Scikit Learn - Hướng dẫn Nhanh
Trong chương này, chúng ta sẽ hiểu Scikit-Learn hoặc Sklearn là gì, nguồn gốc của Scikit-Learn và một số chủ đề liên quan khác như cộng đồng và cộng tác viên chịu trách nhiệm phát triển và duy trì Scikit-Learn, điều kiện tiên quyết, cách cài đặt và các tính năng của nó.
Scikit-Learn là gì (Sklearn)
Scikit-learning (Sklearn) là thư viện hữu ích và mạnh mẽ nhất để học máy bằng Python. Nó cung cấp một loạt các công cụ hiệu quả để học máy và mô hình thống kê bao gồm phân loại, hồi quy, phân cụm và giảm kích thước thông qua giao diện nhất quán trong Python. Thư viện này, phần lớn được viết bằng Python, được xây dựng dựa trênNumPy, SciPy và Matplotlib.
Nguồn gốc của Scikit-Learn
Ban đầu nó được gọi là scikits.learn và ban đầu được phát triển bởi David Cournapeau như một dự án mã mùa hè của Google vào năm 2007. Sau đó, vào năm 2010, Fabian Pedregosa, Gael Varoquaux, Alexandre Gramfort và Vincent Michel, từ FIRCA (Viện Nghiên cứu Khoa học Máy tính và Tự động hóa của Pháp), đã dự án này ở cấp độ khác và phát hành bản phát hành công khai đầu tiên (v0.1 beta) vào ngày 1 tháng 2 năm 2010.
Hãy xem lịch sử phiên bản của nó -
Tháng 5 năm 2019: scikit-learning 0.21.0
Tháng 3 năm 2019: scikit-learning 0.20.3
Tháng 12 năm 2018: scikit-learning 0.20.2
Tháng 11 năm 2018: scikit-learning 0.20.1
Tháng 9 năm 2018: scikit-learning 0.20.0
Tháng 7 năm 2018: scikit-learning 0.19.2
Tháng 7 năm 2017: scikit-learning 0.19.0
Tháng 9 năm 2016. scikit-learning 0.18.0
Tháng 11 năm 2015. scikit-learning 0.17.0
Tháng 3 năm 2015. scikit-learning 0.16.0
Tháng 7 năm 2014. scikit-learning 0.15.0
Tháng 8 năm 2013. scikit-learning 0.14
Cộng đồng và cộng tác viên
Scikit-learning là một nỗ lực của cộng đồng và bất kỳ ai cũng có thể đóng góp cho nó. Dự án này được lưu trữ trênhttps://github.com/scikit-learn/scikit-learn. Những người sau hiện là những người đóng góp cốt lõi cho sự phát triển và duy trì của Sklearn -
Joris Van den Bossche (Nhà khoa học dữ liệu)
Thomas J Fan (Nhà phát triển phần mềm)
Alexandre Gramfort (Nhà nghiên cứu Máy học)
Olivier Grisel (Chuyên gia học máy)
Nicolas Hug (Nhà khoa học nghiên cứu liên kết)
Andreas Mueller (Nhà khoa học học máy)
Hanmin Qin (Kỹ sư phần mềm)
Adrin Jalali (Nhà phát triển nguồn mở)
Nelle Varoquaux (Nhà nghiên cứu Khoa học Dữ liệu)
Roman Yurchak (Nhà khoa học dữ liệu)
Nhiều tổ chức khác nhau như Booking.com, JP Morgan, Evernote, Inria, AWeber, Spotify và nhiều tổ chức khác đang sử dụng Sklearn.
Điều kiện tiên quyết
Trước khi bắt đầu sử dụng bản phát hành mới nhất của scikit-learning, chúng tôi yêu cầu những điều sau:
Python (> = 3.5)
NumPy (> = 1.11.0)
Scipy (> = 0,17,0) li
Joblib (> = 0,11)
Matplotlib (> = 1.5.1) là cần thiết cho khả năng vẽ đồ thị của Sklearn.
Pandas (> = 0.18.0) là bắt buộc đối với một số ví dụ scikit-learning sử dụng cấu trúc và phân tích dữ liệu.
Cài đặt
Nếu bạn đã cài đặt NumPy và Scipy, sau đây là hai cách dễ nhất để cài đặt scikit-learning:
Sử dụng pip
Lệnh sau có thể được sử dụng để cài đặt scikit-learning qua pip:
pip install -U scikit-learnSử dụng chung cư
Lệnh sau có thể được sử dụng để cài đặt scikit-learning qua conda -
conda install scikit-learnMặt khác, nếu NumPy và Scipy chưa được cài đặt trên máy trạm Python của bạn thì bạn có thể cài đặt chúng bằng cách sử dụng pip hoặc là conda.
Một tùy chọn khác để sử dụng scikit-learning là sử dụng các bản phân phối Python như Canopy và Anaconda vì cả hai đều cung cấp phiên bản mới nhất của scikit-learning.
Đặc trưng
Thay vì tập trung vào tải, thao tác và tóm tắt dữ liệu, thư viện Scikit-learning tập trung vào việc mô hình hóa dữ liệu. Một số nhóm mô hình phổ biến nhất do Sklearn cung cấp như sau:
Supervised Learning algorithms - Hầu như tất cả các thuật toán học có giám sát phổ biến, như Hồi quy tuyến tính, Máy vectơ hỗ trợ (SVM), Cây quyết định, v.v., là một phần của scikit-learning.
Unsupervised Learning algorithms - Mặt khác, nó cũng có tất cả các thuật toán học không giám sát phổ biến từ phân nhóm, phân tích nhân tố, PCA (Phân tích thành phần chính) đến mạng nơ-ron không giám sát.
Clustering - Mô hình này được sử dụng để nhóm dữ liệu không được gắn nhãn.
Cross Validation - Nó được sử dụng để kiểm tra độ chính xác của các mô hình được giám sát trên dữ liệu không nhìn thấy.
Dimensionality Reduction - Nó được sử dụng để giảm số lượng các thuộc tính trong dữ liệu có thể được sử dụng thêm để tổng hợp, hiển thị và lựa chọn tính năng.
Ensemble methods - Như tên gợi ý, nó được sử dụng để kết hợp các dự đoán của nhiều mô hình được giám sát.
Feature extraction - Nó được sử dụng để trích xuất các tính năng từ dữ liệu để xác định các thuộc tính trong dữ liệu hình ảnh và văn bản.
Feature selection - Nó được sử dụng để xác định các thuộc tính hữu ích để tạo ra các mô hình được giám sát.
Open Source - Đây là thư viện mã nguồn mở và cũng có thể sử dụng thương mại theo giấy phép BSD.
Chương này đề cập đến quá trình mô hình hóa liên quan đến Sklearn. Hãy để chúng tôi hiểu chi tiết về điều tương tự và bắt đầu với việc tải tập dữ liệu.
Đang tải tập dữ liệu
Tập hợp dữ liệu được gọi là tập dữ liệu. Nó có hai thành phần sau:
Features- Các biến của dữ liệu được gọi là các đặc trưng của nó. Chúng còn được gọi là yếu tố dự đoán, đầu vào hoặc thuộc tính.
Feature matrix - Nó là tập hợp các tính năng, trong trường hợp có nhiều hơn một.
Feature Names - Đây là danh sách tất cả các tên của các đối tượng địa lý.
Response- Biến đầu ra về cơ bản phụ thuộc vào các biến đặc trưng. Chúng còn được gọi là mục tiêu, nhãn hoặc đầu ra.
Response Vector- Nó được sử dụng để biểu diễn cột phản hồi. Nói chung, chúng tôi chỉ có một cột phản hồi.
Target Names - Nó đại diện cho các giá trị có thể được thực hiện bởi một vectơ phản hồi.
Scikit-learning có một số bộ dữ liệu mẫu như iris và digits để phân loại và Boston house prices để hồi quy.
Thí dụ
Sau đây là một ví dụ để tải iris tập dữ liệu -
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
print("Feature names:", feature_names)
print("Target names:", target_names)
print("\nFirst 10 rows of X:\n", X[:10])Đầu ra
Feature names: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
Target names: ['setosa' 'versicolor' 'virginica']
First 10 rows of X:
[
[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]
]Tách tập dữ liệu
Để kiểm tra độ chính xác của mô hình của chúng tôi, chúng tôi có thể chia tập dữ liệu thành hai phần-a training set và a testing set. Sử dụng tập huấn luyện để huấn luyện mô hình và tập thử nghiệm để kiểm tra mô hình. Sau đó, chúng tôi có thể đánh giá mô hình của chúng tôi đã hoạt động tốt như thế nào.
Thí dụ
Ví dụ sau sẽ chia dữ liệu thành tỷ lệ 70:30, tức là 70% dữ liệu sẽ được sử dụng làm dữ liệu đào tạo và 30% sẽ được sử dụng làm dữ liệu thử nghiệm. Tập dữ liệu là tập dữ liệu mống mắt như trong ví dụ trên.
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.3, random_state = 1
)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)Đầu ra
(105, 4)
(45, 4)
(105,)
(45,)Như đã thấy trong ví dụ trên, nó sử dụng train_test_split()chức năng của scikit-learning để chia nhỏ tập dữ liệu. Hàm này có các đối số sau:
X, y - Đây, X là feature matrix và y là response vector, cần được chia nhỏ.
test_size- Điều này thể hiện tỷ lệ của dữ liệu thử nghiệm trên tổng số dữ liệu đã cho. Như trong ví dụ trên, chúng tôi đang thiết lậptest_data = 0.3 cho 150 hàng X. Nó sẽ tạo ra dữ liệu thử nghiệm là 150 * 0,3 = 45 hàng.
random_size- Nó được sử dụng để đảm bảo rằng sự phân chia sẽ luôn giống nhau. Điều này hữu ích trong những trường hợp bạn muốn có kết quả có thể lặp lại.
Huấn luyện người mẫu
Tiếp theo, chúng ta có thể sử dụng tập dữ liệu của mình để đào tạo một số mô hình dự đoán. Như đã thảo luận, scikit-learning có nhiều loạiMachine Learning (ML) algorithms có giao diện nhất quán để lắp, dự đoán độ chính xác, thu hồi, v.v.
Thí dụ
Trong ví dụ dưới đây, chúng ta sẽ sử dụng bộ phân loại KNN (K hàng xóm gần nhất). Đừng đi vào chi tiết của các thuật toán KNN, vì sẽ có một chương riêng cho điều đó. Ví dụ này được sử dụng để giúp bạn chỉ hiểu phần triển khai.
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.4, random_state=1
)
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
classifier_knn = KNeighborsClassifier(n_neighbors = 3)
classifier_knn.fit(X_train, y_train)
y_pred = classifier_knn.predict(X_test)
# Finding accuracy by comparing actual response values(y_test)with predicted response value(y_pred)
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
# Providing sample data and the model will make prediction out of that data
sample = [[5, 5, 3, 2], [2, 4, 3, 5]]
preds = classifier_knn.predict(sample)
pred_species = [iris.target_names[p] for p in preds] print("Predictions:", pred_species)Đầu ra
Accuracy: 0.9833333333333333
Predictions: ['versicolor', 'virginica']Độ bền của mô hình
Sau khi bạn đào tạo mô hình, bạn nên duy trì mô hình đó để sử dụng trong tương lai để chúng ta không cần phải đào tạo lại nó nhiều lần. Nó có thể được thực hiện với sự giúp đỡ củadump và load tính năng của joblib gói hàng.
Hãy xem xét ví dụ dưới đây, trong đó chúng tôi sẽ lưu mô hình được đào tạo ở trên (classifier_knn) để sử dụng trong tương lai -
from sklearn.externals import joblib
joblib.dump(classifier_knn, 'iris_classifier_knn.joblib')Đoạn mã trên sẽ lưu mô hình vào tệp có tên iris_classifier_knn.joblib. Bây giờ, đối tượng có thể được tải lại từ tệp với sự trợ giúp của mã sau:
joblib.load('iris_classifier_knn.joblib')Xử lý trước dữ liệu
Vì chúng ta đang xử lý nhiều dữ liệu và dữ liệu đó ở dạng thô, trước khi nhập dữ liệu đó vào các thuật toán học máy, chúng ta cần chuyển đổi nó thành dữ liệu có ý nghĩa. Quá trình này được gọi là tiền xử lý dữ liệu. Scikit-learning có gói có tênpreprocessingvì mục đích này. Cácpreprocessing gói có các kỹ thuật sau:
Binarisation
Kỹ thuật tiền xử lý này được sử dụng khi chúng ta cần chuyển đổi các giá trị số thành các giá trị Boolean.
Thí dụ
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]]
)
data_binarized = preprocessing.Binarizer(threshold=0.5).transform(input_data)
print("\nBinarized data:\n", data_binarized)Trong ví dụ trên, chúng tôi đã sử dụng threshold value = 0,5 và đó là lý do tại sao, tất cả các giá trị trên 0,5 sẽ được chuyển đổi thành 1 và tất cả các giá trị dưới 0,5 sẽ được chuyển thành 0.
Đầu ra
Binarized data:
[
[ 1. 0. 1.]
[ 0. 1. 1.]
[ 0. 0. 1.]
[ 1. 1. 0.]
]Loại bỏ trung bình
Kỹ thuật này được sử dụng để loại bỏ giá trị trung bình khỏi vectơ đặc trưng để mọi đối tượng đều có tâm là 0.
Thí dụ
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]]
)
#displaying the mean and the standard deviation of the input data
print("Mean =", input_data.mean(axis=0))
print("Stddeviation = ", input_data.std(axis=0))
#Removing the mean and the standard deviation of the input data
data_scaled = preprocessing.scale(input_data)
print("Mean_removed =", data_scaled.mean(axis=0))
print("Stddeviation_removed =", data_scaled.std(axis=0))Đầu ra
Mean = [ 1.75 -1.275 2.2 ]
Stddeviation = [ 2.71431391 4.20022321 4.69414529]
Mean_removed = [ 1.11022302e-16 0.00000000e+00 0.00000000e+00]
Stddeviation_removed = [ 1. 1. 1.]Mở rộng quy mô
Chúng tôi sử dụng kỹ thuật tiền xử lý này để chia tỷ lệ các vectơ đặc trưng. Tỷ lệ của vectơ đối tượng là rất quan trọng, bởi vì các đối tượng địa lý không được tổng hợp lớn hoặc nhỏ.
Thí dụ
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_scaler_minmax = preprocessing.MinMaxScaler(feature_range=(0,1))
data_scaled_minmax = data_scaler_minmax.fit_transform(input_data)
print ("\nMin max scaled data:\n", data_scaled_minmax)Đầu ra
Min max scaled data:
[
[ 0.48648649 0.58252427 0.99122807]
[ 0. 1. 0.81578947]
[ 0.27027027 0. 1. ]
[ 1. 0.99029126 0. ]
]Bình thường hóa
Chúng tôi sử dụng kỹ thuật tiền xử lý này để sửa đổi các vectơ đặc trưng. Chuẩn hóa các vectơ đặc trưng là cần thiết để các vectơ đặc trưng có thể được đo lường ở quy mô chung. Có hai loại chuẩn hóa như sau:
Chuẩn hóa L1
Nó còn được gọi là Sai lệch tuyệt đối ít nhất. Nó sửa đổi giá trị theo cách mà tổng các giá trị tuyệt đối luôn luôn tối đa 1 trong mỗi hàng. Ví dụ sau cho thấy việc thực hiện chuẩn hóa L1 trên dữ liệu đầu vào.
Thí dụ
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_normalized_l1 = preprocessing.normalize(input_data, norm='l1')
print("\nL1 normalized data:\n", data_normalized_l1)Đầu ra
L1 normalized data:
[
[ 0.22105263 -0.2 0.57894737]
[-0.2027027 0.32432432 0.47297297]
[ 0.03571429 -0.56428571 0.4 ]
[ 0.42142857 0.16428571 -0.41428571]
]Chuẩn hóa L2
Còn được gọi là Hình vuông nhỏ nhất. Nó sửa đổi giá trị theo cách mà tổng các ô vuông luôn luôn tối đa 1 trong mỗi hàng. Ví dụ sau cho thấy việc thực hiện chuẩn hóa L2 trên dữ liệu đầu vào.
Thí dụ
import numpy as np
from sklearn import preprocessing
Input_data = np.array(
[
[2.1, -1.9, 5.5],
[-1.5, 2.4, 3.5],
[0.5, -7.9, 5.6],
[5.9, 2.3, -5.8]
]
)
data_normalized_l2 = preprocessing.normalize(input_data, norm='l2')
print("\nL1 normalized data:\n", data_normalized_l2)Đầu ra
L2 normalized data:
[
[ 0.33946114 -0.30713151 0.88906489]
[-0.33325106 0.53320169 0.7775858 ]
[ 0.05156558 -0.81473612 0.57753446]
[ 0.68706914 0.26784051 -0.6754239 ]
]Như chúng ta biết rằng học máy là để tạo mô hình từ dữ liệu. Với mục đích này, máy tính phải hiểu dữ liệu trước. Tiếp theo, chúng ta sẽ thảo luận về các cách khác nhau để biểu diễn dữ liệu để máy tính có thể hiểu được -
Dữ liệu dưới dạng bảng
Cách tốt nhất để biểu diễn dữ liệu trong Scikit-learning là dưới dạng bảng. Một bảng đại diện cho lưới dữ liệu 2-D trong đó các hàng đại diện cho các phần tử riêng lẻ của tập dữ liệu và các cột đại diện cho các đại lượng liên quan đến các phần tử riêng lẻ đó.
Thí dụ
Với ví dụ dưới đây, chúng ta có thể tải xuống iris dataset ở dạng Pandas DataFrame với sự trợ giúp của python seaborn thư viện.
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()Đầu ra
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosaTừ kết quả trên, chúng ta có thể thấy rằng mỗi hàng dữ liệu đại diện cho một bông hoa được quan sát duy nhất và số hàng biểu thị tổng số bông hoa trong tập dữ liệu. Nói chung, chúng tôi coi các hàng của ma trận là các mẫu.
Mặt khác, mỗi cột dữ liệu đại diện cho một thông tin định lượng mô tả mỗi mẫu. Nói chung, chúng tôi gọi các cột của ma trận là các đặc trưng.
Dữ liệu dưới dạng Ma trận tính năng
Ma trận tính năng có thể được định nghĩa là bố cục bảng mà thông tin có thể được coi là ma trận 2-D. Nó được lưu trữ trong một biến có tênXvà giả định là hai chiều với shape [n_samples, n_features]. Hầu hết, nó được chứa trong một mảng NumPy hoặc một Pandas DataFrame. Như đã nói trước đó, các mẫu luôn đại diện cho các đối tượng riêng lẻ được mô tả bởi tập dữ liệu và các tính năng đại diện cho các quan sát riêng biệt mô tả từng mẫu theo cách định lượng.
Dữ liệu dưới dạng mảng Mục tiêu
Cùng với ma trận Đặc điểm, ký hiệu là X, chúng ta cũng có mảng đích. Nó còn được gọi là nhãn. Nó được ký hiệu là y. Nhãn hoặc mảng đích thường là một chiều có độ dài n_samples. Nó thường được chứa trong NumPyarray hoặc gấu trúc Series. Mảng đích có thể có cả giá trị, giá trị số liên tục và giá trị rời rạc.
Mảng mục tiêu khác với các cột tính năng như thế nào?
Chúng ta có thể phân biệt cả hai bằng một điểm rằng mảng đích thường là đại lượng mà chúng ta muốn dự đoán từ dữ liệu, tức là theo thuật ngữ thống kê, nó là biến phụ thuộc.
Thí dụ
Trong ví dụ dưới đây, từ tập dữ liệu mống mắt, chúng tôi dự đoán loài hoa dựa trên các phép đo khác. Trong trường hợp này, cột Loài sẽ được coi là đối tượng địa lý.
import seaborn as sns
iris = sns.load_dataset('iris')
%matplotlib inline
import seaborn as sns; sns.set()
sns.pairplot(iris, hue='species', height=3);Đầu ra
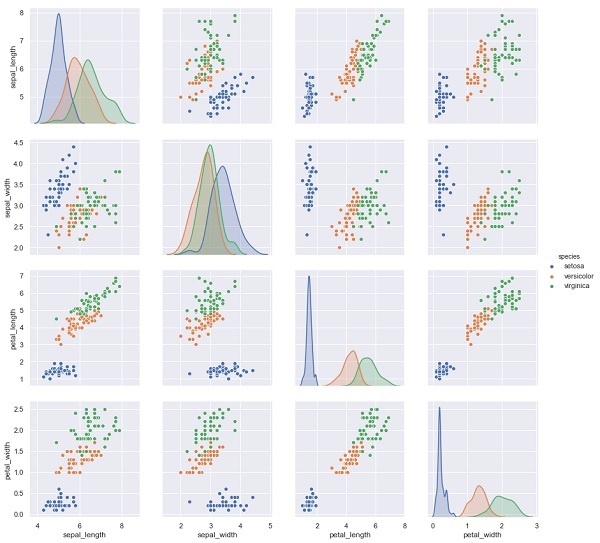
X_iris = iris.drop('species', axis=1)
X_iris.shape
y_iris = iris['species']
y_iris.shapeĐầu ra
(150,4)
(150,)Trong chương này, chúng ta sẽ tìm hiểu về Estimator API(giao diện lập trình ứng dụng). Chúng ta hãy bắt đầu bằng cách hiểu API Công cụ ước tính là gì.
API công cụ ước tính là gì
Nó là một trong những API chính do Scikit-learning triển khai. Nó cung cấp một giao diện nhất quán cho một loạt các ứng dụng ML, đó là lý do tại sao tất cả các thuật toán học máy trong Scikit-Learn đều được triển khai thông qua API Ước tính. Đối tượng học hỏi từ dữ liệu (phù hợp với dữ liệu) là một bộ ước lượng. Nó có thể được sử dụng với bất kỳ thuật toán nào như phân loại, hồi quy, phân cụm hoặc thậm chí với máy biến áp, trích xuất các tính năng hữu ích từ dữ liệu thô.
Để phù hợp với dữ liệu, tất cả các đối tượng ước tính hiển thị một phương thức phù hợp lấy một tập dữ liệu được hiển thị như sau:
estimator.fit(data)Tiếp theo, tất cả các tham số của công cụ ước tính có thể được đặt, như sau, khi nó được khởi tạo bởi thuộc tính tương ứng.
estimator = Estimator (param1=1, param2=2)
estimator.param1Kết quả của phần trên sẽ là 1.
Sau khi dữ liệu được trang bị với công cụ ước tính, các tham số sẽ được ước tính từ dữ liệu hiện có. Bây giờ, tất cả các tham số ước tính sẽ là thuộc tính của đối tượng ước tính kết thúc bằng dấu gạch dưới như sau:
estimator.estimated_param_Sử dụng API công cụ ước tính
Công dụng chính của công cụ ước tính như sau:
Ước tính và giải mã mô hình
Đối tượng Estimator được sử dụng để ước tính và giải mã một mô hình. Hơn nữa, mô hình được ước tính như một hàm xác định của những điều sau:
Các tham số được cung cấp trong cấu trúc đối tượng.
