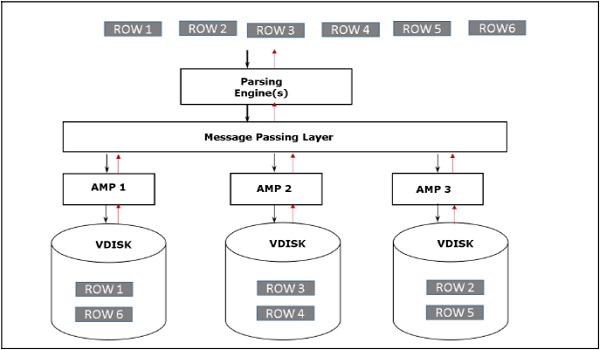
Teradata - Kiến trúc
Kiến trúc Teradata dựa trên kiến trúc Xử lý song song khối lượng lớn (MPP). Các thành phần chính của Teradata là Công cụ phân tích cú pháp, BYNET và Bộ xử lý mô-đun truy cập (AMP). Sơ đồ sau đây cho thấy kiến trúc cấp cao của một nút Teradata.
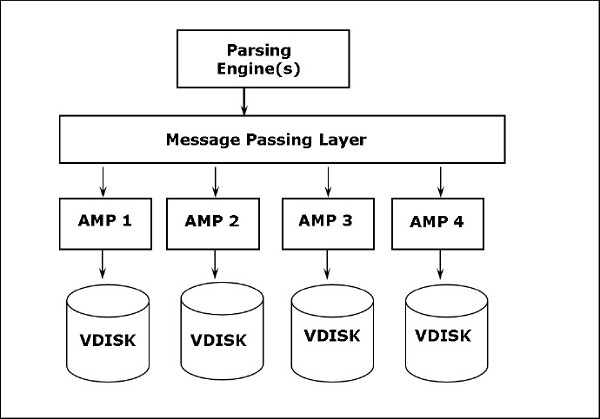
Các thành phần của Teradata
Các thành phần chính của Teradata như sau:
Node- Nó là đơn vị cơ bản trong Hệ thống Teradata. Mỗi máy chủ riêng lẻ trong hệ thống Teradata được gọi là một Node. Một nút bao gồm hệ điều hành riêng, CPU, bộ nhớ, bản sao của phần mềm Teradata RDBMS và không gian đĩa. Một tủ bao gồm một hoặc nhiều nút.
Parsing Engine- Parsing Engine chịu trách nhiệm nhận các truy vấn từ máy khách và chuẩn bị một kế hoạch thực thi hiệu quả. Trách nhiệm của công cụ phân tích cú pháp là -
Nhận truy vấn SQL từ máy khách
Phân tích cú pháp kiểm tra truy vấn SQL để tìm lỗi cú pháp
Kiểm tra xem người dùng có yêu cầu đặc quyền đối với các đối tượng được sử dụng trong truy vấn SQL hay không
Kiểm tra xem các đối tượng được sử dụng trong SQL có thực sự tồn tại hay không
Chuẩn bị kế hoạch thực thi để thực hiện truy vấn SQL và chuyển nó đến BYNET
Nhận kết quả từ AMP và gửi cho khách hàng
Message Passing Layer- Lớp truyền thông báo được gọi là BYNET, là lớp mạng trong hệ thống Teradata. Nó cho phép giao tiếp giữa PE và AMP và cả giữa các nút. Nó nhận kế hoạch thực thi từ Parsing Engine và gửi tới AMP. Tương tự, nó nhận kết quả từ AMP và gửi đến Parsing Engine.
Access Module Processor (AMP)- AMP, được gọi là Bộ xử lý ảo (vprocs) là bộ xử lý thực sự lưu trữ và truy xuất dữ liệu. Các AMP nhận dữ liệu và kế hoạch thực thi từ Parsing Engine, thực hiện bất kỳ chuyển đổi loại dữ liệu nào, tổng hợp, lọc, sắp xếp và lưu trữ dữ liệu trong các đĩa được liên kết với chúng. Bản ghi từ các bảng được phân phối đồng đều giữa các AMP trong hệ thống. Mỗi AMP được liên kết với một bộ đĩa lưu trữ dữ liệu. Chỉ AMP đó mới có thể đọc / ghi dữ liệu từ các đĩa.
Kiến trúc lưu trữ
Khi máy khách chạy các truy vấn để chèn các bản ghi, công cụ phân tích cú pháp sẽ gửi các bản ghi tới BYNET. BYNET truy xuất các bản ghi và gửi hàng tới AMP mục tiêu. AMP lưu trữ các bản ghi này trên đĩa của nó. Sơ đồ sau đây cho thấy kiến trúc lưu trữ của Teradata.
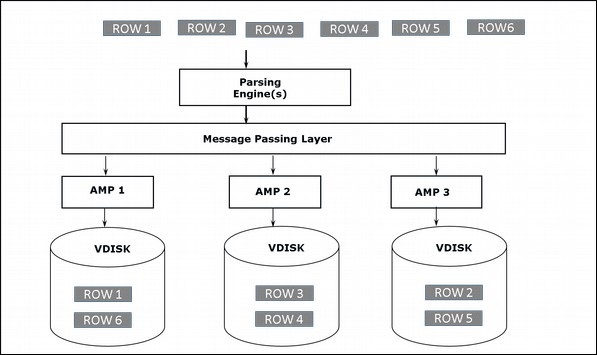
Kiến trúc truy xuất
Khi máy khách chạy các truy vấn để lấy các bản ghi, bộ máy phân tích cú pháp sẽ gửi một yêu cầu đến BYNET. BYNET gửi yêu cầu truy xuất tới các AMP thích hợp. Sau đó, các AMP tìm kiếm đĩa của chúng song song và xác định các bản ghi được yêu cầu và gửi đến BYNET. BYNET sau đó sẽ gửi các bản ghi đến Parsing Engine, đến lượt nó sẽ gửi cho khách hàng. Sau đây là kiến trúc truy xuất của Teradata.