TIKA - Hướng dẫn nhanh
Apache Tika là gì?
Apache Tika là một thư viện được sử dụng để phát hiện loại tài liệu và trích xuất nội dung từ các định dạng tệp khác nhau.
Trong nội bộ, Tika sử dụng các trình phân tích cú pháp tài liệu khác nhau hiện có và các kỹ thuật phát hiện loại tài liệu để phát hiện và trích xuất dữ liệu.
Sử dụng Tika, người ta có thể phát triển một trình phát hiện kiểu phổ quát và trình trích xuất nội dung để trích xuất cả văn bản có cấu trúc cũng như siêu dữ liệu từ các loại tài liệu khác nhau như bảng tính, tài liệu văn bản, hình ảnh, PDF và thậm chí cả các định dạng đầu vào đa phương tiện ở một mức độ nhất định.
Tika cung cấp một API chung duy nhất để phân tích các định dạng tệp khác nhau. Nó sử dụng các thư viện phân tích cú pháp chuyên dụng hiện có cho từng loại tài liệu.
Tất cả các thư viện phân tích cú pháp này được đóng gói trong một giao diện duy nhất được gọi là Parser interface.

Tại sao Tika?
Theo filext.com, có khoảng 15 nghìn đến 51 nghìn loại nội dung và con số này đang tăng lên từng ngày. Dữ liệu đang được lưu trữ ở nhiều định dạng khác nhau như tài liệu văn bản, bảng tính excel, PDF, hình ảnh và các tệp đa phương tiện. Do đó, các ứng dụng như công cụ tìm kiếm và hệ thống quản lý nội dung cần được hỗ trợ thêm để dễ dàng trích xuất dữ liệu từ các loại tài liệu này. Apache Tika phục vụ mục đích này bằng cách cung cấp một API chung để định vị và trích xuất dữ liệu từ nhiều định dạng tệp.
Ứng dụng Apache Tika
Có nhiều ứng dụng khác nhau sử dụng Apache Tika. Ở đây chúng ta sẽ thảo luận về một vài ứng dụng nổi bật phụ thuộc nhiều vào Apache Tika.
Công cụ tìm kiếm
Tika được sử dụng rộng rãi trong khi phát triển công cụ tìm kiếm để lập chỉ mục nội dung văn bản của tài liệu kỹ thuật số.
Công cụ tìm kiếm là hệ thống xử lý thông tin được thiết kế để tìm kiếm thông tin và các tài liệu được lập chỉ mục từ Web.
Crawler là một thành phần quan trọng của công cụ tìm kiếm thu thập thông tin trên Web để tìm nạp các tài liệu sẽ được lập chỉ mục bằng cách sử dụng một số kỹ thuật lập chỉ mục. Sau đó, trình thu thập thông tin chuyển các tài liệu được lập chỉ mục này sang một thành phần trích xuất.
Nhiệm vụ của thành phần trích xuất là trích xuất văn bản và siêu dữ liệu từ tài liệu. Nội dung và siêu dữ liệu được trích xuất như vậy rất hữu ích cho công cụ tìm kiếm. Thành phần chiết xuất này có chứa Tika.
Nội dung được trích xuất sau đó được chuyển tới trình chỉ mục của công cụ tìm kiếm sử dụng nó để xây dựng chỉ mục tìm kiếm. Ngoài ra, công cụ tìm kiếm cũng sử dụng nội dung được trích xuất theo nhiều cách khác.

Phân tích tài liệu
Trong lĩnh vực trí tuệ nhân tạo, có một số công cụ nhất định để phân tích tài liệu tự động ở cấp độ ngữ nghĩa và trích xuất tất cả các loại dữ liệu từ chúng.
Trong các ứng dụng như vậy, các tài liệu được phân loại dựa trên các thuật ngữ nổi bật trong nội dung được trích xuất của tài liệu.
Các công cụ này sử dụng Tika để trích xuất nội dung để phân tích các tài liệu khác nhau từ văn bản thuần túy đến tài liệu kỹ thuật số.
Quản lý tài sản kỹ thuật số
Một số tổ chức quản lý tài sản kỹ thuật số của họ như ảnh, sách điện tử, bản vẽ, nhạc và video bằng cách sử dụng một ứng dụng đặc biệt được gọi là quản lý tài sản kỹ thuật số (DAM).
Các ứng dụng như vậy nhờ sự trợ giúp của trình phát hiện loại tài liệu và trình trích xuất siêu dữ liệu để phân loại các tài liệu khác nhau.
Phân tích nội dung
Các trang web như Amazon giới thiệu nội dung mới phát hành trên trang web của họ cho người dùng cá nhân theo sở thích của họ. Để làm như vậy, các trang web này theomachine learning techniques, hoặc nhờ sự trợ giúp của các trang web truyền thông xã hội như Facebook để trích xuất thông tin cần thiết như lượt thích và sở thích của người dùng. Thông tin thu thập này sẽ ở dạng thẻ html hoặc các định dạng khác yêu cầu phát hiện và trích xuất loại nội dung khác.
Để phân tích nội dung của tài liệu, chúng tôi có các công nghệ triển khai các kỹ thuật máy học, chẳng hạn như UIMA và Mahout. Những công nghệ này rất hữu ích trong việc phân cụm và phân tích dữ liệu trong tài liệu.
Apache Mahoutlà một khuôn khổ cung cấp các thuật toán ML trên Apache Hadoop - một nền tảng điện toán đám mây. Mahout cung cấp một kiến trúc bằng cách tuân theo các kỹ thuật phân cụm và lọc nhất định. Bằng cách tuân theo kiến trúc này, các lập trình viên có thể viết các thuật toán ML của riêng họ để đưa ra các đề xuất bằng cách lấy các kết hợp văn bản và siêu dữ liệu khác nhau. Để cung cấp đầu vào cho các thuật toán này, các phiên bản gần đây của Mahout sử dụng Tika để trích xuất văn bản và siêu dữ liệu từ nội dung nhị phân.
Apache UIMAphân tích và xử lý các ngôn ngữ lập trình khác nhau và tạo ra các chú thích UIMA. Bên trong nó sử dụng Tika Annotator để trích xuất văn bản tài liệu và siêu dữ liệu.
Lịch sử
| Năm | Phát triển |
|---|---|
| 2006 | Ý tưởng của Tika đã được dự kiến trước Ủy ban quản lý dự án Lucene. |
| 2006 | Khái niệm về Tika và tính hữu dụng của nó trong dự án Jackrabbit đã được thảo luận. |
| 2007 | Tika vào lồng ấp Apache. |
| 2008 | Các phiên bản 0,1 và 0,2 đã được phát hành và Tika đã tốt nghiệp từ tủ ấm sang tiểu dự án Lucene. |
| 2009 | Các phiên bản 0.3, 0.4 và 0.5 đã được phát hành. |
| 2010 | Phiên bản 0.6 và 0.7 đã được phát hành và Tika đã hoàn thành dự án Apache cấp cao nhất. |
| 2011 | Tika 1.0 đã được phát hành và cuốn sách về Tika "Tika in Action" cũng được phát hành cùng năm. |
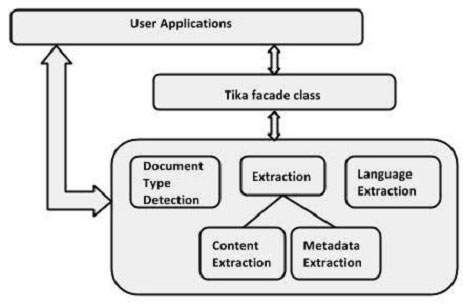
Kiến trúc cấp độ ứng dụng của Tika
Các lập trình viên ứng dụng có thể dễ dàng tích hợp Tika trong ứng dụng của họ. Tika cung cấp Giao diện dòng lệnh và GUI để làm cho nó thân thiện với người dùng.
Trong chương này, chúng ta sẽ thảo luận về bốn mô-đun quan trọng cấu thành kiến trúc Tika. Hình minh họa sau đây cho thấy kiến trúc của Tika cùng với bốn mô-đun của nó:
- Cơ chế phát hiện ngôn ngữ.
- Cơ chế phát hiện MIME.
- Giao diện phân tích cú pháp.
- Lớp Tika Facade.

