuỗi dữ liệu được gọi là giá trị trung bình. Cácmedian() hàm được sử dụng trong R để tính giá trị này.
Cú pháp
Cú pháp cơ bản để tính giá trị trung bình trong R là:
median(x, na.rm = FALSE)Sau đây là mô tả về các tham số được sử dụng:
x là vector đầu vào.
na.rm được sử dụng để loại bỏ các giá trị bị thiếu khỏi vectơ đầu vào.
Thí dụ
# Create the vector.
x <- c(12,7,3,4.2,18,2,54,-21,8,-5)
# Find the median.
median.result <- median(x)
print(median.result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 5.6Chế độ
Chế độ là giá trị có số lần xuất hiện cao nhất trong một tập dữ liệu. Giá trị trung bình và trung vị của Unike, chế độ có thể có cả dữ liệu số và ký tự.
R không có một chức năng tích hợp tiêu chuẩn để tính toán chế độ. Vì vậy, chúng tôi tạo một hàm người dùng để tính toán chế độ của một tập dữ liệu trong R. Hàm này nhận vectơ làm đầu vào và cung cấp giá trị chế độ làm đầu ra.
Thí dụ
# Create the function.
getmode <- function(v) {
uniqv <- unique(v)
uniqv[which.max(tabulate(match(v, uniqv)))]
}
# Create the vector with numbers.
v <- c(2,1,2,3,1,2,3,4,1,5,5,3,2,3)
# Calculate the mode using the user function.
result <- getmode(v)
print(result)
# Create the vector with characters.
charv <- c("o","it","the","it","it")
# Calculate the mode using the user function.
result <- getmode(charv)
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 2
[1] "it"Phân tích hồi quy là một công cụ thống kê được sử dụng rất rộng rãi để thiết lập mô hình mối quan hệ giữa hai biến. Một trong những biến này được gọi là biến dự đoán có giá trị được thu thập thông qua các thử nghiệm. Biến còn lại được gọi là biến phản hồi có giá trị bắt nguồn từ biến dự đoán.
Trong Hồi quy tuyến tính, hai biến này có liên quan với nhau thông qua một phương trình, trong đó số mũ (lũy thừa) của cả hai biến này là 1. Về mặt toán học, một quan hệ tuyến tính biểu diễn một đường thẳng khi được vẽ dưới dạng đồ thị. Một mối quan hệ phi tuyến tính trong đó số mũ của bất kỳ biến nào không bằng 1 sẽ tạo ra một đường cong.
Phương trình toán học tổng quát cho hồi quy tuyến tính là:
y = ax + bSau đây là mô tả về các tham số được sử dụng:
y là biến phản hồi.
x là biến dự báo.
a và b là các hằng số được gọi là hệ số.
Các bước để thiết lập một hồi quy
Một ví dụ đơn giản của hồi quy là dự đoán cân nặng của một người khi biết chiều cao của người đó. Để làm được điều này chúng ta cần có mối quan hệ giữa chiều cao và cân nặng của một người.
Các bước để tạo mối quan hệ là -
Tiến hành thí nghiệm thu thập mẫu các giá trị quan sát được về chiều cao và cân nặng tương ứng.
Tạo mô hình mối quan hệ bằng cách sử dụng lm() hàm trong R.
Tìm các hệ số từ mô hình đã tạo và tạo phương trình toán học bằng cách sử dụng
Nhận tóm tắt mô hình mối quan hệ để biết sai số trung bình trong dự đoán. Còn được gọi làresiduals.
Để dự đoán cân nặng của những người mới, hãy sử dụng predict() hàm trong R.
Dữ liệu đầu vào
Dưới đây là dữ liệu mẫu đại diện cho các quan sát -
# Values of height
151, 174, 138, 186, 128, 136, 179, 163, 152, 131
# Values of weight.
63, 81, 56, 91, 47, 57, 76, 72, 62, 48Hàm lm ()
Hàm này tạo ra mô hình mối quan hệ giữa yếu tố dự đoán và biến phản hồi.
Cú pháp
Cú pháp cơ bản cho lm() hàm trong hồi quy tuyến tính là -
lm(formula,data)Sau đây là mô tả về các tham số được sử dụng:
formula là một biểu tượng trình bày mối quan hệ giữa x và y.
data là vectơ mà công thức sẽ được áp dụng.
Tạo mô hình mối quan hệ và nhận Hệ số
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
print(relation)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Call:
lm(formula = y ~ x)
Coefficients:
(Intercept) x
-38.4551 0.6746Nhận bản tóm tắt mối quan hệ
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
print(summary(relation))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-6.3002 -1.6629 0.0412 1.8944 3.9775
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -38.45509 8.04901 -4.778 0.00139 **
x 0.67461 0.05191 12.997 1.16e-06 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.253 on 8 degrees of freedom
Multiple R-squared: 0.9548, Adjusted R-squared: 0.9491
F-statistic: 168.9 on 1 and 8 DF, p-value: 1.164e-06hàm dự đoán ()
Cú pháp
Cú pháp cơ bản để dự đoán () trong hồi quy tuyến tính là:
predict(object, newdata)Sau đây là mô tả về các tham số được sử dụng:
object là công thức đã được tạo bằng hàm lm ().
newdata là vectơ chứa giá trị mới cho biến dự đoán.
Dự đoán cân nặng của người mới
# The predictor vector.
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
# The resposne vector.
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
# Apply the lm() function.
relation <- lm(y~x)
# Find weight of a person with height 170.
a <- data.frame(x = 170)
result <- predict(relation,a)
print(result)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
1
76.22869Trực quan hóa hồi quy bằng đồ họa
# Create the predictor and response variable.
x <- c(151, 174, 138, 186, 128, 136, 179, 163, 152, 131)
y <- c(63, 81, 56, 91, 47, 57, 76, 72, 62, 48)
relation <- lm(y~x)
# Give the chart file a name.
png(file = "linearregression.png")
# Plot the chart.
plot(y,x,col = "blue",main = "Height & Weight Regression",
abline(lm(x~y)),cex = 1.3,pch = 16,xlab = "Weight in Kg",ylab = "Height in cm")
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
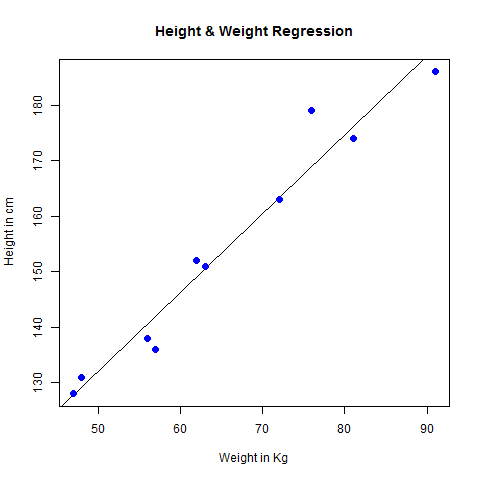
Hồi quy bội là một phần mở rộng của hồi quy tuyến tính vào mối quan hệ giữa nhiều hơn hai biến. Trong quan hệ tuyến tính đơn giản, chúng ta có một biến dự báo và một biến phản hồi, nhưng trong hồi quy bội, chúng ta có nhiều hơn một biến dự báo và một biến phản hồi.
