TIKA - API được tham chiếu
Người dùng có thể nhúng Tika vào các ứng dụng của họ bằng cách sử dụng lớp mặt tiền Tika. Nó có các phương pháp để khám phá tất cả các chức năng của Tika. Vì nó là một lớp mặt tiền, Tika tóm tắt sự phức tạp đằng sau các chức năng của nó. Ngoài ra, người dùng cũng có thể sử dụng các lớp khác nhau của Tika trong các ứng dụng của họ.
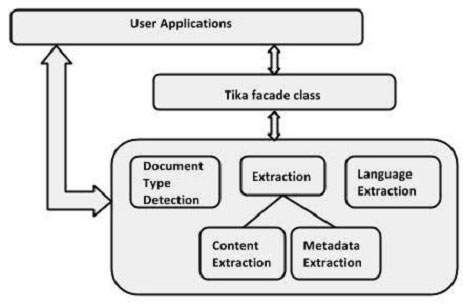
Lớp Tika (mặt tiền)
Đây là lớp nổi bật nhất của thư viện Tika và tuân theo mô hình thiết kế mặt tiền. Do đó, nó tóm tắt tất cả các triển khai bên trong và cung cấp các phương pháp đơn giản để truy cập các chức năng của Tika. Bảng sau liệt kê các hàm tạo của lớp này cùng với các mô tả của chúng.
package - org.apache.tika
class - Tika
| Sr.No. | Cấu tạo & Mô tả |
|---|---|
| 1 | Tika () Sử dụng cấu hình mặc định và xây dựng lớp Tika. |
| 2 | Tika (Detector detector) Tạo mặt tiền Tika bằng cách chấp nhận phiên bản máy dò làm tham số |
| 3 | Tika (Detector detector, Parser parser) Tạo mặt tiền Tika bằng cách chấp nhận các bản sao của trình dò và phân tích cú pháp làm tham số. |
| 4 | Tika (Detector detector, Parser parser, Translator translator) Tạo mặt tiền Tika bằng cách chấp nhận trình phát hiện, trình phân tích cú pháp và phiên dịch làm tham số. |
| 5 | Tika (TikaConfig config) Tạo mặt tiền Tika bằng cách chấp nhận đối tượng của lớp TikaConfig làm tham số. |
Phương pháp và Mô tả
Sau đây là các phương thức quan trọng của lớp mặt tiền Tika:
| Sr.No. | Phương pháp & Mô tả |
|---|---|
| 1 | phân tích cú phápToString (File tập tin) Phương thức này và tất cả các biến thể của nó phân tích cú pháp tệp được truyền dưới dạng tham số và trả về nội dung văn bản được trích xuất ở định dạng Chuỗi. Theo mặc định, độ dài của tham số chuỗi này bị giới hạn. |
| 2 | int getMaxStringLength () Trả về độ dài tối đa của các chuỗi được trả về bởi các phương thức parseToString. |
| 3 | vô hiệu setMaxStringLength (int maxStringLength) Đặt độ dài tối đa của chuỗi được trả về bởi các phương thức parseToString. |
| 4 | Người đọc parse (File tập tin) Phương thức này và tất cả các biến thể của nó phân tích cú pháp tệp được truyền dưới dạng tham số và trả về nội dung văn bản được trích xuất dưới dạng đối tượng java.io.reader. |
| 5 | Chuỗi detect (InputStream suối, Metadata metadata) Phương thức này và tất cả các biến thể của nó chấp nhận một đối tượng InputStream và một đối tượng Siêu dữ liệu làm tham số, phát hiện loại tài liệu đã cho và trả về tên loại tài liệu dưới dạng đối tượng Chuỗi. Phương pháp này tóm tắt các cơ chế phát hiện được Tika sử dụng. |
| 6 | Chuỗi translate (InputStream bản văn, String ngôn ngữ mục tiêu) Phương thức này và tất cả các biến thể của nó chấp nhận đối tượng InputStream và một Chuỗi đại diện cho ngôn ngữ mà chúng ta muốn dịch văn bản của mình và dịch văn bản đã cho sang ngôn ngữ mong muốn, cố gắng tự động phát hiện ngôn ngữ nguồn. |
Giao diện phân tích cú pháp
Đây là giao diện được thực hiện bởi tất cả các lớp phân tích cú pháp của gói Tika.