Cơ chế phát hiện ngôn ngữ
Bất cứ khi nào một tài liệu văn bản được chuyển đến Tika, nó sẽ phát hiện ngôn ngữ mà nó được viết. Nó chấp nhận các tài liệu không có chú thích ngôn ngữ và thêm thông tin đó vào siêu dữ liệu của tài liệu bằng cách phát hiện ngôn ngữ.
Để hỗ trợ nhận dạng ngôn ngữ, Tika có một lớp gọi là Language Identifier trong gói org.apache.tika.languagevà một kho lưu trữ nhận dạng ngôn ngữ bên trong chứa các thuật toán phát hiện ngôn ngữ từ một văn bản nhất định. Tika nội bộ sử dụng thuật toán N-gram để phát hiện ngôn ngữ.
Cơ chế phát hiện MIME
Tika có thể phát hiện loại tài liệu theo tiêu chuẩn MIME. Phát hiện kiểu MIME mặc định trong Tika được thực hiện bằng cách sử dụng org.apache.tika.mime.mimeTypes . Nó sử dụng giao diện org.apache.tika.detect.Detector để phát hiện loại nội dung.
Nội bộ Tika sử dụng một số kỹ thuật như tập tin toàn cầu, gợi ý kiểu nội dung, byte ma thuật, mã hóa ký tự và một số kỹ thuật khác.
Giao diện phân tích cú pháp
Giao diện phân tích cú pháp của org.apache.tika.parser là giao diện chính để phân tích cú pháp tài liệu trong Tika. Giao diện này trích xuất văn bản và siêu dữ liệu từ một tài liệu và tóm tắt nó cho người dùng bên ngoài, những người sẵn sàng viết các plugin phân tích cú pháp.
Sử dụng các lớp phân tích cú pháp cụ thể khác nhau, cụ thể cho các loại tài liệu riêng lẻ, Tika hỗ trợ rất nhiều định dạng tài liệu. Các lớp định dạng cụ thể này cung cấp hỗ trợ cho các định dạng tài liệu khác nhau, bằng cách triển khai trực tiếp logic trình phân tích cú pháp hoặc bằng cách sử dụng các thư viện trình phân tích cú pháp bên ngoài.
Lớp mặt tiền Tika
Sử dụng lớp mặt tiền Tika là cách gọi trực tiếp và đơn giản nhất của Tika từ Java, và nó tuân theo mẫu thiết kế mặt tiền. Bạn có thể tìm thấy lớp mặt tiền Tika trong gói org.apache.tika của API Tika.
Bằng cách triển khai các trường hợp sử dụng cơ bản, Tika hoạt động như một nhà môi giới cảnh quan. Nó tóm tắt sự phức tạp cơ bản của thư viện Tika như cơ chế phát hiện MIME, giao diện phân tích cú pháp và cơ chế phát hiện ngôn ngữ, đồng thời cung cấp cho người dùng một giao diện đơn giản để sử dụng.
Đặc điểm của Tika
Unified parser Interface- Tika đóng gói tất cả các thư viện trình phân tích cú pháp của bên thứ ba trong một giao diện trình phân tích cú pháp duy nhất. Do tính năng này, người dùng thoát khỏi gánh nặng của việc chọn thư viện phân tích cú pháp phù hợp và sử dụng nó theo loại tệp gặp phải.
Low memory usage- Tika tiêu tốn ít tài nguyên bộ nhớ hơn nên có thể dễ dàng nhúng vào các ứng dụng Java. Chúng tôi cũng có thể sử dụng Tika trong ứng dụng chạy trên các nền tảng có ít tài nguyên hơn như PDA di động.
Fast processing - Có thể phát hiện và trích xuất nội dung nhanh chóng từ các ứng dụng.
Flexible metadata - Tika hiểu tất cả các mô hình siêu dữ liệu được sử dụng để mô tả tệp.
Parser integration - Tika có thể sử dụng các thư viện phân tích cú pháp khác nhau có sẵn cho từng loại tài liệu trong một ứng dụng duy nhất.
MIME type detection - Tika có thể phát hiện và trích xuất nội dung từ tất cả các loại phương tiện có trong tiêu chuẩn MIME.
Language detection - Tika bao gồm tính năng nhận dạng ngôn ngữ, do đó có thể được sử dụng trong các tài liệu dựa trên loại ngôn ngữ trong một trang web đa ngôn ngữ.
Chức năng của Tika
Tika hỗ trợ các chức năng khác nhau -
- Phát hiện loại tài liệu
- Trích xuất nội dung
- Trích xuất siêu dữ liệu
- Phát hiện ngôn ngữ
Phát hiện loại tài liệu
Tika sử dụng các kỹ thuật phát hiện khác nhau và phát hiện loại tài liệu được cấp cho nó.

Trích xuất nội dung
Tika có một thư viện phân tích cú pháp có thể phân tích nội dung của nhiều định dạng tài liệu khác nhau và trích xuất chúng. Sau khi phát hiện loại tài liệu, nó chọn trình phân tích cú pháp thích hợp từ kho trình phân tích cú pháp và chuyển tài liệu. Các lớp khác nhau của Tika có các phương thức phân tích cú pháp các định dạng tài liệu khác nhau.

Trích xuất siêu dữ liệu
Cùng với nội dung, Tika trích xuất siêu dữ liệu của tài liệu với quy trình tương tự như trong trích xuất nội dung. Đối với một số loại tài liệu, Tika có các lớp để trích xuất siêu dữ liệu.

Language Detection
Internally, Tika follows algorithms like n-gram to detect the language of the content in a given document. Tika depends on classes like Languageidentifier and Profiler for language identification.

This chapter takes you through the process of setting up Apache Tika on Windows and Linux. User administration is needed while installing the Apache Tika.
System Requirements
| JDK | Java SE 2 JDK 1.6 or above |
| Memory | 1 GB RAM (recommeneded) |
| Disk Space | No minimum requirement |
| Operating System Version | Windows XP or above, Linux |
Step 1: Verifying Java Installation
To verify Java installation, open the console and execute the following java command.
| OS | Task | Command |
|---|---|---|
| Windows | Open command console | \>java –version |
| Linux | Open command terminal | $java –version |
If Java has been installed properly on your system, then you should get one of the following outputs, depending on the platform you are working on.
| OS | Output |
|---|---|
| Windows | Java version "1.7.0_60"
Java (TM) SE Run Time Environment (build 1.7.0_60-b19) Java Hotspot (TM) 64-bit Server VM (build 24.60-b09, mixed mode) |
| Lunix | java version "1.7.0_25" Open JDK Runtime Environment (rhel-2.3.10.4.el6_4-x86_64) Open JDK 64-Bit Server VM (build 23.7-b01, mixed mode) |
We assume the readers of this tutorial have Java 1.7.0_60 installed on their system before proceeding for this tutorial.
In case you do not have Java SDK, download its current version from https://www.oracle.com/technetwork/java/javase/downloads/index.html and have it installed.
Step 2: Setting Java Environment
Set the JAVA_HOME environment variable to point to the base directory location where Java is installed on your machine. For example,
| OS | Output |
|---|---|
| Windows | Set Environmental variable JAVA_HOME to C:\ProgramFiles\java\jdk1.7.0_60 |
| Linux | export JAVA_HOME = /usr/local/java-current |
Append the full path of the Java compiler location to the System Path.
| OS | Output |
|---|---|
| Windows | Append the String; C:\Program Files\Java\jdk1.7.0_60\bin to the end of the system variable PATH. |
| Linux | export PATH = $PATH:$JAVA_HOME/bin/ |
Verify the command java-version from command prompt as explained above.
Step 3: Setting up Apache Tika Environment
Programmers can integrate Apache Tika in their environment by using
- Command line,
- Tika API,
- Command line interface (CLI) of Tika,
- Graphical User interface (GUI) of Tika, or
- the source code.
For any of these approaches, first of all, you have to download the source code of Tika.
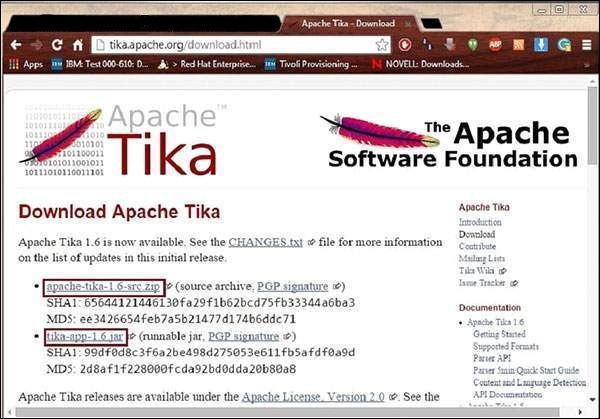
You will find the source code of Tika at https://Tika.apache.org/download.html, where you will find two links −
apache-tika-1.6-src.zip − It contains the source code of Tika, and
Tika -app-1.6.jar − It is a jar file that contains the Tika application.
Download these two files. A snapshot of the official website of Tika is shown below.
After downloading the files, set the classpath for the jar file tika-app-1.6.jar. Add the complete path of the jar file as shown in the table below.
| OS | Output |
|---|---|
| Windows | Append the String “C:\jars\Tika-app-1.6.jar” to the user environment variable CLASSPATH |
| Linux | Export CLASSPATH = $CLASSPATH − /usr/share/jars/Tika-app-1.6.tar − |
Apache provides Tika application, a Graphical User Interface (GUI) application using Eclipse.
Tika-Maven Build using Eclipse
Open eclipse and create a new project.
If you do not having Maven in your Eclipse, set it up by following the given steps.
Open thelink https://wiki.eclipse.org/M2E_updatesite_and_gittags. There you will find the m2e plugin releases in a tabular format
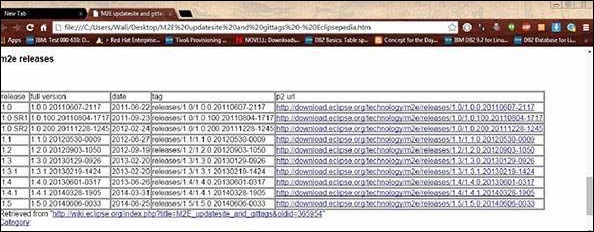
Pick the latest version and save the path of the url in p2 url column.
Now revisit eclipse, in the menu bar, click Help, and choose Install New Software from the dropdown menu

Click the Add button, type any desired name, as it is optional. Now paste the saved url in the Location field.
A new plugin will be added with the name you have chosen in the previous step, check the checkbox in front of it, and click Next.