Phương trình toán học tổng quát cho hồi quy bội là:
y = a + b1x1 + b2x2 +...bnxnSau đây là mô tả về các tham số được sử dụng:
y là biến phản hồi.
a, b1, b2...bn là các hệ số.
x1, x2, ...xn là các biến dự báo.
Chúng tôi tạo mô hình hồi quy bằng cách sử dụng lm()hàm trong R. Mô hình xác định giá trị của các hệ số bằng cách sử dụng dữ liệu đầu vào. Tiếp theo, chúng ta có thể dự đoán giá trị của biến phản hồi cho một tập hợp các biến dự báo nhất định bằng cách sử dụng các hệ số này.
Hàm lm ()
Hàm này tạo ra mô hình mối quan hệ giữa yếu tố dự đoán và biến phản hồi.
Cú pháp
Cú pháp cơ bản cho lm() hàm trong hồi quy bội là -
lm(y ~ x1+x2+x3...,data)Sau đây là mô tả về các tham số được sử dụng:
formula là một ký hiệu trình bày mối quan hệ giữa biến phản ứng và các biến dự báo.
data là vectơ mà công thức sẽ được áp dụng.
Thí dụ
Dữ liệu đầu vào
Hãy xem xét tập dữ liệu "mtcars" có sẵn trong môi trường R. Nó đưa ra sự so sánh giữa các mẫu xe khác nhau về số dặm trên mỗi gallon (mpg), dung tích xi lanh ("disp"), sức ngựa ("hp"), trọng lượng của xe ("wt") và một số thông số khác.
Mục tiêu của mô hình là thiết lập mối quan hệ giữa "mpg" như một biến phản hồi với "disp", "hp" và "wt" là các biến dự báo. Chúng tôi tạo một tập hợp con của các biến này từ tập dữ liệu mtcars cho mục đích này.
input <- mtcars[,c("mpg","disp","hp","wt")]
print(head(input))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
mpg disp hp wt
Mazda RX4 21.0 160 110 2.620
Mazda RX4 Wag 21.0 160 110 2.875
Datsun 710 22.8 108 93 2.320
Hornet 4 Drive 21.4 258 110 3.215
Hornet Sportabout 18.7 360 175 3.440
Valiant 18.1 225 105 3.460Tạo mô hình mối quan hệ và nhận Hệ số
input <- mtcars[,c("mpg","disp","hp","wt")]
# Create the relationship model.
model <- lm(mpg~disp+hp+wt, data = input)
# Show the model.
print(model)
# Get the Intercept and coefficients as vector elements.
cat("# # # # The Coefficient Values # # # ","\n")
a <- coef(model)[1]
print(a)
Xdisp <- coef(model)[2]
Xhp <- coef(model)[3]
Xwt <- coef(model)[4]
print(Xdisp)
print(Xhp)
print(Xwt)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Call:
lm(formula = mpg ~ disp + hp + wt, data = input)
Coefficients:
(Intercept) disp hp wt
37.105505 -0.000937 -0.031157 -3.800891
# # # # The Coefficient Values # # #
(Intercept)
37.10551
disp
-0.0009370091
hp
-0.03115655
wt
-3.800891Tạo phương trình cho mô hình hồi quy
Dựa vào các giá trị hệ số và hệ số chặn ở trên, ta lập phương trình toán học.
Y = a+Xdisp.x1+Xhp.x2+Xwt.x3
or
Y = 37.15+(-0.000937)*x1+(-0.0311)*x2+(-3.8008)*x3Áp dụng phương trình để dự đoán các giá trị mới
Chúng ta có thể sử dụng phương trình hồi quy được tạo ở trên để dự đoán quãng đường đi được khi cung cấp một bộ giá trị mới cho độ dịch chuyển, sức ngựa và trọng lượng.
Đối với một chiếc xe có disp = 221, hp = 102 và wt = 2,91, quãng đường dự đoán là -
Y = 37.15+(-0.000937)*221+(-0.0311)*102+(-3.8008)*2.91 = 22.7104Logistic Regression là một mô hình hồi quy trong đó biến phản hồi (biến phụ thuộc) có các giá trị phân loại như True / False hoặc 0/1. Nó thực sự đo xác suất của một phản hồi nhị phân dưới dạng giá trị của biến phản hồi dựa trên phương trình toán học liên hệ nó với các biến dự đoán.
Phương trình toán học tổng quát cho hồi quy logistic là:
y = 1/(1+e^-(a+b1x1+b2x2+b3x3+...))Sau đây là mô tả về các tham số được sử dụng:
y là biến phản hồi.
x là biến dự báo.
a và b là các hệ số là hằng số.
Hàm được sử dụng để tạo mô hình hồi quy là glm() chức năng.
Cú pháp
Cú pháp cơ bản cho glm() hàm trong hồi quy logistic là -
glm(formula,data,family)Sau đây là mô tả về các tham số được sử dụng:
formula là biểu tượng trình bày mối quan hệ giữa các biến.
data là tập dữ liệu đưa ra giá trị của các biến này.
familylà đối tượng R để chỉ định các chi tiết của mô hình. Giá trị của nó là nhị thức đối với hồi quy logistic.
Thí dụ
Tập dữ liệu tích hợp "mtcars" mô tả các kiểu xe khác nhau với các thông số kỹ thuật động cơ khác nhau của chúng. Trong tập dữ liệu "mtcars", chế độ truyền (tự động hoặc thủ công) được mô tả bởi cột am là một giá trị nhị phân (0 hoặc 1). Chúng ta có thể tạo mô hình hồi quy logistic giữa các cột "am" và 3 cột khác - hp, wt và cyl.