Trạng thái ngẫu nhiên toàn cục (numpy.random) nếu tham số random_state của công cụ ước tính được đặt thành không.
Mọi dữ liệu được chuyển đến cuộc gọi gần đây nhất tới fit, fit_transform, or fit_predict.
Mọi dữ liệu được chuyển trong một chuỗi lệnh gọi tới partial_fit.
Ánh xạ biểu diễn dữ liệu không phải hình chữ nhật thành dữ liệu hình chữ nhật
Nó ánh xạ một biểu diễn dữ liệu không phải hình chữ nhật thành dữ liệu hình chữ nhật. Nói cách đơn giản, nó lấy đầu vào trong đó mỗi mẫu không được biểu diễn dưới dạng đối tượng dạng mảng có độ dài cố định và tạo ra đối tượng dạng mảng gồm các tính năng cho mỗi mẫu.
Phân biệt giữa mẫu lõi và mẫu bên ngoài
Nó mô hình hóa sự phân biệt giữa các mẫu lõi và mẫu bên ngoài bằng cách sử dụng các phương pháp sau:
fit
fit_p Dự đoán nếu chuyển đổi
dự đoán nếu quy nạp
Nguyên tắc hướng dẫn
Trong khi thiết kế API Scikit-Learn, hãy ghi nhớ các nguyên tắc hướng dẫn -
Tính nhất quán
Nguyên tắc này nói rằng tất cả các đối tượng nên chia sẻ một giao diện chung được vẽ từ một tập hợp các phương thức giới hạn. Các tài liệu cũng phải nhất quán.
Hệ thống phân cấp đối tượng hạn chế
Nguyên tắc hướng dẫn này nói:
Các thuật toán phải được biểu diễn bằng các lớp Python
Tập dữ liệu nên được biểu diễn ở định dạng chuẩn như mảng NumPy, Pandas DataFrames, ma trận thưa thớt SciPy.
Tên tham số nên sử dụng chuỗi Python tiêu chuẩn.
Thành phần
Như chúng ta đã biết, các thuật toán ML có thể được biểu thị dưới dạng chuỗi của nhiều thuật toán cơ bản. Scikit-learning sử dụng các thuật toán cơ bản này bất cứ khi nào cần.
Giá trị mặc định hợp lý
Theo nguyên tắc này, thư viện Scikit-learning xác định một giá trị mặc định thích hợp bất cứ khi nào các mô hình ML yêu cầu các tham số do người dùng chỉ định.
Kiểm tra
Theo nguyên tắc hướng dẫn này, mọi giá trị tham số được chỉ định được hiển thị dưới dạng thuộc tính pubic.
Các bước sử dụng API Công cụ ước tính
Tiếp theo là các bước sử dụng API công cụ ước tính Scikit-Learn -
Bước 1: Chọn một loại mô hình
Trong bước đầu tiên này, chúng ta cần chọn một lớp mô hình. Nó có thể được thực hiện bằng cách nhập lớp Công cụ ước tính thích hợp từ Scikit-learning.
Bước 2: Chọn siêu tham số của mô hình
Trong bước này, chúng ta cần chọn siêu tham số của mô hình lớp. Nó có thể được thực hiện bằng cách khởi tạo lớp với các giá trị mong muốn.
Bước 3: Sắp xếp dữ liệu
Tiếp theo, chúng ta cần sắp xếp dữ liệu thành ma trận đặc trưng (X) và vector mục tiêu (y).
Bước 4: Lắp mô hình
Bây giờ, chúng tôi cần điều chỉnh mô hình phù hợp với dữ liệu của bạn. Nó có thể được thực hiện bằng cách gọi phương thức fit () của cá thể mô hình.
Bước 5: Áp dụng mô hình
Sau khi phù hợp với mô hình, chúng tôi có thể áp dụng nó vào dữ liệu mới. Để học có giám sát, hãy sử dụngpredict()phương pháp dự đoán các nhãn cho dữ liệu không xác định. Trong khi học không có giám sát, hãy sử dụngpredict() hoặc là transform() để suy ra các thuộc tính của dữ liệu.
Ví dụ về học tập có giám sát
Ở đây, là một ví dụ về quy trình này, chúng tôi đang sử dụng trường hợp phổ biến của việc điều chỉnh một dòng với (x, y) dữ liệu tức là simple linear regression.
Đầu tiên, chúng ta cần tải tập dữ liệu, chúng tôi đang sử dụng tập dữ liệu mống mắt -
Thí dụ
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shapeĐầu ra
(150, 4)Thí dụ
y_iris = iris['species']
y_iris.shapeĐầu ra
(150,)Thí dụ
Bây giờ, đối với ví dụ hồi quy này, chúng ta sẽ sử dụng dữ liệu mẫu sau:
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);Đầu ra
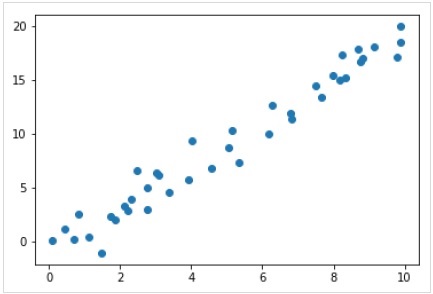
Vì vậy, chúng tôi có dữ liệu trên cho ví dụ hồi quy tuyến tính của chúng tôi.
Bây giờ, với dữ liệu này, chúng ta có thể áp dụng các bước nêu trên.
Chọn một loại mô hình
Ở đây, để tính toán một mô hình hồi quy tuyến tính đơn giản, chúng ta cần nhập lớp hồi quy tuyến tính như sau:
from sklearn.linear_model import LinearRegressionChọn siêu tham số của mô hình
Khi chúng ta chọn một loại mô hình, chúng ta cần thực hiện một số lựa chọn quan trọng thường được biểu diễn dưới dạng siêu tham số hoặc các tham số phải đặt trước khi mô hình phù hợp với dữ liệu. Ở đây, đối với ví dụ này về hồi quy tuyến tính, chúng tôi muốn điều chỉnh hệ số chặn bằng cách sử dụngfit_intercept siêu tham số như sau -
Example
model = LinearRegression(fit_intercept = True)
modelOutput
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None, normalize = False)Sắp xếp dữ liệu
Bây giờ, như chúng ta biết rằng biến mục tiêu của chúng ta y ở dạng đúng nghĩa là chiều dài n_samplesmảng 1-D. Tuy nhiên, chúng ta cần định hình lại ma trận tính năngX để biến nó thành một ma trận có kích thước [n_samples, n_features]. Nó có thể được thực hiện như sau:
Example
X = x[:, np.newaxis]
X.shapeOutput
(40, 1)Phù hợp mô hình
Một khi chúng ta sắp xếp dữ liệu, đã đến lúc phù hợp với mô hình tức là áp dụng mô hình của chúng ta vào dữ liệu. Điều này có thể được thực hiện với sự trợ giúp củafit() phương pháp như sau -
Example
model.fit(X, y)Output
LinearRegression(copy_X = True, fit_intercept = True, n_jobs = None,normalize = False)Trong Scikit-learning, fit() quy trình có một số dấu gạch dưới ở cuối.
Đối với ví dụ này, tham số dưới đây cho thấy độ dốc của sự phù hợp tuyến tính đơn giản của dữ liệu:
Example
model.coef_Output
array([1.99839352])Tham số dưới đây đại diện cho điểm chặn của sự phù hợp tuyến tính đơn giản với dữ liệu -
Example
model.intercept_Output
-0.9895459457775022Áp dụng mô hình cho dữ liệu mới
Sau khi đào tạo mô hình, chúng tôi có thể áp dụng nó vào dữ liệu mới. Vì nhiệm vụ chính của học máy có giám sát là đánh giá mô hình dựa trên dữ liệu mới không phải là một phần của tập huấn luyện. Nó có thể được thực hiện với sự giúp đỡ củapredict() phương pháp như sau -
Example
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);Output
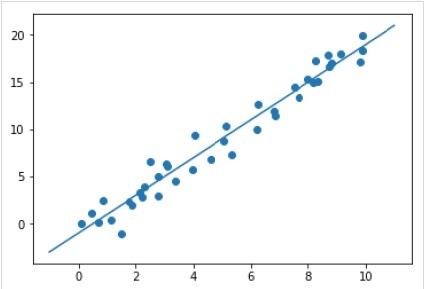
Hoàn thành ví dụ làm việc / thực thi
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model
X = x[:, np.newaxis]
X.shape
model.fit(X, y)
model.coef_
model.intercept_
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit);Ví dụ về học tập không giám sát
Ở đây, như một ví dụ về quy trình này, chúng tôi đang sử dụng trường hợp phổ biến là giảm kích thước của tập dữ liệu Iris để chúng ta có thể hình dung nó dễ dàng hơn. Đối với ví dụ này, chúng ta sẽ sử dụng phân tích thành phần chính (PCA), một kỹ thuật giảm kích thước tuyến tính nhanh.
Giống như ví dụ đã cho ở trên, chúng ta có thể tải và vẽ biểu đồ dữ liệu ngẫu nhiên từ tập dữ liệu mống mắt. Sau đó, chúng ta có thể làm theo các bước như sau:
Chọn một loại mô hình
from sklearn.decomposition import PCAChọn siêu tham số của mô hình
Example
model = PCA(n_components=2)
modelOutput
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None,
svd_solver = 'auto', tol = 0.0, whiten = False)Phù hợp mô hình
Example
model.fit(X_iris)Output
PCA(copy = True, iterated_power = 'auto', n_components = 2, random_state = None,
svd_solver = 'auto', tol = 0.0, whiten = False)Chuyển đổi dữ liệu sang hai chiều
Example
X_2D = model.transform(X_iris)Bây giờ, chúng ta có thể vẽ biểu đồ kết quả như sau:
Output
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue = 'species', data = iris, fit_reg = False);Output
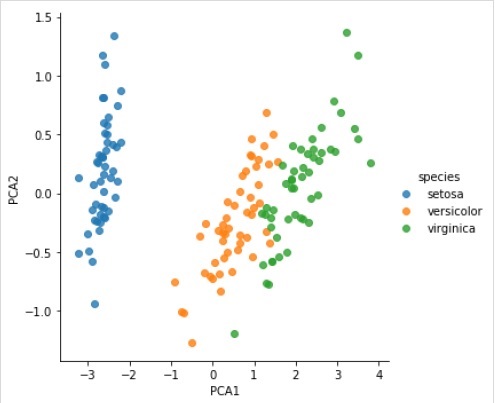
Hoàn thành ví dụ làm việc / thực thi
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
iris = sns.load_dataset('iris')
X_iris = iris.drop('species', axis = 1)
X_iris.shape
y_iris = iris['species']
y_iris.shape
rng = np.random.RandomState(35)
x = 10*rng.rand(40)
y = 2*x-1+rng.randn(40)
plt.scatter(x,y);
from sklearn.decomposition import PCA
model = PCA(n_components=2)
model
model.fit(X_iris)
X_2D = model.transform(X_iris)
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot("PCA1", "PCA2", hue='species', data=iris, fit_reg=False);Các đối tượng của Scikit-learning chia sẻ một API cơ bản thống nhất bao gồm ba giao diện bổ sung sau:
Estimator interface - Nó là để xây dựng và lắp các mô hình.
Predictor interface - Nó là để đưa ra dự đoán.
Transformer interface - Nó là để chuyển đổi dữ liệu.
Các API áp dụng các quy ước đơn giản và các lựa chọn thiết kế đã được hướng dẫn theo cách để tránh sự phổ biến của mã khung.
Mục đích của Công ước
Mục đích của các quy ước là để đảm bảo rằng API tuân thủ các nguyên tắc chung sau:
Consistency - Tất cả các đối tượng cho dù chúng là cơ bản hay hỗn hợp đều phải chia sẻ một giao diện nhất quán bao gồm một tập hợp các phương thức hạn chế.
Inspection - Các tham số cấu tạo và các giá trị tham số được xác định bởi thuật toán học cần được lưu trữ và hiển thị dưới dạng các thuộc tính công khai.
Non-proliferation of classes - Tập dữ liệu nên được biểu diễn dưới dạng mảng NumPy hoặc ma trận thưa thớt Scipy trong khi tên và giá trị siêu tham số nên được biểu diễn dưới dạng chuỗi Python tiêu chuẩn để tránh sự gia tăng của mã khung.
Composition - Các thuật toán cho dù chúng có thể diễn đạt được dưới dạng chuỗi hoặc kết hợp của các phép biến đổi đối với dữ liệu hoặc được xem một cách tự nhiên như các thuật toán meta được tham số hóa trên các thuật toán khác, nên được triển khai và cấu thành từ các khối xây dựng hiện có.
Sensible defaults- Trong scikit-learning bất cứ khi nào một thao tác yêu cầu tham số do người dùng xác định, một giá trị mặc định thích hợp sẽ được xác định. Giá trị mặc định này sẽ làm cho hoạt động được thực hiện theo một cách hợp lý, chẳng hạn như đưa ra giải pháp đường cơ sở cho nhiệm vụ đang thực hiện.
Các quy ước khác nhau
Các quy ước có sẵn trong Sklearn được giải thích dưới đây:
Loại đúc
Nó nói rằng đầu vào phải được truyền tới float64. Trong ví dụ sau, trong đósklearn.random_projection mô-đun được sử dụng để giảm kích thước của dữ liệu, sẽ giải thích nó -
Example
import numpy as np
from sklearn import random_projection
rannge = np.random.RandomState(0)
X = range.rand(10,2000)
X = np.array(X, dtype = 'float32')
X.dtype
Transformer_data = random_projection.GaussianRandomProjection()
X_new = transformer.fit_transform(X)
X_new.dtypeOutput
dtype('float32')
dtype('float64')Trong ví dụ trên, chúng ta có thể thấy rằng X là float32 được đúc tới float64 bởi fit_transform(X).
Trang bị lại và cập nhật các thông số
Siêu tham số của một công cụ ước tính có thể được cập nhật và trang bị lại sau khi nó đã được xây dựng thông qua set_params()phương pháp. Hãy xem ví dụ sau để hiểu nó -
Example
import numpy as np
from sklearn.datasets import load_iris
from sklearn.svm import SVC
X, y = load_iris(return_X_y = True)
clf = SVC()
clf.set_params(kernel = 'linear').fit(X, y)
clf.predict(X[:5])Output
array([0, 0, 0, 0, 0])Khi công cụ ước tính đã được xây dựng, đoạn mã trên sẽ thay đổi hạt nhân mặc định rbf tuyến tính qua SVC.set_params().
Bây giờ, đoạn mã sau sẽ thay đổi kernel thành rbf để trang bị lại bộ ước lượng và đưa ra dự đoán thứ hai.
Example
clf.set_params(kernel = 'rbf', gamma = 'scale').fit(X, y)
clf.predict(X[:5])Output
array([0, 0, 0, 0, 0])Hoàn thành mã
Sau đây là chương trình thực thi hoàn chỉnh:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.svm import SVC
X, y = load_iris(return_X_y = True)
clf = SVC()
clf.set_params(kernel = 'linear').fit(X, y)
clf.predict(X[:5])
clf.set_params(kernel = 'rbf', gamma = 'scale').fit(X, y)
clf.predict(X[:5])Đa thủy tinh & phù hợp nhiều nhãn
Trong trường hợp phù hợp nhiều lớp, cả nhiệm vụ học tập và dự đoán đều phụ thuộc vào định dạng của dữ liệu mục tiêu phù hợp. Mô-đun được sử dụng làsklearn.multiclass. Kiểm tra ví dụ bên dưới, nơi bộ phân loại nhiều lớp phù hợp trên một mảng 1d.
Example
from sklearn.svm import SVC
from sklearn.multiclass import OneVsRestClassifier
from sklearn.preprocessing import LabelBinarizer
X = [[1, 2], [3, 4], [4, 5], [5, 2], [1, 1]]
y = [0, 0, 1, 1, 2]
classif = OneVsRestClassifier(estimator = SVC(gamma = 'scale',random_state = 0))
classif.fit(X, y).predict(X)Output
array([0, 0, 1, 1, 2])Trong ví dụ trên, bộ phân loại phù hợp trên mảng một chiều của các nhãn đa kính và predict()do đó cung cấp dự đoán đa kính tương ứng. Nhưng mặt khác, nó cũng có thể phù hợp với một mảng hai chiều của các chỉ báo nhãn nhị phân như sau:
Example
from sklearn.svm import SVC
from sklearn.multiclass import OneVsRestClassifier
from sklearn.preprocessing import LabelBinarizer
X = [[1, 2], [3, 4], [4, 5], [5, 2], [1, 1]]
y = LabelBinarizer().fit_transform(y)
classif.fit(X, y).predict(X)Output
array(
[
[0, 0, 0],
[0, 0, 0],
[0, 1, 0],
[0, 1, 0],
[0, 0, 0]
]
)Tương tự, trong trường hợp phù hợp nhiều nhãn, một thể hiện có thể được gán nhiều nhãn như sau:
Example
from sklearn.preprocessing import MultiLabelBinarizer
y = [[0, 1], [0, 2], [1, 3], [0, 2, 3], [2, 4]]
y = MultiLabelBinarizer().fit_transform(y)
classif.fit(X, y).predict(X)Output
array(
[
[1, 0, 1, 0, 0],
[1, 0, 1, 0, 0],
[1, 0, 1, 1, 0],
[1, 0, 1, 1, 0],
[1, 0, 1, 0, 0]
]
)Trong ví dụ trên, sklearn.MultiLabelBinarizerđược sử dụng để mã hóa mảng đa nhãn hai chiều để vừa với. Đó là lý do tại sao hàm dự đoán () cung cấp một mảng 2d dưới dạng đầu ra với nhiều nhãn cho mỗi trường hợp.
Chương này sẽ giúp bạn tìm hiểu về mô hình tuyến tính trong Scikit-Learn. Chúng ta hãy bắt đầu bằng cách hiểu hồi quy tuyến tính trong Sklearn là gì.
Bảng sau liệt kê các mô hình tuyến tính khác nhau do Scikit-Learn cung cấp -
| Sr.No | Mô tả về mô hình |
|---|---|
| 1 | Hồi quy tuyến tính Đây là một trong những mô hình thống kê tốt nhất nghiên cứu mối quan hệ giữa một biến phụ thuộc (Y) với một tập hợp các biến độc lập (X) nhất định. |
| 2 | Hồi quy logistic Hồi quy logistic, bất chấp tên gọi của nó, là một thuật toán phân loại chứ không phải là thuật toán hồi quy. Dựa trên một tập hợp các biến độc lập nhất định, nó được sử dụng để ước tính giá trị rời rạc (0 hoặc 1, có / không, đúng / sai). |
| 3 | Hồi quy Ridge Hồi quy Ridge hoặc chính quy Tikhonov là kỹ thuật chính quy hóa thực hiện chính quy hóa L2. Nó sửa đổi hàm mất mát bằng cách thêm phần phạt (đại lượng co rút) tương đương với bình phương độ lớn của các hệ số. |
| 4 | Hồi quy Bayesian Ridge Hồi quy Bayes cho phép một cơ chế tự nhiên tồn tại khi không đủ dữ liệu hoặc dữ liệu được phân phối kém bằng cách xây dựng hồi quy tuyến tính sử dụng các nhà phân phối xác suất thay vì ước lượng điểm. |
| 5 | DÂY CỘT NGỰA LASSO là kỹ thuật chính quy thực hiện chính quy hóa L1. Nó sửa đổi hàm mất mát bằng cách thêm phần phạt (đại lượng co rút) tương đương với tổng giá trị tuyệt đối của các hệ số. |
| 6 | LASSO đa tác vụ Nó cho phép kết hợp nhiều vấn đề hồi quy cùng thực thi các tính năng đã chọn giống nhau cho tất cả các vấn đề hồi quy, còn được gọi là nhiệm vụ. Sklearn cung cấp một mô hình tuyến tính có tên MultiTaskLasso, được đào tạo với chuẩn L1, L2 hỗn hợp để chính quy hóa, ước tính các hệ số thưa thớt cho nhiều bài toán hồi quy cùng nhau. |
| 7 | Mạng đàn hồi Elastic-Net là một phương pháp hồi quy chính quy kết hợp tuyến tính cả hai hình phạt tức là L1 và L2 của phương pháp hồi quy Lasso và Ridge. Nó hữu ích khi có nhiều tính năng tương quan. |
| số 8 | Multi-task Elastic-Net Đây là một mô hình Elastic-Net cho phép kết hợp nhiều vấn đề hồi quy cùng thực thi các tính năng đã chọn giống nhau cho tất cả các vấn đề hồi quy, còn được gọi là nhiệm vụ |
Chương này tập trung vào các tính năng đa thức và các công cụ tạo chuỗi trong Sklearn.
Giới thiệu về các tính năng đa thức
Các mô hình tuyến tính được đào tạo về các hàm phi tuyến tính của dữ liệu thường duy trì hiệu suất nhanh chóng của các phương pháp tuyến tính. Nó cũng cho phép chúng phù hợp với nhiều loại dữ liệu hơn. Đó là lý do trong máy học, các mô hình tuyến tính được đào tạo về các hàm phi tuyến được sử dụng.
Một ví dụ như vậy là một hồi quy tuyến tính đơn giản có thể được mở rộng bằng cách xây dựng các đặc trưng đa thức từ các hệ số.
Về mặt toán học, giả sử chúng ta có mô hình hồi quy tuyến tính tiêu chuẩn thì đối với dữ liệu 2-D, nó sẽ giống như sau:
$$Y=W_{0}+W_{1}X_{1}+W_{2}X_{2}$$Bây giờ, chúng ta có thể kết hợp các tính năng trong đa thức bậc hai và mô hình của chúng ta sẽ giống như sau:
$$Y=W_{0}+W_{1}X_{1}+W_{2}X_{2}+W_{3}X_{1}X_{2}+W_{4}X_1^2+W_{5}X_2^2$$Trên đây vẫn là mô hình tuyến tính. Ở đây, chúng ta thấy rằng hồi quy đa thức thu được nằm trong cùng một loại mô hình tuyến tính và có thể được giải quyết tương tự.
Để làm như vậy, scikit-learning cung cấp một mô-đun có tên PolynomialFeatures. Mô-đun này chuyển ma trận dữ liệu đầu vào thành một ma trận dữ liệu mới có mức độ nhất định.