Proceed with the installation. Once completed, restart the Eclipse.
Now right click on the project, and in the configure option, select convert to maven project.
A new wizard for creating a new pom appears. Enter the Group Id as org.apache.tika, enter the latest version of Tika, select the packaging as jar, and click Finish.
The Maven project is successfully installed, and your project is converted into Maven. Now you have to configure the pom.xml file.
Configure the XML File
Get the Tika maven dependency fromhttps://mvnrepository.com/artifact/org.apache.tika
Shown below is the complete Maven dependency of Apache Tika.
<dependency>
<groupId>org.apache.Tika</groupId>
<artifactId>Tika-core</artifactId>
<version>1.6</version>
<groupId>org.apache.Tika</groupId>
<artifactId> Tika-parsers</artifactId>
<version> 1.6</version>
<groupId> org.apache.Tika</groupId>
<artifactId>Tika</artifactId>
<version>1.6</version>
<groupId>org.apache.Tika</groupId>
< artifactId>Tika-serialization</artifactId>
< version>1.6< /version>
< groupId>org.apache.Tika< /groupId>
< artifactId>Tika-app< /artifactId>
< version>1.6< /version>
<groupId>org.apache.Tika</groupId>
<artifactId>Tika-bundle</artifactId>
<version>1.6</version>
</dependency>Users can embed Tika in their applications using the Tika facade class. It has methods to explore all the functionalities of Tika. Since it is a facade class, Tika abstracts the complexity behind its functions. In addition to this, users can also use the various classes of Tika in their applications.
Tika Class (facade)
This is the most prominent class of the Tika library and follows the facade design pattern. Therefore, it abstracts all the internal implementations and provides simple methods to access the Tika functionalities. The following table lists the constructors of this class along with their descriptions.
package − org.apache.tika
class − Tika
| Sr.No. | Constructor & Description |
|---|---|
| 1 | Tika () Uses default configuration and constructs the Tika class. |
| 2 | Tika (Detector detector) Creates a Tika facade by accepting the detector instance as parameter |
| 3 | Tika (Detector detector, Parser parser) Creates a Tika facade by accepting the detector and parser instances as parameters. |
| 4 | Tika (Detector detector, Parser parser, Translator translator) Creates a Tika facade by accepting the detector, the parser, and the translator instance as parameters. |
| 5 | Tika (TikaConfig config) Creates a Tika facade by accepting the object of the TikaConfig class as parameter. |
Methods and Description
The following are the important methods of Tika facade class −
| Sr.No. | Methods & Description |
|---|---|
| 1 | parseToString (File file) This method and all its variants parses the file passed as parameter and returns the extracted text content in the String format. By default, the length of this string parameter is limited. |
| 2 | int getMaxStringLength () Returns the maximum length of strings returned by the parseToString methods. |
| 3 | void setMaxStringLength (int maxStringLength) Sets the maximum length of strings returned by the parseToString methods. |
| 4 | Reader parse (File file) This method and all its variants parses the file passed as parameter and returns the extracted text content in the form of java.io.reader object. |
| 5 | String detect (InputStream stream, Metadata metadata) This method and all its variants accepts an InputStream object and a Metadata object as parameters, detects the type of the given document, and returns the document type name as String object. This method abstracts the detection mechanisms used by Tika. |
| 6 | String translate (InputStream text, String targetLanguage) This method and all its variants accepts the InputStream object and a String representing the language that we want our text to be translated, and translates the given text to the desired language, attempting to auto-detect the source language. |
Parser Interface
This is the interface that is implemented by all the parser classes of Tika package.
package − org.apache.tika.parser
Interface − Parser
Methods and Description
The following is the important method of Tika Parser interface −
| Sr.No. | Methods & Description |
|---|---|
| 1 | parse (InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) This method parses the given document into a sequence of XHTML and SAX events. After parsing, it places the extracted document content in the object of the ContentHandler class and the metadata in the object of the Metadata class. |
Metadata Class
This class implements various interfaces such as CreativeCommons, Geographic, HttpHeaders, Message, MSOffice, ClimateForcast, TIFF, TikaMetadataKeys, TikaMimeKeys, Serializable to support various data models. The following tables list the constructors and methods of this class along with their descriptions.
package − org.apache.tika.metadata
class − Metadata
| Sr.No. | Constructor & Description |
|---|---|
| 1 | Metadata() Constructs a new, empty metadata. |
| Sr.No. | Methods & Description |
|---|---|
| 1 | add (Property property, String value) Adds a metadata property/value mapping to a given document. Using this function, we can set the value to a property. |
| 2 | add (String name, String value) Adds a metadata property/value mapping to a given document. Using this method, we can set a new name value to the existing metadata of a document. |
| 3 | String get (Property property) Returns the value (if any) of the metadata property given. |
| 4 | String get (String name) Returns the value (if any) of the metadata name given. |
| 5 | Date getDate (Property property) Returns the value of Date metadata property. |
| 6 | String[] getValues (Property property) Returns all the values of a metadata property. |
| 7 | String[] getValues (String name) Returns all the values of a given metadata name. |
| 8 | String[] names() Returns all the names of metadata elements in a metadata object. |
| 9 | set (Property property, Date date) Sets the date value of the given metadata property |
| 10 | set(Property property, String[] values) Sets multiple values to a metadata property. |
Language Identifier Class
This class identifies the language of the given content. The following tables list the constructors of this class along with their descriptions.
package − org.apache.tika.language
class − Language Identifier
| Sr.No. | Constructor & Description |
|---|---|
| 1 | LanguageIdentifier (LanguageProfile profile) Instantiates the language identifier. Here you have to pass a LanguageProfile object as parameter. |
| 2 | LanguageIdentifier (String content) This constructor can instantiate a language identifier by passing on a String from text content. |
| Sr.No. | Methods & Description |
|---|---|
| 1 | String getLanguage () Returns the language given to the current LanguageIdentifier object. |
File Formats Supported by Tika
The following table shows the file formats Tika supports.
| File format | Package Library | Class in Tika |
|---|---|---|
| XML | org.apache.tika.parser.xml | XMLParser |
| HTML | org.apache.tika.parser.html and it uses Tagsoup Library | HtmlParser |
| MS-Office compound document Ole2 till 2007 ooxml 2007 onwards | org.apache.tika.parser.microsoft org.apache.tika.parser.microsoft.ooxml and it uses Apache Poi library |
OfficeParser(ole2) OOXMLParser (ooxml) |
| OpenDocument Format openoffice | org.apache.tika.parser.odf | OpenOfficeParser |
| portable Document Format(PDF) | org.apache.tika.parser.pdf and this package uses Apache PdfBox library | PDFParser |
| Electronic Publication Format (digital books) | org.apache.tika.parser.epub | EpubParser |
| Rich Text format | org.apache.tika.parser.rtf | RTFParser |
| Compression and packaging formats | org.apache.tika.parser.pkg and this package uses Common compress library | PackageParser and CompressorParser and its sub-classes |
| Text format | org.apache.tika.parser.txt | TXTParser |
| Feed and syndication formats | org.apache.tika.parser.feed | FeedParser |
| Audio formats | org.apache.tika.parser.audio and org.apache.tika.parser.mp3 | AudioParser MidiParser Mp3- for mp3parser |
| Imageparsers | org.apache.tika.parser.jpeg | JpegParser-for jpeg images |
| Videoformats | org.apache.tika.parser.mp4 and org.apache.tika.parser.video this parser internally uses Simple Algorithm to parse flash video formats | Mp4parser FlvParser |
| java class files and jar files | org.apache.tika.parser.asm | ClassParser CompressorParser |
| Mobxformat (email messages) | org.apache.tika.parser.mbox | MobXParser |
| Cad formats | org.apache.tika.parser.dwg | DWGParser |
| FontFormats | org.apache.tika.parser.font | TrueTypeParser |
| executable programs and libraries | org.apache.tika.parser.executable | ExecutableParser |
MIME Standards
Multipurpose Internet Mail Extensions (MIME) standards are the best available standards for identifying document types. The knowledge of these standards helps the browser during internal interactions.
Whenever the browser encounters a media file, it chooses a compatible software available with it to display its contents. In case it does not have any suitable application to run a particular media file, it recommends the user to get the suitable plugin software for it.
Type Detection in Tika
Tika supports all the Internet media document types provided in MIME. Whenever a file is passed through Tika, it detects the file and its document type. To detect media types, Tika internally uses the following mechanisms.
File Extensions
Checking the file extensions is the simplest and most-widely used method to detect the format of a file. Many applications and operating systems provide support for these extensions. Shown below are the extension of a few known file types.
| File name | Extention |
|---|---|
| image | .jpg |
| audio | .mp3 |
| java archive file | .jar |
| java class file | .class |
Content-type Hints
Whenever you retrieve a file from a database or attach it to another document, you may lose the file’s name or extension. In such cases, the metadata supplied with the file is used to detect the file extension.
Magic Byte
Observing the raw bytes of a file, you can find some unique character patterns for each file. Some files have special byte prefixes called magic bytes that are specially made and included in a file for the purpose of identifying the file type
For example, you can find CA FE BA BE (hexadecimal format) in a java file and %PDF (ASCII format) in a pdf file. Tika uses this information to identify the media type of a file.
Character Encodings
Files with plain text are encoded using different types of character encoding. The main challenge here is to identify the type of character encoding used in the files. Tika follows character encoding techniques like Bom markers and Byte Frequencies to identify the encoding system used by the plain text content.
XML Root Characters
To detect XML documents, Tika parses the xml documents and extracts the information such as root elements, namespaces, and referenced schemas from where the true media type of the files can be found.
Type Detection using Facade Class
The detect() method of facade class is used to detect the document type. This method accepts a file as input. Shown below is an example program for document type detection with Tika facade class.
import java.io.File;
import org.apache.tika.Tika;
public class Typedetection {
public static void main(String[] args) throws Exception {
//assume example.mp3 is in your current directory
File file = new File("example.mp3");//
//Instantiating tika facade class
Tika tika = new Tika();
//detecting the file type using detect method
String filetype = tika.detect(file);
System.out.println(filetype);
}
}Save the above code as TypeDetection.java and run it from the command prompt using the following commands −
javac TypeDetection.java
java TypeDetection
audio/mpegTika uses various parser libraries to extract content from given parsers. It chooses the right parser for extracting the given document type.
For parsing documents, the parseToString() method of Tika facade class is generally used. Shown below are the steps involved in the parsing process and these are abstracted by the Tika ParsertoString() method.