# Select some columns form mtcars.
input <- mtcars[,c("am","cyl","hp","wt")]
print(head(input))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
am cyl hp wt
Mazda RX4 1 6 110 2.620
Mazda RX4 Wag 1 6 110 2.875
Datsun 710 1 4 93 2.320
Hornet 4 Drive 0 6 110 3.215
Hornet Sportabout 0 8 175 3.440
Valiant 0 6 105 3.460Tạo mô hình hồi quy
Chúng tôi sử dụng glm() chức năng tạo mô hình hồi quy và lấy tóm tắt của nó để phân tích.
input <- mtcars[,c("am","cyl","hp","wt")]
am.data = glm(formula = am ~ cyl + hp + wt, data = input, family = binomial)
print(summary(am.data))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Call:
glm(formula = am ~ cyl + hp + wt, family = binomial, data = input)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.17272 -0.14907 -0.01464 0.14116 1.27641
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 19.70288 8.11637 2.428 0.0152 *
cyl 0.48760 1.07162 0.455 0.6491
hp 0.03259 0.01886 1.728 0.0840 .
wt -9.14947 4.15332 -2.203 0.0276 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 43.2297 on 31 degrees of freedom
Residual deviance: 9.8415 on 28 degrees of freedom
AIC: 17.841
Number of Fisher Scoring iterations: 8Phần kết luận
Tóm lại, vì giá trị p trong cột cuối cùng lớn hơn 0,05 cho các biến "cyl" và "hp", chúng tôi coi chúng là không đáng kể trong việc đóng góp vào giá trị của biến "am". Chỉ trọng số (wt) mới tác động đến giá trị "am" trong mô hình hồi quy này.
Trong một tập hợp dữ liệu ngẫu nhiên từ các nguồn độc lập, người ta thường quan sát thấy việc phân phối dữ liệu là bình thường. Có nghĩa là, khi vẽ một đồ thị với giá trị của biến số trong trục hoành và đếm các giá trị trong trục tung, chúng ta sẽ có được một đường cong hình chuông. Tâm của đường cong biểu thị giá trị trung bình của tập dữ liệu. Trong biểu đồ, năm mươi phần trăm giá trị nằm bên trái giá trị trung bình và năm mươi phần trăm còn lại nằm bên phải biểu đồ. Đây được gọi là phân phối chuẩn trong thống kê.
R có bốn hàm tích hợp để tạo phân phối chuẩn. Chúng được mô tả dưới đây.
dnorm(x, mean, sd)
pnorm(x, mean, sd)
qnorm(p, mean, sd)
rnorm(n, mean, sd)Sau đây là mô tả về các tham số được sử dụng trong các hàm trên:
x là một vectơ của các số.
p là một vectơ xác suất.
n là số lần quan sát (cỡ mẫu).
meanlà giá trị trung bình của dữ liệu mẫu. Giá trị mặc định của nó là 0.
sdlà độ lệch chuẩn. Giá trị mặc định của nó là 1.
dnorm ()
Hàm này cung cấp độ cao của phân phối xác suất tại mỗi điểm đối với giá trị trung bình và độ lệch chuẩn nhất định.
# Create a sequence of numbers between -10 and 10 incrementing by 0.1.
x <- seq(-10, 10, by = .1)
# Choose the mean as 2.5 and standard deviation as 0.5.
y <- dnorm(x, mean = 2.5, sd = 0.5)
# Give the chart file a name.
png(file = "dnorm.png")
plot(x,y)
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
pnorm ()
Hàm này cho xác suất của một số ngẫu nhiên có phân phối chuẩn nhỏ hơn giá trị của một số nhất định. Nó còn được gọi là "Hàm phân phối tích lũy".
# Create a sequence of numbers between -10 and 10 incrementing by 0.2.
x <- seq(-10,10,by = .2)
# Choose the mean as 2.5 and standard deviation as 2.
y <- pnorm(x, mean = 2.5, sd = 2)
# Give the chart file a name.
png(file = "pnorm.png")
# Plot the graph.
plot(x,y)
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
qnorm ()
Hàm này nhận giá trị xác suất và đưa ra một số có giá trị tích lũy khớp với giá trị xác suất.
# Create a sequence of probability values incrementing by 0.02.
x <- seq(0, 1, by = 0.02)
# Choose the mean as 2 and standard deviation as 3.
y <- qnorm(x, mean = 2, sd = 1)
# Give the chart file a name.
png(file = "qnorm.png")
# Plot the graph.
plot(x,y)
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
rnorm ()
Hàm này được sử dụng để tạo các số ngẫu nhiên có phân phối chuẩn. Nó lấy kích thước mẫu làm đầu vào và tạo ra nhiều số ngẫu nhiên. Chúng tôi vẽ một biểu đồ để hiển thị sự phân bố của các số được tạo.
# Create a sample of 50 numbers which are normally distributed.
y <- rnorm(50)
# Give the chart file a name.
png(file = "rnorm.png")
# Plot the histogram for this sample.
hist(y, main = "Normal DIstribution")
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Mô hình phân phối nhị thức đề cập đến việc tìm xác suất thành công của một sự kiện chỉ có hai kết quả có thể xảy ra trong một loạt thử nghiệm. Ví dụ, tung đồng xu luôn cho ra đầu hoặc đuôi. Xác suất tìm thấy chính xác 3 đầu khi tung đồng xu liên tục trong 10 lần được ước tính trong phân phối nhị thức.
R có bốn hàm tích hợp để tạo phân phối nhị thức. Chúng được mô tả dưới đây.
dbinom(x, size, prob)
pbinom(x, size, prob)
qbinom(p, size, prob)
rbinom(n, size, prob)Sau đây là mô tả về các tham số được sử dụng:
x là một vectơ của các số.
p là một vectơ xác suất.
n là số quan sát.
size là số lần thử.
prob là xác suất thành công của mỗi lần thử.
dbinom ()
Hàm này cung cấp phân phối mật độ xác suất tại mỗi điểm.
# Create a sample of 50 numbers which are incremented by 1.
x <- seq(0,50,by = 1)
# Create the binomial distribution.
y <- dbinom(x,50,0.5)
# Give the chart file a name.
png(file = "dbinom.png")
# Plot the graph for this sample.
plot(x,y)
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
pbinom ()
Hàm này cung cấp xác suất tích lũy của một sự kiện. Nó là một giá trị duy nhất đại diện cho xác suất.
# Probability of getting 26 or less heads from a 51 tosses of a coin.
x <- pbinom(26,51,0.5)
print(x)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 0.610116qbinom ()
Hàm này nhận giá trị xác suất và đưa ra một số có giá trị tích lũy khớp với giá trị xác suất.
# How many heads will have a probability of 0.25 will come out when a coin
# is tossed 51 times.
x <- qbinom(0.25,51,1/2)
print(x)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 23rbinom ()
Hàm này tạo ra số lượng giá trị ngẫu nhiên cần thiết của xác suất đã cho từ một mẫu nhất định.