Thông số
Bảng theo dõi bao gồm các thông số được sử dụng bởi PolynomialFeatures mô-đun
| Sr.No | Mô tả về Thông Số |
|---|---|
| 1 | degree - số nguyên, mặc định = 2 Nó đại diện cho mức độ của các đối tượng đa thức. |
| 2 | interaction_only - Boolean, default = false Theo mặc định, nó là false nhưng nếu được đặt là true, các đối tượng địa lý là sản phẩm của hầu hết các tính năng đầu vào khác biệt ở mức độ khác nhau, được tạo ra. Các tính năng như vậy được gọi là tính năng tương tác. |
| 3 | include_bias - Boolean, default = true Nó bao gồm một cột thiên vị tức là tính năng trong đó tất cả các lũy thừa của đa thức đều bằng không. |
| 4 | order - str trong {'C', 'F'}, default = 'C' Tham số này đại diện cho thứ tự của mảng đầu ra trong trường hợp dày đặc. Lệnh 'F' có nghĩa là tính toán nhanh hơn nhưng mặt khác, nó có thể làm chậm các công cụ ước tính tiếp theo. |
Thuộc tính
Bảng theo dõi bao gồm các thuộc tính được sử dụng bởi PolynomialFeatures mô-đun
| Sr.No | Thuộc tính & Mô tả |
|---|---|
| 1 | powers_ - mảng, hình dạng (n_output_features, n_input_features) Nó cho thấy powers_ [i, j] là số mũ của đầu vào thứ j trong đầu ra thứ i. |
| 2 | n_input_features _ - int Như tên cho thấy, nó cung cấp tổng số tính năng đầu vào. |
| 3 | n_output_features _ - int Như tên cho thấy, nó cung cấp tổng số các tính năng đầu ra đa thức. |
Ví dụ triển khai
Sử dụng script Python sau PolynomialFeatures biến áp để biến đổi mảng 8 thành hình dạng (4,2) -
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
Y = np.arange(8).reshape(4, 2)
poly = PolynomialFeatures(degree=2)
poly.fit_transform(Y)Đầu ra
array(
[
[ 1., 0., 1., 0., 0., 1.],
[ 1., 2., 3., 4., 6., 9.],
[ 1., 4., 5., 16., 20., 25.],
[ 1., 6., 7., 36., 42., 49.]
]
)Hợp lý hóa bằng các công cụ Pipeline
Loại tiền xử lý ở trên tức là chuyển đổi ma trận dữ liệu đầu vào thành ma trận dữ liệu mới ở mức độ nhất định, có thể được sắp xếp hợp lý với Pipeline các công cụ về cơ bản được sử dụng để xâu chuỗi nhiều công cụ ước tính thành một.
Thí dụ
Các tập lệnh python dưới đây sử dụng các công cụ Pipeline của Scikit-learning để hợp lý hóa quá trình tiền xử lý (sẽ phù hợp với dữ liệu đa thức bậc 3).
#First, import the necessary packages.
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
import numpy as np
#Next, create an object of Pipeline tool
Stream_model = Pipeline([('poly', PolynomialFeatures(degree=3)), ('linear', LinearRegression(fit_intercept=False))])
#Provide the size of array and order of polynomial data to fit the model.
x = np.arange(5)
y = 3 - 2 * x + x ** 2 - x ** 3
Stream_model = model.fit(x[:, np.newaxis], y)
#Calculate the input polynomial coefficients.
Stream_model.named_steps['linear'].coef_Đầu ra
array([ 3., -2., 1., -1.])Kết quả đầu ra ở trên cho thấy rằng mô hình tuyến tính được đào tạo về các đặc trưng của đa thức có thể khôi phục các hệ số đa thức đầu vào chính xác.
Ở đây, chúng ta sẽ tìm hiểu về một thuật toán tối ưu hóa trong Sklearn, được gọi là Stochastic Gradient Descent (SGD).
Stochastic Gradient Descent (SGD) là một thuật toán tối ưu hóa đơn giản nhưng hiệu quả được sử dụng để tìm các giá trị của tham số / hệ số của các hàm làm tối thiểu hóa hàm chi phí. Nói cách khác, nó được sử dụng để học phân biệt các bộ phân loại tuyến tính dưới các hàm mất lồi như hồi quy SVM và Logistic. Nó đã được áp dụng thành công cho các bộ dữ liệu quy mô lớn bởi vì việc cập nhật các hệ số được thực hiện cho từng phiên bản huấn luyện, thay vì ở cuối các phiên bản.
Bộ phân loại SGD
Bộ phân loại Stochastic Gradient Descent (SGD) về cơ bản thực hiện một quy trình học SGD đơn giản hỗ trợ các hàm và hình phạt mất mát khác nhau để phân loại. Scikit-learning cung cấpSGDClassifier phân hệ thực hiện phân loại SGD.
Thông số
Bảng theo dõi bao gồm các thông số được sử dụng bởi SGDClassifier mô-đun -
| Sr.No | Mô tả về Thông Số |
|---|---|
| 1 | loss - str, default = 'bản lề' Nó đại diện cho hàm mất mát được sử dụng trong khi thực hiện. Giá trị mặc định là 'bản lề' sẽ cung cấp cho chúng ta một SVM tuyến tính. Các tùy chọn khác có thể được sử dụng là -
|
| 2 | penalty - str, 'none', 'l2', 'l1','asticnet ' Nó là thuật ngữ chính quy hóa được sử dụng trong mô hình. Theo mặc định, nó là L2. Chúng ta có thể sử dụng L1 hoặc'asticnet; nhưng cả hai đều có thể mang lại sự thưa thớt cho mô hình, do đó không thể đạt được với L2. |
| 3 | alpha - float, default = 0,0001 Alpha, hằng số nhân với thuật ngữ chính quy, là tham số điều chỉnh quyết định mức độ chúng ta muốn phạt mô hình. Giá trị mặc định là 0,0001. |
| 4 | l1_ratio - float, default = 0.15 Đây được gọi là tham số trộn ElasticNet. Phạm vi của nó là 0 <= l1_ratio <= 1. Nếu l1_ratio = 1, hình phạt sẽ là hình phạt L1. Nếu l1_ratio = 0, hình phạt sẽ là hình phạt L2. |
| 5 | fit_intercept - Boolean, Mặc định = Đúng Tham số này chỉ định rằng một hằng số (thiên vị hoặc chặn) nên được thêm vào hàm quyết định. Không có điểm chặn nào sẽ được sử dụng trong tính toán và dữ liệu sẽ được giả định là đã được căn giữa, nếu nó sẽ được đặt thành false. |
| 6 | tol - float hoặc none, tùy chọn, mặc định = 1.e-3 Tham số này đại diện cho tiêu chí dừng cho các lần lặp. Giá trị mặc định của nó là Sai nhưng nếu được đặt thành Không, các lần lặp sẽ dừng lại khiloss > best_loss - tol for n_iter_no_changecác kỷ nguyên kế tiếp nhau. |
| 7 | shuffle - Boolean, tùy chọn, mặc định = True Tham số này thể hiện rằng chúng ta có muốn dữ liệu đào tạo của mình được xáo trộn sau mỗi kỷ nguyên hay không. |
| số 8 | verbose - số nguyên, mặc định = 0 Nó thể hiện mức độ chi tiết. Giá trị mặc định của nó là 0. |
| 9 | epsilon - float, default = 0,1 Tham số này chỉ định độ rộng của vùng không nhạy cảm. Nếu loss = 'epsilon-insensitive', bất kỳ sự khác biệt nào, giữa dự đoán hiện tại và nhãn chính xác, nhỏ hơn ngưỡng sẽ bị bỏ qua. |
| 10 | max_iter - int, tùy chọn, mặc định = 1000 Như tên gợi ý, nó đại diện cho số lần vượt qua tối đa trong các kỷ nguyên tức là dữ liệu đào tạo. |
| 11 | warm_start - bool, tùy chọn, mặc định = false Với tham số này được đặt thành True, chúng ta có thể sử dụng lại giải pháp của cuộc gọi trước đó để phù hợp với vai trò khởi tạo. Nếu chúng ta chọn default tức là false, nó sẽ xóa giải pháp trước đó. |
| 12 | random_state - int, RandomState instance hoặc None, tùy chọn, default = none Tham số này đại diện cho hạt giống của số ngẫu nhiên giả được tạo ra được sử dụng trong khi xáo trộn dữ liệu. Tiếp theo là các tùy chọn.
|
| 13 | n_jobs - int hoặc none, tùy chọn, Mặc định = Không có Nó đại diện cho số lượng CPU được sử dụng trong tính toán OVA (Một so với tất cả), cho các bài toán nhiều lớp. Giá trị mặc định không có nghĩa là 1. |
| 14 | learning_rate - chuỗi, tùy chọn, mặc định = 'tối ưu'
|
| 15 | eta0 - gấp đôi, mặc định = 0,0 Nó đại diện cho tốc độ học ban đầu cho các tùy chọn tốc độ học tập đã đề cập ở trên, tức là 'không đổi', 'gọi điện' hoặc 'thích ứng'. |
| 16 | power_t - idouble, mặc định = 0,5 Nó là số mũ cho tỷ lệ học tập 'incscalling'. |
| 17 | early_stopping - bool, mặc định = Sai Tham số này thể hiện việc sử dụng tính năng dừng sớm để chấm dứt đào tạo khi điểm xác nhận không được cải thiện. Giá trị mặc định của nó là false nhưng khi được đặt thành true, nó sẽ tự động dành một phần dữ liệu huấn luyện được phân tầng để xác thực và dừng huấn luyện khi điểm xác thực không cải thiện. |
| 18 | validation_fraction - float, default = 0,1 Nó chỉ được sử dụng khi early_stopping là true. Nó đại diện cho tỷ lệ dữ liệu đào tạo để đặt phụ trợ làm bộ xác nhận để kết thúc sớm dữ liệu đào tạo .. |
| 19 | n_iter_no_change - int, default = 5 Nó đại diện cho số lần lặp lại không có cải tiến nên thuật toán chạy trước khi dừng sớm. |
| 20 | classs_weight - dict, {class_label: weight} hoặc "balance", hoặc Không, tùy chọn Tham số này đại diện cho trọng số liên quan đến các lớp. Nếu không được cung cấp, các lớp phải có trọng số 1. |
| 20 | warm_start - bool, tùy chọn, mặc định = false Với tham số này được đặt thành True, chúng ta có thể sử dụng lại giải pháp của cuộc gọi trước đó để phù hợp với vai trò khởi tạo. Nếu chúng ta chọn default tức là false, nó sẽ xóa giải pháp trước đó. |
| 21 | average - iBoolean hoặc int, tùy chọn, default = false Nó đại diện cho số lượng CPU được sử dụng trong tính toán OVA (Một so với tất cả), cho các bài toán nhiều lớp. Giá trị mặc định không có nghĩa là 1. |
Thuộc tính
Bảng sau bao gồm các thuộc tính được sử dụng bởi SGDClassifier mô-đun -
| Sr.No | Thuộc tính & Mô tả |
|---|---|
| 1 | coef_ - mảng, hình dạng (1, n_features) if n_classes == 2, else (n_classes, n_features) Thuộc tính này cung cấp trọng số được gán cho các đối tượng địa lý. |
| 2 | intercept_ - mảng, hình dạng (1,) if n_classes == 2, else (n_classes,) Nó thể hiện thuật ngữ độc lập trong chức năng quyết định. |
| 3 | n_iter_ - int Nó cung cấp số lần lặp lại để đạt được tiêu chí dừng. |
Implementation Example
Giống như các bộ phân loại khác, Stochastic Gradient Descent (SGD) phải được trang bị với hai mảng sau:
Một mảng X chứa các mẫu huấn luyện. Nó có kích thước [n_samples, n_features].
Một mảng Y chứa các giá trị đích tức là nhãn lớp cho các mẫu huấn luyện. Nó có kích thước [n_samples].
Example
Tập lệnh Python sau sử dụng mô hình tuyến tính SGDClassifier -
import numpy as np
from sklearn import linear_model
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
Y = np.array([1, 1, 2, 2])
SGDClf = linear_model.SGDClassifier(max_iter = 1000, tol=1e-3,penalty = "elasticnet")
SGDClf.fit(X, Y)Output
SGDClassifier(
alpha = 0.0001, average = False, class_weight = None,
early_stopping = False, epsilon = 0.1, eta0 = 0.0, fit_intercept = True,
l1_ratio = 0.15, learning_rate = 'optimal', loss = 'hinge', max_iter = 1000,
n_iter = None, n_iter_no_change = 5, n_jobs = None, penalty = 'elasticnet',
power_t = 0.5, random_state = None, shuffle = True, tol = 0.001,
validation_fraction = 0.1, verbose = 0, warm_start = False
)Example
Bây giờ, sau khi được trang bị, mô hình có thể dự đoán các giá trị mới như sau:
SGDClf.predict([[2.,2.]])Output
array([2])Example
Đối với ví dụ trên, chúng ta có thể lấy vector trọng số với sự trợ giúp của tập lệnh python sau:
SGDClf.coef_Output
array([[19.54811198, 9.77200712]])Example
Tương tự, chúng ta có thể nhận giá trị của intercept với sự trợ giúp của tập lệnh python sau:
SGDClf.intercept_Output
array([10.])Example
Chúng ta có thể nhận được khoảng cách đã ký đến siêu phẳng bằng cách sử dụng SGDClassifier.decision_function như được sử dụng trong tập lệnh python sau:
SGDClf.decision_function([[2., 2.]])Output
array([68.6402382])Bộ điều chỉnh SGD
Bộ hồi quy Stochastic Gradient Descent (SGD) về cơ bản thực hiện một quy trình học SGD đơn giản hỗ trợ các hàm và hình phạt mất mát khác nhau để phù hợp với các mô hình hồi quy tuyến tính. Scikit-learning cung cấpSGDRegressor mô-đun thực hiện hồi quy SGD.
Thông số
Các thông số được sử dụng bởi SGDRegressorgần giống như được sử dụng trong mô-đun SGDClassifier. Sự khác biệt nằm ở tham số 'mất mát'. Đối vớiSGDRegressor tham số mất mát của mô-đun các giá trị tích cực như sau:
squared_loss - Nó đề cập đến sự phù hợp với hình vuông nhỏ nhất thông thường.
huber: SGDRegressor- sửa các giá trị ngoại lệ bằng cách chuyển từ tổn thất bình phương sang tuyến tính trong khoảng cách epsilon. Công việc của 'huber' là sửa đổi 'squared_loss' để thuật toán tập trung ít hơn vào việc điều chỉnh các ngoại lệ.
epsilon_insensitive - Trên thực tế, nó bỏ qua các lỗi ít hơn epsilon.
squared_epsilon_insensitive- Nó giống như epsilon_insensitive. Sự khác biệt duy nhất là nó trở thành tổn thất bình phương trước một dung sai epsilon.
Một điểm khác biệt nữa là tham số có tên 'power_t' có giá trị mặc định là 0,25 thay vì 0,5 như trong SGDClassifier. Hơn nữa, nó không có các tham số 'class_weight' và 'n_jobs'.
Thuộc tính
Các thuộc tính của SGDRegressor cũng giống như thuộc tính của mô-đun SGDClassifier. Đúng hơn nó có ba thuộc tính bổ sung như sau:
average_coef_ - mảng, hình dạng (n_features,)
Như tên gợi ý, nó cung cấp trọng lượng trung bình được gán cho các tính năng.
average_intercept_ - mảng, hình dạng (1,)
Như tên gợi ý, nó cung cấp thuật ngữ đánh chặn trung bình.
t_ - int
Nó cung cấp số lần cập nhật trọng lượng được thực hiện trong giai đoạn đào tạo.
Note - các thuộc tính average_coef_ và average_intercept_ sẽ hoạt động sau khi bật tham số 'average' thành True.
Implementation Example
Sử dụng script Python sau SGDRegressor mô hình tuyến tính -
import numpy as np
from sklearn import linear_model
n_samples, n_features = 10, 5
rng = np.random.RandomState(0)
y = rng.randn(n_samples)
X = rng.randn(n_samples, n_features)
SGDReg =linear_model.SGDRegressor(
max_iter = 1000,penalty = "elasticnet",loss = 'huber',tol = 1e-3, average = True
)
SGDReg.fit(X, y)Output
SGDRegressor(
alpha = 0.0001, average = True, early_stopping = False, epsilon = 0.1,
eta0 = 0.01, fit_intercept = True, l1_ratio = 0.15,
learning_rate = 'invscaling', loss = 'huber', max_iter = 1000,
n_iter = None, n_iter_no_change = 5, penalty = 'elasticnet', power_t = 0.25,
random_state = None, shuffle = True, tol = 0.001, validation_fraction = 0.1,
verbose = 0, warm_start = False
)Example
Bây giờ, sau khi được trang bị, chúng ta có thể lấy vector trọng lượng với sự trợ giúp của tập lệnh python sau:
SGDReg.coef_Output
array([-0.00423314, 0.00362922, -0.00380136, 0.00585455, 0.00396787])Example
Tương tự, chúng ta có thể nhận giá trị của intercept với sự trợ giúp của tập lệnh python sau:
SGReg.intercept_Output
SGReg.intercept_Example
Chúng tôi có thể nhận được số lần cập nhật trọng lượng trong giai đoạn đào tạo với sự trợ giúp của tập lệnh python sau:
SGDReg.t_Output
61.0Ưu và nhược điểm của SGD
Theo những ưu điểm của SGD -
Stochastic Gradient Descent (SGD) rất hiệu quả.
Nó rất dễ thực hiện vì có rất nhiều cơ hội để điều chỉnh mã.
Theo nhược điểm của SGD -
Stochastic Gradient Descent (SGD) yêu cầu một số siêu tham số như các tham số chính quy.
Nó nhạy cảm với việc mở rộng tính năng.
Chương này đề cập đến một phương pháp học máy được gọi là Máy vectơ hỗ trợ (SVM).
Giới thiệu
Máy vectơ hỗ trợ (SVM) là phương pháp học máy được giám sát mạnh mẽ nhưng linh hoạt được sử dụng để phân loại, hồi quy và phát hiện các ngoại lệ. SVM rất hiệu quả trong không gian chiều cao và thường được sử dụng trong các bài toán phân loại. SVM phổ biến và hiệu quả về bộ nhớ vì chúng sử dụng một tập hợp con các điểm huấn luyện trong hàm quyết định.
Mục tiêu chính của SVM là chia bộ dữ liệu thành số lớp để tìm maximum marginal hyperplane (MMH) có thể được thực hiện theo hai bước sau:
Máy hỗ trợ Vector đầu tiên sẽ tạo lặp đi lặp lại các siêu máy bay để phân tách các lớp theo cách tốt nhất.
Sau đó, nó sẽ chọn siêu phẳng phân tách các lớp một cách chính xác.
Một số khái niệm quan trọng trong SVM như sau:
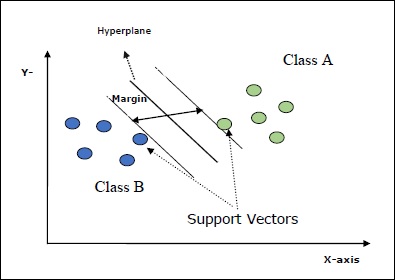
Support Vectors- Chúng có thể được định nghĩa là các điểm dữ liệu gần nhất với siêu phẳng. Các vectơ hỗ trợ giúp quyết định đường phân cách.
Hyperplane - Mặt phẳng quyết định hoặc không gian phân chia tập hợp các đối tượng có các lớp khác nhau.
Margin - Khoảng cách giữa hai dòng trên các điểm dữ liệu tủ của các lớp khác nhau được gọi là lề.
Các sơ đồ sau sẽ cung cấp cho bạn cái nhìn sâu sắc về các khái niệm SVM này -
SVM trong Scikit-learning hỗ trợ cả vectơ mẫu thưa thớt và dày đặc làm đầu vào.
Phân loại SVM
Scikit-learning cung cấp ba lớp cụ thể là SVC, NuSVC và LinearSVC có thể thực hiện phân loại lớp đa kính.
SVC
Đó là phân loại vectơ hỗ trợ C mà việc triển khai dựa trên libsvm. Mô-đun được sử dụng bởi scikit-learning làsklearn.svm.SVC. Lớp này xử lý hỗ trợ đa kính theo sơ đồ một chọi một.
Thông số
Bảng theo dõi bao gồm các thông số được sử dụng bởi sklearn.svm.SVC lớp học -
| Sr.No | Mô tả về Thông Số |
|---|---|
| 1 | C - float, tùy chọn, mặc định = 1.0 Nó là tham số phạt của thuật ngữ lỗi. |
| 2 | kernel - string, option, default = 'rbf' Tham số này chỉ định loại hạt nhân sẽ được sử dụng trong thuật toán. chúng ta có thể chọn bất kỳ cái nào trong số,‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’. Giá trị mặc định của kernel sẽ là‘rbf’. |
| 3 | degree - int, tùy chọn, mặc định = 3 Nó đại diện cho mức độ của chức năng hạt nhân 'poly' và sẽ bị bỏ qua bởi tất cả các hạt nhân khác. |
| 4 | gamma - {'scale', 'auto'} hoặc float, Nó là hệ số nhân cho các nhân 'rbf', 'poly' và 'sigmoid'. |
| 5 | optinal default - = 'quy mô' Nếu bạn chọn mặc định tức là gamma = 'scale' thì giá trị của gamma được SVC sử dụng là 1 / (_ ∗. ()). Mặt khác, nếu gamma = 'auto', nó sử dụng 1 / _. |
| 6 | coef0 - float, tùy chọn, Mặc định = 0.0 Một thuật ngữ độc lập trong hàm nhân chỉ có ý nghĩa trong 'poly' và 'sigmoid'. |
| 7 | tol - float, tùy chọn, mặc định = 1.e-3 Tham số này đại diện cho tiêu chí dừng cho các lần lặp. |
| số 8 | shrinking - Boolean, tùy chọn, mặc định = True Tham số này thể hiện rằng chúng ta có muốn sử dụng heuristic thu nhỏ hay không. |
| 9 | verbose - Boolean, mặc định: false Nó bật hoặc tắt đầu ra dài dòng. Giá trị mặc định của nó là sai. |
| 10 | probability - boolean, tùy chọn, mặc định = true Tham số này bật hoặc tắt các ước tính xác suất. Giá trị mặc định là false, nhưng nó phải được kích hoạt trước khi chúng tôi gọi là fit. |
| 11 | max_iter - int, tùy chọn, mặc định = -1 Như tên gợi ý, nó đại diện cho số lần lặp lại tối đa trong bộ giải. Giá trị -1 nghĩa là không có giới hạn về số lần lặp. |
| 12 | cache_size - phao, tùy chọn Tham số này sẽ chỉ định kích thước của bộ đệm ẩn hạt nhân. Giá trị sẽ tính bằng MB (MegaBytes). |
| 13 | random_state - int, RandomState instance hoặc None, tùy chọn, default = none Tham số này đại diện cho hạt giống của số ngẫu nhiên giả được tạo ra được sử dụng trong khi xáo trộn dữ liệu. Tiếp theo là các tùy chọn -
|
| 14 | class_weight - {dict, 'balance'}, tùy chọn Tham số này sẽ đặt tham số C của lớp j là _ℎ [] ∗ cho SVC. Nếu chúng ta sử dụng tùy chọn mặc định, điều đó có nghĩa là tất cả các lớp phải có trọng số là một. Mặt khác, nếu bạn chọnclass_weight:balanced, nó sẽ sử dụng các giá trị của y để tự động điều chỉnh trọng số. |
| 15 | decision_function_shape - ovo ',' ovr ', default =' ovr ' Tham số này sẽ quyết định liệu thuật toán có trả về hay không ‘ovr’ (một so với phần còn lại) chức năng quyết định của hình dạng như tất cả các bộ phân loại khác, hoặc ban đầu ovo(một đối một) chức năng quyết định của libsvm. |
| 16 | break_ties - boolean, tùy chọn, mặc định = false True - Dự đoán sẽ phá vỡ mối quan hệ theo các giá trị tin cậy của hàm quyết định False - Dự đoán sẽ trả về lớp đầu tiên trong số các lớp bị ràng buộc. |
Thuộc tính
Bảng theo dõi bao gồm các thuộc tính được sử dụng bởi sklearn.svm.SVC lớp học -
| Sr.No | Thuộc tính & Mô tả |
|---|---|
| 1 | support_ - dạng mảng, hình dạng = [n_SV] Nó trả về các chỉ số của các vectơ hỗ trợ. |
| 2 | support_vectors_ - dạng mảng, hình dạng = [n_SV, n_features] Nó trả về các vectơ hỗ trợ. |
| 3 | n_support_ - dạng mảng, dtype = int32, shape = [n_class] Nó đại diện cho số lượng các vectơ hỗ trợ cho mỗi lớp. |
| 4 | dual_coef_ - mảng, hình dạng = [n_class-1, n_SV] Đây là hệ số của các vectơ hỗ trợ trong hàm quyết định. |
| 5 | coef_ - mảng, hình dạng = [n_class * (n_class-1) / 2, n_features] Thuộc tính này, chỉ khả dụng trong trường hợp hạt nhân tuyến tính, cung cấp trọng số được gán cho các tính năng. |
| 6 | intercept_ - mảng, hình dạng = [n_class * (n_class-1) / 2] Nó đại diện cho thuật ngữ độc lập (hằng số) trong chức năng quyết định. |
| 7 | fit_status_ - int Đầu ra sẽ là 0 nếu nó được lắp đúng cách. Đầu ra sẽ là 1 nếu nó được lắp không chính xác. |
| số 8 | classes_ - mảng hình dạng = [n_classes] Nó cung cấp các nhãn của các lớp. |
Implementation Example
Giống như các bộ phân loại khác, SVC cũng phải được trang bị hai mảng sau:
Một mảng Xgiữ các mẫu đào tạo. Nó có kích thước [n_samples, n_features].