Abstracting the parsing process −
Initially when we pass a document to Tika, it uses a suitable type detection mechanism available with it and detects the document type.
Once the document type is known, it chooses a suitable parser from its parser repository. The parser repository contains classes that make use of external libraries.
Then the document is passed to choose the parser which will parse the content, extract the text, and also throw exceptions for unreadable formats.
Content Extraction using Tika
Given below is the program for extracting text from a file using Tika facade class −
import java.io.File;
import java.io.IOException;
import org.apache.tika.Tika;
import org.apache.tika.exception.TikaException;
import org.xml.sax.SAXException;
public class TikaExtraction {
public static void main(final String[] args) throws IOException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//Instantiating Tika facade class
Tika tika = new Tika();
String filecontent = tika.parseToString(file);
System.out.println("Extracted Content: " + filecontent);
}
}Save the above code as TikaExtraction.java and run it from the command prompt −
javac TikaExtraction.java
java TikaExtractionGiven below is the content of sample.txt.
Hi students welcome to tutorialspointIt gives you the following output −
Extracted Content: Hi students welcome to tutorialspointContent Extraction using Parser Interface
The parser package of Tika provides several interfaces and classes using which we can parse a text document. Given below is the block diagram of the org.apache.tika.parser package.

There are several parser classes available, e.g., pdf parser, Mp3Passer, OfficeParser, etc., to parse respective documents individually. All these classes implement the parser interface.
CompositeParser
The given diagram shows Tika’s general-purpose parser classes: CompositeParser and AutoDetectParser. Since the CompositeParser class follows composite design pattern, you can use a group of parser instances as a single parser. The CompositeParser class also allows access to all the classes that implement the parser interface.
AutoDetectParser
This is a subclass of CompositeParser and it provides automatic type detection. Using this functionality, the AutoDetectParser automatically sends the incoming documents to the appropriate parser classes using the composite methodology.
parse() method
Along with parseToString(), you can also use the parse() method of the parser Interface. The prototype of this method is shown below.
parse(InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context)The following table lists the four objects it accepts as parameters.
| Sr.No. | Object & Description |
|---|---|
| 1 | InputStream stream Any Inputstream object that contains the content of the file |
| 2 | ContentHandler handler Tika passes the document as XHTML content to this handler, thereafter the document is processed using SAX API. It provides efficient postprocessing of the contents in a document. |
| 3 | Metadata metadata The metadata object is used both as a source and a target of document metadata. |
| 4 | ParseContext context This object is used in cases where the client application wants to customize the parsing process. |
Example
Given below is an example that shows how the parse() method is used.
Step 1 −
To use the parse() method of the parser interface, instantiate any of the classes providing the implementation for this interface.
There are individual parser classes such as PDFParser, OfficeParser, XMLParser, etc. You can use any of these individual document parsers. Alternatively, you can use either CompositeParser or AutoDetectParser that uses all the parser classes internally and extracts the contents of a document using a suitable parser.
Parser parser = new AutoDetectParser();
(or)
Parser parser = new CompositeParser();
(or)
object of any individual parsers given in Tika LibraryStep 2 −
Create a handler class object. Given below are the three content handlers −
| Sr.No. | Class & Description |
|---|---|
| 1 | BodyContentHandler This class picks the body part of the XHTML output and writes that content to the output writer or output stream. Then it redirects the XHTML content to another content handler instance. |
| 2 | LinkContentHandler This class detects and picks all the H-Ref tags of the XHTML document and forwards those for the use of tools like web crawlers. |
| 3 | TeeContentHandler This class helps in using multiple tools simultaneously. |
Since our target is to extract the text contents from a document, instantiate BodyContentHandler as shown below −
BodyContentHandler handler = new BodyContentHandler( );Step 3 −
Create the Metadata object as shown below −
Metadata metadata = new Metadata();Step 4 −
Create any of the input stream objects, and pass your file that should be extracted to it.
FileInputstream
Instantiate a file object by passing the file path as parameter and pass this object to the FileInputStream class constructor.
Note − The path passed to the file object should not contain spaces.
The problem with these input stream classes is that they don’t support random access reads, which is required to process some file formats efficiently. To resolve this problem, Tika provides TikaInputStream.
File file = new File(filepath)
FileInputStream inputstream = new FileInputStream(file);
(or)
InputStream stream = TikaInputStream.get(new File(filename));Step 5 −
Create a parse context object as shown below −
ParseContext context =new ParseContext();Step 6 −
Instantiate the parser object, invoke the parse method, and pass all the objects required, as shown in the prototype below −
parser.parse(inputstream, handler, metadata, context);Given below is the program for content extraction using the parser interface −
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class ParserExtraction {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//parse method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the file
parser.parse(inputstream, handler, metadata, context);
System.out.println("File content : " + Handler.toString());
}
}Save the above code as ParserExtraction.java and run it from the command prompt −
javac ParserExtraction.java
java ParserExtractionGiven below is the content of sample.txt
Hi students welcome to tutorialspointIf you execute the above program, it will give you the following output −
File content : Hi students welcome to tutorialspointBesides content, Tika also extracts the metadata from a file. Metadata is nothing but the additional information supplied with a file. If we consider an audio file, the artist name, album name, title comes under metadata.
XMP Standards
The Extensible Metadata Platform (XMP) is a standard for processing and storing information related to the content of a file. It was created by Adobe Systems Inc. XMP provides standards for defining, creating, and processing of metadata. You can embed this standard into several file formats such as PDF, JPEG, JPEG, GIF, jpg, HTML etc.
Property Class
Tika uses the Property class to follow XMP property definition. It provides the PropertyType and ValueType enums to capture the name and value of a metadata.
Metadata Class
This class implements various interfaces such as ClimateForcast, CativeCommons, Geographic, TIFF etc. to provide support for various metadata models. In addition, this class provides various methods to extract the content from a file.
Metadata Names
We can extract the list of all metadata names of a file from its metadata object using the method names(). It returns all the names as a string array. Using the name of the metadata, we can get the value using the get() method. It takes a metadata name and returns a value associated with it.
String[] metadaNames = metadata.names();
String value = metadata.get(name);Extracting Metadata using Parse Method
Whenever we parse a file using parse(), we pass an empty metadata object as one of the parameters. This method extracts the metadata of the given file (if that file contains any), and places them in the metadata object. Therefore, after parsing the file using parse(), we can extract the metadata from that object.
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata(); //empty metadata object
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
parser.parse(inputstream, handler, metadata, context);
// now this metadata object contains the extracted metadata of the given file.
metadata.metadata.names();Given below is the complete program to extract metadata from a text file.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class GetMetadata {
public static void main(final String[] args) throws IOException, TikaException {
//Assume that boy.jpg is in your current directory
File file = new File("boy.jpg");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
parser.parse(inputstream, handler, metadata, context);
System.out.println(handler.toString());
//getting the list of all meta data elements
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Save the above code as GetMetadata.java and run it from the command prompt using the following commands −
javac GetMetadata .java
java GetMetadataGiven below is the snapshot of boy.jpg