# Find 8 random values from a sample of 150 with probability of 0.4.
x <- rbinom(8,150,.4)
print(x)Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 58 61 59 66 55 60 61 67Hồi quy Poisson liên quan đến các mô hình hồi quy trong đó biến phản hồi ở dạng số đếm chứ không phải số phân số. Ví dụ, đếm số lần sinh hoặc số trận thắng trong một chuỗi trận đấu bóng đá. Ngoài ra, giá trị của các biến phản hồi tuân theo phân phối Poisson.
Phương trình toán học tổng quát cho hồi quy Poisson là:
log(y) = a + b1x1 + b2x2 + bnxn.....Sau đây là mô tả về các tham số được sử dụng:
y là biến phản hồi.
a và b là các hệ số số.
x là biến dự báo.
Hàm được sử dụng để tạo mô hình hồi quy Poisson là glm() chức năng.
Cú pháp
Cú pháp cơ bản cho glm() hàm trong hồi quy Poisson là -
glm(formula,data,family)Sau đây là mô tả về các tham số được sử dụng trong các hàm trên:
formula là biểu tượng trình bày mối quan hệ giữa các biến.
data là tập dữ liệu đưa ra giá trị của các biến này.
familylà đối tượng R để chỉ định các chi tiết của mô hình. Giá trị của nó là 'Poisson' cho Logistic Regression.
Thí dụ
Chúng tôi có tập dữ liệu tích hợp "sợi dọc" mô tả ảnh hưởng của loại len (A hoặc B) và độ căng (thấp, trung bình hoặc cao) đối với số lượng sợi dọc bị đứt trên mỗi khung dệt. Hãy coi "break" là biến phản hồi là một số lần ngắt. "Loại" và "độ căng" len được lấy làm biến số dự báo.
Input Data
input <- warpbreaks
print(head(input))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
breaks wool tension
1 26 A L
2 30 A L
3 54 A L
4 25 A L
5 70 A L
6 52 A LTạo mô hình hồi quy
output <-glm(formula = breaks ~ wool+tension, data = warpbreaks,
family = poisson)
print(summary(output))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Call:
glm(formula = breaks ~ wool + tension, family = poisson, data = warpbreaks)
Deviance Residuals:
Min 1Q Median 3Q Max
-3.6871 -1.6503 -0.4269 1.1902 4.2616
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.69196 0.04541 81.302 < 2e-16 ***
woolB -0.20599 0.05157 -3.994 6.49e-05 ***
tensionM -0.32132 0.06027 -5.332 9.73e-08 ***
tensionH -0.51849 0.06396 -8.107 5.21e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 297.37 on 53 degrees of freedom
Residual deviance: 210.39 on 50 degrees of freedom
AIC: 493.06
Number of Fisher Scoring iterations: 4Trong phần tóm tắt, chúng tôi tìm kiếm giá trị p trong cột cuối cùng nhỏ hơn 0,05 để xem xét tác động của biến dự báo lên biến phản hồi. Như đã thấy, loại len B có loại căng M và H có ảnh hưởng đến số lần đứt.
Chúng tôi sử dụng phân tích hồi quy để tạo ra các mô hình mô tả tác động của sự thay đổi trong các biến dự báo lên biến phản hồi. Đôi khi, nếu chúng ta có một biến phân loại với các giá trị như Có / Không hoặc Nam / Nữ, v.v. Phân tích hồi quy đơn giản cho nhiều kết quả cho mỗi giá trị của biến phân loại. Trong trường hợp như vậy, chúng ta có thể nghiên cứu ảnh hưởng của biến phân loại bằng cách sử dụng nó cùng với biến dự đoán và so sánh các đường hồi quy cho mỗi cấp của biến phân loại. Phân tích như vậy được gọi làAnalysis of Covariance cũng được gọi là ANCOVA.
Thí dụ
Hãy xem xét các mtcars trong tập dữ liệu R. Trong đó, chúng tôi nhận thấy rằng trường "am" đại diện cho loại hộp số (tự động hoặc thủ công). Nó là một biến phân loại với các giá trị 0 và 1. dặm một giá trị gallon (mpg) của một chiếc xe cũng có thể phụ thuộc vào nó bên cạnh những giá trị của mã lực ( "hp").
Chúng tôi nghiên cứu ảnh hưởng của giá trị "am" đến hồi quy giữa "mpg" và "hp". Nó được thực hiện bằng cách sử dụngaov() theo sau là hàm anova() hàm để so sánh nhiều hồi quy.
Dữ liệu đầu vào
Tạo khung dữ liệu có chứa các trường "mpg", "hp" và "am" từ mtcars tập dữ liệu. Ở đây chúng tôi lấy "mpg" làm biến phản hồi, "hp" làm biến dự đoán và "am" là biến phân loại.
input <- mtcars[,c("am","mpg","hp")]
print(head(input))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
am mpg hp
Mazda RX4 1 21.0 110
Mazda RX4 Wag 1 21.0 110
Datsun 710 1 22.8 93
Hornet 4 Drive 0 21.4 110
Hornet Sportabout 0 18.7 175
Valiant 0 18.1 105Phân tích ANCOVA
Chúng tôi tạo mô hình hồi quy lấy "hp" làm biến dự đoán và "mpg" làm biến phản hồi có tính đến tương tác giữa "am" và "hp".
Mô hình có sự tương tác giữa biến phân loại và biến dự báo
# Get the dataset.
input <- mtcars
# Create the regression model.
result <- aov(mpg~hp*am,data = input)
print(summary(result))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Df Sum Sq Mean Sq F value Pr(>F)
hp 1 678.4 678.4 77.391 1.50e-09 ***
am 1 202.2 202.2 23.072 4.75e-05 ***
hp:am 1 0.0 0.0 0.001 0.981
Residuals 28 245.4 8.8
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Kết quả này cho thấy cả hai mã lực và loại truyền có ảnh hưởng quan trọng trên dặm cho mỗi gallon như giá trị p trong cả hai trường hợp là nhỏ hơn 0,05. Nhưng sự tương tác giữa hai biến này không có ý nghĩa vì giá trị p lớn hơn 0,05.
Mô hình không có tương tác giữa biến phân loại và biến dự báo
# Get the dataset.
input <- mtcars
# Create the regression model.
result <- aov(mpg~hp+am,data = input)
print(summary(result))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Df Sum Sq Mean Sq F value Pr(>F)
hp 1 678.4 678.4 80.15 7.63e-10 ***
am 1 202.2 202.2 23.89 3.46e-05 ***
Residuals 29 245.4 8.5
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Kết quả này cho thấy cả hai mã lực và loại truyền có ảnh hưởng quan trọng trên dặm cho mỗi gallon như giá trị p trong cả hai trường hợp là nhỏ hơn 0,05.