Một mảng Ygiữ các giá trị đích tức là nhãn lớp cho các mẫu huấn luyện. Nó có kích thước [n_samples].
Sử dụng script Python sau sklearn.svm.SVC lớp học -
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import SVC
SVCClf = SVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
SVCClf.fit(X, y)Output
SVC(C = 1.0, cache_size = 200, class_weight = None, coef0 = 0.0,
decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear',
max_iter = -1, probability = False, random_state = None, shrinking = False,
tol = 0.001, verbose = False)Example
Bây giờ, sau khi được trang bị, chúng ta có thể lấy vector trọng lượng với sự trợ giúp của tập lệnh python sau:
SVCClf.coef_Output
array([[0.5, 0.5]])Example
Tương tự, chúng ta có thể lấy giá trị của các thuộc tính khác như sau:
SVCClf.predict([[-0.5,-0.8]])Output
array([1])Example
SVCClf.n_support_Output
array([1, 1])Example
SVCClf.support_vectors_Output
array(
[
[-1., -1.],
[ 1., 1.]
]
)Example
SVCClf.support_Output
array([0, 2])Example
SVCClf.intercept_Output
array([-0.])Example
SVCClf.fit_status_Output
0NuSVC
NuSVC là Phân loại Vectơ hỗ trợ Nu. Nó là một lớp khác được cung cấp bởi scikit-learning có thể thực hiện phân loại nhiều lớp. Nó giống như SVC nhưng NuSVC chấp nhận các bộ tham số hơi khác một chút. Tham số khác với SVC như sau:
nu - float, tùy chọn, mặc định = 0.5
Nó đại diện cho giới hạn trên của phần nhỏ lỗi huấn luyện và giới hạn dưới của phần nhỏ của vectơ hỗ trợ. Giá trị của nó phải nằm trong khoảng (o, 1].
Phần còn lại của các tham số và thuộc tính giống như của SVC.
Ví dụ triển khai
Chúng ta có thể triển khai cùng một ví dụ bằng cách sử dụng sklearn.svm.NuSVC lớp cũng vậy.
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import NuSVC
NuSVCClf = NuSVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
NuSVCClf.fit(X, y)Đầu ra
NuSVC(cache_size = 200, class_weight = None, coef0 = 0.0,
decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear',
max_iter = -1, nu = 0.5, probability = False, random_state = None,
shrinking = False, tol = 0.001, verbose = False)Chúng ta có thể lấy kết quả đầu ra của phần còn lại của các thuộc tính như đã làm trong trường hợp SVC.
LinearSVC
Đó là Phân loại véc tơ hỗ trợ tuyến tính. Nó tương tự như SVC có kernel = 'linear'. Sự khác biệt giữa chúng làLinearSVC được triển khai theo liblinear trong khi SVC được triển khai trong libsvm. Đó là lý doLinearSVClinh hoạt hơn trong việc lựa chọn hình phạt và chức năng thua lỗ. Nó cũng mở rộng quy mô tốt hơn với số lượng lớn mẫu.
Nếu chúng ta nói về các tham số và thuộc tính của nó thì nó không hỗ trợ ‘kernel’ bởi vì nó được giả định là tuyến tính và nó cũng thiếu một số thuộc tính như support_, support_vectors_, n_support_, fit_status_ và, dual_coef_.
Tuy nhiên, nó hỗ trợ penalty và loss các thông số như sau -
penalty − string, L1 or L2(default = ‘L2’)
Tham số này được sử dụng để xác định quy chuẩn (L1 hoặc L2) được sử dụng trong hình phạt (chính quy hóa).
loss − string, hinge, squared_hinge (default = squared_hinge)
Nó đại diện cho hàm mất mát trong đó 'bản lề' là tổn thất SVM tiêu chuẩn và 'bình phương_hóa' là bình phương của tổn thất bản lề.
Ví dụ triển khai
Sử dụng script Python sau sklearn.svm.LinearSVC lớp học -
from sklearn.svm import LinearSVC
from sklearn.datasets import make_classification
X, y = make_classification(n_features = 4, random_state = 0)
LSVCClf = LinearSVC(dual = False, random_state = 0, penalty = 'l1',tol = 1e-5)
LSVCClf.fit(X, y)Đầu ra
LinearSVC(C = 1.0, class_weight = None, dual = False, fit_intercept = True,
intercept_scaling = 1, loss = 'squared_hinge', max_iter = 1000,
multi_class = 'ovr', penalty = 'l1', random_state = 0, tol = 1e-05, verbose = 0)Thí dụ
Bây giờ, sau khi được trang bị, mô hình có thể dự đoán các giá trị mới như sau:
LSVCClf.predict([[0,0,0,0]])Đầu ra
[1]Thí dụ
Đối với ví dụ trên, chúng ta có thể lấy vector trọng số với sự trợ giúp của tập lệnh python sau:
LSVCClf.coef_Đầu ra
[[0. 0. 0.91214955 0.22630686]]Thí dụ
Tương tự, chúng ta có thể nhận giá trị của intercept với sự trợ giúp của tập lệnh python sau:
LSVCClf.intercept_Đầu ra
[0.26860518]Hồi quy với SVM
Như đã thảo luận trước đó, SVM được sử dụng cho cả vấn đề phân loại và hồi quy. Phương pháp phân loại véc tơ hỗ trợ (SVC) của Scikit-learning cũng có thể được mở rộng để giải các bài toán hồi quy. Phương pháp mở rộng đó được gọi là hồi quy vectơ hỗ trợ (SVR).
Điểm giống nhau cơ bản giữa SVM và SVR
Mô hình do SVC tạo ra chỉ phụ thuộc vào một tập con dữ liệu huấn luyện. Tại sao? Bởi vì hàm chi phí cho việc xây dựng mô hình không quan tâm đến các điểm dữ liệu huấn luyện nằm ngoài lề.
Trong khi đó, mô hình được tạo ra bởi SVR (Hồi quy vectơ hỗ trợ) cũng chỉ phụ thuộc vào một tập con của dữ liệu huấn luyện. Tại sao? Bởi vì hàm chi phí để xây dựng mô hình bỏ qua bất kỳ điểm dữ liệu huấn luyện nào gần với dự đoán của mô hình.
Scikit-learning cung cấp ba lớp cụ thể là SVR, NuSVR and LinearSVR như ba cách triển khai khác nhau của SVR.
SVR
Nó là hồi quy vectơ hỗ trợ Epsilon mà việc triển khai dựa trên libsvm. Đối lập vớiSVC Có hai tham số miễn phí trong mô hình là ‘C’ và ‘epsilon’.
epsilon - float, tùy chọn, mặc định = 0,1
Nó đại diện cho epsilon trong mô hình epsilon-SVR và chỉ định ống epsilon trong đó không có hình phạt nào được liên kết trong chức năng mất tập luyện với các điểm được dự đoán trong khoảng cách epsilon so với giá trị thực.
Phần còn lại của các tham số và thuộc tính tương tự như chúng tôi đã sử dụng trong SVC.
Ví dụ triển khai
Sử dụng script Python sau sklearn.svm.SVR lớp học -
from sklearn import svm
X = [[1, 1], [2, 2]]
y = [1, 2]
SVRReg = svm.SVR(kernel = ’linear’, gamma = ’auto’)
SVRReg.fit(X, y)Đầu ra
SVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, epsilon = 0.1, gamma = 'auto',
kernel = 'linear', max_iter = -1, shrinking = True, tol = 0.001, verbose = False)Thí dụ
Bây giờ, sau khi được trang bị, chúng ta có thể lấy vector trọng lượng với sự trợ giúp của tập lệnh python sau:
SVRReg.coef_Đầu ra
array([[0.4, 0.4]])Thí dụ
Tương tự, chúng ta có thể lấy giá trị của các thuộc tính khác như sau:
SVRReg.predict([[1,1]])Đầu ra
array([1.1])Tương tự, chúng ta cũng có thể lấy giá trị của các thuộc tính khác.
NuSVR
NuSVR là hồi quy vectơ hỗ trợ Nu. Nó giống như NuSVC, nhưng NuSVR sử dụng một tham sốnuđể kiểm soát số lượng vectơ hỗ trợ. Và hơn nữa, không giống như NuSVC, nơinu đã thay thế tham số C, ở đây nó thay thế epsilon.
Ví dụ triển khai
Sử dụng script Python sau sklearn.svm.SVR lớp học -
from sklearn.svm import NuSVR
import numpy as np
n_samples, n_features = 20, 15
np.random.seed(0)
y = np.random.randn(n_samples)
X = np.random.randn(n_samples, n_features)
NuSVRReg = NuSVR(kernel = 'linear', gamma = 'auto',C = 1.0, nu = 0.1)^M
NuSVRReg.fit(X, y)Đầu ra
NuSVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, gamma = 'auto',
kernel = 'linear', max_iter = -1, nu = 0.1, shrinking = True, tol = 0.001,
verbose = False)Thí dụ
Bây giờ, sau khi được trang bị, chúng ta có thể lấy vector trọng lượng với sự trợ giúp của tập lệnh python sau:
NuSVRReg.coef_Đầu ra
array(
[
[-0.14904483, 0.04596145, 0.22605216, -0.08125403, 0.06564533,
0.01104285, 0.04068767, 0.2918337 , -0.13473211, 0.36006765,
-0.2185713 , -0.31836476, -0.03048429, 0.16102126, -0.29317051]
]
)Tương tự, chúng ta cũng có thể lấy giá trị của các thuộc tính khác.
Tuyến tínhSVR
Nó là hồi quy vectơ hỗ trợ tuyến tính. Nó tương tự như SVR có kernel = 'linear'. Sự khác biệt giữa chúng làLinearSVR được thực hiện trong điều kiện liblinear, trong khi SVC được triển khai trong libsvm. Đó là lý doLinearSVRlinh hoạt hơn trong việc lựa chọn hình phạt và chức năng thua lỗ. Nó cũng mở rộng quy mô tốt hơn với số lượng lớn mẫu.
Nếu chúng ta nói về các tham số và thuộc tính của nó thì nó không hỗ trợ ‘kernel’ bởi vì nó được giả định là tuyến tính và nó cũng thiếu một số thuộc tính như support_, support_vectors_, n_support_, fit_status_ và, dual_coef_.
Tuy nhiên, nó hỗ trợ các thông số 'mất mát' như sau:
loss - string, option, default = 'epsilon_insensitive'
Nó đại diện cho hàm mất mát trong đó tổn thất epsilon_insensitive là tổn thất L1 và tổn thất không nhạy epsilon bình phương là tổn thất L2.
Ví dụ triển khai
Sử dụng script Python sau sklearn.svm.LinearSVR lớp học -
from sklearn.svm import LinearSVR
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 4, random_state = 0)
LSVRReg = LinearSVR(dual = False, random_state = 0,
loss = 'squared_epsilon_insensitive',tol = 1e-5)
LSVRReg.fit(X, y)Đầu ra
LinearSVR(
C=1.0, dual=False, epsilon=0.0, fit_intercept=True,
intercept_scaling=1.0, loss='squared_epsilon_insensitive',
max_iter=1000, random_state=0, tol=1e-05, verbose=0
)Thí dụ
Bây giờ, sau khi được trang bị, mô hình có thể dự đoán các giá trị mới như sau:
LSRReg.predict([[0,0,0,0]])Đầu ra
array([-0.01041416])Thí dụ
Đối với ví dụ trên, chúng ta có thể lấy vector trọng số với sự trợ giúp của tập lệnh python sau:
LSRReg.coef_Đầu ra
array([20.47354746, 34.08619401, 67.23189022, 87.47017787])Thí dụ
Tương tự, chúng ta có thể nhận giá trị của intercept với sự trợ giúp của tập lệnh python sau:
LSRReg.intercept_Đầu ra
array([-0.01041416])Ở đây, chúng ta sẽ tìm hiểu về phát hiện bất thường trong Sklearn là gì và cách nó được sử dụng để xác định các điểm dữ liệu.
Phát hiện bất thường là một kỹ thuật được sử dụng để xác định các điểm dữ liệu trong tập dữ liệu không khớp với phần còn lại của dữ liệu. Nó có nhiều ứng dụng trong kinh doanh như phát hiện gian lận, phát hiện xâm nhập, theo dõi sức khỏe hệ thống, giám sát và bảo trì dự đoán. Các dị thường, còn được gọi là ngoại lệ, có thể được chia thành ba loại sau:
Point anomalies - Nó xảy ra khi một cá thể dữ liệu riêng lẻ được coi là bất thường trong phần còn lại của dữ liệu.
Contextual anomalies- Loại dị thường như vậy là theo ngữ cảnh cụ thể. Nó xảy ra nếu một cá thể dữ liệu là bất thường trong một ngữ cảnh cụ thể.
Collective anomalies - Nó xảy ra khi một tập hợp các cá thể dữ liệu có liên quan là toàn bộ tập dữ liệu wrt bất thường chứ không phải các giá trị riêng lẻ.
Phương pháp
Hai phương pháp cụ thể là outlier detection và novelty detectioncó thể được sử dụng để phát hiện bất thường. Cần phải xem sự phân biệt giữa chúng.
Phát hiện ngoại vi
Dữ liệu đào tạo chứa các ngoại lệ khác xa với phần còn lại của dữ liệu. Những ngoại lệ như vậy được định nghĩa là những quan sát. Đó là lý do, các nhà ước tính phát hiện ngoại lệ luôn cố gắng điều chỉnh khu vực có dữ liệu đào tạo tập trung nhất trong khi bỏ qua các quan sát sai lệch. Nó còn được gọi là phát hiện bất thường không giám sát.
Phát hiện mới lạ
Nó liên quan đến việc phát hiện một mẫu không được quan sát trong các quan sát mới không được đưa vào dữ liệu đào tạo. Ở đây, dữ liệu đào tạo không bị ô nhiễm bởi các yếu tố bên ngoài. Nó còn được gọi là phát hiện bất thường bán giám sát.
Có một bộ công cụ ML, được cung cấp bởi scikit-learning, có thể được sử dụng cho cả phát hiện ngoại lệ cũng như phát hiện tính mới. Các công cụ này đầu tiên triển khai việc học đối tượng từ dữ liệu trong một phương thức không được giám sát bằng cách sử dụng phương thức fit () như sau:
estimator.fit(X_train)Bây giờ, các quan sát mới sẽ được sắp xếp như inliers (labeled 1) hoặc là outliers (labeled -1) bằng cách sử dụng phương thức dự đoán () như sau:
estimator.fit(X_test)Công cụ ước tính trước tiên sẽ tính toán chức năng tính điểm thô và sau đó phương pháp dự đoán sẽ sử dụng ngưỡng trên chức năng tính điểm thô đó. Chúng tôi có thể truy cập chức năng tính điểm thô này với sự trợ giúp củascore_sample và có thể kiểm soát ngưỡng bằng cách contamination tham số.
Chúng tôi cũng có thể xác định decision_function phương pháp xác định giá trị ngoại lai là giá trị âm và giá trị ngoại lai là giá trị không âm.
estimator.decision_function(X_test)Các thuật toán Sklearn để phát hiện ngoại lệ
Chúng ta hãy bắt đầu bằng cách hiểu một bao thư elip là gì.
Lắp một phong bì hình elip
Thuật toán này giả định rằng dữ liệu thông thường đến từ một phân phối đã biết, chẳng hạn như phân phối Gaussian. Để phát hiện ngoại lệ, Scikit-learning cung cấp một đối tượng có têncovariance.EllipticEnvelop.
Đối tượng này phù hợp với một ước tính hiệp phương sai mạnh mẽ cho dữ liệu và do đó, phù hợp với một hình elip với các điểm dữ liệu trung tâm. Nó bỏ qua những điểm bên ngoài chế độ trung tâm.
Thông số
Bảng sau bao gồm các tham số được sử dụng bởi sklearn. covariance.EllipticEnvelop phương pháp -
| Sr.No | Mô tả về Thông Số |
|---|---|
| 1 | store_precision - Boolean, tùy chọn, mặc định = True Chúng tôi có thể chỉ định nó nếu độ chính xác ước tính được lưu trữ. |
| 2 | assume_centered - Boolean, tùy chọn, mặc định = Sai Nếu chúng ta đặt nó là False, nó sẽ tính toán vị trí và hiệp phương sai mạnh mẽ trực tiếp với sự trợ giúp của thuật toán FastMCD. Mặt khác, nếu đặt True, nó sẽ tính toán hỗ trợ của vị trí mạnh mẽ và đồng loại. |
| 3 | support_fraction - float in (0., 1.), tùy chọn, mặc định = Không có Tham số này cho phương pháp biết tỷ lệ điểm được bao gồm trong hỗ trợ của các ước tính MCD thô. |
| 4 | contamination - float in (0., 1.), tùy chọn, mặc định = 0.1 Nó cung cấp tỷ lệ của các giá trị ngoại lai trong tập dữ liệu. |
| 5 | random_state - int, RandomState instance hoặc None, tùy chọn, default = none Tham số này đại diện cho hạt giống của số ngẫu nhiên giả được tạo ra được sử dụng trong khi xáo trộn dữ liệu. Tiếp theo là các tùy chọn -
|
Thuộc tính
Bảng sau bao gồm các thuộc tính được sử dụng bởi sklearn. covariance.EllipticEnvelop phương pháp -
| Sr.No | Thuộc tính & Mô tả |
|---|---|
| 1 | support_ - dạng mảng, hình dạng (n_samples,) Nó đại diện cho mặt nạ của các quan sát được sử dụng để tính toán các ước tính mạnh mẽ về vị trí và hình dạng. |
| 2 | location_ - dạng mảng, hình dạng (n_features) Nó trả về vị trí mạnh mẽ ước tính. |
| 3 | covariance_ - dạng mảng, hình dạng (n_features, n_features) Nó trả về ma trận hiệp phương sai mạnh mẽ được ước tính. |
| 4 | precision_ - dạng mảng, hình dạng (n_features, n_features) Nó trả về ma trận nghịch đảo giả ước tính. |
| 5 | offset_ - phao Nó được sử dụng để xác định chức năng quyết định từ các điểm số thô. decision_function = score_samples -offset_ |
Implementation Example
import numpy as np^M
from sklearn.covariance import EllipticEnvelope^M
true_cov = np.array([[.5, .6],[.6, .4]])
X = np.random.RandomState(0).multivariate_normal(mean = [0, 0], cov=true_cov,size=500)
cov = EllipticEnvelope(random_state = 0).fit(X)^M
# Now we can use predict method. It will return 1 for an inlier and -1 for an outlier.
cov.predict([[0, 0],[2, 2]])Output
array([ 1, -1])Rừng cách ly
Trong trường hợp tập dữ liệu chiều cao, một cách hiệu quả để phát hiện ngoại lệ là sử dụng các khu rừng ngẫu nhiên. Scikit-learning cung cấpensemble.IsolationForestphương pháp cô lập các quan sát bằng cách chọn ngẫu nhiên một đối tượng địa lý. Sau đó, nó chọn ngẫu nhiên một giá trị giữa các giá trị lớn nhất và nhỏ nhất của các đối tượng địa lý đã chọn.
Ở đây, số lần phân tách cần thiết để phân lập một mẫu tương đương với độ dài đường dẫn từ nút gốc đến nút kết thúc.