package - org.apache.tika.parser
Interface - Trình phân tích cú pháp
Phương pháp và Mô tả
Sau đây là phương pháp quan trọng của giao diện Tika Parser:
| Sr.No. | Phương pháp & Mô tả |
|---|---|
| 1 | parse (InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) Phương thức này phân tích tài liệu đã cho thành một chuỗi các sự kiện XHTML và SAX. Sau khi phân tích cú pháp, nó đặt nội dung tài liệu được trích xuất vào đối tượng của lớp ContentHandler và siêu dữ liệu trong đối tượng của lớp Siêu dữ liệu. |
Lớp siêu dữ liệu
Lớp này thực hiện các giao diện khác nhau như CreativeCommons, Geographic, HttpHeaders, Message, MSOffice, ClimateForcast, TIFF, TikaMetadataKeys, TikaMimeKeys, Serializable để hỗ trợ các mô hình dữ liệu khác nhau. Các bảng sau liệt kê các hàm tạo và phương thức của lớp này cùng với các mô tả của chúng.
package - org.apache.tika.metadata
class - Siêu dữ liệu
| Sr.No. | Cấu tạo & Mô tả |
|---|---|
| 1 | Metadata() Tạo siêu dữ liệu mới, trống. |
| Sr.No. | Phương pháp & Mô tả |
|---|---|
| 1 | add (Property property, String value) Thêm ánh xạ thuộc tính / giá trị siêu dữ liệu vào một tài liệu nhất định. Sử dụng hàm này, chúng ta có thể đặt giá trị cho một thuộc tính. |
| 2 | add (String name, String value) Thêm ánh xạ thuộc tính / giá trị siêu dữ liệu vào một tài liệu nhất định. Sử dụng phương pháp này, chúng ta có thể đặt giá trị tên mới cho siêu dữ liệu hiện có của tài liệu. |
| 3 | String get (Property property) Trả về giá trị (nếu có) của thuộc tính siêu dữ liệu đã cho. |
| 4 | String get (String name) Trả về giá trị (nếu có) của tên siêu dữ liệu đã cho. |
| 5 | Date getDate (Property property) Trả về giá trị của thuộc tính siêu dữ liệu Ngày. |
| 6 | String[] getValues (Property property) Trả về tất cả các giá trị của thuộc tính siêu dữ liệu. |
| 7 | String[] getValues (String name) Trả về tất cả các giá trị của một tên siêu dữ liệu nhất định. |
| số 8 | String[] names() Trả về tất cả tên của các phần tử siêu dữ liệu trong một đối tượng siêu dữ liệu. |
| 9 | set (Property property, Date date) Đặt giá trị ngày của thuộc tính siêu dữ liệu đã cho |
| 10 | set(Property property, String[] values) Đặt nhiều giá trị cho một thuộc tính siêu dữ liệu. |
Lớp định danh ngôn ngữ
Lớp này xác định ngôn ngữ của nội dung đã cho. Các bảng sau liệt kê các hàm tạo của lớp này cùng với các mô tả của chúng.
package - org.apache.tika.language
class - Định danh ngôn ngữ
| Sr.No. | Cấu tạo & Mô tả |
|---|---|
| 1 | LanguageIdentifier (LanguageProfile profile) Khởi tạo mã định danh ngôn ngữ. Ở đây bạn phải truyền một đối tượng LanguageProfile làm tham số. |
| 2 | LanguageIdentifier (String content) Hàm tạo này có thể khởi tạo một mã định danh ngôn ngữ bằng cách chuyển một Chuỗi từ nội dung văn bản. |
| Sr.No. | Phương pháp & Mô tả |
|---|---|
| 1 | String getLanguage () Trả về ngôn ngữ được cung cấp cho đối tượng LanguageIdentifier hiện tại. |