So sánh hai mô hình
Bây giờ chúng ta có thể so sánh hai mô hình để kết luận xem liệu tương tác của các biến có thực sự đáng kể hay không. Đối với điều này, chúng tôi sử dụnganova() chức năng.
# Get the dataset.
input <- mtcars
# Create the regression models.
result1 <- aov(mpg~hp*am,data = input)
result2 <- aov(mpg~hp+am,data = input)
# Compare the two models.
print(anova(result1,result2))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Model 1: mpg ~ hp * am
Model 2: mpg ~ hp + am
Res.Df RSS Df Sum of Sq F Pr(>F)
1 28 245.43
2 29 245.44 -1 -0.0052515 6e-04 0.9806Khi giá trị p lớn hơn 0,05, chúng tôi kết luận rằng sự tương tác giữa sức ngựa và kiểu truyền tải là không đáng kể. Vì vậy, số dặm trên mỗi gallon sẽ phụ thuộc một cách tương tự vào sức ngựa của xe ở cả chế độ hộp số tự động và số tay.
Chuỗi thời gian là một chuỗi các điểm dữ liệu trong đó mỗi điểm dữ liệu được liên kết với một dấu thời gian. Một ví dụ đơn giản là giá cổ phiếu trên thị trường chứng khoán tại các thời điểm khác nhau trong một ngày nhất định. Một ví dụ khác là lượng mưa của một vùng vào các tháng khác nhau trong năm. Ngôn ngữ R sử dụng nhiều chức năng để tạo, thao tác và vẽ biểu đồ dữ liệu chuỗi thời gian. Dữ liệu cho chuỗi thời gian được lưu trữ trong một đối tượng R được gọi làtime-series object. Nó cũng là một đối tượng dữ liệu R giống như một vector hoặc khung dữ liệu.
Đối tượng chuỗi thời gian được tạo bằng cách sử dụng ts() chức năng.
Cú pháp
Cú pháp cơ bản cho ts() chức năng trong phân tích chuỗi thời gian là -
timeseries.object.name <- ts(data, start, end, frequency)Sau đây là mô tả về các tham số được sử dụng:
data là một vectơ hoặc ma trận chứa các giá trị được sử dụng trong chuỗi thời gian.
start chỉ định thời gian bắt đầu cho lần quan sát đầu tiên trong chuỗi thời gian.
end chỉ định thời gian kết thúc cho lần quan sát cuối cùng trong chuỗi thời gian.
frequency chỉ định số lượng quan sát trên một đơn vị thời gian.
Ngoại trừ tham số "dữ liệu" tất cả các tham số khác là tùy chọn.
Thí dụ
Xem xét chi tiết lượng mưa hàng năm tại một địa điểm bắt đầu từ tháng 1 năm 2012. Chúng tôi tạo một đối tượng chuỗi thời gian R trong khoảng thời gian 12 tháng và vẽ biểu đồ cho nó.
# Get the data points in form of a R vector.
rainfall <- c(799,1174.8,865.1,1334.6,635.4,918.5,685.5,998.6,784.2,985,882.8,1071)
# Convert it to a time series object.
rainfall.timeseries <- ts(rainfall,start = c(2012,1),frequency = 12)
# Print the timeseries data.
print(rainfall.timeseries)
# Give the chart file a name.
png(file = "rainfall.png")
# Plot a graph of the time series.
plot(rainfall.timeseries)
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả và biểu đồ sau:
Jan Feb Mar Apr May Jun Jul Aug Sep
2012 799.0 1174.8 865.1 1334.6 635.4 918.5 685.5 998.6 784.2
Oct Nov Dec
2012 985.0 882.8 1071.0Biểu đồ chuỗi thời gian -
Khoảng thời gian khác nhau
Giá trị của frequencytham số trong hàm ts () quyết định khoảng thời gian tại đó các điểm dữ liệu được đo. Giá trị 12 cho biết chuỗi thời gian là 12 tháng. Các giá trị khác và ý nghĩa của nó như sau:
frequency = 12 chốt các điểm dữ liệu cho mỗi tháng trong năm.
frequency = 4 chốt các điểm dữ liệu cho mỗi quý trong năm.
frequency = 6 chốt các điểm dữ liệu cứ 10 phút một giờ một lần.
frequency = 24*6 chốt các điểm dữ liệu cho 10 phút một ngày.
Nhiều chuỗi thời gian
Chúng ta có thể vẽ nhiều chuỗi thời gian trong một biểu đồ bằng cách kết hợp cả hai chuỗi thành một ma trận.
# Get the data points in form of a R vector.
rainfall1 <- c(799,1174.8,865.1,1334.6,635.4,918.5,685.5,998.6,784.2,985,882.8,1071)
rainfall2 <-
c(655,1306.9,1323.4,1172.2,562.2,824,822.4,1265.5,799.6,1105.6,1106.7,1337.8)
# Convert them to a matrix.
combined.rainfall <- matrix(c(rainfall1,rainfall2),nrow = 12)
# Convert it to a time series object.
rainfall.timeseries <- ts(combined.rainfall,start = c(2012,1),frequency = 12)
# Print the timeseries data.
print(rainfall.timeseries)
# Give the chart file a name.
png(file = "rainfall_combined.png")
# Plot a graph of the time series.
plot(rainfall.timeseries, main = "Multiple Time Series")
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả và biểu đồ sau:
Series 1 Series 2
Jan 2012 799.0 655.0
Feb 2012 1174.8 1306.9
Mar 2012 865.1 1323.4
Apr 2012 1334.6 1172.2
May 2012 635.4 562.2
Jun 2012 918.5 824.0
Jul 2012 685.5 822.4
Aug 2012 998.6 1265.5
Sep 2012 784.2 799.6
Oct 2012 985.0 1105.6
Nov 2012 882.8 1106.7
Dec 2012 1071.0 1337.8Biểu đồ chuỗi nhiều thời gian -
Khi mô hình hóa dữ liệu thế giới thực để phân tích hồi quy, chúng tôi nhận thấy rằng hiếm khi xảy ra trường hợp phương trình của mô hình là một phương trình tuyến tính đưa ra một đồ thị tuyến tính. Hầu hết thời gian, phương trình của mô hình dữ liệu thế giới thực liên quan đến các hàm toán học ở mức độ cao hơn như số mũ của 3 hoặc hàm sin. Trong một kịch bản như vậy, biểu đồ của mô hình là một đường cong chứ không phải là một đường thẳng. Mục tiêu của cả hồi quy tuyến tính và phi tuyến tính là điều chỉnh các giá trị của các tham số của mô hình để tìm đường hoặc đường cong gần nhất với dữ liệu của bạn. Khi tìm những giá trị này, chúng tôi sẽ có thể ước tính biến phản hồi với độ chính xác tốt.