Thông số
Bảng theo dõi bao gồm các thông số được sử dụng bởi sklearn. ensemble.IsolationForest phương pháp -
| Sr.No | Mô tả về Thông Số |
|---|---|
| 1 | n_estimators - int, tùy chọn, mặc định = 100 Nó đại diện cho số lượng bộ ước lượng cơ sở trong tập hợp. |
| 2 | max_samples - int hoặc float, tùy chọn, default = “auto” Nó đại diện cho số lượng mẫu sẽ được rút ra từ X để đào tạo mỗi công cụ ước lượng cơ sở. Nếu chúng ta chọn int làm giá trị của nó, nó sẽ vẽ các mẫu max_samples. Nếu chúng ta chọn float làm giá trị của nó, nó sẽ vẽ các mẫu max_samples ∗ .shape [0]. Và, nếu chúng ta chọn auto làm giá trị của nó, nó sẽ vẽ max_samples = min (256, n_samples). |
| 3 | support_fraction - float in (0., 1.), tùy chọn, mặc định = Không có Tham số này cho phương pháp biết tỷ lệ điểm được bao gồm trong hỗ trợ của các ước tính MCD thô. |
| 4 | contamination - auto hoặc float, tùy chọn, default = auto Nó cung cấp tỷ lệ của các giá trị ngoại lai trong tập dữ liệu. Nếu chúng ta đặt nó mặc định tức là tự động, nó sẽ xác định ngưỡng như trong bài báo gốc. Nếu được thiết lập để thả nổi, phạm vi ô nhiễm sẽ nằm trong khoảng [0,0,5]. |
| 5 | random_state - int, RandomState instance hoặc None, tùy chọn, default = none Tham số này đại diện cho hạt giống của số ngẫu nhiên giả được tạo ra được sử dụng trong khi xáo trộn dữ liệu. Tiếp theo là các tùy chọn -
|
| 6 | max_features - int hoặc float, tùy chọn (mặc định = 1.0) Nó đại diện cho số lượng các tính năng được rút ra từ X để đào tạo mỗi công cụ ước tính cơ sở. Nếu chúng ta chọn int làm giá trị của nó, nó sẽ vẽ các đặc điểm max_features. Nếu chúng ta chọn float làm giá trị của nó, nó sẽ vẽ các mẫu max_features * X.shape []. |
| 7 | bootstrap - Boolean, tùy chọn (mặc định = Sai) Tùy chọn mặc định của nó là Sai có nghĩa là việc lấy mẫu sẽ được thực hiện mà không cần thay thế. Và mặt khác, nếu được đặt thành True, có nghĩa là các cây riêng lẻ phù hợp với một tập hợp con ngẫu nhiên của dữ liệu huấn luyện được lấy mẫu thay thế. |
| số 8 | n_jobs - int hoặc None, tùy chọn (mặc định = None) Nó đại diện cho số lượng công việc được chạy song song fit() và predict() cả hai phương pháp. |
| 9 | verbose - int, tùy chọn (mặc định = 0) Tham số này kiểm soát tính chi tiết của quá trình xây dựng cây. |
| 10 | warm_start - Bool, tùy chọn (mặc định = Sai) Nếu warm_start = true, chúng ta có thể sử dụng lại giải pháp cuộc gọi trước đó để phù hợp và có thể thêm nhiều công cụ ước tính hơn vào nhóm. Nhưng nếu được đặt thành false, chúng ta cần phải điều chỉnh một khu rừng hoàn toàn mới. |
Thuộc tính
Bảng sau bao gồm các thuộc tính được sử dụng bởi sklearn. ensemble.IsolationForest phương pháp -
| Sr.No | Thuộc tính & Mô tả |
|---|---|
| 1 | estimators_ - danh sách của Người phân loại Quyết định Cung cấp bộ sưu tập của tất cả các công cụ ước tính phụ được trang bị. |
| 2 | max_samples_ - số nguyên Nó cung cấp số lượng mẫu thực tế được sử dụng. |
| 3 | offset_ - phao Nó được sử dụng để xác định chức năng quyết định từ các điểm số thô. decision_function = score_samples -offset_ |
Implementation Example
Tập lệnh Python bên dưới sẽ sử dụng sklearn. ensemble.IsolationForest phương pháp để phù hợp với 10 cây trên dữ liệu đã cho
from sklearn.ensemble import IsolationForest
import numpy as np
X = np.array([[-1, -2], [-3, -3], [-3, -4], [0, 0], [-50, 60]])
OUTDClf = IsolationForest(n_estimators = 10)
OUTDclf.fit(X)Output
IsolationForest(
behaviour = 'old', bootstrap = False, contamination='legacy',
max_features = 1.0, max_samples = 'auto', n_estimators = 10, n_jobs=None,
random_state = None, verbose = 0
)Yếu tố ngoại lai địa phương
Thuật toán Hệ số ngoại lệ cục bộ (LOF) là một thuật toán hiệu quả khác để thực hiện phát hiện ngoại lệ trên dữ liệu thứ nguyên cao. Scikit-learning cung cấpneighbors.LocalOutlierFactorphương pháp tính điểm, được gọi là hệ số ngoại lệ cục bộ, phản ánh mức độ bất thường của các quan sát. Logic chính của thuật toán này là phát hiện các mẫu có mật độ thấp hơn đáng kể so với các mẫu lân cận của nó. Đó là lý do tại sao nó đo lường độ lệch mật độ cục bộ của các điểm dữ liệu đã cho với hàng xóm của chúng.
Thông số
Bảng theo dõi bao gồm các thông số được sử dụng bởi sklearn. neighbors.LocalOutlierFactor phương pháp
| Sr.No | Mô tả về Thông Số |
|---|---|
| 1 | n_neighbors - int, tùy chọn, mặc định = 20 Nó đại diện cho số lượng hàng xóm được sử dụng theo mặc định cho truy vấn đầu gối. Tất cả các mẫu sẽ được sử dụng nếu. |
| 2 | algorithm - tùy chọn Thuật toán nào được sử dụng để tính toán các nước láng giềng gần nhất.
|
| 3 | leaf_size - int, tùy chọn, mặc định = 30 Giá trị của tham số này có thể ảnh hưởng đến tốc độ xây dựng và truy vấn. Nó cũng ảnh hưởng đến bộ nhớ cần thiết để lưu trữ cây. Tham số này được chuyển cho các thuật toán BallTree hoặc KdTree. |
| 4 | contamination - auto hoặc float, tùy chọn, default = auto Nó cung cấp tỷ lệ của các giá trị ngoại lai trong tập dữ liệu. Nếu chúng ta đặt nó mặc định tức là tự động, nó sẽ xác định ngưỡng như trong bài báo gốc. Nếu được thiết lập để thả nổi, phạm vi ô nhiễm sẽ nằm trong khoảng [0,0,5]. |
| 5 | metric - chuỗi hoặc có thể gọi, mặc định Nó đại diện cho số liệu được sử dụng để tính toán khoảng cách. |
| 6 | P - int, tùy chọn (mặc định = 2) Đây là tham số cho chỉ số Minkowski. P = 1 tương đương với việc sử dụng manhattan_distance tức là L1, trong khi P = 2 tương đương với việc sử dụng euclidean_distance tức là L2. |
| 7 | novelty - Boolean, (mặc định = Sai) Theo mặc định, thuật toán LOF được sử dụng để phát hiện ngoại lệ nhưng nó có thể được sử dụng để phát hiện tính mới nếu chúng ta đặt tính mới = true. |
| số 8 | n_jobs - int hoặc None, tùy chọn (mặc định = None) Nó đại diện cho số lượng công việc được chạy song song cho cả hai phương thức fit () và dự đoán (). |
Thuộc tính
Bảng sau bao gồm các thuộc tính được sử dụng bởi sklearn.neighbors.LocalOutlierFactor phương pháp -
| Sr.No | Thuộc tính & Mô tả |
|---|---|
| 1 | negative_outlier_factor_ - mảng numpy, hình dạng (n_samples,) Cung cấp LOF đối lập của các mẫu đào tạo. |
| 2 | n_neighbors_ - số nguyên Nó cung cấp số lượng hàng xóm thực tế được sử dụng cho các truy vấn hàng xóm. |
| 3 | offset_ - phao Nó được sử dụng để xác định các nhãn nhị phân từ các điểm số thô. |
Implementation Example
Tập lệnh Python được cung cấp bên dưới sẽ sử dụng sklearn.neighbors.LocalOutlierFactor phương thức để xây dựng lớp NeighborsClassifier từ bất kỳ mảng nào tương ứng với tập dữ liệu của chúng tôi
from sklearn.neighbors import NearestNeighbors
samples = [[0., 0., 0.], [0., .5, 0.], [1., 1., .5]]
LOFneigh = NearestNeighbors(n_neighbors = 1, algorithm = "ball_tree",p=1)
LOFneigh.fit(samples)Output
NearestNeighbors(
algorithm = 'ball_tree', leaf_size = 30, metric='minkowski',
metric_params = None, n_jobs = None, n_neighbors = 1, p = 1, radius = 1.0
)Example
Bây giờ, chúng ta có thể hỏi từ bộ phân loại đã xây dựng này là điểm tủ đến [0,5, 1, 1,5] bằng cách sử dụng tập lệnh python sau:
print(neigh.kneighbors([[.5, 1., 1.5]])Output
(array([[1.7]]), array([[1]], dtype = int64))SVM một lớp
SVM Một Lớp, được giới thiệu bởi Schölkopf và các cộng sự, là Phát hiện Ngoại nhân không được giám sát. Nó cũng rất hiệu quả trong dữ liệu chiều cao và ước tính sự hỗ trợ của phân phối chiều cao. Nó được thực hiện trongSupport Vector Machines mô-đun trong Sklearn.svm.OneClassSVMvật. Để xác định biên giới, nó yêu cầu một nhân (chủ yếu được sử dụng là RBF) và một tham số vô hướng.
Để hiểu rõ hơn, hãy điều chỉnh dữ liệu của chúng tôi với svm.OneClassSVM đối tượng -
Thí dụ
from sklearn.svm import OneClassSVM
X = [[0], [0.89], [0.90], [0.91], [1]]
OSVMclf = OneClassSVM(gamma = 'scale').fit(X)Bây giờ, chúng ta có thể nhận được các ví dụ về điểm số cho dữ liệu đầu vào như sau:
OSVMclf.score_samples(X)Đầu ra
array([1.12218594, 1.58645126, 1.58673086, 1.58645127, 1.55713767])Chương này sẽ giúp bạn hiểu các phương thức lân cận gần nhất trong Sklearn.
Phương pháp học tập dựa trên hàng xóm thuộc cả hai loại cụ thể là supervised và unsupervised. Học tập dựa trên hàng xóm có giám sát có thể được sử dụng cho cả phân loại cũng như các bài toán dự đoán hồi quy, nhưng nó chủ yếu được sử dụng cho các bài toán dự đoán phân loại trong ngành.
Phương pháp học tập dựa trên láng giềng không có giai đoạn đào tạo chuyên biệt và sử dụng tất cả dữ liệu để đào tạo trong khi phân loại. Nó cũng không giả định bất cứ điều gì về dữ liệu cơ bản. Đó là lý do tại sao họ lười biếng và không có tham số.
Nguyên tắc chính đằng sau các phương pháp láng giềng gần nhất là:
Để tìm một số lượng xác định trước tủ mẫu đào tạo trong khoảng cách đến điểm dữ liệu mới
Dự đoán nhãn từ số lượng mẫu đào tạo này.
Ở đây, số lượng mẫu có thể là một hằng số do người dùng xác định như trong học hàng xóm gần nhất K hoặc thay đổi dựa trên mật độ cục bộ của điểm như trong học hàng xóm dựa trên bán kính.
Mô-đun sklearn.neighbors
Scikit-learning có sklearn.neighborsmô-đun cung cấp chức năng cho cả phương pháp học tập dựa trên người hàng xóm không giám sát và có giám sát. Là đầu vào, các lớp trong mô-đun này có thể xử lý mảng NumPy hoặcscipy.sparse ma trận.
Các loại thuật toán
Các loại thuật toán khác nhau có thể được sử dụng trong việc triển khai các phương pháp dựa trên hàng xóm như sau:
Lực lượng vũ phu
Tính toán thô bạo của khoảng cách giữa tất cả các cặp điểm trong tập dữ liệu cung cấp triển khai tìm kiếm hàng xóm ngây thơ nhất. Về mặt toán học, đối với N mẫu ở các kích thước D, phương pháp tiếp cận bạo lực cân bằng0[DN2]
Đối với các mẫu dữ liệu nhỏ, thuật toán này có thể rất hữu ích, nhưng nó trở nên không khả thi khi số lượng mẫu tăng lên. Tìm kiếm hàng xóm bạo lực có thể được kích hoạt bằng cách viết từ khóaalgorithm=’brute’.
Cây KD
Một trong những cấu trúc dữ liệu dựa trên cây đã được phát minh để giải quyết sự thiếu hiệu quả trong tính toán của phương pháp tiếp cận brute-force, là cấu trúc dữ liệu cây KD. Về cơ bản, cây KD là một cấu trúc cây nhị phân được gọi là cây K chiều. Nó phân vùng một cách đệ quy không gian tham số dọc theo các trục dữ liệu bằng cách chia nó thành các vùng trực giao lồng nhau để các điểm dữ liệu được lấp đầy.
Ưu điểm
Sau đây là một số ưu điểm của thuật toán cây KD:
Construction is fast - Vì việc phân vùng chỉ được thực hiện dọc theo các trục dữ liệu nên việc xây dựng cây KD diễn ra rất nhanh.
Less distance computations- Thuật toán này cần rất ít tính toán khoảng cách để xác định láng giềng gần nhất của điểm truy vấn. Nó chỉ mất[ ()] tính toán khoảng cách.
Nhược điểm
Fast for only low-dimensional neighbor searches- Tìm kiếm hàng xóm có chiều thấp (D <20) rất nhanh nhưng khi D lớn lên thì nó trở nên không hiệu quả. Vì việc phân vùng chỉ được thực hiện dọc theo các trục dữ liệu,
Tìm kiếm hàng xóm trên cây KD có thể được kích hoạt bằng cách viết từ khóa algorithm=’kd_tree’.
Cây bóng
Như chúng ta biết rằng KD Tree không hiệu quả ở các chiều cao hơn, do đó, để giải quyết sự kém hiệu quả này của KD Tree, cấu trúc dữ liệu Ball tree đã được phát triển. Về mặt toán học, nó phân chia dữ liệu một cách đệ quy, thành các nút được xác định bởi tâm C và bán kính r, theo cách mà mỗi điểm trong nút nằm trong siêu hình cầu được xác định bởi tâmC và bán kính r. Nó sử dụng bất đẳng thức tam giác, được đưa ra bên dưới, làm giảm số điểm ứng viên cho một tìm kiếm hàng xóm
$$\arrowvert X+Y\arrowvert\leq \arrowvert X\arrowvert+\arrowvert Y\arrowvert$$Ưu điểm
Sau đây là một số ưu điểm của thuật toán Cây bóng -
Efficient on highly structured data - Khi cây bóng phân vùng dữ liệu trong một loạt các siêu quả cầu lồng nhau, nó hiệu quả trên dữ liệu có cấu trúc cao.
Out-performs KD-tree - Cây bóng thực hiện được cây KD ở kích thước cao vì nó có dạng hình cầu của các nút cây bóng.
Nhược điểm
Costly - Phân vùng dữ liệu trong một loạt các siêu quả cầu lồng vào nhau làm cho việc xây dựng nó rất tốn kém.
Tìm kiếm hàng xóm cây bóng có thể được kích hoạt bằng cách viết từ khóa algorithm=’ball_tree’.
Chọn thuật toán láng giềng gần nhất
Việc lựa chọn một thuật toán tối ưu cho một tập dữ liệu nhất định phụ thuộc vào các yếu tố sau:
Số lượng mẫu (N) và Kích thước (D)
Đây là những yếu tố quan trọng nhất cần được xem xét khi lựa chọn thuật toán Nearest Neighbor. Đó là bởi vì những lý do được đưa ra dưới đây -
Thời gian truy vấn của thuật toán Brute Force tăng lên là O [DN].
Thời gian truy vấn của thuật toán cây bóng phát triển là O [D log (N)].
Thời gian truy vấn của thuật toán cây KD thay đổi theo D một cách kỳ lạ mà rất khó mô tả. Khi D <20, chi phí là O [D log (N)] và thuật toán này rất hiệu quả. Mặt khác, nó không hiệu quả trong trường hợp D> 20 vì chi phí tăng lên gần O [DN].
Cấu trúc dữ liệu
Một yếu tố khác ảnh hưởng đến hiệu suất của các thuật toán này là kích thước nội tại của dữ liệu hoặc độ thưa thớt của dữ liệu. Đó là vì thời gian truy vấn của các thuật toán cây bóng và cây KD có thể bị ảnh hưởng rất nhiều bởi nó. Trong khi đó, thời gian truy vấn của thuật toán Brute Force không thay đổi theo cấu trúc dữ liệu. Nói chung, các thuật toán cây bóng và cây KD tạo ra thời gian truy vấn nhanh hơn khi được cấy ghép trên dữ liệu thưa hơn với kích thước nội tại nhỏ hơn.
Số hàng xóm (k)
Số lượng hàng xóm (k) được yêu cầu cho một điểm truy vấn ảnh hưởng đến thời gian truy vấn của các thuật toán cây bóng và cây KD. Thời gian truy vấn của họ trở nên chậm hơn khi số lượng hàng xóm (k) tăng lên. Trong khi thời gian truy vấn của Brute Force sẽ không bị ảnh hưởng bởi giá trị của k.
Số điểm truy vấn
Bởi vì, chúng cần giai đoạn xây dựng, cả thuật toán cây KD và cây bóng sẽ hiệu quả nếu có số lượng điểm truy vấn lớn. Mặt khác, nếu có số lượng điểm truy vấn nhỏ hơn, thuật toán Brute Force hoạt động tốt hơn so với thuật toán cây KD và cây bóng.
k-NN (k-Nearest Neighbor), một trong những thuật toán máy học đơn giản nhất, là phi tham số và lười biếng về bản chất. Phi tham số có nghĩa là không có giả định cho phân phối dữ liệu cơ bản tức là cấu trúc mô hình được xác định từ tập dữ liệu. Học tập dựa trên phiên bản hoặc lười biếng có nghĩa là với mục đích tạo mô hình, nó không yêu cầu bất kỳ điểm dữ liệu đào tạo nào và toàn bộ dữ liệu đào tạo được sử dụng trong giai đoạn thử nghiệm.
Thuật toán k-NN bao gồm hai bước sau:
Bước 1
Trong bước này, nó tính toán và lưu trữ k lân cận gần nhất cho mỗi mẫu trong tập huấn luyện.
Bước 2
Trong bước này, đối với một mẫu không được gắn nhãn, nó lấy k lân cận gần nhất từ tập dữ liệu. Sau đó, trong số k-láng giềng gần nhất này, nó dự đoán lớp thông qua bỏ phiếu (lớp có đa số phiếu sẽ thắng).
Mô-đun, sklearn.neighbors triển khai thuật toán k-hàng xóm gần nhất, cung cấp chức năng cho unsupervised cũng như supervised phương pháp học tập dựa trên hàng xóm.
Các hàng xóm gần nhất không được giám sát thực hiện các thuật toán khác nhau (BallTree, KDTree hoặc Brute Force) để tìm (các) hàng xóm gần nhất cho mỗi mẫu. Phiên bản không được giám sát này về cơ bản chỉ là bước 1, đã được thảo luận ở trên và là nền tảng của nhiều thuật toán (KNN và K-có nghĩa là thuật toán nổi tiếng) yêu cầu tìm kiếm hàng xóm. Nói một cách đơn giản, đó là người học Không được giám sát để thực hiện các tìm kiếm hàng xóm.
Mặt khác, học tập dựa trên hàng xóm có giám sát được sử dụng để phân loại cũng như hồi quy.
Học tập KNN không giám sát
Như đã thảo luận, tồn tại nhiều thuật toán như KNN và K-Means yêu cầu tìm kiếm hàng xóm gần nhất. Đó là lý do tại sao Scikit-learning quyết định triển khai phần tìm kiếm hàng xóm với tư cách là “người học” của riêng mình. Lý do đằng sau việc thực hiện tìm kiếm hàng xóm như một người học riêng biệt là việc tính toán tất cả khoảng cách theo cặp để tìm người hàng xóm gần nhất rõ ràng là không hiệu quả lắm. Chúng ta hãy xem mô-đun được Sklearn sử dụng để triển khai việc học hàng xóm gần nhất không được giám sát cùng với ví dụ.
Mô-đun Scikit-learning
sklearn.neighbors.NearestNeighborslà mô-đun được sử dụng để triển khai việc học hàng xóm gần nhất không được giám sát. Nó sử dụng các thuật toán hàng xóm gần nhất cụ thể có tên BallTree, KDTree hoặc Brute Force. Nói cách khác, nó hoạt động như một giao diện thống nhất cho ba thuật toán này.
Thông số
Bảng theo dõi bao gồm các thông số được sử dụng bởi NearestNeighbors mô-đun -
| Sr.No | Mô tả về Thông Số |
|---|---|
| 1 | n_neighbors - int, tùy chọn Số lượng hàng xóm để có được. Giá trị mặc định là 5. |
| 2 | radius - phao, tùy chọn Nó giới hạn khoảng cách trở lại của những người hàng xóm. Giá trị mặc định là 1,0. |
| 3 | algorithm - {'auto', 'ball_tree', 'kd_tree', 'brute'}, tùy chọn Tham số này sẽ sử dụng thuật toán (BallTree, KDTree hoặc Brute-force) mà bạn muốn sử dụng để tính toán các nước láng giềng gần nhất. Nếu bạn cung cấp 'tự động', nó sẽ cố gắng quyết định thuật toán thích hợp nhất dựa trên các giá trị được truyền cho phương thức phù hợp. |
| 4 | leaf_size - int, tùy chọn Nó có thể ảnh hưởng đến tốc độ xây dựng & truy vấn cũng như bộ nhớ cần thiết để lưu trữ cây. Nó được chuyển cho BallTree hoặc KDTree. Mặc dù giá trị tối ưu phụ thuộc vào bản chất của vấn đề, giá trị mặc định của nó là 30. |
| 5 | metric - chuỗi hoặc có thể gọi Nó là số liệu được sử dụng để tính toán khoảng cách giữa các điểm. Chúng ta có thể chuyển nó dưới dạng chuỗi hoặc hàm có thể gọi. Trong trường hợp hàm có thể gọi, số liệu được gọi trên mỗi cặp hàng và giá trị kết quả được ghi lại. Nó kém hiệu quả hơn chuyển tên chỉ số dưới dạng một chuỗi. Chúng tôi có thể chọn từ số liệu từ scikit-learning hoặc scipy.spatial.distance. các giá trị hợp lệ như sau: Scikit-learning - ['cosine', 'manhattan', 'Euclidean', 'l1', 'l2', 'cityblock'] Scipy.spatial.distance - ['braycurtis', 'canberra', 'chebyshev', 'dice', 'hamming', 'jaccard', 'tương quan', 'kulsinski', 'mahalanobis', 'minkowski', 'rogerstanimoto', 'russellrao', ' sokalmicheme ',' sokals bên dưới ',' seuclidean ',' sqeuclidean ',' yule ']. Số liệu mặc định là 'Minkowski'. |
| 6 | P - số nguyên, tùy chọn Đây là tham số cho chỉ số Minkowski. Giá trị mặc định là 2 tương đương với việc sử dụng Euclidean_distance (l2). |
| 7 | metric_params - dict, tùy chọn Đây là đối số từ khóa bổ sung cho hàm số liệu. Giá trị mặc định là không có. |
| số 8 | N_jobs - int hoặc None, tùy chọn Nó cài đặt lại số lượng các công việc song song để chạy tìm kiếm hàng xóm. Giá trị mặc định là không có. |
Implementation Example
Ví dụ dưới đây sẽ tìm các láng giềng gần nhất giữa hai tập dữ liệu bằng cách sử dụng sklearn.neighbors.NearestNeighbors mô-đun.