If you execute the above program, it will give you the following output −
X-Parsed-By: org.apache.tika.parser.DefaultParser
Resolution Units: inch
Compression Type: Baseline
Data Precision: 8 bits
Number of Components: 3
tiff:ImageLength: 3000
Component 2: Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert
Component 1: Y component: Quantization table 0, Sampling factors 2 horiz/2 vert
Image Height: 3000 pixels
X Resolution: 300 dots
Original Transmission Reference:
53616c7465645f5f2368da84ca932841b336ac1a49edb1a93fae938b8db2cb3ec9cc4dc28d7383f1
Image Width: 4000 pixels
IPTC-NAA record: 92 bytes binary data
Component 3: Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert
tiff:BitsPerSample: 8
Application Record Version: 4
tiff:ImageWidth: 4000
Content-Type: image/jpeg
Y Resolution: 300 dotsWe can also get our desired metadata values.
Adding New Metadata Values
We can add new metadata values using the add() method of the metadata class. Given below is the syntax of this method. Here we are adding the author name.
metadata.add(“author”,”Tutorials point”);The Metadata class has predefined properties including the properties inherited from classes like ClimateForcast, CativeCommons, Geographic, etc., to support various data models. Shown below is the usage of the SOFTWARE data type inherited from the TIFF interface implemented by Tika to follow XMP metadata standards for TIFF image formats.
metadata.add(Metadata.SOFTWARE,"ms paint");Given below is the complete program that demonstrates how to add metadata values to a given file. Here the list of the metadata elements is displayed in the output so that you can observe the change in the list after adding new values.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Arrays;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class AddMetadata {
public static void main(final String[] args) throws IOException, SAXException, TikaException {
//create a file object and assume sample.txt is in your current directory
File file = new File("Example.txt");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the document
parser.parse(inputstream, handler, metadata, context);
//list of meta data elements before adding new elements
System.out.println( " metadata elements :" +Arrays.toString(metadata.names()));
//adding new meta data name value pair
metadata.add("Author","Tutorials Point");
System.out.println(" metadata name value pair is successfully added");
//printing all the meta data elements after adding new elements
System.out.println("Here is the list of all the metadata
elements after adding new elements");
System.out.println( Arrays.toString(metadata.names()));
}
}Lưu đoạn mã trên dưới dạng lớp AddMetadata.java và chạy nó từ dấu nhắc lệnh -
javac AddMetadata .java
java AddMetadataDưới đây là nội dung của Example.txt
Hi students welcome to tutorialspointNếu bạn thực hiện chương trình trên, nó sẽ cung cấp cho bạn kết quả sau:
metadata elements of the given file :
[Content-Encoding, Content-Type]
enter the number of metadata name value pairs to be added 1
enter metadata1name:
Author enter metadata1value:
Tutorials point metadata name value pair is successfully added
Here is the list of all the metadata elements after adding new elements
[Content-Encoding, Author, Content-Type]Đặt giá trị cho các phần tử siêu dữ liệu hiện có
Bạn có thể đặt giá trị cho các phần tử siêu dữ liệu hiện có bằng phương thức set (). Cú pháp của việc đặt thuộc tính date bằng phương thức set () như sau:
metadata.set(Metadata.DATE, new Date());Bạn cũng có thể đặt nhiều giá trị cho các thuộc tính bằng cách sử dụng phương thức set (). Cú pháp của việc đặt nhiều giá trị cho thuộc tính Author bằng phương thức set () như sau:
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");Dưới đây là chương trình hoàn chỉnh trình bày phương thức set ().
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Date;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class SetMetadata {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Create a file object and assume example.txt is in your current directory
File file = new File("example.txt");
//parameters of parse() method
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//Parsing the given file
parser.parse(inputstream, handler, metadata, context);
//list of meta data elements elements
System.out.println( " metadata elements and values of the given file :");
String[] metadataNamesb4 = metadata.names();
for(String name : metadataNamesb4) {
System.out.println(name + ": " + metadata.get(name));
}
//setting date meta data
metadata.set(Metadata.DATE, new Date());
//setting multiple values to author property
metadata.set(Metadata.AUTHOR, "ram ,raheem ,robin ");
//printing all the meta data elements with new elements
System.out.println("List of all the metadata elements after adding new elements ");
String[] metadataNamesafter = metadata.names();
for(String name : metadataNamesafter) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Lưu đoạn mã trên dưới dạng SetMetadata.java và chạy nó từ dấu nhắc lệnh -
javac SetMetadata.java
java SetMetadataDưới đây là nội dung của example.txt.
Hi students welcome to tutorialspointNếu bạn thực hiện chương trình trên, nó sẽ cung cấp cho bạn kết quả sau. Trong đầu ra, bạn có thể quan sát các phần tử siêu dữ liệu mới được thêm vào.
metadata elements and values of the given file :
Content-Encoding: ISO-8859-1
Content-Type: text/plain; charset = ISO-8859-1
Here is the list of all the metadata elements after adding new elements
date: 2014-09-24T07:01:32Z
Content-Encoding: ISO-8859-1
Author: ram, raheem, robin
Content-Type: text/plain; charset = ISO-8859-1Cần phát hiện ngôn ngữ
Để phân loại tài liệu dựa trên ngôn ngữ mà chúng được viết trên một trang web đa ngôn ngữ, cần có một công cụ phát hiện ngôn ngữ. Công cụ này phải chấp nhận các tài liệu không có chú thích ngôn ngữ (siêu dữ liệu) và thêm thông tin đó vào siêu dữ liệu của tài liệu bằng cách phát hiện ngôn ngữ.
Các thuật toán cho hồ sơ Corpus
Corpus là gì?
Để phát hiện ngôn ngữ của tài liệu, cấu hình ngôn ngữ được xây dựng và so sánh với cấu hình của các ngôn ngữ đã biết. Tập văn bản của những ngôn ngữ đã biết này được gọi làcorpus.
Ngữ liệu là một tập hợp các văn bản của một ngôn ngữ viết giải thích cách ngôn ngữ đó được sử dụng trong các tình huống thực tế.
Kho ngữ liệu được phát triển từ sách, bảng điểm và các nguồn dữ liệu khác như Internet. Độ chính xác của kho tài liệu phụ thuộc vào thuật toán lập hồ sơ mà chúng tôi sử dụng để tạo khung cho kho tài liệu.
Thuật toán lập hồ sơ là gì?
Cách phổ biến để phát hiện ngôn ngữ là sử dụng từ điển. Các từ được sử dụng trong một đoạn văn bản nhất định sẽ được khớp với những từ có trong từ điển.
Danh sách các từ phổ biến được sử dụng trong một ngôn ngữ sẽ là kho ngữ liệu đơn giản và hiệu quả nhất để phát hiện một ngôn ngữ cụ thể, ví dụ: các bài báo a, an, the bằng tiếng Anh.
Sử dụng Word Sets làm Corpus
Sử dụng tập hợp từ, một thuật toán đơn giản được đóng khung để tìm khoảng cách giữa hai kho ngữ liệu, sẽ bằng tổng chênh lệch giữa các tần số của các từ phù hợp.
Các thuật toán như vậy mắc phải các vấn đề sau:
Vì tần suất so khớp các từ là rất ít nên thuật toán không thể hoạt động hiệu quả với các văn bản nhỏ có ít câu. Nó cần rất nhiều văn bản để khớp chính xác.
Nó không thể phát hiện ranh giới từ đối với các ngôn ngữ có câu ghép và những ngôn ngữ không có ngăn cách từ như dấu cách hoặc dấu chấm câu.
Do những khó khăn này trong việc sử dụng bộ từ làm ngữ liệu, các ký tự riêng lẻ hoặc nhóm ký tự được xem xét.
Sử dụng Bộ ký tự làm Corpus
Vì các ký tự thường được sử dụng trong một ngôn ngữ có số lượng hữu hạn, nên dễ dàng áp dụng một thuật toán dựa trên tần số từ chứ không phải ký tự. Thuật toán này thậm chí còn hoạt động tốt hơn trong trường hợp một số bộ ký tự nhất định được sử dụng trong một hoặc rất ít ngôn ngữ.
Thuật toán này có những nhược điểm sau:
Rất khó để phân biệt hai ngôn ngữ có tần số ký tự giống nhau.
Không có công cụ hoặc thuật toán cụ thể nào để xác định cụ thể một ngôn ngữ với sự trợ giúp của (dưới dạng ngữ liệu) bộ ký tự được sử dụng bởi nhiều ngôn ngữ.
Thuật toán N-gram
Những hạn chế được nêu ở trên đã dẫn đến một cách tiếp cận mới trong việc sử dụng các chuỗi ký tự có độ dài nhất định cho kho ngữ liệu định hình. Nói chung, dãy ký tự như vậy được gọi là N-gram, trong đó N đại diện cho độ dài của dãy ký tự.
Thuật toán N-gram là một cách tiếp cận hiệu quả để phát hiện ngôn ngữ, đặc biệt trong trường hợp các ngôn ngữ châu Âu như tiếng Anh.
Thuật toán này hoạt động tốt với các văn bản ngắn.
Mặc dù có các thuật toán cấu hình ngôn ngữ nâng cao để phát hiện nhiều ngôn ngữ trong một tài liệu đa ngôn ngữ có nhiều tính năng hấp dẫn hơn, Tika sử dụng thuật toán 3 gam, vì nó phù hợp trong hầu hết các tình huống thực tế.
Phát hiện ngôn ngữ trong Tika
Trong số tất cả 184 ngôn ngữ tiêu chuẩn được tiêu chuẩn hóa bởi ISO 639-1, Tika có thể phát hiện 18 ngôn ngữ. Phát hiện ngôn ngữ trong Tika được thực hiện bằng cách sử dụnggetLanguage() phương pháp của LanguageIdentifierlớp học. Phương thức này trả về tên mã của ngôn ngữ ở định dạng Chuỗi. Dưới đây là danh sách 18 cặp mã ngôn ngữ được phát hiện bởi Tika -
| da — tiếng Đan Mạch | de — tiếng Đức | et — tiếng Estonia | el — tiếng Hy Lạp |
| vi — tiếng Anh | es — tiếng Tây Ban Nha | fi — tiếng Phần Lan | fr — tiếng Pháp |
| hu — tiếng Hungary | là — tiếng Iceland | nó — tiếng Ý | nl — tiếng Hà Lan |
| không — tiếng Na Uy | pl — tiếng Ba Lan | pt — tiếng Bồ Đào Nha | ru — tiếng Nga |
| sv — tiếng Thụy Điển | th — Thái |
Trong khi khởi tạo LanguageIdentifier , bạn nên chuyển định dạng Chuỗi của nội dung được trích xuất, hoặc LanguageProfile đối tượng lớp.
LanguageIdentifier object = new LanguageIdentifier(“this is english”);Dưới đây là chương trình ví dụ để phát hiện ngôn ngữ trong Tika.
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.language.LanguageIdentifier;
import org.xml.sax.SAXException;
public class LanguageDetection {
public static void main(String args[])throws IOException, SAXException, TikaException {
LanguageIdentifier identifier = new LanguageIdentifier("this is english ");
String language = identifier.getLanguage();
System.out.println("Language of the given content is : " + language);
}
}Lưu mã trên dưới dạng LanguageDetection.java và chạy nó từ dấu nhắc lệnh bằng các lệnh sau:
javac LanguageDetection.java
java LanguageDetectionNếu bạn thực hiện chương trình trên, nó sẽ đưa ra kết quả sau
Language of the given content is : enPhát hiện ngôn ngữ của tài liệu
Để phát hiện ngôn ngữ của một tài liệu nhất định, bạn phải phân tích cú pháp nó bằng phương thức parse (). Phương thức parse () phân tích cú pháp nội dung và lưu trữ nội dung đó trong đối tượng trình xử lý, được truyền cho nó dưới dạng một trong các đối số. Truyền định dạng Chuỗi của đối tượng trình xử lý tới hàm tạo củaLanguageIdentifier lớp như hình dưới đây -
parser.parse(inputstream, handler, metadata, context);
LanguageIdentifier object = new LanguageIdentifier(handler.toString());Dưới đây là chương trình hoàn chỉnh trình bày cách phát hiện ngôn ngữ của một tài liệu nhất định -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.language.*;
import org.xml.sax.SAXException;
public class DocumentLanguageDetection {
public static void main(final String[] args) throws IOException, SAXException, TikaException {
//Instantiating a file object
File file = new File("Example.txt");
//Parser method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream content = new FileInputStream(file);
//Parsing the given document
parser.parse(content, handler, metadata, new ParseContext());
LanguageIdentifier object = new LanguageIdentifier(handler.toString());
System.out.println("Language name :" + object.getLanguage());
}
}Lưu đoạn mã trên dưới dạng SetMetadata.java và chạy nó từ dấu nhắc lệnh -
javac SetMetadata.java
java SetMetadataDưới đây là nội dung của Example.txt.
Hi students welcome to tutorialspointNếu bạn thực hiện chương trình trên, nó sẽ cung cấp cho bạn kết quả sau:
Language name :enCùng với lọ Tika, Tika cung cấp ứng dụng Giao diện người dùng đồ họa (GUI) và ứng dụng Giao diện dòng lệnh (CLI). Bạn cũng có thể thực thi một ứng dụng Tika từ dấu nhắc lệnh giống như các ứng dụng Java khác.
Giao diện người dùng đồ họa (GUI)
Tika cung cấp một tệp jar cùng với mã nguồn của nó trong liên kết sau https://tika.apache.org/download.html.
Tải xuống cả hai tệp, đặt classpath cho tệp jar.
Giải nén thư mục zip mã nguồn, mở thư mục tika-app.
Trong thư mục được giải nén tại “tika-1.6 \ tika-app \ src \ main \ java \ org \ apache \ Tika \ gui”, bạn sẽ thấy hai tệp lớp: ParsingTransferHandler.java và TikaGUI.java.
Biên dịch cả hai tệp lớp và thực thi tệp lớp TikaGUI.java, nó sẽ mở ra cửa sổ sau.