Trong hồi quy Least Square, chúng tôi thiết lập một mô hình hồi quy trong đó tổng bình phương của các khoảng cách dọc của các điểm khác nhau từ đường cong hồi quy được tối thiểu hóa. Chúng tôi thường bắt đầu với một mô hình xác định và giả định một số giá trị cho các hệ số. Sau đó chúng tôi áp dụngnls() hàm của R để nhận các giá trị chính xác hơn cùng với khoảng tin cậy.
Cú pháp
Cú pháp cơ bản để tạo một phép thử bình phương nhỏ nhất phi tuyến trong R là:
nls(formula, data, start)Sau đây là mô tả về các tham số được sử dụng:
formula là một công thức mô hình phi tuyến bao gồm các biến và tham số.
data là khung dữ liệu dùng để đánh giá các biến trong công thức.
start là danh sách được đặt tên hoặc vectơ số được đặt tên của các ước tính bắt đầu.
Thí dụ
Chúng ta sẽ xem xét một mô hình phi tuyến với giả định các giá trị ban đầu của các hệ số của nó. Tiếp theo, chúng ta sẽ xem khoảng tin cậy của các giá trị giả định này là gì để chúng ta có thể đánh giá mức độ ảnh hưởng của các giá trị này vào mô hình.
Vì vậy, hãy xem xét phương trình dưới đây cho mục đích này -
a = b1*x^2+b2Hãy giả sử các hệ số ban đầu là 1 và 3 và phù hợp với các giá trị này vào hàm nls ().
xvalues <- c(1.6,2.1,2,2.23,3.71,3.25,3.4,3.86,1.19,2.21)
yvalues <- c(5.19,7.43,6.94,8.11,18.75,14.88,16.06,19.12,3.21,7.58)
# Give the chart file a name.
png(file = "nls.png")
# Plot these values.
plot(xvalues,yvalues)
# Take the assumed values and fit into the model.
model <- nls(yvalues ~ b1*xvalues^2+b2,start = list(b1 = 1,b2 = 3))
# Plot the chart with new data by fitting it to a prediction from 100 data points.
new.data <- data.frame(xvalues = seq(min(xvalues),max(xvalues),len = 100))
lines(new.data$xvalues,predict(model,newdata = new.data))
# Save the file.
dev.off()
# Get the sum of the squared residuals.
print(sum(resid(model)^2))
# Get the confidence intervals on the chosen values of the coefficients.
print(confint(model))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
[1] 1.081935
Waiting for profiling to be done...
2.5% 97.5%
b1 1.137708 1.253135
b2 1.497364 2.496484
Chúng ta có thể kết luận rằng giá trị của b1 gần 1 hơn trong khi giá trị của b2 gần 2 hơn chứ không phải 3.
Cây quyết định là một biểu đồ để biểu diễn các lựa chọn và kết quả của chúng ở dạng cây. Các nút trong biểu đồ đại diện cho một sự kiện hoặc lựa chọn và các cạnh của biểu đồ đại diện cho các quy tắc hoặc điều kiện quyết định. Nó chủ yếu được sử dụng trong các ứng dụng Học máy và Khai thác dữ liệu bằng R.
Ví dụ về việc sử dụng địa chỉ quyết định là - dự đoán email là thư rác hay không phải thư rác, dự đoán khối u là ung thư hoặc dự đoán một khoản vay là rủi ro tín dụng tốt hay xấu dựa trên các yếu tố trong mỗi điều này. Nói chung, một mô hình được tạo bằng dữ liệu quan sát còn được gọi là dữ liệu huấn luyện. Sau đó, một tập hợp dữ liệu xác nhận được sử dụng để xác minh và cải thiện mô hình. R có các gói được sử dụng để tạo và hình dung cây quyết định. Đối với tập hợp biến dự đoán mới, chúng tôi sử dụng mô hình này để đi đến quyết định về danh mục (có / Không, spam / không phải spam) của dữ liệu.
Gói R "party" được sử dụng để tạo cây quyết định.
Cài đặt gói R
Sử dụng lệnh dưới đây trong bảng điều khiển R để cài đặt gói. Bạn cũng phải cài đặt các gói phụ thuộc nếu có.
install.packages("party")Gói "party" có chức năng ctree() được sử dụng để tạo và phân tích cây decison.
Cú pháp
Cú pháp cơ bản để tạo cây quyết định trong R là:
ctree(formula, data)Sau đây là mô tả về các tham số được sử dụng:
formula là một công thức mô tả các biến dự báo và phản ứng.
data là tên của tập dữ liệu được sử dụng.
Dữ liệu đầu vào
Chúng tôi sẽ sử dụng tập dữ liệu tích hợp R có tên readingSkillsđể tạo cây quyết định. Nó mô tả điểm số của ReadingSkills của một người nào đó nếu chúng ta biết các biến "tuổi", "kích thước giày", "điểm số" và liệu người đó có phải là người bản xứ hay không.
Đây là dữ liệu mẫu.
# Load the party package. It will automatically load other
# dependent packages.
library(party)
# Print some records from data set readingSkills.
print(head(readingSkills))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả và biểu đồ sau:
nativeSpeaker age shoeSize score
1 yes 5 24.83189 32.29385
2 yes 6 25.95238 36.63105
3 no 11 30.42170 49.60593
4 yes 7 28.66450 40.28456
5 yes 11 31.88207 55.46085
6 yes 10 30.07843 52.83124
Loading required package: methods
Loading required package: grid
...............................
...............................Thí dụ
Chúng tôi sẽ sử dụng ctree() chức năng tạo cây quyết định và xem đồ thị của nó.
# Load the party package. It will automatically load other
# dependent packages.
library(party)
# Create the input data frame.
input.dat <- readingSkills[c(1:105),]
# Give the chart file a name.
png(file = "decision_tree.png")
# Create the tree.
output.tree <- ctree(
nativeSpeaker ~ age + shoeSize + score,
data = input.dat)
# Plot the tree.
plot(output.tree)
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
null device
1
Loading required package: methods
Loading required package: grid
Loading required package: mvtnorm
Loading required package: modeltools
Loading required package: stats4
Loading required package: strucchange
Loading required package: zoo
Attaching package: ‘zoo’
The following objects are masked from ‘package:base’:
as.Date, as.Date.numeric
Loading required package: sandwich
Phần kết luận
Từ cây quyết định hiển thị ở trên, chúng ta có thể kết luận rằng bất kỳ ai có điểm ReadingSkills dưới 38,3 và tuổi trên 6 đều không phải là Người bản ngữ.