Đầu tiên, chúng ta cần nhập mô-đun và các gói cần thiết -
from sklearn.neighbors import NearestNeighbors
import numpy as npBây giờ, sau khi nhập các gói, hãy xác định các tập dữ liệu ở giữa chúng ta muốn tìm các hàng xóm gần nhất -
Input_data = np.array([[-1, 1], [-2, 2], [-3, 3], [1, 2], [2, 3], [3, 4],[4, 5]])Tiếp theo, áp dụng thuật toán học tập không giám sát, như sau:
nrst_neigh = NearestNeighbors(n_neighbors = 3, algorithm = 'ball_tree')Tiếp theo, lắp mô hình với tập dữ liệu đầu vào.
nrst_neigh.fit(Input_data)Bây giờ, hãy tìm K-láng giềng của tập dữ liệu. Nó sẽ trả về các chỉ số và khoảng cách của các điểm lân cận của mỗi điểm.
distances, indices = nbrs.kneighbors(Input_data)
indicesOutput
array(
[
[0, 1, 3],
[1, 2, 0],
[2, 1, 0],
[3, 4, 0],
[4, 5, 3],
[5, 6, 4],
[6, 5, 4]
], dtype = int64
)
distancesOutput
array(
[
[0. , 1.41421356, 2.23606798],
[0. , 1.41421356, 1.41421356],
[0. , 1.41421356, 2.82842712],
[0. , 1.41421356, 2.23606798],
[0. , 1.41421356, 1.41421356],
[0. , 1.41421356, 1.41421356],
[0. , 1.41421356, 2.82842712]
]
)Kết quả trên cho thấy rằng láng giềng gần nhất của mỗi điểm là chính điểm đó, tức là ở điểm không. Đó là vì tập truy vấn khớp với tập huấn luyện.
Example
Chúng tôi cũng có thể hiển thị kết nối giữa các điểm lân cận bằng cách tạo ra một biểu đồ thưa thớt như sau:
nrst_neigh.kneighbors_graph(Input_data).toarray()Output
array(
[
[1., 1., 0., 1., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0.],
[1., 0., 0., 1., 1., 0., 0.],
[0., 0., 0., 1., 1., 1., 0.],
[0., 0., 0., 0., 1., 1., 1.],
[0., 0., 0., 0., 1., 1., 1.]
]
)Một khi chúng tôi phù hợp với không giám sát NearestNeighbors mô hình, dữ liệu sẽ được lưu trữ trong cấu trúc dữ liệu dựa trên giá trị được đặt cho đối số ‘algorithm’. Sau đó, chúng tôi có thể sử dụng người học không giám sát nàykneighbors trong một mô hình yêu cầu tìm kiếm hàng xóm.
Complete working/executable program
from sklearn.neighbors import NearestNeighbors
import numpy as np
Input_data = np.array([[-1, 1], [-2, 2], [-3, 3], [1, 2], [2, 3], [3, 4],[4, 5]])
nrst_neigh = NearestNeighbors(n_neighbors = 3, algorithm='ball_tree')
nrst_neigh.fit(Input_data)
distances, indices = nbrs.kneighbors(Input_data)
indices
distances
nrst_neigh.kneighbors_graph(Input_data).toarray()Học tập KNN có giám sát
Việc học tập dựa trên những người hàng xóm có giám sát được sử dụng để làm theo:
- Phân loại, đối với dữ liệu có nhãn rời rạc
- Hồi quy, đối với dữ liệu có nhãn liên tục.
Bộ phân loại hàng xóm gần nhất
Chúng ta có thể hiểu phân loại dựa trên Láng giềng với sự trợ giúp của hai đặc điểm sau:
- Nó được tính toán từ đa số phiếu đơn giản của những người hàng xóm gần nhất của mỗi điểm.
- Nó chỉ đơn giản là lưu trữ các phiên bản của dữ liệu đào tạo, đó là lý do tại sao nó là một kiểu học không khái quát hóa.
Mô-đun Scikit-learning
Tiếp theo là hai loại phân loại láng giềng gần nhất khác nhau được sử dụng bởi scikit-learning -
| Không. | Bộ phân loại & Mô tả |
|---|---|
| 1. | KNeighborsClassifier K trong tên của bộ phân loại này đại diện cho k lân cận gần nhất, trong đó k là một giá trị nguyên do người dùng chỉ định. Do đó, như tên cho thấy, bộ phân loại này thực hiện học tập dựa trên k láng giềng gần nhất. Sự lựa chọn giá trị của k phụ thuộc vào dữ liệu. |
| 2. | RadiusNeighborsClassifier Bán kính trong tên của bộ phân loại này đại diện cho các hàng xóm gần nhất trong bán kính r được chỉ định, trong đó r là giá trị dấu phẩy động do người dùng chỉ định. Do đó, như tên cho thấy, bộ phân loại này thực hiện việc học tập dựa trên số lân cận trong bán kính r cố định của mỗi điểm đào tạo. |
Nhà điều chỉnh hàng xóm gần nhất
Nó được sử dụng trong các trường hợp nhãn dữ liệu có bản chất liên tục. Các nhãn dữ liệu đã gán được tính toán trên cơ sở trung bình của các nhãn của các hàng xóm gần nhất của nó.
Tiếp theo là hai loại hồi quy lân cận gần nhất khác nhau được sử dụng bởi scikit-learning -
KNeighborsRegressor
K trong tên của hồi quy này đại diện cho k láng giềng gần nhất, trong đó k là một integer valuedo người dùng chỉ định. Do đó, như tên cho thấy, bộ hồi quy này thực hiện học tập dựa trên k lân cận gần nhất. Sự lựa chọn giá trị của k phụ thuộc vào dữ liệu. Hãy hiểu nó nhiều hơn với sự trợ giúp của một ví dụ triển khai.
Tiếp theo là hai loại hồi quy lân cận gần nhất khác nhau được sử dụng bởi scikit-learning -
Ví dụ triển khai
Trong ví dụ này, chúng tôi sẽ triển khai KNN trên tập dữ liệu có tên là tập dữ liệu Iris Flower bằng cách sử dụng scikit-learning KNeighborsRegressor.
Đầu tiên, nhập tập dữ liệu mống mắt như sau:
from sklearn.datasets import load_iris
iris = load_iris()Bây giờ, chúng ta cần chia dữ liệu thành dữ liệu đào tạo và thử nghiệm. Chúng tôi sẽ sử dụng Sklearntrain_test_split chức năng chia dữ liệu thành tỷ lệ 70 (dữ liệu đào tạo) và 20 (dữ liệu thử nghiệm) -
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20)Tiếp theo, chúng tôi sẽ thực hiện chia tỷ lệ dữ liệu với sự trợ giúp của mô-đun tiền xử lý Sklearn như sau:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)Tiếp theo, nhập KNeighborsRegressor lớp từ Sklearn và cung cấp giá trị của hàng xóm như sau.
Thí dụ
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors = 8)
knnr.fit(X_train, y_train)Đầu ra
KNeighborsRegressor(
algorithm = 'auto', leaf_size = 30, metric = 'minkowski',
metric_params = None, n_jobs = None, n_neighbors = 8, p = 2,
weights = 'uniform'
)Thí dụ
Bây giờ, chúng ta có thể tìm thấy MSE (Mean Squared Error) như sau:
print ("The MSE is:",format(np.power(y-knnr.predict(X),4).mean()))Đầu ra
The MSE is: 4.4333349609375Thí dụ
Bây giờ, hãy sử dụng nó để dự đoán giá trị như sau:
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors = 3)
knnr.fit(X, y)
print(knnr.predict([[2.5]]))Đầu ra
[0.66666667]Hoàn thành chương trình làm việc / thực thi
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors=8)
knnr.fit(X_train, y_train)
print ("The MSE is:",format(np.power(y-knnr.predict(X),4).mean()))
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors=3)
knnr.fit(X, y)
print(knnr.predict([[2.5]]))Bán kínhNeighborsRegressor
Bán kính trong tên của bộ hồi quy này đại diện cho các láng giềng gần nhất trong bán kính r được chỉ định, trong đó r là giá trị dấu phẩy động do người dùng chỉ định. Do đó, như tên cho thấy, bộ hồi quy này thực hiện học tập dựa trên các số lân cận trong bán kính r cố định của mỗi điểm đào tạo. Hãy hiểu nó nhiều hơn với sự trợ giúp nếu một ví dụ triển khai -
Ví dụ triển khai
Trong ví dụ này, chúng tôi sẽ triển khai KNN trên tập dữ liệu có tên là tập dữ liệu Iris Flower bằng cách sử dụng scikit-learning RadiusNeighborsRegressor -
Đầu tiên, nhập tập dữ liệu mống mắt như sau:
from sklearn.datasets import load_iris
iris = load_iris()Bây giờ, chúng ta cần chia dữ liệu thành dữ liệu đào tạo và thử nghiệm. Chúng tôi sẽ sử dụng hàm Sklearn train_test_split để chia dữ liệu thành tỷ lệ 70 (dữ liệu đào tạo) và 20 (dữ liệu thử nghiệm) -
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)Tiếp theo, chúng tôi sẽ thực hiện chia tỷ lệ dữ liệu với sự trợ giúp của mô-đun tiền xử lý Sklearn như sau:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)Tiếp theo, nhập RadiusneighborsRegressor từ Sklearn và cung cấp giá trị của bán kính như sau:
import numpy as np
from sklearn.neighbors import RadiusNeighborsRegressor
knnr_r = RadiusNeighborsRegressor(radius=1)
knnr_r.fit(X_train, y_train)Thí dụ
Bây giờ, chúng ta có thể tìm thấy MSE (Mean Squared Error) như sau:
print ("The MSE is:",format(np.power(y-knnr_r.predict(X),4).mean()))Đầu ra
The MSE is: The MSE is: 5.666666666666667Thí dụ
Bây giờ, hãy sử dụng nó để dự đoán giá trị như sau:
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
from sklearn.neighbors import RadiusNeighborsRegressor
knnr_r = RadiusNeighborsRegressor(radius=1)
knnr_r.fit(X, y)
print(knnr_r.predict([[2.5]]))Đầu ra
[1.]Hoàn thành chương trình làm việc / thực thi
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data[:, :4]
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
import numpy as np
from sklearn.neighbors import RadiusNeighborsRegressor
knnr_r = RadiusNeighborsRegressor(radius = 1)
knnr_r.fit(X_train, y_train)
print ("The MSE is:",format(np.power(y-knnr_r.predict(X),4).mean()))
X = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
from sklearn.neighbors import RadiusNeighborsRegressor
knnr_r = RadiusNeighborsRegressor(radius = 1)
knnr_r.fit(X, y)
print(knnr_r.predict([[2.5]]))Các phương pháp Naïve Bayes là một tập hợp các thuật toán học có giám sát dựa trên việc áp dụng định lý Bayes với giả định mạnh mẽ rằng tất cả các yếu tố dự đoán là độc lập với nhau, tức là sự hiện diện của một đối tượng trong một lớp là độc lập với sự hiện diện của bất kỳ đối tượng nào khác trong cùng một lớp học. Đây là giả định ngây thơ đó là lý do tại sao những phương pháp này được gọi là phương pháp Naïve Bayes.
Định lý Bayes phát biểu mối quan hệ sau đây để tìm xác suất sau của lớp tức là xác suất của một nhãn và một số đặc điểm quan sát được, $P\left(\begin{array}{c} Y\arrowvert features\end{array}\right)$.
$$P\left(\begin{array}{c} Y\arrowvert features\end{array}\right)=\left(\frac{P\lgroup Y\rgroup P\left(\begin{array}{c} features\arrowvert Y\end{array}\right)}{P\left(\begin{array}{c} features\end{array}\right)}\right)$$Đây, $P\left(\begin{array}{c} Y\arrowvert features\end{array}\right)$ là xác suất sau của lớp.
$P\left(\begin{array}{c} Y\end{array}\right)$ là xác suất trước của lớp.
$P\left(\begin{array}{c} features\arrowvert Y\end{array}\right)$ là khả năng xảy ra là xác suất của lớp dự đoán đã cho.
$P\left(\begin{array}{c} features\end{array}\right)$ là xác suất trước của dự đoán.
Scikit-learning cung cấp các mô hình phân loại Bayes ngây thơ khác nhau là Gaussian, Multinomial, Complement và Bernoulli. Tất cả chúng khác nhau chủ yếu bởi giả định mà chúng đưa ra về việc phân phối$P\left(\begin{array}{c} features\arrowvert Y\end{array}\right)$ tức là xác suất của lớp dự đoán đã cho.
| Sr.No | Mô tả về mô hình |
|---|---|
| 1 | Gaussian Naïve Bayes Bộ phân loại Gaussian Naïve Bayes giả định rằng dữ liệu từ mỗi nhãn được lấy từ một phân phối Gaussian đơn giản. |
| 2 | Đa thức Naïve Bayes Nó giả định rằng các tính năng được rút ra từ một phân phối Đa thức đơn giản. |
| 3 | Bernoulli Naïve Bayes Giả định trong mô hình này là các tính năng nhị phân (0 và 1) trong tự nhiên. Một ứng dụng của phân loại Bernoulli Naïve Bayes là Phân loại văn bản với mô hình 'túi từ' |
| 4 | Bổ sung Naïve Bayes Nó được thiết kế để điều chỉnh các giả định nghiêm trọng do bộ phân loại Bayes đa thức đưa ra. Loại bộ phân loại NB này phù hợp với các tập dữ liệu không cân bằng |
Xây dựng bộ phân loại Naïve Bayes
Chúng tôi cũng có thể áp dụng trình phân loại Naïve Bayes trên tập dữ liệu Scikit-learning. Trong ví dụ dưới đây, chúng tôi đang áp dụng GaussianNB và điều chỉnh bộ dữ liệu Breast_cancer của Scikit-leran.
Thí dụ
Import Sklearn
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
data = load_breast_cancer()
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']
print(label_names)
print(labels[0])
print(feature_names[0])
print(features[0])
train, test, train_labels, test_labels = train_test_split(
features,labels,test_size = 0.40, random_state = 42
)
from sklearn.naive_bayes import GaussianNB
GNBclf = GaussianNB()
model = GNBclf.fit(train, train_labels)
preds = GNBclf.predict(test)
print(preds)Đầu ra
[
1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1
1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1
1 1 1 0 0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0
1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0
1 1 0 1 1 0 0 0 1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1
0 1 1 0 0 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1
1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1 0 0 0 1 1 0
1 0 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 0 1
1 1 1 1 0 1 0 0 1 1 0 1
]Kết quả trên bao gồm một loạt các số 0 và 1 về cơ bản là các giá trị dự đoán từ các lớp khối u là ác tính và lành tính.
Trong chương này, chúng ta sẽ tìm hiểu về phương pháp học tập trong Sklearn được gọi là cây quyết định.
Quyết định tress (DT) là phương pháp học tập có giám sát phi tham số mạnh mẽ nhất. Chúng có thể được sử dụng cho các nhiệm vụ phân loại và hồi quy. Mục tiêu chính của DTs là tạo ra một mô hình dự đoán giá trị biến mục tiêu bằng cách học các quy tắc quyết định đơn giản được suy ra từ các tính năng dữ liệu. Cây quyết định có hai thực thể chính; một là nút gốc, nơi phân tách dữ liệu, và nút kia là nút quyết định hoặc nút rời, nơi chúng tôi nhận được kết quả cuối cùng.
Các thuật toán cây quyết định
Các thuật toán Cây quyết định khác nhau được giải thích bên dưới:
ID3
Nó được phát triển bởi Ross Quinlan vào năm 1986. Nó còn được gọi là Iterative Dichotomiser 3. Mục tiêu chính của thuật toán này là tìm những đặc điểm phân loại, cho mọi nút, sẽ mang lại mức tăng thông tin lớn nhất cho các mục tiêu phân loại.
Nó cho phép cây được phát triển đến kích thước tối đa và sau đó để cải thiện khả năng của cây trên các dữ liệu không nhìn thấy được, hãy áp dụng bước cắt tỉa. Đầu ra của thuật toán này sẽ là một cây nhiều đường.
C4.5
Nó là sự kế thừa của ID3 và tự động định nghĩa một thuộc tính rời rạc phân chia giá trị thuộc tính liên tục thành một tập hợp các khoảng rời rạc. Đó là lý do nó loại bỏ hạn chế của các tính năng phân loại. Nó chuyển đổi cây được đào tạo ID3 thành các bộ quy tắc 'IF-THEN'.
Để xác định trình tự áp dụng các quy tắc này, trước tiên, độ chính xác của từng quy tắc sẽ được đánh giá.
C5.0
Nó hoạt động tương tự như C4.5 nhưng sử dụng ít bộ nhớ hơn và xây dựng các bộ quy tắc nhỏ hơn. Nó chính xác hơn C4.5.
XE ĐẨY
Nó được gọi là thuật toán phân loại và cây hồi quy. Về cơ bản, nó tạo ra các phân tách nhị phân bằng cách sử dụng các tính năng và ngưỡng mang lại mức tăng thông tin lớn nhất tại mỗi nút (được gọi là chỉ số Gini).
Tính đồng nhất phụ thuộc vào chỉ số Gini, giá trị của chỉ số Gini càng cao thì độ đồng nhất càng cao. Nó giống như thuật toán C4.5, nhưng, sự khác biệt là nó không tính toán các bộ quy tắc và cũng không hỗ trợ các biến mục tiêu số (hồi quy).
Phân loại với cây quyết định
Trong trường hợp này, các biến quyết định là phân loại.
Sklearn Module - Thư viện Scikit-learning cung cấp tên mô-đun DecisionTreeClassifier để thực hiện phân loại đa lớp trên tập dữ liệu.
Thông số
Bảng sau bao gồm các tham số được sử dụng bởi sklearn.tree.DecisionTreeClassifier mô-đun -
| Sr.No | Mô tả về Thông Số |
|---|---|
| 1 | criterion - string, tùy chọn default = “gini” Nó đại diện cho chức năng đo lường chất lượng của một lần tách. Các tiêu chí được hỗ trợ là “gini” và “entropy”. Mặc định là gini dành cho tạp chất Gini trong khi entropy là để thu được thông tin. |
| 2 | splitter - chuỗi, mặc định tùy chọn = “tốt nhất” Nó cho mô hình biết chiến lược nào từ “tốt nhất” hoặc “ngẫu nhiên” để chọn phần tách tại mỗi nút. |
| 3 | max_depth - int hoặc None, mặc định tùy chọn = Không có Thông số này quyết định độ sâu tối đa của cây. Giá trị mặc định là Không có nghĩa là các nút sẽ mở rộng cho đến khi tất cả các lá đều thuần túy hoặc cho đến khi tất cả các lá chứa ít hơn mẫu min_smaples_split. |
| 4 | min_samples_split - int, float, tùy chọn mặc định = 2 Tham số này cung cấp số lượng mẫu tối thiểu cần thiết để tách một nút bên trong. |
| 5 | min_samples_leaf - int, float, tùy chọn mặc định = 1 Tham số này cung cấp số lượng mẫu tối thiểu được yêu cầu tại một nút lá. |
| 6 | min_weight_fraction_leaf - float, tùy chọn mặc định = 0. Với tham số này, mô hình sẽ nhận được phần có trọng số tối thiểu của tổng các trọng số được yêu cầu tại một nút lá. |
| 7 | max_features - int, float, string hoặc None, mặc định tùy chọn = None Nó cung cấp cho mô hình số lượng các tính năng được xem xét khi tìm kiếm sự phân chia tốt nhất. |
| số 8 | random_state - int, RandomState instance hoặc None, tùy chọn, default = none Tham số này đại diện cho hạt giống của số ngẫu nhiên giả được tạo ra được sử dụng trong khi xáo trộn dữ liệu. Tiếp theo là các tùy chọn -
|
| 9 | max_leaf_nodes - int hoặc None, mặc định tùy chọn = Không có Tham số này sẽ cho phép phát triển cây với max_leaf_nodes theo cách tốt nhất. Mặc định là không có nghĩa là sẽ có số lượng nút lá không giới hạn. |
| 10 | min_impurity_decrease - float, tùy chọn mặc định = 0. Giá trị này hoạt động như một tiêu chí cho một nút để tách vì mô hình sẽ tách một nút nếu sự phân tách này làm giảm tạp chất lớn hơn hoặc bằng min_impurity_decrease value. |
| 11 | min_impurity_split - float, default = 1e-7 Nó đại diện cho ngưỡng phát triển sớm của cây. |
| 12 | class_weight - dict, danh sách các phái, "cân bằng" hoặc Không, mặc định = Không có Nó đại diện cho trọng số liên quan đến các lớp. Biểu mẫu là {class_label: weight}. Nếu chúng ta sử dụng tùy chọn mặc định, điều đó có nghĩa là tất cả các lớp phải có trọng số là một. Mặt khác, nếu bạn chọnclass_weight: balanced, nó sẽ sử dụng các giá trị của y để tự động điều chỉnh trọng số. |
| 13 | presort - bool, mặc định tùy chọn = Sai Nó cho mô hình biết có nên sắp xếp trước dữ liệu hay không để tăng tốc độ tìm kiếm các phần tách tốt nhất cho phù hợp. Mặc định là false nhưng được đặt thành true, nó có thể làm chậm quá trình đào tạo. |
Thuộc tính
Bảng sau bao gồm các thuộc tính được sử dụng bởi sklearn.tree.DecisionTreeClassifier mô-đun -
| Sr.No | Mô tả về Thông Số |
|---|---|
| 1 | feature_importances_ - mảng hình dạng = [n_features] Thuộc tính này sẽ trả về tầm quan trọng của tính năng. |
| 2 | classes_: - mảng shape = [n_classes] hoặc danh sách các mảng như vậy Nó đại diện cho các nhãn lớp tức là bài toán đầu ra đơn lẻ, hoặc danh sách các mảng nhãn lớp tức là bài toán đa đầu ra. |
| 3 | max_features_ - int Nó đại diện cho giá trị suy ra của tham số max_features. |
| 4 | n_classes_ - int hoặc danh sách Nó đại diện cho số lớp tức là bài toán đầu ra đơn lẻ, hoặc danh sách số lớp cho mọi đầu ra tức là bài toán nhiều đầu ra. |
| 5 | n_features_ - int Nó cung cấp số lượng features khi phương thức fit () được thực hiện. |
| 6 | n_outputs_ - int Nó cung cấp số lượng outputs khi phương thức fit () được thực hiện. |
Phương pháp
Bảng sau bao gồm các phương pháp được sử dụng bởi sklearn.tree.DecisionTreeClassifier mô-đun -
| Sr.No | Mô tả về Thông Số |
|---|---|
| 1 | apply(self, X [, check_input]) Phương thức này sẽ trả về chỉ mục của lá. |
| 2 | decision_path(self, X [, check_input]) Như tên cho thấy, phương thức này sẽ trả về đường dẫn quyết định trong cây |
| 3 | fit(bản thân, X, y [, sample_weight,…]) Phương thức fit () sẽ xây dựng một bộ phân loại cây quyết định từ tập huấn luyện đã cho (X, y). |
| 4 | get_depth(bản thân) Như tên cho thấy, phương pháp này sẽ trả về độ sâu của cây quyết định |
| 5 | get_n_leaves(bản thân) Như tên cho thấy, phương thức này sẽ trả về số lá của cây quyết định. |
| 6 | get_params(tự [, sâu]) Chúng ta có thể sử dụng phương pháp này để lấy các tham số cho công cụ ước lượng. |
| 7 | predict(self, X [, check_input]) Nó sẽ dự đoán giá trị lớp cho X. |
| số 8 | predict_log_proba(bản thân, X) Nó sẽ dự đoán xác suất nhật ký lớp của các mẫu đầu vào do chúng tôi cung cấp, X. |
| 9 | predict_proba(self, X [, check_input]) Nó sẽ dự đoán xác suất lớp của các mẫu đầu vào do chúng tôi cung cấp, X. |
| 10 | score(self, X, y [, sample_weight]) Như tên của nó, phương thức score () sẽ trả về độ chính xác trung bình trên các nhãn và dữ liệu thử nghiệm đã cho .. |
| 11 | set_params(bản thân, \ * \ * params) Chúng ta có thể thiết lập các tham số của ước lượng bằng phương pháp này. |
Ví dụ triển khai
Tập lệnh Python bên dưới sẽ sử dụng sklearn.tree.DecisionTreeClassifier mô-đun để xây dựng bộ phân loại để dự đoán nam hay nữ từ tập dữ liệu của chúng tôi có 25 mẫu và hai đặc điểm là 'chiều cao' và 'độ dài của tóc' -
from sklearn import tree
from sklearn.model_selection import train_test_split
X=[[165,19],[175,32],[136,35],[174,65],[141,28],[176,15]
,[131,32],[166,6],[128,32],[179,10],[136,34],[186,2],[12
6,25],[176,28],[112,38],[169,9],[171,36],[116,25],[196,2
5], [196,38], [126,40], [197,20], [150,25], [140,32],[136,35]]
Y=['Man','Woman','Woman','Man','Woman','Man','Woman','Ma
n','Woman','Man','Woman','Man','Woman','Woman','Woman','
Man','Woman','Woman','Man', 'Woman', 'Woman', 'Man', 'Man', 'Woman', 'Woman']
data_feature_names = ['height','length of hair']
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.3, random_state = 1)
DTclf = tree.DecisionTreeClassifier()
DTclf = clf.fit(X,Y)
prediction = DTclf.predict([[135,29]])
print(prediction)Đầu ra
['Woman']Chúng tôi cũng có thể dự đoán xác suất của từng lớp bằng cách sử dụng phương thức python dự đoán_proba () như sau:
Thí dụ
prediction = DTclf.predict_proba([[135,29]])
print(prediction)Đầu ra
[[0. 1.]]Hồi quy với cây quyết định
Trong trường hợp này, các biến quyết định là liên tục.