Bây giờ chúng ta hãy xem cách sử dụng Tika GUI.
Trên GUI, bấm mở, duyệt và chọn tệp sẽ được giải nén hoặc kéo tệp đó vào khoảng trắng của cửa sổ.
Tika trích xuất nội dung của các tệp và hiển thị nó ở năm định dạng khác nhau, viz. siêu dữ liệu, văn bản được định dạng, văn bản thuần túy, nội dung chính và văn bản có cấu trúc. Bạn có thể chọn bất kỳ định dạng nào bạn muốn.
Theo cách tương tự, bạn cũng sẽ tìm thấy lớp CLI trong thư mục “tika-1.6 \ tikaapp \ src \ main \ java \ org \ apache \ tika \ cli”.
Hình minh họa sau đây cho thấy những gì Tika có thể làm. Khi chúng tôi thả hình ảnh trên GUI, Tika sẽ trích xuất và hiển thị siêu dữ liệu của nó.
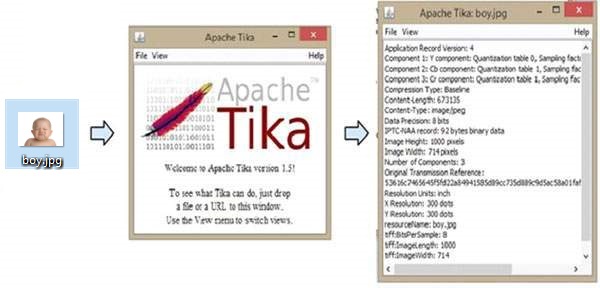
Dưới đây là chương trình trích xuất nội dung và siêu dữ liệu từ một tệp PDF.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.pdf.PDFParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class PdfParse {
public static void main(final String[] args) throws IOException,TikaException {
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.pdf"));
ParseContext pcontext = new ParseContext();
//parsing the document using PDF parser
PDFParser pdfparser = new PDFParser();
pdfparser.parse(inputstream, handler, metadata,pcontext);
//getting the content of the document
System.out.println("Contents of the PDF :" + handler.toString());
//getting metadata of the document
System.out.println("Metadata of the PDF:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name+ " : " + metadata.get(name));
}
}
}Lưu mã trên dưới dạng PdfParse.javavà biên dịch nó từ dấu nhắc lệnh bằng cách sử dụng các lệnh sau:
javac PdfParse.java
java PdfParseDưới đây là ảnh chụp nhanh của example.pdf

PDF chúng tôi đang chuyển có các thuộc tính sau:

Sau khi biên dịch chương trình, bạn sẽ nhận được kết quả như hình dưới đây.
Output -
Contents of the PDF:
Apache Tika is a framework for content type detection and content extraction
which was designed by Apache software foundation. It detects and extracts metadata
and structured text content from different types of documents such as spreadsheets,
text documents, images or PDFs including audio or video input formats to certain extent.
Metadata of the PDF:
dcterms:modified : 2014-09-28T12:31:16Z
meta:creation-date : 2014-09-28T12:31:16Z
meta:save-date : 2014-09-28T12:31:16Z
dc:creator : Krishna Kasyap
pdf:PDFVersion : 1.5
Last-Modified : 2014-09-28T12:31:16Z
Author : Krishna Kasyap
dcterms:created : 2014-09-28T12:31:16Z
date : 2014-09-28T12:31:16Z
modified : 2014-09-28T12:31:16Z
creator : Krishna Kasyap
xmpTPg:NPages : 1
Creation-Date : 2014-09-28T12:31:16Z
pdf:encrypted : false
meta:author : Krishna Kasyap
created : Sun Sep 28 05:31:16 PDT 2014
dc:format : application/pdf; version = 1.5
producer : Microsoft® Word 2013
Content-Type : application/pdf
xmp:CreatorTool : Microsoft® Word 2013
Last-Save-Date : 2014-09-28T12:31:16ZDưới đây là chương trình trích xuất nội dung và siêu dữ liệu từ Định dạng Tài liệu Văn phòng Mở (ODF).
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.odf.OpenDocumentParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class OpenDocumentParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example_open_document_presentation.odp"));
ParseContext pcontext = new ParseContext();
//Open Document Parser
OpenDocumentParser openofficeparser = new OpenDocumentParser ();
openofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}Lưu mã trên dưới dạng OpenDocumentParse.javavà biên dịch nó trong dấu nhắc lệnh bằng cách sử dụng các lệnh sau:
javac OpenDocumentParse.java
java OpenDocumentParseDưới đây là ảnh chụp nhanh của tệp example_open_document_presentation.odp.

Tài liệu này có các thuộc tính sau:
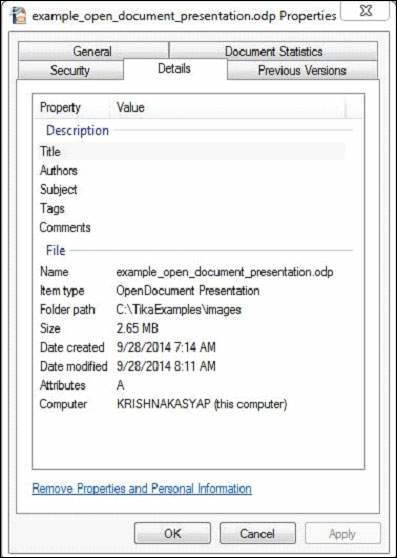
Sau khi biên dịch chương trình, bạn sẽ nhận được kết quả sau.
Output -
Contents of the document:
Apache Tika
Apache Tika is a framework for content type detection and content extraction which was designed
by Apache software foundation. It detects and extracts metadata and structured text content from
different types of documents such as spreadsheets, text documents, images or PDFs including audio
or video input formats to certain extent.
Metadata of the document:
editing-cycles: 4
meta:creation-date: 2009-04-16T11:32:32.86
dcterms:modified: 2014-09-28T07:46:13.03
meta:save-date: 2014-09-28T07:46:13.03
Last-Modified: 2014-09-28T07:46:13.03
dcterms:created: 2009-04-16T11:32:32.86
date: 2014-09-28T07:46:13.03
modified: 2014-09-28T07:46:13.03
nbObject: 36
Edit-Time: PT32M6S
Creation-Date: 2009-04-16T11:32:32.86
Object-Count: 36
meta:object-count: 36
generator: OpenOffice/4.1.0$Win32 OpenOffice.org_project/410m18$Build-9764
Content-Type: application/vnd.oasis.opendocument.presentation
Last-Save-Date: 2014-09-28T07:46:13.03Dưới đây là chương trình trích xuất nội dung và siêu dữ liệu từ Tài liệu Microsoft Office.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.microsoft.ooxml.OOXMLParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class MSExcelParse {
public static void main(final String[] args) throws IOException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example_msExcel.xlsx"));
ParseContext pcontext = new ParseContext();
//OOXml parser
OOXMLParser msofficeparser = new OOXMLParser ();
msofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Lưu mã trên dưới dạng MSExelParse.javavà biên dịch nó từ dấu nhắc lệnh bằng cách sử dụng các lệnh sau:
javac MSExcelParse.java
java MSExcelParseỞ đây chúng tôi đang chuyển tệp Excel mẫu sau.
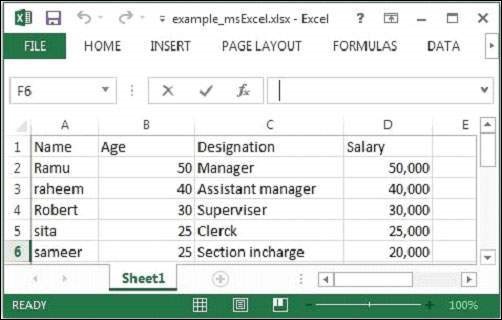
Tệp Excel đã cho có các thuộc tính sau:

Sau khi thực hiện chương trình trên, bạn sẽ nhận được kết quả sau.
Output -
Contents of the document:
Sheet1
Name Age Designation Salary
Ramu 50 Manager 50,000
Raheem 40 Assistant manager 40,000
Robert 30 Superviser 30,000
sita 25 Clerk 25,000
sameer 25 Section in-charge 20,000
Metadata of the document:
meta:creation-date: 2006-09-16T00:00:00Z
dcterms:modified: 2014-09-28T15:18:41Z
meta:save-date: 2014-09-28T15:18:41Z
Application-Name: Microsoft Excel
extended-properties:Company:
dcterms:created: 2006-09-16T00:00:00Z
Last-Modified: 2014-09-28T15:18:41Z
Application-Version: 15.0300
date: 2014-09-28T15:18:41Z
publisher:
modified: 2014-09-28T15:18:41Z
Creation-Date: 2006-09-16T00:00:00Z
extended-properties:AppVersion: 15.0300
protected: false
dc:publisher:
extended-properties:Application: Microsoft Excel
Content-Type: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
Last-Save-Date: 2014-09-28T15:18:41ZDưới đây là chương trình trích xuất nội dung và siêu dữ liệu từ tài liệu Văn bản -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.parser.txt.TXTParser;
import org.xml.sax.SAXException;
public class TextParser {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.txt"));
ParseContext pcontext=new ParseContext();
//Text document parser
TXTParser TexTParser = new TXTParser();
TexTParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}Lưu mã trên dưới dạng TextParser.javavà biên dịch nó từ dấu nhắc lệnh bằng cách sử dụng các lệnh sau:
javac TextParser.java
java TextParserDưới đây là ảnh chụp nhanh của tệp sample.txt -
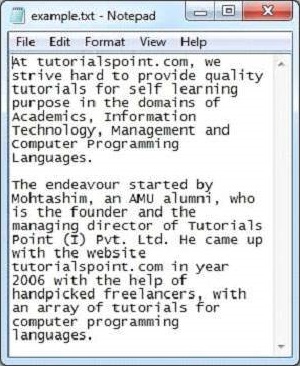
Tài liệu văn bản có các thuộc tính sau:

Nếu bạn thực hiện chương trình trên, nó sẽ cung cấp cho bạn kết quả sau.
Output -
Contents of the document:
At tutorialspoint.com, we strive hard to provide quality tutorials for self-learning
purpose in the domains of Academics, Information Technology, Management and Computer
Programming Languages.
The endeavour started by Mohtashim, an AMU alumni, who is the founder and the managing
director of Tutorials Point (I) Pvt. Ltd. He came up with the website tutorialspoint.com
in year 2006 with the help of handpicked freelancers, with an array of tutorials for
computer programming languages.
Metadata of the document:
Content-Encoding: windows-1252
Content-Type: text/plain; charset = windows-1252Dưới đây là chương trình trích xuất nội dung và siêu dữ liệu từ một tài liệu HTML.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.html.HtmlParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class HtmlParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.html"));
ParseContext pcontext = new ParseContext();
//Html parser
HtmlParser htmlparser = new HtmlParser();
htmlparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Lưu mã trên dưới dạng HtmlParse.javavà biên dịch nó từ dấu nhắc lệnh bằng cách sử dụng các lệnh sau:
javac HtmlParse.java
java HtmlParseDưới đây là ảnh chụp nhanh của tệp example.txt.
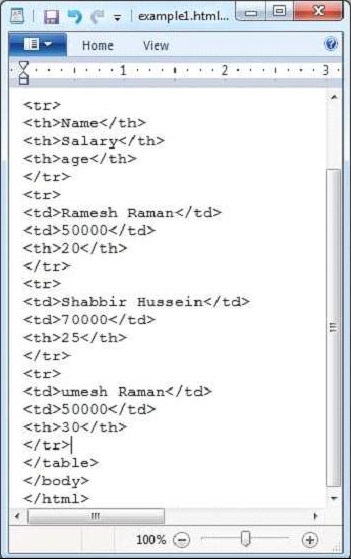
Tài liệu HTML có các thuộc tính sau