Trong phương pháp rừng ngẫu nhiên, một số lượng lớn các cây quyết định được tạo ra. Mọi quan sát được đưa vào mọi cây quyết định. Kết quả chung nhất cho mỗi lần quan sát được sử dụng làm đầu ra cuối cùng. Một quan sát mới được đưa vào tất cả các cây và lấy đa số phiếu cho mỗi mô hình phân loại.
Một ước tính sai số được thực hiện cho các trường hợp không được sử dụng trong khi xây dựng cây. Đó được gọi làOOB (Out-of-bag) ước tính sai số được đề cập dưới dạng phần trăm.
Gói R "randomForest" được sử dụng để tạo rừng ngẫu nhiên.
Cài đặt gói R
Sử dụng lệnh dưới đây trong bảng điều khiển R để cài đặt gói. Bạn cũng phải cài đặt các gói phụ thuộc nếu có.
install.packages("randomForest)Gói "randomForest" có chức năng randomForest() được sử dụng để tạo và phân tích các khu rừng ngẫu nhiên.
Cú pháp
Cú pháp cơ bản để tạo một khu rừng ngẫu nhiên trong R là:
randomForest(formula, data)Sau đây là mô tả về các tham số được sử dụng:
formula là một công thức mô tả các biến dự báo và phản ứng.
data là tên của tập dữ liệu được sử dụng.
Dữ liệu đầu vào
Chúng tôi sẽ sử dụng tập dữ liệu tích hợp R có tên là readSkills để tạo cây quyết định. Nó mô tả điểm số ReadingSkills của ai đó nếu chúng ta biết các biến "tuổi", "cỡ giày", "điểm số" và liệu người đó có phải là người bản xứ hay không.
Đây là dữ liệu mẫu.
# Load the party package. It will automatically load other
# required packages.
library(party)
# Print some records from data set readingSkills.
print(head(readingSkills))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả và biểu đồ sau:
nativeSpeaker age shoeSize score
1 yes 5 24.83189 32.29385
2 yes 6 25.95238 36.63105
3 no 11 30.42170 49.60593
4 yes 7 28.66450 40.28456
5 yes 11 31.88207 55.46085
6 yes 10 30.07843 52.83124
Loading required package: methods
Loading required package: grid
...............................
...............................Thí dụ
Chúng tôi sẽ sử dụng randomForest() để tạo cây quyết định và xem biểu đồ của nó.
# Load the party package. It will automatically load other
# required packages.
library(party)
library(randomForest)
# Create the forest.
output.forest <- randomForest(nativeSpeaker ~ age + shoeSize + score,
data = readingSkills)
# View the forest results.
print(output.forest)
# Importance of each predictor.
print(importance(fit,type = 2))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Call:
randomForest(formula = nativeSpeaker ~ age + shoeSize + score,
data = readingSkills)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 1
OOB estimate of error rate: 1%
Confusion matrix:
no yes class.error
no 99 1 0.01
yes 1 99 0.01
MeanDecreaseGini
age 13.95406
shoeSize 18.91006
score 56.73051Phần kết luận
Từ rừng ngẫu nhiên được hiển thị ở trên, chúng ta có thể kết luận rằng kích cỡ giày và điểm số là những yếu tố quan trọng quyết định một người có phải là người bản ngữ hay không. Ngoài ra, mô hình chỉ có 1% sai số có nghĩa là chúng tôi có thể dự đoán với độ chính xác 99%.
Phân tích sự sống còn liên quan đến việc dự đoán thời gian khi một sự kiện cụ thể sẽ xảy ra. Nó còn được gọi là phân tích thời gian thất bại hoặc phân tích thời gian chết. Ví dụ dự đoán số ngày một người mắc bệnh ung thư sẽ sống sót hoặc dự đoán thời gian khi một hệ thống máy móc sắp hỏng hóc.
Gói R có tên survivalđược sử dụng để thực hiện phân tích tỷ lệ sống sót. Gói này chứa hàmSurv()lấy dữ liệu đầu vào làm công thức R và tạo một đối tượng tồn tại trong số các biến được chọn để phân tích. Sau đó, chúng tôi sử dụng hàmsurvfit() để tạo ra một cốt truyện cho phân tích.
Cài đặt gói
install.packages("survival")Cú pháp
Cú pháp cơ bản để tạo phân tích tỷ lệ sống sót trong R là:
Surv(time,event)
survfit(formula)Sau đây là mô tả về các tham số được sử dụng:
time là thời gian theo dõi cho đến khi sự kiện xảy ra.
event cho biết trạng thái xuất hiện của sự kiện dự kiến.
formula là mối quan hệ giữa các biến dự báo.
Thí dụ
Chúng tôi sẽ xem xét tập dữ liệu có tên "pbc" có trong các gói tồn tại được cài đặt ở trên. Nó mô tả các điểm dữ liệu sống sót về những người bị ảnh hưởng bởi bệnh xơ gan mật nguyên phát (PBC) của gan. Trong số nhiều cột có trong tập dữ liệu, chúng tôi chủ yếu quan tâm đến các trường "thời gian" và "trạng thái". Thời gian thể hiện số ngày từ khi bệnh nhân đăng ký đến trước khi diễn ra sự kiện giữa bệnh nhân được ghép gan hoặc bệnh nhân tử vong.
# Load the library.
library("survival")
# Print first few rows.
print(head(pbc))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả và biểu đồ sau:
id time status trt age sex ascites hepato spiders edema bili chol
1 1 400 2 1 58.76523 f 1 1 1 1.0 14.5 261
2 2 4500 0 1 56.44627 f 0 1 1 0.0 1.1 302
3 3 1012 2 1 70.07255 m 0 0 0 0.5 1.4 176
4 4 1925 2 1 54.74059 f 0 1 1 0.5 1.8 244
5 5 1504 1 2 38.10541 f 0 1 1 0.0 3.4 279
6 6 2503 2 2 66.25873 f 0 1 0 0.0 0.8 248
albumin copper alk.phos ast trig platelet protime stage
1 2.60 156 1718.0 137.95 172 190 12.2 4
2 4.14 54 7394.8 113.52 88 221 10.6 3
3 3.48 210 516.0 96.10 55 151 12.0 4
4 2.54 64 6121.8 60.63 92 183 10.3 4
5 3.53 143 671.0 113.15 72 136 10.9 3
6 3.98 50 944.0 93.00 63 NA 11.0 3Từ dữ liệu trên, chúng tôi đang xem xét thời gian và trạng thái để phân tích.