Sklearn Module - Thư viện Scikit-learning cung cấp tên mô-đun DecisionTreeRegressor để áp dụng cây quyết định cho các bài toán hồi quy.
Thông số
Các thông số được sử dụng bởi DecisionTreeRegressor gần giống như những gì đã được sử dụng trong DecisionTreeClassifiermô-đun. Sự khác biệt nằm ở thông số 'tiêu chí'. Đối vớiDecisionTreeRegressor mô-đun ‘criterion: string, tùy chọn default = “mse” 'tham số có các giá trị sau:
mse- Nó là viết tắt của sai số bình phương trung bình. Nó tương đương với việc giảm phương sai là tiêu chí chọn lọc tính năng. Nó giảm thiểu tổn thất L2 bằng cách sử dụng giá trị trung bình của mỗi nút đầu cuối.
freidman_mse - Nó cũng sử dụng lỗi bình phương trung bình nhưng với điểm cải thiện của Friedman.
mae- Nó là viết tắt của sai số tuyệt đối trung bình. Nó giảm thiểu tổn thất L1 bằng cách sử dụng trung vị của mỗi nút đầu cuối.
Một sự khác biệt nữa là nó không có ‘class_weight’ tham số.
Thuộc tính
Các thuộc tính của DecisionTreeRegressor cũng giống như của DecisionTreeClassifiermô-đun. Sự khác biệt là nó không có‘classes_’ và ‘n_classes_' thuộc tính.
Phương pháp
Phương pháp của DecisionTreeRegressor cũng giống như của DecisionTreeClassifiermô-đun. Sự khác biệt là nó không có‘predict_log_proba()’ và ‘predict_proba()’' thuộc tính.
Ví dụ triển khai
Phương thức fit () trong mô hình hồi quy cây quyết định sẽ nhận các giá trị dấu phẩy động của y. chúng ta hãy xem một ví dụ triển khai đơn giản bằng cách sử dụngSklearn.tree.DecisionTreeRegressor -
from sklearn import tree
X = [[1, 1], [5, 5]]
y = [0.1, 1.5]
DTreg = tree.DecisionTreeRegressor()
DTreg = clf.fit(X, y)Sau khi được trang bị, chúng ta có thể sử dụng mô hình hồi quy này để đưa ra dự đoán như sau:
DTreg.predict([[4, 5]])Đầu ra
array([1.5])Chương này sẽ giúp bạn hiểu cây quyết định ngẫu nhiên trong Sklearn.
Thuật toán cây quyết định ngẫu nhiên
Như chúng ta biết rằng DT thường được đào tạo bằng cách chia nhỏ dữ liệu một cách đệ quy, nhưng dễ bị quá tải, chúng đã được chuyển thành các khu rừng ngẫu nhiên bằng cách đào tạo nhiều cây trên các ví dụ con khác nhau của dữ liệu. Cácsklearn.ensemble mô-đun đang tuân theo hai thuật toán dựa trên cây quyết định ngẫu nhiên -
Thuật toán Rừng ngẫu nhiên
Đối với mỗi tính năng đang được xem xét, nó sẽ tính toán tổ hợp tính năng / phân tách tối ưu cục bộ. Trong Rừng ngẫu nhiên, mỗi cây quyết định trong nhóm được xây dựng từ một mẫu được rút ra với sự thay thế từ tập huấn luyện, sau đó lấy dự đoán từ mỗi người trong số họ và cuối cùng chọn ra giải pháp tốt nhất bằng cách bỏ phiếu. Nó có thể được sử dụng cho cả nhiệm vụ phân loại cũng như hồi quy.
Phân loại với Rừng ngẫu nhiên
Để tạo bộ phân loại rừng ngẫu nhiên, mô-đun Scikit-learning cung cấp sklearn.ensemble.RandomForestClassifier. Trong khi xây dựng bộ phân loại rừng ngẫu nhiên, các tham số chính mà mô-đun này sử dụng là‘max_features’ và ‘n_estimators’.
Đây, ‘max_features’là kích thước của các tập hợp con ngẫu nhiên của các tính năng cần xem xét khi tách một nút. Nếu chúng ta chọn giá trị của tham số này là không thì nó sẽ xem xét tất cả các tính năng hơn là một tập hợp con ngẫu nhiên. Mặt khác,n_estimatorslà số lượng cây trong rừng. Số lượng cây càng nhiều thì kết quả càng tốt. Nhưng cũng sẽ mất nhiều thời gian hơn để tính toán.
Ví dụ triển khai
Trong ví dụ sau, chúng tôi đang xây dựng một bộ phân loại rừng ngẫu nhiên bằng cách sử dụng sklearn.ensemble.RandomForestClassifier và cũng kiểm tra độ chính xác của nó bằng cách sử dụng cross_val_score mô-đun.
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
X, y = make_blobs(n_samples = 10000, n_features = 10, centers = 100,random_state = 0) RFclf = RandomForestClassifier(n_estimators = 10,max_depth = None,min_samples_split = 2, random_state = 0)
scores = cross_val_score(RFclf, X, y, cv = 5)
scores.mean()Đầu ra
0.9997Thí dụ
Chúng tôi cũng có thể sử dụng bộ dữ liệu sklearn để xây dựng bộ phân loại Rừng Ngẫu nhiên. Như trong ví dụ sau, chúng tôi đang sử dụng tập dữ liệu mống mắt. Chúng tôi cũng sẽ tìm thấy điểm chính xác và ma trận nhầm lẫn của nó.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
path = "https://archive.ics.uci.edu/ml/machine-learning-database
s/iris/iris.data"
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
dataset = pd.read_csv(path, names = headernames)
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 4].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
RFclf = RandomForestClassifier(n_estimators = 50)
RFclf.fit(X_train, y_train)
y_pred = RFclf.predict(X_test)
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:",)
print (result1)
result2 = accuracy_score(y_test,y_pred)
print("Accuracy:",result2)Đầu ra
Confusion Matrix:
[[14 0 0]
[ 0 18 1]
[ 0 0 12]]
Classification Report:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 14
Iris-versicolor 1.00 0.95 0.97 19
Iris-virginica 0.92 1.00 0.96 12
micro avg 0.98 0.98 0.98 45
macro avg 0.97 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
Accuracy: 0.9777777777777777Hồi quy với Rừng ngẫu nhiên
Để tạo một hồi quy rừng ngẫu nhiên, mô-đun Scikit-learning cung cấp sklearn.ensemble.RandomForestRegressor. Trong khi xây dựng bộ hồi quy rừng ngẫu nhiên, nó sẽ sử dụng các tham số giống như được sử dụng bởisklearn.ensemble.RandomForestClassifier.
Ví dụ triển khai
Trong ví dụ sau, chúng tôi đang xây dựng một công cụ hồi quy rừng ngẫu nhiên bằng cách sử dụng sklearn.ensemble.RandomForestregressor và cũng dự đoán cho các giá trị mới bằng cách sử dụng phương thức dự đoán ().
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 10, n_informative = 2,random_state = 0, shuffle = False)
RFregr = RandomForestRegressor(max_depth = 10,random_state = 0,n_estimators = 100)
RFregr.fit(X, y)Đầu ra
RandomForestRegressor(
bootstrap = True, criterion = 'mse', max_depth = 10,
max_features = 'auto', max_leaf_nodes = None,
min_impurity_decrease = 0.0, min_impurity_split = None,
min_samples_leaf = 1, min_samples_split = 2,
min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None,
oob_score = False, random_state = 0, verbose = 0, warm_start = False
)Sau khi được trang bị, chúng ta có thể dự đoán từ mô hình hồi quy như sau:
print(RFregr.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))Đầu ra
[98.47729198]Phương pháp ngoài cây
Đối với mỗi tính năng đang được xem xét, nó sẽ chọn một giá trị ngẫu nhiên cho phần tách. Lợi ích của việc sử dụng phương pháp cây phụ là nó cho phép giảm phương sai của mô hình nhiều hơn một chút. Nhược điểm của việc sử dụng các phương pháp này là nó làm tăng nhẹ độ chệch.
Phân loại với phương pháp cây phụ
Để tạo bộ phân loại bằng phương pháp Extra-tree, mô-đun Scikit-learning cung cấp sklearn.ensemble.ExtraTreesClassifier. Nó sử dụng các tham số giống như được sử dụng bởisklearn.ensemble.RandomForestClassifier. Sự khác biệt duy nhất là trong cách, đã thảo luận ở trên, họ xây dựng cây.
Ví dụ triển khai
Trong ví dụ sau, chúng tôi đang xây dựng một bộ phân loại rừng ngẫu nhiên bằng cách sử dụng sklearn.ensemble.ExtraTreeClassifier và cũng kiểm tra độ chính xác của nó bằng cách sử dụng cross_val_score mô-đun.
from sklearn.model_selection import cross_val_score
from sklearn.datasets import make_blobs
from sklearn.ensemble import ExtraTreesClassifier
X, y = make_blobs(n_samples = 10000, n_features = 10, centers=100,random_state = 0)
ETclf = ExtraTreesClassifier(n_estimators = 10,max_depth = None,min_samples_split = 10, random_state = 0)
scores = cross_val_score(ETclf, X, y, cv = 5)
scores.mean()Đầu ra
1.0Thí dụ
Chúng ta cũng có thể sử dụng bộ dữ liệu sklearn để xây dựng bộ phân loại bằng phương pháp Extra-Tree. Như trong ví dụ sau, chúng tôi đang sử dụng tập dữ liệu Pima-Indian.
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import ExtraTreesClassifier
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names=headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
seed = 7
kfold = KFold(n_splits=10, random_state=seed)
num_trees = 150
max_features = 5
ETclf = ExtraTreesClassifier(n_estimators=num_trees, max_features=max_features)
results = cross_val_score(ETclf, X, Y, cv=kfold)
print(results.mean())Đầu ra
0.7551435406698566Hồi quy với phương pháp cây phụ
Để tạo một Extra-Tree hồi quy, mô-đun Scikit-learning cung cấp sklearn.ensemble.ExtraTreesRegressor. Trong khi xây dựng bộ hồi quy rừng ngẫu nhiên, nó sẽ sử dụng các tham số giống như được sử dụng bởisklearn.ensemble.ExtraTreesClassifier.
Ví dụ triển khai
Trong ví dụ sau, chúng tôi đang áp dụng sklearn.ensemble.ExtraTreesregressorvà trên cùng dữ liệu mà chúng tôi đã sử dụng khi tạo bộ hồi quy rừng ngẫu nhiên. Hãy xem sự khác biệt trong đầu ra
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 10, n_informative = 2,random_state = 0, shuffle = False)
ETregr = ExtraTreesRegressor(max_depth = 10,random_state = 0,n_estimators = 100)
ETregr.fit(X, y)Đầu ra
ExtraTreesRegressor(bootstrap = False, criterion = 'mse', max_depth = 10,
max_features = 'auto', max_leaf_nodes = None,
min_impurity_decrease = 0.0, min_impurity_split = None,
min_samples_leaf = 1, min_samples_split = 2,
min_weight_fraction_leaf = 0.0, n_estimators = 100, n_jobs = None,
oob_score = False, random_state = 0, verbose = 0, warm_start = False)Thí dụ
Sau khi được trang bị, chúng ta có thể dự đoán từ mô hình hồi quy như sau:
print(ETregr.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))Đầu ra
[85.50955817]Trong chương này, chúng ta sẽ tìm hiểu về các phương pháp thúc đẩy trong Sklearn, cho phép xây dựng một mô hình tập hợp.
Các phương pháp thúc đẩy xây dựng mô hình tổng hợp theo cách tăng dần. Nguyên tắc chính là xây dựng mô hình tăng dần bằng cách đào tạo tuần tự từng công cụ ước lượng mô hình cơ sở. Để xây dựng nhóm mạnh mẽ, các phương pháp này về cơ bản kết hợp những người học vài tuần được đào tạo tuần tự qua nhiều lần lặp lại dữ liệu đào tạo. Mô-đun sklearn.ensemble đang có hai phương pháp thúc đẩy sau.
AdaBoost
Đây là một trong những phương pháp tổng hợp tăng cường thành công nhất mà chìa khóa chính nằm ở cách chúng cung cấp trọng số cho các thể hiện trong tập dữ liệu. Đó là lý do tại sao thuật toán cần ít chú ý đến các thể hiện trong khi xây dựng các mô hình tiếp theo.
Phân loại với AdaBoost
Để tạo bộ phân loại AdaBoost, mô-đun Scikit-learning cung cấp sklearn.ensemble.AdaBoostClassifier. Trong khi xây dựng bộ phân loại này, tham số chính mà mô-đun này sử dụng làbase_estimator. Ở đây, base_estimator là giá trị củabase estimatortừ đó nhóm tăng cường được xây dựng. Nếu chúng tôi chọn giá trị của thông số này thành không thì công cụ ước tính cơ sở sẽ làDecisionTreeClassifier(max_depth=1).
Ví dụ triển khai
Trong ví dụ sau, chúng tôi đang xây dựng bộ phân loại AdaBoost bằng cách sử dụng sklearn.ensemble.AdaBoostClassifier và dự đoán và kiểm tra điểm của nó.
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples = 1000, n_features = 10,n_informative = 2, n_redundant = 0,random_state = 0, shuffle = False)
ADBclf = AdaBoostClassifier(n_estimators = 100, random_state = 0)
ADBclf.fit(X, y)Đầu ra
AdaBoostClassifier(algorithm = 'SAMME.R', base_estimator = None,
learning_rate = 1.0, n_estimators = 100, random_state = 0)Thí dụ
Sau khi được trang bị, chúng tôi có thể dự đoán các giá trị mới như sau:
print(ADBclf.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))Đầu ra
[1]Thí dụ
Bây giờ chúng ta có thể kiểm tra điểm số như sau:
ADBclf.score(X, y)Đầu ra
0.995Thí dụ
Chúng ta cũng có thể sử dụng bộ dữ liệu sklearn để xây dựng bộ phân loại bằng phương pháp Extra-Tree. Ví dụ, trong một ví dụ dưới đây, chúng tôi đang sử dụng tập dữ liệu Pima-Indian.
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import AdaBoostClassifier
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names = headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
seed = 5
kfold = KFold(n_splits = 10, random_state = seed)
num_trees = 100
max_features = 5
ADBclf = AdaBoostClassifier(n_estimators = num_trees, max_features = max_features)
results = cross_val_score(ADBclf, X, Y, cv = kfold)
print(results.mean())Đầu ra
0.7851435406698566Hồi quy với AdaBoost
Để tạo một bộ hồi quy với phương pháp Ada Boost, thư viện Scikit-learning cung cấp sklearn.ensemble.AdaBoostRegressor. Trong khi xây dựng bộ hồi quy, nó sẽ sử dụng các tham số giống như được sử dụng bởisklearn.ensemble.AdaBoostClassifier.
Ví dụ triển khai
Trong ví dụ sau, chúng tôi đang xây dựng bộ hồi quy AdaBoost bằng cách sử dụng sklearn.ensemble.AdaBoostregressor và cũng dự đoán cho các giá trị mới bằng cách sử dụng phương thức dự đoán ().
from sklearn.ensemble import AdaBoostRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 10, n_informative = 2,random_state = 0, shuffle = False)
ADBregr = RandomForestRegressor(random_state = 0,n_estimators = 100)
ADBregr.fit(X, y)Đầu ra
AdaBoostRegressor(base_estimator = None, learning_rate = 1.0, loss = 'linear',
n_estimators = 100, random_state = 0)Thí dụ
Sau khi được trang bị, chúng ta có thể dự đoán từ mô hình hồi quy như sau:
print(ADBregr.predict([[0, 2, 3, 0, 1, 1, 1, 1, 2, 2]]))Đầu ra
[85.50955817]Tăng cường cây Gradient
Nó còn được gọi là Gradient Boosted Regression Trees(GRBT). Về cơ bản, nó là sự tổng quát của việc tăng cường đến các chức năng mất mát có thể phân biệt tùy ý. Nó tạo ra một mô hình dự đoán dưới dạng một tập hợp các mô hình dự đoán tuần. Nó có thể được sử dụng cho các bài toán hồi quy và phân loại. Lợi thế chính của chúng nằm ở chỗ chúng xử lý dữ liệu kiểu hỗn hợp một cách tự nhiên.
Phân loại với Gradient Tree Boost
Để tạo bộ phân loại Gradient Tree Boost, mô-đun Scikit-learning cung cấp sklearn.ensemble.GradientBoostingClassifier. Trong khi xây dựng bộ phân loại này, tham số chính mà mô-đun này sử dụng là 'loss'. Ở đây, 'loss' là giá trị của hàm mất mát cần được tối ưu hóa. Nếu chúng ta chọn mất mát = độ lệch, nó đề cập đến độ lệch để phân loại với đầu ra có xác suất.
Mặt khác, nếu chúng ta chọn giá trị của thông số này thành hàm mũ thì nó sẽ khôi phục thuật toán AdaBoost. Thông sốn_estimatorssẽ kiểm soát số lượng người học trong tuần. Một siêu tham số có tênlearning_rate (trong khoảng (0,0, 1,0]) sẽ kiểm soát việc trang bị quá mức thông qua độ co rút.
Ví dụ triển khai
Trong ví dụ sau, chúng tôi đang xây dựng bộ phân loại Gradient Bo boost bằng cách sử dụng sklearn.ensemble.GradientBoostingClassifier. Chúng tôi đang lắp trình phân loại này với những người học 50 tuần.
from sklearn.datasets import make_hastie_10_2
from sklearn.ensemble import GradientBoostingClassifier
X, y = make_hastie_10_2(random_state = 0)
X_train, X_test = X[:5000], X[5000:]
y_train, y_test = y[:5000], y[5000:]
GDBclf = GradientBoostingClassifier(n_estimators = 50, learning_rate = 1.0,max_depth = 1, random_state = 0).fit(X_train, y_train)
GDBclf.score(X_test, y_test)Đầu ra
0.8724285714285714Thí dụ
Chúng tôi cũng có thể sử dụng bộ dữ liệu sklearn để xây dựng bộ phân loại bằng cách sử dụng Bộ phân loại tăng cường Gradient. Như trong ví dụ sau, chúng tôi đang sử dụng tập dữ liệu Pima-Indian.
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import GradientBoostingClassifier
path = r"C:\pima-indians-diabetes.csv"
headernames = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path, names = headernames)
array = data.values
X = array[:,0:8]
Y = array[:,8]
seed = 5
kfold = KFold(n_splits = 10, random_state = seed)
num_trees = 100
max_features = 5
ADBclf = GradientBoostingClassifier(n_estimators = num_trees, max_features = max_features)
results = cross_val_score(ADBclf, X, Y, cv = kfold)
print(results.mean())Đầu ra
0.7946582356674234Hồi quy với Gradient Tree Boost
Để tạo một bộ hồi quy với phương pháp Gradient Tree Boost, thư viện Scikit-learning cung cấp sklearn.ensemble.GradientBoostingRegressor. Nó có thể chỉ định hàm mất mát cho hồi quy thông qua mất tên tham số. Giá trị mặc định cho sự mất mát là 'ls'.
Ví dụ triển khai
Trong ví dụ sau, chúng tôi đang xây dựng một bộ hồi quy Gradient Bo boost bằng cách sử dụng sklearn.ensemble.GradientBoostingregressor và cũng tìm ra lỗi bình phương trung bình bằng cách sử dụng phương thức mean_squared_error ().
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
X, y = make_friedman1(n_samples = 2000, random_state = 0, noise = 1.0)
X_train, X_test = X[:1000], X[1000:]
y_train, y_test = y[:1000], y[1000:]
GDBreg = GradientBoostingRegressor(n_estimators = 80, learning_rate=0.1,
max_depth = 1, random_state = 0, loss = 'ls').fit(X_train, y_train)Sau khi được trang bị, chúng ta có thể tìm thấy lỗi bình phương trung bình như sau:
mean_squared_error(y_test, GDBreg.predict(X_test))Đầu ra
5.391246106657164Ở đây, chúng ta sẽ nghiên cứu về các phương pháp phân cụm trong Sklearn sẽ giúp xác định bất kỳ sự giống nhau nào trong các mẫu dữ liệu.
Phương pháp phân cụm, một trong những phương pháp ML không giám sát hữu ích nhất, được sử dụng để tìm các mẫu tương tự & mối quan hệ giữa các mẫu dữ liệu. Sau đó, họ phân cụm các mẫu đó thành các nhóm có sự giống nhau dựa trên các tính năng. Phân cụm xác định nhóm nội tại giữa các dữ liệu không được gắn nhãn hiện tại, đó là lý do tại sao nó quan trọng.
Thư viện Scikit-learning có sklearn.clusterđể thực hiện phân cụm dữ liệu không được gắn nhãn. Trong mô-đun này, scikit-leran có các phương pháp phân nhóm sau:
KMeans
Thuật toán này tính toán các centroid và lặp lại cho đến khi nó tìm thấy centroid tối ưu. Nó yêu cầu số lượng cụm phải được chỉ định, đó là lý do tại sao nó giả định rằng chúng đã được biết đến. Logic chính của thuật toán này là tập hợp các mẫu phân tách dữ liệu thành n nhóm có phương sai bằng nhau bằng cách giảm thiểu tiêu chí được gọi là quán tính. Số lượng các cụm được xác định bằng thuật toán được biểu thị bằng 'K.