Nếu bạn thực hiện chương trình trên, nó sẽ cung cấp cho bạn kết quả sau.
Output -
Contents of the document:
Name Salary age
Ramesh Raman 50000 20
Shabbir Hussein 70000 25
Umesh Raman 50000 30
Somesh 50000 35
Metadata of the document:
title: HTML Table Header
Content-Encoding: windows-1252
Content-Type: text/html; charset = windows-1252
dc:title: HTML Table HeaderDưới đây là chương trình trích xuất nội dung và siêu dữ liệu từ một tài liệu XML -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.xml.XMLParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class XmlParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("pom.xml"));
ParseContext pcontext = new ParseContext();
//Xml parser
XMLParser xmlparser = new XMLParser();
xmlparser.parse(inputstream, handler, metadata, pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Lưu mã trên dưới dạng XmlParse.javavà biên dịch nó từ dấu nhắc lệnh bằng cách sử dụng các lệnh sau:
javac XmlParse.java
java XmlParseDưới đây là ảnh chụp nhanh của tệp example.xml
Tài liệu này có các thuộc tính sau:

Nếu bạn thực hiện chương trình trên, nó sẽ cung cấp cho bạn kết quả sau:
Output -
Contents of the document:
4.0.0
org.apache.tika
tika
1.6
org.apache.tika
tika-core
1.6
org.apache.tika
tika-parsers
1.6
src
maven-compiler-plugin
3.1
1.7
1.7
Metadata of the document:
Content-Type: application/xmlDưới đây là chương trình trích xuất nội dung và siêu dữ liệu từ tệp .class.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.asm.ClassParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class JavaClassParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.class"));
ParseContext pcontext = new ParseContext();
//Html parser
ClassParser ClassParser = new ClassParser();
ClassParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}Lưu mã trên dưới dạng JavaClassParse.javavà biên dịch nó từ dấu nhắc lệnh bằng cách sử dụng các lệnh sau:
javac JavaClassParse.java
java JavaClassParseDưới đây là ảnh chụp nhanh của Example.java sẽ tạo ra lớp Example.class sau khi biên dịch.

Example.class tệp có các thuộc tính sau:
Sau khi thực hiện chương trình trên, bạn sẽ nhận được kết quả sau.
Output -
Contents of the document:
package tutorialspoint.tika.examples;
public synchronized class Example {
public void Example();
public static void main(String[]);
}
Metadata of the document:
title: Example
resourceName: Example.class
dc:title: ExampleDưới đây là chương trình trích xuất nội dung và siêu dữ liệu từ tệp Lưu trữ Java (jar) -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.apache.tika.parser.pkg.PackageParser;
import org.xml.sax.SAXException;
public class PackageParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("Example.jar"));
ParseContext pcontext = new ParseContext();
//Package parser
PackageParser packageparser = new PackageParser();
packageparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document: " + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Lưu mã trên dưới dạng PackageParse.javavà biên dịch nó từ dấu nhắc lệnh bằng cách sử dụng các lệnh sau:
javac PackageParse.java
java PackageParseDưới đây là ảnh chụp nhanh của Example.java nằm bên trong gói.

Tệp jar có các thuộc tính sau:

Sau khi thực hiện chương trình trên, nó sẽ cung cấp cho bạn kết quả sau:
Output -
Contents of the document:
META-INF/MANIFEST.MF
tutorialspoint/tika/examples/Example.class
Metadata of the document:
Content-Type: application/zipDưới đây là chương trình trích xuất nội dung và dữ liệu meta từ hình ảnh JPEG.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.jpeg.JpegParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class JpegParse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("boy.jpg"));
ParseContext pcontext = new ParseContext();
//Jpeg Parse
JpegParser JpegParser = new JpegParser();
JpegParser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Lưu mã trên dưới dạng JpegParse.javavà biên dịch nó từ dấu nhắc lệnh bằng cách sử dụng các lệnh sau:
javac JpegParse.java
java JpegParseDưới đây là ảnh chụp nhanh của Example.jpeg -

Tệp JPEG có các thuộc tính sau:
Sau khi thực hiện chương trình, bạn sẽ nhận được kết quả sau.
Output −
Contents of the document:
Meta data of the document:
Resolution Units: inch
Compression Type: Baseline
Data Precision: 8 bits
Number of Components: 3
tiff:ImageLength: 3000
Component 2: Cb component: Quantization table 1, Sampling factors 1 horiz/1 vert
Component 1: Y component: Quantization table 0, Sampling factors 2 horiz/2 vert
Image Height: 3000 pixels
X Resolution: 300 dots
Original Transmission Reference: 53616c7465645f5f2368da84ca932841b336ac1a49edb1a93fae938b8db2cb3ec9cc4dc28d7383f1
Image Width: 4000 pixels
IPTC-NAA record: 92 bytes binary data
Component 3: Cr component: Quantization table 1, Sampling factors 1 horiz/1 vert
tiff:BitsPerSample: 8
Application Record Version: 4
tiff:ImageWidth: 4000
Y Resolution: 300 dotsDưới đây là chương trình trích xuất nội dung và siêu dữ liệu từ các tệp mp4 -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.mp4.MP4Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class Mp4Parse {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.mp4"));
ParseContext pcontext = new ParseContext();
//Html parser
MP4Parser MP4Parser = new MP4Parser();
MP4Parser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document: :" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Lưu đoạn mã trên dưới dạng JpegParse.java và biên dịch nó từ dấu nhắc lệnh bằng cách sử dụng các lệnh sau:
javac Mp4Parse.java
java Mp4ParseDưới đây là ảnh chụp nhanh các thuộc tính của tệp Example.mp4.

Sau khi thực hiện chương trình trên, bạn sẽ nhận được kết quả sau:
Output -
Contents of the document:
Metadata of the document:
dcterms:modified: 2014-01-06T12:10:27Z
meta:creation-date: 1904-01-01T00:00:00Z
meta:save-date: 2014-01-06T12:10:27Z
Last-Modified: 2014-01-06T12:10:27Z
dcterms:created: 1904-01-01T00:00:00Z
date: 2014-01-06T12:10:27Z
tiff:ImageLength: 360
modified: 2014-01-06T12:10:27Z
Creation-Date: 1904-01-01T00:00:00Z
tiff:ImageWidth: 640
Content-Type: video/mp4
Last-Save-Date: 2014-01-06T12:10:27ZDưới đây là chương trình trích xuất nội dung và siêu dữ liệu từ các tệp mp3 -
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.mp3.LyricsHandler;
import org.apache.tika.parser.mp3.Mp3Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class Mp3Parse {
public static void main(final String[] args) throws Exception, IOException, SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example.mp3"));
ParseContext pcontext = new ParseContext();
//Mp3 parser
Mp3Parser Mp3Parser = new Mp3Parser();
Mp3Parser.parse(inputstream, handler, metadata, pcontext);
LyricsHandler lyrics = new LyricsHandler(inputstream,handler);
while(lyrics.hasLyrics()) {
System.out.println(lyrics.toString());
}
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}Lưu mã trên dưới dạng JpegParse.javavà biên dịch nó từ dấu nhắc lệnh bằng cách sử dụng các lệnh sau:
javac Mp3Parse.java
java Mp3ParseTệp example.mp3 có các thuộc tính sau:
Bạn sẽ nhận được đầu ra sau khi thực hiện chương trình. Nếu tệp đã cho có bất kỳ lời bài hát nào, ứng dụng của chúng tôi sẽ chụp và hiển thị cùng với kết quả đầu ra.
Output -
Contents of the document:
Kanulanu Thaake
Arijit Singh
Manam (2014), track 01/06
2014
Soundtrack
30171.65
eng -
DRGM
Arijit Singh
Manam (2014), track 01/06
2014
Soundtrack
30171.65
eng -
DRGM
Metadata of the document:
xmpDM:releaseDate: 2014
xmpDM:duration: 30171.650390625
xmpDM:audioChannelType: Stereo
dc:creator: Arijit Singh
xmpDM:album: Manam (2014)
Author: Arijit Singh
xmpDM:artist: Arijit Singh
channels: 2
xmpDM:audioSampleRate: 44100
xmpDM:logComment: eng -
DRGM
xmpDM:trackNumber: 01/06
version: MPEG 3 Layer III Version 1
creator: Arijit Singh
xmpDM:composer: Music : Anoop Rubens | Lyrics : Vanamali
xmpDM:audioCompressor: MP3
title: Kanulanu Thaake
samplerate: 44100
meta:author: Arijit Singh
xmpDM:genre: Soundtrack
Content-Type: audio/mpeg
xmpDM:albumArtist: Manam (2014)
dc:title: Kanulanu Thaake