Áp dụng hàm Surv () và survfit ()
Bây giờ chúng tôi tiến hành áp dụng Surv() chức năng của tập dữ liệu trên và tạo một biểu đồ sẽ hiển thị xu hướng.
# Load the library.
library("survival")
# Create the survival object.
survfit(Surv(pbc$time,pbc$status == 2)~1) # Give the chart file a name. png(file = "survival.png") # Plot the graph. plot(survfit(Surv(pbc$time,pbc$status == 2)~1))
# Save the file.
dev.off()Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả và biểu đồ sau:
Call: survfit(formula = Surv(pbc$time, pbc$status == 2) ~ 1)
n events median 0.95LCL 0.95UCL
418 161 3395 3090 3853
Xu hướng trong biểu đồ trên giúp chúng ta dự đoán xác suất sống sót vào cuối một số ngày nhất định.
Chi-Square testlà một phương pháp thống kê để xác định xem hai biến phân loại có mối tương quan đáng kể giữa chúng hay không. Cả hai biến đó phải từ cùng một quần thể và chúng phải được phân loại như - Có / Không, Nam / Nữ, Đỏ / Xanh lá cây, v.v.
Ví dụ: chúng ta có thể xây dựng một tập dữ liệu với những quan sát về cách mua kem của mọi người và cố gắng tương quan giới tính của một người với hương vị của loại kem họ thích. Nếu tìm thấy mối tương quan, chúng tôi có thể lập kế hoạch cho kho hương vị phù hợp bằng cách biết số lượng giới tính của những người ghé thăm.
Cú pháp
Chức năng được sử dụng để thực hiện kiểm tra chi-Square là chisq.test().
Cú pháp cơ bản để tạo kiểm tra chi-square trong R là:
chisq.test(data)Sau đây là mô tả về các tham số được sử dụng:
data là dữ liệu dưới dạng bảng chứa giá trị đếm của các biến trong quan sát.
Thí dụ
Chúng tôi sẽ lấy dữ liệu Cars93 trong thư viện "MASS" đại diện cho doanh số bán các mẫu xe hơi khác nhau trong năm 1993.
library("MASS")
print(str(Cars93))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
'data.frame': 93 obs. of 27 variables:
$ Manufacturer : Factor w/ 32 levels "Acura","Audi",..: 1 1 2 2 3 4 4 4 4 5 ...
$ Model : Factor w/ 93 levels "100","190E","240",..: 49 56 9 1 6 24 54 74 73 35 ... $ Type : Factor w/ 6 levels "Compact","Large",..: 4 3 1 3 3 3 2 2 3 2 ...
$ Min.Price : num 12.9 29.2 25.9 30.8 23.7 14.2 19.9 22.6 26.3 33 ... $ Price : num 15.9 33.9 29.1 37.7 30 15.7 20.8 23.7 26.3 34.7 ...
$ Max.Price : num 18.8 38.7 32.3 44.6 36.2 17.3 21.7 24.9 26.3 36.3 ... $ MPG.city : int 25 18 20 19 22 22 19 16 19 16 ...
$ MPG.highway : int 31 25 26 26 30 31 28 25 27 25 ... $ AirBags : Factor w/ 3 levels "Driver & Passenger",..: 3 1 2 1 2 2 2 2 2 2 ...
$ DriveTrain : Factor w/ 3 levels "4WD","Front",..: 2 2 2 2 3 2 2 3 2 2 ... $ Cylinders : Factor w/ 6 levels "3","4","5","6",..: 2 4 4 4 2 2 4 4 4 5 ...
$ EngineSize : num 1.8 3.2 2.8 2.8 3.5 2.2 3.8 5.7 3.8 4.9 ... $ Horsepower : int 140 200 172 172 208 110 170 180 170 200 ...
$ RPM : int 6300 5500 5500 5500 5700 5200 4800 4000 4800 4100 ... $ Rev.per.mile : int 2890 2335 2280 2535 2545 2565 1570 1320 1690 1510 ...
$ Man.trans.avail : Factor w/ 2 levels "No","Yes": 2 2 2 2 2 1 1 1 1 1 ... $ Fuel.tank.capacity: num 13.2 18 16.9 21.1 21.1 16.4 18 23 18.8 18 ...
$ Passengers : int 5 5 5 6 4 6 6 6 5 6 ... $ Length : int 177 195 180 193 186 189 200 216 198 206 ...
$ Wheelbase : int 102 115 102 106 109 105 111 116 108 114 ... $ Width : int 68 71 67 70 69 69 74 78 73 73 ...
$ Turn.circle : int 37 38 37 37 39 41 42 45 41 43 ... $ Rear.seat.room : num 26.5 30 28 31 27 28 30.5 30.5 26.5 35 ...
$ Luggage.room : int 11 15 14 17 13 16 17 21 14 18 ... $ Weight : int 2705 3560 3375 3405 3640 2880 3470 4105 3495 3620 ...
$ Origin : Factor w/ 2 levels "USA","non-USA": 2 2 2 2 2 1 1 1 1 1 ... $ Make : Factor w/ 93 levels "Acura Integra",..: 1 2 4 3 5 6 7 9 8 10 ...Kết quả trên cho thấy tập dữ liệu có nhiều biến Nhân tố có thể được coi là biến phân loại. Đối với mô hình của chúng tôi, chúng tôi sẽ xem xét các biến "AirBags" và "Loại". Ở đây, chúng tôi mong muốn tìm hiểu bất kỳ mối tương quan đáng kể nào giữa các loại xe được bán và loại Túi khí mà nó có. Nếu quan sát được mối tương quan, chúng ta có thể ước tính loại xe nào có thể bán chạy hơn với loại túi khí nào.
# Load the library.
library("MASS")
# Create a data frame from the main data set.
car.data <- data.frame(Cars93$AirBags, Cars93$Type)
# Create a table with the needed variables.
car.data = table(Cars93$AirBags, Cars93$Type)
print(car.data)
# Perform the Chi-Square test.
print(chisq.test(car.data))Khi chúng tôi thực thi đoạn mã trên, nó tạo ra kết quả sau:
Compact Large Midsize Small Sporty Van
Driver & Passenger 2 4 7 0 3 0
Driver only 9 7 11 5 8 3
None 5 0 4 16 3 6
Pearson's Chi-squared test
data: car.data
X-squared = 33.001, df = 10, p-value = 0.0002723
Warning message:
In chisq.test(car.data) : Chi-squared approximation may be incorrectPhần kết luận
Kết quả cho thấy giá trị p nhỏ hơn 0,05 cho thấy mối tương quan chuỗi.