Scikit-learning có sklearn.cluster.KMeansmô-đun để thực hiện phân cụm K-Means. Trong khi tính toán trung tâm cụm và giá trị quán tính, tham số có tênsample_weight cho phép sklearn.cluster.KMeans để gán thêm trọng lượng cho một số mẫu.
Tuyên truyền sở thích
Thuật toán này dựa trên khái niệm 'truyền thông điệp' giữa các cặp mẫu khác nhau cho đến khi hội tụ. Nó không yêu cầu số lượng cụm phải được chỉ định trước khi chạy thuật toán. Thuật toán có độ phức tạp về thời gian của thứ tự (2), đây là nhược điểm lớn nhất của nó.
Scikit-learning có sklearn.cluster.AffinityPropagation mô-đun để thực hiện phân cụm Truyền bá mối quan hệ.
Dịch chuyển trung bình
Thuật toán này chủ yếu phát hiện ra blobsvới mật độ mẫu mịn. Nó chỉ định lặp đi lặp lại các điểm dữ liệu cho các cụm bằng cách dịch chuyển các điểm về phía mật độ điểm dữ liệu cao nhất. Thay vì dựa vào một tham số có tênbandwidth ra lệnh cho kích thước của khu vực cần tìm kiếm, nó sẽ tự động đặt số lượng cụm.
Scikit-learning có sklearn.cluster.MeanShift để thực hiện phân cụm Mean Shift.
Phân cụm quang phổ
Trước khi phân cụm, thuật toán này về cơ bản sử dụng các giá trị riêng tức là phổ của ma trận tương tự của dữ liệu để thực hiện việc giảm kích thước ở các chiều ít hơn. Việc sử dụng thuật toán này không được khuyến khích khi có số lượng lớn các cụm.
Scikit-learning có sklearn.cluster.SpectralClustering module để thực hiện phân cụm Quang phổ.
Phân cụm theo thứ bậc
Thuật toán này xây dựng các cụm lồng nhau bằng cách hợp nhất hoặc tách các cụm liên tiếp. Hệ thống phân cấp cụm này được biểu diễn dưới dạng dendrogram tức là cây. Nó bao gồm hai loại sau:
Agglomerative hierarchical algorithms- Trong loại thuật toán phân cấp này, mọi điểm dữ liệu được coi như một cụm duy nhất. Sau đó, nó liên tiếp kết tụ các cặp cụm. Điều này sử dụng cách tiếp cận từ dưới lên.
Divisive hierarchical algorithms- Trong thuật toán phân cấp này, tất cả các điểm dữ liệu được coi như một cụm lớn. Trong quá trình phân cụm này bao gồm việc phân chia, bằng cách sử dụng cách tiếp cận từ trên xuống, một cụm lớn thành các cụm nhỏ khác nhau.
Scikit-learning có sklearn.cluster.AgglomerativeClustering mô-đun để thực hiện phân cụm Agglomerative Hierarchical.
DBSCAN
Nó là viết tắt của “Density-based spatial clustering of applications with noise”. Thuật toán này dựa trên khái niệm trực quan về "cụm" & "nhiễu" rằng các cụm là các vùng dày đặc có mật độ thấp hơn trong không gian dữ liệu, được phân tách bằng các vùng có mật độ thấp hơn của các điểm dữ liệu.
Scikit-learning có sklearn.cluster.DBSCANmô-đun để thực hiện phân cụm DBSCAN. Có hai tham số quan trọng là min_samples và eps được sử dụng bởi thuật toán này để xác định mật độ.
Giá trị cao hơn của tham số min_samples hoặc giá trị thấp hơn của tham số eps sẽ cho biết mật độ điểm dữ liệu cao hơn cần thiết để tạo thành một cụm.
QUANG HỌC
Nó là viết tắt của “Ordering points to identify the clustering structure”. Thuật toán này cũng tìm các cụm dựa trên mật độ trong dữ liệu không gian. Logic làm việc cơ bản của nó giống như DBSCAN.
Nó giải quyết một điểm yếu chính của thuật toán DBSCAN - vấn đề phát hiện các cụm có ý nghĩa trong dữ liệu có mật độ khác nhau - bằng cách sắp xếp thứ tự các điểm của cơ sở dữ liệu theo cách mà các điểm gần nhất về mặt không gian trở thành hàng xóm trong thứ tự.
Scikit-learning có sklearn.cluster.OPTICS module để thực hiện phân cụm OPTICS.
CHIM
Nó là viết tắt của cụm từ Giảm và phân cụm lặp đi lặp lại Balanced bằng cách sử dụng cấu trúc phân cấp. Nó được sử dụng để thực hiện phân cụm phân cấp trên các tập dữ liệu lớn. Nó xây dựng một cái cây có tênCFT I E Characteristics Feature Tree, đối với dữ liệu đã cho.
Ưu điểm của CFT là các nút dữ liệu được gọi là nút CF (Tính năng Đặc điểm) giữ thông tin cần thiết cho việc phân cụm, điều này ngăn chặn nhu cầu giữ toàn bộ dữ liệu đầu vào trong bộ nhớ.
Scikit-learning có sklearn.cluster.Birch module để thực hiện phân cụm BIRCH.
So sánh các thuật toán phân cụm
Bảng sau sẽ đưa ra so sánh (dựa trên các tham số, khả năng mở rộng và số liệu) của các thuật toán phân cụm trong scikit-learning.
| Sr.No | Tên thuật toán | Thông số | Khả năng mở rộng | Số liệu được sử dụng |
|---|---|---|---|---|
| 1 | K-Means | Số cụm | N_samples rất lớn | Khoảng cách giữa các điểm. |
| 2 | Tuyên truyền sở thích | Giảm xóc | Nó không thể mở rộng với n_samples | Khoảng cách đồ thị |
| 3 | Mean-Shift | Băng thông | Nó không thể mở rộng với n_samples. | Khoảng cách giữa các điểm. |
| 4 | Phân cụm quang phổ | Số cụm | Mức độ mở rộng trung bình với n_samples. Mức độ mở rộng nhỏ với n_clusters. | Khoảng cách đồ thị |
| 5 | Phân cụm theo thứ bậc | Ngưỡng khoảng cách hoặc Số cụm | N_samples lớn n_clusters lớn | Khoảng cách giữa các điểm. |
| 6 | DBSCAN | Kích thước của vùng lân cận | N_samples rất lớn và n_clusters vừa. | Khoảng cách điểm gần nhất |
| 7 | QUANG HỌC | Tư cách thành viên nhóm tối thiểu | N_samples rất lớn và n_clusters lớn. | Khoảng cách giữa các điểm. |
| số 8 | CHIM | Hệ số ngưỡng, phân nhánh | N_samples lớn n_clusters lớn | Khoảng cách Euclide giữa các điểm. |
K-Means Clustering trên bộ dữ liệu Scikit-learning Digit
Trong ví dụ này, chúng tôi sẽ áp dụng phân cụm K-mean trên tập dữ liệu chữ số. Thuật toán này sẽ xác định các chữ số tương tự mà không cần sử dụng thông tin nhãn gốc. Việc triển khai được thực hiện trên sổ ghi chép Jupyter.
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
digits = load_digits()
digits.data.shapeĐầu ra
1797, 64)Kết quả này cho thấy tập dữ liệu chữ số đang có 1797 mẫu với 64 tính năng.
Thí dụ
Bây giờ, thực hiện phân cụm K-Means như sau:
kmeans = KMeans(n_clusters = 10, random_state = 0)
clusters = kmeans.fit_predict(digits.data)
kmeans.cluster_centers_.shapeĐầu ra
(10, 64)Kết quả này cho thấy K-mean clustering đã tạo ra 10 cụm với 64 tính năng.
Thí dụ
fig, ax = plt.subplots(2, 5, figsize = (8, 3))
centers = kmeans.cluster_centers_.reshape(10, 8, 8)
for axi, center in zip(ax.flat, centers):
axi.set(xticks = [], yticks = [])
axi.imshow(center, interpolation = 'nearest', cmap = plt.cm.binary)Đầu ra
Đầu ra bên dưới có hình ảnh hiển thị các trung tâm cụm được học bởi K-Means Clustering.

Tiếp theo, tập lệnh Python bên dưới sẽ khớp các nhãn cụm đã học (bởi K-Means) với các nhãn thực được tìm thấy trong chúng -
from scipy.stats import mode
labels = np.zeros_like(clusters)
for i in range(10):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]Chúng tôi cũng có thể kiểm tra độ chính xác với sự trợ giúp của lệnh được đề cập bên dưới.
from sklearn.metrics import accuracy_score
accuracy_score(digits.target, labels)Đầu ra
0.7935447968836951Hoàn thành ví dụ triển khai
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
digits = load_digits()
digits.data.shape
kmeans = KMeans(n_clusters = 10, random_state = 0)
clusters = kmeans.fit_predict(digits.data)
kmeans.cluster_centers_.shape
fig, ax = plt.subplots(2, 5, figsize = (8, 3))
centers = kmeans.cluster_centers_.reshape(10, 8, 8)
for axi, center in zip(ax.flat, centers):
axi.set(xticks=[], yticks = [])
axi.imshow(center, interpolation = 'nearest', cmap = plt.cm.binary)
from scipy.stats import mode
labels = np.zeros_like(clusters)
for i in range(10):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]
from sklearn.metrics import accuracy_score
accuracy_score(digits.target, labels)Có nhiều chức năng khác nhau với sự trợ giúp của chúng tôi có thể đánh giá hiệu suất của các thuật toán phân cụm.
Sau đây là một số hàm quan trọng và được sử dụng nhiều nhất do Scikit-learning đưa ra để đánh giá hiệu suất phân cụm -
Chỉ số ngẫu nhiên được điều chỉnh
Rand Index là một hàm tính toán độ đo tương tự giữa hai phân nhóm. Đối với chỉ số rand tính toán này xem xét tất cả các cặp mẫu và các cặp đếm được gán trong các cụm tương tự hoặc khác nhau trong phân nhóm được dự đoán và đúng. Sau đó, điểm Chỉ số Rand thô được 'điều chỉnh theo cơ hội' thành điểm Chỉ số Rand được Điều chỉnh bằng cách sử dụng công thức sau:
$$Adjusted\:RI=\left(RI-Expected_{-}RI\right)/\left(max\left(RI\right)-Expected_{-}RI\right)$$Nó có hai tham số cụ thể là labels_true, là nhãn lớp chân lý cơ bản và labels_pred, là các nhãn cụm để đánh giá.
Thí dụ
from sklearn.metrics.cluster import adjusted_rand_score
labels_true = [0, 0, 1, 1, 1, 1]
labels_pred = [0, 0, 2, 2, 3, 3]
adjusted_rand_score(labels_true, labels_pred)Đầu ra
0.4444444444444445Ghi nhãn hoàn hảo sẽ được điểm 1 và ghi nhãn xấu hoặc ghi nhãn độc lập sẽ bị điểm 0 hoặc âm.
Điểm dựa trên thông tin lẫn nhau
Thông tin lẫn nhau là một chức năng tính toán thỏa thuận của hai nhiệm vụ. Nó bỏ qua các hoán vị. Có sẵn các phiên bản sau -
Thông tin lẫn nhau được chuẩn hóa (NMI)
Scikit học có sklearn.metrics.normalized_mutual_info_score mô-đun.
Thí dụ
from sklearn.metrics.cluster import normalized_mutual_info_score
labels_true = [0, 0, 1, 1, 1, 1]
labels_pred = [0, 0, 2, 2, 3, 3]
normalized_mutual_info_score (labels_true, labels_pred)Đầu ra
0.7611702597222881Thông tin tương hỗ được điều chỉnh (AMI)
Scikit học có sklearn.metrics.adjusted_mutual_info_score mô-đun.
Thí dụ
from sklearn.metrics.cluster import adjusted_mutual_info_score
labels_true = [0, 0, 1, 1, 1, 1]
labels_pred = [0, 0, 2, 2, 3, 3]
adjusted_mutual_info_score (labels_true, labels_pred)Đầu ra
0.4444444444444448Điểm Fowlkes-Mallows
Hàm Fowlkes-Mallows đo mức độ giống nhau của hai nhóm của một tập hợp các điểm. Nó có thể được định nghĩa là giá trị trung bình hình học của độ chính xác và độ thu hồi từng cặp.
Về mặt toán học,
$$FMS=\frac{TP}{\sqrt{\left(TP+FP\right)\left(TP+FN\right)}}$$Đây, TP = True Positive - số cặp điểm thuộc cùng một cụm trong nhãn đúng cũng như dự đoán cả hai.
FP = False Positive - số cặp điểm thuộc các cụm giống nhau trong nhãn đúng nhưng không thuộc nhãn dự đoán.
FN = False Negative - số lượng cặp điểm thuộc cùng một cụm trong các nhãn dự đoán nhưng không thuộc nhãn thực.
Học Scikit có mô-đun sklearn.metrics.fowlkes_mallows_score -
Thí dụ
from sklearn.metrics.cluster import fowlkes_mallows_score
labels_true = [0, 0, 1, 1, 1, 1]
labels_pred = [0, 0, 2, 2, 3, 3]
fowlkes_mallows__score (labels_true, labels_pred)Đầu ra
0.6546536707079771Hệ số Silhouette
Chức năng Silhouette sẽ tính toán Hệ số Silhouette trung bình của tất cả các mẫu bằng cách sử dụng khoảng cách trung bình trong cụm và khoảng cách trung bình gần nhất cho mỗi mẫu.
Về mặt toán học,
$$S=\left(b-a\right)/max\left(a,b\right)$$Ở đây, a là khoảng cách trong cụm.
và b là khoảng cách trung bình của cụm gần nhất.
Học Scikit có sklearn.metrics.silhouette_score mô-đun -
Thí dụ
from sklearn import metrics.silhouette_score
from sklearn.metrics import pairwise_distances
from sklearn import datasets
import numpy as np
from sklearn.cluster import KMeans
dataset = datasets.load_iris()
X = dataset.data
y = dataset.target
kmeans_model = KMeans(n_clusters = 3, random_state = 1).fit(X)
labels = kmeans_model.labels_
silhouette_score(X, labels, metric = 'euclidean')Đầu ra
0.5528190123564091Ma trận dự phòng
Ma trận này sẽ báo cáo số lượng giao nhau cho mọi cặp đáng tin cậy (đúng, dự đoán). Ma trận nhầm lẫn cho các bài toán phân loại là một ma trận dự phòng vuông.
Học Scikit có sklearn.metrics.contingency_matrix mô-đun.
Thí dụ
from sklearn.metrics.cluster import contingency_matrix
x = ["a", "a", "a", "b", "b", "b"]
y = [1, 1, 2, 0, 1, 2]
contingency_matrix(x, y)Đầu ra
array([
[0, 2, 1],
[1, 1, 1]
])Hàng đầu tiên của kết quả ở trên cho thấy rằng trong số ba mẫu có cụm thực là “a”, không có mẫu nào ở 0, hai trong số đó ở 1 và 1 thuộc về 2. Mặt khác, hàng thứ hai cho thấy rằng trong số ba mẫu có cụm đúng là “b”, 1 ở 0, 1 ở 1 và 1 ở 2.
Giảm kích thước, một phương pháp học máy không giám sát được sử dụng để giảm số lượng biến tính năng cho mỗi tập hợp lựa chọn mẫu dữ liệu của các tính năng chính. Phân tích thành phần chính (PCA) là một trong những thuật toán phổ biến để giảm kích thước.
PCA chính xác
Principal Component Analysis (PCA) được sử dụng để giảm kích thước tuyến tính bằng cách sử dụng Singular Value Decomposition(SVD) của dữ liệu để chiếu nó lên không gian có chiều thấp hơn. Trong khi phân rã bằng PCA, dữ liệu đầu vào được căn giữa nhưng không được chia tỷ lệ cho từng tính năng trước khi áp dụng SVD.
Thư viện Scikit-learning ML cung cấp sklearn.decomposition.PCAmô-đun được triển khai như một đối tượng biến áp học n thành phần trong phương thức fit () của nó. Nó cũng có thể được sử dụng trên dữ liệu mới để chiếu nó lên các thành phần này.
Thí dụ
Ví dụ dưới đây sẽ sử dụng mô-đun sklearn.decomposition.PCA để tìm 5 thành phần chính tốt nhất từ bộ dữ liệu bệnh tiểu đường của người da đỏ Pima.
from pandas import read_csv
from sklearn.decomposition import PCA
path = r'C:\Users\Leekha\Desktop\pima-indians-diabetes.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', ‘class']
dataframe = read_csv(path, names = names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
pca = PCA(n_components = 5)
fit = pca.fit(X)
print(("Explained Variance: %s") % (fit.explained_variance_ratio_))
print(fit.components_)Đầu ra
Explained Variance: [0.88854663 0.06159078 0.02579012 0.01308614 0.00744094]
[
[-2.02176587e-03 9.78115765e-02 1.60930503e-02 6.07566861e-029.93110844e-01 1.40108085e-02 5.37167919e-04 -3.56474430e-03]
[-2.26488861e-02 -9.72210040e-01 -1.41909330e-01 5.78614699e-029.46266913e-02 -4.69729766e-02 -8.16804621e-04 -1.40168181e-01]
[-2.24649003e-02 1.43428710e-01 -9.22467192e-01 -3.07013055e-012.09773019e-02 -1.32444542e-01 -6.39983017e-04 -1.25454310e-01]
[-4.90459604e-02 1.19830016e-01 -2.62742788e-01 8.84369380e-01-6.55503615e-02 1.92801728e-01 2.69908637e-03 -3.01024330e-01]
[ 1.51612874e-01 -8.79407680e-02 -2.32165009e-01 2.59973487e-01-1.72312241e-04 2.14744823e-02 1.64080684e-03 9.20504903e-01]
]PCA gia tăng
Incremental Principal Component Analysis (IPCA) được sử dụng để giải quyết hạn chế lớn nhất của Phân tích thành phần chính (PCA) và đó là PCA chỉ hỗ trợ xử lý hàng loạt, có nghĩa là tất cả dữ liệu đầu vào được xử lý phải nằm trong bộ nhớ.
Thư viện Scikit-learning ML cung cấp sklearn.decomposition.IPCA mô-đun giúp bạn có thể triển khai PCA ngoài lõi bằng cách sử dụng partial_fit phương pháp dựa trên các phần dữ liệu được tìm nạp liên tục hoặc bằng cách cho phép sử dụng np.memmap, một tệp ánh xạ bộ nhớ, mà không cần tải toàn bộ tệp vào bộ nhớ.
Tương tự như PCA, trong khi phân rã bằng IPCA, dữ liệu đầu vào được căn giữa nhưng không được chia tỷ lệ cho từng tính năng trước khi áp dụng SVD.
Thí dụ
Ví dụ dưới đây sẽ sử dụng sklearn.decomposition.IPCA mô-đun trên bộ dữ liệu chữ số Sklearn.
from sklearn.datasets import load_digits
from sklearn.decomposition import IncrementalPCA
X, _ = load_digits(return_X_y = True)
transformer = IncrementalPCA(n_components = 10, batch_size = 100)
transformer.partial_fit(X[:100, :])
X_transformed = transformer.fit_transform(X)
X_transformed.shapeĐầu ra
(1797, 10)Ở đây, chúng tôi có thể điều chỉnh một phần các lô dữ liệu nhỏ hơn (như chúng tôi đã làm với 100 mỗi lô) hoặc bạn có thể để fit() chức năng chia dữ liệu thành nhiều lô.
Kernel PCA
Phân tích thành phần chính của nhân, một phần mở rộng của PCA, đạt được khả năng giảm kích thước phi tuyến tính bằng cách sử dụng nhân. Nó hỗ trợ cả haitransform and inverse_transform.
Thư viện Scikit-learning ML cung cấp sklearn.decomposition.KernelPCA mô-đun.
Thí dụ
Ví dụ dưới đây sẽ sử dụng sklearn.decomposition.KernelPCAmô-đun trên bộ dữ liệu chữ số Sklearn. Chúng tôi đang sử dụng hạt nhân sigmoid.
from sklearn.datasets import load_digits
from sklearn.decomposition import KernelPCA
X, _ = load_digits(return_X_y = True)
transformer = KernelPCA(n_components = 10, kernel = 'sigmoid')
X_transformed = transformer.fit_transform(X)
X_transformed.shapeĐầu ra
(1797, 10)PCA sử dụng SVD ngẫu nhiên
Phân tích thành phần chính (PCA) sử dụng SVD ngẫu nhiên được sử dụng để chiếu dữ liệu vào không gian chiều thấp hơn bảo toàn hầu hết phương sai bằng cách loại bỏ vectơ kỳ dị của các thành phần được liên kết với các giá trị kỳ dị thấp hơn. Đây,sklearn.decomposition.PCA mô-đun với tham số tùy chọn svd_solver=’randomized’ sẽ rất hữu ích.
Thí dụ
Ví dụ dưới đây sẽ sử dụng sklearn.decomposition.PCA mô-đun với tham số tùy chọn svd_solver = 'randomized' để tìm ra 7 thành phần chính tốt nhất từ tập dữ liệu bệnh tiểu đường của người da đỏ Pima.
from pandas import read_csv
from sklearn.decomposition import PCA
path = r'C:\Users\Leekha\Desktop\pima-indians-diabetes.csv'
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
dataframe = read_csv(path, names = names)
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
pca = PCA(n_components = 7,svd_solver = 'randomized')
fit = pca.fit(X)
print(("Explained Variance: %s") % (fit.explained_variance_ratio_))
print(fit.components_)Đầu ra
Explained Variance: [8.88546635e-01 6.15907837e-02 2.57901189e-02 1.30861374e-027.44093864e-03 3.02614919e-03 5.12444875e-04]
[
[-2.02176587e-03 9.78115765e-02 1.60930503e-02 6.07566861e-029.93110844e-01 1.40108085e-02 5.37167919e-04 -3.56474430e-03]
[-2.26488861e-02 -9.72210040e-01 -1.41909330e-01 5.78614699e-029.46266913e-02 -4.69729766e-02 -8.16804621e-04 -1.40168181e-01]
[-2.24649003e-02 1.43428710e-01 -9.22467192e-01 -3.07013055e-012.09773019e-02 -1.32444542e-01 -6.39983017e-04 -1.25454310e-01]
[-4.90459604e-02 1.19830016e-01 -2.62742788e-01 8.84369380e-01-6.55503615e-02 1.92801728e-01 2.69908637e-03 -3.01024330e-01]
[ 1.51612874e-01 -8.79407680e-02 -2.32165009e-01 2.59973487e-01-1.72312241e-04 2.14744823e-02 1.64080684e-03 9.20504903e-01]
[-5.04730888e-03 5.07391813e-02 7.56365525e-02 2.21363068e-01-6.13326472e-03 -9.70776708e-01 -2.02903702e-03 -1.51133239e-02]
[ 9.86672995e-01 8.83426114e-04 -1.22975947e-03 -3.76444746e-041.42307394e-03 -2.73046214e-03 -6.34402965e-03 -1.62555343e-01]
]